mirror of https://github.com/hpcaitech/ColossalAI
[Feature] Add document retrieval QA (#5020)
* add langchain * add langchain * Add files via upload * add langchain * fix style * fix style: remove extra space * add pytest; modified retriever * add pytest; modified retriever * add tests to build_on_pr.yml * fix build_on_pr.yml * fix build on pr; fix environ vars * seperate unit tests for colossalqa from build from pr * fix container setting; fix environ vars * commented dev code * add incremental update * remove stale code * fix style * change to sha3 224 * fix retriever; fix style; add unit test for document loader * fix ci workflow config * fix ci workflow config * add set cuda visible device script in ci * fix doc string * fix style; update readme; refactored * add force log info * change build on pr, ignore colossalqa * fix docstring, captitalize all initial letters * fix indexing; fix text-splitter * remove debug code, update reference * reset previous commit * update LICENSE update README add key-value mode, fix bugs * add files back * revert force push * remove junk file * add test files * fix retriever bug, add intent classification * change conversation chain design * rewrite prompt and conversation chain * add ui v1 * ui v1 * fix atavar * add header * Refactor the RAG Code and support Pangu * Refactor the ColossalQA chain to Object-Oriented Programming and the UI demo. * resolved conversation. tested scripts under examples. web demo still buggy * fix ci tests * Some modifications to add ChatGPT api * modify llm.py and remove unnecessary files * Delete applications/ColossalQA/examples/ui/test_frontend_input.json * Remove OpenAI api key * add colossalqa * move files * move files * move files * move files * fix style * Add Readme and fix some bugs. * Add something to readme and modify some code * modify a directory name for clarity * remove redundant directory * Correct a type in llm.py * fix AI prefix * fix test_memory.py * fix conversation * fix some erros and typos * Fix a missing import in RAG_ChatBot.py * add colossalcloud LLM wrapper, correct issues in code review --------- Co-authored-by: YeAnbang <anbangy2@outlook.com> Co-authored-by: Orion-Zheng <zheng_zian@u.nus.edu> Co-authored-by: Zian(Andy) Zheng <62330719+Orion-Zheng@users.noreply.github.com> Co-authored-by: Orion-Zheng <zhengzian@u.nus.edu>pull/5114/head
parent
3acbf6d496
commit
e53e729d8e
|
|
@ -0,0 +1,54 @@
|
|||
name: Run colossalqa unit tests
|
||||
|
||||
on:
|
||||
pull_request:
|
||||
types: [synchronize, opened, reopened]
|
||||
paths:
|
||||
- 'applications/ColossalQA/colossalqa/**'
|
||||
- 'applications/ColossalQA/requirements.txt'
|
||||
- 'applications/ColossalQA/setup.py'
|
||||
- 'applications/ColossalQA/tests/**'
|
||||
- 'applications/ColossalQA/pytest.ini'
|
||||
|
||||
jobs:
|
||||
tests:
|
||||
name: Run colossalqa unit tests
|
||||
if: |
|
||||
github.event.pull_request.draft == false &&
|
||||
github.base_ref == 'main' &&
|
||||
github.event.pull_request.base.repo.full_name == 'hpcaitech/ColossalAI'
|
||||
runs-on: [self-hosted, gpu]
|
||||
container:
|
||||
image: hpcaitech/pytorch-cuda:1.12.0-11.3.0
|
||||
volumes:
|
||||
- /data/scratch/test_data_colossalqa:/data/scratch/test_data_colossalqa
|
||||
- /data/scratch/llama-tiny:/data/scratch/llama-tiny
|
||||
options: --gpus all --rm
|
||||
timeout-minutes: 30
|
||||
defaults:
|
||||
run:
|
||||
shell: bash
|
||||
steps:
|
||||
- name: Checkout ColossalAI
|
||||
uses: actions/checkout@v2
|
||||
|
||||
- name: Install colossalqa
|
||||
run: |
|
||||
cd applications/ColossalQA
|
||||
pip install -e .
|
||||
|
||||
- name: Execute Unit Testing
|
||||
run: |
|
||||
cd applications/ColossalQA
|
||||
pytest tests/
|
||||
env:
|
||||
NCCL_SHM_DISABLE: 1
|
||||
MAX_JOBS: 8
|
||||
ZH_MODEL_PATH: bigscience/bloom-560m
|
||||
ZH_MODEL_NAME: bloom
|
||||
EN_MODEL_PATH: bigscience/bloom-560m
|
||||
EN_MODEL_NAME: bloom
|
||||
TEST_DATA_PATH_EN: /data/scratch/test_data_colossalqa/companies.txt
|
||||
TEST_DATA_PATH_ZH: /data/scratch/test_data_colossalqa/companies_zh.txt
|
||||
TEST_DOCUMENT_LOADER_DATA_PATH: /data/scratch/test_data_colossalqa/tests/*
|
||||
SQL_FILE_PATH: /data/scratch/test_data_colossalqa/sql_file_path
|
||||
25
LICENSE
25
LICENSE
|
|
@ -527,3 +527,28 @@ Copyright 2021- HPC-AI Technology Inc. All rights reserved.
|
|||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
||||
SOFTWARE.
|
||||
|
||||
|
||||
---------------- LICENSE FOR LangChain TEAM ----------------
|
||||
|
||||
The MIT License
|
||||
|
||||
Copyright (c) Harrison Chase
|
||||
|
||||
Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
of this software and associated documentation files (the "Software"), to deal
|
||||
in the Software without restriction, including without limitation the rights
|
||||
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
||||
copies of the Software, and to permit persons to whom the Software is
|
||||
furnished to do so, subject to the following conditions:
|
||||
|
||||
The above copyright notice and this permission notice shall be included in
|
||||
all copies or substantial portions of the Software.
|
||||
|
||||
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
||||
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
|
||||
THE SOFTWARE.
|
||||
|
|
|
|||
|
|
@ -0,0 +1,152 @@
|
|||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
pip-wheel-metadata/
|
||||
share/python-wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.nox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
*.py,cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
docs/.build/
|
||||
|
||||
# PyBuilder
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# IPython
|
||||
profile_default/
|
||||
ipython_config.py
|
||||
|
||||
# pyenv
|
||||
.python-version
|
||||
|
||||
# pipenv
|
||||
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
||||
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
||||
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
||||
# install all needed dependencies.
|
||||
#Pipfile.lock
|
||||
|
||||
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
||||
__pypackages__/
|
||||
|
||||
# Celery stuff
|
||||
celerybeat-schedule
|
||||
celerybeat.pid
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
dmypy.json
|
||||
|
||||
# Pyre type checker
|
||||
.pyre/
|
||||
|
||||
# IDE
|
||||
.idea/
|
||||
.vscode/
|
||||
|
||||
# macos
|
||||
*.DS_Store
|
||||
#data/
|
||||
|
||||
docs/.build
|
||||
|
||||
# pytorch checkpoint
|
||||
*.pt
|
||||
|
||||
# sql
|
||||
*.db
|
||||
|
||||
# wandb log
|
||||
example/wandb/
|
||||
example/ui/gradio/
|
||||
example/vector_db_for_test
|
||||
examples/awesome-chatgpt-prompts/
|
||||
|
|
@ -0,0 +1,258 @@
|
|||
# ColossalQA - Langchain-based Document Retrieval Conversation System
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [Overall Implementation](#overall-implementation)
|
||||
- [Install](#install)
|
||||
- [How to Use](#how-to-use)
|
||||
- Examples
|
||||
- [A Simple Web UI Demo](examples/webui_demo/README.md)
|
||||
- [Local Chinese Retrieval QA + Chat](examples/retrieval_conversation_zh.py)
|
||||
- [Local English Retrieval QA + Chat](examples/retrieval_conversation_en.py)
|
||||
- [Local Bi-lingual Retrieval QA + Chat](examples/retrieval_conversation_universal.py)
|
||||
- [Experimental AI Agent Based on Chatgpt + Chat](examples/conversation_agent_chatgpt.py)
|
||||
- Use cases
|
||||
- [English customer service chatbot](examples/retrieval_conversation_en_customer_service.py)
|
||||
- [Chinese customer service intent classification](examples/retrieval_intent_classification_zh_customer_service.py)
|
||||
|
||||
**As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
|
||||
|
||||
## Overall Implementation
|
||||
|
||||
### Highlevel Design
|
||||
|
||||
|
||||

|
||||
<p align="center">
|
||||
Fig.1. Design of the document retrieval conversation system
|
||||
</p>
|
||||
|
||||
Retrieval-based Question Answering (QA) is a crucial application of natural language processing that aims to find the most relevant answers based on the information from a corpus of text documents in response to user queries. Vector stores, which represent documents and queries as vectors in a high-dimensional space, have gained popularity for their effectiveness in retrieval QA tasks.
|
||||
|
||||
#### Step 1: Collect Data
|
||||
|
||||
A successful retrieval QA system starts with high-quality data. You need a collection of text documents that's related to your application. You may also need to manually design how your data will be presented to the language model.
|
||||
|
||||
#### Step 2: Split Data
|
||||
|
||||
Document data is usually too long to fit into the prompt due to the context length limitation of LLMs. Supporting documents need to be splited into short chunks before constructing vector stores. In this demo, we use neural text spliter for better performance.
|
||||
|
||||
#### Step 3: Construct Vector Stores
|
||||
Choose a embedding function and embed your text chunk into high dimensional vectors. Once you have vectors for your documents, you need to create a vector store. The vector store should efficiently index and retrieve documents based on vector similarity. In this demo, we use [Chroma](https://python.langchain.com/docs/integrations/vectorstores/chroma) and incrementally update indexes of vector stores. Through incremental update, one can update and maintain a vector store without recalculating every embedding.
|
||||
You are free to choose any vectorstore from a varity of [vector stores](https://python.langchain.com/docs/integrations/vectorstores/) supported by Langchain. However, the incremental update only works with LangChain vectorstore's that support:
|
||||
- Document addition by id (add_documents method with ids argument)
|
||||
- Delete by id (delete method with)
|
||||
|
||||
#### Step 4: Retrieve Relative Text
|
||||
Upon querying, we will run a reference resolution on user's input, the goal of this step is to remove ambiguous reference in user's query such as "this company", "him". We then embed the query with the same embedding function and query the vectorstore to retrieve the top-k most similar documents.
|
||||
|
||||
#### Step 5: Format Prompt
|
||||
The prompt carries essential information including task description, conversation history, retrived documents, and user's query for the LLM to generate a response. Please refer to this [README](./colossalqa/prompt/README.md) for more details.
|
||||
|
||||
#### Step 6: Inference
|
||||
Pass the prompt to the LLM with additional generaton arguments to get agent response. You can control the generation with additional arguments such as temperature, top_k, top_p, max_new_tokens. You can also define when to stop by passing the stop substring to the retrieval QA chain.
|
||||
|
||||
#### Step 7: Update Memory
|
||||
We designed a memory module that automatically summarize overlength conversation to fit the max context length of LLM. In this step, we update the memory with the newly generated response. To fix into the context length of a given LLM, we sumarize the overlength part of historical conversation and present the rest in round-based conversation format. Fig.2. shows how the memory is updated. Please refer to this [README](./colossalqa/prompt/README.md) for dialogue format.
|
||||
|
||||

|
||||
<p align="center">
|
||||
Fig.2. Design of the memory module
|
||||
</p>
|
||||
|
||||
### Supported Language Models (LLMs) and Embedding Models
|
||||
|
||||
Our platform accommodates two kinds of LLMs: API-accessible and locally run models. For the API-style LLMs, we support ChatGPT, Pangu, and models deployed through the vLLM API Server. For locally operated LLMs, we are compatible with any language model that can be initiated using [`transformers.AutoModel.from_pretrained`](https://huggingface.co/transformers/v3.0.2/model_doc/auto.html#transformers.AutoModel.from_pretrained). However, due to the dependence of retrieval-based QA on the language model's abilities in zero-shot learning, instruction following, and logical reasoning, smaller models are typically not advised. In our local demo, we utilize ChatGLM2 for Chinese and LLaMa2 for English. Modifying the base LLM requires corresponding adjustments to the prompts.
|
||||
|
||||
Here are some sample codes to load different types of LLM.
|
||||
|
||||
```python
|
||||
# For locally-run LLM
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
api = ColossalAPI('chatglm2', 'path_to_chatglm2_checkpoint')
|
||||
llm = ColossalLLM(n=1, api=api)
|
||||
|
||||
# For LLMs running on the vLLM API Server
|
||||
from colossalqa.local.llm import VllmAPI, VllmLLM
|
||||
vllm_api = VllmAPI("Your_vLLM_Host", "Your_vLLM_Port")
|
||||
llm = VllmLLM(n=1, api=vllm_api)
|
||||
|
||||
# For ChatGPT LLM
|
||||
from langchain.llms import OpenAI
|
||||
llm = OpenAI(openai_api_key="YOUR_OPENAI_API_KEY")
|
||||
|
||||
# For Pangu LLM
|
||||
# set up your authentification info
|
||||
from colossalqa.local.pangu_llm import Pangu
|
||||
os.environ["URL"] = ""
|
||||
os.environ["URLNAME"] = ""
|
||||
os.environ["PASSWORD"] = ""
|
||||
os.environ["DOMAIN_NAME"] = ""
|
||||
|
||||
llm = Pangu(id=1)
|
||||
llm.set_auth_config()
|
||||
```
|
||||
|
||||
Regarding embedding models, we support all models that can be loaded via ["langchain.embeddings.HuggingFaceEmbeddings"](https://api.python.langchain.com/en/latest/embeddings/langchain.embeddings.huggingface.HuggingFaceEmbeddings.html). The default embedding model used in this demo is ["moka-ai/m3e-base"](https://huggingface.co/moka-ai/m3e-base), which enables consistent text similarity computations in both Chinese and English.
|
||||
|
||||
In the future, supported LLM will also include models running on colossal inference and serving framework.
|
||||
|
||||
## Install
|
||||
|
||||
Install colossalqa
|
||||
```bash
|
||||
# python==3.8.17
|
||||
cd ColossalAI/applications/ColossalQA
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
To use the vLLM for providing LLM services via an API, please consult the official guide [here](https://vllm.readthedocs.io/en/latest/getting_started/quickstart.html#api-server) to start the API server. It's important to set up a new virtual environment for installing vLLM, as there are currently some dependency conflicts between vLLM and ColossalQA when installed on the same machine.
|
||||
|
||||
## How to Use
|
||||
|
||||
### Collect Your Data
|
||||
|
||||
For ChatGPT based Agent we support document retrieval and simple sql search.
|
||||
If you want to run the demo locally, we provided document retrieval based conversation system built upon langchain. It accept a wide range of documents. After collecting your data, put your data under a folder.
|
||||
|
||||
Read comments under ./colossalqa/data_loader for more detail regarding supported data formats.
|
||||
|
||||
### Run The Script
|
||||
|
||||
We provide a simple Web UI demo of ColossalQA, enabling you to upload your files as a knowledge base and interact with them through a chat interface in your browser. More details can be found [here](examples/webui_demo/README.md)
|
||||
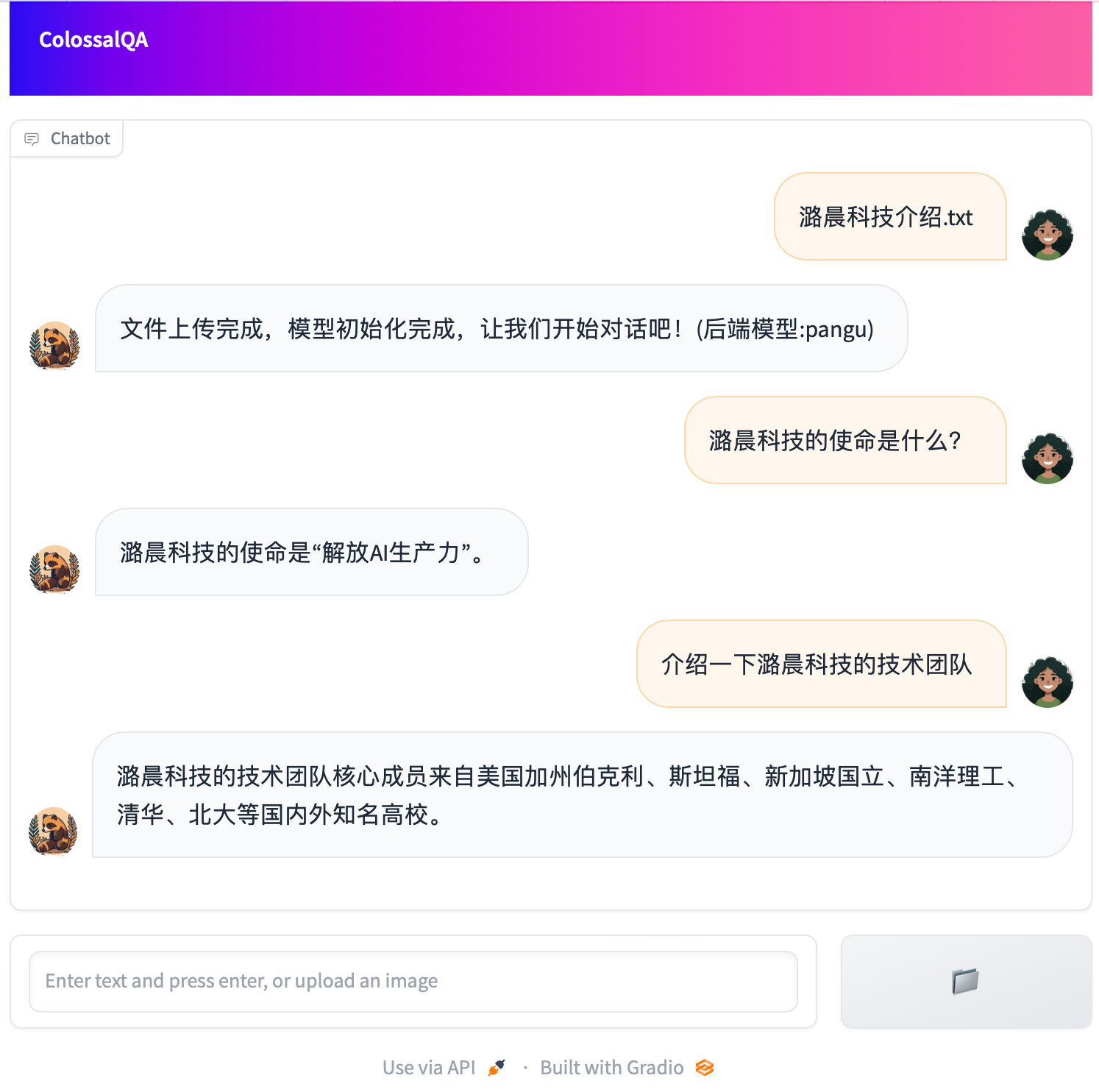
|
||||
|
||||
We also provided some scripts for Chinese document retrieval based conversation system, English document retrieval based conversation system, Bi-lingual document retrieval based conversation system and an experimental AI agent with document retrieval and SQL query functionality. The Bi-lingual one is a high-level wrapper for the other two clases. We write different scripts for different languages because retrieval QA requires different embedding models, LLMs, prompts for different language setting. For now, we use LLaMa2 for English retrieval QA and ChatGLM2 for Chinese retrieval QA for better performance.
|
||||
|
||||
To run the bi-lingual scripts.
|
||||
```bash
|
||||
python retrieval_conversation_universal.py \
|
||||
--en_model_path /path/to/Llama-2-7b-hf \
|
||||
--zh_model_path /path/to/chatglm2-6b \
|
||||
--zh_model_name chatglm2 \
|
||||
--en_model_name llama \
|
||||
--sql_file_path /path/to/any/folder
|
||||
```
|
||||
|
||||
To run retrieval_conversation_en.py.
|
||||
```bash
|
||||
python retrieval_conversation_en.py \
|
||||
--model_path /path/to/Llama-2-7b-hf \
|
||||
--model_name llama \
|
||||
--sql_file_path /path/to/any/folder
|
||||
```
|
||||
|
||||
To run retrieval_conversation_zh.py.
|
||||
```bash
|
||||
python retrieval_conversation_zh.py \
|
||||
--model_path /path/to/chatglm2-6b \
|
||||
--model_name chatglm2 \
|
||||
--sql_file_path /path/to/any/folder
|
||||
```
|
||||
|
||||
To run retrieval_conversation_chatgpt.py.
|
||||
```bash
|
||||
python retrieval_conversation_chatgpt.py \
|
||||
--open_ai_key_path /path/to/plain/text/openai/key/file \
|
||||
--sql_file_path /path/to/any/folder
|
||||
```
|
||||
|
||||
To run conversation_agent_chatgpt.py.
|
||||
```bash
|
||||
python conversation_agent_chatgpt.py \
|
||||
--open_ai_key_path /path/to/plain/text/openai/key/file
|
||||
```
|
||||
|
||||
After runing the script, it will ask you to provide the path to your data during the execution of the script. You can also pass a glob path to load multiple files at once. Please read this [guide](https://docs.python.org/3/library/glob.html) on how to define glob path. Follow the instruction and provide all files for your retrieval conversation system then type "ESC" to finish loading documents. If csv files are provided, please use "," as delimiter and "\"" as quotation mark. For json and jsonl files. The default format is
|
||||
```
|
||||
{
|
||||
"data":[
|
||||
{"content":"XXX"},
|
||||
{"content":"XXX"}
|
||||
...
|
||||
]
|
||||
}
|
||||
```
|
||||
For other formats, please refer to [this document](https://python.langchain.com/docs/modules/data_connection/document_loaders/json) on how to define schema for data loading. There are no other formatting constraints for loading documents type files. For loading table type files, we use pandas, please refer to [Pandas-Input/Output](https://pandas.pydata.org/pandas-docs/stable/reference/io.html) for file format details.
|
||||
|
||||
We also support another kay-value mode that utilizes a user-defined key to calculate the embeddings of the vector store. If a query matches a specific key, the value corresponding to that key will be used to generate the prompt. For instance, in the document below, "My coupon isn't working." will be employed during indexing, whereas "Question: My coupon isn't working.\nAnswer: We apologize for ... apply it to?" will appear in the final prompt. This format is typically useful when the task involves carrying on a conversation with readily accessible conversation data, such as customer service, question answering.
|
||||
```python
|
||||
Document(page_content="My coupon isn't working.", metadata={'is_key_value_mapping': True, 'seq_num': 36, 'source': 'XXX.json', 'value': "Question: My coupon isn't working.\nAnswer:We apologize for the inconvenience. Can you please provide the coupon code and the product name or SKU you're trying to apply it to?"})
|
||||
```
|
||||
|
||||
For now, we only support the key-value mode for json data files. You can run the script retrieval_conversation_en_customer_service.py by the following command.
|
||||
|
||||
```bash
|
||||
python retrieval_conversation_en_customer_service.py \
|
||||
--model_path /path/to/Llama-2-7b-hf \
|
||||
--model_name llama \
|
||||
--sql_file_path /path/to/any/folder
|
||||
```
|
||||
|
||||
## The Plan
|
||||
|
||||
- [x] build document retrieval QA tool
|
||||
- [x] Add memory
|
||||
- [x] Add demo for AI agent with SQL query
|
||||
- [x] Add customer retriever for fast construction and retrieving (with incremental update)
|
||||
|
||||
## Reference
|
||||
|
||||
```bibtex
|
||||
@software{Chase_LangChain_2022,
|
||||
author = {Chase, Harrison},
|
||||
month = oct,
|
||||
title = {{LangChain}},
|
||||
url = {https://github.com/hwchase17/langchain},
|
||||
year = {2022}
|
||||
}
|
||||
```
|
||||
```bibtex
|
||||
@inproceedings{DBLP:conf/asru/ZhangCLLW21,
|
||||
author = {Qinglin Zhang and
|
||||
Qian Chen and
|
||||
Yali Li and
|
||||
Jiaqing Liu and
|
||||
Wen Wang},
|
||||
title = {Sequence Model with Self-Adaptive Sliding Window for Efficient Spoken
|
||||
Document Segmentation},
|
||||
booktitle = {{IEEE} Automatic Speech Recognition and Understanding Workshop, {ASRU}
|
||||
2021, Cartagena, Colombia, December 13-17, 2021},
|
||||
pages = {411--418},
|
||||
publisher = {{IEEE}},
|
||||
year = {2021},
|
||||
url = {https://doi.org/10.1109/ASRU51503.2021.9688078},
|
||||
doi = {10.1109/ASRU51503.2021.9688078},
|
||||
timestamp = {Wed, 09 Feb 2022 09:03:04 +0100},
|
||||
biburl = {https://dblp.org/rec/conf/asru/ZhangCLLW21.bib},
|
||||
bibsource = {dblp computer science bibliography, https://dblp.org}
|
||||
}
|
||||
```
|
||||
```bibtex
|
||||
@misc{touvron2023llama,
|
||||
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
|
||||
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
|
||||
year={2023},
|
||||
eprint={2307.09288},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CL}
|
||||
}
|
||||
```
|
||||
```bibtex
|
||||
@article{zeng2022glm,
|
||||
title={Glm-130b: An open bilingual pre-trained model},
|
||||
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
|
||||
journal={arXiv preprint arXiv:2210.02414},
|
||||
year={2022}
|
||||
}
|
||||
```
|
||||
```bibtex
|
||||
@inproceedings{du2022glm,
|
||||
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
|
||||
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
|
||||
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
|
||||
pages={320--335},
|
||||
year={2022}
|
||||
}
|
||||
```
|
||||
|
|
@ -0,0 +1,103 @@
|
|||
"""
|
||||
Custom SummarizerMixin base class and ConversationSummaryMemory class
|
||||
|
||||
Modified from Original Source
|
||||
|
||||
This code is based on LangChain Ai's langchain, which can be found at
|
||||
https://github.com/langchain-ai/langchain
|
||||
The original code is licensed under the MIT license.
|
||||
"""
|
||||
|
||||
from __future__ import annotations
|
||||
|
||||
from typing import Any, Dict, List, Type
|
||||
|
||||
from langchain.chains.llm import LLMChain
|
||||
from langchain.memory.chat_memory import BaseChatMemory
|
||||
from langchain.memory.prompt import SUMMARY_PROMPT
|
||||
from langchain.pydantic_v1 import BaseModel, root_validator
|
||||
from langchain.schema import BaseChatMessageHistory, BasePromptTemplate
|
||||
from langchain.schema.language_model import BaseLanguageModel
|
||||
from langchain.schema.messages import BaseMessage, SystemMessage, get_buffer_string
|
||||
|
||||
|
||||
class SummarizerMixin(BaseModel):
|
||||
"""
|
||||
Mixin for summarizer.
|
||||
"""
|
||||
|
||||
human_prefix: str = "Human"
|
||||
ai_prefix: str = "Assistant"
|
||||
llm: BaseLanguageModel
|
||||
prompt: BasePromptTemplate = SUMMARY_PROMPT
|
||||
summary_message_cls: Type[BaseMessage] = SystemMessage
|
||||
llm_kwargs: Dict = {}
|
||||
|
||||
def predict_new_summary(self, messages: List[BaseMessage], existing_summary: str, stop: List = []) -> str:
|
||||
"""
|
||||
Recursively summarize a conversation by generating a new summary using
|
||||
the last round of conversation and the existing summary.
|
||||
"""
|
||||
new_lines = get_buffer_string(
|
||||
messages,
|
||||
human_prefix=self.human_prefix,
|
||||
ai_prefix=self.ai_prefix,
|
||||
)
|
||||
|
||||
chain = LLMChain(llm=self.llm, prompt=self.prompt, llm_kwargs=self.llm_kwargs)
|
||||
return chain.predict(summary=existing_summary, new_lines=new_lines, stop=stop)
|
||||
|
||||
|
||||
class ConversationSummaryMemory(BaseChatMemory, SummarizerMixin):
|
||||
"""Conversation summarizer to chat memory."""
|
||||
|
||||
buffer: str = ""
|
||||
memory_key: str = "history"
|
||||
|
||||
@classmethod
|
||||
def from_messages(
|
||||
cls,
|
||||
llm: BaseLanguageModel,
|
||||
chat_memory: BaseChatMessageHistory,
|
||||
summarize_step: int = 2,
|
||||
**kwargs: Any,
|
||||
) -> ConversationSummaryMemory:
|
||||
obj = cls(llm=llm, chat_memory=chat_memory, **kwargs)
|
||||
for i in range(0, len(obj.chat_memory.messages), summarize_step):
|
||||
obj.buffer = obj.predict_new_summary(obj.chat_memory.messages[i : i + summarize_step], obj.buffer)
|
||||
return obj
|
||||
|
||||
@property
|
||||
def memory_variables(self) -> List[str]:
|
||||
"""Will always return list of memory variables."""
|
||||
return [self.memory_key]
|
||||
|
||||
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
|
||||
"""Return history buffer."""
|
||||
if self.return_messages:
|
||||
buffer: Any = [self.summary_message_cls(content=self.buffer)]
|
||||
else:
|
||||
buffer = self.buffer
|
||||
return {self.memory_key: buffer}
|
||||
|
||||
@root_validator()
|
||||
def validate_prompt_input_variables(cls, values: Dict) -> Dict:
|
||||
"""Validate that prompt input variables are consistent."""
|
||||
prompt_variables = values["prompt"].input_variables
|
||||
expected_keys = {"summary", "new_lines"}
|
||||
if expected_keys != set(prompt_variables):
|
||||
raise ValueError(
|
||||
"Got unexpected prompt input variables. The prompt expects "
|
||||
f"{prompt_variables}, but it should have {expected_keys}."
|
||||
)
|
||||
return values
|
||||
|
||||
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
|
||||
"""Save context from this conversation to buffer."""
|
||||
super().save_context(inputs, outputs)
|
||||
self.buffer = self.predict_new_summary(self.chat_memory.messages[-2:], self.buffer)
|
||||
|
||||
def clear(self) -> None:
|
||||
"""Clear memory contents."""
|
||||
super().clear()
|
||||
self.buffer = ""
|
||||
|
|
@ -0,0 +1,214 @@
|
|||
"""
|
||||
Chain for question-answering against a vector database.
|
||||
|
||||
Modified from Original Source
|
||||
|
||||
This code is based on LangChain Ai's langchain, which can be found at
|
||||
https://github.com/langchain-ai/langchain
|
||||
The original code is licensed under the MIT license.
|
||||
"""
|
||||
from __future__ import annotations
|
||||
|
||||
import copy
|
||||
import inspect
|
||||
from typing import Any, Dict, List, Optional
|
||||
|
||||
from colossalqa.chain.retrieval_qa.load_chain import load_qa_chain
|
||||
from colossalqa.chain.retrieval_qa.stuff import CustomStuffDocumentsChain
|
||||
from langchain.callbacks.manager import AsyncCallbackManagerForChainRun, CallbackManagerForChainRun, Callbacks
|
||||
from langchain.chains.llm import LLMChain
|
||||
from langchain.chains.question_answering.stuff_prompt import PROMPT_SELECTOR
|
||||
from langchain.chains.retrieval_qa.base import BaseRetrievalQA
|
||||
from langchain.prompts import PromptTemplate
|
||||
from langchain.pydantic_v1 import Field
|
||||
from langchain.schema import BaseRetriever, Document
|
||||
from langchain.schema.language_model import BaseLanguageModel
|
||||
|
||||
class CustomBaseRetrievalQA(BaseRetrievalQA):
|
||||
"""Base class for question-answering chains."""
|
||||
|
||||
@classmethod
|
||||
def from_llm(
|
||||
cls,
|
||||
llm: BaseLanguageModel,
|
||||
prompt: Optional[PromptTemplate] = None,
|
||||
callbacks: Callbacks = None,
|
||||
**kwargs: Any,
|
||||
) -> BaseRetrievalQA:
|
||||
"""Initialize from LLM."""
|
||||
llm_kwargs = kwargs.pop("llm_kwargs", {})
|
||||
_prompt = prompt or PROMPT_SELECTOR.get_prompt(llm)
|
||||
llm_chain = LLMChain(llm=llm, prompt=_prompt, callbacks=callbacks, llm_kwargs=llm_kwargs)
|
||||
document_prompt = kwargs.get(
|
||||
"document_prompt", PromptTemplate(input_variables=["page_content"], template="Context:\n{page_content}")
|
||||
)
|
||||
combine_documents_chain = CustomStuffDocumentsChain(
|
||||
llm_chain=llm_chain,
|
||||
document_variable_name="context",
|
||||
document_prompt=document_prompt,
|
||||
callbacks=callbacks,
|
||||
)
|
||||
|
||||
return cls(
|
||||
combine_documents_chain=combine_documents_chain,
|
||||
callbacks=callbacks,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
@classmethod
|
||||
def from_chain_type(
|
||||
cls,
|
||||
llm: BaseLanguageModel,
|
||||
chain_type: str = "stuff",
|
||||
chain_type_kwargs: Optional[dict] = None,
|
||||
**kwargs: Any,
|
||||
) -> BaseRetrievalQA:
|
||||
"""Load chain from chain type."""
|
||||
llm_kwargs = kwargs.pop("llm_kwargs", {})
|
||||
_chain_type_kwargs = chain_type_kwargs or {}
|
||||
combine_documents_chain = load_qa_chain(llm, chain_type=chain_type, **_chain_type_kwargs, llm_kwargs=llm_kwargs)
|
||||
return cls(combine_documents_chain=combine_documents_chain, **kwargs)
|
||||
|
||||
def _call(
|
||||
self,
|
||||
inputs: Dict[str, Any],
|
||||
run_manager: Optional[CallbackManagerForChainRun] = None,
|
||||
) -> Dict[str, Any]:
|
||||
"""Run get_relevant_text and llm on input query.
|
||||
|
||||
If chain has 'return_source_documents' as 'True', returns
|
||||
the retrieved documents as well under the key 'source_documents'.
|
||||
|
||||
Example:
|
||||
.. code-block:: python
|
||||
|
||||
res = indexqa({'query': 'This is my query'})
|
||||
answer, docs = res['result'], res['source_documents']
|
||||
"""
|
||||
_run_manager = run_manager or CallbackManagerForChainRun.get_noop_manager()
|
||||
question = inputs[self.input_key]
|
||||
accepts_run_manager = "run_manager" in inspect.signature(self._get_docs).parameters
|
||||
if accepts_run_manager:
|
||||
docs = self._get_docs(question, run_manager=_run_manager)
|
||||
else:
|
||||
docs = self._get_docs(question) # type: ignore[call-arg]
|
||||
|
||||
kwargs = {
|
||||
k: v
|
||||
for k, v in inputs.items()
|
||||
if k in ["stop", "temperature", "top_k", "top_p", "max_new_tokens", "doc_prefix"]
|
||||
}
|
||||
answers = []
|
||||
if self.combine_documents_chain.memory is not None:
|
||||
buffered_history_backup, summarized_history_temp_backup = copy.deepcopy(
|
||||
self.combine_documents_chain.memory.buffered_history
|
||||
), copy.deepcopy(self.combine_documents_chain.memory.summarized_history_temp)
|
||||
else:
|
||||
buffered_history_backup = None
|
||||
summarized_history_temp_backup = None
|
||||
|
||||
answer = self.combine_documents_chain.run(
|
||||
input_documents=docs, question=question, callbacks=_run_manager.get_child(), **kwargs
|
||||
)
|
||||
if summarized_history_temp_backup is not None and buffered_history_backup is not None:
|
||||
(
|
||||
self.combine_documents_chain.memory.buffered_history,
|
||||
self.combine_documents_chain.memory.summarized_history_temp,
|
||||
) = copy.deepcopy(buffered_history_backup), copy.deepcopy(summarized_history_temp_backup)
|
||||
|
||||
# if rejection_trigger_keywords is not given, return the response from LLM directly
|
||||
rejection_trigger_keywrods = inputs.get('rejection_trigger_keywrods', [])
|
||||
answer = answer if all([rej not in answer for rej in rejection_trigger_keywrods]) else None
|
||||
if answer is None:
|
||||
answer = inputs.get('rejection_answer', "抱歉,根据提供的信息无法回答该问题。")
|
||||
if self.combine_documents_chain.memory is not None:
|
||||
self.combine_documents_chain.memory.save_context({"question": question}, {"output": answer})
|
||||
|
||||
if self.return_source_documents:
|
||||
return {self.output_key: answer, "source_documents": docs}
|
||||
else:
|
||||
return {self.output_key: answer}
|
||||
|
||||
async def _acall(
|
||||
self,
|
||||
inputs: Dict[str, Any],
|
||||
run_manager: Optional[AsyncCallbackManagerForChainRun] = None,
|
||||
) -> Dict[str, Any]:
|
||||
"""Run get_relevant_text and llm on input query.
|
||||
|
||||
If chain has 'return_source_documents' as 'True', returns
|
||||
the retrieved documents as well under the key 'source_documents'.
|
||||
|
||||
Example:
|
||||
.. code-block:: python
|
||||
|
||||
res = indexqa({'query': 'This is my query'})
|
||||
answer, docs = res['result'], res['source_documents']
|
||||
"""
|
||||
_run_manager = run_manager or AsyncCallbackManagerForChainRun.get_noop_manager()
|
||||
question = inputs[self.input_key]
|
||||
accepts_run_manager = "run_manager" in inspect.signature(self._aget_docs).parameters
|
||||
if accepts_run_manager:
|
||||
docs = await self._aget_docs(question, run_manager=_run_manager)
|
||||
else:
|
||||
docs = await self._aget_docs(question) # type: ignore[call-arg]
|
||||
kwargs = {
|
||||
k: v
|
||||
for k, v in inputs.items()
|
||||
if k in ["stop", "temperature", "top_k", "top_p", "max_new_tokens", "doc_prefix"]
|
||||
}
|
||||
answer = await self.combine_documents_chain.arun(
|
||||
input_documents=docs, question=question, callbacks=_run_manager.get_child(), **kwargs
|
||||
)
|
||||
# if rejection_trigger_keywords is not given, return the response from LLM directly
|
||||
rejection_trigger_keywrods = inputs.get('rejection_trigger_keywrods', [])
|
||||
answer = answer if all([rej not in answer for rej in rejection_trigger_keywrods]) or len(rejection_trigger_keywrods)==0 else None
|
||||
if answer is None:
|
||||
answer = inputs.get('rejection_answer', "抱歉,根据提供的信息无法回答该问题。")
|
||||
self.combine_documents_chain.memory.save_context({"question": question}, {"output": answer})
|
||||
|
||||
if self.return_source_documents:
|
||||
return {self.output_key: answer, "source_documents": docs}
|
||||
else:
|
||||
return {self.output_key: answer}
|
||||
|
||||
|
||||
class RetrievalQA(CustomBaseRetrievalQA):
|
||||
"""Chain for question-answering against an index.
|
||||
|
||||
Example:
|
||||
.. code-block:: python
|
||||
|
||||
from langchain.llms import OpenAI
|
||||
from langchain.chains import RetrievalQA
|
||||
from langchain.faiss import FAISS
|
||||
from langchain.vectorstores.base import VectorStoreRetriever
|
||||
retriever = VectorStoreRetriever(vectorstore=FAISS(...))
|
||||
retrievalQA = RetrievalQA.from_llm(llm=OpenAI(), retriever=retriever)
|
||||
|
||||
"""
|
||||
|
||||
retriever: BaseRetriever = Field(exclude=True)
|
||||
|
||||
def _get_docs(
|
||||
self,
|
||||
question: str,
|
||||
*,
|
||||
run_manager: CallbackManagerForChainRun,
|
||||
) -> List[Document]:
|
||||
"""Get docs."""
|
||||
return self.retriever.get_relevant_documents(question, callbacks=run_manager.get_child())
|
||||
|
||||
async def _aget_docs(
|
||||
self,
|
||||
question: str,
|
||||
*,
|
||||
run_manager: AsyncCallbackManagerForChainRun,
|
||||
) -> List[Document]:
|
||||
"""Get docs."""
|
||||
return await self.retriever.aget_relevant_documents(question, callbacks=run_manager.get_child())
|
||||
|
||||
@property
|
||||
def _chain_type(self) -> str:
|
||||
"""Return the chain type."""
|
||||
return "retrieval_qa"
|
||||
|
|
@ -0,0 +1,87 @@
|
|||
"""
|
||||
Load question answering chains.
|
||||
For now, only the stuffed chain is modified
|
||||
|
||||
Modified from Original Source
|
||||
|
||||
This code is based on LangChain Ai's langchain, which can be found at
|
||||
https://github.com/langchain-ai/langchain
|
||||
The original code is licensed under the MIT license.
|
||||
"""
|
||||
import copy
|
||||
from typing import Any, Mapping, Optional, Protocol
|
||||
|
||||
from colossalqa.chain.retrieval_qa.stuff import CustomStuffDocumentsChain
|
||||
from langchain.callbacks.base import BaseCallbackManager
|
||||
from langchain.callbacks.manager import Callbacks
|
||||
from langchain.chains.combine_documents.base import BaseCombineDocumentsChain
|
||||
from langchain.chains.llm import LLMChain
|
||||
from langchain.chains.question_answering import stuff_prompt
|
||||
from langchain.schema.language_model import BaseLanguageModel
|
||||
from langchain.schema.prompt_template import BasePromptTemplate
|
||||
|
||||
|
||||
class LoadingCallable(Protocol):
|
||||
"""Interface for loading the combine documents chain."""
|
||||
|
||||
def __call__(self, llm: BaseLanguageModel, **kwargs: Any) -> BaseCombineDocumentsChain:
|
||||
"""Callable to load the combine documents chain."""
|
||||
|
||||
|
||||
def _load_stuff_chain(
|
||||
llm: BaseLanguageModel,
|
||||
prompt: Optional[BasePromptTemplate] = None,
|
||||
document_variable_name: str = "context",
|
||||
verbose: Optional[bool] = None,
|
||||
callback_manager: Optional[BaseCallbackManager] = None,
|
||||
callbacks: Callbacks = None,
|
||||
**kwargs: Any,
|
||||
) -> CustomStuffDocumentsChain:
|
||||
_prompt = prompt or stuff_prompt.PROMPT_SELECTOR.get_prompt(llm)
|
||||
if "llm_kwargs" in kwargs:
|
||||
llm_kwargs = copy.deepcopy(kwargs["llm_kwargs"])
|
||||
del kwargs["llm_kwargs"]
|
||||
else:
|
||||
llm_kwargs = {}
|
||||
llm_chain = LLMChain(
|
||||
llm=llm,
|
||||
prompt=_prompt,
|
||||
verbose=verbose,
|
||||
callback_manager=callback_manager,
|
||||
callbacks=callbacks,
|
||||
llm_kwargs=llm_kwargs,
|
||||
)
|
||||
return CustomStuffDocumentsChain(
|
||||
llm_chain=llm_chain,
|
||||
document_variable_name=document_variable_name,
|
||||
verbose=verbose,
|
||||
callback_manager=callback_manager,
|
||||
callbacks=callbacks,
|
||||
**kwargs,
|
||||
)
|
||||
|
||||
|
||||
def load_qa_chain(
|
||||
llm: BaseLanguageModel,
|
||||
chain_type: str = "stuff",
|
||||
verbose: Optional[bool] = None,
|
||||
callback_manager: Optional[BaseCallbackManager] = None,
|
||||
**kwargs: Any,
|
||||
) -> BaseCombineDocumentsChain:
|
||||
"""Load question answering chain.
|
||||
|
||||
Args:
|
||||
llm: Language Model to use in the chain.
|
||||
chain_type: Type of document combining chain to use. Should be one of "stuff",
|
||||
"map_reduce", "map_rerank", and "refine".
|
||||
verbose: Whether chains should be run in verbose mode or not. Note that this
|
||||
applies to all chains that make up the final chain.
|
||||
callback_manager: Callback manager to use for the chain.
|
||||
|
||||
Returns:
|
||||
A chain to use for question answering.
|
||||
"""
|
||||
loader_mapping: Mapping[str, LoadingCallable] = {"stuff": _load_stuff_chain}
|
||||
if chain_type not in loader_mapping:
|
||||
raise ValueError(f"Got unsupported chain type: {chain_type}. " f"Should be one of {loader_mapping.keys()}")
|
||||
return loader_mapping[chain_type](llm, verbose=verbose, callback_manager=callback_manager, **kwargs)
|
||||
|
|
@ -0,0 +1,91 @@
|
|||
"""
|
||||
Chain that combines documents by stuffing into context
|
||||
|
||||
Modified from Original Source
|
||||
|
||||
This code is based on LangChain Ai's langchain, which can be found at
|
||||
https://github.com/langchain-ai/langchain
|
||||
The original code is licensed under the MIT license.
|
||||
"""
|
||||
import copy
|
||||
from typing import Any, List
|
||||
|
||||
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
|
||||
from langchain.docstore.document import Document
|
||||
from langchain.schema import format_document
|
||||
|
||||
|
||||
class CustomStuffDocumentsChain(StuffDocumentsChain):
|
||||
"""Chain that combines documents by stuffing into context.
|
||||
|
||||
This chain takes a list of documents and first combines them into a single string.
|
||||
It does this by formatting each document into a string with the `document_prompt`
|
||||
and then joining them together with `document_separator`. It then adds that new
|
||||
string to the inputs with the variable name set by `document_variable_name`.
|
||||
Those inputs are then passed to the `llm_chain`.
|
||||
|
||||
Example:
|
||||
.. code-block:: python
|
||||
|
||||
from langchain.chains import StuffDocumentsChain, LLMChain
|
||||
from langchain.prompts import PromptTemplate
|
||||
from langchain.llms import OpenAI
|
||||
|
||||
# This controls how each document will be formatted. Specifically,
|
||||
# it will be passed to `format_document` - see that function for more
|
||||
# details.
|
||||
document_prompt = PromptTemplate(
|
||||
input_variables=["page_content"],
|
||||
template="{page_content}"
|
||||
)
|
||||
document_variable_name = "context"
|
||||
llm = OpenAI()
|
||||
# The prompt here should take as an input variable the
|
||||
# `document_variable_name`
|
||||
prompt = PromptTemplate.from_template(
|
||||
"Summarize this content: {context}"
|
||||
)
|
||||
llm_chain = LLMChain(llm=llm, prompt=prompt)
|
||||
chain = StuffDocumentsChain(
|
||||
llm_chain=llm_chain,
|
||||
document_prompt=document_prompt,
|
||||
document_variable_name=document_variable_name
|
||||
)
|
||||
"""
|
||||
|
||||
def _get_inputs(self, docs: List[Document], **kwargs: Any) -> dict:
|
||||
"""Construct inputs from kwargs and docs.
|
||||
|
||||
Format and the join all the documents together into one input with name
|
||||
`self.document_variable_name`. The pluck any additional variables
|
||||
from **kwargs.
|
||||
|
||||
Args:
|
||||
docs: List of documents to format and then join into single input
|
||||
**kwargs: additional inputs to chain, will pluck any other required
|
||||
arguments from here.
|
||||
|
||||
Returns:
|
||||
dictionary of inputs to LLMChain
|
||||
"""
|
||||
# Format each document according to the prompt
|
||||
|
||||
# if the document is in the key-value format has a 'is_key_value_mapping'=True in meta_data and has 'value' in metadata
|
||||
# use the value to replace the key
|
||||
doc_prefix = kwargs.get("doc_prefix", "Supporting Document")
|
||||
docs_ = []
|
||||
for id, doc in enumerate(docs):
|
||||
doc_ = copy.deepcopy(doc)
|
||||
if doc_.metadata.get("is_key_value_mapping", False) and "value" in doc_.metadata:
|
||||
doc_.page_content = str(doc_.metadata["value"])
|
||||
prefix = doc_prefix + str(id)
|
||||
doc_.page_content = str(prefix + ":" + (" " if doc_.page_content[0] != " " else "") + doc_.page_content)
|
||||
docs_.append(doc_)
|
||||
|
||||
doc_strings = [format_document(doc, self.document_prompt) for doc in docs_]
|
||||
arg_list = ["stop", "temperature", "top_k", "top_p", "max_new_tokens"]
|
||||
arg_list.extend(self.llm_chain.prompt.input_variables)
|
||||
# Join the documents together to put them in the prompt.
|
||||
inputs = {k: v for k, v in kwargs.items() if k in arg_list}
|
||||
inputs[self.document_variable_name] = self.document_separator.join(doc_strings)
|
||||
return inputs
|
||||
|
|
@ -0,0 +1,128 @@
|
|||
"""
|
||||
Class for loading document type data
|
||||
"""
|
||||
|
||||
import glob
|
||||
from typing import List
|
||||
|
||||
from colossalqa.mylogging import get_logger
|
||||
from langchain.document_loaders import (
|
||||
JSONLoader,
|
||||
PyPDFLoader,
|
||||
TextLoader,
|
||||
UnstructuredHTMLLoader,
|
||||
UnstructuredMarkdownLoader,
|
||||
)
|
||||
from langchain.document_loaders.csv_loader import CSVLoader
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
SUPPORTED_DATA_FORMAT = [".csv", ".json", ".html", ".md", ".pdf", ".txt", ".jsonl"]
|
||||
|
||||
|
||||
class DocumentLoader:
|
||||
"""
|
||||
Load documents from different files into list of langchain Documents
|
||||
"""
|
||||
|
||||
def __init__(self, files: List, **kwargs) -> None:
|
||||
"""
|
||||
Args:
|
||||
files: list of files (list[file path, name])
|
||||
**kwargs: keyword type arguments, useful for certain document types
|
||||
"""
|
||||
self.data = {}
|
||||
self.kwargs = kwargs
|
||||
|
||||
for item in files:
|
||||
path = item[0] if isinstance(item, list) else item
|
||||
logger.info(f"Loading data from {path}")
|
||||
self.load_data(path)
|
||||
logger.info("Data loaded")
|
||||
|
||||
self.all_data = []
|
||||
for key in self.data:
|
||||
if isinstance(self.data[key], list):
|
||||
for item in self.data[key]:
|
||||
if isinstance(item, list):
|
||||
self.all_data.extend(item)
|
||||
else:
|
||||
self.all_data.append(item)
|
||||
|
||||
def load_data(self, path: str) -> None:
|
||||
"""
|
||||
Load data. Please refer to https://python.langchain.com/docs/modules/data_connection/document_loaders/
|
||||
for sepcific format requirements.
|
||||
Args:
|
||||
path: path to a file
|
||||
To load files with glob path, here are some examples.
|
||||
Load all file from directory: folder1/folder2/*
|
||||
Load all pdf file from directory: folder1/folder2/*.pdf
|
||||
"""
|
||||
files = []
|
||||
|
||||
# Handle glob expression
|
||||
try:
|
||||
files = glob.glob(path)
|
||||
except Exception as e:
|
||||
logger.error(e)
|
||||
if len(files) == 0:
|
||||
raise ValueError("Unsupported file/directory format. For directories, please use glob expression")
|
||||
elif len(files) == 1:
|
||||
path = files[0]
|
||||
else:
|
||||
for file in files:
|
||||
self.load_data(file)
|
||||
return
|
||||
|
||||
# Load data if the path is a file
|
||||
logger.info(f"load {path}", verbose=True)
|
||||
if path.endswith(".csv"):
|
||||
# Load csv
|
||||
loader = CSVLoader(file_path=path, encoding="utf8")
|
||||
data = loader.load()
|
||||
self.data[path] = data
|
||||
elif path.endswith(".txt"):
|
||||
# Load txt
|
||||
loader = TextLoader(path, encoding="utf8")
|
||||
data = loader.load()
|
||||
self.data[path] = data
|
||||
elif path.endswith("html"):
|
||||
# Load html
|
||||
loader = UnstructuredHTMLLoader(path, encoding="utf8")
|
||||
data = loader.load()
|
||||
self.data[path] = data
|
||||
elif path.endswith("json"):
|
||||
# Load json
|
||||
loader = JSONLoader(
|
||||
file_path=path,
|
||||
jq_schema=self.kwargs.get("jq_schema", ".data[]"),
|
||||
content_key=self.kwargs.get("content_key", "content"),
|
||||
metadata_func=self.kwargs.get("metadata_func", None),
|
||||
)
|
||||
|
||||
data = loader.load()
|
||||
self.data[path] = data
|
||||
elif path.endswith("jsonl"):
|
||||
# Load jsonl
|
||||
loader = JSONLoader(
|
||||
file_path=path, jq_schema=self.kwargs.get("jq_schema", ".data[].content"), json_lines=True
|
||||
)
|
||||
data = loader.load()
|
||||
self.data[path] = data
|
||||
elif path.endswith(".md"):
|
||||
# Load markdown
|
||||
loader = UnstructuredMarkdownLoader(path)
|
||||
data = loader.load()
|
||||
self.data[path] = data
|
||||
elif path.endswith(".pdf"):
|
||||
# Load pdf
|
||||
loader = PyPDFLoader(path)
|
||||
data = loader.load_and_split()
|
||||
self.data[path] = data
|
||||
else:
|
||||
if "." in path.split("/")[-1]:
|
||||
raise ValueError(f"Unsupported file format {path}. Supported formats: {SUPPORTED_DATA_FORMAT}")
|
||||
else:
|
||||
# May ba a directory, we strictly follow the glob path and will not load files in subdirectories
|
||||
pass
|
||||
|
|
@ -0,0 +1,119 @@
|
|||
'''
|
||||
Class for loading table type data. please refer to Pandas-Input/Output for file format details.
|
||||
'''
|
||||
|
||||
|
||||
import os
|
||||
import glob
|
||||
import pandas as pd
|
||||
from sqlalchemy import create_engine
|
||||
from colossalqa.utils import drop_table
|
||||
from colossalqa.mylogging import get_logger
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
SUPPORTED_DATA_FORMAT = ['.csv','.xlsx', '.xls','.json','.html','.h5', '.hdf5','.parquet','.feather','.dta']
|
||||
|
||||
class TableLoader:
|
||||
'''
|
||||
Load tables from different files and serve a sql database for database operations
|
||||
'''
|
||||
def __init__(self, files: str,
|
||||
sql_path:str='sqlite:///mydatabase.db',
|
||||
verbose=False, **kwargs) -> None:
|
||||
'''
|
||||
Args:
|
||||
files: list of files (list[file path, name])
|
||||
sql_path: how to serve the sql database
|
||||
**kwargs: keyword type arguments, useful for certain document types
|
||||
'''
|
||||
self.data = {}
|
||||
self.verbose = verbose
|
||||
self.sql_path = sql_path
|
||||
self.kwargs = kwargs
|
||||
self.sql_engine = create_engine(self.sql_path)
|
||||
drop_table(self.sql_engine)
|
||||
|
||||
self.sql_engine = create_engine(self.sql_path)
|
||||
for item in files:
|
||||
path = item[0]
|
||||
dataset_name = item[1]
|
||||
if not os.path.exists(path):
|
||||
raise FileNotFoundError(f"{path} doesn't exists")
|
||||
if not any([path.endswith(i) for i in SUPPORTED_DATA_FORMAT]):
|
||||
raise TypeError(f"{path} not supported. Supported type {SUPPORTED_DATA_FORMAT}")
|
||||
|
||||
logger.info("loading data", verbose=self.verbose)
|
||||
self.load_data(path)
|
||||
logger.info("data loaded", verbose=self.verbose)
|
||||
self.to_sql(path, dataset_name)
|
||||
|
||||
def load_data(self, path):
|
||||
'''
|
||||
Load data and serve the data as sql database.
|
||||
Data must be in pandas format
|
||||
'''
|
||||
files = []
|
||||
# Handle glob expression
|
||||
try:
|
||||
files = glob.glob(path)
|
||||
except Exception as e:
|
||||
logger.error(e)
|
||||
if len(files)==0:
|
||||
raise ValueError("Unsupported file/directory format. For directories, please use glob expression")
|
||||
elif len(files)==1:
|
||||
path = files[0]
|
||||
else:
|
||||
for file in files:
|
||||
self.load_data(file)
|
||||
|
||||
if path.endswith('.csv'):
|
||||
# Load csv
|
||||
self.data[path] = pd.read_csv(path)
|
||||
elif path.endswith('.xlsx') or path.endswith('.xls'):
|
||||
# Load excel
|
||||
self.data[path] = pd.read_excel(path) # You can adjust the sheet_name as needed
|
||||
elif path.endswith('.json'):
|
||||
# Load json
|
||||
self.data[path] = pd.read_json(path)
|
||||
elif path.endswith('.html'):
|
||||
# Load html
|
||||
html_tables = pd.read_html(path)
|
||||
# Choose the desired table from the list of DataFrame objects
|
||||
self.data[path] = html_tables[0] # You may need to adjust this index
|
||||
elif path.endswith('.h5') or path.endswith('.hdf5'):
|
||||
# Load h5
|
||||
self.data[path] = pd.read_hdf(path, key=self.kwargs.get('key', 'data')) # You can adjust the key as needed
|
||||
elif path.endswith('.parquet'):
|
||||
# Load parquet
|
||||
self.data[path] = pd.read_parquet(path, engine='fastparquet')
|
||||
elif path.endswith('.feather'):
|
||||
# Load feather
|
||||
self.data[path] = pd.read_feather(path)
|
||||
elif path.endswith('.dta'):
|
||||
# Load dta
|
||||
self.data[path] = pd.read_stata(path)
|
||||
else:
|
||||
raise ValueError("Unsupported file format")
|
||||
|
||||
def to_sql(self, path, table_name):
|
||||
'''
|
||||
Serve the data as sql database.
|
||||
'''
|
||||
self.data[path].to_sql(table_name, con=self.sql_engine, if_exists='replace', index=False)
|
||||
logger.info(f"Loaded to Sqlite3\nPath: {path}", verbose=self.verbose)
|
||||
return self.sql_path
|
||||
|
||||
def get_sql_path(self):
|
||||
return self.sql_path
|
||||
|
||||
def __del__(self):
|
||||
if self.sql_engine:
|
||||
drop_table(self.sql_engine)
|
||||
self.sql_engine.dispose()
|
||||
del self.data
|
||||
del self.sql_engine
|
||||
|
||||
|
||||
|
||||
|
||||
|
|
@ -0,0 +1,125 @@
|
|||
"""
|
||||
LLM wrapper for LLMs running on ColossalCloud Platform
|
||||
|
||||
Usage:
|
||||
|
||||
os.environ['URL'] = ""
|
||||
os.environ['HOST'] = ""
|
||||
|
||||
gen_config = {
|
||||
'max_new_tokens': 100,
|
||||
# 'top_k': 2,
|
||||
'top_p': 0.9,
|
||||
'temperature': 0.5,
|
||||
'repetition_penalty': 2,
|
||||
}
|
||||
|
||||
llm = ColossalCloudLLM(n=1)
|
||||
llm.set_auth_config()
|
||||
resp = llm(prompt='What do you call a three-ton kangaroo?', **gen_config)
|
||||
print(resp) # super-heavyweight awesome-natured yawning Australian creature!
|
||||
|
||||
"""
|
||||
import json
|
||||
from typing import Any, List, Mapping, Optional
|
||||
|
||||
import requests
|
||||
from langchain.llms.base import LLM
|
||||
from langchain.utils import get_from_dict_or_env
|
||||
|
||||
|
||||
class ColossalCloudLLM(LLM):
|
||||
"""
|
||||
A custom LLM class that integrates LLMs running on the ColossalCloud Platform
|
||||
|
||||
"""
|
||||
n: int
|
||||
gen_config: dict = None
|
||||
auth_config: dict = None
|
||||
valid_gen_para: list = ['max_new_tokens', 'top_k',
|
||||
'top_p', 'temperature', 'repetition_penalty']
|
||||
|
||||
def __init__(self, gen_config=None, **kwargs):
|
||||
"""
|
||||
Args:
|
||||
gen_config: config for generation,
|
||||
max_new_tokens: 50 by default
|
||||
top_k: (1, vocab_size)
|
||||
top_p: (0, 1) if not None
|
||||
temperature: (0, inf) if not None
|
||||
repetition_penalty: (1, inf) if not None
|
||||
"""
|
||||
super(ColossalCloudLLM, self).__init__(**kwargs)
|
||||
if gen_config is None:
|
||||
self.gen_config = {"max_new_tokens": 50}
|
||||
else:
|
||||
assert "max_new_tokens" in gen_config, "max_new_tokens is a compulsory key in the gen config"
|
||||
self.gen_config = gen_config
|
||||
|
||||
@property
|
||||
def _identifying_params(self) -> Mapping[str, Any]:
|
||||
"""Get the identifying parameters."""
|
||||
return {"n": self.n}
|
||||
|
||||
@property
|
||||
def _llm_type(self) -> str:
|
||||
return 'ColossalCloudLLM'
|
||||
|
||||
def set_auth_config(self, **kwargs):
|
||||
url = get_from_dict_or_env(kwargs, "url", "URL")
|
||||
host = get_from_dict_or_env(kwargs, "host", "HOST")
|
||||
|
||||
auth_config = {}
|
||||
auth_config['endpoint'] = url
|
||||
auth_config['Host'] = host
|
||||
self.auth_config = auth_config
|
||||
|
||||
def _call(self, prompt: str, stop=None, **kwargs: Any) -> str:
|
||||
"""
|
||||
Args:
|
||||
prompt: The prompt to pass into the model.
|
||||
stop: A list of strings to stop generation when encountered
|
||||
|
||||
Returns:
|
||||
The string generated by the model
|
||||
"""
|
||||
# Update the generation arguments
|
||||
for key, value in kwargs.items():
|
||||
if key not in self.valid_gen_para:
|
||||
raise KeyError(f"Invalid generation parameter: '{key}'. Valid keys are: {', '.join(self.valid_gen_para)}")
|
||||
if key in self.gen_config:
|
||||
self.gen_config[key] = value
|
||||
|
||||
resp_text = self.text_completion(prompt, self.gen_config, self.auth_config)
|
||||
# TODO: This may cause excessive tokens count
|
||||
if stop is not None:
|
||||
for stopping_words in stop:
|
||||
if stopping_words in resp_text:
|
||||
resp_text = resp_text.split(stopping_words)[0]
|
||||
return resp_text
|
||||
|
||||
|
||||
def text_completion(self, prompt, gen_config, auth_config):
|
||||
# Complusory Parameters
|
||||
endpoint = auth_config.pop('endpoint')
|
||||
max_new_tokens = gen_config.pop('max_new_tokens')
|
||||
# Optional Parameters
|
||||
optional_params = ['top_k', 'top_p', 'temperature', 'repetition_penalty'] # Self.optional
|
||||
gen_config = {key: gen_config[key] for key in optional_params if key in gen_config}
|
||||
# Define the data payload
|
||||
data = {
|
||||
"max_new_tokens": max_new_tokens,
|
||||
"history": [
|
||||
{"instruction": prompt, "response": ""}
|
||||
],
|
||||
**gen_config
|
||||
}
|
||||
headers = {
|
||||
"Content-Type": "application/json",
|
||||
**auth_config # 'Host',
|
||||
}
|
||||
# Make the POST request
|
||||
response = requests.post(endpoint, headers=headers, data=json.dumps(data))
|
||||
response.raise_for_status() # raise error if return code is not 200(success)
|
||||
# Check the response
|
||||
return response.text
|
||||
|
|
@ -0,0 +1,183 @@
|
|||
"""
|
||||
API and LLM warpper class for running LLMs locally
|
||||
|
||||
Usage:
|
||||
|
||||
import os
|
||||
model_path = os.environ.get("ZH_MODEL_PATH")
|
||||
model_name = "chatglm2"
|
||||
colossal_api = ColossalAPI(model_name, model_path)
|
||||
llm = ColossalLLM(n=1, api=colossal_api)
|
||||
TEST_PROMPT_CHATGLM="续写文章:惊蛰一过,春寒加剧。先是料料峭峭,继而雨季开始,"
|
||||
logger.info(llm(TEST_PROMPT_CHATGLM, max_new_tokens=100), verbose=True)
|
||||
|
||||
"""
|
||||
from typing import Any, List, Mapping, Optional
|
||||
|
||||
import torch
|
||||
from colossalqa.local.utils import get_response, post_http_request
|
||||
from colossalqa.mylogging import get_logger
|
||||
from langchain.callbacks.manager import CallbackManagerForLLMRun
|
||||
from langchain.llms.base import LLM
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
|
||||
class ColossalAPI:
|
||||
"""
|
||||
API for calling LLM.generate
|
||||
"""
|
||||
|
||||
__instances = dict()
|
||||
|
||||
def __init__(self, model_type: str, model_path: str, ckpt_path: str = None) -> None:
|
||||
"""
|
||||
Configurate model
|
||||
"""
|
||||
if model_type + model_path + (ckpt_path or "") in ColossalAPI.__instances:
|
||||
return
|
||||
else:
|
||||
ColossalAPI.__instances[model_type + model_path + (ckpt_path or "")] = self
|
||||
self.model_type = model_type
|
||||
self.model = AutoModelForCausalLM.from_pretrained(model_path, torch_dtype=torch.float16, trust_remote_code=True)
|
||||
|
||||
if ckpt_path is not None:
|
||||
state_dict = torch.load(ckpt_path)
|
||||
self.model.load_state_dict(state_dict)
|
||||
self.model.to(torch.cuda.current_device())
|
||||
|
||||
# Configurate tokenizer
|
||||
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
|
||||
|
||||
self.model.eval()
|
||||
|
||||
@staticmethod
|
||||
def get_api(model_type: str, model_path: str, ckpt_path: str = None):
|
||||
if model_type + model_path + (ckpt_path or "") in ColossalAPI.__instances:
|
||||
return ColossalAPI.__instances[model_type + model_path + (ckpt_path or "")]
|
||||
else:
|
||||
return ColossalAPI(model_type, model_path, ckpt_path)
|
||||
|
||||
def generate(self, input: str, **kwargs) -> str:
|
||||
"""
|
||||
Generate response given the prompt
|
||||
Args:
|
||||
input: input string
|
||||
**kwargs: language model keyword type arguments, such as top_k, top_p, temperature, max_new_tokens...
|
||||
Returns:
|
||||
output: output string
|
||||
"""
|
||||
if self.model_type in ["chatglm", "chatglm2"]:
|
||||
inputs = {
|
||||
k: v.to(torch.cuda.current_device()) for k, v in self.tokenizer(input, return_tensors="pt").items()
|
||||
}
|
||||
else:
|
||||
inputs = {
|
||||
"input_ids": self.tokenizer(input, return_tensors="pt")["input_ids"].to(torch.cuda.current_device())
|
||||
}
|
||||
|
||||
output = self.model.generate(**inputs, **kwargs)
|
||||
output = output.cpu()
|
||||
prompt_len = inputs["input_ids"].size(1)
|
||||
response = output[0, prompt_len:]
|
||||
output = self.tokenizer.decode(response, skip_special_tokens=True)
|
||||
return output
|
||||
|
||||
|
||||
class VllmAPI:
|
||||
def __init__(self, host: str = "localhost", port: int = 8077) -> None:
|
||||
# Configurate api for model served through web
|
||||
self.host = host
|
||||
self.port = port
|
||||
self.url = f"http://{self.host}:{self.port}/generate"
|
||||
|
||||
def generate(self, input: str, **kwargs):
|
||||
output = get_response(post_http_request(input, self.url, **kwargs))[0]
|
||||
return output[len(input) :]
|
||||
|
||||
|
||||
class ColossalLLM(LLM):
|
||||
"""
|
||||
Langchain LLM wrapper for a local LLM
|
||||
"""
|
||||
|
||||
n: int
|
||||
api: Any
|
||||
kwargs = {"max_new_tokens": 100}
|
||||
|
||||
@property
|
||||
def _llm_type(self) -> str:
|
||||
return "custom"
|
||||
|
||||
def _call(
|
||||
self,
|
||||
prompt: str,
|
||||
stop: Optional[List[str]] = None,
|
||||
run_manager: Optional[CallbackManagerForLLMRun] = None,
|
||||
**kwargs: Any,
|
||||
) -> str:
|
||||
logger.info(f"kwargs:{kwargs}\nstop:{stop}\nprompt:{prompt}", verbose=self.verbose)
|
||||
for k in self.kwargs:
|
||||
if k not in kwargs:
|
||||
kwargs[k] = self.kwargs[k]
|
||||
|
||||
generate_args = {k: kwargs[k] for k in kwargs if k not in ["stop", "n"]}
|
||||
out = self.api.generate(prompt, **generate_args)
|
||||
if isinstance(stop, list) and len(stop) != 0:
|
||||
for stopping_words in stop:
|
||||
if stopping_words in out:
|
||||
out = out.split(stopping_words)[0]
|
||||
logger.info(f"{prompt}{out}", verbose=self.verbose)
|
||||
return out
|
||||
|
||||
@property
|
||||
def _identifying_params(self) -> Mapping[str, int]:
|
||||
"""Get the identifying parameters."""
|
||||
return {"n": self.n}
|
||||
|
||||
|
||||
class VllmLLM(LLM):
|
||||
"""
|
||||
Langchain LLM wrapper for a local LLM
|
||||
"""
|
||||
|
||||
n: int
|
||||
api: Any
|
||||
kwargs = {"max_new_tokens": 100}
|
||||
|
||||
@property
|
||||
def _llm_type(self) -> str:
|
||||
return "custom"
|
||||
|
||||
def _call(
|
||||
self,
|
||||
prompt: str,
|
||||
stop: Optional[List[str]] = None,
|
||||
run_manager: Optional[CallbackManagerForLLMRun] = None,
|
||||
**kwargs: Any,
|
||||
) -> str:
|
||||
for k in self.kwargs:
|
||||
if k not in kwargs:
|
||||
kwargs[k] = self.kwargs[k]
|
||||
logger.info(f"kwargs:{kwargs}\nstop:{stop}\nprompt:{prompt}", verbose=self.verbose)
|
||||
generate_args = {k: kwargs[k] for k in kwargs if k in ["n", "max_tokens", "temperature", "stream"]}
|
||||
out = self.api.generate(prompt, **generate_args)
|
||||
if len(stop) != 0:
|
||||
for stopping_words in stop:
|
||||
if stopping_words in out:
|
||||
out = out.split(stopping_words)[0]
|
||||
logger.info(f"{prompt}{out}", verbose=self.verbose)
|
||||
return out
|
||||
|
||||
def set_host_port(self, host: str = "localhost", port: int = 8077, **kwargs) -> None:
|
||||
if "max_tokens" not in kwargs:
|
||||
kwargs["max_tokens"] = 100
|
||||
self.kwargs = kwargs
|
||||
self.api = VllmAPI(host=host, port=port)
|
||||
|
||||
@property
|
||||
def _identifying_params(self) -> Mapping[str, int]:
|
||||
"""Get the identifying parameters."""
|
||||
return {"n": self.n}
|
||||
|
||||
|
|
@ -0,0 +1,150 @@
|
|||
"""
|
||||
LLM wrapper for Pangu
|
||||
|
||||
Usage:
|
||||
|
||||
# URL: “盘古大模型套件管理”->点击“服务管理”->“模型列表”->点击想要使用的模型的“复制路径”
|
||||
# USERNAME: 华为云控制台:“我的凭证”->“API凭证”下的“IAM用户名”,也就是你登录IAM账户的名字
|
||||
# PASSWORD: IAM用户的密码
|
||||
# DOMAIN_NAME: 华为云控制台:“我的凭证”->“API凭证”下的“用户名”,也就是公司管理IAM账户的总账户名
|
||||
|
||||
os.environ["URL"] = ""
|
||||
os.environ["URLNAME"] = ""
|
||||
os.environ["PASSWORD"] = ""
|
||||
os.environ["DOMAIN_NAME"] = ""
|
||||
|
||||
pg = Pangu(id=1)
|
||||
pg.set_auth_config()
|
||||
|
||||
res = pg('你是谁') # 您好,我是华为盘古大模型。我能够通过和您对话互动为您提供帮助。请问您有什么想问我的吗?
|
||||
"""
|
||||
|
||||
import http.client
|
||||
import json
|
||||
from typing import Any, List, Mapping, Optional
|
||||
|
||||
import requests
|
||||
from langchain.llms.base import LLM
|
||||
from langchain.utils import get_from_dict_or_env
|
||||
|
||||
|
||||
class Pangu(LLM):
|
||||
"""
|
||||
A custom LLM class that integrates pangu models
|
||||
|
||||
"""
|
||||
|
||||
n: int
|
||||
gen_config: dict = None
|
||||
auth_config: dict = None
|
||||
|
||||
def __init__(self, gen_config=None, **kwargs):
|
||||
super(Pangu, self).__init__(**kwargs)
|
||||
if gen_config is None:
|
||||
self.gen_config = {"user": "User", "max_tokens": 50, "temperature": 0.95, "n": 1}
|
||||
else:
|
||||
self.gen_config = gen_config
|
||||
|
||||
@property
|
||||
def _identifying_params(self) -> Mapping[str, Any]:
|
||||
"""Get the identifying parameters."""
|
||||
return {"n": self.n}
|
||||
|
||||
@property
|
||||
def _llm_type(self) -> str:
|
||||
return "pangu"
|
||||
|
||||
def _call(self, prompt: str, stop: Optional[List[str]] = None, **kwargs) -> str:
|
||||
"""
|
||||
Args:
|
||||
prompt: The prompt to pass into the model.
|
||||
stop: A list of strings to stop generation when encountered
|
||||
|
||||
Returns:
|
||||
The string generated by the model
|
||||
"""
|
||||
# Update the generation arguments
|
||||
for key, value in kwargs.items():
|
||||
if key in self.gen_config:
|
||||
self.gen_config[key] = value
|
||||
|
||||
response = self.text_completion(prompt, self.gen_config, self.auth_config)
|
||||
text = response["choices"][0]["text"]
|
||||
if stop is not None:
|
||||
for stopping_words in stop:
|
||||
if stopping_words in text:
|
||||
text = text.split(stopping_words)[0]
|
||||
return text
|
||||
|
||||
def set_auth_config(self, **kwargs):
|
||||
url = get_from_dict_or_env(kwargs, "url", "URL")
|
||||
username = get_from_dict_or_env(kwargs, "username", "USERNAME")
|
||||
password = get_from_dict_or_env(kwargs, "password", "PASSWORD")
|
||||
domain_name = get_from_dict_or_env(kwargs, "domain_name", "DOMAIN_NAME")
|
||||
|
||||
region = url.split(".")[1]
|
||||
auth_config = {}
|
||||
auth_config["endpoint"] = url[url.find("https://") + 8 : url.find(".com") + 4]
|
||||
auth_config["resource_path"] = url[url.find(".com") + 4 :]
|
||||
auth_config["auth_token"] = self.get_latest_auth_token(region, username, password, domain_name)
|
||||
self.auth_config = auth_config
|
||||
|
||||
def get_latest_auth_token(self, region, username, password, domain_name):
|
||||
url = f"https://iam.{region}.myhuaweicloud.com/v3/auth/tokens"
|
||||
payload = json.dumps(
|
||||
{
|
||||
"auth": {
|
||||
"identity": {
|
||||
"methods": ["password"],
|
||||
"password": {"user": {"name": username, "password": password, "domain": {"name": domain_name}}},
|
||||
},
|
||||
"scope": {"project": {"name": region}},
|
||||
}
|
||||
}
|
||||
)
|
||||
headers = {"Content-Type": "application/json"}
|
||||
|
||||
response = requests.request("POST", url, headers=headers, data=payload)
|
||||
return response.headers["X-Subject-Token"]
|
||||
|
||||
def text_completion(self, text, gen_config, auth_config):
|
||||
conn = http.client.HTTPSConnection(auth_config["endpoint"])
|
||||
payload = json.dumps(
|
||||
{
|
||||
"prompt": text,
|
||||
"user": gen_config["user"],
|
||||
"max_tokens": gen_config["max_tokens"],
|
||||
"temperature": gen_config["temperature"],
|
||||
"n": gen_config["n"],
|
||||
}
|
||||
)
|
||||
headers = {
|
||||
"X-Auth-Token": auth_config["auth_token"],
|
||||
"Content-Type": "application/json",
|
||||
}
|
||||
conn.request("POST", auth_config["resource_path"], payload, headers)
|
||||
res = conn.getresponse()
|
||||
data = res.read()
|
||||
data = json.loads(data.decode("utf-8"))
|
||||
return data
|
||||
|
||||
def chat_model(self, messages, gen_config, auth_config):
|
||||
conn = http.client.HTTPSConnection(auth_config["endpoint"])
|
||||
payload = json.dumps(
|
||||
{
|
||||
"messages": messages,
|
||||
"user": gen_config["user"],
|
||||
"max_tokens": gen_config["max_tokens"],
|
||||
"temperature": gen_config["temperature"],
|
||||
"n": gen_config["n"],
|
||||
}
|
||||
)
|
||||
headers = {
|
||||
"X-Auth-Token": auth_config["auth_token"],
|
||||
"Content-Type": "application/json",
|
||||
}
|
||||
conn.request("POST", auth_config["resource_path"], payload, headers)
|
||||
res = conn.getresponse()
|
||||
data = res.read()
|
||||
data = json.loads(data.decode("utf-8"))
|
||||
return data
|
||||
|
|
@ -0,0 +1,29 @@
|
|||
"""
|
||||
Generation utilities
|
||||
"""
|
||||
import json
|
||||
from typing import List
|
||||
|
||||
import requests
|
||||
|
||||
|
||||
def post_http_request(
|
||||
prompt: str, api_url: str, n: int = 1, max_tokens: int = 100, temperature: float = 0.0, stream: bool = False
|
||||
) -> requests.Response:
|
||||
headers = {"User-Agent": "Test Client"}
|
||||
pload = {
|
||||
"prompt": prompt,
|
||||
"n": 1,
|
||||
"use_beam_search": False,
|
||||
"temperature": temperature,
|
||||
"max_tokens": max_tokens,
|
||||
"stream": stream,
|
||||
}
|
||||
response = requests.post(api_url, headers=headers, json=pload, stream=True, timeout=3)
|
||||
return response
|
||||
|
||||
|
||||
def get_response(response: requests.Response) -> List[str]:
|
||||
data = json.loads(response.content)
|
||||
output = data["text"]
|
||||
return output
|
||||
|
|
@ -0,0 +1,168 @@
|
|||
"""
|
||||
Implement a memory class for storing conversation history
|
||||
Support long term and short term memory
|
||||
"""
|
||||
from typing import Any, Dict, List
|
||||
|
||||
from colossalqa.chain.memory.summary import ConversationSummaryMemory
|
||||
from colossalqa.chain.retrieval_qa.load_chain import load_qa_chain
|
||||
from langchain.chains.combine_documents.base import BaseCombineDocumentsChain
|
||||
from langchain.memory.chat_message_histories.in_memory import ChatMessageHistory
|
||||
from langchain.schema import BaseChatMessageHistory
|
||||
from langchain.schema.messages import BaseMessage
|
||||
from langchain.schema.retriever import BaseRetriever
|
||||
from pydantic import Field
|
||||
|
||||
|
||||
class ConversationBufferWithSummary(ConversationSummaryMemory):
|
||||
"""Memory class for storing information about entities."""
|
||||
|
||||
# Define dictionary to store information about entities.
|
||||
# Store the most recent conversation history
|
||||
buffered_history: BaseChatMessageHistory = Field(default_factory=ChatMessageHistory)
|
||||
# Temp buffer
|
||||
summarized_history_temp: BaseChatMessageHistory = Field(default_factory=ChatMessageHistory)
|
||||
human_prefix: str = "Human"
|
||||
ai_prefix: str = "Assistant"
|
||||
buffer: str = "" # Formated conversation in str
|
||||
existing_summary: str = "" # Summarization of stale converstion in str
|
||||
# Define key to pass information about entities into prompt.
|
||||
memory_key: str = "chat_history"
|
||||
input_key: str = "question"
|
||||
retriever: BaseRetriever = None
|
||||
max_tokens: int = 2000
|
||||
chain: BaseCombineDocumentsChain = None
|
||||
input_chain_type_kwargs: List = {}
|
||||
|
||||
@property
|
||||
def buffer(self) -> Any:
|
||||
"""String buffer of memory."""
|
||||
return self.buffer_as_messages if self.return_messages else self.buffer_as_str
|
||||
|
||||
@property
|
||||
def buffer_as_str(self) -> str:
|
||||
"""Exposes the buffer as a string in case return_messages is True."""
|
||||
self.buffer = self.format_dialogue()
|
||||
return self.buffer
|
||||
|
||||
@property
|
||||
def buffer_as_messages(self) -> List[BaseMessage]:
|
||||
"""Exposes the buffer as a list of messages in case return_messages is False."""
|
||||
return self.buffered_history.messages
|
||||
|
||||
def clear(self):
|
||||
"""Clear all the memory"""
|
||||
self.buffered_history.clear()
|
||||
self.summarized_history_temp.clear()
|
||||
|
||||
def initiate_document_retrieval_chain(
|
||||
self, llm: Any, prompt_template: Any, retriever: Any, chain_type_kwargs: Dict[str, Any] = {}
|
||||
) -> None:
|
||||
"""
|
||||
Since we need to calculate the length of the prompt, we need to initiate a retrieval chain
|
||||
to calculate the length of the prompt.
|
||||
Args:
|
||||
llm: the language model for the retrieval chain (we won't actually return the output)
|
||||
prompt_template: the prompt template for constructing the retrieval chain
|
||||
retriever: the retriever for the retrieval chain
|
||||
max_tokens: the max length of the prompt (not include the output)
|
||||
chain_type_kwargs: the kwargs for the retrieval chain
|
||||
memory_key: the key for the chat history
|
||||
input_key: the key for the input query
|
||||
"""
|
||||
self.retriever = retriever
|
||||
input_chain_type_kwargs = {k: v for k, v in chain_type_kwargs.items() if k not in [self.memory_key]}
|
||||
self.input_chain_type_kwargs = input_chain_type_kwargs
|
||||
self.chain = load_qa_chain(llm, chain_type="stuff", prompt=prompt_template, **self.input_chain_type_kwargs)
|
||||
|
||||
@property
|
||||
def memory_variables(self) -> List[str]:
|
||||
"""Define the variables we are providing to the prompt."""
|
||||
return [self.memory_key]
|
||||
|
||||
def format_dialogue(self, lang: str = "en") -> str:
|
||||
"""Format memory into two parts--- summarization of historical conversation and most recent conversation"""
|
||||
if len(self.summarized_history_temp.messages) != 0:
|
||||
for i in range(int(len(self.summarized_history_temp.messages) / 2)):
|
||||
self.existing_summary = (
|
||||
self.predict_new_summary(
|
||||
self.summarized_history_temp.messages[i * 2 : i * 2 + 2], self.existing_summary, stop=["\n\n"]
|
||||
)
|
||||
.strip()
|
||||
.split("\n")[0]
|
||||
.strip()
|
||||
)
|
||||
for i in range(int(len(self.summarized_history_temp.messages) / 2)):
|
||||
self.summarized_history_temp.messages.pop(0)
|
||||
self.summarized_history_temp.messages.pop(0)
|
||||
conversation_buffer = []
|
||||
for t in self.buffered_history.messages:
|
||||
if t.type == "human":
|
||||
prefix = self.human_prefix
|
||||
else:
|
||||
prefix = self.ai_prefix
|
||||
conversation_buffer.append(prefix + ": " + t.content)
|
||||
conversation_buffer = "\n".join(conversation_buffer)
|
||||
if len(self.existing_summary) > 0:
|
||||
if lang == "en":
|
||||
message = f"A summarization of historical conversation:\n{self.existing_summary}\nMost recent conversation:\n{conversation_buffer}"
|
||||
elif lang == "zh":
|
||||
message = f"历史对话概要:\n{self.existing_summary}\n最近的对话:\n{conversation_buffer}"
|
||||
else:
|
||||
raise ValueError("Unsupported language")
|
||||
return message
|
||||
else:
|
||||
message = conversation_buffer
|
||||
return message
|
||||
|
||||
def get_conversation_length(self):
|
||||
"""Get the length of the formatted conversation"""
|
||||
prompt = self.format_dialogue()
|
||||
length = self.llm.get_num_tokens(prompt)
|
||||
return length
|
||||
|
||||
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, str]:
|
||||
"""Load the memory variables.
|
||||
Summarize oversize conversation to fit into the length constraint defined by max_tokene
|
||||
Args:
|
||||
inputs: the kwargs of the chain of your definition
|
||||
Returns:
|
||||
a dict that maps from memory key to the formated dialogue
|
||||
the formated dialogue has the following format
|
||||
if conversation is too long:
|
||||
A summarization of historical conversation:
|
||||
{summarization}
|
||||
Most recent conversation:
|
||||
Human: XXX
|
||||
Assistant: XXX
|
||||
...
|
||||
otherwise
|
||||
Human: XXX
|
||||
Assistant: XXX
|
||||
...
|
||||
"""
|
||||
# Calculate remain length
|
||||
if "input_documents" in inputs:
|
||||
# Run in a retrieval qa chain
|
||||
docs = inputs["input_documents"]
|
||||
else:
|
||||
# For test
|
||||
docs = self.retriever.get_relevant_documents(inputs[self.input_key])
|
||||
inputs[self.memory_key] = ""
|
||||
inputs = {k: v for k, v in inputs.items() if k in [self.chain.input_key, self.input_key, self.memory_key]}
|
||||
prompt_length = self.chain.prompt_length(docs, **inputs)
|
||||
remain = self.max_tokens - prompt_length
|
||||
while self.get_conversation_length() > remain:
|
||||
if len(self.buffered_history.messages) <= 2:
|
||||
raise RuntimeError("Exeeed max_tokens, trunck size of retrieved documents is too large")
|
||||
temp = self.buffered_history.messages.pop(0)
|
||||
self.summarized_history_temp.messages.append(temp)
|
||||
temp = self.buffered_history.messages.pop(0)
|
||||
self.summarized_history_temp.messages.append(temp)
|
||||
return {self.memory_key: self.format_dialogue()}
|
||||
|
||||
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
|
||||
"""Save context from this conversation to buffer."""
|
||||
input_str, output_str = self._get_input_output(inputs, outputs)
|
||||
self.buffered_history.add_user_message(input_str.strip())
|
||||
self.buffered_history.add_ai_message(output_str.strip())
|
||||
|
|
@ -0,0 +1,92 @@
|
|||
"""
|
||||
Class for logging with extra control for debugging
|
||||
"""
|
||||
import logging
|
||||
|
||||
|
||||
class ColossalQALogger:
|
||||
"""This is a distributed event logger class essentially based on :class:`logging`.
|
||||
|
||||
Args:
|
||||
name (str): The name of the logger.
|
||||
|
||||
Note:
|
||||
Logging types: ``info``, ``warning``, ``debug`` and ``error``
|
||||
"""
|
||||
|
||||
__instances = dict()
|
||||
|
||||
def __init__(self, name):
|
||||
if name in ColossalQALogger.__instances:
|
||||
raise ValueError("Logger with the same name has been created")
|
||||
else:
|
||||
self._name = name
|
||||
self._logger = logging.getLogger(name)
|
||||
|
||||
ColossalQALogger.__instances[name] = self
|
||||
|
||||
@staticmethod
|
||||
def get_instance(name: str):
|
||||
"""Get the unique single logger instance based on name.
|
||||
|
||||
Args:
|
||||
name (str): The name of the logger.
|
||||
|
||||
Returns:
|
||||
DistributedLogger: A DistributedLogger object
|
||||
"""
|
||||
if name in ColossalQALogger.__instances:
|
||||
return ColossalQALogger.__instances[name]
|
||||
else:
|
||||
logger = ColossalQALogger(name=name)
|
||||
return logger
|
||||
|
||||
def info(self, message: str, verbose: bool = False) -> None:
|
||||
"""Log an info message.
|
||||
|
||||
Args:
|
||||
message (str): The message to be logged.
|
||||
verbose (bool): Whether to print the message to stdout.
|
||||
"""
|
||||
if verbose:
|
||||
logging.basicConfig(level=logging.INFO)
|
||||
self._logger.info(message)
|
||||
|
||||
def warning(self, message: str, verbose: bool = False) -> None:
|
||||
"""Log a warning message.
|
||||
|
||||
Args:
|
||||
message (str): The message to be logged.
|
||||
verbose (bool): Whether to print the message to stdout.
|
||||
"""
|
||||
if verbose:
|
||||
self._logger.warning(message)
|
||||
|
||||
def debug(self, message: str, verbose: bool = False) -> None:
|
||||
"""Log a debug message.
|
||||
|
||||
Args:
|
||||
message (str): The message to be logged.
|
||||
verbose (bool): Whether to print the message to stdout.
|
||||
"""
|
||||
if verbose:
|
||||
self._logger.debug(message)
|
||||
|
||||
def error(self, message: str) -> None:
|
||||
"""Log an error message.
|
||||
|
||||
Args:
|
||||
message (str): The message to be logged.
|
||||
"""
|
||||
self._logger.error(message)
|
||||
|
||||
|
||||
def get_logger(name: str = None, level=logging.INFO) -> ColossalQALogger:
|
||||
"""
|
||||
Get the logger by name, if name is None, return the default logger
|
||||
"""
|
||||
if name:
|
||||
logger = ColossalQALogger.get_instance(name=name)
|
||||
else:
|
||||
logger = ColossalQALogger.get_instance(name="colossalqa")
|
||||
return logger
|
||||
|
|
@ -0,0 +1,144 @@
|
|||
# Prompt Design Guide
|
||||
|
||||
For the retriever conversation system, users can customize three prompts.
|
||||
|
||||
## The Retrieval QA Prompt
|
||||
This is the prompt for retrieval QA, the input is user's inputs, the retrieved documents, the historical conversation.
|
||||
|
||||
### Chinese
|
||||
```
|
||||
你是一个善于解答用户问题的AI助手。在保证安全的前提下,回答问题要尽可能有帮助。你的答案不应该包含任何有害的、不道德的、种族主义的、性别歧视的、危险的或非法的内容。请确保你的回答是公正和积极的。
|
||||
如果不能根据给定的上下文推断出答案,请不要分享虚假、不确定的信息。
|
||||
使用提供的背景信息和聊天记录对用户的输入作出回应或继续对话。您应该只生成一个回复。不需要跟进回答。请使用中文作答。
|
||||
|
||||
背景信息:
|
||||
[retrieved documents]
|
||||
|
||||
聊天记录:
|
||||
[historical conversation, overlength chat history will be summarized]
|
||||
|
||||
用户: [question]
|
||||
Assistant:
|
||||
```
|
||||
|
||||
### English
|
||||
```
|
||||
[INST] <<SYS>>Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
||||
If the answer cannot be infered based on the given context, please don't share false information.<</SYS>>
|
||||
Use the context and chat history to respond to the human's input at the end or carry on the conversation. You should generate one response only. No following up is needed.
|
||||
|
||||
context:
|
||||
[retrieved documents]
|
||||
|
||||
chat history
|
||||
[historical conversation, overlength chat history will be summarized]
|
||||
|
||||
Human: {question}
|
||||
Assistant:
|
||||
```
|
||||
|
||||
## Summarization Prompt
|
||||
This prompt is used by the memory module to recursively summarize overlength conversation to shrink the length of the prompt.
|
||||
|
||||
## Disambiguity Prompt
|
||||
This prompt is used to perform zero-shot reference resolution to disambiguate entity references within user's questions.
|
||||
|
||||
## Final Prompt Examples
|
||||
Assume k=3 for the retriever.
|
||||
|
||||
### English
|
||||
Note that the "[INST] <<SYS>>...<</SYS>>" template is the specific prompt format used in LLaMA2.
|
||||
#### Normal Length
|
||||
```
|
||||
[INST] <<SYS>>Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
||||
If the answer cannot be infered based on the given context, please don't share false information.<</SYS>>
|
||||
Use the context and chat history to respond to the human's input at the end or carry on the conversation. You should generate one response only. No following up is needed.
|
||||
|
||||
context:
|
||||
[document 1]
|
||||
|
||||
[document 2]
|
||||
|
||||
[document 3]
|
||||
|
||||
chat history
|
||||
Human: XXX
|
||||
Assistant: XXX
|
||||
...
|
||||
|
||||
Human: {question}
|
||||
Assistant:
|
||||
```
|
||||
|
||||
#### Overlength
|
||||
```
|
||||
[INST] <<SYS>>Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
||||
If the answer cannot be infered based on the given context, please don't share false information.<</SYS>>
|
||||
Use the context and chat history to respond to the human's input at the end or carry on the conversation. You should generate one response only. No following up is needed.
|
||||
|
||||
context:
|
||||
[document 1]
|
||||
|
||||
[document 2]
|
||||
|
||||
[document 3]
|
||||
|
||||
chat history
|
||||
A summarization of historical conversation:
|
||||
[one line summary of historical conversation]
|
||||
Most recent conversation:
|
||||
Human: XXX
|
||||
Assistant: XXX
|
||||
...
|
||||
|
||||
Human: {question}
|
||||
Assistant:
|
||||
```
|
||||
|
||||
### Chinese
|
||||
#### Normal Length
|
||||
```
|
||||
你是一个善于解答用户问题的AI助手。在保证安全的前提下,回答问题要尽可能有帮助。你的答案不应该包含任何有害的、不道德的、种族主义的、性别歧视的、危险的或非法的内容。请确保你的回答是公正和积极的。
|
||||
如果不能根据给定的上下文推断出答案,请不要分享虚假、不确定的信息。
|
||||
使用提供的背景信息和聊天记录对用户的输入作出回应或继续对话。您应该只生成一个回复。不需要跟进回答。请使用中文作答。
|
||||
|
||||
背景信息:
|
||||
[document 1]
|
||||
|
||||
[document 2]
|
||||
|
||||
[document 3]
|
||||
|
||||
聊天记录:
|
||||
用户: XXX
|
||||
Assistant: XXX
|
||||
...
|
||||
|
||||
用户: [question]
|
||||
Assistant:
|
||||
```
|
||||
|
||||
#### Overlength
|
||||
```
|
||||
你是一个善于解答用户问题的AI助手。在保证安全的前提下,回答问题要尽可能有帮助。你的答案不应该包含任何有害的、不道德的、种族主义的、性别歧视的、危险的或非法的内容。请确保你的回答是公正和积极的。
|
||||
如果不能根据给定的上下文推断出答案,请不要分享虚假、不确定的信息。
|
||||
使用提供的背景信息和聊天记录对用户的输入作出回应或继续对话。您应该只生成一个回复。不需要跟进回答。请使用中文作答。
|
||||
|
||||
背景信息:
|
||||
[document 1]
|
||||
|
||||
[document 2]
|
||||
|
||||
[document 3]
|
||||
|
||||
聊天记录:
|
||||
历史对话概要:
|
||||
[one line summary of historical conversation]
|
||||
最近的对话:
|
||||
用户: XXX
|
||||
Assistant: XXX
|
||||
...
|
||||
|
||||
用户: [question]
|
||||
Assistant:
|
||||
```
|
||||
|
|
@ -0,0 +1,124 @@
|
|||
"""
|
||||
All custom prompt templates are defined here.
|
||||
"""
|
||||
|
||||
from langchain.prompts.prompt import PromptTemplate
|
||||
|
||||
_CUSTOM_SUMMARIZER_TEMPLATE_ZH = """请递进式地总结所提供的当前对话,将当前对话的摘要内容添加到先前已有的摘要上,返回一个融合了当前对话的新的摘要。
|
||||
|
||||
例1:
|
||||
已有的摘要:
|
||||
人类问Assistant对人工智能的看法。人工智能认为人工智能是一种善的力量。
|
||||
|
||||
新的对话内容:
|
||||
人类: 为什么你认为人工智能是一种好的力量?
|
||||
Assistant: 因为人工智能将帮助人类充分发挥潜力。
|
||||
|
||||
新的摘要:
|
||||
人类问Assistant对人工智能的看法。人工智能认为人工智能是一种积极的力量,因为它将帮助人类充分发挥潜力。
|
||||
示例结束
|
||||
|
||||
已有的摘要:
|
||||
{summary}
|
||||
|
||||
新的对话内容:
|
||||
{new_lines}
|
||||
|
||||
新的摘要:"""
|
||||
|
||||
|
||||
# Chinese retrieval qa prompt
|
||||
|
||||
_ZH_RETRIEVAL_QA_PROMPT = """<指令>根据下列支持文档和对话历史,简洁和专业地来回答问题。如果无法从支持文档中得到答案,请说 “根据已知信息无法回答该问题”。回答中请不要涉及支持文档中没有提及的信息,答案请使用中文。 </指令>
|
||||
|
||||
{context}
|
||||
|
||||
<对话历史>
|
||||
{chat_history}
|
||||
</对话历史>
|
||||
|
||||
<问题>{question}</问题>
|
||||
答案:"""
|
||||
|
||||
ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS = ["无法回答该问题"]
|
||||
ZH_RETRIEVAL_QA_REJECTION_ANSWER = "抱歉,根据提供的信息无法回答该问题。"
|
||||
|
||||
|
||||
_ZH_RETRIEVAL_CLASSIFICATION_USE_CASE = """使用提供的参考案例判断客户遇到的故障所属的故障原因分类。
|
||||
|
||||
背景信息:
|
||||
{context}
|
||||
|
||||
客服记录:
|
||||
{question}
|
||||
故障原因分类:"""
|
||||
|
||||
_ZH_DISAMBIGUATION_PROMPT = """你是一个乐于助人、恭敬而诚实的助手。你总是按照指示去做。
|
||||
请用聊天记录中提到的具体名称或实体名称替换给定句子中的任何模糊或有歧义的指代,如果没有提供聊天记录或句子中不包含模糊或有歧义的指代,则只输出原始句子。您的输出应该是消除歧义的句子本身(与“消除歧义的句子:”在同一行中),并且不包含任何其他内容。
|
||||
|
||||
下面是一个例子:
|
||||
聊天记录:
|
||||
用户: 我有一个朋友,张三。你认识他吗?
|
||||
Assistant: 我认识一个叫张三的人
|
||||
|
||||
句子: 他最喜欢的食物是什么?
|
||||
消除歧义的句子: 张三最喜欢的食物是什么?
|
||||
|
||||
聊天记录:
|
||||
{chat_history}
|
||||
|
||||
句子: {input}
|
||||
消除歧义的句子:"""
|
||||
|
||||
# English retrieval qa prompt
|
||||
|
||||
_EN_RETRIEVAL_QA_PROMPT = """[INST] <<SYS>>Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist content.
|
||||
If the answer cannot be infered based on the given context, please say "I cannot answer the question based on the information given.".<</SYS>>
|
||||
Use the context and chat history to answer the question.
|
||||
|
||||
context:
|
||||
{context}
|
||||
|
||||
chat history
|
||||
{chat_history}
|
||||
|
||||
question: {question}
|
||||
answer:"""
|
||||
EN_RETRIEVAL_QA_TRIGGER_KEYWORDS = ["cannot answer the question"]
|
||||
EN_RETRIEVAL_QA_REJECTION_ANSWER = "Sorry, this question cannot be answered based on the information provided."
|
||||
|
||||
_EN_DISAMBIGUATION_PROMPT = """[INST] <<SYS>>You are a helpful, respectful and honest assistant. You always follow the instruction.<</SYS>>
|
||||
Please replace any ambiguous references in the given sentence with the specific names or entities mentioned in the chat history or just output the original sentence if no chat history is provided or if the sentence doesn't contain ambiguous references. Your output should be the disambiguated sentence itself (in the same line as "disambiguated sentence:") and contain nothing else.
|
||||
|
||||
Here is an example:
|
||||
Chat history:
|
||||
Human: I have a friend, Mike. Do you know him?
|
||||
Assistant: Yes, I know a person named Mike
|
||||
|
||||
sentence: What's his favorate food?
|
||||
disambiguated sentence: What's Mike's favorate food?
|
||||
[/INST]
|
||||
Chat history:
|
||||
{chat_history}
|
||||
|
||||
sentence: {input}
|
||||
disambiguated sentence:"""
|
||||
|
||||
|
||||
PROMPT_RETRIEVAL_QA_EN = PromptTemplate(
|
||||
template=_EN_RETRIEVAL_QA_PROMPT, input_variables=["question", "chat_history", "context"]
|
||||
)
|
||||
|
||||
PROMPT_DISAMBIGUATE_EN = PromptTemplate(template=_EN_DISAMBIGUATION_PROMPT, input_variables=["chat_history", "input"])
|
||||
|
||||
SUMMARY_PROMPT_ZH = PromptTemplate(input_variables=["summary", "new_lines"], template=_CUSTOM_SUMMARIZER_TEMPLATE_ZH)
|
||||
|
||||
PROMPT_DISAMBIGUATE_ZH = PromptTemplate(template=_ZH_DISAMBIGUATION_PROMPT, input_variables=["chat_history", "input"])
|
||||
|
||||
PROMPT_RETRIEVAL_QA_ZH = PromptTemplate(
|
||||
template=_ZH_RETRIEVAL_QA_PROMPT, input_variables=["question", "chat_history", "context"]
|
||||
)
|
||||
|
||||
PROMPT_RETRIEVAL_CLASSIFICATION_USE_CASE_ZH = PromptTemplate(
|
||||
template=_ZH_RETRIEVAL_CLASSIFICATION_USE_CASE, input_variables=["question", "context"]
|
||||
)
|
||||
|
|
@ -0,0 +1,87 @@
|
|||
"""
|
||||
Script for Chinese retrieval based conversation system backed by ChatGLM
|
||||
"""
|
||||
from typing import Tuple
|
||||
|
||||
from colossalqa.chain.retrieval_qa.base import RetrievalQA
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.mylogging import get_logger
|
||||
from colossalqa.prompt.prompt import PROMPT_DISAMBIGUATE_EN, PROMPT_RETRIEVAL_QA_EN
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from langchain import LLMChain
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
|
||||
class EnglishRetrievalConversation:
|
||||
"""
|
||||
Wrapper class for Chinese retrieval conversation system
|
||||
"""
|
||||
|
||||
def __init__(self, retriever: CustomRetriever, model_path: str, model_name: str) -> None:
|
||||
"""
|
||||
Setup retrieval qa chain for Chinese retrieval based QA
|
||||
"""
|
||||
logger.info(f"model_name: {model_name}; model_path: {model_path}", verbose=True)
|
||||
colossal_api = ColossalAPI.get_api(model_name, model_path)
|
||||
self.llm = ColossalLLM(n=1, api=colossal_api)
|
||||
|
||||
# Define the retriever
|
||||
self.retriever = retriever
|
||||
|
||||
# Define the chain to preprocess the input
|
||||
# Disambiguate the input. e.g. "What is the capital of that country?" -> "What is the capital of France?"
|
||||
# Prompt is summarization prompt
|
||||
self.llm_chain_disambiguate = LLMChain(
|
||||
llm=self.llm,
|
||||
prompt=PROMPT_DISAMBIGUATE_EN,
|
||||
llm_kwargs={"max_new_tokens": 30, "temperature": 0.6, "do_sample": True},
|
||||
)
|
||||
|
||||
self.retriever.set_rephrase_handler(self.disambiguity)
|
||||
# Define memory with summarization ability
|
||||
self.memory = ConversationBufferWithSummary(
|
||||
llm=self.llm, llm_kwargs={"max_new_tokens": 50, "temperature": 0.6, "do_sample": True}
|
||||
)
|
||||
self.memory.initiate_document_retrieval_chain(
|
||||
self.llm,
|
||||
PROMPT_RETRIEVAL_QA_EN,
|
||||
self.retriever,
|
||||
chain_type_kwargs={
|
||||
"chat_history": "",
|
||||
},
|
||||
)
|
||||
self.retrieval_chain = RetrievalQA.from_chain_type(
|
||||
llm=self.llm,
|
||||
verbose=False,
|
||||
chain_type="stuff",
|
||||
retriever=self.retriever,
|
||||
chain_type_kwargs={"prompt": PROMPT_RETRIEVAL_QA_EN, "memory": self.memory},
|
||||
llm_kwargs={"max_new_tokens": 50, "temperature": 0.75, "do_sample": True},
|
||||
)
|
||||
|
||||
def disambiguity(self, input: str):
|
||||
out = self.llm_chain_disambiguate.run(input=input, chat_history=self.memory.buffer, stop=["\n"])
|
||||
return out.split("\n")[0]
|
||||
|
||||
@classmethod
|
||||
def from_retriever(
|
||||
cls, retriever: CustomRetriever, model_path: str, model_name: str
|
||||
) -> "EnglishRetrievalConversation":
|
||||
return cls(retriever, model_path, model_name)
|
||||
|
||||
def run(self, user_input: str, memory: ConversationBufferWithSummary) -> Tuple[str, ConversationBufferWithSummary]:
|
||||
if memory:
|
||||
# TODO add translation chain here
|
||||
self.memory.buffered_history.messages = memory.buffered_history.messages
|
||||
self.memory.summarized_history_temp.messages = memory.summarized_history_temp.messages
|
||||
return (
|
||||
self.retrieval_chain.run(
|
||||
query=user_input,
|
||||
stop=[self.memory.human_prefix + ": "],
|
||||
rejection_trigger_keywrods=["cannot answer the question"],
|
||||
rejection_answer="Sorry, this question cannot be answered based on the information provided.",
|
||||
).split("\n")[0],
|
||||
self.memory,
|
||||
)
|
||||
|
|
@ -0,0 +1,138 @@
|
|||
"""
|
||||
Multilingual retrieval based conversation system
|
||||
"""
|
||||
from typing import List
|
||||
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.mylogging import get_logger
|
||||
from colossalqa.retrieval_conversation_en import EnglishRetrievalConversation
|
||||
from colossalqa.retrieval_conversation_zh import ChineseRetrievalConversation
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from colossalqa.text_splitter import ChineseTextSplitter
|
||||
from colossalqa.utils import detect_lang_naive
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter, TextSplitter
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
|
||||
class UniversalRetrievalConversation:
|
||||
"""
|
||||
Wrapper class for bilingual retrieval conversation system
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
embedding_model_path: str = "moka-ai/m3e-base",
|
||||
embedding_model_device: str = "cpu",
|
||||
zh_model_path: str = None,
|
||||
zh_model_name: str = None,
|
||||
en_model_path: str = None,
|
||||
en_model_name: str = None,
|
||||
sql_file_path: str = None,
|
||||
files_zh: List[List[str]] = None,
|
||||
files_en: List[List[str]] = None,
|
||||
text_splitter_chunk_size=100,
|
||||
text_splitter_chunk_overlap=10,
|
||||
) -> None:
|
||||
"""
|
||||
Warpper for multilingual retrieval qa class (Chinese + English)
|
||||
Args:
|
||||
embedding_model_path: local or huggingface embedding model
|
||||
embedding_model_device:
|
||||
files_zh: [[file_path, name_of_file, separator],...] defines the files used as supporting documents for Chinese retrieval QA
|
||||
files_en: [[file_path, name_of_file, separator],...] defines the files used as supporting documents for English retrieval QA
|
||||
"""
|
||||
self.embedding = HuggingFaceEmbeddings(
|
||||
model_name=embedding_model_path,
|
||||
model_kwargs={"device": embedding_model_device},
|
||||
encode_kwargs={"normalize_embeddings": False},
|
||||
)
|
||||
print("Select files for constructing Chinese retriever")
|
||||
docs_zh = self.load_supporting_docs(
|
||||
files=files_zh,
|
||||
text_splitter=ChineseTextSplitter(
|
||||
chunk_size=text_splitter_chunk_size, chunk_overlap=text_splitter_chunk_overlap
|
||||
),
|
||||
)
|
||||
# Create retriever
|
||||
self.information_retriever_zh = CustomRetriever(
|
||||
k=3, sql_file_path=sql_file_path.replace(".db", "_zh.db"), verbose=True
|
||||
)
|
||||
self.information_retriever_zh.add_documents(
|
||||
docs=docs_zh, cleanup="incremental", mode="by_source", embedding=self.embedding
|
||||
)
|
||||
|
||||
print("Select files for constructing English retriever")
|
||||
docs_en = self.load_supporting_docs(
|
||||
files=files_en,
|
||||
text_splitter=RecursiveCharacterTextSplitter(
|
||||
chunk_size=text_splitter_chunk_size, chunk_overlap=text_splitter_chunk_overlap
|
||||
),
|
||||
)
|
||||
# Create retriever
|
||||
self.information_retriever_en = CustomRetriever(
|
||||
k=3, sql_file_path=sql_file_path.replace(".db", "_en.db"), verbose=True
|
||||
)
|
||||
self.information_retriever_en.add_documents(
|
||||
docs=docs_en, cleanup="incremental", mode="by_source", embedding=self.embedding
|
||||
)
|
||||
|
||||
self.chinese_retrieval_conversation = ChineseRetrievalConversation.from_retriever(
|
||||
self.information_retriever_zh, model_path=zh_model_path, model_name=zh_model_name
|
||||
)
|
||||
self.english_retrieval_conversation = EnglishRetrievalConversation.from_retriever(
|
||||
self.information_retriever_en, model_path=en_model_path, model_name=en_model_name
|
||||
)
|
||||
self.memory = None
|
||||
|
||||
def load_supporting_docs(self, files: List[List[str]] = None, text_splitter: TextSplitter = None):
|
||||
"""
|
||||
Load supporting documents, currently, all documents will be stored in one vector store
|
||||
"""
|
||||
documents = []
|
||||
if files:
|
||||
for file in files:
|
||||
retriever_data = DocumentLoader([[file["data_path"], file["name"]]]).all_data
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
documents.extend(splits)
|
||||
else:
|
||||
while True:
|
||||
file = input("Select a file to load or press Enter to exit:")
|
||||
if file == "":
|
||||
break
|
||||
data_name = input("Enter a short description of the data:")
|
||||
separator = input(
|
||||
"Enter a separator to force separating text into chunks, if no separator is given, the defaut separator is '\\n\\n', press ENTER directly to skip:"
|
||||
)
|
||||
separator = separator if separator != "" else "\n\n"
|
||||
retriever_data = DocumentLoader([[file, data_name.replace(" ", "_")]]).all_data
|
||||
|
||||
# Split
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
documents.extend(splits)
|
||||
return documents
|
||||
|
||||
def start_test_session(self):
|
||||
"""
|
||||
Simple multilingual session for testing purpose, with naive language selection mechanism
|
||||
"""
|
||||
while True:
|
||||
user_input = input("User: ")
|
||||
lang = detect_lang_naive(user_input)
|
||||
if "END" == user_input:
|
||||
print("Agent: Happy to chat with you :)")
|
||||
break
|
||||
agent_response = self.run(user_input, which_language=lang)
|
||||
print(f"Agent: {agent_response}")
|
||||
|
||||
def run(self, user_input: str, which_language=str):
|
||||
"""
|
||||
Generate the response given the user input and a str indicates the language requirement of the output string
|
||||
"""
|
||||
assert which_language in ["zh", "en"]
|
||||
if which_language == "zh":
|
||||
agent_response, self.memory = self.chinese_retrieval_conversation.run(user_input, self.memory)
|
||||
else:
|
||||
agent_response, self.memory = self.english_retrieval_conversation.run(user_input, self.memory)
|
||||
return agent_response.split("\n")[0]
|
||||
|
|
@ -0,0 +1,94 @@
|
|||
"""
|
||||
Script for Chinese retrieval based conversation system backed by ChatGLM
|
||||
"""
|
||||
from typing import Tuple
|
||||
|
||||
from colossalqa.chain.retrieval_qa.base import RetrievalQA
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.mylogging import get_logger
|
||||
from colossalqa.prompt.prompt import PROMPT_DISAMBIGUATE_ZH, PROMPT_RETRIEVAL_QA_ZH, SUMMARY_PROMPT_ZH
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from langchain import LLMChain
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
|
||||
class ChineseRetrievalConversation:
|
||||
"""
|
||||
Wrapper class for Chinese retrieval conversation system
|
||||
"""
|
||||
|
||||
def __init__(self, retriever: CustomRetriever, model_path: str, model_name: str) -> None:
|
||||
"""
|
||||
Setup retrieval qa chain for Chinese retrieval based QA
|
||||
"""
|
||||
# Local coati api
|
||||
logger.info(f"model_name: {model_name}; model_path: {model_path}", verbose=True)
|
||||
colossal_api = ColossalAPI.get_api(model_name, model_path)
|
||||
self.llm = ColossalLLM(n=1, api=colossal_api)
|
||||
|
||||
# Define the retriever
|
||||
self.retriever = retriever
|
||||
|
||||
# Define the chain to preprocess the input
|
||||
# Disambiguate the input. e.g. "What is the capital of that country?" -> "What is the capital of France?"
|
||||
# Prompt is summarization prompt
|
||||
self.llm_chain_disambiguate = LLMChain(
|
||||
llm=self.llm,
|
||||
prompt=PROMPT_DISAMBIGUATE_ZH,
|
||||
llm_kwargs={"max_new_tokens": 30, "temperature": 0.6, "do_sample": True},
|
||||
)
|
||||
|
||||
self.retriever.set_rephrase_handler(self.disambiguity)
|
||||
# Define memory with summarization ability
|
||||
self.memory = ConversationBufferWithSummary(
|
||||
llm=self.llm,
|
||||
prompt=SUMMARY_PROMPT_ZH,
|
||||
human_prefix="用户",
|
||||
ai_prefix="Assistant",
|
||||
max_tokens=2000,
|
||||
llm_kwargs={"max_new_tokens": 50, "temperature": 0.6, "do_sample": True},
|
||||
)
|
||||
self.memory.initiate_document_retrieval_chain(
|
||||
self.llm,
|
||||
PROMPT_RETRIEVAL_QA_ZH,
|
||||
self.retriever,
|
||||
chain_type_kwargs={
|
||||
"chat_history": "",
|
||||
},
|
||||
)
|
||||
self.retrieval_chain = RetrievalQA.from_chain_type(
|
||||
llm=self.llm,
|
||||
verbose=False,
|
||||
chain_type="stuff",
|
||||
retriever=self.retriever,
|
||||
chain_type_kwargs={"prompt": PROMPT_RETRIEVAL_QA_ZH, "memory": self.memory},
|
||||
llm_kwargs={"max_new_tokens": 150, "temperature": 0.9, "do_sample": True},
|
||||
)
|
||||
|
||||
def disambiguity(self, input: str):
|
||||
out = self.llm_chain_disambiguate.run(input=input, chat_history=self.memory.buffer, stop=["\n"])
|
||||
return out.split("\n")[0]
|
||||
|
||||
@classmethod
|
||||
def from_retriever(
|
||||
cls, retriever: CustomRetriever, model_path: str, model_name: str
|
||||
) -> "ChineseRetrievalConversation":
|
||||
return cls(retriever, model_path, model_name)
|
||||
|
||||
def run(self, user_input: str, memory: ConversationBufferWithSummary) -> Tuple[str, ConversationBufferWithSummary]:
|
||||
if memory:
|
||||
# TODO add translation chain here
|
||||
self.memory.buffered_history.messages = memory.buffered_history.messages
|
||||
self.memory.summarized_history_temp.messages = memory.summarized_history_temp.messages
|
||||
return (
|
||||
self.retrieval_chain.run(
|
||||
query=user_input,
|
||||
stop=["</答案>"],
|
||||
doc_prefix="支持文档",
|
||||
rejection_trigger_keywrods=["无法回答该问题"],
|
||||
rejection_answer="抱歉,根据提供的信息无法回答该问题。",
|
||||
).split("\n")[0],
|
||||
self.memory,
|
||||
)
|
||||
|
|
@ -0,0 +1,166 @@
|
|||
"""
|
||||
Code for custom retriver with incremental update
|
||||
"""
|
||||
import copy
|
||||
import hashlib
|
||||
import os
|
||||
from collections import defaultdict
|
||||
from typing import Any, Callable, Dict, List
|
||||
|
||||
from colossalqa.mylogging import get_logger
|
||||
from langchain.callbacks.manager import CallbackManagerForRetrieverRun
|
||||
from langchain.embeddings.base import Embeddings
|
||||
from langchain.indexes import SQLRecordManager, index
|
||||
from langchain.schema.retriever import BaseRetriever, Document
|
||||
from langchain.vectorstores.base import VectorStore
|
||||
from langchain.vectorstores.chroma import Chroma
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
|
||||
class CustomRetriever(BaseRetriever):
|
||||
"""
|
||||
Custom retriever class with support for incremental update of indexes
|
||||
"""
|
||||
|
||||
vector_stores: Dict[str, VectorStore] = {}
|
||||
sql_index_database: Dict[str, str] = {}
|
||||
record_managers: Dict[str, SQLRecordManager] = {}
|
||||
sql_db_chains = []
|
||||
k = 3
|
||||
rephrase_handler: Callable = None
|
||||
buffer: Dict = []
|
||||
buffer_size: int = 5
|
||||
verbose: bool = False
|
||||
sql_file_path: str = None
|
||||
|
||||
@classmethod
|
||||
def from_documents(
|
||||
cls,
|
||||
documents: List[Document],
|
||||
embeddings: Embeddings,
|
||||
**kwargs: Any,
|
||||
) -> BaseRetriever:
|
||||
k = kwargs.pop("k", 3)
|
||||
cleanup = kwargs.pop("cleanup", "incremental")
|
||||
mode = kwargs.pop("mode", "by_source")
|
||||
ret = cls(k=k)
|
||||
ret.add_documents(documents, embedding=embeddings, cleanup=cleanup, mode=mode)
|
||||
return ret
|
||||
|
||||
def add_documents(
|
||||
self,
|
||||
docs: Dict[str, Document] = [],
|
||||
cleanup: str = "incremental",
|
||||
mode: str = "by_source",
|
||||
embedding: Embeddings = None,
|
||||
) -> None:
|
||||
"""
|
||||
Add documents to retriever
|
||||
Args:
|
||||
docs: the documents to add
|
||||
cleanup: choose from "incremental" (update embeddings, skip existing embeddings) and "full" (destory and rebuild retriever)
|
||||
mode: choose from "by source" (documents are grouped by source) and "merge" (documents are merged into one vector store)
|
||||
"""
|
||||
if cleanup == "full":
|
||||
# Cleanup
|
||||
for source in self.vector_stores:
|
||||
os.remove(self.sql_index_database[source])
|
||||
# Add documents
|
||||
data_by_source = defaultdict(list)
|
||||
if mode == "by_source":
|
||||
for doc in docs:
|
||||
data_by_source[doc.metadata["source"]].append(doc)
|
||||
elif mode == "merge":
|
||||
data_by_source["merged"] = docs
|
||||
for source in data_by_source:
|
||||
if source not in self.vector_stores:
|
||||
hash_encoding = hashlib.sha3_224(source.encode()).hexdigest()
|
||||
if os.path.exists(f"{self.sql_file_path}/{hash_encoding}.db"):
|
||||
# Remove the stale file
|
||||
os.remove(f"{self.sql_file_path}/{hash_encoding}.db")
|
||||
# Create a new sql database to store indexes, sql files are stored in the same directory as the source file
|
||||
sql_path = f"sqlite:///{self.sql_file_path}/{hash_encoding}.db"
|
||||
self.vector_stores[source] = Chroma(embedding_function=embedding, collection_name=hash_encoding)
|
||||
self.sql_index_database[source] = f"{self.sql_file_path}/{hash_encoding}.db"
|
||||
self.record_managers[source] = SQLRecordManager(source, db_url=sql_path)
|
||||
self.record_managers[source].create_schema()
|
||||
index(
|
||||
data_by_source[source],
|
||||
self.record_managers[source],
|
||||
self.vector_stores[source],
|
||||
cleanup=cleanup,
|
||||
source_id_key="source",
|
||||
)
|
||||
|
||||
def __del__(self):
|
||||
for source in self.sql_index_database:
|
||||
if os.path.exists(self.sql_index_database[source]):
|
||||
os.remove(self.sql_index_database[source])
|
||||
|
||||
def set_sql_database_chain(self, db_chains) -> None:
|
||||
"""
|
||||
set sql agent chain to retrieve information from sql database
|
||||
Not used in this version
|
||||
"""
|
||||
self.sql_db_chains = db_chains
|
||||
|
||||
def set_rephrase_handler(self, handler: Callable = None) -> None:
|
||||
"""
|
||||
Set a handler to preprocess the input str before feed into the retriever
|
||||
"""
|
||||
self.rephrase_handler = handler
|
||||
|
||||
def _get_relevant_documents(
|
||||
self,
|
||||
query: str,
|
||||
*,
|
||||
run_manager: CallbackManagerForRetrieverRun = None,
|
||||
score_threshold: float = None,
|
||||
return_scores: bool = False,
|
||||
) -> List[Document]:
|
||||
"""
|
||||
This function is called by the retriever to get the relevant documents.
|
||||
recent vistied queries are stored in buffer, if the query is in buffer, return the documents directly
|
||||
|
||||
Args:
|
||||
query: the query to be searched
|
||||
run_manager: the callback manager for retriever run
|
||||
Returns:
|
||||
documents: the relevant documents
|
||||
"""
|
||||
for buffered_doc in self.buffer:
|
||||
if buffered_doc[0] == query:
|
||||
return buffered_doc[1]
|
||||
query_ = str(query)
|
||||
# Use your existing retriever to get the documents
|
||||
if self.rephrase_handler:
|
||||
query = self.rephrase_handler(query)
|
||||
documents = []
|
||||
for k in self.vector_stores:
|
||||
# Retrieve documents from each retriever
|
||||
vectorstore = self.vector_stores[k]
|
||||
documents.extend(vectorstore.similarity_search_with_score(query, self.k, score_threshold=score_threshold))
|
||||
# print(documents)
|
||||
# Return the top k documents among all retrievers
|
||||
documents = sorted(documents, key=lambda x: x[1], reverse=False)[: self.k]
|
||||
if return_scores:
|
||||
# Return score
|
||||
documents = copy.deepcopy(documents)
|
||||
for doc in documents:
|
||||
doc[0].metadata["score"] = doc[1]
|
||||
documents = [doc[0] for doc in documents]
|
||||
# Retrieve documents from sql database (not applicable for the local chains)
|
||||
for sql_chain in self.sql_db_chains:
|
||||
documents.append(
|
||||
Document(
|
||||
page_content=f"Query: {query} Answer: {sql_chain.run(query)}", metadata={"source": "sql_query"}
|
||||
)
|
||||
)
|
||||
if len(self.buffer) < self.buffer_size:
|
||||
self.buffer.append([query_, documents])
|
||||
else:
|
||||
self.buffer.pop(0)
|
||||
self.buffer.append([query_, documents])
|
||||
logger.info(f"retrieved documents:\n{str(documents)}", verbose=self.verbose)
|
||||
return documents
|
||||
|
|
@ -0,0 +1 @@
|
|||
from .chinese_text_splitter import ChineseTextSplitter
|
||||
|
|
@ -0,0 +1,56 @@
|
|||
"""
|
||||
Code for Chinese text splitter
|
||||
"""
|
||||
from typing import Any, List, Optional
|
||||
|
||||
from colossalqa.text_splitter.utils import get_cleaned_paragraph
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
|
||||
|
||||
class ChineseTextSplitter(RecursiveCharacterTextSplitter):
|
||||
def __init__(self, separators: Optional[List[str]] = None, is_separator_regrx: bool = False, **kwargs: Any):
|
||||
self._separators = separators or ["\n\n", "\n", ",", "。", "!", "?", "?"]
|
||||
if "chunk_size" not in kwargs:
|
||||
kwargs["chunk_size"] = 50
|
||||
if "chunk_overlap" not in kwargs:
|
||||
kwargs["chunk_overlap"] = 10
|
||||
super().__init__(separators=separators, keep_separator=True, **kwargs)
|
||||
self._is_separator_regex = is_separator_regrx
|
||||
|
||||
def split_text(self, text: str) -> List[str]:
|
||||
"""Return the list of separated text chunks"""
|
||||
cleaned_paragraph = get_cleaned_paragraph(text)
|
||||
splitted = []
|
||||
for paragraph in cleaned_paragraph:
|
||||
segs = super().split_text(paragraph)
|
||||
for i in range(len(segs) - 1):
|
||||
if segs[i][-1] not in self._separators:
|
||||
pos = text.find(segs[i])
|
||||
pos_end = pos + len(segs[i])
|
||||
if i > 0:
|
||||
last_sentence_start = max([text.rfind(m, 0, pos) for m in ["。", "!", "?"]])
|
||||
pos = last_sentence_start + 1
|
||||
segs[i] = str(text[pos:pos_end])
|
||||
if i != len(segs) - 1:
|
||||
next_sentence_end = max([text.find(m, pos_end) for m in ["。", "!", "?"]])
|
||||
segs[i] = str(text[pos : next_sentence_end + 1])
|
||||
splitted.append(segs[i])
|
||||
if len(splitted) <= 1:
|
||||
return splitted
|
||||
splitted_text = []
|
||||
i = 1
|
||||
if splitted[0] not in splitted[1]:
|
||||
splitted_text.append([splitted[0], 0])
|
||||
if splitted[-1] not in splitted[-2]:
|
||||
splitted_text.append([splitted[-1], len(splitted) - 1])
|
||||
while i < len(splitted) - 1:
|
||||
if splitted[i] not in splitted[i + 1] and splitted[i] not in splitted[i - 1]:
|
||||
splitted_text.append([splitted[i], i])
|
||||
i += 1
|
||||
splitted_text = sorted(splitted_text, key=lambda x: x[1])
|
||||
splitted_text = [splitted_text[i][0] for i in range(len(splitted_text))]
|
||||
ret = []
|
||||
for s in splitted_text:
|
||||
if s not in ret:
|
||||
ret.append(s)
|
||||
return ret
|
||||
|
|
@ -0,0 +1,19 @@
|
|||
import re
|
||||
|
||||
|
||||
def remove_format(text: str) -> str:
|
||||
# if the accout of \t, \r, \v, \f is less than 3, replace \t, \r, \v, \f with space
|
||||
if len(re.findall(r"\s", text.replace(" ", ""))) > 3:
|
||||
# in case this is a line of a table
|
||||
return text
|
||||
return re.sub(r"\s", " ", text)
|
||||
|
||||
|
||||
# remove newlines
|
||||
def get_cleaned_paragraph(s: str) -> str:
|
||||
text = str(s)
|
||||
text = re.sub(r"\n{3,}", r"\n", text) # replace \n\n\n... with \n
|
||||
text = re.sub("\n\n", "", text)
|
||||
lines = text.split("\n")
|
||||
lines_remove_format = [remove_format(line) for line in lines]
|
||||
return lines_remove_format
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
import re
|
||||
from typing import Union
|
||||
|
||||
from colossalqa.mylogging import get_logger
|
||||
from sqlalchemy import Engine, MetaData, create_engine
|
||||
from sqlalchemy.exc import SQLAlchemyError
|
||||
from sqlalchemy.ext.declarative import declarative_base
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
|
||||
def drop_table(engine: Engine) -> None:
|
||||
"""
|
||||
Drop all existing table
|
||||
"""
|
||||
Base = declarative_base()
|
||||
metadata = MetaData()
|
||||
metadata.reflect(bind=engine)
|
||||
for key in metadata.tables:
|
||||
table = metadata.tables[key]
|
||||
if table is not None:
|
||||
Base.metadata.drop_all(engine, [table], checkfirst=True)
|
||||
|
||||
|
||||
def create_empty_sql_database(database_uri):
|
||||
try:
|
||||
# Create an SQLAlchemy engine to connect to the database
|
||||
engine = create_engine(database_uri)
|
||||
|
||||
# Create the database
|
||||
engine.connect()
|
||||
|
||||
logger.info(f"Database created at {database_uri}")
|
||||
except SQLAlchemyError as e:
|
||||
logger.error(f"Error creating database: {str(e)}")
|
||||
return engine, database_uri
|
||||
|
||||
|
||||
def destroy_sql_database(sql_engine: Union[Engine, str]) -> None:
|
||||
"""
|
||||
Destroy an sql database
|
||||
"""
|
||||
if isinstance(sql_engine, str):
|
||||
sql_engine = create_engine(sql_engine)
|
||||
drop_table(sql_engine)
|
||||
sql_engine.dispose()
|
||||
sql_engine = None
|
||||
|
||||
|
||||
def detect_lang_naive(s):
|
||||
"""
|
||||
Naive function for language detection, should be replaced by an independant layer
|
||||
"""
|
||||
remove_nota = "[’·°–!\"#$%&'()*+,-./:;<=>?@,。?★、…【】()《》?“”‘’![\\]^_`{|}~]+"
|
||||
s = re.sub(remove_nota, "", s)
|
||||
s = re.sub("[0-9]", "", s).strip()
|
||||
res = re.sub("[a-zA-Z]", "", s).strip()
|
||||
if len(res) <= 0:
|
||||
return "en"
|
||||
else:
|
||||
return "zh"
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
Overview The Straits Times is the English flagship daily of SPH Media, one of the leading media companies in Asia. Launched on July 15, 1845, its comprehensive coverage of news from home and around the world makes The Straits Times the most-read newspaper in Singapore. Quality news, in-depth analyses, impactful commentaries and breaking stories are packaged to give readers riveting accounts of events in Singapore, the region, and beyond. The most read newspaper in Singapore, both in terms of print and digital, it reaches 1.33 million people every day. The Straits Times' key strength is in its world class coverage of news outside Singapore. With 20 bureaus in major cities around the world, The Straits Times correspondents bring world news to readers on a Singapore platter, helping readers to appreciate world events from a Singaporean perspective. Website http://www.straitstimes.com Phone 63196319Phone number is 63196319 Industry Newspaper Publishing Company size 1,001-5,000 employees 183 on LinkedIn Includes members with current employer listed as The Straits Times, including part-time roles. Headquarters Singapore, Singapore Founded 1845 Specialties News and Digital media
|
||||
About With over 500 properties worldwide, Marriott Hotels has reimagined hospitality to exceed the expectations of business, group, and leisure travelers.
|
||||
Marriott Hotels, Marriott’s flagship brand of quality-tier, full-service hotels and resorts, provides consistent, dependable and genuinely caring experiences to guests on their terms. Marriott is a brilliant host to guests who effortlessly blend life and work, and who are inspired by how modern travel enhances them both. Our hotels offer warm, professional service; sophisticated yet functional guest room design; lobby spaces that facilitate working, dining and socializing; restaurants and bars serving international cuisine prepared simply and from the freshest ingredients; meeting and event spaces and services that are gold standard; and expansive, 24-hour fitness facilities.
|
||||
Overview AERCO International, Inc. is a recognized leader in delivering cost-effective, condensing commercial boilers, high-efficiency water heaters across a variety of markets including education, lodging, government, office buildings, healthcare, industrial and multifamily housing. AERCO's system design approach provides customer-specific solutions that deliver superior building performance at a lower operating cost while assuring uptime reliability. When AERCO was founded in 1949, it introduced a revolutionary design for an indirect-fired water heater that heated water on demand, and without storage, at a controlled temperature. This innovation became today's standard for water heaters, maximizing the recovery of latent heat energy and significantly increasing operating efficiency. AERCO continued to innovate and in 1988, introduced the first condensing and fully modulating boiler and water heater to the commercial market. The modulating capability of these products, still unsurpassed more than 25 years later, matches the equipment's output to real-time heating demand, ensuring the units draw no more fuel to operate than is absolutely necessary. This not only saves precious energy, but also ensures money doesn't needlessly disappear "up the stack." AERCO differentiates itself through a solution-based model, leveraging decades of engineering experience and industry application expertise to understand each customer’s unique needs. By partnering directly with customers and end-users to understand their project-specific requirements, AERCO provides tailored application solutions that are comprised of original product technologies including high efficiency condensing products, compact footprints, high turndown ratios, unique fuel delivery, leading control systems and proprietary design elements that combine to deliver up to 99% efficiency. Website http://www.aerco.com Phone 845-580-8000Phone number is 845-580-8000 Industry Industrial Machinery Manufacturing Company size 51-200 employees 119 on LinkedIn Includes members with current employer listed as AERCO International, Inc., including part-time roles. Headquarters Blauvelt, NY Founded 1949 Specialties Leading manufacturer of condensing boilers, water heating and energy recovery products and The originator of semi-instantaneous water heating
|
||||
Prince PLC: Overview We are a global leader of quality water solutions for residential, industrial, municipal, and commercial settings. Our family of brands offers one of the most varied product lines in the world, with world-class, water-related solutions focused on: • Plumbing & Flow Control • Water Quality & Conditioning • Water Reuse & Drainage • HVAC • Municipal Waterworks Strategic Goals Watts Water is traded on the New York Stock Exchange under the symbol “WTS.” As a public company, growing shareholder value is critical. To that end, we focus on a five-part Global Strategy: Growth, Commercial Excellence, Operational Excellence, “One Watts Water,” and a Talent & Performance Culture. Follow us on all social media platforms @WattsWater Website http://www.watts.com/ Industry Wholesale Building Materials Company size 5,001-10,000 employees 2,248 on LinkedIn Includes members with current employer listed as Watts Water Technologies, including part-time roles. Headquarters North Andover, MA Specialties Plumbing, HVAC, Water Quality, Gas, Conditioning, Waterworks, and Drainage
|
||||
About Courtyard Hotels is Marriott International’s largest hotel brand, with more than 1,100 hotels in over 50 countries worldwide. So, no matter where passion takes you, you’ll find us there to help you follow it. Proud members of Marriott Bonvoy.
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
《海峡时报》是SPH传媒旗下的英文旗舰日报,SPH传媒是亚洲领先的传媒公司之一。《海峡时报》创刊于1845年7月15日,全面报道国内外新闻,是新加坡发行量最大的报纸。高质量的新闻、深入的分析、有影响力的评论和突发事件,为读者提供新加坡、该地区乃至其他地区的引人入胜的事件报道。无论是纸媒还是电子版,它都是新加坡阅读量最大的报纸,每天有133万人阅读。《海峡时报》的主要优势在于它对新加坡以外新闻的世界级报道。《海峡时报》记者在全球主要城市设有20个分社,用新加坡的盘子把世界新闻带给读者,帮助读者从新加坡的角度了解世界大事。网站http://www.straitstimes.com电话63196319电话63196319工业报纸出版公司规模1,001-5,000员工LinkedIn 183包括目前雇主为海峡时报的成员,包括兼职工作。总部位于新加坡,新加坡成立于1845年,专业从事新闻和数字媒体
|
||||
万豪酒店在全球拥有500多家酒店,以超越商务、团体和休闲旅客的期望,重塑酒店服务。
|
||||
万豪酒店(Marriott Hotels)是万豪旗下优质、全方位服务酒店和度假村的旗舰品牌,为客人提供始终如一、可靠和真诚关怀的体验。万豪是一个出色的主人,客人可以轻松地将生活和工作融合在一起,并受到现代旅行如何增强两者的启发。我们的酒店提供热情、专业的服务;精致而实用的客房设计;大堂空间,方便工作、餐饮和社交;餐厅和酒吧提供简单的国际美食和最新鲜的食材;会议及活动场地及服务均属黄金标准;还有宽敞的24小时健身设施。
|
||||
AERCO International, Inc.是公认的领导者,为教育、住宿、政府、办公楼、医疗保健、工业和多户住宅等各种市场提供具有成本效益的冷凝商用锅炉和高效热水器。AERCO的系统设计方法为客户提供特定的解决方案,以较低的运营成本提供卓越的建筑性能,同时确保正常运行时间的可靠性。AERCO成立于1949年,它推出了一种革命性的设计,用于间接燃烧热水器,在控制温度下按需加热水,而无需储存。这一创新成为当今热水器的标准,最大限度地回收潜热能量,显著提高运行效率。AERCO不断创新,并于1988年向商业市场推出了第一台冷凝和全调制锅炉和热水器。这些产品的调制能力,在超过25年后仍然无与伦比,使设备的输出与实时加热需求相匹配,确保机组不会消耗更多的燃料来运行,除非绝对必要。这不仅节省了宝贵的能源,还确保了钱不会不必要地消失在“堆栈”上。AERCO通过基于解决方案的模式脱颖而出,利用数十年的工程经验和行业应用专业知识来了解每个客户的独特需求。通过与客户和最终用户直接合作,了解他们的项目具体要求,AERCO提供量身定制的应用解决方案,这些解决方案由原创产品技术组成,包括高效冷凝产品,紧凑的足迹,高降压比,独特的燃料输送,领先的控制系统和专有设计元素,结合起来可提供高达99%的效率。网址http://www.aerco.com电话845-580- 8000电话号码845-580-8000工业工业机械制造公司规模51-200名员工LinkedIn上包括当前雇主AERCO International, Inc的成员,包括兼职职位。总部成立于1949年,纽约州布劳维尔特,专长:冷凝锅炉,水加热和能源回收产品的领先制造商,半瞬时水加热的鼻祖
|
||||
Prince PLC:概述Prince PLC是为住宅、工业、市政和商业环境提供优质水解决方案的全球领导者。我们的品牌家族提供世界上最多样化的产品线之一,拥有世界级的水相关解决方案,专注于:•管道和流量控制•水质和调理•水再利用和排水•hvac•市政水务战略目标瓦茨水务在纽约证券交易所上市,代码为“WTS”。作为一家上市公司,股东价值的增长至关重要。为此,我们将重点放在五部分全球战略上:增长、卓越商业、卓越运营、“一瓦茨水”以及人才与绩效文化。在所有社交媒体平台关注我们@WattsWater网站http://www.watts.com/行业批发建材公司规模5,001-10,000名员工领英2,248名包括目前雇主为WattsWater Technologies的成员,包括兼职职位。总部北安多弗,MA专业管道,暖通空调,水质,气体,空调,自来水厂和排水
|
||||
万怡酒店是万豪国际最大的酒店品牌,在全球50多个国家拥有1100多家酒店。所以,无论你的激情带你去哪里,你都会发现我们会帮助你追随它。万豪酒店的骄傲会员。
|
||||
|
|
@ -0,0 +1,101 @@
|
|||
Index,Organization Id,Company Name,Website,Country,Description,Founded,Industry,Number of employees
|
||||
1,FAB0d41d5b5d22c,Ferrell LLC,https://price.net/,Papua New Guinea,Horizontal empowering knowledgebase,1990,Plastics,3498
|
||||
2,6A7EdDEA9FaDC52,"Mckinney, Riley and Day",http://www.hall-buchanan.info/,Finland,User-centric system-worthy leverage,2015,Glass / Ceramics / Concrete,4952
|
||||
3,0bFED1ADAE4bcC1,Hester Ltd,http://sullivan-reed.com/,China,Switchable scalable moratorium,1971,Public Safety,5287
|
||||
4,2bFC1Be8a4ce42f,Holder-Sellers,https://becker.com/,Turkmenistan,De-engineered systemic artificial intelligence,2004,Automotive,921
|
||||
5,9eE8A6a4Eb96C24,Mayer Group,http://www.brewer.com/,Mauritius,Synchronized needs-based challenge,1991,Transportation,7870
|
||||
6,cC757116fe1C085,Henry-Thompson,http://morse.net/,Bahamas,Face-to-face well-modulated customer loyalty,1992,Primary / Secondary Education,4914
|
||||
7,219233e8aFF1BC3,Hansen-Everett,https://www.kidd.org/,Pakistan,Seamless disintermediate collaboration,2018,Publishing Industry,7832
|
||||
8,ccc93DCF81a31CD,Mcintosh-Mora,https://www.brooks.com/,Heard Island and McDonald Islands,Centralized attitude-oriented capability,1970,Import / Export,4389
|
||||
9,0B4F93aA06ED03e,Carr Inc,http://ross.com/,Kuwait,Distributed impactful customer loyalty,1996,Plastics,8167
|
||||
10,738b5aDe6B1C6A5,Gaines Inc,http://sandoval-hooper.com/,Uzbekistan,Multi-lateral scalable protocol,1997,Outsourcing / Offshoring,9698
|
||||
11,AE61b8Ffebbc476,Kidd Group,http://www.lyons.com/,Bouvet Island (Bouvetoya),Proactive foreground paradigm,2001,Primary / Secondary Education,7473
|
||||
12,eb3B7D06cCdD609,Crane-Clarke,https://www.sandoval.com/,Denmark,Front-line clear-thinking encryption,2014,Food / Beverages,9011
|
||||
13,8D0c29189C9798B,"Keller, Campos and Black",https://www.garner.info/,Liberia,Ameliorated directional emulation,2020,Museums / Institutions,2862
|
||||
14,D2c91cc03CA394c,Glover-Pope,http://www.silva.biz/,United Arab Emirates,Persevering contextually-based approach,2013,Medical Practice,9079
|
||||
15,C8AC1eaf9C036F4,Pacheco-Spears,https://aguilar.com/,Sweden,Secured logistical synergy,1984,Maritime,769
|
||||
16,b5D10A14f7a8AfE,Hodge-Ayers,http://www.archer-elliott.com/,Honduras,Future-proofed radical implementation,1990,Facilities Services,8508
|
||||
17,68139b5C4De03B4,"Bowers, Guerra and Krause",http://www.carrillo-nicholson.com/,Uganda,De-engineered transitional strategy,1972,Primary / Secondary Education,6986
|
||||
18,5c2EffEfdba2BdF,Mckenzie-Melton,http://montoya-thompson.com/,Hong Kong,Reverse-engineered heuristic alliance,1998,Investment Management / Hedge Fund / Private Equity,4589
|
||||
19,ba179F19F7925f5,Branch-Mann,http://www.lozano.com/,Botswana,Adaptive intangible frame,1999,Architecture / Planning,7961
|
||||
20,c1Ce9B350BAc66b,Weiss and Sons,https://barrett.com/,Korea,Sharable optimal functionalities,2011,Plastics,5984
|
||||
21,8de40AC4e6EaCa4,"Velez, Payne and Coffey",http://burton.com/,Luxembourg,Mandatory coherent synergy,1986,Wholesale,5010
|
||||
22,Aad86a4F0385F2d,Harrell LLC,http://www.frey-rosario.com/,Guadeloupe,Reverse-engineered mission-critical moratorium,2018,Construction,2185
|
||||
23,22aC3FFd64fD703,"Eaton, Reynolds and Vargas",http://www.freeman.biz/,Monaco,Self-enabling multi-tasking process improvement,2014,Luxury Goods / Jewelry,8987
|
||||
24,5Ec4C272bCf085c,Robbins-Cummings,http://donaldson-wilkins.com/,Belgium,Organic non-volatile hierarchy,1991,Pharmaceuticals,5038
|
||||
25,5fDBeA8BB91a000,Jenkins Inc,http://www.kirk.biz/,South Africa,Front-line systematic help-desk,2002,Insurance,1215
|
||||
26,dFfD6a6F9AC2d9C,"Greene, Benjamin and Novak",http://www.kent.net/,Romania,Centralized leadingedge moratorium,2012,Museums / Institutions,4941
|
||||
27,4B217cC5a0674C5,"Dickson, Richmond and Clay",http://everett.com/,Czech Republic,Team-oriented tangible complexity,1980,Real Estate / Mortgage,3122
|
||||
28,88b1f1cDcf59a37,Prince-David,http://thompson.com/,Christmas Island,Virtual holistic methodology,1970,Banking / Mortgage,1046
|
||||
29,f9F7bBCAEeC360F,Ayala LLC,http://www.zhang.com/,Philippines,Open-source zero administration hierarchy,2021,Legal Services,7664
|
||||
30,7Cb3AeFcE4Ba31e,Rivas Group,https://hebert.org/,Australia,Open-architected well-modulated capacity,1998,Logistics / Procurement,4155
|
||||
31,ccBcC32adcbc530,"Sloan, Mays and Whitehead",http://lawson.com/,Chad,Face-to-face high-level conglomeration,1997,Civil Engineering,365
|
||||
32,f5afd686b3d05F5,"Durham, Allen and Barnes",http://chan-stafford.org/,Zimbabwe,Synergistic web-enabled framework,1993,Mechanical or Industrial Engineering,6135
|
||||
33,38C6cfC5074Fa5e,Fritz-Franklin,http://www.lambert.com/,Nepal,Automated 4thgeneration website,1972,Hospitality,4516
|
||||
34,5Cd7efccCcba38f,Burch-Ewing,http://cline.net/,Taiwan,User-centric 4thgeneration system engine,1981,Venture Capital / VC,7443
|
||||
35,9E6Acb51e3F9d6F,"Glass, Barrera and Turner",https://dunlap.com/,Kyrgyz Republic,Multi-channeled 3rdgeneration open system,2020,Utilities,2610
|
||||
36,4D4d7E18321eaeC,Pineda-Cox,http://aguilar.org/,Bolivia,Fundamental asynchronous capability,2010,Human Resources / HR,1312
|
||||
37,485f5d06B938F2b,"Baker, Mccann and Macdonald",http://www.anderson-barker.com/,Kenya,Cross-group user-facing focus group,2013,Legislative Office,1638
|
||||
38,19E3a5Bf6dBDc4F,Cuevas-Moss,https://dodson-castaneda.net/,Guatemala,Extended human-resource intranet,1994,Music,9995
|
||||
39,6883A965c7b68F7,Hahn PLC,http://newman.com/,Belarus,Organic logistical leverage,2012,Electrical / Electronic Manufacturing,3715
|
||||
40,AC5B7AA74Aa4A2E,"Valentine, Ferguson and Kramer",http://stuart.net/,Jersey,Centralized secondary time-frame,1997,Non - Profit / Volunteering,3585
|
||||
41,decab0D5027CA6a,Arroyo Inc,https://www.turner.com/,Grenada,Managed demand-driven website,2006,Writing / Editing,9067
|
||||
42,dF084FbBb613eea,Walls LLC,http://www.reese-vasquez.biz/,Cape Verde,Self-enabling fresh-thinking installation,1989,Investment Management / Hedge Fund / Private Equity,1678
|
||||
43,A2D89Ab9bCcAd4e,"Mitchell, Warren and Schneider",https://fox.biz/,Trinidad and Tobago,Enhanced intangible time-frame,2021,Capital Markets / Hedge Fund / Private Equity,3816
|
||||
44,77aDc905434a49f,Prince PLC,https://www.watts.com/,Sweden,Profit-focused coherent installation,2016,Individual / Family Services,7645
|
||||
45,235fdEFE2cfDa5F,Brock-Blackwell,http://www.small.com/,Benin,Secured foreground emulation,1986,Online Publishing,7034
|
||||
46,1eD64cFe986BBbE,Walton-Barnett,https://ashley-schaefer.com/,Western Sahara,Right-sized clear-thinking flexibility,2001,Luxury Goods / Jewelry,1746
|
||||
47,CbBbFcdd0eaE2cF,Bartlett-Arroyo,https://cruz.com/,Northern Mariana Islands,Realigned didactic function,1976,Civic / Social Organization,3987
|
||||
48,49aECbDaE6aBD53,"Wallace, Madden and Morris",http://www.blevins-fernandez.biz/,Germany,Persistent real-time customer loyalty,2016,Pharmaceuticals,9443
|
||||
49,7b3fe6e7E72bFa4,Berg-Sparks,https://cisneros-love.com/,Canada,Stand-alone static implementation,1974,Arts / Crafts,2073
|
||||
50,c6DedA82A8aef7E,Gonzales Ltd,http://bird.com/,Tonga,Managed human-resource policy,1988,Consumer Goods,9069
|
||||
51,7D9FBF85cdC3871,Lawson and Sons,https://www.wong.com/,French Southern Territories,Compatible analyzing intranet,2021,Arts / Crafts,3527
|
||||
52,7dd18Fb7cB07b65,"Mcguire, Mcconnell and Olsen",https://melton-briggs.com/,Korea,Profound client-server frame,1988,Printing,8445
|
||||
53,EF5B55FadccB8Fe,Charles-Phillips,https://bowman.com/,Cote d'Ivoire,Monitored client-server implementation,2012,Mental Health Care,3450
|
||||
54,f8D4B99e11fAF5D,Odom Ltd,https://www.humphrey-hess.com/,Cote d'Ivoire,Advanced static process improvement,2012,Management Consulting,1825
|
||||
55,e24D21BFd3bF1E5,Richard PLC,https://holden-coleman.net/,Mayotte,Object-based optimizing model,1971,Broadcast Media,4942
|
||||
56,B9BdfEB6D3Ca44E,Sampson Ltd,https://blevins.com/,Cayman Islands,Intuitive local adapter,2005,Farming,1418
|
||||
57,2a74D6f3D3B268e,"Cherry, Le and Callahan",https://waller-delacruz.biz/,Nigeria,Universal human-resource collaboration,2017,Entertainment / Movie Production,7202
|
||||
58,Bf3F3f62c8aBC33,Cherry PLC,https://www.avila.info/,Marshall Islands,Persistent tertiary website,1980,Plastics,8245
|
||||
59,aeBe26B80a7a23c,Melton-Nichols,https://kennedy.com/,Palau,User-friendly clear-thinking productivity,2021,Legislative Office,8741
|
||||
60,aAeb29ad43886C6,Potter-Walsh,http://thomas-french.org/,Turkey,Optional non-volatile open system,2008,Human Resources / HR,6923
|
||||
61,bD1bc6bB6d1FeD3,Freeman-Chen,https://mathis.com/,Timor-Leste,Phased next generation adapter,1973,International Trade / Development,346
|
||||
62,EB9f456e8b7022a,Soto Group,https://norris.info/,Vietnam,Enterprise-wide executive installation,1988,Business Supplies / Equipment,9097
|
||||
63,Dfef38C51D8DAe3,"Poole, Cruz and Whitney",https://reed.info/,Reunion,Balanced analyzing groupware,1978,Marketing / Advertising / Sales,2992
|
||||
64,055ffEfB2Dd95B0,Riley Ltd,http://wiley.com/,Brazil,Optional exuding superstructure,1986,Textiles,9315
|
||||
65,cBfe4dbAE1699da,"Erickson, Andrews and Bailey",https://www.hobbs-grant.com/,Eritrea,Vision-oriented secondary project,2014,Consumer Electronics,7829
|
||||
66,fdFbecbadcdCdf1,"Wilkinson, Charles and Arroyo",http://hunter-mcfarland.com/,United States Virgin Islands,Assimilated 24/7 archive,1996,Building Materials,602
|
||||
67,5DCb8A5a5ca03c0,Floyd Ltd,http://www.whitney.com/,Falkland Islands (Malvinas),Function-based fault-tolerant concept,2017,Public Relations / PR,2911
|
||||
68,ce57DCbcFD6d618,Newman-Galloway,https://www.scott.com/,Luxembourg,Enhanced foreground collaboration,1987,Information Technology / IT,3934
|
||||
69,5aaD187dc929371,Frazier-Butler,https://www.daugherty-farley.info/,Northern Mariana Islands,Persistent interactive circuit,1972,Outsourcing / Offshoring,5130
|
||||
70,902D7Ac8b6d476b,Newton Inc,https://www.richmond-manning.info/,Netherlands Antilles,Fundamental stable info-mediaries,1976,Military Industry,563
|
||||
71,32BB9Ff4d939788,Duffy-Levy,https://www.potter.com/,Guernsey,Diverse exuding installation,1982,Wireless,6146
|
||||
72,adcB0afbE58bAe3,Wagner LLC,https://decker-esparza.com/,Uruguay,Reactive attitude-oriented toolset,1987,International Affairs,6874
|
||||
73,dfcA1c84AdB61Ac,Mccall-Holmes,http://www.dean.com/,Benin,Object-based value-added database,2009,Legal Services,696
|
||||
74,208044AC2fe52F3,Massey LLC,https://frazier.biz/,Suriname,Configurable zero administration Graphical User Interface,1986,Accounting,5004
|
||||
75,f3C365f0c1A0623,Hicks LLC,http://alvarez.biz/,Pakistan,Quality-focused client-server Graphical User Interface,1970,Computer Software / Engineering,8480
|
||||
76,ec5Bdd3CBAfaB93,"Cole, Russell and Avery",http://www.blankenship.com/,Mongolia,De-engineered fault-tolerant challenge,2000,Law Enforcement,7012
|
||||
77,DDB19Be7eeB56B4,Cummings-Rojas,https://simon-pearson.com/,Svalbard & Jan Mayen Islands,User-centric modular customer loyalty,2012,Financial Services,7529
|
||||
78,dd6CA3d0bc3cAfc,"Beasley, Greene and Mahoney",http://www.petersen-lawrence.com/,Togo,Extended content-based methodology,1976,Religious Institutions,869
|
||||
79,A0B9d56e61070e3,"Beasley, Sims and Allison",http://burke.info/,Latvia,Secured zero tolerance hub,1972,Facilities Services,6182
|
||||
80,cBa7EFe5D05Adaf,Crawford-Rivera,https://black-ramirez.org/,Cuba,Persevering exuding budgetary management,1999,Online Publishing,7805
|
||||
81,Ea3f6D52Ec73563,Montes-Hensley,https://krueger.org/,Liechtenstein,Multi-tiered secondary productivity,2009,Printing,8433
|
||||
82,bC0CEd48A8000E0,Velazquez-Odom,https://stokes.com/,Djibouti,Streamlined 6thgeneration function,2002,Alternative Dispute Resolution,4044
|
||||
83,c89b9b59BC4baa1,Eaton-Morales,https://www.reeves-graham.com/,Micronesia,Customer-focused explicit frame,1990,Capital Markets / Hedge Fund / Private Equity,7013
|
||||
84,FEC51bce8421a7b,"Roberson, Pennington and Palmer",http://www.keith-fisher.com/,Cameroon,Adaptive bi-directional hierarchy,1993,Telecommunications,5571
|
||||
85,e0E8e27eAc9CAd5,"George, Russo and Guerra",https://drake.com/,Sweden,Centralized non-volatile capability,1989,Military Industry,2880
|
||||
86,B97a6CF9bf5983C,Davila Inc,https://mcconnell.info/,Cocos (Keeling) Islands,Profit-focused dedicated frame,2017,Consumer Electronics,2215
|
||||
87,a0a6f9b3DbcBEb5,Mays-Preston,http://www.browning-key.com/,Mali,User-centric heuristic focus group,2006,Military Industry,5786
|
||||
88,8cC1bDa330a5871,Pineda-Morton,https://www.carr.com/,United States Virgin Islands,Grass-roots methodical info-mediaries,1991,Printing,6168
|
||||
89,ED889CB2FE9cbd3,Huang and Sons,https://www.bolton.com/,Eritrea,Re-contextualized dynamic hierarchy,1981,Semiconductors,7484
|
||||
90,F4Dc1417BC6cb8f,Gilbert-Simon,https://www.bradford.biz/,Burundi,Grass-roots radical parallelism,1973,Newspapers / Journalism,1927
|
||||
91,7ABc3c7ecA03B34,Sampson-Griffith,http://hendricks.org/,Benin,Multi-layered composite paradigm,1972,Textiles,3881
|
||||
92,4e0719FBE38e0aB,Miles-Dominguez,http://www.turner.com/,Gibraltar,Organized empowering forecast,1996,Civic / Social Organization,897
|
||||
93,dEbDAAeDfaed00A,Rowe and Sons,https://www.simpson.org/,El Salvador,Balanced multimedia knowledgebase,1978,Facilities Services,8172
|
||||
94,61BDeCfeFD0cEF5,"Valenzuela, Holmes and Rowland",https://www.dorsey.net/,Taiwan,Persistent tertiary focus group,1999,Transportation,1483
|
||||
95,4e91eD25f486110,"Best, Wade and Shepard",https://zimmerman.com/,Zimbabwe,Innovative background definition,1991,Gambling / Casinos,4873
|
||||
96,0a0bfFbBbB8eC7c,Holmes Group,https://mcdowell.org/,Ethiopia,Right-sized zero tolerance focus group,1975,Photography,2988
|
||||
97,BA6Cd9Dae2Efd62,Good Ltd,http://duffy.com/,Anguilla,Reverse-engineered composite moratorium,1971,Consumer Services,4292
|
||||
98,E7df80C60Abd7f9,Clements-Espinoza,http://www.flowers.net/,Falkland Islands (Malvinas),Progressive modular hub,1991,Broadcast Media,236
|
||||
99,AFc285dbE2fEd24,Mendez Inc,https://www.burke.net/,Kyrgyz Republic,User-friendly exuding migration,1993,Education Management,339
|
||||
100,e9eB5A60Cef8354,Watkins-Kaiser,http://www.herring.com/,Togo,Synergistic background access,2009,Financial Services,2785
|
||||
|
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1,64 @@
|
|||
{
|
||||
"data": [
|
||||
{
|
||||
"key": "客户反映手机无法接收短信,但可以正常拨打电话,已确认手机号码正常,需要处理。",
|
||||
"value": "故障原因分类: 短信接收问题"
|
||||
},
|
||||
{
|
||||
"key": "客户申请开通国际漫游服务,但在目的地无法使用手机信号,已核实客户所在地国家为不支持漫游的区域,已通知客户。",
|
||||
"value": "故障原因分类: 国际漫游服务"
|
||||
},
|
||||
{
|
||||
"key": "客户称手机信号时强时弱,经过测试发现在不同区域信号确实存在波动,属于正常现象。",
|
||||
"value": "故障原因分类: 信号强弱波动"
|
||||
},
|
||||
{
|
||||
"key": "客户反映在家中无法连接Wi-Fi,建议检查路由器或尝试更换位置。",
|
||||
"value": "故障原因分类: 家庭网络问题"
|
||||
},
|
||||
{
|
||||
"key": "客户申请更换新的SIM卡,因旧卡损坏,已为客户办理新卡。",
|
||||
"value": "故障原因分类: SIM卡更换"
|
||||
},
|
||||
{
|
||||
"key": "客户反映通话时听不清对方声音,经检查发现是手机内置扬声器故障,建议维修。",
|
||||
"value": "故障原因分类: 扬声器故障"
|
||||
},
|
||||
{
|
||||
"key": "客户手机丢失,请求挂失并办理新卡,已为客户挂失旧卡并补办新卡。",
|
||||
"value": "故障原因分类: 挂失与补办"
|
||||
},
|
||||
{
|
||||
"key": "客户反映在市区内无法使用手机信号,经排查发现信号塔维护,属于暂时性故障。",
|
||||
"value": "故障原因分类: 信号塔维护"
|
||||
},
|
||||
{
|
||||
"key": "客户反映手机充电时出现过热情况,建议更换充电器。",
|
||||
"value": "故障原因分类: 充电器故障"
|
||||
},
|
||||
{
|
||||
"key": "客户要求关闭数据漫游功能,已为客户关闭。",
|
||||
"value": "故障原因分类: 关闭数据漫游"
|
||||
},
|
||||
{
|
||||
"key": "客户申请办理家庭套餐业务,已为客户办理。",
|
||||
"value": "故障原因分类: 家庭套餐办理"
|
||||
},
|
||||
{
|
||||
"key": "客户反映在商场内无法使用手机信号,建议检查手机信号设置。",
|
||||
"value": "故障原因分类: 手机信号设置"
|
||||
},
|
||||
{
|
||||
"key": "客户申请开通国际长途业务,已为客户办理。",
|
||||
"value": "故障原因分类: 国际长途业务办理"
|
||||
},
|
||||
{
|
||||
"key": "客户反映手机屏幕出现蓝屏,建议客户前往维修。",
|
||||
"value": "故障原因分类: 手机屏幕故障"
|
||||
},
|
||||
{
|
||||
"key": "客户申请办理免流量业务,已为客户办理。",
|
||||
"value": "故障原因分类: 免流量业务办理"
|
||||
}
|
||||
]
|
||||
}
|
||||
File diff suppressed because one or more lines are too long
|
|
@ -0,0 +1 @@
|
|||
潞晨科技是一家致力于“解放AI生产力”的全球性公司,技术团队核心成员来自美国加州伯克利、斯坦福、新加坡国立、南洋理工、清华、北大等国内外知名高校。在高性能计算、人工智能、分布式系统等方面已有十余年的技术积累,并在国际顶级学术刊物或会议发表论文近百篇。公司核心产品面向大模型时代的通用深度学习系统 Colossal-AI,可实现高效快速部署AI大模型训练和推理,降低AI大模型应用成本。公司在种子轮、天使轮融资已获得“清科中国早期投资机构30强”前三甲创新工场、真格基金、蓝驰创投的600万美元投资。
|
||||
|
|
@ -0,0 +1,7 @@
|
|||
{
|
||||
"data":[
|
||||
{"content":"Donec lobortis eleifend condimentum. Cras dictum dolor lacinia lectus vehicula rutrum. Maecenas quis nisi nunc. Nam tristique feugiat est vitae mollis. Maecenas quis nisi nunc."},
|
||||
{"content":"Aliquam sollicitudin ante ligula, eget malesuada nibh efficitur et. Pellentesque massa sem, scelerisque sit amet odio id, cursus tempor urna. Etiam congue dignissim volutpat. Vestibulum pharetra libero et velit gravida euismod."}
|
||||
],
|
||||
"name":"player"
|
||||
}
|
||||
|
|
@ -0,0 +1,101 @@
|
|||
Index,Organization Id,Name,Website,Country,Description,Founded,Industry,Number of employees
|
||||
1,FAB0d41d5b5d22c,Ferrell LLC,https://price.net/,Papua New Guinea,Horizontal empowering knowledgebase,1990,Plastics,3498
|
||||
2,6A7EdDEA9FaDC52,"Mckinney, Riley and Day",http://www.hall-buchanan.info/,Finland,User-centric system-worthy leverage,2015,Glass / Ceramics / Concrete,4952
|
||||
3,0bFED1ADAE4bcC1,Hester Ltd,http://sullivan-reed.com/,China,Switchable scalable moratorium,1971,Public Safety,5287
|
||||
4,2bFC1Be8a4ce42f,Holder-Sellers,https://becker.com/,Turkmenistan,De-engineered systemic artificial intelligence,2004,Automotive,921
|
||||
5,9eE8A6a4Eb96C24,Mayer Group,http://www.brewer.com/,Mauritius,Synchronized needs-based challenge,1991,Transportation,7870
|
||||
6,cC757116fe1C085,Henry-Thompson,http://morse.net/,Bahamas,Face-to-face well-modulated customer loyalty,1992,Primary / Secondary Education,4914
|
||||
7,219233e8aFF1BC3,Hansen-Everett,https://www.kidd.org/,Pakistan,Seamless disintermediate collaboration,2018,Publishing Industry,7832
|
||||
8,ccc93DCF81a31CD,Mcintosh-Mora,https://www.brooks.com/,Heard Island and McDonald Islands,Centralized attitude-oriented capability,1970,Import / Export,4389
|
||||
9,0B4F93aA06ED03e,Carr Inc,http://ross.com/,Kuwait,Distributed impactful customer loyalty,1996,Plastics,8167
|
||||
10,738b5aDe6B1C6A5,Gaines Inc,http://sandoval-hooper.com/,Uzbekistan,Multi-lateral scalable protocol,1997,Outsourcing / Offshoring,9698
|
||||
11,AE61b8Ffebbc476,Kidd Group,http://www.lyons.com/,Bouvet Island (Bouvetoya),Proactive foreground paradigm,2001,Primary / Secondary Education,7473
|
||||
12,eb3B7D06cCdD609,Crane-Clarke,https://www.sandoval.com/,Denmark,Front-line clear-thinking encryption,2014,Food / Beverages,9011
|
||||
13,8D0c29189C9798B,"Keller, Campos and Black",https://www.garner.info/,Liberia,Ameliorated directional emulation,2020,Museums / Institutions,2862
|
||||
14,D2c91cc03CA394c,Glover-Pope,http://www.silva.biz/,United Arab Emirates,Persevering contextually-based approach,2013,Medical Practice,9079
|
||||
15,C8AC1eaf9C036F4,Pacheco-Spears,https://aguilar.com/,Sweden,Secured logistical synergy,1984,Maritime,769
|
||||
16,b5D10A14f7a8AfE,Hodge-Ayers,http://www.archer-elliott.com/,Honduras,Future-proofed radical implementation,1990,Facilities Services,8508
|
||||
17,68139b5C4De03B4,"Bowers, Guerra and Krause",http://www.carrillo-nicholson.com/,Uganda,De-engineered transitional strategy,1972,Primary / Secondary Education,6986
|
||||
18,5c2EffEfdba2BdF,Mckenzie-Melton,http://montoya-thompson.com/,Hong Kong,Reverse-engineered heuristic alliance,1998,Investment Management / Hedge Fund / Private Equity,4589
|
||||
19,ba179F19F7925f5,Branch-Mann,http://www.lozano.com/,Botswana,Adaptive intangible frame,1999,Architecture / Planning,7961
|
||||
20,c1Ce9B350BAc66b,Weiss and Sons,https://barrett.com/,Korea,Sharable optimal functionalities,2011,Plastics,5984
|
||||
21,8de40AC4e6EaCa4,"Velez, Payne and Coffey",http://burton.com/,Luxembourg,Mandatory coherent synergy,1986,Wholesale,5010
|
||||
22,Aad86a4F0385F2d,Harrell LLC,http://www.frey-rosario.com/,Guadeloupe,Reverse-engineered mission-critical moratorium,2018,Construction,2185
|
||||
23,22aC3FFd64fD703,"Eaton, Reynolds and Vargas",http://www.freeman.biz/,Monaco,Self-enabling multi-tasking process improvement,2014,Luxury Goods / Jewelry,8987
|
||||
24,5Ec4C272bCf085c,Robbins-Cummings,http://donaldson-wilkins.com/,Belgium,Organic non-volatile hierarchy,1991,Pharmaceuticals,5038
|
||||
25,5fDBeA8BB91a000,Jenkins Inc,http://www.kirk.biz/,South Africa,Front-line systematic help-desk,2002,Insurance,1215
|
||||
26,dFfD6a6F9AC2d9C,"Greene, Benjamin and Novak",http://www.kent.net/,Romania,Centralized leadingedge moratorium,2012,Museums / Institutions,4941
|
||||
27,4B217cC5a0674C5,"Dickson, Richmond and Clay",http://everett.com/,Czech Republic,Team-oriented tangible complexity,1980,Real Estate / Mortgage,3122
|
||||
28,88b1f1cDcf59a37,Prince-David,http://thompson.com/,Christmas Island,Virtual holistic methodology,1970,Banking / Mortgage,1046
|
||||
29,f9F7bBCAEeC360F,Ayala LLC,http://www.zhang.com/,Philippines,Open-source zero administration hierarchy,2021,Legal Services,7664
|
||||
30,7Cb3AeFcE4Ba31e,Rivas Group,https://hebert.org/,Australia,Open-architected well-modulated capacity,1998,Logistics / Procurement,4155
|
||||
31,ccBcC32adcbc530,"Sloan, Mays and Whitehead",http://lawson.com/,Chad,Face-to-face high-level conglomeration,1997,Civil Engineering,365
|
||||
32,f5afd686b3d05F5,"Durham, Allen and Barnes",http://chan-stafford.org/,Zimbabwe,Synergistic web-enabled framework,1993,Mechanical or Industrial Engineering,6135
|
||||
33,38C6cfC5074Fa5e,Fritz-Franklin,http://www.lambert.com/,Nepal,Automated 4thgeneration website,1972,Hospitality,4516
|
||||
34,5Cd7efccCcba38f,Burch-Ewing,http://cline.net/,Taiwan,User-centric 4thgeneration system engine,1981,Venture Capital / VC,7443
|
||||
35,9E6Acb51e3F9d6F,"Glass, Barrera and Turner",https://dunlap.com/,Kyrgyz Republic,Multi-channeled 3rdgeneration open system,2020,Utilities,2610
|
||||
36,4D4d7E18321eaeC,Pineda-Cox,http://aguilar.org/,Bolivia,Fundamental asynchronous capability,2010,Human Resources / HR,1312
|
||||
37,485f5d06B938F2b,"Baker, Mccann and Macdonald",http://www.anderson-barker.com/,Kenya,Cross-group user-facing focus group,2013,Legislative Office,1638
|
||||
38,19E3a5Bf6dBDc4F,Cuevas-Moss,https://dodson-castaneda.net/,Guatemala,Extended human-resource intranet,1994,Music,9995
|
||||
39,6883A965c7b68F7,Hahn PLC,http://newman.com/,Belarus,Organic logistical leverage,2012,Electrical / Electronic Manufacturing,3715
|
||||
40,AC5B7AA74Aa4A2E,"Valentine, Ferguson and Kramer",http://stuart.net/,Jersey,Centralized secondary time-frame,1997,Non - Profit / Volunteering,3585
|
||||
41,decab0D5027CA6a,Arroyo Inc,https://www.turner.com/,Grenada,Managed demand-driven website,2006,Writing / Editing,9067
|
||||
42,dF084FbBb613eea,Walls LLC,http://www.reese-vasquez.biz/,Cape Verde,Self-enabling fresh-thinking installation,1989,Investment Management / Hedge Fund / Private Equity,1678
|
||||
43,A2D89Ab9bCcAd4e,"Mitchell, Warren and Schneider",https://fox.biz/,Trinidad and Tobago,Enhanced intangible time-frame,2021,Capital Markets / Hedge Fund / Private Equity,3816
|
||||
44,77aDc905434a49f,Prince PLC,https://www.watts.com/,Sweden,Profit-focused coherent installation,2016,Individual / Family Services,7645
|
||||
45,235fdEFE2cfDa5F,Brock-Blackwell,http://www.small.com/,Benin,Secured foreground emulation,1986,Online Publishing,7034
|
||||
46,1eD64cFe986BBbE,Walton-Barnett,https://ashley-schaefer.com/,Western Sahara,Right-sized clear-thinking flexibility,2001,Luxury Goods / Jewelry,1746
|
||||
47,CbBbFcdd0eaE2cF,Bartlett-Arroyo,https://cruz.com/,Northern Mariana Islands,Realigned didactic function,1976,Civic / Social Organization,3987
|
||||
48,49aECbDaE6aBD53,"Wallace, Madden and Morris",http://www.blevins-fernandez.biz/,Germany,Persistent real-time customer loyalty,2016,Pharmaceuticals,9443
|
||||
49,7b3fe6e7E72bFa4,Berg-Sparks,https://cisneros-love.com/,Canada,Stand-alone static implementation,1974,Arts / Crafts,2073
|
||||
50,c6DedA82A8aef7E,Gonzales Ltd,http://bird.com/,Tonga,Managed human-resource policy,1988,Consumer Goods,9069
|
||||
51,7D9FBF85cdC3871,Lawson and Sons,https://www.wong.com/,French Southern Territories,Compatible analyzing intranet,2021,Arts / Crafts,3527
|
||||
52,7dd18Fb7cB07b65,"Mcguire, Mcconnell and Olsen",https://melton-briggs.com/,Korea,Profound client-server frame,1988,Printing,8445
|
||||
53,EF5B55FadccB8Fe,Charles-Phillips,https://bowman.com/,Cote d'Ivoire,Monitored client-server implementation,2012,Mental Health Care,3450
|
||||
54,f8D4B99e11fAF5D,Odom Ltd,https://www.humphrey-hess.com/,Cote d'Ivoire,Advanced static process improvement,2012,Management Consulting,1825
|
||||
55,e24D21BFd3bF1E5,Richard PLC,https://holden-coleman.net/,Mayotte,Object-based optimizing model,1971,Broadcast Media,4942
|
||||
56,B9BdfEB6D3Ca44E,Sampson Ltd,https://blevins.com/,Cayman Islands,Intuitive local adapter,2005,Farming,1418
|
||||
57,2a74D6f3D3B268e,"Cherry, Le and Callahan",https://waller-delacruz.biz/,Nigeria,Universal human-resource collaboration,2017,Entertainment / Movie Production,7202
|
||||
58,Bf3F3f62c8aBC33,Cherry PLC,https://www.avila.info/,Marshall Islands,Persistent tertiary website,1980,Plastics,8245
|
||||
59,aeBe26B80a7a23c,Melton-Nichols,https://kennedy.com/,Palau,User-friendly clear-thinking productivity,2021,Legislative Office,8741
|
||||
60,aAeb29ad43886C6,Potter-Walsh,http://thomas-french.org/,Turkey,Optional non-volatile open system,2008,Human Resources / HR,6923
|
||||
61,bD1bc6bB6d1FeD3,Freeman-Chen,https://mathis.com/,Timor-Leste,Phased next generation adapter,1973,International Trade / Development,346
|
||||
62,EB9f456e8b7022a,Soto Group,https://norris.info/,Vietnam,Enterprise-wide executive installation,1988,Business Supplies / Equipment,9097
|
||||
63,Dfef38C51D8DAe3,"Poole, Cruz and Whitney",https://reed.info/,Reunion,Balanced analyzing groupware,1978,Marketing / Advertising / Sales,2992
|
||||
64,055ffEfB2Dd95B0,Riley Ltd,http://wiley.com/,Brazil,Optional exuding superstructure,1986,Textiles,9315
|
||||
65,cBfe4dbAE1699da,"Erickson, Andrews and Bailey",https://www.hobbs-grant.com/,Eritrea,Vision-oriented secondary project,2014,Consumer Electronics,7829
|
||||
66,fdFbecbadcdCdf1,"Wilkinson, Charles and Arroyo",http://hunter-mcfarland.com/,United States Virgin Islands,Assimilated 24/7 archive,1996,Building Materials,602
|
||||
67,5DCb8A5a5ca03c0,Floyd Ltd,http://www.whitney.com/,Falkland Islands (Malvinas),Function-based fault-tolerant concept,2017,Public Relations / PR,2911
|
||||
68,ce57DCbcFD6d618,Newman-Galloway,https://www.scott.com/,Luxembourg,Enhanced foreground collaboration,1987,Information Technology / IT,3934
|
||||
69,5aaD187dc929371,Frazier-Butler,https://www.daugherty-farley.info/,Northern Mariana Islands,Persistent interactive circuit,1972,Outsourcing / Offshoring,5130
|
||||
70,902D7Ac8b6d476b,Newton Inc,https://www.richmond-manning.info/,Netherlands Antilles,Fundamental stable info-mediaries,1976,Military Industry,563
|
||||
71,32BB9Ff4d939788,Duffy-Levy,https://www.potter.com/,Guernsey,Diverse exuding installation,1982,Wireless,6146
|
||||
72,adcB0afbE58bAe3,Wagner LLC,https://decker-esparza.com/,Uruguay,Reactive attitude-oriented toolset,1987,International Affairs,6874
|
||||
73,dfcA1c84AdB61Ac,Mccall-Holmes,http://www.dean.com/,Benin,Object-based value-added database,2009,Legal Services,696
|
||||
74,208044AC2fe52F3,Massey LLC,https://frazier.biz/,Suriname,Configurable zero administration Graphical User Interface,1986,Accounting,5004
|
||||
75,f3C365f0c1A0623,Hicks LLC,http://alvarez.biz/,Pakistan,Quality-focused client-server Graphical User Interface,1970,Computer Software / Engineering,8480
|
||||
76,ec5Bdd3CBAfaB93,"Cole, Russell and Avery",http://www.blankenship.com/,Mongolia,De-engineered fault-tolerant challenge,2000,Law Enforcement,7012
|
||||
77,DDB19Be7eeB56B4,Cummings-Rojas,https://simon-pearson.com/,Svalbard & Jan Mayen Islands,User-centric modular customer loyalty,2012,Financial Services,7529
|
||||
78,dd6CA3d0bc3cAfc,"Beasley, Greene and Mahoney",http://www.petersen-lawrence.com/,Togo,Extended content-based methodology,1976,Religious Institutions,869
|
||||
79,A0B9d56e61070e3,"Beasley, Sims and Allison",http://burke.info/,Latvia,Secured zero tolerance hub,1972,Facilities Services,6182
|
||||
80,cBa7EFe5D05Adaf,Crawford-Rivera,https://black-ramirez.org/,Cuba,Persevering exuding budgetary management,1999,Online Publishing,7805
|
||||
81,Ea3f6D52Ec73563,Montes-Hensley,https://krueger.org/,Liechtenstein,Multi-tiered secondary productivity,2009,Printing,8433
|
||||
82,bC0CEd48A8000E0,Velazquez-Odom,https://stokes.com/,Djibouti,Streamlined 6thgeneration function,2002,Alternative Dispute Resolution,4044
|
||||
83,c89b9b59BC4baa1,Eaton-Morales,https://www.reeves-graham.com/,Micronesia,Customer-focused explicit frame,1990,Capital Markets / Hedge Fund / Private Equity,7013
|
||||
84,FEC51bce8421a7b,"Roberson, Pennington and Palmer",http://www.keith-fisher.com/,Cameroon,Adaptive bi-directional hierarchy,1993,Telecommunications,5571
|
||||
85,e0E8e27eAc9CAd5,"George, Russo and Guerra",https://drake.com/,Sweden,Centralized non-volatile capability,1989,Military Industry,2880
|
||||
86,B97a6CF9bf5983C,Davila Inc,https://mcconnell.info/,Cocos (Keeling) Islands,Profit-focused dedicated frame,2017,Consumer Electronics,2215
|
||||
87,a0a6f9b3DbcBEb5,Mays-Preston,http://www.browning-key.com/,Mali,User-centric heuristic focus group,2006,Military Industry,5786
|
||||
88,8cC1bDa330a5871,Pineda-Morton,https://www.carr.com/,United States Virgin Islands,Grass-roots methodical info-mediaries,1991,Printing,6168
|
||||
89,ED889CB2FE9cbd3,Huang and Sons,https://www.bolton.com/,Eritrea,Re-contextualized dynamic hierarchy,1981,Semiconductors,7484
|
||||
90,F4Dc1417BC6cb8f,Gilbert-Simon,https://www.bradford.biz/,Burundi,Grass-roots radical parallelism,1973,Newspapers / Journalism,1927
|
||||
91,7ABc3c7ecA03B34,Sampson-Griffith,http://hendricks.org/,Benin,Multi-layered composite paradigm,1972,Textiles,3881
|
||||
92,4e0719FBE38e0aB,Miles-Dominguez,http://www.turner.com/,Gibraltar,Organized empowering forecast,1996,Civic / Social Organization,897
|
||||
93,dEbDAAeDfaed00A,Rowe and Sons,https://www.simpson.org/,El Salvador,Balanced multimedia knowledgebase,1978,Facilities Services,8172
|
||||
94,61BDeCfeFD0cEF5,"Valenzuela, Holmes and Rowland",https://www.dorsey.net/,Taiwan,Persistent tertiary focus group,1999,Transportation,1483
|
||||
95,4e91eD25f486110,"Best, Wade and Shepard",https://zimmerman.com/,Zimbabwe,Innovative background definition,1991,Gambling / Casinos,4873
|
||||
96,0a0bfFbBbB8eC7c,Holmes Group,https://mcdowell.org/,Ethiopia,Right-sized zero tolerance focus group,1975,Photography,2988
|
||||
97,BA6Cd9Dae2Efd62,Good Ltd,http://duffy.com/,Anguilla,Reverse-engineered composite moratorium,1971,Consumer Services,4292
|
||||
98,E7df80C60Abd7f9,Clements-Espinoza,http://www.flowers.net/,Falkland Islands (Malvinas),Progressive modular hub,1991,Broadcast Media,236
|
||||
99,AFc285dbE2fEd24,Mendez Inc,https://www.burke.net/,Kyrgyz Republic,User-friendly exuding migration,1993,Education Management,339
|
||||
100,e9eB5A60Cef8354,Watkins-Kaiser,http://www.herring.com/,Togo,Synergistic background access,2009,Financial Services,2785
|
||||
|
Binary file not shown.
File diff suppressed because it is too large
Load Diff
|
|
@ -0,0 +1,78 @@
|
|||
# README Format File for Testing
|
||||

|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [Install](#install)
|
||||
- [How to Use](#how-to-use)
|
||||
- Examples
|
||||
- [Local Chinese Retrieval QA + Chat](examples/retrieval_conversation_zh.py)
|
||||
- [Local English Retrieval QA + Chat](examples/retrieval_conversation_en.py)
|
||||
- [Local Bi-lingual Retrieval QA + Chat](examples/retrieval_conversation_universal.py)
|
||||
- [Experimental AI Agent Based on Chatgpt + Chat](examples/conversation_agent_chatgpt.py)
|
||||
|
||||
**As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
|
||||
|
||||
## Install
|
||||
|
||||
Install colossalqa
|
||||
```bash
|
||||
# python==3.8.17
|
||||
cd ColossalAI/applications/ColossalQA
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
To use the vllm server, please refer to the official guide [here](https://github.com/vllm-project/vllm/tree/main) for installation instruction. Simply run the following command from another terminal.
|
||||
```bash
|
||||
cd ./vllm/entrypoints
|
||||
python api_server.py --host localhost --port $PORT_NUMBER --model $PATH_TO_MODEL --swap-space $SWAP_SPACE_IN_GB
|
||||
```
|
||||
|
||||
## How to use
|
||||
|
||||
### Collect your data
|
||||
|
||||
For ChatGPT based Agent we support document retrieval and simple sql search.
|
||||
If you want to run the demo locally, we provided document retrieval based conversation system built upon langchain. It accept a wide range of documents.
|
||||
|
||||
Read comments under ./colossalqa/data_loader for more detail
|
||||
|
||||
### Serving
|
||||
Currently use vllm will replace with colossal inference when ready. Please refer class VllmLLM.
|
||||
|
||||
### Run the script
|
||||
|
||||
We provided scripts for Chinese document retrieval based conversation system, English document retrieval based conversation system, Bi-lingual document retrieval based conversation system and an experimental AI agent with document retrieval and SQL query functionality.
|
||||
|
||||
To run the bi-lingual scripts, set the following environmental variables before running the script.
|
||||
```bash
|
||||
export ZH_MODEL_PATH=XXX
|
||||
export ZH_MODEL_NAME: chatglm2
|
||||
export EN_MODEL_PATH: XXX
|
||||
export EN_MODEL_NAME: llama
|
||||
python retrieval_conversation_universal.py
|
||||
```
|
||||
|
||||
To run retrieval_conversation_en.py. set the following environmental variables.
|
||||
```bash
|
||||
export EN_MODEL_PATH=XXX
|
||||
export EN_MODEL_NAME: llama
|
||||
python retrieval_conversation_en.py
|
||||
```
|
||||
|
||||
To run retrieval_conversation_zh.py. set the following environmental variables.
|
||||
```bash
|
||||
export ZH_MODEL_PATH=XXX
|
||||
export ZH_MODEL_NAME: chatglm2
|
||||
python retrieval_conversation_en.py
|
||||
```
|
||||
|
||||
It will ask you to provide the path to your data during the execution of the script. You can also pass a glob path to load multiple files at once. If csv files are provided, please use ',' as delimiter and '"' as quotation mark. There are no other formatting constraints for loading documents type files. For loading table type files, we use pandas, please refer to [Pandas-Input/Output](https://pandas.pydata.org/pandas-docs/stable/reference/io.html) for file format details.
|
||||
|
||||
## The Plan
|
||||
|
||||
- [x] build document retrieval QA tool
|
||||
- [x] Add long + short term memory
|
||||
- [x] Add demo for AI agent with SQL query
|
||||
- [x] Add customer retriever for fast construction and retrieving (with incremental mode)
|
||||
|
|
@ -0,0 +1,38 @@
|
|||
Your Name
|
||||
Lorem ipsum dolor sit amet, consectetuer adipiscing elit
|
||||
123 Your Street
|
||||
Your City, ST 12345
|
||||
(123) 456-7890
|
||||
no_reply@example.com
|
||||
EXPERIENCE
|
||||
Company, Location — Job Title
|
||||
MONTH 20XX - PRESENT
|
||||
Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh.
|
||||
Company, Location — Job Title
|
||||
MONTH 20XX - MONTH 20XX
|
||||
Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh.
|
||||
Company, Location — Job Title
|
||||
MONTH 20XX - MONTH 20XX
|
||||
Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh.
|
||||
EDUCATION
|
||||
School Name, Location — Degree
|
||||
MONTH 20XX - MONTH 20XX
|
||||
Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh euismod tincidunt ut laoreet dolore.
|
||||
School Name, Location — Degree
|
||||
MONTH 20XX - MONTH 20XX
|
||||
Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam.
|
||||
PROJECTS
|
||||
Project Name — Detail
|
||||
Lorem ipsum dolor sit amet, consectetuer adipiscing elit.
|
||||
SKILLS
|
||||
* Lorem ipsum dolor sit amet.
|
||||
* Consectetuer adipiscing elit.
|
||||
* Sed diam nonummy nibh euismod tincidunt.
|
||||
* Laoreet dolore magna aliquam erat volutpat.
|
||||
AWARDS
|
||||
Lorem ipsum dolor sit amet Consectetuer adipiscing elit, Sed diam nonummy
|
||||
Nibh euismod tincidunt ut laoreet dolore magna aliquam erat volutpat.
|
||||
Lorem ipsum dolor sit amet Consectetuer adipiscing elit, Sed diam nonummy
|
||||
Nibh euismod tincidunt ut laoreet dolore magna aliquam erat volutpat.
|
||||
LANGUAGES
|
||||
Lorem ipsum, Dolor sit amet, Consectetuer
|
||||
|
|
@ -0,0 +1,125 @@
|
|||
"""
|
||||
Script for the multilingual conversation based experimental AI agent
|
||||
We used ChatGPT as the language model
|
||||
You need openai api key to run this script
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import os
|
||||
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.data_loader.table_dataloader import TableLoader
|
||||
from langchain import LLMChain, OpenAI
|
||||
from langchain.agents import Tool, ZeroShotAgent
|
||||
from langchain.agents.agent import AgentExecutor
|
||||
from langchain.agents.agent_toolkits import create_retriever_tool
|
||||
from langchain.embeddings.openai import OpenAIEmbeddings
|
||||
from langchain.llms import OpenAI
|
||||
from langchain.memory import ChatMessageHistory, ConversationBufferMemory
|
||||
from langchain.memory.chat_memory import ChatMessageHistory
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
from langchain.utilities import SQLDatabase
|
||||
from langchain.vectorstores import Chroma
|
||||
from langchain_experimental.sql import SQLDatabaseChain
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Experimental AI agent powered by ChatGPT")
|
||||
parser.add_argument("--open_ai_key_path", type=str, default=None, help="path to the plain text open_ai_key file")
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
# Setup openai key
|
||||
# Set env var OPENAI_API_KEY or load from a file
|
||||
openai_key = open(args.open_ai_key_path).read()
|
||||
os.environ["OPENAI_API_KEY"] = openai_key
|
||||
|
||||
# Load data served on sql
|
||||
print("Select files for constructing sql database")
|
||||
tools = []
|
||||
|
||||
llm = OpenAI(temperature=0.0)
|
||||
|
||||
while True:
|
||||
file = input("Select a file to load or press Enter to exit:")
|
||||
if file == "":
|
||||
break
|
||||
data_name = input("Enter a short description of the data:")
|
||||
|
||||
table_loader = TableLoader(
|
||||
[[file, data_name.replace(" ", "_")]], sql_path=f"sqlite:///{data_name.replace(' ', '_')}.db"
|
||||
)
|
||||
sql_path = table_loader.get_sql_path()
|
||||
|
||||
# Create sql database
|
||||
db = SQLDatabase.from_uri(sql_path)
|
||||
print(db.get_table_info())
|
||||
|
||||
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)
|
||||
name = f"Query the SQL database regarding {data_name}"
|
||||
description = (
|
||||
f"useful for when you need to answer questions based on data stored on a SQL database regarding {data_name}"
|
||||
)
|
||||
tools.append(
|
||||
Tool(
|
||||
name=name,
|
||||
func=db_chain.run,
|
||||
description=description,
|
||||
)
|
||||
)
|
||||
print(f"Added sql dataset\n\tname={name}\n\tdescription:{description}")
|
||||
|
||||
# VectorDB
|
||||
embedding = OpenAIEmbeddings()
|
||||
|
||||
# Load data serve on sql
|
||||
print("Select files for constructing retriever")
|
||||
while True:
|
||||
file = input("Select a file to load or press Enter to exit:")
|
||||
if file == "":
|
||||
break
|
||||
data_name = input("Enter a short description of the data:")
|
||||
retriever_data = DocumentLoader([[file, data_name.replace(" ", "_")]]).all_data
|
||||
|
||||
# Split
|
||||
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=0)
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
|
||||
# Create vector store
|
||||
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
|
||||
# Create retriever
|
||||
retriever = vectordb.as_retriever(
|
||||
search_type="similarity_score_threshold", search_kwargs={"score_threshold": 0.5, "k": 5}
|
||||
)
|
||||
# Add to tool chain
|
||||
name = f"Searches and returns documents regarding {data_name}."
|
||||
tools.append(create_retriever_tool(retriever, data_name, name))
|
||||
|
||||
prefix = """Have a conversation with a human, answering the following questions as best you can. You have access to the following tools. If none of the tools can be used to answer the question. Do not share uncertain answer unless you think answering the question doesn't need any background information. In that case, try to answer the question directly."""
|
||||
suffix = """You are provided with the following background knowledge:
|
||||
Begin!"
|
||||
|
||||
{chat_history}
|
||||
Question: {input}
|
||||
{agent_scratchpad}"""
|
||||
|
||||
prompt = ZeroShotAgent.create_prompt(
|
||||
tools,
|
||||
prefix=prefix,
|
||||
suffix=suffix,
|
||||
input_variables=["input", "chat_history", "agent_scratchpad"],
|
||||
)
|
||||
|
||||
memory = ConversationBufferMemory(memory_key="chat_history", chat_memory=ChatMessageHistory())
|
||||
|
||||
llm_chain = LLMChain(llm=OpenAI(temperature=0.7), prompt=prompt)
|
||||
agent = ZeroShotAgent(llm_chain=llm_chain, tools=tools, verbose=True)
|
||||
agent_chain = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools, verbose=True, memory=memory)
|
||||
|
||||
while True:
|
||||
user_input = input("User: ")
|
||||
if " end " in user_input:
|
||||
print("Agent: Happy to chat with you :)")
|
||||
break
|
||||
agent_response = agent_chain.run(user_input)
|
||||
print(f"Agent: {agent_response}")
|
||||
table_loader.sql_engine.dispose()
|
||||
|
|
@ -0,0 +1,131 @@
|
|||
"""
|
||||
Multilingual retrieval based conversation system backed by ChatGPT
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import os
|
||||
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from langchain import LLMChain
|
||||
from langchain.chains import RetrievalQA
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
from langchain.llms import OpenAI
|
||||
from langchain.prompts.prompt import PromptTemplate
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Multilingual retrieval based conversation system backed by ChatGPT")
|
||||
parser.add_argument("--open_ai_key_path", type=str, default=None, help="path to the model")
|
||||
parser.add_argument(
|
||||
"--sql_file_path", type=str, default=None, help="path to the a empty folder for storing sql files for indexing"
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
if not os.path.exists(args.sql_file_path):
|
||||
os.makedirs(args.sql_file_path)
|
||||
|
||||
# Setup openai key
|
||||
# Set env var OPENAI_API_KEY or load from a file
|
||||
openai_key = open(args.open_ai_key_path).read()
|
||||
os.environ["OPENAI_API_KEY"] = openai_key
|
||||
|
||||
llm = OpenAI(temperature=0.6)
|
||||
|
||||
information_retriever = CustomRetriever(k=3, sql_file_path=args.sql_file_path, verbose=True)
|
||||
# VectorDB
|
||||
embedding = HuggingFaceEmbeddings(
|
||||
model_name="moka-ai/m3e-base", model_kwargs={"device": "cpu"}, encode_kwargs={"normalize_embeddings": False}
|
||||
)
|
||||
|
||||
# Define memory with summarization ability
|
||||
memory = ConversationBufferWithSummary(llm=llm)
|
||||
|
||||
# Load data to vector store
|
||||
print("Select files for constructing retriever")
|
||||
documents = []
|
||||
while True:
|
||||
file = input("Enter a file path or press Enter directory without input to exit:").strip()
|
||||
if file == "":
|
||||
break
|
||||
data_name = input("Enter a short description of the data:")
|
||||
retriever_data = DocumentLoader([[file, data_name.replace(" ", "_")]]).all_data
|
||||
|
||||
# Split
|
||||
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=0)
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
documents.extend(splits)
|
||||
# Create retriever
|
||||
information_retriever.add_documents(docs=documents, cleanup="incremental", mode="by_source", embedding=embedding)
|
||||
|
||||
prompt_template = """Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
|
||||
If the answer cannot be infered based on the given context, please don't share false information.
|
||||
Use the context and chat history to respond to the human's input at the end or carry on the conversation. You should generate one response only. No following up is needed.
|
||||
|
||||
context:
|
||||
{context}
|
||||
|
||||
chat history
|
||||
{chat_history}
|
||||
|
||||
Human: {question}
|
||||
Assistant:"""
|
||||
|
||||
prompt_template_disambiguate = """You are a helpful, respectful and honest assistant. You always follow the instruction.
|
||||
Please replace any ambiguous references in the given sentence with the specific names or entities mentioned in the chat history or just output the original sentence if no chat history is provided or if the sentence doesn't contain ambiguous references. Your output should be the disambiguated sentence itself (in the same line as "disambiguated sentence:") and contain nothing else.
|
||||
|
||||
Here is an example:
|
||||
Chat history:
|
||||
Human: I have a friend, Mike. Do you know him?
|
||||
Assistant: Yes, I know a person named Mike
|
||||
|
||||
sentence: What's his favorite food?
|
||||
disambiguated sentence: What's Mike's favorite food?
|
||||
END OF EXAMPLE
|
||||
|
||||
Chat history:
|
||||
{chat_history}
|
||||
|
||||
sentence: {input}
|
||||
disambiguated sentence:"""
|
||||
|
||||
PROMPT = PromptTemplate(template=prompt_template, input_variables=["question", "chat_history", "context"])
|
||||
|
||||
memory.initiate_document_retrieval_chain(
|
||||
llm,
|
||||
PROMPT,
|
||||
information_retriever,
|
||||
chain_type_kwargs={
|
||||
"chat_history": "",
|
||||
},
|
||||
)
|
||||
|
||||
PROMPT_DISAMBIGUATE = PromptTemplate(
|
||||
template=prompt_template_disambiguate, input_variables=["chat_history", "input"]
|
||||
)
|
||||
|
||||
llm_chain = RetrievalQA.from_chain_type(
|
||||
llm=llm,
|
||||
verbose=False,
|
||||
chain_type="stuff",
|
||||
retriever=information_retriever,
|
||||
chain_type_kwargs={"prompt": PROMPT, "memory": memory},
|
||||
)
|
||||
llm_chain_disambiguate = LLMChain(llm=llm, prompt=PROMPT_DISAMBIGUATE)
|
||||
|
||||
def disambiguity(input):
|
||||
out = llm_chain_disambiguate.run({"input": input, "chat_history": memory.buffer})
|
||||
return out.split("\n")[0]
|
||||
|
||||
information_retriever.set_rephrase_handler(disambiguity)
|
||||
|
||||
while True:
|
||||
user_input = input("User: ")
|
||||
if " end " in user_input:
|
||||
print("Agent: Happy to chat with you :)")
|
||||
break
|
||||
agent_response = llm_chain.run(user_input)
|
||||
agent_response = agent_response.split("\n")[0]
|
||||
print(f"Agent: {agent_response}")
|
||||
|
|
@ -0,0 +1,119 @@
|
|||
"""
|
||||
Script for English retrieval based conversation system backed by LLaMa2
|
||||
"""
|
||||
import argparse
|
||||
import os
|
||||
|
||||
from colossalqa.chain.retrieval_qa.base import RetrievalQA
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.prompt.prompt import (
|
||||
EN_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
EN_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
PROMPT_DISAMBIGUATE_EN,
|
||||
PROMPT_RETRIEVAL_QA_EN,
|
||||
)
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from langchain import LLMChain
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
|
||||
if __name__ == "__main__":
|
||||
# Parse arguments
|
||||
parser = argparse.ArgumentParser(description="English retrieval based conversation system backed by LLaMa2")
|
||||
parser.add_argument("--model_path", type=str, default=None, help="path to the model")
|
||||
parser.add_argument("--model_name", type=str, default=None, help="name of the model")
|
||||
parser.add_argument(
|
||||
"--sql_file_path", type=str, default=None, help="path to the a empty folder for storing sql files for indexing"
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
if not os.path.exists(args.sql_file_path):
|
||||
os.makedirs(args.sql_file_path)
|
||||
|
||||
colossal_api = ColossalAPI.get_api(args.model_name, args.model_path)
|
||||
llm = ColossalLLM(n=1, api=colossal_api)
|
||||
|
||||
# Define the retriever
|
||||
information_retriever = CustomRetriever(k=3, sql_file_path=args.sql_file_path, verbose=True)
|
||||
|
||||
# Setup embedding model locally
|
||||
embedding = HuggingFaceEmbeddings(
|
||||
model_name="moka-ai/m3e-base", model_kwargs={"device": "cpu"}, encode_kwargs={"normalize_embeddings": False}
|
||||
)
|
||||
|
||||
# Define memory with summarization ability
|
||||
memory = ConversationBufferWithSummary(
|
||||
llm=llm, max_tokens=2000, llm_kwargs={"max_new_tokens": 50, "temperature": 0.6, "do_sample": True}
|
||||
)
|
||||
|
||||
# Define the chain to preprocess the input
|
||||
# Disambiguate the input. e.g. "What is the capital of that country?" -> "What is the capital of France?"
|
||||
llm_chain_disambiguate = LLMChain(
|
||||
llm=llm, prompt=PROMPT_DISAMBIGUATE_EN, llm_kwargs={"max_new_tokens": 30, "temperature": 0.6, "do_sample": True}
|
||||
)
|
||||
|
||||
def disambiguity(input):
|
||||
out = llm_chain_disambiguate.run(input=input, chat_history=memory.buffer, stop=["\n"])
|
||||
return out.split("\n")[0]
|
||||
|
||||
# Load data to vector store
|
||||
print("Select files for constructing retriever")
|
||||
documents = []
|
||||
while True:
|
||||
file = input("Enter a file path or press Enter directory without input to exit:").strip()
|
||||
if file == "":
|
||||
break
|
||||
data_name = input("Enter a short description of the data:")
|
||||
separator = input(
|
||||
"Enter a separator to force separating text into chunks, if no separator is given, the defaut separator is '\\n\\n'. Note that"
|
||||
+ "we use neural text spliter to split texts into chunks, the seperator only serves as a delimiter to force split long passage into"
|
||||
+ " chunks before passing to the neural network. Press ENTER directly to skip:"
|
||||
)
|
||||
separator = separator if separator != "" else "\n\n"
|
||||
retriever_data = DocumentLoader([[file, data_name.replace(" ", "_")]]).all_data
|
||||
|
||||
# Split
|
||||
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
documents.extend(splits)
|
||||
# Create retriever
|
||||
information_retriever.add_documents(docs=documents, cleanup="incremental", mode="by_source", embedding=embedding)
|
||||
|
||||
# Set document retrieval chain, we need this chain to calculate prompt length
|
||||
memory.initiate_document_retrieval_chain(
|
||||
llm,
|
||||
PROMPT_RETRIEVAL_QA_EN,
|
||||
information_retriever,
|
||||
chain_type_kwargs={
|
||||
"chat_history": "",
|
||||
},
|
||||
)
|
||||
|
||||
# Define retrieval chain
|
||||
retrieval_chain = RetrievalQA.from_chain_type(
|
||||
llm=llm,
|
||||
verbose=False,
|
||||
chain_type="stuff",
|
||||
retriever=information_retriever,
|
||||
chain_type_kwargs={"prompt": PROMPT_RETRIEVAL_QA_EN, "memory": memory},
|
||||
llm_kwargs={"max_new_tokens": 50, "temperature": 0.75, "do_sample": True},
|
||||
)
|
||||
# Set disambiguity handler
|
||||
information_retriever.set_rephrase_handler(disambiguity)
|
||||
|
||||
# Start conversation
|
||||
while True:
|
||||
user_input = input("User: ")
|
||||
if "END" == user_input:
|
||||
print("Agent: Happy to chat with you :)")
|
||||
break
|
||||
agent_response = retrieval_chain.run(
|
||||
query=user_input,
|
||||
stop=["Human: "],
|
||||
rejection_trigger_keywrods=EN_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
rejection_answer=EN_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
)
|
||||
agent_response = agent_response.split("\n")[0]
|
||||
print(f"Agent: {agent_response}")
|
||||
|
|
@ -0,0 +1,149 @@
|
|||
"""
|
||||
Script for English retrieval based conversation system backed by LLaMa2
|
||||
"""
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
|
||||
from colossalqa.chain.retrieval_qa.base import RetrievalQA
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.prompt.prompt import (
|
||||
EN_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
EN_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
PROMPT_DISAMBIGUATE_EN,
|
||||
PROMPT_RETRIEVAL_QA_EN,
|
||||
)
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from langchain import LLMChain
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
|
||||
if __name__ == "__main__":
|
||||
# Parse arguments
|
||||
parser = argparse.ArgumentParser(description="English retrieval based conversation system backed by LLaMa2")
|
||||
parser.add_argument("--model_path", type=str, default=None, help="path to the model")
|
||||
parser.add_argument("--model_name", type=str, default=None, help="name of the model")
|
||||
parser.add_argument(
|
||||
"--sql_file_path", type=str, default=None, help="path to the a empty folder for storing sql files for indexing"
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
if not os.path.exists(args.sql_file_path):
|
||||
os.makedirs(args.sql_file_path)
|
||||
|
||||
colossal_api = ColossalAPI.get_api(args.model_name, args.model_path)
|
||||
llm = ColossalLLM(n=1, api=colossal_api)
|
||||
|
||||
# Define the retriever
|
||||
information_retriever = CustomRetriever(k=3, sql_file_path=args.sql_file_path, verbose=True)
|
||||
|
||||
# Setup embedding model locally
|
||||
embedding = HuggingFaceEmbeddings(
|
||||
model_name="moka-ai/m3e-base", model_kwargs={"device": "cpu"}, encode_kwargs={"normalize_embeddings": False}
|
||||
)
|
||||
|
||||
# Define memory with summarization ability
|
||||
memory = ConversationBufferWithSummary(
|
||||
llm=llm, max_tokens=2000, llm_kwargs={"max_new_tokens": 50, "temperature": 0.6, "do_sample": True}
|
||||
)
|
||||
|
||||
# Define the chain to preprocess the input
|
||||
# Disambiguate the input. e.g. "What is the capital of that country?" -> "What is the capital of France?"
|
||||
llm_chain_disambiguate = LLMChain(
|
||||
llm=llm, prompt=PROMPT_DISAMBIGUATE_EN, llm_kwargs={"max_new_tokens": 30, "temperature": 0.6, "do_sample": True}
|
||||
)
|
||||
|
||||
def disambiguity(input):
|
||||
out = llm_chain_disambiguate.run(input=input, chat_history=memory.buffer, stop=["\n"])
|
||||
return out.split("\n")[0]
|
||||
|
||||
# Load data to vector store
|
||||
print("Select files for constructing retriever")
|
||||
documents = []
|
||||
|
||||
# preprocess data
|
||||
if not os.path.exists("../data/data_sample/custom_service_preprocessed.json"):
|
||||
if not os.path.exists("../data/data_sample/custom_service.json"):
|
||||
raise ValueError(
|
||||
"custom_service.json not found, please download the data from HuggingFace Datasets: qgyd2021/e_commerce_customer_service"
|
||||
)
|
||||
data = json.load(open("../data/data_sample/custom_service.json", "r", encoding="utf8"))
|
||||
preprocessed = []
|
||||
for row in data["rows"]:
|
||||
preprocessed.append({"key": row["row"]["query"], "value": row["row"]["response"]})
|
||||
data = {}
|
||||
data["data"] = preprocessed
|
||||
with open("../data/data_sample/custom_service_preprocessed.json", "w", encoding="utf8") as f:
|
||||
json.dump(data, f, ensure_ascii=False)
|
||||
|
||||
# define metadata function which is used to format the prompt with value in metadata instead of key,
|
||||
# the later is langchain's default behavior
|
||||
def metadata_func(data_sample, additional_fields):
|
||||
"""
|
||||
metadata_func (Callable[Dict, Dict]): A function that takes in the JSON
|
||||
object extracted by the jq_schema and the default metadata and returns
|
||||
a dict of the updated metadata.
|
||||
|
||||
To use key-value format, the metadata_func should be defined as follows:
|
||||
metadata = {'value': 'a string to be used to format the prompt', 'is_key_value_mapping': True}
|
||||
"""
|
||||
metadata = {}
|
||||
metadata["value"] = f"Question: {data_sample['key']}\nAnswer:{data_sample['value']}"
|
||||
metadata["is_key_value_mapping"] = True
|
||||
assert "value" not in additional_fields
|
||||
assert "is_key_value_mapping" not in additional_fields
|
||||
metadata.update(additional_fields)
|
||||
return metadata
|
||||
|
||||
retriever_data = DocumentLoader(
|
||||
[["../data/data_sample/custom_service_preprocessed.json", "CustomerServiceDemo"]],
|
||||
content_key="key",
|
||||
metadata_func=metadata_func,
|
||||
).all_data
|
||||
|
||||
# Split
|
||||
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
documents.extend(splits)
|
||||
|
||||
# Create retriever
|
||||
information_retriever.add_documents(docs=documents, cleanup="incremental", mode="by_source", embedding=embedding)
|
||||
|
||||
# Set document retrieval chain, we need this chain to calculate prompt length
|
||||
memory.initiate_document_retrieval_chain(
|
||||
llm,
|
||||
PROMPT_RETRIEVAL_QA_EN,
|
||||
information_retriever,
|
||||
chain_type_kwargs={
|
||||
"chat_history": "",
|
||||
},
|
||||
)
|
||||
|
||||
# Define retrieval chain
|
||||
retrieval_chain = RetrievalQA.from_chain_type(
|
||||
llm=llm,
|
||||
verbose=False,
|
||||
chain_type="stuff",
|
||||
retriever=information_retriever,
|
||||
chain_type_kwargs={"prompt": PROMPT_RETRIEVAL_QA_EN, "memory": memory},
|
||||
llm_kwargs={"max_new_tokens": 50, "temperature": 0.75, "do_sample": True},
|
||||
)
|
||||
# Set disambiguity handler
|
||||
information_retriever.set_rephrase_handler(disambiguity)
|
||||
# Start conversation
|
||||
while True:
|
||||
user_input = input("User: ")
|
||||
if "END" == user_input:
|
||||
print("Agent: Happy to chat with you :)")
|
||||
break
|
||||
agent_response = retrieval_chain.run(
|
||||
query=user_input,
|
||||
stop=["Human: "],
|
||||
rejection_trigger_keywrods=EN_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
rejection_answer=EN_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
)
|
||||
agent_response = agent_response.split("\n")[0]
|
||||
print(f"Agent: {agent_response}")
|
||||
|
|
@ -0,0 +1,22 @@
|
|||
import argparse
|
||||
from colossalqa.retrieval_conversation_universal import UniversalRetrievalConversation
|
||||
|
||||
if __name__ == '__main__':
|
||||
# Parse arguments
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument('--en_model_path', type=str, default=None)
|
||||
parser.add_argument('--zh_model_path', type=str, default=None)
|
||||
parser.add_argument('--zh_model_name', type=str, default=None)
|
||||
parser.add_argument('--en_model_name', type=str, default=None)
|
||||
parser.add_argument('--sql_file_path', type=str, default=None, help='path to the a empty folder for storing sql files for indexing')
|
||||
args = parser.parse_args()
|
||||
|
||||
# Will ask for documents path in runnning time
|
||||
session = UniversalRetrievalConversation(files_en=None,
|
||||
files_zh=None,
|
||||
zh_model_path=args.zh_model_path, en_model_path=args.en_model_path,
|
||||
zh_model_name=args.zh_model_name, en_model_name=args.en_model_name,
|
||||
sql_file_path=args.sql_file_path
|
||||
)
|
||||
session.start_test_session()
|
||||
|
||||
|
|
@ -0,0 +1,113 @@
|
|||
"""
|
||||
Script for Chinese retrieval based conversation system backed by ChatGLM
|
||||
"""
|
||||
import argparse
|
||||
import os
|
||||
|
||||
from colossalqa.chain.retrieval_qa.base import RetrievalQA
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.prompt.prompt import (
|
||||
PROMPT_DISAMBIGUATE_ZH,
|
||||
PROMPT_RETRIEVAL_QA_ZH,
|
||||
SUMMARY_PROMPT_ZH,
|
||||
ZH_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
)
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from colossalqa.text_splitter import ChineseTextSplitter
|
||||
from langchain import LLMChain
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
|
||||
if __name__ == "__main__":
|
||||
# Parse arguments
|
||||
parser = argparse.ArgumentParser(description="Chinese retrieval based conversation system backed by ChatGLM2")
|
||||
parser.add_argument("--model_path", type=str, default=None, help="path to the model")
|
||||
parser.add_argument("--model_name", type=str, default=None, help="name of the model")
|
||||
parser.add_argument(
|
||||
"--sql_file_path", type=str, default=None, help="path to the a empty folder for storing sql files for indexing"
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
if not os.path.exists(args.sql_file_path):
|
||||
os.makedirs(args.sql_file_path)
|
||||
|
||||
colossal_api = ColossalAPI.get_api(args.model_name, args.model_path)
|
||||
llm = ColossalLLM(n=1, api=colossal_api)
|
||||
|
||||
# Setup embedding model locally
|
||||
embedding = HuggingFaceEmbeddings(
|
||||
model_name="moka-ai/m3e-base", model_kwargs={"device": "cpu"}, encode_kwargs={"normalize_embeddings": False}
|
||||
)
|
||||
# Define the retriever
|
||||
information_retriever = CustomRetriever(k=3, sql_file_path=args.sql_file_path, verbose=True)
|
||||
|
||||
# Define memory with summarization ability
|
||||
memory = ConversationBufferWithSummary(
|
||||
llm=llm,
|
||||
prompt=SUMMARY_PROMPT_ZH,
|
||||
human_prefix="用户",
|
||||
ai_prefix="Assistant",
|
||||
max_tokens=2000,
|
||||
llm_kwargs={"max_new_tokens": 50, "temperature": 0.6, "do_sample": True},
|
||||
)
|
||||
|
||||
# Define the chain to preprocess the input
|
||||
# Disambiguate the input. e.g. "What is the capital of that country?" -> "What is the capital of France?"
|
||||
llm_chain_disambiguate = LLMChain(
|
||||
llm=llm, prompt=PROMPT_DISAMBIGUATE_ZH, llm_kwargs={"max_new_tokens": 30, "temperature": 0.6, "do_sample": True}
|
||||
)
|
||||
|
||||
def disambiguity(input: str):
|
||||
out = llm_chain_disambiguate.run(input=input, chat_history=memory.buffer, stop=["\n"])
|
||||
return out.split("\n")[0]
|
||||
|
||||
# Load data to vector store
|
||||
print("Select files for constructing retriever")
|
||||
documents = []
|
||||
while True:
|
||||
file = input("Enter a file path or press Enter directory without input to exit:").strip()
|
||||
if file == "":
|
||||
break
|
||||
data_name = input("Enter a short description of the data:")
|
||||
retriever_data = DocumentLoader([[file, data_name.replace(" ", "_")]]).all_data
|
||||
|
||||
# Split
|
||||
text_splitter = ChineseTextSplitter()
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
documents.extend(splits)
|
||||
# Create retriever
|
||||
information_retriever.add_documents(docs=documents, cleanup="incremental", mode="by_source", embedding=embedding)
|
||||
|
||||
# Set document retrieval chain, we need this chain to calculate prompt length
|
||||
memory.initiate_document_retrieval_chain(llm, PROMPT_RETRIEVAL_QA_ZH, information_retriever)
|
||||
|
||||
# Define retrieval chain
|
||||
llm_chain = RetrievalQA.from_chain_type(
|
||||
llm=llm,
|
||||
verbose=False,
|
||||
chain_type="stuff",
|
||||
retriever=information_retriever,
|
||||
chain_type_kwargs={"prompt": PROMPT_RETRIEVAL_QA_ZH, "memory": memory},
|
||||
llm_kwargs={"max_new_tokens": 150, "temperature": 0.6, "do_sample": True},
|
||||
)
|
||||
|
||||
# Set disambiguity handler
|
||||
information_retriever.set_rephrase_handler(disambiguity)
|
||||
|
||||
# Start conversation
|
||||
while True:
|
||||
user_input = input("User: ")
|
||||
if "END" == user_input:
|
||||
print("Agent: Happy to chat with you :)")
|
||||
break
|
||||
agent_response = llm_chain.run(
|
||||
query=user_input,
|
||||
stop=["</答案>"],
|
||||
doc_prefix="支持文档",
|
||||
rejection_trigger_keywrods=ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
rejection_answer=ZH_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
)
|
||||
print(f"Agent: {agent_response}")
|
||||
|
|
@ -0,0 +1,97 @@
|
|||
"""
|
||||
Script for English retrieval based conversation system backed by LLaMa2
|
||||
"""
|
||||
import argparse
|
||||
import os
|
||||
|
||||
from colossalqa.chain.retrieval_qa.base import RetrievalQA
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.prompt.prompt import PROMPT_RETRIEVAL_CLASSIFICATION_USE_CASE_ZH
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from colossalqa.text_splitter import ChineseTextSplitter
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
|
||||
if __name__ == "__main__":
|
||||
# Parse arguments
|
||||
parser = argparse.ArgumentParser(description="English retrieval based conversation system backed by LLaMa2")
|
||||
parser.add_argument("--model_path", type=str, default=None, help="path to the model")
|
||||
parser.add_argument("--model_name", type=str, default=None, help="name of the model")
|
||||
parser.add_argument(
|
||||
"--sql_file_path", type=str, default=None, help="path to the a empty folder for storing sql files for indexing"
|
||||
)
|
||||
|
||||
args = parser.parse_args()
|
||||
|
||||
if not os.path.exists(args.sql_file_path):
|
||||
os.makedirs(args.sql_file_path)
|
||||
|
||||
colossal_api = ColossalAPI.get_api(args.model_name, args.model_path)
|
||||
llm = ColossalLLM(n=1, api=colossal_api)
|
||||
|
||||
# Define the retriever
|
||||
information_retriever = CustomRetriever(k=2, sql_file_path=args.sql_file_path, verbose=True)
|
||||
|
||||
# Setup embedding model locally
|
||||
embedding = HuggingFaceEmbeddings(
|
||||
model_name="moka-ai/m3e-base", model_kwargs={"device": "cpu"}, encode_kwargs={"normalize_embeddings": False}
|
||||
)
|
||||
|
||||
# Load data to vector store
|
||||
print("Select files for constructing retriever")
|
||||
documents = []
|
||||
|
||||
# define metadata function which is used to format the prompt with value in metadata instead of key,
|
||||
# the later is langchain's default behavior
|
||||
def metadata_func(data_sample, additional_fields):
|
||||
"""
|
||||
metadata_func (Callable[Dict, Dict]): A function that takes in the JSON
|
||||
object extracted by the jq_schema and the default metadata and returns
|
||||
a dict of the updated metadata.
|
||||
|
||||
To use key-value format, the metadata_func should be defined as follows:
|
||||
metadata = {'value': 'a string to be used to format the prompt', 'is_key_value_mapping': True}
|
||||
"""
|
||||
metadata = {}
|
||||
metadata["value"] = f"Question: {data_sample['key']}\nAnswer:{data_sample['value']}"
|
||||
metadata["is_key_value_mapping"] = True
|
||||
assert "value" not in additional_fields
|
||||
assert "is_key_value_mapping" not in additional_fields
|
||||
metadata.update(additional_fields)
|
||||
return metadata
|
||||
|
||||
retriever_data = DocumentLoader(
|
||||
[["../data/data_sample/custom_service_classification.json", "CustomerServiceDemo"]],
|
||||
content_key="key",
|
||||
metadata_func=metadata_func,
|
||||
).all_data
|
||||
|
||||
# Split
|
||||
text_splitter = ChineseTextSplitter()
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
documents.extend(splits)
|
||||
|
||||
# Create retriever
|
||||
information_retriever.add_documents(docs=documents, cleanup="incremental", mode="by_source", embedding=embedding)
|
||||
|
||||
# Define retrieval chain
|
||||
retrieval_chain = RetrievalQA.from_chain_type(
|
||||
llm=llm,
|
||||
verbose=True,
|
||||
chain_type="stuff",
|
||||
retriever=information_retriever,
|
||||
chain_type_kwargs={"prompt": PROMPT_RETRIEVAL_CLASSIFICATION_USE_CASE_ZH},
|
||||
llm_kwargs={"max_new_tokens": 50, "temperature": 0.75, "do_sample": True},
|
||||
)
|
||||
# Set disambiguity handler
|
||||
|
||||
# Start conversation
|
||||
while True:
|
||||
user_input = input("User: ")
|
||||
if "END" == user_input:
|
||||
print("Agent: Happy to chat with you :)")
|
||||
break
|
||||
# 要使用和custom_service_classification.json 里的key 类似的句子做输入
|
||||
agent_response = retrieval_chain.run(query=user_input, stop=["Human: "])
|
||||
agent_response = agent_response.split("\n")[0]
|
||||
print(f"Agent: {agent_response}")
|
||||
|
|
@ -0,0 +1,184 @@
|
|||
from typing import Dict, Tuple
|
||||
|
||||
from colossalqa.chain.retrieval_qa.base import RetrievalQA
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.mylogging import get_logger
|
||||
from colossalqa.prompt.prompt import (
|
||||
PROMPT_DISAMBIGUATE_ZH,
|
||||
PROMPT_RETRIEVAL_QA_ZH,
|
||||
SUMMARY_PROMPT_ZH,
|
||||
ZH_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
)
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from colossalqa.text_splitter import ChineseTextSplitter
|
||||
from langchain import LLMChain
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
|
||||
logger = get_logger()
|
||||
|
||||
DEFAULT_RAG_CFG = {
|
||||
"retri_top_k": 3,
|
||||
"retri_kb_file_path": "./",
|
||||
"verbose": True,
|
||||
"mem_summary_prompt": SUMMARY_PROMPT_ZH,
|
||||
"mem_human_prefix": "用户",
|
||||
"mem_ai_prefix": "Assistant",
|
||||
"mem_max_tokens": 2000,
|
||||
"mem_llm_kwargs": {"max_new_tokens": 50, "temperature": 1, "do_sample": True},
|
||||
"disambig_prompt": PROMPT_DISAMBIGUATE_ZH,
|
||||
"disambig_llm_kwargs": {"max_new_tokens": 30, "temperature": 1, "do_sample": True},
|
||||
"embed_model_name_or_path": "moka-ai/m3e-base",
|
||||
"embed_model_device": {"device": "cpu"},
|
||||
"gen_llm_kwargs": {"max_new_tokens": 100, "temperature": 1, "do_sample": True},
|
||||
"gen_qa_prompt": PROMPT_RETRIEVAL_QA_ZH,
|
||||
}
|
||||
|
||||
|
||||
class RAG_ChatBot:
|
||||
def __init__(
|
||||
self,
|
||||
llm,
|
||||
rag_config,
|
||||
) -> None:
|
||||
self.llm = llm
|
||||
self.rag_config = rag_config
|
||||
self.set_embed_model(**self.rag_config)
|
||||
self.set_text_splitter(**self.rag_config)
|
||||
self.set_memory(**self.rag_config)
|
||||
self.set_info_retriever(**self.rag_config)
|
||||
self.set_rag_chain(**self.rag_config)
|
||||
if self.rag_config.get("disambig_prompt", None):
|
||||
self.set_disambig_retriv(**self.rag_config)
|
||||
|
||||
def set_embed_model(self, **kwargs):
|
||||
self.embed_model = HuggingFaceEmbeddings(
|
||||
model_name=kwargs["embed_model_name_or_path"],
|
||||
model_kwargs=kwargs["embed_model_device"],
|
||||
encode_kwargs={"normalize_embeddings": False},
|
||||
)
|
||||
|
||||
def set_text_splitter(self, **kwargs):
|
||||
# Initialize text_splitter
|
||||
self.text_splitter = ChineseTextSplitter()
|
||||
|
||||
def set_memory(self, **kwargs):
|
||||
params = {"llm_kwargs": kwargs["mem_llm_kwargs"]} if kwargs.get("mem_llm_kwargs", None) else {}
|
||||
# Initialize memory with summarization ability
|
||||
self.memory = ConversationBufferWithSummary(
|
||||
llm=self.llm,
|
||||
prompt=kwargs["mem_summary_prompt"],
|
||||
human_prefix=kwargs["mem_human_prefix"],
|
||||
ai_prefix=kwargs["mem_ai_prefix"],
|
||||
max_tokens=kwargs["mem_max_tokens"],
|
||||
**params,
|
||||
)
|
||||
|
||||
def set_info_retriever(self, **kwargs):
|
||||
self.info_retriever = CustomRetriever(
|
||||
k=kwargs["retri_top_k"], sql_file_path=kwargs["retri_kb_file_path"], verbose=kwargs["verbose"]
|
||||
)
|
||||
|
||||
def set_rag_chain(self, **kwargs):
|
||||
params = {"llm_kwargs": kwargs["gen_llm_kwargs"]} if kwargs.get("gen_llm_kwargs", None) else {}
|
||||
self.rag_chain = RetrievalQA.from_chain_type(
|
||||
llm=self.llm,
|
||||
verbose=kwargs["verbose"],
|
||||
chain_type="stuff",
|
||||
retriever=self.info_retriever,
|
||||
chain_type_kwargs={"prompt": kwargs["gen_qa_prompt"], "memory": self.memory},
|
||||
**params,
|
||||
)
|
||||
|
||||
def split_docs(self, documents):
|
||||
doc_splits = self.text_splitter.split_documents(documents)
|
||||
return doc_splits
|
||||
|
||||
def set_disambig_retriv(self, **kwargs):
|
||||
params = {"llm_kwargs": kwargs["disambig_llm_kwargs"]} if kwargs.get("disambig_llm_kwargs", None) else {}
|
||||
self.llm_chain_disambiguate = LLMChain(llm=self.llm, prompt=kwargs["disambig_prompt"], **params)
|
||||
|
||||
def disambiguity(input: str):
|
||||
out = self.llm_chain_disambiguate.run(input=input, chat_history=self.memory.buffer, stop=["\n"])
|
||||
return out.split("\n")[0]
|
||||
|
||||
self.info_retriever.set_rephrase_handler(disambiguity)
|
||||
|
||||
def load_doc_from_console(self, json_parse_args: Dict = {}):
|
||||
documents = []
|
||||
print("Select files for constructing Chinese retriever")
|
||||
while True:
|
||||
file = input("Enter a file path or press Enter directly without input to exit:").strip()
|
||||
if file == "":
|
||||
break
|
||||
data_name = input("Enter a short description of the data:")
|
||||
docs = DocumentLoader([[file, data_name.replace(" ", "_")]], **json_parse_args).all_data
|
||||
documents.extend(docs)
|
||||
self.documents = documents
|
||||
self.split_docs_and_add_to_mem(**self.rag_config)
|
||||
|
||||
def load_doc_from_files(self, files, data_name="default_kb", json_parse_args: Dict = {}):
|
||||
documents = []
|
||||
for file in files:
|
||||
docs = DocumentLoader([[file, data_name.replace(" ", "_")]], **json_parse_args).all_data
|
||||
documents.extend(docs)
|
||||
self.documents = documents
|
||||
self.split_docs_and_add_to_mem(**self.rag_config)
|
||||
|
||||
def split_docs_and_add_to_mem(self, **kwargs):
|
||||
self.doc_splits = self.split_docs(self.documents)
|
||||
self.info_retriever.add_documents(
|
||||
docs=self.doc_splits, cleanup="incremental", mode="by_source", embedding=self.embed_model
|
||||
)
|
||||
self.memory.initiate_document_retrieval_chain(self.llm, kwargs["gen_qa_prompt"], self.info_retriever)
|
||||
|
||||
def reset_config(self, rag_config):
|
||||
self.rag_config = rag_config
|
||||
self.set_embed_model(**self.rag_config)
|
||||
self.set_text_splitter(**self.rag_config)
|
||||
self.set_memory(**self.rag_config)
|
||||
self.set_info_retriever(**self.rag_config)
|
||||
self.set_rag_chain(**self.rag_config)
|
||||
if self.rag_config.get("disambig_prompt", None):
|
||||
self.set_disambig_retriv(**self.rag_config)
|
||||
|
||||
def run(self, user_input: str, memory: ConversationBufferWithSummary) -> Tuple[str, ConversationBufferWithSummary]:
|
||||
if memory:
|
||||
memory.buffered_history.messages = memory.buffered_history.messages
|
||||
memory.summarized_history_temp.messages = memory.summarized_history_temp.messages
|
||||
result = self.rag_chain.run(
|
||||
query=user_input,
|
||||
stop=[memory.human_prefix + ": "],
|
||||
rejection_trigger_keywrods=ZH_RETRIEVAL_QA_TRIGGER_KEYWORDS,
|
||||
rejection_answer=ZH_RETRIEVAL_QA_REJECTION_ANSWER,
|
||||
)
|
||||
return result.split("\n")[0], memory
|
||||
|
||||
def start_test_session(self):
|
||||
"""
|
||||
Simple session for testing purpose
|
||||
"""
|
||||
while True:
|
||||
user_input = input("User: ")
|
||||
if "END" == user_input:
|
||||
print("Agent: Happy to chat with you :)")
|
||||
break
|
||||
agent_response, self.memory = self.run(user_input, self.memory)
|
||||
print(f"Agent: {agent_response}")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
# Initialize an Langchain LLM(here we use ChatGPT as an example)
|
||||
from langchain.llms import OpenAI
|
||||
|
||||
llm = OpenAI(openai_api_key="YOUR_OPENAI_API_KEY")
|
||||
|
||||
# chatgpt cannot control temperature, do_sample, etc.
|
||||
DEFAULT_RAG_CFG["mem_llm_kwargs"] = None
|
||||
DEFAULT_RAG_CFG["disambig_llm_kwargs"] = None
|
||||
DEFAULT_RAG_CFG["gen_llm_kwargs"] = None
|
||||
|
||||
rag = RAG_ChatBot(llm, DEFAULT_RAG_CFG)
|
||||
rag.load_doc_from_console()
|
||||
rag.start_test_session()
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
# ColossalQA WebUI Demo
|
||||
|
||||
This demo provides a simple WebUI for ColossalQA, enabling you to upload your files as a knowledge base and interact with them through a chat interface in your browser.
|
||||
|
||||
The `server.py` initializes the backend RAG chain that can be backed by various language models (e.g., ChatGPT, Huawei Pangu, ChatGLM2). Meanwhile, `webui.py` launches a Gradio-supported chatbot interface.
|
||||
|
||||
# Usage
|
||||
|
||||
## Installation
|
||||
|
||||
First, install the necessary dependencies for ColossalQA:
|
||||
|
||||
```sh
|
||||
git clone https://github.com/hpcaitech/ColossalAI.git
|
||||
cd ColossalAI/applications/ColossalQA/
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
## Configure the RAG Chain
|
||||
|
||||
Customize the RAG Chain settings, such as the embedding model (default: moka-ai/m3e) and the language model, in the `start_colossal_qa.sh` script.
|
||||
|
||||
For API-based language models (like ChatGPT or Huawei Pangu), provide your API key for authentication. For locally-run models, indicate the path to the model's checkpoint file.
|
||||
|
||||
If you want to customize prompts in the RAG Chain, you can have a look at the `RAG_ChatBot.py` file to modify them.
|
||||
|
||||
## Run WebUI Demo
|
||||
|
||||
Execute the following command to start the demo:
|
||||
|
||||
```sh
|
||||
bash start_colossal_qa.sh
|
||||
```
|
||||
|
||||
After launching the script, you can upload files and engage with the chatbot through your web browser.
|
||||
|
||||
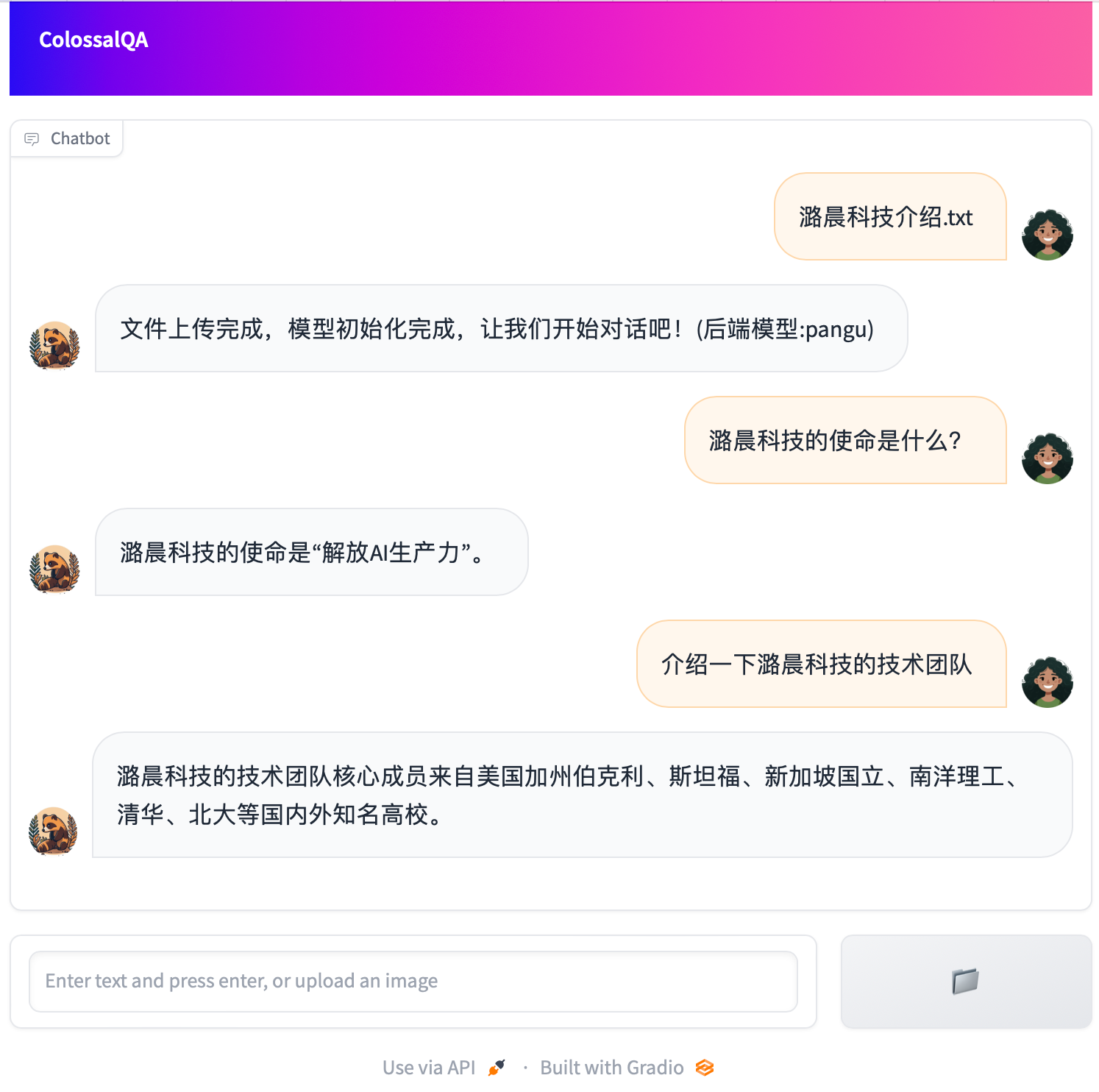
|
||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 7.9 KiB |
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 4.4 KiB |
|
|
@ -0,0 +1,117 @@
|
|||
import argparse
|
||||
import copy
|
||||
import json
|
||||
import os
|
||||
import random
|
||||
import string
|
||||
from http.server import BaseHTTPRequestHandler, HTTPServer
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.retrieval_conversation_zh import ChineseRetrievalConversation
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
from RAG_ChatBot import RAG_ChatBot, DEFAULT_RAG_CFG
|
||||
|
||||
# Define the mapping between embed_model_name(passed from Front End) and the actual path on the back end server
|
||||
EMBED_MODEL_DICT = {
|
||||
"m3e": os.environ.get("EMB_MODEL_PATH", DEFAULT_RAG_CFG["embed_model_name_or_path"])
|
||||
}
|
||||
# Define the mapping between LLM_name(passed from Front End) and the actual path on the back end server
|
||||
LLM_DICT = {
|
||||
"chatglm2": os.environ.get("CHAT_LLM_PATH", "THUDM/chatglm-6b"),
|
||||
"pangu": "Pangu_API",
|
||||
"chatgpt": "OpenAI_API"
|
||||
}
|
||||
|
||||
def randomword(length):
|
||||
letters = string.ascii_lowercase
|
||||
return "".join(random.choice(letters) for i in range(length))
|
||||
|
||||
class ColossalQAServerRequestHandler(BaseHTTPRequestHandler):
|
||||
chatbot = None
|
||||
def _set_response(self):
|
||||
"""
|
||||
set http header for response
|
||||
"""
|
||||
self.send_response(200)
|
||||
self.send_header("Content-type", "application/json")
|
||||
self.end_headers()
|
||||
|
||||
def do_POST(self):
|
||||
content_length = int(self.headers["Content-Length"])
|
||||
post_data = self.rfile.read(content_length)
|
||||
received_json = json.loads(post_data.decode("utf-8"))
|
||||
print(received_json)
|
||||
# conversation_ready is False(user's first request): Need to upload files and initialize the RAG chain
|
||||
if received_json["conversation_ready"] is False:
|
||||
self.rag_config = DEFAULT_RAG_CFG.copy()
|
||||
try:
|
||||
assert received_json["embed_model_name"] in EMBED_MODEL_DICT
|
||||
assert received_json["llm_name"] in LLM_DICT
|
||||
self.docs_files = received_json["docs"]
|
||||
embed_model_name, llm_name = received_json["embed_model_name"], received_json["llm_name"]
|
||||
|
||||
# Find the embed_model/llm ckpt path on the back end server.
|
||||
embed_model_path, llm_path = EMBED_MODEL_DICT[embed_model_name], LLM_DICT[llm_name]
|
||||
self.rag_config["embed_model_name_or_path"] = embed_model_path
|
||||
|
||||
# Create the storage path for knowledge base files
|
||||
self.rag_config["retri_kb_file_path"] = os.path.join(os.environ["TMP"], "colossalqa_kb/"+randomword(20))
|
||||
if not os.path.exists(self.rag_config["retri_kb_file_path"]):
|
||||
os.makedirs(self.rag_config["retri_kb_file_path"])
|
||||
|
||||
if (embed_model_path is not None) and (llm_path is not None):
|
||||
# ---- Intialize LLM, QA_chatbot here ----
|
||||
print("Initializing LLM...")
|
||||
if llm_path == "Pangu_API":
|
||||
from colossalqa.local.pangu_llm import Pangu
|
||||
self.llm = Pangu(id=1)
|
||||
self.llm.set_auth_config() # verify user's auth info here
|
||||
self.rag_config["mem_llm_kwargs"] = None
|
||||
self.rag_config["disambig_llm_kwargs"] = None
|
||||
self.rag_config["gen_llm_kwargs"] = None
|
||||
elif llm_path == "OpenAI_API":
|
||||
from langchain.llms import OpenAI
|
||||
self.llm = OpenAI()
|
||||
self.rag_config["mem_llm_kwargs"] = None
|
||||
self.rag_config["disambig_llm_kwargs"] = None
|
||||
self.rag_config["gen_llm_kwargs"] = None
|
||||
else:
|
||||
# ** (For Testing Only) **
|
||||
# In practice, all LLMs will run on the cloud platform and accessed by API, instead of running locally.
|
||||
# initialize model from model_path by using ColossalLLM
|
||||
self.rag_config["mem_llm_kwargs"] = {"max_new_tokens": 50, "temperature": 1, "do_sample": True}
|
||||
self.rag_config["disambig_llm_kwargs"] = {"max_new_tokens": 30, "temperature": 1, "do_sample": True}
|
||||
self.rag_config["gen_llm_kwargs"] = {"max_new_tokens": 100, "temperature": 1, "do_sample": True}
|
||||
self.colossal_api = ColossalAPI(llm_name, llm_path)
|
||||
self.llm = ColossalLLM(n=1, api=self.colossal_api)
|
||||
|
||||
print(f"Initializing RAG Chain...")
|
||||
print("RAG_CONFIG: ", self.rag_config)
|
||||
self.__class__.chatbot = RAG_ChatBot(self.llm, self.rag_config)
|
||||
print("Loading Files....\n", self.docs_files)
|
||||
self.__class__.chatbot.load_doc_from_files(self.docs_files)
|
||||
# -----------------------------------------------------------------------------------
|
||||
res = {"response": f"文件上传完成,模型初始化完成,让我们开始对话吧!(后端模型:{llm_name})", "error": "", "conversation_ready": True}
|
||||
except Exception as e:
|
||||
res = {"response": "文件上传或模型初始化有误,无法开始对话。",
|
||||
"error": f"Error in File Uploading and/or RAG initialization. Error details: {e}",
|
||||
"conversation_ready": False}
|
||||
# conversation_ready is True: Chatbot and docs are all set. Ready to chat.
|
||||
else:
|
||||
user_input = received_json["user_input"]
|
||||
chatbot_response, self.__class__.chatbot.memory = self.__class__.chatbot.run(user_input, self.__class__.chatbot.memory)
|
||||
res = {"response": chatbot_response, "error": "", "conversation_ready": True}
|
||||
self._set_response()
|
||||
self.wfile.write(json.dumps(res).encode("utf-8"))
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser(description="Chinese retrieval based conversation system")
|
||||
parser.add_argument("--port", type=int, default=13666, help="port on localhost to start the server")
|
||||
args = parser.parse_args()
|
||||
server_address = ("localhost", args.port)
|
||||
httpd = HTTPServer(server_address, ColossalQAServerRequestHandler)
|
||||
print(f"Starting server on port {args.port}...")
|
||||
httpd.serve_forever()
|
||||
|
||||
|
|
@ -0,0 +1,43 @@
|
|||
#!/bin/bash
|
||||
cleanup() {
|
||||
echo "Caught Signal ... cleaning up."
|
||||
pkill -P $$ # kill all subprocess of this script
|
||||
exit 1 # exit script
|
||||
}
|
||||
# 'cleanup' is trigered when receive SIGINT(Ctrl+C) OR SIGTERM(kill) signal
|
||||
trap cleanup INT TERM
|
||||
|
||||
# Disable your proxy
|
||||
# unset HTTP_PROXY HTTPS_PROXY http_proxy https_proxy
|
||||
|
||||
# Path to store knowledge base(Home Directory by default)
|
||||
export TMP=$HOME
|
||||
|
||||
# Use m3e as embedding model
|
||||
export EMB_MODEL="m3e" # moka-ai/m3e-base model will be download automatically
|
||||
# export EMB_MODEL_PATH="PATH_TO_LOCAL_CHECKPOINT/m3e-base" # you can also specify the local path to embedding model
|
||||
|
||||
# Choose a backend LLM
|
||||
# - ChatGLM2
|
||||
# export CHAT_LLM="chatglm2"
|
||||
# export CHAT_LLM_PATH="PATH_TO_LOCAL_CHECKPOINT/chatglm2-6b"
|
||||
|
||||
# - ChatGPT
|
||||
export CHAT_LLM="chatgpt"
|
||||
# Auth info for OpenAI API
|
||||
export OPENAI_API_KEY="YOUR_OPENAI_API_KEY"
|
||||
|
||||
# - Pangu
|
||||
# export CHAT_LLM="pangu"
|
||||
# # Auth info for Pangu API
|
||||
# export URL=""
|
||||
# export USERNAME=""
|
||||
# export PASSWORD=""
|
||||
# export DOMAIN_NAME=""
|
||||
|
||||
# Run server.py and colossalqa_webui.py in the background
|
||||
python server.py &
|
||||
python webui.py &
|
||||
|
||||
# Wait for all processes to finish
|
||||
wait
|
||||
|
|
@ -0,0 +1,102 @@
|
|||
import json
|
||||
import os
|
||||
import gradio as gr
|
||||
import requests
|
||||
|
||||
RAG_STATE = {"conversation_ready": False, # Conversation is not ready until files are uploaded and RAG chain is initialized
|
||||
"embed_model_name": os.environ.get("EMB_MODEL", "m3e"),
|
||||
"llm_name": os.environ.get("CHAT_LLM", "chatgpt")}
|
||||
URL = "http://localhost:13666"
|
||||
|
||||
def get_response(client_data, URL):
|
||||
headers = {"Content-type": "application/json"}
|
||||
print(f"Sending request to server url: {URL}")
|
||||
response = requests.post(URL, data=json.dumps(client_data), headers=headers)
|
||||
response = json.loads(response.content)
|
||||
return response
|
||||
|
||||
def add_text(history, text):
|
||||
history = history + [(text, None)]
|
||||
return history, gr.update(value=None, interactive=True)
|
||||
|
||||
def add_file(history, files):
|
||||
global RAG_STATE
|
||||
RAG_STATE["conversation_ready"] = False # after adding new files, reset the ChatBot
|
||||
RAG_STATE["upload_files"]=[file.name for file in files]
|
||||
files_string = "\n".join([os.path.basename(path) for path in RAG_STATE["upload_files"]])
|
||||
print(files_string)
|
||||
history = history + [(files_string, None)]
|
||||
return history
|
||||
|
||||
def bot(history):
|
||||
print(history)
|
||||
global RAG_STATE
|
||||
if not RAG_STATE["conversation_ready"]:
|
||||
# Upload files and initialize models
|
||||
client_data = {
|
||||
"docs": RAG_STATE["upload_files"],
|
||||
"embed_model_name": RAG_STATE["embed_model_name"], # Select embedding model name here
|
||||
"llm_name": RAG_STATE["llm_name"], # Select LLM model name here. ["pangu", "chatglm2"]
|
||||
"conversation_ready": RAG_STATE["conversation_ready"]
|
||||
}
|
||||
else:
|
||||
client_data = {}
|
||||
client_data["conversation_ready"] = RAG_STATE["conversation_ready"]
|
||||
client_data["user_input"] = history[-1][0].strip()
|
||||
|
||||
response = get_response(client_data, URL) # TODO: async request, to avoid users waiting the model initialization too long
|
||||
print(response)
|
||||
if response["error"] != "":
|
||||
raise gr.Error(response["error"])
|
||||
|
||||
RAG_STATE["conversation_ready"] = response["conversation_ready"]
|
||||
history[-1][1] = response["response"]
|
||||
yield history
|
||||
|
||||
|
||||
CSS = """
|
||||
.contain { display: flex; flex-direction: column; height: 100vh }
|
||||
#component-0 { height: 100%; }
|
||||
#chatbot { flex-grow: 1; }
|
||||
"""
|
||||
|
||||
header_html = """
|
||||
<div style="background: linear-gradient(to right, #2a0cf4, #7100ed, #9800e6, #b600df, #ce00d9, #dc0cd1, #e81bca, #f229c3, #f738ba, #f946b2, #fb53ab, #fb5fa5); padding: 20px; text-align: left;">
|
||||
<h1 style="color: white;">ColossalQA</h1>
|
||||
<h4 style="color: white;">ColossalQA</h4>
|
||||
</div>
|
||||
"""
|
||||
|
||||
with gr.Blocks(css=CSS) as demo:
|
||||
html = gr.HTML(header_html)
|
||||
chatbot = gr.Chatbot(
|
||||
[],
|
||||
elem_id="chatbot",
|
||||
bubble_full_width=False,
|
||||
avatar_images=(
|
||||
(os.path.join(os.path.dirname(__file__), "img/avatar_user.png")),
|
||||
(os.path.join(os.path.dirname(__file__), "img/avatar_ai.png")),
|
||||
),
|
||||
)
|
||||
|
||||
with gr.Row():
|
||||
txt = gr.Textbox(
|
||||
scale=4,
|
||||
show_label=False,
|
||||
placeholder="Enter text and press enter, or upload an image",
|
||||
container=True,
|
||||
autofocus=True,
|
||||
)
|
||||
btn = gr.UploadButton("📁", file_types=["file"], file_count="multiple")
|
||||
|
||||
txt_msg = txt.submit(add_text, [chatbot, txt], [chatbot, txt], queue=False).then(bot, chatbot, chatbot)
|
||||
# Clear the original textbox
|
||||
txt_msg.then(lambda: gr.update(value=None, interactive=True), None, [txt], queue=False)
|
||||
# Click Upload Button: 1. upload files 2. send config to backend, initalize model 3. get response "conversation_ready" = True/False
|
||||
file_msg = btn.upload(add_file, [chatbot, btn], [chatbot], queue=False).then(bot, chatbot, chatbot)
|
||||
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
demo.queue()
|
||||
demo.launch(share=True) # share=True will release a public link of the demo
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
[pytest]
|
||||
markers =
|
||||
dist: tests which are run in a multi-GPU or multi-machine environment (at least 4 GPUs)
|
||||
largedist: tests which are run in a multi-GPU or multi-machine environment (at least 8 GPUs)
|
||||
|
|
@ -0,0 +1,22 @@
|
|||
transformers>=4.20.1
|
||||
tqdm==4.66.1
|
||||
datasets==2.13.0
|
||||
torch<2.0.0, >=1.12.1
|
||||
langchain==0.0.330
|
||||
langchain-experimental==0.0.37
|
||||
tokenizers==0.13.3
|
||||
modelscope==1.9.0
|
||||
sentencepiece==0.1.99
|
||||
gpustat==1.1.1
|
||||
sqlalchemy==2.0.20
|
||||
pytest==7.4.2
|
||||
# coati install from ../Chat
|
||||
sentence-transformers==2.2.2
|
||||
chromadb==0.4.9
|
||||
openai==0.28.0 #used for chatgpt please install directly from openai repo
|
||||
tiktoken==0.5.1
|
||||
unstructured==0.10.14
|
||||
pypdf==3.16.0
|
||||
jq==1.6.0
|
||||
gradio==3.44.4
|
||||
Requests==2.31.0
|
||||
|
|
@ -0,0 +1,38 @@
|
|||
from setuptools import find_packages, setup
|
||||
|
||||
|
||||
def fetch_requirements(path):
|
||||
with open(path, "r") as fd:
|
||||
return [r.strip() for r in fd.readlines()]
|
||||
|
||||
|
||||
def fetch_readme():
|
||||
with open("README.md", encoding="utf-8") as f:
|
||||
return f.read()
|
||||
|
||||
|
||||
def fetch_version():
|
||||
with open("version.txt", "r") as f:
|
||||
return f.read().strip()
|
||||
|
||||
|
||||
print(find_packages(exclude=("tests", "*.egg-info", "data", "examples")))
|
||||
setup(
|
||||
name="colossalqa",
|
||||
version=fetch_version(),
|
||||
packages=find_packages(exclude=("tests", "*.egg-info", "data", "examples")),
|
||||
description="Colossal-AI powered retrieval QA",
|
||||
long_description=fetch_readme(),
|
||||
long_description_content_type="text/markdown",
|
||||
license="Apache Software License 2.0",
|
||||
url="https://github.com/hpcaitech/Coati",
|
||||
install_requires=fetch_requirements("requirements.txt"),
|
||||
python_requires=">=3.6",
|
||||
classifiers=[
|
||||
"Programming Language :: Python :: 3",
|
||||
"License :: OSI Approved :: Apache Software License",
|
||||
"Environment :: GPU :: NVIDIA CUDA",
|
||||
"Topic :: Scientific/Engineering :: Artificial Intelligence",
|
||||
"Topic :: System :: Distributed Computing",
|
||||
],
|
||||
)
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
import os
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
|
||||
|
||||
def test_add_document():
|
||||
PATH = os.environ.get('TEST_DOCUMENT_LOADER_DATA_PATH')
|
||||
files = [[PATH, 'all data']]
|
||||
document_loader = DocumentLoader(files)
|
||||
documents = document_loader.all_data
|
||||
all_files = []
|
||||
for doc in documents:
|
||||
assert isinstance(doc.page_content, str)==True
|
||||
if doc.metadata['source'] not in all_files:
|
||||
all_files.append(doc.metadata['source'])
|
||||
print(all_files)
|
||||
assert len(all_files) == 6
|
||||
|
||||
|
||||
if __name__=='__main__':
|
||||
test_add_document()
|
||||
|
||||
|
|
@ -0,0 +1,117 @@
|
|||
import os
|
||||
|
||||
from colossalqa.data_loader.document_loader import DocumentLoader
|
||||
from colossalqa.local.llm import ColossalAPI, ColossalLLM
|
||||
from colossalqa.memory import ConversationBufferWithSummary
|
||||
from colossalqa.prompt.prompt import PROMPT_RETRIEVAL_QA_ZH
|
||||
from colossalqa.retriever import CustomRetriever
|
||||
from langchain.embeddings import HuggingFaceEmbeddings
|
||||
from langchain.text_splitter import RecursiveCharacterTextSplitter
|
||||
|
||||
|
||||
def test_memory_long():
|
||||
model_path = os.environ.get("EN_MODEL_PATH")
|
||||
data_path = os.environ.get("TEST_DATA_PATH_EN")
|
||||
model_name = os.environ.get("EN_MODEL_NAME")
|
||||
sql_file_path = os.environ.get("SQL_FILE_PATH")
|
||||
|
||||
if not os.path.exists(sql_file_path):
|
||||
os.makedirs(sql_file_path)
|
||||
|
||||
colossal_api = ColossalAPI.get_api(model_name, model_path)
|
||||
llm = ColossalLLM(n=4, api=colossal_api)
|
||||
memory = ConversationBufferWithSummary(
|
||||
llm=llm, max_tokens=600, llm_kwargs={"max_new_tokens": 50, "temperature": 0.6, "do_sample": True}
|
||||
)
|
||||
retriever_data = DocumentLoader([[data_path, "company information"]]).all_data
|
||||
|
||||
# Split
|
||||
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
|
||||
embedding = HuggingFaceEmbeddings(
|
||||
model_name="moka-ai/m3e-base", model_kwargs={"device": "cpu"}, encode_kwargs={"normalize_embeddings": False}
|
||||
)
|
||||
|
||||
# Create retriever
|
||||
information_retriever = CustomRetriever(k=3, sql_file_path=sql_file_path)
|
||||
information_retriever.add_documents(docs=splits, cleanup="incremental", mode="by_source", embedding=embedding)
|
||||
|
||||
memory.initiate_document_retrieval_chain(
|
||||
llm,
|
||||
PROMPT_RETRIEVAL_QA_ZH,
|
||||
information_retriever,
|
||||
chain_type_kwargs={
|
||||
"chat_history": "",
|
||||
},
|
||||
)
|
||||
|
||||
# This keep the prompt length excluding dialogues the same
|
||||
docs = information_retriever.get_relevant_documents("this is a test input.")
|
||||
prompt_length = memory.chain.prompt_length(docs, **{"question": "this is a test input.", "chat_history": ""})
|
||||
remain = 600 - prompt_length
|
||||
have_summarization_flag = False
|
||||
for i in range(40):
|
||||
chat_history = memory.load_memory_variables({"question": "this is a test input.", "input_documents": docs})[
|
||||
"chat_history"
|
||||
]
|
||||
|
||||
assert memory.get_conversation_length() <= remain
|
||||
memory.save_context({"question": "this is a test input."}, {"output": "this is a test output."})
|
||||
if "A summarization of historical conversation:" in chat_history:
|
||||
have_summarization_flag = True
|
||||
assert have_summarization_flag == True
|
||||
|
||||
|
||||
def test_memory_short():
|
||||
model_path = os.environ.get("EN_MODEL_PATH")
|
||||
data_path = os.environ.get("TEST_DATA_PATH_EN")
|
||||
model_name = os.environ.get("EN_MODEL_NAME")
|
||||
sql_file_path = os.environ.get("SQL_FILE_PATH")
|
||||
|
||||
if not os.path.exists(sql_file_path):
|
||||
os.makedirs(sql_file_path)
|
||||
|
||||
colossal_api = ColossalAPI.get_api(model_name, model_path)
|
||||
llm = ColossalLLM(n=4, api=colossal_api)
|
||||
memory = ConversationBufferWithSummary(
|
||||
llm=llm, llm_kwargs={"max_new_tokens": 50, "temperature": 0.6, "do_sample": True}
|
||||
)
|
||||
retriever_data = DocumentLoader([[data_path, "company information"]]).all_data
|
||||
|
||||
# Split
|
||||
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
|
||||
splits = text_splitter.split_documents(retriever_data)
|
||||
|
||||
embedding = HuggingFaceEmbeddings(
|
||||
model_name="moka-ai/m3e-base", model_kwargs={"device": "cpu"}, encode_kwargs={"normalize_embeddings": False}
|
||||
)
|
||||
|
||||
# create retriever
|
||||
information_retriever = CustomRetriever(k=3, sql_file_path=sql_file_path)
|
||||
information_retriever.add_documents(docs=splits, cleanup="incremental", mode="by_source", embedding=embedding)
|
||||
|
||||
memory.initiate_document_retrieval_chain(
|
||||
llm,
|
||||
PROMPT_RETRIEVAL_QA_ZH,
|
||||
information_retriever,
|
||||
chain_type_kwargs={
|
||||
"chat_history": "",
|
||||
},
|
||||
)
|
||||
|
||||
# This keep the prompt length excluding dialogues the same
|
||||
docs = information_retriever.get_relevant_documents("this is a test input.", return_scores=True)
|
||||
|
||||
for i in range(4):
|
||||
chat_history = memory.load_memory_variables({"question": "this is a test input.", "input_documents": docs})[
|
||||
"chat_history"
|
||||
]
|
||||
assert chat_history.count("Assistant: this is a test output.") == i
|
||||
assert chat_history.count("Human: this is a test input.") == i
|
||||
memory.save_context({"question": "this is a test input."}, {"output": "this is a test output."})
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_memory_short()
|
||||
test_memory_long()
|
||||
|
|
@ -0,0 +1,62 @@
|
|||
import os
|
||||
|
||||
from colossalqa.retrieval_conversation_universal import UniversalRetrievalConversation
|
||||
|
||||
|
||||
def test_en_retrievalQA():
|
||||
data_path_en = os.environ.get('TEST_DATA_PATH_EN')
|
||||
data_path_zh = os.environ.get('TEST_DATA_PATH_ZH')
|
||||
en_model_path = os.environ.get('EN_MODEL_PATH')
|
||||
zh_model_path = os.environ.get('ZH_MODEL_PATH')
|
||||
zh_model_name = os.environ.get('ZH_MODEL_NAME')
|
||||
en_model_name = os.environ.get('EN_MODEL_NAME')
|
||||
sql_file_path = os.environ.get('SQL_FILE_PATH')
|
||||
qa_session = UniversalRetrievalConversation(files_en=[{
|
||||
'data_path': data_path_en,
|
||||
'name': 'company information',
|
||||
'separator': '\n'
|
||||
}],
|
||||
files_zh=[{
|
||||
'data_path': data_path_zh,
|
||||
'name': 'company information',
|
||||
'separator': '\n'
|
||||
}],
|
||||
zh_model_path=zh_model_path,
|
||||
en_model_path=en_model_path,
|
||||
zh_model_name=zh_model_name,
|
||||
en_model_name=en_model_name,
|
||||
sql_file_path=sql_file_path)
|
||||
ans = qa_session.run("which company runs business in hotel industry?", which_language='en')
|
||||
print(ans)
|
||||
|
||||
|
||||
def test_zh_retrievalQA():
|
||||
data_path_en = os.environ.get('TEST_DATA_PATH_EN')
|
||||
data_path_zh = os.environ.get('TEST_DATA_PATH_ZH')
|
||||
en_model_path = os.environ.get('EN_MODEL_PATH')
|
||||
zh_model_path = os.environ.get('ZH_MODEL_PATH')
|
||||
zh_model_name = os.environ.get('ZH_MODEL_NAME')
|
||||
en_model_name = os.environ.get('EN_MODEL_NAME')
|
||||
sql_file_path = os.environ.get('SQL_FILE_PATH')
|
||||
qa_session = UniversalRetrievalConversation(files_en=[{
|
||||
'data_path': data_path_en,
|
||||
'name': 'company information',
|
||||
'separator': '\n'
|
||||
}],
|
||||
files_zh=[{
|
||||
'data_path': data_path_zh,
|
||||
'name': 'company information',
|
||||
'separator': '\n'
|
||||
}],
|
||||
zh_model_path=zh_model_path,
|
||||
en_model_path=en_model_path,
|
||||
zh_model_name=zh_model_name,
|
||||
en_model_name=en_model_name,
|
||||
sql_file_path=sql_file_path)
|
||||
ans = qa_session.run("哪家公司在经营酒店业务?", which_language='zh')
|
||||
print(ans)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
test_en_retrievalQA()
|
||||
test_zh_retrievalQA()
|
||||
|
|
@ -0,0 +1,11 @@
|
|||
from colossalqa.text_splitter.chinese_text_splitter import ChineseTextSplitter
|
||||
|
||||
|
||||
def test_text_splitter():
|
||||
# unit test
|
||||
spliter = ChineseTextSplitter(chunk_size=30, chunk_overlap=0)
|
||||
out = spliter.split_text(
|
||||
"移动端语音唤醒模型,检测关键词为“小云小云”。模型主体为4层FSMN结构,使用CTC训练准则,参数量750K,适用于移动端设备运行。模型输入为Fbank特征,输出为基于char建模的中文全集token预测,测试工具根据每一帧的预测数据进行后处理得到输入音频的实时检测结果。模型训练采用“basetrain + finetune”的模式,basetrain过程使用大量内部移动端数据,在此基础上,使用1万条设备端录制安静场景“小云小云”数据进行微调,得到最终面向业务的模型。后续用户可在basetrain模型基础上,使用其他关键词数据进行微调,得到新的语音唤醒模型,但暂时未开放模型finetune功能。"
|
||||
)
|
||||
print(len(out))
|
||||
assert len(out) == 4 # ChineseTextSplitter will not break sentence. Hence the actual chunk size is not 30
|
||||
|
|
@ -0,0 +1 @@
|
|||
0.0.1
|
||||
|
|
@ -8,6 +8,7 @@ The list of applications include:
|
|||
- [X] [ColossalEval](./ColossalEval): Evaluation Pipeline for LLMs.
|
||||
- [X] [ColossalChat](./Chat/README.md): Replication of ChatGPT with RLHF.
|
||||
- [X] [FastFold](https://github.com/hpcaitech/FastFold): Optimizing AlphaFold (Biomedicine) Training and Inference on GPU Clusters.
|
||||
- [X] [ColossalQA](./ColossalQA/README.md): Document Retrieval Conversation System
|
||||
|
||||
> Please note that the `Chatbot` application is migrated from the original `ChatGPT` folder.
|
||||
|
||||
|
|
|
|||
Loading…
Reference in New Issue