diff --git a/README-zh-Hans.md b/README-zh-Hans.md
index 54db2a70e..904753c8e 100644
--- a/README-zh-Hans.md
+++ b/README-zh-Hans.md
@@ -71,26 +71,30 @@
Colossal-AI 为您提供了一系列并行训练组件。我们的目标是让您的分布式 AI 模型训练像普通的单 GPU 模型一样简单。我们提供的友好工具可以让您在几行代码内快速开始分布式训练。
-- 数据并行
-- 流水线并行
-- 1维, 2维, 2.5维, 3维张量并行
-- 序列并行
-- 友好的 trainer 和 engine
-- 可扩展新的并行方式
-- 混合精度
-- 零冗余优化器 (ZeRO)
-
+- 并行化策略
+ - 数据并行
+ - 流水线并行
+ - 1维, [2维](https://arxiv.org/abs/2104.05343), [2.5维](https://arxiv.org/abs/2105.14500), [3维](https://arxiv.org/abs/2105.14450) 张量并行
+ - [序列并行](https://arxiv.org/abs/2105.13120)
+ - [零冗余优化器 (ZeRO)](https://arxiv.org/abs/2108.05818)
+- 异构内存管理
+ - [PatrickStar](https://arxiv.org/abs/2108.05818)
+- 使用友好
+ - 基于参数文件的并行化
(返回顶端)
## 展示样例
### ViT
-
+
 +
+
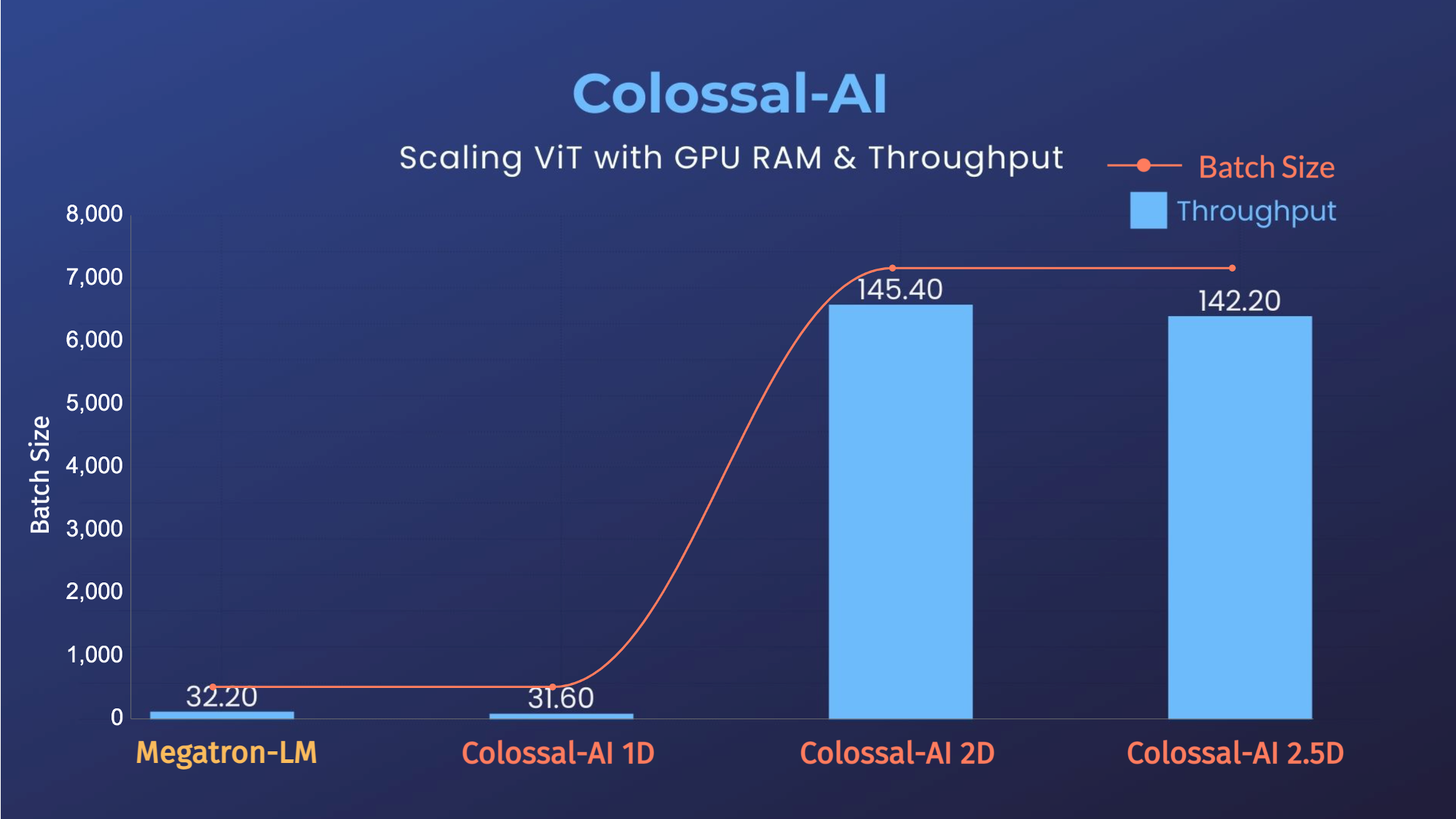
- 14倍批大小和5倍训练速度(张量并行=64)
### GPT-3
+
 +
+
- 释放 50% GPU 资源占用, 或 10.7% 加速
diff --git a/README.md b/README.md
index c790f1f36..843127b89 100644
--- a/README.md
+++ b/README.md
@@ -76,15 +76,15 @@ distributed training in a few lines.
- Parallelism strategies
- Data Parallelism
- Pipeline Parallelism
- - 1D, [2D](https://arxiv.org/abs/2104.05343), [2.5D](https://arxiv.org/abs/2105.14500), 3D Tensor parallelism
- - [Sequence parallelism](https://arxiv.org/abs/2105.13120)
+ - 1D, [2D](https://arxiv.org/abs/2104.05343), [2.5D](https://arxiv.org/abs/2105.14500), [3D](https://arxiv.org/abs/2105.14450) Tensor Parallelism
+ - [Sequence Parallelism](https://arxiv.org/abs/2105.13120)
- [Zero Redundancy Optimizer (ZeRO)](https://arxiv.org/abs/2108.05818)
- Heterogeneous Memory Menagement
- [PatrickStar](https://arxiv.org/abs/2108.05818)
- Friendly Usage
- - Configuration file based
+ - Parallelism based on configuration file
(back to top)