mirror of https://github.com/hpcaitech/ColossalAI
fix readme
parent
9179d4088e
commit
dccc9e14ba
|
|
@ -0,0 +1,162 @@
|
|||
# Byte-compiled / optimized / DLL files
|
||||
__pycache__/
|
||||
*.py[cod]
|
||||
*$py.class
|
||||
|
||||
# C extensions
|
||||
*.so
|
||||
|
||||
# Distribution / packaging
|
||||
.Python
|
||||
build/
|
||||
develop-eggs/
|
||||
dist/
|
||||
downloads/
|
||||
eggs/
|
||||
.eggs/
|
||||
lib/
|
||||
lib64/
|
||||
parts/
|
||||
sdist/
|
||||
var/
|
||||
wheels/
|
||||
pip-wheel-metadata/
|
||||
share/python-wheels/
|
||||
*.egg-info/
|
||||
.installed.cfg
|
||||
*.egg
|
||||
MANIFEST
|
||||
|
||||
# PyInstaller
|
||||
# Usually these files are written by a python script from a template
|
||||
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
||||
*.manifest
|
||||
*.spec
|
||||
|
||||
# Installer logs
|
||||
pip-log.txt
|
||||
pip-delete-this-directory.txt
|
||||
|
||||
# Unit test / coverage reports
|
||||
htmlcov/
|
||||
.tox/
|
||||
.nox/
|
||||
.coverage
|
||||
.coverage.*
|
||||
.cache
|
||||
nosetests.xml
|
||||
coverage.xml
|
||||
*.cover
|
||||
*.py,cover
|
||||
.hypothesis/
|
||||
.pytest_cache/
|
||||
|
||||
# Translations
|
||||
*.mo
|
||||
*.pot
|
||||
|
||||
# Django stuff:
|
||||
*.log
|
||||
local_settings.py
|
||||
db.sqlite3
|
||||
db.sqlite3-journal
|
||||
|
||||
# Flask stuff:
|
||||
instance/
|
||||
.webassets-cache
|
||||
|
||||
# Scrapy stuff:
|
||||
.scrapy
|
||||
|
||||
# Sphinx documentation
|
||||
docs/_build/
|
||||
docs/.build/
|
||||
|
||||
# PyBuilder
|
||||
target/
|
||||
|
||||
# Jupyter Notebook
|
||||
.ipynb_checkpoints
|
||||
|
||||
# IPython
|
||||
profile_default/
|
||||
ipython_config.py
|
||||
|
||||
# pyenv
|
||||
.python-version
|
||||
|
||||
# pipenv
|
||||
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
||||
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
||||
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
||||
# install all needed dependencies.
|
||||
#Pipfile.lock
|
||||
|
||||
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
|
||||
__pypackages__/
|
||||
|
||||
# Celery stuff
|
||||
celerybeat-schedule
|
||||
celerybeat.pid
|
||||
|
||||
# SageMath parsed files
|
||||
*.sage.py
|
||||
|
||||
# Environments
|
||||
.env
|
||||
.venv
|
||||
env/
|
||||
venv/
|
||||
ENV/
|
||||
env.bak/
|
||||
venv.bak/
|
||||
|
||||
# Spyder project settings
|
||||
.spyderproject
|
||||
.spyproject
|
||||
|
||||
# Rope project settings
|
||||
.ropeproject
|
||||
|
||||
# mkdocs documentation
|
||||
/site
|
||||
|
||||
# mypy
|
||||
.mypy_cache/
|
||||
.dmypy.json
|
||||
dmypy.json
|
||||
|
||||
# Pyre type checker
|
||||
.pyre/
|
||||
|
||||
# IDE
|
||||
.idea/
|
||||
.vscode/
|
||||
|
||||
# macos
|
||||
*.DS_Store
|
||||
#data/
|
||||
|
||||
docs/.build
|
||||
|
||||
# pytorch checkpoint
|
||||
*.pt
|
||||
|
||||
# wandb log
|
||||
examples/wandb/
|
||||
examples/logs/
|
||||
examples/output/
|
||||
examples/training_scripts/logs
|
||||
examples/training_scripts/wandb
|
||||
examples/training_scripts/output
|
||||
|
||||
examples/awesome-chatgpt-prompts/
|
||||
temp/
|
||||
|
||||
# ColossalChat
|
||||
applications/ColossalChat/logs
|
||||
applications/ColossalChat/models
|
||||
applications/ColossalChat/sft_data
|
||||
applications/ColossalChat/prompt_data
|
||||
applications/ColossalChat/preference_data
|
||||
applications/ColossalChat/temp
|
||||
|
|
@ -0,0 +1,202 @@
|
|||
Copyright 2021- HPC-AI Technology Inc. All rights reserved.
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright 2021- HPC-AI Technology Inc.
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
|
|
@ -0,0 +1,601 @@
|
|||
<h1 align="center">
|
||||
<img width="auto" height="100px", src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/logo_coati.png"/>
|
||||
<br/>
|
||||
<span>ColossalChat</span>
|
||||
</h1>
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [What is ColossalChat and Coati ?](#what-is-colossalchat-and-coati-)
|
||||
- [Online demo](#online-demo)
|
||||
- [Install](#install)
|
||||
- [Install the environment](#install-the-environment)
|
||||
- [Install the Transformers](#install-the-transformers)
|
||||
- [How to use?](#how-to-use)
|
||||
- [Supervised datasets collection](#step-1-data-collection)
|
||||
- [RLHF Training Stage1 - Supervised instructs tuning](#rlhf-training-stage1---supervised-instructs-tuning)
|
||||
- [RLHF Training Stage2 - Training reward model](#rlhf-training-stage2---training-reward-model)
|
||||
- [RLHF Training Stage3 - Training model with reinforcement learning by human feedback](#rlhf-training-stage3---proximal-policy-optimization)
|
||||
- [Inference Quantization and Serving - After Training](#inference-quantization-and-serving---after-training)
|
||||
- [Coati7B examples](#coati7b-examples)
|
||||
- [Generation](#generation)
|
||||
- [Open QA](#open-qa)
|
||||
- [Limitation for LLaMA-finetuned models](#limitation)
|
||||
- [Limitation of dataset](#limitation)
|
||||
- [Alternative Option For RLHF: DPO](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||
- [Alternative Option For RLHF: SimPO](#alternative-option-for-rlhf-simple-preference-optimization-simpo)
|
||||
- [Alternative Option For RLHF: ORPO](#alternative-option-for-rlhf-odds-ratio-preference-optimization-orpo)
|
||||
- [Alternative Option For RLHF: KTO](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
||||
- [FAQ](#faq)
|
||||
- [How to save/load checkpoint](#faq)
|
||||
- [How to train with limited resources](#faq)
|
||||
- [The Plan](#the-plan)
|
||||
- [Real-time progress](#real-time-progress)
|
||||
- [Invitation to open-source contribution](#invitation-to-open-source-contribution)
|
||||
- [Quick Preview](#quick-preview)
|
||||
- [Authors](#authors)
|
||||
- [Citations](#citations)
|
||||
- [Licenses](#licenses)
|
||||
|
||||
---
|
||||
|
||||
## What Is ColossalChat And Coati ?
|
||||
|
||||
[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat) is the project to implement LLM with RLHF, powered by the [Colossal-AI](https://github.com/hpcaitech/ColossalAI) project.
|
||||
|
||||
Coati stands for `ColossalAI Talking Intelligence`. It is the name for the module implemented in this project and is also the name of the large language model developed by the ColossalChat project.
|
||||
|
||||
The Coati package provides a unified large language model framework that has implemented the following functions
|
||||
|
||||
- Supports comprehensive large-model training acceleration capabilities for ColossalAI, without requiring knowledge of complex distributed training algorithms
|
||||
- Supervised datasets collection
|
||||
- Supervised instructions fine-tuning
|
||||
- Training reward model
|
||||
- Reinforcement learning with human feedback
|
||||
- Quantization inference
|
||||
- Fast model deploying
|
||||
- Perfectly integrated with the Hugging Face ecosystem, a high degree of model customization
|
||||
|
||||
<div align="center">
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chatgpt/chatgpt.png" width=700/>
|
||||
</p>
|
||||
|
||||
Image source: https://openai.com/blog/chatgpt
|
||||
|
||||
</div>
|
||||
|
||||
**As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
|
||||
|
||||
More details can be found in the latest news.
|
||||
|
||||
- [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
|
||||
- [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
|
||||
|
||||
## Online demo
|
||||
|
||||
<div align="center">
|
||||
<a href="https://www.youtube.com/watch?v=HcTiHzApHm0">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/ColossalChat%20YouTube.png" width="700" />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
[ColossalChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat): An open-source solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline.
|
||||
[[code]](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)
|
||||
[[blog]](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
|
||||
[[demo]](https://www.youtube.com/watch?v=HcTiHzApHm0)
|
||||
[[tutorial]](https://www.youtube.com/watch?v=-qFBZFmOJfg)
|
||||
|
||||
<p id="ColossalChat-Speed" align="center">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/ColossalChat%20Speed.jpg" width=450/>
|
||||
</p>
|
||||
|
||||
> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: `torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32`
|
||||
|
||||
## Install
|
||||
|
||||
### Install the Environment
|
||||
|
||||
```bash
|
||||
# Create new environment
|
||||
conda create -n colossal-chat python=3.10.9 (>=3.8.7)
|
||||
conda activate colossal-chat
|
||||
|
||||
# Install flash-attention
|
||||
git clone -b v2.0.5 https://github.com/Dao-AILab/flash-attention.git
|
||||
cd $FLASH_ATTENTION_ROOT/
|
||||
pip install .
|
||||
cd $FLASH_ATTENTION_ROOT/csrc/xentropy
|
||||
pip install .
|
||||
cd $FLASH_ATTENTION_ROOT/csrc/layer_norm
|
||||
pip install .
|
||||
cd $FLASH_ATTENTION_ROOT/csrc/rotary
|
||||
pip install .
|
||||
|
||||
# Clone Colossalai
|
||||
git clone https://github.com/hpcaitech/ColossalAI.git
|
||||
|
||||
# Install ColossalAI
|
||||
cd $COLOSSAL_AI_ROOT
|
||||
BUILD_EXT=1 pip install .
|
||||
|
||||
# Install ColossalChat
|
||||
cd $COLOSSAL_AI_ROOT/applications/Chat
|
||||
pip install .
|
||||
```
|
||||
|
||||
## How To Use?
|
||||
|
||||
### RLHF Training Stage1 - Supervised Instructs Tuning
|
||||
|
||||
Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of the RLHF training process, as it involves training a machine learning model using human-provided instructions to learn the initial behavior for the task at hand. Here's a detailed guide on how to SFT your LLM with ColossalChat. More details can be found in [example guideline](./examples/README.md).
|
||||
|
||||
#### Step 1: Data Collection
|
||||
The first step in Stage 1 is to collect a dataset of human demonstrations of the following format.
|
||||
|
||||
```json
|
||||
[
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "user",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
},
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you looking for practical joke ideas?"
|
||||
},
|
||||
]
|
||||
},
|
||||
]
|
||||
```
|
||||
|
||||
#### Step 2: Preprocessing
|
||||
Once you have collected your SFT dataset, you will need to preprocess it. This involves four steps: data cleaning, data deduplication, formatting and tokenization. In this section, we will focus on formatting and tokenization.
|
||||
|
||||
In this code, we provide a flexible way for users to set the conversation template for formatting chat data using Huggingface's newest feature--- chat template. Please follow the [example guideline](./examples/README.md) on how to format and tokenize data.
|
||||
|
||||
#### Step 3: Training
|
||||
Choose a suitable model architecture for your task. Note that your model should be compatible with the tokenizer that you used to tokenize the SFT dataset. You can run [train_sft.sh](./examples/training_scripts/train_sft.sh) to start a supervised instructs fine-tuning. More details can be found in [example guideline](./examples/README.md).
|
||||
|
||||
### RLHF Training Stage2 - Training Reward Model
|
||||
|
||||
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model.
|
||||
|
||||
#### Step 1: Data Collection
|
||||
Below shows the preference dataset format used in training the reward model.
|
||||
|
||||
```json
|
||||
[
|
||||
{"context": [
|
||||
{
|
||||
"from": "human",
|
||||
"content": "Introduce butterflies species in Oregon."
|
||||
}
|
||||
],
|
||||
"chosen": [
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "About 150 species of butterflies live in Oregon, with about 100 species are moths..."
|
||||
},
|
||||
],
|
||||
"rejected": [
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you interested in just the common butterflies? There are a few common ones which will be easy to find..."
|
||||
},
|
||||
]
|
||||
},
|
||||
]
|
||||
```
|
||||
|
||||
#### Step 2: Preprocessing
|
||||
Similar to the second step in the previous stage, we format the reward data into the same structured format as used in step 2 of the SFT stage. You can run [prepare_preference_dataset.sh](./examples/data_preparation_scripts/prepare_preference_dataset.sh) to prepare the preference data for reward model training.
|
||||
|
||||
#### Step 3: Training
|
||||
You can run [train_rm.sh](./examples/training_scripts/train_rm.sh) to start the reward model training. More details can be found in [example guideline](./examples/README.md).
|
||||
|
||||
### RLHF Training Stage3 - Proximal Policy Optimization
|
||||
|
||||
In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimization (PPO), which is the most complex part of the training process:
|
||||
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/stage-3.jpeg" width=800/>
|
||||
</p>
|
||||
|
||||
#### Step 1: Data Collection
|
||||
PPO uses two kind of training data--- the prompt data and the sft data (optional). The first dataset is mandatory, data samples within the prompt dataset ends with a line from "human" and thus the "assistant" needs to generate a response to answer to the "human". Note that you can still use conversation that ends with a line from the "assistant", in that case, the last line will be dropped. Here is an example of the prompt dataset format.
|
||||
|
||||
```json
|
||||
[
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "human",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
}
|
||||
]
|
||||
},
|
||||
]
|
||||
```
|
||||
|
||||
#### Step 2: Data Preprocessing
|
||||
To prepare the prompt dataset for PPO training, simply run [prepare_prompt_dataset.sh](./examples/data_preparation_scripts/prepare_prompt_dataset.sh)
|
||||
|
||||
#### Step 3: Training
|
||||
You can run the [train_ppo.sh](./examples/training_scripts/train_ppo.sh) to start PPO training. Here are some unique arguments for PPO, please refer to the training configuration section for other training configuration. More detais can be found in [example guideline](./examples/README.md).
|
||||
|
||||
```bash
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--rm_pretrain $PRETRAINED_MODEL_PATH \ # reward model architectual
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--rm_checkpoint_path $REWARD_MODEL_PATH \ # reward model checkpoint path
|
||||
--prompt_dataset ${prompt_dataset[@]} \ # List of string, the prompt dataset
|
||||
--ptx_dataset ${ptx_dataset[@]} \ # List of string, the SFT data used in the SFT stage
|
||||
--ptx_batch_size 1 \ # batch size for calculate ptx loss
|
||||
--ptx_coef 0.0 \ # none-zero if ptx loss is enable
|
||||
--num_episodes 2000 \ # number of episodes to train
|
||||
--num_collect_steps 1 \
|
||||
--num_update_steps 1 \
|
||||
--experience_batch_size 8 \
|
||||
--train_batch_size 4 \
|
||||
--accumulation_steps 2
|
||||
```
|
||||
|
||||
Each episode has two phases, the collect phase and the update phase. During the collect phase, we will collect experiences (answers generated by actor), store those in ExperienceBuffer. Then data in ExperienceBuffer is used during the update phase to update parameter of actor and critic.
|
||||
|
||||
- Without tensor parallelism,
|
||||
```
|
||||
experience buffer size
|
||||
= num_process * num_collect_steps * experience_batch_size
|
||||
= train_batch_size * accumulation_steps * num_process
|
||||
```
|
||||
|
||||
- With tensor parallelism,
|
||||
```
|
||||
num_tp_group = num_process / tp
|
||||
experience buffer size
|
||||
= num_tp_group * num_collect_steps * experience_batch_size
|
||||
= train_batch_size * accumulation_steps * num_tp_group
|
||||
```
|
||||
|
||||
## Alternative Option For RLHF: Direct Preference Optimization (DPO)
|
||||
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in this [paper](https://arxiv.org/abs/2305.18290), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### DPO Training Stage1 - Supervised Instructs Tuning
|
||||
|
||||
Please refer the [sft section](#dpo-training-stage1---supervised-instructs-tuning) in the PPO part.
|
||||
|
||||
### DPO Training Stage2 - DPO Training
|
||||
#### Step 1: Data Collection & Preparation
|
||||
For DPO training, you only need the preference dataset. Please follow the instruction in the [preference dataset preparation section](#rlhf-training-stage2---training-reward-model) to prepare the preference data for DPO training.
|
||||
|
||||
#### Step 2: Training
|
||||
You can run the [train_dpo.sh](./examples/training_scripts/train_dpo.sh) to start DPO training. More detais can be found in [example guideline](./examples/README.md).
|
||||
|
||||
## Alternative Option For RLHF: Simple Preference Optimization (SimPO)
|
||||
Simple Preference Optimization (SimPO) from this [paper](https://arxiv.org/pdf/2405.14734) is similar to DPO but it abandons the use of the reference model, which makes the training more efficient. It also adds a reward shaping term called target reward margin to enhance training stability. It also use length normalization to better align with the inference process. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
## Alternative Option For RLHF: Odds Ratio Preference Optimization (ORPO)
|
||||
Odds Ratio Preference Optimization (ORPO) from this [paper](https://arxiv.org/pdf/2403.07691) is a reference model free alignment method that use a mixture of SFT loss and a reinforcement leanring loss calculated based on odds-ratio-based implicit reward to makes the training more efficient and stable. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
## Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)
|
||||
We support the method introduced in the paper [KTO:Model Alignment as Prospect Theoretic Optimization](https://arxiv.org/pdf/2402.01306) (KTO). Which is a aligment method that directly maximize "human utility" of generation results. Read this [README](./examples/README.md) for more information.
|
||||
|
||||
### Inference Quantization and Serving - After Training
|
||||
|
||||
We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
|
||||
|
||||
We support 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inference.
|
||||
|
||||
Online inference server scripts can help you deploy your own services.
|
||||
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
||||
|
||||
## Coati7B examples
|
||||
|
||||
### Generation
|
||||
|
||||
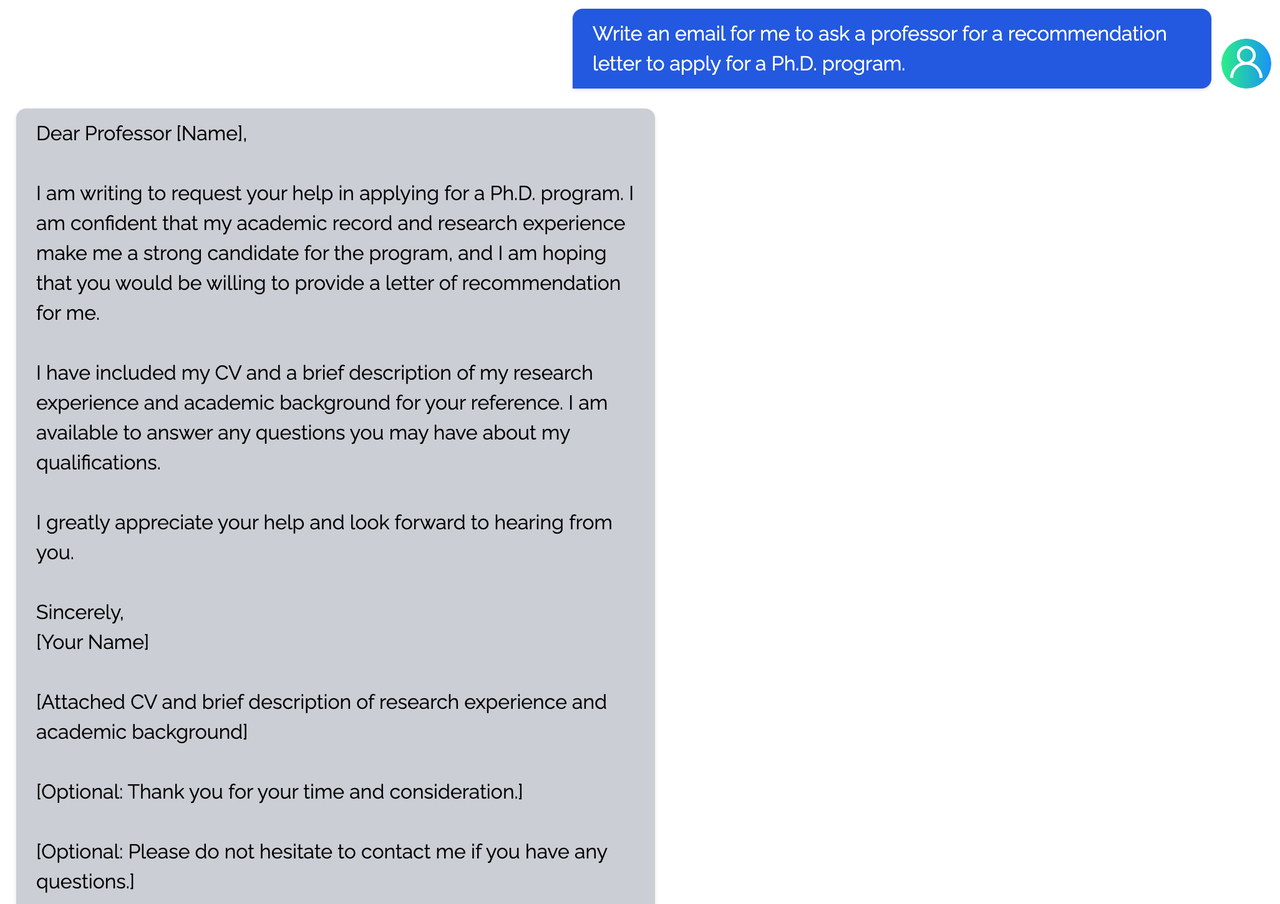
<details><summary><b>E-mail</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
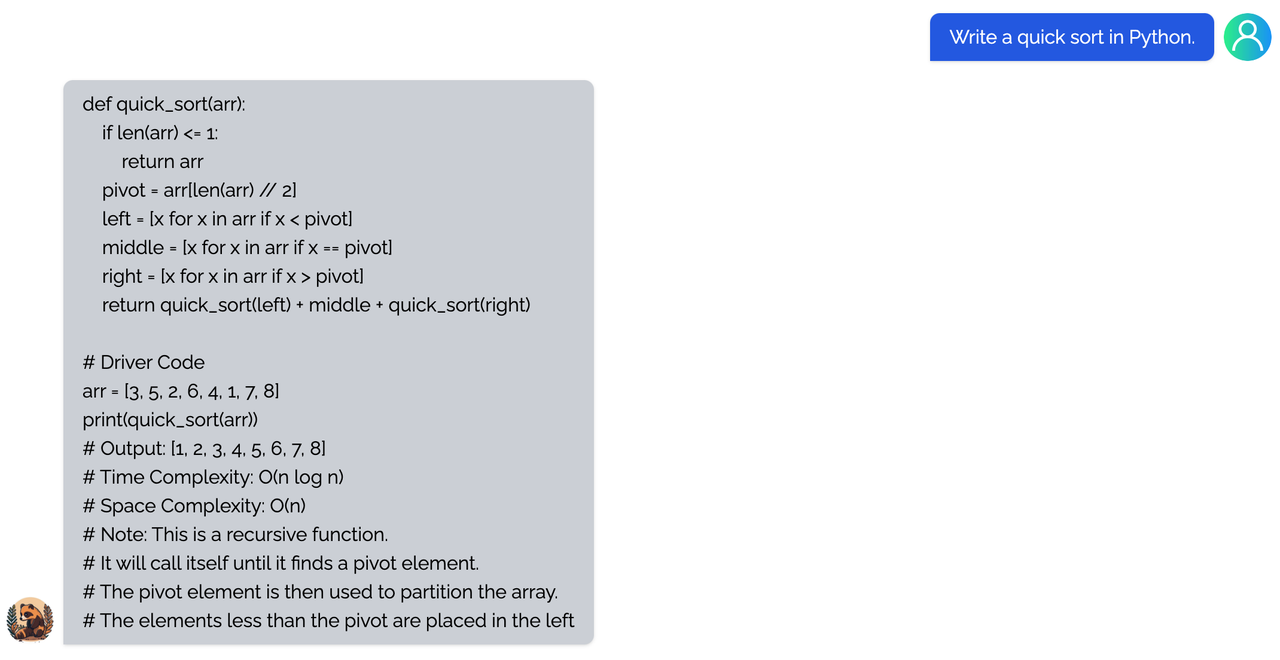
<details><summary><b>coding</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>regex</b></summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Tex</b></summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
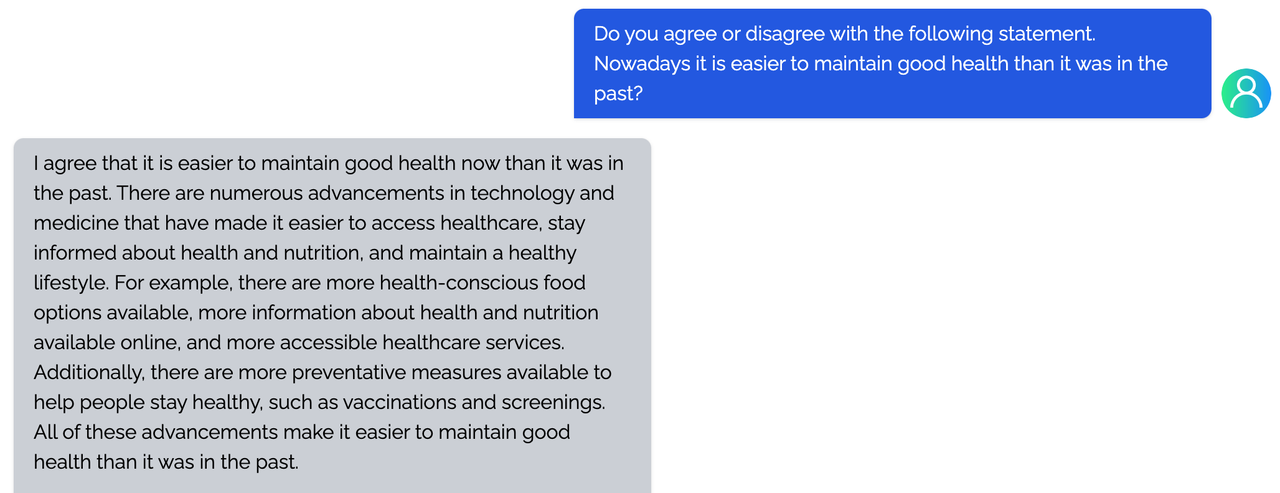
<details><summary><b>writing</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
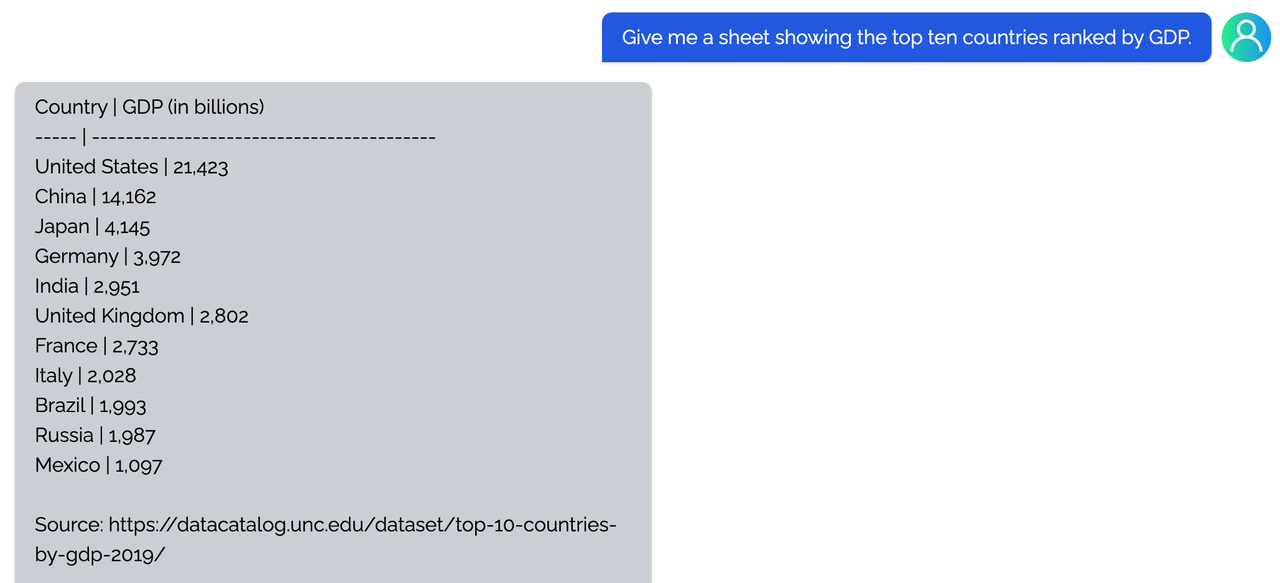
<details><summary><b>Table</b></summary>
|
||||
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
### Open QA
|
||||
|
||||
<details><summary><b>Game</b></summary>
|
||||
|
||||
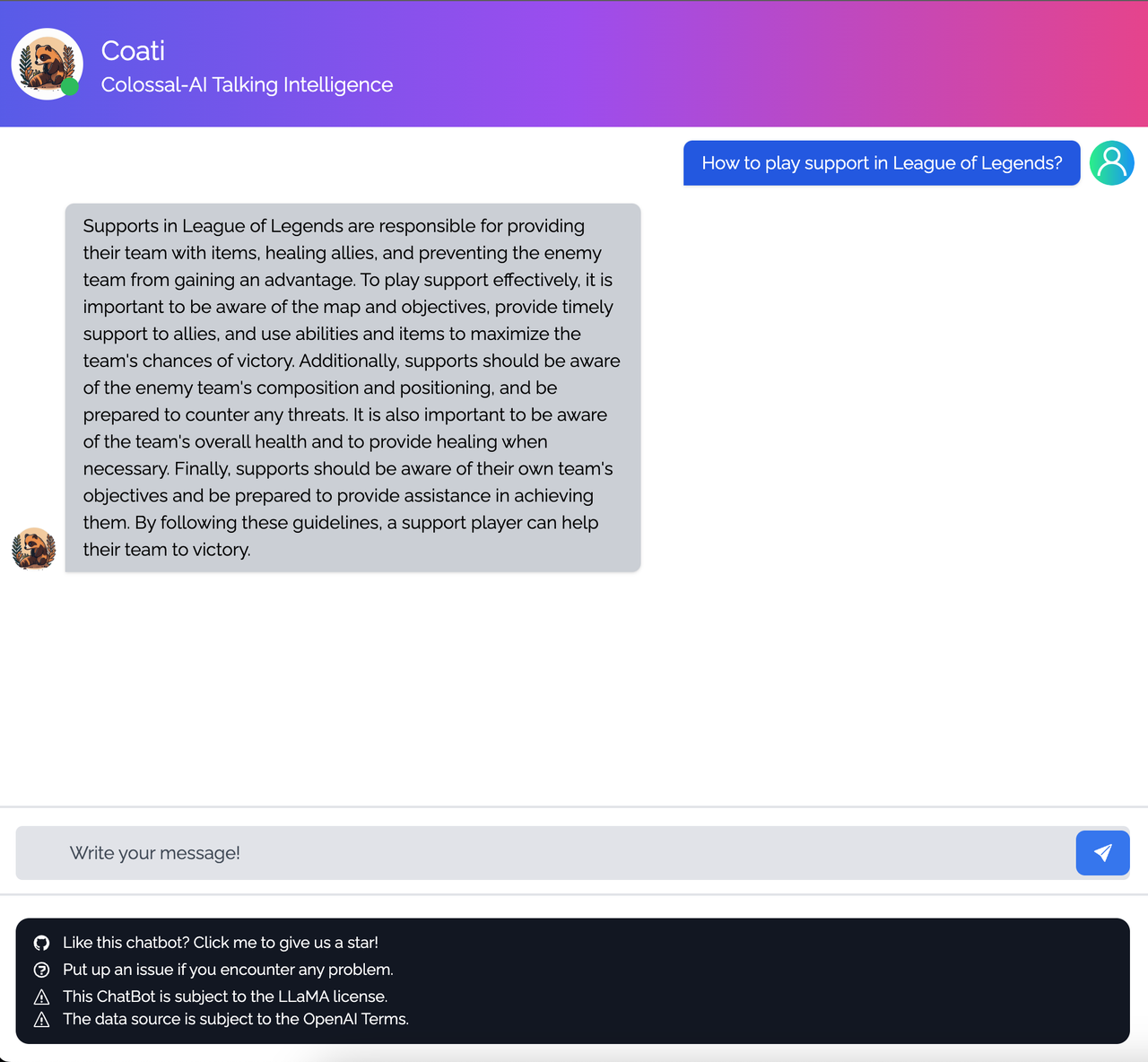
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Travel</b></summary>
|
||||
|
||||
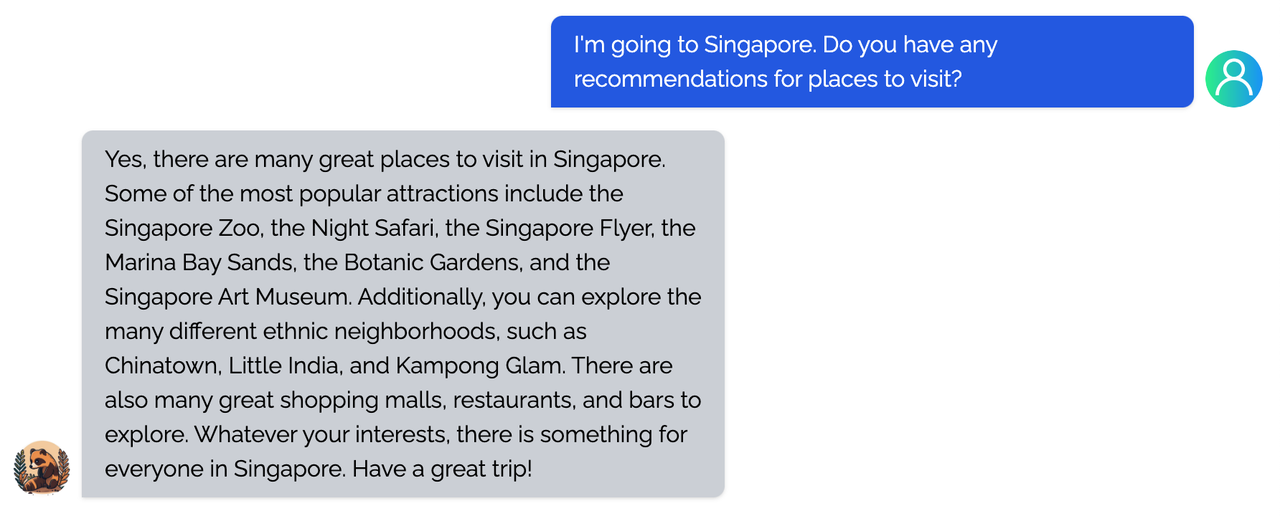
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Physical</b></summary>
|
||||
|
||||
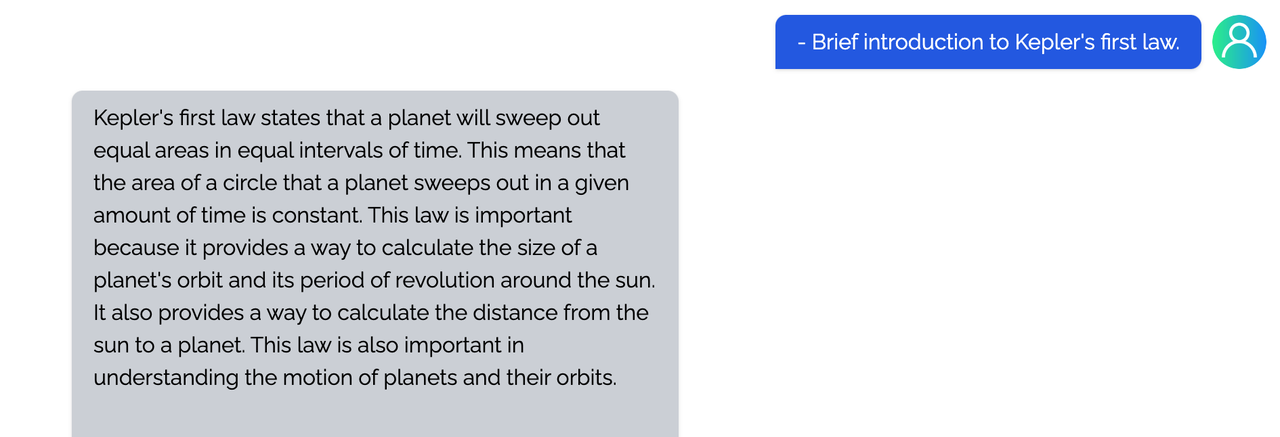
|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Chemical</b></summary>
|
||||
|
||||

|
||||
|
||||
</details>
|
||||
|
||||
<details><summary><b>Economy</b></summary>
|
||||
|
||||
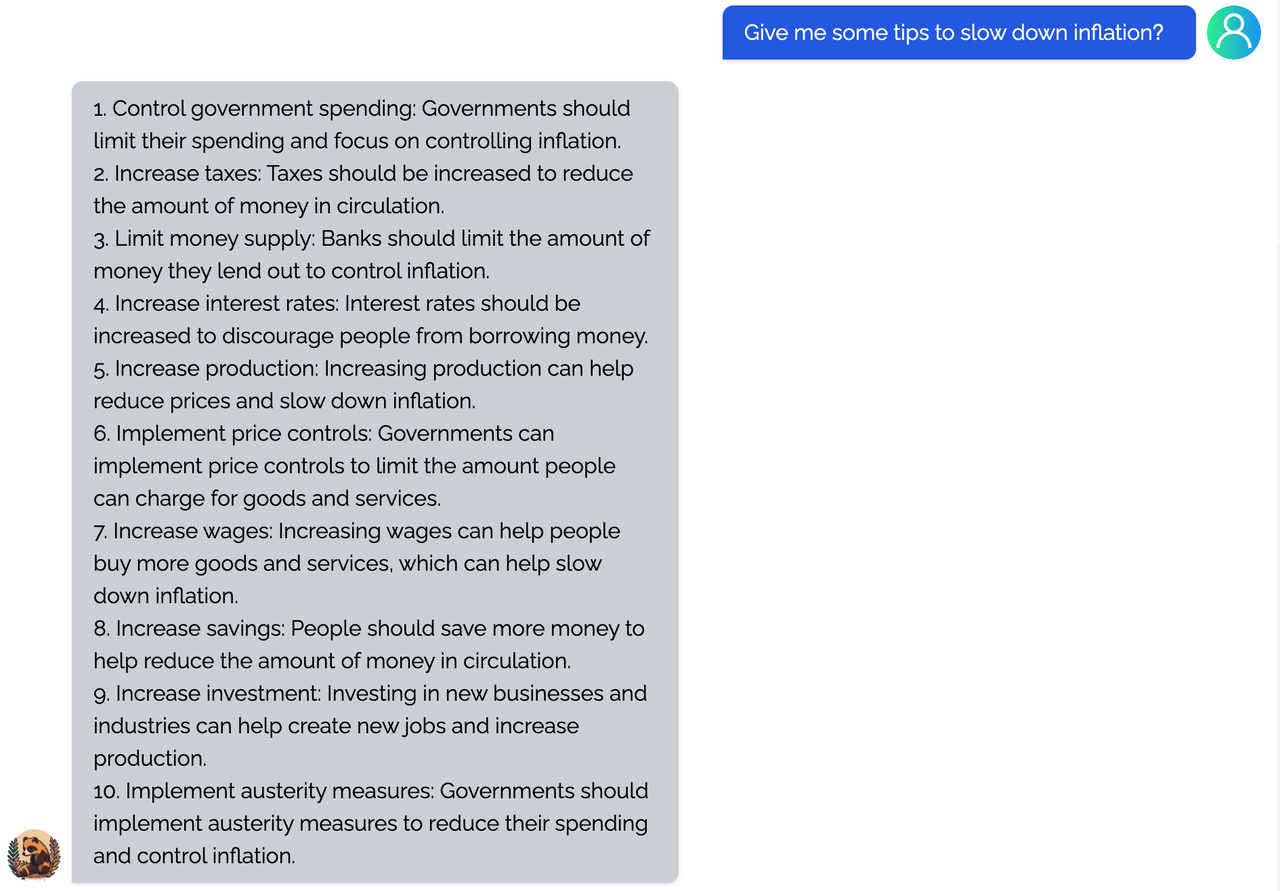
|
||||
|
||||
</details>
|
||||
|
||||
You can find more examples in this [repo](https://github.com/XueFuzhao/InstructionWild/blob/main/comparison.md).
|
||||
|
||||
### Limitation
|
||||
|
||||
<details><summary><b>Limitation for LLaMA-finetuned models</b></summary>
|
||||
- Both Alpaca and ColossalChat are based on LLaMA. It is hard to compensate for the missing knowledge in the pre-training stage.
|
||||
- Lack of counting ability: Cannot count the number of items in a list.
|
||||
- Lack of Logics (reasoning and calculation)
|
||||
- Tend to repeat the last sentence (fail to produce the end token).
|
||||
- Poor multilingual results: LLaMA is mainly trained on English datasets (Generation performs better than QA).
|
||||
</details>
|
||||
|
||||
<details><summary><b>Limitation of dataset</b></summary>
|
||||
- Lack of summarization ability: No such instructions in finetune datasets.
|
||||
- Lack of multi-turn chat: No such instructions in finetune datasets
|
||||
- Lack of self-recognition: No such instructions in finetune datasets
|
||||
- Lack of Safety:
|
||||
- When the input contains fake facts, the model makes up false facts and explanations.
|
||||
- Cannot abide by OpenAI's policy: When generating prompts from OpenAI API, it always abides by its policy. So no violation case is in the datasets.
|
||||
</details>
|
||||
|
||||
## FAQ
|
||||
|
||||
<details><summary><b>How to save/load checkpoint</b></summary>
|
||||
|
||||
We have integrated the Transformers save and load pipeline, allowing users to freely call Hugging Face's language models and save them in the HF format.
|
||||
|
||||
- Option 1: Save the model weights, model config and generation config (Note: tokenizer will not be saved) which can be loaded using HF's from_pretrained method.
|
||||
```python
|
||||
# if use lora, you can choose to merge lora weights before saving
|
||||
if args.lora_rank > 0 and args.merge_lora_weights:
|
||||
from coati.models.lora import LORA_MANAGER
|
||||
|
||||
# NOTE: set model to eval to merge LoRA weights
|
||||
LORA_MANAGER.merge_weights = True
|
||||
model.eval()
|
||||
# save model checkpoint after fitting on only rank0
|
||||
booster.save_model(model, os.path.join(args.save_dir, "modeling"), shard=True)
|
||||
|
||||
```
|
||||
|
||||
- Option 2: Save the model weights, model config, generation config, as well as the optimizer, learning rate scheduler, running states (Note: tokenizer will not be saved) which are needed for resuming training.
|
||||
```python
|
||||
from coati.utils import save_checkpoint
|
||||
# save model checkpoint after fitting on only rank0
|
||||
save_checkpoint(
|
||||
save_dir=actor_save_dir,
|
||||
booster=actor_booster,
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
epoch=0,
|
||||
step=step,
|
||||
batch_size=train_batch_size,
|
||||
coordinator=coordinator,
|
||||
)
|
||||
```
|
||||
To load the saved checkpoint
|
||||
```python
|
||||
from coati.utils import load_checkpoint
|
||||
start_epoch, start_step, sampler_start_idx = load_checkpoint(
|
||||
load_dir=checkpoint_path,
|
||||
booster=booster,
|
||||
model=model,
|
||||
optimizer=optim,
|
||||
lr_scheduler=lr_scheduler,
|
||||
)
|
||||
```
|
||||
</details>
|
||||
|
||||
<details><summary><b>How to train with limited resources</b></summary>
|
||||
|
||||
Here are some suggestions that can allow you to train a 7B model on a single or multiple consumer-grade GPUs.
|
||||
|
||||
`batch_size`, `lora_rank` and `grad_checkpoint` are the most important parameters to successfully train the model. To maintain a descent batch size for gradient calculation, consider increase the accumulation_step and reduce the batch_size on each rank.
|
||||
|
||||
If you only have a single 24G GPU. Generally, using lora and "zero2-cpu" will be sufficient.
|
||||
|
||||
`gemini` and `gemini-auto` can enable a single 24G GPU to train the whole model without using LoRA if you have sufficient CPU memory. But that strategy doesn't support gradient accumulation.
|
||||
|
||||
If you have multiple GPUs each has very limited VRAM, say 8GB. You can try the `3d` for the plugin option, which supports tensor parellelism, set `--tp` to the number of GPUs that you have.
|
||||
</details>
|
||||
|
||||
### Real-time progress
|
||||
|
||||
You will find our progress in github [project broad](https://github.com/orgs/hpcaitech/projects/17/views/1).
|
||||
|
||||
## Invitation to open-source contribution
|
||||
|
||||
Referring to the successful attempts of [BLOOM](https://bigscience.huggingface.co/) and [Stable Diffusion](https://en.wikipedia.org/wiki/Stable_Diffusion), any and all developers and partners with computing powers, datasets, models are welcome to join and build the Colossal-AI community, making efforts towards the era of big AI models from the starting point of replicating ChatGPT!
|
||||
|
||||
You may contact us or participate in the following ways:
|
||||
|
||||
1. [Leaving a Star ⭐](https://github.com/hpcaitech/ColossalAI/stargazers) to show your like and support. Thanks!
|
||||
2. Posting an [issue](https://github.com/hpcaitech/ColossalAI/issues/new/choose), or submitting a PR on GitHub follow the guideline in [Contributing](https://github.com/hpcaitech/ColossalAI/blob/main/CONTRIBUTING.md).
|
||||
3. Join the Colossal-AI community on
|
||||
[Slack](https://github.com/hpcaitech/public_assets/tree/main/colossalai/contact/slack),
|
||||
and [WeChat(微信)](https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/WeChat.png "qrcode") to share your ideas.
|
||||
4. Send your official proposal to email contact@hpcaitech.com
|
||||
|
||||
Thanks so much to all of our amazing contributors!
|
||||
|
||||
## Quick Preview
|
||||
|
||||
<div align="center">
|
||||
<a href="https://chat.colossalai.org/">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/Chat-demo.png" width="700" />
|
||||
</a>
|
||||
</div>
|
||||
|
||||
- An open-source low-cost solution for cloning [ChatGPT](https://openai.com/blog/chatgpt/) with a complete RLHF pipeline. [[demo]](https://chat.colossalai.org)
|
||||
|
||||
<p id="ChatGPT_scaling" align="center">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chatgpt/ChatGPT%20scaling.png" width=800/>
|
||||
</p>
|
||||
|
||||
- Up to 7.73 times faster for single server training and 1.42 times faster for single-GPU inference
|
||||
|
||||
<p id="ChatGPT-1GPU" align="center">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chatgpt/ChatGPT-1GPU.jpg" width=450/>
|
||||
</p>
|
||||
|
||||
- Up to 10.3x growth in model capacity on one GPU
|
||||
- A mini demo training process requires only 1.62GB of GPU memory (any consumer-grade GPU)
|
||||
|
||||
<p id="inference" align="center">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chatgpt/LoRA%20data.jpg" width=600/>
|
||||
</p>
|
||||
|
||||
- Increase the capacity of the fine-tuning model by up to 3.7 times on a single GPU
|
||||
- Keep in a sufficiently high running speed
|
||||
|
||||
| Model Pair | Alpaca-7B ⚔ Coati-7B | Coati-7B ⚔ Alpaca-7B |
|
||||
| :-----------: | :------------------: | :------------------: |
|
||||
| Better Cases | 38 ⚔ **41** | **45** ⚔ 33 |
|
||||
| Win Rate | 48% ⚔ **52%** | **58%** ⚔ 42% |
|
||||
| Average Score | 7.06 ⚔ **7.13** | **7.31** ⚔ 6.82 |
|
||||
|
||||
- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
|
||||
|
||||
## Authors
|
||||
|
||||
Coati is developed by ColossalAI Team:
|
||||
|
||||
- [ver217](https://github.com/ver217) Leading the project while contributing to the main framework.
|
||||
- [FrankLeeeee](https://github.com/FrankLeeeee) Providing ML infra support and also taking charge of both front-end and back-end development.
|
||||
- [htzhou](https://github.com/ht-zhou) Contributing to the algorithm and development for RM and PPO training.
|
||||
- [Fazzie](https://fazzie-key.cool/about/index.html) Contributing to the algorithm and development for SFT.
|
||||
- [ofey404](https://github.com/ofey404) Contributing to both front-end and back-end development.
|
||||
- [Wenhao Chen](https://github.com/CWHer) Contributing to subsequent code enhancements and performance improvements.
|
||||
- [Anbang Ye](https://github.com/YeAnbang) Contributing to the refactored PPO version with updated acceleration framework. Add support for DPO, SimPO, ORPO.
|
||||
|
||||
The PhD student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
|
||||
- [Zangwei Zheng](https://github.com/zhengzangw)
|
||||
- [Xue Fuzhao](https://github.com/XueFuzhao)
|
||||
|
||||
We also appreciate the valuable suggestions provided by [Jian Hu](https://github.com/hijkzzz) regarding the convergence of the PPO algorithm.
|
||||
|
||||
## Citations
|
||||
|
||||
```bibtex
|
||||
@article{Hu2021LoRALA,
|
||||
title = {LoRA: Low-Rank Adaptation of Large Language Models},
|
||||
author = {Edward J. Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Weizhu Chen},
|
||||
journal = {ArXiv},
|
||||
year = {2021},
|
||||
volume = {abs/2106.09685}
|
||||
}
|
||||
|
||||
@article{ouyang2022training,
|
||||
title={Training language models to follow instructions with human feedback},
|
||||
author={Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others},
|
||||
journal={arXiv preprint arXiv:2203.02155},
|
||||
year={2022}
|
||||
}
|
||||
|
||||
@article{touvron2023llama,
|
||||
title={LLaMA: Open and Efficient Foundation Language Models},
|
||||
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume},
|
||||
journal={arXiv preprint arXiv:2302.13971},
|
||||
year={2023}
|
||||
}
|
||||
|
||||
@misc{alpaca,
|
||||
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
|
||||
title = {Stanford Alpaca: An Instruction-following LLaMA model},
|
||||
year = {2023},
|
||||
publisher = {GitHub},
|
||||
journal = {GitHub repository},
|
||||
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
|
||||
}
|
||||
|
||||
@misc{instructionwild,
|
||||
author = {Fuzhao Xue and Zangwei Zheng and Yang You },
|
||||
title = {Instruction in the Wild: A User-based Instruction Dataset},
|
||||
year = {2023},
|
||||
publisher = {GitHub},
|
||||
journal = {GitHub repository},
|
||||
howpublished = {\url{https://github.com/XueFuzhao/InstructionWild}},
|
||||
}
|
||||
|
||||
@misc{meng2024simposimplepreferenceoptimization,
|
||||
title={SimPO: Simple Preference Optimization with a Reference-Free Reward},
|
||||
author={Yu Meng and Mengzhou Xia and Danqi Chen},
|
||||
year={2024},
|
||||
eprint={2405.14734},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CL},
|
||||
url={https://arxiv.org/abs/2405.14734},
|
||||
}
|
||||
|
||||
@misc{rafailov2023directpreferenceoptimizationlanguage,
|
||||
title={Direct Preference Optimization: Your Language Model is Secretly a Reward Model},
|
||||
author={Rafael Rafailov and Archit Sharma and Eric Mitchell and Stefano Ermon and Christopher D. Manning and Chelsea Finn},
|
||||
year={2023},
|
||||
eprint={2305.18290},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.LG},
|
||||
url={https://arxiv.org/abs/2305.18290},
|
||||
}
|
||||
|
||||
@misc{hong2024orpomonolithicpreferenceoptimization,
|
||||
title={ORPO: Monolithic Preference Optimization without Reference Model},
|
||||
author={Jiwoo Hong and Noah Lee and James Thorne},
|
||||
year={2024},
|
||||
eprint={2403.07691},
|
||||
archivePrefix={arXiv},
|
||||
primaryClass={cs.CL},
|
||||
url={https://arxiv.org/abs/2403.07691},
|
||||
}
|
||||
```
|
||||
|
||||
## Licenses
|
||||
|
||||
Coati is licensed under the [Apache 2.0 License](LICENSE).
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
{
|
||||
"chat_template": "{% for message in messages %}{% if message['role'] == 'user' %}{{'Human: ' + bos_token + message['content'].strip() + eos_token }}{% elif message['role'] == 'system' %}{{ message['content'].strip() + '\\n\\n' }}{% elif message['role'] == 'assistant' %}{{ 'Assistant: ' + bos_token + message['content'].strip() + eos_token }}{% endif %}{% endfor %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"human_line_start": [
|
||||
2
|
||||
],
|
||||
"human_line_end": [
|
||||
2
|
||||
],
|
||||
"assistant_line_start": [
|
||||
2
|
||||
],
|
||||
"assistant_line_end": [
|
||||
2
|
||||
],
|
||||
"end_of_system_line_position": 0
|
||||
}
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
# Benchmarks
|
||||
|
||||
## Benchmark OPT with LoRA on dummy prompt data
|
||||
|
||||
We provide various OPT models (string in parentheses is the corresponding model name used in this script):
|
||||
|
||||
- OPT-125M (125m)
|
||||
- OPT-350M (350m)
|
||||
- OPT-700M (700m)
|
||||
- OPT-1.3B (1.3b)
|
||||
- OPT-2.7B (2.7b)
|
||||
- OPT-3.5B (3.5b)
|
||||
- OPT-5.5B (5.5b)
|
||||
- OPT-6.7B (6.7b)
|
||||
- OPT-10B (10b)
|
||||
- OPT-13B (13b)
|
||||
|
||||
We also provide various training strategies:
|
||||
|
||||
- gemini: ColossalAI GeminiPlugin with `placement_policy="cuda"`, like zero3
|
||||
- gemini_auto: ColossalAI GeminiPlugin with `placement_policy="cpu"`, like zero3-offload
|
||||
- zero2: ColossalAI zero2
|
||||
- zero2_cpu: ColossalAI zero2-offload
|
||||
- 3d: ColossalAI HybridParallelPlugin with TP, DP support
|
||||
|
||||
## How to Run
|
||||
```bash
|
||||
cd ../tests
|
||||
# Prepare data for benchmark
|
||||
SFT_DATASET=/path/to/sft/data/ \
|
||||
PROMPT_DATASET=/path/to/prompt/data/ \
|
||||
PRETRAIN_DATASET=/path/to/ptx/data/ \
|
||||
PREFERENCE_DATASET=/path/to/preference/data \
|
||||
./test_data_preparation.sh
|
||||
# Start benchmark
|
||||
./benchmark_ppo.sh
|
||||
```
|
||||
|
|
@ -0,0 +1,51 @@
|
|||
#!/bin/bash
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
local n=${1:-"9999"}
|
||||
echo "GPU Memory Usage:"
|
||||
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||
tail -n +2 |
|
||||
nl -v 0 |
|
||||
tee /dev/tty |
|
||||
sort -g -k 2 |
|
||||
awk '{print $1}' |
|
||||
head -n $n)
|
||||
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||
}
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 4
|
||||
|
||||
PROJECT_NAME="dpo"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/dpo" # Path to benchmark data
|
||||
DATASET_SIZE=320
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type preference
|
||||
|
||||
|
||||
colossalai run --nproc_per_node 4 --master_port 31313 ../examples/training_scripts/train_dpo.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin "zero2_cpu" \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \
|
||||
--batch_size 4 \
|
||||
--lr 1e-6 \
|
||||
--beta 0.1 \
|
||||
--mixed_precision "bf16" \
|
||||
--grad_clip 1.0 \
|
||||
--max_length 2048 \
|
||||
--weight_decay 0.01 \
|
||||
--warmup_steps 60 \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
|
|
@ -0,0 +1,51 @@
|
|||
#!/bin/bash
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
local n=${1:-"9999"}
|
||||
echo "GPU Memory Usage:"
|
||||
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||
tail -n +2 |
|
||||
nl -v 0 |
|
||||
tee /dev/tty |
|
||||
sort -g -k 2 |
|
||||
awk '{print $1}' |
|
||||
head -n $n)
|
||||
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||
}
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 4
|
||||
|
||||
PROJECT_NAME="kto"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/kto" # Path to benchmark data
|
||||
DATASET_SIZE=80
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type kto
|
||||
|
||||
|
||||
colossalai run --nproc_per_node 2 --master_port 31313 ../examples/training_scripts/train_kto.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin "zero2_cpu" \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \
|
||||
--batch_size 2 \
|
||||
--lr 1e-5 \
|
||||
--beta 0.1 \
|
||||
--mixed_precision "bf16" \
|
||||
--grad_clip 1.0 \
|
||||
--max_length 2048 \
|
||||
--weight_decay 0.01 \
|
||||
--warmup_steps 60 \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
Model=Opt-125m; lora_rank=0; plugin=zero2
|
||||
Max CUDA memory usage: 26123.16 MB
|
||||
Model=Opt-125m; lora_rank=0; plugin=zero2
|
||||
Max CUDA memory usage: 26123.91 MB
|
||||
|
|
@ -0,0 +1,51 @@
|
|||
#!/bin/bash
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
local n=${1:-"9999"}
|
||||
echo "GPU Memory Usage:"
|
||||
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||
tail -n +2 |
|
||||
nl -v 0 |
|
||||
tee /dev/tty |
|
||||
sort -g -k 2 |
|
||||
awk '{print $1}' |
|
||||
head -n $n)
|
||||
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||
}
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 2
|
||||
|
||||
PROJECT_NAME="orpo"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/orpo" # Path to benchmark data
|
||||
DATASET_SIZE=160
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type preference
|
||||
|
||||
|
||||
colossalai run --nproc_per_node 2 --master_port 31313 ../examples/training_scripts/train_orpo.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin "zero2" \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \
|
||||
--batch_size 4 \
|
||||
--lr 8e-6 \
|
||||
--lam 0.5 \
|
||||
--mixed_precision "bf16" \
|
||||
--grad_clip 1.0 \
|
||||
--max_length 2048 \
|
||||
--weight_decay 0.01 \
|
||||
--warmup_steps 60 \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
facebook/opt-125m; 0; zero2
|
||||
Performance summary:
|
||||
Generate 768 samples, throughput: 188.48 samples/s, TFLOPS per GPU: 361.23
|
||||
Train 768 samples, throughput: 448.38 samples/s, TFLOPS per GPU: 82.84
|
||||
Overall throughput: 118.42 samples/s
|
||||
Overall time per sample: 0.01 s
|
||||
Make experience time per sample: 0.01 s, 62.83%
|
||||
Learn time per sample: 0.00 s, 26.41%
|
||||
facebook/opt-125m; 0; zero2
|
||||
Performance summary:
|
||||
Generate 768 samples, throughput: 26.32 samples/s, TFLOPS per GPU: 50.45
|
||||
Train 768 samples, throughput: 71.15 samples/s, TFLOPS per GPU: 13.14
|
||||
Overall throughput: 18.86 samples/s
|
||||
Overall time per sample: 0.05 s
|
||||
Make experience time per sample: 0.04 s, 71.66%
|
||||
Learn time per sample: 0.01 s, 26.51%
|
||||
|
|
@ -0,0 +1,523 @@
|
|||
"""
|
||||
For becnhmarking ppo. Mudified from examples/training_scripts/train_ppo.py
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import os
|
||||
import resource
|
||||
from contextlib import nullcontext
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from coati.dataset import (
|
||||
DataCollatorForPromptDataset,
|
||||
DataCollatorForSupervisedDataset,
|
||||
StatefulDistributedSampler,
|
||||
load_tokenized_dataset,
|
||||
setup_conversation_template,
|
||||
setup_distributed_dataloader,
|
||||
)
|
||||
from coati.models import Critic, RewardModel, convert_to_lora_module, disable_dropout
|
||||
from coati.trainer import PPOTrainer
|
||||
from coati.trainer.callbacks import PerformanceEvaluator
|
||||
from coati.trainer.utils import is_rank_0
|
||||
from coati.utils import load_checkpoint, replace_with_flash_attention
|
||||
from transformers import AutoTokenizer, OPTForCausalLM
|
||||
from transformers.models.opt.configuration_opt import OPTConfig
|
||||
|
||||
import colossalai
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, LowLevelZeroPlugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.lazy import LazyInitContext
|
||||
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
|
||||
from colossalai.nn.optimizer import HybridAdam
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
|
||||
def get_model_numel(model: torch.nn.Module, plugin: str, tp: int) -> int:
|
||||
numel = sum(p.numel() for p in model.parameters())
|
||||
if plugin == "3d" and tp > 1:
|
||||
numel *= dist.get_world_size()
|
||||
return numel
|
||||
|
||||
|
||||
def get_gpt_config(model_name: str) -> OPTConfig:
|
||||
model_map = {
|
||||
"125m": OPTConfig.from_pretrained("facebook/opt-125m"),
|
||||
"350m": OPTConfig(hidden_size=1024, ffn_dim=4096, num_hidden_layers=24, num_attention_heads=16),
|
||||
"700m": OPTConfig(hidden_size=1280, ffn_dim=5120, num_hidden_layers=36, num_attention_heads=20),
|
||||
"1.3b": OPTConfig.from_pretrained("facebook/opt-1.3b"),
|
||||
"2.7b": OPTConfig.from_pretrained("facebook/opt-2.7b"),
|
||||
"3.5b": OPTConfig(hidden_size=3072, ffn_dim=12288, num_hidden_layers=32, num_attention_heads=32),
|
||||
"5.5b": OPTConfig(hidden_size=3840, ffn_dim=15360, num_hidden_layers=32, num_attention_heads=32),
|
||||
"6.7b": OPTConfig.from_pretrained("facebook/opt-6.7b"),
|
||||
"10b": OPTConfig(hidden_size=5120, ffn_dim=20480, num_hidden_layers=32, num_attention_heads=32),
|
||||
"13b": OPTConfig.from_pretrained("facebook/opt-13b"),
|
||||
}
|
||||
try:
|
||||
return model_map[model_name]
|
||||
except KeyError:
|
||||
raise ValueError(f'Unknown model "{model_name}"')
|
||||
|
||||
|
||||
def benchmark_train(args):
|
||||
# ==============================
|
||||
# Initialize Distributed Training
|
||||
# ==============================
|
||||
colossalai.launch_from_torch()
|
||||
coordinator = DistCoordinator()
|
||||
|
||||
# ======================================================
|
||||
# Initialize Model, Objective, Optimizer and LR Scheduler
|
||||
# ======================================================
|
||||
init_ctx = LazyInitContext(default_device=get_current_device()) if "gemini" in args.plugin else nullcontext()
|
||||
|
||||
booster_policy = None
|
||||
with init_ctx:
|
||||
actor = OPTForCausalLM(config=get_gpt_config(args.pretrain))
|
||||
# Disable dropout
|
||||
disable_dropout(actor)
|
||||
ref_model = OPTForCausalLM(config=get_gpt_config(args.pretrain))
|
||||
reward_model = RewardModel(config=get_gpt_config("350m"))
|
||||
critic = Critic(config=get_gpt_config("350m"))
|
||||
disable_dropout(critic)
|
||||
|
||||
actor_numel = get_model_numel(actor, args.plugin, args.tp)
|
||||
critic_numel = get_model_numel(critic, args.plugin, args.tp)
|
||||
initial_model_numel = get_model_numel(ref_model, args.plugin, args.tp)
|
||||
reward_model_numel = get_model_numel(reward_model, args.plugin, args.tp)
|
||||
|
||||
performance_evaluator = PerformanceEvaluator(
|
||||
actor_numel,
|
||||
critic_numel,
|
||||
initial_model_numel,
|
||||
reward_model_numel,
|
||||
enable_grad_checkpoint=False,
|
||||
ignore_episodes=2,
|
||||
train_config={"model": "facebook/opt-" + args.pretrain, "lora_rank": args.lora_rank, "plugin": args.plugin},
|
||||
save_path="./benchmark_performance_summarization.txt",
|
||||
)
|
||||
|
||||
if args.tp > 1:
|
||||
if reward_model.model.config.architectures[0] != critic.model.config.architectures[0]:
|
||||
raise ValueError("Reward model and critic model must have the same architecture")
|
||||
if reward_model.model.config.architectures[0] == "BloomForCausalLM":
|
||||
from colossalai.shardformer.policies.bloom import BloomPolicy
|
||||
|
||||
booster_policy = BloomPolicy()
|
||||
elif reward_model.model.config.architectures[0] == "LlamaForCausalLM":
|
||||
from colossalai.shardformer.policies.llama import LlamaPolicy
|
||||
|
||||
booster_policy = LlamaPolicy()
|
||||
elif reward_model.model.config.architectures[0] == "GPT2LMHeadModel":
|
||||
from colossalai.shardformer.policies.gpt2 import GPT2Policy
|
||||
|
||||
booster_policy = GPT2Policy()
|
||||
elif reward_model.model.config.architectures[0] == "ChatGLMModel":
|
||||
from colossalai.shardformer.policies.chatglm2 import ChatGLMPolicy
|
||||
|
||||
booster_policy = ChatGLMPolicy()
|
||||
elif reward_model.model.config.architectures[0] == "OPTForCausalLM":
|
||||
from colossalai.shardformer.policies.opt import OPTPolicy
|
||||
|
||||
booster_policy = OPTPolicy()
|
||||
else:
|
||||
raise ValueError("Unknown model architecture for policy")
|
||||
|
||||
if args.lora_rank > 0:
|
||||
actor = convert_to_lora_module(actor, args.lora_rank, lora_train_bias=args.lora_train_bias)
|
||||
critic = convert_to_lora_module(critic, args.lora_rank, lora_train_bias=args.lora_train_bias)
|
||||
|
||||
if args.grad_checkpoint and args.lora_rank == 0:
|
||||
actor.gradient_checkpointing_enable()
|
||||
critic.model.gradient_checkpointing_enable()
|
||||
coordinator.print_on_master(msg="Gradient checkpointing enabled successfully")
|
||||
elif args.lora_rank > 0:
|
||||
coordinator.print_on_master(msg="Gradient checkpointing will be disabled when LoRA is enabled")
|
||||
|
||||
if args.use_flash_attn:
|
||||
replace_with_flash_attention(model=actor)
|
||||
replace_with_flash_attention(model=critic)
|
||||
coordinator.print_on_master(msg="Flash-attention enabled successfully")
|
||||
|
||||
# configure tokenizer
|
||||
tokenizer_dir = args.tokenizer_dir if args.tokenizer_dir is not None else args.pretrain
|
||||
tokenizer = AutoTokenizer.from_pretrained(tokenizer_dir)
|
||||
if os.path.exists(args.conversation_template_config):
|
||||
conversation_template_config = json.load(open(args.conversation_template_config, "r", encoding="utf8"))
|
||||
conversation_template = setup_conversation_template(
|
||||
tokenizer, chat_template_config=conversation_template_config, save_path=args.conversation_template_config
|
||||
)
|
||||
stop_token_ids = (
|
||||
conversation_template.assistant_line_end if len(conversation_template.assistant_line_end) > 0 else None
|
||||
)
|
||||
else:
|
||||
raise ValueError("Conversation template config is not provided or incorrect")
|
||||
if hasattr(tokenizer, "pad_token") and hasattr(tokenizer, "eos_token") and tokenizer.eos_token is not None:
|
||||
try:
|
||||
# Some tokenizers doesn't allow to set pad_token mannually e.g., Qwen
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
except AttributeError as e:
|
||||
logger.warning(f"Unable to set pad token to eos token, {str(e)}")
|
||||
if not hasattr(tokenizer, "pad_token") or tokenizer.pad_token is None:
|
||||
logger.warning(
|
||||
"The tokenizer does not have a pad token which is required. May lead to unintended behavior in training, Please consider manually set them."
|
||||
)
|
||||
tokenizer.add_bos_token = False
|
||||
tokenizer.add_eos_token = False
|
||||
tokenizer.padding_side = "left" # left padding for generation (online learning)
|
||||
|
||||
# configure generation config
|
||||
actor.generation_config.update(
|
||||
pad_token_id=tokenizer.eos_token_id, bos_token_id=tokenizer.bos_token_id, eos_token_id=tokenizer.eos_token_id
|
||||
)
|
||||
|
||||
# configure optimizer
|
||||
coordinator.print_on_master(f"setting up optimizer for actor: lr={args.lr}, weight_decay={args.weight_decay}")
|
||||
actor_optim = HybridAdam(
|
||||
model_params=actor.parameters(),
|
||||
lr=args.lr,
|
||||
betas=(0.9, 0.95),
|
||||
weight_decay=args.weight_decay,
|
||||
adamw_mode=True,
|
||||
)
|
||||
|
||||
coordinator.print_on_master(f"setting up optimizer for critic: lr={args.lr}, weight_decay={args.weight_decay}")
|
||||
critic_optim = HybridAdam(
|
||||
model_params=critic.parameters(),
|
||||
lr=args.critic_lr,
|
||||
betas=(0.9, 0.95),
|
||||
weight_decay=args.weight_decay,
|
||||
adamw_mode=True,
|
||||
)
|
||||
|
||||
# configure dataset
|
||||
coordinator.print_on_master(f"Load dataset: {args.prompt_dataset}")
|
||||
mode_map = {"train": "train", "valid": "validation", "test": "test"}
|
||||
train_prompt_dataset = load_tokenized_dataset(dataset_paths=args.prompt_dataset, mode="train", mode_map=mode_map)
|
||||
coordinator.print_on_master(f"prompt dataset size: {len(train_prompt_dataset)}")
|
||||
data_collator = DataCollatorForPromptDataset(tokenizer=tokenizer, max_length=args.max_length - args.max_seq_len)
|
||||
train_prompt_dataloader = setup_distributed_dataloader(
|
||||
dataset=train_prompt_dataset,
|
||||
batch_size=args.experience_batch_size,
|
||||
shuffle=True,
|
||||
drop_last=True,
|
||||
collate_fn=data_collator,
|
||||
use_tp=args.tp > 1,
|
||||
)
|
||||
|
||||
if len(args.pretrain_dataset) > 0:
|
||||
train_pretrain_dataset = load_tokenized_dataset(
|
||||
dataset_paths=args.pretrain_dataset, mode="train", mode_map=mode_map
|
||||
)
|
||||
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer, max_length=args.max_length)
|
||||
train_pretrain_dataloader = setup_distributed_dataloader(
|
||||
dataset=train_pretrain_dataset,
|
||||
batch_size=args.ptx_batch_size,
|
||||
shuffle=True,
|
||||
drop_last=True,
|
||||
collate_fn=data_collator,
|
||||
use_tp=args.tp > 1,
|
||||
)
|
||||
else:
|
||||
train_pretrain_dataloader = None
|
||||
|
||||
if args.warmup_steps is None:
|
||||
args.warmup_steps = int(0.025 * args.num_episodes)
|
||||
coordinator.print_on_master(f"Warmup steps is set to {args.warmup_steps}")
|
||||
|
||||
actor_lr_scheduler = CosineAnnealingWarmupLR(
|
||||
optimizer=actor_optim,
|
||||
total_steps=args.num_episodes,
|
||||
warmup_steps=args.warmup_steps,
|
||||
eta_min=0.1 * args.lr,
|
||||
)
|
||||
|
||||
critic_lr_scheduler = CosineAnnealingWarmupLR(
|
||||
optimizer=critic_optim,
|
||||
total_steps=args.num_episodes,
|
||||
warmup_steps=args.warmup_steps,
|
||||
eta_min=0.1 * args.lr,
|
||||
)
|
||||
|
||||
# ==============================
|
||||
# Initialize Booster
|
||||
# ==============================
|
||||
if args.plugin == "gemini":
|
||||
plugin = GeminiPlugin(
|
||||
precision=args.mixed_precision,
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
)
|
||||
elif args.plugin == "gemini_auto":
|
||||
plugin = GeminiPlugin(
|
||||
precision=args.mixed_precision,
|
||||
placement_policy="auto",
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
)
|
||||
elif args.plugin == "zero2":
|
||||
plugin = LowLevelZeroPlugin(
|
||||
stage=2,
|
||||
precision=args.mixed_precision,
|
||||
initial_scale=2**16,
|
||||
max_norm=args.grad_clip,
|
||||
)
|
||||
elif args.plugin == "zero2_cpu":
|
||||
plugin = LowLevelZeroPlugin(
|
||||
stage=2,
|
||||
precision=args.mixed_precision,
|
||||
initial_scale=2**16,
|
||||
cpu_offload=True,
|
||||
max_norm=args.grad_clip,
|
||||
)
|
||||
elif args.plugin == "3d":
|
||||
plugin = HybridParallelPlugin(
|
||||
tp_size=args.tp,
|
||||
pp_size=1,
|
||||
zero_stage=0,
|
||||
precision=args.mixed_precision,
|
||||
)
|
||||
custom_plugin = HybridParallelPlugin(
|
||||
tp_size=args.tp,
|
||||
pp_size=1,
|
||||
zero_stage=0,
|
||||
precision=args.mixed_precision,
|
||||
custom_policy=booster_policy,
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unknown plugin {args.plugin}")
|
||||
|
||||
if args.plugin != "3d":
|
||||
custom_plugin = plugin
|
||||
|
||||
actor_booster = Booster(plugin=plugin)
|
||||
ref_booster = Booster(plugin=plugin)
|
||||
rm_booster = Booster(plugin=custom_plugin)
|
||||
critic_booster = Booster(plugin=custom_plugin)
|
||||
|
||||
default_dtype = torch.float16 if args.mixed_precision == "fp16" else torch.bfloat16
|
||||
torch.set_default_dtype(default_dtype)
|
||||
actor, actor_optim, _, train_prompt_dataloader, actor_lr_scheduler = actor_booster.boost(
|
||||
model=actor,
|
||||
optimizer=actor_optim,
|
||||
lr_scheduler=actor_lr_scheduler,
|
||||
dataloader=train_prompt_dataloader,
|
||||
)
|
||||
|
||||
critic, critic_optim, _, _, critic_lr_scheduler = critic_booster.boost(
|
||||
model=critic,
|
||||
optimizer=critic_optim,
|
||||
lr_scheduler=critic_lr_scheduler,
|
||||
dataloader=train_prompt_dataloader,
|
||||
)
|
||||
reward_model, _, _, _, _ = rm_booster.boost(model=reward_model, dataloader=train_prompt_dataloader)
|
||||
ref_model, _, _, _, _ = ref_booster.boost(model=ref_model, dataloader=train_prompt_dataloader)
|
||||
|
||||
torch.set_default_dtype(torch.float)
|
||||
|
||||
coordinator.print_on_master(f"Booster init max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB")
|
||||
coordinator.print_on_master(
|
||||
f"Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||
)
|
||||
|
||||
sampler_start_idx = 0
|
||||
start_step = 0
|
||||
|
||||
if args.rm_checkpoint_path is not None:
|
||||
if "modeling" in args.rm_checkpoint_path:
|
||||
rm_booster.load_model(reward_model, args.rm_checkpoint_path)
|
||||
else:
|
||||
_, _, _ = load_checkpoint(
|
||||
load_dir=args.rm_checkpoint_path,
|
||||
booster=rm_booster,
|
||||
model=reward_model,
|
||||
optimizer=None,
|
||||
lr_scheduler=None,
|
||||
)
|
||||
coordinator.print_on_master(f"Loaded reward model checkpoint {args.rm_checkpoint_path}")
|
||||
|
||||
if args.checkpoint_path is not None:
|
||||
if "modeling" in args.checkpoint_path:
|
||||
actor_booster.load_model(actor, args.checkpoint_path)
|
||||
ref_booster.load_model(ref_model, args.checkpoint_path)
|
||||
coordinator.print_on_master(f"Loaded actor and reference model {args.checkpoint_path}")
|
||||
else:
|
||||
_, start_step, sampler_start_idx = load_checkpoint(
|
||||
load_dir=args.checkpoint_path,
|
||||
booster=actor_booster,
|
||||
model=actor,
|
||||
optimizer=actor_optim,
|
||||
lr_scheduler=actor_lr_scheduler,
|
||||
)
|
||||
_, _, _ = load_checkpoint(
|
||||
load_dir=args.checkpoint_path,
|
||||
booster=ref_booster,
|
||||
model=ref_model,
|
||||
optimizer=critic_optim,
|
||||
lr_scheduler=critic_lr_scheduler,
|
||||
)
|
||||
assert isinstance(train_prompt_dataloader.sampler, StatefulDistributedSampler)
|
||||
train_prompt_dataloader.sampler.set_start_index(start_index=sampler_start_idx)
|
||||
|
||||
coordinator.print_on_master(
|
||||
f"Loaded actor and reference model checkpoint {args.checkpoint_path} at spisode {start_step}"
|
||||
)
|
||||
coordinator.print_on_master(f"Loaded sample at index {sampler_start_idx}")
|
||||
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded CUDA memory: {torch.cuda.memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||
)
|
||||
|
||||
if args.critic_checkpoint_path is not None:
|
||||
if "modeling" in args.critic_checkpoint_path:
|
||||
critic_booster.load_model(critic, args.critic_checkpoint_path)
|
||||
else:
|
||||
_, _, _ = load_checkpoint(
|
||||
load_dir=args.critic_checkpoint_path,
|
||||
booster=critic_booster,
|
||||
model=critic,
|
||||
optimizer=critic_optim,
|
||||
lr_scheduler=critic_lr_scheduler,
|
||||
)
|
||||
coordinator.print_on_master(f"Loaded critic checkpoint {args.critic_checkpoint_path}")
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded max CUDA memory: {torch.cuda.max_memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded CUDA memory: {torch.cuda.memory_allocated() / 1024 ** 2:.2f} MB"
|
||||
)
|
||||
coordinator.print_on_master(
|
||||
f"Checkpoint loaded max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss / 1024:.2f} MB"
|
||||
)
|
||||
|
||||
# configure trainer
|
||||
trainer = PPOTrainer(
|
||||
actor_booster,
|
||||
critic_booster,
|
||||
actor,
|
||||
critic,
|
||||
reward_model,
|
||||
ref_model,
|
||||
actor_optim,
|
||||
critic_optim,
|
||||
actor_lr_scheduler,
|
||||
critic_lr_scheduler,
|
||||
tokenizer=tokenizer,
|
||||
stop_token_ids=stop_token_ids,
|
||||
kl_coef=args.kl_coef,
|
||||
ptx_coef=args.ptx_coef,
|
||||
train_batch_size=args.train_batch_size,
|
||||
buffer_limit=args.num_collect_steps * args.experience_batch_size,
|
||||
max_length=args.max_length,
|
||||
max_new_tokens=args.max_seq_len,
|
||||
use_cache=True,
|
||||
do_sample=True,
|
||||
temperature=0.7,
|
||||
accumulation_steps=args.accumulation_steps,
|
||||
save_dir=args.save_path,
|
||||
save_interval=args.save_interval,
|
||||
top_k=50,
|
||||
use_tp=args.tp > 1,
|
||||
offload_inference_models="gemini" not in args.plugin,
|
||||
callbacks=[performance_evaluator],
|
||||
coordinator=coordinator,
|
||||
)
|
||||
|
||||
trainer.fit(
|
||||
num_episodes=args.num_episodes,
|
||||
num_collect_steps=args.num_collect_steps,
|
||||
num_update_steps=args.num_update_steps,
|
||||
prompt_dataloader=train_prompt_dataloader,
|
||||
pretrain_dataloader=train_pretrain_dataloader,
|
||||
log_dir=args.log_dir,
|
||||
use_wandb=args.use_wandb,
|
||||
)
|
||||
|
||||
if args.lora_rank > 0 and args.merge_lora_weights:
|
||||
from coati.models.lora import LORA_MANAGER
|
||||
|
||||
# NOTE: set model to eval to merge LoRA weights
|
||||
LORA_MANAGER.merge_weights = True
|
||||
actor.eval()
|
||||
critic.eval()
|
||||
# save model checkpoint after fitting on only rank0
|
||||
coordinator.print_on_master("Start saving final actor model checkpoint")
|
||||
actor_booster.save_model(actor, os.path.join(trainer.actor_save_dir, "modeling"), shard=True)
|
||||
coordinator.print_on_master(
|
||||
f"Saved final actor model checkpoint at episodes {args.num_episodes} at folder {args.save_path}"
|
||||
)
|
||||
coordinator.print_on_master("Start saving final critic model checkpoint")
|
||||
critic_booster.save_model(critic, os.path.join(trainer.critic_save_dir, "modeling"), shard=True)
|
||||
coordinator.print_on_master(
|
||||
f"Saved final critic model checkpoint at episodes {args.num_episodes} at folder {args.save_path}"
|
||||
)
|
||||
memory_consumption = torch.cuda.max_memory_allocated() / 1024**2
|
||||
if is_rank_0():
|
||||
with open("./benchmark_memory_consumption.txt", "a+") as f:
|
||||
f.write(
|
||||
f"Model=Opt-{args.pretrain}; lora_rank={args.lora_rank}; plugin={args.plugin}\nMax CUDA memory usage: {memory_consumption:.2f} MB\n"
|
||||
)
|
||||
coordinator.print_on_master(f"Max CUDA memory usage: {memory_consumption:.2f} MB")
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--prompt_dataset", nargs="+", default=[])
|
||||
parser.add_argument("--pretrain_dataset", nargs="+", default=[])
|
||||
parser.add_argument(
|
||||
"--plugin",
|
||||
type=str,
|
||||
default="gemini",
|
||||
choices=["gemini", "gemini_auto", "zero2", "zero2_cpu", "3d"],
|
||||
help="Choose which plugin to use",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--conversation_template_config",
|
||||
type=str,
|
||||
default=None,
|
||||
help="Path \
|
||||
to save conversation template config files.",
|
||||
)
|
||||
parser.add_argument("--grad_clip", type=float, default=1.0, help="Gradient clipping value")
|
||||
parser.add_argument("--weight_decay", type=float, default=0.1, help="Weight decay")
|
||||
parser.add_argument("--warmup_steps", type=int, default=None, help="Warmup steps")
|
||||
parser.add_argument("--tokenizer_dir", type=str, default=None)
|
||||
parser.add_argument("--tp", type=int, default=1)
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--checkpoint_path", type=str, default=None)
|
||||
parser.add_argument("--critic_checkpoint_path", type=str, default=None)
|
||||
parser.add_argument("--rm_checkpoint_path", type=str, help="Reward model checkpoint path")
|
||||
parser.add_argument("--save_path", type=str, default="actor_checkpoint_prompts")
|
||||
parser.add_argument("--num_episodes", type=int, default=1)
|
||||
parser.add_argument("--num_collect_steps", type=int, default=2)
|
||||
parser.add_argument("--num_update_steps", type=int, default=5)
|
||||
parser.add_argument("--save_interval", type=int, default=1000)
|
||||
parser.add_argument("--train_batch_size", type=int, default=16)
|
||||
parser.add_argument("--experience_batch_size", type=int, default=16)
|
||||
parser.add_argument("--ptx_batch_size", type=int, default=1)
|
||||
parser.add_argument("--lora_train_bias", type=str, default="none")
|
||||
parser.add_argument("--mixed_precision", type=str, default="fp16", choices=["fp16", "bf16"], help="Mixed precision")
|
||||
parser.add_argument("--accumulation_steps", type=int, default=8)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
parser.add_argument("--merge_lora_weights", type=bool, default=True)
|
||||
parser.add_argument("--lr", type=float, default=9e-6)
|
||||
parser.add_argument("--critic_lr", type=float, default=9e-6)
|
||||
parser.add_argument("--kl_coef", type=float, default=0.1)
|
||||
parser.add_argument("--ptx_coef", type=float, default=0.0)
|
||||
parser.add_argument("--max_length", type=int, default=512)
|
||||
parser.add_argument("--max_seq_len", type=int, default=256)
|
||||
parser.add_argument("--log_dir", default="logs", type=str)
|
||||
parser.add_argument("--use_wandb", default=False, action="store_true")
|
||||
parser.add_argument("--grad_checkpoint", default=False, action="store_true")
|
||||
parser.add_argument("--use_flash_attn", default=False, action="store_true")
|
||||
args = parser.parse_args()
|
||||
benchmark_train(args)
|
||||
|
|
@ -0,0 +1,119 @@
|
|||
#!/usr/bin/env bash
|
||||
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
local n=${1:-"9999"}
|
||||
echo "GPU Memory Usage:"
|
||||
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||
tail -n +2 |
|
||||
nl -v 0 |
|
||||
tee /dev/tty |
|
||||
sort -g -k 2 |
|
||||
awk '{print $1}' |
|
||||
head -n $n)
|
||||
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||
}
|
||||
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 8
|
||||
|
||||
set -xu
|
||||
|
||||
NUM_RETRY=3
|
||||
BASE_DIR=$(dirname $(dirname $(realpath $BASH_SOURCE)))
|
||||
EXAMPLES_DIR=$BASE_DIR/examples
|
||||
TEMP_DIR=$BASE_DIR/temp
|
||||
MODEL_SAVE_PATH=$TEMP_DIR/rlhf_models
|
||||
MODELS_DIR=$TEMP_DIR/models_config
|
||||
# To benchmark different models, change the following line
|
||||
# MODELS=('125m' '350m' '700m' '1.3b' '2.7b' '3.5b' '5.5b' '6.7b' '10b' '13b')
|
||||
MODELS=('125m')
|
||||
# To benchmark different strategies, change the following line
|
||||
# PLUGINS=('zero2', 'zero2_cpu', '3d')
|
||||
PLUGINS=('zero2')
|
||||
LORA_RANK=('0')
|
||||
|
||||
export OMP_NUM_THREADS=8
|
||||
|
||||
rm ./benchmark_memory_consumption.txt
|
||||
rm ./benchmark_performance_summarization.txt
|
||||
|
||||
# install requirements
|
||||
pip install -r $EXAMPLES_DIR/requirements.txt
|
||||
|
||||
random_choice() {
|
||||
local arr=("$@")
|
||||
local len=${#arr[@]}
|
||||
local idx=$((RANDOM % len))
|
||||
echo ${arr[$idx]}
|
||||
}
|
||||
|
||||
echo "[Test]: testing ppo ..."
|
||||
|
||||
SKIPPED_TESTS=(
|
||||
)
|
||||
|
||||
GRAD_CKPTS=('' '--grad_checkpoint')
|
||||
GRAD_CKPTS=('')
|
||||
for lora_rank in ${LORA_RANK[@]}; do
|
||||
for model in ${MODELS[@]}; do
|
||||
plugins=($(shuf -e "${PLUGINS[@]}"))
|
||||
for plugin in ${plugins[@]}; do
|
||||
if [[ " ${SKIPPED_TESTS[*]} " =~ " $model-$plugin-$lora_rank " ]]; then
|
||||
echo "[Test]: Skipped $model-$plugin-$lora_rank"
|
||||
continue
|
||||
elif [[ " ${SKIPPED_TESTS[*]} " =~ " $model-$plugin " ]]; then
|
||||
echo "[Test]: Skipped $model-$plugin"
|
||||
continue
|
||||
fi
|
||||
pretrain=$model
|
||||
tokenizer_dir="facebook/opt-125m"
|
||||
grad_ckpt=$(random_choice "${GRAD_CKPTS[@]}")
|
||||
tp='1'
|
||||
if [[ $plugin == "3d" ]]; then
|
||||
tp='4'
|
||||
fi
|
||||
for i in $(seq $NUM_RETRY); do
|
||||
echo "[Test]: $model-$plugin-$lora_rank, attempt $i"
|
||||
declare -a prompt_dataset=()
|
||||
for split in $(seq -f "%05g" 0 9); do
|
||||
prompt_dataset+=("$TEMP_DIR/benchmark/arrow/part-$split")
|
||||
done
|
||||
colossalai run --nproc_per_node 8 --master_port 28547 $BASE_DIR/benchmarks/benchmark_ppo.py \
|
||||
--pretrain $pretrain \
|
||||
--tokenizer_dir $tokenizer_dir \
|
||||
--prompt_dataset ${prompt_dataset[@]} \
|
||||
--ptx_coef 0 \
|
||||
--save_path $MODEL_SAVE_PATH \
|
||||
--conversation_template_config ./Opt.json \
|
||||
--lora_rank $lora_rank \
|
||||
--plugin $plugin \
|
||||
--num_episodes 5 \
|
||||
--num_collect_steps 1 \
|
||||
--num_update_steps 1 \
|
||||
--max_seq_len 128 \
|
||||
--max_length 512 \
|
||||
--experience_batch_size 32 \
|
||||
--train_batch_size 32 \
|
||||
--accumulation_steps 1 \
|
||||
--lr 9e-6 \
|
||||
--mixed_precision "bf16" \
|
||||
--grad_clip 1.0 \
|
||||
--use_flash_attn \
|
||||
--tp $tp \
|
||||
--lr 2e-5 \
|
||||
$grad_ckpt
|
||||
passed=$?
|
||||
if [ $passed -eq 0 ]; then
|
||||
rm -rf $MODEL_SAVE_PATH/*
|
||||
rm -rf $MODELS_DIR/*
|
||||
break
|
||||
fi
|
||||
done
|
||||
if [ $passed -ne 0 ]; then
|
||||
echo "[Test]: Failed $model-$plugin-$lora_rank"
|
||||
exit 1
|
||||
fi
|
||||
done
|
||||
done
|
||||
done
|
||||
|
|
@ -0,0 +1,50 @@
|
|||
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
local n=${1:-"9999"}
|
||||
echo "GPU Memory Usage:"
|
||||
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||
tail -n +2 |
|
||||
nl -v 0 |
|
||||
tee /dev/tty |
|
||||
sort -g -k 2 |
|
||||
awk '{print $1}' |
|
||||
head -n $n)
|
||||
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||
}
|
||||
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 4
|
||||
|
||||
PROJECT_NAME="sft"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/sft" # Path to benchmark data
|
||||
DATASET_SIZE=640
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
CONFIG_FILE="${PARENT_CONFIG_FILE}-${FULL_PROJECT_NAME}.json"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type sft
|
||||
|
||||
|
||||
# the real batch size for gradient descent is number_of_node_in_hostfile * nproc_per_node * train_batch_size
|
||||
colossalai run --nproc_per_node 1 --master_port 31312 ../examples/training_scripts/train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin zero2 \
|
||||
--batch_size 8 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \
|
||||
--lr 5e-5 \
|
||||
--lora_rank 32 \
|
||||
--max_len 2048 \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
|
|
@ -0,0 +1,55 @@
|
|||
#!/bin/bash
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES() {
|
||||
local n=${1:-"9999"}
|
||||
echo "GPU Memory Usage:"
|
||||
local FIRST_N_GPU_IDS=$(nvidia-smi --query-gpu=memory.used --format=csv |
|
||||
tail -n +2 |
|
||||
nl -v 0 |
|
||||
tee /dev/tty |
|
||||
sort -g -k 2 |
|
||||
awk '{print $1}' |
|
||||
head -n $n)
|
||||
export CUDA_VISIBLE_DEVICES=$(echo $FIRST_N_GPU_IDS | sed 's/ /,/g')
|
||||
echo "Now CUDA_VISIBLE_DEVICES is set to:"
|
||||
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
|
||||
}
|
||||
set_n_least_used_CUDA_VISIBLE_DEVICES 4
|
||||
|
||||
PROJECT_NAME="simpo"
|
||||
PARENT_CONFIG_FILE="./benchmark_config" # Path to a folder to save training config logs
|
||||
PRETRAINED_MODEL_PATH="" # huggingface or local model path
|
||||
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
|
||||
BENCHMARK_DATA_DIR="./temp/simpo" # Path to benchmark data
|
||||
DATASET_SIZE=640
|
||||
|
||||
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
|
||||
FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
|
||||
declare -a dataset=(
|
||||
$BENCHMARK_DATA_DIR/arrow/part-0
|
||||
)
|
||||
|
||||
# Generate dummy test data
|
||||
python prepare_dummy_test_dataset.py --data_dir $BENCHMARK_DATA_DIR --dataset_size $DATASET_SIZE --max_length 2048 --data_type preference
|
||||
|
||||
|
||||
colossalai run --nproc_per_node 4 --master_port 31313 ../examples/training_scripts/train_dpo.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--plugin "zero2_cpu" \
|
||||
--loss_type "simpo_loss" \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \
|
||||
--batch_size 8 \
|
||||
--lr 1e-6 \
|
||||
--beta 0.1 \
|
||||
--gamma 0.6 \
|
||||
--mixed_precision "bf16" \
|
||||
--grad_clip 1.0 \
|
||||
--max_length 2048 \
|
||||
--weight_decay 0.01 \
|
||||
--warmup_steps 60 \
|
||||
--disable_reference_model \
|
||||
--length_normalization \
|
||||
--grad_checkpoint \
|
||||
--use_flash_attn
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
SAVE_DIR=""
|
||||
|
||||
|
||||
BASE_DIR=$(dirname $(dirname $(realpath $BASH_SOURCE)))
|
||||
EXAMPLES_DIR=$BASE_DIR/examples
|
||||
SAVE_DIR=$BASE_DIR/temp/benchmark
|
||||
|
||||
rm -rf $SAVE_DIR
|
||||
|
||||
python $EXAMPLES_DIR/data_preparation_scripts/prepare_prompt_dataset.py --data_input_dirs "/home/yeanbang/data/dataset/sft_data/alpaca/data_preprocessed/train" \
|
||||
--conversation_template_config ./Opt.json \
|
||||
--tokenizer_dir "facebook/opt-125m" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
--num_samples_per_datafile 30
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
from typing import Callable
|
||||
|
||||
from torch.utils.data import Dataset
|
||||
|
||||
|
||||
class DummyLLMDataset(Dataset):
|
||||
def __init__(self, keys, seq_len, size=500, gen_fn={}):
|
||||
self.keys = keys
|
||||
self.gen_fn = gen_fn
|
||||
self.seq_len = seq_len
|
||||
self.data = self._generate_data()
|
||||
self.size = size
|
||||
|
||||
def _generate_data(self):
|
||||
data = {}
|
||||
for key in self.keys:
|
||||
if key in self.gen_fn:
|
||||
data[key] = self.gen_fn[key]
|
||||
else:
|
||||
data[key] = [1] * self.seq_len
|
||||
return data
|
||||
|
||||
def __len__(self):
|
||||
return self.size
|
||||
|
||||
def __getitem__(self, idx):
|
||||
return {
|
||||
key: self.data[key] if not isinstance(self.data[key], Callable) else self.data[key](idx)
|
||||
for key in self.keys
|
||||
}
|
||||
|
|
@ -0,0 +1,105 @@
|
|||
import argparse
|
||||
import json
|
||||
import os
|
||||
import time
|
||||
from multiprocessing import cpu_count
|
||||
|
||||
from datasets import load_dataset
|
||||
from dummy_dataset import DummyLLMDataset
|
||||
|
||||
from colossalai.logging import get_dist_logger
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--data_dir",
|
||||
type=str,
|
||||
required=True,
|
||||
default=None,
|
||||
help="The output dir",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--dataset_size",
|
||||
type=int,
|
||||
required=True,
|
||||
default=None,
|
||||
help="The size of data",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--max_length",
|
||||
type=int,
|
||||
required=True,
|
||||
default=None,
|
||||
help="The max length of data",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--data_type",
|
||||
type=str,
|
||||
required=True,
|
||||
default=None,
|
||||
help="The type of data, choose one from ['sft', 'prompt', 'preference', 'kto']",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
if args.data_type == "sft":
|
||||
dataset = DummyLLMDataset(["input_ids", "attention_mask", "labels"], args.max_length, args.dataset_size)
|
||||
elif args.data_type == "prompt":
|
||||
# pass PPO dataset is prepared separately
|
||||
pass
|
||||
elif args.data_type == "preference":
|
||||
dataset = DummyLLMDataset(
|
||||
["chosen_input_ids", "chosen_loss_mask", "rejected_input_ids", "rejected_loss_mask"],
|
||||
args.max_length,
|
||||
args.dataset_size,
|
||||
)
|
||||
elif args.data_type == "kto":
|
||||
dataset = DummyLLMDataset(
|
||||
["prompt", "completion", "label"],
|
||||
args.max_length - 512,
|
||||
args.dataset_size,
|
||||
gen_fn={
|
||||
"completion": lambda x: [1] * 512,
|
||||
"label": lambda x: x % 2,
|
||||
},
|
||||
)
|
||||
else:
|
||||
raise ValueError(f"Unknown data type {args.data_type}")
|
||||
|
||||
# Save each jsonl spliced dataset.
|
||||
output_index = "0"
|
||||
output_name = f"part-{output_index}"
|
||||
os.makedirs(args.data_dir, exist_ok=True)
|
||||
output_jsonl_path = os.path.join(args.data_dir, "json")
|
||||
output_arrow_path = os.path.join(args.data_dir, "arrow")
|
||||
output_cache_path = os.path.join(args.data_dir, "cache")
|
||||
os.makedirs(output_jsonl_path, exist_ok=True)
|
||||
os.makedirs(output_arrow_path, exist_ok=True)
|
||||
output_jsonl_file_path = os.path.join(output_jsonl_path, output_name + ".jsonl")
|
||||
st = time.time()
|
||||
with open(file=output_jsonl_file_path, mode="w", encoding="utf-8") as fp_writer:
|
||||
count = 0
|
||||
for i in range(len(dataset)):
|
||||
data_point = dataset[i]
|
||||
if count % 500 == 0:
|
||||
logger.info(f"processing {count} spliced data points for {fp_writer.name}")
|
||||
count += 1
|
||||
fp_writer.write(json.dumps(data_point, ensure_ascii=False) + "\n")
|
||||
logger.info(
|
||||
f"Current file {fp_writer.name}; "
|
||||
f"Data size: {len(dataset)}; "
|
||||
f"Time cost: {round((time.time() - st) / 60, 6)} minutes."
|
||||
)
|
||||
# Save each arrow spliced dataset
|
||||
output_arrow_file_path = os.path.join(output_arrow_path, output_name)
|
||||
logger.info(f"Start to save {output_arrow_file_path}")
|
||||
dataset = load_dataset(
|
||||
path="json",
|
||||
data_files=[output_jsonl_file_path],
|
||||
cache_dir=os.path.join(output_cache_path, "tokenized"),
|
||||
keep_in_memory=False,
|
||||
num_proc=cpu_count(),
|
||||
split="train",
|
||||
)
|
||||
dataset.save_to_disk(dataset_path=output_arrow_file_path, num_proc=min(len(dataset), cpu_count()))
|
||||
|
|
@ -0,0 +1,192 @@
|
|||
import argparse
|
||||
import os
|
||||
import socket
|
||||
from functools import partial
|
||||
|
||||
import ray
|
||||
import torch
|
||||
from coati.quant import llama_load_quant, low_resource_init
|
||||
from coati.ray.detached_trainer_ppo import DetachedPPOTrainer
|
||||
from coati.ray.experience_maker_holder import ExperienceMakerHolder
|
||||
from coati.ray.utils import (
|
||||
get_actor_from_args,
|
||||
get_critic_from_args,
|
||||
get_receivers_per_sender,
|
||||
get_reward_model_from_args,
|
||||
get_strategy_from_args,
|
||||
)
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import AutoConfig, AutoTokenizer
|
||||
from transformers.modeling_utils import no_init_weights
|
||||
|
||||
|
||||
def get_free_port():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
|
||||
s.bind(("", 0))
|
||||
return s.getsockname()[1]
|
||||
|
||||
|
||||
def get_local_ip():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
|
||||
s.connect(("8.8.8.8", 80))
|
||||
return s.getsockname()[0]
|
||||
|
||||
|
||||
def main(args):
|
||||
master_addr = str(get_local_ip())
|
||||
# trainer_env_info
|
||||
trainer_port = str(get_free_port())
|
||||
env_info_trainers = [
|
||||
{
|
||||
"local_rank": "0",
|
||||
"rank": str(rank),
|
||||
"world_size": str(args.num_trainers),
|
||||
"master_port": trainer_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
for rank in range(args.num_trainers)
|
||||
]
|
||||
|
||||
# maker_env_info
|
||||
maker_port = str(get_free_port())
|
||||
env_info_maker = {
|
||||
"local_rank": "0",
|
||||
"rank": "0",
|
||||
"world_size": "1",
|
||||
"master_port": maker_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
|
||||
# configure tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.pretrain)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
def model_fn():
|
||||
actor_cfg = AutoConfig.from_pretrained(args.pretrain)
|
||||
critic_cfg = AutoConfig.from_pretrained(args.critic_pretrain)
|
||||
actor = get_actor_from_args(args.model, config=actor_cfg).requires_grad_(False).half().cuda()
|
||||
critic = get_critic_from_args(args.critic_model, config=critic_cfg).requires_grad_(False).half().cuda()
|
||||
reward_model = (
|
||||
get_reward_model_from_args(args.critic_model, config=critic_cfg).requires_grad_(False).half().cuda()
|
||||
)
|
||||
if args.initial_model_quant_ckpt is not None and args.model == "llama":
|
||||
# quantize initial model
|
||||
with low_resource_init(), no_init_weights():
|
||||
initial_model = get_actor_from_args(args.model, config=actor_cfg)
|
||||
initial_model.model = (
|
||||
llama_load_quant(
|
||||
initial_model.model, args.initial_model_quant_ckpt, args.quant_bits, args.quant_group_size
|
||||
)
|
||||
.cuda()
|
||||
.requires_grad_(False)
|
||||
)
|
||||
else:
|
||||
initial_model = get_actor_from_args(args.model, config=actor_cfg).requires_grad_(False).half().cuda()
|
||||
return actor, critic, reward_model, initial_model
|
||||
|
||||
# configure Experience Maker
|
||||
experience_holder_ref = ExperienceMakerHolder.options(name="maker0", num_gpus=1, max_concurrency=2).remote(
|
||||
detached_trainer_name_list=[f"trainer{i}" for i in range(args.num_trainers)],
|
||||
strategy_fn=partial(get_strategy_from_args, args.maker_strategy),
|
||||
model_fn=model_fn,
|
||||
env_info=env_info_maker,
|
||||
kl_coef=0.1,
|
||||
debug=args.debug,
|
||||
# sync_models_from_trainers=True,
|
||||
# generation kwargs:
|
||||
max_length=512,
|
||||
do_sample=True,
|
||||
temperature=1.0,
|
||||
top_k=50,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
eval_performance=True,
|
||||
use_cache=True,
|
||||
)
|
||||
|
||||
def trainer_model_fn():
|
||||
actor = get_actor_from_args(args.model, config=AutoConfig.from_pretrained(args.pretrain)).half().cuda()
|
||||
critic = (
|
||||
get_critic_from_args(args.critic_model, config=AutoConfig.from_pretrained(args.critic_pretrain))
|
||||
.half()
|
||||
.cuda()
|
||||
)
|
||||
return actor, critic
|
||||
|
||||
# configure Trainer
|
||||
trainer_refs = [
|
||||
DetachedPPOTrainer.options(name=f"trainer{i}", num_gpus=1, max_concurrency=2).remote(
|
||||
experience_maker_holder_name_list=[
|
||||
f"maker{x}" for x in get_receivers_per_sender(i, args.num_trainers, 1, allow_idle_sender=True)
|
||||
],
|
||||
strategy_fn=partial(get_strategy_from_args, args.trainer_strategy),
|
||||
model_fn=trainer_model_fn,
|
||||
env_info=env_info_trainer,
|
||||
train_batch_size=args.train_batch_size,
|
||||
buffer_limit=16,
|
||||
eval_performance=True,
|
||||
debug=args.debug,
|
||||
)
|
||||
for i, env_info_trainer in enumerate(env_info_trainers)
|
||||
]
|
||||
|
||||
dataset_size = args.experience_batch_size * 4
|
||||
|
||||
def data_gen_fn():
|
||||
input_ids = torch.randint(tokenizer.vocab_size, (256,), device=torch.cuda.current_device())
|
||||
attn_mask = torch.ones_like(input_ids)
|
||||
return {"input_ids": input_ids, "attention_mask": attn_mask}
|
||||
|
||||
def build_dataloader(size):
|
||||
dataset = [data_gen_fn() for _ in range(size)]
|
||||
dataloader = DataLoader(dataset, batch_size=args.experience_batch_size)
|
||||
return dataloader
|
||||
|
||||
# uncomment this function if sync_models_from_trainers is True
|
||||
# ray.get([
|
||||
# trainer_ref.sync_models_to_remote_makers.remote()
|
||||
# for trainer_ref in trainer_refs
|
||||
# ])
|
||||
|
||||
wait_tasks = []
|
||||
|
||||
wait_tasks.append(
|
||||
experience_holder_ref.workingloop.remote(
|
||||
partial(build_dataloader, dataset_size), num_steps=args.experience_steps
|
||||
)
|
||||
)
|
||||
|
||||
total_steps = args.experience_batch_size * args.experience_steps // (args.num_trainers * args.train_batch_size)
|
||||
for trainer_ref in trainer_refs:
|
||||
wait_tasks.append(trainer_ref.fit.remote(total_steps, args.update_steps, args.train_epochs))
|
||||
|
||||
ray.get(wait_tasks)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--num_trainers", type=int, default=1)
|
||||
parser.add_argument(
|
||||
"--trainer_strategy",
|
||||
choices=["ddp", "colossalai_gemini", "colossalai_zero2", "colossalai_gemini_cpu", "colossalai_zero2_cpu"],
|
||||
default="ddp",
|
||||
)
|
||||
parser.add_argument("--maker_strategy", choices=["naive"], default="naive")
|
||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--critic_model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--critic_pretrain", type=str, default=None)
|
||||
parser.add_argument("--experience_steps", type=int, default=4)
|
||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
||||
parser.add_argument("--train_epochs", type=int, default=1)
|
||||
parser.add_argument("--update_steps", type=int, default=2)
|
||||
parser.add_argument("--train_batch_size", type=int, default=8)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
|
||||
parser.add_argument("--initial_model_quant_ckpt", type=str, default=None)
|
||||
parser.add_argument("--quant_bits", type=int, default=4)
|
||||
parser.add_argument("--quant_group_size", type=int, default=128)
|
||||
parser.add_argument("--debug", action="store_true")
|
||||
args = parser.parse_args()
|
||||
ray.init(namespace=os.environ["RAY_NAMESPACE"], runtime_env={"env_vars": dict(os.environ)})
|
||||
main(args)
|
||||
|
|
@ -0,0 +1,209 @@
|
|||
import argparse
|
||||
import os
|
||||
import socket
|
||||
from functools import partial
|
||||
|
||||
import ray
|
||||
import torch
|
||||
from coati.quant import llama_load_quant, low_resource_init
|
||||
from coati.ray.detached_trainer_ppo import DetachedPPOTrainer
|
||||
from coati.ray.experience_maker_holder import ExperienceMakerHolder
|
||||
from coati.ray.utils import (
|
||||
get_actor_from_args,
|
||||
get_critic_from_args,
|
||||
get_receivers_per_sender,
|
||||
get_reward_model_from_args,
|
||||
get_strategy_from_args,
|
||||
)
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import AutoConfig, AutoTokenizer
|
||||
from transformers.modeling_utils import no_init_weights
|
||||
|
||||
|
||||
def get_free_port():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
|
||||
s.bind(("", 0))
|
||||
return s.getsockname()[1]
|
||||
|
||||
|
||||
def get_local_ip():
|
||||
with socket.socket(socket.AF_INET, socket.SOCK_DGRAM) as s:
|
||||
s.connect(("8.8.8.8", 80))
|
||||
return s.getsockname()[0]
|
||||
|
||||
|
||||
def main(args):
|
||||
master_addr = str(get_local_ip())
|
||||
# trainer_env_info
|
||||
trainer_port = str(get_free_port())
|
||||
env_info_trainers = [
|
||||
{
|
||||
"local_rank": "0",
|
||||
"rank": str(rank),
|
||||
"world_size": str(args.num_trainers),
|
||||
"master_port": trainer_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
for rank in range(args.num_trainers)
|
||||
]
|
||||
|
||||
# maker_env_info
|
||||
maker_port = str(get_free_port())
|
||||
env_info_makers = [
|
||||
{
|
||||
"local_rank": "0",
|
||||
"rank": str(rank),
|
||||
"world_size": str(args.num_makers),
|
||||
"master_port": maker_port,
|
||||
"master_addr": master_addr,
|
||||
}
|
||||
for rank in range(args.num_makers)
|
||||
]
|
||||
|
||||
# configure tokenizer
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.pretrain)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
|
||||
def model_fn():
|
||||
actor_cfg = AutoConfig.from_pretrained(args.pretrain)
|
||||
critic_cfg = AutoConfig.from_pretrained(args.critic_pretrain)
|
||||
actor = get_actor_from_args(args.model, config=actor_cfg).requires_grad_(False).half().cuda()
|
||||
critic = get_critic_from_args(args.critic_model, config=critic_cfg).requires_grad_(False).half().cuda()
|
||||
reward_model = (
|
||||
get_reward_model_from_args(args.critic_model, config=critic_cfg).requires_grad_(False).half().cuda()
|
||||
)
|
||||
if args.initial_model_quant_ckpt is not None and args.model == "llama":
|
||||
# quantize initial model
|
||||
with low_resource_init(), no_init_weights():
|
||||
initial_model = get_actor_from_args(args.model, config=actor_cfg)
|
||||
initial_model.model = (
|
||||
llama_load_quant(
|
||||
initial_model.model, args.initial_model_quant_ckpt, args.quant_bits, args.quant_group_size
|
||||
)
|
||||
.cuda()
|
||||
.requires_grad_(False)
|
||||
)
|
||||
else:
|
||||
initial_model = get_actor_from_args(args.model, config=actor_cfg).requires_grad_(False).half().cuda()
|
||||
return actor, critic, reward_model, initial_model
|
||||
|
||||
# configure Experience Maker
|
||||
experience_holder_refs = [
|
||||
ExperienceMakerHolder.options(name=f"maker{i}", num_gpus=1, max_concurrency=2).remote(
|
||||
detached_trainer_name_list=[
|
||||
f"trainer{x}"
|
||||
for x in get_receivers_per_sender(i, args.num_makers, args.num_trainers, allow_idle_sender=False)
|
||||
],
|
||||
strategy_fn=partial(get_strategy_from_args, args.maker_strategy),
|
||||
model_fn=model_fn,
|
||||
env_info=env_info_maker,
|
||||
kl_coef=0.1,
|
||||
debug=args.debug,
|
||||
# sync_models_from_trainers=True,
|
||||
# generation kwargs:
|
||||
max_length=512,
|
||||
do_sample=True,
|
||||
temperature=1.0,
|
||||
top_k=50,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
eval_performance=True,
|
||||
use_cache=True,
|
||||
)
|
||||
for i, env_info_maker in enumerate(env_info_makers)
|
||||
]
|
||||
|
||||
def trainer_model_fn():
|
||||
actor = get_actor_from_args(args.model, config=AutoConfig.from_pretrained(args.pretrain)).half().cuda()
|
||||
critic = (
|
||||
get_critic_from_args(args.critic_model, config=AutoConfig.from_pretrained(args.critic_pretrain))
|
||||
.half()
|
||||
.cuda()
|
||||
)
|
||||
return actor, critic
|
||||
|
||||
# configure Trainer
|
||||
trainer_refs = [
|
||||
DetachedPPOTrainer.options(name=f"trainer{i}", num_gpus=1, max_concurrency=2).remote(
|
||||
experience_maker_holder_name_list=[
|
||||
f"maker{x}"
|
||||
for x in get_receivers_per_sender(i, args.num_trainers, args.num_makers, allow_idle_sender=True)
|
||||
],
|
||||
strategy_fn=partial(get_strategy_from_args, args.trainer_strategy),
|
||||
model_fn=trainer_model_fn,
|
||||
env_info=env_info_trainer,
|
||||
train_batch_size=args.train_batch_size,
|
||||
buffer_limit=16,
|
||||
eval_performance=True,
|
||||
debug=args.debug,
|
||||
)
|
||||
for i, env_info_trainer in enumerate(env_info_trainers)
|
||||
]
|
||||
|
||||
dataset_size = args.experience_batch_size * 4
|
||||
|
||||
def data_gen_fn():
|
||||
input_ids = torch.randint(tokenizer.vocab_size, (256,), device=torch.cuda.current_device())
|
||||
attn_mask = torch.ones_like(input_ids)
|
||||
return {"input_ids": input_ids, "attention_mask": attn_mask}
|
||||
|
||||
def build_dataloader(size):
|
||||
dataset = [data_gen_fn() for _ in range(size)]
|
||||
dataloader = DataLoader(dataset, batch_size=args.experience_batch_size)
|
||||
return dataloader
|
||||
|
||||
# uncomment this function if sync_models_from_trainers is True
|
||||
# ray.get([
|
||||
# trainer_ref.sync_models_to_remote_makers.remote()
|
||||
# for trainer_ref in trainer_refs
|
||||
# ])
|
||||
|
||||
wait_tasks = []
|
||||
|
||||
for experience_holder_ref in experience_holder_refs:
|
||||
wait_tasks.append(
|
||||
experience_holder_ref.workingloop.remote(
|
||||
partial(build_dataloader, dataset_size), num_steps=args.experience_steps
|
||||
)
|
||||
)
|
||||
|
||||
total_steps = (
|
||||
args.experience_batch_size
|
||||
* args.experience_steps
|
||||
* args.num_makers
|
||||
// (args.num_trainers * args.train_batch_size)
|
||||
)
|
||||
for trainer_ref in trainer_refs:
|
||||
wait_tasks.append(trainer_ref.fit.remote(total_steps, args.update_steps, args.train_epochs))
|
||||
|
||||
ray.get(wait_tasks)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--num_makers", type=int, default=1)
|
||||
parser.add_argument("--num_trainers", type=int, default=1)
|
||||
parser.add_argument(
|
||||
"--trainer_strategy",
|
||||
choices=["ddp", "colossalai_gemini", "colossalai_zero2", "colossalai_gemini_cpu", "colossalai_zero2_cpu"],
|
||||
default="ddp",
|
||||
)
|
||||
parser.add_argument("--maker_strategy", choices=["naive"], default="naive")
|
||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--critic_model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--critic_pretrain", type=str, default=None)
|
||||
parser.add_argument("--experience_steps", type=int, default=4)
|
||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
||||
parser.add_argument("--train_epochs", type=int, default=1)
|
||||
parser.add_argument("--update_steps", type=int, default=2)
|
||||
parser.add_argument("--train_batch_size", type=int, default=8)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
|
||||
parser.add_argument("--initial_model_quant_ckpt", type=str, default=None)
|
||||
parser.add_argument("--quant_bits", type=int, default=4)
|
||||
parser.add_argument("--quant_group_size", type=int, default=128)
|
||||
parser.add_argument("--debug", action="store_true")
|
||||
args = parser.parse_args()
|
||||
ray.init(namespace=os.environ["RAY_NAMESPACE"], runtime_env={"env_vars": dict(os.environ)})
|
||||
main(args)
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
from .conversation import Conversation, setup_conversation_template
|
||||
from .loader import (
|
||||
DataCollatorForKTODataset,
|
||||
DataCollatorForPreferenceDataset,
|
||||
DataCollatorForPromptDataset,
|
||||
DataCollatorForSupervisedDataset,
|
||||
StatefulDistributedSampler,
|
||||
load_tokenized_dataset,
|
||||
)
|
||||
from .tokenization_utils import tokenize_kto, tokenize_prompt, tokenize_rlhf, tokenize_sft
|
||||
|
||||
__all__ = [
|
||||
"tokenize_prompt",
|
||||
"DataCollatorForPromptDataset",
|
||||
"is_rank_0",
|
||||
"DataCollatorForPreferenceDataset",
|
||||
"DataCollatorForSupervisedDataset",
|
||||
"DataCollatorForKTODataset",
|
||||
"StatefulDistributedSampler",
|
||||
"load_tokenized_dataset",
|
||||
"tokenize_sft",
|
||||
"tokenize_rlhf",
|
||||
"tokenize_kto",
|
||||
"setup_conversation_template",
|
||||
"Conversation",
|
||||
]
|
||||
|
|
@ -0,0 +1,149 @@
|
|||
import dataclasses
|
||||
import json
|
||||
import os
|
||||
from typing import Any, Dict, List
|
||||
|
||||
import torch.distributed as dist
|
||||
from transformers import AutoTokenizer, PreTrainedTokenizer
|
||||
|
||||
from colossalai.logging import get_dist_logger
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class Conversation:
|
||||
tokenizer: PreTrainedTokenizer
|
||||
system_message: str
|
||||
chat_template: str
|
||||
stop_ids: List[int]
|
||||
end_of_assistant: str
|
||||
roles = ["user", "assistant"]
|
||||
|
||||
@classmethod
|
||||
def from_config(cls, tokenizer: PreTrainedTokenizer, config: Dict):
|
||||
"""
|
||||
Setup the conversation template from config
|
||||
"""
|
||||
tokenizer.chat_template = config["chat_template"]
|
||||
conv = cls(
|
||||
tokenizer, config["system_message"], config["chat_template"], config["stop_ids"], config["end_of_assistant"]
|
||||
)
|
||||
conv.clear()
|
||||
return conv
|
||||
|
||||
def clear(self):
|
||||
self.messages = []
|
||||
|
||||
@classmethod
|
||||
def get_conversation_template_keys(cls):
|
||||
return ["system_message", "chat_template"]
|
||||
|
||||
def __str__(self):
|
||||
return json.dumps(
|
||||
{k: self.__dict__[k] for k in self.__dict__ if k not in ["tokenizer", "messages"]},
|
||||
ensure_ascii=False,
|
||||
indent=4,
|
||||
)
|
||||
|
||||
def get_prompt(self, length: int = None, add_generation_prompt=False) -> Any:
|
||||
"""
|
||||
Retrieves the prompt for the conversation.
|
||||
|
||||
Args:
|
||||
length (int, optional): The number of messages to include in the prompt. Defaults to None.
|
||||
get_seps_info (bool, optional): Whether to include separator information in the output. Defaults to False.
|
||||
add_generation_prompt (bool, optional): Whether to add the assistant line start token in generation (for generation only). Defaults to False.
|
||||
|
||||
Returns:
|
||||
str or tuple: The prompt string if get_seps_info is False, otherwise a tuple containing the prompt string and separator information.
|
||||
"""
|
||||
|
||||
if length is None:
|
||||
length = len(self.messages)
|
||||
|
||||
assert length <= len(self.messages)
|
||||
if self.system_message is not None:
|
||||
messages = [{"role": "system", "content": self.system_message}] + self.messages[:length]
|
||||
else:
|
||||
messages = self.messages[:length]
|
||||
prompt = self.tokenizer.apply_chat_template(
|
||||
messages, tokenize=False, add_generation_prompt=add_generation_prompt
|
||||
)
|
||||
return prompt
|
||||
|
||||
def save_prompt(self):
|
||||
return self.get_prompt()
|
||||
|
||||
def append_message(self, role: str, message: str):
|
||||
"""
|
||||
Append a message to the conversation.
|
||||
|
||||
Args:
|
||||
role (str): The role of the message sender. Must be either 'user' or 'assistant'.
|
||||
message (str): The content of the message.
|
||||
|
||||
Raises:
|
||||
AssertionError: If the role is not 'user' or 'assistant'.
|
||||
"""
|
||||
assert role in self.roles
|
||||
self.messages.append({"role": role, "content": message})
|
||||
|
||||
def copy(self):
|
||||
return Conversation(tokenizer=self.tokenizer, chat_template=self.chat_template)
|
||||
|
||||
|
||||
def setup_conversation_template(
|
||||
tokenizer: PreTrainedTokenizer, chat_template_config: Dict = None, save_path: str = None
|
||||
) -> Conversation:
|
||||
"""
|
||||
Setup the conversation template, if chat_template is given, will replace the default chat_template of the tokenizer
|
||||
with it. Otherwise, the default chat_template will be used. If the tokenizer doesn't have a default chat_template,
|
||||
raise error to remind the user to set it manually.
|
||||
|
||||
Args:
|
||||
tokenizer: The tokenizer to use
|
||||
chat_template_config:
|
||||
{
|
||||
"system_message": str The system message to use
|
||||
"chat_template": str The chat_template to use, if can be a chat_template, a huggingface model path or a local model.
|
||||
if a huggeface model path or a local model, the chat_template will be loaded from the model's tokenizer's default chat template.
|
||||
"stop_ids": List[int], the token ids used to terminate generation. You need to provide this for ppo training and generation.
|
||||
}
|
||||
"""
|
||||
if any([s not in chat_template_config.keys() for s in Conversation.get_conversation_template_keys()]):
|
||||
# Try to automatically set up conversation template, if fail, it throws an error that you need to do it manually
|
||||
if "end_of_assistant" not in chat_template_config:
|
||||
raise ValueError("Please set the end of assistant token.")
|
||||
if "system_message" not in chat_template_config:
|
||||
logger.warning("No system message is provided, will not use system message.")
|
||||
if "chat_template" not in chat_template_config:
|
||||
logger.warning("No chat_template is provided, will try to load it from the tokenizer.")
|
||||
if tokenizer.chat_template != None:
|
||||
chat_template_config["chat_template"] = tokenizer.chat_template
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Load a tokenizer from {chat_template_config['chat_template']}, which doesn't have a default chat template, please set it manually."
|
||||
)
|
||||
else:
|
||||
try:
|
||||
tokenizer = AutoTokenizer.from_pretrained(chat_template_config["chat_template"])
|
||||
if tokenizer.chat_template != None:
|
||||
chat_template_config["chat_template"] = tokenizer.chat_template
|
||||
else:
|
||||
raise ValueError(
|
||||
f"Load a tokenizer from {chat_template_config['chat_template']}, which doesn't have a default chat template, please set it manually."
|
||||
)
|
||||
logger.warning(
|
||||
f"chat_template is provided as a local model path or huggingface model path, loaded chat_template from \"{chat_template_config['chat_template']}\"."
|
||||
)
|
||||
except OSError:
|
||||
pass
|
||||
except ValueError as e:
|
||||
raise ValueError(e)
|
||||
if not dist.is_initialized() or dist.get_rank() == 0:
|
||||
os.makedirs(os.path.dirname(save_path), exist_ok=True)
|
||||
with open(save_path, "w", encoding="utf8") as f:
|
||||
logger.info(f"Successfully generated a conversation tempalte config, save to {save_path}.")
|
||||
json.dump(chat_template_config, f, indent=4, ensure_ascii=False)
|
||||
return Conversation.from_config(tokenizer, chat_template_config)
|
||||
|
|
@ -0,0 +1,346 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
Dataloader for sft, dpo, ppo
|
||||
"""
|
||||
|
||||
import os
|
||||
from dataclasses import dataclass
|
||||
from typing import Dict, Iterator, List, Optional, Sequence, Union
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from coati.dataset.utils import chuncate_sequence, pad_to_max_len
|
||||
from datasets import Dataset as HFDataset
|
||||
from datasets import dataset_dict, load_from_disk
|
||||
from torch.utils.data import ConcatDataset, Dataset, DistributedSampler
|
||||
from transformers.tokenization_utils import PreTrainedTokenizer
|
||||
|
||||
DatasetType = Union[Dataset, ConcatDataset, dataset_dict.Dataset]
|
||||
PathType = Union[str, os.PathLike]
|
||||
|
||||
|
||||
def load_tokenized_dataset(
|
||||
dataset_paths: Union[PathType, List[PathType]], mode: str = "train", **kwargs
|
||||
) -> Optional[DatasetType]:
|
||||
"""
|
||||
Load pre-tokenized dataset.
|
||||
Each instance of dataset is a dictionary with
|
||||
`{'input_ids': List[int], 'labels': List[int], sequence: str}` format.
|
||||
"""
|
||||
if not dataset_paths:
|
||||
return None
|
||||
mode_map = kwargs.get("mode_map", {"train": "train", "dev": "validation", "test": "test"})
|
||||
assert mode in tuple(mode_map), f"Unsupported mode {mode}, it must be in {tuple(mode_map)}"
|
||||
|
||||
if isinstance(dataset_paths, (str, os.PathLike)):
|
||||
dataset_paths = [dataset_paths]
|
||||
|
||||
datasets = [] # `List[datasets.dataset_dict.Dataset]`
|
||||
for ds_path in dataset_paths:
|
||||
ds_path = os.path.abspath(ds_path)
|
||||
assert os.path.exists(ds_path), f"Not existed file path {ds_path}"
|
||||
ds_dict = load_from_disk(dataset_path=ds_path, keep_in_memory=False)
|
||||
if isinstance(ds_dict, HFDataset):
|
||||
datasets.append(ds_dict)
|
||||
else:
|
||||
if mode_map[mode] in ds_dict:
|
||||
datasets.append(ds_dict[mode_map[mode]])
|
||||
if len(datasets) == 0:
|
||||
return None
|
||||
if len(datasets) == 1:
|
||||
return datasets.pop()
|
||||
return ConcatDataset(datasets=datasets)
|
||||
|
||||
|
||||
@dataclass
|
||||
class DataCollatorForSupervisedDataset(object):
|
||||
"""
|
||||
Collate instances for supervised dataset.
|
||||
Each instance is a tokenized dictionary with fields
|
||||
`input_ids`(List[int]), `labels`(List[int]) and `sequence`(str).
|
||||
"""
|
||||
|
||||
tokenizer: PreTrainedTokenizer
|
||||
max_length: int = 4096
|
||||
ignore_index: int = -100
|
||||
|
||||
def __call__(self, instances: Sequence[Dict[str, List[int]]]) -> Dict[str, torch.Tensor]:
|
||||
"""
|
||||
|
||||
Args:
|
||||
instances (`Sequence[Dict[str, List[int]]]`):
|
||||
Mini-batch samples, each sample is stored in an individual dictionary.
|
||||
|
||||
Returns:
|
||||
(`Dict[str, torch.Tensor]`): Contains the following `torch.Tensor`:
|
||||
`input_ids`: `torch.Tensor` of shape (bsz, max_len);
|
||||
`attention_mask`: `torch.BoolTensor` of shape (bsz, max_len);
|
||||
`labels`: `torch.Tensor` of shape (bsz, max_len), which contains `IGNORE_INDEX`.
|
||||
"""
|
||||
assert isinstance(self.tokenizer.pad_token_id, int) and self.tokenizer.pad_token_id >= 0, (
|
||||
f"`{self.tokenizer.__class__.__name__}.pad_token_id` must be a valid non-negative integer index value, "
|
||||
f"but now `{self.tokenizer.pad_token_id}`"
|
||||
)
|
||||
|
||||
# `List[torch.Tensor]`
|
||||
batch_input_ids = [
|
||||
(
|
||||
torch.LongTensor(instance["input_ids"][: self.max_length])
|
||||
if len(instance["input_ids"]) > self.max_length
|
||||
else torch.LongTensor(instance["input_ids"])
|
||||
)
|
||||
for instance in instances
|
||||
]
|
||||
batch_labels = [
|
||||
(
|
||||
torch.LongTensor(instance["labels"][: self.max_length])
|
||||
if len(instance["labels"]) > self.max_length
|
||||
else torch.LongTensor(instance["labels"])
|
||||
)
|
||||
for instance in instances
|
||||
]
|
||||
if self.tokenizer.padding_side == "right":
|
||||
input_ids = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=batch_input_ids,
|
||||
batch_first=True,
|
||||
padding_value=self.tokenizer.pad_token_id,
|
||||
) # (bsz, max_len)
|
||||
labels = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=batch_labels,
|
||||
batch_first=True,
|
||||
padding_value=self.ignore_index,
|
||||
) # (bsz, max_len)
|
||||
# pad to max
|
||||
to_pad = self.max_length - input_ids.size(1)
|
||||
input_ids = F.pad(input_ids, (0, to_pad), value=self.tokenizer.pad_token_id)
|
||||
labels = F.pad(labels, (0, to_pad), value=self.ignore_index)
|
||||
elif self.tokenizer.padding_side == "left":
|
||||
reversed_input_ids = [seq.flip(dims=(0,)) for seq in batch_input_ids]
|
||||
reversed_input_ids = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=reversed_input_ids,
|
||||
batch_first=True,
|
||||
padding_value=self.tokenizer.pad_token_id,
|
||||
) # (bsz, max_len)
|
||||
input_ids = torch.flip(reversed_input_ids, dims=(1,)) # (bsz, max_len)
|
||||
reversed_labels = [seq.flip(dims=(0,)) for seq in batch_labels]
|
||||
reversed_labels = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=reversed_labels,
|
||||
batch_first=True,
|
||||
padding_value=self.ignore_index,
|
||||
) # (bsz, max_len)
|
||||
labels = torch.flip(reversed_labels, dims=(1,)) # (bsz, max_len)
|
||||
else:
|
||||
raise RuntimeError(
|
||||
f"`{self.tokenizer.__class__.__name__}.padding_side` can only be `left` or `right`, "
|
||||
f"but now `{self.tokenizer.padding_side}`"
|
||||
)
|
||||
|
||||
attention_mask = input_ids.ne(self.tokenizer.pad_token_id) # `torch.BoolTensor`, (bsz, max_len)
|
||||
|
||||
return dict(input_ids=input_ids, attention_mask=attention_mask, labels=labels)
|
||||
|
||||
|
||||
@dataclass
|
||||
class DataCollatorForPromptDataset(DataCollatorForSupervisedDataset):
|
||||
def __call__(self, instances: Sequence[Dict[str, List[int]]]) -> Dict[str, torch.Tensor]:
|
||||
"""
|
||||
|
||||
Args:
|
||||
instances (`Sequence[Dict[str, List[int]]]`):
|
||||
Mini-batch samples, each sample is stored in an individual dictionary.
|
||||
|
||||
Returns:
|
||||
(`Dict[str, torch.Tensor]`): Contains the following `torch.Tensor`:
|
||||
`input_ids`: `torch.Tensor` of shape (bsz, max_len);
|
||||
`attention_mask`: `torch.BoolTensor` of shape (bsz, max_len);
|
||||
"""
|
||||
instances = [{"input_ids": ins["input_ids"], "labels": ins["input_ids"]} for ins in instances]
|
||||
ret = super().__call__(instances=instances)
|
||||
input_ids = F.pad(
|
||||
ret["input_ids"], (self.max_length - ret["input_ids"].size(1), 0), value=self.tokenizer.pad_token_id
|
||||
)
|
||||
attention_mask = F.pad(ret["attention_mask"], (self.max_length - ret["attention_mask"].size(1), 0), value=False)
|
||||
return {"input_ids": input_ids, "attention_mask": attention_mask}
|
||||
|
||||
|
||||
@dataclass
|
||||
class DataCollatorForPreferenceDataset(object):
|
||||
"""
|
||||
Collate instances for supervised dataset.
|
||||
Each instance is a tokenized dictionary with fields
|
||||
`input_ids`(List[int]), `labels`(List[int]) and `sequence`(str).
|
||||
"""
|
||||
|
||||
tokenizer: PreTrainedTokenizer
|
||||
max_length: int = 4096
|
||||
|
||||
def __call__(self, instances: Sequence[Dict[str, List[int]]]) -> Dict[str, torch.Tensor]:
|
||||
"""
|
||||
|
||||
Args:
|
||||
instances (`Sequence[Dict[str, List[int]]]`):
|
||||
Mini-batch samples, each sample is stored in an individual dictionary.
|
||||
|
||||
Returns:
|
||||
(`Dict[str, torch.Tensor]`): Contains the following `torch.Tensor`:
|
||||
`input_ids`: `torch.Tensor` of shape (bsz, max_len);
|
||||
`attention_mask`: `torch.BoolTensor` of shape (bsz, max_len);
|
||||
`labels`: `torch.Tensor` of shape (bsz, max_len), which contains `IGNORE_INDEX`.
|
||||
"""
|
||||
assert isinstance(self.tokenizer.pad_token_id, int) and self.tokenizer.pad_token_id >= 0, (
|
||||
f"`{self.tokenizer.__class__.__name__}.pad_token_id` must be a valid non-negative integer index value, "
|
||||
f"but now `{self.tokenizer.pad_token_id}`"
|
||||
)
|
||||
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_loss_mask, # [batch_size * seq_len]
|
||||
reject_input_ids,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
chuncate_sequence([ins["chosen_input_ids"] for ins in instances], self.max_length, torch.int64),
|
||||
chuncate_sequence([ins["chosen_loss_mask"] for ins in instances], self.max_length, torch.bool),
|
||||
chuncate_sequence([ins["rejected_input_ids"] for ins in instances], self.max_length, torch.int64),
|
||||
chuncate_sequence([ins["rejected_loss_mask"] for ins in instances], self.max_length, torch.bool),
|
||||
)
|
||||
|
||||
padding_side = self.tokenizer.padding_side
|
||||
chosen_attention_mask = [torch.ones_like(seq).bool() for seq in chosen_input_ids]
|
||||
reject_attention_mask = [torch.ones_like(seq).bool() for seq in reject_input_ids]
|
||||
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
chosen_loss_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
pad_to_max_len(chosen_input_ids, self.max_length, self.tokenizer.pad_token_id, padding_side=padding_side),
|
||||
pad_to_max_len(chosen_attention_mask, self.max_length, False, padding_side=padding_side),
|
||||
pad_to_max_len(chosen_loss_mask, self.max_length, False, padding_side=padding_side),
|
||||
pad_to_max_len(reject_input_ids, self.max_length, self.tokenizer.pad_token_id, padding_side=padding_side),
|
||||
pad_to_max_len(reject_attention_mask, self.max_length, False, padding_side=padding_side),
|
||||
pad_to_max_len(reject_loss_mask, self.max_length, False, padding_side=padding_side),
|
||||
)
|
||||
|
||||
return dict(
|
||||
chosen_input_ids=chosen_input_ids,
|
||||
chosen_attention_mask=chosen_attention_mask,
|
||||
chosen_loss_mask=chosen_loss_mask,
|
||||
reject_input_ids=reject_input_ids,
|
||||
reject_attention_mask=reject_attention_mask,
|
||||
reject_loss_mask=reject_loss_mask,
|
||||
)
|
||||
|
||||
|
||||
@dataclass
|
||||
class DataCollatorForKTODataset(object):
|
||||
"""
|
||||
Collate instances for kto dataset.
|
||||
Each input instance is a tokenized dictionary with fields
|
||||
`prompt`(List[int]), `completion`(List[int]) and `label`(bool).
|
||||
Each output instance is a tokenized dictionary with fields
|
||||
`kl_input_ids`(List[int]), `kl_attention_mask`(List[int]) and `kl_loss_mask`(List[int]).
|
||||
`input_ids`(List[int]), `attention_mask`(List[int]), `loss_mask`(List[int]) and `label`(bool).
|
||||
"""
|
||||
|
||||
tokenizer: PreTrainedTokenizer
|
||||
max_length: int = 4096
|
||||
ignore_index: int = -100
|
||||
|
||||
def __call__(self, instances: Sequence[Dict[str, List[int]]]) -> Dict[str, torch.Tensor]:
|
||||
"""
|
||||
|
||||
Args:
|
||||
instances (`Sequence[Dict[str, List[int]]]`):
|
||||
Mini-batch samples, each sample is stored in an individual dictionary contains the following fields:
|
||||
`prompt`(List[int]), `completion`(List[int]) and `label`(bool, if the sample is desirable or not).
|
||||
|
||||
Returns:
|
||||
(`Dict[str, torch.Tensor]`): Contains the following `torch.Tensor`:
|
||||
`input_ids`: `torch.Tensor` of shape (bsz, max_len);
|
||||
`attention_mask`: `torch.BoolTensor` of shape (bsz, max_len);
|
||||
`labels`: `torch.Tensor` of shape (bsz, max_len), which contains `IGNORE_INDEX`.
|
||||
"""
|
||||
assert isinstance(self.tokenizer.pad_token_id, int) and self.tokenizer.pad_token_id >= 0, (
|
||||
f"`{self.tokenizer.__class__.__name__}.pad_token_id` must be a valid non-negative integer index value, "
|
||||
f"but now `{self.tokenizer.pad_token_id}`"
|
||||
)
|
||||
# prepare the preference data
|
||||
prompt = [torch.LongTensor(instance["prompt"]) for instance in instances]
|
||||
prompt_zeros = [torch.zeros_like(t) for t in prompt]
|
||||
completion = [torch.LongTensor(instance["completion"]) for instance in instances]
|
||||
completion_ones = [torch.ones_like(t) for t in completion]
|
||||
label = [torch.tensor(instance["label"], dtype=torch.bool) for instance in instances]
|
||||
input_ids = [torch.cat([prompt[i], completion[i]], dim=-1) for i in range(len(instances))]
|
||||
loss_mask = [torch.cat([prompt_zeros[i], completion_ones[i]], dim=-1) for i in range(len(instances))]
|
||||
# right padding
|
||||
input_ids = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=input_ids,
|
||||
batch_first=True,
|
||||
padding_value=self.tokenizer.pad_token_id,
|
||||
) # (bsz, max_len)
|
||||
loss_mask = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=loss_mask, batch_first=True, padding_value=0
|
||||
) # (bsz, max_len)
|
||||
to_pad = self.max_length - input_ids.size(1)
|
||||
input_ids = F.pad(input_ids, (0, to_pad), value=self.tokenizer.pad_token_id)
|
||||
loss_mask = F.pad(loss_mask, (0, to_pad), value=0)
|
||||
attention_mask = input_ids.ne(self.tokenizer.pad_token_id) # `torch.BoolTensor`, (bsz, max_len)
|
||||
|
||||
# prepare kt data
|
||||
kl_completion = completion[::-1] # y'
|
||||
kl_completion_ones = [torch.ones_like(t) for t in kl_completion]
|
||||
kl_input_ids = [torch.cat([prompt[i], kl_completion[i]], dim=-1) for i in range(len(instances))]
|
||||
kl_loss_mask = [torch.cat([prompt_zeros[i], kl_completion_ones[i]], dim=-1) for i in range(len(instances))]
|
||||
# right padding
|
||||
kl_input_ids = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=kl_input_ids,
|
||||
batch_first=True,
|
||||
padding_value=self.tokenizer.pad_token_id,
|
||||
) # (bsz, max_len)
|
||||
kl_loss_mask = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=kl_loss_mask, batch_first=True, padding_value=0
|
||||
) # (bsz, max_len)
|
||||
to_pad = self.max_length - kl_input_ids.size(1)
|
||||
kl_input_ids = F.pad(kl_input_ids, (0, to_pad), value=self.tokenizer.pad_token_id)
|
||||
kl_loss_mask = F.pad(kl_loss_mask, (0, to_pad), value=0)
|
||||
kl_attention_mask = kl_input_ids.ne(self.tokenizer.pad_token_id) # `torch.BoolTensor`, (bsz, max_len)
|
||||
data_dict = {
|
||||
"input_ids": input_ids,
|
||||
"attention_mask": attention_mask,
|
||||
"loss_mask": loss_mask,
|
||||
"label": torch.stack(label),
|
||||
"kl_input_ids": kl_input_ids,
|
||||
"kl_attention_mask": kl_attention_mask,
|
||||
"kl_loss_mask": kl_loss_mask,
|
||||
}
|
||||
return data_dict
|
||||
|
||||
|
||||
class StatefulDistributedSampler(DistributedSampler):
|
||||
def __init__(
|
||||
self,
|
||||
dataset: Dataset,
|
||||
num_replicas: Optional[int] = None,
|
||||
rank: Optional[int] = None,
|
||||
shuffle: bool = True,
|
||||
seed: int = 0,
|
||||
drop_last: bool = False,
|
||||
) -> None:
|
||||
super().__init__(dataset, num_replicas, rank, shuffle, seed, drop_last)
|
||||
self.start_index: int = 0
|
||||
|
||||
def __iter__(self) -> Iterator:
|
||||
iterator = super().__iter__()
|
||||
indices = list(iterator)
|
||||
indices = indices[self.start_index :]
|
||||
return iter(indices)
|
||||
|
||||
def __len__(self) -> int:
|
||||
return self.num_samples - self.start_index
|
||||
|
||||
def set_start_index(self, start_index: int) -> None:
|
||||
self.start_index = start_index
|
||||
|
|
@ -0,0 +1,395 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
tokenization utils for constructing dataset for ppo, dpo, sft, rm
|
||||
"""
|
||||
|
||||
import warnings
|
||||
from copy import deepcopy
|
||||
from typing import Any, Dict, List, Union
|
||||
|
||||
from coati.dataset.conversation import Conversation
|
||||
from coati.dataset.utils import split_templated_prompt_into_chunks, tokenize_and_concatenate
|
||||
from datasets import dataset_dict
|
||||
from torch.utils.data import ConcatDataset, Dataset
|
||||
from transformers import PreTrainedTokenizer
|
||||
|
||||
from colossalai.logging import get_dist_logger
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
IGNORE_INDEX = -100
|
||||
|
||||
DSType = Union[Dataset, ConcatDataset, dataset_dict.Dataset]
|
||||
|
||||
|
||||
def tokenize_sft(
|
||||
data_point: Dict[str, str],
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
conversation_template: Conversation = None,
|
||||
max_length: int = 4096,
|
||||
) -> Dict[str, Union[int, str, List[int]]]:
|
||||
"""
|
||||
A tokenization function to tokenize an original pretraining data point as following
|
||||
and calculate corresponding labels for sft training:
|
||||
"Something here can be system message[user_line_start]User line[User line end][Assistant line start]Assistant line[Assistant line end]...[Assistant line end]Something here"
|
||||
^
|
||||
end_of_system_line_position
|
||||
|
||||
Args:
|
||||
data_point: the data point of the following format
|
||||
{"messages": [{"from": "user", "content": "xxx"}, {"from": "assistant", "content": "xxx"}]}
|
||||
tokenizer: the tokenizer whose
|
||||
conversation_template: the conversation template to apply
|
||||
ignore_index: the ignore index when calculate loss during training
|
||||
max_length: the maximum context length
|
||||
"""
|
||||
|
||||
ignore_index = IGNORE_INDEX
|
||||
|
||||
messages = data_point["messages"]
|
||||
template = deepcopy(conversation_template)
|
||||
|
||||
if messages[0]["from"] == "system":
|
||||
template.system_message = str(messages[0]["content"])
|
||||
messages.pop(0)
|
||||
template.messages = []
|
||||
for idx, mess in enumerate(messages):
|
||||
if mess["from"] != template.roles[idx % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a \
|
||||
line from the user. Got the following data:\n{messages}"
|
||||
)
|
||||
template.append_message(mess["from"], mess["content"])
|
||||
|
||||
if len(template.messages) % 2 != 0:
|
||||
# Force to end with assistant response
|
||||
template.messages = template.messages[0:-1]
|
||||
|
||||
# tokenize and calculate masked labels -100 for positions corresponding to non-assistant lines
|
||||
prompt = template.get_prompt()
|
||||
chunks, require_loss = split_templated_prompt_into_chunks(
|
||||
template.messages, prompt, conversation_template.end_of_assistant
|
||||
)
|
||||
tokenized, starts, ends = tokenize_and_concatenate(tokenizer, chunks, require_loss, max_length=max_length)
|
||||
if tokenized is None:
|
||||
return dict(
|
||||
input_ids=None,
|
||||
labels=None,
|
||||
inputs_decode=None,
|
||||
labels_decode=None,
|
||||
seq_length=None,
|
||||
seq_category=None,
|
||||
)
|
||||
|
||||
labels = [ignore_index] * len(tokenized)
|
||||
for start, end in zip(starts, ends):
|
||||
labels[start:end] = tokenized[start:end]
|
||||
|
||||
if tokenizer.bos_token_id is not None:
|
||||
# Force to add bos token at the beginning of the tokenized sequence if the input ids doesn;t starts with bos
|
||||
if tokenized[0] != tokenizer.bos_token_id:
|
||||
# Some chat templates already include bos token
|
||||
tokenized = [tokenizer.bos_token_id] + tokenized
|
||||
labels = [-100] + labels
|
||||
|
||||
# log decoded inputs and labels for debugging
|
||||
inputs_decode = tokenizer.decode(tokenized)
|
||||
start = 0
|
||||
end = 0
|
||||
label_decode = []
|
||||
for i in range(len(labels)):
|
||||
if labels[i] == ignore_index:
|
||||
if start != end:
|
||||
label_decode.append(tokenizer.decode(labels[start + 1 : i], skip_special_tokens=False))
|
||||
start = i
|
||||
end = i
|
||||
else:
|
||||
end = i
|
||||
if i == len(labels) - 1:
|
||||
label_decode.append(tokenizer.decode(labels[start + 1 :], skip_special_tokens=False))
|
||||
|
||||
# Check if all labels are ignored, this may happen when the tokenized length is too long
|
||||
if labels.count(ignore_index) == len(labels):
|
||||
return dict(
|
||||
input_ids=None,
|
||||
labels=None,
|
||||
inputs_decode=None,
|
||||
labels_decode=None,
|
||||
seq_length=None,
|
||||
seq_category=None,
|
||||
)
|
||||
|
||||
return dict(
|
||||
input_ids=tokenized,
|
||||
labels=labels,
|
||||
inputs_decode=inputs_decode,
|
||||
labels_decode=label_decode,
|
||||
seq_length=len(tokenized),
|
||||
seq_category=data_point["category"] if "category" in data_point else "None",
|
||||
)
|
||||
|
||||
|
||||
def tokenize_prompt(
|
||||
data_point: Dict[str, str],
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
conversation_template: Conversation = None,
|
||||
max_length: int = 4096,
|
||||
) -> Dict[str, Union[int, str, List[int]]]:
|
||||
"""
|
||||
A tokenization function to tokenize an original pretraining data point as following for ppo training:
|
||||
"Something here can be system message[user_line_start]User line[User line end][Assistant line start]Assistant line[Assistant line end]...[Assistant line start]"
|
||||
Args:
|
||||
data_point: the data point of the following format
|
||||
{"messages": [{"from": "user", "content": "xxx"}, {"from": "assistant", "content": "xxx"}]}
|
||||
tokenizer: the tokenizer whose
|
||||
conversation_template: the conversation template to apply
|
||||
ignore_index: the ignore index when calculate loss during training
|
||||
max_length: the maximum context length
|
||||
"""
|
||||
|
||||
messages = data_point["messages"]
|
||||
template = deepcopy(conversation_template)
|
||||
template.messages = []
|
||||
|
||||
if messages[0]["from"] == "system":
|
||||
template.system_message = str(messages[0]["content"])
|
||||
messages.pop(0)
|
||||
|
||||
for idx, mess in enumerate(messages):
|
||||
if mess["from"] != template.roles[idx % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a line from the user. Got the following data:\n{messages}"
|
||||
)
|
||||
template.append_message(mess["from"], mess["content"])
|
||||
|
||||
# `target_turn_index` is the number of turns which exceeds `max_length - 1` for the first time.
|
||||
if len(template.messages) % 2 != 1:
|
||||
# exclude the answer if provided. keep only the prompt
|
||||
template.messages = template.messages[:-1]
|
||||
|
||||
# Prepare data
|
||||
prompt = template.get_prompt(length=len(template.messages), add_generation_prompt=True)
|
||||
tokenized = tokenizer([prompt], add_special_tokens=False)["input_ids"][0]
|
||||
|
||||
if tokenizer.bos_token_id is not None:
|
||||
if tokenized[0] != tokenizer.bos_token_id:
|
||||
tokenized = [tokenizer.bos_token_id] + tokenized
|
||||
|
||||
if len(tokenized) > max_length:
|
||||
return dict(
|
||||
input_ids=None,
|
||||
inputs_decode=None,
|
||||
seq_length=None,
|
||||
seq_category=None,
|
||||
)
|
||||
|
||||
# `inputs_decode` can be used to check whether the tokenization method is true.
|
||||
return dict(
|
||||
input_ids=tokenized,
|
||||
inputs_decode=prompt,
|
||||
seq_length=len(tokenized),
|
||||
seq_category=data_point["category"] if "category" in data_point else "None",
|
||||
)
|
||||
|
||||
|
||||
def apply_rlhf_data_format(template: Conversation, tokenizer: Any):
|
||||
target_turn = int(len(template.messages) / 2)
|
||||
prompt = template.get_prompt(target_turn * 2)
|
||||
chunks, require_loss = split_templated_prompt_into_chunks(
|
||||
template.messages[: 2 * target_turn], prompt, template.end_of_assistant
|
||||
)
|
||||
# no truncation applied
|
||||
tokenized, starts, ends = tokenize_and_concatenate(tokenizer, chunks, require_loss, max_length=None)
|
||||
|
||||
loss_mask = [0] * len(tokenized)
|
||||
label_decode = []
|
||||
# only the last round (chosen/rejected) is used to calculate loss
|
||||
for i in range(starts[-1], ends[-1]):
|
||||
loss_mask[i] = 1
|
||||
label_decode.append(tokenizer.decode(tokenized[starts[-1] : ends[-1]], skip_special_tokens=False))
|
||||
if tokenizer.bos_token_id is not None:
|
||||
if tokenized[0] != tokenizer.bos_token_id:
|
||||
tokenized = [tokenizer.bos_token_id] + tokenized
|
||||
loss_mask = [0] + loss_mask
|
||||
|
||||
return {"input_ids": tokenized, "loss_mask": loss_mask, "label_decode": label_decode}
|
||||
|
||||
|
||||
def tokenize_rlhf(
|
||||
data_point: Dict[str, str],
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
conversation_template: Conversation = None,
|
||||
max_length: int = 4096,
|
||||
) -> Dict[str, Union[int, str, List[int]]]:
|
||||
"""
|
||||
A tokenization function to tokenize an original pretraining data point as following:
|
||||
{"context": [{"from": "user", "content": "xxx"}, {"from": "assistant", "content": "xxx"}],
|
||||
"chosen": {"from": "assistant", "content": "xxx"}, "rejected": {"from": "assistant", "content": "xxx"}}
|
||||
"""
|
||||
|
||||
context = data_point["context"]
|
||||
template = deepcopy(conversation_template)
|
||||
template.clear()
|
||||
|
||||
if context[0]["from"] == "system":
|
||||
template.system_message = str(context[0]["content"])
|
||||
context.pop(0)
|
||||
|
||||
for idx, mess in enumerate(context):
|
||||
if mess["from"] != template.roles[idx % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a \
|
||||
line from the user. Got the following data:\n{context}"
|
||||
)
|
||||
template.append_message(mess["from"], mess["content"])
|
||||
|
||||
if len(template.messages) % 2 != 1:
|
||||
warnings.warn(
|
||||
"Please make sure leading context starts and ends with a line from user\nLeading context: "
|
||||
+ str(template.messages)
|
||||
)
|
||||
return dict(
|
||||
chosen_input_ids=None,
|
||||
chosen_loss_mask=None,
|
||||
chosen_label_decode=None,
|
||||
rejected_input_ids=None,
|
||||
rejected_loss_mask=None,
|
||||
rejected_label_decode=None,
|
||||
)
|
||||
|
||||
assert context[-1]["from"].lower() == template.roles[0], "The last message in context should be from user."
|
||||
chosen = deepcopy(template)
|
||||
rejected = deepcopy(template)
|
||||
chosen_continuation = data_point["chosen"]
|
||||
rejected_continuation = data_point["rejected"]
|
||||
for round in range(len(chosen_continuation)):
|
||||
if chosen_continuation[round]["from"] != template.roles[(round + 1) % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a \
|
||||
line from the user. Got the following data:\n{chosen_continuation}"
|
||||
)
|
||||
chosen.append_message(chosen_continuation[round]["from"], chosen_continuation[round]["content"])
|
||||
|
||||
for round in range(len(rejected_continuation)):
|
||||
if rejected_continuation[round]["from"] != template.roles[(round + 1) % 2]:
|
||||
raise ValueError(
|
||||
f"Message should iterate between user and assistant and starts with a \
|
||||
line from the user. Got the following data:\n{rejected_continuation}"
|
||||
)
|
||||
rejected.append_message(rejected_continuation[round]["from"], rejected_continuation[round]["content"])
|
||||
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_loss_mask,
|
||||
chosen_label_decode,
|
||||
rejected_input_ids,
|
||||
rejected_loss_mask,
|
||||
rejected_label_decode,
|
||||
) = (None, None, None, None, None, None)
|
||||
|
||||
chosen_data_packed = apply_rlhf_data_format(chosen, tokenizer)
|
||||
(chosen_input_ids, chosen_loss_mask, chosen_label_decode) = (
|
||||
chosen_data_packed["input_ids"],
|
||||
chosen_data_packed["loss_mask"],
|
||||
chosen_data_packed["label_decode"],
|
||||
)
|
||||
|
||||
rejected_data_packed = apply_rlhf_data_format(rejected, tokenizer)
|
||||
(rejected_input_ids, rejected_loss_mask, rejected_label_decode) = (
|
||||
rejected_data_packed["input_ids"],
|
||||
rejected_data_packed["loss_mask"],
|
||||
rejected_data_packed["label_decode"],
|
||||
)
|
||||
|
||||
if len(chosen_input_ids) > max_length or len(rejected_input_ids) > max_length:
|
||||
return dict(
|
||||
chosen_input_ids=None,
|
||||
chosen_loss_mask=None,
|
||||
chosen_label_decode=None,
|
||||
rejected_input_ids=None,
|
||||
rejected_loss_mask=None,
|
||||
rejected_label_decode=None,
|
||||
)
|
||||
# Check if loss mask is all 0s (no loss), this may happen when the tokenized length is too long
|
||||
if chosen_loss_mask.count(1) == 0 or rejected_loss_mask.count(1) == 0:
|
||||
return dict(
|
||||
chosen_input_ids=None,
|
||||
chosen_loss_mask=None,
|
||||
chosen_label_decode=None,
|
||||
rejected_input_ids=None,
|
||||
rejected_loss_mask=None,
|
||||
rejected_label_decode=None,
|
||||
)
|
||||
|
||||
return {
|
||||
"chosen_input_ids": chosen_input_ids,
|
||||
"chosen_loss_mask": chosen_loss_mask,
|
||||
"chosen_label_decode": chosen_label_decode,
|
||||
"rejected_input_ids": rejected_input_ids,
|
||||
"rejected_loss_mask": rejected_loss_mask,
|
||||
"rejected_label_decode": rejected_label_decode,
|
||||
}
|
||||
|
||||
|
||||
def tokenize_kto(
|
||||
data_point: Dict[str, str],
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
conversation_template: Conversation = None,
|
||||
max_length: int = 4096,
|
||||
) -> Dict[str, Union[int, str, List[int]]]:
|
||||
"""
|
||||
Tokenize a dataset for KTO training
|
||||
The raw input data is conversation that have the following format
|
||||
{
|
||||
"prompt": [{"from": "user", "content": "xxx"}...],
|
||||
"completion": {"from": "assistant", "content": "xxx"},
|
||||
"label": true/false
|
||||
}
|
||||
It returns three fields
|
||||
The context, which contain the query and the assistant start,
|
||||
the completion, which only contains the assistance's answer,
|
||||
and a binary label, which indicates if the sample is prefered or not
|
||||
"""
|
||||
prompt = data_point["prompt"]
|
||||
completion = data_point["completion"]
|
||||
template = deepcopy(conversation_template)
|
||||
template.clear()
|
||||
|
||||
if prompt[0]["from"] == "system":
|
||||
template.system_message = str(prompt[0]["content"])
|
||||
prompt.pop(0)
|
||||
|
||||
if prompt[0].get("from", None) != "user":
|
||||
raise ValueError("conversation should start with user")
|
||||
if completion.get("from", None) != "assistant":
|
||||
raise ValueError("conversation should end with assistant")
|
||||
|
||||
for mess in prompt:
|
||||
if mess.get("from", None) == "user":
|
||||
template.append_message("user", mess["content"])
|
||||
elif mess.get("from", None) == "assistant":
|
||||
template.append_message("assistant", mess["content"])
|
||||
else:
|
||||
raise ValueError(f"Unsupported role {mess.get('from', None)}")
|
||||
generation_prompt = template.get_prompt(len(prompt), add_generation_prompt=True)
|
||||
template.append_message("assistant", completion["content"])
|
||||
full_prompt = template.get_prompt(len(prompt) + 1, add_generation_prompt=False)
|
||||
tokenized_full_prompt = tokenizer(full_prompt, add_special_tokens=False)["input_ids"]
|
||||
if len(tokenized_full_prompt) + 1 > max_length:
|
||||
return dict(prompt=None, completion=None, label=None, input_id_decode=None, completion_decode=None)
|
||||
tokenized_generation_prompt = tokenizer(generation_prompt, add_special_tokens=False)["input_ids"]
|
||||
tokenized_completion = tokenized_full_prompt[len(tokenized_generation_prompt) :]
|
||||
tokenized_completion = deepcopy(tokenized_completion)
|
||||
if tokenizer.bos_token_id is not None and tokenized_generation_prompt[0] != tokenizer.bos_token_id:
|
||||
tokenized_generation_prompt = [tokenizer.bos_token_id] + tokenized_generation_prompt
|
||||
decoded_full_prompt = tokenizer.decode(tokenized_full_prompt, skip_special_tokens=False)
|
||||
decoded_completion = tokenizer.decode(tokenized_completion, skip_special_tokens=False)
|
||||
|
||||
return {
|
||||
"prompt": tokenized_generation_prompt,
|
||||
"completion": tokenized_completion,
|
||||
"label": data_point["label"],
|
||||
"input_id_decode": decoded_full_prompt,
|
||||
"completion_decode": decoded_completion,
|
||||
}
|
||||
|
|
@ -0,0 +1,170 @@
|
|||
import io
|
||||
import json
|
||||
from typing import Any, Dict, List
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.nn.functional as F
|
||||
from transformers import PreTrainedTokenizer
|
||||
|
||||
|
||||
def is_rank_0() -> bool:
|
||||
return not dist.is_initialized() or dist.get_rank() == 0
|
||||
|
||||
|
||||
def _make_r_io_base(f, mode: str):
|
||||
if not isinstance(f, io.IOBase):
|
||||
f = open(f, mode=mode)
|
||||
return f
|
||||
|
||||
|
||||
def jload(f, mode="r"):
|
||||
"""Load a .json file into a dictionary."""
|
||||
f = _make_r_io_base(f, mode)
|
||||
jdict = json.load(f)
|
||||
f.close()
|
||||
return jdict
|
||||
|
||||
|
||||
def read_string_by_schema(data: Dict[str, Any], schema: str) -> str:
|
||||
"""
|
||||
Read a feild of the dataset be schema
|
||||
Args:
|
||||
data: Dict[str, Any]
|
||||
schema: cascaded feild names seperated by '.'. e.g. person.name.first will access data['person']['name']['first']
|
||||
"""
|
||||
keys = schema.split(".")
|
||||
result = data
|
||||
for key in keys:
|
||||
result = result.get(key, None)
|
||||
if result is None:
|
||||
return ""
|
||||
assert isinstance(result, str), f"dataset element is not a string: {result}"
|
||||
return result
|
||||
|
||||
|
||||
def pad_to_max_len(
|
||||
sequence: List[torch.Tensor], max_length: int, padding_value: int, batch_first: bool = True, padding_side="left"
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
sequence: a batch of tensor of shape [batch_size, seq_len] if batch_first==True
|
||||
"""
|
||||
if padding_side == "left":
|
||||
reversed_sequence = [seq.flip(dims=(0,)) for seq in sequence]
|
||||
padded = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=reversed_sequence, batch_first=batch_first, padding_value=padding_value
|
||||
)
|
||||
to_pad = max_length - padded.size(1)
|
||||
padded = F.pad(padded, (0, to_pad), value=padding_value)
|
||||
return torch.flip(padded, dims=(1,))
|
||||
elif padding_side == "right":
|
||||
padded = torch.nn.utils.rnn.pad_sequence(
|
||||
sequences=sequence, batch_first=batch_first, padding_value=padding_value
|
||||
)
|
||||
to_pad = max_length - padded.size(1)
|
||||
return F.pad(padded, (0, to_pad), value=padding_value)
|
||||
else:
|
||||
raise RuntimeError(f"`padding_side` can only be `left` or `right`, " f"but now `{padding_side}`")
|
||||
|
||||
|
||||
def chuncate_sequence(sequence: List[torch.Tensor], max_length: int, dtype: Any):
|
||||
"""
|
||||
Args:
|
||||
sequence: a batch of tensor of shape [batch_size, seq_len] if batch_first==True
|
||||
"""
|
||||
return [
|
||||
torch.Tensor(seq[:max_length]).to(dtype) if len(seq) > max_length else torch.Tensor(seq).to(dtype)
|
||||
for seq in sequence
|
||||
]
|
||||
|
||||
|
||||
def find_first_occurrence_subsequence(seq: torch.Tensor, subseq: torch.Tensor, start_index: int = 0) -> int:
|
||||
if subseq is None:
|
||||
return 0
|
||||
for i in range(start_index, len(seq) - len(subseq) + 1):
|
||||
if torch.all(seq[i : i + len(subseq)] == subseq):
|
||||
return i
|
||||
return -1
|
||||
|
||||
|
||||
def tokenize_and_concatenate(
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
text: List[str],
|
||||
require_loss: List[bool],
|
||||
max_length: int,
|
||||
discard_non_loss_tokens_at_tail: bool = True,
|
||||
):
|
||||
"""
|
||||
Tokenizes a list of texts using the provided tokenizer and concatenates the tokenized outputs.
|
||||
|
||||
Args:
|
||||
tokenizer (PreTrainedTokenizer): The tokenizer to use for tokenization.
|
||||
text (List[str]): The list of texts to tokenize.
|
||||
require_loss (List[bool]): A list of boolean values indicating whether each text requires loss calculation.
|
||||
max_length: used to truncate the input ids
|
||||
discard_non_loss_tokens_at_tail: whether to discard the non-loss tokens at the tail
|
||||
|
||||
if the first round has already exeeded max length
|
||||
- if the user query already exeeded max length, discard the sample
|
||||
- if only the first assistant response exeeded max length, truncate the response to fit the max length
|
||||
else keep the first several complete rounds of the conversations until max length is reached
|
||||
|
||||
Returns:
|
||||
Tuple[List[int], List[int], List[int]]: A tuple containing the concatenated tokenized input ids,
|
||||
the start positions of loss spans, and the end positions of loss spans.
|
||||
"""
|
||||
input_ids = []
|
||||
loss_starts = []
|
||||
loss_ends = []
|
||||
for s, r in zip(text, require_loss):
|
||||
tokenized = tokenizer(s, add_special_tokens=False)["input_ids"]
|
||||
if not max_length or len(input_ids) + len(tokenized) <= max_length or len(loss_ends) == 0:
|
||||
if r:
|
||||
loss_starts.append(len(input_ids))
|
||||
loss_ends.append(len(input_ids) + len(tokenized))
|
||||
input_ids.extend(tokenized)
|
||||
if max_length and loss_starts[0] >= max_length:
|
||||
return None, None, None
|
||||
if discard_non_loss_tokens_at_tail:
|
||||
input_ids = input_ids[: loss_ends[-1]]
|
||||
if max_length:
|
||||
input_ids = input_ids[:max_length]
|
||||
loss_ends[-1] = min(max_length, loss_ends[-1])
|
||||
return input_ids, loss_starts, loss_ends
|
||||
|
||||
|
||||
def split_templated_prompt_into_chunks(messages: List[Dict[str, str]], prompt: str, end_of_assistant: str):
|
||||
# Seperate templated prompt into chunks by human/assistant's lines, prepare data for tokenize_and_concatenate
|
||||
start_idx = 0
|
||||
chunks = []
|
||||
require_loss = []
|
||||
for line in messages:
|
||||
content_length = len(line["content"])
|
||||
first_occur = prompt.find(line["content"], start_idx)
|
||||
if line["role"].lower() == "assistant" and end_of_assistant in prompt[first_occur + content_length :]:
|
||||
content_length = (
|
||||
prompt.find(end_of_assistant, first_occur + content_length) + len(end_of_assistant) - first_occur
|
||||
)
|
||||
# if the tokenized content start with a leading space, we want to keep it in loss calculation
|
||||
# e.g., Assistant: I am saying...
|
||||
# if the tokenized content doesn't start with a leading space, we only need to keep the content in loss calculation
|
||||
# e.g.,
|
||||
# Assistant: # '\n' as line breaker
|
||||
# I am saying...
|
||||
if prompt[first_occur - 1] != " ":
|
||||
chunks.append(prompt[start_idx:first_occur])
|
||||
chunks.append(prompt[first_occur : first_occur + content_length])
|
||||
else:
|
||||
chunks.append(prompt[start_idx : first_occur - 1])
|
||||
chunks.append(prompt[first_occur - 1 : first_occur + content_length])
|
||||
start_idx = first_occur + content_length
|
||||
if line["role"].lower() == "assistant":
|
||||
require_loss.append(False)
|
||||
require_loss.append(True)
|
||||
else:
|
||||
require_loss.append(False)
|
||||
require_loss.append(False)
|
||||
chunks.append(prompt[start_idx:])
|
||||
require_loss.append(False)
|
||||
return chunks, require_loss
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
from .base import ExperienceBuffer
|
||||
from .naive import NaiveExperienceBuffer
|
||||
|
||||
__all__ = ["ExperienceBuffer", "NaiveExperienceBuffer"]
|
||||
|
|
@ -0,0 +1,43 @@
|
|||
from abc import ABC, abstractmethod
|
||||
from typing import Any
|
||||
|
||||
from coati.experience_maker.base import Experience
|
||||
|
||||
|
||||
class ExperienceBuffer(ABC):
|
||||
"""Experience buffer base class. It stores experience.
|
||||
|
||||
Args:
|
||||
sample_batch_size (int): Batch size when sampling.
|
||||
limit (int, optional): Limit of number of experience samples. A number <= 0 means unlimited. Defaults to 0.
|
||||
"""
|
||||
|
||||
def __init__(self, sample_batch_size: int, limit: int = 0) -> None:
|
||||
super().__init__()
|
||||
self.sample_batch_size = sample_batch_size
|
||||
# limit <= 0 means unlimited
|
||||
self.limit = limit
|
||||
|
||||
@abstractmethod
|
||||
def append(self, experience: Experience) -> None:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def clear(self) -> None:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def sample(self) -> Experience:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def __len__(self) -> int:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def __getitem__(self, idx: int) -> Any:
|
||||
pass
|
||||
|
||||
@abstractmethod
|
||||
def collate_fn(self, batch: Any) -> Experience:
|
||||
pass
|
||||
|
|
@ -0,0 +1,69 @@
|
|||
import random
|
||||
from typing import List
|
||||
|
||||
import torch
|
||||
from coati.experience_maker.base import Experience
|
||||
|
||||
from colossalai.logging import get_dist_logger
|
||||
|
||||
from .base import ExperienceBuffer
|
||||
from .utils import BufferItem, make_experience_batch, split_experience_batch
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
|
||||
class NaiveExperienceBuffer(ExperienceBuffer):
|
||||
"""Naive experience buffer class. It stores experience.
|
||||
|
||||
Args:
|
||||
sample_batch_size (int): Batch size when sampling.
|
||||
limit (int, optional): Limit of number of experience samples. A number <= 0 means unlimited. Defaults to 0.
|
||||
cpu_offload (bool, optional): Whether to offload experience to cpu when sampling. Defaults to True.
|
||||
"""
|
||||
|
||||
def __init__(self, sample_batch_size: int, limit: int = 0, cpu_offload: bool = True) -> None:
|
||||
super().__init__(sample_batch_size, limit)
|
||||
self.cpu_offload = cpu_offload
|
||||
self.target_device = torch.device(f"cuda:{torch.cuda.current_device()}")
|
||||
# TODO(ver217): add prefetch
|
||||
self.items: List[BufferItem] = []
|
||||
|
||||
@torch.no_grad()
|
||||
def append(self, experience: Experience) -> None:
|
||||
if self.cpu_offload:
|
||||
experience.to_device(torch.device("cpu"))
|
||||
items = split_experience_batch(experience)
|
||||
self.items.extend(items)
|
||||
|
||||
if self.limit > 0:
|
||||
samples_to_remove = len(self.items) - self.limit
|
||||
if samples_to_remove > 0:
|
||||
logger.warning(f"Experience buffer is full. Removing {samples_to_remove} samples.")
|
||||
self.items = self.items[samples_to_remove:]
|
||||
|
||||
def clear(self) -> None:
|
||||
self.items.clear()
|
||||
|
||||
@torch.no_grad()
|
||||
def sample(self) -> Experience:
|
||||
"""
|
||||
Randomly samples experiences from the buffer.
|
||||
|
||||
Returns:
|
||||
A batch of sampled experiences.
|
||||
"""
|
||||
items = random.sample(self.items, self.sample_batch_size)
|
||||
experience = make_experience_batch(items)
|
||||
if self.cpu_offload:
|
||||
experience.to_device(self.target_device)
|
||||
return experience
|
||||
|
||||
def __len__(self) -> int:
|
||||
return len(self.items)
|
||||
|
||||
def __getitem__(self, idx: int) -> BufferItem:
|
||||
return self.items[idx]
|
||||
|
||||
def collate_fn(self, batch) -> Experience:
|
||||
experience = make_experience_batch(batch)
|
||||
return experience
|
||||
|
|
@ -0,0 +1,75 @@
|
|||
from dataclasses import dataclass
|
||||
from typing import List, Optional
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from coati.experience_maker.base import Experience
|
||||
|
||||
|
||||
@dataclass
|
||||
class BufferItem:
|
||||
"""BufferItem is an item of experience data.
|
||||
|
||||
Shapes of each tensor:
|
||||
sequences: (S)
|
||||
action_log_probs: (A)
|
||||
values: (1)
|
||||
reward: (1)
|
||||
advantages: (1)
|
||||
attention_mask: (S)
|
||||
action_mask: (A)
|
||||
|
||||
"A" is the number of actions.
|
||||
"""
|
||||
|
||||
sequences: torch.Tensor
|
||||
action_log_probs: torch.Tensor
|
||||
values: torch.Tensor
|
||||
reward: torch.Tensor
|
||||
kl: torch.Tensor
|
||||
advantages: torch.Tensor
|
||||
attention_mask: Optional[torch.LongTensor]
|
||||
action_mask: Optional[torch.BoolTensor]
|
||||
|
||||
|
||||
def split_experience_batch(experience: Experience) -> List[BufferItem]:
|
||||
batch_size = experience.sequences.size(0)
|
||||
batch_kwargs = [{} for _ in range(batch_size)]
|
||||
keys = ("sequences", "action_log_probs", "values", "reward", "kl", "advantages", "attention_mask", "action_mask")
|
||||
for key in keys:
|
||||
value = getattr(experience, key)
|
||||
if isinstance(value, torch.Tensor):
|
||||
vals = torch.unbind(value)
|
||||
else:
|
||||
# None
|
||||
vals = [value for _ in range(batch_size)]
|
||||
assert batch_size == len(vals)
|
||||
for i, v in enumerate(vals):
|
||||
batch_kwargs[i][key] = v
|
||||
items = [BufferItem(**kwargs) for kwargs in batch_kwargs]
|
||||
return items
|
||||
|
||||
|
||||
def _zero_pad_sequences(sequences: List[torch.Tensor], side: str = "left") -> torch.Tensor:
|
||||
assert side in ("left", "right")
|
||||
max_len = max(seq.size(0) for seq in sequences)
|
||||
padded_sequences = []
|
||||
for seq in sequences:
|
||||
pad_len = max_len - seq.size(0)
|
||||
padding = (pad_len, 0) if side == "left" else (0, pad_len)
|
||||
padded_sequences.append(F.pad(seq, padding))
|
||||
return torch.stack(padded_sequences, dim=0)
|
||||
|
||||
|
||||
def make_experience_batch(items: List[BufferItem]) -> Experience:
|
||||
kwargs = {}
|
||||
to_pad_keys = set(("action_log_probs", "action_mask"))
|
||||
keys = ("sequences", "action_log_probs", "values", "reward", "kl", "advantages", "attention_mask", "action_mask")
|
||||
for key in keys:
|
||||
vals = [getattr(item, key) for item in items]
|
||||
if key in to_pad_keys:
|
||||
batch_data = _zero_pad_sequences(vals)
|
||||
else:
|
||||
batch_data = torch.stack(vals, dim=0)
|
||||
kwargs[key] = batch_data
|
||||
return Experience(**kwargs)
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
from .base import Experience, ExperienceMaker
|
||||
from .naive import NaiveExperienceMaker
|
||||
|
||||
__all__ = ["Experience", "ExperienceMaker", "NaiveExperienceMaker"]
|
||||
|
|
@ -0,0 +1,90 @@
|
|||
from abc import ABC, abstractmethod
|
||||
from dataclasses import dataclass
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from coati.models import Critic, RewardModel
|
||||
from transformers import PreTrainedModel
|
||||
|
||||
|
||||
@dataclass
|
||||
class Experience:
|
||||
"""Experience is a batch of data.
|
||||
These data should have the sequence length and number of actions.
|
||||
Left padding for sequences is applied.
|
||||
|
||||
Shapes of each tensor:
|
||||
sequences: (B, S)
|
||||
action_log_probs: (B, A)
|
||||
values: (B)
|
||||
reward: (B)
|
||||
advantages: (B)
|
||||
attention_mask: (B, S)
|
||||
action_mask: (B, A)
|
||||
|
||||
"A" is the number of actions.
|
||||
"""
|
||||
|
||||
sequences: torch.Tensor
|
||||
action_log_probs: torch.Tensor
|
||||
values: torch.Tensor
|
||||
reward: torch.Tensor
|
||||
kl: torch.Tensor
|
||||
advantages: torch.Tensor
|
||||
attention_mask: Optional[torch.LongTensor]
|
||||
action_mask: Optional[torch.BoolTensor]
|
||||
|
||||
@torch.no_grad()
|
||||
def to_device(self, device: torch.device) -> None:
|
||||
self.sequences = self.sequences.to(device)
|
||||
self.action_log_probs = self.action_log_probs.to(device)
|
||||
self.values = self.values.to(device)
|
||||
self.reward = self.reward.to(device)
|
||||
self.advantages = self.advantages.to(device)
|
||||
self.kl = self.kl.to(device)
|
||||
if self.attention_mask is not None:
|
||||
self.attention_mask = self.attention_mask.to(device)
|
||||
if self.action_mask is not None:
|
||||
self.action_mask = self.action_mask.to(device)
|
||||
|
||||
def pin_memory(self):
|
||||
self.sequences = self.sequences.pin_memory()
|
||||
self.action_log_probs = self.action_log_probs.pin_memory()
|
||||
self.values = self.values.pin_memory()
|
||||
self.reward = self.reward.pin_memory()
|
||||
self.advantages = self.advantages.pin_memory()
|
||||
self.kl = self.kl.pin_memory()
|
||||
if self.attention_mask is not None:
|
||||
self.attention_mask = self.attention_mask.pin_memory()
|
||||
if self.action_mask is not None:
|
||||
self.action_mask = self.action_mask.pin_memory()
|
||||
return self
|
||||
|
||||
|
||||
class ExperienceMaker(ABC):
|
||||
"""
|
||||
Base class for experience makers.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self, actor: PreTrainedModel, critic: Critic, reward_model: RewardModel, initial_model: PreTrainedModel
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.actor = actor
|
||||
self.critic = critic
|
||||
self.reward_model = reward_model
|
||||
self.initial_model = initial_model
|
||||
|
||||
@abstractmethod
|
||||
def make_experience(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **generate_kwargs) -> Experience:
|
||||
"""
|
||||
Abstract method to generate an experience.
|
||||
|
||||
Args:
|
||||
input_ids (torch.Tensor): The input tensor.
|
||||
attention_mask (torch.Tensor): The attention mask tensor.
|
||||
**generate_kwargs: Additional keyword arguments for generating the experience.
|
||||
|
||||
Returns:
|
||||
Experience: The generated experience.
|
||||
"""
|
||||
|
|
@ -0,0 +1,180 @@
|
|||
"""
|
||||
experience maker.
|
||||
"""
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
from coati.dataset.utils import find_first_occurrence_subsequence
|
||||
from coati.models import Critic, RewardModel
|
||||
from coati.models.generation import generate
|
||||
from coati.models.utils import calc_action_log_probs, compute_reward
|
||||
from transformers import PreTrainedModel, PreTrainedTokenizer
|
||||
|
||||
from colossalai.logging import get_dist_logger
|
||||
|
||||
from .base import Experience, ExperienceMaker
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
import torch.distributed as dist
|
||||
|
||||
|
||||
def is_rank_0() -> bool:
|
||||
return not dist.is_initialized() or dist.get_rank() == 0
|
||||
|
||||
|
||||
class NaiveExperienceMaker(ExperienceMaker):
|
||||
"""
|
||||
Naive experience maker.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
actor: PreTrainedModel,
|
||||
critic: Critic,
|
||||
reward_model: RewardModel,
|
||||
initial_model: PreTrainedModel,
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
kl_coef: float = 0.01,
|
||||
gamma: float = 1.0,
|
||||
lam: float = 0.95,
|
||||
) -> None:
|
||||
super().__init__(actor, critic, reward_model, initial_model)
|
||||
self.tokenizer = tokenizer
|
||||
self.kl_coef = kl_coef
|
||||
self.gamma = gamma
|
||||
self.lam = lam
|
||||
|
||||
@torch.no_grad()
|
||||
def calculate_advantage(self, value: torch.Tensor, reward: torch.Tensor, num_actions: int) -> torch.Tensor:
|
||||
"""
|
||||
Calculates the advantage values for each action based on the value and reward tensors.
|
||||
|
||||
Args:
|
||||
value (torch.Tensor): Tensor containing the predicted values from critic.
|
||||
reward (torch.Tensor): reward of the shape [B, len].
|
||||
num_actions (int): Number of actions.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: Tensor containing the calculated advantages for each action.
|
||||
"""
|
||||
lastgaelam = 0
|
||||
advantages_reversed = []
|
||||
for t in reversed(range(num_actions)):
|
||||
nextvalues = value[:, t + 1] if t < num_actions - 1 else 0.0
|
||||
delta = reward[:, t] + self.gamma * nextvalues - value[:, t]
|
||||
lastgaelam = delta + self.gamma * self.lam * lastgaelam
|
||||
advantages_reversed.append(lastgaelam)
|
||||
advantages = torch.stack(advantages_reversed[::-1], dim=1)
|
||||
return advantages
|
||||
|
||||
@torch.no_grad()
|
||||
def make_experience(self, input_ids: torch.Tensor, attention_mask: torch.Tensor, **generate_kwargs) -> Experience:
|
||||
"""
|
||||
Generates an experience using the given input_ids and attention_mask.
|
||||
|
||||
Args:
|
||||
input_ids (torch.Tensor): The input tensor containing the tokenized input sequence.
|
||||
attention_mask (torch.Tensor): The attention mask tensor indicating which tokens to attend to.
|
||||
**generate_kwargs: Additional keyword arguments for the generation process.
|
||||
|
||||
Returns:
|
||||
Experience: The generated experience object.
|
||||
|
||||
"""
|
||||
self.actor.eval()
|
||||
self.critic.eval()
|
||||
self.initial_model.eval()
|
||||
self.reward_model.eval()
|
||||
pad_token_id = self.tokenizer.pad_token_id
|
||||
|
||||
stop_token_ids = generate_kwargs.get("stop_token_ids", None)
|
||||
torch.manual_seed(41) # for tp, gurantee the same input for reward model
|
||||
|
||||
sequences = generate(self.actor, input_ids, self.tokenizer, **generate_kwargs)
|
||||
|
||||
# Pad to max length
|
||||
sequences = F.pad(sequences, (0, generate_kwargs["max_length"] - sequences.size(1)), value=pad_token_id)
|
||||
sequence_length = sequences.size(1)
|
||||
|
||||
# Calculate auxiliary tensors
|
||||
attention_mask = None
|
||||
if pad_token_id is not None:
|
||||
attention_mask = sequences.not_equal(pad_token_id).to(dtype=torch.long, device=sequences.device)
|
||||
|
||||
input_len = input_ids.size(1)
|
||||
if stop_token_ids is None:
|
||||
# End the sequence with eos token
|
||||
eos_token_id = self.tokenizer.eos_token_id
|
||||
if eos_token_id is None:
|
||||
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
||||
else:
|
||||
# Left padding may be applied, only mask action
|
||||
action_mask = (sequences[:, input_len:] == eos_token_id).cumsum(dim=-1) == 0
|
||||
action_mask = F.pad(action_mask, (1 + input_len, -1), value=True) # include eos token and input
|
||||
else:
|
||||
# stop_token_ids are given, generation ends with stop_token_ids
|
||||
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
||||
for i in range(sequences.size(0)):
|
||||
stop_index = find_first_occurrence_subsequence(
|
||||
sequences[i][input_len:], torch.tensor(stop_token_ids).to(sequences.device)
|
||||
)
|
||||
if stop_index == -1:
|
||||
# Sequence does not contain stop_token_ids, this should never happen BTW
|
||||
logger.warning(
|
||||
"Generated sequence does not contain stop_token_ids. Please check your chat template config"
|
||||
)
|
||||
else:
|
||||
# Keep stop tokens
|
||||
stop_index = input_len + stop_index
|
||||
action_mask[i, stop_index + len(stop_token_ids) :] = False
|
||||
|
||||
generation_end_index = (action_mask == True).sum(dim=-1) - 1
|
||||
action_mask[:, :input_len] = False
|
||||
action_mask = action_mask[:, 1:]
|
||||
action_mask = action_mask[:, -(sequences.size(1) - input_len) :]
|
||||
num_actions = action_mask.size(1)
|
||||
|
||||
actor_output = self.actor(input_ids=sequences, attention_mask=attention_mask)["logits"]
|
||||
action_log_probs = calc_action_log_probs(actor_output, sequences, num_actions)
|
||||
|
||||
base_model_output = self.initial_model(input_ids=sequences, attention_mask=attention_mask)["logits"]
|
||||
|
||||
base_action_log_probs = calc_action_log_probs(base_model_output, sequences, num_actions)
|
||||
|
||||
# Convert to right padding for the reward model and the critic model
|
||||
input_ids_rm = torch.zeros_like(sequences, device=sequences.device)
|
||||
attention_mask_rm = torch.zeros_like(sequences, device=sequences.device)
|
||||
for i in range(sequences.size(0)):
|
||||
sequence = sequences[i]
|
||||
bos_index = (sequence != pad_token_id).nonzero().reshape([-1])[0]
|
||||
eos_index = generation_end_index[i]
|
||||
sequence_to_pad = sequence[bos_index:eos_index]
|
||||
sequence_padded = F.pad(
|
||||
sequence_to_pad, (0, sequence_length - sequence_to_pad.size(0)), value=self.tokenizer.pad_token_id
|
||||
)
|
||||
input_ids_rm[i] = sequence_padded
|
||||
if sequence_length - sequence_to_pad.size(0) > 0:
|
||||
attention_mask_rm[i, : sequence_to_pad.size(0) + 1] = 1
|
||||
else:
|
||||
attention_mask_rm[i, :] = 1
|
||||
attention_mask_rm = attention_mask_rm.to(dtype=torch.bool)
|
||||
|
||||
r = self.reward_model(
|
||||
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
||||
attention_mask=attention_mask_rm.to(device=sequences.device),
|
||||
)
|
||||
|
||||
value = self.critic(
|
||||
input_ids=input_ids_rm.to(dtype=torch.long, device=sequences.device),
|
||||
attention_mask=attention_mask_rm.to(device=sequences.device),
|
||||
)
|
||||
reward, kl = compute_reward(r, self.kl_coef, action_log_probs, base_action_log_probs, action_mask=action_mask)
|
||||
value = value[:, -num_actions:] * action_mask
|
||||
advantages = self.calculate_advantage(value, reward, num_actions)
|
||||
|
||||
advantages = advantages.detach()
|
||||
value = value.detach()
|
||||
r = r.detach()
|
||||
|
||||
return Experience(sequences, action_log_probs, value, r, kl, advantages, attention_mask, action_mask)
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
from .base import BaseModel
|
||||
from .critic import Critic
|
||||
from .generation import generate, generate_streaming, prepare_inputs_fn, update_model_kwargs_fn
|
||||
from .lora import LoraConfig, convert_to_lora_module, lora_manager
|
||||
from .loss import DpoLoss, KTOLoss, LogExpLoss, LogSigLoss, PolicyLoss, ValueLoss
|
||||
from .reward_model import RewardModel
|
||||
from .utils import disable_dropout
|
||||
|
||||
__all__ = [
|
||||
"BaseModel",
|
||||
"Critic",
|
||||
"RewardModel",
|
||||
"PolicyLoss",
|
||||
"ValueLoss",
|
||||
"LogSigLoss",
|
||||
"LogExpLoss",
|
||||
"LoraConfig",
|
||||
"lora_manager",
|
||||
"convert_to_lora_module",
|
||||
"DpoLoss",
|
||||
"KTOLoss" "generate",
|
||||
"generate_streaming",
|
||||
"disable_dropout",
|
||||
"update_model_kwargs_fn",
|
||||
"prepare_inputs_fn",
|
||||
]
|
||||
|
|
@ -0,0 +1,57 @@
|
|||
"""
|
||||
Base class for critic and reward model
|
||||
"""
|
||||
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from transformers import AutoModel, PretrainedConfig
|
||||
|
||||
|
||||
class BaseModel(nn.Module):
|
||||
"""
|
||||
Actor model base class.
|
||||
|
||||
Args:
|
||||
pretrained (str): path to pretrained model.
|
||||
config (PretrainedConfig): PretrainedConfig used to initiate the base model.
|
||||
**kwargs: all other kwargs as in AutoModel.from_pretrained
|
||||
"""
|
||||
|
||||
def __init__(self, pretrained: str = None, config: Optional[PretrainedConfig] = None, **kwargs) -> None:
|
||||
super().__init__()
|
||||
if pretrained is not None:
|
||||
if config is not None:
|
||||
# initialize with config and load weights from pretrained
|
||||
self.model = AutoModel.from_pretrained(pretrained, config=config, **kwargs)
|
||||
else:
|
||||
# initialize with pretrained
|
||||
self.model = AutoModel.from_pretrained(pretrained, **kwargs)
|
||||
elif config is not None:
|
||||
# initialize with config
|
||||
self.model = AutoModel.from_config(config, **kwargs)
|
||||
else:
|
||||
raise ValueError("Either pretrained or config must be provided.")
|
||||
|
||||
self.config = self.model.config
|
||||
# create dummy input to get the size of the last hidden state
|
||||
if "use_flash_attention_2" in kwargs:
|
||||
self.model = self.model.cuda()
|
||||
dummy_input = torch.zeros((1, 1), dtype=torch.long).to(self.model.device)
|
||||
out = self.model(dummy_input)
|
||||
self.last_hidden_state_size = out.last_hidden_state.shape[-1]
|
||||
self.model = self.model.cpu()
|
||||
|
||||
def resize_token_embeddings(self, *args, **kwargs):
|
||||
"""
|
||||
Resize the token embeddings of the model.
|
||||
|
||||
Args:
|
||||
*args: Variable length argument list.
|
||||
**kwargs: Arbitrary keyword arguments.
|
||||
|
||||
Returns:
|
||||
The resized token embeddings.
|
||||
"""
|
||||
return self.model.resize_token_embeddings(*args, **kwargs)
|
||||
|
|
@ -0,0 +1,40 @@
|
|||
"""
|
||||
Critic model
|
||||
"""
|
||||
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from coati.models import BaseModel
|
||||
from transformers import PretrainedConfig
|
||||
|
||||
|
||||
class Critic(BaseModel):
|
||||
"""
|
||||
Critic model class.
|
||||
|
||||
Args:
|
||||
pretrained (str): path to pretrained model.
|
||||
config (PretrainedConfig): PretrainedConfig used to initiate the base model.
|
||||
"""
|
||||
|
||||
def __init__(self, pretrained: str = None, config: Optional[PretrainedConfig] = None, **kwargs) -> None:
|
||||
super().__init__(pretrained=pretrained, config=config, **kwargs)
|
||||
# et last hidden state size with dummy input
|
||||
self.value_head = nn.Linear(self.last_hidden_state_size, 1)
|
||||
|
||||
def forward(self, input_ids: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
outputs = self.model(input_ids, attention_mask=attention_mask)
|
||||
last_hidden_states = outputs["last_hidden_state"]
|
||||
sequence_hidden_states = last_hidden_states[torch.arange(last_hidden_states.size(0)), :].type(
|
||||
self.value_head.weight.dtype
|
||||
)
|
||||
values = self.value_head(sequence_hidden_states).squeeze(-1) # ensure shape is (B, sequence length)
|
||||
return values
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.get_input_embeddings()
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.model.get_output_embeddings()
|
||||
|
|
@ -0,0 +1,428 @@
|
|||
from typing import Any, Callable, List, Optional
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from transformers import PreTrainedTokenizer
|
||||
|
||||
try:
|
||||
from transformers.generation_logits_process import (
|
||||
LogitsProcessorList,
|
||||
TemperatureLogitsWarper,
|
||||
TopKLogitsWarper,
|
||||
TopPLogitsWarper,
|
||||
)
|
||||
except ImportError:
|
||||
from transformers.generation import LogitsProcessorList, TemperatureLogitsWarper, TopKLogitsWarper, TopPLogitsWarper
|
||||
|
||||
|
||||
def _prepare_logits_processor(
|
||||
top_k: Optional[int] = None, top_p: Optional[float] = None, temperature: Optional[float] = None
|
||||
) -> LogitsProcessorList:
|
||||
"""
|
||||
Prepare the logits processor list based on the given parameters.
|
||||
|
||||
Args:
|
||||
top_k (Optional[int]): The number of highest probability logits to keep for each token.
|
||||
top_p (Optional[float]): The cumulative probability threshold for selecting tokens.
|
||||
temperature (Optional[float]): The temperature value to apply to the logits.
|
||||
|
||||
Returns:
|
||||
LogitsProcessorList: The list of logits processors.
|
||||
|
||||
"""
|
||||
processor_list = LogitsProcessorList()
|
||||
if temperature is not None and temperature != 1.0:
|
||||
processor_list.append(TemperatureLogitsWarper(temperature))
|
||||
if top_k is not None and top_k != 0:
|
||||
processor_list.append(TopKLogitsWarper(top_k))
|
||||
if top_p is not None and top_p < 1.0:
|
||||
processor_list.append(TopPLogitsWarper(top_p))
|
||||
return processor_list
|
||||
|
||||
|
||||
def _is_sequence_finished(unfinished_sequences: torch.Tensor) -> bool:
|
||||
"""
|
||||
Check if the sequence generation is finished.
|
||||
|
||||
Args:
|
||||
unfinished_sequences (torch.Tensor): Tensor indicating the unfinished sequences.
|
||||
|
||||
Returns:
|
||||
bool: True if all sequences are finished, False otherwise.
|
||||
"""
|
||||
if dist.is_initialized() and dist.get_world_size() > 1:
|
||||
# consider DP
|
||||
unfinished_sequences = unfinished_sequences.clone()
|
||||
dist.all_reduce(unfinished_sequences)
|
||||
return unfinished_sequences.max() == 0
|
||||
|
||||
|
||||
def update_model_kwargs_fn(outputs: dict, new_mask, **model_kwargs) -> dict:
|
||||
"""
|
||||
Update the model keyword arguments based on the outputs and new mask.
|
||||
|
||||
Args:
|
||||
outputs (dict): The outputs from the model.
|
||||
new_mask: The new attention mask.
|
||||
**model_kwargs: Additional model keyword arguments.
|
||||
|
||||
Returns:
|
||||
dict: The updated model keyword arguments.
|
||||
"""
|
||||
|
||||
if "past_key_values" in outputs:
|
||||
model_kwargs["past_key_values"] = outputs["past_key_values"]
|
||||
else:
|
||||
model_kwargs["past_key_values"] = None
|
||||
|
||||
# update token_type_ids with last value
|
||||
if "token_type_ids" in model_kwargs:
|
||||
token_type_ids = model_kwargs["token_type_ids"]
|
||||
model_kwargs["token_type_ids"] = torch.cat([token_type_ids, token_type_ids[:, -1].unsqueeze(-1)], dim=-1)
|
||||
|
||||
# update attention mask
|
||||
if "attention_mask" in model_kwargs:
|
||||
attention_mask = model_kwargs["attention_mask"]
|
||||
model_kwargs["attention_mask"] = torch.cat([attention_mask, new_mask], dim=-1)
|
||||
|
||||
return model_kwargs
|
||||
|
||||
|
||||
def prepare_inputs_fn(input_ids: torch.Tensor, pad_token_id: int, **model_kwargs) -> dict:
|
||||
model_kwargs["input_ids"] = input_ids
|
||||
return model_kwargs
|
||||
|
||||
|
||||
def _sample(
|
||||
model: Any,
|
||||
input_ids: torch.Tensor,
|
||||
max_length: int,
|
||||
early_stopping: bool = True,
|
||||
eos_token_id: Optional[int] = None,
|
||||
pad_token_id: Optional[int] = None,
|
||||
stop_token_ids: Optional[List[int]] = None,
|
||||
top_k: Optional[int] = None,
|
||||
top_p: Optional[float] = None,
|
||||
temperature: Optional[float] = None,
|
||||
max_new_tokens: int = None,
|
||||
prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
|
||||
update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
|
||||
stream_interval: int = 2,
|
||||
**model_kwargs,
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Generates new tokens using the given model and input_ids.
|
||||
|
||||
Args:
|
||||
model (Any): The model used for token generation.
|
||||
input_ids (torch.Tensor): The input tensor containing the initial tokens.
|
||||
max_length (int): The maximum length of the generated tokens.
|
||||
early_stopping (bool, optional): Whether to stop generating tokens early if all sequences are finished. Defaults to True.
|
||||
eos_token_id (int, optional): The ID of the end-of-sequence token. Defaults to None.
|
||||
pad_token_id (int, optional): The ID of the padding token. Defaults to None.
|
||||
stop_token_ids (List[int], optional): A list of token IDs that, if encountered, will stop the generation process. Defaults to None.
|
||||
top_k (int, optional): The number of top-k tokens to consider during sampling. Defaults to None.
|
||||
top_p (float, optional): The cumulative probability threshold for top-p sampling. Defaults to None.
|
||||
temperature (float, optional): The temperature value for token sampling. Defaults to None.
|
||||
max_new_tokens (int, optional): The maximum number of new tokens to generate. Defaults to None.
|
||||
prepare_inputs_fn (Callable[[torch.Tensor, Any], dict], optional): A function to prepare the model inputs. Defaults to None.
|
||||
update_model_kwargs_fn (Callable[[dict, Any], dict], optional): A function to update the model kwargs. Defaults to None.
|
||||
stream_interval (int, optional): The interval for streaming generation. Defaults to 2.
|
||||
**model_kwargs: Additional keyword arguments for the model.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The tensor containing the generated tokens.
|
||||
"""
|
||||
context_length = input_ids.size(1)
|
||||
if max_new_tokens is None:
|
||||
max_new_tokens = max_length - context_length
|
||||
if context_length + max_new_tokens > max_length or max_new_tokens == 0:
|
||||
return input_ids
|
||||
|
||||
logits_processor = _prepare_logits_processor(top_k, top_p, temperature)
|
||||
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
|
||||
past = None
|
||||
for i in range(context_length, context_length + max_new_tokens):
|
||||
# Calculate attention mask
|
||||
if "attention_mask" not in model_kwargs:
|
||||
model_kwargs["attention_mask"] = input_ids.ne(pad_token_id)
|
||||
model_inputs = (
|
||||
prepare_inputs_fn(input_ids, past=past, **model_kwargs)
|
||||
if prepare_inputs_fn is not None
|
||||
else {"input_ids": input_ids, "attention_mask": input_ids.ne(pad_token_id)}
|
||||
)
|
||||
outputs = model(**model_inputs)
|
||||
|
||||
if "past_key_values" in outputs:
|
||||
past = outputs.past_key_values
|
||||
elif "mems" in outputs:
|
||||
past = outputs.mems
|
||||
|
||||
# NOTE: this is correct only in left padding mode
|
||||
next_token_logits = outputs["logits"][:, -1, :]
|
||||
next_token_logits = logits_processor(input_ids, next_token_logits)
|
||||
|
||||
# Sample
|
||||
probs = torch.softmax(next_token_logits, dim=-1, dtype=torch.float)
|
||||
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
|
||||
|
||||
# Finished sentences should have their next token be a padding token
|
||||
if eos_token_id is not None:
|
||||
assert pad_token_id is not None, "If `eos_token_id` is defined, make sure that `pad_token_id` is defined."
|
||||
next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
|
||||
|
||||
# Update generated ids, model inputs for next step
|
||||
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
|
||||
|
||||
if update_model_kwargs_fn is not None:
|
||||
model_kwargs = update_model_kwargs_fn(outputs, model_kwargs)
|
||||
|
||||
# If eos_token was found in one sentence, set sentence to finished
|
||||
if eos_token_id is not None:
|
||||
unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
|
||||
|
||||
if stop_token_ids is not None:
|
||||
# If the last len(stop_token_ids) tokens of input_ids are equal to stop_token_ids, set sentence to finished.
|
||||
tokens_to_check = input_ids[:, -len(stop_token_ids) :]
|
||||
unfinished_sequences = unfinished_sequences.mul(
|
||||
torch.any(tokens_to_check != torch.LongTensor(stop_token_ids).to(input_ids.device), dim=1).long()
|
||||
)
|
||||
|
||||
# Stop when each sentence is finished if early_stopping=True
|
||||
if (early_stopping and _is_sequence_finished(unfinished_sequences)) or i == context_length + max_new_tokens - 1:
|
||||
if i == context_length + max_new_tokens - 1:
|
||||
# Force to end with stop token ids
|
||||
input_ids[input_ids[:, -1] != pad_token_id, -len(stop_token_ids) :] = (
|
||||
torch.LongTensor(stop_token_ids).to(input_ids.device).long()
|
||||
)
|
||||
return input_ids
|
||||
|
||||
|
||||
@torch.inference_mode()
|
||||
def generate(
|
||||
model: Any,
|
||||
input_ids: torch.Tensor,
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
max_length: int,
|
||||
num_beams: int = 1,
|
||||
do_sample: bool = True,
|
||||
early_stopping: bool = True,
|
||||
top_k: Optional[int] = None,
|
||||
top_p: Optional[float] = None,
|
||||
temperature: Optional[float] = None,
|
||||
prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
|
||||
update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
|
||||
**model_kwargs,
|
||||
) -> torch.Tensor:
|
||||
"""Generate token sequence. The returned sequence is input_ids + generated_tokens.
|
||||
|
||||
Args:
|
||||
model (nn.Module): model
|
||||
input_ids (torch.Tensor): input sequence
|
||||
max_length (int): max length of the returned sequence
|
||||
num_beams (int, optional): number of beams. Defaults to 1.
|
||||
do_sample (bool, optional): whether to do sample. Defaults to True.
|
||||
early_stopping (bool, optional): if True, the sequence length may be smaller than max_length due to finding eos. Defaults to False.
|
||||
top_k (Optional[int], optional): the number of highest probability vocabulary tokens to keep for top-k-filtering. Defaults to None.
|
||||
top_p (Optional[float], optional): If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation. Defaults to None.
|
||||
temperature (Optional[float], optional): The value used to module the next token probabilities. Defaults to None.
|
||||
prepare_inputs_fn (Optional[Callable[[torch.Tensor, Any], dict]], optional): Function to preprocess model inputs. Arguments of this function should be input_ids and model_kwargs. Defaults to None.
|
||||
update_model_kwargs_fn (Optional[Callable[[dict, Any], dict]], optional): Function to update model_kwargs based on outputs. Arguments of this function should be outputs and model_kwargs. Defaults to None.
|
||||
"""
|
||||
assert tokenizer.padding_side == "left", "Current generation only supports left padding."
|
||||
is_greedy_gen_mode = (num_beams == 1) and do_sample is False
|
||||
is_sample_gen_mode = (num_beams == 1) and do_sample is True
|
||||
is_beam_gen_mode = (num_beams > 1) and do_sample is False
|
||||
if is_greedy_gen_mode:
|
||||
raise NotImplementedError
|
||||
elif is_sample_gen_mode:
|
||||
# Run sample
|
||||
res = _sample(
|
||||
model,
|
||||
input_ids,
|
||||
max_length,
|
||||
early_stopping=early_stopping,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
top_k=top_k,
|
||||
top_p=top_p,
|
||||
temperature=temperature,
|
||||
prepare_inputs_fn=prepare_inputs_fn,
|
||||
update_model_kwargs_fn=update_model_kwargs_fn,
|
||||
**model_kwargs,
|
||||
)
|
||||
return res
|
||||
elif is_beam_gen_mode:
|
||||
raise NotImplementedError
|
||||
else:
|
||||
raise ValueError("Unsupported generation mode")
|
||||
|
||||
|
||||
def _sample_streaming(
|
||||
model: Any,
|
||||
input_ids: torch.Tensor,
|
||||
max_length: int,
|
||||
early_stopping: bool = False,
|
||||
eos_token_id: Optional[int] = None,
|
||||
pad_token_id: Optional[int] = None,
|
||||
stop_token_ids: Optional[List[int]] = None,
|
||||
top_k: Optional[int] = None,
|
||||
top_p: Optional[float] = None,
|
||||
temperature: Optional[float] = None,
|
||||
max_new_tokens: int = None,
|
||||
prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
|
||||
update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
|
||||
stream_interval: int = 2,
|
||||
**model_kwargs,
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Generates new tokens using a streaming approach.
|
||||
|
||||
Args:
|
||||
model (Any): The model used for token generation.
|
||||
input_ids (torch.Tensor): The input tensor containing the initial tokens.
|
||||
max_length (int): The maximum length of the generated sequence.
|
||||
early_stopping (bool, optional): Whether to stop generating tokens for a sequence if it is finished. Defaults to False.
|
||||
eos_token_id (int, optional): The ID of the end-of-sequence token. Defaults to None.
|
||||
pad_token_id (int, optional): The ID of the padding token. Defaults to None.
|
||||
stop_token_ids (List[int], optional): A list of token IDs that, if encountered, will mark the sequence as finished. Defaults to None.
|
||||
top_k (int, optional): The number of top-k tokens to consider during sampling. Defaults to None.
|
||||
top_p (float, optional): The cumulative probability threshold for top-p sampling. Defaults to None.
|
||||
temperature (float, optional): The temperature value for sampling. Defaults to None.
|
||||
max_new_tokens (int, optional): The maximum number of new tokens to generate. Defaults to None.
|
||||
prepare_inputs_fn (Callable[[torch.Tensor, Any], dict], optional): A function to prepare the model inputs. Defaults to None.
|
||||
update_model_kwargs_fn (Callable[[dict, Any], dict], optional): A function to update the model keyword arguments. Defaults to None.
|
||||
stream_interval (int, optional): The interval at which to yield the generated tokens. Defaults to 2.
|
||||
**model_kwargs: Additional keyword arguments to be passed to the model.
|
||||
|
||||
Yields:
|
||||
torch.Tensor: The generated tokens at each step.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The final generated tokens.
|
||||
"""
|
||||
|
||||
context_length = input_ids.size(1)
|
||||
if max_new_tokens is None:
|
||||
max_new_tokens = max_length - context_length
|
||||
if context_length + max_new_tokens > max_length or max_new_tokens == 0:
|
||||
return input_ids
|
||||
|
||||
logits_processor = _prepare_logits_processor(top_k, top_p, temperature)
|
||||
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
|
||||
|
||||
past = None
|
||||
for i in range(context_length, context_length + max_new_tokens):
|
||||
# calculate attention mask
|
||||
if "attention_mask" not in model_kwargs:
|
||||
model_kwargs["attention_mask"] = input_ids.ne(pad_token_id)
|
||||
model_inputs = (
|
||||
prepare_inputs_fn(input_ids, past=past, **model_kwargs)
|
||||
if prepare_inputs_fn is not None
|
||||
else {"input_ids": input_ids, "attention_mask": input_ids.ne(pad_token_id)}
|
||||
)
|
||||
outputs = model(**model_inputs)
|
||||
if "past_key_values" in outputs:
|
||||
past = outputs.past_key_values
|
||||
elif "mems" in outputs:
|
||||
past = outputs.mems
|
||||
|
||||
# NOTE: this is correct only in left padding mode
|
||||
next_token_logits = outputs["logits"][:, -1, :]
|
||||
next_token_logits = logits_processor(input_ids, next_token_logits)
|
||||
# sample
|
||||
probs = torch.softmax(next_token_logits, dim=-1, dtype=torch.float)
|
||||
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
|
||||
|
||||
# finished sentences should have their next token be a padding token
|
||||
if eos_token_id is not None:
|
||||
assert pad_token_id is not None, "If `eos_token_id` is defined, make sure that `pad_token_id` is defined."
|
||||
next_tokens = next_tokens * unfinished_sequences + pad_token_id * (1 - unfinished_sequences)
|
||||
|
||||
# update generated ids, model inputs for next step
|
||||
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
|
||||
|
||||
if update_model_kwargs_fn is not None:
|
||||
model_kwargs = update_model_kwargs_fn(outputs, model_kwargs)
|
||||
|
||||
# if eos_token was found in one sentence, set sentence to finished
|
||||
if eos_token_id is not None:
|
||||
unfinished_sequences = unfinished_sequences.mul((next_tokens != eos_token_id).long())
|
||||
|
||||
if stop_token_ids is not None:
|
||||
# If the last len(stop_token_ids) tokens of input_ids are equal to stop_token_ids, set sentence to finished.
|
||||
tokens_to_check = input_ids[:, -len(stop_token_ids) :]
|
||||
unfinished_sequences = unfinished_sequences.mul(
|
||||
torch.any(tokens_to_check != torch.LongTensor(stop_token_ids).to(input_ids.device), dim=1).long()
|
||||
)
|
||||
|
||||
# Stop when each sentence is finished if early_stopping=True
|
||||
if (
|
||||
(early_stopping and _is_sequence_finished(unfinished_sequences))
|
||||
or (i - context_length) % stream_interval == 0
|
||||
or i == context_length + max_new_tokens - 1
|
||||
):
|
||||
yield input_ids
|
||||
if early_stopping and _is_sequence_finished(unfinished_sequences):
|
||||
break
|
||||
|
||||
|
||||
@torch.inference_mode()
|
||||
def generate_streaming(
|
||||
model: Any,
|
||||
input_ids: torch.Tensor,
|
||||
tokenizer: PreTrainedTokenizer,
|
||||
max_length: int,
|
||||
num_beams: int = 1,
|
||||
do_sample: bool = True,
|
||||
early_stopping: bool = False,
|
||||
top_k: Optional[int] = None,
|
||||
top_p: Optional[float] = None,
|
||||
temperature: Optional[float] = None,
|
||||
prepare_inputs_fn: Optional[Callable[[torch.Tensor, Any], dict]] = None,
|
||||
update_model_kwargs_fn: Optional[Callable[[dict, Any], dict]] = None,
|
||||
**model_kwargs,
|
||||
):
|
||||
"""Generate token sequence. The returned sequence is input_ids + generated_tokens.
|
||||
|
||||
Args:
|
||||
model (nn.Module): model
|
||||
input_ids (torch.Tensor): input sequence
|
||||
max_length (int): max length of the returned sequence
|
||||
num_beams (int, optional): number of beams. Defaults to 1.
|
||||
do_sample (bool, optional): whether to do sample. Defaults to True.
|
||||
early_stopping (bool, optional): if True, the sequence length may be smaller than max_length due to finding eos. Defaults to False.
|
||||
top_k (Optional[int], optional): the number of highest probability vocabulary tokens to keep for top-k-filtering. Defaults to None.
|
||||
top_p (Optional[float], optional): If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation. Defaults to None.
|
||||
temperature (Optional[float], optional): The value used to module the next token probabilities. Defaults to None.
|
||||
prepare_inputs_fn (Optional[Callable[[torch.Tensor, Any], dict]], optional): Function to preprocess model inputs. Arguments of this function should be input_ids and model_kwargs. Defaults to None.
|
||||
update_model_kwargs_fn (Optional[Callable[[dict, Any], dict]], optional): Function to update model_kwargs based on outputs. Arguments of this function should be outputs and model_kwargs. Defaults to None.
|
||||
"""
|
||||
assert tokenizer.padding_side == "left", "Current generation only supports left padding."
|
||||
is_greedy_gen_mode = (num_beams == 1) and do_sample is False
|
||||
is_sample_gen_mode = (num_beams == 1) and do_sample is True
|
||||
is_beam_gen_mode = (num_beams > 1) and do_sample is False
|
||||
if is_greedy_gen_mode:
|
||||
# run greedy search
|
||||
raise NotImplementedError
|
||||
elif is_sample_gen_mode:
|
||||
# run sample
|
||||
for res in _sample_streaming(
|
||||
model,
|
||||
input_ids,
|
||||
max_length,
|
||||
early_stopping=early_stopping,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
top_k=top_k,
|
||||
top_p=top_p,
|
||||
temperature=temperature,
|
||||
prepare_inputs_fn=prepare_inputs_fn,
|
||||
update_model_kwargs_fn=update_model_kwargs_fn,
|
||||
**model_kwargs,
|
||||
):
|
||||
yield res
|
||||
elif is_beam_gen_mode:
|
||||
raise NotImplementedError
|
||||
else:
|
||||
raise ValueError("Unsupported generation mode")
|
||||
|
|
@ -0,0 +1,367 @@
|
|||
"""
|
||||
LORA utils
|
||||
"""
|
||||
|
||||
import dataclasses
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Union
|
||||
|
||||
import loralib as lora
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
|
||||
from colossalai.logging import get_dist_logger
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class LoraManager:
|
||||
able_to_merge: bool = True
|
||||
|
||||
|
||||
lora_manager = LoraManager()
|
||||
|
||||
|
||||
@dataclasses.dataclass
|
||||
class LoraConfig:
|
||||
r: int = 0
|
||||
lora_alpha: int = 32
|
||||
linear_lora_dropout: float = 0.1
|
||||
embedding_lora_dropout: float = 0.0
|
||||
lora_train_bias: str = "none"
|
||||
lora_initialization_method: str = "kaiming_uniform"
|
||||
target_modules: List = None
|
||||
|
||||
@classmethod
|
||||
def from_file(cls, config_file: str):
|
||||
import json
|
||||
|
||||
with open(config_file, "r") as f:
|
||||
config = json.load(f)
|
||||
return cls(**config)
|
||||
|
||||
|
||||
class LoraBase(lora.LoRALayer, nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
r: int = 0,
|
||||
lora_alpha: int = 32,
|
||||
lora_dropout: float = 0.1,
|
||||
lora_initialization_method: str = "kaiming_uniform",
|
||||
):
|
||||
nn.Module.__init__(self)
|
||||
lora.LoRALayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=False)
|
||||
self.r = r
|
||||
self.lora_alpha = lora_alpha
|
||||
self.lora_dropout = nn.Dropout(lora_dropout)
|
||||
self.merged = False
|
||||
self.lora_initialization_method = lora_initialization_method
|
||||
self.weight = None
|
||||
self.bias = None
|
||||
self.lora_A = None
|
||||
self.lora_B = None
|
||||
|
||||
def reset_parameters(self):
|
||||
if hasattr(self, "lora_A"):
|
||||
if self.lora_initialization_method == "kaiming_uniform" or self.weight.size() != (
|
||||
self.out_features,
|
||||
self.in_features,
|
||||
):
|
||||
# Initialize A with the default values for nn.Linear and set B to zero.
|
||||
nn.init.kaiming_uniform_(self.lora_A, a=math.sqrt(5))
|
||||
nn.init.zeros_(self.lora_B)
|
||||
elif self.lora_initialization_method == "PiSSA":
|
||||
# PiSSA method in this paper: https://arxiv.org/abs/2404.02948
|
||||
# Assume the SVD of the original weights is W = USV^T
|
||||
# Initialize a frozen weight to U[:,r:]S[r:,r:]V^T[:,r:] to store less significent part of W
|
||||
# Only A, B are trainable, which are initialized to S[r:,:r]^0.5V^T[:,:r] and U[:,:r]S[r:,:r] respectively
|
||||
# self.scaling = 1.
|
||||
# SVD
|
||||
U, S, Vh = torch.svd_lowrank(
|
||||
self.weight.to(torch.float32).data, self.r, niter=4
|
||||
) # U: [out_features, in_features], S: [in_features], V: [in_features, in_features]
|
||||
# weight_backup = self.weight.clone()
|
||||
|
||||
# Initialize A, B
|
||||
S = S / self.scaling
|
||||
self.lora_B.data = (U @ torch.diag(torch.sqrt(S))).to(torch.float32).contiguous()
|
||||
self.lora_A.data = (torch.diag(torch.sqrt(S)) @ Vh.T).to(torch.float32).contiguous()
|
||||
# Initialize weight
|
||||
# To reduce floating point error, we use residual instead of directly using U[:, :self.r] @ S[:self.r] @ Vh[:self.r, :]
|
||||
self.weight.data = (
|
||||
((self.weight - self.scaling * self.lora_B @ self.lora_A)).contiguous().to(self.weight.dtype)
|
||||
)
|
||||
self.lora_A.requires_grad = True
|
||||
self.lora_B.requires_grad = True
|
||||
else:
|
||||
raise ValueError(f"Unknown LoRA initialization method {self.lora_initialization_method}")
|
||||
|
||||
def train(self, mode: bool = True):
|
||||
"""
|
||||
This function runs when model.train() is invoked. It is used to prepare the linear layer for training
|
||||
"""
|
||||
|
||||
self.training = mode
|
||||
if mode and self.merged:
|
||||
warnings.warn("Invoke module.train() would unmerge LoRA weights.")
|
||||
raise NotImplementedError("LoRA unmerge is not tested.")
|
||||
elif not mode and not self.merged and lora_manager.able_to_merge:
|
||||
warnings.warn("Invoke module.eval() would merge LoRA weights.")
|
||||
# Merge the weights and mark it
|
||||
if self.r > 0:
|
||||
self.weight.data += self.lora_B @ self.lora_A * self.scaling
|
||||
delattr(self, "lora_A")
|
||||
delattr(self, "lora_B")
|
||||
self.merged = True
|
||||
|
||||
return self
|
||||
|
||||
|
||||
class LoraLinear(LoraBase):
|
||||
"""Replace in-place ops to out-of-place ops to fit gemini. Convert a torch.nn.Linear to LoraLinear."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
weight: nn.Parameter,
|
||||
bias: Union[nn.Parameter, bool],
|
||||
r: int = 0,
|
||||
lora_alpha: int = 32,
|
||||
lora_dropout: float = 0.0,
|
||||
lora_initialization_method: str = "kaiming_uniform",
|
||||
):
|
||||
super().__init__(
|
||||
r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, lora_initialization_method=lora_initialization_method
|
||||
)
|
||||
self.weight = weight
|
||||
self.bias = bias
|
||||
if bias is True:
|
||||
self.bias = nn.Parameter(torch.zeros(weight.shape[0]))
|
||||
if bias is not None:
|
||||
self.bias.requires_grad = True
|
||||
|
||||
out_features, in_features = weight.shape
|
||||
self.in_features = in_features
|
||||
self.out_features = out_features
|
||||
assert lora_initialization_method in ["kaiming_uniform", "PiSSA"]
|
||||
self.lora_initialization_method = lora_initialization_method
|
||||
# Actual trainable parameters
|
||||
if r > 0:
|
||||
self.lora_A = nn.Parameter(torch.randn((r, in_features)))
|
||||
self.lora_B = nn.Parameter(torch.randn((out_features, r)))
|
||||
self.scaling = self.lora_alpha / self.r
|
||||
# Freezing the pre-trained weight matrix
|
||||
self.weight.requires_grad = False
|
||||
self.reset_parameters()
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
if self.r > 0 and not self.merged:
|
||||
result = F.linear(x, self.weight, bias=self.bias)
|
||||
result = result + (self.lora_dropout(x) @ self.lora_A.t() @ self.lora_B.t()) * self.scaling
|
||||
return result
|
||||
else:
|
||||
return F.linear(x, self.weight, bias=self.bias)
|
||||
|
||||
|
||||
class LoraEmbedding(LoraBase):
|
||||
"""Replace in-place ops to out-of-place ops to fit gemini. Convert a torch.nn.Linear to LoraLinear."""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
weight: nn.Parameter,
|
||||
r: int = 0,
|
||||
lora_alpha: int = 32,
|
||||
lora_dropout: float = 0.1,
|
||||
num_embeddings: int = None,
|
||||
embedding_dim: int = None,
|
||||
padding_idx: Optional[int] = None,
|
||||
max_norm: Optional[float] = None,
|
||||
norm_type: float = 2.0,
|
||||
scale_grad_by_freq: bool = False,
|
||||
sparse: bool = False,
|
||||
lora_initialization_method: str = "kaiming_uniform",
|
||||
):
|
||||
super().__init__(
|
||||
r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, lora_initialization_method=lora_initialization_method
|
||||
)
|
||||
self.padding_idx = padding_idx
|
||||
self.max_norm = max_norm
|
||||
self.norm_type = norm_type
|
||||
self.scale_grad_by_freq = scale_grad_by_freq
|
||||
self.sparse = sparse
|
||||
self.num_embeddings = num_embeddings
|
||||
self.embedding_dim = embedding_dim
|
||||
|
||||
self.weight = weight
|
||||
|
||||
in_features, out_features = num_embeddings, embedding_dim
|
||||
self.in_features = in_features
|
||||
self.out_features = out_features
|
||||
assert lora_initialization_method in ["kaiming_uniform", "PiSSA"]
|
||||
self.lora_initialization_method = lora_initialization_method
|
||||
|
||||
# Actual trainable parameters
|
||||
if r > 0:
|
||||
self.lora_A = nn.Parameter(torch.randn((r, in_features)))
|
||||
self.lora_B = nn.Parameter(torch.randn((out_features, r)))
|
||||
self.scaling = self.lora_alpha / self.r
|
||||
# Freezing the pre-trained weight matrix
|
||||
self.weight.requires_grad = False
|
||||
|
||||
# reset parameters
|
||||
nn.init.zeros_(self.lora_A)
|
||||
nn.init.normal_(self.lora_B)
|
||||
|
||||
def _embed(self, x: torch.Tensor, weight) -> torch.Tensor:
|
||||
return F.embedding(
|
||||
x,
|
||||
weight,
|
||||
padding_idx=self.padding_idx,
|
||||
max_norm=self.max_norm,
|
||||
norm_type=self.norm_type,
|
||||
scale_grad_by_freq=self.scale_grad_by_freq,
|
||||
sparse=self.sparse,
|
||||
)
|
||||
|
||||
def forward(self, x: torch.Tensor):
|
||||
base_embedding = self._embed(x, self.weight)
|
||||
# base_embedding.requires_grad = True # force the embedding layer to be trainable for gradient checkpointing
|
||||
if self.r > 0 and not self.merged:
|
||||
lora_A_embedding = self._embed(x, self.lora_A.t())
|
||||
embedding = base_embedding + (lora_A_embedding @ self.lora_B.t()) * self.scaling
|
||||
return embedding
|
||||
else:
|
||||
return base_embedding
|
||||
|
||||
def train(self, mode: bool = True):
|
||||
"""
|
||||
This function runs when model.train() is invoked. It is used to prepare the linear layer for training
|
||||
"""
|
||||
|
||||
self.training = mode
|
||||
if mode and self.merged:
|
||||
warnings.warn("Invoke module.train() would unmerge LoRA weights.")
|
||||
raise NotImplementedError("LoRA unmerge is not tested.")
|
||||
elif not mode and not self.merged and lora_manager.able_to_merge:
|
||||
warnings.warn("Invoke module.eval() would merge LoRA weights.")
|
||||
# Merge the weights and mark it
|
||||
if self.r > 0:
|
||||
self.weight.data += self.lora_A.t() @ self.lora_B.t() * self.scaling
|
||||
delattr(self, "lora_A")
|
||||
delattr(self, "lora_B")
|
||||
self.merged = True
|
||||
|
||||
return self
|
||||
|
||||
|
||||
def _lora_linear_wrapper(linear: nn.Linear, lora_config: LoraConfig) -> LoraLinear:
|
||||
"""
|
||||
Wraps a linear layer with LoRA functionality.
|
||||
|
||||
Args:
|
||||
linear (nn.Linear): The linear layer to be wrapped.
|
||||
lora_rank (int): The rank of the LoRA decomposition.
|
||||
lora_train_bias (str): Whether to train the bias. Can be "none", "all", "lora".
|
||||
lora_initialization_method (str): The initialization method for LoRA. Can be "kaiming_uniform" or "PiSSA".
|
||||
|
||||
Returns:
|
||||
LoraLinear: The wrapped linear layer with LoRA functionality.
|
||||
"""
|
||||
assert (
|
||||
lora_config.r <= linear.in_features
|
||||
), f"LoRA rank ({lora_config.r}) must be less than or equal to in features ({linear.in_features})"
|
||||
bias = None
|
||||
if lora_config.lora_train_bias in ["all", "lora"]:
|
||||
bias = linear.bias
|
||||
if bias is None:
|
||||
bias = True
|
||||
lora_linear = LoraLinear(
|
||||
linear.weight, bias, r=lora_config.r, lora_initialization_method=lora_config.lora_initialization_method
|
||||
)
|
||||
return lora_linear
|
||||
|
||||
|
||||
def _convert_to_lora_recursively(module: nn.Module, parent_name: str, lora_config: LoraConfig) -> None:
|
||||
"""
|
||||
Recursively converts the given module and its children to LoRA (Low-Rank Approximation) form.
|
||||
|
||||
Args:
|
||||
module (nn.Module): The module to convert to LoRA form.
|
||||
lora_rank (int): The rank of the LoRA approximation.
|
||||
lora_train_bias (str): Whether to train the bias. Can be "none", "all", "lora".
|
||||
parent_name (str): The name of the parent module.
|
||||
lora_initialization_method (str): The initialization method for LoRA. Can be "kaiming_uniform" or "PiSSA".
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
for name, child in module.named_children():
|
||||
if isinstance(child, nn.Linear):
|
||||
if lora_config.target_modules is None or any(
|
||||
[name in target_module for target_module in lora_config.target_modules]
|
||||
):
|
||||
if dist.is_initialized() and dist.get_rank() == 0:
|
||||
logger.info(f"Converting {parent_name}.{name} to LoRA")
|
||||
setattr(module, name, _lora_linear_wrapper(child, lora_config))
|
||||
elif isinstance(child, nn.Embedding):
|
||||
if lora_config.target_modules is None or any(
|
||||
[name in target_module for target_module in lora_config.target_modules]
|
||||
):
|
||||
if dist.is_initialized() and dist.get_rank() == 0:
|
||||
logger.info(f"Converting {parent_name}.{name} to LoRA")
|
||||
setattr(
|
||||
module,
|
||||
name,
|
||||
LoraEmbedding(
|
||||
child.weight,
|
||||
r=lora_config.r,
|
||||
lora_alpha=lora_config.lora_alpha,
|
||||
lora_dropout=lora_config.embedding_lora_dropout,
|
||||
num_embeddings=child.num_embeddings,
|
||||
embedding_dim=child.embedding_dim,
|
||||
padding_idx=child.padding_idx,
|
||||
max_norm=child.max_norm,
|
||||
norm_type=child.norm_type,
|
||||
scale_grad_by_freq=child.scale_grad_by_freq,
|
||||
sparse=child.sparse,
|
||||
lora_initialization_method=lora_config.lora_initialization_method,
|
||||
),
|
||||
)
|
||||
else:
|
||||
_convert_to_lora_recursively(child, f"{parent_name}.{name}", lora_config)
|
||||
|
||||
|
||||
def convert_to_lora_module(module: nn.Module, lora_config: LoraConfig) -> nn.Module:
|
||||
"""Convert a torch.nn.Module to a LoRA module.
|
||||
|
||||
Args:
|
||||
module (nn.Module): The module to convert.
|
||||
lora_rank (int): LoRA rank.
|
||||
lora_train_bias (str): Whether to train the bias. Can be "none", "all", "lora".
|
||||
lora_initialization_method (str): The initialization method for LoRA. Can be "kaiming_uniform" or "PiSSA".
|
||||
|
||||
Returns:
|
||||
nn.Module: The converted module.
|
||||
"""
|
||||
if lora_config.r <= 0:
|
||||
return module
|
||||
# make all parameter not trainable, if lora_train_bias is "all", set bias to trainable
|
||||
total_parameter_size = 0
|
||||
for name, p in module.named_parameters():
|
||||
p.requires_grad = False
|
||||
if "bias" in name and lora_config.lora_train_bias == "all":
|
||||
p.requires_grad = True
|
||||
total_parameter_size += p.numel()
|
||||
_convert_to_lora_recursively(module, "", lora_config)
|
||||
trainable_parameter_size = 0
|
||||
for name, p in module.named_parameters():
|
||||
if p.requires_grad == True:
|
||||
trainable_parameter_size += p.numel()
|
||||
if dist.is_initialized() and dist.get_rank() == 0:
|
||||
logger.info(
|
||||
f"Trainable parameter size: {trainable_parameter_size/1024/1024:.2f}M\nOriginal trainable parameter size: {total_parameter_size/1024/1024:.2f}M\nPercentage: {trainable_parameter_size/total_parameter_size*100:.2f}%"
|
||||
)
|
||||
return module
|
||||
|
|
@ -0,0 +1,281 @@
|
|||
"""
|
||||
loss functions
|
||||
"""
|
||||
|
||||
from typing import Optional, Tuple
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.nn as nn
|
||||
|
||||
from .utils import masked_mean
|
||||
|
||||
|
||||
class GPTLMLoss(nn.Module):
|
||||
"""
|
||||
GPT Language Model Loss
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
# NOTE: default ignore_index is -100, which is equal to IGNORE_INDEX in sft_dataset.py
|
||||
self.loss = nn.CrossEntropyLoss()
|
||||
|
||||
def forward(self, logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
|
||||
shift_logits = logits[..., :-1, :].contiguous()
|
||||
shift_labels = labels[..., 1:].contiguous()
|
||||
# Flatten the tokens
|
||||
return self.loss(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
|
||||
|
||||
|
||||
class PolicyLoss(nn.Module):
|
||||
"""
|
||||
Policy Loss for PPO
|
||||
"""
|
||||
|
||||
def __init__(self, clip_eps: float = 0.2, skip_threshold: float = 20.0) -> None:
|
||||
super().__init__()
|
||||
self.clip_eps = clip_eps
|
||||
self.skip_threshold = skip_threshold
|
||||
|
||||
def forward(
|
||||
self,
|
||||
log_probs: torch.Tensor,
|
||||
old_log_probs: torch.Tensor,
|
||||
advantages: torch.Tensor,
|
||||
action_mask: Optional[torch.Tensor] = None,
|
||||
) -> torch.Tensor:
|
||||
skip = False
|
||||
if action_mask is None:
|
||||
ratio_ = (log_probs - old_log_probs).exp()
|
||||
else:
|
||||
ratio_ = ((log_probs - old_log_probs) * action_mask).exp()
|
||||
|
||||
# note that if dropout is disabled (recommanded), ratio will always be 1.
|
||||
if ratio_.mean() > self.skip_threshold:
|
||||
skip = True
|
||||
|
||||
ratio = ratio_.clamp(0.0, 10.0)
|
||||
surr1 = ratio * advantages
|
||||
surr2 = ratio.clamp(1 - self.clip_eps, 1 + self.clip_eps) * advantages
|
||||
loss = -torch.min(surr1, surr2)
|
||||
if action_mask is not None:
|
||||
loss = masked_mean(loss, action_mask)
|
||||
else:
|
||||
loss = loss.mean(dim=1)
|
||||
loss = loss.mean()
|
||||
return loss, skip, ratio_.max()
|
||||
|
||||
|
||||
class ValueLoss(nn.Module):
|
||||
"""
|
||||
Value Loss for PPO
|
||||
"""
|
||||
|
||||
def __init__(self, clip_eps: float = 0.2) -> None:
|
||||
super().__init__()
|
||||
self.clip_eps = clip_eps
|
||||
|
||||
def forward(
|
||||
self,
|
||||
values: torch.Tensor,
|
||||
old_values: torch.Tensor,
|
||||
advantage: torch.Tensor,
|
||||
action_mask: Optional[torch.Tensor] = None,
|
||||
) -> torch.Tensor:
|
||||
returns = advantage + old_values
|
||||
values_clipped = old_values + (values - old_values).clamp(-self.clip_eps, self.clip_eps)
|
||||
surr1 = (values_clipped - returns) ** 2
|
||||
surr2 = (values - returns) ** 2
|
||||
if action_mask is not None:
|
||||
loss = torch.sum(torch.max(surr1, surr2) / torch.sum(action_mask) * action_mask)
|
||||
else:
|
||||
loss = torch.mean(torch.max(surr1, surr2))
|
||||
return 0.5 * loss
|
||||
|
||||
|
||||
class DpoLoss(nn.Module):
|
||||
"""
|
||||
Dpo loss
|
||||
Details: https://arxiv.org/pdf/2305.18290.pdf
|
||||
|
||||
SimPO loss:
|
||||
Details: https://arxiv.org/pdf/2405.14734.pdf
|
||||
"""
|
||||
|
||||
def __init__(self, beta: float = 0.1, gamma: float = 0.0):
|
||||
"""
|
||||
Args:
|
||||
beta: The temperature parameter in the DPO paper.
|
||||
gamma: The margin parameter in the SimPO paper.
|
||||
length_normalization: Whether to normalize the loss by the length of chosen and rejected responses.
|
||||
Refer to the length normalization in the SimPO paper
|
||||
"""
|
||||
super().__init__()
|
||||
self.beta = beta
|
||||
self.gamma = gamma
|
||||
|
||||
def forward(
|
||||
self,
|
||||
logprob_actor_chosen: torch.Tensor,
|
||||
logprob_actor_reject: torch.Tensor,
|
||||
logprob_ref_chosen: torch.Tensor,
|
||||
logprob_ref_reject: torch.Tensor,
|
||||
chosen_mask: torch.Tensor,
|
||||
reject_mask: torch.Tensor,
|
||||
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
|
||||
"""Compute the DPO/SimPO loss for a batch of policy and reference model log probabilities.
|
||||
|
||||
# adapted from https://github.com/huggingface/trl/blob/main/trl/trainer/dpo_trainer.py#L328
|
||||
|
||||
Args:
|
||||
logprob_actor_chosen: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)
|
||||
logprob_actor_reject: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)
|
||||
logprob_ref_chosen: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)
|
||||
logprob_ref_reject: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)
|
||||
chosen_mask: Mask tensor indicating which responses were chosen. Shape: (batch_size,)
|
||||
reject_mask: Mask tensor indicating which responses were rejected. Shape: (batch_size,)
|
||||
|
||||
Returns:
|
||||
A tuple of three tensors: (losses, chosen_rewards, rejected_rewards).
|
||||
The losses tensor contains the DPO loss for each example in the batch.
|
||||
The chosen_rewards and rejected_rewards tensors contain the rewards for the chosen and rejected responses, respectively.
|
||||
"""
|
||||
logprob_actor_chosen = logprob_actor_chosen * chosen_mask
|
||||
logprob_actor_reject = logprob_actor_reject * reject_mask
|
||||
if logprob_ref_chosen is not None and logprob_ref_reject is not None:
|
||||
logprob_ref_chosen = logprob_ref_chosen * chosen_mask
|
||||
logprob_ref_reject = logprob_ref_reject * reject_mask
|
||||
if len(logprob_ref_chosen.shape) == 2:
|
||||
ref_logratios = logprob_ref_chosen.sum(-1) - logprob_ref_reject.sum(-1)
|
||||
else:
|
||||
ref_logratios = logprob_ref_chosen - logprob_ref_reject
|
||||
else:
|
||||
# If no reference model is provided
|
||||
ref_logratios = 0.0
|
||||
pi_logratios = logprob_actor_chosen.sum(-1) - logprob_actor_reject.sum(-1)
|
||||
logits = pi_logratios - ref_logratios - self.gamma / self.beta
|
||||
losses = -torch.nn.functional.logsigmoid(self.beta * logits)
|
||||
|
||||
# Calculate rewards for logging
|
||||
if logprob_ref_chosen is not None:
|
||||
chosen_rewards = self.beta * (logprob_actor_chosen.sum(-1) - logprob_ref_chosen.sum(-1)).detach()
|
||||
else:
|
||||
chosen_rewards = self.beta * logprob_actor_chosen.sum(-1).detach()
|
||||
if logprob_ref_reject is not None:
|
||||
rejected_rewards = self.beta * (logprob_actor_reject.sum(-1) - logprob_ref_reject.sum(-1)).detach()
|
||||
else:
|
||||
rejected_rewards = self.beta * logprob_actor_reject.sum(-1).detach()
|
||||
|
||||
return losses, chosen_rewards, rejected_rewards
|
||||
|
||||
|
||||
class LogSigLoss(nn.Module):
|
||||
"""
|
||||
Pairwise Loss for Reward Model
|
||||
Details: https://arxiv.org/abs/2203.02155
|
||||
"""
|
||||
|
||||
def forward(self, chosen_reward: torch.Tensor, reject_reward: torch.Tensor) -> torch.Tensor:
|
||||
return -torch.nn.functional.logsigmoid(chosen_reward - reject_reward).mean()
|
||||
|
||||
|
||||
class LogExpLoss(nn.Module):
|
||||
"""
|
||||
Pairwise Loss for Reward Model
|
||||
Details: https://arxiv.org/abs/2204.05862
|
||||
"""
|
||||
|
||||
def forward(self, chosen_reward: torch.Tensor, reject_reward: torch.Tensor) -> torch.Tensor:
|
||||
loss = torch.log(1 + torch.exp(reject_reward - chosen_reward)).mean()
|
||||
return loss
|
||||
|
||||
|
||||
class OddsRatioLoss(nn.Module):
|
||||
"""
|
||||
Odds Ratio Loss in ORPO
|
||||
Details: https://arxiv.org/pdf/2403.07691
|
||||
"""
|
||||
|
||||
def forward(
|
||||
self,
|
||||
chosen_logp: torch.Tensor,
|
||||
reject_logp: torch.Tensor,
|
||||
chosen_loss_mask: torch.Tensor,
|
||||
reject_loss_mask: torch.Tensor,
|
||||
) -> torch.Tensor:
|
||||
chosen_logp = chosen_logp.to(dtype=torch.float32)
|
||||
reject_logp = reject_logp.to(dtype=torch.float32)
|
||||
chosen_odds = chosen_logp - torch.log(-torch.exp(chosen_logp) + 1.0001)
|
||||
chosen_odds_masked = torch.sum(chosen_odds * chosen_loss_mask.float()) / torch.sum(chosen_loss_mask)
|
||||
reject_odds = reject_logp - torch.log(-torch.exp(reject_logp) + 1.0001)
|
||||
reject_odds_masked = torch.sum(reject_odds * reject_loss_mask.float()) / torch.sum(reject_loss_mask)
|
||||
log_odds_ratio = chosen_odds_masked - reject_odds_masked
|
||||
ratio = torch.log(torch.nn.functional.sigmoid(log_odds_ratio))
|
||||
return ratio.to(dtype=torch.bfloat16), log_odds_ratio
|
||||
|
||||
|
||||
class KTOLoss(nn.Module):
|
||||
def __init__(self, beta: float = 0.1, desirable_weight: float = 1.0, undesirable_weight: float = 1.0):
|
||||
"""
|
||||
Args:
|
||||
beta: The temperature parameter in the KTO paper.
|
||||
desirable_weight: The weight for the desirable responses.
|
||||
undesirable_weight: The weight for the undesirable
|
||||
"""
|
||||
super().__init__()
|
||||
self.beta = beta
|
||||
self.desirable_weight = desirable_weight
|
||||
self.undesirable_weight = undesirable_weight
|
||||
|
||||
def forward(
|
||||
self,
|
||||
chosen_logps: torch.Tensor,
|
||||
rejected_logps: torch.Tensor,
|
||||
kl_logps: torch.Tensor,
|
||||
ref_chosen_logps: torch.Tensor,
|
||||
ref_rejected_logps: torch.Tensor,
|
||||
ref_kl_logps: torch.Tensor,
|
||||
):
|
||||
"""
|
||||
Reference:
|
||||
https://github.com/huggingface/trl/blob/a2adfb836a90d1e37b1253ab43dace05f1241e04/trl/trainer/kto_trainer.py#L585
|
||||
|
||||
Compute the KTO loss for a batch of policy and reference model log probabilities.
|
||||
Args:
|
||||
chosen_logps: Log probabilities of the policy model for the chosen responses. Shape: (batch_size,)
|
||||
rejected_logps: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)
|
||||
kl_logps: KL divergence of the policy model. Shape: (batch_size,)
|
||||
ref_chosen_logps: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)
|
||||
ref_rejected_logps: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)
|
||||
ref_kl_logps: KL divergence of the reference model. Shape: (batch_size,)
|
||||
beta: The temperature parameter in the DPO paper.
|
||||
desirable_weight: The weight for the desirable responses.
|
||||
undesirable_weight: The weight for the undesirable responses.
|
||||
|
||||
Refer to the KTO paper for details about hyperparameters https://arxiv.org/pdf/2402.01306
|
||||
"""
|
||||
kl = (kl_logps - ref_kl_logps).mean().detach()
|
||||
# all gather
|
||||
dist.all_reduce(kl, op=dist.ReduceOp.SUM)
|
||||
kl = (kl / dist.get_world_size()).clamp(min=0)
|
||||
|
||||
if chosen_logps.shape[0] != 0 and ref_chosen_logps.shape[0] != 0:
|
||||
chosen_logratios = chosen_logps - ref_chosen_logps
|
||||
chosen_losses = 1 - nn.functional.sigmoid(self.beta * (chosen_logratios - kl))
|
||||
chosen_rewards = self.beta * chosen_logratios.detach()
|
||||
else:
|
||||
chosen_losses = torch.Tensor([]).to(kl_logps.device)
|
||||
chosen_rewards = torch.Tensor([]).to(kl_logps.device)
|
||||
|
||||
if rejected_logps.shape[0] != 0 and ref_rejected_logps.shape[0] != 0:
|
||||
rejected_logratios = rejected_logps - ref_rejected_logps
|
||||
rejected_losses = 1 - nn.functional.sigmoid(self.beta * (kl - rejected_logratios))
|
||||
rejected_rewards = self.beta * rejected_logratios.detach()
|
||||
else:
|
||||
rejected_losses = torch.Tensor([]).to(kl_logps.device)
|
||||
rejected_rewards = torch.Tensor([]).to(kl_logps.device)
|
||||
|
||||
losses = torch.cat((self.desirable_weight * chosen_losses, self.undesirable_weight * rejected_losses), 0).mean()
|
||||
|
||||
return losses, chosen_rewards, rejected_rewards, kl
|
||||
|
|
@ -0,0 +1,45 @@
|
|||
"""
|
||||
reward model
|
||||
"""
|
||||
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
from coati.models import BaseModel
|
||||
from transformers import PretrainedConfig
|
||||
|
||||
|
||||
class RewardModel(BaseModel):
|
||||
"""
|
||||
Reward model class.
|
||||
|
||||
Args:
|
||||
pretrained str: huggingface or local model path
|
||||
config: PretrainedConfig object
|
||||
**kwargs: all other kwargs as in AutoModel.from_pretrained
|
||||
"""
|
||||
|
||||
def __init__(self, pretrained: str = None, config: Optional[PretrainedConfig] = None, **kwargs) -> None:
|
||||
super().__init__(pretrained=pretrained, config=config, **kwargs)
|
||||
self.value_head = nn.Linear(self.last_hidden_state_size, 1)
|
||||
self.value_head.weight.data.normal_(mean=0.0, std=1 / (self.last_hidden_state_size + 1))
|
||||
|
||||
def forward(self, input_ids: torch.LongTensor, attention_mask: Optional[torch.Tensor] = None) -> torch.Tensor:
|
||||
outputs = self.model(input_ids, attention_mask=attention_mask)
|
||||
|
||||
last_hidden_states = outputs["last_hidden_state"]
|
||||
sequence_lengths = torch.max(attention_mask * torch.arange(input_ids.size(1), device=input_ids.device), dim=1)[
|
||||
0
|
||||
]
|
||||
sequence_hidden_states = last_hidden_states[torch.arange(last_hidden_states.size(0)), sequence_lengths].type(
|
||||
self.value_head.weight.dtype
|
||||
)
|
||||
values = self.value_head(sequence_hidden_states).squeeze(-1) # Ensure shape is (B,)
|
||||
return values
|
||||
|
||||
def get_input_embeddings(self):
|
||||
return self.model.get_input_embeddings()
|
||||
|
||||
def get_output_embeddings(self):
|
||||
return self.model.get_output_embeddings()
|
||||
|
|
@ -0,0 +1,144 @@
|
|||
import json
|
||||
import os
|
||||
from typing import Any, Dict, Optional, Union
|
||||
|
||||
import torch
|
||||
import torch.nn.functional as F
|
||||
|
||||
|
||||
def get_model_numel(model: torch.nn.Module) -> int:
|
||||
return sum(p.numel() for p in model.parameters())
|
||||
|
||||
|
||||
def compute_reward(
|
||||
r: Union[torch.Tensor, float],
|
||||
kl_coef: float,
|
||||
log_probs: torch.Tensor,
|
||||
log_probs_base: torch.Tensor,
|
||||
action_mask: Optional[torch.Tensor] = None,
|
||||
reward_eps=5,
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Args:
|
||||
log_probs: [batch_size, response_length]
|
||||
log_probs_base: [batch_size, response_length]
|
||||
action_mask: [batch_size, response_length]
|
||||
r: float
|
||||
Returns:
|
||||
reward: [batch_size, response_length]
|
||||
"""
|
||||
log_ratio = log_probs - log_probs_base # address numerical instability issue
|
||||
kl = -kl_coef * log_ratio * action_mask
|
||||
reward = kl
|
||||
r_clip = torch.clamp(r, -reward_eps, reward_eps)
|
||||
for i in range(action_mask.size(0)):
|
||||
assert action_mask[i].sum() > 0
|
||||
reward[i, : action_mask[i].sum()] += r_clip[i]
|
||||
reward[i, action_mask[i].sum() :] *= 0
|
||||
return reward, ((log_ratio * (log_ratio < 10)).exp() - 1 - log_ratio) * action_mask
|
||||
|
||||
|
||||
def _log_probs_from_logits(logits: torch.Tensor, labels: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Compute the log probabilities from logits for the given labels.
|
||||
|
||||
Args:
|
||||
logits (torch.Tensor): The input logits.
|
||||
labels (torch.Tensor): The target labels.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The log probabilities corresponding to the labels.
|
||||
"""
|
||||
log_probs = F.log_softmax(logits, dim=-1)
|
||||
log_probs_labels = log_probs.gather(dim=-1, index=labels.unsqueeze(-1))
|
||||
return log_probs_labels.squeeze(-1)
|
||||
|
||||
|
||||
def calc_action_log_probs(logits: torch.Tensor, sequences: torch.LongTensor, num_actions: int) -> torch.Tensor:
|
||||
"""Calculate action log probs.
|
||||
|
||||
Args:
|
||||
output (torch.Tensor): Output tensor of Actor.forward.logits.
|
||||
sequences (torch.LongTensor): Input sequences.
|
||||
num_actions (int): Number of actions.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: Action log probs.
|
||||
"""
|
||||
log_probs = _log_probs_from_logits(logits[:, :-1, :], sequences[:, 1:])
|
||||
return log_probs[:, -num_actions:]
|
||||
|
||||
|
||||
def masked_mean(tensor: torch.Tensor, mask: torch.Tensor, dim: int = 1) -> torch.Tensor:
|
||||
"""
|
||||
Compute the masked mean of a tensor along a specified dimension.
|
||||
|
||||
Args:
|
||||
tensor (torch.Tensor): The input tensor.
|
||||
mask (torch.Tensor): The mask tensor with the same shape as the input tensor.
|
||||
dim (int, optional): The dimension along which to compute the mean. Default is 1.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The masked mean tensor.
|
||||
|
||||
"""
|
||||
tensor = tensor * mask
|
||||
tensor = tensor.sum(dim=dim)
|
||||
mask_sum = mask.sum(dim=dim)
|
||||
mean = tensor / (mask_sum + 1e-8)
|
||||
return mean
|
||||
|
||||
|
||||
def calc_masked_log_probs(
|
||||
logits: torch.Tensor, sequences: torch.LongTensor, mask: torch.Tensor, length_normalization: bool = False
|
||||
) -> torch.Tensor:
|
||||
"""
|
||||
Calculate the masked log probabilities for a given sequence of logits.
|
||||
|
||||
Args:
|
||||
logits (torch.Tensor): The input logits tensor of shape (batch_size, sequence_length, vocab_size).
|
||||
sequences (torch.LongTensor): The input sequence tensor of shape (batch_size, sequence_length).
|
||||
mask (torch.Tensor): The mask tensor of shape (batch_size, sequence_length).
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The masked log probabilities tensor of shape (batch_size, sequence_length - 1).
|
||||
"""
|
||||
# logits are probabilities of the next token, so we shift them to the left by one
|
||||
log_probs = _log_probs_from_logits(logits[:, :-1, :], sequences[:, 1:])
|
||||
|
||||
if not length_normalization:
|
||||
return log_probs * mask
|
||||
else:
|
||||
return log_probs * mask / (mask.sum(dim=-1, keepdim=True) + 0.01)
|
||||
|
||||
|
||||
def load_json(file_path: Union[str, os.PathLike]) -> Dict[str, Any]:
|
||||
"""
|
||||
Load file in JSON format
|
||||
"""
|
||||
with open(file=file_path, mode="r", encoding="utf-8") as fp:
|
||||
return json.load(fp)
|
||||
|
||||
|
||||
def save_json(data: Dict[str, Any], file_path: Union[str, os.PathLike]) -> None:
|
||||
"""
|
||||
Save as JSON format
|
||||
"""
|
||||
with open(file=file_path, mode="w", encoding="utf-8") as fp:
|
||||
json.dump(data, fp=fp, ensure_ascii=False, indent=4)
|
||||
|
||||
|
||||
def disable_dropout(model: torch.nn.Module):
|
||||
"""
|
||||
Disables dropout in a PyTorch model. This is used in PPO Training
|
||||
|
||||
Args:
|
||||
model (torch.nn.Module): The PyTorch model.
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
if model is not None:
|
||||
for module in model.modules():
|
||||
if isinstance(module, torch.nn.Dropout):
|
||||
module.p = 0.0
|
||||
|
|
@ -0,0 +1,7 @@
|
|||
from .llama_gptq import load_quant as llama_load_quant
|
||||
from .utils import low_resource_init
|
||||
|
||||
__all__ = [
|
||||
"llama_load_quant",
|
||||
"low_resource_init",
|
||||
]
|
||||
|
|
@ -0,0 +1,5 @@
|
|||
from .loader import load_quant
|
||||
|
||||
__all__ = [
|
||||
"load_quant",
|
||||
]
|
||||
|
|
@ -0,0 +1,27 @@
|
|||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
from .model_utils import find_layers
|
||||
from .quant import make_quant
|
||||
|
||||
|
||||
def load_quant(model: nn.Module, checkpoint: str, wbits: int, groupsize: int):
|
||||
model = model.eval()
|
||||
layers = find_layers(model)
|
||||
|
||||
# ignore lm head
|
||||
layers = find_layers(model)
|
||||
for name in ["lm_head"]:
|
||||
if name in layers:
|
||||
del layers[name]
|
||||
|
||||
make_quant(model, layers, wbits, groupsize)
|
||||
|
||||
if checkpoint.endswith(".safetensors"):
|
||||
from safetensors.torch import load_file as safe_load
|
||||
|
||||
model.load_state_dict(safe_load(checkpoint))
|
||||
else:
|
||||
model.load_state_dict(torch.load(checkpoint))
|
||||
|
||||
return model
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
# copied from https://github.com/qwopqwop200/GPTQ-for-LLaMa/blob/past/modelutils.py
|
||||
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
def find_layers(module, layers=[nn.Conv2d, nn.Linear], name=""):
|
||||
if type(module) in layers:
|
||||
return {name: module}
|
||||
res = {}
|
||||
for name1, child in module.named_children():
|
||||
res.update(find_layers(child, layers=layers, name=name + "." + name1 if name != "" else name1))
|
||||
return res
|
||||
|
|
@ -0,0 +1,283 @@
|
|||
# copied from https://github.com/qwopqwop200/GPTQ-for-LLaMa/blob/past/quant.py
|
||||
|
||||
import math
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
|
||||
|
||||
def quantize(x, scale, zero, maxq):
|
||||
q = torch.clamp(torch.round(x / scale) + zero, 0, maxq)
|
||||
return scale * (q - zero)
|
||||
|
||||
|
||||
class Quantizer(nn.Module):
|
||||
def __init__(self, shape=1):
|
||||
super(Quantizer, self).__init__()
|
||||
self.register_buffer("maxq", torch.tensor(0))
|
||||
self.register_buffer("scale", torch.zeros(shape))
|
||||
self.register_buffer("zero", torch.zeros(shape))
|
||||
|
||||
def configure(self, bits, perchannel=False, sym=True, mse=False, norm=2.4, grid=100, maxshrink=0.8):
|
||||
self.maxq = torch.tensor(2**bits - 1)
|
||||
self.perchannel = perchannel
|
||||
self.sym = sym
|
||||
self.mse = mse
|
||||
self.norm = norm
|
||||
self.grid = grid
|
||||
self.maxshrink = maxshrink
|
||||
|
||||
def find_params(self, x, weight=False):
|
||||
dev = x.device
|
||||
self.maxq = self.maxq.to(dev)
|
||||
|
||||
shape = x.shape
|
||||
if self.perchannel:
|
||||
if weight:
|
||||
x = x.flatten(1)
|
||||
else:
|
||||
if len(shape) == 4:
|
||||
x = x.permute([1, 0, 2, 3])
|
||||
x = x.flatten(1)
|
||||
if len(shape) == 3:
|
||||
x = x.reshape((-1, shape[-1])).t()
|
||||
if len(shape) == 2:
|
||||
x = x.t()
|
||||
else:
|
||||
x = x.flatten().unsqueeze(0)
|
||||
|
||||
tmp = torch.zeros(x.shape[0], device=dev)
|
||||
xmin = torch.minimum(x.min(1)[0], tmp)
|
||||
xmax = torch.maximum(x.max(1)[0], tmp)
|
||||
|
||||
if self.sym:
|
||||
xmax = torch.maximum(torch.abs(xmin), xmax)
|
||||
tmp = xmin < 0
|
||||
if torch.any(tmp):
|
||||
xmin[tmp] = -xmax[tmp]
|
||||
tmp = (xmin == 0) & (xmax == 0)
|
||||
xmin[tmp] = -1
|
||||
xmax[tmp] = +1
|
||||
|
||||
self.scale = (xmax - xmin) / self.maxq
|
||||
if self.sym:
|
||||
self.zero = torch.full_like(self.scale, (self.maxq + 1) / 2)
|
||||
else:
|
||||
self.zero = torch.round(-xmin / self.scale)
|
||||
|
||||
if self.mse:
|
||||
best = torch.full([x.shape[0]], float("inf"), device=dev)
|
||||
for i in range(int(self.maxshrink * self.grid)):
|
||||
p = 1 - i / self.grid
|
||||
xmin1 = p * xmin
|
||||
xmax1 = p * xmax
|
||||
scale1 = (xmax1 - xmin1) / self.maxq
|
||||
zero1 = torch.round(-xmin1 / scale1) if not self.sym else self.zero
|
||||
q = quantize(x, scale1.unsqueeze(1), zero1.unsqueeze(1), self.maxq)
|
||||
q -= x
|
||||
q.abs_()
|
||||
q.pow_(self.norm)
|
||||
err = torch.sum(q, 1)
|
||||
tmp = err < best
|
||||
if torch.any(tmp):
|
||||
best[tmp] = err[tmp]
|
||||
self.scale[tmp] = scale1[tmp]
|
||||
self.zero[tmp] = zero1[tmp]
|
||||
if not self.perchannel:
|
||||
if weight:
|
||||
tmp = shape[0]
|
||||
else:
|
||||
tmp = shape[1] if len(shape) != 3 else shape[2]
|
||||
self.scale = self.scale.repeat(tmp)
|
||||
self.zero = self.zero.repeat(tmp)
|
||||
|
||||
if weight:
|
||||
shape = [-1] + [1] * (len(shape) - 1)
|
||||
self.scale = self.scale.reshape(shape)
|
||||
self.zero = self.zero.reshape(shape)
|
||||
return
|
||||
if len(shape) == 4:
|
||||
self.scale = self.scale.reshape((1, -1, 1, 1))
|
||||
self.zero = self.zero.reshape((1, -1, 1, 1))
|
||||
if len(shape) == 3:
|
||||
self.scale = self.scale.reshape((1, 1, -1))
|
||||
self.zero = self.zero.reshape((1, 1, -1))
|
||||
if len(shape) == 2:
|
||||
self.scale = self.scale.unsqueeze(0)
|
||||
self.zero = self.zero.unsqueeze(0)
|
||||
|
||||
def quantize(self, x):
|
||||
if self.ready():
|
||||
return quantize(x, self.scale, self.zero, self.maxq)
|
||||
return x
|
||||
|
||||
def enabled(self):
|
||||
return self.maxq > 0
|
||||
|
||||
def ready(self):
|
||||
return torch.all(self.scale != 0)
|
||||
|
||||
|
||||
try:
|
||||
import quant_cuda
|
||||
except:
|
||||
print("CUDA extension not installed.")
|
||||
|
||||
# Assumes layer is perfectly divisible into 256 * 256 blocks
|
||||
|
||||
|
||||
class QuantLinear(nn.Module):
|
||||
def __init__(self, bits, groupsize, infeatures, outfeatures):
|
||||
super().__init__()
|
||||
if bits not in [2, 3, 4, 8]:
|
||||
raise NotImplementedError("Only 2,3,4,8 bits are supported.")
|
||||
self.infeatures = infeatures
|
||||
self.outfeatures = outfeatures
|
||||
self.bits = bits
|
||||
if groupsize != -1 and groupsize < 32 and groupsize != int(math.pow(2, int(math.log2(groupsize)))):
|
||||
raise NotImplementedError("groupsize supports powers of 2 greater than 32. (e.g. : 32,64,128,etc)")
|
||||
groupsize = groupsize if groupsize != -1 else infeatures
|
||||
self.groupsize = groupsize
|
||||
self.register_buffer(
|
||||
"qzeros", torch.zeros((math.ceil(infeatures / groupsize), outfeatures // 256 * (bits * 8)), dtype=torch.int)
|
||||
)
|
||||
self.register_buffer("scales", torch.zeros((math.ceil(infeatures / groupsize), outfeatures)))
|
||||
self.register_buffer("bias", torch.zeros(outfeatures))
|
||||
self.register_buffer("qweight", torch.zeros((infeatures // 256 * (bits * 8), outfeatures), dtype=torch.int))
|
||||
self._initialized_quant_state = False
|
||||
|
||||
def pack(self, linear, scales, zeros):
|
||||
scales = scales.t().contiguous()
|
||||
zeros = zeros.t().contiguous()
|
||||
scale_zeros = zeros * scales
|
||||
self.scales = scales.clone()
|
||||
if linear.bias is not None:
|
||||
self.bias = linear.bias.clone()
|
||||
|
||||
intweight = []
|
||||
for idx in range(self.infeatures):
|
||||
g_idx = idx // self.groupsize
|
||||
intweight.append(
|
||||
torch.round((linear.weight.data[:, idx] + scale_zeros[g_idx]) / self.scales[g_idx]).to(torch.int)[
|
||||
:, None
|
||||
]
|
||||
)
|
||||
intweight = torch.cat(intweight, dim=1)
|
||||
intweight = intweight.t().contiguous()
|
||||
intweight = intweight.numpy().astype(np.uint32)
|
||||
qweight = np.zeros((intweight.shape[0] // 256 * (self.bits * 8), intweight.shape[1]), dtype=np.uint32)
|
||||
i = 0
|
||||
row = 0
|
||||
while row < qweight.shape[0]:
|
||||
if self.bits in [2, 4, 8]:
|
||||
for j in range(i, i + (32 // self.bits)):
|
||||
qweight[row] |= intweight[j] << (self.bits * (j - i))
|
||||
i += 32 // self.bits
|
||||
row += 1
|
||||
elif self.bits == 3:
|
||||
for j in range(i, i + 10):
|
||||
qweight[row] |= intweight[j] << (3 * (j - i))
|
||||
i += 10
|
||||
qweight[row] |= intweight[i] << 30
|
||||
row += 1
|
||||
qweight[row] |= (intweight[i] >> 2) & 1
|
||||
i += 1
|
||||
for j in range(i, i + 10):
|
||||
qweight[row] |= intweight[j] << (3 * (j - i) + 1)
|
||||
i += 10
|
||||
qweight[row] |= intweight[i] << 31
|
||||
row += 1
|
||||
qweight[row] |= (intweight[i] >> 1) & 0x3
|
||||
i += 1
|
||||
for j in range(i, i + 10):
|
||||
qweight[row] |= intweight[j] << (3 * (j - i) + 2)
|
||||
i += 10
|
||||
row += 1
|
||||
else:
|
||||
raise NotImplementedError("Only 2,3,4,8 bits are supported.")
|
||||
|
||||
qweight = qweight.astype(np.int32)
|
||||
self.qweight = torch.from_numpy(qweight)
|
||||
|
||||
zeros -= 1
|
||||
zeros = zeros.numpy().astype(np.uint32)
|
||||
qzeros = np.zeros((zeros.shape[0], zeros.shape[1] // 256 * (self.bits * 8)), dtype=np.uint32)
|
||||
i = 0
|
||||
col = 0
|
||||
while col < qzeros.shape[1]:
|
||||
if self.bits in [2, 4, 8]:
|
||||
for j in range(i, i + (32 // self.bits)):
|
||||
qzeros[:, col] |= zeros[:, j] << (self.bits * (j - i))
|
||||
i += 32 // self.bits
|
||||
col += 1
|
||||
elif self.bits == 3:
|
||||
for j in range(i, i + 10):
|
||||
qzeros[:, col] |= zeros[:, j] << (3 * (j - i))
|
||||
i += 10
|
||||
qzeros[:, col] |= zeros[:, i] << 30
|
||||
col += 1
|
||||
qzeros[:, col] |= (zeros[:, i] >> 2) & 1
|
||||
i += 1
|
||||
for j in range(i, i + 10):
|
||||
qzeros[:, col] |= zeros[:, j] << (3 * (j - i) + 1)
|
||||
i += 10
|
||||
qzeros[:, col] |= zeros[:, i] << 31
|
||||
col += 1
|
||||
qzeros[:, col] |= (zeros[:, i] >> 1) & 0x3
|
||||
i += 1
|
||||
for j in range(i, i + 10):
|
||||
qzeros[:, col] |= zeros[:, j] << (3 * (j - i) + 2)
|
||||
i += 10
|
||||
col += 1
|
||||
else:
|
||||
raise NotImplementedError("Only 2,3,4,8 bits are supported.")
|
||||
|
||||
qzeros = qzeros.astype(np.int32)
|
||||
self.qzeros = torch.from_numpy(qzeros)
|
||||
|
||||
def forward(self, x):
|
||||
intermediate_dtype = torch.float32
|
||||
|
||||
if not self._initialized_quant_state:
|
||||
# Do we even have a bias? Check for at least one non-zero element.
|
||||
if self.bias is not None and bool(torch.any(self.bias != 0)):
|
||||
# Then make sure it's the right type.
|
||||
self.bias.data = self.bias.data.to(intermediate_dtype)
|
||||
else:
|
||||
self.bias = None
|
||||
|
||||
outshape = list(x.shape)
|
||||
outshape[-1] = self.outfeatures
|
||||
x = x.reshape(-1, x.shape[-1])
|
||||
if self.bias is None:
|
||||
y = torch.zeros(x.shape[0], outshape[-1], dtype=intermediate_dtype, device=x.device)
|
||||
else:
|
||||
y = self.bias.clone().repeat(x.shape[0], 1)
|
||||
|
||||
output_dtype = x.dtype
|
||||
x = x.to(intermediate_dtype)
|
||||
if self.bits == 2:
|
||||
quant_cuda.vecquant2matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
|
||||
elif self.bits == 3:
|
||||
quant_cuda.vecquant3matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
|
||||
elif self.bits == 4:
|
||||
quant_cuda.vecquant4matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
|
||||
elif self.bits == 8:
|
||||
quant_cuda.vecquant8matmul(x, self.qweight, y, self.scales, self.qzeros, self.groupsize)
|
||||
else:
|
||||
raise NotImplementedError("Only 2,3,4,8 bits are supported.")
|
||||
y = y.to(output_dtype)
|
||||
return y.reshape(outshape)
|
||||
|
||||
|
||||
def make_quant(module, names, bits, groupsize, name=""):
|
||||
if isinstance(module, QuantLinear):
|
||||
return
|
||||
for attr in dir(module):
|
||||
tmp = getattr(module, attr)
|
||||
name1 = name + "." + attr if name != "" else attr
|
||||
if name1 in names:
|
||||
setattr(module, attr, QuantLinear(bits, groupsize, tmp.in_features, tmp.out_features))
|
||||
for name1, child in module.named_children():
|
||||
make_quant(child, names, bits, groupsize, name + "." + name1 if name != "" else name1)
|
||||
|
|
@ -0,0 +1,27 @@
|
|||
from contextlib import contextmanager
|
||||
|
||||
import torch
|
||||
|
||||
|
||||
def _noop(*args, **kwargs):
|
||||
pass
|
||||
|
||||
|
||||
@contextmanager
|
||||
def low_resource_init():
|
||||
"""This context manager disables weight initialization and sets the default float dtype to half."""
|
||||
old_kaiming_uniform_ = torch.nn.init.kaiming_uniform_
|
||||
old_uniform_ = torch.nn.init.uniform_
|
||||
old_normal_ = torch.nn.init.normal_
|
||||
dtype = torch.get_default_dtype()
|
||||
try:
|
||||
torch.nn.init.kaiming_uniform_ = _noop
|
||||
torch.nn.init.uniform_ = _noop
|
||||
torch.nn.init.normal_ = _noop
|
||||
torch.set_default_dtype(torch.half)
|
||||
yield
|
||||
finally:
|
||||
torch.nn.init.kaiming_uniform_ = old_kaiming_uniform_
|
||||
torch.nn.init.uniform_ = old_uniform_
|
||||
torch.nn.init.normal_ = old_normal_
|
||||
torch.set_default_dtype(dtype)
|
||||
|
|
@ -0,0 +1,175 @@
|
|||
:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
|
||||
|
||||
# Distributed PPO Training on Stage 3
|
||||
|
||||
## Detach Experience Makers and Trainers
|
||||
|
||||
We can completely separate the trainers and makers.
|
||||
|
||||
<p align="center">
|
||||
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/chat/basic_structure.png?raw=true" width=600/>
|
||||
</p>
|
||||
|
||||
- The experience maker performs inference, produces experience, and remotely delivers it to the trainer (1).
|
||||
- The trainer consumes experience to train models, and periodically transmits new model parameters to the maker (2.1, 2.2).
|
||||
- Using an experience buffer to overlap transmission and computing.
|
||||
|
||||
In this manner, each node will work continuously without model idle time, and different optimization strategies can be applied for inference and training to meet the needs of speed or storage. It is also helpful for scalability.
|
||||
|
||||
`DetachedPPOTrainer` and `ExperienceMakerHolder` are Ray Actors (distinguished from Actor Model), representing Trainer and Experience Maker on the graph above, respectively.
|
||||
|
||||
[More about Ray Core](https://docs.ray.io/en/latest/ray-core/walkthrough.html)
|
||||
|
||||
## Usage
|
||||
|
||||
See examples at `ColossalAI/application/Chat/examples/ray`
|
||||
|
||||
### Setup Makers
|
||||
|
||||
- define makers' environment variables :
|
||||
|
||||
```python
|
||||
env_info_makers = [{
|
||||
'local_rank': '0',
|
||||
'rank': str(rank),
|
||||
'world_size': str(num_makers),
|
||||
'master_port': maker_port,
|
||||
'master_addr': master_addr
|
||||
} for rank in range(num_makers)]
|
||||
|
||||
```
|
||||
|
||||
- define maker models :
|
||||
|
||||
```python
|
||||
def model_fn():
|
||||
actor = get_actor_from_args(...)
|
||||
critic = get_critic_from_args(...)
|
||||
reward_model = get_reward_model_from_args(...)
|
||||
initial_model = get_actor_from_args(...)
|
||||
return actor, critic, reward_model, initial_model
|
||||
|
||||
```
|
||||
|
||||
- set experience_holder_refs :
|
||||
|
||||
```python
|
||||
experience_holder_refs = [
|
||||
ExperienceMakerHolder.options(
|
||||
name=f"maker_{i}",
|
||||
num_gpus=1,
|
||||
max_concurrency=2
|
||||
).remote(
|
||||
detached_trainer_name_list=[f"trainer_{x}" for x in target_trainers(...)],
|
||||
model_fn=model_fn,
|
||||
...)
|
||||
for i, env_info_maker in enumerate(env_info_makers)
|
||||
]
|
||||
```
|
||||
|
||||
The names in the `detached_trainer_name_list` refer to the target trainers that the maker should send experience to.
|
||||
We set a trainer's name the same as a maker, by `.options(name="str")`. See below.
|
||||
|
||||
### Setup Trainers
|
||||
|
||||
- define trainers' environment variables :
|
||||
```python
|
||||
env_info_trainers = [{
|
||||
'local_rank': '0',
|
||||
'rank': str(rank),
|
||||
'world_size': str(num_trainers),
|
||||
'master_port': trainer_port,
|
||||
'master_addr': master_addr
|
||||
} for rank in range(num_trainers)]
|
||||
```
|
||||
- define trainer models :
|
||||
|
||||
```python
|
||||
def trainer_model_fn():
|
||||
actor = get_actor_from_args(...)
|
||||
critic = get_critic_from_args(...)
|
||||
return actor, critic
|
||||
```
|
||||
|
||||
- set trainer_refs :
|
||||
```python
|
||||
trainer_refs = [
|
||||
DetachedPPOTrainer.options(
|
||||
name=f"trainer{i}",
|
||||
num_gpus=1,
|
||||
max_concurrency=2
|
||||
).remote(
|
||||
experience_maker_holder_name_list=[f"maker{x}" for x in target_makers(...)],
|
||||
model_fn = trainer_model_fn(),
|
||||
...)
|
||||
for i, env_info_trainer in enumerate(env_info_trainers)
|
||||
]
|
||||
```
|
||||
The names in `experience_maker_holder_name_list` refer to the target makers that the trainer should send updated models to.
|
||||
By setting `detached_trainer_name_list` and `experience_maker_holder_name_list`, we can customize the transmission graph.
|
||||
|
||||
### Launch Jobs
|
||||
|
||||
- define data_loader :
|
||||
|
||||
```python
|
||||
def data_loader_fn():
|
||||
return = torch.utils.data.DataLoader(dataset=dataset)
|
||||
|
||||
```
|
||||
|
||||
- launch makers :
|
||||
|
||||
```python
|
||||
wait_tasks = []
|
||||
for experience_holder_ref in experience_holder_refs:
|
||||
wait_tasks.append(
|
||||
experience_holder_ref.workingloop.remote(data_loader_fn(),
|
||||
num_steps=experience_steps))
|
||||
|
||||
```
|
||||
|
||||
- launch trainers :
|
||||
|
||||
```python
|
||||
for trainer_ref in trainer_refs:
|
||||
wait_tasks.append(trainer_ref.fit.remote(total_steps, update_steps, train_epochs))
|
||||
```
|
||||
|
||||
- wait for done :
|
||||
```python
|
||||
ray.get(wait_tasks)
|
||||
```
|
||||
|
||||
## Flexible Structure
|
||||
|
||||
We can deploy different strategies to makers and trainers. Here are some notions.
|
||||
|
||||
### 2 Makers 1 Trainer
|
||||
|
||||
<p align="center">
|
||||
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/chat/2m1t.png?raw=true" width=600/>
|
||||
</p>
|
||||
|
||||
### 2 Makers 2 Trainer
|
||||
|
||||
<p align="center">
|
||||
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/chat/2m2t.png?raw=true" width=600/>
|
||||
</p>
|
||||
|
||||
### Maker Inference Quantization
|
||||
|
||||
<p align="center">
|
||||
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/chat/2m2t_quantize.png?raw=true" width=600/>
|
||||
</p>
|
||||
|
||||
### Tensor Parallel
|
||||
|
||||
<p align="center">
|
||||
<img src="https://github.com/hpcaitech/public_assets/blob/main/applications/chat/tp_ddp_hybrid.png?raw=true" width=600/>
|
||||
</p>
|
||||
|
||||
## TODO
|
||||
|
||||
- [ ] Support LoRA
|
||||
- [ ] Support TP & PP
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
from .base import MakerCallback, TrainerCallback
|
||||
from .performance_evaluator import ExperienceMakerPerformanceEvaluator, TrainerPerformanceEvaluator
|
||||
|
||||
__all__ = [
|
||||
"TrainerCallback",
|
||||
"MakerCallback",
|
||||
"ExperienceMakerPerformanceEvaluator",
|
||||
"TrainerPerformanceEvaluator",
|
||||
]
|
||||
|
|
@ -0,0 +1,65 @@
|
|||
from abc import ABC
|
||||
|
||||
from coati.experience_maker import Experience
|
||||
|
||||
|
||||
class TrainerCallback(ABC):
|
||||
"""
|
||||
Base callback class. It defines the interface for callbacks.
|
||||
"""
|
||||
|
||||
def on_fit_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_fit_end(self) -> None:
|
||||
pass
|
||||
|
||||
def on_episode_start(self, episode: int) -> None:
|
||||
pass
|
||||
|
||||
def on_episode_end(self, episode: int) -> None:
|
||||
pass
|
||||
|
||||
def on_epoch_start(self, epoch: int) -> None:
|
||||
pass
|
||||
|
||||
def on_epoch_end(self, epoch: int) -> None:
|
||||
pass
|
||||
|
||||
def on_batch_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_batch_end(self, metrics: dict, experience: Experience) -> None:
|
||||
pass
|
||||
|
||||
def on_update_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_update_end(self) -> None:
|
||||
pass
|
||||
|
||||
|
||||
class MakerCallback(ABC):
|
||||
def on_loop_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_loop_end(self) -> None:
|
||||
pass
|
||||
|
||||
def on_make_experience_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_make_experience_end(self, experience: Experience) -> None:
|
||||
pass
|
||||
|
||||
def on_send_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_send_end(self) -> None:
|
||||
pass
|
||||
|
||||
def on_batch_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_batch_end(self) -> None:
|
||||
pass
|
||||
|
|
@ -0,0 +1,214 @@
|
|||
from time import time
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from coati.experience_maker import Experience
|
||||
|
||||
from .base import MakerCallback, TrainerCallback
|
||||
|
||||
|
||||
def get_world_size() -> int:
|
||||
if dist.is_initialized():
|
||||
return dist.get_world_size()
|
||||
return 1
|
||||
|
||||
|
||||
def print_rank_0(*args, **kwargs) -> None:
|
||||
if not dist.is_initialized() or dist.get_rank() == 0:
|
||||
print(*args, **kwargs)
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def all_reduce_mean(x: float, world_size: int) -> float:
|
||||
if world_size == 1:
|
||||
return x
|
||||
tensor = torch.tensor([x], device=torch.cuda.current_device())
|
||||
dist.all_reduce(tensor)
|
||||
tensor = tensor / world_size
|
||||
return tensor.item()
|
||||
|
||||
|
||||
class Timer:
|
||||
def __init__(self) -> None:
|
||||
self.start_time: Optional[float] = None
|
||||
self.duration: float = 0.0
|
||||
|
||||
def start(self) -> None:
|
||||
self.start_time = time()
|
||||
|
||||
def end(self) -> None:
|
||||
self.duration += time() - self.start_time
|
||||
|
||||
def reset(self) -> None:
|
||||
self.duration = 0.0
|
||||
|
||||
|
||||
class ExperienceMakerPerformanceEvaluator(MakerCallback):
|
||||
def __init__(
|
||||
self, actor_num_params: int, critic_num_params: int, initial_model_num_params: int, reward_model_num_params: int
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.world_size = get_world_size()
|
||||
self.actor_num_params = actor_num_params
|
||||
self.critic_num_params = critic_num_params
|
||||
self.initial_model_num_params = initial_model_num_params
|
||||
self.reward_model_num_params = reward_model_num_params
|
||||
|
||||
self.batch_timer = Timer()
|
||||
self.send_timer = Timer()
|
||||
self.make_experience_timer = Timer()
|
||||
self.total_samples: int = 0
|
||||
self.make_experience_flop: int = 0
|
||||
|
||||
print_rank_0(
|
||||
f"ExperienceMaker actor: {actor_num_params/1024**3:.2f}B, critic: {critic_num_params/1024**3:.2f}B, initial model: {initial_model_num_params/1024**3:.2f}B, reward model: {reward_model_num_params/1024**3:.2f}B, world size: {self.world_size}"
|
||||
)
|
||||
|
||||
def on_make_experience_start(self) -> None:
|
||||
self.make_experience_timer.start()
|
||||
|
||||
def on_make_experience_end(self, experience: Experience) -> None:
|
||||
self.make_experience_timer.end()
|
||||
|
||||
batch_size, seq_len = experience.sequences.shape
|
||||
|
||||
self.total_samples += batch_size
|
||||
|
||||
# actor generate
|
||||
num_actions = experience.action_mask.size(1)
|
||||
input_len = seq_len - num_actions
|
||||
total_seq_len = (input_len + seq_len - 1) * num_actions / 2
|
||||
self.make_experience_flop += self.actor_num_params * batch_size * total_seq_len * 2
|
||||
# actor forward
|
||||
self.make_experience_flop += self.actor_num_params * batch_size * seq_len * 2
|
||||
# critic forward
|
||||
self.make_experience_flop += self.critic_num_params * batch_size * seq_len * 2
|
||||
# initial model forward
|
||||
self.make_experience_flop += self.initial_model_num_params * batch_size * seq_len * 2
|
||||
# reward model forward
|
||||
self.make_experience_flop += self.reward_model_num_params * batch_size * seq_len * 2
|
||||
|
||||
def on_send_start(self) -> None:
|
||||
self.send_timer.start()
|
||||
|
||||
def on_send_end(self) -> None:
|
||||
self.send_timer.end()
|
||||
|
||||
def on_batch_start(self) -> None:
|
||||
self.batch_timer.start()
|
||||
|
||||
def on_batch_end(self) -> None:
|
||||
self.batch_timer.end()
|
||||
|
||||
def on_loop_end(self) -> None:
|
||||
avg_make_experience_duration = all_reduce_mean(self.make_experience_timer.duration, self.world_size)
|
||||
avg_overall_duration = all_reduce_mean(self.batch_timer.duration, self.world_size)
|
||||
avg_send_duration = all_reduce_mean(self.send_timer.duration, self.world_size)
|
||||
|
||||
avg_throughput = self.total_samples * self.world_size / (avg_overall_duration + 1e-12)
|
||||
avg_make_experience_tflops = self.make_experience_flop / 1e12 / (avg_make_experience_duration + 1e-12)
|
||||
avg_time_per_sample = (avg_overall_duration + 1e-12) / (self.total_samples * self.world_size)
|
||||
avg_make_experience_time_per_sample = (avg_make_experience_duration + 1e-12) / (
|
||||
self.total_samples * self.world_size
|
||||
)
|
||||
avg_send_time_per_sample = (avg_send_duration + 1e-12) / (self.total_samples * self.world_size)
|
||||
|
||||
print_rank_0(
|
||||
"Making Experience Performance Summary:\n"
|
||||
+ f"Throughput: {avg_throughput:.3f} samples/sec\n"
|
||||
+ f"TFLOPS per GPU: {avg_make_experience_tflops:.3f}\n"
|
||||
+ f"Sample time (overall): {avg_time_per_sample:.3f} s\n"
|
||||
+ f"Sample time (make experience): {avg_make_experience_time_per_sample:.3f} s, {avg_make_experience_time_per_sample/avg_time_per_sample*100:.2f}%\n"
|
||||
+ f"Sample time (send): {avg_send_time_per_sample:.3f} s, {avg_send_time_per_sample/avg_time_per_sample*100:.2f}%\n"
|
||||
)
|
||||
|
||||
|
||||
class TrainerPerformanceEvaluator(TrainerCallback):
|
||||
def __init__(
|
||||
self,
|
||||
actor_num_params: int,
|
||||
critic_num_params: int,
|
||||
enable_grad_checkpoint: bool = False,
|
||||
ignore_first_episodes: int = 1,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.world_size = get_world_size()
|
||||
self.actor_num_params = actor_num_params
|
||||
self.critic_num_params = critic_num_params
|
||||
self.enable_grad_checkpoint = enable_grad_checkpoint
|
||||
self.ignore_first_episodes = ignore_first_episodes
|
||||
self.ignore_this_episode = False
|
||||
|
||||
self.episode_timer = Timer()
|
||||
self.batch_timer = Timer()
|
||||
self.update_timer = Timer()
|
||||
self.total_samples: int = 0
|
||||
self.learn_flop: int = 0
|
||||
|
||||
print_rank_0(
|
||||
f"Trainer actor: {self.actor_num_params/1024**3:.2f}B, critic: {self.critic_num_params/1024**3:.2f}B, world size: {self.world_size}"
|
||||
)
|
||||
|
||||
def on_episode_start(self, episodes: int) -> None:
|
||||
self.ignore_this_episode = episodes < self.ignore_first_episodes
|
||||
if self.ignore_this_episode:
|
||||
return
|
||||
self.episode_timer.start()
|
||||
|
||||
def on_episode_end(self, episodes: int) -> None:
|
||||
if self.ignore_this_episode:
|
||||
return
|
||||
self.episode_timer.end()
|
||||
|
||||
def on_batch_start(self) -> None:
|
||||
if self.ignore_this_episode:
|
||||
return
|
||||
self.batch_timer.start()
|
||||
|
||||
def on_batch_end(self, metrics: dict, experience: Experience) -> None:
|
||||
if self.ignore_this_episode:
|
||||
return
|
||||
self.batch_timer.end()
|
||||
|
||||
batch_size, seq_len = experience.sequences.shape
|
||||
|
||||
self.total_samples += batch_size
|
||||
|
||||
# actor forward-backward, 3 means forward(1) + backward(2)
|
||||
self.learn_flop += self.actor_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
|
||||
# critic forward-backward
|
||||
self.learn_flop += self.critic_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
|
||||
|
||||
def on_update_start(self) -> None:
|
||||
if self.ignore_this_episode:
|
||||
return
|
||||
self.update_timer.start()
|
||||
|
||||
def on_update_end(self) -> None:
|
||||
if self.ignore_this_episode:
|
||||
return
|
||||
self.update_timer.end()
|
||||
|
||||
def on_fit_end(self) -> None:
|
||||
if self.total_samples == 0:
|
||||
print_rank_0("No samples are collected, skip trainer performance evaluation")
|
||||
return
|
||||
avg_train_duration = all_reduce_mean(self.batch_timer.duration, self.world_size)
|
||||
avg_update_duration = all_reduce_mean(self.update_timer.duration, self.world_size)
|
||||
avg_episode_duration = all_reduce_mean(self.episode_timer.duration, self.world_size)
|
||||
|
||||
avg_throughput = self.total_samples * self.world_size / (avg_episode_duration + 1e-12)
|
||||
avg_learn_tflops = self.learn_flop / 1e12 / (avg_train_duration + 1e-12)
|
||||
avg_time_per_sample = (avg_episode_duration + 1e-12) / (self.total_samples * self.world_size)
|
||||
avg_train_time_per_sample = (avg_train_duration + 1e-12) / (self.total_samples * self.world_size)
|
||||
avg_update_time_per_sample = (avg_update_duration + 1e-12) / (self.total_samples * self.world_size)
|
||||
|
||||
print_rank_0(
|
||||
"Learning Performance Summary:\n"
|
||||
+ f"Throughput: {avg_throughput:.3f} samples/sec\n"
|
||||
+ f"TFLOPS per GPU: {avg_learn_tflops:.3f}\n"
|
||||
+ f"Sample time (overall): {avg_time_per_sample:.3f} s\n"
|
||||
+ f"Sample time (train): {avg_train_time_per_sample:.3f} s, {avg_train_time_per_sample/avg_time_per_sample*100:.2f}%\n"
|
||||
+ f"Sample time (update): {avg_update_time_per_sample:.3f} s, {avg_update_time_per_sample/avg_time_per_sample*100:.2f}%\n"
|
||||
)
|
||||
|
|
@ -0,0 +1,70 @@
|
|||
from typing import List
|
||||
|
||||
import torch
|
||||
from coati.experience_buffer.utils import BufferItem, make_experience_batch, split_experience_batch
|
||||
from coati.experience_maker.base import Experience
|
||||
|
||||
# from torch.multiprocessing import Queue
|
||||
from ray.util.queue import Queue
|
||||
|
||||
|
||||
class DetachedReplayBuffer:
|
||||
"""
|
||||
Detached replay buffer. Share Experience across workers on the same node.
|
||||
Therefore, a trainer node is expected to have only one instance.
|
||||
It is ExperienceMakerHolder's duty to call append(exp) method, remotely.
|
||||
|
||||
Args:
|
||||
sample_batch_size: Batch size when sampling. Exp won't enqueue until they formed a batch.
|
||||
tp_world_size: Number of workers in the same tp group
|
||||
limit: Limit of number of experience sample BATCHs. A number <= 0 means unlimited. Defaults to 0.
|
||||
cpu_offload: Whether to offload experience to cpu when sampling. Defaults to True.
|
||||
"""
|
||||
|
||||
def __init__(self, sample_batch_size: int, limit: int = 0) -> None:
|
||||
self.sample_batch_size = sample_batch_size
|
||||
self.limit = limit
|
||||
self.items = Queue(self.limit, actor_options={"num_cpus": 1})
|
||||
self.batch_collector: List[BufferItem] = []
|
||||
|
||||
@torch.no_grad()
|
||||
def append(self, experience: Experience) -> None:
|
||||
"""
|
||||
Expected to be called remotely.
|
||||
"""
|
||||
items = split_experience_batch(experience)
|
||||
self.extend(items)
|
||||
|
||||
@torch.no_grad()
|
||||
def extend(self, items: List[BufferItem]) -> None:
|
||||
"""
|
||||
Expected to be called remotely.
|
||||
"""
|
||||
self.batch_collector.extend(items)
|
||||
while len(self.batch_collector) >= self.sample_batch_size:
|
||||
items = self.batch_collector[: self.sample_batch_size]
|
||||
experience = make_experience_batch(items)
|
||||
self.items.put(experience, block=True)
|
||||
self.batch_collector = self.batch_collector[self.sample_batch_size :]
|
||||
|
||||
def clear(self) -> None:
|
||||
# self.items.close()
|
||||
self.items.shutdown()
|
||||
self.items = Queue(self.limit)
|
||||
self.worker_state = [False] * self.tp_world_size
|
||||
self.batch_collector = []
|
||||
|
||||
@torch.no_grad()
|
||||
def sample(self, worker_rank=0, to_device="cpu") -> Experience:
|
||||
ret = self._sample_and_erase()
|
||||
ret.to_device(to_device)
|
||||
return ret
|
||||
|
||||
@torch.no_grad()
|
||||
def _sample_and_erase(self) -> Experience:
|
||||
ret = self.items.get(block=True)
|
||||
return ret
|
||||
|
||||
def get_length(self) -> int:
|
||||
ret = self.items.qsize()
|
||||
return ret
|
||||
|
|
@ -0,0 +1,179 @@
|
|||
import os
|
||||
from abc import ABC, abstractmethod
|
||||
from typing import Any, Dict, List
|
||||
|
||||
import ray
|
||||
import torch
|
||||
from coati.experience_buffer.utils import BufferItem
|
||||
from coati.experience_maker import Experience
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import tqdm
|
||||
|
||||
from .callbacks import TrainerCallback
|
||||
from .detached_replay_buffer import DetachedReplayBuffer
|
||||
from .utils import is_rank_0
|
||||
|
||||
|
||||
class DetachedTrainer(ABC):
|
||||
"""
|
||||
Base class for detached rlhf trainers.
|
||||
'detach' means that the experience maker is detached compared to a normal Trainer.
|
||||
Please set name attribute during init:
|
||||
>>> trainer = DetachedTrainer.options(..., name = "xxx", ...).remote()
|
||||
So an ExperienceMakerHolder can reach the detached_replay_buffer by Actor's name.
|
||||
Args:
|
||||
detached_strategy (DetachedStrategy): the strategy to use for training
|
||||
detached_replay_buffer_ref (ObjectRef[DetachedReplayBuffer]): the replay buffer to use for training
|
||||
data_loader_pin_memory (bool, defaults to True): whether to pin memory for data loader
|
||||
callbacks (List[Callback], defaults to []): the callbacks to call during training process
|
||||
generate_kwargs (dict, optional): the kwargs to use while model generating
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
experience_maker_holder_name_list: List[str],
|
||||
train_batch_size: int = 8,
|
||||
buffer_limit: int = 0,
|
||||
dataloader_pin_memory: bool = True,
|
||||
callbacks: List[TrainerCallback] = [],
|
||||
debug: bool = False,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.detached_replay_buffer = DetachedReplayBuffer(train_batch_size, limit=buffer_limit)
|
||||
self.dataloader_pin_memory = dataloader_pin_memory
|
||||
self.callbacks = callbacks
|
||||
self.target_holder_name_list = experience_maker_holder_name_list
|
||||
self.target_holder_list = []
|
||||
self._is_target_holder_initialized = False
|
||||
self._debug = debug
|
||||
|
||||
def update_target_holder_list(self):
|
||||
# as the length of target_holder_list may be zero, we need to check it by a bool flag
|
||||
if not self._is_target_holder_initialized:
|
||||
for name in self.target_holder_name_list:
|
||||
self.target_holder_list.append(ray.get_actor(name, namespace=os.environ["RAY_NAMESPACE"]))
|
||||
self._is_target_holder_initialized = True
|
||||
|
||||
@abstractmethod
|
||||
def _update_remote_makers(self, fully_update: bool = False, **kwargs):
|
||||
pass
|
||||
|
||||
def sync_models_to_remote_makers(self, **kwargs):
|
||||
self._update_remote_makers(fully_update=True, **kwargs)
|
||||
|
||||
@abstractmethod
|
||||
def training_step(self, experience: Experience) -> Dict[str, Any]:
|
||||
pass
|
||||
|
||||
def _learn(self, update_steps: int, train_epochs: int) -> None:
|
||||
data = []
|
||||
# warmup
|
||||
pbar = tqdm(range(update_steps), desc=f"Train epoch [1/{train_epochs}]", disable=not is_rank_0())
|
||||
self._on_epoch_start(0)
|
||||
self._learn_epoch(pbar, data)
|
||||
self._on_epoch_end(0)
|
||||
# item is already a batch
|
||||
dataloader = DataLoader(
|
||||
data, batch_size=1, shuffle=True, pin_memory=self.dataloader_pin_memory, collate_fn=lambda x: x[0]
|
||||
)
|
||||
for epoch in range(1, train_epochs):
|
||||
pbar = tqdm(dataloader, desc=f"Train epoch [{epoch + 1}/{train_epochs}]", disable=not is_rank_0())
|
||||
self._on_epoch_start(epoch)
|
||||
self._learn_epoch(pbar, data)
|
||||
self._on_epoch_end(epoch)
|
||||
|
||||
def _learn_epoch(self, pbar: tqdm, data: List[Experience]) -> None:
|
||||
is_warmup = len(data) == 0
|
||||
for x in pbar:
|
||||
if self._debug:
|
||||
print("[trainer] training step")
|
||||
# sample a batch and then train to avoid waiting
|
||||
experience = x if not is_warmup else self._buffer_sample()
|
||||
experience.to_device(torch.cuda.current_device())
|
||||
self._on_batch_start()
|
||||
metrics = self.training_step(experience)
|
||||
self._on_batch_end(metrics, experience)
|
||||
|
||||
if self._debug:
|
||||
print("[trainer] step over")
|
||||
experience.to_device("cpu")
|
||||
if is_warmup:
|
||||
data.append(experience)
|
||||
pbar.set_postfix(metrics)
|
||||
|
||||
def fit(self, total_steps: int, update_steps: int, train_epochs: int = 1) -> None:
|
||||
self._on_fit_start()
|
||||
for i in tqdm(range(total_steps // update_steps), desc="Trainer", disable=not is_rank_0()):
|
||||
self._on_episode_start(i)
|
||||
self._learn(update_steps, train_epochs)
|
||||
self._on_update_start()
|
||||
self._update_remote_makers()
|
||||
self._on_update_end()
|
||||
self._on_episode_end(i)
|
||||
self._on_fit_end()
|
||||
|
||||
@ray.method(concurrency_group="buffer_length")
|
||||
def buffer_get_length(self):
|
||||
# called by ExperienceMakerHolder
|
||||
if self._debug:
|
||||
print("[trainer] telling length")
|
||||
return self.detached_replay_buffer.get_length()
|
||||
|
||||
@ray.method(concurrency_group="buffer_append")
|
||||
def buffer_append(self, experience: Experience):
|
||||
# called by ExperienceMakerHolder
|
||||
if self._debug:
|
||||
print(f"[trainer] receiving exp.")
|
||||
self.detached_replay_buffer.append(experience)
|
||||
|
||||
@ray.method(concurrency_group="buffer_append")
|
||||
def buffer_extend(self, items: List[BufferItem]):
|
||||
# called by ExperienceMakerHolder
|
||||
if self._debug:
|
||||
print(f"[trainer] receiving exp.")
|
||||
self.detached_replay_buffer.extend(items)
|
||||
|
||||
@ray.method(concurrency_group="buffer_sample")
|
||||
def _buffer_sample(self):
|
||||
return self.detached_replay_buffer.sample()
|
||||
|
||||
def _on_fit_start(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_fit_start()
|
||||
|
||||
def _on_fit_end(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_fit_end()
|
||||
|
||||
def _on_episode_start(self, episode: int) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_episode_start(episode)
|
||||
|
||||
def _on_episode_end(self, episode: int) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_episode_end(episode)
|
||||
|
||||
def _on_epoch_start(self, epoch: int) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_epoch_start(epoch)
|
||||
|
||||
def _on_epoch_end(self, epoch: int) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_epoch_end(epoch)
|
||||
|
||||
def _on_batch_start(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_batch_start()
|
||||
|
||||
def _on_batch_end(self, metrics: dict, experience: Experience) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_batch_end(metrics, experience)
|
||||
|
||||
def _on_update_start(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_update_start()
|
||||
|
||||
def _on_update_end(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_update_end()
|
||||
|
|
@ -0,0 +1,191 @@
|
|||
from typing import Callable, Dict, List, Tuple
|
||||
|
||||
import ray
|
||||
import torch
|
||||
from coati.experience_maker import Experience
|
||||
from coati.models.base import Actor, Critic
|
||||
from coati.models.loss import PolicyLoss, ValueLoss
|
||||
from coati.trainer.strategies import GeminiStrategy, LowLevelZeroStrategy, Strategy
|
||||
from torch.optim import Adam
|
||||
|
||||
from colossalai.nn.optimizer import HybridAdam
|
||||
|
||||
from .callbacks import TrainerCallback, TrainerPerformanceEvaluator
|
||||
from .detached_trainer_base import DetachedTrainer
|
||||
from .lora_constructor import LoRAConstructor
|
||||
from .utils import get_model_numel, get_rank, set_dist_env, state_dict_to
|
||||
|
||||
|
||||
@ray.remote(
|
||||
concurrency_groups={"buffer_length": 1, "buffer_append": 1, "buffer_sample": 1, "model_io": 1, "compute": 1}
|
||||
)
|
||||
class DetachedPPOTrainer(DetachedTrainer):
|
||||
"""
|
||||
Detached Trainer for PPO algorithm
|
||||
Args:
|
||||
strategy (Strategy): the strategy to use for training
|
||||
model (str) : for actor / critic init
|
||||
pretrained (str) : for actor / critic init
|
||||
lora_rank (int) : for actor / critic init
|
||||
train_batch_size (int, defaults to 8): the batch size to use for training
|
||||
train_batch_size (int, defaults to 8): the batch size to use for training
|
||||
buffer_limit (int, defaults to 0): the max_size limitation of replay buffer
|
||||
buffer_cpu_offload (bool, defaults to True): whether to offload replay buffer to cpu
|
||||
eps_clip (float, defaults to 0.2): the clip coefficient of policy loss
|
||||
value_clip (float, defaults to 0.4): the clip coefficient of value loss
|
||||
experience_batch_size (int, defaults to 8): the batch size to use for experience generation
|
||||
max_epochs (int, defaults to 1): the number of epochs of training process
|
||||
dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
|
||||
callbacks (List[Callback], defaults to []): the callbacks to call during training process
|
||||
generate_kwargs (dict, optional): the kwargs to use while model generating
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
experience_maker_holder_name_list: List[str],
|
||||
strategy_fn: Callable[[], Strategy],
|
||||
model_fn: Callable[[], Tuple[Actor, Critic]],
|
||||
env_info: Dict[str, str] = None,
|
||||
train_batch_size: int = 8,
|
||||
buffer_limit: int = 0,
|
||||
eps_clip: float = 0.2,
|
||||
value_clip: float = 0.4,
|
||||
dataloader_pin_memory: bool = True,
|
||||
callbacks: List[TrainerCallback] = [],
|
||||
eval_performance: bool = False,
|
||||
debug: bool = False,
|
||||
update_lora_weights: bool = False,
|
||||
) -> None:
|
||||
# set environment variables
|
||||
if env_info:
|
||||
set_dist_env(env_info=env_info)
|
||||
# configure strategy
|
||||
self.strategy = strategy_fn()
|
||||
# configure models, loss and optimizers
|
||||
with self.strategy.model_init_context():
|
||||
self.actor, self.critic = model_fn()
|
||||
|
||||
if eval_performance:
|
||||
actor_numel = get_model_numel(self.actor)
|
||||
critic_numel = get_model_numel(self.critic)
|
||||
evaluator = TrainerPerformanceEvaluator(actor_numel, critic_numel)
|
||||
callbacks = callbacks + [evaluator]
|
||||
|
||||
if isinstance(self.strategy, (LowLevelZeroStrategy, GeminiStrategy)):
|
||||
self.actor_optim = HybridAdam(self.actor.parameters(), lr=1e-7)
|
||||
self.critic_optim = HybridAdam(self.critic.parameters(), lr=1e-7)
|
||||
else:
|
||||
self.actor_optim = Adam(self.actor.parameters(), lr=1e-7)
|
||||
self.critic_optim = Adam(self.critic.parameters(), lr=1e-7)
|
||||
|
||||
(self.actor, self.actor_optim), (self.critic, self.critic_optim) = self.strategy.prepare(
|
||||
(self.actor, self.actor_optim), (self.critic, self.critic_optim)
|
||||
)
|
||||
|
||||
# configure trainer
|
||||
self.actor_loss_fn = PolicyLoss(eps_clip)
|
||||
self.critic_loss_fn = ValueLoss(value_clip)
|
||||
|
||||
super().__init__(
|
||||
experience_maker_holder_name_list,
|
||||
train_batch_size=train_batch_size,
|
||||
buffer_limit=buffer_limit,
|
||||
dataloader_pin_memory=dataloader_pin_memory,
|
||||
callbacks=callbacks,
|
||||
debug=debug,
|
||||
)
|
||||
if self._debug:
|
||||
print(f"[trainer{get_rank()}] will send state dict to {experience_maker_holder_name_list}")
|
||||
|
||||
self._update_lora_weights = update_lora_weights
|
||||
|
||||
@ray.method(concurrency_group="model_io")
|
||||
@torch.no_grad()
|
||||
def _update_remote_makers(self, fully_update: bool = False, **config):
|
||||
# TODO: balance duties
|
||||
if not fully_update:
|
||||
config["requires_grad_only"] = True
|
||||
self.update_target_holder_list()
|
||||
# mark start, ensure order
|
||||
tasks = []
|
||||
for target_holder in self.target_holder_list:
|
||||
tasks.append(target_holder.update_experience_maker.remote(chunk_start=True, fully_update=fully_update))
|
||||
ray.get(tasks)
|
||||
# sending loop
|
||||
tasks = []
|
||||
|
||||
for state_dict_shard in self._get_model_state_dict_shard(self.actor, fully_update=fully_update, **config):
|
||||
for target_holder in self.target_holder_list:
|
||||
tasks.append(
|
||||
target_holder.update_experience_maker.remote(
|
||||
new_actor_state_dict=state_dict_shard,
|
||||
new_actor_lora_config_dict=self._get_model_lora_config_dict(self.actor),
|
||||
fully_update=fully_update,
|
||||
)
|
||||
)
|
||||
# sending loop
|
||||
for state_dict_shard in self._get_model_state_dict_shard(self.critic, fully_update=fully_update, **config):
|
||||
for target_holder in self.target_holder_list:
|
||||
tasks.append(
|
||||
target_holder.update_experience_maker.remote(
|
||||
new_critic_state_dict=state_dict_shard,
|
||||
new_critic_lora_config_dict=self._get_model_lora_config_dict(self.critic),
|
||||
fully_update=fully_update,
|
||||
)
|
||||
)
|
||||
ray.get(tasks)
|
||||
# mark end
|
||||
for target_holder in self.target_holder_list:
|
||||
target_holder.update_experience_maker.remote(chunk_end=True, fully_update=fully_update)
|
||||
|
||||
@ray.method(concurrency_group="compute")
|
||||
def training_step(self, experience: Experience) -> Dict[str, float]:
|
||||
self.actor.train()
|
||||
self.critic.train()
|
||||
|
||||
num_actions = experience.action_mask.size(1)
|
||||
action_log_probs = self.actor(experience.sequences, num_actions, attention_mask=experience.attention_mask)
|
||||
actor_loss = self.actor_loss_fn(
|
||||
action_log_probs, experience.action_log_probs, experience.advantages, action_mask=experience.action_mask
|
||||
)
|
||||
self.strategy.backward(actor_loss, self.actor, self.actor_optim)
|
||||
self.strategy.optimizer_step(self.actor_optim)
|
||||
self.actor_optim.zero_grad()
|
||||
|
||||
values = self.critic(
|
||||
experience.sequences, action_mask=experience.action_mask, attention_mask=experience.attention_mask
|
||||
)
|
||||
critic_loss = self.critic_loss_fn(
|
||||
values, experience.values, experience.reward, action_mask=experience.action_mask
|
||||
)
|
||||
|
||||
self.strategy.backward(critic_loss, self.critic, self.critic_optim)
|
||||
self.strategy.optimizer_step(self.critic_optim)
|
||||
self.critic_optim.zero_grad()
|
||||
return {"actor_loss": actor_loss.item(), "critic_loss": critic_loss.item()}
|
||||
|
||||
def strategy_save_actor(self, path: str, only_rank0: bool = False) -> None:
|
||||
self.strategy.save_model(self.actor, path, only_rank0)
|
||||
|
||||
def strategy_save_critic(self, path: str, only_rank0: bool = False) -> None:
|
||||
self.strategy.save_model(self.critic, path, only_rank0)
|
||||
|
||||
def strategy_save_actor_optim(self, path: str, only_rank0: bool = False) -> None:
|
||||
self.strategy.save_optimizer(self.actor_optim, path, only_rank0)
|
||||
|
||||
def strategy_save_critic_optim(self, path: str, only_rank0: bool = False) -> None:
|
||||
self.strategy.save_optimizer(self.critic_optim, path, only_rank0)
|
||||
|
||||
def _get_model_state_dict_shard(self, model: torch.nn.Module, fully_update=False, **config):
|
||||
for state_dict in self.strategy.get_model_state_dict_shard(model, **config):
|
||||
if not self._update_lora_weights or fully_update:
|
||||
yield state_dict_to(state_dict)
|
||||
else:
|
||||
state_dict_lora, _ = LoRAConstructor.filter_state_dict_lora(state_dict)
|
||||
yield state_dict_to(state_dict_lora)
|
||||
|
||||
def _get_model_lora_config_dict(self, model: torch.nn.Module):
|
||||
if not self._update_lora_weights:
|
||||
return None
|
||||
unwrapped_model = self.strategy.unwrap_model(model)
|
||||
return LoRAConstructor.extract_lora_config(unwrapped_model)
|
||||
|
|
@ -0,0 +1,274 @@
|
|||
import os
|
||||
import time
|
||||
import tracemalloc
|
||||
from threading import Lock
|
||||
from typing import Any, Callable, Dict, Iterable, List, Tuple, Union
|
||||
|
||||
import ray
|
||||
import torch
|
||||
from coati.experience_buffer.utils import split_experience_batch
|
||||
from coati.experience_maker import Experience, NaiveExperienceMaker
|
||||
from coati.models.base import Actor, Critic, RewardModel
|
||||
from coati.trainer.strategies import Strategy
|
||||
from torch import Tensor
|
||||
from tqdm import tqdm
|
||||
|
||||
from .callbacks import ExperienceMakerPerformanceEvaluator, MakerCallback
|
||||
from .lora_constructor import LoRAConstructor
|
||||
from .utils import get_model_numel, get_rank, is_rank_0, set_dist_env, state_dict_to
|
||||
|
||||
|
||||
@ray.remote(concurrency_groups={"experience_io": 1, "model_io": 1, "compute": 1})
|
||||
class ExperienceMakerHolder:
|
||||
"""
|
||||
Args:
|
||||
detached_trainer_name_list: str list to get ray actor handles
|
||||
strategy:
|
||||
kl_coef: the coefficient of kl divergence loss
|
||||
sync_models_from_trainers: whether to sync models from trainers. If True, you must call sync_models_to_remote_makers() in trainers to sync models.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
detached_trainer_name_list: List[str],
|
||||
strategy_fn: Callable[[], Strategy],
|
||||
# a function returns (actor, critic, reward_model, initial_model)
|
||||
model_fn: Callable[[], Tuple[Actor, Critic, RewardModel, Actor]],
|
||||
env_info: Dict[str, str] = None,
|
||||
sync_models_from_trainers: bool = False,
|
||||
buffer_cpu_offload: bool = True,
|
||||
kl_coef: float = 0.1,
|
||||
callbacks: List[MakerCallback] = [],
|
||||
eval_performance: bool = False,
|
||||
debug: bool = False,
|
||||
update_lora_weights: bool = False,
|
||||
**generate_kwargs,
|
||||
):
|
||||
# set environment variables
|
||||
if env_info:
|
||||
set_dist_env(env_info=env_info)
|
||||
self.target_trainer_list = []
|
||||
assert len(detached_trainer_name_list) > 0
|
||||
self._detached_trainer_name_list = detached_trainer_name_list
|
||||
self.strategy = strategy_fn()
|
||||
self.buffer_cpu_offload = buffer_cpu_offload
|
||||
self.kl_coef = kl_coef
|
||||
# init models
|
||||
with self.strategy.model_init_context():
|
||||
actor, critic, reward_model, initial_model = model_fn()
|
||||
self.generate_kwargs = _set_default_generate_kwargs(generate_kwargs, actor)
|
||||
if eval_performance:
|
||||
actor_numel = get_model_numel(actor)
|
||||
critic_numel = get_model_numel(critic)
|
||||
initial_model_numel = get_model_numel(initial_model)
|
||||
reward_model_numel = get_model_numel(reward_model)
|
||||
evaluator = ExperienceMakerPerformanceEvaluator(
|
||||
actor_numel, critic_numel, initial_model_numel, reward_model_numel
|
||||
)
|
||||
callbacks = callbacks + [evaluator]
|
||||
|
||||
actor, critic, reward_model, initial_model = self.strategy.prepare(actor, critic, reward_model, initial_model)
|
||||
self.experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model, self.kl_coef)
|
||||
self.callbacks = callbacks
|
||||
|
||||
self._model_visit_lock = Lock()
|
||||
|
||||
self._is_fully_initialized = not sync_models_from_trainers
|
||||
|
||||
self._debug = debug
|
||||
self._update_lora_weights = update_lora_weights
|
||||
if self._update_lora_weights:
|
||||
self.actor_lora_constructor = LoRAConstructor()
|
||||
self.critic_lora_constructor = LoRAConstructor()
|
||||
|
||||
self.target_auto_balance = False
|
||||
|
||||
self._target_idx = 0
|
||||
|
||||
if self._debug:
|
||||
print(f"[maker{get_rank()}] will send items to {self._detached_trainer_name_list}")
|
||||
if not self._is_fully_initialized:
|
||||
print(f"[maker{get_rank()}] Waiting for INIT")
|
||||
|
||||
def _get_ready(self):
|
||||
while not self._fully_initialized():
|
||||
time.sleep(1.0)
|
||||
|
||||
def _fully_initialized(self):
|
||||
return self._is_fully_initialized
|
||||
|
||||
def _init_target_trainer_list(self):
|
||||
if len(self.target_trainer_list) > 0:
|
||||
return
|
||||
for name in self._detached_trainer_name_list:
|
||||
self.target_trainer_list.append(ray.get_actor(name, namespace=os.environ["RAY_NAMESPACE"]))
|
||||
|
||||
# copy from ../trainer/base.py
|
||||
@ray.method(concurrency_group="compute")
|
||||
def _make_experience(self, inputs: Union[Tensor, Dict[str, Tensor]]) -> Experience:
|
||||
if isinstance(inputs, Tensor):
|
||||
return self.experience_maker.make_experience(inputs, **self.generate_kwargs)
|
||||
elif isinstance(inputs, dict):
|
||||
return self.experience_maker.make_experience(**inputs, **self.generate_kwargs)
|
||||
else:
|
||||
raise ValueError(f'Unsupported input type "{type(inputs)}"')
|
||||
|
||||
@ray.method(concurrency_group="experience_io")
|
||||
def _send_items(self, experience: Experience) -> None:
|
||||
self._init_target_trainer_list()
|
||||
items = split_experience_batch(experience)
|
||||
items_per_trainer = [[] for _ in range(len(self.target_trainer_list))]
|
||||
for item in items:
|
||||
items_per_trainer[self._target_idx].append(item)
|
||||
self._target_idx = (self._target_idx + 1) % len(self.target_trainer_list)
|
||||
for i, target_trainer in enumerate(self.target_trainer_list):
|
||||
if len(items_per_trainer[i]) > 0:
|
||||
target_trainer.buffer_extend.remote(items_per_trainer[i])
|
||||
|
||||
def _inference_step(self, batch) -> None:
|
||||
self._on_batch_start()
|
||||
with self._model_visit_lock:
|
||||
self._on_make_experience_start()
|
||||
experience = self._make_experience(batch)
|
||||
self._on_make_experience_end(experience)
|
||||
self._on_send_start()
|
||||
if self.buffer_cpu_offload:
|
||||
experience.to_device("cpu")
|
||||
self._send_items(experience)
|
||||
self._on_send_end()
|
||||
self._on_batch_end()
|
||||
|
||||
def workingloop(self, dataloader_fn: Callable[[], Iterable], num_epochs: int = 1, num_steps: int = 0):
|
||||
"""Working loop of the experience maker.
|
||||
|
||||
Args:
|
||||
dataloader_fn (Callable[[], Iterable]): A function that returns a dataloader.
|
||||
num_epochs (int, optional): Iterate the dataloader for number of epochs. Defaults to 1.
|
||||
num_steps (int, optional): Iterate the dataloader for number if steps. If this value > 0, num_epochs will be ignored. Defaults to 0.
|
||||
"""
|
||||
self._get_ready()
|
||||
self._on_loop_start()
|
||||
dataloader = dataloader_fn()
|
||||
if num_steps > 0:
|
||||
# ignore num epochs
|
||||
it = iter(dataloader)
|
||||
for _ in tqdm(range(num_steps), desc="ExperienceMaker", disable=not is_rank_0()):
|
||||
try:
|
||||
batch = next(it)
|
||||
except StopIteration:
|
||||
it = iter(dataloader)
|
||||
batch = next(it)
|
||||
self._inference_step(batch)
|
||||
else:
|
||||
with tqdm(total=num_epochs * len(dataloader), desc="ExperienceMaker", disable=not is_rank_0()) as pbar:
|
||||
for _ in range(num_epochs):
|
||||
for batch in dataloader:
|
||||
self._inference_step(batch)
|
||||
pbar.update()
|
||||
self._on_loop_end()
|
||||
|
||||
@ray.method(concurrency_group="model_io")
|
||||
def update_experience_maker(
|
||||
self,
|
||||
new_actor_state_dict: Dict[str, Any] = None,
|
||||
new_actor_lora_config_dict: Dict[str, Any] = None,
|
||||
new_critic_state_dict: Dict[str, Any] = None,
|
||||
new_critic_lora_config_dict: Dict[str, Any] = None,
|
||||
fully_update: bool = False,
|
||||
chunk_start: bool = None,
|
||||
chunk_end: bool = None,
|
||||
):
|
||||
"""
|
||||
called by trainer
|
||||
chunk_start: Set True at the first call. Before sending state_dict calls
|
||||
chunk_end: Set True at the last call. After sending state_dict calls.
|
||||
fully_update: Set True if you want to sync models when initializing
|
||||
|
||||
TODO: load_state_dict integrate with model-sharding strategy
|
||||
"""
|
||||
_watch_memory = self._debug
|
||||
if chunk_start:
|
||||
if self._debug:
|
||||
print("[maker] UPDATE ")
|
||||
if _watch_memory:
|
||||
tracemalloc.start()
|
||||
self._model_visit_lock.acquire()
|
||||
|
||||
with torch.no_grad():
|
||||
if new_actor_state_dict is not None:
|
||||
if not self._update_lora_weights or fully_update:
|
||||
self.experience_maker.actor.model.load_state_dict(new_actor_state_dict, strict=False)
|
||||
else:
|
||||
new_actor_state_dict = state_dict_to(new_actor_state_dict, device=torch.cuda.current_device())
|
||||
state_dict_increase = self.actor_lora_constructor.reconstruct_increase(
|
||||
new_actor_state_dict, new_actor_lora_config_dict
|
||||
)
|
||||
self.actor_lora_constructor.load_state_dict_increase(
|
||||
self.experience_maker.actor.model, state_dict_increase
|
||||
)
|
||||
if new_critic_state_dict is not None:
|
||||
if not self._update_lora_weights or fully_update:
|
||||
self.experience_maker.critic.load_state_dict(new_critic_state_dict, strict=False)
|
||||
else:
|
||||
new_critic_state_dict = state_dict_to(new_critic_state_dict, device=torch.cuda.current_device())
|
||||
state_dict_increase = self.critic_lora_constructor.reconstruct_increase(
|
||||
new_critic_state_dict, new_critic_lora_config_dict
|
||||
)
|
||||
self.critic_lora_constructor.load_state_dict_increase(
|
||||
self.experience_maker.critic, state_dict_increase
|
||||
)
|
||||
|
||||
# the lock must be released after both actor and critic being updated
|
||||
if chunk_end:
|
||||
self._model_visit_lock.release()
|
||||
if _watch_memory:
|
||||
current, peak = tracemalloc.get_traced_memory()
|
||||
print(f"Current memory usage is {current / 10**6}MB; Peak was {peak / 10**6}MB")
|
||||
tracemalloc.stop()
|
||||
if fully_update:
|
||||
self._is_fully_initialized = True
|
||||
|
||||
def _on_make_experience_start(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_make_experience_start()
|
||||
|
||||
def _on_make_experience_end(self, experience: Experience) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_make_experience_end(experience)
|
||||
|
||||
def _on_loop_start(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_loop_start()
|
||||
|
||||
def _on_loop_end(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_loop_end()
|
||||
|
||||
def _on_send_start(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_send_start()
|
||||
|
||||
def _on_send_end(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_send_end()
|
||||
|
||||
def _on_batch_start(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_batch_start()
|
||||
|
||||
def _on_batch_end(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_batch_end()
|
||||
|
||||
|
||||
def _set_default_generate_kwargs(generate_kwargs: dict, actor: Actor) -> None:
|
||||
origin_model = actor.model
|
||||
new_kwargs = {**generate_kwargs}
|
||||
# use huggingface models method directly
|
||||
if "prepare_inputs_fn" not in generate_kwargs and hasattr(origin_model, "prepare_inputs_for_generation"):
|
||||
new_kwargs["prepare_inputs_fn"] = origin_model.prepare_inputs_for_generation
|
||||
|
||||
if "update_model_kwargs_fn" not in generate_kwargs and hasattr(origin_model, "_update_model_kwargs_for_generation"):
|
||||
new_kwargs["update_model_kwargs_fn"] = origin_model._update_model_kwargs_for_generation
|
||||
|
||||
return new_kwargs
|
||||
|
|
@ -0,0 +1,123 @@
|
|||
from collections import OrderedDict
|
||||
from dataclasses import dataclass
|
||||
from typing import Any, Dict
|
||||
|
||||
import torch.nn as nn
|
||||
from coati.models.lora import LoraLinear
|
||||
|
||||
|
||||
@dataclass
|
||||
class LoRAConfig:
|
||||
r: int = 0
|
||||
lora_alpha: int = 1
|
||||
lora_dropout: float = 0
|
||||
fan_in_fan_out: bool = False
|
||||
|
||||
|
||||
class LoRAConstructor:
|
||||
"""
|
||||
Tools for reconstructing a model from a remote LoRA model.
|
||||
(Transferring only LoRA data costs much less!)
|
||||
Usage:
|
||||
Step 1 (Sender):
|
||||
filter_state_dict_lora()
|
||||
|
||||
Step 2 (Sender, Optional):
|
||||
extract_lora_config()
|
||||
|
||||
Step 3 (Sender):
|
||||
send state_dict_lora and lora_config_dict
|
||||
|
||||
Step 4 (Receiver):
|
||||
reconstruct_increase()
|
||||
|
||||
Step 5 (Receiver):
|
||||
load_state_dict_increase()
|
||||
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.lora_config_dict = None
|
||||
|
||||
def register_lora_config(self, lora_config_dict: Dict[str, Any]):
|
||||
self.lora_config_dict = lora_config_dict
|
||||
|
||||
def reconstruct_increase(self, state_dict_lora: Dict[str, Any], lora_config_dict: Dict[str, Any]):
|
||||
"""
|
||||
xxx.lora_A, xxx.lora_B -->> xxx.weight
|
||||
Warning: the xxx.weight here is the increment actually.
|
||||
"""
|
||||
if lora_config_dict is not None:
|
||||
self.register_lora_config(lora_config_dict)
|
||||
|
||||
state_dict_increase = OrderedDict()
|
||||
config_iter = iter(self.lora_config_dict.items())
|
||||
lora_A, lora_B, layer_prefix = None, None, None
|
||||
for k, v in state_dict_lora.items():
|
||||
if k.rpartition(".")[-1] == "lora_A":
|
||||
lora_A = v
|
||||
layer_prefix = k.rpartition(".")[0]
|
||||
elif k.rpartition(".")[-1] == "lora_B":
|
||||
assert layer_prefix == k.rpartition(".")[0], "unmatched (lora_A, lora_B) pair"
|
||||
layer_prefix_2, config = next(config_iter)
|
||||
assert layer_prefix_2 == layer_prefix, "unmatched (state_dict, config_dict) pair"
|
||||
lora_B = v
|
||||
weight_data_increase = self._compute(lora_A, lora_B, config)
|
||||
state_dict_increase[layer_prefix + ".weight"] = weight_data_increase
|
||||
lora_A, lora_B, layer_prefix = None, None, None
|
||||
else:
|
||||
raise ValueError("unexpected key")
|
||||
return state_dict_increase
|
||||
|
||||
def _compute(self, lora_A, lora_B, config=LoRAConfig()):
|
||||
def T(w):
|
||||
return w.T if config.fan_in_fan_out else w
|
||||
|
||||
if config.r > 0:
|
||||
scaling = config.lora_alpha / config.r
|
||||
weight_data_increase = T(lora_B @ lora_A) * scaling
|
||||
return weight_data_increase
|
||||
return 0
|
||||
|
||||
def load_state_dict_increase(self, model: nn.Module, state_dict_increase: Dict[str, Any]):
|
||||
"""
|
||||
The final reconstruction step
|
||||
"""
|
||||
# naive approach
|
||||
model.load_state_dict({k: v + model.state_dict()[k] for k, v in state_dict_increase.items()}, strict=False)
|
||||
|
||||
@staticmethod
|
||||
def filter_state_dict_lora(state_dict: Dict[str, Any], keep_non_lora=False):
|
||||
"""
|
||||
if keep_non_lora, also return non_lora state_dict
|
||||
"""
|
||||
state_dict_lora = OrderedDict()
|
||||
state_dict_non_lora = OrderedDict()
|
||||
for k, v in state_dict.items():
|
||||
if "lora_A" in k or "lora_B" in k:
|
||||
state_dict_lora[k] = v
|
||||
elif keep_non_lora:
|
||||
state_dict_non_lora[k] = v
|
||||
if keep_non_lora:
|
||||
return state_dict_lora, state_dict_non_lora
|
||||
else:
|
||||
return state_dict_lora, None
|
||||
|
||||
@staticmethod
|
||||
def extract_lora_config(model: nn.Module) -> Dict[str, LoRAConfig]:
|
||||
"""
|
||||
extract LoraLinear model.
|
||||
return OrderedDict(): name -> LoRAConfig
|
||||
"""
|
||||
lora_config_dict = OrderedDict()
|
||||
|
||||
for name, child in model.named_modules():
|
||||
if isinstance(child, LoraLinear):
|
||||
lora_config_dict[name] = LoRAConfig(
|
||||
r=child.r,
|
||||
lora_alpha=child.lora_alpha,
|
||||
lora_dropout=child.lora_dropout,
|
||||
fan_in_fan_out=child.fan_in_fan_out,
|
||||
)
|
||||
|
||||
return lora_config_dict
|
||||
|
|
@ -0,0 +1,142 @@
|
|||
import os
|
||||
from collections import OrderedDict
|
||||
from typing import Any, Dict
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.nn as nn
|
||||
from coati.models.bloom import BLOOMRM, BLOOMActor, BLOOMCritic
|
||||
from coati.models.gpt import GPTRM, GPTActor, GPTCritic
|
||||
from coati.models.llama import LlamaActor, LlamaCritic, LlamaRM
|
||||
from coati.models.opt import OPTRM, OPTActor, OPTCritic
|
||||
from coati.trainer.strategies import DDPStrategy, GeminiStrategy, LowLevelZeroStrategy
|
||||
from transformers import AutoTokenizer, BloomTokenizerFast, GPT2Tokenizer
|
||||
|
||||
|
||||
def is_rank_0() -> bool:
|
||||
return not dist.is_initialized() or dist.get_rank() == 0
|
||||
|
||||
|
||||
def get_rank() -> int:
|
||||
return dist.get_rank() if dist.is_initialized() else 0
|
||||
|
||||
|
||||
def get_world_size() -> int:
|
||||
return dist.get_world_size() if dist.is_initialized() else 1
|
||||
|
||||
|
||||
def get_actor_from_args(model: str, pretrained: str = None, config=None, lora_rank=0):
|
||||
if model == "gpt2":
|
||||
actor = GPTActor(pretrained=pretrained, config=config, lora_rank=lora_rank)
|
||||
elif model == "bloom":
|
||||
actor = BLOOMActor(pretrained=pretrained, config=config, lora_rank=lora_rank)
|
||||
elif model == "opt":
|
||||
actor = OPTActor(pretrained=pretrained, config=config, lora_rank=lora_rank)
|
||||
elif model == "llama":
|
||||
actor = LlamaActor(pretrained=pretrained, config=config, lora_rank=lora_rank)
|
||||
else:
|
||||
raise ValueError(f'Unsupported actor model "{model}"')
|
||||
return actor
|
||||
|
||||
|
||||
def get_critic_from_args(model: str, pretrained: str = None, config=None, lora_rank=0):
|
||||
if model == "gpt2":
|
||||
critic = GPTCritic(pretrained=pretrained, lora_rank=lora_rank, config=config)
|
||||
elif model == "bloom":
|
||||
critic = BLOOMCritic(pretrained=pretrained, lora_rank=lora_rank, config=config)
|
||||
elif model == "opt":
|
||||
critic = OPTCritic(pretrained=pretrained, lora_rank=lora_rank, config=config)
|
||||
elif model == "llama":
|
||||
critic = LlamaCritic(pretrained=pretrained, lora_rank=lora_rank, config=config)
|
||||
else:
|
||||
raise ValueError(f'Unsupported reward model "{model}"')
|
||||
return critic
|
||||
|
||||
|
||||
def get_reward_model_from_args(model: str, pretrained: str = None, config=None):
|
||||
if model == "gpt2":
|
||||
reward_model = GPTRM(pretrained=pretrained, config=config)
|
||||
elif model == "bloom":
|
||||
reward_model = BLOOMRM(pretrained=pretrained, config=config)
|
||||
elif model == "opt":
|
||||
reward_model = OPTRM(pretrained=pretrained, config=config)
|
||||
elif model == "llama":
|
||||
reward_model = LlamaRM(pretrained=pretrained, config=config)
|
||||
else:
|
||||
raise ValueError(f'Unsupported reward model "{model}"')
|
||||
return reward_model
|
||||
|
||||
|
||||
def get_strategy_from_args(strategy: str):
|
||||
if strategy == "ddp":
|
||||
strategy_ = DDPStrategy()
|
||||
elif strategy == "colossalai_gemini":
|
||||
strategy_ = GeminiStrategy(placement_policy="static", initial_scale=2**5)
|
||||
elif strategy == "colossalai_zero2":
|
||||
strategy_ = LowLevelZeroStrategy(stage=2, placement_policy="cuda")
|
||||
elif strategy == "colossalai_gemini_cpu":
|
||||
strategy_ = GeminiStrategy(
|
||||
placement_policy="static", offload_optim_frac=1.0, offload_param_frac=1.0, initial_scale=2**5
|
||||
)
|
||||
elif strategy == "colossalai_zero2_cpu":
|
||||
strategy_ = LowLevelZeroStrategy(stage=2, placement_policy="cpu")
|
||||
else:
|
||||
raise ValueError(f'Unsupported strategy "{strategy}"')
|
||||
return strategy_
|
||||
|
||||
|
||||
def get_tokenizer_from_args(model: str, **kwargs):
|
||||
if model == "gpt2":
|
||||
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
|
||||
elif model == "bloom":
|
||||
tokenizer = BloomTokenizerFast.from_pretrained("bigscience/bloom-560m")
|
||||
elif model == "opt":
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
|
||||
elif model == "llama":
|
||||
pretrain_path = kwargs["pretrain"]
|
||||
tokenizer = AutoTokenizer.from_pretrained(pretrain_path)
|
||||
else:
|
||||
raise ValueError(f'Unsupported model "{model}"')
|
||||
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
return tokenizer
|
||||
|
||||
|
||||
def set_dist_env(env_info: Dict[str, str]):
|
||||
os.environ["RANK"] = env_info["rank"]
|
||||
os.environ["LOCAL_RANK"] = env_info["local_rank"]
|
||||
os.environ["WORLD_SIZE"] = env_info["world_size"]
|
||||
os.environ["MASTER_PORT"] = env_info["master_port"]
|
||||
os.environ["MASTER_ADDR"] = env_info["master_addr"]
|
||||
|
||||
|
||||
def get_model_numel(model: nn.Module) -> int:
|
||||
numel = sum(p.numel() for p in model.parameters())
|
||||
return numel
|
||||
|
||||
|
||||
def get_receivers_per_sender(sender_idx: int, num_senders: int, num_receivers: int, allow_idle_sender: bool) -> list:
|
||||
target_receivers = []
|
||||
if num_senders <= num_receivers or allow_idle_sender:
|
||||
# a sender will send data to one or more receivers
|
||||
# a receiver only has one sender
|
||||
for i in range(num_receivers):
|
||||
if i % num_senders == sender_idx:
|
||||
target_receivers.append(i)
|
||||
else:
|
||||
# a sender will send data to one receiver
|
||||
# a receiver may have more than one sender
|
||||
target_receivers.append(sender_idx % num_receivers)
|
||||
return target_receivers
|
||||
|
||||
|
||||
def state_dict_to(
|
||||
state_dict: Dict[str, Any], dtype: torch.dtype = torch.float16, device: torch.device = torch.device("cpu")
|
||||
):
|
||||
"""
|
||||
keep state_dict intact
|
||||
"""
|
||||
new_state_dict = OrderedDict()
|
||||
for k, v in state_dict.items():
|
||||
new_state_dict[k] = v.to(dtype=dtype, device=device)
|
||||
return new_state_dict
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
from .base import OLTrainer, SLTrainer
|
||||
from .dpo import DPOTrainer
|
||||
from .kto import KTOTrainer
|
||||
from .orpo import ORPOTrainer
|
||||
from .ppo import PPOTrainer
|
||||
from .rm import RewardModelTrainer
|
||||
from .sft import SFTTrainer
|
||||
|
||||
__all__ = [
|
||||
"SLTrainer",
|
||||
"OLTrainer",
|
||||
"RewardModelTrainer",
|
||||
"SFTTrainer",
|
||||
"PPOTrainer",
|
||||
"DPOTrainer",
|
||||
"ORPOTrainer",
|
||||
"KTOTrainer",
|
||||
]
|
||||
|
|
@ -0,0 +1,214 @@
|
|||
"""
|
||||
Base trainers for online and offline training
|
||||
SLTrainer: supervised learning trainer
|
||||
pretrain, sft, dpo, reward model training
|
||||
OLTrainer: online learning trainer
|
||||
rlhf-ppo
|
||||
"""
|
||||
|
||||
from abc import ABC, abstractmethod
|
||||
from contextlib import contextmanager
|
||||
from typing import Callable, List
|
||||
|
||||
import torch.nn as nn
|
||||
import tqdm
|
||||
from coati.experience_buffer import NaiveExperienceBuffer
|
||||
from coati.experience_maker import Experience
|
||||
from torch.optim import Optimizer
|
||||
|
||||
from colossalai.booster import Booster
|
||||
|
||||
from .utils import is_rank_0
|
||||
|
||||
|
||||
class SLTrainer(ABC):
|
||||
"""
|
||||
Base class for supervised learning trainers.
|
||||
|
||||
Args:
|
||||
strategy (Strategy):the strategy to use for training
|
||||
max_epochs (int, defaults to 1): the number of epochs of training process
|
||||
model (nn.Module): the model to train
|
||||
optim (Optimizer): the optimizer to use for training
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
booster: Booster,
|
||||
max_epochs: int,
|
||||
model: nn.Module,
|
||||
optimizer: Optimizer,
|
||||
start_epoch: int = 0,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.booster = booster
|
||||
self.max_epochs = max_epochs
|
||||
self.model = model
|
||||
self.optimizer = optimizer
|
||||
self.start_epoch = start_epoch
|
||||
|
||||
@abstractmethod
|
||||
def _train(self, epoch):
|
||||
raise NotImplementedError()
|
||||
|
||||
@abstractmethod
|
||||
def _eval(self, epoch):
|
||||
raise NotImplementedError()
|
||||
|
||||
@abstractmethod
|
||||
def _before_fit(self):
|
||||
raise NotImplementedError()
|
||||
|
||||
def fit(self, *args, **kwargs):
|
||||
self._before_fit(*args, **kwargs)
|
||||
for epoch in tqdm.trange(self.start_epoch, self.max_epochs, desc="Epochs", disable=not is_rank_0()):
|
||||
self._train(epoch)
|
||||
self._eval(epoch)
|
||||
|
||||
|
||||
class OLTrainer(ABC):
|
||||
"""
|
||||
Base class for online learning trainers, e.g. PPO.
|
||||
|
||||
Args:
|
||||
strategy (Strategy):the strategy to use for training
|
||||
data_buffer (NaiveExperienceBuffer): the buffer to collect experiences
|
||||
sample_buffer (bool, defaults to False): whether to sample from buffer
|
||||
dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
|
||||
callbacks (List[Callback], defaults to []): the callbacks to call during training process
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
actor_booster: Booster,
|
||||
critic_booster: Booster,
|
||||
data_buffer: NaiveExperienceBuffer,
|
||||
sample_buffer: bool,
|
||||
dataloader_pin_memory: bool,
|
||||
callbacks: List[Callable] = [],
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.actor_booster = actor_booster
|
||||
self.critic_booster = critic_booster
|
||||
self.data_buffer = data_buffer
|
||||
self.sample_buffer = sample_buffer
|
||||
self.dataloader_pin_memory = dataloader_pin_memory
|
||||
self.callbacks = callbacks
|
||||
|
||||
@contextmanager
|
||||
def _fit_ctx(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_fit_start()
|
||||
try:
|
||||
yield
|
||||
finally:
|
||||
for callback in self.callbacks:
|
||||
callback.on_fit_end()
|
||||
|
||||
@contextmanager
|
||||
def _episode_ctx(self, episode: int) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_episode_start(episode)
|
||||
try:
|
||||
yield
|
||||
finally:
|
||||
for callback in self.callbacks:
|
||||
callback.on_episode_end(episode)
|
||||
|
||||
def _on_make_experience_start(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_make_experience_start()
|
||||
|
||||
def _on_make_experience_end(self, experience: Experience) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_make_experience_end(experience)
|
||||
|
||||
def _on_learn_epoch_start(self, epoch: int) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_learn_epoch_start(epoch)
|
||||
|
||||
def _on_learn_epoch_end(self, epoch: int) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_learn_epoch_end(epoch)
|
||||
|
||||
def _on_learn_batch_start(self) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_learn_batch_start()
|
||||
|
||||
def _on_learn_batch_end(self, experience: Experience) -> None:
|
||||
for callback in self.callbacks:
|
||||
callback.on_learn_batch_end(experience)
|
||||
|
||||
@abstractmethod
|
||||
def _make_experience(self, collect_step: int):
|
||||
"""
|
||||
Implement this method to make experience.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
@abstractmethod
|
||||
def _learn(self, update_step: int):
|
||||
"""
|
||||
Implement this method to learn from experience, either
|
||||
sample from buffer or transform buffer into dataloader.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
@abstractmethod
|
||||
def _setup_update_phrase_dataload(self):
|
||||
"""
|
||||
Implement this method to setup dataloader for update phase.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
@abstractmethod
|
||||
def _save_checkpoint(self, episode: int = 0):
|
||||
"""
|
||||
Implement this method to save checkpoint.
|
||||
"""
|
||||
raise NotImplementedError()
|
||||
|
||||
def _collect_phase(self, collect_step: int):
|
||||
self._on_make_experience_start()
|
||||
experience = self._make_experience(collect_step)
|
||||
self._on_make_experience_end(experience)
|
||||
self.data_buffer.append(experience)
|
||||
|
||||
def _update_phase(self, update_step: int):
|
||||
self._on_learn_epoch_start(update_step)
|
||||
self._learn(update_step)
|
||||
self._on_learn_epoch_end(update_step)
|
||||
|
||||
def _before_fit(self, *args, **kwargs):
|
||||
raise NotImplementedError()
|
||||
|
||||
def fit(
|
||||
self,
|
||||
num_episodes: int,
|
||||
num_collect_steps: int,
|
||||
num_update_steps: int,
|
||||
*args,
|
||||
**kwargs,
|
||||
):
|
||||
"""
|
||||
The main training loop of on-policy rl trainers.
|
||||
|
||||
Args:
|
||||
num_episodes (int): the number of episodes to train
|
||||
num_collect_steps (int): the number of collect steps per episode
|
||||
num_update_steps (int): the number of update steps per episode
|
||||
"""
|
||||
self._before_fit(*args, **kwargs)
|
||||
with self._fit_ctx():
|
||||
for episode in tqdm.trange(num_episodes, desc="Episodes", disable=not is_rank_0()):
|
||||
with self._episode_ctx(episode):
|
||||
for collect_step in tqdm.trange(num_collect_steps, desc="Collect steps", disable=not is_rank_0()):
|
||||
self._collect_phase(collect_step)
|
||||
if not self.sample_buffer:
|
||||
self._setup_update_phrase_dataload()
|
||||
for update_step in tqdm.trange(num_update_steps, desc="Update steps", disable=not is_rank_0()):
|
||||
self._update_phase(update_step)
|
||||
# NOTE: this is for on-policy algorithms
|
||||
self.data_buffer.clear()
|
||||
if self.save_interval > 0 and (episode + 1) % (self.save_interval) == 0:
|
||||
self._save_checkpoint(episode + 1)
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
from .base import Callback
|
||||
from .performance_evaluator import PerformanceEvaluator
|
||||
|
||||
__all__ = ["Callback", "PerformanceEvaluator"]
|
||||
|
|
@ -0,0 +1,39 @@
|
|||
from abc import ABC
|
||||
|
||||
from coati.experience_maker import Experience
|
||||
|
||||
|
||||
class Callback(ABC):
|
||||
"""
|
||||
Base callback class. It defines the interface for callbacks.
|
||||
"""
|
||||
|
||||
def on_fit_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_fit_end(self) -> None:
|
||||
pass
|
||||
|
||||
def on_episode_start(self, episode: int) -> None:
|
||||
pass
|
||||
|
||||
def on_episode_end(self, episode: int) -> None:
|
||||
pass
|
||||
|
||||
def on_make_experience_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_make_experience_end(self, experience: Experience) -> None:
|
||||
pass
|
||||
|
||||
def on_learn_epoch_start(self, epoch: int) -> None:
|
||||
pass
|
||||
|
||||
def on_learn_epoch_end(self, epoch: int) -> None:
|
||||
pass
|
||||
|
||||
def on_learn_batch_start(self) -> None:
|
||||
pass
|
||||
|
||||
def on_learn_batch_end(self, experience: Experience) -> None:
|
||||
pass
|
||||
|
|
@ -0,0 +1,191 @@
|
|||
from time import time
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from coati.experience_maker import Experience
|
||||
|
||||
from .base import Callback
|
||||
|
||||
|
||||
def get_world_size() -> int:
|
||||
if dist.is_initialized():
|
||||
return dist.get_world_size()
|
||||
return 1
|
||||
|
||||
|
||||
def save_eval_result_rank_0(s: str, save_path: str, **kwargs) -> None:
|
||||
if not dist.is_initialized() or dist.get_rank() == 0:
|
||||
with open(save_path, "a+") as f:
|
||||
train_config = "; ".join([str(kwargs[key]) for key in kwargs])
|
||||
f.write(train_config + "\n" + s + "\n")
|
||||
|
||||
|
||||
def divide(x: float, y: float) -> float:
|
||||
if y == 0:
|
||||
return float("inf")
|
||||
elif y == float("inf"):
|
||||
return float("nan")
|
||||
return x / y
|
||||
|
||||
|
||||
@torch.no_grad()
|
||||
def all_reduce_mean(x: float, world_size: int) -> float:
|
||||
if world_size == 1:
|
||||
return x
|
||||
tensor = torch.tensor([x], device=torch.cuda.current_device())
|
||||
dist.all_reduce(tensor)
|
||||
tensor = tensor / world_size
|
||||
return tensor.item()
|
||||
|
||||
|
||||
class Timer:
|
||||
def __init__(self) -> None:
|
||||
self.start_time: Optional[float] = None
|
||||
self.duration: float = 0.0
|
||||
|
||||
def start(self) -> None:
|
||||
self.start_time = time()
|
||||
|
||||
def end(self) -> None:
|
||||
assert self.start_time is not None
|
||||
self.duration += time() - self.start_time
|
||||
self.start_time = None
|
||||
|
||||
def reset(self) -> None:
|
||||
self.duration = 0.0
|
||||
|
||||
|
||||
class PerformanceEvaluator(Callback):
|
||||
"""
|
||||
Callback for valuate the performance of the model.
|
||||
Args:
|
||||
actor_num_params: The number of parameters of the actor model.
|
||||
critic_num_params: The number of parameters of the critic model.
|
||||
initial_model_num_params: The number of parameters of the initial model.
|
||||
reward_model_num_params: The number of parameters of the reward model.
|
||||
enable_grad_checkpoint: Whether to enable gradient checkpointing.
|
||||
ignore_episodes: The number of episodes to ignore when calculating the performance.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
actor_num_params: int,
|
||||
critic_num_params: int,
|
||||
initial_model_num_params: int,
|
||||
reward_model_num_params: int,
|
||||
enable_grad_checkpoint: bool = False,
|
||||
ignore_episodes: int = 0,
|
||||
train_config: Optional[dict] = None,
|
||||
save_path: Optional[str] = None,
|
||||
) -> None:
|
||||
super().__init__()
|
||||
self.world_size = get_world_size()
|
||||
self.actor_num_params = actor_num_params
|
||||
self.critic_num_params = critic_num_params
|
||||
self.initial_model_num_params = initial_model_num_params
|
||||
self.reward_model_num_params = reward_model_num_params
|
||||
self.enable_grad_checkpoint = enable_grad_checkpoint
|
||||
self.ignore_episodes = ignore_episodes
|
||||
self.disable: bool = False
|
||||
|
||||
self.overall_timer = Timer()
|
||||
self.make_experience_timer = Timer()
|
||||
self.learn_timer = Timer()
|
||||
self.make_experience_num_samples: int = 0
|
||||
self.make_experience_flop: int = 0
|
||||
self.learn_num_samples: int = 0
|
||||
self.learn_flop: int = 0
|
||||
self.train_config = train_config
|
||||
self.save_path = save_path
|
||||
|
||||
def on_episode_start(self, episode: int) -> None:
|
||||
self.disable = self.ignore_episodes > 0 and episode < self.ignore_episodes
|
||||
if self.disable:
|
||||
return
|
||||
self.overall_timer.start()
|
||||
|
||||
def on_episode_end(self, episode: int) -> None:
|
||||
if self.disable:
|
||||
return
|
||||
self.overall_timer.end()
|
||||
|
||||
def on_make_experience_start(self) -> None:
|
||||
if self.disable:
|
||||
return
|
||||
self.make_experience_timer.start()
|
||||
|
||||
def on_make_experience_end(self, experience: Experience) -> None:
|
||||
if self.disable:
|
||||
return
|
||||
self.make_experience_timer.end()
|
||||
|
||||
batch_size, seq_len = experience.sequences.shape
|
||||
|
||||
self.make_experience_num_samples += batch_size
|
||||
|
||||
# actor generate
|
||||
num_actions = experience.action_mask.size(1)
|
||||
input_len = seq_len - num_actions
|
||||
total_seq_len = (input_len + seq_len - 1) * num_actions / 2
|
||||
self.make_experience_flop += self.actor_num_params * batch_size * total_seq_len * 2
|
||||
# actor forward
|
||||
self.make_experience_flop += self.actor_num_params * batch_size * seq_len * 2
|
||||
# critic forward
|
||||
self.make_experience_flop += self.critic_num_params * batch_size * seq_len * 2
|
||||
# initial model forward
|
||||
self.make_experience_flop += self.initial_model_num_params * batch_size * seq_len * 2
|
||||
# reward model forward
|
||||
self.make_experience_flop += self.reward_model_num_params * batch_size * seq_len * 2
|
||||
|
||||
def on_learn_batch_start(self) -> None:
|
||||
if self.disable:
|
||||
return
|
||||
self.learn_timer.start()
|
||||
|
||||
def on_learn_batch_end(self, experience: Experience) -> None:
|
||||
if self.disable:
|
||||
return
|
||||
self.learn_timer.end()
|
||||
|
||||
batch_size, seq_len = experience.sequences.shape
|
||||
|
||||
self.learn_num_samples += batch_size
|
||||
|
||||
# actor forward-backward, 3 means forward(1) + backward(2)
|
||||
self.learn_flop += self.actor_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
|
||||
# critic forward-backward
|
||||
self.learn_flop += self.critic_num_params * batch_size * seq_len * 2 * (3 + int(self.enable_grad_checkpoint))
|
||||
|
||||
def on_fit_end(self) -> None:
|
||||
avg_make_experience_duration = all_reduce_mean(self.make_experience_timer.duration, self.world_size)
|
||||
avg_learn_duration = all_reduce_mean(self.learn_timer.duration, self.world_size)
|
||||
avg_overall_duration = all_reduce_mean(self.overall_timer.duration, self.world_size)
|
||||
|
||||
avg_make_experience_throughput = (
|
||||
self.make_experience_num_samples * self.world_size / (avg_make_experience_duration + 1e-12)
|
||||
)
|
||||
avg_make_experience_tflops = self.make_experience_flop / 1e12 / (avg_make_experience_duration + 1e-12)
|
||||
|
||||
avg_learn_throughput = self.learn_num_samples * self.world_size / (avg_learn_duration + 1e-12)
|
||||
avg_learn_tflops = self.learn_flop / 1e12 / (avg_learn_duration + 1e-12)
|
||||
|
||||
num_effective_samples = min(self.learn_num_samples, self.make_experience_num_samples) * self.world_size
|
||||
|
||||
avg_overall_throughput = num_effective_samples / (avg_overall_duration + 1e-12)
|
||||
|
||||
overall_time_per_sample = divide(1, avg_overall_throughput)
|
||||
make_experience_time_per_sample = divide(avg_make_experience_duration, num_effective_samples)
|
||||
learn_time_per_sample = divide(avg_learn_duration, num_effective_samples)
|
||||
|
||||
save_eval_result_rank_0(
|
||||
f"Performance summary:\n"
|
||||
+ f"Generate {self.make_experience_num_samples * self.world_size} samples, throughput: {avg_make_experience_throughput:.2f} samples/s, TFLOPS per GPU: {avg_make_experience_tflops:.2f}\n"
|
||||
+ f"Train {self.learn_num_samples * self.world_size} samples, throughput: {avg_learn_throughput:.2f} samples/s, TFLOPS per GPU: {avg_learn_tflops:.2f}\n"
|
||||
+ f"Overall throughput: {avg_overall_throughput:.2f} samples/s\n"
|
||||
+ f"Overall time per sample: {overall_time_per_sample:.2f} s\n"
|
||||
+ f"Make experience time per sample: {make_experience_time_per_sample:.2f} s, {make_experience_time_per_sample/overall_time_per_sample*100:.2f}%\n"
|
||||
+ f"Learn time per sample: {learn_time_per_sample:.2f} s, {learn_time_per_sample/overall_time_per_sample*100:.2f}%",
|
||||
self.save_path,
|
||||
**self.train_config,
|
||||
)
|
||||
|
|
@ -0,0 +1,359 @@
|
|||
"""
|
||||
Dpo trainer
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Any, Optional
|
||||
|
||||
import torch
|
||||
from coati.models.loss import DpoLoss
|
||||
from coati.models.utils import calc_masked_log_probs
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import trange
|
||||
from transformers import PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
from .base import SLTrainer
|
||||
from .utils import is_rank_0, to_device
|
||||
|
||||
|
||||
class DPOTrainer(SLTrainer):
|
||||
"""
|
||||
Trainer for DPO algorithm.
|
||||
|
||||
Args:
|
||||
actor (Actor): the actor model in ppo algorithm
|
||||
ref_model (Critic): the reference model in ppo algorithm
|
||||
booster (Strategy): the strategy to use for training
|
||||
actor_optim (Optimizer): the optimizer to use for actor model
|
||||
actor_lr_scheduler (_LRScheduler): the lr scheduler to use for actor model
|
||||
tokenizer (PreTrainedTokenizerBase): the tokenizer to use for encoding
|
||||
max_epochs (int, defaults to 1): the max number of epochs to train
|
||||
beta (float, defaults to 0.1): the beta parameter in dpo loss
|
||||
accumulation_steps (int): the number of steps to accumulate gradients
|
||||
start_epoch (int, defaults to 0): the start epoch, non-zero if resumed from a checkpoint
|
||||
save_interval (int): the interval to save model checkpoints, default to 0, which means no checkpoint will be saved during trainning
|
||||
save_dir (str): the directory to save checkpoints
|
||||
coordinator (DistCoordinator): the coordinator to use for distributed logging
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
actor: Any,
|
||||
ref_model: Any,
|
||||
booster: Booster,
|
||||
actor_optim: Optimizer,
|
||||
actor_lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
max_epochs: int = 1,
|
||||
beta: float = 0.1,
|
||||
gamma: float = 0.0,
|
||||
length_normalization: bool = False,
|
||||
apply_loss_mask: bool = True,
|
||||
accumulation_steps: int = 1,
|
||||
start_epoch: int = 0,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
coordinator: DistCoordinator = None,
|
||||
) -> None:
|
||||
super().__init__(booster, max_epochs=max_epochs, model=actor, optimizer=actor_optim, start_epoch=start_epoch)
|
||||
self.ref_model = ref_model
|
||||
self.actor_scheduler = actor_lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.actor_loss_fn = DpoLoss(beta, gamma)
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.save_interval = save_interval
|
||||
self.coordinator = coordinator
|
||||
self.save_dir = save_dir
|
||||
self.num_train_step = 0
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.device = get_current_device()
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
self.length_normalization = length_normalization
|
||||
|
||||
def _before_fit(
|
||||
self,
|
||||
train_preference_dataloader: DataLoader = None,
|
||||
eval_preference_dataloader: DataLoader = None,
|
||||
log_dir: Optional[str] = None,
|
||||
use_wandb: bool = False,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
prompt_dataloader (DataLoader): the dataloader to use for prompt data
|
||||
pretrain_dataloader (DataLoader): the dataloader to use for pretrain data
|
||||
"""
|
||||
self.train_dataloader = train_preference_dataloader
|
||||
self.eval_dataloader = eval_preference_dataloader
|
||||
self.writer = None
|
||||
if use_wandb and is_rank_0():
|
||||
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||
import wandb
|
||||
|
||||
self.wandb_run = wandb.init(project="Coati-dpo", sync_tensorboard=True)
|
||||
if log_dir is not None and is_rank_0():
|
||||
import os
|
||||
import time
|
||||
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
log_dir = os.path.join(log_dir, "dpo")
|
||||
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||
self.writer = SummaryWriter(log_dir=log_dir)
|
||||
|
||||
def _train(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
self.model.train()
|
||||
self.accumulative_meter.reset()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
chosen_loss_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["chosen_loss_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
if not self.apply_loss_mask:
|
||||
chosen_loss_mask = chosen_loss_mask.fill_(1.0)
|
||||
reject_loss_mask = reject_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
|
||||
actor_all_logits = self.model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
actor_chosen_logits = actor_all_logits[:batch_size]
|
||||
actor_reject_logits = actor_all_logits[batch_size:]
|
||||
logprob_actor_chosen = calc_masked_log_probs(
|
||||
actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
logprob_actor_reject = calc_masked_log_probs(
|
||||
actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
if self.ref_model is not None:
|
||||
self.ref_model.eval()
|
||||
with torch.no_grad():
|
||||
ref_all_logits = self.ref_model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
ref_chosen_logits = ref_all_logits[:batch_size]
|
||||
ref_reject_logits = ref_all_logits[batch_size:]
|
||||
logprob_ref_chosen = calc_masked_log_probs(
|
||||
ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
logprob_ref_reject = calc_masked_log_probs(
|
||||
ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
else:
|
||||
logprob_ref_chosen = None
|
||||
logprob_ref_reject = None
|
||||
|
||||
losses, chosen_rewards, rejected_rewards = self.actor_loss_fn(
|
||||
logprob_actor_chosen,
|
||||
logprob_actor_reject,
|
||||
logprob_ref_chosen if logprob_ref_chosen is not None else None,
|
||||
logprob_ref_reject if logprob_ref_reject is not None else None,
|
||||
chosen_loss_mask[:, 1:],
|
||||
reject_loss_mask[:, 1:],
|
||||
)
|
||||
reward_accuracies = (chosen_rewards > rejected_rewards).float().mean()
|
||||
|
||||
# DPO Loss
|
||||
loss = losses.mean()
|
||||
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
|
||||
# sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_rewards)
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=rejected_rewards)
|
||||
reward_accuracies_mean = all_reduce_mean(tensor=reward_accuracies)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||
|
||||
if i % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.num_train_step += 1
|
||||
step_bar.update()
|
||||
# logging
|
||||
if self.writer and is_rank_0():
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
||||
self.writer.add_scalar(
|
||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/rejected_rewards",
|
||||
self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/margin",
|
||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/accuracy",
|
||||
self.accumulative_meter.get("accuracy"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
if self.save_dir is not None and (self.num_train_step + 1) % self.save_interval == 0:
|
||||
# save checkpoint
|
||||
self.coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.actor_scheduler,
|
||||
epoch=epoch,
|
||||
step=i + 1,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
||||
)
|
||||
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
if self.eval_dataloader is None:
|
||||
self.coordinator.print_on_master("No eval dataloader is provided, skip evaluation")
|
||||
return
|
||||
self.model.eval()
|
||||
self.ref_model.eval()
|
||||
self.coordinator.print_on_master("\nStart evaluation...")
|
||||
|
||||
step_bar = trange(
|
||||
len(self.eval_dataloader),
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
with torch.no_grad():
|
||||
for i, batch in enumerate(self.eval_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
chosen_loss_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["chosen_loss_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
if not self.apply_loss_mask:
|
||||
chosen_loss_mask = chosen_loss_mask.fill_(1.0)
|
||||
reject_loss_mask = reject_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
|
||||
actor_all_logits = self.model(
|
||||
torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
actor_chosen_logits = actor_all_logits[:batch_size]
|
||||
actor_reject_logits = actor_all_logits[batch_size:]
|
||||
|
||||
logprob_actor_chosen = calc_masked_log_probs(
|
||||
actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
logprob_actor_reject = calc_masked_log_probs(
|
||||
actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
self.ref_model.eval()
|
||||
|
||||
ref_all_logits = self.ref_model(
|
||||
torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
)["logits"]
|
||||
ref_chosen_logits = ref_all_logits[:batch_size]
|
||||
ref_reject_logits = ref_all_logits[batch_size:]
|
||||
logprob_ref_chosen = calc_masked_log_probs(
|
||||
ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
logprob_ref_reject = calc_masked_log_probs(
|
||||
ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
|
||||
)
|
||||
|
||||
losses, chosen_rewards, rejected_rewards = self.actor_loss_fn(
|
||||
logprob_actor_chosen,
|
||||
logprob_actor_reject,
|
||||
logprob_ref_chosen if logprob_ref_chosen is not None else None,
|
||||
logprob_ref_reject if logprob_ref_reject is not None else None,
|
||||
chosen_loss_mask[:, 1:],
|
||||
reject_loss_mask[:, 1:],
|
||||
)
|
||||
reward_accuracies = (chosen_rewards > rejected_rewards).float().mean()
|
||||
loss = losses.mean()
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_rewards)
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=rejected_rewards)
|
||||
reward_accuracies_mean = all_reduce_mean(tensor=reward_accuracies)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add(
|
||||
"margin", (chosen_rewards_mean - rejected_rewards_mean).to(torch.float16).mean().item()
|
||||
)
|
||||
step_bar.update()
|
||||
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss", "chosen_rewards", "rejected_rewards", "accuracy", "margin"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
self.coordinator.print_on_master(msg)
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
|
|
@ -0,0 +1,349 @@
|
|||
"""
|
||||
KTO trainer
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Any, Optional
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from coati.models.loss import KTOLoss
|
||||
from coati.models.utils import calc_masked_log_probs
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import trange
|
||||
from transformers import PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
from .base import SLTrainer
|
||||
from .utils import is_rank_0, to_device
|
||||
|
||||
|
||||
class KTOTrainer(SLTrainer):
|
||||
"""
|
||||
Trainer for KTO algorithm.
|
||||
|
||||
Args:
|
||||
actor (Actor): the actor model in ppo algorithm
|
||||
ref_model (Critic): the reference model in ppo algorithm
|
||||
booster (Strategy): the strategy to use for training
|
||||
actor_optim (Optimizer): the optimizer to use for actor model
|
||||
actor_lr_scheduler (_LRScheduler): the lr scheduler to use for actor model
|
||||
tokenizer (PreTrainedTokenizerBase): the tokenizer to use for encoding
|
||||
max_epochs (int, defaults to 1): the max number of epochs to train
|
||||
accumulation_steps (int): the number of steps to accumulate gradients
|
||||
start_epoch (int, defaults to 0): the start epoch, non-zero if resumed from a checkpoint
|
||||
save_interval (int): the interval to save model checkpoints, default to 0, which means no checkpoint will be saved during trainning
|
||||
save_dir (str): the directory to save checkpoints
|
||||
coordinator (DistCoordinator): the coordinator to use for distributed logging
|
||||
beta (float, defaults to 0.1): the beta parameter in kto loss
|
||||
desirable_weight (float, defaults to 1.0): the weight for desirable reward
|
||||
undesirable_weight (float, defaults to 1.0): the weight for undesirable reward
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
actor: Any,
|
||||
ref_model: Any,
|
||||
booster: Booster,
|
||||
actor_optim: Optimizer,
|
||||
actor_lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
max_epochs: int = 1,
|
||||
beta: float = 0.1,
|
||||
desirable_weight: float = 1.0,
|
||||
undesirable_weight: float = 1.0,
|
||||
apply_loss_mask: bool = True,
|
||||
accumulation_steps: int = 1,
|
||||
start_epoch: int = 0,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
coordinator: DistCoordinator = None,
|
||||
) -> None:
|
||||
super().__init__(booster, max_epochs=max_epochs, model=actor, optimizer=actor_optim, start_epoch=start_epoch)
|
||||
self.ref_model = ref_model
|
||||
self.actor_scheduler = actor_lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.kto_loss = KTOLoss(beta=beta, desirable_weight=desirable_weight, undesirable_weight=undesirable_weight)
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.save_interval = save_interval
|
||||
self.coordinator = coordinator
|
||||
self.save_dir = save_dir
|
||||
self.num_train_step = 0
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.device = get_current_device()
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
self.desirable_weight = desirable_weight
|
||||
self.undesirable_weight = undesirable_weight
|
||||
self.beta = beta
|
||||
|
||||
def _before_fit(
|
||||
self,
|
||||
train_preference_dataloader: DataLoader = None,
|
||||
eval_preference_dataloader: DataLoader = None,
|
||||
log_dir: Optional[str] = None,
|
||||
use_wandb: bool = False,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
prompt_dataloader (DataLoader): the dataloader to use for prompt data
|
||||
pretrain_dataloader (DataLoader): the dataloader to use for pretrain data
|
||||
"""
|
||||
self.train_dataloader = train_preference_dataloader
|
||||
self.eval_dataloader = eval_preference_dataloader
|
||||
self.writer = None
|
||||
if use_wandb and is_rank_0():
|
||||
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||
import wandb
|
||||
|
||||
self.wandb_run = wandb.init(project="Coati-kto", sync_tensorboard=True)
|
||||
if log_dir is not None and is_rank_0():
|
||||
import os
|
||||
import time
|
||||
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
log_dir = os.path.join(log_dir, "kto")
|
||||
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||
self.writer = SummaryWriter(log_dir=log_dir)
|
||||
|
||||
def _train(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
self.model.train()
|
||||
self.accumulative_meter.reset()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(input_ids, attention_mask, loss_mask, label, kl_input_ids, kl_attention_mask, kl_loss_mask) = (
|
||||
batch["input_ids"],
|
||||
batch["attention_mask"],
|
||||
batch["loss_mask"],
|
||||
batch["label"],
|
||||
batch["kl_input_ids"],
|
||||
batch["kl_attention_mask"],
|
||||
batch["kl_loss_mask"],
|
||||
)
|
||||
if not self.apply_loss_mask:
|
||||
loss_mask = loss_mask.fill_(1.0)
|
||||
kl_loss_mask = kl_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = input_ids.size()[0]
|
||||
|
||||
# actor logits
|
||||
with torch.no_grad():
|
||||
# calculate KL term with KT data
|
||||
kl_logits = self.model(
|
||||
input_ids=kl_input_ids,
|
||||
attention_mask=kl_attention_mask,
|
||||
)["logits"]
|
||||
|
||||
logits = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
)["logits"]
|
||||
|
||||
logprob = calc_masked_log_probs(logits, input_ids, loss_mask[:, 1:]).sum(-1)
|
||||
kl_logprob = calc_masked_log_probs(kl_logits, kl_input_ids, kl_loss_mask[:, 1:]).sum(-1)
|
||||
chosen_index = [i for i in range(batch_size) if label[i] == 1]
|
||||
rejected_index = [i for i in range(batch_size) if label[i] == 0]
|
||||
chosen_logprob = logprob[chosen_index]
|
||||
rejected_logprob = logprob[rejected_index]
|
||||
with torch.no_grad():
|
||||
ref_kl_logits = self.ref_model(
|
||||
input_ids=kl_input_ids,
|
||||
attention_mask=kl_attention_mask,
|
||||
)["logits"]
|
||||
ref_logits = self.ref_model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
)["logits"]
|
||||
|
||||
ref_logprob = calc_masked_log_probs(ref_logits, input_ids, loss_mask[:, 1:]).sum(-1)
|
||||
ref_kl_logprob = calc_masked_log_probs(ref_kl_logits, kl_input_ids, kl_loss_mask[:, 1:]).sum(-1)
|
||||
ref_chosen_logprob = ref_logprob[chosen_index]
|
||||
ref_rejected_logprob = ref_logprob[rejected_index]
|
||||
|
||||
loss, chosen_rewards, rejected_rewards, kl = self.kto_loss(
|
||||
chosen_logprob, rejected_logprob, kl_logprob, ref_chosen_logprob, ref_rejected_logprob, ref_kl_logprob
|
||||
)
|
||||
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
|
||||
# sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_reward_mean = chosen_rewards.mean()
|
||||
chosen_rewards_list = [
|
||||
torch.tensor(0, dtype=loss.dtype, device=loss.device) for _ in range(dist.get_world_size())
|
||||
]
|
||||
dist.all_gather(chosen_rewards_list, chosen_reward_mean)
|
||||
rejected_reward_mean = rejected_rewards.mean()
|
||||
rejected_rewards_list = [
|
||||
torch.tensor(0, dtype=loss.dtype, device=loss.device) for _ in range(dist.get_world_size())
|
||||
]
|
||||
dist.all_gather(rejected_rewards_list, rejected_reward_mean)
|
||||
chosen_rewards_list = [i for i in chosen_rewards_list if not i.isnan()]
|
||||
rejected_rewards_list = [i for i in rejected_rewards_list if not i.isnan()]
|
||||
chosen_rewards_mean = (
|
||||
torch.stack(chosen_rewards_list).mean()
|
||||
if len(chosen_rewards_list) > 0
|
||||
else torch.tensor(torch.nan, dtype=loss.dtype, device=loss.device)
|
||||
)
|
||||
rejected_rewards_mean = (
|
||||
torch.stack(rejected_rewards_list).mean()
|
||||
if len(rejected_rewards_list) > 0
|
||||
else torch.tensor(torch.nan, dtype=loss.dtype, device=loss.device)
|
||||
)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).detach().item())
|
||||
|
||||
if i % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.num_train_step += 1
|
||||
step_bar.update()
|
||||
# logging
|
||||
if self.writer and is_rank_0():
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
||||
self.writer.add_scalar(
|
||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/rejected_rewards",
|
||||
self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/margin",
|
||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
if self.save_dir is not None and (self.num_train_step + 1) % self.save_interval == 0:
|
||||
# save checkpoint
|
||||
self.coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.actor_scheduler,
|
||||
epoch=epoch,
|
||||
step=i + 1,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
||||
)
|
||||
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
if self.eval_dataloader is None:
|
||||
self.coordinator.print_on_master("No eval dataloader is provided, skip evaluation")
|
||||
return
|
||||
self.model.eval()
|
||||
self.accumulative_meter.reset()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(input_ids, attention_mask, loss_mask, label, kl_input_ids, kl_attention_mask, kl_loss_mask) = (
|
||||
batch["input_ids"],
|
||||
batch["attention_mask"],
|
||||
batch["loss_mask"],
|
||||
batch["label"],
|
||||
batch["kl_input_ids"],
|
||||
batch["kl_attention_mask"],
|
||||
batch["kl_loss_mask"],
|
||||
)
|
||||
|
||||
if not self.apply_loss_mask:
|
||||
loss_mask = loss_mask.fill_(1.0)
|
||||
kl_loss_mask = kl_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = input_ids.size()[0]
|
||||
|
||||
# actor logits
|
||||
with torch.no_grad():
|
||||
# calculate KL term with KT data
|
||||
kl_logits = self.model(
|
||||
input_ids=kl_input_ids,
|
||||
attention_mask=kl_attention_mask,
|
||||
)["logits"]
|
||||
|
||||
logits = self.model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
)["logits"]
|
||||
|
||||
logprob = calc_masked_log_probs(logits, input_ids, loss_mask[:, 1:]).sum(-1)
|
||||
kl_logprob = calc_masked_log_probs(kl_logits, kl_input_ids, kl_loss_mask[:, 1:]).sum(-1)
|
||||
chosen_index = [i for i in range(batch_size) if label[i] == 1]
|
||||
rejected_index = [i for i in range(batch_size) if label[i] == 0]
|
||||
chosen_logprob = logprob[chosen_index]
|
||||
rejected_logprob = logprob[rejected_index]
|
||||
with torch.no_grad():
|
||||
ref_kl_logits = self.ref_model(
|
||||
input_ids=kl_input_ids,
|
||||
attention_mask=kl_attention_mask,
|
||||
)["logits"]
|
||||
|
||||
ref_logits = self.ref_model(
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
)["logits"]
|
||||
|
||||
ref_logprob = calc_masked_log_probs(ref_logits, input_ids, loss_mask[:, 1:]).sum(-1)
|
||||
ref_kl_logprob = calc_masked_log_probs(ref_kl_logits, kl_input_ids, kl_loss_mask[:, 1:]).sum(-1)
|
||||
ref_chosen_logprob = ref_logprob[chosen_index]
|
||||
ref_rejected_logprob = ref_logprob[rejected_index]
|
||||
|
||||
loss, chosen_rewards, rejected_rewards, kl = self.kto_loss(
|
||||
chosen_logprob, rejected_logprob, kl_logprob, ref_chosen_logprob, ref_rejected_logprob, ref_kl_logprob
|
||||
)
|
||||
|
||||
# sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_rewards.mean())
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=rejected_rewards.mean())
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).detach().item())
|
||||
self.accumulative_meter.add(
|
||||
"margin", (chosen_rewards_mean - rejected_rewards_mean).to(torch.float16).mean().item()
|
||||
)
|
||||
step_bar.update()
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss", "chosen_rewards", "rejected_rewards", "margin"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
self.coordinator.print_on_master(msg)
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
|
|
@ -0,0 +1,326 @@
|
|||
"""
|
||||
Orpo trainer
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Any, Optional
|
||||
|
||||
import torch
|
||||
from coati.models.loss import OddsRatioLoss
|
||||
from coati.models.utils import calc_masked_log_probs
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import trange
|
||||
from transformers import PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
from .base import SLTrainer
|
||||
from .utils import is_rank_0, to_device
|
||||
|
||||
|
||||
class ORPOTrainer(SLTrainer):
|
||||
"""
|
||||
Trainer for ORPO algorithm.
|
||||
|
||||
Args:
|
||||
actor (Actor): the actor model in ppo algorithm
|
||||
booster (Strategy): the strategy to use for training
|
||||
actor_optim (Optimizer): the optimizer to use for actor model
|
||||
actor_lr_scheduler (_LRScheduler): the lr scheduler to use for actor model
|
||||
tokenizer (PreTrainedTokenizerBase): the tokenizer to use for encoding
|
||||
max_epochs (int, defaults to 1): the max number of epochs to train
|
||||
lam (float, defaults to 0.1): the lambda parameter in ORPO loss
|
||||
accumulation_steps (int): the number of steps to accumulate gradients
|
||||
start_epoch (int, defaults to 0): the start epoch, non-zero if resumed from a checkpoint
|
||||
save_interval (int): the interval to save model checkpoints, default to 0, which means no checkpoint will be saved during trainning
|
||||
save_dir (str): the directory to save checkpoints
|
||||
coordinator (DistCoordinator): the coordinator to use for distributed logging
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
actor: Any,
|
||||
booster: Booster,
|
||||
actor_optim: Optimizer,
|
||||
actor_lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
max_epochs: int = 1,
|
||||
lam: float = 0.1,
|
||||
apply_loss_mask: bool = True,
|
||||
accumulation_steps: int = 1,
|
||||
start_epoch: int = 0,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
coordinator: DistCoordinator = None,
|
||||
) -> None:
|
||||
super().__init__(booster, max_epochs=max_epochs, model=actor, optimizer=actor_optim, start_epoch=start_epoch)
|
||||
self.actor_scheduler = actor_lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.odds_ratio_loss_fn = OddsRatioLoss()
|
||||
self.save_interval = save_interval
|
||||
self.coordinator = coordinator
|
||||
self.save_dir = save_dir
|
||||
self.num_train_step = 0
|
||||
self.lam = lam
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.device = get_current_device()
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
|
||||
def _before_fit(
|
||||
self,
|
||||
train_preference_dataloader: DataLoader = None,
|
||||
eval_preference_dataloader: DataLoader = None,
|
||||
log_dir: Optional[str] = None,
|
||||
use_wandb: bool = False,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
prompt_dataloader (DataLoader): the dataloader to use for prompt data
|
||||
pretrain_dataloader (DataLoader): the dataloader to use for pretrain data
|
||||
"""
|
||||
self.train_dataloader = train_preference_dataloader
|
||||
self.eval_dataloader = eval_preference_dataloader
|
||||
self.writer = None
|
||||
if use_wandb and is_rank_0():
|
||||
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||
import wandb
|
||||
|
||||
self.wandb_run = wandb.init(project="Coati-orpo", sync_tensorboard=True)
|
||||
if log_dir is not None and is_rank_0():
|
||||
import os
|
||||
import time
|
||||
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
log_dir = os.path.join(log_dir, "orpo")
|
||||
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||
self.writer = SummaryWriter(log_dir=log_dir)
|
||||
|
||||
def _train(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
self.model.train()
|
||||
self.accumulative_meter.reset()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
chosen_loss_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["chosen_loss_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
|
||||
if not self.apply_loss_mask:
|
||||
chosen_loss_mask = chosen_loss_mask.fill_(1.0)
|
||||
reject_loss_mask = reject_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
actor_out = self.model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
labels=torch.cat(
|
||||
[chosen_input_ids, torch.ones_like(reject_input_ids, dtype=reject_input_ids.dtype) * -100]
|
||||
),
|
||||
)
|
||||
torch.autograd.set_detect_anomaly(True)
|
||||
actor_all_logits = actor_out["logits"].to(torch.float32)
|
||||
actor_chosen_logits = actor_all_logits[:batch_size]
|
||||
actor_reject_logits = actor_all_logits[batch_size:]
|
||||
logprob_actor_chosen = calc_masked_log_probs(actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:])
|
||||
|
||||
logprob_actor_reject = calc_masked_log_probs(actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:])
|
||||
# label_chosen[chosen_loss_mask[:, 1:] == 0] = -100
|
||||
chosen_nll = actor_out["loss"]
|
||||
odds_ratio_loss, log_odds_ratio = self.odds_ratio_loss_fn(
|
||||
logprob_actor_chosen, logprob_actor_reject, chosen_loss_mask[:, 1:], reject_loss_mask[:, 1:]
|
||||
)
|
||||
loss = chosen_nll - odds_ratio_loss * self.lam
|
||||
step_bar.set_description(f"Epoch {epoch + 1}/{self.max_epochs} Loss: {loss.detach().cpu().item():.4f}")
|
||||
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
|
||||
chosen_rewards = torch.sum(logprob_actor_chosen) / torch.sum(chosen_loss_mask[:, 1:])
|
||||
rejected_rewards = torch.sum(logprob_actor_reject) / torch.sum(reject_loss_mask[:, 1:])
|
||||
reward_accuracies = torch.sum((log_odds_ratio > 0).float()) / torch.sum(log_odds_ratio != 0)
|
||||
|
||||
# sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_rewards)
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=rejected_rewards)
|
||||
reward_accuracies_mean = all_reduce_mean(tensor=reward_accuracies)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("log_odds_ratio", log_odds_ratio.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||
|
||||
if i % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.num_train_step += 1
|
||||
step_bar.update()
|
||||
# logging
|
||||
if self.writer and is_rank_0():
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
||||
self.writer.add_scalar(
|
||||
"train/chosen_rewards", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/rejected_rewards",
|
||||
self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/margin",
|
||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/accuracy",
|
||||
self.accumulative_meter.get("accuracy"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/log_odds_ratio",
|
||||
self.accumulative_meter.get("log_odds_ratio"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
if self.save_dir is not None and (self.num_train_step + 1) % self.save_interval == 0:
|
||||
# save checkpoint
|
||||
self.coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.actor_scheduler,
|
||||
epoch=epoch,
|
||||
step=i + 1,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.save_interval} at folder {self.save_dir}"
|
||||
)
|
||||
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch: int):
|
||||
"""
|
||||
Args:
|
||||
epoch int: the number of current epoch
|
||||
"""
|
||||
if self.eval_dataloader is None:
|
||||
self.coordinator.print_on_master("No eval dataloader is provided, skip evaluation")
|
||||
return
|
||||
self.model.eval()
|
||||
self.coordinator.print_on_master("\nStart evaluation...")
|
||||
|
||||
step_bar = trange(
|
||||
len(self.eval_dataloader),
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
with torch.no_grad():
|
||||
for i, batch in enumerate(self.eval_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
chosen_loss_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
reject_loss_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["chosen_loss_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
batch["reject_loss_mask"],
|
||||
)
|
||||
|
||||
if not self.apply_loss_mask:
|
||||
chosen_loss_mask = chosen_loss_mask.fill_(1.0)
|
||||
reject_loss_mask = reject_loss_mask.fill_(1.0)
|
||||
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
actor_out = self.model(
|
||||
input_ids=torch.cat([chosen_input_ids, reject_input_ids]),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask]),
|
||||
labels=torch.cat(
|
||||
[chosen_input_ids, torch.ones_like(reject_input_ids, dtype=reject_input_ids.dtype) * -100]
|
||||
),
|
||||
)
|
||||
torch.autograd.set_detect_anomaly(True)
|
||||
actor_all_logits = actor_out["logits"].to(torch.float32)
|
||||
actor_chosen_logits = actor_all_logits[:batch_size]
|
||||
actor_reject_logits = actor_all_logits[batch_size:]
|
||||
logprob_actor_chosen = calc_masked_log_probs(
|
||||
actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:]
|
||||
)
|
||||
|
||||
logprob_actor_reject = calc_masked_log_probs(
|
||||
actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:]
|
||||
)
|
||||
chosen_nll = actor_out["loss"]
|
||||
odds_ratio_loss, log_odds_ratio = self.odds_ratio_loss_fn(
|
||||
logprob_actor_chosen, logprob_actor_reject, chosen_loss_mask[:, 1:], reject_loss_mask[:, 1:]
|
||||
)
|
||||
loss = chosen_nll - odds_ratio_loss * self.lam
|
||||
step_bar.set_description(f"Epoch {epoch + 1}/{self.max_epochs} Loss: {loss.detach().cpu().item():.4f}")
|
||||
|
||||
chosen_rewards = torch.sum(logprob_actor_chosen) / torch.sum(chosen_loss_mask[:, 1:])
|
||||
rejected_rewards = torch.sum(logprob_actor_reject) / torch.sum(reject_loss_mask[:, 1:])
|
||||
reward_accuracies = torch.sum((log_odds_ratio > 0).float()) / torch.sum(log_odds_ratio != 0)
|
||||
|
||||
# sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_rewards)
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=rejected_rewards)
|
||||
reward_accuracies_mean = all_reduce_mean(tensor=reward_accuracies)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("log_odds_ratio", log_odds_ratio.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("accuracy", reward_accuracies_mean.to(torch.float16).item())
|
||||
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss", "chosen_rewards", "rejected_rewards", "log_odds_ratio", "accuracy"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
self.coordinator.print_on_master(msg)
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
|
|
@ -0,0 +1,411 @@
|
|||
"""
|
||||
PPO trainer
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Dict, List, Optional
|
||||
|
||||
import torch
|
||||
import wandb
|
||||
from coati.experience_buffer import NaiveExperienceBuffer
|
||||
from coati.experience_maker import Experience, NaiveExperienceMaker
|
||||
from coati.models import Critic, RewardModel
|
||||
from coati.models.loss import GPTLMLoss, PolicyLoss, ValueLoss
|
||||
from coati.models.utils import calc_action_log_probs
|
||||
from coati.trainer.callbacks import Callback
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader, DistributedSampler
|
||||
from tqdm import tqdm
|
||||
from transformers import PreTrainedModel, PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.booster.plugin import GeminiPlugin
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
from .base import OLTrainer
|
||||
from .utils import CycledDataLoader, is_rank_0, to_device
|
||||
|
||||
|
||||
def _set_default_generate_kwargs(actor: PreTrainedModel) -> Dict:
|
||||
"""
|
||||
Set default keyword arguments for generation based on the actor model.
|
||||
|
||||
Args:
|
||||
actor (PreTrainedModel): The actor model.
|
||||
|
||||
Returns:
|
||||
Dict: A dictionary containing the default keyword arguments for generation.
|
||||
"""
|
||||
unwrapped_model = actor.unwrap()
|
||||
new_kwargs = {}
|
||||
# use huggingface models method directly
|
||||
if hasattr(unwrapped_model, "prepare_inputs_for_generation"):
|
||||
new_kwargs["prepare_inputs_fn"] = unwrapped_model.prepare_inputs_for_generation
|
||||
|
||||
if hasattr(unwrapped_model, "_update_model_kwargs_for_generation"):
|
||||
new_kwargs["update_model_kwargs_fn"] = unwrapped_model._update_model_kwargs_for_generation
|
||||
return new_kwargs
|
||||
|
||||
|
||||
class PPOTrainer(OLTrainer):
|
||||
"""
|
||||
Trainer for PPO algorithm.
|
||||
|
||||
Args:
|
||||
strategy (Booster): the strategy to use for training
|
||||
actor (Actor): the actor model in ppo algorithm
|
||||
critic (Critic): the critic model in ppo algorithm
|
||||
reward_model (RewardModel): the reward model in rlhf algorithm to make reward of sentences
|
||||
initial_model (Actor): the initial model in rlhf algorithm to generate reference logics to limit the update of actor
|
||||
actor_optim (Optimizer): the optimizer to use for actor model
|
||||
critic_optim (Optimizer): the optimizer to use for critic model
|
||||
kl_coef (float, defaults to 0.1): the coefficient of kl divergence loss
|
||||
train_batch_size (int, defaults to 8): the batch size to use for training
|
||||
buffer_limit (int, defaults to 0): the max_size limitation of buffer
|
||||
buffer_cpu_offload (bool, defaults to True): whether to offload buffer to cpu
|
||||
eps_clip (float, defaults to 0.2): the clip coefficient of policy loss
|
||||
vf_coef (float, defaults to 1.0): the coefficient of value loss
|
||||
ptx_coef (float, defaults to 0.9): the coefficient of ptx loss
|
||||
value_clip (float, defaults to 0.4): the clip coefficient of value loss
|
||||
sample_buffer (bool, defaults to False): whether to sample from buffer
|
||||
dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader
|
||||
offload_inference_models (bool, defaults to True): whether to offload inference models to cpu during training process
|
||||
callbacks (List[Callback], defaults to []): the callbacks to call during training process
|
||||
generate_kwargs (dict, optional): the kwargs to use while model generating
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
actor_booster: Booster,
|
||||
critic_booster: Booster,
|
||||
actor: PreTrainedModel,
|
||||
critic: Critic,
|
||||
reward_model: RewardModel,
|
||||
initial_model: PreTrainedModel,
|
||||
actor_optim: Optimizer,
|
||||
critic_optim: Optimizer,
|
||||
actor_lr_scheduler: _LRScheduler,
|
||||
critic_lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
kl_coef: float = 0.1,
|
||||
ptx_coef: float = 0.9,
|
||||
train_batch_size: int = 8,
|
||||
buffer_limit: int = 0,
|
||||
buffer_cpu_offload: bool = True,
|
||||
eps_clip: float = 0.2,
|
||||
vf_coef: float = 1.0,
|
||||
value_clip: float = 0.2,
|
||||
sample_buffer: bool = False,
|
||||
dataloader_pin_memory: bool = True,
|
||||
offload_inference_models: bool = True,
|
||||
apply_loss_mask: bool = True,
|
||||
accumulation_steps: int = 1,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
use_tp: bool = False,
|
||||
coordinator: DistCoordinator = None,
|
||||
callbacks: List[Callback] = [],
|
||||
**generate_kwargs,
|
||||
) -> None:
|
||||
if isinstance(actor_booster, GeminiPlugin):
|
||||
assert not offload_inference_models, "GeminiPlugin is not compatible with manual model.to('cpu')"
|
||||
|
||||
data_buffer = NaiveExperienceBuffer(train_batch_size, buffer_limit, buffer_cpu_offload)
|
||||
super().__init__(
|
||||
actor_booster, critic_booster, data_buffer, sample_buffer, dataloader_pin_memory, callbacks=callbacks
|
||||
)
|
||||
self.generate_kwargs = _set_default_generate_kwargs(actor)
|
||||
self.generate_kwargs.update(generate_kwargs)
|
||||
|
||||
self.actor = actor
|
||||
self.critic = critic
|
||||
self.actor_booster = actor_booster
|
||||
self.critic_booster = critic_booster
|
||||
self.actor_scheduler = actor_lr_scheduler
|
||||
self.critic_scheduler = critic_lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.experience_maker = NaiveExperienceMaker(
|
||||
self.actor, self.critic, reward_model, initial_model, self.tokenizer, kl_coef
|
||||
)
|
||||
self.train_batch_size = train_batch_size
|
||||
|
||||
self.actor_loss_fn = PolicyLoss(eps_clip)
|
||||
self.critic_loss_fn = ValueLoss(value_clip)
|
||||
self.vf_coef = vf_coef
|
||||
self.ptx_loss_fn = GPTLMLoss()
|
||||
self.ptx_coef = ptx_coef
|
||||
self.actor_optim = actor_optim
|
||||
self.critic_optim = critic_optim
|
||||
self.save_interval = save_interval
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.coordinator = coordinator
|
||||
self.actor_save_dir = os.path.join(save_dir, "actor")
|
||||
self.critic_save_dir = os.path.join(save_dir, "critic")
|
||||
self.num_train_step = 0
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.use_tp = use_tp
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
self.offload_inference_models = offload_inference_models
|
||||
self.device = get_current_device()
|
||||
|
||||
def _before_fit(
|
||||
self,
|
||||
prompt_dataloader: DataLoader,
|
||||
pretrain_dataloader: Optional[DataLoader] = None,
|
||||
log_dir: Optional[str] = None,
|
||||
use_wandb: bool = False,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
prompt_dataloader (DataLoader): the dataloader to use for prompt data
|
||||
pretrain_dataloader (DataLoader): the dataloader to use for pretrain data
|
||||
"""
|
||||
self.prompt_dataloader = CycledDataLoader(prompt_dataloader)
|
||||
self.pretrain_dataloader = CycledDataLoader(pretrain_dataloader) if pretrain_dataloader is not None else None
|
||||
|
||||
self.writer = None
|
||||
if use_wandb and is_rank_0():
|
||||
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||
import wandb
|
||||
|
||||
self.wandb_run = wandb.init(project="Coati-ppo", sync_tensorboard=True)
|
||||
if log_dir is not None and is_rank_0():
|
||||
import os
|
||||
import time
|
||||
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
log_dir = os.path.join(log_dir, "ppo")
|
||||
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||
self.writer = SummaryWriter(log_dir=log_dir)
|
||||
|
||||
def _setup_update_phrase_dataload(self):
|
||||
"""
|
||||
why not use distributed_dataloader?
|
||||
if tp is used, input on each rank is the same and we use the same dataloader to feed same experience to all ranks
|
||||
if tp is not used, input on each rank is different and we expect different experiences to be fed to each rank
|
||||
"""
|
||||
self.dataloader = DataLoader(
|
||||
self.data_buffer,
|
||||
batch_size=self.train_batch_size,
|
||||
shuffle=True,
|
||||
drop_last=True,
|
||||
pin_memory=self.dataloader_pin_memory,
|
||||
collate_fn=self.data_buffer.collate_fn,
|
||||
)
|
||||
|
||||
def _make_experience(self, collect_step: int) -> Experience:
|
||||
"""
|
||||
Make experience
|
||||
"""
|
||||
prompts = self.prompt_dataloader.next()
|
||||
if self.offload_inference_models:
|
||||
# TODO(ver217): this may be controlled by strategy if they are prepared by strategy
|
||||
self.experience_maker.initial_model.to(self.device)
|
||||
self.experience_maker.reward_model.to(self.device)
|
||||
return self.experience_maker.make_experience(
|
||||
input_ids=prompts["input_ids"].to(get_current_device()),
|
||||
attention_mask=prompts["attention_mask"].to(get_current_device()),
|
||||
**self.generate_kwargs,
|
||||
)
|
||||
|
||||
def _training_step(self, experience: Experience):
|
||||
"""
|
||||
Args:
|
||||
experience:
|
||||
sequences: [batch_size, prompt_length + response_length] --- <PAD>...<PAD><PROMPT>...<PROMPT><RESPONSE>...<RESPONSE><PAD>...<PAD>
|
||||
"""
|
||||
self.num_train_step += 1
|
||||
self.actor.train()
|
||||
self.critic.train()
|
||||
num_actions = experience.action_log_probs.size(1)
|
||||
# policy loss
|
||||
|
||||
actor_logits = self.actor(input_ids=experience.sequences, attention_mask=experience.attention_mask)[
|
||||
"logits"
|
||||
] # [batch size, prompt_length + response_length]
|
||||
action_log_probs = calc_action_log_probs(actor_logits, experience.sequences, num_actions)
|
||||
|
||||
actor_loss, to_skip, max_ratio = self.actor_loss_fn(
|
||||
action_log_probs,
|
||||
experience.action_log_probs,
|
||||
experience.advantages,
|
||||
action_mask=experience.action_mask if self.apply_loss_mask else None,
|
||||
)
|
||||
actor_loss = (1 - self.ptx_coef) * actor_loss
|
||||
if not to_skip:
|
||||
self.actor_booster.backward(loss=actor_loss, optimizer=self.actor_optim)
|
||||
|
||||
# ptx loss
|
||||
if self.ptx_coef != 0:
|
||||
batch = self.pretrain_dataloader.next()
|
||||
batch = to_device(batch, self.device)
|
||||
outputs = self.actor(batch["input_ids"], attention_mask=batch["attention_mask"], labels=batch["labels"])
|
||||
ptx_loss = outputs.loss
|
||||
ptx_loss = self.ptx_coef * ptx_loss
|
||||
self.actor_booster.backward(loss=ptx_loss, optimizer=self.actor_optim)
|
||||
|
||||
# value loss
|
||||
values = self.critic(
|
||||
input_ids=experience.sequences, attention_mask=experience.attention_mask
|
||||
) # [batch size, prompt_length + response_length]
|
||||
critic_loss = self.critic_loss_fn(
|
||||
values[:, -num_actions:],
|
||||
experience.values,
|
||||
experience.advantages,
|
||||
action_mask=experience.action_mask if self.apply_loss_mask else None,
|
||||
)
|
||||
critic_loss = critic_loss * self.vf_coef
|
||||
self.critic_booster.backward(loss=critic_loss, optimizer=self.critic_optim)
|
||||
|
||||
# sync
|
||||
actor_loss_mean = all_reduce_mean(tensor=actor_loss)
|
||||
critic_loss_mean = all_reduce_mean(tensor=critic_loss)
|
||||
max_ratio_mean = all_reduce_mean(tensor=max_ratio)
|
||||
reward_mean = all_reduce_mean(tensor=experience.reward.mean())
|
||||
value_mean = all_reduce_mean(tensor=experience.values.mean())
|
||||
advantages_mean = all_reduce_mean(tensor=experience.advantages.mean())
|
||||
kl_mean = all_reduce_mean(tensor=experience.kl.mean())
|
||||
if self.ptx_coef != 0:
|
||||
ptx_loss_mean = all_reduce_mean(tensor=ptx_loss)
|
||||
|
||||
self.accumulative_meter.add("actor_loss", actor_loss_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("critic_loss", critic_loss_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("max_ratio", max_ratio_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("reward", reward_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("value", value_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("advantages", advantages_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("skip_ratio", 1.0 if to_skip else 0.0)
|
||||
self.accumulative_meter.add("kl", kl_mean.to(torch.float16).item())
|
||||
if self.ptx_coef != 0:
|
||||
self.accumulative_meter.add("ptx_loss", ptx_loss_mean.to(torch.float16).mean().item())
|
||||
|
||||
if self.num_train_step % self.accumulation_steps == self.accumulation_steps - 1:
|
||||
self.actor_optim.step()
|
||||
self.critic_optim.step()
|
||||
self.actor_optim.zero_grad()
|
||||
self.critic_optim.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
self.critic_scheduler.step()
|
||||
|
||||
# preparing logging model output and corresponding rewards.
|
||||
if self.num_train_step % 10 == 1:
|
||||
response_text = self.experience_maker.tokenizer.batch_decode(
|
||||
experience.sequences, skip_special_tokens=True
|
||||
)
|
||||
for i in range(len(response_text)):
|
||||
response_text[i] = response_text[i] + f"\n\nReward: {experience.reward[i]}"
|
||||
|
||||
if self.writer and is_rank_0() and "wandb_run" in self.__dict__:
|
||||
# log output to wandb
|
||||
my_table = wandb.Table(
|
||||
columns=[f"sample response {i}" for i in range(len(response_text))], data=[response_text]
|
||||
)
|
||||
try:
|
||||
self.wandb_run.log({"sample_response": my_table})
|
||||
except OSError as e:
|
||||
self.coordinator.print_on_master(e)
|
||||
elif self.writer and is_rank_0():
|
||||
for line in response_text:
|
||||
self.coordinator.print_on_master(line)
|
||||
|
||||
if self.writer and is_rank_0():
|
||||
self.writer.add_scalar("train/max_ratio", self.accumulative_meter.get("max_ratio"), self.num_train_step)
|
||||
self.writer.add_scalar(
|
||||
"train/skip_ratio", self.accumulative_meter.get("skip_ratio"), self.num_train_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/actor_loss", self.accumulative_meter.get("actor_loss"), self.num_train_step
|
||||
)
|
||||
self.writer.add_scalar("train/lr_actor", self.actor_optim.param_groups[0]["lr"], self.num_train_step)
|
||||
self.writer.add_scalar("train/lr_critic", self.critic_optim.param_groups[0]["lr"], self.num_train_step)
|
||||
self.writer.add_scalar(
|
||||
"train/critic_loss", self.accumulative_meter.get("critic_loss"), self.num_train_step
|
||||
)
|
||||
if self.ptx_coef != 0:
|
||||
self.writer.add_scalar(
|
||||
"train/ptx_loss", self.accumulative_meter.get("ptx_loss"), self.num_train_step
|
||||
)
|
||||
self.writer.add_scalar("reward", self.accumulative_meter.get("reward"), self.num_train_step)
|
||||
self.writer.add_scalar("approx_kl", self.accumulative_meter.get("kl"), self.num_train_step)
|
||||
self.writer.add_scalar("value", self.accumulative_meter.get("value"), self.num_train_step)
|
||||
self.writer.add_scalar("advantages", self.accumulative_meter.get("advantages"), self.num_train_step)
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
def _learn(self, update_step: int):
|
||||
"""
|
||||
Perform the learning step of the PPO algorithm.
|
||||
|
||||
Args:
|
||||
update_step (int): The current update step.
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
if self.offload_inference_models:
|
||||
self.experience_maker.initial_model.to("cpu")
|
||||
self.experience_maker.reward_model.to("cpu")
|
||||
|
||||
# buffer may be empty at first, we should rebuild at each training
|
||||
if self.sample_buffer:
|
||||
experience = self.data_buffer.sample()
|
||||
self._on_learn_batch_start()
|
||||
experience.to_device(self.device)
|
||||
self._training_step(experience)
|
||||
self._on_learn_batch_end(experience)
|
||||
else:
|
||||
if isinstance(self.dataloader.sampler, DistributedSampler):
|
||||
self.dataloader.sampler.set_epoch(update_step)
|
||||
pbar = tqdm(self.dataloader, desc=f"Train epoch [{update_step + 1}]", disable=not is_rank_0())
|
||||
for experience in pbar:
|
||||
self._on_learn_batch_start()
|
||||
experience.to_device(self.device)
|
||||
self._training_step(experience)
|
||||
self._on_learn_batch_end(experience)
|
||||
|
||||
def _save_checkpoint(self, episode: int = 0):
|
||||
"""
|
||||
Save the actor and critic checkpoints with running states.
|
||||
|
||||
Args:
|
||||
episode (int): The current episode number.
|
||||
|
||||
Returns:
|
||||
None
|
||||
"""
|
||||
|
||||
self.coordinator.print_on_master("\nStart saving actor checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.actor_save_dir,
|
||||
booster=self.actor_booster,
|
||||
model=self.actor,
|
||||
optimizer=self.actor_optim,
|
||||
lr_scheduler=self.actor_scheduler,
|
||||
epoch=0,
|
||||
step=episode + 1,
|
||||
batch_size=self.train_batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved actor checkpoint at episode {(episode + 1)} at folder {self.actor_save_dir}"
|
||||
)
|
||||
|
||||
self.coordinator.print_on_master("\nStart saving critic checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.critic_save_dir,
|
||||
booster=self.critic_booster,
|
||||
model=self.critic,
|
||||
optimizer=self.critic_optim,
|
||||
lr_scheduler=self.critic_scheduler,
|
||||
epoch=0,
|
||||
step=episode + 1,
|
||||
batch_size=self.train_batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved critic checkpoint at episode {(episode + 1)} at folder {self.critic_save_dir}"
|
||||
)
|
||||
|
|
@ -0,0 +1,243 @@
|
|||
"""
|
||||
Reward model trianer
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Any, Callable, Optional
|
||||
|
||||
import torch
|
||||
import tqdm
|
||||
from coati.models import LogSigLoss
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader
|
||||
from transformers import PreTrainedTokenizerBase
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.cluster import DistCoordinator
|
||||
from colossalai.utils import get_current_device
|
||||
|
||||
from .base import SLTrainer
|
||||
from .utils import is_rank_0, to_device
|
||||
|
||||
|
||||
class RewardModelTrainer(SLTrainer):
|
||||
"""
|
||||
Trainer for PPO algorithm.
|
||||
|
||||
Args:
|
||||
actor (Actor): the actor model in ppo algorithm
|
||||
ref_model (Critic): the reference model in ppo algorithm
|
||||
booster (Strategy): the strategy to use for training
|
||||
actor_optim (Optimizer): the optimizer to use for actor model
|
||||
actor_lr_scheduler (_LRScheduler): the lr scheduler to use for actor model
|
||||
tokenizer (PreTrainedTokenizerBase): the tokenizer to use for encoding
|
||||
max_epochs (int, defaults to 1): the max number of epochs to train
|
||||
beta (float, defaults to 0.1): the beta parameter in dpo loss
|
||||
accumulation_steps (int): the number of steps to accumulate gradients
|
||||
start_epoch (int, defaults to 0): the start epoch, non-zero if resumed from a checkpoint
|
||||
save_interval (int): the interval to save model checkpoints, default to 0, which means no checkpoint will be saved during trainning
|
||||
save_dir (str): the directory to save checkpoints
|
||||
coordinator (DistCoordinator): the coordinator to use for distributed logging
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model: Any,
|
||||
booster: Booster,
|
||||
optimizer: Optimizer,
|
||||
lr_scheduler: _LRScheduler,
|
||||
tokenizer: PreTrainedTokenizerBase,
|
||||
loss_fn: Optional[Callable] = None,
|
||||
max_epochs: int = 1,
|
||||
beta: float = 0.1,
|
||||
accumulation_steps: int = 1,
|
||||
start_epoch: int = 0,
|
||||
save_interval: int = 0,
|
||||
save_dir: str = None,
|
||||
coordinator: DistCoordinator = None,
|
||||
) -> None:
|
||||
super().__init__(booster, max_epochs=max_epochs, model=model, optimizer=optimizer, start_epoch=start_epoch)
|
||||
self.actor_scheduler = lr_scheduler
|
||||
self.tokenizer = tokenizer
|
||||
self.loss_fn = loss_fn if loss_fn is not None else LogSigLoss(beta=beta)
|
||||
self.save_interval = save_interval
|
||||
self.coordinator = coordinator
|
||||
self.save_dir = save_dir
|
||||
self.num_train_step = 0
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.device = get_current_device()
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
|
||||
def _before_fit(
|
||||
self,
|
||||
train_preference_dataloader: DataLoader = None,
|
||||
eval_preference_dataloader: DataLoader = None,
|
||||
log_dir: Optional[str] = None,
|
||||
use_wandb: bool = False,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
prompt_dataloader (DataLoader): the dataloader to use for prompt data
|
||||
pretrain_dataloader (DataLoader): the dataloader to use for pretrain data
|
||||
"""
|
||||
self.train_dataloader = train_preference_dataloader
|
||||
self.eval_dataloader = eval_preference_dataloader
|
||||
self.writer = None
|
||||
if use_wandb and is_rank_0():
|
||||
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||
import wandb
|
||||
|
||||
self.wandb_run = wandb.init(project="Coati-rm", sync_tensorboard=True)
|
||||
if log_dir is not None and is_rank_0():
|
||||
import os
|
||||
import time
|
||||
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
log_dir = os.path.join(log_dir, "rm")
|
||||
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||
self.writer = SummaryWriter(log_dir=log_dir)
|
||||
|
||||
def _train(self, epoch):
|
||||
self.model.train()
|
||||
step_bar = tqdm.trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
)
|
||||
batch_size = chosen_input_ids.size()[0]
|
||||
|
||||
# Concatenate for better parrallelism
|
||||
reward = self.model(
|
||||
torch.cat([chosen_input_ids, reject_input_ids], dim=0),
|
||||
attention_mask=torch.cat([chosen_attention_mask, reject_attention_mask], dim=0),
|
||||
)
|
||||
chosen_reward = reward[:batch_size]
|
||||
reject_reward = reward[batch_size:]
|
||||
loss = self.loss_fn(chosen_reward, reject_reward).mean()
|
||||
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
|
||||
accuracy = (chosen_reward > reject_reward).float()
|
||||
|
||||
# Sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_reward)
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=reject_reward)
|
||||
accuracy_mean = all_reduce_mean(tensor=accuracy)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
self.accumulative_meter.add("accuracy", accuracy_mean.mean().to(torch.float16).item())
|
||||
|
||||
if (i + 1) % self.accumulation_steps == 0:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.actor_scheduler.step()
|
||||
step_bar.update()
|
||||
self.num_train_step += 1
|
||||
|
||||
# Logging
|
||||
if self.writer and is_rank_0():
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
||||
self.writer.add_scalar("train/lr", self.optimizer.param_groups[0]["lr"], self.num_train_step)
|
||||
self.writer.add_scalar(
|
||||
"train/dist",
|
||||
self.accumulative_meter.get("chosen_rewards") - self.accumulative_meter.get("rejected_rewards"),
|
||||
self.num_train_step,
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/reward_chosen", self.accumulative_meter.get("chosen_rewards"), self.num_train_step
|
||||
)
|
||||
self.writer.add_scalar(
|
||||
"train/reward_reject", self.accumulative_meter.get("rejected_rewards"), self.num_train_step
|
||||
)
|
||||
self.writer.add_scalar("train/acc", self.accumulative_meter.get("accuracy"), self.num_train_step)
|
||||
|
||||
self.accumulative_meter.reset()
|
||||
|
||||
# Save checkpoint
|
||||
if self.save_interval > 0 and (self.num_train_step + 1) % self.save_interval == 0:
|
||||
self.coordinator.print_on_master("\nStart saving model checkpoint with running states")
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.actor_scheduler,
|
||||
epoch=epoch,
|
||||
step=i + 1,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {(i + 1)/self.accumulation_steps} at folder {self.save_dir}"
|
||||
)
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch):
|
||||
if self.eval_dataloader is None:
|
||||
self.coordinator.print_on_master("No eval dataloader is provided, skip evaluation")
|
||||
return
|
||||
self.model.eval()
|
||||
step_bar = tqdm.trange(
|
||||
len(self.eval_dataloader), desc=f"Epoch {epoch + 1}/{self.max_epochs}", disable=not is_rank_0()
|
||||
)
|
||||
with torch.no_grad():
|
||||
for i, batch in enumerate(self.eval_dataloader):
|
||||
batch = to_device(batch, self.device)
|
||||
(
|
||||
chosen_input_ids,
|
||||
chosen_attention_mask,
|
||||
reject_input_ids,
|
||||
reject_attention_mask,
|
||||
) = (
|
||||
batch["chosen_input_ids"],
|
||||
batch["chosen_attention_mask"],
|
||||
batch["reject_input_ids"],
|
||||
batch["reject_attention_mask"],
|
||||
)
|
||||
|
||||
chosen_reward = self.model(chosen_input_ids, attention_mask=chosen_attention_mask)
|
||||
reject_reward = self.model(reject_input_ids, attention_mask=reject_attention_mask)
|
||||
loss = self.loss_fn(chosen_reward, reject_reward).mean()
|
||||
|
||||
# Sync
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
chosen_rewards_mean = all_reduce_mean(tensor=chosen_reward)
|
||||
rejected_rewards_mean = all_reduce_mean(tensor=reject_reward)
|
||||
self.accumulative_meter.add("chosen_rewards", chosen_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("rejected_rewards", rejected_rewards_mean.to(torch.float16).mean().item())
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
|
||||
step_bar.update()
|
||||
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss", "chosen_rewards", "rejected_rewards"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
msg = (
|
||||
msg
|
||||
+ f"distance: {self.accumulative_meter.get('chosen_rewards')-self.accumulative_meter.get('rejected_rewards')}\n"
|
||||
)
|
||||
self.coordinator.print_on_master(msg)
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
|
|
@ -0,0 +1,183 @@
|
|||
"""
|
||||
SFT trainer
|
||||
"""
|
||||
|
||||
import os
|
||||
from typing import Optional
|
||||
|
||||
import torch
|
||||
from coati.trainer.utils import all_reduce_mean
|
||||
from coati.utils import AccumulativeMeanMeter, save_checkpoint
|
||||
from torch.optim import Optimizer
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.utils.data import DataLoader
|
||||
from tqdm import trange
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.cluster import DistCoordinator
|
||||
|
||||
from .base import SLTrainer
|
||||
from .utils import is_rank_0, to_device
|
||||
|
||||
|
||||
class SFTTrainer(SLTrainer):
|
||||
"""
|
||||
Trainer to use while training reward model.
|
||||
|
||||
Args:
|
||||
model (torch.nn.Module): the model to train
|
||||
strategy (Strategy): the strategy to use for training
|
||||
optim(Optimizer): the optimizer to use for training
|
||||
lr_scheduler(_LRScheduler): the lr scheduler to use for training
|
||||
max_epochs (int, defaults to 2): the number of epochs to train
|
||||
accumulation_steps (int, defaults to 8): the number of steps to accumulate gradients
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model,
|
||||
booster: Booster,
|
||||
optim: Optimizer,
|
||||
lr_scheduler: _LRScheduler,
|
||||
max_epochs: int = 2,
|
||||
accumulation_steps: int = 8,
|
||||
apply_loss_mask: bool = True,
|
||||
start_epoch=0,
|
||||
save_interval: int = None,
|
||||
save_dir: str = None,
|
||||
coordinator: Optional[DistCoordinator] = None,
|
||||
) -> None:
|
||||
super().__init__(booster, max_epochs, model, optim, start_epoch=start_epoch)
|
||||
|
||||
self.accumulation_steps = accumulation_steps
|
||||
self.scheduler = lr_scheduler
|
||||
self.save_interval = save_interval
|
||||
self.save_dir = save_dir
|
||||
self.coordinator = coordinator
|
||||
self.num_train_step = 0
|
||||
self.num_eval_step = 0
|
||||
self.apply_loss_mask = apply_loss_mask
|
||||
self.accumulative_meter = AccumulativeMeanMeter()
|
||||
|
||||
def _before_fit(
|
||||
self,
|
||||
train_dataloader: DataLoader,
|
||||
eval_dataloader: Optional[DataLoader] = None,
|
||||
log_dir: Optional[str] = None,
|
||||
use_wandb: bool = False,
|
||||
):
|
||||
"""
|
||||
Args:
|
||||
train_dataloader: the dataloader to use for training
|
||||
eval_dataloader: the dataloader to use for evaluation
|
||||
log_dir: the directory to save logs
|
||||
use_wandb: whether to use wandb for logging
|
||||
"""
|
||||
self.train_dataloader = train_dataloader
|
||||
self.eval_dataloader = eval_dataloader
|
||||
|
||||
self.writer = None
|
||||
if use_wandb and is_rank_0():
|
||||
assert log_dir is not None, "log_dir must be provided when use_wandb is True"
|
||||
import wandb
|
||||
|
||||
wandb.init(project="Coati-sft", sync_tensorboard=True)
|
||||
if log_dir is not None and is_rank_0():
|
||||
import os
|
||||
import time
|
||||
|
||||
from torch.utils.tensorboard import SummaryWriter
|
||||
|
||||
log_dir = os.path.join(log_dir, "sft")
|
||||
log_dir = os.path.join(log_dir, time.strftime("%Y-%m-%d_%H:%M:%S", time.localtime()))
|
||||
self.writer = SummaryWriter(log_dir=log_dir)
|
||||
|
||||
def _train(self, epoch: int):
|
||||
self.model.train()
|
||||
step_bar = trange(
|
||||
len(self.train_dataloader) // self.accumulation_steps,
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for i, batch in enumerate(self.train_dataloader):
|
||||
batch = to_device(batch, torch.cuda.current_device())
|
||||
batch_size = batch["input_ids"].size(0)
|
||||
outputs = self.model(
|
||||
batch["input_ids"],
|
||||
attention_mask=batch["attention_mask"],
|
||||
labels=batch["labels"] if self.apply_loss_mask else batch["input_ids"],
|
||||
)
|
||||
loss = outputs.loss
|
||||
|
||||
self.booster.backward(loss=loss, optimizer=self.optimizer)
|
||||
|
||||
loss_mean = all_reduce_mean(tensor=loss)
|
||||
self.accumulative_meter.add("loss", loss_mean.to(torch.float16).item())
|
||||
|
||||
# Gradient accumulation
|
||||
if (i + 1) % self.accumulation_steps == 0:
|
||||
self.optimizer.step()
|
||||
self.optimizer.zero_grad()
|
||||
self.scheduler.step()
|
||||
|
||||
step_bar.set_postfix({"train/loss": self.accumulative_meter.get("loss")})
|
||||
if self.writer:
|
||||
self.writer.add_scalar("train/loss", self.accumulative_meter.get("loss"), self.num_train_step)
|
||||
self.writer.add_scalar("train/lr", self.scheduler.get_last_lr()[0], self.num_train_step)
|
||||
self.num_train_step += 1
|
||||
self.accumulative_meter.reset()
|
||||
step_bar.update()
|
||||
|
||||
# Save checkpoint
|
||||
if (
|
||||
self.save_dir is not None
|
||||
and self.save_interval is not None
|
||||
and (self.num_train_step + 1) % self.save_interval == 0
|
||||
):
|
||||
save_checkpoint(
|
||||
save_dir=self.save_dir,
|
||||
booster=self.booster,
|
||||
model=self.model,
|
||||
optimizer=self.optimizer,
|
||||
lr_scheduler=self.scheduler,
|
||||
epoch=epoch,
|
||||
step=self.num_train_step + 1,
|
||||
batch_size=batch_size,
|
||||
coordinator=self.coordinator,
|
||||
)
|
||||
self.coordinator.print_on_master(
|
||||
f"Saved checkpoint at epoch {epoch} step {self.num_train_step} at folder {self.save_dir}"
|
||||
)
|
||||
step_bar.close()
|
||||
|
||||
def _eval(self, epoch: int):
|
||||
if self.eval_dataloader is None:
|
||||
self.coordinator.print_on_master("No eval dataloader is provided, skip evaluation")
|
||||
return
|
||||
self.accumulative_meter.reset()
|
||||
self.model.eval()
|
||||
with torch.no_grad():
|
||||
step_bar = trange(
|
||||
len(self.eval_dataloader),
|
||||
desc=f"Epoch {epoch + 1}/{self.max_epochs}",
|
||||
disable=not is_rank_0(),
|
||||
)
|
||||
for batch in self.eval_dataloader:
|
||||
batch = to_device(batch, torch.cuda.current_device())
|
||||
outputs = self.model(
|
||||
batch["input_ids"],
|
||||
attention_mask=batch["attention_mask"],
|
||||
labels=batch["labels"] if self.apply_loss_mask else batch["input_ids"],
|
||||
)
|
||||
loss_mean = all_reduce_mean(tensor=outputs.loss)
|
||||
self.accumulative_meter.add("loss", loss_mean.item(), count_update=batch["input_ids"].size(0))
|
||||
step_bar.update()
|
||||
loss_mean = self.accumulative_meter.get("loss")
|
||||
msg = "Evaluation Result:\n"
|
||||
for tag in ["loss"]:
|
||||
msg = msg + f"{tag}: {self.accumulative_meter.get(tag)}\n"
|
||||
self.coordinator.print_on_master(msg)
|
||||
os.makedirs(self.save_dir, exist_ok=True)
|
||||
with open(os.path.join(self.save_dir, f"eval_result_epoch{epoch}.txt"), "w") as f:
|
||||
f.write(msg)
|
||||
step_bar.close()
|
||||
|
|
@ -0,0 +1,114 @@
|
|||
"""
|
||||
Training utilities for Coati.
|
||||
"""
|
||||
|
||||
from typing import Any
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from torch.utils._pytree import tree_map
|
||||
from torch.utils.data import DataLoader
|
||||
|
||||
|
||||
class CycledDataLoader:
|
||||
"""
|
||||
A data loader that cycles through the data when it reaches the end.
|
||||
|
||||
Args:
|
||||
dataloader (DataLoader): The original data loader.
|
||||
|
||||
Attributes:
|
||||
dataloader (DataLoader): The original data loader.
|
||||
count (int): The number of times the data loader has been cycled.
|
||||
dataloader_iter (iterable): The iterator for the data loader.
|
||||
|
||||
Methods:
|
||||
next(): Returns the next batch of data from the data loader, cycling through the data if necessary.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
dataloader: DataLoader,
|
||||
) -> None:
|
||||
self.dataloader = dataloader
|
||||
|
||||
self.count = 0
|
||||
self.dataloader_iter = None
|
||||
|
||||
def next(self):
|
||||
"""
|
||||
Returns the next batch of data from the data loader, cycling through the data if necessary.
|
||||
|
||||
Returns:
|
||||
Any: The next batch of data from the data loader.
|
||||
"""
|
||||
# defer initialization
|
||||
if self.dataloader_iter is None:
|
||||
self.dataloader_iter = iter(self.dataloader)
|
||||
|
||||
self.count += 1
|
||||
try:
|
||||
return next(self.dataloader_iter)
|
||||
except StopIteration:
|
||||
self.count = 0
|
||||
self.dataloader_iter = iter(self.dataloader)
|
||||
return next(self.dataloader_iter)
|
||||
|
||||
|
||||
def is_rank_0() -> bool:
|
||||
"""
|
||||
Check if the current process is the rank 0 process in a distributed training setup.
|
||||
|
||||
Returns:
|
||||
bool: True if the current process is the rank 0 process, False otherwise.
|
||||
"""
|
||||
return not dist.is_initialized() or dist.get_rank() == 0
|
||||
|
||||
|
||||
def to_device(x: Any, device: torch.device) -> Any:
|
||||
"""
|
||||
Move the input tensor or nested structure of tensors to the specified device.
|
||||
|
||||
Args:
|
||||
x (Any): The input tensor or nested structure of tensors.
|
||||
device (torch.device): The target device to move the tensors to.
|
||||
|
||||
Returns:
|
||||
Any: The tensor or nested structure of tensors moved to the target device.
|
||||
"""
|
||||
|
||||
def _to(t: Any):
|
||||
if isinstance(t, torch.Tensor):
|
||||
return t.to(device)
|
||||
return t
|
||||
|
||||
return tree_map(_to, x)
|
||||
|
||||
|
||||
def all_reduce_mean(tensor: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Perform all-reduce operation on the given tensor and compute the mean across all processes.
|
||||
|
||||
Args:
|
||||
tensor (torch.Tensor): The input tensor to be reduced.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The reduced tensor with mean computed across all processes.
|
||||
"""
|
||||
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM)
|
||||
tensor.div_(dist.get_world_size())
|
||||
return tensor
|
||||
|
||||
|
||||
def all_reduce_sum(tensor: torch.Tensor) -> torch.Tensor:
|
||||
"""
|
||||
Performs an all-reduce operation to sum the values of the given tensor across all processes.
|
||||
|
||||
Args:
|
||||
tensor (torch.Tensor): The input tensor to be reduced.
|
||||
|
||||
Returns:
|
||||
torch.Tensor: The reduced tensor with the sum of values across all processes.
|
||||
"""
|
||||
dist.all_reduce(tensor=tensor, op=dist.ReduceOp.SUM)
|
||||
return tensor
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
from .accumulative_meter import AccumulativeMeanMeter
|
||||
from .ckpt_io import load_checkpoint, save_checkpoint
|
||||
|
||||
__all__ = ["load_checkpoint", "save_checkpoint", "AccumulativeMeanMeter"]
|
||||
|
|
@ -0,0 +1,69 @@
|
|||
"""
|
||||
A class that can be used to calculate the mean of a variable
|
||||
"""
|
||||
|
||||
|
||||
class AccumulativeMeanVariable:
|
||||
"""
|
||||
A class that calculates the accumulative mean of a variable.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self._sum = 0
|
||||
self._count = 0
|
||||
|
||||
def add(self, value, count_update=1):
|
||||
"""
|
||||
Adds a value to the sum and updates the count.
|
||||
|
||||
Args:
|
||||
value (float): The value to be added.
|
||||
count_update (int, optional): The amount to update the count by. Defaults to 1.
|
||||
"""
|
||||
self._sum += value
|
||||
self._count += count_update
|
||||
|
||||
def get(self):
|
||||
"""
|
||||
Calculates and returns the accumulative mean.
|
||||
|
||||
Returns:
|
||||
float: The accumulative mean.
|
||||
"""
|
||||
return self._sum / self._count if self._count > 0 else 0
|
||||
|
||||
def reset(self):
|
||||
"""
|
||||
Resets the sum and count to zero.
|
||||
"""
|
||||
self._sum = 0
|
||||
self._count = 0
|
||||
|
||||
|
||||
class AccumulativeMeanMeter:
|
||||
"""
|
||||
A class for calculating and storing the accumulative mean of variables.
|
||||
|
||||
Attributes:
|
||||
variable_dict (dict): A dictionary to store the accumulative mean variables.
|
||||
|
||||
Methods:
|
||||
add(name, value, count_update=1): Adds a value to the specified variable.
|
||||
get(name): Retrieves the accumulative mean value of the specified variable.
|
||||
reset(): Resets all the accumulative mean variables to their initial state.
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.variable_dict = {}
|
||||
|
||||
def add(self, name, value, count_update=1):
|
||||
if name not in self.variable_dict:
|
||||
self.variable_dict[name] = AccumulativeMeanVariable()
|
||||
self.variable_dict[name].add(value, count_update=count_update)
|
||||
|
||||
def get(self, name):
|
||||
return self.variable_dict[name].get()
|
||||
|
||||
def reset(self):
|
||||
for name in self.variable_dict:
|
||||
self.variable_dict[name].reset()
|
||||
|
|
@ -0,0 +1,93 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
|
||||
"""
|
||||
Helper functions for IO save load checkpoints
|
||||
"""
|
||||
|
||||
import json
|
||||
import os
|
||||
from typing import Any, Dict, Tuple, Union
|
||||
|
||||
import torch
|
||||
from torch.optim.lr_scheduler import _LRScheduler
|
||||
from torch.optim.optimizer import Optimizer
|
||||
|
||||
from colossalai.booster import Booster
|
||||
from colossalai.cluster import DistCoordinator
|
||||
|
||||
|
||||
def load_json(file_path: Union[str, os.PathLike]) -> Dict[str, Any]:
|
||||
"""
|
||||
Load file in JSON format
|
||||
"""
|
||||
with open(file=file_path, mode="r", encoding="utf-8") as fp:
|
||||
return json.load(fp)
|
||||
|
||||
|
||||
def save_json(data: Dict[str, Any], file_path: Union[str, os.PathLike]) -> None:
|
||||
"""
|
||||
Save as JSON format
|
||||
"""
|
||||
with open(file=file_path, mode="w", encoding="utf-8") as fp:
|
||||
json.dump(data, fp=fp, ensure_ascii=False, indent=4)
|
||||
|
||||
|
||||
def save_checkpoint(
|
||||
save_dir: Union[str, os.PathLike],
|
||||
booster: Booster,
|
||||
model: torch.nn.Module,
|
||||
optimizer: Optimizer,
|
||||
lr_scheduler: _LRScheduler,
|
||||
epoch: int,
|
||||
step: int,
|
||||
batch_size: int,
|
||||
coordinator: DistCoordinator,
|
||||
) -> None:
|
||||
"""
|
||||
Save model checkpoint, optimizer, LR scheduler and intermedidate running states.
|
||||
"""
|
||||
|
||||
save_dir = os.path.join(save_dir, f"epoch-{epoch}_step-{step}")
|
||||
os.makedirs(os.path.join(save_dir, "modeling"), exist_ok=True)
|
||||
|
||||
booster.save_model(model, os.path.join(save_dir, "modeling"), shard=True)
|
||||
|
||||
"""
|
||||
Temporary disable the following as save_optimizer causes all processes to hang in a multi-gpu environment,
|
||||
working on fixing this bug
|
||||
"""
|
||||
|
||||
booster.save_optimizer(optimizer, os.path.join(save_dir, "optimizer"), shard=True)
|
||||
booster.save_lr_scheduler(lr_scheduler, os.path.join(save_dir, "lr_scheduler"))
|
||||
running_states = {
|
||||
"epoch": epoch,
|
||||
"step": step,
|
||||
"sample_start_index": step * batch_size,
|
||||
}
|
||||
if coordinator.is_master():
|
||||
save_json(running_states, os.path.join(save_dir, "running_states.json"))
|
||||
|
||||
|
||||
def load_checkpoint(
|
||||
load_dir: Union[str, os.PathLike],
|
||||
booster: Booster,
|
||||
model: torch.nn.Module,
|
||||
optimizer: Optimizer,
|
||||
lr_scheduler: _LRScheduler,
|
||||
) -> Tuple[int, int, int]:
|
||||
"""
|
||||
Load model checkpoint, optimizer, LR scheduler and intermedidate running states.
|
||||
"""
|
||||
|
||||
# Update booster params states.
|
||||
booster.load_model(model=model, checkpoint=os.path.join(load_dir, "modeling"))
|
||||
booster.load_optimizer(optimizer=optimizer, checkpoint=os.path.join(load_dir, "optimizer"))
|
||||
booster.load_lr_scheduler(lr_scheduler=lr_scheduler, checkpoint=os.path.join(load_dir, "lr_scheduler"))
|
||||
|
||||
running_states = load_json(file_path=os.path.join(load_dir, "running_states.json"))
|
||||
return (
|
||||
running_states["epoch"],
|
||||
running_states["step"],
|
||||
running_states["sample_start_index"],
|
||||
)
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
{
|
||||
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ '<|im_start|>user\\n' + content + '<|im_end|>\\n<|im_start|>assistant\\n' }}{% elif message['role'] == 'assistant' %}{{ content + '<|im_end|>' + '\\n' }}{% endif %}{% endfor %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
7
|
||||
],
|
||||
"end_of_assistant": "<|im_end|>"
|
||||
}
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
{
|
||||
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
151645,
|
||||
151643
|
||||
],
|
||||
"end_of_assistant": "<|im_end|>"
|
||||
}
|
||||
|
|
@ -0,0 +1,9 @@
|
|||
{
|
||||
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
151645,
|
||||
151643
|
||||
],
|
||||
"end_of_assistant": "<|im_end|>"
|
||||
}
|
||||
|
|
@ -0,0 +1,12 @@
|
|||
{
|
||||
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
31007,
|
||||
326,
|
||||
30962,
|
||||
437,
|
||||
31007
|
||||
],
|
||||
"end_of_assistant": "<|im_end|>"
|
||||
}
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
{
|
||||
"chat_template": "{% for message in messages %}{% if loop.first %}[gMASK]sop<|{{ message['role'] }}|>\n {{ message['content'] }}{% else %}<|{{ message['role'] }}|>\n {{ message['content'] }}{% endif %}{% endfor %}{% if add_generation_prompt %}<|assistant|>{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
2
|
||||
],
|
||||
"end_of_assistant": "<|user|>"
|
||||
}
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
{
|
||||
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
2
|
||||
],
|
||||
"end_of_assistant": "<|im_end|>"
|
||||
}
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
{
|
||||
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{% if message['role'] == 'user' %}{{'Human: ' + bos_token + message['content'].strip() + eos_token }}{% elif message['role'] == 'system' %}{{ message['content'].strip() + '\\n\\n' }}{% elif message['role'] == 'assistant' %}{{ 'Assistant: ' + bos_token + message['content'].strip() + eos_token }}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ 'Assistant: ' + bos_token }}{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
2
|
||||
],
|
||||
"end_of_assistant": "</s>"
|
||||
}
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
{
|
||||
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{{ bos_token }}{% for message in messages %}{% if message['role'] == 'user' %}{{ 'User: ' + message['content'] + '\n\n' }}{% elif message['role'] == 'assistant' %}{{ 'Assistant: ' + message['content'] + eos_token }}{% elif message['role'] == 'system' %}{{ message['content'] + '\n\n' }}{% endif %}{% endfor %}{% if add_generation_prompt %}{{ 'Assistant:' }}{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
100001
|
||||
],
|
||||
"end_of_assistant": "<|end▁of▁sentence|>"
|
||||
}
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
{
|
||||
"chat_template": "{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}{% set system_message = messages[0]['content'] %}{% else %}{% set loop_messages = messages %}{% set system_message = false %}{% endif %}{% for message in loop_messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if loop.index0 == 0 and system_message != false %}{% set content = '<<SYS>>\\n' + system_message + '\\n<</SYS>>\\n\\n' + message['content'] %}{% else %}{% set content = message['content'] %}{% endif %}{% if message['role'] == 'user' %}{{ bos_token + '[INST] ' + content.strip() + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ ' ' + content.strip() + ' ' + eos_token }}{% endif %}{% endfor %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
2
|
||||
],
|
||||
"end_of_assistant": "</s>"
|
||||
}
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
{
|
||||
"chat_template": "{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
50256
|
||||
],
|
||||
"end_of_assistant": "<|im_end|>"
|
||||
}
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
{
|
||||
"chat_template": "{{ bos_token }}{% for message in messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if message['role'] == 'user' %}{{ '[INST] ' + message['content'] + ' [/INST]' }}{% elif message['role'] == 'assistant' %}{{ message['content'] + eos_token}}{% else %}{{ raise_exception('Only user and assistant roles are supported!') }}{% endif %}{% endfor %}",
|
||||
"system_message": null,
|
||||
"stop_ids": [
|
||||
2
|
||||
],
|
||||
"end_of_assistant": "</s>"
|
||||
}
|
||||
|
|
@ -0,0 +1,8 @@
|
|||
{
|
||||
"chat_template": "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}",
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n",
|
||||
"stop_ids": [
|
||||
2
|
||||
],
|
||||
"end_of_assistant": "</s>"
|
||||
}
|
||||
|
|
@ -0,0 +1,906 @@
|
|||
# Examples
|
||||
|
||||
|
||||
## Table of Contents
|
||||
|
||||
|
||||
- [Examples](#examples)
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [Install Requirements](#install-requirements)
|
||||
- [Get Start with ColossalRun](#get-start-with-colossalrun)
|
||||
- [Training Configuration](#training-configuration)
|
||||
- [Parameter Efficient Finetuning (PEFT)](#parameter-efficient-finetuning-peft)
|
||||
- [RLHF Stage 1: Supervised Instruction Tuning](#rlhf-training-stage1---supervised-instructs-tuning)
|
||||
- [Step 1: Data Collection](#step-1-data-collection)
|
||||
- [Step 2: Preprocessing](#step-2-preprocessing)
|
||||
- [Step 3: Training](#step-3-training)
|
||||
- [RLHF Stage 2: Training Reward Model](#rlhf-training-stage2---training-reward-model)
|
||||
- [Step 1: Data Collection](#step-1-data-collection-1)
|
||||
- [Step 2: Preprocessing](#step-2-preprocessing-1)
|
||||
- [Step 3: Training](#step-3-training-1)
|
||||
- [Features and Tricks in RM Training](#features-and-tricks-in-rm-training)
|
||||
- [RLHF Stage 3: Proximal Policy Optimization](#rlhf-training-stage3---proximal-policy-optimization)
|
||||
- [Step 1: Data Collection](#step-1-data-collection-2)
|
||||
- [Step 2: Preprocessing](#step-2-preprocessing-2)
|
||||
- [Step 3: Training](#step-3-training-3)
|
||||
- [PPO Training Results](#sample-training-results-using-default-script)
|
||||
- [Reward](#reward)
|
||||
- [KL Divergence](#approximate-kl-divergence)
|
||||
- [Note on PPO Training](#note-on-ppo-training)
|
||||
- [Alternative Option For RLHF: Direct Preference Optimization](#alternative-option-for-rlhf-direct-preference-optimization)
|
||||
- [DPO Stage 1: Supervised Instruction Tuning](#dpo-training-stage1---supervised-instructs-tuning)
|
||||
- [DPO Stage 2: DPO Training](#dpo-training-stage2---dpo-training)
|
||||
- [Alternative Option For RLHF: Simple Preference Optimization](#alternative-option-for-rlhf-simple-preference-optimization)
|
||||
- [Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)](#alternative-option-for-rlhf-kahneman-tversky-optimization-kto)
|
||||
- [Alternative Option For RLHF: Odds Ratio Preference Optimization](#alternative-option-for-rlhf-odds-ratio-preference-optimization)
|
||||
- [List of Supported Models](#list-of-supported-models)
|
||||
- [Hardware Requirements](#hardware-requirements)
|
||||
- [Inference example](#inference-example)
|
||||
- [Attention](#attention)
|
||||
|
||||
|
||||
---
|
||||
|
||||
|
||||
## Install requirements
|
||||
|
||||
|
||||
```shell
|
||||
pip install -r requirements.txt
|
||||
```
|
||||
|
||||
## Get Start with ColossalRun
|
||||
|
||||
|
||||
You can use colossalai run to launch multi-node training:
|
||||
```
|
||||
colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
|
||||
train.py --OTHER_CONFIGURATIONS
|
||||
```
|
||||
Here is a sample hostfile:
|
||||
|
||||
|
||||
```
|
||||
hostname1
|
||||
hostname2
|
||||
hostname3
|
||||
hostname4
|
||||
```
|
||||
|
||||
|
||||
Make sure the master node can access all nodes (including itself) by ssh without a password. Here are some other arguments.
|
||||
|
||||
|
||||
- nnodes: number of nodes used in the training
|
||||
- nproc-per-node: specifies the number of processes to be launched per node
|
||||
- rdzv-endpoint: address of the host node
|
||||
|
||||
|
||||
### Training Configuration
|
||||
|
||||
|
||||
This section gives a simple introduction on different training strategies that you can use and how to use them with our boosters and plugins to reduce training time and VRAM consumption. For more details regarding training strategies, please refer to [here](https://colossalai.org/docs/concepts/paradigms_of_parallelism). For details regarding boosters and plugins, please refer to [here](https://colossalai.org/docs/basics/booster_plugins).
|
||||
|
||||
|
||||
<details><summary><b>Gemini (Zero3)</b></summary>
|
||||
|
||||
|
||||
This plugin implements Zero-3 with chunk-based and heterogeneous memory management. It can train large models without much loss in speed. It also does not support local gradient accumulation. More details can be found in [Gemini Doc](https://colossalai.org/docs/features/zero_with_chunk).
|
||||
|
||||
|
||||
Below shows how to use the gemini in SFT training.
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin gemini \
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \ # the gradient accumulation has to be disabled
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details><summary><b>Gemini-Auto (Zero3 with Auto-Resource-Allocation-Policy)</b></summary>
|
||||
|
||||
|
||||
This option uses gemini and will automatically offload tensors with low priority to cpu. It also does not support local gradient accumulation. More details can be found in [Gemini Doc](https://colossalai.org/docs/features/zero_with_chunk).
|
||||
|
||||
|
||||
Below shows how to use the gemini-auto in SFT training.
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin gemini_auto \
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 1 \ # the gradient accumulation has to be disabled
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details><summary><b>Zero2</b></summary>
|
||||
|
||||
|
||||
This option will distribute the optimizer parameters and the gradient to multiple GPUs and won't offload weights to cpu. It uses reduce and gather to synchronize gradients and weights. It does not support local gradient accumulation. Though you can accumulate gradients if you insist, it cannot reduce communication cost. That is to say, it's not a good idea to use Zero-2 with pipeline parallelism.
|
||||
|
||||
|
||||
Below shows how to use the zero2 in SFT training.
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin zero2 \
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 4 \
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
|
||||
<details><summary><b>Zero2CPU</b></summary>
|
||||
|
||||
|
||||
This option will distribute the optimizer parameters and the gradient to multiple GPUs as well as offload parameters to cpu. It does not support local gradient accumulation. Though you can accumulate gradients if you insist, it cannot reduce communication cost.
|
||||
|
||||
|
||||
Below shows how to use the zero2-cpu in SFT training.
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin zero2_cpu \
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 4 \
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details><summary><b>Tensor Parallelism</b></summary>
|
||||
|
||||
|
||||
This option supports Tensor Parallelism (TP). Note that if you want to use TP, TP split large model weights/optimizer parameters/gradients into multiple small ones and distributes them to multiple GPUs, hence it is recommended to use TP when your model is large (e.g. 20B and above) or your training algorithm consumes a lot of memory (e.g. PPO). Currently, we have added support for TP for the following model architectures.
|
||||
|
||||
|
||||
```
|
||||
bert, LLaMA, T5, GPT2, GPT-J, OPT, Bloom, Whisper, Sam, Blip2, ChatGLM (up to ChatGLM2), Falcon, Qwen2
|
||||
```
|
||||
|
||||
|
||||
Below shows how to use the TP in PPO training.
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --hostfile hostfile --master_port 30039 train_ppo.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--rm_pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--rm_checkpoint_path $REWARD_MODEL_PATH \
|
||||
--prompt_dataset ${prompt_dataset[@]} \
|
||||
--pretrain_dataset ${ptx_dataset[@]} \
|
||||
--ptx_batch_size 1 \
|
||||
--ptx_coef 0.0 \
|
||||
--plugin "3d" \
|
||||
--save_interval 200 \
|
||||
--save_path $SAVE_DIR \
|
||||
--num_episodes 2000 \
|
||||
--num_collect_steps 4 \
|
||||
--num_update_steps 1 \
|
||||
--experience_batch_size 8 \
|
||||
--train_batch_size 4 \
|
||||
--accumulation_steps 8 \
|
||||
--tp 4 \ # TP size, nproc_per_node must be divisible by it
|
||||
--lr 9e-6 \
|
||||
--mixed_precision "bf16" \
|
||||
--grad_clip 1.0 \
|
||||
--weight_decay 0.01 \
|
||||
--warmup_steps 100 \
|
||||
--grad_checkpoint \
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details><summary><b>Sequence Parallelism</b></summary>
|
||||
|
||||
|
||||
This option supports Sequence Parallelism (SP). It is recommended to use SP when your input sequence is very long (e.g. 50K and above). Please refer to this [SP Doc](https://github.com/hpcaitech/ColossalAI/blob/b96c6390f4363f58c0df56c0ca28755f8a5f1aa2/examples/tutorial/sequence_parallel/README.md?plain=1#L1) for more information.
|
||||
|
||||
Below shows how to use the SP in SFT training.
|
||||
```
|
||||
# use the `split_gather` or `ring` sp mode
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin 3d \
|
||||
--tp 4 \ # TP size, nproc_per_node must be divisible by it
|
||||
--sp 1 \ # SP size, must be 1
|
||||
--sp_mode 'split_gather' \ # or 'ring'
|
||||
--enable_sequence_parallelism \ # must be set
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 4 \
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--use_wandb
|
||||
|
||||
# use the `all_to_all` sp mode
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin 3d \
|
||||
--tp 1 \ # TP size, must be 1
|
||||
--sp 4 \ # SP size, nproc_per_node must be divisible by it
|
||||
--sp_mode 'all_to_all' \
|
||||
--enable_sequence_parallelism \ # must be set
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 4 \
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details><summary><b>Advanced Training Configuration with the Hybrid Plugin</b></summary>
|
||||
|
||||
User can use our HybridParallelPlugin for more advanced policy control. Currently, we have added support for the following model architectures.
|
||||
|
||||
|
||||
```
|
||||
bert, LLaMA, T5, GPT2, GPT-J, OPT, Bloom, Whisper, Sam, Blip2, ChatGLM (up to ChatGLM2), Falcon, Qwen2
|
||||
```
|
||||
|
||||
- We support mixing tensor parallelism with zero1/zero2/zero3:
|
||||
to do that, set both `tp` and `zero_stage`
|
||||
- We support mixing tensor parallelism with pipeline parallelism:
|
||||
to do that, set both `tp` and `pp`
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
|
||||
<details><summary><b>Gradient Checkpointing</b></summary>
|
||||
|
||||
|
||||
This option saves VRAM consumption by selectively recomputing some of the intermediate value on-the-fly during the backward pass, rather than storing them in memory.
|
||||
|
||||
|
||||
To enable gradient checkpointing, add --grad_checkpoint to your training script.
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin zero2_cpu \
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 4 \
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--grad_checkpoint \ # This enables gradient checkpointing
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details><summary><b>Flash Attention</b></summary>
|
||||
|
||||
|
||||
Details about flash attention can be found in the paper: [FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/abs/2205.14135).
|
||||
|
||||
|
||||
To enable flash attention, add --use_flash_attn to your training script.
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin zero2_cpu \
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 4 \
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--use_flash_attn \ # This enables flash attention
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
<details><summary><b>Other Training Arguments</b></summary>
|
||||
|
||||
|
||||
- grad_clip: gradients larger than this value will be clipped.
|
||||
- weight_decay: weight decay hyper-parameter.
|
||||
- warmup_steps: number of warmup steps used in setting up the learning rate scheduler.
|
||||
- pretrain: pretrain model path, weights will be loaded from this pretrained model unless checkpoint_path is provided.
|
||||
- tokenizer_dir: specify where to load the tokenizer, if not provided, tokenizer will be loaded from the pretrained model path.
|
||||
- dataset: a list of strings, each is a path to a folder containing buffered dataset files in arrow format.
|
||||
- checkpoint_path: if provided, will load weights from the checkpoint_path.
|
||||
- config_file: path to store the training config file.
|
||||
- save_dir: path to store the model checkpoints.
|
||||
- max_length: input will be padded/truncated to max_length before feeding to the model.
|
||||
- max_epochs: number of epochs to train.
|
||||
- disable_loss_mask: whether to use the loss mask to mask the loss or not. For example, in SFT, if the loss mask is disabled, the model will compute the loss across all tokens in the sequence, if the loss mask is applied, only tokens correspond to the assistant responses will contribute to the final loss.
|
||||
- batch_size: training batch size.
|
||||
- mixed_precision: precision to use in training. Support 'fp16' and 'bf16'. Note that some devices may not support the 'bf16' option, please refer to [Nvidia](https://developer.nvidia.com/) to check compatibility.
|
||||
- save_interval: save the model weights as well as optimizer/scheduler states every save_interval steps/episodes.
|
||||
- merge_lora_weights: whether to merge lora weights before saving the model
|
||||
- lr: the learning rate used in training.
|
||||
- accumulation_steps: accumulate gradient every accumulation_steps.
|
||||
- log_dir: path to store the log.
|
||||
- use_wandb: if this flag is up, you can view logs on wandb.
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
### Parameter Efficient Finetuning (PEFT)
|
||||
|
||||
Currently, we have support LoRA (low-rank adaptation) and PiSSA (principal singular values and singular vectors adaptation). Both help to reduce the running-time VRAM consumption as well as timing at the cost of overall model performance.
|
||||
|
||||
|
||||
<details><summary><b>Low Rank Adaption and PiSSA</b></summary>
|
||||
|
||||
|
||||
Details about Low Rank Adaption (LoRA) can be found in the paper: [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685). Details about Principal Singular Values and Singular Vectors Adaptation (PiSSA) can be found in the paper: [PiSSA: Principal Singular Values and Singular Vectors Adaptation of Large Language Models](https://arxiv.org/abs/2404.02948). Both help to reduce the running-time VRAM consumption as well as timing at the cost of overall model performance. It is suitable for training LLM with constrained resources.
|
||||
|
||||
To use LoRA/PiSSA in training, please create a config file as in the following example and set the `--lora_config` to that configuration file.
|
||||
|
||||
```json
|
||||
{
|
||||
"r": 128,
|
||||
"embedding_lora_dropout": 0.0,
|
||||
"linear_lora_dropout": 0.1,
|
||||
"lora_alpha": 32,
|
||||
"lora_train_bias": "all",
|
||||
"lora_initialization_method": "PiSSA",
|
||||
"target_modules": ["q_proj", "o_proj", "k_proj", "v_proj", "gate_proj", "up_proj", "down_proj", "embed_tokens"]
|
||||
}
|
||||
```
|
||||
#### Lora Parameters
|
||||
- r: lora rank
|
||||
- embedding_lora_dropout: dropout probability for embedding layer
|
||||
- linear_lora_dropout: dropout probability for linear layer
|
||||
- lora_alpha: lora alpha, controls how much the adaptor can deviate from the pretrained model.
|
||||
- lora_train_bias: whether to add trainable bias to lora layers, choose from "all" (all layers (including but not limited to lora layers) will have trainable biases), "none" (no trainable biases), "lora" (only lora layers will have trainable biases)
|
||||
- lora_initialization_method: how to initialize lora weights, choose one from ["kaiming_uniform", "PiSSA"], default to "kaiming_uniform". Use "kaiming_uniform" for standard LoRA and "PiSSA" for PiSSA.
|
||||
- target_modules: which module(s) should be converted to lora layers, if the module's name contain the keywords in target modules and the module is a linear or embedding layer, the module will be converted. Otherwise, the module will be frozen. Setting this field to None will automatically convert all linear and embedding layer to their LoRA counterparts. Note that this example only works for LLaMA, for other models, you need to modify it.
|
||||
|
||||
|
||||
```
|
||||
colossalai run --nproc_per_node 4 --master_port 28534 --hostfile ./hostfile train_sft.py \
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--dataset ${dataset[@]} \
|
||||
--save_interval 5000 \
|
||||
--save_path $SAVE_DIR \
|
||||
--config_file $CONFIG_FILE \
|
||||
--plugin zero2_cpu \
|
||||
--batch_size 4 \
|
||||
--max_epochs 1 \
|
||||
--accumulation_steps 4 \
|
||||
--lr 2e-5 \
|
||||
--max_len 2048 \
|
||||
--lora_config /PATH/TO/THE/LORA/CONFIG/FILE.json \ # Setting this enables LoRA
|
||||
--use_wandb
|
||||
```
|
||||
|
||||
|
||||
</details>
|
||||
|
||||
|
||||
### RLHF Training Stage1 - Supervised Instructs Tuning
|
||||
|
||||
|
||||
Stage1 is supervised instructs fine-tuning (SFT). This step is a crucial part of the RLHF training process, as it involves training a machine learning model using human-provided instructions to learn the initial behavior for the task at hand. Here's a detailed guide on how to SFT your LLM with ColossalChat:
|
||||
|
||||
|
||||
#### Step 1: Data Collection
|
||||
The first step in Stage 1 is to collect a dataset of human demonstrations of the following JSONL format.
|
||||
|
||||
|
||||
```json
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "user",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
},
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you looking for practical joke ideas?"
|
||||
},
|
||||
...
|
||||
]
|
||||
},
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
#### Step 2: Preprocessing
|
||||
Once you have collected your SFT dataset, you will need to preprocess it. This involves four steps: data cleaning, data deduplication, formatting and tokenization. In this section, we will focus on formatting and tokenization.
|
||||
|
||||
|
||||
In this code we provide a flexible way for users to set the conversation template for formatting chat data using Huggingface's newest feature--- chat template. Please follow the following steps to define your chat template and preprocess your data.
|
||||
|
||||
|
||||
- Step 1: (Optional). Define your conversation template. You need to provide a conversation template config file similar to the config files under the ./config/conversation_template directory. This config should include the following fields.
|
||||
```json
|
||||
{
|
||||
"chat_template": "A string of chat_template used for formatting chat data",
|
||||
"system_message": "A string of system message to be added at the beginning of the prompt. If no is provided (None), no system message will be added",
|
||||
"end_of_assistant": "The token(s) in string that denotes the end of assistance's response",
|
||||
"stop_ids": "A list of integers corresponds to the `end_of_assistant` tokens that indicate the end of assistance's response during the rollout stage of PPO training"
|
||||
}
|
||||
```
|
||||
* `chat_template`: (Optional), A string of chat_template used for formatting chat data. If not set (None), will use the default chat template of the provided tokenizer. If a path to a huggingface model or local model is provided, will use the chat_template of that model. To use a custom chat template, you need to manually set this field. For more details on how to write a chat template in Jinja format, please read https://huggingface.co/docs/transformers/main/chat_templating.
|
||||
* `system_message`: A string of system message to be added at the beginning of the prompt. If no is provided (None), no system message will be added.
|
||||
* `end_of_assistant`: The token(s) in string that denotes the end of assistance's response". For example, in the ChatGLM2 prompt format,
|
||||
```
|
||||
<|im_start|>system
|
||||
system messages
|
||||
|
||||
<|im_end|>
|
||||
<|im_start|>user
|
||||
How far is the moon? <|im_end|>
|
||||
<|im_start|>assistant\n The moon is about 384,400 kilometers away from Earth.<|im_end|>...
|
||||
```
|
||||
the `end_of_assistant` tokens are "<|im_end|>"
|
||||
* `stop_ids`: (Optional), A list of integers corresponds to the `end_of_assistant` tokens that indicate the end of assistance's response during the rollout stage of PPO training. It's recommended to set this manually for PPO training. If not set, will set to tokenizer.eos_token_ids automatically.
|
||||
|
||||
On your first run of the data preparation script, you only need to define the `chat_template` (if you want to use custom chat template) and the `system message` (if you want to use a custom system message)
|
||||
|
||||
- Step 2: Run the data preparation script--- [prepare_sft_dataset.sh](./data_preparation_scripts/prepare_sft_dataset.sh). Note that whether or not you have skipped the first step, you need to provide the path to the conversation template config file (via the conversation_template_config arg). If you skipped the first step, an auto-generated conversation template will be stored at the designated file path.
|
||||
|
||||
|
||||
- Step 3: (Optional) Check the correctness of the processed data. We provided an easy way for you to do a manual checking on the processed data by checking the "$SAVE_DIR/jsonl/part-XXXX.jsonl" files.
|
||||
|
||||
|
||||
Finishing the above steps, you have converted the raw conversation to the designated chat format and tokenized the formatted conversation, calculate input_ids, labels, attention_masks and buffer those into binary dataset files under "$SAVE_DIR/arrow/part-XXXX" folders.
|
||||
|
||||
|
||||
For example, our Colossal-LLaMA-2 format looks like,
|
||||
```
|
||||
<s> A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.
|
||||
|
||||
|
||||
Human: <s> what are some pranks with a pen i can do?</s> Assistant: <s> Are you looking for practical joke ideas?</s>
|
||||
...
|
||||
```
|
||||
|
||||
|
||||
#### Step 3: Training
|
||||
Choose a suitable model architecture for your task. Note that your model should be compatible with the tokenizer that you used to tokenize the SFT dataset. You can run [train_sft.sh](./training_scripts/train_sft.sh) to start a supervised instructs fine-tuning. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
|
||||
|
||||
|
||||
### RLHF Training Stage2 - Training Reward Model
|
||||
|
||||
|
||||
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model.
|
||||
|
||||
|
||||
#### Step 1: Data Collection
|
||||
Below shows the preference dataset format used in training the reward model.
|
||||
|
||||
|
||||
```json
|
||||
[
|
||||
{"context": [
|
||||
{
|
||||
"from": "user",
|
||||
"content": "Introduce butterflies species in Oregon."
|
||||
}
|
||||
]
|
||||
"chosen": [
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "About 150 species of butterflies live in Oregon, with about 100 species are moths..."
|
||||
},
|
||||
...
|
||||
],
|
||||
"rejected": [
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Are you interested in just the common butterflies? There are a few common ones which will be easy to find..."
|
||||
},
|
||||
...
|
||||
]
|
||||
},
|
||||
...
|
||||
]
|
||||
```
|
||||
|
||||
|
||||
#### Step 2: Preprocessing
|
||||
Similar to the second step in the previous stage, we format the reward data into the same structured format as used in step 2 of the SFT stage. You can run [prepare_preference_dataset.sh](./data_preparation_scripts/prepare_preference_dataset.sh) to prepare the preference data for reward model training.
|
||||
|
||||
|
||||
#### Step 3: Training
|
||||
You can run [train_rm.sh](./training_scripts/train_rm.sh) to start the reward model training. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
|
||||
|
||||
|
||||
#### Features and Tricks in RM Training
|
||||
|
||||
|
||||
- We recommend using the [Anthropic/hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)and[rm-static](https://huggingface.co/datasets/Dahoas/rm-static) datasets for training the reward model.
|
||||
- We support 2 kinds of loss function named `log_sig`(used by OpenAI) and `log_exp`(used by Anthropic).
|
||||
- We log the training accuracy `train/acc`, `reward_chosen` and `reward_rejected` to monitor progress during training.
|
||||
- We use cosine-reducing lr-scheduler for RM training.
|
||||
- We set value_head as one liner layer and initialize the weight of value_head using the N(0,1/(d_model + 1)) distribution.
|
||||
|
||||
|
||||
#### Note on Reward Model Training
|
||||
|
||||
|
||||
Before you move on to the next stage, please check the following list to ensure that your reward model is stable and robust. You can check the reward chart and the accuracy chart on wandb.
|
||||
- The mean reward for chosen data is much higher than those for rejected data
|
||||
- The accuracy is larger than 0.5 by a significant margin (usually should be greater than 0.6)
|
||||
- Optional:check the reward is positive for chosen data vice versa
|
||||
|
||||
|
||||
Your training reward curves should look similar to the following charts.
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/mean_reward_chart.png">
|
||||
</p>
|
||||
|
||||
|
||||
### RLHF Training Stage3 - Proximal Policy Optimization
|
||||
|
||||
|
||||
In stage3 we will use reinforcement learning algorithm--- Proximal Policy Optimization (PPO), which is the most complex part of the training process:
|
||||
|
||||
|
||||
<p align="center">
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/stage-3.jpeg" width=800/>
|
||||
</p>
|
||||
|
||||
|
||||
#### Step 1: Data Collection
|
||||
PPO uses two kinds of training data--- the prompt data and the pretrain data (optional). The first dataset is mandatory, data samples within the prompt dataset ends with a line from "user" and thus the "assistant" needs to generate a response to answer to the "user". Note that you can still use conversation that ends with a line from the "assistant", in that case, the last line will be dropped. Here is an example of the prompt dataset format.
|
||||
|
||||
|
||||
```json
|
||||
[
|
||||
{"messages":
|
||||
[
|
||||
{
|
||||
"from": "user",
|
||||
"content": "what are some pranks with a pen i can do?"
|
||||
}
|
||||
...
|
||||
]
|
||||
},
|
||||
]
|
||||
```
|
||||
|
||||
|
||||
The second dataset--- pretrained dataset is optional, provide it if you want to use the ptx loss introduced in the [InstructGPT paper](https://arxiv.org/abs/2203.02155). It follows the following format.
|
||||
|
||||
|
||||
```json
|
||||
[
|
||||
{
|
||||
"source": "", # system instruction
|
||||
"Target": "Provide a list of the top 10 most popular mobile games in Asia\nThe top 10 most popular mobile games in Asia are:\n1) PUBG Mobile\n2) Pokemon Go\n3) Candy Crush Saga\n4) Free Fire\n5) Clash of Clans\n6) Mario Kart Tour\n7) Arena of Valor\n8) Fantasy Westward Journey\n9) Subway Surfers\n10) ARK Survival Evolved",
|
||||
},
|
||||
...
|
||||
]
|
||||
```
|
||||
#### Step 2: Preprocessing
|
||||
To prepare the prompt dataset for PPO training, simply run [prepare_prompt_dataset.sh](./data_preparation_scripts/prepare_prompt_dataset.sh)
|
||||
|
||||
|
||||
You can use the SFT dataset you prepared in the SFT stage or prepare a new one from different source for the ptx dataset. The ptx data is used to calculate ptx loss, which stabilizes the training according to the [InstructGPT paper](https://arxiv.org/pdf/2203.02155.pdf).
|
||||
|
||||
|
||||
#### Step 3: Training
|
||||
You can run the [train_ppo.sh](./training_scripts/train_ppo.sh) to start PPO training. Here are some unique arguments for PPO, please refer to the training configuration section for other training configuration. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
|
||||
|
||||
|
||||
```bash
|
||||
--pretrain $PRETRAINED_MODEL_PATH \
|
||||
--rm_pretrain $PRETRAINED_MODEL_PATH \ # reward model architectural
|
||||
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
|
||||
--rm_checkpoint_path $REWARD_MODEL_PATH \ # reward model checkpoint path
|
||||
--prompt_dataset ${prompt_dataset[@]} \ # List of string, prompt dataset
|
||||
--conversation_template_config $CONVERSATION_TEMPLATE_CONFIG_PATH \ # path to the conversation template config file
|
||||
--pretrain_dataset ${ptx_dataset[@]} \ # List of string, the sft dataset
|
||||
--ptx_batch_size 1 \ # batch size for calculate ptx loss
|
||||
--ptx_coef 0.0 \ # none-zero if ptx loss is enable
|
||||
--num_episodes 2000 \ # number of episodes to train
|
||||
--num_collect_steps 1 \
|
||||
--num_update_steps 1 \
|
||||
--experience_batch_size 8 \
|
||||
--train_batch_size 4 \
|
||||
--accumulation_steps 2
|
||||
```
|
||||
|
||||
|
||||
Each episode has two phases, the collect phase and the update phase. During the collect phase, we will collect experiences (answers generated by the actor), store those in ExperienceBuffer. Then data in ExperienceBuffer is used during the update phase to update parameters of actor and critic.
|
||||
|
||||
|
||||
- Without tensor parallelism,
|
||||
```
|
||||
experience buffer size
|
||||
= num_process * num_collect_steps * experience_batch_size
|
||||
= train_batch_size * accumulation_steps * num_process
|
||||
```
|
||||
|
||||
|
||||
- With tensor parallelism,
|
||||
```
|
||||
num_tp_group = num_process / tp
|
||||
experience buffer size
|
||||
= num_tp_group * num_collect_steps * experience_batch_size
|
||||
= train_batch_size * accumulation_steps * num_tp_group
|
||||
```
|
||||
|
||||
|
||||
### Sample Training Results Using Default Script
|
||||
#### Reward
|
||||
<p align="center">
|
||||
<img width="700" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/reward.png">
|
||||
</p>
|
||||
|
||||
|
||||
### Note on PPO Training
|
||||
#### Q1: My reward is negative
|
||||
Answer: Check your reward model trained in stage 1. If the reward model only generates negative reward, we actually will expect a negative reward. However, even though the reward is negative, the reward should go up.
|
||||
|
||||
|
||||
#### Q2: My actor loss is negative
|
||||
Answer: This is normal for actor loss as PPO doesn't restrict the actor loss to be positive.
|
||||
|
||||
|
||||
#### Q3: My reward doesn't go up (decreases)
|
||||
Answer: The causes of this problem are two-fold. Check your reward model, make sure that it gives positive and strong reward for good cases and negative, strong reward for bad responses. You should also try different hyperparameter settings.
|
||||
|
||||
|
||||
#### Q4: Generation is garbage
|
||||
Answer: Yes, this happens and is well documented by other implementations. After training for too many episodes, the actor gradually deviate from its original state, which may leads to decrease in language modeling capabilities. A way to fix this is to add supervised loss during PPO. Set ptx_coef to an non-zero value (between 0 and 1), which balances PPO loss and sft loss.
|
||||
|
||||
|
||||
## Alternative Option For RLHF: Direct Preference Optimization
|
||||
|
||||
|
||||
For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in the paper (available at [https://arxiv.org/abs/2305.18290](https://arxiv.org/abs/2305.18290)), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO.
|
||||
|
||||
|
||||
### DPO Training Stage1 - Supervised Instructs Tuning
|
||||
|
||||
|
||||
Please refer the [sft section](#dpo-training-stage1---supervised-instructs-tuning) in the PPO part.
|
||||
|
||||
|
||||
### DPO Training Stage2 - DPO Training
|
||||
#### Step 1: Data Collection & Preparation
|
||||
For DPO training, you only need the preference dataset. Please follow the instruction in the [preference dataset preparation section](#rlhf-training-stage2---training-reward-model) to prepare the preference data for DPO training.
|
||||
|
||||
|
||||
#### Step 2: Training
|
||||
You can run the [train_dpo.sh](./training_scripts/train_dpo.sh) to start DPO training. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options. Following the trend of recent research on DPO-like alignment methods, we added option for the user to choose from, including whether to do length normalization , reward shaping and whether to use a reference model in calculating implicit reward. Here are those options,
|
||||
|
||||
```
|
||||
--beta 0.1 \ # the temperature in DPO loss, Default to 0.1
|
||||
--gamma 0.0 \ # the reward target margin in the SimPO paper, Default to 0.
|
||||
--disable_reference_model \ # whether to disable the reference model, if set, the implicit reward will be calculated solely from the actor. Default to enable reference model in DPO
|
||||
--length_normalization \ # whether to apply length normalization, Default to not use
|
||||
```
|
||||
|
||||
#### DPO Result
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/DPO.png">
|
||||
</p>
|
||||
|
||||
### Alternative Option For RLHF: Simple Preference Optimization
|
||||
|
||||
We support the method introduced in the paper [SimPO: Simple Preference Optimization
|
||||
with a Reference-Free Reward](https://arxiv.org/pdf/2405.14734) (SimPO). Which is a reference model free aligment method that add length normalization and reward shaping to the DPO loss to enhance training stability and efficiency. As the method doesn't deviate too much from DPO, we add support for length normalization and SimPO reward shaping in our DPO implementation. To use SimPO in alignment, use the [train_dpo.sh](./training_scripts/train_dpo.sh) script, set the `loss_type` to `simpo_loss`, you can also set the value for temperature (`beta`) and reward target margin (`gamma`) but it is optional.
|
||||
|
||||
#### SimPO Result
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/SimPO_margin.png">
|
||||
</p>
|
||||
|
||||
|
||||
### Alternative Option For RLHF: Odds Ratio Preference Optimization
|
||||
We support the method introduced in the paper [ORPO: Monolithic Preference Optimization without Reference Model](https://arxiv.org/abs/2403.07691) (ORPO). Which is a reference model free aligment method that mixes the SFT loss with a reinforcement learning loss that uses odds ratio as the implicit reward to enhance training stability and efficiency. To use ORPO in alignment, use the [train_orpo.sh](./training_scripts/train_orpo.sh) script, You can set the value for `lambda` (which determine how strongly the reinforcement learning loss affect the training) but it is optional.
|
||||
|
||||
#### ORPO Result
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/ORPO_margin.png">
|
||||
</p>
|
||||
|
||||
### Alternative Option For RLHF: Kahneman-Tversky Optimization (KTO)
|
||||
We support the method introduced in the paper [KTO:Model Alignment as Prospect Theoretic Optimization](https://arxiv.org/pdf/2402.01306) (KTO). Which is a aligment method that directly maximize "human utility" of generation results.
|
||||
|
||||
For KTO data preparation, please use the script [prepare_kto_dataset.sh](./examples/data_preparation_scripts/prepare_kto_dataset.sh). You will need preference data, different from DPO and its derivatives, you no longer need a pair of chosen/rejected response for the same input. You only need data whose response is associated with a preference label--- whether the response is okay or not, read the papre for more details. You also need to convert your data to the following intermediate format before you run the data preparation script.
|
||||
|
||||
```jsonl
|
||||
{
|
||||
"prompt": [
|
||||
{
|
||||
"from": "user",
|
||||
"content": "What are some praise words in english?"
|
||||
},
|
||||
{
|
||||
"from": "assistant",
|
||||
"content": "Here's an incomplete list.\n\nexcellent, fantastic, impressive ..."
|
||||
},
|
||||
{
|
||||
"from": "user",
|
||||
"content": "What's your favorite one?"
|
||||
}
|
||||
],
|
||||
"completion": {
|
||||
"from": "assistant",
|
||||
"content": "impressive."
|
||||
},
|
||||
"label": true
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
For training, use the [train_kto.sh](./examples/training_scripts/train_orpo.sh) script, You may need to set the value for `beta` (which determine how strongly the reinforcement learning loss affect the training), `desirable_weight` and `undesirable_weight` if your data is biased (has unequal number of chosen and rejected samples).
|
||||
|
||||
#### KTO Result
|
||||
<p align="center">
|
||||
<img width="1000" alt="image" src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/applications/chat/KTO.png">
|
||||
</p>
|
||||
|
||||
## Hardware Requirements
|
||||
|
||||
For SFT, we recommend using zero2 or zero2-cpu for 7B model and tp is your model is extra large. We tested the VRAM consumption on a dummy dataset with a sequence length of 2048. In all experiments, we use H800 GPUs with 80GB VRAM and enable gradient checkpointing and flash attention.
|
||||
- 2 H800 GPU
|
||||
- zero2-cpu, micro batch size=4, VRAM Usage=22457.98 MB
|
||||
- zero2, micro batch size=4, VRAM Usage=72390.95 MB
|
||||
- 4 H800 GPUs
|
||||
- zero2_cpu, micro batch size=8, VRAM Usage=19412.77 MB
|
||||
- zero2, micro batch size=8, VRAM Usage=43446.31 MB
|
||||
- zero2, micro batch size=16, VRAM Usage=58082.30 MB
|
||||
- zero2, micro batch size=8, lora_rank=8, VRAM Usage=21167.73 MB
|
||||
- zero2, micro batch size=8, lora_rank=32, VRAM Usage=21344.17 MB
|
||||
|
||||
For PPO, we suggest using Tensor Parallelism. The following table shows the VRAM consumption of training a 7B model (llama2-7B-hf) on a dummy dataset with a sequence length of 2048 and a layout length of 512 with different tp_size (equal to the number of GPUs).
|
||||
| PPO | tp=8 | tp=4 |
|
||||
|-------|---------------|---------------|
|
||||
| bs=1 | 18485.19 MB | 42934.45 MB |
|
||||
| bs=4 | 25585.65 MB | 42941.93 MB |
|
||||
| bs=16 | 41408.28 MB | 56778.97 MB |
|
||||
| bs=30 | 64047.42 MB | failed |
|
||||
|
||||
|
||||
For DPO, we recommend using zero2 or zero2-cpu. We tested the VRAM consumption on a dummy dataset with 2048 sequence length.
|
||||
|
||||
- 2 H800 GPU
|
||||
- zero2-cpu, micro batch size=2, VRAM Usage=36989.37 MB
|
||||
- zero2-cpu, micro batch size=4, VRAM Usage=48081.67 MB
|
||||
- 4 H800 GPUs
|
||||
- zero2, micro batch size=4, VRAM Usage=67483.44 MB
|
||||
|
||||
For SimPO, we recommend using zero2 or zero2-cpu. We tested the VRAM consumption on a dummy dataset with 2048 sequence length.
|
||||
|
||||
- 2 H800 GPU
|
||||
- zero2-cpu, micro batch size=4, VRAM 25705.26 MB
|
||||
- zero2, micro batch size=4, VRAM Usage=73375.04 MB
|
||||
- 4 H800 GPUs
|
||||
- zero2_cpu, micro batch size=8, VRAM Usage=36709.36 MB
|
||||
- zero2, micro batch size=4, VRAM Usage=44330.90 MB
|
||||
- zero2, micro batch size=8, VRAM Usage=56086.12 MB
|
||||
|
||||
For ORPO, we recommend using zero2 or zero2-cpu. We tested the VRAM consumption on a dummy dataset with 2048 sequence length.
|
||||
|
||||
- 2 H800 GPU
|
||||
- zero2-cpu, micro batch size=4, VRAM 26693.38 MB
|
||||
- zero2, micro batch size=4, VRAM Usage=74332.65 MB
|
||||
- 4 H800 GPUs
|
||||
- zero2_cpu, micro batch size=8, VRAM Usage=38709.73 MB
|
||||
- zero2, micro batch size=4, VRAM Usage=45309.52 MB
|
||||
- zero2, micro batch size=8, VRAM Usage=58086.37 MB
|
||||
|
||||
For KTO, we recommend using zero2-cpu or zero2 plugin, We tested the VRAM consumption on a dummy dataset with 2048 sequence length.
|
||||
- 2 H800 GPU
|
||||
- zero2-cpu, micro batch size=2, VRAM Usage=35241.98 MB
|
||||
- zero2-cpu, micro batch size=4, VRAM Usage=38989.37 MB
|
||||
- 4 H800 GPUs
|
||||
- zero2_cpu, micro batch size=2, VRAM_USAGE=32443.22 MB
|
||||
- zero2, micro batch size=4, VRAM_USAGE=59307.97 MB
|
||||
|
||||
## List of Supported Models
|
||||
|
||||
For SFT, we support the following models/series:
|
||||
- Colossal-LLaMA-2
|
||||
- ChatGLM2
|
||||
- ChatGLM3 (only with zero2, zero2_cpu plugin)
|
||||
- Baichuan2
|
||||
- LLaMA2
|
||||
- Qwen1.5-7B-Chat (with transformers==4.39.1)
|
||||
- Yi-1.5
|
||||
|
||||
For PPO and DPO, we theoratically support the following models/series (without guarantee):
|
||||
- Colossal-LLaMA-2 (tested)
|
||||
- ChatGLM2
|
||||
- Baichuan2
|
||||
- LLaMA2 (tested)
|
||||
- Qwen1.5-7B-Chat (with transformers==4.39.1)
|
||||
- Yi-1.5
|
||||
|
||||
*-* The zero2, zero2_cpu plugin also support a wide range of chat models not listed above.
|
||||
|
||||
## Inference example
|
||||
|
||||
|
||||
We support different inference options, including int8 and int4 quantization.
|
||||
For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
|
||||
|
||||
|
||||
## Attention
|
||||
|
||||
|
||||
The examples are demos for the whole training process. You need to change the hyper-parameters to reach great performance.
|
||||
|
|
@ -0,0 +1,29 @@
|
|||
:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
|
||||
|
||||
# Community Examples
|
||||
|
||||
---
|
||||
|
||||
We are thrilled to announce the latest updates to ColossalChat, an open-source solution for cloning ChatGPT with a complete RLHF (Reinforcement Learning with Human Feedback) pipeline.
|
||||
|
||||
As Colossal-AI undergoes major updates, we are actively maintaining ColossalChat to stay aligned with the project's progress. With the introduction of Community-driven example, we aim to create a collaborative platform for developers to contribute exotic features built on top of ColossalChat.
|
||||
|
||||
## Community Example
|
||||
|
||||
Community-driven Examples is an initiative that allows users to contribute their own examples to the ColossalChat package, fostering a sense of community and making it easy for others to access and benefit from shared work. The primary goal with community-driven examples is to have a community-maintained collection of diverse and exotic functionalities built on top of the ColossalChat package, which is powered by the Colossal-AI project and its Coati module (ColossalAI Talking Intelligence).
|
||||
|
||||
For more information about community pipelines, please have a look at this [issue](https://github.com/hpcaitech/ColossalAI/issues/3487).
|
||||
|
||||
## Community Examples
|
||||
|
||||
Community examples consist of both inference and training examples that have been added by the community. Please have a look at the following table to get an overview of all community examples. Click on the Code Example to get a copy-and-paste ready code example that you can try out. If a community doesn't work as expected, please open an issue and ping the author on it.
|
||||
|
||||
| Example | Description | Code Example | Colab | Author |
|
||||
| :------------------- | :----------------------------------------------------- | :-------------------------------------------------------------------------------------------------------------- | :---- | ------------------------------------------------: |
|
||||
| Peft | Adding Peft support for SFT and Prompts model training | [Huggingface Peft](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/peft) | - | [YY Lin](https://github.com/yynil) |
|
||||
| Train prompts on Ray | A Ray based implementation of Train prompts example | [Training On Ray](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/ray) | - | [MisterLin1995](https://github.com/MisterLin1995) |
|
||||
| ... | ... | ... | ... | ... |
|
||||
|
||||
### How to get involved
|
||||
|
||||
To join our community-driven initiative, please visit the [ColossalChat GitHub repository](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples), review the provided information, and explore the codebase. To contribute, create a new issue outlining your proposed feature or enhancement, and our team will review and provide feedback. We look forward to collaborating with you on this exciting project!
|
||||
|
|
@ -0,0 +1,30 @@
|
|||
:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
|
||||
|
||||
# Add Peft support for SFT and Prompts model training
|
||||
|
||||
The original implementation just adopts the loralib and merges the layers into the final model. The huggingface peft is a better lora model implementation and can be easily training and distributed.
|
||||
|
||||
Since reward model is relative small, I just keep it as original one. I suggest train full model to get the proper reward/critic model.
|
||||
|
||||
# Preliminary installation
|
||||
|
||||
Since the current pypi peft package(0.2) has some bugs, please install the peft package using source.
|
||||
|
||||
```
|
||||
git clone https://github.com/huggingface/peft
|
||||
cd peft
|
||||
pip install .
|
||||
```
|
||||
|
||||
# Usage
|
||||
|
||||
For SFT training, just call train_peft_sft.py
|
||||
|
||||
Its arguments are almost identical to train_sft.py instead adding a new eval_dataset if you have an eval_dataset file. The data file is just a plain datafile, please check the format in the easy_dataset.py.
|
||||
|
||||
For stage-3 rlhf training, call train_peft_prompts.py.
|
||||
Its arguments are almost identical to train_prompts.py. The only difference is that I use text files to indicate the prompt and pretrained data file. The models are included in easy_models.py. Currently only bloom models are tested, but technically gpt2/opt/llama should be supported.
|
||||
|
||||
# Dataformat
|
||||
|
||||
Please refer the formats in test_sft.txt, test_prompts.txt, test_pretrained.txt.
|
||||
|
|
@ -0,0 +1,240 @@
|
|||
import copy
|
||||
import json
|
||||
from typing import Dict, Sequence
|
||||
|
||||
import torch
|
||||
from torch.utils.data import Dataset
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
IGNORE_INDEX = -100
|
||||
|
||||
|
||||
def _tokenize_fn(strings: Sequence[str], tokenizer: AutoTokenizer, max_length: int = 512) -> Dict:
|
||||
"""Tokenize a list of strings."""
|
||||
tokenized_list = [
|
||||
tokenizer(
|
||||
text,
|
||||
return_tensors="pt",
|
||||
padding="longest",
|
||||
max_length=max_length,
|
||||
truncation=True,
|
||||
)
|
||||
for text in strings
|
||||
]
|
||||
input_ids = labels = [tokenized.input_ids[0] for tokenized in tokenized_list]
|
||||
input_ids_lens = labels_lens = [
|
||||
tokenized.input_ids.ne(tokenizer.pad_token_id).sum().item() for tokenized in tokenized_list
|
||||
]
|
||||
return dict(
|
||||
input_ids=input_ids,
|
||||
labels=labels,
|
||||
input_ids_lens=input_ids_lens,
|
||||
labels_lens=labels_lens,
|
||||
)
|
||||
|
||||
|
||||
def preprocess(sources: Sequence[str], targets: Sequence[str], tokenizer: AutoTokenizer, max_length: int = 512) -> Dict:
|
||||
"""Preprocess the data by tokenizing."""
|
||||
examples = [s + t for s, t in zip(sources, targets)]
|
||||
examples_tokenized, sources_tokenized = [
|
||||
_tokenize_fn(strings, tokenizer, max_length) for strings in (examples, sources)
|
||||
]
|
||||
input_ids = examples_tokenized["input_ids"]
|
||||
labels = copy.deepcopy(input_ids)
|
||||
for label, source_len in zip(labels, sources_tokenized["input_ids_lens"]):
|
||||
label[:source_len] = IGNORE_INDEX
|
||||
return dict(input_ids=input_ids, labels=labels)
|
||||
|
||||
|
||||
class EasySupervisedDataset(Dataset):
|
||||
def __init__(self, data_file: str, tokenizer: AutoTokenizer, max_length: int = 512) -> None:
|
||||
super(EasySupervisedDataset, self).__init__()
|
||||
with open(data_file, "r", encoding="UTF-8") as f:
|
||||
all_lines = f.readlines()
|
||||
# split to source and target ,source the characters before "回答:" including "回答:", target the characters after "回答:"
|
||||
sources, targets = [], []
|
||||
for line in all_lines:
|
||||
if "回答:" in line:
|
||||
sep_index = line.index("回答:")
|
||||
sources.append(line[: sep_index + 3])
|
||||
targets.append(line[sep_index + 3 :] + tokenizer.eos_token)
|
||||
else:
|
||||
sources.append(line)
|
||||
targets.append("" + tokenizer.eos_token)
|
||||
data_dict = preprocess(sources, targets, tokenizer, max_length)
|
||||
|
||||
self.input_ids = data_dict["input_ids"]
|
||||
self.labels = data_dict["labels"]
|
||||
self.data_file = data_file
|
||||
|
||||
def __len__(self):
|
||||
return len(self.input_ids)
|
||||
|
||||
def __getitem__(self, i) -> Dict[str, torch.Tensor]:
|
||||
return dict(input_ids=self.input_ids[i], labels=self.labels[i])
|
||||
|
||||
def __repr__(self):
|
||||
return f"LawSupervisedDataset(data_file={self.data_file}, input_ids_len={len(self.input_ids)}, labels_len={len(self.labels)})"
|
||||
|
||||
def __str__(self):
|
||||
return f"LawSupervisedDataset(data_file={self.data_file}, input_ids_len={len(self.input_ids)}, labels_len={len(self.labels)})"
|
||||
|
||||
|
||||
class EasyPromptsDataset(Dataset):
|
||||
def __init__(self, data_file: str, tokenizer: AutoTokenizer, max_length: int = 96) -> None:
|
||||
super(EasyPromptsDataset, self).__init__()
|
||||
with open(data_file, "r", encoding="UTF-8") as f:
|
||||
all_lines = f.readlines()
|
||||
all_lines = [line if "回答:" not in line else line[: line.index("回答:") + 3] for line in all_lines]
|
||||
self.prompts = [
|
||||
tokenizer(line, return_tensors="pt", max_length=max_length, padding="max_length", truncation=True)[
|
||||
"input_ids"
|
||||
]
|
||||
.to(torch.cuda.current_device())
|
||||
.squeeze(0)
|
||||
for line in tqdm(all_lines)
|
||||
]
|
||||
self.data_file = data_file
|
||||
|
||||
def __len__(self):
|
||||
return len(self.prompts)
|
||||
|
||||
def __getitem__(self, idx):
|
||||
return self.prompts[idx]
|
||||
|
||||
def __repr__(self):
|
||||
return f"LawPromptsDataset(data_file={self.data_file}, prompts_len={len(self.prompts)})"
|
||||
|
||||
def __str__(self):
|
||||
return f"LawPromptsDataset(data_file={self.data_file}, prompts_len={len(self.prompts)})"
|
||||
|
||||
|
||||
class EasyRewardDataset(Dataset):
|
||||
def __init__(self, train_file: str, tokenizer: AutoTokenizer, special_token=None, max_length=512) -> None:
|
||||
super(EasyRewardDataset, self).__init__()
|
||||
self.chosen = []
|
||||
self.reject = []
|
||||
if special_token is None:
|
||||
self.end_token = tokenizer.eos_token
|
||||
else:
|
||||
self.end_token = special_token
|
||||
print(self.end_token)
|
||||
# read all lines in the train_file to a list
|
||||
with open(train_file, "r", encoding="UTF-8") as f:
|
||||
all_lines = f.readlines()
|
||||
for line in tqdm(all_lines):
|
||||
data = json.loads(line)
|
||||
prompt = "提问:" + data["prompt"] + " 回答:"
|
||||
|
||||
chosen = prompt + data["chosen"] + self.end_token
|
||||
chosen_token = tokenizer(
|
||||
chosen, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt"
|
||||
)
|
||||
self.chosen.append(
|
||||
{"input_ids": chosen_token["input_ids"], "attention_mask": chosen_token["attention_mask"]}
|
||||
)
|
||||
|
||||
reject = prompt + data["rejected"] + self.end_token
|
||||
reject_token = tokenizer(
|
||||
reject, max_length=max_length, padding="max_length", truncation=True, return_tensors="pt"
|
||||
)
|
||||
self.reject.append(
|
||||
{"input_ids": reject_token["input_ids"], "attention_mask": reject_token["attention_mask"]}
|
||||
)
|
||||
|
||||
def __len__(self):
|
||||
length = len(self.chosen)
|
||||
return length
|
||||
|
||||
def __getitem__(self, idx):
|
||||
return (
|
||||
self.chosen[idx]["input_ids"],
|
||||
self.chosen[idx]["attention_mask"],
|
||||
self.reject[idx]["input_ids"],
|
||||
self.reject[idx]["attention_mask"],
|
||||
)
|
||||
|
||||
# python representation of the object and the string representation of the object
|
||||
def __repr__(self):
|
||||
return f"LawRewardDataset(chosen_len={len(self.chosen)}, reject_len={len(self.reject)})"
|
||||
|
||||
def __str__(self):
|
||||
return f"LawRewardDataset(chosen_len={len(self.chosen)}, reject_len={len(self.reject)})"
|
||||
|
||||
|
||||
"""
|
||||
Easy SFT just accept a text file which can be read line by line. However the datasets will group texts together to max_length so LLM will learn the texts meaning better.
|
||||
If individual lines are not related, just set is_group_texts to False.
|
||||
"""
|
||||
|
||||
|
||||
class EasySFTDataset(Dataset):
|
||||
def __init__(self, data_file: str, tokenizer: AutoTokenizer, max_length=512, is_group_texts=True) -> None:
|
||||
super().__init__()
|
||||
# read the data_file line by line
|
||||
with open(data_file, "r", encoding="UTF-8") as f:
|
||||
# encode the text data line by line and put raw python list input_ids only to raw_input_ids list
|
||||
raw_input_ids = []
|
||||
for line in f:
|
||||
encoded_ids = tokenizer.encode(line)
|
||||
# if the encoded_ids is longer than max_length, then split it into several parts
|
||||
if len(encoded_ids) > max_length:
|
||||
for i in range(0, len(encoded_ids), max_length):
|
||||
raw_input_ids.append(encoded_ids[i : i + max_length])
|
||||
else:
|
||||
raw_input_ids.append(encoded_ids)
|
||||
|
||||
grouped_input_ids = []
|
||||
current_input_ids = []
|
||||
attention_mask = []
|
||||
if tokenizer.pad_token_id is None:
|
||||
tokenizer.pad_token_id = tokenizer.eos_token_id
|
||||
if is_group_texts:
|
||||
for input_ids in raw_input_ids:
|
||||
if len(current_input_ids) + len(input_ids) > max_length:
|
||||
# pad the current_input_ids to max_length with tokenizer.pad_token_id
|
||||
padded_length = max_length - len(current_input_ids)
|
||||
current_input_ids.extend([tokenizer.pad_token_id] * padded_length)
|
||||
grouped_input_ids.append(torch.tensor(current_input_ids, dtype=torch.long))
|
||||
attention_mask.append(
|
||||
torch.tensor([1] * (max_length - padded_length) + [0] * padded_length, dtype=torch.long)
|
||||
)
|
||||
current_input_ids = []
|
||||
else:
|
||||
current_input_ids.extend(input_ids)
|
||||
if len(current_input_ids) > 0:
|
||||
padded_length = max_length - len(current_input_ids)
|
||||
current_input_ids.extend([tokenizer.pad_token_id] * padded_length)
|
||||
grouped_input_ids.append(torch.tensor(current_input_ids, dtype=torch.long))
|
||||
attention_mask.append(
|
||||
torch.tensor([1] * (max_length - padded_length) + [0] * padded_length, dtype=torch.long)
|
||||
)
|
||||
else:
|
||||
# just append the raw_input_ids to max_length
|
||||
for input_ids in raw_input_ids:
|
||||
padded_length = max_length - len(input_ids)
|
||||
input_ids.extend([tokenizer.pad_token_id] * padded_length)
|
||||
attention_mask.append(
|
||||
torch.tensor([1] * (max_length - padded_length) + [0] * padded_length, dtype=torch.long)
|
||||
)
|
||||
grouped_input_ids.append(torch.tensor(input_ids, dtype=torch.long))
|
||||
self.input_ids = grouped_input_ids
|
||||
self.labels = copy.deepcopy(self.input_ids)
|
||||
self.file_name = data_file
|
||||
self.attention_mask = attention_mask
|
||||
|
||||
def __len__(self):
|
||||
return len(self.input_ids)
|
||||
|
||||
# get item from dataset
|
||||
def __getitem__(self, idx):
|
||||
return dict(input_ids=self.input_ids[idx], labels=self.labels[idx], attention_mask=self.attention_mask[idx])
|
||||
|
||||
# generate the dataset description to be printed by print in python
|
||||
def __repr__(self):
|
||||
return f"EasySFTDataset(len={len(self)},\nfile_name is {self.file_name})"
|
||||
|
||||
# generate the dataset description to be printed by print in python
|
||||
def __str__(self):
|
||||
return f"EasySFTDataset(len={len(self)},\nfile_name is {self.file_name})"
|
||||
|
|
@ -0,0 +1,93 @@
|
|||
from typing import Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from coati.models.generation import generate
|
||||
from coati.models.utils import log_probs_from_logits
|
||||
from peft import PeftModel
|
||||
from torch.nn.modules import Module
|
||||
from transformers import BloomConfig, BloomForCausalLM
|
||||
|
||||
|
||||
class Actor(Module):
|
||||
"""
|
||||
Actor model base class.
|
||||
|
||||
Args:
|
||||
model (nn.Module): Actor Model.
|
||||
"""
|
||||
|
||||
def __init__(self, model: nn.Module) -> None:
|
||||
super().__init__()
|
||||
self.model = model
|
||||
|
||||
@torch.no_grad()
|
||||
def generate(
|
||||
self, input_ids: torch.Tensor, return_action_mask: bool = True, **kwargs
|
||||
) -> Union[Tuple[torch.LongTensor, torch.LongTensor], Tuple[torch.LongTensor, torch.LongTensor, torch.BoolTensor]]:
|
||||
sequences = generate(self.model, input_ids, **kwargs)
|
||||
attention_mask = None
|
||||
pad_token_id = kwargs.get("pad_token_id", None)
|
||||
if pad_token_id is not None:
|
||||
attention_mask = sequences.not_equal(pad_token_id).to(dtype=torch.long, device=sequences.device)
|
||||
if not return_action_mask:
|
||||
return sequences, attention_mask, None
|
||||
input_len = input_ids.size(1)
|
||||
eos_token_id = kwargs.get("eos_token_id", None)
|
||||
if eos_token_id is None:
|
||||
action_mask = torch.ones_like(sequences, dtype=torch.bool)
|
||||
else:
|
||||
# left padding may be applied, only mask action
|
||||
action_mask = (sequences[:, input_len:] == eos_token_id).cumsum(dim=-1) == 0
|
||||
action_mask = F.pad(action_mask, (1 + input_len, -1), value=True) # include eos token and input
|
||||
action_mask[:, :input_len] = False
|
||||
action_mask = action_mask[:, 1:]
|
||||
return sequences, attention_mask, action_mask[:, -(sequences.size(1) - input_len) :]
|
||||
|
||||
def forward(
|
||||
self, sequences: torch.LongTensor, num_actions: int, attention_mask: Optional[torch.Tensor] = None
|
||||
) -> torch.Tensor:
|
||||
"""Returns action log probs"""
|
||||
output = self.model(sequences, attention_mask=attention_mask)
|
||||
logits = output["logits"]
|
||||
log_probs = log_probs_from_logits(logits[:, :-1, :], sequences[:, 1:])
|
||||
return log_probs[:, -num_actions:]
|
||||
|
||||
def get_base_model(self):
|
||||
return self.model
|
||||
|
||||
|
||||
class BLOOMActor(Actor):
|
||||
"""
|
||||
BLOOM Actor model.
|
||||
|
||||
Args:
|
||||
pretrained (str): Pretrained model name or path.
|
||||
config (BloomConfig): Model config.
|
||||
checkpoint (bool): Enable gradient checkpointing.
|
||||
lora_rank (int): LoRA rank.
|
||||
lora_train_bias (str): LoRA bias training mode.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
pretrained: str = None,
|
||||
config: Optional[BloomConfig] = None,
|
||||
checkpoint: bool = False,
|
||||
lora_path: str = None,
|
||||
) -> None:
|
||||
if pretrained is not None:
|
||||
model = BloomForCausalLM.from_pretrained(pretrained)
|
||||
elif config is not None:
|
||||
model = BloomForCausalLM(config)
|
||||
else:
|
||||
model = BloomForCausalLM(BloomConfig())
|
||||
if lora_path is not None:
|
||||
model = PeftModel.from_pretrained(model, lora_path)
|
||||
if checkpoint:
|
||||
model.gradient_checkpointing_enable()
|
||||
super().__init__(model)
|
||||
|
||||
def print_trainable_parameters(self):
|
||||
self.get_base_model().print_trainable_parameters()
|
||||
|
|
@ -0,0 +1,224 @@
|
|||
import argparse
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from coati.dataset import DataCollatorForSupervisedDataset
|
||||
from coati.models.bloom import BLOOMRM, BLOOMCritic
|
||||
from coati.models.gpt import GPTRM, GPTCritic
|
||||
from coati.models.llama import LlamaCritic, LlamaRM
|
||||
from coati.models.opt import OPTRM, OPTCritic
|
||||
from coati.trainer import PPOTrainer
|
||||
from coati.trainer.strategies import DDPStrategy, GeminiStrategy, LowLevelZeroStrategy
|
||||
from easy_dataset import EasyPromptsDataset, EasySupervisedDataset
|
||||
from easy_models import BLOOMActor
|
||||
from torch.optim import Adam
|
||||
from torch.utils.data import DataLoader
|
||||
from torch.utils.data.distributed import DistributedSampler
|
||||
from transformers import AutoTokenizer, BloomTokenizerFast, GPT2Tokenizer, LlamaTokenizer
|
||||
|
||||
from colossalai.nn.optimizer import HybridAdam
|
||||
|
||||
|
||||
def main(args):
|
||||
# configure strategy
|
||||
if args.strategy == "ddp":
|
||||
strategy = DDPStrategy()
|
||||
elif args.strategy == "colossalai_gemini":
|
||||
strategy = GeminiStrategy(
|
||||
placement_policy="static", offload_optim_frac=1.0, offload_param_frac=1.0, initial_scale=2**5
|
||||
)
|
||||
elif args.strategy == "colossalai_zero2":
|
||||
strategy = LowLevelZeroStrategy(stage=2, placement_policy="cpu")
|
||||
else:
|
||||
raise ValueError(f'Unsupported strategy "{args.strategy}"')
|
||||
|
||||
if args.rm_path is not None:
|
||||
state_dict = torch.load(args.rm_path, map_location="cpu")
|
||||
|
||||
# configure model
|
||||
if args.model == "bloom":
|
||||
# initial_model = BLOOMActor(pretrained=args.pretrain)
|
||||
print("Using peft lora to load Bloom model as initial_model")
|
||||
initial_model = BLOOMActor(pretrained=args.pretrain, lora_path=args.sft_lora_path)
|
||||
print("Using peft lora to load Bloom model as initial_model (Done)")
|
||||
else:
|
||||
raise ValueError(f'Unsupported actor model "{args.model}"')
|
||||
|
||||
if args.rm_model == None:
|
||||
rm_model_name = args.model
|
||||
else:
|
||||
rm_model_name = args.rm_model
|
||||
|
||||
if rm_model_name == "gpt2":
|
||||
reward_model = GPTRM(pretrained=args.rm_pretrain)
|
||||
elif rm_model_name == "bloom":
|
||||
print("load bloom reward model ", args.rm_pretrain)
|
||||
reward_model = BLOOMRM(pretrained=args.rm_pretrain)
|
||||
elif rm_model_name == "opt":
|
||||
reward_model = OPTRM(pretrained=args.rm_pretrain)
|
||||
elif rm_model_name == "llama":
|
||||
reward_model = LlamaRM(pretrained=args.rm_pretrain)
|
||||
else:
|
||||
raise ValueError(f'Unsupported reward model "{rm_model_name}"')
|
||||
|
||||
if args.rm_path is not None:
|
||||
print("Loading reward model from", args.rm_path)
|
||||
reward_model.load_state_dict(state_dict)
|
||||
|
||||
if args.strategy != "colossalai_gemini":
|
||||
initial_model.to(torch.float16).to(torch.cuda.current_device())
|
||||
reward_model.to(torch.float16).to(torch.cuda.current_device())
|
||||
|
||||
with strategy.model_init_context():
|
||||
if args.model == "bloom":
|
||||
# actor = BLOOMActor(pretrained=args.pretrain, lora_rank=args.lora_rank)
|
||||
print("Using peft lora to load Bloom model as Actor")
|
||||
actor = BLOOMActor(pretrained=args.pretrain, lora_path=args.sft_lora_path)
|
||||
print("Using peft lora to load Bloom model as Actor (Done)")
|
||||
else:
|
||||
raise ValueError(f'Unsupported actor model "{args.model}"')
|
||||
|
||||
if rm_model_name == "gpt2":
|
||||
critic = GPTCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
|
||||
elif rm_model_name == "bloom":
|
||||
print("load bloom critic ", args.rm_pretrain, " lora_rank ", args.lora_rank, " use_action_mask ", True)
|
||||
critic = BLOOMCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
|
||||
print("load bloom critic (Done) ")
|
||||
elif rm_model_name == "opt":
|
||||
critic = OPTCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
|
||||
elif rm_model_name == "llama":
|
||||
critic = LlamaCritic(pretrained=args.rm_pretrain, lora_rank=args.lora_rank, use_action_mask=True)
|
||||
else:
|
||||
raise ValueError(f'Unsupported reward model "{rm_model_name}"')
|
||||
|
||||
if args.rm_path is not None:
|
||||
print("Loading reward model from", args.rm_path)
|
||||
critic.load_state_dict(state_dict)
|
||||
del state_dict
|
||||
|
||||
if args.strategy != "colossalai_gemini":
|
||||
critic.to(torch.float16).to(torch.cuda.current_device())
|
||||
actor.to(torch.float16).to(torch.cuda.current_device())
|
||||
|
||||
# configure optimizer
|
||||
if args.strategy.startswith("colossalai"):
|
||||
actor_optim = HybridAdam(actor.parameters(), lr=1e-7)
|
||||
critic_optim = HybridAdam(critic.parameters(), lr=1e-7)
|
||||
else:
|
||||
actor_optim = Adam(actor.parameters(), lr=1e-7)
|
||||
critic_optim = Adam(critic.parameters(), lr=1e-7)
|
||||
|
||||
# configure tokenizer
|
||||
if args.model == "gpt2":
|
||||
tokenizer = GPT2Tokenizer.from_pretrained(args.rm_pretrain)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
elif args.model == "bloom":
|
||||
tokenizer = BloomTokenizerFast.from_pretrained(args.rm_pretrain)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
elif args.model == "opt":
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.rm_pretrain)
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
elif args.model == "llama":
|
||||
tokenizer = LlamaTokenizer.from_pretrained(args.pretrain)
|
||||
tokenizer.eos_token = "</s>"
|
||||
tokenizer.pad_token = tokenizer.unk_token
|
||||
else:
|
||||
raise ValueError(f'Unsupported model "{args.model}"')
|
||||
|
||||
data_collator = DataCollatorForSupervisedDataset(tokenizer=tokenizer)
|
||||
|
||||
prompt_dataset = EasyPromptsDataset(args.prompt_path, tokenizer)
|
||||
if dist.is_initialized() and dist.get_world_size() > 1:
|
||||
prompt_sampler = DistributedSampler(prompt_dataset, shuffle=True, seed=42, drop_last=True)
|
||||
else:
|
||||
prompt_sampler = None
|
||||
prompt_dataloader = DataLoader(
|
||||
prompt_dataset, shuffle=(prompt_sampler is None), sampler=prompt_sampler, batch_size=args.train_batch_size
|
||||
)
|
||||
|
||||
pretrain_dataset = EasySupervisedDataset(args.pretrain_dataset, tokenizer)
|
||||
if dist.is_initialized() and dist.get_world_size() > 1:
|
||||
pretrain_sampler = DistributedSampler(pretrain_dataset, shuffle=True, seed=42, drop_last=True)
|
||||
else:
|
||||
pretrain_sampler = None
|
||||
pretrain_dataloader = DataLoader(
|
||||
pretrain_dataset,
|
||||
shuffle=(pretrain_sampler is None),
|
||||
sampler=pretrain_sampler,
|
||||
batch_size=args.ptx_batch_size,
|
||||
collate_fn=data_collator,
|
||||
)
|
||||
|
||||
def tokenize_fn(texts):
|
||||
# MUST padding to max length to ensure inputs of all ranks have the same length
|
||||
# Different length may lead to hang when using gemini, as different generation steps
|
||||
batch = tokenizer(texts, return_tensors="pt", max_length=96, padding="max_length", truncation=True)
|
||||
return {k: v.to(torch.cuda.current_device()) for k, v in batch.items()}
|
||||
|
||||
(actor, actor_optim), (critic, critic_optim) = strategy.prepare((actor, actor_optim), (critic, critic_optim))
|
||||
|
||||
# configure trainer
|
||||
trainer = PPOTrainer(
|
||||
strategy,
|
||||
actor,
|
||||
critic,
|
||||
reward_model,
|
||||
initial_model,
|
||||
actor_optim,
|
||||
critic_optim,
|
||||
kl_coef=args.kl_coef,
|
||||
ptx_coef=args.ptx_coef,
|
||||
train_batch_size=args.train_batch_size,
|
||||
experience_batch_size=args.experience_batch_size,
|
||||
tokenizer=tokenize_fn,
|
||||
max_length=512,
|
||||
do_sample=True,
|
||||
temperature=1.0,
|
||||
top_k=50,
|
||||
pad_token_id=tokenizer.pad_token_id,
|
||||
eos_token_id=tokenizer.eos_token_id,
|
||||
)
|
||||
|
||||
trainer.fit(
|
||||
prompt_dataloader=prompt_dataloader,
|
||||
pretrain_dataloader=pretrain_dataloader,
|
||||
num_episodes=args.num_episodes,
|
||||
num_update_steps=args.num_update_steps,
|
||||
num_collect_steps=args.num_collect_steps,
|
||||
)
|
||||
|
||||
# save model checkpoint after fitting
|
||||
trainer.save_model(args.save_path, only_rank0=True, tokenizer=tokenizer)
|
||||
# save optimizer checkpoint on all ranks
|
||||
if args.need_optim_ckpt:
|
||||
strategy.save_optimizer(
|
||||
actor_optim, "actor_optim_checkpoint_prompts_%d.pt" % (torch.cuda.current_device()), only_rank0=False
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--prompt_path", type=str, default=None, help="path to the prompt dataset")
|
||||
parser.add_argument("--pretrain_dataset", type=str, default=None, help="path to the pretrained dataset")
|
||||
parser.add_argument(
|
||||
"--strategy", choices=["ddp", "colossalai_gemini", "colossalai_zero2"], default="ddp", help="strategy to use"
|
||||
)
|
||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--sft_lora_path", type=str, default=None)
|
||||
parser.add_argument("--rm_model", default=None, choices=["gpt2", "bloom", "opt", "llama"])
|
||||
parser.add_argument("--rm_path", type=str, default=None)
|
||||
parser.add_argument("--rm_pretrain", type=str, default=None)
|
||||
parser.add_argument("--save_path", type=str, default="actor_checkpoint_prompts")
|
||||
parser.add_argument("--need_optim_ckpt", type=bool, default=False)
|
||||
parser.add_argument("--num_episodes", type=int, default=10)
|
||||
parser.add_argument("--num_collect_steps", type=int, default=10)
|
||||
parser.add_argument("--num_update_steps", type=int, default=5)
|
||||
parser.add_argument("--train_batch_size", type=int, default=2)
|
||||
parser.add_argument("--ptx_batch_size", type=int, default=1)
|
||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
parser.add_argument("--kl_coef", type=float, default=0.1)
|
||||
parser.add_argument("--ptx_coef", type=float, default=0.9)
|
||||
args = parser.parse_args()
|
||||
main(args)
|
||||
185
applications/ColossalChat/ColossalChat/examples/community/peft/train_peft_sft.py
Executable file
185
applications/ColossalChat/ColossalChat/examples/community/peft/train_peft_sft.py
Executable file
|
|
@ -0,0 +1,185 @@
|
|||
import argparse
|
||||
import os
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from coati.trainer import SFTTrainer
|
||||
from coati.trainer.strategies import DDPStrategy, GeminiStrategy, LowLevelZeroStrategy
|
||||
from easy_dataset import EasyDataset
|
||||
from peft import LoraConfig, PeftModel, TaskType, get_peft_model
|
||||
from torch.optim import Adam
|
||||
from torch.utils.data import DataLoader
|
||||
from torch.utils.data.dataloader import default_collate
|
||||
from torch.utils.data.distributed import DistributedSampler
|
||||
from transformers import AutoModelForCausalLM, AutoTokenizer, BloomTokenizerFast
|
||||
from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
|
||||
|
||||
from colossalai.logging import get_dist_logger
|
||||
from colossalai.nn.optimizer import HybridAdam
|
||||
from colossalai.tensor import ColoParameter
|
||||
|
||||
|
||||
def train(args):
|
||||
# configure strategy
|
||||
if args.strategy == "ddp":
|
||||
strategy = DDPStrategy()
|
||||
elif args.strategy == "colossalai_gemini":
|
||||
strategy = GeminiStrategy(placement_policy="static")
|
||||
elif args.strategy == "colossalai_zero2":
|
||||
strategy = LowLevelZeroStrategy(stage=2, placement_policy="cuda")
|
||||
else:
|
||||
raise ValueError(f'Unsupported strategy "{args.strategy}"')
|
||||
|
||||
# configure model
|
||||
with strategy.model_init_context():
|
||||
print("Warning: currently only bloom is tested, gpt2,llama and opt are not tested")
|
||||
model = AutoModelForCausalLM.from_pretrained(args.pretrain).to(torch.cuda.current_device())
|
||||
# if the args.save_path exists and args.save_path+'/adapter_config.json' exists, we'll load the adapter_config.json
|
||||
if (
|
||||
os.path.exists(args.save_path)
|
||||
and os.path.exists(args.save_path + "/adapter_config.json")
|
||||
and os.path.exists(args.save_path + "/adapter_model.bin")
|
||||
):
|
||||
print("loading from saved peft model ", args.save_path)
|
||||
model = PeftModel.from_pretrained(model, args.save_path)
|
||||
else:
|
||||
# we'll use peft lora library to do the lora
|
||||
lora_rank = args.lora_rank if args.lora_rank > 0 else 32
|
||||
# config lora with rank of lora_rank
|
||||
lora_config = LoraConfig(
|
||||
task_type=TaskType.CAUSAL_LM, inference_mode=False, r=lora_rank, lora_alpha=32, lora_dropout=0.1
|
||||
)
|
||||
model = get_peft_model(model, lora_config)
|
||||
model.print_trainable_parameters()
|
||||
|
||||
# configure tokenizer
|
||||
if args.model == "gpt2":
|
||||
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
elif args.model == "bloom":
|
||||
tokenizer = BloomTokenizerFast.from_pretrained("bigscience/bloom-560m")
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
elif args.model == "opt":
|
||||
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
elif args.model == "llama":
|
||||
tokenizer = AutoTokenizer.from_pretrained(
|
||||
args.pretrain,
|
||||
padding_side="right",
|
||||
use_fast=False,
|
||||
)
|
||||
tokenizer.eos_token = "</s>"
|
||||
tokenizer.pad_token = tokenizer.unk_token
|
||||
else:
|
||||
raise ValueError(f'Unsupported model "{args.model}"')
|
||||
|
||||
if args.model == "llama" and args.strategy == "colossalai_gemini":
|
||||
# this is a hack to deal with the resized embedding
|
||||
# to make sure all parameters are ColoParameter for Colossal-AI Gemini Compatibility
|
||||
for name, param in model.named_parameters():
|
||||
if not isinstance(param, ColoParameter):
|
||||
sub_module_name = ".".join(name.split(".")[:-1])
|
||||
weight_name = name.split(".")[-1]
|
||||
sub_module = model.get_submodule(sub_module_name)
|
||||
setattr(sub_module, weight_name, ColoParameter(param))
|
||||
|
||||
# configure optimizer
|
||||
if args.strategy.startswith("colossalai"):
|
||||
optim = HybridAdam(model.parameters(), lr=args.lr, clipping_norm=1.0)
|
||||
else:
|
||||
optim = Adam(model.parameters(), lr=args.lr)
|
||||
|
||||
logger = get_dist_logger()
|
||||
logger.set_level("WARNING")
|
||||
|
||||
# configure dataset
|
||||
law_dataset = EasyDataset(args.dataset, tokenizer=tokenizer, is_group_texts=not args.is_short_text)
|
||||
train_dataset = law_dataset
|
||||
print(train_dataset)
|
||||
eval_dataset = None
|
||||
if args.eval_dataset is not None:
|
||||
eval_dataset = EasyDataset(args.eval_dataset, tokenizer=tokenizer, is_group_texts=not args.is_short_text)
|
||||
data_collator = default_collate
|
||||
if dist.is_initialized() and dist.get_world_size() > 1:
|
||||
train_sampler = DistributedSampler(
|
||||
train_dataset,
|
||||
shuffle=True,
|
||||
seed=42,
|
||||
drop_last=True,
|
||||
rank=dist.get_rank(),
|
||||
num_replicas=dist.get_world_size(),
|
||||
)
|
||||
if eval_dataset is not None:
|
||||
eval_sampler = DistributedSampler(
|
||||
eval_dataset,
|
||||
shuffle=False,
|
||||
seed=42,
|
||||
drop_last=False,
|
||||
rank=dist.get_rank(),
|
||||
num_replicas=dist.get_world_size(),
|
||||
)
|
||||
else:
|
||||
train_sampler = None
|
||||
eval_sampler = None
|
||||
|
||||
train_dataloader = DataLoader(
|
||||
train_dataset,
|
||||
shuffle=(train_sampler is None),
|
||||
sampler=train_sampler,
|
||||
batch_size=args.batch_size,
|
||||
collate_fn=data_collator,
|
||||
pin_memory=True,
|
||||
)
|
||||
if eval_dataset is not None:
|
||||
eval_dataloader = DataLoader(
|
||||
eval_dataset,
|
||||
shuffle=(eval_sampler is None),
|
||||
sampler=eval_sampler,
|
||||
batch_size=args.batch_size,
|
||||
collate_fn=data_collator,
|
||||
pin_memory=True,
|
||||
)
|
||||
else:
|
||||
eval_dataloader = None
|
||||
|
||||
trainer = SFTTrainer(
|
||||
model=model,
|
||||
strategy=strategy,
|
||||
optim=optim,
|
||||
train_dataloader=train_dataloader,
|
||||
eval_dataloader=eval_dataloader,
|
||||
batch_size=args.batch_size,
|
||||
max_epochs=args.max_epochs,
|
||||
accumulation_steps=args.accumulation_steps,
|
||||
)
|
||||
|
||||
trainer.fit(logger=logger, log_interval=args.log_interval)
|
||||
|
||||
# save model checkpoint after fitting on only rank0
|
||||
trainer.save_model(path=args.save_path, only_rank0=True, tokenizer=tokenizer)
|
||||
# save optimizer checkpoint on all ranks
|
||||
if args.need_optim_ckpt:
|
||||
strategy.save_optimizer(
|
||||
trainer.optimizer, "rm_optim_checkpoint_%d.pt" % (torch.cuda.current_device()), only_rank0=False
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--strategy", choices=["ddp", "colossalai_gemini", "colossalai_zero2"], default="ddp")
|
||||
parser.add_argument("--model", choices=["gpt2", "bloom", "opt", "llama"], default="bloom")
|
||||
parser.add_argument("--pretrain", type=str, default=None)
|
||||
parser.add_argument("--dataset", type=str, default=None)
|
||||
parser.add_argument("--eval_dataset", type=str, default=None)
|
||||
parser.add_argument("--save_path", type=str, default="output")
|
||||
parser.add_argument("--need_optim_ckpt", type=bool, default=False)
|
||||
parser.add_argument("--max_epochs", type=int, default=3)
|
||||
parser.add_argument("--batch_size", type=int, default=4)
|
||||
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
|
||||
parser.add_argument("--log_interval", type=int, default=100, help="how many steps to log")
|
||||
parser.add_argument("--lr", type=float, default=5e-6)
|
||||
parser.add_argument("--accumulation_steps", type=int, default=8)
|
||||
parser.add_argument("--enable_peft_lora", action="store_true", default=False)
|
||||
parser.add_argument("--is_short_text", action="store_true", default=False)
|
||||
args = parser.parse_args()
|
||||
train(args)
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
|
||||
|
||||
# ColossalAI on Ray
|
||||
|
||||
## Abstract
|
||||
|
||||
This is an experimental effort to run ColossalAI Chat training on Ray
|
||||
|
||||
## How to use?
|
||||
|
||||
### 1. Setup Ray clusters
|
||||
|
||||
Please follow the official [Ray cluster setup instructions](https://docs.ray.io/en/latest/cluster/getting-started.html) to setup an cluster with GPU support. Record the cluster's api server endpoint, it should be something similar to http://your.head.node.addrees:8265
|
||||
|
||||
### 2. Clone repo
|
||||
|
||||
Clone this project:
|
||||
|
||||
```shell
|
||||
git clone https://github.com/hpcaitech/ColossalAI.git
|
||||
```
|
||||
|
||||
### 3. Submit the ray job
|
||||
|
||||
```shell
|
||||
python applications/Chat/examples/community/ray/ray_job_script.py http://your.head.node.addrees:8265
|
||||
```
|
||||
|
||||
### 4. View your job on the Ray Dashboard
|
||||
|
||||
Open your ray cluster dashboard http://your.head.node.addrees:8265 to view your submitted training job.
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
import sys
|
||||
|
||||
from ray.job_submission import JobSubmissionClient
|
||||
|
||||
|
||||
def main(api_server_endpoint="http://127.0.0.1:8265"):
|
||||
client = JobSubmissionClient(api_server_endpoint)
|
||||
client.submit_job(
|
||||
entrypoint="python experimental/ray/train_prompts_on_ray.py --strategy colossalai_zero2 --prompt_csv_url https://huggingface.co/datasets/fka/awesome-chatgpt-prompts/resolve/main/prompts.csv",
|
||||
runtime_env={
|
||||
"working_dir": "applications/Chat",
|
||||
"pip": [
|
||||
"torch==1.13.1",
|
||||
"transformers>=4.20.1",
|
||||
"datasets",
|
||||
"loralib",
|
||||
"colossalai>=0.2.4",
|
||||
"langchain",
|
||||
"tokenizers",
|
||||
"fastapi",
|
||||
"sse_starlette",
|
||||
"wandb",
|
||||
"sentencepiece",
|
||||
"gpustat",
|
||||
],
|
||||
},
|
||||
)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main(sys.argv[1])
|
||||
|
|
@ -0,0 +1,569 @@
|
|||
import argparse
|
||||
import logging
|
||||
import os
|
||||
import socket
|
||||
from copy import deepcopy
|
||||
from typing import Type
|
||||
|
||||
import ray
|
||||
import torch
|
||||
from coati.experience_maker.base import Experience
|
||||
from coati.models.base import RewardModel
|
||||
from coati.models.bloom import BLOOMActor, BLOOMCritic
|
||||
from coati.models.gpt import GPTActor, GPTCritic
|
||||
from coati.models.lora import LoRAModule
|
||||
from coati.models.loss import PolicyLoss, ValueLoss
|
||||
from coati.models.opt import OPTActor, OPTCritic
|
||||
from coati.models.utils import compute_reward
|
||||
from coati.trainer.strategies import DDPStrategy, GeminiStrategy, LowLevelZeroStrategy
|
||||
from ray.util.placement_group import placement_group
|
||||
from ray.util.scheduling_strategies import PlacementGroupSchedulingStrategy
|
||||
from torch.optim import Adam
|
||||
from transformers import AutoTokenizer, BloomTokenizerFast
|
||||
from transformers.models.gpt2.tokenization_gpt2 import GPT2Tokenizer
|
||||
|
||||
from colossalai.nn.optimizer import HybridAdam
|
||||
|
||||
|
||||
class ExperienceCompositionRefs:
|
||||
def __init__(
|
||||
self,
|
||||
sequences_attention_mask_action_mask_ref: ray.ObjectRef,
|
||||
action_log_probs_ref: ray.ObjectRef,
|
||||
base_action_log_probs_ref: ray.ObjectRef,
|
||||
value_ref: ray.ObjectRef,
|
||||
r_ref: ray.ObjectRef,
|
||||
) -> None:
|
||||
self.sequences_attention_mask_action_mask_ref = sequences_attention_mask_action_mask_ref
|
||||
self.action_log_probs_ref = action_log_probs_ref
|
||||
self.base_action_log_probs_ref = base_action_log_probs_ref
|
||||
self.value_ref = value_ref
|
||||
self.r_ref = r_ref
|
||||
|
||||
|
||||
class ExperienceMaker:
|
||||
def __init__(self, kl_coef) -> None:
|
||||
self.kl_coef = kl_coef
|
||||
|
||||
@torch.no_grad()
|
||||
def make_experience(self, experiment_computation_refs: ExperienceCompositionRefs):
|
||||
sequences, attention_mask, action_mask = ray.get(
|
||||
experiment_computation_refs.sequences_attention_mask_action_mask_ref
|
||||
)
|
||||
action_log_probs = ray.get(experiment_computation_refs.action_log_probs_ref)
|
||||
base_action_log_probs = ray.get(experiment_computation_refs.base_action_log_probs_ref)
|
||||
r = ray.get(experiment_computation_refs.r_ref)
|
||||
reward = compute_reward(r, self.kl_coef, action_log_probs, base_action_log_probs, action_mask=action_mask)
|
||||
value = ray.get(experiment_computation_refs.value_ref)
|
||||
advantage = reward - value
|
||||
if advantage.ndim == 1:
|
||||
advantage = advantage.unsqueeze(-1)
|
||||
experience = Experience(sequences, action_log_probs, value, reward, advantage, attention_mask, action_mask)
|
||||
return experience
|
||||
|
||||
|
||||
class DistributedTorchRayActor:
|
||||
def __init__(self, world_size, rank, local_rank, master_addr, master_port):
|
||||
logging.basicConfig(
|
||||
format="%(asctime)s %(levelname)-8s %(message)s", level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S"
|
||||
)
|
||||
self._model = None
|
||||
self._world_size = world_size
|
||||
self._rank = rank
|
||||
self._local_rank = local_rank
|
||||
self._master_addr = master_addr if master_addr else self._get_current_node_ip()
|
||||
self._master_port = master_port if master_port else self._get_free_port()
|
||||
os.environ["MASTER_ADDR"] = self._master_addr
|
||||
os.environ["MASTER_PORT"] = str(self._master_port)
|
||||
os.environ["WORLD_SIZE"] = str(self._world_size)
|
||||
os.environ["RANK"] = str(self._rank)
|
||||
os.environ["LOCAL_RANK"] = str(self._local_rank)
|
||||
|
||||
@staticmethod
|
||||
def _get_current_node_ip():
|
||||
return ray._private.services.get_node_ip_address()
|
||||
|
||||
@staticmethod
|
||||
def _get_free_port():
|
||||
with socket.socket() as sock:
|
||||
sock.bind(("", 0))
|
||||
return sock.getsockname()[1]
|
||||
|
||||
def get_master_addr_port(self):
|
||||
return self._master_addr, self._master_port
|
||||
|
||||
|
||||
class BasePPORole(DistributedTorchRayActor):
|
||||
def add_experience_maker(self, kl_coef: float = 0.1):
|
||||
self._experience_maker = ExperienceMaker(kl_coef)
|
||||
|
||||
def make_experience(self, experience_computation_ref: ExperienceCompositionRefs):
|
||||
return self._experience_maker.make_experience(experience_computation_ref)
|
||||
|
||||
def _init_strategy(self, strategy: str):
|
||||
# configure strategy
|
||||
if strategy == "ddp":
|
||||
self._strategy = DDPStrategy()
|
||||
elif strategy == "colossalai_gemini":
|
||||
self._strategy = GeminiStrategy(placement_policy="cuda", initial_scale=2**5)
|
||||
elif strategy == "colossalai_zero2":
|
||||
self._strategy = LowLevelZeroStrategy(stage=2, placement_policy="cuda")
|
||||
else:
|
||||
raise ValueError(f'Unsupported strategy "{strategy}"')
|
||||
|
||||
def _init_optimizer(self):
|
||||
if isinstance(self._strategy, (GeminiStrategy, LowLevelZeroStrategy)):
|
||||
self._optimizer = HybridAdam(self._model.parameters(), lr=5e-6)
|
||||
else:
|
||||
self._optimizer = Adam(self._model.parameters(), lr=5e-6)
|
||||
|
||||
def _prepare_model_with_strategy(self, has_optimizer: bool):
|
||||
if has_optimizer:
|
||||
self._init_optimizer()
|
||||
(self._model, self._optimizer) = self._strategy.prepare((self._model, self._optimizer))
|
||||
else:
|
||||
self._model = self._strategy.prepare(self._model)
|
||||
|
||||
def _load_model_from_pretrained(self, model_class: Type[LoRAModule], pretrain: str):
|
||||
raise NotImplementedError()
|
||||
|
||||
def init_model_from_pretrained(
|
||||
self, strategy: str, model_class: Type[LoRAModule], pretrain: str, has_optimizer=False
|
||||
):
|
||||
self._init_strategy(strategy)
|
||||
self._load_model_from_pretrained(model_class, pretrain)
|
||||
self._prepare_model_with_strategy(has_optimizer)
|
||||
|
||||
def eval(self):
|
||||
self._model.eval()
|
||||
|
||||
|
||||
class TrainablePPORole(BasePPORole):
|
||||
def _load_model_from_pretrained(self, model_class, pretrain):
|
||||
with self._strategy.model_init_context():
|
||||
self._model = model_class(pretrain).to(torch.cuda.current_device())
|
||||
|
||||
def _train(self):
|
||||
self._model.train()
|
||||
|
||||
def _training_step(self, experience: Experience):
|
||||
raise NotImplementedError()
|
||||
|
||||
def learn_on_experiences(self, experience_refs):
|
||||
experiences = ray.get(experience_refs)
|
||||
device = torch.cuda.current_device()
|
||||
self._train()
|
||||
for exp in experiences:
|
||||
exp.to_device(device)
|
||||
self._training_step(exp)
|
||||
self.eval()
|
||||
|
||||
|
||||
@ray.remote(num_gpus=1)
|
||||
class RayPPOActor(TrainablePPORole):
|
||||
def set_loss_function(self, eps_clip: float):
|
||||
self._actor_loss_fn = PolicyLoss(eps_clip)
|
||||
|
||||
def load_tokenizer_from_pretrained(self, model_type: str, pretrained):
|
||||
if model_type == "gpt2":
|
||||
self._model_tokenizer = GPT2Tokenizer.from_pretrained(pretrained)
|
||||
self._model_tokenizer.pad_token = self._model_tokenizer.eos_token
|
||||
elif model_type == "bloom":
|
||||
self._model_tokenizer = BloomTokenizerFast.from_pretrained(pretrained)
|
||||
self._model_tokenizer.pad_token = self._model_tokenizer.eos_token
|
||||
elif model_type == "opt":
|
||||
self._model_tokenizer = AutoTokenizer.from_pretrained(pretrained)
|
||||
else:
|
||||
raise ValueError(f'Unsupported model "{model_type}"')
|
||||
|
||||
# Set tokenize function for sequence generation
|
||||
def _text_input_tokenize_fn(texts):
|
||||
batch = self._model_tokenizer(texts, return_tensors="pt", max_length=96, padding=True, truncation=True)
|
||||
return {k: v.cuda() for k, v in batch.items()}
|
||||
|
||||
self._sample_tokenize_function = _text_input_tokenize_fn
|
||||
|
||||
def setup_generate_kwargs(self, generate_kwargs: dict):
|
||||
from coati.trainer.ppo import _set_default_generate_kwargs
|
||||
|
||||
self._generate_kwargs = _set_default_generate_kwargs(self._strategy, generate_kwargs, self._model)
|
||||
self._generate_kwargs["pad_token_id"] = self._model_tokenizer.pad_token_id
|
||||
self._generate_kwargs["eos_token_id"] = self._model_tokenizer.eos_token_id
|
||||
|
||||
def load_csv_prompt_file_from_url_to_sampler(self, prompt_url):
|
||||
import pandas as pd
|
||||
|
||||
prompts = pd.read_csv(prompt_url)["prompt"]
|
||||
self._sampler = self._strategy.setup_sampler(prompts)
|
||||
|
||||
def _generate(self, input_ids, **generate_kwargs):
|
||||
return self._model.generate(input_ids, return_action_mask=True, **generate_kwargs)
|
||||
|
||||
def sample_prompts_and_make_sequence(self, experience_batch_size):
|
||||
sampled_prompts = self._sampler.sample(experience_batch_size)
|
||||
input_ids = self._sample_tokenize_function(sampled_prompts)
|
||||
if isinstance(input_ids, dict):
|
||||
return self._generate(**input_ids, **self._generate_kwargs)
|
||||
else:
|
||||
return self._generate(input_ids, **self._generate_kwargs)
|
||||
|
||||
@torch.no_grad()
|
||||
def calculate_action_log_probs(self, sequence_attention_action_mask):
|
||||
sequences, attention_mask, action_mask = sequence_attention_action_mask
|
||||
return self._model.forward(sequences, action_mask.size(1), attention_mask)
|
||||
|
||||
def _training_step(self, experience):
|
||||
num_actions = experience.action_mask.size(1)
|
||||
action_log_probs = self._model(experience.sequences, num_actions, attention_mask=experience.attention_mask)
|
||||
actor_loss = self._actor_loss_fn(
|
||||
action_log_probs, experience.action_log_probs, experience.advantages, action_mask=experience.action_mask
|
||||
)
|
||||
self._strategy.backward(actor_loss, self._model, self._optimizer)
|
||||
self._strategy.optimizer_step(self._optimizer)
|
||||
self._optimizer.zero_grad()
|
||||
logging.info("actor_loss: {}".format(actor_loss))
|
||||
|
||||
def save_checkpoint(self, save_path, should_save_optimizer: bool):
|
||||
if self._rank == 0:
|
||||
# save model checkpoint only on rank 0
|
||||
self._strategy.save_model(self._model, save_path, only_rank0=True)
|
||||
# save optimizer checkpoint on all ranks
|
||||
if should_save_optimizer:
|
||||
self._strategy.save_optimizer(
|
||||
self._optimizer,
|
||||
"actor_optim_checkpoint_prompts_%d.pt" % (torch.cuda.current_device()),
|
||||
only_rank0=False,
|
||||
)
|
||||
|
||||
def generate_answer(self, prompt, max_length=30, num_return_sequences=5):
|
||||
encoded_input = self._model_tokenizer(prompt, return_tensors="pt")
|
||||
input_ids = {k: v.cuda() for k, v in encoded_input.items()}
|
||||
sequence, _ = self._model.generate(
|
||||
**input_ids, max_length=max_length, return_action_mask=False, num_return_sequences=num_return_sequences
|
||||
)
|
||||
token_list = list(sequence.data[0])
|
||||
output = " ".join([self._model_tokenizer.decode(token) for token in token_list])
|
||||
return output
|
||||
|
||||
|
||||
@ray.remote(num_gpus=1)
|
||||
class RayPPOCritic(TrainablePPORole):
|
||||
def set_loss_function(self, value_clip: float):
|
||||
self._critic_loss_fn = ValueLoss(value_clip)
|
||||
|
||||
def _training_step(self, experience):
|
||||
values = self._model(
|
||||
experience.sequences, action_mask=experience.action_mask, attention_mask=experience.attention_mask
|
||||
)
|
||||
critic_loss = self._critic_loss_fn(
|
||||
values, experience.values, experience.reward, action_mask=experience.action_mask
|
||||
)
|
||||
self._strategy.backward(critic_loss, self._model, self._optimizer)
|
||||
self._strategy.optimizer_step(self._optimizer)
|
||||
self._optimizer.zero_grad()
|
||||
logging.info("critic_loss: {}".format(critic_loss))
|
||||
|
||||
@torch.no_grad()
|
||||
def calculate_value(self, sequence_attention_action_mask):
|
||||
sequences, attention_mask, action_mask = sequence_attention_action_mask
|
||||
return self._model(sequences, action_mask, attention_mask)
|
||||
|
||||
|
||||
@ray.remote(num_gpus=1)
|
||||
class RayPPORewardModel(BasePPORole):
|
||||
def _load_model_from_pretrained(self, model_class, pretrain):
|
||||
with self._strategy.model_init_context():
|
||||
critic = model_class(pretrained=pretrain).to(torch.cuda.current_device())
|
||||
self._model = RewardModel(deepcopy(critic.model), deepcopy(critic.value_head)).to(
|
||||
torch.cuda.current_device()
|
||||
)
|
||||
|
||||
@torch.no_grad()
|
||||
def calculate_r(self, sequence_attention_action_mask):
|
||||
sequences, attention_mask, _ = sequence_attention_action_mask
|
||||
return self._model(sequences, attention_mask)
|
||||
|
||||
|
||||
@ray.remote(num_gpus=1)
|
||||
class RayPPOInitialModel(BasePPORole):
|
||||
def _load_model_from_pretrained(self, model_class, pretrain):
|
||||
with self._strategy.model_init_context():
|
||||
self._model = model_class(pretrain).to(torch.cuda.current_device())
|
||||
|
||||
@torch.no_grad()
|
||||
def calculate_base_action_log_probs(self, sequence_attention_action_mask):
|
||||
sequences, attention_mask, action_mask = sequence_attention_action_mask
|
||||
return self._model(sequences, action_mask.size(1), attention_mask)
|
||||
|
||||
|
||||
class PPORayActorGroup:
|
||||
"""
|
||||
A group of ray actors
|
||||
Functions start with 'async' should return list of object refs
|
||||
"""
|
||||
|
||||
def __init__(self, num_nodes, num_gpus_per_node, ray_actor_type: Type[BasePPORole]) -> None:
|
||||
self._num_nodes = num_nodes
|
||||
self._num_gpus_per_node = num_gpus_per_node
|
||||
self.ray_actor_type = ray_actor_type
|
||||
self._initiate_actors()
|
||||
|
||||
def _initiate_actors(self):
|
||||
world_size = self._num_nodes * self._num_gpus_per_node
|
||||
# Use placement group to lock resources for models of same type
|
||||
pg = None
|
||||
if self._num_gpus_per_node > 1:
|
||||
bundles = [{"GPU": self._num_gpus_per_node, "CPU": self._num_gpus_per_node} for _ in range(self._num_nodes)]
|
||||
pg = placement_group(bundles, strategy="STRICT_SPREAD")
|
||||
ray.get(pg.ready())
|
||||
if pg:
|
||||
master_actor = self.ray_actor_type.options(
|
||||
scheduling_strategy=PlacementGroupSchedulingStrategy(placement_group=pg, placement_group_bundle_index=0)
|
||||
).remote(world_size, 0, 0, None, None)
|
||||
else:
|
||||
master_actor = self.ray_actor_type.options(num_gpus=1).remote(world_size, 0, 0, None, None)
|
||||
self._actor_handlers = [master_actor]
|
||||
|
||||
# Create worker actors
|
||||
if world_size > 1:
|
||||
master_addr, master_port = ray.get(master_actor.get_master_addr_port.remote())
|
||||
for rank in range(1, world_size):
|
||||
local_rank = rank % self._num_gpus_per_node
|
||||
if pg:
|
||||
worker_actor = self.ray_actor_type.options(
|
||||
scheduling_strategy=PlacementGroupSchedulingStrategy(
|
||||
placement_group=pg, placement_group_bundle_index=rank // self._num_gpus_per_node
|
||||
)
|
||||
).remote(world_size, rank, local_rank, master_addr, master_port)
|
||||
else:
|
||||
worker_actor = self.ray_actor_type.options(num_gpus=1).remote(
|
||||
world_size, rank, local_rank, master_addr, master_port
|
||||
)
|
||||
self._actor_handlers.append(worker_actor)
|
||||
|
||||
def async_init_model_from_pretrained(
|
||||
self, strategy: str, model_class: Type[LoRAModule], pretrain: str, has_optimizer: bool
|
||||
):
|
||||
return [
|
||||
actor.init_model_from_pretrained.remote(strategy, model_class, pretrain, has_optimizer)
|
||||
for actor in self._actor_handlers
|
||||
]
|
||||
|
||||
|
||||
class TrainableModelRayActorGroup(PPORayActorGroup):
|
||||
def async_learn_on_experiences(self, experience_refs):
|
||||
num_actors = len(self._actor_handlers)
|
||||
learn_result_refs = []
|
||||
for i in range(num_actors):
|
||||
exp_refs_batch = experience_refs[i::num_actors]
|
||||
learn_result_refs.append(self._actor_handlers[i].learn_on_experiences.remote(exp_refs_batch))
|
||||
return learn_result_refs
|
||||
|
||||
|
||||
class PPOActorRayActorGroup(TrainableModelRayActorGroup):
|
||||
def __init__(self, num_nodes, num_gpus_per_node) -> None:
|
||||
super().__init__(num_nodes, num_gpus_per_node, RayPPOActor)
|
||||
|
||||
def async_prepare_for_sequence_generation(self, model: str, pretrain: str, generation_kwargs: dict):
|
||||
refs = []
|
||||
for actor in self._actor_handlers:
|
||||
refs.append(actor.load_tokenizer_from_pretrained.remote(model, pretrain))
|
||||
refs.append(actor.setup_generate_kwargs.remote(generation_kwargs))
|
||||
return refs
|
||||
|
||||
def load_csv_prompt_file_from_url_to_sampler(self, csv_url):
|
||||
ray.get([actor.load_csv_prompt_file_from_url_to_sampler.remote(csv_url) for actor in self._actor_handlers])
|
||||
|
||||
def async_sample_prompts_and_make_sequence(self, experience_batch_size):
|
||||
return [actor.sample_prompts_and_make_sequence.remote(experience_batch_size) for actor in self._actor_handlers]
|
||||
|
||||
def async_calculate_action_log_probs(self, sequences_attention_mask_action_mask_refs):
|
||||
num_actors = len(self._actor_handlers)
|
||||
action_log_probs_refs = []
|
||||
for i in range(len(sequences_attention_mask_action_mask_refs)):
|
||||
action_log_probs_ref = self._actor_handlers[i % num_actors].calculate_action_log_probs.remote(
|
||||
sequences_attention_mask_action_mask_refs[i]
|
||||
)
|
||||
action_log_probs_refs.append(action_log_probs_ref)
|
||||
return action_log_probs_refs
|
||||
|
||||
def set_loss_function(self, eps_clip: float = 0.2):
|
||||
ray.get([actor.set_loss_function.remote(eps_clip) for actor in self._actor_handlers])
|
||||
|
||||
def save_checkpoint(self, save_path, should_save_optimizer):
|
||||
ray.get([actor.save_checkpoint.remote(save_path, should_save_optimizer) for actor in self._actor_handlers])
|
||||
|
||||
|
||||
class PPOCriticRayActorGroup(TrainableModelRayActorGroup):
|
||||
def __init__(self, num_nodes, num_gpus_per_node) -> None:
|
||||
super().__init__(num_nodes, num_gpus_per_node, RayPPOCritic)
|
||||
|
||||
def async_calculate_value(self, sequences_attention_mask_action_mask_refs):
|
||||
num_actors = len(self._actor_handlers)
|
||||
value_refs = []
|
||||
for i in range(len(sequences_attention_mask_action_mask_refs)):
|
||||
value_ref = self._actor_handlers[i % num_actors].calculate_value.remote(
|
||||
sequences_attention_mask_action_mask_refs[i]
|
||||
)
|
||||
value_refs.append(value_ref)
|
||||
return value_refs
|
||||
|
||||
def set_loss_function(self, value_clip: float = 0.4):
|
||||
ray.get([actor.set_loss_function.remote(value_clip) for actor in self._actor_handlers])
|
||||
|
||||
|
||||
class PPOInitialRayActorGroup(PPORayActorGroup):
|
||||
def __init__(self, num_nodes, num_gpus_per_node) -> None:
|
||||
super().__init__(num_nodes, num_gpus_per_node, RayPPOInitialModel)
|
||||
|
||||
def async_calculate_base_action_log_probs(self, sequences_attention_mask_action_mask_refs):
|
||||
num_actors = len(self._actor_handlers)
|
||||
base_action_log_probs_refs = []
|
||||
for i in range(len(sequences_attention_mask_action_mask_refs)):
|
||||
base_action_log_probs_ref = self._actor_handlers[i % num_actors].calculate_base_action_log_probs.remote(
|
||||
sequences_attention_mask_action_mask_refs[i]
|
||||
)
|
||||
base_action_log_probs_refs.append(base_action_log_probs_ref)
|
||||
return base_action_log_probs_refs
|
||||
|
||||
|
||||
class PPORewardRayActorGroup(PPORayActorGroup):
|
||||
def __init__(self, num_nodes, num_gpus_per_node) -> None:
|
||||
super().__init__(num_nodes, num_gpus_per_node, RayPPORewardModel)
|
||||
|
||||
def async_calculate_r(self, sequences_attention_mask_action_mask_refs):
|
||||
num_actors = len(self._actor_handlers)
|
||||
r_refs = []
|
||||
for i in range(len(sequences_attention_mask_action_mask_refs)):
|
||||
r_ref = self._actor_handlers[i % num_actors].calculate_r.remote(
|
||||
sequences_attention_mask_action_mask_refs[i]
|
||||
)
|
||||
r_refs.append(r_ref)
|
||||
return r_refs
|
||||
|
||||
|
||||
def main(args):
|
||||
logging.basicConfig(
|
||||
format="%(asctime)s %(levelname)-8s %(message)s", level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S"
|
||||
)
|
||||
if args.model == "gpt2":
|
||||
actor_model_class, critic_model_class = GPTActor, GPTCritic
|
||||
elif args.model == "bloom":
|
||||
actor_model_class, critic_model_class = BLOOMActor, BLOOMCritic
|
||||
elif args.model == "opt":
|
||||
actor_model_class, critic_model_class = OPTActor, OPTCritic
|
||||
else:
|
||||
raise ValueError(f'Unsupported model "{args.model}"')
|
||||
|
||||
logging.info("Start creating actors")
|
||||
# Initialize 4 models (actor, critic, initial_model and reward_model)
|
||||
actor_group = PPOActorRayActorGroup(num_nodes=args.num_actor_nodes, num_gpus_per_node=args.num_gpus_per_node)
|
||||
critic_group = PPOCriticRayActorGroup(num_nodes=args.num_critic_nodes, num_gpus_per_node=args.num_gpus_per_node)
|
||||
initial_group = PPOInitialRayActorGroup(num_nodes=args.num_initial_nodes, num_gpus_per_node=args.num_gpus_per_node)
|
||||
reward_group = PPORewardRayActorGroup(num_nodes=args.num_reward_nodes, num_gpus_per_node=args.num_gpus_per_node)
|
||||
logging.info("Actors created")
|
||||
|
||||
# Prepare model for training
|
||||
generate_kwargs = {"max_length": 128, "do_sample": True, "temperature": 1.0, "top_k": 50}
|
||||
ray.get(
|
||||
actor_group.async_init_model_from_pretrained(args.strategy, actor_model_class, args.pretrain, True)
|
||||
+ critic_group.async_init_model_from_pretrained(args.strategy, critic_model_class, args.pretrain, True)
|
||||
+ initial_group.async_init_model_from_pretrained(args.strategy, actor_model_class, args.pretrain, False)
|
||||
+ reward_group.async_init_model_from_pretrained(args.strategy, critic_model_class, args.pretrain, False)
|
||||
+ actor_group.async_prepare_for_sequence_generation(args.model, args.pretrain, generate_kwargs)
|
||||
)
|
||||
logging.info("Models prepared for training")
|
||||
|
||||
# Prepare models for training
|
||||
actor_group.load_csv_prompt_file_from_url_to_sampler(args.prompt_csv_url)
|
||||
actor_group.set_loss_function()
|
||||
critic_group.set_loss_function()
|
||||
# Training parameter
|
||||
num_episodes = args.num_episodes
|
||||
max_timesteps = args.max_timesteps
|
||||
update_timesteps = args.update_timesteps
|
||||
experience_batch_size = args.experience_batch_size
|
||||
# Start training
|
||||
logging.info("Training start")
|
||||
# Set all models to eval and add experience maker
|
||||
all_ray_actors = (
|
||||
actor_group._actor_handlers
|
||||
+ critic_group._actor_handlers
|
||||
+ initial_group._actor_handlers
|
||||
+ reward_group._actor_handlers
|
||||
)
|
||||
num_ray_actors = len(all_ray_actors)
|
||||
ray.get([ray_actor.eval.remote() for ray_actor in all_ray_actors])
|
||||
ray.get([ray_actor.add_experience_maker.remote() for ray_actor in all_ray_actors])
|
||||
# Used as a queue to coordinate experience making
|
||||
experience_composition_refs = []
|
||||
time = 0
|
||||
for episode in range(num_episodes):
|
||||
logging.info("episode {} started".format(episode))
|
||||
for _ in range(max_timesteps):
|
||||
time += 1
|
||||
# Experience queueing stage
|
||||
sequences_attention_mask_action_mask_refs = actor_group.async_sample_prompts_and_make_sequence(
|
||||
experience_batch_size
|
||||
)
|
||||
base_action_log_probs_refs = initial_group.async_calculate_base_action_log_probs(
|
||||
sequences_attention_mask_action_mask_refs
|
||||
)
|
||||
values_refs = critic_group.async_calculate_value(sequences_attention_mask_action_mask_refs)
|
||||
r_refs = reward_group.async_calculate_r(sequences_attention_mask_action_mask_refs)
|
||||
action_log_probs_refs = actor_group.async_calculate_action_log_probs(
|
||||
sequences_attention_mask_action_mask_refs
|
||||
)
|
||||
experience_composition_refs.extend(
|
||||
[
|
||||
ExperienceCompositionRefs(
|
||||
sequences_attention_mask_action_mask_refs[i],
|
||||
action_log_probs_refs[i],
|
||||
base_action_log_probs_refs[i],
|
||||
values_refs[i],
|
||||
r_refs[i],
|
||||
)
|
||||
for i in range(len(sequences_attention_mask_action_mask_refs))
|
||||
]
|
||||
)
|
||||
# Learning stage
|
||||
if time % update_timesteps == 0:
|
||||
experience_refs = []
|
||||
# calculate experiences
|
||||
for i, experience_composition_ref in enumerate(experience_composition_refs):
|
||||
exp_composition_ref = experience_composition_ref
|
||||
selected_ray_actor = all_ray_actors[i % num_ray_actors]
|
||||
experience_refs.append(selected_ray_actor.make_experience.remote(exp_composition_ref))
|
||||
# backward
|
||||
ray.get(
|
||||
actor_group.async_learn_on_experiences(experience_refs)
|
||||
+ critic_group.async_learn_on_experiences(experience_refs)
|
||||
)
|
||||
# clear refs queue
|
||||
experience_composition_refs.clear()
|
||||
logging.info("Training finished")
|
||||
# Save checkpoint
|
||||
actor_group.save_checkpoint(args.save_path, args.need_optim_ckpt)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("--prompt_csv_url", type=str)
|
||||
parser.add_argument("--strategy", choices=["ddp", "colossalai_gemini", "colossalai_zero2"], default="ddp")
|
||||
parser.add_argument("--model", default="gpt2", choices=["gpt2", "bloom", "opt"])
|
||||
parser.add_argument("--pretrain", type=str, default="gpt2")
|
||||
parser.add_argument("--save_path", type=str, default="actor_checkpoint_prompts.pt")
|
||||
parser.add_argument("--need_optim_ckpt", type=bool, default=False)
|
||||
parser.add_argument("--num_episodes", type=int, default=10)
|
||||
parser.add_argument("--max_timesteps", type=int, default=10)
|
||||
parser.add_argument("--update_timesteps", type=int, default=10)
|
||||
parser.add_argument("--train_batch_size", type=int, default=8)
|
||||
parser.add_argument("--experience_batch_size", type=int, default=8)
|
||||
parser.add_argument("--num_actor_nodes", type=int, help="num of nodes to use to host actor model", default=1)
|
||||
parser.add_argument("--num_critic_nodes", type=int, help="num of nodes to use to host critic model", default=1)
|
||||
parser.add_argument("--num_initial_nodes", type=int, help="num of nodes to use to host initial model", default=1)
|
||||
parser.add_argument("--num_reward_nodes", type=int, help="num of nodes to use to host reward model", default=1)
|
||||
parser.add_argument("--num_gpus_per_node", type=int, help="num of gpus on a ray node", default=1)
|
||||
args = parser.parse_args()
|
||||
ray.init()
|
||||
main(args)
|
||||
|
|
@ -0,0 +1,273 @@
|
|||
#!/usr/bin/env python3
|
||||
# -*- coding: utf-8 -*-
|
||||
"""
|
||||
Prepare dataset scripts
|
||||
|
||||
Usage:
|
||||
- For SFT dataset preparation (SFT)
|
||||
python prepare_dataset.py --type sft \
|
||||
--data_input_dirs /PATH/TO/SFT/DATASET \
|
||||
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
|
||||
- For prompt dataset preparation (PPO)
|
||||
python prepare_dataset.py --type prompt \
|
||||
--data_input_dirs /PATH/TO/SFT/DATASET \
|
||||
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
|
||||
- For Preference dataset preparation (DPO and Reward model training)
|
||||
python prepare_dataset.py --type preference \
|
||||
--data_input_dirs /PATH/TO/SFT/DATASET \
|
||||
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
"""
|
||||
|
||||
import argparse
|
||||
import json
|
||||
import math
|
||||
import os
|
||||
import random
|
||||
import time
|
||||
from multiprocessing import cpu_count
|
||||
|
||||
from coati.dataset import setup_conversation_template, tokenize_kto, tokenize_prompt, tokenize_rlhf, tokenize_sft
|
||||
from datasets import dataset_dict, load_dataset
|
||||
from transformers import AutoTokenizer
|
||||
|
||||
from colossalai.logging import get_dist_logger
|
||||
|
||||
logger = get_dist_logger()
|
||||
|
||||
|
||||
def main():
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument(
|
||||
"--type",
|
||||
type=str,
|
||||
required=True,
|
||||
default=None,
|
||||
choices=["sft", "prompt", "preference", "kto"],
|
||||
help="Type of dataset, chose from 'sft', 'prompt', 'preference'. 'kto'",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--data_input_dirs",
|
||||
type=str,
|
||||
required=True,
|
||||
default=None,
|
||||
help="Comma(i.e., ',') separated list of all data directories containing `.jsonl` data files.",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--tokenizer_dir", type=str, required=True, default=None, help="A directory containing the tokenizer"
|
||||
)
|
||||
parser.add_argument(
|
||||
"--conversation_template_config",
|
||||
type=str,
|
||||
default="conversation_template_config",
|
||||
help="Path \
|
||||
to save conversation template config files.",
|
||||
)
|
||||
parser.add_argument("--data_cache_dir", type=str, default="cache", help="Data cache directory")
|
||||
parser.add_argument(
|
||||
"--data_jsonl_output_dir",
|
||||
type=str,
|
||||
default="jsonl_output",
|
||||
help="Output directory of spliced dataset with jsonl format",
|
||||
)
|
||||
parser.add_argument(
|
||||
"--data_arrow_output_dir",
|
||||
type=str,
|
||||
default="arrow_output",
|
||||
help="Output directory of spliced dataset with arrow format",
|
||||
)
|
||||
parser.add_argument("--max_length", type=int, default=4096, help="Max length of each spliced tokenized sequence")
|
||||
parser.add_argument("--num_spliced_dataset_bins", type=int, default=10, help="Number of spliced dataset bins")
|
||||
parser.add_argument(
|
||||
"--num_samples_per_datafile",
|
||||
type=int,
|
||||
default=-1,
|
||||
help="Number of samples to be generated from each data file. -1 denote all samples.",
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
if args.num_spliced_dataset_bins >= 100000:
|
||||
raise ValueError("Too many spliced divisions, must be smaller than 100000")
|
||||
|
||||
assert not os.path.exists(args.data_cache_dir), f"Find existed data cache dir {args.data_cache_dir}"
|
||||
assert not os.path.exists(
|
||||
args.data_jsonl_output_dir
|
||||
), f"Find existed jsonl data output dir {args.data_jsonl_output_dir}"
|
||||
assert not os.path.exists(
|
||||
args.data_arrow_output_dir
|
||||
), f"Find existed arrow data output dir {args.data_arrow_output_dir}"
|
||||
os.makedirs(args.data_jsonl_output_dir)
|
||||
os.makedirs(args.data_arrow_output_dir)
|
||||
|
||||
# Prepare to all input datasets
|
||||
input_data_paths = []
|
||||
input_data_dirs = args.data_input_dirs.split(",")
|
||||
for ds_dir in input_data_dirs:
|
||||
ds_dir = os.path.abspath(ds_dir)
|
||||
assert os.path.exists(ds_dir), f"Not find data dir {ds_dir}"
|
||||
ds_files = [name for name in os.listdir(ds_dir) if name.endswith(".jsonl")]
|
||||
ds_paths = [os.path.join(ds_dir, name) for name in ds_files]
|
||||
input_data_paths.extend(ds_paths)
|
||||
|
||||
# Prepare to data splitting.
|
||||
train_splits = []
|
||||
split_interval = math.ceil(100 / args.num_spliced_dataset_bins)
|
||||
for i in range(0, 100, split_interval):
|
||||
start = i
|
||||
end = i + split_interval
|
||||
if end > 100:
|
||||
end = 100
|
||||
train_splits.append(f"train[{start}%:{end}%]")
|
||||
|
||||
# Prepare the tokenizer.
|
||||
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_dir, use_fast=False, trust_remote_code=True)
|
||||
if os.path.exists(args.conversation_template_config):
|
||||
chat_template_config = json.load(open(args.conversation_template_config, "r", encoding="utf8"))
|
||||
else:
|
||||
chat_template_config = {
|
||||
"system_message": "A chat between a curious human and an artificial intelligence assistant. "
|
||||
"The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n"
|
||||
} # Use default system message
|
||||
if args.type == "preference":
|
||||
if "stop_ids" not in chat_template_config:
|
||||
# Ask the user to define stop_ids for PPO training
|
||||
dummy_messages = [
|
||||
{"role": "user", "content": "Hello, how are you?"},
|
||||
{"role": "assistant", "content": "I'm doing great. How can I help you today?"},
|
||||
{"role": "user", "content": "Who made you?"},
|
||||
{"role": "assistant", "content": "I am a chatbot trained by Colossal-AI."},
|
||||
]
|
||||
dummy_prompt = tokenizer.apply_chat_template(dummy_messages, tokenize=False)
|
||||
tokenized = tokenizer(dummy_prompt, add_special_tokens=False)["input_ids"]
|
||||
tokens = tokenizer.convert_ids_to_tokens(tokenized, skip_special_tokens=False)
|
||||
corresponding_str = [tokenizer.convert_tokens_to_string([token]) for token in tokens]
|
||||
token_id_mapping = [{"token": s, "id": tokenized[i]} for i, s in enumerate(corresponding_str)]
|
||||
stop_ids = input(
|
||||
"For PPO, we recommend to provide stop_ids for the properly stop the generation during roll out stage. "
|
||||
"stop_ids are the ids of repetitive pattern that indicate the end of the assistant's response. "
|
||||
"Here is an example of formatted prompt and token-id mapping, you can set stop_ids by entering a list "
|
||||
"of integers, separate by space, press `Enter` to end. Or you can press `Enter` without input if you are "
|
||||
"not using PPO or you prefer to not set the stop_ids, in that case, stop_ids will be set to tokenizer.eos_token_id. "
|
||||
f"\nPrompt:\n{dummy_prompt}\nToken-id Mapping:\n{token_id_mapping}\nstop_ids:"
|
||||
)
|
||||
if stop_ids == "":
|
||||
chat_template_config["stop_ids"] = [tokenizer.eos_token_id]
|
||||
else:
|
||||
try:
|
||||
chat_template_config["stop_ids"] = [int(s) for s in stop_ids.split()]
|
||||
except ValueError:
|
||||
raise ValueError("Invalid input, please provide a list of integers.")
|
||||
else:
|
||||
# Set stop_ids to eos_token_id for other dataset types if not exist
|
||||
if "stop_ids" not in chat_template_config:
|
||||
chat_template_config["stop_ids"] = [tokenizer.eos_token_id]
|
||||
|
||||
conversation_template = setup_conversation_template(
|
||||
tokenizer, chat_template_config=chat_template_config, save_path=args.conversation_template_config
|
||||
)
|
||||
if hasattr(tokenizer, "pad_token") and hasattr(tokenizer, "eos_token") and tokenizer.eos_token is not None:
|
||||
try:
|
||||
# Some tokenizers doesn't allow to set pad_token mannually e.g., Qwen
|
||||
tokenizer.pad_token = tokenizer.eos_token
|
||||
except AttributeError as e:
|
||||
logger.warning(f"Unable to set pad token to eos token, {str(e)}")
|
||||
if not hasattr(tokenizer, "pad_token") or tokenizer.pad_token is None:
|
||||
logger.warning(
|
||||
"The tokenizer does not have a pad token which is required. May lead to unintended behavior in training, Please consider manually set them."
|
||||
)
|
||||
|
||||
list_dataset = load_dataset(
|
||||
path="json",
|
||||
data_files=input_data_paths,
|
||||
cache_dir=os.path.join(args.data_cache_dir, "raw"),
|
||||
keep_in_memory=False,
|
||||
split=train_splits,
|
||||
num_proc=cpu_count(),
|
||||
)
|
||||
|
||||
if args.type == "sft":
|
||||
preparation_function = tokenize_sft
|
||||
elif args.type == "prompt":
|
||||
preparation_function = tokenize_prompt
|
||||
elif args.type == "preference":
|
||||
preparation_function = tokenize_rlhf
|
||||
elif args.type == "kto":
|
||||
preparation_function = tokenize_kto
|
||||
else:
|
||||
raise ValueError("Unknow dataset type. Please choose one from ['sft', 'prompt', 'preference']")
|
||||
|
||||
for index, dataset in enumerate(list_dataset):
|
||||
assert isinstance(dataset, dataset_dict.Dataset)
|
||||
if len(dataset) == 0:
|
||||
# Hack: Skip empty dataset. If dataset contains less than num_of_rank samples, some rank may have empty dataset and leads to error
|
||||
continue
|
||||
if args.num_samples_per_datafile > 0:
|
||||
# limit the number of samples in each dataset
|
||||
dataset = dataset.select(
|
||||
random.sample(range(len(dataset)), min(args.num_samples_per_datafile, len(dataset)))
|
||||
)
|
||||
logger.info(f"Start to process part-{index}/{len(list_dataset)} of all original datasets.")
|
||||
dataset = dataset.map(
|
||||
function=preparation_function,
|
||||
fn_kwargs={
|
||||
"tokenizer": tokenizer,
|
||||
"conversation_template": conversation_template,
|
||||
"max_length": args.max_length,
|
||||
},
|
||||
keep_in_memory=False,
|
||||
num_proc=min(len(dataset), cpu_count()),
|
||||
)
|
||||
if args.type == "kto":
|
||||
filter_by = "completion"
|
||||
elif args.type == "preference":
|
||||
filter_by = "chosen_input_ids"
|
||||
else:
|
||||
filter_by = "input_ids"
|
||||
dataset = dataset.filter(lambda data: data[filter_by] is not None)
|
||||
|
||||
# Save each jsonl spliced dataset.
|
||||
output_index = "0" * (5 - len(str(index))) + str(index)
|
||||
output_name = f"part-{output_index}"
|
||||
output_jsonl_path = os.path.join(args.data_jsonl_output_dir, output_name + ".jsonl")
|
||||
st = time.time()
|
||||
with open(file=output_jsonl_path, mode="w", encoding="utf-8") as fp_writer:
|
||||
count = 0
|
||||
for data_point in dataset:
|
||||
if count % 500 == 0:
|
||||
logger.info(f"processing {count} spliced data points for {fp_writer.name}")
|
||||
count += 1
|
||||
fp_writer.write(json.dumps(data_point, ensure_ascii=False) + "\n")
|
||||
logger.info(
|
||||
f"Current file {fp_writer.name}; "
|
||||
f"Data size: {len(dataset)}; "
|
||||
f"Time cost: {round((time.time() - st) / 60, 6)} minutes."
|
||||
)
|
||||
# Save each arrow spliced dataset
|
||||
output_arrow_path = os.path.join(args.data_arrow_output_dir, output_name)
|
||||
logger.info(f"Start to save {output_arrow_path}")
|
||||
dataset = load_dataset(
|
||||
path="json",
|
||||
data_files=[output_jsonl_path],
|
||||
cache_dir=os.path.join(args.data_cache_dir, "tokenized"),
|
||||
keep_in_memory=False,
|
||||
num_proc=cpu_count(),
|
||||
split="train",
|
||||
)
|
||||
dataset.save_to_disk(dataset_path=output_arrow_path, num_proc=min(len(dataset), cpu_count()))
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
main()
|
||||
|
|
@ -0,0 +1,14 @@
|
|||
SAVE_DIR=""
|
||||
|
||||
rm -rf $SAVE_DIR/cache
|
||||
rm -rf $SAVE_DIR/jsonl
|
||||
rm -rf $SAVE_DIR/arrow
|
||||
|
||||
python prepare_dataset.py --type kto \
|
||||
--data_input_dirs /PATH/TO/KTO/DATASET \
|
||||
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
--max_length 1024
|
||||
|
|
@ -0,0 +1,14 @@
|
|||
SAVE_DIR=""
|
||||
|
||||
rm -rf $SAVE_DIR/cache
|
||||
rm -rf $SAVE_DIR/jsonl
|
||||
rm -rf $SAVE_DIR/arrow
|
||||
|
||||
python prepare_dataset.py --type preference \
|
||||
--data_input_dirs /PATH/TO/PREFERENCE/DATASET \
|
||||
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
--max_length 1024
|
||||
|
|
@ -0,0 +1,14 @@
|
|||
SAVE_DIR=""
|
||||
|
||||
rm -rf $SAVE_DIR/cache
|
||||
rm -rf $SAVE_DIR/jsonl
|
||||
rm -rf $SAVE_DIR/arrow
|
||||
|
||||
python prepare_dataset.py --type prompt \
|
||||
--data_input_dirs /PATH/TO/PROMPT/DATASET \
|
||||
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
--max_length 1024
|
||||
|
|
@ -0,0 +1,14 @@
|
|||
SAVE_DIR=""
|
||||
|
||||
rm -rf $SAVE_DIR/cache
|
||||
rm -rf $SAVE_DIR/jsonl
|
||||
rm -rf $SAVE_DIR/arrow
|
||||
|
||||
python prepare_dataset.py --type sft \
|
||||
--data_input_dirs /PATH/TO/SFT/DATASET \
|
||||
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
|
||||
--tokenizer_dir "" \
|
||||
--data_cache_dir $SAVE_DIR/cache \
|
||||
--data_jsonl_output_dir $SAVE_DIR/jsonl \
|
||||
--data_arrow_output_dir $SAVE_DIR/arrow \
|
||||
--max_length 4096
|
||||
|
|
@ -0,0 +1,168 @@
|
|||
"""
|
||||
command line IO utils for chatbot
|
||||
"""
|
||||
|
||||
import abc
|
||||
import re
|
||||
|
||||
from prompt_toolkit import PromptSession
|
||||
from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
|
||||
from prompt_toolkit.completion import WordCompleter
|
||||
from prompt_toolkit.history import InMemoryHistory
|
||||
from rich.console import Console
|
||||
from rich.live import Live
|
||||
from rich.markdown import Markdown
|
||||
|
||||
|
||||
class ChatIO(abc.ABC):
|
||||
@abc.abstractmethod
|
||||
def prompt_for_input(self, role: str) -> str:
|
||||
"""Prompt for input from a role."""
|
||||
|
||||
@abc.abstractmethod
|
||||
def prompt_for_output(self, role: str):
|
||||
"""Prompt for output from a role."""
|
||||
|
||||
@abc.abstractmethod
|
||||
def stream_output(self, output_stream):
|
||||
"""Stream output."""
|
||||
|
||||
|
||||
class SimpleChatIO(ChatIO):
|
||||
def prompt_for_input(self, role) -> str:
|
||||
return input(f"{role}: ")
|
||||
|
||||
def prompt_for_output(self, role: str):
|
||||
print(f"{role}: ", end="", flush=True)
|
||||
|
||||
def stream_output(self, output_stream):
|
||||
pre = 0
|
||||
for outputs in output_stream:
|
||||
outputs = outputs.strip()
|
||||
outputs = outputs.split(" ")
|
||||
now = len(outputs) - 1
|
||||
if now > pre:
|
||||
print(" ".join(outputs[pre:now]), end=" ", flush=True)
|
||||
pre = now
|
||||
print(" ".join(outputs[pre:]), flush=True)
|
||||
return " ".join(outputs)
|
||||
|
||||
|
||||
class RichChatIO(ChatIO):
|
||||
def __init__(self):
|
||||
self._prompt_session = PromptSession(history=InMemoryHistory())
|
||||
self._completer = WordCompleter(words=["!exit", "!reset"], pattern=re.compile("$"))
|
||||
self._console = Console()
|
||||
|
||||
def prompt_for_input(self, role) -> str:
|
||||
self._console.print(f"[bold]{role}:")
|
||||
prompt_input = self._prompt_session.prompt(
|
||||
completer=self._completer,
|
||||
multiline=False,
|
||||
auto_suggest=AutoSuggestFromHistory(),
|
||||
key_bindings=None,
|
||||
)
|
||||
self._console.print()
|
||||
return prompt_input
|
||||
|
||||
def prompt_for_output(self, role: str) -> str:
|
||||
self._console.print(f"[bold]{role}:")
|
||||
|
||||
def stream_output(self, output_stream):
|
||||
"""Stream output from a role."""
|
||||
# Create a Live context for updating the console output
|
||||
with Live(console=self._console, refresh_per_second=60) as live:
|
||||
# Read lines from the stream
|
||||
for outputs in output_stream:
|
||||
accumulated_text = outputs
|
||||
if not accumulated_text:
|
||||
continue
|
||||
# Render the accumulated text as Markdown
|
||||
# NOTE: this is a workaround for the rendering "unstandard markdown"
|
||||
# in rich. The chatbots output treat "\n" as a new line for
|
||||
# better compatibility with real-world text. However, rendering
|
||||
# in markdown would break the format. It is because standard markdown
|
||||
# treat a single "\n" in normal text as a space.
|
||||
# Our workaround is adding two spaces at the end of each line.
|
||||
# This is not a perfect solution, as it would
|
||||
# introduce trailing spaces (only) in code block, but it works well
|
||||
# especially for console output, because in general the console does not
|
||||
# care about trailing spaces.
|
||||
lines = []
|
||||
for line in accumulated_text.splitlines():
|
||||
lines.append(line)
|
||||
if line.startswith("```"):
|
||||
# Code block marker - do not add trailing spaces, as it would
|
||||
# break the syntax highlighting
|
||||
lines.append("\n")
|
||||
else:
|
||||
lines.append(" \n")
|
||||
markdown = Markdown("".join(lines))
|
||||
# Update the Live console output
|
||||
live.update(markdown)
|
||||
self._console.print()
|
||||
return outputs
|
||||
|
||||
|
||||
class DummyChatIO(ChatIO):
|
||||
"""
|
||||
Dummy ChatIO class for testing
|
||||
"""
|
||||
|
||||
def __init__(self):
|
||||
self.roles = []
|
||||
self._console = Console()
|
||||
|
||||
def prompt_for_input(self, role) -> str:
|
||||
self.roles.append(role)
|
||||
if len(self.roles) == 1:
|
||||
ret = "Hello"
|
||||
elif len(self.roles) == 2:
|
||||
ret = "What's the value of 1+1?"
|
||||
else:
|
||||
ret = "exit"
|
||||
self._console.print(f"[bold]{role}:{ret}")
|
||||
return ret
|
||||
|
||||
def prompt_for_output(self, role: str) -> str:
|
||||
self._console.print(f"[bold]{role}:")
|
||||
|
||||
def stream_output(self, output_stream):
|
||||
"""Stream output from a role."""
|
||||
# Create a Live context for updating the console output
|
||||
with Live(console=self._console, refresh_per_second=60) as live:
|
||||
# Read lines from the stream
|
||||
for outputs in output_stream:
|
||||
accumulated_text = outputs
|
||||
if not accumulated_text:
|
||||
continue
|
||||
# Render the accumulated text as Markdown
|
||||
# NOTE: this is a workaround for the rendering "unstandard markdown"
|
||||
# in rich. The chatbots output treat "\n" as a new line for
|
||||
# better compatibility with real-world text. However, rendering
|
||||
# in markdown would break the format. It is because standard markdown
|
||||
# treat a single "\n" in normal text as a space.
|
||||
# Our workaround is adding two spaces at the end of each line.
|
||||
# This is not a perfect solution, as it would
|
||||
# introduce trailing spaces (only) in code block, but it works well
|
||||
# especially for console output, because in general the console does not
|
||||
# care about trailing spaces.
|
||||
lines = []
|
||||
for line in accumulated_text.splitlines():
|
||||
lines.append(line)
|
||||
if line.startswith("```"):
|
||||
# Code block marker - do not add trailing spaces, as it would
|
||||
# break the syntax highlighting
|
||||
lines.append("\n")
|
||||
else:
|
||||
lines.append(" \n")
|
||||
markdown = Markdown("".join(lines))
|
||||
# Update the Live console output
|
||||
live.update(markdown)
|
||||
self._console.print()
|
||||
return outputs
|
||||
|
||||
|
||||
simple_io = SimpleChatIO()
|
||||
rich_io = RichChatIO()
|
||||
dummy_io = DummyChatIO()
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue