From d8b1ea4ac90317ad6126acbd854e66583a8f9c8f Mon Sep 17 00:00:00 2001
From: Yuanheng Zhao <54058983+yuanheng-zhao@users.noreply.github.com>
Date: Mon, 20 May 2024 22:50:04 +0800
Subject: [PATCH] [doc] Update Inference Readme (#5736)
* [doc] update inference readme
* add contents
* trivial
---
colossalai/inference/README.md | 251 ++++++++++++++++++++-------------
1 file changed, 153 insertions(+), 98 deletions(-)
diff --git a/colossalai/inference/README.md b/colossalai/inference/README.md
index abecd4886..cd130a463 100644
--- a/colossalai/inference/README.md
+++ b/colossalai/inference/README.md
@@ -5,75 +5,28 @@
- [⚡️ ColossalAI-Inference](#️-colossalai-inference)
- [📚 Table of Contents](#-table-of-contents)
- [📌 Introduction](#-introduction)
- - [🛠 Design and Implementation](#-design-and-implementation)
- [🕹 Usage](#-usage)
- - [🪅 Support Matrix](#-support-matrix)
- [🗺 Roadmap](#-roadmap)
+ - [🪅 Support Matrix](#-support-matrix)
+ - [🛠 Design and Components](#-design-and-components)
+ - [Overview](#overview)
+ - [Engine](#engine)
+ - [Blocked KV Cache Manager](#kv-cache)
+ - [Batching](#batching)
+ - [Modeling](#modeling)
- [🌟 Acknowledgement](#-acknowledgement)
## 📌 Introduction
ColossalAI-Inference is a module which offers acceleration to the inference execution of Transformers models, especially LLMs. In ColossalAI-Inference, we leverage high-performance kernels, KV cache, paged attention, continous batching and other techniques to accelerate the inference of LLMs. We also provide simple and unified APIs for the sake of user-friendliness.
-## 🛠 Design and Implementation
-
-### :book: Overview
-
-ColossalAI-Inference has **4** major components, namely namely `engine`,`request handler`,`cache manager`, and `modeling`.
-
-- **Engine**: It orchestrates the inference step. During inference, it recives a request, calls `request handler` to schedule a decoding batch, and executes the model forward pass to perform a iteration. It returns the inference results back to the user at the end.
-- **Request Handler**: It manages requests and schedules a proper batch from exisiting requests.
-- **Cache manager** It is bound within the `request handler`, updates cache blocks and logical block tables as scheduled by the `request handler`.
-- **Modelling**: We rewrite the model and layers of LLMs to simplify and optimize the forward pass for inference.
-
-
-A high-level view of the inter-component interaction is given below. We would also introduce more details in the next few sections.
-
-
-
-
-
-
-### :mailbox_closed: Engine
-Engine is designed as the entry point where the user kickstarts an inference loop. User can easily instantialize an inference engine with the inference configuration and execute requests. The engine object will expose the following APIs for inference:
-
-- `generate`: main function which handles inputs, performs inference and returns outputs
-- `add_request`: add request to the waiting list
-- `step`: perform one decoding iteration. The `request handler` first schedules a batch to do prefill/decoding. Then, it invokes a model to generate a batch of token and afterwards does logit processing and sampling, checks and decodes finished requests.
-
-### :game_die: Request Handler
-
-Request handler is responsible for managing requests and scheduling a proper batch from exisiting requests. According to the existing work and experiments, we do believe that it is beneficial to increase the length of decoding sequences. In our design, we partition requests into three priorities depending on their lengths, the longer sequences are first considered.
-
-
-
-
-
-
-### :radio: KV cache and cache manager
-
-We design a unified block cache and cache manager to allocate and manage memory. The physical memory is allocated before decoding and represented by a logical block table. During decoding process, cache manager administrates the physical memory through `block table` and other components(i.e. engine) can focus on the lightweight `block table`. More details are given below.
-
-- `cache block`: We group physical memory into different memory blocks. A typical cache block is shaped `(num_kv_heads, head_size, block_size)`. We determine the block number beforehand. The memory allocation and computation are executed at the granularity of memory block.
-- `block table`: Block table is the logical representation of cache blocks. Concretely, a block table of a single sequence is a 1D tensor, with each element holding a block ID. Block ID of `-1` means "Not Allocated". In each iteration, we pass through a batch block table to the corresponding model.
-
-
-
-
-
- Example of Batch Block Table
-
-
-
-
-### :railway_car: Modeling
-
-Modeling contains models and layers, which are hand-crafted for better performance easier usage. Deeply integrated with `shardformer`, we also construct policy for our models. In order to minimize users' learning costs, our models are aligned with [Transformers](https://github.com/huggingface/transformers)
## 🕹 Usage
### :arrow_right: Quick Start
+The sample usage of the inference engine is given below:
+
```python
import torch
import transformers
@@ -95,7 +48,6 @@ inference_config = InferenceConfig(
max_input_len=1024,
max_output_len=512,
use_cuda_kernel=True,
- use_cuda_graph=False, # Turn on if you want to use CUDA Graph to accelerate inference
)
# Step 3: create an engine with model and config
@@ -107,63 +59,168 @@ response = engine.generate(prompts)
pprint(response)
```
-### :bookmark: Customize your inference engine
-Besides the basic quick-start inference, you can also customize your inference engine via modifying config or upload your own model or decoding components (logit processors or sampling strategies).
-
-#### Inference Config
-Inference Config is a unified api for generation process. You can define the value of args to control the generation, like `max_batch_size`,`max_output_len`,`dtype` to decide the how many sequences can be handled at a time, and how many tokens to output. Refer to the source code for more detail.
-
-#### Generation Config
-In colossal-inference, Generation config api is inherited from [Transformers](https://github.com/huggingface/transformers). Usage is aligned. By default, it is automatically generated by our system and you don't bother to construct one. If you have such demand, you can also create your own and send it to your engine.
-
-#### Logit Processors
-The `Logit Processosr` receives logits and return processed results. You can take the following step to make your own.
-
-```python
-@register_logit_processor("name")
-def xx_logit_processor(logits, args):
- logits = do_some_process(logits)
- return logits
+You could run the sample code by
+```bash
+colossalai run --nproc_per_node 1 your_sample_name.py
```
-#### Sampling Strategies
-We offer 3 main sampling strategies now (i.e. `greedy sample`, `multinomial sample`, `beam_search sample`), you can refer to [sampler](/ColossalAI/colossalai/inference/sampler.py) for more details. We would strongly appreciate if you can contribute your varities.
+For detailed examples, you might want to check [inference examples](../../examples/inference/llama/README.md).
-## 🪅 Support Matrix
+### :bookmark: Customize your inference engine
+Besides the basic quick-start inference, you can also customize your inference engine via modifying inference config or uploading your own models, policies, or decoding components (logits processors or sampling strategies).
-| Model | KV Cache | Paged Attention | Kernels | Tensor Parallelism | Speculative Decoding |
-| - | - | - | - | - | - |
-| Llama | ✅ | ✅ | ✅ | 🔜 | ✅ |
+#### Inference Config
+Inference Config is a unified config for initializing the inference engine, controlling multi-GPU generation (Tensor Parallelism), as well as presetting generation configs. Below are some commonly used `InferenceConfig`'s arguments:
+- `max_batch_size`: The maximum batch size. Defaults to 8.
+- `max_input_len`: The maximum input length (number of tokens). Defaults to 256.
+- `max_output_len`: The maximum output length (number of tokens). Defaults to 256.
+- `dtype`: The data type of the model for inference. This can be one of `fp16`, `bf16`, or `fp32`. Defaults to `fp16`.
+- `kv_cache_dtype`: The data type used for KVCache. Defaults to the same data type as the model (`dtype`). KVCache quantization will be automatically enabled if it is different from that of model (`dtype`).
+- `use_cuda_kernel`: Determine whether to use CUDA kernels or not. If disabled, Triton kernels will be used. Defaults to False.
+- `tp_size`: Tensor-Parallelism size. Defaults to 1 (tensor parallelism is turned off by default).
-Notations:
-- ✅: supported
-- ❌: not supported
-- 🔜: still developing, will support soon
+#### Generation Config
+Refer to transformers [GenerationConfig](https://huggingface.co/docs/transformers/en/main_classes/text_generation#transformers.GenerationConfig) on functionalities and usage of specific configs. In ColossalAI-Inference, generation configs can be preset in `InferenceConfig`. Supported generation configs include:
+
+- `do_sample`: Whether or not to use sampling. Defaults to False (greedy decoding).
+- `top_k`: The number of highest probability vocabulary tokens to keep for top-k-filtering. Defaults to 50.
+- `top_p`: If set to float < 1, only the smallest set of most probable tokens with probabilities that add up to top_p or higher are kept for generation. Defaults to 1.0.
+- `temperature`: The value used to modulate the next token probabilities. Defaults to 1.0.
+- `no_repeat_ngram_size`: If set to int > 0, all ngrams of that size can only occur once. Defaults to 0.
+- `repetition_penalty`: The parameter for repetition penalty. 1.0 means no penalty. Defaults to 1.0.
+- `forced_eos_token_id`: The id of the token to force as the last generated token when max_length is reached. Defaults to `None`.
+
+Users can also create a transformers [GenerationConfig](https://huggingface.co/docs/transformers/en/main_classes/text_generation#transformers.GenerationConfig) as an input argument for `InferenceEngine.generate` API. For example
+
+```python
+generation_config = GenerationConfig(
+ max_length=128,
+ do_sample=True,
+ temperature=0.7,
+ top_k=50,
+ top_p=1.0,
+)
+response = engine.generate(prompts=prompts, generation_config=generation_config)
+```
## 🗺 Roadmap
-- [x] KV Cache
+We will follow the following roadmap to develop major features of ColossalAI-Inference:
+
+- [x] Blocked KV Cache
- [x] Paged Attention
-- [x] High-Performance Kernels
-- [x] Llama Modelling
-- [x] User Documentation
+- 🟩 Fused Kernels
- [x] Speculative Decoding
-- [ ] Tensor Parallelism
-- [ ] Beam Search
-- [ ] Early stopping
-- [ ] Logger system
-- [ ] SplitFuse
-- [ ] Continuous Batching
+- [x] Continuous Batching
+- 🟩 Tensor Parallelism
- [ ] Online Inference
-- [ ] Benchmarking
+- [ ] Beam Search
+- [ ] SplitFuse
+
+Notations:
+- [x] Completed
+- 🟩 Model specific and in still progress.
+
+## 🪅 Support Matrix
+
+| Model | Model Card | Tensor Parallel | Lazy Initialization | Paged Attention | Fused Kernels | Speculative Decoding |
+|-----------|------------------------------------------------------------------------------------------------|-----------------|---------------------|-----------------|---------------|----------------------|
+| Baichuan | `baichuan-inc/Baichuan2-7B-Base`, `baichuan-inc/Baichuan2-13B-Base`, etc | ✅ | [ ] | ✅ | ✅ | [ ] |
+| ChatGLM | | [ ] | [ ] | [ ] | [ ] | [ ] |
+| DeepSeek | | [ ] | [ ] | [ ] | [ ] | [ ] |
+| Llama | `meta-llama/Llama-2-7b`, `meta-llama/Llama-2-13b`, `meta-llama/Meta-Llama-3-8B`, `meta-llama/Meta-Llama-3-70B`, etc | ✅ | [ ] | ✅ | ✅ | ✅ |
+| Mixtral | | [ ] | [ ] | [ ] | [ ] | [ ] |
+| Qwen | | [ ] | [ ] | [ ] | [ ] | [ ] |
+| Vicuna | `lmsys/vicuna-13b-v1.3`, `lmsys/vicuna-7b-v1.5` | ✅ | [ ] | ✅ | ✅ | ✅ |
+| Yi | `01-ai/Yi-34B`, etc | ✅ | [ ] | ✅ | ✅ | ✅ |
+
+
+## 🛠 Design and Components
+
+### Overview
+
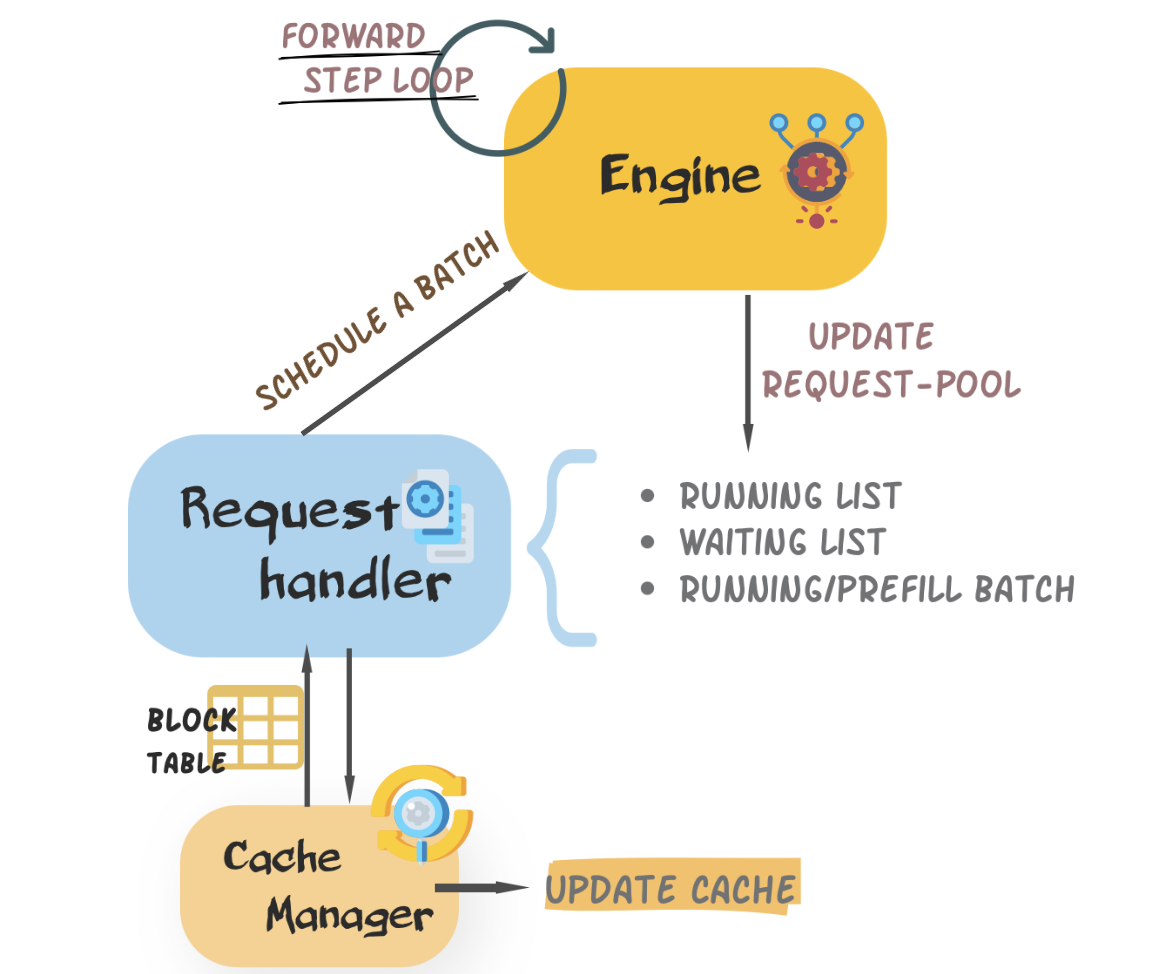
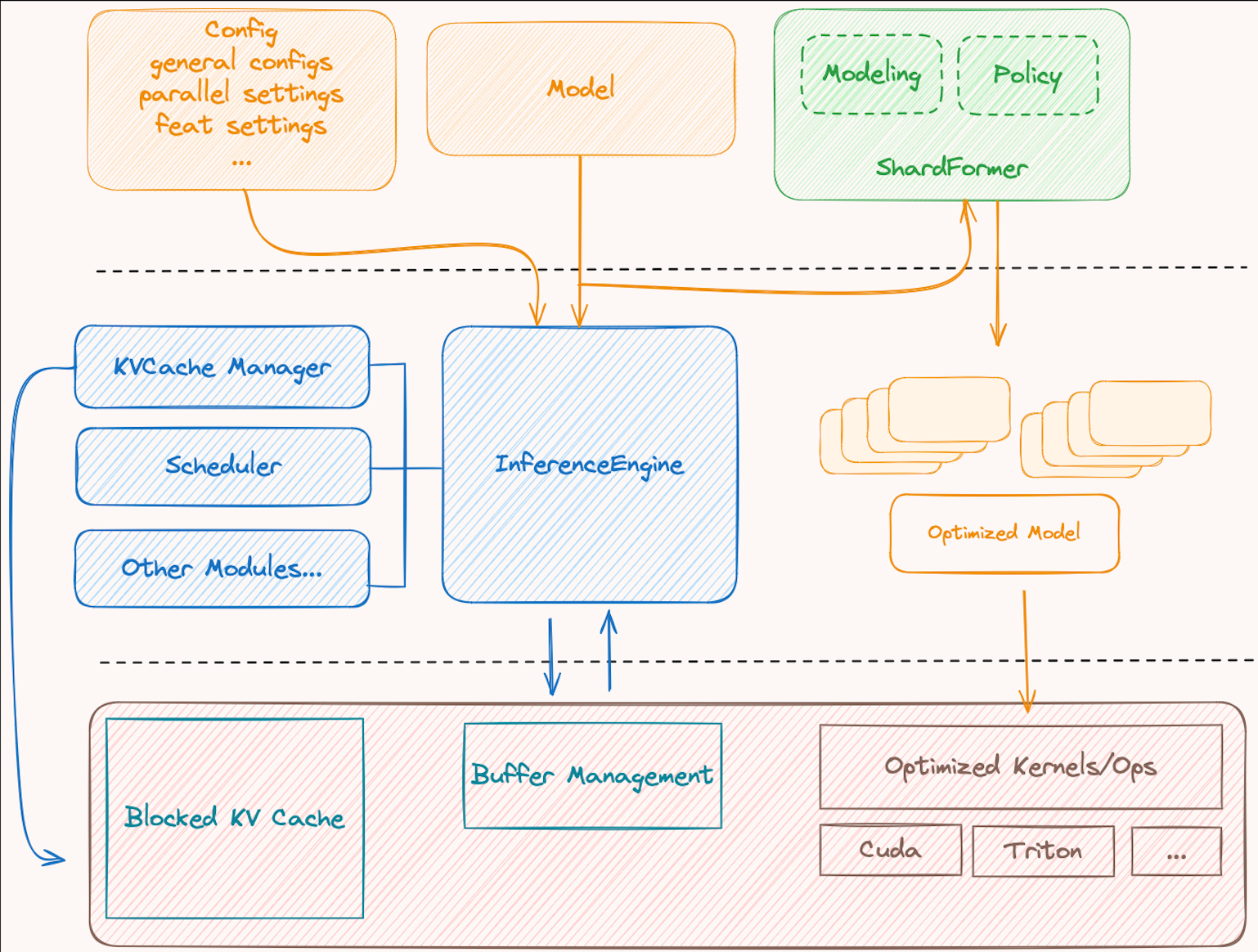
+ColossalAI-Inference has **4** major components, namely `engine`, `request handler`, `kv cache manager`, and `modeling`.
+
+
+
+
+
+
+- **Engine**: It orchestrates the inference step. During inference, it recives a request, calls `request handler` to schedule a decoding batch, and executes the model forward pass to perform a iteration. It returns the inference results back to the user at the end.
+- **Request Handler**: It manages requests and schedules a proper batch from exisiting requests.
+- **KV Cache Manager** It is bound within the `request handler`, updates cache blocks and logical block tables as scheduled by the `request handler`.
+- **Modelling**: We rewrite the model and layers of LLMs to simplify and optimize the forward pass for inference.
+
+
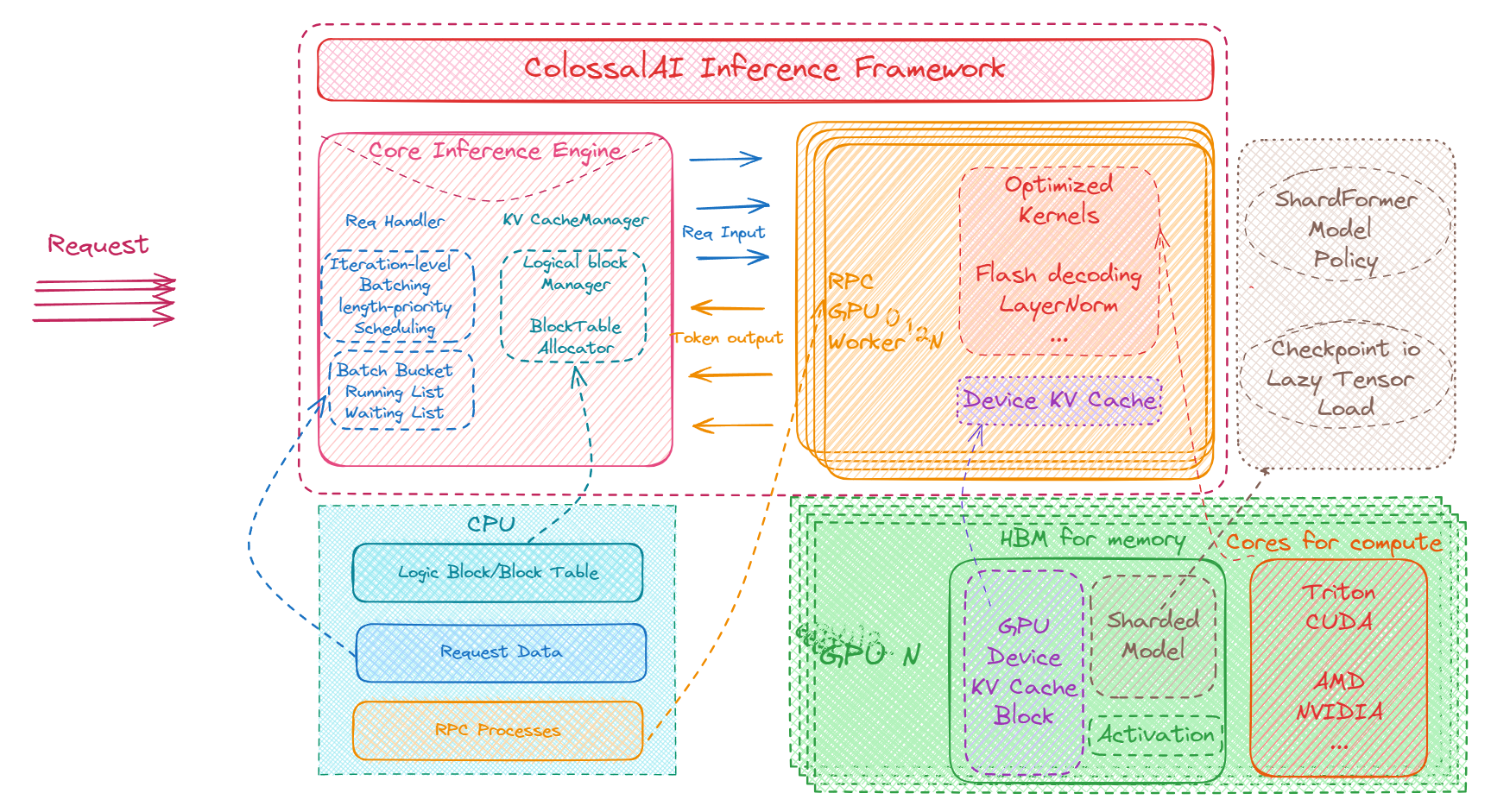
+An overview of the inter-component interaction is given below (RPC version). We would also introduce more details in the next few sections.
+
+
+
+
+
+
+### Engine
+
+Engine is designed as the entry point where the user kickstarts an inference loop. User can easily initialize an inference engine with the inference configurations and execute with their requests. We provided several versions of inference engines, namely `InferenceEngine`, `RPCInferenceEngine`, and `AsyncInferenceEngine`, which are used for different conditions and purposes.
+
+For examples/inference/llama and `RPCInferenceEngine`, we expose the following APIs for inference:
+
+- `generate`: main function which handles inputs, performs inference and returns outputs.
+- `add_request`: add a single or multiple requests to the inference engine.
+- `step`: perform one decoding iteration. The `request handler` first schedules a batch to do prefill/decoding. Then, it invokes a model to generate a batch of token and afterwards does logit processing and sampling, checks and decodes finished requests.
+- `enable_spec_dec`: used for speculative decoding. Enable speculative decoding for subsequent generations.
+- `disable_spec_dec`: used for speculative decoding. Disable speculative decoding for subsequent generations
+- `clear_spec_dec`: clear structures and models related to speculative decoding, if exists.
+
+For `AsyncInferenceEngine`, we expose the following APIs for inference:
+- `add_request`: async method. Add a request to the inference engine, as well as to the waiting queue of the background tracker.
+- `generate`: async method. Perform inference from a request.
+- `step`: async method. Perform one decoding iteration, if there exists any request in waiting queue.
+
+For now, `InferenceEngine` is used for offline generation; `AsyncInferenceEngine` is used for online serving with a single card; and `RPCInferenceEngine` is used for online serving with multiple cards. In future, we will focus on `RPCInferenceEngine` and improve user experience of LLM serving.
+
+
+### KV cache
+
+Learnt from [PagedAttention](https://arxiv.org/abs/2309.06180) by [vLLM](https://github.com/vllm-project/vllm) team, we use a unified blocked KV cache and cache manager to allocate and manage memory. The physical memory is pre-allocated during initialization and represented by a logical block table. During decoding process, cache manager administrates the physical memory through `block table` of a batch and so that other components (i.e. engine) can focus on the lightweight `block table`. More details are given below.
+
+- `logical cache block`: We group physical memory into different memory blocks. A typical cache block is shaped `(num_kv_heads, block_size, head_size)`. We determine the block number beforehand. The memory allocation and computation are executed at the granularity of memory block.
+- `block table`: Block table is the logical representation of cache blocks. Concretely, a block table of a single sequence is a 1D tensor, with each element holding a block ID. Block ID of `-1` means "Not Allocated". In each iteration, we pass through a batch block table to the corresponding model.
+
+
+
+
+ Example of block table for a batch
+
+
+
+### Batching
+
+Request handler is responsible for managing requests and scheduling a proper batch from exisiting requests. Based on [Orca's](https://www.usenix.org/conference/osdi22/presentation/yu) and [vLLM's](https://github.com/vllm-project/vllm) research and work on batching requests, we applied continuous batching with unpadded sequences, which enables various number of sequences to pass projections (i.e. Q, K, and V) together in different steps by hiding the dimension of number of sequences, and decrement the latency of incoming sequences by inserting a prefill batch during a decoding step and then decoding together.
+
+
+
+
+ Naive Batching: decode until each sequence encounters eos in a batch
+
+
+
+
+
+ Continuous Batching: dynamically adjust the batch size by popping out finished sequences and inserting prefill batch
+
+
+### Modeling
+
+Modeling contains models, layers, and policy, which are hand-crafted for better performance easier usage. Integrated with `shardformer`, users can define their own policy or use our preset policies for specific models. Our modeling files are aligned with [Transformers](https://github.com/huggingface/transformers). For more details about the usage of modeling and policy, please check `colossalai/shardformer`.
+
## 🌟 Acknowledgement
This project was written from scratch but we learned a lot from several other great open-source projects during development. Therefore, we wish to fully acknowledge their contribution to the open-source community. These projects include
- [vLLM](https://github.com/vllm-project/vllm)
-- [LightLLM](https://github.com/ModelTC/lightllm)
- [flash-attention](https://github.com/Dao-AILab/flash-attention)
If you wish to cite relevant research papars, you can find the reference below.
@@ -189,6 +246,4 @@ If you wish to cite relevant research papars, you can find the reference below.
author={Dao, Tri},
year={2023}
}
-
-# we do not find any research work related to lightllm
```
 -
-  -
-  -
-  +
+  +
+  +
+  +
+