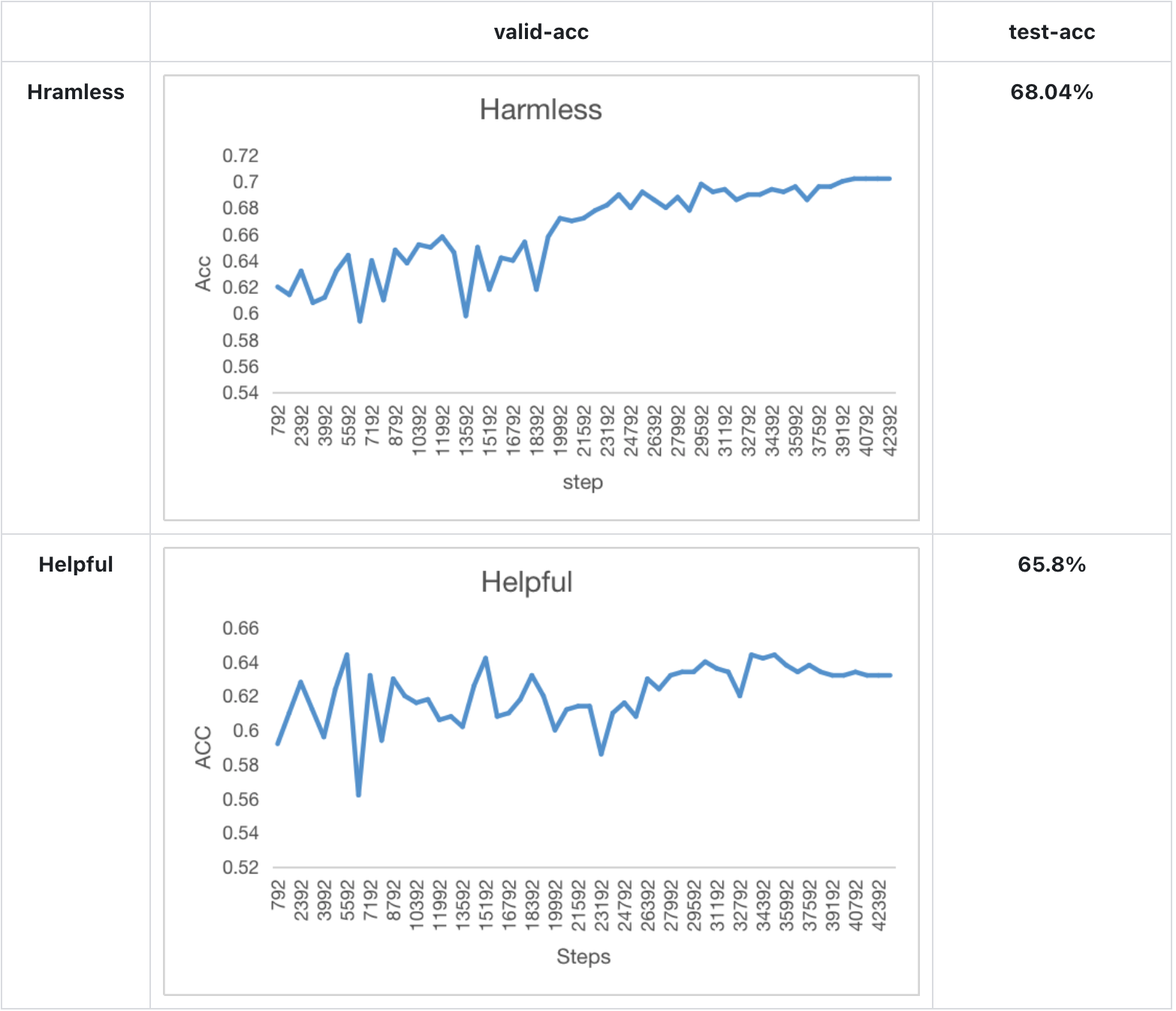
We also train the reward model based on LLaMA-7B, which reaches the ACC of 72.06% after 1 epoch, performing almost the same as Anthropic's best RM.
-## Train with dummy prompt data (Stage 3)
+### Arg List
+- --strategy: the strategy using for training, choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'], default='naive'
+- --model: model type, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
+- --pretrain: pretrain model, type=str, default=None
+- --model_path: the path of rm model(if continue to train), type=str, default=None
+- --save_path: path to save the model, type=str, default='output'
+- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
+- --max_epochs: max epochs for training, type=int, default=3
+- --dataset: dataset name, type=str, choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static']
+- --subset: subset of the dataset, type=str, default=None
+- --batch_size: batch size while training, type=int, default=4
+- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
+- --loss_func: which kind of loss function, choices=['log_sig', 'log_exp']
+- --max_len: max sentence length for generation, type=int, default=512
+- --test: whether is only tesing, if it's ture, the dataset will be small
-This script supports 4 kinds of strategies:
+## Stage3 - Training model using prompts with RL
-- naive
-- ddp
-- colossalai_zero2
-- colossalai_gemini
+Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process, as shown below:
-It uses random generated prompt data.
+
+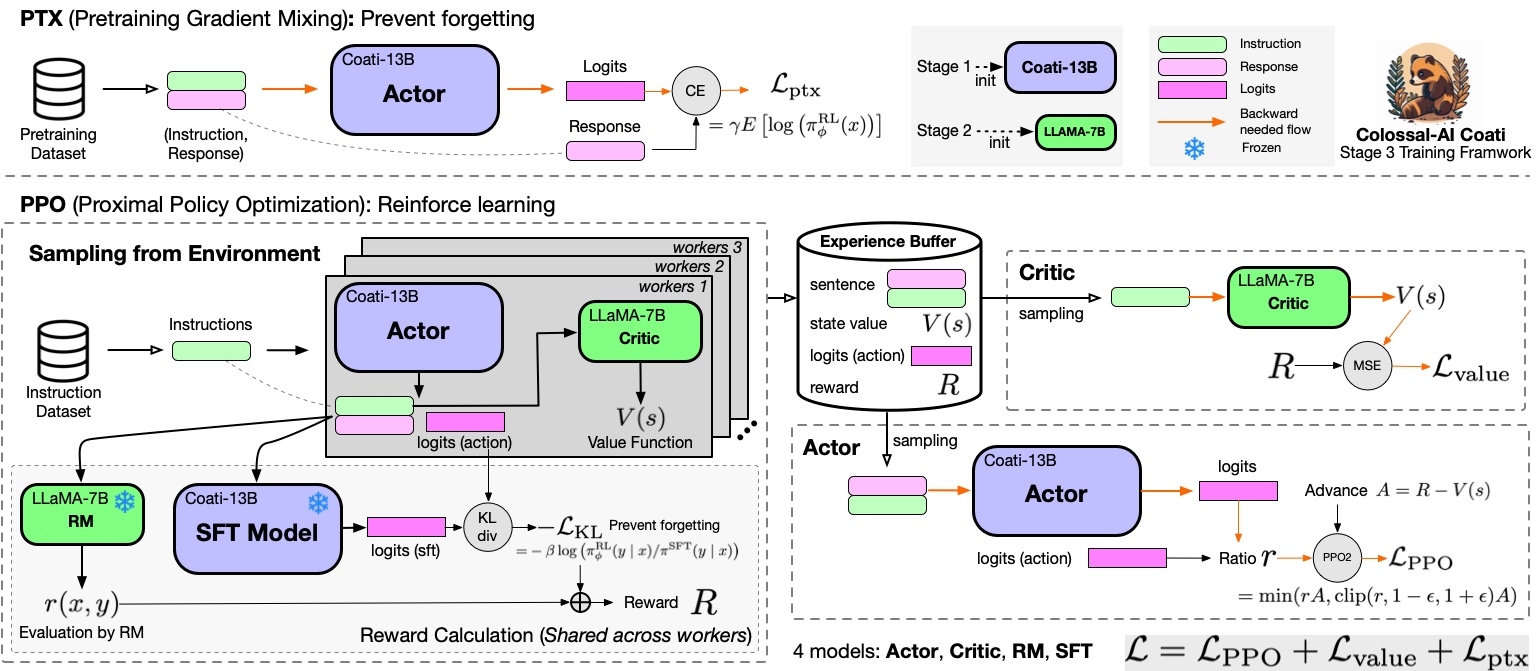 +
+
-Naive strategy only support single GPU training:
+You can run the `examples/train_prompts.sh` to start PPO training.
+You can also use the cmd following to start PPO training.
-```shell
-python train_dummy.py --strategy naive
-# display cli help
-python train_dummy.py -h
```
-
-DDP strategy and ColossalAI strategy support multi GPUs training:
-
-```shell
-# run DDP on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy ddp
-# run ColossalAI on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_dummy.py --strategy colossalai_zero2
+torchrun --standalone --nproc_per_node=4 train_prompts.py \
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy colossalai_zero2 \
+ --prompt_path /path/to/your/prompt_dataset \
+ --pretrain_dataset /path/to/your/pretrain_dataset \
+ --rm_pretrain /your/pretrain/rm/defination \
+ --rm_path /your/rm/model/path
```
+### Arg List
+- --strategy: the strategy using for training, choices=['naive', 'ddp', 'colossalai_gemini', 'colossalai_zero2'], default='naive'
+- --model: model type of actor, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
+- --pretrain: pretrain model, type=str, default=None
+- --rm_pretrain: pretrain model for reward model, type=str, default=None
+- --rm_path: the path of rm model, type=str, default=None
+- --save_path: path to save the model, type=str, default='output'
+- --prompt_path: path of the prompt dataset, type=str, default=None
+- --pretrain_dataset: path of the ptx dataset, type=str, default=None
+- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
+- --num_episodes: num of episodes for training, type=int, default=10
+- --max_epochs: max epochs for training in one episode, type=int, default=5
+- --max_timesteps: max episodes in one batch, type=int, default=10
+- --update_timesteps: timesteps to update, type=int, default=10
+- --train_batch_size: batch size while training, type=int, default=8
+- --ptx_batch_size: batch size to compute ptx loss, type=int, default=1
+- --experience_batch_size: batch size to make experience, type=int, default=8
+- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
+- --kl_coef: kl_coef using for computing reward, type=float, default=0.1
+- --ptx_coef: ptx_coef using for computing policy loss, type=float, default=0.9
-## Train with real prompt data (Stage 3)
+## Inference example - After Stage3
+We support different inference options, including int8 and int4 quantization.
+For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
-We use [awesome-chatgpt-prompts](https://huggingface.co/datasets/fka/awesome-chatgpt-prompts) as example dataset. It is a small dataset with hundreds of prompts.
-
-You should download `prompts.csv` first.
-
-This script also supports 4 strategies.
-
-```shell
-# display cli help
-python train_dummy.py -h
-# run naive on 1 GPU
-python train_prompts.py prompts.csv --strategy naive
-# run DDP on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy ddp
-# run ColossalAI on 2 GPUs
-torchrun --standalone --nproc_per_node=2 train_prompts.py prompts.csv --strategy colossalai_zero2
-```
-
-## Inference example(After Stage3)
-We support naive inference demo after training.
-```shell
-# inference, using pretrain path to configure model
-python inference.py --model_path
--model --pretrain
-# example
-python inference.py --model_path ./actor_checkpoint_prompts.pt --pretrain bigscience/bloom-560m --model bloom
-```
## Attention
-The examples is just a demo for testing our progress of RM and PPO training.
-
+The examples are demos for the whole training process.You need to change the hyper-parameters to reach great performance.
#### data
- [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
@@ -111,25 +166,13 @@ The examples is just a demo for testing our progress of RM and PPO training.
- [ ] GPT2-XL (xl)
- [x] GPT2-4B (4b)
- [ ] GPT2-6B (6b)
-- [ ] GPT2-8B (8b)
-- [ ] GPT2-10B (10b)
-- [ ] GPT2-12B (12b)
-- [ ] GPT2-15B (15b)
-- [ ] GPT2-18B (18b)
-- [ ] GPT2-20B (20b)
-- [ ] GPT2-24B (24b)
-- [ ] GPT2-28B (28b)
-- [ ] GPT2-32B (32b)
-- [ ] GPT2-36B (36b)
-- [ ] GPT2-40B (40b)
-- [ ] GPT3 (175b)
### BLOOM
- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
- [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
- [x] [BLOOM-7b](https://huggingface.co/bigscience/bloom-7b1)
-- [ ] BLOOM-175b
+- [ ] [BLOOM-175b](https://huggingface.co/bigscience/bloom)
### OPT
- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
@@ -139,3 +182,9 @@ The examples is just a demo for testing our progress of RM and PPO training.
- [ ] [OPT-6.7B](https://huggingface.co/facebook/opt-6.7b)
- [ ] [OPT-13B](https://huggingface.co/facebook/opt-13b)
- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
+
+### [LLaMA](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md)
+- [x] LLaMA-7B
+- [x] LLaMA-13B
+- [ ] LLaMA-33B
+- [ ] LLaMA-65B
 +
+ +
+ +
+