diff --git a/README-zh-Hans.md b/README-zh-Hans.md
index 57cf90586..ec9014deb 100644
--- a/README-zh-Hans.md
+++ b/README-zh-Hans.md
@@ -38,12 +38,12 @@
并行训练样例展示
@@ -59,6 +59,7 @@
@@ -102,6 +103,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
- 1维, [2维](https://arxiv.org/abs/2104.05343), [2.5维](https://arxiv.org/abs/2105.14500), [3维](https://arxiv.org/abs/2105.14450) 张量并行
- [序列并行](https://arxiv.org/abs/2105.13120)
- [零冗余优化器 (ZeRO)](https://arxiv.org/abs/1910.02054)
+ - [自动并行](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/gpt/auto_parallel_with_gpt)
- 异构内存管理
- [PatrickStar](https://arxiv.org/abs/2108.05818)
- 使用友好
@@ -113,12 +115,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
(返回顶端)
## 并行训练样例展示
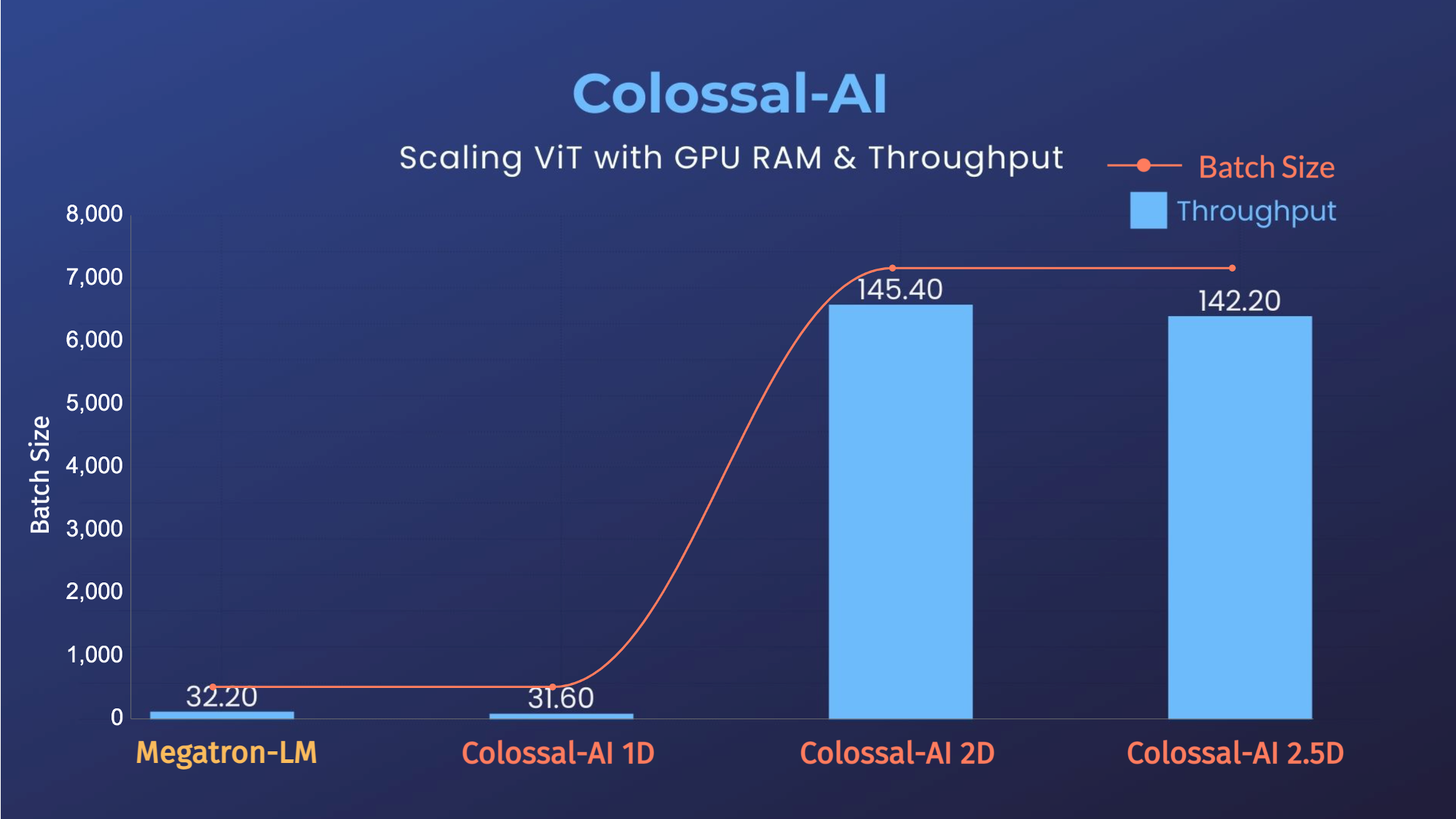
-### ViT
-
- -
-
-- 14倍批大小和5倍训练速度(张量并行=64)
### GPT-3
@@ -153,6 +150,12 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
请访问我们的 [文档](https://www.colossalai.org/) 和 [例程](https://github.com/hpcaitech/ColossalAI-Examples) 以了解详情。
+### ViT
+
+
+
+
+- 14倍批大小和5倍训练速度(张量并行=64)
### 推荐系统模型
- [Cached Embedding](https://github.com/hpcaitech/CachedEmbedding), 使用软件Cache实现Embeddings,用更少GPU显存训练更大的模型。
@@ -199,23 +202,38 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
- [OPT推理服务](https://service.colossalai.org/opt): 无需注册,免费体验1750亿参数OPT在线推理服务
+
+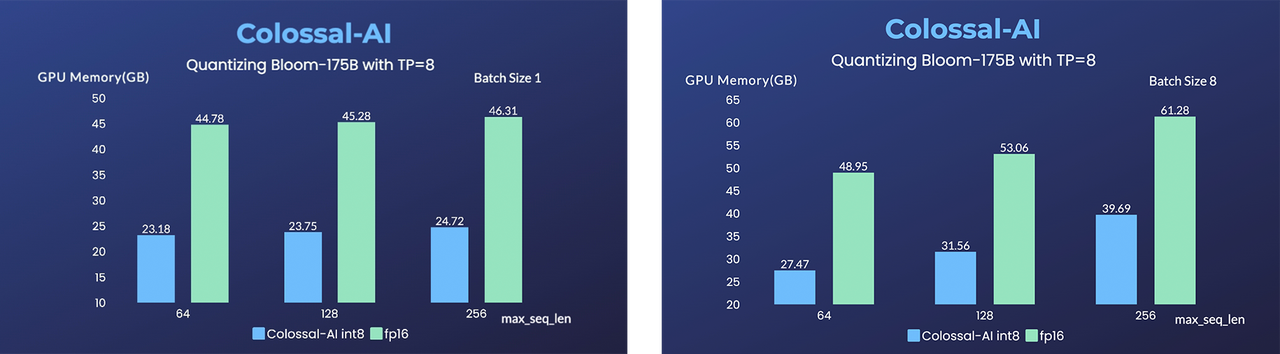 +
+
+
+- [BLOOM](https://github.com/hpcaitech/EnergonAI/tree/main/examples/bloom): 降低1750亿参数BLOOM模型部署推理成本超10倍
(返回顶端)
## Colossal-AI 成功案例
### AIGC
-加速AIGC(AI内容生成)模型,如[Stable Diffusion](https://github.com/CompVis/stable-diffusion)
+加速AIGC(AI内容生成)模型,如[Stable Diffusion v1](https://github.com/CompVis/stable-diffusion) 和 [Stable Diffusion v2](https://github.com/Stability-AI/stablediffusion)
+
-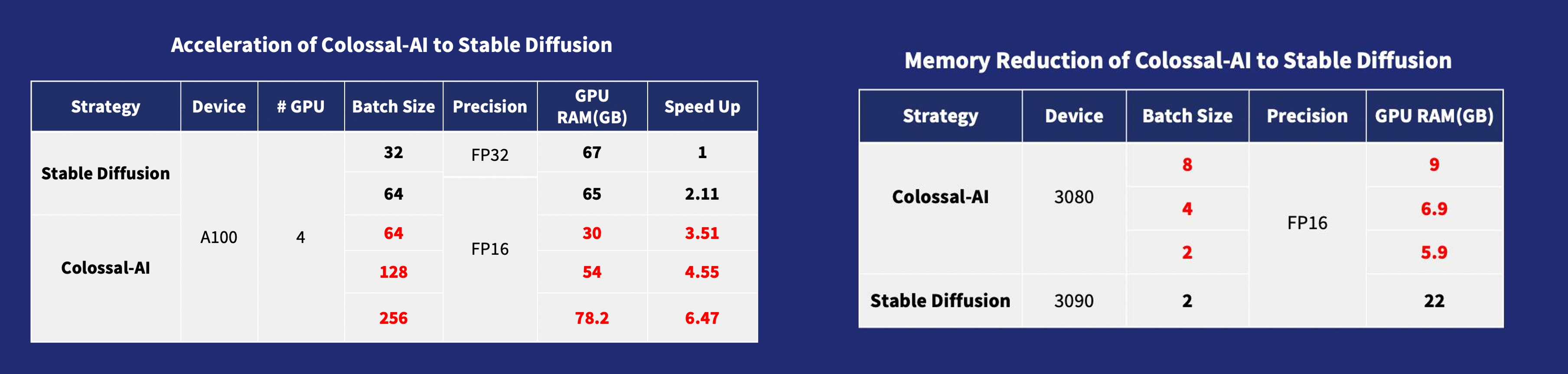 +
+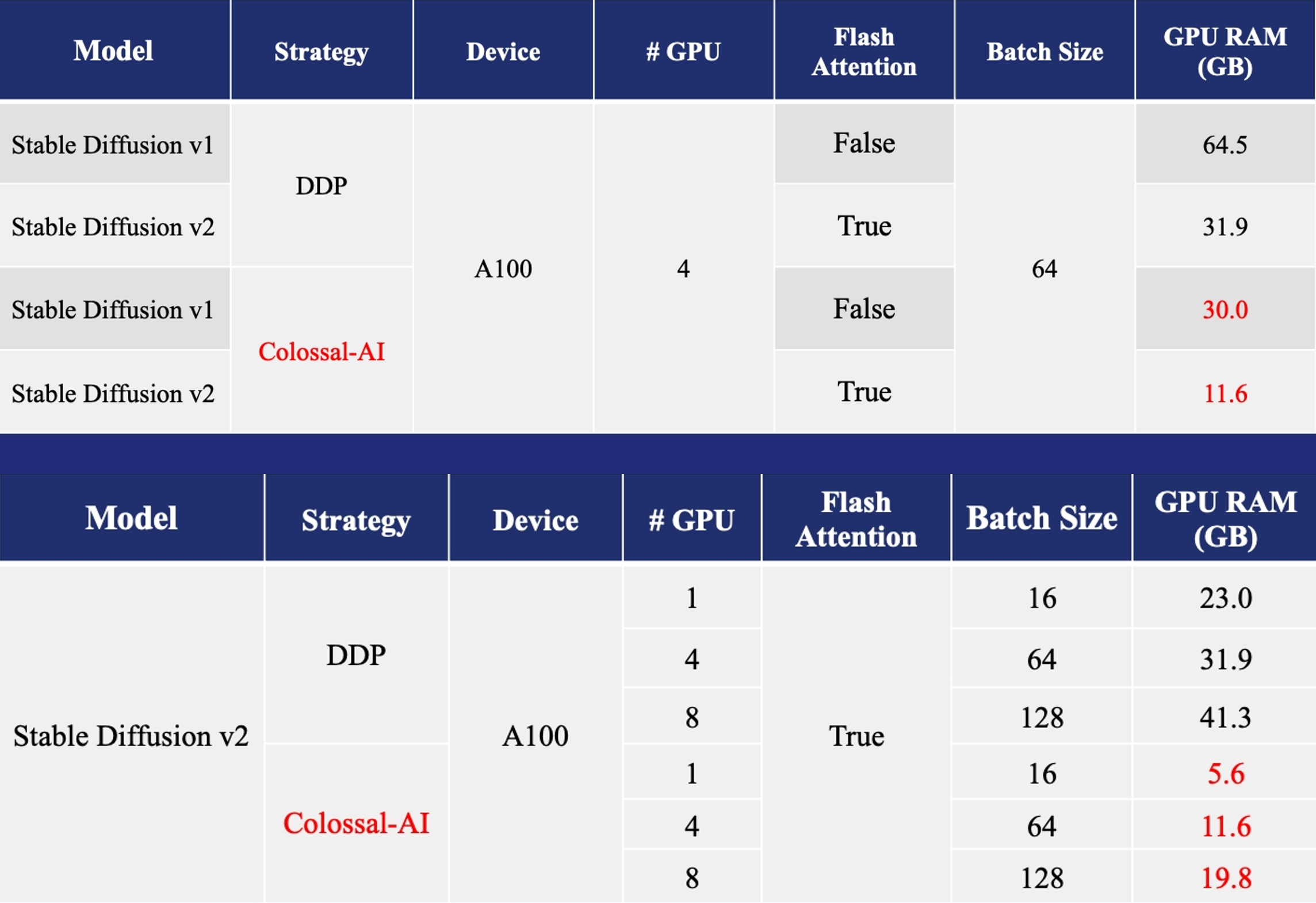
-- [Colossal-AI优化Stable Diffusion](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion): 6.5倍训练加速和预训练成本降低, 微调硬件成本下降约7倍(从RTX3090/4090到RTX3050/2070)
+- [训练](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion): 减少5.6倍显存消耗,硬件成本最高降低46倍(从A100到RTX3060)
- +
+
+- [DreamBooth微调](https://github.com/hpcaitech/ColossalAI/tree/hotfix/doc/examples/images/dreambooth): 仅需3-5张目标主题图像个性化微调
+
+
+ +
+
+
+- [推理](https://github.com/hpcaitech/EnergonAI/tree/main/examples/bloom): GPU推理显存消耗降低2.5倍
+
+
(返回顶端)
### 生物医药
diff --git a/README.md b/README.md
index 36d5c2e82..c58ad5e5c 100644
--- a/README.md
+++ b/README.md
@@ -38,12 +38,12 @@
Parallel Training Demo
@@ -59,6 +59,7 @@
@@ -104,6 +105,7 @@ distributed training and inference in a few lines.
- 1D, [2D](https://arxiv.org/abs/2104.05343), [2.5D](https://arxiv.org/abs/2105.14500), [3D](https://arxiv.org/abs/2105.14450) Tensor Parallelism
- [Sequence Parallelism](https://arxiv.org/abs/2105.13120)
- [Zero Redundancy Optimizer (ZeRO)](https://arxiv.org/abs/1910.02054)
+ - [Auto-Parallelism](https://github.com/hpcaitech/ColossalAI/tree/main/examples/language/gpt/auto_parallel_with_gpt)
- Heterogeneous Memory Management
- [PatrickStar](https://arxiv.org/abs/2108.05818)
@@ -119,12 +121,6 @@ distributed training and inference in a few lines.
(back to top)
## Parallel Training Demo
-### ViT
-
-
-
-
-- 14x larger batch size, and 5x faster training for Tensor Parallelism = 64
### GPT-3
@@ -158,6 +154,13 @@ distributed training and inference in a few lines.
Please visit our [documentation](https://www.colossalai.org/) and [examples](https://github.com/hpcaitech/ColossalAI-Examples) for more details.
+### ViT
+
+
+
+
+- 14x larger batch size, and 5x faster training for Tensor Parallelism = 64
+
### Recommendation System Models
- [Cached Embedding](https://github.com/hpcaitech/CachedEmbedding), utilize software cache to train larger embedding tables with a smaller GPU memory budget.
@@ -202,22 +205,37 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
- [OPT Serving](https://service.colossalai.org/opt): Try 175-billion-parameter OPT online services for free, without any registration whatsoever.
+
+
+
+
+- [BLOOM](https://github.com/hpcaitech/EnergonAI/tree/main/examples/bloom): Reduce hardware deployment costs of 175-billion-parameter BLOOM by more than 10 times.
+
(back to top)
## Colossal-AI in the Real World
### AIGC
-Acceleration of AIGC (AI-Generated Content) models such as [Stable Diffusion](https://github.com/CompVis/stable-diffusion)
+Acceleration of AIGC (AI-Generated Content) models such as [Stable Diffusion v1](https://github.com/CompVis/stable-diffusion) and [Stable Diffusion v2](https://github.com/Stability-AI/stablediffusion).
-
+
-- [Stable Diffusion with Colossal-AI](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion): 6.5x faster training and pretraining cost saving, the hardware cost of fine-tuning can be almost 7X cheaper (from RTX3090/4090 to RTX3050/2070)
+- [Training](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion): Reduce Stable Diffusion memory consumption by up to 5.6x and hardware cost by up to 46x (from A100 to RTX3060).
-
+
+- [DreamBooth Fine-tuning](https://github.com/hpcaitech/ColossalAI/tree/hotfix/doc/examples/images/dreambooth): Personalize your model using just 3-5 images of the desired subject.
+
+
+
+
+
+- [Inference](https://github.com/hpcaitech/EnergonAI/tree/main/examples/bloom): Reduce inference GPU memory consumption by 2.5x.
+
+
(back to top)
### Biomedicine