mirror of https://github.com/hpcaitech/ColossalAI
fix typo change JOSNL TO JSONL etc. (#5116)
parent
2899cfdabf
commit
9110406a47
|
|
@ -57,7 +57,7 @@ We conducted comprehensive evaluation on 4 dataset and compare our Colossal-Llam
|
|||
* We use 5-shot for AGIEval and only calculate scores for 4-choice questions using a combination metric of exact match and the logits of first predicted token. If any of the exact match or logits of first predicted token is correct, the model will get the score.
|
||||
* We use 0-shot for GAOKAO-Bench and only calculate scores for 4-choice questions based on the logits of first predicted token.
|
||||
The generation config for all dataset is greedy search.
|
||||
* We also provided CEval scores from its lastest leaderboard or the official repository of the model.
|
||||
* We also provided CEval scores from its latest leaderboard or the official repository of the model.
|
||||
|
||||
| | Backbone | Tokens Consumed | | MMLU | CMMLU | AGIEval | GAOKAO | CEval |
|
||||
| :----------------------------: | :--------: | :-------------: | :------------------: | :-----------: | :-----: | :----: | :----: | :------------------------------: |
|
||||
|
|
@ -233,7 +233,7 @@ You are allowed to customize the category tags or use `unknown` to define the ca
|
|||
Command to convert jsonl dataset to arrow format:
|
||||
```
|
||||
python prepare_pretrain_dataset.py \
|
||||
--data_input_dirs "<JOSNL_DIR_1>,<JOSNL_DIR_2>,<JOSNL_DIR_3>" \
|
||||
--data_input_dirs "<JSONL_DIR_1>,<JSONL_DIR_2>,<JSONL_DIR_3>" \
|
||||
--tokenizer_dir "<TOKENIZER_DIR>" \
|
||||
--data_cache_dir "jsonl_to_arrow_cache" \
|
||||
--data_jsonl_output_dir "spliced_tokenized_output_jsonl" \
|
||||
|
|
@ -242,7 +242,7 @@ python prepare_pretrain_dataset.py \
|
|||
--num_spliced_dataset_bins 10
|
||||
```
|
||||
Here is details about CLI arguments:
|
||||
* Source data directory: `data_input_dirs`. Each `<JOSNL_DIR>` can have multiple file in `jsonl` format.
|
||||
* Source data directory: `data_input_dirs`. Each `<JSONL_DIR>` can have multiple file in `jsonl` format.
|
||||
* Tokenzier directory: `tokenizer_dir`. Path to the tokenizer in Hugging Face format.
|
||||
* Data cache directory: `data_cache_dir`. Directory to store Hugging Face data cache. Default case will create `cache` folder locally.
|
||||
* Output directory for jsonl format: `data_jsonl_output_dir`. Output directory to store converted dataset in jsonl format.
|
||||
|
|
|
|||
|
|
@ -6,33 +6,34 @@
|
|||
|
||||
## Table of Contents
|
||||
|
||||
- [Table of Contents](#table-of-contents)
|
||||
- [Overview](#overview)
|
||||
- [Leaderboard](#leaderboard)
|
||||
- [Install](#install)
|
||||
- [Evaluation Process](#evaluation-process)
|
||||
- [Inference](#inference)
|
||||
- [Dataset Preparation](#dataset-preparation)
|
||||
- [Dataset Preparation](#dataset-preparation)
|
||||
- [Configuration](#configuration)
|
||||
- [How to Use](#how-to-use)
|
||||
- [Evaluation](#evaluation)
|
||||
- [Dataset Evaluation](#dataset-evaluation)
|
||||
- [Configuration](#dataset-evaluation)
|
||||
- [How to Use](#dataset-evaluation)
|
||||
- [Configuration](#configuration-1)
|
||||
- [How to Use](#how-to-use-1)
|
||||
- [GPT Evaluation](#gpt-evaluation)
|
||||
- [Configuration](#gpt-evaluation)
|
||||
- [How to Use](#gpt-evaluation)
|
||||
- [Configuration](#configuration-2)
|
||||
- [How to Use](#how-to-use-2)
|
||||
- [More Details](#more-details)
|
||||
- [Inference Details](#inference-details)
|
||||
- [Evaluation Details](#evaluation-details)
|
||||
- [Inference](#inference-1)
|
||||
- [Evaluation](#evaluation-1)
|
||||
- [Metrics](#metrics)
|
||||
- [examples](#examples)
|
||||
- [Examples](#examples)
|
||||
- [Dataset Evaluation Example](#dataset-evaluation-example)
|
||||
- [GPT Evaluation Example](#gpt-evaluation-example)
|
||||
- [To Do](#to-do)
|
||||
- [FAQ](#faq)
|
||||
- [How to Add a New Metric?](#how-to-add-a-new-metric)
|
||||
- [How to Add a New Dataset?](#how-to-add-a-new-dataset)
|
||||
- [How to Add a New Model?](#how-to-add-a-new-model)
|
||||
- [To do](#to-do)
|
||||
- [Citations](#citations)
|
||||
|
||||
## Overview
|
||||
|
|
@ -47,7 +48,7 @@ We conducted comprehensive evaluation on 4 dataset and compare our Colossal-Llam
|
|||
- We use 5-shot for AGIEval and only calculate scores for 4-choice questions using a combination metric of exact match and the logits of first predicted token. If any of the exact match or logits of first predicted token is correct, the model will get the score.
|
||||
- We use 0-shot for GAOKAO-Bench and only calculate scores for 4-choice questions based on the logits of first predicted token.
|
||||
- The generation config for all dataset is greedy search.
|
||||
- We also provided CEval scores from its lastest leaderboard or the official repository of the model.
|
||||
- We also provided CEval scores from its latest leaderboard or the official repository of the model.
|
||||
|
||||
More details about metrics can be found in [Metrics](#metrics).
|
||||
|
||||
|
|
|
|||
|
|
@ -36,25 +36,25 @@ A successful retrieval QA system starts with high-quality data. You need a colle
|
|||
|
||||
#### Step 2: Split Data
|
||||
|
||||
Document data is usually too long to fit into the prompt due to the context length limitation of LLMs. Supporting documents need to be splited into short chunks before constructing vector stores. In this demo, we use neural text spliter for better performance.
|
||||
Document data is usually too long to fit into the prompt due to the context length limitation of LLMs. Supporting documents need to be split into short chunks before constructing vector stores. In this demo, we use neural text splitter for better performance.
|
||||
|
||||
#### Step 3: Construct Vector Stores
|
||||
Choose a embedding function and embed your text chunk into high dimensional vectors. Once you have vectors for your documents, you need to create a vector store. The vector store should efficiently index and retrieve documents based on vector similarity. In this demo, we use [Chroma](https://python.langchain.com/docs/integrations/vectorstores/chroma) and incrementally update indexes of vector stores. Through incremental update, one can update and maintain a vector store without recalculating every embedding.
|
||||
You are free to choose any vectorstore from a varity of [vector stores](https://python.langchain.com/docs/integrations/vectorstores/) supported by Langchain. However, the incremental update only works with LangChain vectorstore's that support:
|
||||
You are free to choose any vector store from a variety of [vector stores](https://python.langchain.com/docs/integrations/vectorstores/) supported by Langchain. However, the incremental update only works with LangChain vector stores that support:
|
||||
- Document addition by id (add_documents method with ids argument)
|
||||
- Delete by id (delete method with)
|
||||
|
||||
#### Step 4: Retrieve Relative Text
|
||||
Upon querying, we will run a reference resolution on user's input, the goal of this step is to remove ambiguous reference in user's query such as "this company", "him". We then embed the query with the same embedding function and query the vectorstore to retrieve the top-k most similar documents.
|
||||
Upon querying, we will run a reference resolution on user's input, the goal of this step is to remove ambiguous reference in user's query such as "this company", "him". We then embed the query with the same embedding function and query the vector store to retrieve the top-k most similar documents.
|
||||
|
||||
#### Step 5: Format Prompt
|
||||
The prompt carries essential information including task description, conversation history, retrived documents, and user's query for the LLM to generate a response. Please refer to this [README](./colossalqa/prompt/README.md) for more details.
|
||||
The prompt carries essential information including task description, conversation history, retrieved documents, and user's query for the LLM to generate a response. Please refer to this [README](./colossalqa/prompt/README.md) for more details.
|
||||
|
||||
#### Step 6: Inference
|
||||
Pass the prompt to the LLM with additional generaton arguments to get agent response. You can control the generation with additional arguments such as temperature, top_k, top_p, max_new_tokens. You can also define when to stop by passing the stop substring to the retrieval QA chain.
|
||||
Pass the prompt to the LLM with additional generation arguments to get agent response. You can control the generation with additional arguments such as temperature, top_k, top_p, max_new_tokens. You can also define when to stop by passing the stop substring to the retrieval QA chain.
|
||||
|
||||
#### Step 7: Update Memory
|
||||
We designed a memory module that automatically summarize overlength conversation to fit the max context length of LLM. In this step, we update the memory with the newly generated response. To fix into the context length of a given LLM, we sumarize the overlength part of historical conversation and present the rest in round-based conversation format. Fig.2. shows how the memory is updated. Please refer to this [README](./colossalqa/prompt/README.md) for dialogue format.
|
||||
We designed a memory module that automatically summarize overlength conversation to fit the max context length of LLM. In this step, we update the memory with the newly generated response. To fix into the context length of a given LLM, we summarize the overlength part of historical conversation and present the rest in round-based conversation format. Fig.2. shows how the memory is updated. Please refer to this [README](./colossalqa/prompt/README.md) for dialogue format.
|
||||
|
||||

|
||||
<p align="center">
|
||||
|
|
@ -83,7 +83,7 @@ from langchain.llms import OpenAI
|
|||
llm = OpenAI(openai_api_key="YOUR_OPENAI_API_KEY")
|
||||
|
||||
# For Pangu LLM
|
||||
# set up your authentification info
|
||||
# set up your authentication info
|
||||
from colossalqa.local.pangu_llm import Pangu
|
||||
os.environ["URL"] = ""
|
||||
os.environ["URLNAME"] = ""
|
||||
|
|
@ -123,7 +123,7 @@ Read comments under ./colossalqa/data_loader for more detail regarding supported
|
|||
We provide a simple Web UI demo of ColossalQA, enabling you to upload your files as a knowledge base and interact with them through a chat interface in your browser. More details can be found [here](examples/webui_demo/README.md)
|
||||
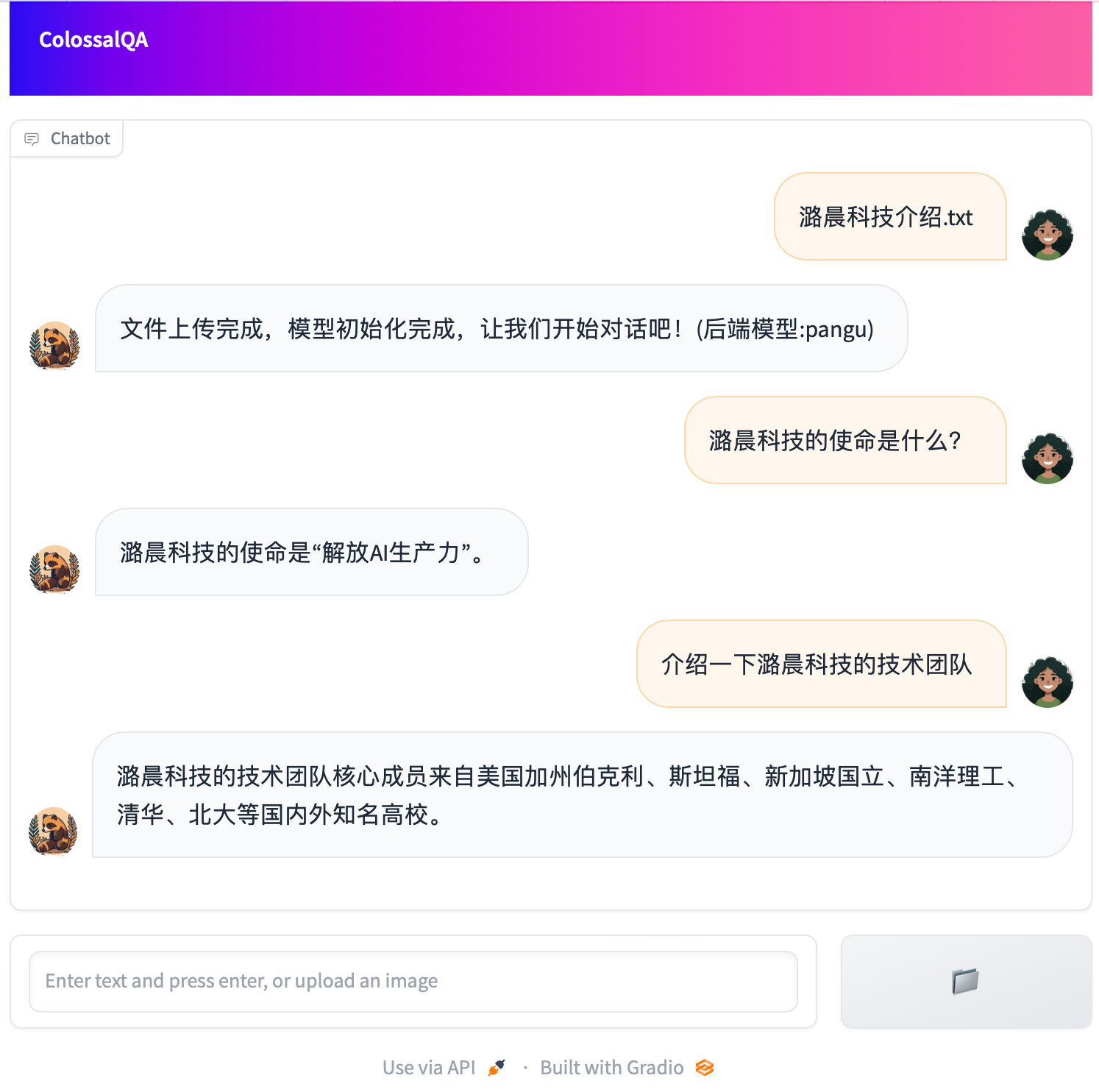
|
||||
|
||||
We also provided some scripts for Chinese document retrieval based conversation system, English document retrieval based conversation system, Bi-lingual document retrieval based conversation system and an experimental AI agent with document retrieval and SQL query functionality. The Bi-lingual one is a high-level wrapper for the other two clases. We write different scripts for different languages because retrieval QA requires different embedding models, LLMs, prompts for different language setting. For now, we use LLaMa2 for English retrieval QA and ChatGLM2 for Chinese retrieval QA for better performance.
|
||||
We also provided some scripts for Chinese document retrieval based conversation system, English document retrieval based conversation system, Bi-lingual document retrieval based conversation system and an experimental AI agent with document retrieval and SQL query functionality. The Bi-lingual one is a high-level wrapper for the other two classes. We write different scripts for different languages because retrieval QA requires different embedding models, LLMs, prompts for different language setting. For now, we use LLaMa2 for English retrieval QA and ChatGLM2 for Chinese retrieval QA for better performance.
|
||||
|
||||
To run the bi-lingual scripts.
|
||||
```bash
|
||||
|
|
@ -164,7 +164,7 @@ python conversation_agent_chatgpt.py \
|
|||
--open_ai_key_path /path/to/plain/text/openai/key/file
|
||||
```
|
||||
|
||||
After runing the script, it will ask you to provide the path to your data during the execution of the script. You can also pass a glob path to load multiple files at once. Please read this [guide](https://docs.python.org/3/library/glob.html) on how to define glob path. Follow the instruction and provide all files for your retrieval conversation system then type "ESC" to finish loading documents. If csv files are provided, please use "," as delimiter and "\"" as quotation mark. For json and jsonl files. The default format is
|
||||
After running the script, it will ask you to provide the path to your data during the execution of the script. You can also pass a glob path to load multiple files at once. Please read this [guide](https://docs.python.org/3/library/glob.html) on how to define glob path. Follow the instruction and provide all files for your retrieval conversation system then type "ESC" to finish loading documents. If csv files are provided, please use "," as delimiter and "\"" as quotation mark. For json and jsonl files. The default format is
|
||||
```
|
||||
{
|
||||
"data":[
|
||||
|
|
|
|||
Loading…
Reference in New Issue