diff --git a/examples/language/llama2/README.md b/examples/language/llama2/README.md
index b64b5d29e..483eae88a 100644
--- a/examples/language/llama2/README.md
+++ b/examples/language/llama2/README.md
@@ -1,4 +1,22 @@
-# Pretraining LLaMA-2: best practices for building LLaMA-2-like base models
+# Pretraining LLaMA-1/2: best practices for building LLaMA-1/2-like base models
+
+### LLaMA2
+
+ +
+
+
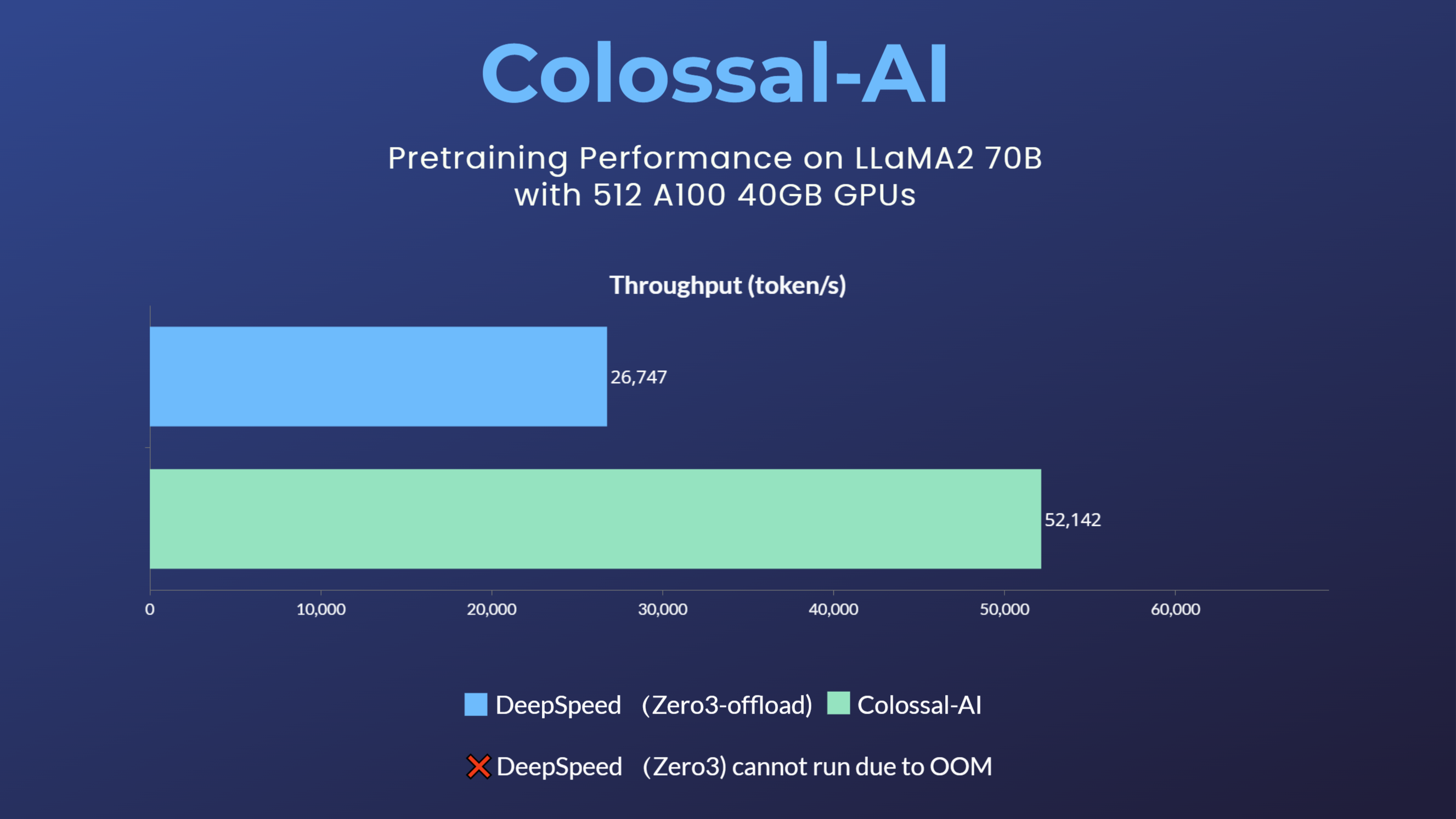
+- 70 billion parameter LLaMA2 model training accelerated by 195%
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama)
+[[blog]](https://www.hpc-ai.tech/blog/70b-llama2-training)
+
+### LLaMA1
+
+ +
+
+
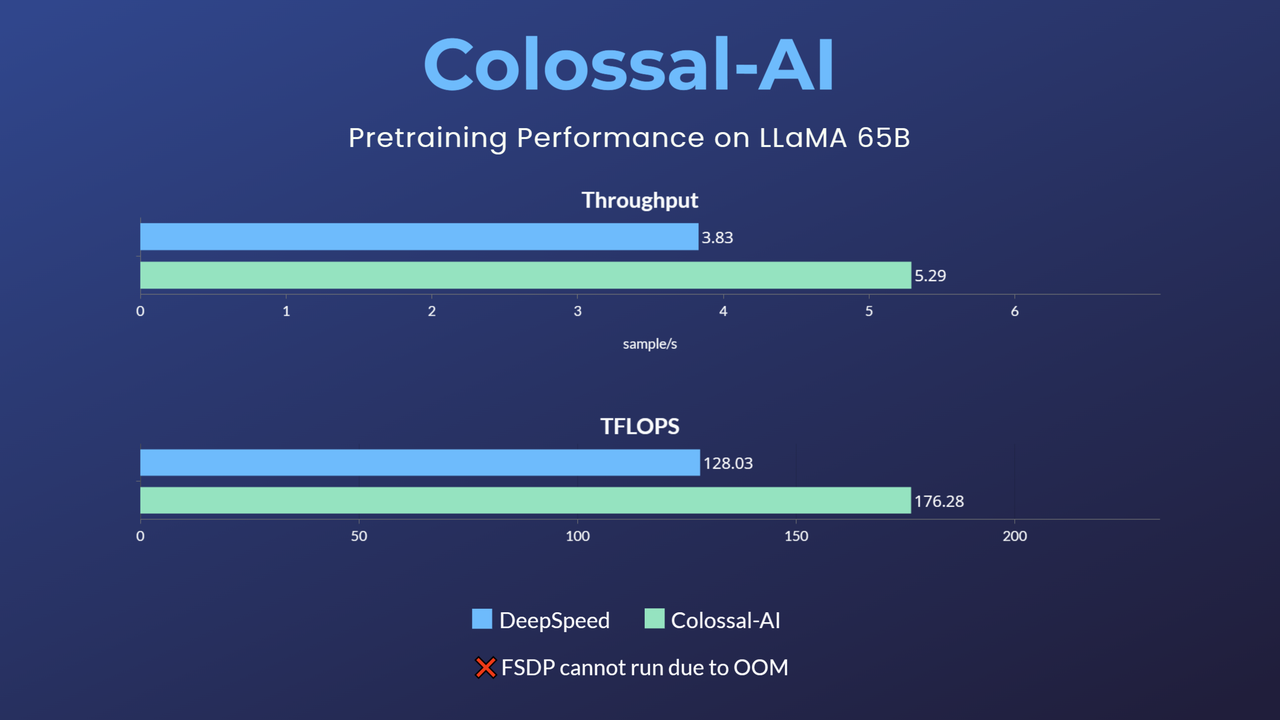
+- 65-billion-parameter large model pretraining accelerated by 38%
+[[code]](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama)
+[[blog]](https://www.hpc-ai.tech/blog/large-model-pretraining)
## Dataset
@@ -73,7 +91,7 @@ Make sure master node can access all nodes (including itself) by ssh without pas
Here is details about CLI arguments:
-- Model configuration: `-c`, `--config`. `7b`, `13b`, `30b` and `65b` are supported.
+- Model configuration: `-c`, `--config`. `7b`, `13b`, `30b` and `65b` are supported for LLaMA-1, `7b`, `13b`, and `70b` are supported for LLaMA-2.
- Booster plugin: `-p`, `--plugin`. `gemini`, `gemini_auto`, `zero2` and `zero2_cpu` are supported. For more details, please refer to [Booster plugins](https://colossalai.org/docs/basics/booster_plugins).
- Dataset path: `-d`, `--dataset`. The default dataset is `togethercomputer/RedPajama-Data-1T-Sample`. It support any dataset from `datasets` with the same data format as RedPajama.
- Number of epochs: `-e`, `--num_epochs`. The default value is 1.
@@ -105,7 +123,7 @@ Here we will show an example of how to run training
llama pretraining with `gemini, batch_size=16, sequence_length=4096, gradient_checkpoint=True, flash_attn=True`.
#### a. Running environment
-This experiment was performed on 4 computing nodes with 32 A800 GPUs in total. The nodes are
+This experiment was performed on 4 computing nodes with 32 A800 GPUs in total for LLaMA-1 65B. The nodes are
connected with RDMA and GPUs within one node are fully connected with NVLink.
#### b. Running command