diff --git a/applications/ColossalChat/README.md b/applications/ColossalChat/README.md
index 769f0b3d0..81009da9d 100755
--- a/applications/ColossalChat/README.md
+++ b/applications/ColossalChat/README.md
@@ -264,7 +264,10 @@ experience buffer size
## Alternative Option For RLHF: Direct Preference Optimization
-For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in the paper (available at [https://arxiv.org/abs/2305.18290](https://arxiv.org/abs/2305.18290)), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO.
+For those seeking an alternative to Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO) presents a compelling option. DPO, as detailed in this [paper](https://arxiv.org/abs/2305.18290), DPO offers an low-cost way to perform RLHF and usually request less computation resources compares to PPO.
+
+## Alternative Option For RLHF: Simple Preference Optimization
+Simple Preference Optimization (SimPO) from this [paper](https://arxiv.org/pdf/2405.14734) is similar to DPO but it abandons the use of the reference model, which makes the training more efficient. It also adds a reward shaping term called target reward margin to enhance training stability. It also use length normalization to better align with the inference process.
### DPO Training Stage1 - Supervised Instructs Tuning
@@ -522,7 +525,7 @@ Coati is developed by ColossalAI Team:
- [Fazzie](https://fazzie-key.cool/about/index.html) Contributing to the algorithm and development for SFT.
- [ofey404](https://github.com/ofey404) Contributing to both front-end and back-end development.
- [Wenhao Chen](https://github.com/CWHer) Contributing to subsequent code enhancements and performance improvements.
-- [Anbang Ye](https://github.com/YeAnbang) Contributing to the refactored version with updated acceleration framework, LoRA, DPO and PPO.
+- [Anbang Ye](https://github.com/YeAnbang) Contributing to the refactored PPO version with updated acceleration framework. Add support for DPO, SimPO.
The PhD student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
- [Zangwei Zheng](https://github.com/zhengzangw)
diff --git a/applications/ColossalChat/coati/models/loss.py b/applications/ColossalChat/coati/models/loss.py
index aaef447a4..fd5c82efc 100755
--- a/applications/ColossalChat/coati/models/loss.py
+++ b/applications/ColossalChat/coati/models/loss.py
@@ -88,11 +88,22 @@ class DpoLoss(nn.Module):
"""
Dpo loss
Details: https://arxiv.org/pdf/2305.18290.pdf
+
+ SimPO loss:
+ Details: https://arxiv.org/pdf/2405.14734.pdf
"""
- def __init__(self, beta: float = 0.1):
+ def __init__(self, beta: float = 0.1, gamma: float = 0.0):
+ """
+ Args:
+ beta: The temperature parameter in the DPO paper.
+ gamma: The margin parameter in the SimPO paper.
+ length_normalization: Whether to normalize the loss by the length of chosen and rejected responses.
+ Refer to the length normalization in the SimPO paper
+ """
super().__init__()
self.beta = beta
+ self.gamma = gamma
def forward(
self,
@@ -103,7 +114,7 @@ class DpoLoss(nn.Module):
chosen_mask: torch.Tensor,
reject_mask: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
- """Compute the DPO loss for a batch of policy and reference model log probabilities.
+ """Compute the DPO/SimPO loss for a batch of policy and reference model log probabilities.
# adapted from https://github.com/huggingface/trl/blob/main/trl/trainer/dpo_trainer.py#L328
@@ -112,6 +123,8 @@ class DpoLoss(nn.Module):
logprob_actor_reject: Log probabilities of the policy model for the rejected responses. Shape: (batch_size,)
logprob_ref_chosen: Log probabilities of the reference model for the chosen responses. Shape: (batch_size,)
logprob_ref_reject: Log probabilities of the reference model for the rejected responses. Shape: (batch_size,)
+ chosen_mask: Mask tensor indicating which responses were chosen. Shape: (batch_size,)
+ reject_mask: Mask tensor indicating which responses were rejected. Shape: (batch_size,)
Returns:
A tuple of three tensors: (losses, chosen_rewards, rejected_rewards).
@@ -126,13 +139,12 @@ class DpoLoss(nn.Module):
if len(logprob_ref_chosen.shape) == 2:
ref_logratios = logprob_ref_chosen.sum(-1) - logprob_ref_reject.sum(-1)
else:
- ref_logratios = logprob_ref_chosen.squeeze() - logprob_ref_reject.squeeze()
+ ref_logratios = logprob_ref_chosen - logprob_ref_reject
else:
# If no reference model is provided
ref_logratios = 0.0
-
pi_logratios = logprob_actor_chosen.sum(-1) - logprob_actor_reject.sum(-1)
- logits = pi_logratios - ref_logratios
+ logits = pi_logratios - ref_logratios - self.gamma / self.beta
losses = -torch.nn.functional.logsigmoid(self.beta * logits)
# Calculate rewards for logging
diff --git a/applications/ColossalChat/coati/models/utils.py b/applications/ColossalChat/coati/models/utils.py
index ce672534c..e3df0b148 100755
--- a/applications/ColossalChat/coati/models/utils.py
+++ b/applications/ColossalChat/coati/models/utils.py
@@ -89,7 +89,9 @@ def masked_mean(tensor: torch.Tensor, mask: torch.Tensor, dim: int = 1) -> torch
return mean
-def calc_masked_log_probs(logits: torch.Tensor, sequences: torch.LongTensor, mask: torch.Tensor) -> torch.Tensor:
+def calc_masked_log_probs(
+ logits: torch.Tensor, sequences: torch.LongTensor, mask: torch.Tensor, length_normalization: bool = False
+) -> torch.Tensor:
"""
Calculate the masked log probabilities for a given sequence of logits.
@@ -103,7 +105,13 @@ def calc_masked_log_probs(logits: torch.Tensor, sequences: torch.LongTensor, mas
"""
# logits are probabilities of the next token, so we shift them to the left by one
log_probs = _log_probs_from_logits(logits[:, :-1, :], sequences[:, 1:])
- return log_probs * mask
+
+ if not length_normalization:
+ return log_probs * mask
+ else:
+ if torch.any(mask.sum(dim=-1) == 0):
+ print("Mask should not be all zeros.")
+ return log_probs * mask / (mask.sum(dim=-1, keepdim=True) + 0.01)
def load_json(file_path: Union[str, os.PathLike]) -> Dict[str, Any]:
diff --git a/applications/ColossalChat/coati/trainer/dpo.py b/applications/ColossalChat/coati/trainer/dpo.py
index cbe7d7ca8..97552fa7a 100755
--- a/applications/ColossalChat/coati/trainer/dpo.py
+++ b/applications/ColossalChat/coati/trainer/dpo.py
@@ -53,6 +53,8 @@ class DPOTrainer(SLTrainer):
tokenizer: PreTrainedTokenizerBase,
max_epochs: int = 1,
beta: float = 0.1,
+ gamma: float = 0.0,
+ length_normalization: bool = False,
accumulation_steps: int = 1,
start_epoch: int = 0,
save_interval: int = 0,
@@ -63,7 +65,7 @@ class DPOTrainer(SLTrainer):
self.ref_model = ref_model
self.actor_scheduler = actor_lr_scheduler
self.tokenizer = tokenizer
- self.actor_loss_fn = DpoLoss(beta)
+ self.actor_loss_fn = DpoLoss(beta, gamma)
self.save_interval = save_interval
self.coordinator = coordinator
self.save_dir = save_dir
@@ -71,6 +73,7 @@ class DPOTrainer(SLTrainer):
self.accumulation_steps = accumulation_steps
self.device = get_current_device()
self.accumulative_meter = AccumulativeMeanMeter()
+ self.length_normalization = length_normalization
def _before_fit(
self,
@@ -140,9 +143,13 @@ class DPOTrainer(SLTrainer):
)["logits"].to(torch.float32)
actor_chosen_logits = actor_all_logits[:batch_size]
actor_reject_logits = actor_all_logits[batch_size:]
- logprob_actor_chosen = calc_masked_log_probs(actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:])
+ logprob_actor_chosen = calc_masked_log_probs(
+ actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
+ )
- logprob_actor_reject = calc_masked_log_probs(actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:])
+ logprob_actor_reject = calc_masked_log_probs(
+ actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
+ )
if self.ref_model is not None:
self.ref_model.eval()
@@ -154,10 +161,10 @@ class DPOTrainer(SLTrainer):
ref_chosen_logits = ref_all_logits[:batch_size]
ref_reject_logits = ref_all_logits[batch_size:]
logprob_ref_chosen = calc_masked_log_probs(
- ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:]
+ ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
)
logprob_ref_reject = calc_masked_log_probs(
- ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:]
+ ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
)
else:
logprob_ref_chosen = None
@@ -288,11 +295,11 @@ class DPOTrainer(SLTrainer):
actor_reject_logits = actor_all_logits[batch_size:]
logprob_actor_chosen = calc_masked_log_probs(
- actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:]
+ actor_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
)
logprob_actor_reject = calc_masked_log_probs(
- actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:]
+ actor_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
)
self.ref_model.eval()
@@ -303,8 +310,12 @@ class DPOTrainer(SLTrainer):
)["logits"].to(torch.float32)
ref_chosen_logits = ref_all_logits[:batch_size]
ref_reject_logits = ref_all_logits[batch_size:]
- logprob_ref_chosen = calc_masked_log_probs(ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:])
- logprob_ref_reject = calc_masked_log_probs(ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:])
+ logprob_ref_chosen = calc_masked_log_probs(
+ ref_chosen_logits, chosen_input_ids, chosen_loss_mask[:, 1:], self.length_normalization
+ )
+ logprob_ref_reject = calc_masked_log_probs(
+ ref_reject_logits, reject_input_ids, reject_loss_mask[:, 1:], self.length_normalization
+ )
losses, chosen_rewards, rejected_rewards = self.actor_loss_fn(
logprob_actor_chosen,
diff --git a/applications/ColossalChat/coati/trainer/sft.py b/applications/ColossalChat/coati/trainer/sft.py
index c95f5b65a..08a4d4d1a 100755
--- a/applications/ColossalChat/coati/trainer/sft.py
+++ b/applications/ColossalChat/coati/trainer/sft.py
@@ -102,6 +102,8 @@ class SFTTrainer(SLTrainer):
batch_size = batch["input_ids"].size(0)
outputs = self.model(batch["input_ids"], attention_mask=batch["attention_mask"], labels=batch["labels"])
loss = outputs.loss
+ step_bar.set_description(f"Epoch {epoch + 1}/{self.max_epochs} Loss: {loss.detach().cpu().item():.4f}")
+
self.booster.backward(loss=loss, optimizer=self.optimizer)
loss_mean = all_reduce_mean(tensor=loss)
diff --git a/applications/ColossalChat/examples/README.md b/applications/ColossalChat/examples/README.md
index a29fc7508..1a7ddd5a0 100755
--- a/applications/ColossalChat/examples/README.md
+++ b/applications/ColossalChat/examples/README.md
@@ -29,6 +29,7 @@
- [Alternative Option For RLHF: Direct Preference Optimization](#alternative-option-for-rlhf-direct-preference-optimization)
- [DPO Stage 1: Supervised Instruction Tuning](#dpo-training-stage1---supervised-instructs-tuning)
- [DPO Stage 2: DPO Training](#dpo-training-stage2---dpo-training)
+ - [Alternative Option For RLHF: Simple Preference Optimization](#alternative-option-for-rlhf-simple-preference-optimization)
- [List of Supported Models](#list-of-supported-models)
- [Hardware Requirements](#hardware-requirements)
- [Inference example](#inference-example)
@@ -717,14 +718,29 @@ For DPO training, you only need the preference dataset. Please follow the instru
#### Step 2: Training
-You can run the [train_dpo.sh](./examples/training_scripts/train_dpo.sh) to start DPO training. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options.
+You can run the [train_dpo.sh](./examples/training_scripts/train_dpo.sh) to start DPO training. Please refer to the [training configuration](#training-configuration) section for details regarding supported training options. Following the trend of recent research on DPO-like alignment methods, we added option for the user to choose from, including whether to do length normalization , reward shaping and whether to use a reference model in calculating implicit reward. Here are those options,
+```
+--beta 0.1 \ # the temperature in DPO loss, Default to 0.1
+--gamma 0.0 \ # the reward target margin in the SimPO paper, Default to 0.
+--disable_reference_model \ # whether to disable the reference model, if set, the implicit reward will be calculated solely from the actor. Default to enable reference model in DPO
+--length_normalization \ # whether to apply length normalization, Default to not use
+```
#### DPO Result
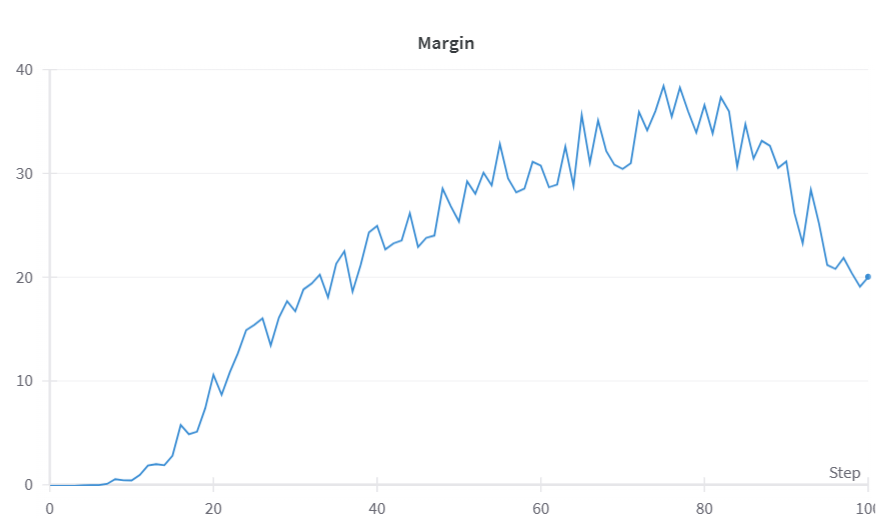
+### Alternative Option For RLHF: Simple Preference Optimization
+
+We support the method introduced in the paper [SimPO: Simple Preference Optimization
+with a Reference-Free Reward](https://arxiv.org/pdf/2405.14734) (SimPO). Which is a reference model free aligment method that add length normalization and reward shaping to the DPO loss to enhance training stability and efficiency. As the method doesn't deviate too much from DPO, we add support for length normalization and SimPO reward shaping in our DPO implementation. Simply set the flag to disable the use of the reference model, set the reward target margin and enable length normalization in the DPO training script.
+
+#### SimPO Result
+
+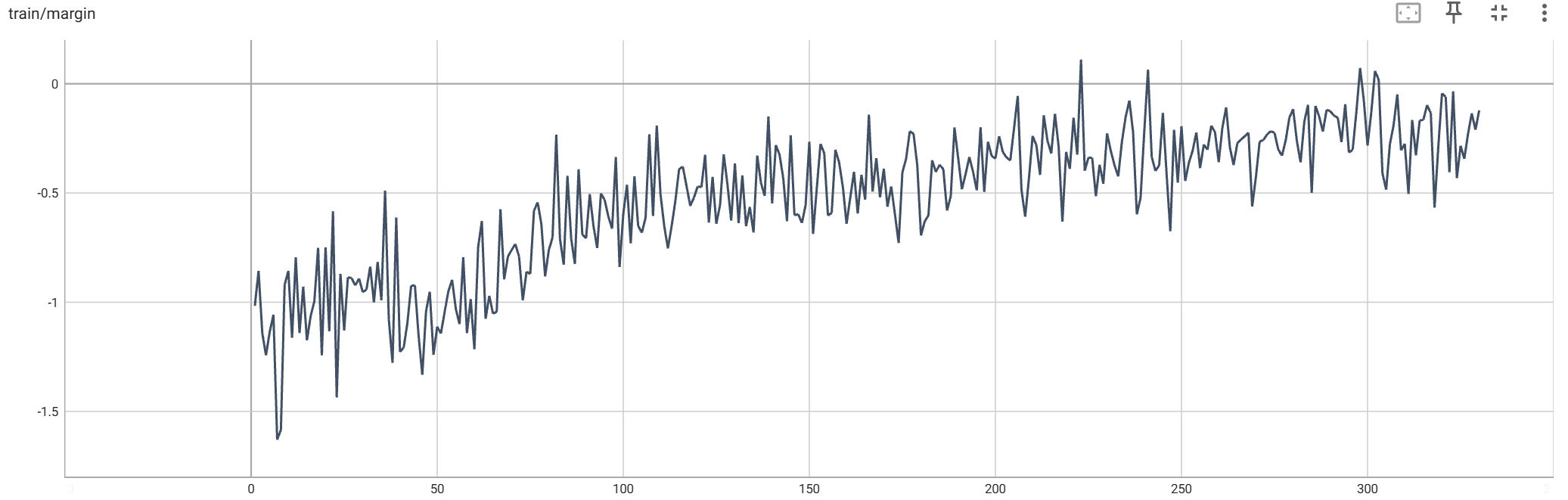 +
+
## Hardware Requirements
For PPO, we suggest using Tensor Parallelism. The following table shows the VRAM consumption of training a 7B model on a dummy dataset with 2048 sequence length and 512 layout length with different tp_size (equal to the number of GPUs). In this experiment, we use an H800 GPU with 80GB VRAM.
diff --git a/applications/ColossalChat/examples/data_preparation_scripts/prepare_preference_dataset.sh b/applications/ColossalChat/examples/data_preparation_scripts/prepare_preference_dataset.sh
index 999d7778b..b6546a21e 100755
--- a/applications/ColossalChat/examples/data_preparation_scripts/prepare_preference_dataset.sh
+++ b/applications/ColossalChat/examples/data_preparation_scripts/prepare_preference_dataset.sh
@@ -5,7 +5,7 @@ rm -rf $SAVE_DIR/jsonl
rm -rf $SAVE_DIR/arrow
python prepare_dataset.py --type preference \
- --data_input_dirs "PATH/TO/PREFERENCE/DATA" \
+ --data_input_dirs /PATH/TO/PREFERENCE/DATASET \
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
--tokenizer_dir "" \
--data_cache_dir $SAVE_DIR/cache \
diff --git a/applications/ColossalChat/examples/data_preparation_scripts/prepare_sft_dataset.sh b/applications/ColossalChat/examples/data_preparation_scripts/prepare_sft_dataset.sh
index 8562b47ee..25874f077 100755
--- a/applications/ColossalChat/examples/data_preparation_scripts/prepare_sft_dataset.sh
+++ b/applications/ColossalChat/examples/data_preparation_scripts/prepare_sft_dataset.sh
@@ -5,7 +5,7 @@ rm -rf $SAVE_DIR/jsonl
rm -rf $SAVE_DIR/arrow
python prepare_dataset.py --type sft \
- --data_input_dirs "PATH/TO/SFT/DATA" \
+ --data_input_dirs /PATH/TO/PREFERENCE/DATASET \
--conversation_template_config /PATH/TO/CHAT/TEMPLATE/CONFIG.json \
--tokenizer_dir "" \
--data_cache_dir $SAVE_DIR/cache \
diff --git a/applications/ColossalChat/examples/training_scripts/hostfile b/applications/ColossalChat/examples/training_scripts/hostfile
index c7aed75a3..2fbb50c4a 100755
--- a/applications/ColossalChat/examples/training_scripts/hostfile
+++ b/applications/ColossalChat/examples/training_scripts/hostfile
@@ -1,5 +1 @@
-XXX.XX.XXX.XXX # Your master IP
-XXX.XX.XXX.XXX # Your slave IPs
-XXX.XX.XXX.XXX # Your slave IPs
-XXX.XX.XXX.XXX # Your slave IPs
-XXX.XX.XXX.XXX # Your slave IPs
+localhost
diff --git a/applications/ColossalChat/examples/training_scripts/train_dpo.py b/applications/ColossalChat/examples/training_scripts/train_dpo.py
index a5b4cb3bd..b7a2c02d3 100755
--- a/applications/ColossalChat/examples/training_scripts/train_dpo.py
+++ b/applications/ColossalChat/examples/training_scripts/train_dpo.py
@@ -116,7 +116,7 @@ def train(args):
else:
model = AutoModelForCausalLM.from_pretrained(args.pretrain)
disable_dropout(model)
- if args.enable_reference_model:
+ if not args.disable_reference_model:
if args.use_flash_attn:
ref_model = AutoModelForCausalLM.from_pretrained(
args.pretrain,
@@ -128,7 +128,7 @@ def train(args):
disable_dropout(ref_model)
else:
ref_model = None
-
+ print("ref_model is None", args.disable_reference_model, ref_model is None)
if args.lora_rank > 0:
model = convert_to_lora_module(model, args.lora_rank, lora_train_bias=args.lora_train_bias)
@@ -255,6 +255,9 @@ def train(args):
save_interval=args.save_interval,
save_dir=args.save_dir,
coordinator=coordinator,
+ beta=args.beta,
+ gamma=args.gamma,
+ length_normalization=args.length_normalization,
)
trainer.fit(
@@ -296,6 +299,9 @@ if __name__ == "__main__":
parser.add_argument("--tp", type=int, default=1)
parser.add_argument("--pp", type=int, default=1)
parser.add_argument("--sp", type=int, default=1)
+ parser.add_argument("--beta", type=float, default=0.1, help="beta in DPO loss")
+ parser.add_argument("--gamma", type=float, default=0.0, help="gamma in SimPO loss")
+ parser.add_argument("--length_normalization", default=False, action="store_true")
parser.add_argument("--enable_sequence_parallelism", default=False, action="store_true")
parser.add_argument("--zero_stage", type=int, default=0, help="Zero stage", choices=[0, 1, 2])
parser.add_argument("--zero_cpu_offload", default=False, action="store_true")
@@ -312,7 +318,12 @@ if __name__ == "__main__":
parser.add_argument("--max_length", type=int, default=2048, help="Model max length")
parser.add_argument("--max_epochs", type=int, default=3)
parser.add_argument("--batch_size", type=int, default=4)
- parser.add_argument("--enable_reference_model", type=bool, default=True)
+ parser.add_argument(
+ "--disable_reference_model",
+ action="store_true",
+ default=False,
+ help="Disable the reference model (enabled by default)",
+ )
parser.add_argument("--mixed_precision", type=str, default="fp16", choices=["fp16", "bf16"], help="Mixed precision")
parser.add_argument("--lora_rank", type=int, default=0, help="low-rank adaptation matrices rank")
parser.add_argument(
diff --git a/applications/ColossalChat/examples/training_scripts/train_dpo.sh b/applications/ColossalChat/examples/training_scripts/train_dpo.sh
index 80fc30c3d..5eba46be8 100755
--- a/applications/ColossalChat/examples/training_scripts/train_dpo.sh
+++ b/applications/ColossalChat/examples/training_scripts/train_dpo.sh
@@ -13,7 +13,7 @@ set_n_least_used_CUDA_VISIBLE_DEVICES() {
echo "Now CUDA_VISIBLE_DEVICES is set to:"
echo "CUDA_VISIBLE_DEVICES=$CUDA_VISIBLE_DEVICES"
}
-set_n_least_used_CUDA_VISIBLE_DEVICES 8
+set_n_least_used_CUDA_VISIBLE_DEVICES 4
# export CUDA_VISIBLE_DEVICES=6
PROJECT_NAME="dpo"
@@ -24,16 +24,16 @@ PRETRAINED_MODEL_PATH="" # huggingface or local model path
PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
declare -a dataset=(
- YOUR/DATA/DIR/arrow/part-00000
- YOUR/DATA/DIR/arrow/part-00001
- YOUR/DATA/DIR/arrow/part-00002
- YOUR/DATA/DIR/arrow/part-00003
- YOUR/DATA/DIR/arrow/part-00004
- YOUR/DATA/DIR/arrow/part-00005
- YOUR/DATA/DIR/arrow/part-00006
- YOUR/DATA/DIR/arrow/part-00007
- YOUR/DATA/DIR/arrow/part-00008
- YOUR/DATA/DIR/arrow/part-00009
+ /Your/Preference/Data/arrow/part-00000
+ /Your/Preference/Data/arrow/part-00001
+ /Your/Preference/Data/arrow/part-00002
+ /Your/Preference/Data/arrow/part-00003
+ /Your/Preference/Data/arrow/part-00004
+ /Your/Preference/Data/arrow/part-00005
+ /Your/Preference/Data/arrow/part-00006
+ /Your/Preference/Data/arrow/part-00007
+ /Your/Preference/Data/arrow/part-00008
+ /Your/Preference/Data/arrow/part-00009
)
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
@@ -41,7 +41,7 @@ FULL_PROJECT_NAME="${PROJECT_NAME}-${TIMESTAMP}"
SAVE_DIR="${PARENT_SAVE_DIR}${FULL_PROJECT_NAME}"
CONFIG_FILE="${PARENT_CONFIG_FILE}-${FULL_PROJECT_NAME}.json"
-colossalai run --nproc_per_node 8 --hostfile hostfile --master_port 31312 train_dpo.py \
+colossalai run --nproc_per_node 4 --hostfile hostfile --master_port 31313 train_dpo.py \
--pretrain $PRETRAINED_MODEL_PATH \
--checkpoint_path $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
@@ -51,12 +51,14 @@ colossalai run --nproc_per_node 8 --hostfile hostfile --master_port 31312 train_
--save_dir $SAVE_DIR \
--config_file $CONFIG_FILE \
--max_epochs 1 \
- --accumulation_steps 4 \
- --batch_size 2 \
+ --accumulation_steps 2 \
+ --batch_size 16 \
--lr 1e-6 \
+ --beta 0.1 \
--mixed_precision "bf16" \
--grad_clip 1.0 \
+ --max_length 1024 \
--weight_decay 0.01 \
- --warmup_steps 100 \
+ --warmup_steps 60 \
--grad_checkpoint \
--use_wandb
diff --git a/applications/ColossalChat/examples/training_scripts/train_sft.py b/applications/ColossalChat/examples/training_scripts/train_sft.py
index 08e7550df..3ae0a63a1 100755
--- a/applications/ColossalChat/examples/training_scripts/train_sft.py
+++ b/applications/ColossalChat/examples/training_scripts/train_sft.py
@@ -271,7 +271,7 @@ def train(args):
# save model checkpoint after fitting on only rank0
coordinator.print_on_master("Start saving final model checkpoint")
- # booster.save_model(model, os.path.join(args.save_path, "modeling"), shard=True)
+ booster.save_model(model, os.path.join(args.save_path, "modeling"), shard=True)
coordinator.print_on_master(f"Saved final model checkpoint at epoch {args.max_epochs} at folder {args.save_path}")
coordinator.print_on_master(f"Max CUDA memory usage: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB")
diff --git a/applications/ColossalChat/examples/training_scripts/train_sft.sh b/applications/ColossalChat/examples/training_scripts/train_sft.sh
index 53c712901..04c3b4814 100755
--- a/applications/ColossalChat/examples/training_scripts/train_sft.sh
+++ b/applications/ColossalChat/examples/training_scripts/train_sft.sh
@@ -17,22 +17,22 @@ set_n_least_used_CUDA_VISIBLE_DEVICES() {
# export CUDA_VISIBLE_DEVICES=4,5,6
set_n_least_used_CUDA_VISIBLE_DEVICES 2
PROJECT_NAME="sft"
-PARENT_SAVE_DIR="" # Path to a folder to save checkpoints
-PARENT_TENSORBOARD_DIR="" # Path to a folder to save logs
-PARENT_CONFIG_FILE="" # Path to a folder to save training config logs
-PRETRAINED_MODEL_PATH="" # huggingface or local model path
-PRETRAINED_TOKENIZER_PATH="" # huggingface or local tokenizer path
+PARENT_SAVE_DIR="/home/yeanbang/data/experiment/rlhf_cont/dpo/ckpt" # Path to a folder to save checkpoints
+PARENT_TENSORBOARD_DIR="/home/yeanbang/data/experiment/rlhf_cont/dpo/log" # Path to a folder to save logs
+PARENT_CONFIG_FILE="/home/yeanbang/data/experiment/rlhf_cont/dpo/log" # Path to a folder to save training config logs
+PRETRAINED_MODEL_PATH="/home/yeanbang/data/models/Sheared-LLaMA-1.3B" # huggingface or local model path
+PRETRAINED_TOKENIZER_PATH="/home/yeanbang/data/models/Sheared-LLaMA-1.3B" # huggingface or local tokenizer path
declare -a dataset=(
- YOUR/SFT/DATA/DIR/arrow/part-00000
- YOUR/SFT/DATA/DIR/arrow/part-00001
- YOUR/SFT/DATA/DIR/arrow/part-00002
- YOUR/SFT/DATA/DIR/arrow/part-00003
- YOUR/SFT/DATA/DIR/arrow/part-00004
- YOUR/SFT/DATA/DIR/arrow/part-00005
- YOUR/SFT/DATA/DIR/arrow/part-00006
- YOUR/SFT/DATA/DIR/arrow/part-00007
- YOUR/SFT/DATA/DIR/arrow/part-00008
- YOUR/SFT/DATA/DIR/arrow/part-00009
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00000
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00001
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00002
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00003
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00004
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00005
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00006
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00007
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00008
+ /home/yeanbang/data/experiment/rlhf_cont/dpo/dataset_tokenized/sft/arrow/part-00009
)
TIMESTAMP=$(date +%Y-%m-%d-%H-%M-%S)
@@ -43,7 +43,7 @@ CONFIG_FILE="${PARENT_CONFIG_FILE}-${FULL_PROJECT_NAME}.json"
echo $(which colossalai)
echo $(which python)
# the real batch size for gradient descent is number_of_node_in_hostfile * nproc_per_node * train_batch_size
-colossalai run --nproc_per_node 2 --master_port 31312 --hostfile ./hostfile train_sft.py \
+colossalai run --nproc_per_node 1 --master_port 31312 --hostfile ./hostfile train_sft.py \
--pretrain $PRETRAINED_MODEL_PATH \
--tokenizer_dir $PRETRAINED_TOKENIZER_PATH \
--save_interval 4000 \
@@ -51,15 +51,12 @@ colossalai run --nproc_per_node 2 --master_port 31312 --hostfile ./hostfile trai
--save_path $SAVE_DIR \
--config_file $CONFIG_FILE \
--lora_rank 0 \
- --plugin 3d \
- --tp 2 \
- --pp 1 \
- --zero_stage 0 \
- --batch_size 2 \
- --max_epochs 3 \
- --accumulation_steps 1 \
+ --plugin zero2 \
+ --batch_size 4 \
+ --max_epochs 1 \
+ --accumulation_steps 4 \
--lr 5e-5 \
- --max_len 400 \
+ --max_len 1000 \
--grad_checkpoint \
--use_wandb \
--use_flash_attn
diff --git a/applications/ColossalChat/tests/test_train.sh b/applications/ColossalChat/tests/test_train.sh
index d1a685174..c8da944d8 100755
--- a/applications/ColossalChat/tests/test_train.sh
+++ b/applications/ColossalChat/tests/test_train.sh
@@ -30,7 +30,7 @@ MODEL_SAVE_PATH=$TEMP_DIR/rlhf_models
MODELS_DIR=$TEMP_DIR/models_config
# Skip those tests due to CI tests timeout
MODELS=('llama')
-ADVANCED_PLUGINS=('sp_split_gather' 'sp_ring' 'sp_all_to_all' 'tp_zero2' '3d' 'gemini' 'gemini_auto' 'zero2' 'zero2_cpu') # pp is still buggy
+ADVANCED_PLUGINS=('pp' 'sp_split_gather' 'sp_ring' 'sp_all_to_all' 'tp_zero2' '3d' 'gemini' 'gemini_auto' 'zero2' 'zero2_cpu') # pp is still buggy
PLUGINS=('3d' 'gemini' 'gemini_auto' 'zero2' 'zero2_cpu')
LORA_RANK=('0') # skip to reduce CI execution time, can pass all locally