- AIGC: 加速 Stable Diffusion
- 生物医药: 加速AlphaFold蛋白质结构预测
@@ -131,7 +131,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
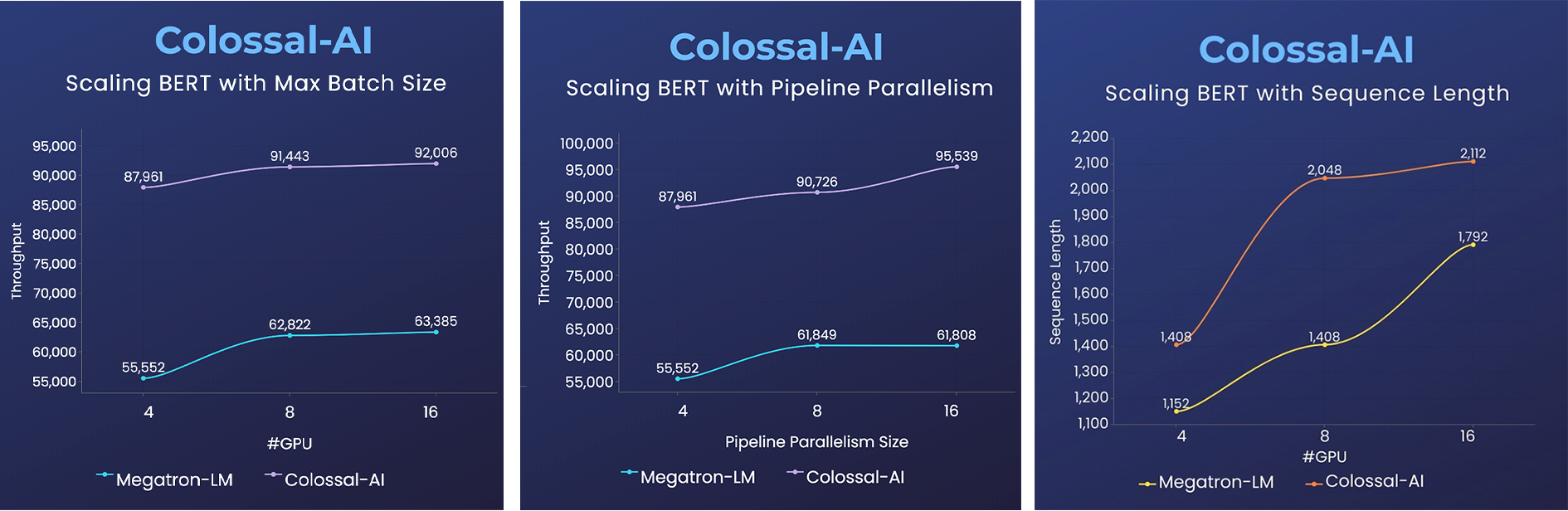
GPT-2.png) - 用相同的硬件训练24倍大的模型
-- 超3倍的吞吐量
+- 超3倍的吞吐量
### BERT
- 用相同的硬件训练24倍大的模型
-- 超3倍的吞吐量
+- 超3倍的吞吐量
### BERT
 @@ -145,7 +145,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
@@ -145,7 +145,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
 - [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), 由Meta发布的1750亿语言模型,由于完全公开了预训练参数权重,因此促进了下游任务和应用部署的发展。
-- 加速45%,仅用几行代码以低成本微调OPT。[[样例]](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/language/opt) [[在线推理]](https://service.colossalai.org/opt)
+- 加速45%,仅用几行代码以低成本微调OPT。[[样例]](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/language/opt) [[在线推理]](https://github.com/hpcaitech/ColossalAI-Documentation/blob/main/i18n/zh-Hans/docusaurus-plugin-content-docs/current/advanced_tutorials/opt_service.md)
请访问我们的 [文档](https://www.colossalai.org/) 和 [例程](https://github.com/hpcaitech/ColossalAI-Examples) 以了解详情。
@@ -199,7 +199,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), 由Meta发布的1750亿语言模型,由于完全公开了预训练参数权重,因此促进了下游任务和应用部署的发展。
-- 加速45%,仅用几行代码以低成本微调OPT。[[样例]](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/language/opt) [[在线推理]](https://service.colossalai.org/opt)
+- 加速45%,仅用几行代码以低成本微调OPT。[[样例]](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/language/opt) [[在线推理]](https://github.com/hpcaitech/ColossalAI-Documentation/blob/main/i18n/zh-Hans/docusaurus-plugin-content-docs/current/advanced_tutorials/opt_service.md)
请访问我们的 [文档](https://www.colossalai.org/) 和 [例程](https://github.com/hpcaitech/ColossalAI-Examples) 以了解详情。
@@ -199,7 +199,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
 -- [OPT推理服务](https://service.colossalai.org/opt): 无需注册,免费体验1750亿参数OPT在线推理服务
+- [OPT推理服务](https://github.com/hpcaitech/ColossalAI-Documentation/blob/main/i18n/zh-Hans/docusaurus-plugin-content-docs/current/advanced_tutorials/opt_service.md): 无需注册,免费体验1750亿参数OPT在线推理服务
-- [OPT推理服务](https://service.colossalai.org/opt): 无需注册,免费体验1750亿参数OPT在线推理服务
+- [OPT推理服务](https://github.com/hpcaitech/ColossalAI-Documentation/blob/main/i18n/zh-Hans/docusaurus-plugin-content-docs/current/advanced_tutorials/opt_service.md): 无需注册,免费体验1750亿参数OPT在线推理服务
 @@ -255,6 +255,28 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
## 安装
+### 从PyPI安装
+
+您可以用下面的命令直接从PyPI上下载并安装Colossal-AI。我们默认不会安装PyTorch扩展包
+
+```bash
+pip install colossalai
+```
+
+但是,如果你想在安装时就直接构建PyTorch扩展,您可以设置环境变量`CUDA_EXT=1`.
+
+```bash
+CUDA_EXT=1 pip install colossalai
+```
+
+**否则,PyTorch扩展只会在你实际需要使用他们时在运行时里被构建。**
+
+与此同时,我们也每周定时发布Nightly版本,这能让你提前体验到新的feature和bug fix。你可以通过以下命令安装Nightly版本。
+
+```bash
+pip install colossalai-nightly
+```
+
### 从官方安装
您可以访问我们[下载](https://www.colossalai.org/download)页面来安装Colossal-AI,在这个页面上发布的版本都预编译了CUDA扩展。
@@ -274,10 +296,10 @@ pip install -r requirements/requirements.txt
pip install .
```
-如果您不想安装和启用 CUDA 内核融合(使用融合优化器时强制安装):
+我们默认在`pip install`时不安装PyTorch扩展,而是在运行时临时编译,如果你想要提前安装这些扩展的话(在使用融合优化器时会用到),可以使用一下命令。
```shell
-NO_CUDA_EXT=1 pip install .
+CUDA_EXT=1 pip install .
```
@@ -255,6 +255,28 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
## 安装
+### 从PyPI安装
+
+您可以用下面的命令直接从PyPI上下载并安装Colossal-AI。我们默认不会安装PyTorch扩展包
+
+```bash
+pip install colossalai
+```
+
+但是,如果你想在安装时就直接构建PyTorch扩展,您可以设置环境变量`CUDA_EXT=1`.
+
+```bash
+CUDA_EXT=1 pip install colossalai
+```
+
+**否则,PyTorch扩展只会在你实际需要使用他们时在运行时里被构建。**
+
+与此同时,我们也每周定时发布Nightly版本,这能让你提前体验到新的feature和bug fix。你可以通过以下命令安装Nightly版本。
+
+```bash
+pip install colossalai-nightly
+```
+
### 从官方安装
您可以访问我们[下载](https://www.colossalai.org/download)页面来安装Colossal-AI,在这个页面上发布的版本都预编译了CUDA扩展。
@@ -274,10 +296,10 @@ pip install -r requirements/requirements.txt
pip install .
```
-如果您不想安装和启用 CUDA 内核融合(使用融合优化器时强制安装):
+我们默认在`pip install`时不安装PyTorch扩展,而是在运行时临时编译,如果你想要提前安装这些扩展的话(在使用融合优化器时会用到),可以使用一下命令。
```shell
-NO_CUDA_EXT=1 pip install .
+CUDA_EXT=1 pip install .
```
(返回顶端)
@@ -327,6 +349,11 @@ docker run -ti --gpus all --rm --ipc=host colossalai bash
(返回顶端)
+## CI/CD
+
+我们使用[GitHub Actions](https://github.com/features/actions)来自动化大部分开发以及部署流程。如果想了解这些工作流是如何运行的,请查看这个[文档](.github/workflows/README.md).
+
+
## 引用我们
```
@@ -338,4 +365,6 @@ docker run -ti --gpus all --rm --ipc=host colossalai bash
}
```
+Colossal-AI 已被 [SC](https://sc22.supercomputing.org/), [AAAI](https://aaai.org/Conferences/AAAI-23/), [PPoPP](https://ppopp23.sigplan.org/) 等顶级会议录取为官方教程。
+
(返回顶端)
diff --git a/README.md b/README.md
index 1b0ca7e97..01e7b0ec5 100644
--- a/README.md
+++ b/README.md
@@ -149,7 +149,7 @@ distributed training and inference in a few lines.
- [Open Pretrained Transformer (OPT)](https://github.com/facebookresearch/metaseq), a 175-Billion parameter AI language model released by Meta, which stimulates AI programmers to perform various downstream tasks and application deployments because public pretrained model weights.
-- 45% speedup fine-tuning OPT at low cost in lines. [[Example]](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/language/opt) [[Online Serving]](https://service.colossalai.org/opt)
+- 45% speedup fine-tuning OPT at low cost in lines. [[Example]](https://github.com/hpcaitech/ColossalAI-Examples/tree/main/language/opt) [[Online Serving]](https://github.com/hpcaitech/ColossalAI-Documentation/blob/main/i18n/en/docusaurus-plugin-content-docs/current/advanced_tutorials/opt_service.md)
Please visit our [documentation](https://www.colossalai.org/) and [examples](https://github.com/hpcaitech/ColossalAI-Examples) for more details.
@@ -202,7 +202,7 @@ Please visit our [documentation](https://www.colossalai.org/) and [examples](htt
-- [OPT Serving](https://service.colossalai.org/opt): Try 175-billion-parameter OPT online services for free, without any registration whatsoever.
+- [OPT Serving](https://github.com/hpcaitech/ColossalAI-Documentation/blob/main/i18n/en/docusaurus-plugin-content-docs/current/advanced_tutorials/opt_service.md): Try 175-billion-parameter OPT online services for free, without any registration whatsoever.
@@ -257,9 +257,32 @@ Acceleration of [AlphaFold Protein Structure](https://alphafold.ebi.ac.uk/)
## Installation
+### Install from PyPI
+
+You can easily install Colossal-AI with the following command. **By defualt, we do not build PyTorch extensions during installation.**
+
+```bash
+pip install colossalai
+```
+
+However, if you want to build the PyTorch extensions during installation, you can set `CUDA_EXT=1`.
+
+```bash
+CUDA_EXT=1 pip install colossalai
+```
+
+**Otherwise, CUDA kernels will be built during runtime when you actually need it.**
+
+We also keep release the nightly version to PyPI on a weekly basis. This allows you to access the unreleased features and bug fixes in the main branch.
+Installation can be made via
+
+```bash
+pip install colossalai-nightly
+```
+
### Download From Official Releases
-You can visit the [Download](https://www.colossalai.org/download) page to download Colossal-AI with pre-built CUDA extensions.
+You can visit the [Download](https://www.colossalai.org/download) page to download Colossal-AI with pre-built PyTorch extensions.
### Download From Source
@@ -270,9 +293,6 @@ You can visit the [Download](https://www.colossalai.org/download) page to downlo
git clone https://github.com/hpcaitech/ColossalAI.git
cd ColossalAI
-# install dependency
-pip install -r requirements/requirements.txt
-
# install colossalai
pip install .
```
@@ -333,6 +353,11 @@ Thanks so much to all of our amazing contributors!
(back to top)
+## CI/CD
+
+We leverage the power of [GitHub Actions](https://github.com/features/actions) to automate our development, release and deployment workflows. Please check out this [documentation](.github/workflows/README.md) on how the automated workflows are operated.
+
+
## Cite Us
```
@@ -344,4 +369,6 @@ Thanks so much to all of our amazing contributors!
}
```
+Colossal-AI has been accepted as official tutorials by top conference [SC](https://sc22.supercomputing.org/), [AAAI](https://aaai.org/Conferences/AAAI-23/), [PPoPP](https://ppopp23.sigplan.org/), etc.
+
(back to top)
diff --git a/colossalai/auto_parallel/passes/runtime_apply_pass.py b/colossalai/auto_parallel/passes/runtime_apply_pass.py
index 7f2aac42b..9d83f1057 100644
--- a/colossalai/auto_parallel/passes/runtime_apply_pass.py
+++ b/colossalai/auto_parallel/passes/runtime_apply_pass.py
@@ -128,6 +128,8 @@ def _shape_consistency_apply(gm: torch.fx.GraphModule):
runtime_apply,
args=(node, origin_dict_node, input_dict_node,
node_to_index_dict[node], user_node_index))
+ if 'activation_checkpoint' in user_node.meta:
+ shape_consistency_node.meta['activation_checkpoint'] = user_node.meta['activation_checkpoint']
new_args = list(user_node.args)
new_kwargs = dict(user_node.kwargs)
@@ -208,6 +210,37 @@ def _comm_spec_apply(gm: torch.fx.GraphModule):
# substitute the origin node with comm_spec_apply_node
new_kwargs[str(node)] = comm_spec_apply_node
user.kwargs = new_kwargs
+
+ if 'activation_checkpoint' in node.meta:
+ comm_spec_apply_node.meta['activation_checkpoint'] = node.meta['activation_checkpoint']
+
+ return gm
+
+
+def _act_annotataion_pass(gm: torch.fx.GraphModule):
+ """
+ This pass is used to add the act annotation to the new inserted nodes.
+ """
+ mod_graph = gm.graph
+ nodes = tuple(mod_graph.nodes)
+
+ for node in nodes:
+ if not hasattr(node.meta, 'activation_checkpoint'):
+ from .runtime_preparation_pass import size_processing
+
+ user_act_annotation = -1
+ input_act_annotation = -1
+ for user_node in node.users.keys():
+ if 'activation_checkpoint' in user_node.meta:
+ user_act_annotation = user_node.meta['activation_checkpoint']
+ break
+ for input_node in node._input_nodes.keys():
+ if 'activation_checkpoint' in input_node.meta:
+ input_act_annotation = input_node.meta['activation_checkpoint']
+ break
+ if user_act_annotation == input_act_annotation and user_act_annotation != -1:
+ node.meta['activation_checkpoint'] = user_act_annotation
+
return gm
diff --git a/colossalai/auto_parallel/passes/runtime_preparation_pass.py b/colossalai/auto_parallel/passes/runtime_preparation_pass.py
index f9b890263..1c25e4c94 100644
--- a/colossalai/auto_parallel/passes/runtime_preparation_pass.py
+++ b/colossalai/auto_parallel/passes/runtime_preparation_pass.py
@@ -179,6 +179,8 @@ def _size_value_converting(gm: torch.fx.GraphModule, device_mesh: DeviceMesh):
# It will be used to replace the original node with processing node in slice object
node_pairs[node] = size_processing_node
size_processing_node._meta_data = node._meta_data
+ if 'activation_checkpoint' in node.meta:
+ size_processing_node.meta['activation_checkpoint'] = node.meta['activation_checkpoint']
user_list = list(node.users.keys())
for user in user_list:
diff --git a/colossalai/auto_parallel/tensor_shard/initialize.py b/colossalai/auto_parallel/tensor_shard/initialize.py
index 0dce2564c..387a682a1 100644
--- a/colossalai/auto_parallel/tensor_shard/initialize.py
+++ b/colossalai/auto_parallel/tensor_shard/initialize.py
@@ -18,6 +18,7 @@ from colossalai.auto_parallel.tensor_shard.solver import (
)
from colossalai.device.alpha_beta_profiler import AlphaBetaProfiler
from colossalai.device.device_mesh import DeviceMesh
+from colossalai.fx.graph_module import ColoGraphModule
from colossalai.fx.tracer import ColoTracer
from colossalai.tensor.sharding_spec import ShardingSpec
@@ -28,7 +29,7 @@ class ModuleWrapper(nn.Module):
into the forward function.
'''
- def __init__(self, module: GraphModule, sharding_spec_dict: Dict[int, List[ShardingSpec]],
+ def __init__(self, module: ColoGraphModule, sharding_spec_dict: Dict[int, List[ShardingSpec]],
origin_spec_dict: Dict[int, ShardingSpec], comm_actions_dict: Dict[int, Dict[str, CommAction]]):
'''
Args:
@@ -59,18 +60,6 @@ def extract_meta_args_from_dataloader(data_loader: torch.utils.data.DataLoader,
pass
-def search_best_logical_mesh_shape(world_size: int, alpha_beta_dict: Dict[Tuple[int], Tuple[float]]):
- '''
- This method is used to search the best logical mesh shape for the given world size
- based on the alpha_beta_dict.
-
- For example:
- if the world_size is 8, and the possible logical shape will be (1, 8), (2, 4), (4, 2), (8, 1).
- '''
- # TODO: implement this function
- return (world_size, 1)
-
-
def extract_alpha_beta_for_device_mesh(alpha_beta_dict: Dict[Tuple[int], Tuple[float]], logical_mesh_shape: Tuple[int]):
'''
This method is used to extract the mesh_alpha and mesh_beta for the given logical_mesh_shape
@@ -93,7 +82,7 @@ def build_strategy_constructor(graph: Graph, device_mesh: DeviceMesh):
return strategies_constructor
-def solve_solution(gm: GraphModule, strategy_constructor: StrategiesConstructor, memory_budget: float = -1.0):
+def solve_solution(gm: ColoGraphModule, strategy_constructor: StrategiesConstructor, memory_budget: float = -1.0):
'''
This method is used to solve the best solution for the given graph.
The solution is a list of integers, each integer represents the best strategy index of the corresponding node.
@@ -109,7 +98,7 @@ def solve_solution(gm: GraphModule, strategy_constructor: StrategiesConstructor,
return solution
-def transform_to_sharded_model(gm: GraphModule, solution: List[int], device_mesh: DeviceMesh,
+def transform_to_sharded_model(gm: ColoGraphModule, solution: List[int], device_mesh: DeviceMesh,
strategies_constructor: StrategiesConstructor):
'''
This method is used to transform the original graph to the sharded graph.
@@ -127,39 +116,56 @@ def transform_to_sharded_model(gm: GraphModule, solution: List[int], device_mesh
def initialize_device_mesh(world_size: int = -1,
+ physical_devices: List[int] = None,
alpha_beta_dict: Dict[Tuple[int], Tuple[float]] = None,
- logical_mesh_shape: Tuple[int] = None):
+ logical_mesh_shape: Tuple[int] = None,
+ logical_mesh_id: torch.Tensor = None):
'''
This method is used to initialize the device mesh.
Args:
- world_size(optional): the size of device mesh. If the world_size is -1,
+ world_size: the size of device mesh. If the world_size is -1,
the world size will be set to the number of GPUs in the current machine.
+ physical_devices: the physical devices used to initialize the device mesh.
alpha_beta_dict(optional): the alpha_beta_dict contains the alpha and beta values
for each devices. if the alpha_beta_dict is None, the alpha_beta_dict will be
generated by profile_alpha_beta function.
logical_mesh_shape(optional): the logical_mesh_shape is used to specify the logical
- mesh shape. If the logical_mesh_shape is None, the logical_mesh_shape will be
- generated by search_best_logical_mesh_shape function.
+ mesh shape.
+ logical_mesh_id(optional): the logical_mesh_id is used to specify the logical mesh id.
'''
# if world_size is not set, use the world size from torch.distributed
if world_size == -1:
world_size = dist.get_world_size()
- device1d = [i for i in range(world_size)]
+
+ if physical_devices is None:
+ physical_devices = [i for i in range(world_size)]
+ physical_mesh = torch.tensor(physical_devices)
if alpha_beta_dict is None:
# if alpha_beta_dict is not given, use a series of executions to profile alpha and beta values for each device
- alpha_beta_dict = profile_alpha_beta(device1d)
+ ab_profiler = AlphaBetaProfiler(physical_devices)
+ alpha_beta_dict = ab_profiler.alpha_beta_dict
+ else:
+ ab_profiler = AlphaBetaProfiler(physical_devices, alpha_beta_dict=alpha_beta_dict)
- if logical_mesh_shape is None:
+ if logical_mesh_shape is None and logical_mesh_id is None:
# search for the best logical mesh shape
- logical_mesh_shape = search_best_logical_mesh_shape(world_size, alpha_beta_dict)
+ logical_mesh_id = ab_profiler.search_best_logical_mesh()
+ logical_mesh_id = torch.Tensor(logical_mesh_id).to(torch.int)
+ logical_mesh_shape = logical_mesh_id.shape
+
+ # extract alpha and beta values for the chosen logical mesh shape
+ mesh_alpha, mesh_beta = ab_profiler.extract_alpha_beta_for_device_mesh()
+
+ elif logical_mesh_shape is not None and logical_mesh_id is None:
+ logical_mesh_id = physical_mesh.reshape(logical_mesh_shape)
+
+ # extract alpha and beta values for the chosen logical mesh shape
+ mesh_alpha, mesh_beta = extract_alpha_beta_for_device_mesh(alpha_beta_dict, logical_mesh_id)
- # extract alpha and beta values for the chosen logical mesh shape
- mesh_alpha, mesh_beta = extract_alpha_beta_for_device_mesh(alpha_beta_dict, logical_mesh_shape)
- physical_mesh = torch.tensor(device1d)
device_mesh = DeviceMesh(physical_mesh_id=physical_mesh,
- mesh_shape=logical_mesh_shape,
+ logical_mesh_id=logical_mesh_id,
mesh_alpha=mesh_alpha,
mesh_beta=mesh_beta,
init_process_group=True)
@@ -192,10 +198,10 @@ def initialize_model(model: nn.Module,
solution will be used to debug or help to analyze the sharding result. Therefore, we will not just
return a series of integers, but return the best strategies.
'''
- tracer = ColoTracer()
+ tracer = ColoTracer(trace_act_ckpt=True)
graph = tracer.trace(root=model, meta_args=meta_args)
- gm = GraphModule(model, graph, model.__class__.__name__)
+ gm = ColoGraphModule(model, graph, model.__class__.__name__)
gm.recompile()
strategies_constructor = build_strategy_constructor(graph, device_mesh)
if load_solver_solution:
@@ -224,6 +230,7 @@ def autoparallelize(model: nn.Module,
data_process_func: callable = None,
alpha_beta_dict: Dict[Tuple[int], Tuple[float]] = None,
logical_mesh_shape: Tuple[int] = None,
+ logical_mesh_id: torch.Tensor = None,
save_solver_solution: bool = False,
load_solver_solution: bool = False,
solver_solution_path: str = None,
@@ -245,6 +252,7 @@ def autoparallelize(model: nn.Module,
logical_mesh_shape(optional): the logical_mesh_shape is used to specify the logical
mesh shape. If the logical_mesh_shape is None, the logical_mesh_shape will be
generated by search_best_logical_mesh_shape function.
+ logical_mesh_id(optional): the logical_mesh_id is used to specify the logical mesh id.
save_solver_solution(optional): if the save_solver_solution is True, the solution will be saved
to the solution_path.
load_solver_solution(optional): if the load_solver_solution is True, the solution will be loaded
@@ -254,7 +262,9 @@ def autoparallelize(model: nn.Module,
memory_budget(optional): the max cuda memory could be used. If the memory budget is -1.0,
the memory budget will be infinity.
'''
- device_mesh = initialize_device_mesh(alpha_beta_dict=alpha_beta_dict, logical_mesh_shape=logical_mesh_shape)
+ device_mesh = initialize_device_mesh(alpha_beta_dict=alpha_beta_dict,
+ logical_mesh_shape=logical_mesh_shape,
+ logical_mesh_id=logical_mesh_id)
if meta_args is None:
meta_args = extract_meta_args_from_dataloader(data_loader, data_process_func)
@@ -263,7 +273,7 @@ def autoparallelize(model: nn.Module,
device_mesh,
save_solver_solution=save_solver_solution,
load_solver_solution=load_solver_solution,
- solver_solution_path=solver_solution_path,
+ solution_path=solver_solution_path,
return_solution=return_solution,
memory_budget=memory_budget)
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/__init__.py b/colossalai/auto_parallel/tensor_shard/node_handler/__init__.py
index a5e3f649a..87bd8966b 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/__init__.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/__init__.py
@@ -11,6 +11,7 @@ from .layer_norm_handler import LayerNormModuleHandler
from .linear_handler import LinearFunctionHandler, LinearModuleHandler
from .matmul_handler import MatMulHandler
from .normal_pooling_handler import NormPoolingHandler
+from .option import ShardOption
from .output_handler import OutputHandler
from .placeholder_handler import PlaceholderHandler
from .registry import operator_registry
@@ -27,5 +28,5 @@ __all__ = [
'UnaryElementwiseHandler', 'ReshapeHandler', 'PlaceholderHandler', 'OutputHandler', 'WhereHandler',
'NormPoolingHandler', 'BinaryElementwiseHandler', 'MatMulHandler', 'operator_registry', 'ADDMMFunctionHandler',
'GetItemHandler', 'GetattrHandler', 'ViewHandler', 'PermuteHandler', 'TensorConstructorHandler',
- 'EmbeddingModuleHandler', 'EmbeddingFunctionHandler', 'SumHandler', 'SoftmaxHandler'
+ 'EmbeddingModuleHandler', 'EmbeddingFunctionHandler', 'SumHandler', 'SoftmaxHandler', 'ShardOption'
]
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/binary_elementwise_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/binary_elementwise_handler.py
index f510f7477..db8f0b54d 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/binary_elementwise_handler.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/binary_elementwise_handler.py
@@ -32,20 +32,32 @@ class BinaryElementwiseHandler(MetaInfoNodeHandler):
return OperationDataType.ARG
def _get_arg_value(idx):
+ non_tensor = False
if isinstance(self.node.args[idx], Node):
meta_data = self.node.args[idx]._meta_data
+ # The meta_data of node type argument could also possibly be a non-tensor object.
+ if not isinstance(meta_data, torch.Tensor):
+ assert isinstance(meta_data, (int, float))
+ meta_data = torch.Tensor([meta_data]).to('meta')
+ non_tensor = True
+
else:
# this is in fact a real data like int 1
# but we can deem it as meta data
# as it won't affect the strategy generation
assert isinstance(self.node.args[idx], (int, float))
meta_data = torch.Tensor([self.node.args[idx]]).to('meta')
- return meta_data
+ non_tensor = True
- input_meta_data = _get_arg_value(0)
- other_meta_data = _get_arg_value(1)
+ return meta_data, non_tensor
+
+ input_meta_data, non_tensor_input = _get_arg_value(0)
+ other_meta_data, non_tensor_other = _get_arg_value(1)
output_meta_data = self.node._meta_data
-
+ # we need record op_data with non-tensor data in this list,
+ # and filter the non-tensor op_data in post_process.
+ self.non_tensor_list = []
+ # assert False
input_op_data = OperationData(name=str(self.node.args[0]),
type=_get_op_data_type(input_meta_data),
data=input_meta_data,
@@ -58,6 +70,10 @@ class BinaryElementwiseHandler(MetaInfoNodeHandler):
type=OperationDataType.OUTPUT,
data=output_meta_data,
logical_shape=bcast_shape)
+ if non_tensor_input:
+ self.non_tensor_list.append(input_op_data)
+ if non_tensor_other:
+ self.non_tensor_list.append(other_op_data)
mapping = {'input': input_op_data, 'other': other_op_data, 'output': output_op_data}
return mapping
@@ -73,9 +89,10 @@ class BinaryElementwiseHandler(MetaInfoNodeHandler):
op_data_mapping = self.get_operation_data_mapping()
for op_name, op_data in op_data_mapping.items():
- if not isinstance(op_data.data, torch.Tensor):
+ if op_data in self.non_tensor_list:
# remove the sharding spec if the op_data is not a tensor, e.g. torch.pow(tensor, 2)
strategy.sharding_specs.pop(op_data)
+
else:
# convert the logical sharding spec to physical sharding spec if broadcast
# e.g. torch.rand(4, 4) + torch.rand(4)
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py b/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
index 78dc58c90..fbab2b61e 100644
--- a/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/node_handler.py
@@ -5,6 +5,7 @@ import torch
from torch.fx.node import Node
from colossalai.auto_parallel.meta_profiler.metainfo import MetaInfo, meta_register
+from colossalai.auto_parallel.tensor_shard.node_handler.option import ShardOption
from colossalai.auto_parallel.tensor_shard.sharding_strategy import (
OperationData,
OperationDataType,
@@ -35,12 +36,14 @@ class NodeHandler(ABC):
node: Node,
device_mesh: DeviceMesh,
strategies_vector: StrategiesVector,
+ shard_option: ShardOption = ShardOption.STANDARD,
) -> None:
self.node = node
self.predecessor_node = list(node._input_nodes.keys())
self.successor_node = list(node.users.keys())
self.device_mesh = device_mesh
self.strategies_vector = strategies_vector
+ self.shard_option = shard_option
def update_resharding_cost(self, strategy: ShardingStrategy) -> None:
"""
@@ -181,6 +184,21 @@ class NodeHandler(ABC):
if op_data.data is not None and isinstance(op_data.data, torch.Tensor):
check_sharding_spec_validity(sharding_spec, op_data.data)
+ remove_strategy_list = []
+ for strategy in self.strategies_vector:
+ shard_level = 0
+ for op_data, sharding_spec in strategy.sharding_specs.items():
+ if op_data.data is not None and isinstance(op_data.data, torch.Tensor):
+ for dim, shard_axis in sharding_spec.dim_partition_dict.items():
+ shard_level += len(shard_axis)
+ if self.shard_option == ShardOption.SHARD and shard_level == 0:
+ remove_strategy_list.append(strategy)
+ if self.shard_option == ShardOption.FULL_SHARD and shard_level <= 1:
+ remove_strategy_list.append(strategy)
+
+ for strategy in remove_strategy_list:
+ self.strategies_vector.remove(strategy)
+
return self.strategies_vector
def post_process(self, strategy: ShardingStrategy) -> Union[ShardingStrategy, List[ShardingStrategy]]:
diff --git a/colossalai/auto_parallel/tensor_shard/node_handler/option.py b/colossalai/auto_parallel/tensor_shard/node_handler/option.py
new file mode 100644
index 000000000..dffb0386d
--- /dev/null
+++ b/colossalai/auto_parallel/tensor_shard/node_handler/option.py
@@ -0,0 +1,17 @@
+from enum import Enum
+
+__all__ = ['ShardOption']
+
+
+class ShardOption(Enum):
+ """
+ This enum class is to define the shard level required in node strategies.
+
+ Notes:
+ STANDARD: We do not add any extra shard requirements.
+ SHARD: We require the node to be shard using at least one device mesh axis.
+ FULL_SHARD: We require the node to be shard using all device mesh axes.
+ """
+ STANDARD = 0
+ SHARD = 1
+ FULL_SHARD = 2
diff --git a/colossalai/autochunk/autochunk_codegen.py b/colossalai/autochunk/autochunk_codegen.py
new file mode 100644
index 000000000..8c3155a60
--- /dev/null
+++ b/colossalai/autochunk/autochunk_codegen.py
@@ -0,0 +1,523 @@
+from typing import Any, Dict, Iterable, List, Tuple
+
+import torch
+
+import colossalai
+from colossalai.fx.codegen.activation_checkpoint_codegen import CODEGEN_AVAILABLE
+
+if CODEGEN_AVAILABLE:
+ from torch.fx.graph import (
+ CodeGen,
+ PythonCode,
+ _custom_builtins,
+ _CustomBuiltin,
+ _format_target,
+ _is_from_torch,
+ _Namespace,
+ _origin_type_map,
+ inplace_methods,
+ magic_methods,
+ )
+
+from torch.fx.node import Argument, Node, _get_qualified_name, _type_repr, map_arg
+
+from .search_chunk import SearchChunk
+from .utils import delete_free_var_from_last_use, find_idx_by_name, get_logger, get_node_shape
+
+
+def _gen_chunk_slice_dim(chunk_dim: int, chunk_indice_name: str, shape: List) -> str:
+ """
+ Generate chunk slice string, eg. [:, :, chunk_idx_name:chunk_idx_name + chunk_size, :]
+
+ Args:
+ chunk_dim (int)
+ chunk_indice_name (str): chunk indice name
+ shape (List): node shape
+
+ Returns:
+ new_shape (str): return slice
+ """
+ new_shape = "["
+ for idx, _ in enumerate(shape):
+ if idx == chunk_dim:
+ new_shape += "%s:%s + chunk_size" % (chunk_indice_name, chunk_indice_name)
+ else:
+ new_shape += ":"
+ new_shape += ", "
+ new_shape = new_shape[:-2] + "]"
+ return new_shape
+
+
+def _gen_loop_start(chunk_input: List[Node], chunk_output: Node, chunk_ouput_dim: int, chunk_size=2) -> str:
+ """
+ Generate chunk loop start
+
+ eg. chunk_result = torch.empty([100, 100], dtype=input_node.dtype, device=input_node.device)
+ chunk_size = 32
+ for chunk_idx in range(0, 100, 32):
+ ......
+
+ Args:
+ chunk_input (List[Node]): chunk input node
+ chunk_output (Node): chunk output node
+ chunk_ouput_dim (int): chunk output node chunk dim
+ chunk_size (int): chunk size. Defaults to 2.
+
+ Returns:
+ context (str): generated str
+ """
+ input_node = chunk_input[0]
+ out_shape = get_node_shape(chunk_output)
+ out_str = str(list(out_shape))
+ context = (
+ "chunk_result = torch.empty(%s, dtype=%s.dtype, device=%s.device); chunk_size = %d\nfor chunk_idx in range" %
+ (out_str, input_node.name, input_node.name, chunk_size))
+ context += "(0, %d, chunk_size):\n" % (out_shape[chunk_ouput_dim])
+ return context
+
+
+def _gen_loop_end(
+ chunk_inputs: List[Node],
+ chunk_non_compute_inputs: List[Node],
+ chunk_outputs: Node,
+ chunk_outputs_dim: int,
+ node_list: List[Node],
+) -> str:
+ """
+ Generate chunk loop end
+
+ eg. chunk_result[chunk_idx:chunk_idx + chunk_size] = output_node
+ output_node = chunk_result; xx = None; xx = None
+
+ Args:
+ chunk_inputs (List[Node]): chunk input node
+ chunk_non_compute_inputs (List[Node]): input node without chunk
+ chunk_outputs (Node): chunk output node
+ chunk_outputs_dim (int): chunk output node chunk dim
+ node_list (List)
+
+ Returns:
+ context (str): generated str
+ """
+ chunk_outputs_name = chunk_outputs.name
+ chunk_outputs_idx = find_idx_by_name(chunk_outputs_name, node_list)
+ chunk_output_shape = chunk_outputs.meta["tensor_meta"].shape
+ chunk_slice = _gen_chunk_slice_dim(chunk_outputs_dim, "chunk_idx", chunk_output_shape)
+ context = " chunk_result%s = %s; %s = None\n" % (
+ chunk_slice,
+ chunk_outputs_name,
+ chunk_outputs_name,
+ )
+ context += (chunk_outputs_name + " = chunk_result; chunk_result = None; chunk_size = None")
+
+ # determine if its the last use for chunk input
+ for chunk_input in chunk_inputs + chunk_non_compute_inputs:
+ if all([find_idx_by_name(user.name, node_list) <= chunk_outputs_idx for user in chunk_input.users.keys()]):
+ context += "; %s = None" % chunk_input.name
+
+ context += "\n"
+ return context
+
+
+def _replace_name(context: str, name_from: str, name_to: str) -> str:
+ """
+ replace node name
+ """
+ patterns = [(" ", " "), (" ", "."), (" ", ","), ("(", ")"), ("(", ","), (" ", ")"), (" ", ""), ("", " ")]
+ for p in patterns:
+ source = p[0] + name_from + p[1]
+ target = p[0] + name_to + p[1]
+ if source in context:
+ context = context.replace(source, target)
+ break
+ return context
+
+
+def _replace_reshape_size(context: str, node_name: str, reshape_size_dict: Dict) -> str:
+ """
+ replace reshape size, some may have changed due to chunk
+ """
+ if node_name not in reshape_size_dict:
+ return context
+ context = context.replace(reshape_size_dict[node_name][0], reshape_size_dict[node_name][1])
+ return context
+
+
+def _replace_ones_like(
+ search_chunk: SearchChunk,
+ chunk_infos: List[Dict],
+ region_idx: int,
+ node_idx: int,
+ node: Node,
+ body: List[str],
+) -> List[str]:
+ """
+ add chunk slice for new tensor op such as ones like
+ """
+ if "ones_like" in node.name:
+ meta_node = search_chunk.trace_indice.node_list[node_idx]
+ chunk_dim = chunk_infos[region_idx]["node_chunk_dim"][meta_node]["chunk_dim"]
+ if get_node_shape(meta_node)[chunk_dim] != 1:
+ source_node = meta_node.args[0].args[0]
+ if (source_node not in chunk_infos[region_idx]["node_chunk_dim"]
+ or chunk_infos[region_idx]["node_chunk_dim"][source_node]["chunk_dim"] is None):
+ chunk_slice = _gen_chunk_slice_dim(chunk_dim, "chunk_idx", get_node_shape(node))
+ body[-1] = _replace_name(body[-1], node.args[0].name, node.args[0].name + chunk_slice)
+ return body
+
+
+def _replace_input_node(
+ chunk_inputs: List[Node],
+ region_idx: int,
+ chunk_inputs_dim: Dict,
+ node_idx: int,
+ body: List[str],
+) -> List[str]:
+ """
+ add chunk slice for input nodes
+ """
+ for input_node_idx, input_node in enumerate(chunk_inputs[region_idx]):
+ for idx, dim in chunk_inputs_dim[region_idx][input_node_idx].items():
+ if idx == node_idx:
+ chunk_slice = _gen_chunk_slice_dim(dim[0], "chunk_idx", get_node_shape(input_node))
+ body[-1] = _replace_name(body[-1], input_node.name, input_node.name + chunk_slice)
+ return body
+
+
+def emit_code_with_chunk(
+ body: List[str],
+ nodes: Iterable[Node],
+ emit_node_func,
+ delete_unused_value_func,
+ search_chunk: SearchChunk,
+ chunk_infos: List,
+):
+ """
+ Emit code with chunk according to chunk_infos.
+
+ It will generate a for loop in chunk regions, and
+ replace inputs and outputs of regions with chunked variables.
+
+ Args:
+ body: forward code
+ nodes: graph.nodes
+ emit_node_func: function to emit node
+ delete_unused_value_func: function to remove the unused value
+ search_chunk: the class to search all chunks
+ chunk_infos: store all information about all chunks.
+ """
+ node_list = list(nodes)
+
+ # chunk region
+ chunk_starts = [i["region"][0] for i in chunk_infos]
+ chunk_ends = [i["region"][1] for i in chunk_infos]
+
+ # chunk inputs
+ chunk_inputs = [i["inputs"] for i in chunk_infos] # input with chunk
+ chunk_inputs_non_chunk = [i["inputs_non_chunk"] for i in chunk_infos] # input without chunk
+ chunk_inputs_dim = [i["inputs_dim"] for i in chunk_infos] # input chunk dim
+ chunk_inputs_names = [j.name for i in chunk_inputs for j in i] + [j.name for i in chunk_inputs_non_chunk for j in i]
+
+ # chunk outputs
+ chunk_outputs = [i["outputs"][0] for i in chunk_infos]
+ chunk_outputs_dim = [i["outputs_dim"] for i in chunk_infos]
+
+ node_list = search_chunk.reorder_graph.reorder_node_list(node_list)
+ node_idx = 0
+ region_idx = 0
+ within_chunk_region = False
+
+ while node_idx < len(node_list):
+ node = node_list[node_idx]
+
+ # if is chunk start, generate for loop start
+ if node_idx in chunk_starts:
+ within_chunk_region = True
+ region_idx = chunk_starts.index(node_idx)
+ body.append(
+ _gen_loop_start(
+ chunk_inputs[region_idx],
+ chunk_outputs[region_idx],
+ chunk_outputs_dim[region_idx],
+ chunk_infos[region_idx]["chunk_size"],
+ ))
+
+ if within_chunk_region:
+ emit_node_func(node, body)
+ # replace input var with chunk var
+ body = _replace_input_node(chunk_inputs, region_idx, chunk_inputs_dim, node_idx, body)
+ # ones like
+ body = _replace_ones_like(search_chunk, chunk_infos, region_idx, node_idx, node, body)
+ # reassgin reshape size
+ body[-1] = _replace_reshape_size(body[-1], node.name, chunk_infos[region_idx]["reshape_size"])
+ body[-1] = " " + body[-1]
+ delete_unused_value_func(node, body, chunk_inputs_names)
+ else:
+ emit_node_func(node, body)
+ if node_idx not in chunk_inputs:
+ delete_unused_value_func(node, body, chunk_inputs_names)
+
+ # generate chunk region end
+ if node_idx in chunk_ends:
+ body.append(
+ _gen_loop_end(
+ chunk_inputs[region_idx],
+ chunk_inputs_non_chunk[region_idx],
+ chunk_outputs[region_idx],
+ chunk_outputs_dim[region_idx],
+ node_list,
+ ))
+ within_chunk_region = False
+
+ node_idx += 1
+
+
+if CODEGEN_AVAILABLE:
+
+ class AutoChunkCodeGen(CodeGen):
+
+ def __init__(self,
+ meta_graph,
+ max_memory: int = None,
+ print_mem: bool = False,
+ print_progress: bool = False) -> None:
+ super().__init__()
+ # find the chunk regions
+ self.search_chunk = SearchChunk(meta_graph, max_memory, print_mem, print_progress)
+ self.chunk_infos = self.search_chunk.search_region()
+ if print_progress:
+ get_logger().info("AutoChunk start codegen")
+
+ def _gen_python_code(self, nodes, root_module: str, namespace: _Namespace) -> PythonCode:
+ free_vars: List[str] = []
+ body: List[str] = []
+ globals_: Dict[str, Any] = {}
+ wrapped_fns: Dict[str, None] = {}
+
+ # Wrap string in list to pass by reference
+ maybe_return_annotation: List[str] = [""]
+
+ def add_global(name_hint: str, obj: Any):
+ """Add an obj to be tracked as a global.
+
+ We call this for names that reference objects external to the
+ Graph, like functions or types.
+
+ Returns: the global name that should be used to reference 'obj' in generated source.
+ """
+ if (_is_from_torch(obj) and obj != torch.device): # to support registering torch.device
+ # HACK: workaround for how torch custom ops are registered. We
+ # can't import them like normal modules so they must retain their
+ # fully qualified name.
+ return _get_qualified_name(obj)
+
+ # normalize the name hint to get a proper identifier
+ global_name = namespace.create_name(name_hint, obj)
+
+ if global_name in globals_:
+ assert globals_[global_name] is obj
+ return global_name
+ globals_[global_name] = obj
+ return global_name
+
+ # set _custom_builtins here so that we needn't import colossalai in forward
+ _custom_builtins["colossalai"] = _CustomBuiltin("import colossalai", colossalai)
+
+ # Pre-fill the globals table with registered builtins.
+ for name, (_, obj) in _custom_builtins.items():
+ add_global(name, obj)
+
+ def type_repr(o: Any):
+ if o == ():
+ # Empty tuple is used for empty tuple type annotation Tuple[()]
+ return "()"
+
+ typename = _type_repr(o)
+
+ if hasattr(o, "__origin__"):
+ # This is a generic type, e.g. typing.List[torch.Tensor]
+ origin_type = _origin_type_map.get(o.__origin__, o.__origin__)
+ origin_typename = add_global(_type_repr(origin_type), origin_type)
+
+ if hasattr(o, "__args__"):
+ # Assign global names for each of the inner type variables.
+ args = [type_repr(arg) for arg in o.__args__]
+
+ if len(args) == 0:
+ # Bare type, such as `typing.Tuple` with no subscript
+ # This code-path used in Python < 3.9
+ return origin_typename
+
+ return f'{origin_typename}[{",".join(args)}]'
+ else:
+ # Bare type, such as `typing.Tuple` with no subscript
+ # This code-path used in Python 3.9+
+ return origin_typename
+
+ # Common case: this is a regular module name like 'foo.bar.baz'
+ return add_global(typename, o)
+
+ def _format_args(args: Tuple[Argument, ...], kwargs: Dict[str, Argument]) -> str:
+
+ def _get_repr(arg):
+ # Handle NamedTuples (if it has `_fields`) via add_global.
+ if isinstance(arg, tuple) and hasattr(arg, "_fields"):
+ qualified_name = _get_qualified_name(type(arg))
+ global_name = add_global(qualified_name, type(arg))
+ return f"{global_name}{repr(tuple(arg))}"
+ return repr(arg)
+
+ args_s = ", ".join(_get_repr(a) for a in args)
+ kwargs_s = ", ".join(f"{k} = {_get_repr(v)}" for k, v in kwargs.items())
+ if args_s and kwargs_s:
+ return f"{args_s}, {kwargs_s}"
+ return args_s or kwargs_s
+
+ # Run through reverse nodes and record the first instance of a use
+ # of a given node. This represents the *last* use of the node in the
+ # execution order of the program, which we will use to free unused
+ # values
+ node_to_last_use: Dict[Node, Node] = {}
+ user_to_last_uses: Dict[Node, List[Node]] = {}
+
+ def register_last_uses(n: Node, user: Node):
+ if n not in node_to_last_use:
+ node_to_last_use[n] = user
+ user_to_last_uses.setdefault(user, []).append(n)
+
+ for node in reversed(nodes):
+ map_arg(node.args, lambda n: register_last_uses(n, node))
+ map_arg(node.kwargs, lambda n: register_last_uses(n, node))
+
+ delete_free_var_from_last_use(user_to_last_uses)
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def delete_unused_values(user: Node, body, to_keep=[]):
+ """
+ Delete values after their last use. This ensures that values that are
+ not used in the remainder of the code are freed and the memory usage
+ of the code is optimal.
+ """
+ if user.op == "placeholder":
+ return
+ if user.op == "output":
+ body.append("\n")
+ return
+ nodes_to_delete = user_to_last_uses.get(user, [])
+ nodes_to_delete = [i for i in nodes_to_delete if i.name not in to_keep]
+ if len(nodes_to_delete):
+ to_delete_str = " = ".join([repr(n) for n in nodes_to_delete] + ["None"])
+ body.append(f"; {to_delete_str}\n")
+ else:
+ body.append("\n")
+
+ # NOTE: we add a variable to distinguish body and ckpt_func
+ def emit_node(node: Node, body):
+ maybe_type_annotation = ("" if node.type is None else f" : {type_repr(node.type)}")
+ if node.op == "placeholder":
+ assert isinstance(node.target, str)
+ maybe_default_arg = ("" if not node.args else f" = {repr(node.args[0])}")
+ free_vars.append(f"{node.target}{maybe_type_annotation}{maybe_default_arg}")
+ raw_name = node.target.replace("*", "")
+ if raw_name != repr(node):
+ body.append(f"{repr(node)} = {raw_name}\n")
+ return
+ elif node.op == "call_method":
+ assert isinstance(node.target, str)
+ body.append(
+ f"{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.target)}"
+ f"({_format_args(node.args[1:], node.kwargs)})")
+ return
+ elif node.op == "call_function":
+ assert callable(node.target)
+ # pretty print operators
+ if (node.target.__module__ == "_operator" and node.target.__name__ in magic_methods):
+ assert isinstance(node.args, tuple)
+ body.append(f"{repr(node)}{maybe_type_annotation} = "
+ f"{magic_methods[node.target.__name__].format(*(repr(a) for a in node.args))}")
+ return
+
+ # pretty print inplace operators; required for jit.script to work properly
+ # not currently supported in normal FX graphs, but generated by torchdynamo
+ if (node.target.__module__ == "_operator" and node.target.__name__ in inplace_methods):
+ body.append(f"{inplace_methods[node.target.__name__].format(*(repr(a) for a in node.args))}; "
+ f"{repr(node)}{maybe_type_annotation} = {repr(node.args[0])}")
+ return
+
+ qualified_name = _get_qualified_name(node.target)
+ global_name = add_global(qualified_name, node.target)
+ # special case for getattr: node.args could be 2-argument or 3-argument
+ # 2-argument: attribute access; 3-argument: fall through to attrib function call with default value
+ if (global_name == "getattr" and isinstance(node.args, tuple) and isinstance(node.args[1], str)
+ and node.args[1].isidentifier() and len(node.args) == 2):
+ body.append(
+ f"{repr(node)}{maybe_type_annotation} = {_format_target(repr(node.args[0]), node.args[1])}")
+ return
+ body.append(
+ f"{repr(node)}{maybe_type_annotation} = {global_name}({_format_args(node.args, node.kwargs)})")
+ if node.meta.get("is_wrapped", False):
+ wrapped_fns.setdefault(global_name)
+ return
+ elif node.op == "call_module":
+ assert isinstance(node.target, str)
+ body.append(f"{repr(node)}{maybe_type_annotation} = "
+ f"{_format_target(root_module, node.target)}({_format_args(node.args, node.kwargs)})")
+ return
+ elif node.op == "get_attr":
+ assert isinstance(node.target, str)
+ body.append(f"{repr(node)}{maybe_type_annotation} = {_format_target(root_module, node.target)}")
+ return
+ elif node.op == "output":
+ if node.type is not None:
+ maybe_return_annotation[0] = f" -> {type_repr(node.type)}"
+ body.append(self.generate_output(node.args[0]))
+ return
+ raise NotImplementedError(f"node: {node.op} {node.target}")
+
+ # Modified for activation checkpointing
+ ckpt_func = []
+
+ # if any node has a list of labels for activation_checkpoint, we
+ # will use nested type of activation checkpoint codegen
+ emit_code_with_chunk(
+ body,
+ nodes,
+ emit_node,
+ delete_unused_values,
+ self.search_chunk,
+ self.chunk_infos,
+ )
+
+ if len(body) == 0:
+ # If the Graph has no non-placeholder nodes, no lines for the body
+ # have been emitted. To continue to have valid Python code, emit a
+ # single pass statement
+ body.append("pass\n")
+
+ if len(wrapped_fns) > 0:
+ wrap_name = add_global("wrap", torch.fx.wrap)
+ wrap_stmts = "\n".join([f'{wrap_name}("{name}")' for name in wrapped_fns])
+ else:
+ wrap_stmts = ""
+
+ if self._body_transformer:
+ body = self._body_transformer(body)
+
+ for name, value in self.additional_globals():
+ add_global(name, value)
+
+ # as we need colossalai.utils.checkpoint, we need to import colossalai
+ # in forward function
+ prologue = self.gen_fn_def(free_vars, maybe_return_annotation[0])
+ prologue = "".join(ckpt_func) + prologue
+ prologue = prologue
+
+ code = "".join(body)
+ code = "\n".join(" " + line for line in code.split("\n"))
+ fn_code = f"""
+{wrap_stmts}
+
+{prologue}
+{code}"""
+ # print(fn_code)
+ return PythonCode(fn_code, globals_)
diff --git a/colossalai/autochunk/estimate_memory.py b/colossalai/autochunk/estimate_memory.py
new file mode 100644
index 000000000..a03a5413b
--- /dev/null
+++ b/colossalai/autochunk/estimate_memory.py
@@ -0,0 +1,323 @@
+import copy
+from typing import Any, Callable, Dict, Iterable, List, Tuple
+
+import torch
+from torch.fx.node import Node, map_arg
+
+from colossalai.fx.profiler import activation_size, parameter_size
+
+from .utils import delete_free_var_from_last_use, find_idx_by_name, get_node_shape, is_non_memory_node
+
+
+class EstimateMemory(object):
+ """
+ Estimate memory with chunk
+ """
+
+ def __init__(self) -> None:
+ pass
+
+ def _get_meta_node_size(self, x):
+ x = x.meta["tensor_meta"]
+ x = x.numel * torch.tensor([], dtype=x.dtype).element_size()
+ return x
+
+ def _get_output_node(self, n):
+ out_size = activation_size(n.meta["fwd_out"])
+ out_node = [n.name] if out_size > 0 else []
+ return out_size, out_node
+
+ def _get_output_node_size(self, n):
+ return self._get_output_node(n)[0]
+
+ def _add_active_node(self, n, active_list):
+ new_active = self._get_output_node(n)[1]
+ if n.op == "placeholder" and get_node_shape(n) is not None:
+ new_active.append(n.name)
+ for i in new_active:
+ if i not in active_list and get_node_shape(n) is not None:
+ active_list.append(i)
+
+ def _get_delete_node(self, user, user_to_last_uses, to_keep=None):
+ delete_size = 0
+ delete_node = []
+ if user.op not in ("output",):
+ nodes_to_delete = user_to_last_uses.get(user, [])
+ if len(user.users) == 0:
+ nodes_to_delete.append(user)
+ if to_keep is not None:
+ keep_list = []
+ for n in nodes_to_delete:
+ if n.name in to_keep:
+ keep_list.append(n)
+ for n in keep_list:
+ if n in nodes_to_delete:
+ nodes_to_delete.remove(n)
+ if len(nodes_to_delete):
+ out_node = [self._get_output_node(i) for i in nodes_to_delete]
+ delete_size = sum([i[0] for i in out_node])
+ for i in range(len(out_node)):
+ if out_node[i][0] > 0:
+ delete_node.append(out_node[i][1][0])
+ elif nodes_to_delete[i].op == "placeholder":
+ delete_node.append(nodes_to_delete[i].name)
+ # elif any(j in nodes_to_delete[i].name for j in ['transpose', 'permute', 'view']):
+ # delete_node.append(nodes_to_delete[i].name)
+ return delete_size, delete_node
+
+ def _get_delete_node_size(self, user, user_to_last_uses, to_keep):
+ return self._get_delete_node(user, user_to_last_uses, to_keep)[0]
+
+ def _remove_deactive_node(self, user, user_to_last_uses, active_list):
+ delete_node = self._get_delete_node(user, user_to_last_uses)[1]
+ for i in delete_node:
+ if i in active_list:
+ active_list.remove(i)
+
+ def _get_chunk_inputs_size(self, chunk_inputs, chunk_inputs_non_chunk, node_list, chunk_end_idx):
+ nodes_to_delete = []
+ for chunk_input in chunk_inputs + chunk_inputs_non_chunk:
+ chunk_input_users = chunk_input.users.keys()
+ chunk_input_users_idx = [find_idx_by_name(i.name, node_list) for i in chunk_input_users]
+ if all(i <= chunk_end_idx for i in chunk_input_users_idx):
+ if chunk_input not in nodes_to_delete:
+ nodes_to_delete.append(chunk_input)
+ out_node = [self._get_output_node(i) for i in nodes_to_delete]
+ delete_size = sum([i[0] for i in out_node])
+ return delete_size
+
+ def _get_last_usr(self, nodes):
+ node_to_last_use: Dict[Node, Node] = {}
+ user_to_last_uses: Dict[Node, List[Node]] = {}
+
+ def register_last_uses(n: Node, user: Node):
+ if n not in node_to_last_use:
+ node_to_last_use[n] = user
+ user_to_last_uses.setdefault(user, []).append(n)
+
+ for node in reversed(nodes):
+ map_arg(node.args, lambda n: register_last_uses(n, node))
+ map_arg(node.kwargs, lambda n: register_last_uses(n, node))
+ return user_to_last_uses
+
+ def _get_contiguous_memory(self, node, not_contiguous_list, delete=False):
+ mem = 0
+ not_contiguous_ops = ["permute"]
+ inherit_contiguous_ops = ["transpose", "view"]
+
+ if node.op == "call_function" and any(n in node.name for n in ["matmul", "reshape"]):
+ for n in node.args:
+ if n in not_contiguous_list:
+ # matmul won't change origin tensor, but create a tmp copy
+ mem += self._get_output_node_size(n)
+ elif node.op == "call_module":
+ for n in node.args:
+ if n in not_contiguous_list:
+ # module will just make origin tensor to contiguous
+ if delete:
+ not_contiguous_list.remove(n)
+ elif node.op == "call_method" and any(i in node.name for i in not_contiguous_ops):
+ if node not in not_contiguous_list:
+ not_contiguous_list.append(node)
+ return mem
+
+ def _get_chunk_ratio(self, node, chunk_node_dim, chunk_size):
+ if node not in chunk_node_dim:
+ return 1.0
+ node_shape = get_node_shape(node)
+ chunk_dim = chunk_node_dim[node]["chunk_dim"]
+ if chunk_dim is None:
+ return 1.0
+ else:
+ return float(chunk_size) / node_shape[chunk_dim]
+
+ def _get_chunk_delete_node_size(self, user, user_to_last_uses, chunk_ratio, chunk_inputs_names):
+ # if any(j in user.name for j in ['transpose', 'permute', 'view']):
+ # return 0
+ if user.op in ("placeholder", "output"):
+ return 0
+ nodes_to_delete = user_to_last_uses.get(user, [])
+ if len(user.users) == 0:
+ nodes_to_delete.append(user)
+ delete_size = 0
+ for n in nodes_to_delete:
+ if n.name in chunk_inputs_names:
+ continue
+ delete_size += self._get_output_node_size(n) * chunk_ratio
+ return delete_size
+
+ def _print_mem_log(self, log, nodes, title=None):
+ if title:
+ print(title)
+ for idx, (l, n) in enumerate(zip(log, nodes)):
+ print("%s:%.2f \t" % (n.name, l), end="")
+ if (idx + 1) % 3 == 0:
+ print("")
+ print("\n")
+
+ def _print_compute_op_mem_log(self, log, nodes, title=None):
+ if title:
+ print(title)
+ for idx, (l, n) in enumerate(zip(log, nodes)):
+ if n.op in ["placeholder", "get_attr", "output"]:
+ continue
+ if any(i in n.name for i in ["getitem", "getattr"]):
+ continue
+ print("%s:%.2f \t" % (n.name, l), end="")
+ if (idx + 1) % 3 == 0:
+ print("")
+ print("\n")
+
+ def estimate_chunk_inference_mem(
+ self,
+ node_list: List,
+ chunk_infos=None,
+ print_mem=False,
+ ):
+ """
+ Estimate inference memory with chunk
+
+ Args:
+ node_list (List): _description_
+ chunk_infos (Dict): Chunk information. Defaults to None.
+ print_mem (bool): Wether to print peak memory of every node. Defaults to False.
+
+ Returns:
+ act_memory_peak_log (List): peak memory of every node
+ act_memory_after_node_log (List): memory after excuting every node
+ active_node_list_log (List): active nodes of every node. active nodes refer to
+ nodes generated but not deleted.
+ """
+ act_memory = 0.0
+ act_memory_peak_log = []
+ act_memory_after_node_log = []
+ active_node_list = []
+ active_node_list_log = []
+ not_contiguous_list = []
+ user_to_last_uses = self._get_last_usr(node_list)
+ user_to_last_uses_no_free_var = self._get_last_usr(node_list)
+ delete_free_var_from_last_use(user_to_last_uses_no_free_var)
+
+ use_chunk = True if chunk_infos is not None else False
+ chunk_within = False
+ chunk_region_idx = None
+ chunk_ratio = 1 # use it to estimate chunk mem
+ chunk_inputs_names = []
+
+ if use_chunk:
+ chunk_regions = [i["region"] for i in chunk_infos]
+ chunk_starts = [i[0] for i in chunk_regions]
+ chunk_ends = [i[1] for i in chunk_regions]
+ chunk_inputs = [i["inputs"] for i in chunk_infos]
+ chunk_inputs_non_chunk = [i["inputs_non_chunk"] for i in chunk_infos]
+ chunk_inputs_names = [j.name for i in chunk_inputs for j in i
+ ] + [j.name for i in chunk_inputs_non_chunk for j in i]
+ chunk_outputs = [i["outputs"][0] for i in chunk_infos]
+ chunk_node_dim = [i["node_chunk_dim"] for i in chunk_infos]
+ chunk_sizes = [i["chunk_size"] if "chunk_size" in i else 1 for i in chunk_infos]
+
+ for idx, node in enumerate(node_list):
+ # if node in chunk start nodes, change chunk ratio and add chunk_tensor
+ if use_chunk and idx in chunk_starts:
+ chunk_within = True
+ chunk_region_idx = chunk_starts.index(idx)
+ act_memory += self._get_output_node_size(chunk_outputs[chunk_region_idx]) / (1024**2)
+
+ # determine chunk ratio for current node
+ if chunk_within:
+ chunk_ratio = self._get_chunk_ratio(
+ node,
+ chunk_node_dim[chunk_region_idx],
+ chunk_sizes[chunk_region_idx],
+ )
+
+ # if node is placeholder, just add the size of the node
+ if node.op == "placeholder":
+ act_memory += self._get_meta_node_size(node) * chunk_ratio / (1024**2)
+ act_memory_peak_log.append(act_memory)
+ # skip output
+ elif node.op == "output":
+ continue
+ # no change for non compute node
+ elif is_non_memory_node(node):
+ act_memory_peak_log.append(act_memory)
+ # node is a compute op
+ # calculate tmp, output node and delete node memory
+ else:
+ # forward memory
+ # TODO: contiguous_memory still not accurate for matmul, view, reshape and transpose
+ act_memory += (self._get_contiguous_memory(node, not_contiguous_list) * chunk_ratio / (1024**2))
+ act_memory += (self._get_output_node_size(node) * chunk_ratio / (1024**2))
+ # record max act memory
+ act_memory_peak_log.append(act_memory)
+ # delete useless memory
+ act_memory -= (self._get_contiguous_memory(node, not_contiguous_list, delete=True) * chunk_ratio /
+ (1024**2))
+ # delete unused vars not in chunk_input_list
+ # we can't delete input nodes until chunk ends
+ if chunk_within:
+ act_memory -= self._get_chunk_delete_node_size(
+ node,
+ user_to_last_uses_no_free_var,
+ chunk_ratio,
+ chunk_inputs_names,
+ ) / (1024**2)
+ else:
+ act_memory -= self._get_delete_node_size(node, user_to_last_uses_no_free_var,
+ chunk_inputs_names) / (1024**2)
+
+ # log active node, only effective without chunk
+ self._add_active_node(node, active_node_list)
+ self._remove_deactive_node(node, user_to_last_uses, active_node_list)
+
+ # if node in chunk end nodes, restore chunk settings
+ if use_chunk and idx in chunk_ends:
+ act_memory -= (self._get_output_node_size(node) * chunk_ratio / (1024**2))
+ act_memory -= self._get_chunk_inputs_size(
+ chunk_inputs[chunk_region_idx],
+ chunk_inputs_non_chunk[chunk_region_idx],
+ node_list,
+ chunk_regions[chunk_region_idx][1],
+ ) / (1024**2)
+ chunk_within = False
+ chunk_ratio = 1
+ chunk_region_idx = None
+
+ act_memory_after_node_log.append(act_memory)
+ active_node_list_log.append(copy.deepcopy(active_node_list))
+
+ if print_mem:
+ print("with chunk" if use_chunk else "without chunk")
+ # self._print_mem_log(act_memory_peak_log, node_list, "peak")
+ # self._print_mem_log(act_memory_after_node_log, node_list, "after")
+ self._print_compute_op_mem_log(act_memory_peak_log, node_list, "peak")
+ # self._print_compute_op_mem_log(
+ # act_memory_after_node_log, node_list, "after"
+ # )
+
+ # param_memory = parameter_size(gm)
+ # all_memory = act_memory + param_memory
+ return act_memory_peak_log, act_memory_after_node_log, active_node_list_log
+
+ def get_active_nodes(self, node_list: List) -> List:
+ """
+ Get active nodes for every node
+
+ Args:
+ node_list (List): _description_
+
+ Returns:
+ active_node_list_log (List): active nodes of every node. active nodes refer to
+ nodes generated but not deleted.
+ """
+ active_node_list = []
+ active_node_list_log = []
+ user_to_last_uses = self._get_last_usr(node_list)
+ user_to_last_uses_no_free_var = self._get_last_usr(node_list)
+ delete_free_var_from_last_use(user_to_last_uses_no_free_var)
+ for _, node in enumerate(node_list):
+ # log active node, only effective without chunk
+ self._add_active_node(node, active_node_list)
+ self._remove_deactive_node(node, user_to_last_uses, active_node_list)
+ active_node_list_log.append(copy.deepcopy(active_node_list))
+ return active_node_list_log
diff --git a/colossalai/autochunk/reorder_graph.py b/colossalai/autochunk/reorder_graph.py
new file mode 100644
index 000000000..0343e52ee
--- /dev/null
+++ b/colossalai/autochunk/reorder_graph.py
@@ -0,0 +1,117 @@
+from .trace_indice import TraceIndice
+from .utils import find_idx_by_name
+
+
+class ReorderGraph(object):
+ """
+ Reorder node list and indice trace list
+ """
+
+ def __init__(self, trace_indice: TraceIndice) -> None:
+ self.trace_indice = trace_indice
+ self.all_reorder_map = {
+ i: i for i in range(len(self.trace_indice.indice_trace_list))
+ }
+
+ def _get_reorder_map(self, chunk_info):
+ reorder_map = {i: i for i in range(len(self.trace_indice.node_list))}
+
+ chunk_region_start = chunk_info["region"][0]
+ chunk_region_end = chunk_info["region"][1]
+ chunk_prepose_nodes = chunk_info["args"]["prepose_nodes"]
+ chunk_prepose_nodes_idx = [
+ find_idx_by_name(i.name, self.trace_indice.node_list)
+ for i in chunk_prepose_nodes
+ ]
+ # put prepose nodes ahead
+ for idx, n in enumerate(chunk_prepose_nodes):
+ n_idx = chunk_prepose_nodes_idx[idx]
+ reorder_map[n_idx] = chunk_region_start + idx
+ # put other nodes after prepose nodes
+ for n in self.trace_indice.node_list[chunk_region_start : chunk_region_end + 1]:
+ if n in chunk_prepose_nodes:
+ continue
+ n_idx = find_idx_by_name(n.name, self.trace_indice.node_list)
+ pos = sum([n_idx < i for i in chunk_prepose_nodes_idx])
+ reorder_map[n_idx] = n_idx + pos
+
+ return reorder_map
+
+ def _reorder_chunk_info(self, chunk_info, reorder_map):
+ # update chunk info
+ chunk_info["region"] = (
+ chunk_info["region"][0] + len(chunk_info["args"]["prepose_nodes"]),
+ chunk_info["region"][1],
+ )
+ new_inputs_dim = []
+ for idx, input_dim in enumerate(chunk_info["inputs_dim"]):
+ new_input_dim = {}
+ for k, v in input_dim.items():
+ new_input_dim[reorder_map[k]] = v
+ new_inputs_dim.append(new_input_dim)
+ chunk_info["inputs_dim"] = new_inputs_dim
+ return chunk_info
+
+ def _update_all_reorder_map(self, reorder_map):
+ for origin_idx, map_idx in self.all_reorder_map.items():
+ self.all_reorder_map[origin_idx] = reorder_map[map_idx]
+
+ def _reorder_self_node_list(self, reorder_map):
+ new_node_list = [None for _ in range(len(self.trace_indice.node_list))]
+ for old_idx, new_idx in reorder_map.items():
+ new_node_list[new_idx] = self.trace_indice.node_list[old_idx]
+ self.trace_indice.node_list = new_node_list
+
+ def _reorder_idx_trace(self, reorder_map):
+ # reorder list
+ new_idx_trace_list = [
+ None for _ in range(len(self.trace_indice.indice_trace_list))
+ ]
+ for old_idx, new_idx in reorder_map.items():
+ new_idx_trace_list[new_idx] = self.trace_indice.indice_trace_list[old_idx]
+ self.trace_indice.indice_trace_list = new_idx_trace_list
+ # update compute
+ for idx_trace in self.trace_indice.indice_trace_list:
+ compute = idx_trace["compute"]
+ for dim_compute in compute:
+ for idx, i in enumerate(dim_compute):
+ dim_compute[idx] = reorder_map[i]
+ # update source
+ for idx_trace in self.trace_indice.indice_trace_list:
+ source = idx_trace["source"]
+ for dim_idx, dim_source in enumerate(source):
+ new_dim_source = {}
+ for k, v in dim_source.items():
+ new_dim_source[reorder_map[k]] = v
+ source[dim_idx] = new_dim_source
+
+ def reorder_all(self, chunk_info):
+ if chunk_info is None:
+ return chunk_info
+ if len(chunk_info["args"]["prepose_nodes"]) == 0:
+ return chunk_info
+ reorder_map = self._get_reorder_map(chunk_info)
+ self._update_all_reorder_map(reorder_map)
+ self._reorder_idx_trace(reorder_map)
+ self._reorder_self_node_list(reorder_map)
+ chunk_info = self._reorder_chunk_info(chunk_info, reorder_map)
+ return chunk_info
+
+ def reorder_node_list(self, node_list):
+ new_node_list = [None for _ in range(len(node_list))]
+ for old_idx, new_idx in self.all_reorder_map.items():
+ new_node_list[new_idx] = node_list[old_idx]
+ return new_node_list
+
+ def tmp_reorder(self, node_list, chunk_info):
+ if len(chunk_info["args"]["prepose_nodes"]) == 0:
+ return node_list, chunk_info
+ reorder_map = self._get_reorder_map(chunk_info)
+
+ # new tmp node list
+ new_node_list = [None for _ in range(len(node_list))]
+ for old_idx, new_idx in reorder_map.items():
+ new_node_list[new_idx] = node_list[old_idx]
+
+ chunk_info = self._reorder_chunk_info(chunk_info, reorder_map)
+ return new_node_list, chunk_info
diff --git a/colossalai/autochunk/search_chunk.py b/colossalai/autochunk/search_chunk.py
new file mode 100644
index 000000000..a86196712
--- /dev/null
+++ b/colossalai/autochunk/search_chunk.py
@@ -0,0 +1,319 @@
+import copy
+from typing import Dict, List, Tuple
+
+from torch.fx.node import Node
+
+from .estimate_memory import EstimateMemory
+from .reorder_graph import ReorderGraph
+from .select_chunk import SelectChunk
+from .trace_flow import TraceFlow
+from .trace_indice import TraceIndice
+from .utils import get_logger, get_node_shape, is_non_compute_node, is_non_compute_node_except_placeholder
+
+
+class SearchChunk(object):
+ """
+ This is the core class for AutoChunk.
+
+ It defines the framework of the strategy of AutoChunk.
+ Chunks will be selected one by one utill search stops.
+
+ The chunk search is as follows:
+ 1. find the peak memory node
+ 2. find the max chunk region according to the peak memory node
+ 3. find all possible chunk regions in the max chunk region
+ 4. find the best chunk region for current status
+ 5. goto 1
+
+ Attributes:
+ gm: graph model
+ print_mem (bool): print estimated memory
+ trace_index: trace the flow of every dim of every node to find all free dims
+ trace_flow: determine the region chunk strategy
+ reorder_graph: reorder nodes to improve chunk efficiency
+ estimate_memory: estimate memory with chunk
+ select_chunk: select the best chunk region
+
+ Args:
+ gm: graph model
+ max_memory (int): max memory in MB
+ print_mem (bool): print estimated memory
+ """
+
+ def __init__(self, gm, max_memory=None, print_mem=False, print_progress=False) -> None:
+ self.print_mem = print_mem
+ self.print_progress = print_progress
+ self.trace_indice = TraceIndice(list(gm.graph.nodes))
+ self.estimate_memory = EstimateMemory()
+ self._init_trace()
+ self.trace_flow = TraceFlow(self.trace_indice)
+ self.reorder_graph = ReorderGraph(self.trace_indice)
+ self.select_chunk = SelectChunk(
+ self.trace_indice,
+ self.estimate_memory,
+ self.reorder_graph,
+ max_memory=max_memory,
+ )
+
+ def _init_trace(self) -> None:
+ """
+ find the max trace range for every node
+ reduce the computation complexity of trace_indice
+ """
+ # find all max ranges
+ active_nodes = self.estimate_memory.get_active_nodes(self.trace_indice.node_list)
+ cur_node_idx = len(self._get_free_var_idx())
+ max_chunk_region_list = []
+ while True:
+ max_chunk_region = self._search_max_chunk_region(active_nodes, cur_node_idx)
+ cur_node_idx = max_chunk_region[1]
+ if cur_node_idx == len(active_nodes) - 1:
+ break
+ max_chunk_region_list.append(max_chunk_region)
+
+ # nothing to limit for the first range
+ max_chunk_region_list = max_chunk_region_list[1:]
+ max_chunk_region_list[0] = (0, max_chunk_region_list[0][1])
+
+ # set trace range and do the trace
+ if self.print_progress:
+ get_logger().info("AutoChunk start tracing indice")
+ self.trace_indice.set_trace_range(max_chunk_region_list, active_nodes)
+ self.trace_indice.trace_indice()
+
+ def _find_peak_node(self, mem_peak: List) -> int:
+ max_value = max(mem_peak)
+ max_idx = mem_peak.index(max_value)
+ return max_idx
+
+ def _get_free_var_idx(self) -> List:
+ """
+ Get free var index
+
+ Returns:
+ free_var_idx (List): all indexs of free vars
+ """
+ free_var_idx = []
+ for idx, n in enumerate(self.trace_indice.node_list):
+ if n.op == "placeholder" and get_node_shape(n) is not None:
+ free_var_idx.append(idx)
+ return free_var_idx
+
+ def _search_max_chunk_region(self, active_node: List, peak_node_idx: int, chunk_regions: List = None) -> Tuple:
+ """
+ Search max chunk region according to peak memory node
+
+ Chunk region starts extending from the peak node, stops where free var num is min
+
+ Args:
+ active_node (List): active node status for every node
+ peak_node_idx (int): peak memory node idx
+ chunk_regions (List): chunk region infos
+
+ Returns:
+ chunk_region_start (int)
+ chunk_region_end (int)
+ """
+ free_vars = self._get_free_var_idx()
+ free_var_num = len(free_vars)
+ active_node_num = [len(i) for i in active_node]
+ min_active_node_num = min(active_node_num[free_var_num:])
+ threshold = max(free_var_num, min_active_node_num)
+
+ # from peak_node to free_var
+ inside_flag = False
+ chunk_region_start = free_var_num
+ for i in range(peak_node_idx, -1, -1):
+ if active_node_num[i] <= threshold:
+ inside_flag = True
+ if inside_flag and active_node_num[i] > threshold:
+ chunk_region_start = i + 1
+ break
+
+ # from peak_node to len-2
+ inside_flag = False
+ chunk_region_end = len(active_node) - 1
+ for i in range(peak_node_idx, len(active_node)):
+ if active_node_num[i] <= threshold:
+ inside_flag = True
+ if inside_flag and active_node_num[i] > threshold:
+ chunk_region_end = i
+ break
+
+ # avoid chunk regions overlap
+ if chunk_regions is not None:
+ for i in chunk_regions:
+ region = i["region"]
+ if chunk_region_start >= region[0] and chunk_region_end <= region[1]:
+ return None
+ elif (region[0] <= chunk_region_start <= region[1] and chunk_region_end > region[1]):
+ chunk_region_start = region[1] + 1
+ elif (region[0] <= chunk_region_end <= region[1] and chunk_region_start < region[0]):
+ chunk_region_end = region[0] - 1
+ return chunk_region_start, chunk_region_end
+
+ def _find_chunk_info(self, input_trace, output_trace, start_idx, end_idx) -> List:
+ """
+ Find chunk info for a region.
+
+ We are given the region start and region end, and need to find out all chunk info for it.
+ We first loop every dim of start node and end node, to see if we can find dim pair,
+ which is linked in a flow and not computed.
+ If found, we then search flow in the whole region to find out all chunk infos.
+
+ Args:
+ input_trace (List): node's input trace in region
+ output_trace (List): node's output trace in region
+ start_idx (int): region start node index
+ end_idx (int): region end node index
+
+ Returns:
+ chunk_infos: possible regions found
+ """
+ start_traces = input_trace[start_idx]
+ end_trace = output_trace[end_idx]
+ end_node = self.trace_indice.node_list[end_idx]
+ chunk_infos = []
+ for end_dim, _ in enumerate(end_trace["indice"]):
+ if len(start_traces) > 1:
+ continue
+ for start_node, start_trace in start_traces.items():
+ for start_dim, _ in enumerate(start_trace["indice"]):
+ # dim size cannot be 1
+ if (get_node_shape(end_node)[end_dim] == 1 or get_node_shape(start_node)[start_dim] == 1):
+ continue
+ # must have users
+ if len(end_node.users) == 0:
+ continue
+ # check index source align
+ if not self.trace_flow.check_index_source(start_dim, start_node, start_idx, end_dim, end_node):
+ continue
+ # check index copmute
+ if not self.trace_flow.check_index_compute(start_idx, end_dim, end_node, end_idx):
+ continue
+ # flow search
+ chunk_info = self.trace_flow.flow_search(start_idx, start_dim, end_idx, end_dim)
+ if chunk_info is None:
+ continue
+ # check index copmute
+ if not self.trace_flow.check_index_duplicate(chunk_info):
+ continue
+ chunk_infos.append(chunk_info)
+ return chunk_infos
+
+ def _search_possible_chunk_regions(self, max_chunk_region: Tuple, peak_node: Node) -> List:
+ """
+ Search every possible region within the max chunk region.
+
+ Args:
+ max_chunk_region (Tuple)
+ peak_node (Node): peak memory node
+
+ Returns:
+ possible_chunk_region (List)
+ """
+ possible_chunk_region = []
+ output_trace = copy.deepcopy(self.trace_indice.indice_trace_list)
+ input_trace = [] # trace of a node's input nodes
+ for _, n in enumerate(self.trace_indice.node_list):
+ cur_trace = {}
+ for arg in n.args:
+ if type(arg) == type(n) and not is_non_compute_node_except_placeholder(arg):
+ cur_trace[arg] = self.trace_indice._find_trace_from_node(arg)
+ input_trace.append(cur_trace)
+
+ for start_idx in range(max_chunk_region[0], peak_node + 1):
+ for end_idx in range(peak_node, max_chunk_region[1] + 1):
+ # skip non compute nodes
+ if is_non_compute_node(self.trace_indice.node_list[start_idx]) or is_non_compute_node(
+ self.trace_indice.node_list[end_idx]):
+ continue
+
+ # select free dim
+ chunk_info = self._find_chunk_info(input_trace, output_trace, start_idx, end_idx)
+ if len(chunk_info) > 0:
+ possible_chunk_region.extend(chunk_info)
+ return possible_chunk_region
+
+ def _step_search(
+ self,
+ mem_peak: List[float],
+ active_node: List[List[Node]],
+ chunk_infos: List[Dict],
+ ) -> Dict:
+ """
+ Find one chunk region
+
+ The chunk search is as follows:
+ 1. find the peak memory node
+ 2. find the max chunk region according to the peak memory node
+ 3. find all possible chunk regions in the max chunk region
+ 4. find the best chunk region for current status
+
+ Args:
+ mem_peak (List): peak memory for every node
+ active_node (List[List[Node]]): active node for every node
+ chunk_infos (List[Dict]): all chunk info
+
+ Returns:
+ best_chunk_region (Dict)
+ """
+ peak_node = self._find_peak_node(mem_peak)
+ max_chunk_region = self._search_max_chunk_region(active_node, peak_node, chunk_infos)
+ if max_chunk_region == None:
+ return None
+ possible_chunk_regions = self._search_possible_chunk_regions(max_chunk_region, peak_node)
+ best_chunk_region = self.select_chunk._select_best_chunk_region(possible_chunk_regions, chunk_infos, peak_node,
+ max_chunk_region, mem_peak)
+ best_chunk_region = self.reorder_graph.reorder_all(best_chunk_region)
+ return best_chunk_region
+
+ def _stop_search(self, init_mem_peak, mem_peak):
+ sorted_init_mem_peak = sorted(init_mem_peak)
+ if max(mem_peak) < sorted_init_mem_peak[int(len(sorted_init_mem_peak) * 0.5)]:
+ return True
+ return False
+
+ def search_region(self) -> Dict:
+ """
+ Search all chunk regions:
+ 1. Estimate current memory
+ 2. Find best chunk for current memory
+ 3. goto 1
+
+ Returns:
+ chunk_infos (Dict)
+ """
+ if self.print_progress:
+ get_logger().info("AutoChunk start searching chunk regions")
+
+ chunk_infos = []
+ (
+ init_mem_peak,
+ _,
+ active_node,
+ ) = self.estimate_memory.estimate_chunk_inference_mem(self.trace_indice.node_list)
+ mem_peak = init_mem_peak
+
+ while True:
+ chunk_info = self._step_search(mem_peak, active_node, chunk_infos)
+ if chunk_info is None:
+ break
+ chunk_infos.append(chunk_info)
+
+ (
+ mem_peak,
+ _,
+ active_node,
+ ) = self.estimate_memory.estimate_chunk_inference_mem(self.trace_indice.node_list, chunk_infos)
+
+ if self.print_progress:
+ get_logger().info("AutoChunk find chunk region %d = (%d, %d)" %
+ (len(chunk_infos), chunk_info["region"][0], chunk_info["region"][1]))
+
+ if self._stop_search(init_mem_peak, mem_peak):
+ break
+ if self.print_mem:
+ self.print_mem = False
+ self.estimate_memory.estimate_chunk_inference_mem(self.trace_indice.node_list, chunk_infos, print_mem=True)
+ return chunk_infos
diff --git a/colossalai/autochunk/select_chunk.py b/colossalai/autochunk/select_chunk.py
new file mode 100644
index 000000000..f0612e45a
--- /dev/null
+++ b/colossalai/autochunk/select_chunk.py
@@ -0,0 +1,224 @@
+from .estimate_memory import EstimateMemory
+from .reorder_graph import ReorderGraph
+from .trace_indice import TraceIndice
+from .utils import is_non_compute_node
+
+
+class SelectChunk(object):
+ def __init__(
+ self,
+ trace_indice: TraceIndice,
+ estimate_memory: EstimateMemory,
+ reorder_graph: ReorderGraph,
+ max_memory=None,
+ ):
+ self.trace_indice = trace_indice
+ self.estimate_memory = estimate_memory
+ self.reorder_graph = reorder_graph
+ if max_memory is not None:
+ self.stratge = "fit_memory"
+ self.max_memory = max_memory # MB
+ else:
+ self.stratge = "min_memory"
+
+ def _select_best_chunk_region(
+ self, possible_chunk_regions, chunk_infos, peak_node, max_chunk_region, mem_peak
+ ):
+ if self.stratge == "min_memory":
+ best_region = self._select_min_memory_chunk_region(
+ possible_chunk_regions,
+ chunk_infos,
+ peak_node,
+ max_chunk_region,
+ mem_peak,
+ )
+ elif self.stratge == "fit_memory":
+ best_region = self._select_fit_memory_chunk_region(
+ possible_chunk_regions,
+ chunk_infos,
+ peak_node,
+ max_chunk_region,
+ mem_peak,
+ )
+ else:
+ raise RuntimeError()
+ return best_region
+
+ def _select_fit_memory_chunk_region(
+ self, possible_chunk_regions, chunk_infos, peak_node, max_chunk_region, mem_peak
+ ):
+ # stop chunk if max memory satisfy memory limit
+ if max(mem_peak) < self.max_memory:
+ return None
+
+ # remove illegal regions
+ illegal_regions = []
+ for i in possible_chunk_regions:
+ if not self._is_legal_region(i, chunk_infos):
+ illegal_regions.append(i)
+ for i in illegal_regions:
+ if i in possible_chunk_regions:
+ possible_chunk_regions.remove(i)
+
+ if len(possible_chunk_regions) == 0:
+ return None
+
+ # get mem for chunk region
+ regions_dict = []
+ for region in possible_chunk_regions:
+ cur_region = region.copy()
+ cur_node_list, cur_region = self.reorder_graph.tmp_reorder(
+ self.trace_indice.node_list, cur_region
+ )
+ cur_chunk_infos = chunk_infos + [cur_region]
+ cur_mem_peak = self.estimate_memory.estimate_chunk_inference_mem(
+ cur_node_list, cur_chunk_infos
+ )[0]
+ cur_chunk_region_peak = cur_mem_peak[
+ max_chunk_region[0] : max_chunk_region[1] + 1
+ ]
+ cur_chunk_region_max_peak = max(cur_chunk_region_peak)
+ if cur_chunk_region_max_peak < self.max_memory:
+ regions_dict.append(
+ {
+ "chunk_info": region,
+ "chunk_max_mem": cur_chunk_region_max_peak,
+ "chunk_len": self._get_compute_node_num(
+ region["region"][0], region["region"][1]
+ ),
+ "reorder_chunk_info": cur_region,
+ "reorder_node_list": cur_node_list,
+ }
+ )
+ # no region found
+ if len(regions_dict) == 0:
+ raise RuntimeError("Search failed. Try a larger memory threshold.")
+
+ # select the min chunk len
+ chunk_len = [i["chunk_len"] for i in regions_dict]
+ best_region_idx = chunk_len.index(min(chunk_len))
+ best_region = regions_dict[best_region_idx]
+
+ # get max chunk size
+ best_region = self._get_fit_chunk_size(best_region, chunk_infos)
+ return best_region
+
+ def _get_fit_chunk_size(self, chunk_region_dict, chunk_infos):
+ chunk_size = 1
+ reorder_chunk_info = chunk_region_dict["reorder_chunk_info"]
+ reorder_chunk_info["chunk_size"] = chunk_size
+ cur_chunk_max_mem = 0
+ # search a region
+ while cur_chunk_max_mem < self.max_memory:
+ chunk_size *= 2
+ reorder_chunk_info["chunk_size"] = chunk_size
+ cur_chunk_infos = chunk_infos + [reorder_chunk_info]
+ cur_mem_peak = self.estimate_memory.estimate_chunk_inference_mem(
+ chunk_region_dict["reorder_node_list"], cur_chunk_infos
+ )[0]
+ cur_chunk_max_mem = max(
+ cur_mem_peak[
+ reorder_chunk_info["region"][0] : reorder_chunk_info["region"][1]
+ + 1
+ ]
+ )
+ # search exact size
+ chunk_info = chunk_region_dict["chunk_info"]
+ chunk_info["chunk_size"] = self._chunk_size_binary_search(
+ chunk_size // 2, chunk_size, chunk_region_dict, chunk_infos
+ )
+ return chunk_info
+
+ def _chunk_size_binary_search(self, left, right, chunk_region_dict, chunk_infos):
+ if left >= 16:
+ gap = 4
+ else:
+ gap = 1
+ chunk_info = chunk_region_dict["reorder_chunk_info"]
+ while right >= left + gap:
+ mid = int((left + right) / 2 + 0.5)
+ chunk_info["chunk_size"] = mid
+ cur_chunk_infos = chunk_infos + [chunk_info]
+ cur_mem_peak = self.estimate_memory.estimate_chunk_inference_mem(
+ chunk_region_dict["reorder_node_list"], cur_chunk_infos
+ )[0]
+ cur_chunk_max_mem = max(
+ cur_mem_peak[chunk_info["region"][0] : chunk_info["region"][1] + 1]
+ )
+ if cur_chunk_max_mem >= self.max_memory:
+ right = mid - gap
+ else:
+ left = mid + gap
+ return left
+
+ def _get_compute_node_num(self, start, end):
+ count = 0
+ for i in self.trace_indice.node_list[start : end + 1]:
+ if not is_non_compute_node(i):
+ count += 1
+ return count
+
+ def _select_min_memory_chunk_region(
+ self, possible_chunk_regions, chunk_infos, peak_node, max_chunk_region, mem_peak
+ ):
+ # remove illegal regions
+ illegal_regions = []
+ for i in possible_chunk_regions:
+ if not self._is_legal_region(i, chunk_infos):
+ illegal_regions.append(i)
+ for i in illegal_regions:
+ if i in possible_chunk_regions:
+ possible_chunk_regions.remove(i)
+
+ if len(possible_chunk_regions) == 0:
+ return None
+
+ # get mem for chunk region
+ regions_dict = []
+ for region in possible_chunk_regions:
+ cur_region = region.copy()
+ cur_node_list, cur_region = self.reorder_graph.tmp_reorder(
+ self.trace_indice.node_list, cur_region
+ )
+ cur_chunk_infos = chunk_infos + [cur_region]
+ cur_mem_peak = self.estimate_memory.estimate_chunk_inference_mem(
+ cur_node_list, cur_chunk_infos
+ )[0]
+ cur_chunk_region_peak = cur_mem_peak[
+ max_chunk_region[0] : max_chunk_region[1] + 1
+ ]
+ cur_chunk_region_max_peak = max(cur_chunk_region_peak)
+ regions_dict.append(
+ {
+ "chunk_info": region,
+ "chunk_max_mem": cur_chunk_region_max_peak,
+ "chunk_len": self._get_compute_node_num(
+ region["region"][0], region["region"][1]
+ ),
+ "reorder_chunk_info": cur_region,
+ "reorder_node_list": cur_node_list,
+ }
+ )
+
+ # select the min mem
+ chunk_max_mem = [i["chunk_max_mem"] for i in regions_dict]
+ best_region_idx = chunk_max_mem.index(min(chunk_max_mem))
+ best_region = regions_dict[best_region_idx]["chunk_info"]
+ if best_region is not None:
+ best_region["chunk_size"] = 1
+ return best_region
+
+ def _is_legal_region(self, cur_chunk_info, chunk_infos):
+ (chunk_region_start, chunk_region_end) = cur_chunk_info["region"]
+ if cur_chunk_info in chunk_infos:
+ return False
+ if chunk_region_end < chunk_region_start:
+ return False
+ for i in chunk_infos:
+ region = i["region"]
+ if not (
+ (chunk_region_start > region[1] and chunk_region_end > region[1])
+ or (chunk_region_start < region[0] and chunk_region_end < region[0])
+ ):
+ return False
+ return True
diff --git a/colossalai/autochunk/trace_flow.py b/colossalai/autochunk/trace_flow.py
new file mode 100644
index 000000000..830b4629e
--- /dev/null
+++ b/colossalai/autochunk/trace_flow.py
@@ -0,0 +1,445 @@
+from typing import Dict, List, Tuple
+
+from torch.fx.node import Node
+
+from .trace_indice import TraceIndice
+from .utils import (
+ find_chunk_all_input_nodes,
+ find_chunk_compute_input_and_output_nodes,
+ find_idx_by_name,
+ flat_list,
+ get_node_shape,
+ is_non_compute_node,
+ is_non_compute_node_except_placeholder,
+)
+
+
+class TraceFlow(object):
+
+ def __init__(self, trace_indice: TraceIndice) -> None:
+ self.trace_indice = trace_indice
+
+ def check_index_source(self, start_dim, start_node, start_idx, end_dim, end_node):
+ """
+ Check 2 given index: one index should be source of the other
+ Args:
+ start_idx(int): start node chunk dim
+ start_node(node): start node
+ end_idx(int): end node chunk dim
+ end_node(node): end node
+
+ Returns:
+ bool: True if check pass
+ """
+ start_node_idx = find_idx_by_name(start_node.name, self.trace_indice.node_list)
+ end_node_trace = self.trace_indice._find_trace_from_node(end_node)
+ end_node_trace_source = end_node_trace["source"][end_dim]
+ sorted_source = sorted(end_node_trace_source.items(), key=lambda d: d[0], reverse=True)
+ for node_idx, node_dim in sorted_source:
+ if node_idx == start_node_idx and start_dim in node_dim:
+ return True
+ # it means we meet a node outside the loop, and the node is not input node
+ if node_idx < start_idx:
+ return False
+ return False
+
+ def check_index_compute(self, start_idx, end_dim, end_node, end_idx):
+ """
+ Check 2 given index: check they haven't been computed in the source trace.
+ Args:
+ start_idx(int): start node chunk dim
+ start_node(node): start node
+ end_idx(int): end node chunk dim
+ end_node(node): end node
+
+ Returns:
+ bool: True if check pass
+ """
+ end_node_trace = self.trace_indice._find_trace_from_node(end_node)
+ end_node_compute = end_node_trace["compute"][end_dim]
+ if any(start_idx <= i <= end_idx for i in end_node_compute):
+ return False
+ return True
+
+ def get_node_chunk_dim(self, node_from, node_from_dim, node_to):
+ node_from_source = self.trace_indice._find_source_trace_from_node(node_from)
+ dim_source = node_from_source[node_from_dim]
+ node_to_idx = find_idx_by_name(node_to.name, self.trace_indice.node_list)
+ for k, v in dim_source.items():
+ if k == node_to_idx:
+ return v
+ return None
+
+ def _find_inherit_dim(self, input_node, input_dim, node):
+ input_node_idx = find_idx_by_name(input_node.name, self.trace_indice.node_list)
+ node_trace_source = self.trace_indice._find_source_trace_from_node(node)
+ for node_dim in range(len(get_node_shape(node))):
+ if (input_node_idx in node_trace_source[node_dim]
+ and input_dim[0] in node_trace_source[node_dim][input_node_idx]):
+ return node_dim
+ return None
+
+ def check_index_duplicate(self, chunk_infos, return_dim=False):
+ input_dim_after_node = {}
+ for input_node_idx, input_node in enumerate(chunk_infos["inputs"]):
+ for k, v in chunk_infos["inputs_dim"][input_node_idx].items():
+ inherit_dim = self._find_inherit_dim(input_node, v, self.trace_indice.node_list[k])
+ if inherit_dim:
+ input_dim_after_node[k] = inherit_dim
+
+ for node in self.trace_indice.node_list[chunk_infos["region"][0]:chunk_infos["region"][1] + 1]:
+ if is_non_compute_node_except_placeholder(node):
+ continue
+ count = 0
+ duplicate_dims = []
+ node_trace_source = self.trace_indice._find_source_trace_from_node(node)
+ for node_dim in range(len(get_node_shape(node))):
+ duplicate_dim = []
+ duplicate_flag = False
+ dim_source = node_trace_source[node_dim]
+ for k, v in dim_source.items():
+ if chunk_infos["region"][0] <= k <= chunk_infos["region"][1]:
+ if k in input_dim_after_node and input_dim_after_node[k] in v:
+ duplicate_flag = True
+ duplicate_dim.append((k, v))
+ duplicate_dims.append(duplicate_dim)
+ if duplicate_flag:
+ count += 1
+
+ if count > 1:
+ if return_dim:
+ return False, duplicate_dims
+ else:
+ return False
+ if return_dim:
+ return True, None
+ else:
+ return True
+
+ def _assgin_single_node_flow(
+ self,
+ arg_node: Node,
+ start_idx: int,
+ end_idx: int,
+ cur_node_dim: int,
+ cur_node_compute: Dict,
+ cur_node_source: Dict,
+ cur_node_fix_dim: List,
+ all_node_info: Dict,
+ next_node_list: List,
+ ) -> bool:
+ """
+ Given the current node and one of its arg node,
+ this function finds out arg node's chunk dim and fix dim
+
+ Args:
+ arg_node (Node): input node
+ start_idx (int): chunk region start
+ end_idx (int): chunk region end
+ cur_node_dim (int): current node chunk dim
+ cur_node_compute (Dict): current node compute dict
+ cur_node_source (Dict): current node source dict
+ cur_node_fix_dim (List): current node fix dim
+ all_node_info (Dict): all node chunk info in the chunk region
+ next_node_list (List)
+
+ Returns:
+ bool: True if this node can be added to the flow, vice versa.
+ """
+ arg_idx = find_idx_by_name(arg_node.name, self.trace_indice.node_list)
+ # arg in chunk range or be inputs
+ if not (start_idx <= arg_idx < end_idx):
+ return True
+
+ # find arg dim
+ if cur_node_dim is not None:
+ # dim is computed
+ if arg_idx in cur_node_compute[cur_node_dim]:
+ return False
+ if arg_idx not in cur_node_source[cur_node_dim]:
+ arg_dim = None
+ else:
+ arg_dim = cur_node_source[cur_node_dim][arg_idx][0]
+ # chunk dim should be None if shape size is 1
+ if get_node_shape(arg_node)[arg_dim] == 1:
+ arg_dim = None
+ else:
+ arg_dim = None
+
+ # get fix dim
+ arg_fix_dim = []
+ if cur_node_dim is not None:
+ for i in cur_node_fix_dim:
+ fix_dim_source = cur_node_source[i]
+ if arg_idx in fix_dim_source:
+ arg_fix_dim.append(fix_dim_source[arg_idx][0])
+
+ # if already in node_info, arg dim must be same
+ if arg_node in all_node_info:
+ if all_node_info[arg_node]["chunk_dim"] != arg_dim:
+ return False
+ all_node_info[arg_node]["fix_dim"] = list(set(all_node_info[arg_node]["fix_dim"] + arg_fix_dim))
+ # else add it to list
+ else:
+ all_node_info[arg_node] = {"chunk_dim": arg_dim, "fix_dim": arg_fix_dim}
+
+ next_node_list.append(arg_node)
+ return True
+
+ def _get_all_node_info(self, end_dim, start_idx, end_idx):
+ cur_node_list = [self.trace_indice.node_list[end_idx]] # start from the last node
+ all_node_info = {cur_node_list[0]: {"chunk_dim": end_dim, "fix_dim": []}}
+
+ while len(cur_node_list) > 0:
+ next_node_list = []
+
+ for cur_node in cur_node_list:
+ # get cur node info
+ cur_node_chunk_dim = all_node_info[cur_node]["chunk_dim"]
+ cur_node_fix_dim = all_node_info[cur_node]["fix_dim"]
+ if cur_node_chunk_dim is not None:
+ cur_node_compute = self.trace_indice._find_compute_trace_from_node(cur_node)
+ cur_node_source = self.trace_indice._find_source_trace_from_node(cur_node)
+ else:
+ cur_node_compute = cur_node_source = None
+
+ # get all valid args
+ arg_list = []
+ for arg in cur_node.all_input_nodes:
+ if type(arg) != type(cur_node):
+ continue
+ if is_non_compute_node(arg):
+ continue
+ arg_list.append(arg)
+ flow_flag = self._assgin_single_node_flow(
+ arg,
+ start_idx,
+ end_idx,
+ cur_node_chunk_dim,
+ cur_node_compute,
+ cur_node_source,
+ cur_node_fix_dim,
+ all_node_info,
+ next_node_list,
+ )
+ if flow_flag == False:
+ return None
+
+ if len(arg_list) == 2:
+ if any(i in cur_node.name for i in ["add", "mul", "truediv"]):
+ for arg in arg_list:
+ if not (start_idx <= find_idx_by_name(arg.name, self.trace_indice.node_list) < end_idx):
+ continue
+ arg_chunk_dim = all_node_info[arg]["chunk_dim"]
+ arg_fix_dim = all_node_info[arg]["fix_dim"]
+ arg_shape = get_node_shape(arg)
+ # add all dim as fix dim except chunk dim
+ for i, shape in enumerate(arg_shape):
+ if shape != 1 and i != cur_node_chunk_dim:
+ if i == arg_chunk_dim:
+ return None
+ if i not in arg_fix_dim:
+ arg_fix_dim.append(i)
+ elif "einsum" in cur_node.name:
+ pass
+ elif "matmul" in cur_node.name:
+ pass
+ else:
+ raise NotImplementedError()
+ cur_node_list = next_node_list
+ return all_node_info
+
+ def _get_input_nodes_dim(self, inputs: List[Node], start_idx: int, end_idx: int, all_node_info: Dict) -> Tuple:
+ """
+ Get chunk dim for every input node for their every entry, remove unchunked nodes
+
+ Args:
+ inputs (List[Node]): input nodes
+ all_node_info (Dict): describe all node's chunk dim and fix dim
+ start_idx (int): chunk start idx
+ end_idx (int): chunk end idx
+
+ Returns:
+ inputs (List(Node)): new inputs
+ inputs_dim (List): chunk dim for inputs
+ """
+ inputs_dim = []
+ remove_inputs = []
+ for input_node in inputs:
+ input_dict = {}
+ input_node_idx = find_idx_by_name(input_node.name, self.trace_indice.node_list)
+ for user in input_node.users.keys():
+ # skip non compute
+ if is_non_compute_node(user):
+ continue
+ # untraced node, mostly non compute
+ if user not in all_node_info:
+ continue
+ user_idx = find_idx_by_name(user.name, self.trace_indice.node_list)
+ if start_idx <= user_idx <= end_idx:
+ chunk_dim = all_node_info[user]["chunk_dim"]
+ if chunk_dim is not None:
+ user_source = self.trace_indice._find_source_trace_from_node(user)[chunk_dim]
+ if input_node_idx in user_source:
+ if get_node_shape(input_node)[user_source[input_node_idx][0]] == 1:
+ input_dict[user_idx] = [None]
+ else:
+ input_dict[user_idx] = user_source[input_node_idx]
+ else:
+ return None, None
+ if len(input_dict) == 0:
+ remove_inputs.append(input_node)
+ else:
+ inputs_dim.append(input_dict)
+ # remove unchunked inputs
+ for i in remove_inputs:
+ if i in inputs:
+ inputs.remove(i)
+ return inputs, inputs_dim
+
+ def _get_prepose_nodes(self, all_node_info: Dict, start_idx: int, end_idx: int) -> List[Node]:
+ """
+ get all useless nodes in chunk region and prepose them
+
+ Args:
+ all_node_info (Dict): describe all node's chunk dim and fix dim
+ start_idx (int): chunk start idx
+ end_idx (int): chunk end idx
+
+ Returns:
+ List[Node]: all nodes to be preposed
+ """
+ # get all possible prepose nodes
+ maybe_prepose_nodes = []
+ for node, node_info in all_node_info.items():
+ if node_info["chunk_dim"] is None:
+ maybe_prepose_nodes.append(node)
+ maybe_prepose_nodes.sort(
+ key=lambda x: find_idx_by_name(x.name, self.trace_indice.node_list),
+ reverse=True,
+ ) # from last node to first node
+ prepose_nodes = []
+ # set every node as root, search its args, if all legal, turn root and args as prepose nodes
+ while len(maybe_prepose_nodes) > 0:
+ tmp_cur_prepose_nodes = [maybe_prepose_nodes[0]]
+ tmp_cur_related_prepose_nodes = []
+ prepose_flag = True
+
+ # loop cur node's all arg until out of chunk
+ while len(tmp_cur_prepose_nodes) > 0:
+ if prepose_flag == False:
+ break
+ tmp_next_prepose_nodes = []
+ tmp_cur_related_prepose_nodes.extend(tmp_cur_prepose_nodes)
+ for cur_prepose_node in tmp_cur_prepose_nodes:
+ if prepose_flag == False:
+ break
+ for cur_prepose_node_arg in cur_prepose_node.all_input_nodes:
+ if type(cur_prepose_node_arg) != type(cur_prepose_node):
+ continue
+ # out of loop
+ if not (start_idx <= find_idx_by_name(cur_prepose_node_arg.name, self.trace_indice.node_list) <
+ end_idx):
+ continue
+ # compute op in loop
+ elif cur_prepose_node_arg in all_node_info:
+ if all_node_info[cur_prepose_node_arg]["chunk_dim"] is None:
+ tmp_next_prepose_nodes.append(cur_prepose_node_arg)
+ else:
+ prepose_flag = False
+ break
+ # non compute op
+ else:
+ tmp_next_prepose_nodes.append(cur_prepose_node_arg)
+ tmp_cur_prepose_nodes = tmp_next_prepose_nodes
+
+ if prepose_flag == False:
+ maybe_prepose_nodes.remove(maybe_prepose_nodes[0])
+ continue
+ else:
+ for n in tmp_cur_related_prepose_nodes:
+ if n not in prepose_nodes:
+ prepose_nodes.append(n)
+ if n in maybe_prepose_nodes:
+ maybe_prepose_nodes.remove(n)
+ # sort by index
+ prepose_nodes.sort(key=lambda x: find_idx_by_name(x.name, self.trace_indice.node_list))
+
+ return prepose_nodes
+
+ def _get_non_chunk_inputs(self, chunk_info, start_idx, end_idx):
+ # we need to log input nodes to avoid deleteing them in the loop
+ chunk_node_list = self.trace_indice.node_list[start_idx:end_idx + 1]
+ # also need to get some prepose node's arg out of non_chunk_inputs
+ for n in chunk_info["args"]["prepose_nodes"]:
+ chunk_node_list.remove(n)
+ non_chunk_inputs = find_chunk_all_input_nodes(chunk_node_list)
+ for i in non_chunk_inputs:
+ if i not in chunk_info["inputs"]:
+ chunk_info["inputs_non_chunk"].append(i)
+ return chunk_info
+
+ def flow_search(self, start_idx, start_dim, end_idx, end_dim):
+ inputs, outputs = find_chunk_compute_input_and_output_nodes(self.trace_indice.node_list[start_idx:end_idx + 1])
+ # only single ouput
+ if len(outputs) > 1:
+ return None
+
+ # get every node's chunk dim and fix dim
+ all_node_info = self._get_all_node_info(end_dim, start_idx, end_idx)
+ if all_node_info is None:
+ return None
+
+ # get input nodes' chunk dim
+ inputs, inputs_dim = self._get_input_nodes_dim(inputs, start_idx, end_idx, all_node_info)
+ if inputs is None:
+ return None
+
+ chunk_info = {
+ "region": (start_idx, end_idx),
+ "inputs": inputs,
+ "inputs_non_chunk": [],
+ "inputs_dim": inputs_dim,
+ "outputs": outputs,
+ "outputs_dim": end_dim,
+ "node_chunk_dim": all_node_info,
+ "args": {},
+ }
+
+ # move useless nodes ahead of loop
+ chunk_info["args"]["prepose_nodes"] = self._get_prepose_nodes(all_node_info, start_idx, end_idx)
+
+ # find non chunk inputs
+ chunk_info = self._get_non_chunk_inputs(chunk_info, start_idx, end_idx)
+
+ # reassgin reshape size, some size may have changed due to chunk
+ chunk_info = self._reassgin_reshape_size(chunk_info)
+
+ return chunk_info
+
+ def _reassgin_reshape_size(self, chunk_info):
+ """
+ Some shape args in reshape may have changed due to chunk
+ reassgin those changed shape
+ """
+ chunk_region = chunk_info["region"]
+ reshape_size = {}
+ chunk_shape = get_node_shape(chunk_info["outputs"][0])[chunk_info["outputs_dim"]]
+ for node in self.trace_indice.node_list[chunk_region[0]:chunk_region[1] + 1]:
+ if any(i in node.name for i in ["reshape", "view"]):
+ reshape_args = flat_list(node.args[1:])
+ chunk_dim = chunk_info["node_chunk_dim"][node]["chunk_dim"]
+ new_shape = ""
+ for reshape_arg_dim, reshape_arg in enumerate(reshape_args):
+ if reshape_arg_dim == chunk_dim:
+ new_shape += "min(chunk_size, %d - chunk_idx), " % chunk_shape
+ else:
+ if isinstance(reshape_arg, int):
+ new_shape += "%s, " % str(reshape_arg)
+ else:
+ new_shape += "%s, " % reshape_arg.name
+ new_shape = new_shape[:-2]
+ origin_shape = str(reshape_args)[1:-1]
+ reshape_size[node.name] = [origin_shape, new_shape]
+ chunk_info["reshape_size"] = reshape_size
+ return chunk_info
diff --git a/colossalai/autochunk/trace_indice.py b/colossalai/autochunk/trace_indice.py
new file mode 100644
index 000000000..827f60d8b
--- /dev/null
+++ b/colossalai/autochunk/trace_indice.py
@@ -0,0 +1,703 @@
+import copy
+from typing import Dict, List, Tuple
+
+from torch.fx.node import Node
+
+from .utils import find_first_tensor_arg, find_idx_by_name, flat_list, get_node_shape
+
+
+class TraceIndice(object):
+ """
+ Trace all indice infomation for every node.
+
+ Indice is a logical concept. Equal dims can been treated as one indice.
+ eg. dim(x1) = [a, b, c]
+ dim(x2) = [d, e, f]
+ and we have x3 = x1 * x2.
+ then a=d, b=e, c=f, due to the broadcast property,
+ dim(x1)=dim(x2)=dim(x3)=[a, b, c]
+ This class will record every node's dims' indice, compute and source.
+
+ Attibutes:
+ node_list (List)
+ indice_trace_list (List): [{"indice": [...], "compute": [...], "source": [...]}, {...}]
+ indice_view_list (Dict): not used for now
+ indice_count (int): record indice number
+
+ Args:
+ node_list (List)
+ """
+
+ def __init__(self, node_list: List[Node]) -> None:
+ self.node_list = node_list
+ self.indice_trace_list = self._init_indice_trace_list()
+ self.indice_view_list = {}
+ self.indice_count = -1
+ self.trace_range = []
+ self.active_node_list = []
+
+ def _init_indice_trace_list(self):
+ indice_trace_list = []
+ for n in self.node_list:
+ if get_node_shape(n) != None:
+ cur_trace = {
+ "indice": [None for _ in range(len(get_node_shape(n)))],
+ "compute": [[] for _ in range(len(get_node_shape(n)))],
+ "source": [{} for _ in range(len(get_node_shape(n)))],
+ }
+ else:
+ cur_trace = {"indice": [], "compute": [], "source": []}
+ indice_trace_list.append(cur_trace)
+ return indice_trace_list
+
+ def set_trace_range(self, trace_range: List, active_node_list: List) -> None:
+ self.trace_range = trace_range
+ self.active_node_list = active_node_list
+
+ def _add_indice(self):
+ """
+ Update the count and return it. To record the idx number.
+
+ Returns:
+ indice_count: int
+ """
+ self.indice_count += 1
+ return self.indice_count
+
+ def _del_dim(self, idx, dim_idx):
+ self.indice_trace_list[idx]["indice"].pop(dim_idx)
+ self.indice_trace_list[idx]["compute"].pop(dim_idx)
+ self.indice_trace_list[idx]["source"].pop(dim_idx)
+
+ def _add_dim(self, node_idx, dim_idx):
+ self.indice_trace_list[node_idx]["indice"].insert(dim_idx, self._add_indice())
+ self.indice_trace_list[node_idx]["compute"].insert(dim_idx, [])
+ self.indice_trace_list[node_idx]["source"].insert(dim_idx, {})
+
+ def _transform_indice(self, node, node_dim):
+ node_idx = self._find_indice_trace_from_node(node)
+ dims = list(range(len(node_idx)))
+ return dims[node_dim]
+
+ def _inherit_indice(self, node_from, node_from_dim, node_to, node_to_dim):
+ node_from_dim = self._transform_indice(node_from, node_from_dim)
+ node_to_dim = self._transform_indice(node_to, node_to_dim)
+ node_from_trace = self._find_trace_from_node(node_from)
+ node_to_trace = self._find_trace_from_node(node_to)
+ node_to_trace["indice"][node_to_dim] = node_from_trace["indice"][node_from_dim]
+ node_to_trace["compute"][node_to_dim] = copy.deepcopy(node_from_trace["compute"][node_from_dim])
+ self._add_source(node_from, node_from_dim, node_to, node_to_dim, init=True)
+
+ def _inherit_all_computation(self, node_from, node_to):
+ node_from_compute = self._find_compute_trace_from_node(node_from)
+ node_to_compute = self._find_compute_trace_from_node(node_to)
+ assert len(node_from_compute) == len(node_to_compute)
+ for i in range(len(node_from_compute)):
+ self._add_source(node_from, i, node_to, i)
+ node_to_compute[i] = copy.deepcopy(node_from_compute[i])
+
+ def _add_source(self, node_from, node_from_dim, node_to, node_to_dim, init=False):
+ node_from_dim = self._transform_indice(node_from, node_from_dim)
+ node_from_trace_source = self._find_source_trace_from_node(node_from)
+ node_to_dim = self._transform_indice(node_to, node_to_dim)
+ node_to_trace_source = self._find_source_trace_from_node(node_to)
+ node_from_idx = find_idx_by_name(node_from.name, self.node_list)
+ if init:
+ node_to_trace_source[node_to_dim] = {}
+ # add dim to cur new source
+ if node_from_idx not in node_to_trace_source[node_to_dim]:
+ node_to_trace_source[node_to_dim][node_from_idx] = [node_from_dim]
+ else:
+ if node_from_dim not in node_to_trace_source[node_to_dim][node_from_idx]:
+ node_to_trace_source[node_to_dim][node_from_idx].append(node_from_dim)
+ # update inputs source
+ for node_idx, node_dim in node_from_trace_source[node_from_dim].items():
+ if node_idx not in node_to_trace_source[node_to_dim]:
+ node_to_trace_source[node_to_dim][node_idx] = copy.deepcopy(node_dim)
+ else:
+ for d in node_dim:
+ if d not in node_to_trace_source[node_to_dim][node_idx]:
+ node_to_trace_source[node_to_dim][node_idx].append(d)
+
+ def _mark_computation_from_node(self, node_from, node_to, exclude=None):
+ if exclude == None:
+ exclude = []
+ else:
+ exclude = [self._transform_indice(node_to, i) for i in exclude]
+ node_from_compute = self._find_compute_trace_from_node(node_from)
+ node_to_compute = self._find_compute_trace_from_node(node_to)
+ # assert len(node_from_compute) == len(node_to_compute)
+ for i in range(-1, -min(len(node_from_compute), len(node_to_compute)) - 1, -1):
+ if self._transform_indice(node_to, i) in exclude:
+ continue
+ self._add_source(node_from, i, node_to, i)
+ for j in node_from_compute[i]:
+ if j not in node_to_compute[i]:
+ node_to_compute[i].append(j)
+
+ def _mark_computation(self, node, idx, dim):
+ """
+ Mark some dims of node as computed.
+
+ Args:
+ node (node)
+ idx (int): node index
+ dim (list or int): dims to be marked as computed
+ """
+ if isinstance(dim, int):
+ dim = [dim]
+ dims = list(range(len(get_node_shape(node))))
+ for d in dim:
+ cur_dim = dims[d]
+ if idx not in self.indice_trace_list[idx]["compute"][cur_dim]:
+ self.indice_trace_list[idx]["compute"][cur_dim].append(idx)
+
+ def _find_trace_from_node(self, node):
+ """
+ Find node idx and compute trace by the node.
+
+ Args:
+ node (node)
+ Returns:
+ idx (list): idx of the node
+ compute (list): computed idx of the node.
+ """
+ node_idx = find_idx_by_name(node.name, self.node_list)
+ node_dict = self.indice_trace_list[node_idx]
+ return node_dict
+
+ def _find_source_trace_from_node(self, node):
+ """
+ Find node source trace by the node.
+
+ Args:
+ node (node)
+ Returns:
+ idx (list): idx of the node
+ compute (list): computed idx of the node.
+ """
+ node_idx = find_idx_by_name(node.name, self.node_list)
+ node_dict = self.indice_trace_list[node_idx]
+ return node_dict["source"]
+
+ def _find_indice_trace_from_node(self, node):
+ """
+ Find node idx trace by the node.
+
+ Args:
+ node (node)
+ Returns:
+ idx (list): idx of the node
+ """
+ node_idx = find_idx_by_name(node.name, self.node_list)
+ return self.indice_trace_list[node_idx]["indice"]
+
+ def _find_compute_trace_from_node(self, node):
+ """
+ Find node compute trace by the node.
+
+ Args:
+ node (node)
+ Returns:
+ compute (list): computed idx of the node.
+ """
+ node_idx = find_idx_by_name(node.name, self.node_list)
+ return self.indice_trace_list[node_idx]["compute"]
+
+ def _assign_indice_as_input(self, node: Node, node_idx: int, input_node=None):
+ """
+ Assign node's trace as its input node.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ if input_node == None:
+ input_node = find_first_tensor_arg(node)
+ input_node_idx = find_idx_by_name(input_node.name, self.node_list)
+ input_node_idx_trace = self.indice_trace_list[input_node_idx]["indice"]
+
+ new_idx_trace = copy.deepcopy(input_node_idx_trace)
+ self.indice_trace_list[node_idx]["indice"] = new_idx_trace
+
+ self._inherit_all_computation(input_node, node)
+
+ def _assign_all_indice(self, node: Node, node_idx: int):
+ """
+ Add new indice for all node's dims.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ shape = node.meta["tensor_meta"].shape
+ if shape is None:
+ return
+ new_trace = []
+ for _ in shape:
+ new_trace.append(self._add_indice())
+ self.indice_trace_list[node_idx]["indice"] = new_trace
+
+ def _assign_transpose_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for transpose op.
+ 1. swap input's dim according to transpose args
+ 2. inherit input's computation
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ input_node = node.args[0]
+ tranpose_dim = node.args[1:]
+
+ self._assign_indice_as_input(node, node_idx, input_node)
+ self._inherit_indice(input_node, tranpose_dim[1], node, tranpose_dim[0])
+ self._inherit_indice(input_node, tranpose_dim[0], node, tranpose_dim[1])
+
+ def _assign_permute_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for permute op.
+ 1. swap input's dim according to permute args
+ 2. inherit input's computation
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ permute_dim = flat_list(node.args[1:])
+ input_node = node.args[0]
+
+ self._assign_indice_as_input(node, node_idx, input_node)
+ for idx, d in enumerate(permute_dim):
+ self._inherit_indice(input_node, d, node, idx)
+
+ def _assign_linear_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for linear op.
+ 1. copy trace from input node and change last indice accroding to weight
+ 2. mark equal for input node last indice, weight first dim and bias dim.
+ 3. inherit input's computation, mark computation for last dim.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ if len(node.args) == 2:
+ _, weight = node.args
+ else:
+ _, weight, _ = node.args
+
+ self._assign_indice_as_input(node, node_idx)
+ self._inherit_indice(weight, 1, node, -1)
+
+ self._mark_computation(node, node_idx, [-1])
+
+ def _assign_matmul_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for matmul op.
+ 1. copy trace from matmul_left and change last indice accroding to matmul_right. (assert they have same length)
+ 2. mark equal for input matmul_left -1 indice and matmul_right -2 dim.
+ 3. inherit matmul_left and matmul_right computation, mark computation for last dim.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ matmul_left, matmul_right = node.args
+
+ assert len(get_node_shape(matmul_left)) == len(get_node_shape(matmul_right))
+ self._assign_indice_as_input(node, node_idx, matmul_left)
+ self._inherit_indice(matmul_right, -1, node, -1)
+
+ self._mark_computation_from_node(matmul_right, node, [-1, -2])
+ self._mark_computation(node, node_idx, [-1])
+
+ def _assign_layernorm_indice(self, node, idx):
+ """
+ Assign indice for layernorm op.
+ 1. assign indice as input node
+ 2. inherit computation and mark last 2 dims as computed.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_indice_as_input(node, idx)
+ self._mark_computation(node, idx, [-1])
+
+ def _assign_elementwise_indice(self, node, idx):
+ """
+ Assign indice for element-wise op (eg. relu sigmoid add mul).
+ 1. assign indice as input node
+ 2. inherit computation from all input nodes.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_indice_as_input(node, idx)
+ nodes_in = []
+ for node_in in node.args:
+ if type(node_in) == type(node):
+ nodes_in.append(node_in)
+ self._mark_computation_from_node(node_in, node)
+ assert len(nodes_in) <= 2
+
+ def _assgin_no_change_indice(self, node, idx):
+ self._assign_indice_as_input(node, idx)
+ for node_in in node.args:
+ if type(node_in) == type(node):
+ self._mark_computation_from_node(node_in, node)
+
+ def _assign_einsum_indice(self, node, idx):
+ """
+ Assign indice for einsum op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ patterns = node.args[0]
+ input_nodes = node.args[1:]
+
+ patterns = patterns.replace(" ", "")
+ left, right = patterns.split("->")
+ left = left.split(",")
+
+ if '...' in right:
+ replace_list = "!@#$%^&*"
+ target_len = len(get_node_shape(node))
+ add_len = target_len - len(right) + 3
+ replace_str = replace_list[:add_len]
+ right = right.replace("...", replace_str)
+ for ll in range(len(left)):
+ left[ll] = left[ll].replace("...", replace_str)
+
+ all_index = []
+ for i in left:
+ for c in i:
+ all_index.append(c)
+ all_index = set(all_index)
+
+ for right_idx, right_indice in enumerate(right):
+ for left_idx, left_str in enumerate(left):
+ if right_indice in left_str:
+ source_idx = left_str.index(right_indice)
+ self._inherit_indice(input_nodes[left_idx], source_idx, node, right_idx)
+
+ def _assign_softmax_indice(self, node, idx):
+ """
+ Assign indice for softmax op.
+ 1. assign indice as input node
+ 2. inherit computation and mark softmax dim as computed.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_indice_as_input(node, idx)
+ self._mark_computation(node, idx, [node.kwargs["dim"]])
+
+ def _assign_unsqueeze_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for unsqueeze op.
+ 1. assign new indice for unsqueeze dim
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._del_dim(node_idx, -1)
+ self._assign_indice_as_input(node, node_idx)
+ dim_idx = node.args[1]
+ # unsqueeze(-1) = unsqueeze(shape_num + 1)
+ if dim_idx < 0:
+ dim_idx = list(range(len(get_node_shape(node))))[dim_idx]
+ self._add_dim(node_idx, dim_idx)
+
+ def _assign_dropout_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for unsqueeze op.
+ 1. assign new indice for unsqueeze dim
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_indice_as_input(node, node_idx)
+
+ def _assign_ones_like_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for oneslike op.
+ 1. assign new indice for all dim
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ self._assign_all_indice(node, node_idx)
+
+ def _assign_cat_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for cat op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ nodes_in = flat_list(node.args[0])
+ self._assign_indice_as_input(node, node_idx, input_node=nodes_in[0])
+ for n in nodes_in[1:]:
+ self._mark_computation_from_node(n, node)
+ cat_dim = node.kwargs["dim"]
+ self._del_dim(node_idx, cat_dim)
+ self._add_dim(node_idx, cat_dim)
+
+ def _assign_sum_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for sum op.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ nodes_in = flat_list(node.args[0])
+ self._add_dim(node_idx, 0)
+ self._assign_indice_as_input(node, node_idx, input_node=nodes_in[0])
+ for n in nodes_in[1:]:
+ self._mark_computation_from_node(n, node)
+ cat_dim = node.kwargs["dim"]
+ self._del_dim(node_idx, cat_dim)
+
+ def _assign_getitem_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for getitem.
+ getitem can act like slice sometimes
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ node_args = flat_list(node.args[1:])
+ flag = False
+ for node_arg in node_args:
+ node_arg_str = str(node_arg)
+ if any(i == node_arg_str for i in ["None", "Ellipsis"]):
+ flag = True
+ break
+ if "slice" in node_arg_str:
+ flag = True
+ break
+ if flag == False:
+ return
+
+ # node args should be like [Ellipsis, slice(start, step, end), None]
+ node_shape = get_node_shape(node)
+ origin_idx_count = 0
+ new_idx_count = 0
+ new_dim_num = sum([1 if str(i) == "None" else 0 for i in node_args])
+ for _ in range(new_dim_num):
+ self._del_dim(node_idx, 0)
+ delete_dim_num = sum([1 if str(i) == "0" else 0 for i in node_args])
+ for _ in range(delete_dim_num):
+ self._add_dim(node_idx, 0)
+ self._assign_indice_as_input(node, node_idx)
+
+ for _, node_arg in enumerate(node_args):
+ node_arg_str = str(node_arg)
+ # Ellipsis means [..., ]
+ if "Ellipsis" == node_arg_str:
+ shape_gap = len(node_shape) - len(node_args) + 1
+ origin_idx_count += shape_gap
+ new_idx_count += shape_gap
+ # slice(None, None, None) means all indexes
+ elif "slice" in node_arg_str:
+ if "slice(None, None, None)" != node_arg_str:
+ self._del_dim(node_idx, new_idx_count)
+ self._add_dim(node_idx, new_idx_count)
+ origin_idx_count += 1
+ new_idx_count += 1
+ # None means a new dim
+ elif "None" == node_arg_str:
+ self._add_dim(node_idx, new_idx_count)
+ new_idx_count += 1
+ elif "0" == node_arg_str:
+ self._del_dim(node_idx, new_idx_count)
+ origin_idx_count += 1
+ else:
+ raise NotImplementedError()
+
+ def _assign_view_reshape_indice(self, node: Node, node_idx: int):
+ """
+ Assign indice for view and reshape op.
+ 1. get origin shape and target shape by meta info.
+ 2. compute the real value of -1 in target shape.
+ 3. determine changed dim, and assgin indice for generated dim.
+ 4. log changed dim and generated dim for restore
+ 5. inherit computation.
+ 6. TODO: look into view list to see whether the view is associated with other,
+ if so assgin equal dim according to previous view.
+
+ Args:
+ node (node)
+ node_idx (int)
+ """
+ # get data, turn into number
+ origin_node = node.args[0]
+ origin_shape = origin_node.meta["tensor_meta"].shape
+ target_shape = []
+ unflated_args = flat_list(node.args)
+ for i in range(1, len(unflated_args)):
+ if isinstance(unflated_args[i], int):
+ target_shape.append(unflated_args[i])
+ else:
+ target_shape.append(unflated_args[i].meta["fwd_out"][0])
+
+ # compute the value of -1
+ if -1 in target_shape:
+ origin_product = 1
+ for i in origin_shape:
+ origin_product *= i
+ target_product = -1
+ for i in target_shape:
+ target_product *= i
+ shape_idx = target_shape.index(-1)
+ target_shape[shape_idx] = origin_product // target_product
+
+ # determine changed dim
+ len_diff = len(origin_shape) - len(target_shape)
+ if len_diff == 1:
+ # dim merge
+ dim_equal = [i == j for i, j in zip(origin_shape[:-1], target_shape)]
+ dim_to = [dim_equal.index(False)]
+ dim_from = [dim_equal.index(False), dim_equal.index(False) + 1]
+ self._add_dim(node_idx, -1)
+ elif len_diff == -1:
+ # dim expand
+ dim_equal = [i == j for i, j in zip(origin_shape, target_shape[:-1])]
+ dim_from = [dim_equal.index(False)]
+ dim_to = [dim_equal.index(False), dim_equal.index(False) + 1]
+ self._del_dim(node_idx, -1)
+ else:
+ raise NotImplementedError("shape" + str(origin_shape) + "and" + str(target_shape) + "view not implemented")
+
+ # get new indice
+ origin_trace = self._find_indice_trace_from_node(origin_node)
+ self._assign_indice_as_input(node, node_idx, origin_node)
+ dim_from.reverse()
+ for i in dim_from:
+ self._del_dim(node_idx, i)
+ for i in dim_to:
+ self._add_dim(node_idx, i)
+
+ # inherit computation
+ compute_log = self._find_compute_trace_from_node(origin_node)
+ for i in dim_from:
+ if origin_trace[i] in compute_log:
+ for j in dim_to:
+ self._mark_computation(node, node_idx, [j])
+ break
+
+ # log view, not used now
+ view_dict = {
+ "idx_from": [origin_trace[i] for i in dim_from],
+ "dim_from": dim_from,
+ "idx_to": [self.indice_trace_list[node_idx]["indice"][i] for i in dim_to],
+ "dim_to": dim_to,
+ }
+ self.indice_view_list[node] = view_dict
+
+ def _clear_trace(self, node_idx: int) -> None:
+ """
+ clear too far trace to speed up computation
+ """
+ trace_range = None
+ for i in range(len(self.trace_range)):
+ if self.trace_range[i][1] == node_idx:
+ trace_range = (self.trace_range[i][0], self.trace_range[i][1])
+ break
+ if self.trace_range[i][1] > node_idx:
+ break
+ if trace_range is None:
+ return
+
+ active_nodes = self.active_node_list[trace_range[0]:trace_range[1] + 1]
+ active_nodes = set(flat_list(active_nodes))
+ active_nodes = [find_idx_by_name(i, self.node_list) for i in active_nodes]
+ for i in range(trace_range[0], trace_range[1] + 1):
+ trace = self.indice_trace_list[i]
+ # clear compute
+ for dim_compute in trace["compute"]:
+ for i in range(len(dim_compute) - 1, -1, -1):
+ if dim_compute[i] < trace_range[0] and dim_compute[i] not in active_nodes:
+ dim_compute.pop(i)
+ continue
+ # clear source
+ for dim_source in trace["source"]:
+ for k in list(dim_source.keys()):
+ if k < trace_range[0] and k not in active_nodes:
+ dim_source.pop(k)
+
+ def trace_indice(self):
+ for idx, node in enumerate(self.node_list):
+ if node.op == "placeholder":
+ self._assign_all_indice(node, idx)
+ elif node.op == "call_method":
+ if "transpose" in node.name:
+ self._assign_transpose_indice(node, idx)
+ elif "permute" in node.name:
+ self._assign_permute_indice(node, idx)
+ elif "view" in node.name or "reshape" in node.name:
+ self._assign_view_reshape_indice(node, idx)
+ elif "unsqueeze" in node.name:
+ self._assign_unsqueeze_indice(node, idx)
+ elif any(i in node.name for i in ["to", "contiguous", "clone"]):
+ self._assgin_no_change_indice(node, idx)
+ elif "new_ones" in node.name:
+ self._assign_ones_like_indice(node, idx)
+ else:
+ raise NotImplementedError(node.name, "method not implemented yet!")
+ elif node.op == "call_function":
+ if "linear" in node.name:
+ self._assign_linear_indice(node, idx)
+ elif "cat" in node.name:
+ self._assign_cat_indice(node, idx)
+ elif "matmul" in node.name:
+ self._assign_matmul_indice(node, idx)
+ elif "softmax" in node.name:
+ self._assign_softmax_indice(node, idx)
+ elif any(n in node.name for n in ["mul", "add", "sigmoid", "relu", "sub", "truediv"]):
+ self._assign_elementwise_indice(node, idx)
+ elif "ones_like" in node.name:
+ self._assign_ones_like_indice(node, idx)
+ elif "dropout" in node.name:
+ self._assign_dropout_indice(node, idx)
+ elif "einsum" in node.name:
+ self._assign_einsum_indice(node, idx)
+ elif "sum" in node.name:
+ self._assign_sum_indice(node, idx)
+ elif "layer_norm" in node.name:
+ self._assign_layernorm_indice(node, idx)
+ elif "getitem" in node.name:
+ self._assign_getitem_indice(node, idx)
+ elif any(i in node.name for i in ["getattr", "getitem", "eq", "_assert"]):
+ continue
+ else:
+ raise NotImplementedError(node.name, "function not implemented yet!")
+ elif node.op == "call_module":
+ if any(n in node.name for n in ["layernorm", "norm"]):
+ self._assign_layernorm_indice(node, idx)
+ elif any(n in node.name for n in ["sigmoid", "dropout", "relu"]):
+ self._assign_elementwise_indice(node, idx)
+ else:
+ raise NotImplementedError(node.name, "module not implemented yet!")
+ elif node.op == "get_attr":
+ self._assign_all_indice(node, idx) # get param
+ elif node.op == "output":
+ continue
+ else:
+ raise NotImplementedError(node.op, "op not implemented yet!")
+
+ # limit trace range
+ self._clear_trace(idx)
diff --git a/colossalai/autochunk/utils.py b/colossalai/autochunk/utils.py
new file mode 100644
index 000000000..e87068512
--- /dev/null
+++ b/colossalai/autochunk/utils.py
@@ -0,0 +1,132 @@
+from typing import Any, Callable, Dict, Iterable, List, Tuple
+
+from torch.fx.node import Node
+
+from colossalai.logging import get_dist_logger
+
+logger = get_dist_logger()
+
+
+def get_logger():
+ return logger
+
+
+def flat_list(inputs: Any) -> List:
+ """
+ flat a list by recursion
+ """
+ if not (isinstance(inputs, list) or isinstance(inputs, set) or isinstance(inputs, tuple)):
+ return [inputs]
+ res = []
+ for i in inputs:
+ if isinstance(i, list) or isinstance(i, set) or isinstance(i, tuple):
+ res.extend(flat_list(i))
+ else:
+ res.append(i)
+ return res
+
+
+def find_first_tensor_arg(node: Node) -> Node:
+ """
+ Find the first input tensor arg for a node
+ """
+ for arg in node.args:
+ if type(arg) == type(node):
+ return arg
+ raise RuntimeError()
+
+
+def is_non_compute_node(node: Node) -> bool:
+ if any(i in node.op for i in ["placeholder", "get_attr", "output"]) or any(i in node.name for i in ["getattr"]):
+ return True
+ if "getitem" in node.name:
+ node_args = flat_list(node.args[1:])
+ for node_arg in node_args:
+ if any(i == str(node_arg) for i in ["None", "Ellipsis"]):
+ return False
+ if "slice" in str(node_arg):
+ return False
+ return True
+ return False
+
+
+def get_node_shape(node: Node) -> List:
+ if hasattr(node.meta["tensor_meta"], "shape"):
+ return node.meta["tensor_meta"].shape
+ return None
+
+
+def is_non_memory_node(node: Node) -> bool:
+ if "getitem" in node.name:
+ return True
+ if "output" in node.op:
+ return True
+ return is_non_compute_node(node)
+
+
+def is_non_compute_node_except_placeholder(node):
+ if "placeholder" in node.op:
+ return False
+ return is_non_compute_node(node)
+
+
+def is_non_compute_node_except_placeholder_output(node):
+ if "output" in node.op:
+ return False
+ return is_non_compute_node_except_placeholder(node)
+
+
+def find_idx_by_name(name, nodes_list):
+ for idx, node in enumerate(nodes_list):
+ if node.name == name:
+ return idx
+ raise RuntimeError("name %s not found in node list" % name)
+
+
+def delete_free_var_from_last_use(user_to_last_uses):
+ for key, value in user_to_last_uses.items():
+ for n in value:
+ if n.op == "placeholder":
+ user_to_last_uses[key].remove(n)
+
+
+def find_chunk_all_input_nodes(nodes: List[Node]):
+ """
+ Find non-compute input and output node names.
+ input nodes are nodes used in the list
+ output nodes are nodes will use nodes in the list
+ """
+ input_nodes = []
+ for node in nodes:
+ for input_node in node._input_nodes.keys():
+ if input_node not in nodes and input_node not in input_nodes:
+ input_nodes.append(input_node)
+ return input_nodes
+
+
+def find_chunk_compute_input_and_output_nodes(nodes: List[Node]):
+ """
+ Find non-compute input and output node names.
+ input nodes are nodes used in the list
+ output nodes are nodes will use nodes in the list
+ """
+ input_nodes = []
+ output_nodes = []
+
+ # if a node has an input node which is not in the node list
+ # we treat that input node as the input of the checkpoint function
+ for node in nodes:
+ for input_node in node._input_nodes.keys():
+ if (input_node not in nodes and input_node not in input_nodes
+ and not is_non_compute_node_except_placeholder(input_node)):
+ input_nodes.append(input_node)
+
+ # if a node has a user node which is not in the node list
+ # we treat that user node as the node receiving the current node output
+ for node in nodes:
+ for output_node in node.users.keys():
+ if (output_node not in nodes and node not in output_nodes
+ and not is_non_compute_node_except_placeholder_output(output_node)):
+ output_nodes.append(node)
+
+ return input_nodes, output_nodes
diff --git a/colossalai/cli/launcher/hostinfo.py b/colossalai/cli/launcher/hostinfo.py
index 2f0830c58..065cbc371 100644
--- a/colossalai/cli/launcher/hostinfo.py
+++ b/colossalai/cli/launcher/hostinfo.py
@@ -1,5 +1,5 @@
-from typing import List
import socket
+from typing import List
class HostInfo:
@@ -35,9 +35,14 @@ class HostInfo:
if port is None:
port = 22 # no port specified, lets just use the ssh port
- hostname = socket.getfqdn(hostname)
+
+ # socket.getfqdn("127.0.0.1") does not return localhost
+ # on some users' machines
+ # thus, we directly return True if hostname is locahost, 127.0.0.1 or 0.0.0.0
if hostname in ("localhost", "127.0.0.1", "0.0.0.0"):
return True
+
+ hostname = socket.getfqdn(hostname)
localhost = socket.gethostname()
localaddrs = socket.getaddrinfo(localhost, port)
targetaddrs = socket.getaddrinfo(hostname, port)
diff --git a/colossalai/cli/launcher/multinode_runner.py b/colossalai/cli/launcher/multinode_runner.py
index c45ad5e5a..a51e1e371 100644
--- a/colossalai/cli/launcher/multinode_runner.py
+++ b/colossalai/cli/launcher/multinode_runner.py
@@ -1,8 +1,10 @@
-import fabric
-from .hostinfo import HostInfo, HostInfoList
from multiprocessing import Pipe, Process
from multiprocessing import connection as mp_connection
+
import click
+import fabric
+
+from .hostinfo import HostInfo, HostInfoList
def run_on_host(hostinfo: HostInfo, workdir: str, recv_conn: mp_connection.Connection,
@@ -45,8 +47,10 @@ def run_on_host(hostinfo: HostInfo, workdir: str, recv_conn: mp_connection.Conne
# execute on the remote machine
fab_conn.run(cmds, hide=False)
send_conn.send('success')
- except:
- click.echo(f"Error: failed to run {cmds} on {hostinfo.hostname}")
+ except Exception as e:
+ click.echo(
+ f"Error: failed to run {cmds} on {hostinfo.hostname}, is localhost: {hostinfo.is_local_host}, exception: {e}"
+ )
send_conn.send('failure')
# shutdown
diff --git a/colossalai/cli/launcher/run.py b/colossalai/cli/launcher/run.py
index e078a57c1..6411b4302 100644
--- a/colossalai/cli/launcher/run.py
+++ b/colossalai/cli/launcher/run.py
@@ -1,13 +1,16 @@
-import click
-import sys
import os
-import torch
-from colossalai.context import Config
-from .multinode_runner import MultiNodeRunner
-from .hostinfo import HostInfo, HostInfoList
+import sys
from typing import List
+
+import click
+import torch
from packaging import version
+from colossalai.context import Config
+
+from .hostinfo import HostInfo, HostInfoList
+from .multinode_runner import MultiNodeRunner
+
# Constants that define our syntax
NODE_SEP = ','
@@ -15,7 +18,7 @@ NODE_SEP = ','
def fetch_hostfile(hostfile_path: str, ssh_port: int) -> HostInfoList:
"""
Parse the hostfile to obtain a list of hosts.
-
+
A hostfile should look like:
worker-0
worker-1
@@ -63,7 +66,7 @@ def parse_device_filter(device_pool: HostInfoList, include_str=None, exclude_str
device_pool (HostInfoList): a list of HostInfo objects
include_str (str): --include option passed by user, default None
exclude_str (str): --exclude option passed by user, default None
-
+
Returns:
filtered_hosts (HostInfoList): filtered hosts after inclusion/exclusion
'''
@@ -192,7 +195,7 @@ def launch_multi_processes(args: Config) -> None:
Launch multiple processes on a single node or multiple nodes.
The overall logic can be summarized as the pseudo code below:
-
+
if hostfile given:
hostinfo = parse_hostfile(hostfile)
hostinfo = include_or_exclude_hosts(hostinfo)
@@ -202,7 +205,7 @@ def launch_multi_processes(args: Config) -> None:
launch_on_multi_nodes(hostinfo)
else:
launch_on_current_node()
-
+
Args:
args (Config): the arguments taken from command line
@@ -276,6 +279,33 @@ def launch_multi_processes(args: Config) -> None:
extra_launch_args=args.extra_launch_args)
runner.send(hostinfo=hostinfo, cmd=cmd)
- runner.recv_from_all()
+ # start training
+ msg_from_node = runner.recv_from_all()
+ has_error = False
+
+ # print node status
+ click.echo("\n====== Training on All Nodes =====")
+ for hostname, msg in msg_from_node.items():
+ click.echo(f"{hostname}: {msg}")
+
+ # check if a process failed
+ if msg == "failure":
+ has_error = True
+
+ # stop all nodes
runner.stop_all()
- runner.recv_from_all()
+
+ # receive the stop status
+ msg_from_node = runner.recv_from_all()
+
+ # printe node status
+ click.echo("\n====== Stopping All Nodes =====")
+ for hostname, msg in msg_from_node.items():
+ click.echo(f"{hostname}: {msg}")
+
+ # give the process an exit code
+ # so that it behaves like a normal process
+ if has_error:
+ sys.exit(1)
+ else:
+ sys.exit(0)
diff --git a/colossalai/device/alpha_beta_profiler.py b/colossalai/device/alpha_beta_profiler.py
index 9c66cb85d..af2b10928 100644
--- a/colossalai/device/alpha_beta_profiler.py
+++ b/colossalai/device/alpha_beta_profiler.py
@@ -381,6 +381,8 @@ class AlphaBetaProfiler:
first_latency, first_bandwidth = _extract_alpha_beta(first_axis, first_axis_process_group)
second_latency, second_bandwidth = _extract_alpha_beta(second_axis, second_axis_process_group)
mesh_alpha = [first_latency, second_latency]
- mesh_beta = [1 / first_bandwidth, 1 / second_bandwidth]
+ # The beta values have been enlarged by 1e10 times temporarilly because the computation cost
+ # is still estimated in the unit of TFLOPs instead of time. We will remove this factor in future.
+ mesh_beta = [1e10 / first_bandwidth, 1e10 / second_bandwidth]
return mesh_alpha, mesh_beta
diff --git a/colossalai/device/device_mesh.py b/colossalai/device/device_mesh.py
index 7596a100b..b5a97eded 100644
--- a/colossalai/device/device_mesh.py
+++ b/colossalai/device/device_mesh.py
@@ -1,5 +1,6 @@
import operator
from functools import reduce
+from typing import List, Tuple
import torch
import torch.distributed as dist
@@ -15,7 +16,8 @@ class DeviceMesh:
Arguments:
physical_mesh_id (torch.Tensor): physical view of the devices in global rank.
- mesh_shape (torch.Size): shape of logical view.
+ logical_mesh_id (torch.Tensor): logical view of the devices in global rank.
+ mesh_shape (torch.Size, optional): shape of logical view.
mesh_alpha (List[float], optional): coefficients used for computing
communication cost (default: None)
mesh_beta (List[float], optional): coefficients used for computing
@@ -28,15 +30,21 @@ class DeviceMesh:
"""
def __init__(self,
- physical_mesh_id,
- mesh_shape,
- mesh_alpha=None,
- mesh_beta=None,
- init_process_group=False,
- need_flatten=True):
+ physical_mesh_id: torch.Tensor,
+ mesh_shape: torch.Size = None,
+ logical_mesh_id: torch.Tensor = None,
+ mesh_alpha: List[float] = None,
+ mesh_beta: List[float] = None,
+ init_process_group: bool = False,
+ need_flatten: bool = True):
self.physical_mesh_id = physical_mesh_id
- self.mesh_shape = mesh_shape
- self._logical_mesh_id = self.physical_mesh_id.reshape(self.mesh_shape)
+ if logical_mesh_id is None:
+ self.mesh_shape = mesh_shape
+ self._logical_mesh_id = self.physical_mesh_id.reshape(self.mesh_shape)
+ else:
+ self._logical_mesh_id = logical_mesh_id
+ self.mesh_shape = self._logical_mesh_id.shape
+
# map global rank into logical rank
self.convert_map = {}
self._global_rank_to_logical_rank_map(self._logical_mesh_id, [])
@@ -54,8 +62,8 @@ class DeviceMesh:
if self.need_flatten and self._logical_mesh_id.dim() > 1:
self.flatten_device_mesh = self.flatten()
# Create a new member `flatten_device_meshes` to distinguish from original flatten methods (Because I'm not sure if there are functions that rely on the self.flatten())
- self.flatten_device_meshes = FlattenDeviceMesh(self.physical_mesh_id, self.mesh_shape, self.mesh_alpha,
- self.mesh_beta)
+ # self.flatten_device_meshes = FlattenDeviceMesh(self.physical_mesh_id, self.mesh_shape, self.mesh_alpha,
+ # self.mesh_beta)
@property
def shape(self):
diff --git a/colossalai/fx/graph_module.py b/colossalai/fx/graph_module.py
index fbafd326c..ebb9975f2 100644
--- a/colossalai/fx/graph_module.py
+++ b/colossalai/fx/graph_module.py
@@ -1,24 +1,34 @@
import os
import warnings
+from pathlib import Path
+from typing import Any, Dict, List, Optional, Set, Type, Union
+
import torch
import torch.nn as nn
from torch.nn.modules.module import _addindent
-from typing import Type, Dict, List, Any, Union, Optional, Set
-from pathlib import Path
+
try:
- from torch.fx.graph_module import GraphModule, _EvalCacheLoader, _WrappedCall, _exec_with_source, _forward_from_src
- from torch.fx.graph import Graph, _PyTreeCodeGen, _is_from_torch, _custom_builtins, PythonCode
+ from torch.fx.graph import Graph, PythonCode, _custom_builtins, _is_from_torch, _PyTreeCodeGen
+ from torch.fx.graph_module import GraphModule, _EvalCacheLoader, _exec_with_source, _forward_from_src, _WrappedCall
+
+ from colossalai.fx.codegen.activation_checkpoint_codegen import ActivationCheckpointCodeGen
COLOGM = True
except:
- from torch.fx.graph_module import GraphModule
from torch.fx.graph import Graph
+ from torch.fx.graph_module import GraphModule
COLOGM = False
if COLOGM:
class ColoGraphModule(GraphModule):
- def __init__(self, root: Union[torch.nn.Module, Dict[str, Any]], graph: Graph, class_name: str = 'GraphModule'):
+ def __init__(self,
+ root: Union[torch.nn.Module, Dict[str, Any]],
+ graph: Graph,
+ class_name: str = 'GraphModule',
+ ckpt_codegen: bool = True):
+ if ckpt_codegen:
+ graph.set_codegen(ActivationCheckpointCodeGen())
super().__init__(root, graph, class_name)
def bind(self, ckpt_def, globals):
diff --git a/colossalai/fx/passes/adding_split_node_pass.py b/colossalai/fx/passes/adding_split_node_pass.py
index 373d20c51..0499769d8 100644
--- a/colossalai/fx/passes/adding_split_node_pass.py
+++ b/colossalai/fx/passes/adding_split_node_pass.py
@@ -9,6 +9,40 @@ def pipe_split():
pass
+def avgcompute_split_pass(gm: torch.fx.GraphModule, pp_size: int):
+ """
+ In avgcompute_split_pass, we split module by the fwd flops.
+ """
+ mod_graph = gm.graph
+ # To use avgcompute_split_pass, we need run meta_info_prop interpreter first.
+ # If nodes don't have meta info, this pass will fall back to normal balanced split pass.
+ check_node = list(mod_graph.nodes)[0]
+ if 'tensor_meta' not in check_node.meta:
+ return balanced_split_pass(gm, pp_size)
+
+ total_fwd_flop = 0
+ for node in mod_graph.nodes:
+ total_fwd_flop += node.fwd_flop
+
+ partition_flop = total_fwd_flop // pp_size
+ accumulate_fwd_flop = 0
+ for node in mod_graph.nodes:
+ if pp_size <= 1:
+ break
+ if 'pipe_split' in node.name:
+ continue
+ accumulate_fwd_flop += node.fwd_flop
+ if accumulate_fwd_flop >= partition_flop:
+ total_fwd_flop = total_fwd_flop - accumulate_fwd_flop
+ accumulate_fwd_flop = 0
+ pp_size -= 1
+ partition_flop = total_fwd_flop // pp_size
+ with mod_graph.inserting_after(node):
+ split_node = mod_graph.create_node('call_function', pipe_split)
+ gm.recompile()
+ return gm
+
+
def avgnode_split_pass(gm: torch.fx.GraphModule, pp_size: int):
"""
In avgnode_split_pass, simpliy split graph by node number.
@@ -104,8 +138,10 @@ def balanced_split_pass_v2(gm: torch.fx.GraphModule, pp_size: int):
continue
accumulate_node_size += node.node_size
if accumulate_node_size >= partition_size:
+ total_element_size = total_element_size - accumulate_node_size
accumulate_node_size = 0
pp_size -= 1
+ partition_size = total_element_size // pp_size
with mod_graph.inserting_after(node):
split_node = mod_graph.create_node('call_function', pipe_split)
gm.recompile()
diff --git a/colossalai/fx/passes/meta_info_prop.py b/colossalai/fx/passes/meta_info_prop.py
index 5137494ad..281cae41f 100644
--- a/colossalai/fx/passes/meta_info_prop.py
+++ b/colossalai/fx/passes/meta_info_prop.py
@@ -112,7 +112,8 @@ class MetaInfoProp(torch.fx.Interpreter):
n.meta['tensor_meta'] = tensor_meta
n.meta = {**n.meta, **asdict(meta_info)} # extend MetaInfo to `n.meta`
# TODO: the attribute node_size should be removed in the future
- setattr(n, 'node_size', activation_size(n.meta.get('fwd_in', 0)) + activation_size(n.meta.get('fwd_tmp', 0)))
+ setattr(n, 'node_size', activation_size(n.meta.get('fwd_out', 0)) + activation_size(n.meta.get('fwd_tmp', 0)))
+ setattr(n, 'fwd_flop', n.meta.get('fwd_flop', 0))
n.meta['type'] = type(result)
# retain the autograd graph
diff --git a/colossalai/fx/profiler/opcount.py b/colossalai/fx/profiler/opcount.py
index 1c39dc247..6bd612ad2 100644
--- a/colossalai/fx/profiler/opcount.py
+++ b/colossalai/fx/profiler/opcount.py
@@ -249,6 +249,8 @@ if version.parse(torch.__version__) >= version.parse('1.12.0'):
aten.sum.default,
aten.sum.dim_IntList,
aten.mean.dim,
+ aten.sub.Tensor,
+ aten.sub_.Tensor,
# activation op
aten.hardswish.default,
@@ -313,7 +315,8 @@ if version.parse(torch.__version__) >= version.parse('1.12.0'):
aten.where.self,
aten.zero_.default,
aten.zeros_like.default,
- ]
+ aten.fill_.Scalar
+ ] # yapf: disable
for op in zero_flop_aten:
flop_mapping[op] = zero_flop_jit
diff --git a/colossalai/fx/profiler/tensor.py b/colossalai/fx/profiler/tensor.py
index 43165305f..7606f17cf 100644
--- a/colossalai/fx/profiler/tensor.py
+++ b/colossalai/fx/profiler/tensor.py
@@ -1,6 +1,4 @@
import uuid
-from copy import deepcopy
-from typing import Optional
import torch
from torch.types import _bool, _device, _dtype
@@ -28,8 +26,6 @@ class MetaTensor(torch.Tensor):
_tensor: torch.Tensor
- __slots__ = ['_tensor']
-
@staticmethod
def __new__(cls, elem, fake_device=None):
# Avoid multiple wrapping
@@ -47,7 +43,7 @@ class MetaTensor(torch.Tensor):
storage_offset=elem.storage_offset(),
dtype=elem.dtype,
layout=elem.layout,
- device=fake_device if fake_device is not None else elem.device,
+ device=fake_device if fake_device is not None else torch.device('cpu'),
requires_grad=elem.requires_grad) # deceive the frontend for aten selections
r._tensor = elem
# ...the real tensor is held as an element on the tensor.
@@ -59,8 +55,8 @@ class MetaTensor(torch.Tensor):
def __repr__(self):
if self.grad_fn:
- return f"MetaTensor({self._tensor}, fake_device='{self.device}', grad_fn={self.grad_fn})"
- return f"MetaTensor({self._tensor}, fake_device='{self.device}')"
+ return f"MetaTensor(..., size={tuple(self.shape)}, device='{self.device}', dtype={self.dtype}, grad_fn={self.grad_fn})"
+ return f"MetaTensor(..., size={tuple(self.shape)}, device='{self.device}', dtype={self.dtype})"
@classmethod
def __torch_dispatch__(cls, func, types, args=(), kwargs=None):
@@ -76,13 +72,13 @@ class MetaTensor(torch.Tensor):
x = x.to(torch.device('meta'))
return x
+ args = tree_map(unwrap, args)
+ kwargs = tree_map(unwrap, kwargs)
+
if 'device' in kwargs:
fake_device = kwargs['device']
kwargs['device'] = torch.device('meta')
- args = tree_map(unwrap, args)
- kwargs = tree_map(unwrap, kwargs)
-
# run aten for backend=CPU but actually on backend=Meta
out = func(*args, **kwargs)
@@ -118,23 +114,24 @@ class MetaTensor(torch.Tensor):
MetaTensor(tensor(..., device='meta', size=(10,)), fake_device='vulkan')
"""
# this imitates c++ function in the way of @overload
- device = None
- for arg in args:
- if isinstance(arg, str) or isinstance(arg, _device):
- device = arg
- if 'device' in kwargs:
- device = kwargs['device']
- result = super().to(*args, **kwargs)
- if device is not None:
- result = MetaTensor(result, fake_device=device)
- return result
+ fake_device = None
+
+ def replace(x):
+ nonlocal fake_device
+ if isinstance(x, str) or isinstance(x, _device):
+ fake_device = x
+ return 'meta'
+ return x
+
+ elem = self._tensor.to(*tree_map(replace, args), **tree_map(replace, kwargs))
+ return MetaTensor(elem, fake_device=fake_device)
def cpu(self, *args, **kwargs):
if self.device.type == 'cpu':
return self.to(*args, **kwargs)
return self.to(*args, device='cpu', **kwargs)
- def cuda(self, *args, **kwargs):
- if self.device.type == 'cuda':
- return self.to(*args, **kwargs)
- return self.to(*args, device='cuda', **kwargs)
+ def cuda(self, device=None, non_blocking=False):
+ if device is not None:
+ return self.to(device=device, non_blocking=non_blocking)
+ return self.to(device='cuda:0', non_blocking=non_blocking)
diff --git a/colossalai/fx/tracer/_symbolic_trace.py b/colossalai/fx/tracer/_symbolic_trace.py
index bff2f6a10..5c04eeace 100644
--- a/colossalai/fx/tracer/_symbolic_trace.py
+++ b/colossalai/fx/tracer/_symbolic_trace.py
@@ -13,6 +13,7 @@ def symbolic_trace(
root: Union[torch.nn.Module, Callable[..., Any]],
concrete_args: Optional[Dict[str, Any]] = None,
meta_args: Optional[Dict[str, Any]] = None,
+ trace_act_ckpt=False,
) -> ColoGraphModule:
"""
Symbolic tracing API
@@ -49,6 +50,6 @@ def symbolic_trace(
This API is still under development and can incur some bugs. Feel free to report any bugs to the Colossal-AI team.
"""
- graph = ColoTracer().trace(root, concrete_args=concrete_args, meta_args=meta_args)
+ graph = ColoTracer(trace_act_ckpt=trace_act_ckpt).trace(root, concrete_args=concrete_args, meta_args=meta_args)
name = root.__class__.__name__ if isinstance(root, torch.nn.Module) else root.__name__
return ColoGraphModule(root, graph, name)
diff --git a/colossalai/fx/tracer/experimental.py b/colossalai/fx/tracer/experimental.py
index 6fee5f5d0..88b65b618 100644
--- a/colossalai/fx/tracer/experimental.py
+++ b/colossalai/fx/tracer/experimental.py
@@ -1,7 +1,7 @@
import enum
import functools
-import operator
import inspect
+import operator
from contextlib import contextmanager
from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Union
@@ -286,7 +286,6 @@ class ColoTracer(Tracer):
self.graph.lint()
return self.graph
-
@contextmanager
def trace_activation_checkpoint(self, enabled: bool):
if enabled:
@@ -316,7 +315,6 @@ class ColoTracer(Tracer):
# recover the checkpoint function upon exit
torch.utils.checkpoint.CheckpointFunction = orig_ckpt_func
-
def _post_check(self, non_concrete_arg_names: Set[str]):
# This is necessary because concrete args are added as input to the traced module since
# https://github.com/pytorch/pytorch/pull/55888.
@@ -385,18 +383,23 @@ def symbolic_trace(
root: Union[torch.nn.Module, Callable[..., Any]],
concrete_args: Optional[Dict[str, Any]] = None,
meta_args: Optional[Dict[str, Any]] = None,
+ trace_act_ckpt=False,
) -> ColoGraphModule:
if is_compatible_with_meta():
if meta_args is not None:
root.to(default_device())
wrap_fn = lambda x: MetaTensor(x, fake_device=default_device()) if isinstance(x, torch.Tensor) else x
- graph = ColoTracer().trace(root, concrete_args=concrete_args, meta_args=tree_map(wrap_fn, meta_args))
+ graph = ColoTracer(trace_act_ckpt=trace_act_ckpt).trace(root,
+ concrete_args=concrete_args,
+ meta_args=tree_map(wrap_fn, meta_args))
root.cpu()
else:
graph = Tracer().trace(root, concrete_args=concrete_args)
else:
from .tracer import ColoTracer as OrigColoTracer
- graph = OrigColoTracer().trace(root, concrete_args=concrete_args, meta_args=meta_args)
+ graph = OrigColoTracer(trace_act_ckpt=trace_act_ckpt).trace(root,
+ concrete_args=concrete_args,
+ meta_args=meta_args)
name = root.__class__.__name__ if isinstance(root, torch.nn.Module) else root.__name__
return ColoGraphModule(root, graph, name)
@@ -471,11 +474,11 @@ def meta_prop_pass(gm: ColoGraphModule,
node._meta_data = _meta_data_computing(meta_args, concrete_args, root, node.op, node.target, node.args,
node.kwargs)
+
def _meta_data_computing(meta_args, concrete_args, root, kind, target, args, kwargs):
unwrap_fn = lambda n: n._meta_data if isinstance(n, Node) else n
if kind == 'placeholder':
- meta_out = meta_args[target] if target in meta_args else concrete_args.get(
- _truncate_suffix(target), None)
+ meta_out = meta_args[target] if target in meta_args else concrete_args.get(_truncate_suffix(target), None)
elif kind == 'get_attr':
attr_itr = root
atoms = target.split(".")
@@ -490,7 +493,7 @@ def _meta_data_computing(meta_args, concrete_args, root, kind, target, args, kwa
else:
if target not in _TensorPropertyMethod:
meta_out = getattr(unwrap_fn(args[0]), target)(*tree_map(unwrap_fn, args[1:]),
- **tree_map(unwrap_fn, kwargs))
+ **tree_map(unwrap_fn, kwargs))
elif kind == 'call_module':
mod = root.get_submodule(target)
meta_out = mod.forward(*tree_map(unwrap_fn, args), **tree_map(unwrap_fn, kwargs))
@@ -498,6 +501,7 @@ def _meta_data_computing(meta_args, concrete_args, root, kind, target, args, kwa
meta_out = None
return meta_out
+
def _meta_data_computing_v0(meta_args, root, kind, target, args, kwargs):
if kind == "placeholder" and target in meta_args and meta_args[target].is_meta:
meta_out = meta_args[target]
@@ -568,7 +572,7 @@ def _meta_data_computing_v0(meta_args, root, kind, target, args, kwargs):
return meta_out
-def bias_addition_pass(gm: ColoGraphModule, root_model: torch.nn.Module, meta_args: Optional[Dict[str, Any]]=None):
+def bias_addition_pass(gm: ColoGraphModule, root_model: torch.nn.Module, meta_args: Optional[Dict[str, Any]] = None):
result_graph = Graph()
value_remap = {}
unwrap_fn = lambda n: n._meta_data if isinstance(n, Node) else n
@@ -601,20 +605,24 @@ def bias_addition_pass(gm: ColoGraphModule, root_model: torch.nn.Module, meta_ar
if target == torch.nn.functional.linear:
if 'bias' in kwargs and kwargs['bias'] is not None:
function_to_substitute = func_to_func_dict[target]
- handle = bias_addition_function.get(target)(tracer, target, args_proxy, kwargs_proxy, function_to_substitute)
+ handle = bias_addition_function.get(target)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
else:
function_to_substitute = func_to_func_dict[target]
- handle = bias_addition_function.get(target)(tracer, target, args_proxy, kwargs_proxy, function_to_substitute)
+ handle = bias_addition_function.get(target)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
elif bias_addition_function.has(target.__name__):
# use name for some builtin op like @ (matmul)
function_to_substitute = func_to_func_dict[target]
- handle = bias_addition_function.get(target.__name__)(tracer, target, args_proxy, kwargs_proxy, function_to_substitute)
+ handle = bias_addition_function.get(target.__name__)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
elif kind == "call_method":
method = getattr(args_metas[0].__class__, target)
if bias_addition_method.has(method):
function_to_substitute = method_to_func_dict[method]
- handle = bias_addition_method.get(method)(tracer, target, args_proxy, kwargs_proxy, function_to_substitute)
+ handle = bias_addition_method.get(method)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
elif kind == "call_module":
# if not hasattr(self, "orig_forward"):
@@ -623,20 +631,20 @@ def bias_addition_pass(gm: ColoGraphModule, root_model: torch.nn.Module, meta_ar
mod_type = type(mod)
if bias_addition_module.has(mod_type) and mod.bias is not None:
function_to_substitute = module_to_func_dict[mod_type]
- handle = bias_addition_module.get(mod_type)(tracer, target, args_proxy, kwargs_proxy, function_to_substitute)
+ handle = bias_addition_module.get(mod_type)(tracer, target, args_proxy, kwargs_proxy,
+ function_to_substitute)
if handle is not None:
handle.generate()
for node_inserted in tracer.graph.nodes:
- value_remap[node_inserted] = result_graph.node_copy(node_inserted, lambda n : value_remap[n])
+ value_remap[node_inserted] = result_graph.node_copy(node_inserted, lambda n: value_remap[n])
last_node = value_remap[node_inserted]
value_remap[orig_node] = last_node
else:
- value_remap[orig_node] = result_graph.node_copy(orig_node, lambda n : value_remap[n])
+ value_remap[orig_node] = result_graph.node_copy(orig_node, lambda n: value_remap[n])
del tracer
gm.graph = result_graph
gm.recompile()
meta_prop_pass(gm, root_model, meta_args)
-
diff --git a/colossalai/gemini/chunk/search_utils.py b/colossalai/gemini/chunk/search_utils.py
index 312d77f18..572c3d945 100644
--- a/colossalai/gemini/chunk/search_utils.py
+++ b/colossalai/gemini/chunk/search_utils.py
@@ -6,17 +6,14 @@ import torch.nn as nn
from colossalai.gemini.memory_tracer import MemStats, OrderedParamGenerator
from colossalai.tensor import ColoParameter
-
-
-def in_ddp(param: nn.Parameter) -> bool:
- return not getattr(param, '_ddp_to_ignore', False)
+from colossalai.utils import is_ddp_ignored
def _filter_exlarge_params(model: nn.Module, size_dict: Dict[int, List[int]]) -> None:
"""
Filter those parameters whose size is too large (more than 3x standard deviations) from others.
"""
- params_size = [p.numel() for p in model.parameters() if in_ddp(p)]
+ params_size = [p.numel() for p in model.parameters() if not is_ddp_ignored(p)]
params_size_arr = np.array(params_size)
std = np.std(params_size_arr)
@@ -56,7 +53,7 @@ def classify_params_by_dp_degree(param_order: OrderedParamGenerator) -> Dict[int
params_dict: Dict[int, List[ColoParameter]] = dict()
for param in param_order.generate():
assert isinstance(param, ColoParameter), "please init model in the ColoInitContext"
- if not in_ddp(param):
+ if is_ddp_ignored(param):
continue
param_key = param.process_group.dp_world_size()
diff --git a/colossalai/gemini/chunk/utils.py b/colossalai/gemini/chunk/utils.py
index e9a9f84e7..ebfdee778 100644
--- a/colossalai/gemini/chunk/utils.py
+++ b/colossalai/gemini/chunk/utils.py
@@ -6,8 +6,14 @@ import torch.distributed as dist
import torch.nn as nn
from colossalai.gemini.chunk import ChunkManager
-from colossalai.gemini.chunk.search_utils import in_ddp, search_chunk_configuration
-from colossalai.gemini.memory_tracer import MemStats
+from colossalai.gemini.chunk.search_utils import search_chunk_configuration
+from colossalai.utils import is_ddp_ignored
+
+
+def safe_div(a, b):
+ if a == 0:
+ return 0
+ return a / b
def init_chunk_manager(model: nn.Module,
@@ -16,7 +22,6 @@ def init_chunk_manager(model: nn.Module,
search_range_mb: Optional[float] = None,
min_chunk_size_mb: Optional[float] = None,
filter_exlarge_params: Optional[bool] = None) -> ChunkManager:
-
kwargs_dict = dict()
if hidden_dim:
@@ -34,7 +39,7 @@ def init_chunk_manager(model: nn.Module,
if filter_exlarge_params:
kwargs_dict["filter_exlarge_params"] = filter_exlarge_params
- params_sizes = [p.numel() for p in model.parameters() if in_ddp(p)]
+ params_sizes = [p.numel() for p in model.parameters() if not is_ddp_ignored(p)]
total_size = sum(params_sizes) / 1024**2
dist.barrier()
@@ -50,7 +55,7 @@ def init_chunk_manager(model: nn.Module,
if dist.get_rank() == 0:
print("searching chunk configuration is completed in {:.2f} s.\n".format(span_s),
"used number: {:.2f} MB, wasted number: {:.2f} MB\n".format(total_size, wasted_size),
- "total wasted percentage is {:.2f}%".format(100 * wasted_size / (total_size + wasted_size)),
+ "total wasted percentage is {:.2f}%".format(100 * safe_div(wasted_size, total_size + wasted_size)),
sep='',
flush=True)
dist.barrier()
diff --git a/colossalai/gemini/gemini_mgr.py b/colossalai/gemini/gemini_mgr.py
index 08961b958..08fc0cf92 100644
--- a/colossalai/gemini/gemini_mgr.py
+++ b/colossalai/gemini/gemini_mgr.py
@@ -50,6 +50,17 @@ class GeminiManager:
self._warmup = True
self._comp_cuda_demand_time = 0
+ def reset_attributes(self):
+ self._compute_idx = -1
+ self._h2d_volume = 0
+ self._d2h_volume = 0
+ self._layout_time = 0
+ self._evict_time = 0
+ self._comp_cuda_demand_time = 0
+
+ def is_warmup(self):
+ return self._warmup
+
def memstats(self):
"""memstats
@@ -73,12 +84,7 @@ class GeminiManager:
if self._mem_stats_collector and self._warmup:
self._mem_stats_collector.finish_collection()
self._warmup = False
- self._compute_idx = -1
- self._h2d_volume = 0
- self._d2h_volume = 0
- self._layout_time = 0
- self._evict_time = 0
- self._comp_cuda_demand_time = 0
+ self.reset_attributes()
def adjust_layout(self, chunks: Tuple[Chunk, ...]) -> None:
""" Adjust the layout of stateful tensors according to the information provided
diff --git a/colossalai/initialize.py b/colossalai/initialize.py
index e907efdde..f3719dcb4 100644
--- a/colossalai/initialize.py
+++ b/colossalai/initialize.py
@@ -15,26 +15,25 @@ from torch.optim.lr_scheduler import _LRScheduler
from torch.optim.optimizer import Optimizer
from torch.utils.data import DataLoader
-from colossalai.core import global_context as gpc
-from colossalai.context.moe_context import MOE_CONTEXT
-
-from colossalai.logging import get_dist_logger
-
-from colossalai.engine.schedule import NonPipelineSchedule, PipelineSchedule, InterleavedPipelineSchedule, get_tensor_shape
-from colossalai.engine import Engine
-from colossalai.gemini.ophooks import BaseOpHook
-
-from colossalai.utils import (get_current_device, is_using_ddp, is_using_pp, is_using_sequence, sync_model_param)
-from colossalai.utils.moe import sync_moe_model_param
-
from colossalai.amp import AMP_TYPE, convert_to_amp
from colossalai.amp.naive_amp import NaiveAMPModel
from colossalai.builder.builder import build_gradient_handler
from colossalai.context import Config, ConfigException, ParallelMode
+from colossalai.context.moe_context import MOE_CONTEXT
+from colossalai.core import global_context as gpc
+from colossalai.engine import Engine
from colossalai.engine.gradient_accumulation import accumulate_gradient
-
+from colossalai.engine.schedule import (
+ InterleavedPipelineSchedule,
+ NonPipelineSchedule,
+ PipelineSchedule,
+ get_tensor_shape,
+)
+from colossalai.gemini.ophooks import BaseOpHook
+from colossalai.logging import get_dist_logger
from colossalai.nn.optimizer.colossalai_optimizer import ColossalaiOptimizer
-
+from colossalai.utils import get_current_device, is_using_ddp, is_using_pp, is_using_sequence, sync_model_param
+from colossalai.utils.moe import sync_moe_model_param
from colossalai.zero import convert_to_zero_v2
from colossalai.zero.sharded_optim.sharded_optim_v2 import ShardedOptimizerV2
@@ -301,9 +300,9 @@ def initialize(model: nn.Module,
model = model().to(get_current_device())
# optimizer maybe a optimizer_cls
- logger.warning("Initializing an non ZeRO model with optimizer class")
if isinstance(optimizer, Callable):
optimizer = optimizer(model.parameters())
+ logger.warning("Initializing an non ZeRO model with optimizer class")
if not use_zero:
if is_using_sequence():
diff --git a/colossalai/kernel/cuda_native/scaled_softmax.py b/colossalai/kernel/cuda_native/scaled_softmax.py
index 3f0260aae..44d750c5c 100644
--- a/colossalai/kernel/cuda_native/scaled_softmax.py
+++ b/colossalai/kernel/cuda_native/scaled_softmax.py
@@ -114,6 +114,13 @@ class FusedScaleMaskSoftmax(nn.Module):
self.softmax_in_fp32 = softmax_in_fp32
self.scale = scale
+ try:
+ from colossalai._C import scaled_masked_softmax
+ except ImportError:
+ from colossalai.kernel.op_builder.scaled_masked_softmax import ScaledMaskedSoftmaxBuilder
+ scaled_masked_softmax = ScaledMaskedSoftmaxBuilder().load()
+ self.scaled_masked_softmax = scaled_masked_softmax
+
assert (self.scale is None or softmax_in_fp32), "softmax should be in fp32 when scaled"
def forward(self, input, mask):
@@ -178,11 +185,5 @@ class FusedScaleMaskSoftmax(nn.Module):
return probs
- @staticmethod
- def get_batch_per_block(sq, sk, b, np):
- try:
- import colossalai._C.scaled_masked_softmax
- except ImportError:
- raise RuntimeError('ScaledMaskedSoftmax requires cuda extensions')
-
- return colossalai._C.scaled_masked_softmax.get_batch_per_block(sq, sk, b, np)
+ def get_batch_per_block(self, sq, sk, b, np):
+ return self.scaled_masked_softmax.get_batch_per_block(sq, sk, b, np)
diff --git a/colossalai/nn/optimizer/cpu_adam.py b/colossalai/nn/optimizer/cpu_adam.py
index a8c352279..54036973e 100644
--- a/colossalai/nn/optimizer/cpu_adam.py
+++ b/colossalai/nn/optimizer/cpu_adam.py
@@ -19,7 +19,7 @@ class CPUAdam(NVMeOptimizer):
* Parameters on GPU and gradients on GPU is allowed.
* Parameters on GPU and gradients on CPU is **not** allowed.
- Requires ColossalAI to be installed via ``pip install .``.
+ `CPUAdam` requires CUDA extensions which can be built during installation or runtime.
This version of CPU Adam accelates parameters updating on CPU with SIMD.
Support of AVX2 or AVX512 is required.
diff --git a/colossalai/nn/optimizer/fused_adam.py b/colossalai/nn/optimizer/fused_adam.py
index 2f6bde5ca..941866d55 100644
--- a/colossalai/nn/optimizer/fused_adam.py
+++ b/colossalai/nn/optimizer/fused_adam.py
@@ -9,8 +9,7 @@ from colossalai.utils import multi_tensor_applier
class FusedAdam(torch.optim.Optimizer):
"""Implements Adam algorithm.
- Currently GPU-only. Requires ColossalAI to be installed via
- ``pip install .``.
+ `FusedAdam` requires CUDA extensions which can be built during installation or runtime.
This version of fused Adam implements 2 fusions.
diff --git a/colossalai/nn/optimizer/fused_lamb.py b/colossalai/nn/optimizer/fused_lamb.py
index 891a76da7..72520064e 100644
--- a/colossalai/nn/optimizer/fused_lamb.py
+++ b/colossalai/nn/optimizer/fused_lamb.py
@@ -9,8 +9,7 @@ from colossalai.utils import multi_tensor_applier
class FusedLAMB(torch.optim.Optimizer):
"""Implements LAMB algorithm.
- Currently GPU-only. Requires ColossalAI to be installed via
- ``pip install .``.
+ `FusedLAMB` requires CUDA extensions which can be built during installation or runtime.
This version of fused LAMB implements 2 fusions.
diff --git a/colossalai/nn/optimizer/fused_sgd.py b/colossalai/nn/optimizer/fused_sgd.py
index 41e6d5248..468713b22 100644
--- a/colossalai/nn/optimizer/fused_sgd.py
+++ b/colossalai/nn/optimizer/fused_sgd.py
@@ -10,8 +10,7 @@ from colossalai.utils import multi_tensor_applier
class FusedSGD(Optimizer):
r"""Implements stochastic gradient descent (optionally with momentum).
- Currently GPU-only. Requires ColossalAI to be installed via
- ``pip install .``.
+ `FusedSGD` requires CUDA extensions which can be built during installation or runtime.
This version of fused SGD implements 2 fusions.
diff --git a/colossalai/nn/optimizer/hybrid_adam.py b/colossalai/nn/optimizer/hybrid_adam.py
index 5196d4338..1d0fb92de 100644
--- a/colossalai/nn/optimizer/hybrid_adam.py
+++ b/colossalai/nn/optimizer/hybrid_adam.py
@@ -19,7 +19,7 @@ class HybridAdam(NVMeOptimizer):
* Parameters on GPU and gradients on GPU is allowed.
* Parameters on GPU and gradients on CPU is **not** allowed.
- Requires ColossalAI to be installed via ``pip install .``
+ `HybriadAdam` requires CUDA extensions which can be built during installation or runtime.
This version of Hybrid Adam is an hybrid of CPUAdam and FusedAdam.
diff --git a/colossalai/nn/optimizer/zero_optimizer.py b/colossalai/nn/optimizer/zero_optimizer.py
index 2786d4496..9f761efdb 100644
--- a/colossalai/nn/optimizer/zero_optimizer.py
+++ b/colossalai/nn/optimizer/zero_optimizer.py
@@ -1,4 +1,5 @@
import math
+import warnings
from enum import Enum
from typing import Any, Dict, Set, Tuple
@@ -12,7 +13,7 @@ from colossalai.gemini.chunk import Chunk, ChunkManager
from colossalai.logging import get_dist_logger
from colossalai.nn.optimizer import ColossalaiOptimizer, CPUAdam, FusedAdam, HybridAdam
from colossalai.nn.parallel.data_parallel import ZeroDDP
-from colossalai.utils import disposable, get_current_device
+from colossalai.utils import disposable, get_current_device, is_ddp_ignored
_AVAIL_OPTIM_LIST = {FusedAdam, CPUAdam, HybridAdam}
@@ -78,8 +79,16 @@ class ZeroOptimizer(ColossalaiOptimizer):
if self.clipping_flag:
assert norm_type == 2.0, "ZeroOptimizer only supports L2 norm now"
- params_list = [p for p in module.parameters() if not getattr(p, '_ddp_to_ignore', False)]
- for p, fp32_p in zip(params_list, module.fp32_params):
+ ddp_param_list = []
+ for name, param in module.named_parameters():
+ if is_ddp_ignored(param):
+ if param.requires_grad:
+ warnings.warn(f"Parameter `{name}` is ignored by DDP but requires gradient! "
+ "You should handle its optimizer update by yourself!")
+ else:
+ ddp_param_list.append(param)
+
+ for p, fp32_p in zip(ddp_param_list, module.fp32_params):
chunk_16 = self.chunk_manager.get_chunk(p)
if chunk_16 not in self.chunk16_set:
chunk_16.l2_norm_flag = self.clipping_flag
@@ -140,6 +149,10 @@ class ZeroOptimizer(ColossalaiOptimizer):
return self._found_overflow.item() > 0
+ def _clear_global_norm(self) -> None:
+ for c16 in self.chunk16_set:
+ c16.l2_norm = None
+
def _calc_global_norm(self) -> float:
norm_sqr: float = 0.0
group_to_norm = dict()
@@ -201,6 +214,7 @@ class ZeroOptimizer(ColossalaiOptimizer):
self.optim_state = OptimState.UNSCALED # no need to unscale grad
self.grad_scaler.update(found_inf) # update gradient scaler
self._logger.info(f'Found overflow. Skip step')
+ self._clear_global_norm() # clear recorded norm
self.zero_grad() # reset all gradients
self._update_fp16_params()
return
@@ -285,6 +299,8 @@ class ZeroOptimizer(ColossalaiOptimizer):
fake_params_list = list()
for param in group['params']:
+ if is_ddp_ignored(param):
+ continue
chunk16 = self.chunk_manager.get_chunk(param)
range_pair = get_range_pair(chunk16, param)
if range_pair[0] >= range_pair[1]:
diff --git a/colossalai/nn/parallel/data_parallel.py b/colossalai/nn/parallel/data_parallel.py
index e3bb83347..a742946f4 100644
--- a/colossalai/nn/parallel/data_parallel.py
+++ b/colossalai/nn/parallel/data_parallel.py
@@ -12,12 +12,14 @@ from colossalai.gemini.memory_tracer import OrderedParamGenerator
from colossalai.logging import get_dist_logger
from colossalai.nn.parallel.utils import get_temp_total_chunk_on_cuda
from colossalai.tensor import ProcessGroup as ColoProcessGroup
+from colossalai.tensor import ReplicaSpec
from colossalai.tensor.colo_parameter import ColoParameter, ColoTensor, ColoTensorSpec
from colossalai.tensor.param_op_hook import ColoParamOpHookManager
-from colossalai.utils import get_current_device
+from colossalai.utils import get_current_device, is_ddp_ignored
from colossalai.zero.utils.gemini_hook import GeminiZeROHook
from .reducer import Reducer
+from .utils import get_static_torch_model
try:
from torch.nn.modules.module import _EXTRA_STATE_KEY_SUFFIX, _IncompatibleKeys
@@ -80,7 +82,7 @@ class ColoDDP(torch.nn.Module):
self.reducer = Reducer(bucket_cap_mb)
self.rebuild_bucket = rebuild_bucket
for p in module.parameters():
- if getattr(p, '_ddp_to_ignore', False):
+ if is_ddp_ignored(p):
continue
if p.requires_grad:
p.register_hook(partial(self.grad_handle, p))
@@ -115,7 +117,7 @@ class ColoDDP(torch.nn.Module):
if self.rebuild_bucket:
self.reducer.free()
for p in self.module.parameters():
- if getattr(p, '_ddp_to_ignore', False):
+ if is_ddp_ignored(p):
continue
if p.grad.device.type != "cpu":
p.grad = p._saved_grad
@@ -199,14 +201,18 @@ class ZeroDDP(ColoDDP):
gemini_manager (GeminiManager): Manages the chunk manager and heterogeneous momery space.
For more details, see the API reference of ``GeminiManager``.
pin_memory (bool): Chunks on CPU Memory use pin-memory.
- force_outputs_fp32 (bool): If set to True, outputs will be fp32. Otherwise, outputs will be fp16. Defaults to False.
+ force_outputs_fp32 (bool): If set to True, outputs will be fp32. Otherwise, outputs will be fp16.
+ Defaults to False.
+ strict_ddp_mode (bool): If set to True, there is no tensor sharding, each tensor is replicated.
+ Defaults to False. Users can set it to True, when they clearly know that they only need DDP.
"""
def __init__(self,
module: torch.nn.Module,
gemini_manager: GeminiManager,
pin_memory: bool = False,
- force_outputs_fp32: bool = False) -> None:
+ force_outputs_fp32: bool = False,
+ strict_ddp_mode: bool = False) -> None:
super().__init__(module, process_group=ColoProcessGroup())
self.gemini_manager = gemini_manager
self.chunk_manager: ChunkManager = gemini_manager.chunk_manager
@@ -231,8 +237,11 @@ class ZeroDDP(ColoDDP):
for p in param_order.generate():
assert isinstance(p, ColoParameter)
- if getattr(p, '_ddp_to_ignore', False):
- p.data = p.data.half()
+ if strict_ddp_mode and not p.is_replicate():
+ p.set_dist_spec(ReplicaSpec())
+
+ if is_ddp_ignored(p):
+ p.data = p.data.to(device=get_current_device(), dtype=torch.float16)
continue
fp32_data = p.data.float()
@@ -251,10 +260,11 @@ class ZeroDDP(ColoDDP):
pin_memory=pin_memory)
self.fp32_params.append(fp32_p)
self.grads_device[p] = self.gemini_manager.default_device
+
self.chunk_manager.close_all_groups()
self._cast_buffers()
- params_list = [p for p in param_order.generate() if not getattr(p, '_ddp_to_ignore', False)]
+ params_list = [p for p in param_order.generate() if not is_ddp_ignored(p)]
for p, fp32_p in zip(params_list, self.fp32_params):
chunk_16 = self.chunk_manager.get_chunk(p)
chunk_32 = self.chunk_manager.get_chunk(fp32_p)
@@ -266,19 +276,42 @@ class ZeroDDP(ColoDDP):
self._logger = get_dist_logger()
+ def _post_forward(self):
+ """This function is only triggered for inference.
+ """
+ access_list = list(self.chunk_manager.accessed_chunks)
+ # we need to scatter all accessed chunks and move them to their original places
+ for chunk in access_list:
+ assert chunk.can_release
+ self.chunk_manager.release_chunk(chunk)
+ first_param = next(iter(chunk.tensors_info))
+ self.chunk_manager.move_chunk(chunk, self.grads_device[first_param])
+ assert self.chunk_manager.accessed_mem == 0
+ # reset all recorded attributes
+ self.gemini_manager.reset_attributes()
+
def forward(self, *args, **kwargs):
+ # check whether we are in a inference mode
+ grad_flag = torch.is_grad_enabled()
+ if not grad_flag:
+ assert not self.gemini_manager.is_warmup(), "You should run a completed iteration as your warmup iter"
+
args, kwargs = _cast_float(args, torch.half), _cast_float(kwargs, torch.half)
self.module.zero_grad(set_to_none=True)
self.gemini_manager.pre_iter(*args)
with ColoParamOpHookManager.use_hooks(self.param_op_hook):
outputs = self.module(*args, **kwargs)
+ # scatter chunks in the inference mode
+ if not grad_flag:
+ self._post_forward()
+
if self.force_outputs_fp32:
return _cast_float(outputs, torch.float)
return outputs
def _setup_grads_ptr(self):
for p in self.module.parameters():
- if getattr(p, '_ddp_to_ignore', False):
+ if is_ddp_ignored(p):
continue
p.grad = None
@@ -331,12 +364,10 @@ class ZeroDDP(ColoDDP):
for tensor in chunk.get_tensors():
self.grads_device[tensor] = device
- def state_dict(self, destination=None, prefix='', keep_vars=False, only_rank_0: bool = True):
- r"""Returns a dictionary containing a whole state of the module.
-
- Both parameters and persistent buffers (e.g. running averages) are
- included. Keys are corresponding parameter and buffer names.
- Parameters and buffers set to ``None`` are not included.
+ def state_dict(self, destination=None, prefix='', keep_vars=False, only_rank_0: bool = True, strict: bool = True):
+ """
+ Args:
+ strict (bool): whether to reture the whole model state as the pytorch `Module.state_dict()`
Returns:
dict:
@@ -346,7 +377,30 @@ class ZeroDDP(ColoDDP):
>>> module.state_dict().keys()
['bias', 'weight']
+ """
+ if strict:
+ assert keep_vars is False, "`state_dict` with parameter, `keep_vars=True`, is not supported now."
+ torch_model = get_static_torch_model(zero_ddp_model=self, only_rank_0=only_rank_0)
+ return torch_model.state_dict(destination=destination, prefix=prefix, keep_vars=keep_vars)
+ return self._non_strict_state_dict(destination=destination,
+ prefix=prefix,
+ keep_vars=keep_vars,
+ only_rank_0=only_rank_0)
+ def _non_strict_state_dict(self, destination=None, prefix='', keep_vars=False, only_rank_0: bool = True):
+ """Returns a dictionary containing a whole state of the module.
+
+ Both parameters and persistent buffers (e.g. running averages) are included.
+ Keys are corresponding parameter and buffer names.
+ Parameters and buffers set to ``None`` are not included.
+
+ Warning: The non strict state dict would ignore the parameters if the tensors of the parameters
+ are shared with other parameters which have been included in the dictionary.
+ When you need to load the state dict, you should set the argument `strict` to False.
+
+ Returns:
+ dict:
+ a dictionary containing a whole state of the module
"""
if destination is None:
destination = OrderedDict()
@@ -405,8 +459,14 @@ class ZeroDDP(ColoDDP):
assert keep_vars is False, "`state_dict` with parameter, `keep_vars=True`, is not supported now."
param_to_save_data = self._get_param_to_save_data(self.fp32_params, only_rank_0)
- # TODO: (HELSON) deal with ddp ignored parameters
- for (name, p), fp32_p in zip(self.named_parameters(), self.fp32_params):
+ ddp_param_list = []
+ for name, param in self.named_parameters():
+ if is_ddp_ignored(param):
+ # deal with ddp ignored parameters
+ destination[prefix + name] = param if keep_vars else param.detach()
+ else:
+ ddp_param_list.append((name, param))
+ for (name, p), fp32_p in zip(ddp_param_list, self.fp32_params):
if p is not None:
assert fp32_p in param_to_save_data, "Parameter '{}' is neglected in the chunk list".format(name)
record_parameter = param_to_save_data[fp32_p]
@@ -542,8 +602,16 @@ class ZeroDDP(ColoDDP):
def load_fp32_parameter(chunk_slice, data):
chunk_slice.copy_(data.flatten())
+ ddp_param_list = []
+ for name, param in self.named_parameters():
+ if is_ddp_ignored(param):
+ # deal with ddp ignored parameters
+ load(name, param, param.copy_)
+ else:
+ ddp_param_list.append((name, param))
+
fp32_to_name = dict()
- for (name, p), fp32_p in zip(self.named_parameters(), self.fp32_params):
+ for (name, p), fp32_p in zip(ddp_param_list, self.fp32_params):
if p is not None:
fp32_to_name[fp32_p] = name
diff --git a/colossalai/nn/parallel/gemini_parallel.py b/colossalai/nn/parallel/gemini_parallel.py
index cd5ef424a..868a3960f 100644
--- a/colossalai/nn/parallel/gemini_parallel.py
+++ b/colossalai/nn/parallel/gemini_parallel.py
@@ -17,6 +17,7 @@ class GeminiDDP(ZeroDDP):
placement_policy: str = "cpu",
pin_memory: bool = False,
force_outputs_fp32: bool = False,
+ strict_ddp_mode: bool = False,
search_range_mb: int = 32,
hidden_dim: Optional[int] = None,
min_chunk_size_mb: Optional[float] = None,
@@ -54,4 +55,4 @@ class GeminiDDP(ZeroDDP):
search_range_mb=search_range_mb,
min_chunk_size_mb=min_chunk_size_mb)
gemini_manager = GeminiManager(placement_policy, chunk_manager, memstats)
- super().__init__(module, gemini_manager, pin_memory, force_outputs_fp32)
+ super().__init__(module, gemini_manager, pin_memory, force_outputs_fp32, strict_ddp_mode)
diff --git a/colossalai/nn/parallel/utils.py b/colossalai/nn/parallel/utils.py
index 1205cbc3a..d323556d5 100644
--- a/colossalai/nn/parallel/utils.py
+++ b/colossalai/nn/parallel/utils.py
@@ -47,30 +47,29 @@ def _get_shallow_copy_model(model: nn.Module):
"""Get a shallow copy of the given model. Each submodule is different from the original submodule.
But the new submodule and the old submodule share all attributes.
"""
- name_to_module = dict()
+ old_to_new = dict()
for name, module in _get_dfs_module_list(model):
new_module = copy(module)
new_module._modules = OrderedDict()
for subname, submodule in module._modules.items():
if submodule is None:
continue
- full_name = name + ('.' if name else '') + subname
- setattr(new_module, subname, name_to_module[full_name])
- name_to_module[name] = new_module
- return name_to_module['']
+ setattr(new_module, subname, old_to_new[submodule])
+ old_to_new[module] = new_module
+ return old_to_new[model]
-def get_static_torch_model(gemini_ddp_model,
+def get_static_torch_model(zero_ddp_model,
device=torch.device("cpu"),
dtype=torch.float32,
only_rank_0=True) -> torch.nn.Module:
- """Get a static torch.nn.Module model from the given GeminiDDP module.
- You should notice that the original GeminiDDP model is not modified.
+ """Get a static torch.nn.Module model from the given ZeroDDP module.
+ You should notice that the original ZeroDDP model is not modified.
Thus, you can use the original model in further training.
But you should not use the returned torch model to train, this can cause unexpected errors.
Args:
- gemini_ddp_model (GeminiDDP): a gemini ddp model
+ zero_ddp_model (ZeroDDP): a zero ddp model
device (torch.device): the device of the final torch model
dtype (torch.dtype): the dtype of the final torch model
only_rank_0 (bool): if True, only rank0 has the coverted torch model
@@ -78,11 +77,11 @@ def get_static_torch_model(gemini_ddp_model,
Returns:
torch.nn.Module: a static torch model used for saving checkpoints or numeric checks
"""
- from colossalai.nn.parallel import GeminiDDP
- assert isinstance(gemini_ddp_model, GeminiDDP)
+ from colossalai.nn.parallel import ZeroDDP
+ assert isinstance(zero_ddp_model, ZeroDDP)
- state_dict = gemini_ddp_model.state_dict(only_rank_0=only_rank_0)
- colo_model = gemini_ddp_model.module
+ state_dict = zero_ddp_model.state_dict(only_rank_0=only_rank_0, strict=False)
+ colo_model = zero_ddp_model.module
torch_model = _get_shallow_copy_model(colo_model)
if not only_rank_0 or dist.get_rank() == 0:
diff --git a/colossalai/pipeline/rpc/_pipeline_base.py b/colossalai/pipeline/rpc/_pipeline_base.py
index 4739cdaa9..1edc1ac70 100644
--- a/colossalai/pipeline/rpc/_pipeline_base.py
+++ b/colossalai/pipeline/rpc/_pipeline_base.py
@@ -211,7 +211,7 @@ class WorkerBase(ABC):
refcount = 0
with self.output_list_condition_lock:
- if refcount < lifecycle:
+ if refcount <= lifecycle:
self.output_list[key] = output_work_item
self.output_list_condition_lock.notify_all()
@@ -390,7 +390,7 @@ class WorkerBase(ABC):
subscribe_forward_futures[target_index] = []
else:
subscribe_forward_futures[target_index] = producer_worker_rref.rpc_async().get_output_by_key(
- producer_output_key, rank=self.pp_rank)
+ producer_output_key, rank=self.pp_rank, offsets=offsets)
else:
for i in range(producer_num):
diff --git a/colossalai/pipeline/rpc/_pipeline_schedule.py b/colossalai/pipeline/rpc/_pipeline_schedule.py
index e6aa961f1..0d572231d 100644
--- a/colossalai/pipeline/rpc/_pipeline_schedule.py
+++ b/colossalai/pipeline/rpc/_pipeline_schedule.py
@@ -29,9 +29,6 @@ class FillDrainWorker(WorkerBase):
target_key = UniqueKey(target_microbatch_id, target_phase)
- with self.work_list_condition_lock:
- self.work_list_condition_lock.wait_for(lambda: target_key in self.work_list)
-
return target_key
diff --git a/colossalai/utils/__init__.py b/colossalai/utils/__init__.py
index 875b5a93b..3f16bd91e 100644
--- a/colossalai/utils/__init__.py
+++ b/colossalai/utils/__init__.py
@@ -1,22 +1,46 @@
-from .cuda import empty_cache, get_current_device, set_to_cuda, synchronize
from .activation_checkpoint import checkpoint
from .checkpointing import load_checkpoint, save_checkpoint
-from .common import (clip_grad_norm_fp32, conditional_context, copy_tensor_parallel_attributes, count_zeros_fp32,
- ensure_path_exists, free_port, is_dp_rank_0, is_model_parallel_parameter, is_no_pp_or_last_stage,
- is_tp_rank_0, is_using_ddp, is_using_pp, is_using_sequence, multi_tensor_applier,
- param_is_not_tensor_parallel_duplicate, print_rank_0, switch_virtual_pipeline_parallel_rank,
- sync_model_param, disposable)
+from .common import (
+ clip_grad_norm_fp32,
+ conditional_context,
+ copy_tensor_parallel_attributes,
+ count_zeros_fp32,
+ disposable,
+ ensure_path_exists,
+ free_port,
+ is_ddp_ignored,
+ is_dp_rank_0,
+ is_model_parallel_parameter,
+ is_no_pp_or_last_stage,
+ is_tp_rank_0,
+ is_using_ddp,
+ is_using_pp,
+ is_using_sequence,
+ multi_tensor_applier,
+ param_is_not_tensor_parallel_duplicate,
+ print_rank_0,
+ switch_virtual_pipeline_parallel_rank,
+ sync_model_param,
+)
+from .cuda import empty_cache, get_current_device, set_to_cuda, synchronize
from .data_sampler import DataParallelSampler, get_dataloader
-from .memory import (report_memory_usage, colo_device_memory_used, colo_set_process_memory_fraction,
- colo_device_memory_capacity, colo_set_cpu_memory_capacity, colo_get_cpu_memory_capacity)
-from .timer import MultiTimer, Timer
+from .memory import (
+ colo_device_memory_capacity,
+ colo_device_memory_used,
+ colo_get_cpu_memory_capacity,
+ colo_set_cpu_memory_capacity,
+ colo_set_process_memory_fraction,
+ report_memory_usage,
+)
from .tensor_detector import TensorDetector
+from .timer import MultiTimer, Timer
__all__ = [
'checkpoint',
'free_port',
'print_rank_0',
'sync_model_param',
+ 'is_ddp_ignored',
'is_dp_rank_0',
'is_tp_rank_0',
'is_no_pp_or_last_stage',
diff --git a/colossalai/utils/common.py b/colossalai/utils/common.py
index 7575fa292..2099883fb 100644
--- a/colossalai/utils/common.py
+++ b/colossalai/utils/common.py
@@ -126,14 +126,18 @@ def is_model_parallel_parameter(p):
return hasattr(p, IS_TENSOR_PARALLEL) and getattr(p, IS_TENSOR_PARALLEL)
+def is_ddp_ignored(p):
+ return getattr(p, '_ddp_to_ignore', False)
+
+
def _calc_l2_norm(grads):
- # we should not
+ # we should not
global fused_optim
if fused_optim is None:
from colossalai.kernel.op_builder import FusedOptimBuilder
fused_optim = FusedOptimBuilder().load()
-
+
norm = 0.0
if len(grads) > 0:
dummy_overflow_buf = torch.cuda.IntTensor([0])
diff --git a/colossalai/utils/model/experimental.py b/colossalai/utils/model/experimental.py
new file mode 100644
index 000000000..8291227b7
--- /dev/null
+++ b/colossalai/utils/model/experimental.py
@@ -0,0 +1,440 @@
+import contextlib
+import copy
+import gc
+import pprint
+from typing import Callable, List, Optional, Union
+
+import torch
+import torch.nn as nn
+from torch.utils._pytree import tree_map
+
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.fx.profiler import MetaTensor
+from colossalai.tensor.shape_consistency import ShapeConsistencyManager
+from colossalai.tensor.sharding_spec import ShardingSpec
+
+# reference: https://pytorch.org/cppdocs/notes/tensor_creation.html
+_TorchFactoryMethod = [
+ "arange",
+ "empty",
+ "eye",
+ "full",
+ "linspace",
+ "logspace",
+ "ones",
+ "rand",
+ "randn",
+ "randint",
+ "randperm",
+ "zeros",
+ "tensor",
+]
+
+orig_empty = torch.empty # avoid override
+
+scm = ShapeConsistencyManager()
+
+
+class LazyTensor(torch.Tensor):
+ """A naive implementation of LazyTensor (https://arxiv.org/pdf/2102.13267.pdf).
+
+ Usage:
+ 1. Use ``LazyTensor`` instead of ``torch.Tensor``.
+ >>> x = LazyTensor(torch.zeros, 2, 3)
+ >>> x += 1
+ >>> y = x * x
+ >>> y = y.cuda().half()
+ >>> y[0, 0] = 0
+ >>> y = y.materialize() # materialize the tensor
+ >>> print(y)
+ tensor([[0., 1., 1.],
+ [1., 1., 1.]], device='cuda:0', dtype=torch.float16)
+
+ 2. Generate ``MetaTensor`` from ``LazyTensor``
+ >>> x = LazyTensor(torch.zeros, 2, 3)
+ >>> x.reshape(3, 2)
+ >>> x = x.traceable() # generate ``MetaTensor``
+ >>> print(x)
+ MetaTensor(..., size=(3, 2), device=cpu, dtype=torch.float32)
+
+ 3. Use ``LazyTensor`` to generate sharded ``nn.Parameter``.
+ >>> x = LazyTensor(torch.zeros, 2, 3)
+ >>> x.spec = ... # some ``ShardingSpec``
+ >>> x.distribute() # distribute the tensor according to the ``ShardingSpec``
+
+ Warnings:
+ 1. Cases that ``LazyTensor`` can't deal with.
+ >>> x = LazyTensor(torch.ones, 2, 3)
+ >>> x[0, 0] = -x[0, 0] # this will cause infinite recursion
+
+ 2. ``LazyTensor.materialize()`` can't be called multiple times.
+ >>> x = LazyTensor(torch.ones, 2, 3)
+ >>> x.materialize()
+ >>> x.materialize() # this is disallowed
+ """
+
+ _repr = True
+ _meta_data: Optional[MetaTensor] = None # shape, dtype, device
+ _cached_data: Optional[torch.Tensor] = None # materialized data
+
+ @staticmethod
+ def __new__(cls, func, *args, dtype=None, device=None, **kwargs):
+ elem = func(*args, dtype=dtype, device='meta', **kwargs)
+ r = torch.Tensor._make_wrapper_subclass(cls,
+ elem.size(),
+ strides=elem.stride(),
+ storage_offset=elem.storage_offset(),
+ dtype=elem.dtype,
+ layout=elem.layout,
+ device=device if device is not None else torch.device('cpu'),
+ requires_grad=elem.requires_grad)
+ r._meta_data = MetaTensor(elem, fake_device=device)
+ return r
+
+ def __init__(self, func, *args, dtype=None, device=None, **kwargs):
+ self._factory_method = (func, args, {'dtype': dtype, 'device': device, **kwargs}) # (func, args, kwargs)
+ self._cached_buffer = list() # (func, args, kwargs)
+ self._spec = None
+ self._data = self
+
+ def __repr__(self):
+ if self._repr:
+ # avoid recursive representation
+ self.__class__._repr = False
+ s = f'LazyTensor(..., size={tuple(self._meta_data.shape)}, device={self._meta_data.device}, dtype={self._meta_data.dtype})\n'\
+ f'factory method: {self._factory_method}\n'\
+ f'cached: {pprint.pformat(self._cached_buffer) if self._cached_data is None else self._cached_data}\n'\
+ f'spec: {self._spec}'
+ self.__class__._repr = True
+ return s
+ else:
+ return 'LazyTensor(...)'
+
+ def materialize(self) -> torch.Tensor:
+ """Materialize the ``LazyTensor`` to ``torch.Tensor``.
+
+ Warnings:
+ Calling ``self.materialize()`` will clear all cached sequence and factory method,
+ because we don't allow materialize the same ``LazyTensor`` twice.
+ This is mentioned in the paper: https://arxiv.org/pdf/2102.13267.pdf (Part 4.3).
+
+ Returns:
+ torch.Tensor: The materialized tensor.
+ """
+ target = self._data._realize_cached_data()
+ if isinstance(self, nn.Parameter):
+ target = nn.Parameter(target, requires_grad=self.requires_grad)
+ self._clear_all()
+ return target
+
+ def traceable(self) -> MetaTensor:
+ """Generate ``MetaTensor`` from ``LazyTensor``. (Mostly for tracing)
+
+ Returns:
+ MetaTensor: The generated ``MetaTensor``.
+ """
+ if isinstance(self, nn.Parameter):
+ return nn.Parameter(self._meta_data, requires_grad=self.requires_grad)
+ else:
+ return self._meta_data
+
+ def distribute(self) -> torch.Tensor:
+ """Distribute the ``LazyTensor`` according to the ``ShardingSpec``.
+
+ Returns:
+ torch.Tensor: The sharded tensor.
+ """
+ if self._spec is None:
+ raise RuntimeError('ShardingSpec is not set for\n{self}')
+ spec, device_mesh = self._spec, self._spec.device_mesh
+ target = self.materialize()
+
+ # TODO(some man): better not be coupled with auto-parallel
+ target.data = scm.apply_for_autoparallel_runtime(target.data, ShardingSpec(device_mesh, target.shape, {}),
+ spec).detach().clone()
+ return target
+
+ def _realize_cached_data(self) -> torch.Tensor:
+ # self._cached_data should be generated after the first call of this function
+ if self._cached_data is None:
+ if self._factory_method is not None:
+ # apply factory method
+ func, args, kwargs = self._factory_method
+
+ # apply cached sequence
+ self._cached_data = self._apply_cache_buffer(func(*args, **kwargs))
+ else:
+ # apply cached sequence only
+ self._cached_data = self._apply_cache_buffer()
+ return self._cached_data
+
+ def _apply_cache_buffer(self, target=None) -> torch.Tensor:
+ # dump all cached sequence
+ # super-dainiu: support methods for single Tensor only
+ def replace(x):
+ if x is self:
+ return target
+ elif isinstance(x, LazyTensor):
+ return x._realize_cached_data()
+ return x
+
+ packed = None
+
+ for (func, args, kwargs) in self._cached_buffer:
+ if func == torch.Tensor.requires_grad_:
+ packed = func, args, kwargs # requires grad should be set at last
+ else:
+ o = func(*tree_map(replace, args), **tree_map(replace, kwargs))
+ target = o if isinstance(o, torch.Tensor) else target # if func returns non-Tensor, discard the value
+
+ # super-dainiu: set requires_grad after all inplace-ops are done
+ if packed is not None:
+ func, args, kwargs = packed
+ func(*tree_map(replace, args), **tree_map(replace, kwargs))
+
+ return target
+
+ # clear all means:
+ # 1. clear factory method
+ # 2. clear cached sequence
+ # 3. clear cached data
+ def _clear_all(self):
+ self._cached_data = None
+ self._cached_buffer = None
+ self._data = None
+ gc.collect() # avoid memory leak
+
+ # cache everything with __torch_function__
+ @classmethod
+ def __torch_function__(cls, func, types, args=(), kwargs=None):
+ if kwargs is None:
+ kwargs = {}
+ target = None
+
+ if isinstance(func, torch._C.ScriptMethod):
+
+ def unwrap(x):
+ if isinstance(x, LazyTensor):
+ return x._meta_data
+ return x
+
+ target: LazyTensor = args[0].clone()
+ target._cached_buffer.append((func, args, kwargs))
+ target._meta_data = getattr(target._meta_data, func.name)(*tree_map(unwrap, args[1:]),
+ **tree_map(unwrap, kwargs))
+
+ else:
+
+ def unwrap(x):
+ nonlocal target
+ if isinstance(x, LazyTensor):
+ target = x if (func.__name__.endswith('_') and not (func.__name__.endswith('__'))
+ or func.__name__ == "__setitem__") else x.clone()
+ target._cached_buffer.append((func, args, kwargs))
+ return x._meta_data
+ return x
+
+ args = tree_map(unwrap, args)
+ kwargs = tree_map(unwrap, kwargs)
+ o = func(*args, **kwargs)
+
+ if isinstance(o, MetaTensor):
+ target._meta_data = o
+ return target
+ else:
+ return o
+
+ @classmethod
+ def __torch_dispatch__(cls, func, types, args=(), kwargs=None):
+ pass # skip
+
+ def clone(self) -> "LazyTensor":
+ """Create a new ``LazyTensor`` with same cached sequence and factory method.
+
+ Returns:
+ LazyTensor: the new ``LazyTensor``
+ """
+ target = LazyTensor(orig_empty, 0, dtype=self._meta_data.dtype, device=self._meta_data.device)
+ target._factory_method = None
+ target._cached_buffer = list()
+ target._meta_data = self._meta_data.clone()
+ target._cached_data = self._cached_data.clone() if self._cached_data is not None else None
+ target._spec = copy.deepcopy(self._spec)
+ return target
+
+ def detach(self) -> "LazyTensor":
+ target = self.clone()
+ target._cached_buffer.append((torch.Tensor.detach_, (self,), {}))
+ return target
+
+ @property
+ def spec(self) -> ShardingSpec:
+ return self._spec
+
+ @spec.setter
+ def spec(self, other: ShardingSpec):
+ self._spec = other
+
+ @property
+ def data(self) -> "LazyTensor":
+ return self._data.detach()
+
+ @data.setter
+ def data(self, other: "LazyTensor") -> "LazyTensor":
+ """This avoid the following infinite recursion, which is very common in ``nn.Module`` initialization.
+
+ Usage:
+ >>> a = LazyTensor(torch.empty, 0, dtype=torch.float32, device='cpu')
+ >>> b = a.cuda()
+ >>> a.data = b
+ """
+ self._data = other
+
+
+class LazyInitContext():
+ """Context manager for lazy initialization. Enables initializing the model without allocating real memory.
+
+ Usage:
+ 1. The model is initialized, but no real memory is allocated.
+ >>> ctx = LazyInitContext()
+ >>> with ctx:
+ >>> model = MyModel().cuda()
+
+ 2. The model is initialized with ``MetaTensor`` as weights, but still no real memory is allocated.
+ >>> with ctx.traceable(model):
+ >>> gm = symbolic_trace(model, meta_args=meta_args)
+ >>> # Solve the execution strategy and apply the strategy to the model
+ >>> strategy = StrategyAndSpec()
+
+ 3. The model is initialized with ``torch.Tensor`` as weights, and real memory is allocated. (single device)
+ >>> model = ctx.materialize(model)
+
+ 3. The model is initialized with sharded ``torch.Tensor`` as weights, and real memory is allocated. (distributed scenario)
+ >>> model = apply_strategy_to_all_params(model, strategy)
+ >>> model = ctx.distribute(model)
+
+ Warnings:
+ This API is still experimental and further modifications can be made to it.
+ For example:
+ 1. Quantization strategies can be applied before allocating real memory.
+ 2. Lazy initialization seems slower than normal initialization.
+ """
+
+ def __init__(self):
+ self.overrides = {}
+
+ def __enter__(self):
+
+ def wrap_factory_method(target):
+ # factory functions (eg. torch.empty())
+ def wrapper(*args, **kwargs):
+ return LazyTensor(target, *args, **kwargs)
+
+ return wrapper, target
+
+ def wrap_factory_like_method(orig_target, target):
+ # factory_like functions (eg. torch.empty_like())
+ def wrapper(*args, **kwargs):
+ orig_t = args[0]
+ return LazyTensor(orig_target, *args[1:], device=orig_t.device, dtype=orig_t.dtype, **kwargs)
+
+ return wrapper, target
+
+ self.overrides = {
+ target: wrap_factory_method(getattr(torch, target))
+ for target in _TorchFactoryMethod
+ if callable(getattr(torch, target, None))
+ }
+
+ self.overrides.update({
+ target + '_like': wrap_factory_like_method(getattr(torch, target), getattr(torch, target + '_like'))
+ for target in _TorchFactoryMethod
+ if callable(getattr(torch, target + '_like', None))
+ })
+
+ for name, (wrapper, orig) in self.overrides.items():
+ setattr(torch, name, wrapper)
+
+ def __exit__(self, exc_type, exc_val, exc_tb):
+ for name, (wrapper, orig) in self.overrides.items():
+ setattr(torch, name, orig)
+
+ @staticmethod
+ def materialize(module: torch.nn.Module):
+ """Initialize all ``nn.Parameter`` from ``LazyTensor``.
+
+ Args:
+ module (torch.nn.Module): Target ``nn.Module``
+ """
+
+ @torch.no_grad()
+ def init_recursively(module: nn.Module):
+ # recursively initialize the module
+ for mod in module.children():
+ init_recursively(mod)
+
+ # initialize tensors directly attached to the current module
+ for name, param in module.named_parameters(recurse=False):
+ setattr(module, name, param.materialize())
+
+ for name, buf in module.named_buffers(recurse=False):
+ setattr(module, name, buf.materialize())
+
+ init_recursively(module)
+ return module
+
+ @staticmethod
+ def distribute(module: torch.nn.Module):
+ """Initialize and shard all ``nn.Parameter`` from ``LazyTensor``.
+
+ Args:
+ module (torch.nn.Module): Sharded target ``nn.Module``
+ """
+
+ @torch.no_grad()
+ def init_recursively(module: nn.Module):
+ # recursively initialize the module
+ for mod in module.children():
+ init_recursively(mod)
+
+ # initialize tensors directly attached to the current module
+ for name, param in module.named_parameters(recurse=False):
+ setattr(module, name, param.distribute())
+
+ for name, buf in module.named_buffers(recurse=False):
+ setattr(module, name, buf.distribute())
+
+ init_recursively(module)
+ return module
+
+ @staticmethod
+ @contextlib.contextmanager
+ def traceable(module: torch.nn.Module):
+ """Initialize all ``nn.Parameters`` as ``MetaTensor``. This enables ``ColoTracer`` with control flow.
+
+ Args:
+ module (torch.nn.Module): Traceable ``nn.Module`` with ``MetaTensor`` as parameters.
+ """
+ orig_val = dict()
+
+ def init_recursively(module: nn.Module):
+ # recursively initialize the module
+ for mod in module.children():
+ init_recursively(mod)
+
+ # initialize tensors directly attached to the current module
+ for name, param in module.named_parameters(recurse=False):
+ setattr(module, name, param.traceable())
+ orig_val[(module, name)] = param
+
+ for name, buf in module.named_buffers(recurse=False):
+ setattr(module, name, buf.traceable())
+ orig_val[(module, name)] = buf
+
+ init_recursively(module)
+
+ yield
+
+ # restore original values
+ for (module, name), val in orig_val.items():
+ setattr(module, name, val)
diff --git a/colossalai/zero/sharded_optim/_utils.py b/colossalai/zero/sharded_optim/_utils.py
index 9a839a570..70d9c040c 100644
--- a/colossalai/zero/sharded_optim/_utils.py
+++ b/colossalai/zero/sharded_optim/_utils.py
@@ -1,4 +1,5 @@
import math
+from typing import Optional
import torch
import torch.distributed as dist
@@ -7,6 +8,7 @@ from torch._utils import _flatten_dense_tensors, _unflatten_dense_tensors
from colossalai.context import ParallelMode
from colossalai.core import global_context as gpc
+from colossalai.tensor import ProcessGroup
from colossalai.utils import is_model_parallel_parameter
@@ -101,7 +103,11 @@ def split_half_float_double(tensor_list):
return buckets
-def reduce_tensor(tensor, dtype=None, dst_rank=None, parallel_mode=ParallelMode.DATA):
+def reduce_tensor_dp_group(tensor: torch.Tensor,
+ dtype: Optional[torch.dtype] = None,
+ dst_local_rank: Optional[int] = None,
+ dst_global_rank: Optional[int] = None,
+ group: Optional[dist.ProcessGroup] = None):
"""
Reduce the tensor in the data parallel process group
@@ -114,7 +120,7 @@ def reduce_tensor(tensor, dtype=None, dst_rank=None, parallel_mode=ParallelMode.
:type tensor: torch.Tensor
:type dtype: torch.dtype, optional
:type dst_rank: int, optional
- :type parallel_mode: ParallelMode, optional
+ :type pg: ProcessGroup, optional
"""
# use the original dtype
if dtype is None:
@@ -126,25 +132,22 @@ def reduce_tensor(tensor, dtype=None, dst_rank=None, parallel_mode=ParallelMode.
else:
tensor_to_reduce = tensor
- world_size = gpc.get_world_size(parallel_mode)
- group = gpc.get_group(parallel_mode)
+ world_size = dist.get_world_size(group=group)
tensor_to_reduce.div_(world_size)
# if rank is None, all reduce will be used
# else, reduce is used
- use_all_reduce = dst_rank is None
+ use_all_reduce = dst_local_rank is None
if use_all_reduce:
dist.all_reduce(tensor_to_reduce, group=group)
else:
- ranks_in_group = gpc.get_ranks_in_group(parallel_mode)
- global_rank = ranks_in_group[dst_rank]
- dist.reduce(tensor=tensor_to_reduce, dst=global_rank, group=group)
+ dist.reduce(tensor=tensor_to_reduce, dst=dst_global_rank, group=group)
# recover the original dtype
if tensor.dtype != dtype and tensor is not tensor_to_reduce:
- local_rank = gpc.get_local_rank(parallel_mode)
- if use_all_reduce or dst_rank == local_rank:
+ local_rank = dist.get_rank(group=group)
+ if use_all_reduce or dst_local_rank == local_rank:
tensor.copy_(tensor_to_reduce)
return tensor
diff --git a/colossalai/zero/sharded_optim/bookkeeping/base_store.py b/colossalai/zero/sharded_optim/bookkeeping/base_store.py
index d4436acaa..2ebd12246 100644
--- a/colossalai/zero/sharded_optim/bookkeeping/base_store.py
+++ b/colossalai/zero/sharded_optim/bookkeeping/base_store.py
@@ -1,12 +1,12 @@
-from colossalai.context import ParallelMode
-from colossalai.core import global_context as gpc
+import torch.distributed as dist
+from torch.distributed import ProcessGroup
class BaseStore:
- def __init__(self, dp_parallel_mode=ParallelMode.DATA):
- self._world_size = gpc.get_world_size(dp_parallel_mode)
- self._local_rank = gpc.get_local_rank(dp_parallel_mode)
+ def __init__(self, torch_pg: ProcessGroup):
+ self._world_size = dist.get_world_size(group=torch_pg)
+ self._local_rank = dist.get_rank(group=torch_pg)
@property
def world_size(self):
diff --git a/colossalai/zero/sharded_optim/bookkeeping/bucket_store.py b/colossalai/zero/sharded_optim/bookkeeping/bucket_store.py
index 0f2b1bb88..ec322a78b 100644
--- a/colossalai/zero/sharded_optim/bookkeeping/bucket_store.py
+++ b/colossalai/zero/sharded_optim/bookkeeping/bucket_store.py
@@ -1,14 +1,12 @@
-from colossalai.context import ParallelMode
-from colossalai.core import global_context as gpc
+from torch.distributed import ProcessGroup
from .base_store import BaseStore
class BucketStore(BaseStore):
- def __init__(self, dp_parallel_mode):
- super().__init__(dp_parallel_mode)
- self._grads = dict()
+ def __init__(self, torch_pg: ProcessGroup):
+ super().__init__(torch_pg)
self._params = dict()
self._num_elements_in_bucket = dict()
@@ -20,25 +18,24 @@ class BucketStore(BaseStore):
def add_num_elements_in_bucket(self, num_elements, reduce_rank: int = None):
self._num_elements_in_bucket[reduce_rank] += num_elements
- def add_grad(self, tensor, reduce_rank: int = None):
- self._grads[reduce_rank].append(tensor)
-
def add_param(self, tensor, reduce_rank: int = None):
self._params[reduce_rank].append(tensor)
def reset(self):
keys = [None] + list(range(self._world_size))
- self._grads = {rank: [] for rank in keys}
self._params = {rank: [] for rank in keys}
self._num_elements_in_bucket = {rank: 0 for rank in keys}
def reset_by_rank(self, reduce_rank=None):
- self._grads[reduce_rank] = []
self._params[reduce_rank] = []
self._num_elements_in_bucket[reduce_rank] = 0
def get_grad(self, reduce_rank: int = None):
- return self._grads[reduce_rank]
+ param_list = self.get_param(reduce_rank)
+ for param in param_list:
+ # the param must have grad for reduction
+ assert param.grad is not None, f'Parameter of size ({param.size()}) has None grad, cannot be reduced'
+ return [param.grad for param in param_list]
def get_param(self, reduce_rank: int = None):
return self._params[reduce_rank]
diff --git a/colossalai/zero/sharded_optim/bookkeeping/parameter_store.py b/colossalai/zero/sharded_optim/bookkeeping/parameter_store.py
index 09ebaaf99..cbf708b34 100644
--- a/colossalai/zero/sharded_optim/bookkeeping/parameter_store.py
+++ b/colossalai/zero/sharded_optim/bookkeeping/parameter_store.py
@@ -1,14 +1,15 @@
from typing import List
from torch import Tensor
+from torch.distributed import ProcessGroup
from .base_store import BaseStore
class ParameterStore(BaseStore):
- def __init__(self, dp_paralle_mode):
- super().__init__(dp_paralle_mode)
+ def __init__(self, torch_pg: ProcessGroup):
+ super().__init__(torch_pg)
# param partitioning data structures
self._fp16_param_to_rank = dict()
self._rank_groupid_to_fp16_param_list = dict()
diff --git a/colossalai/zero/sharded_optim/low_level_optim.py b/colossalai/zero/sharded_optim/low_level_optim.py
index c437ac549..f45b5e200 100644
--- a/colossalai/zero/sharded_optim/low_level_optim.py
+++ b/colossalai/zero/sharded_optim/low_level_optim.py
@@ -1,5 +1,5 @@
from functools import partial
-from itertools import groupby
+from typing import Optional
import torch
import torch.distributed as dist
@@ -10,6 +10,7 @@ from colossalai.context import ParallelMode
from colossalai.core import global_context as gpc
from colossalai.logging import get_dist_logger
from colossalai.nn.optimizer import ColossalaiOptimizer
+from colossalai.tensor import ColoParameter, ProcessGroup
from colossalai.utils.cuda import get_current_device
from ._utils import (
@@ -18,7 +19,7 @@ from ._utils import (
flatten,
get_grad_accumulate_object,
has_inf_or_nan,
- reduce_tensor,
+ reduce_tensor_dp_group,
release_param_grad,
split_half_float_double,
sync_param,
@@ -33,35 +34,21 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
def __init__(
self,
optimizer: Optimizer,
-
- # grad scaler config
- initial_scale=2**16,
- min_scale=1,
- growth_factor=2,
- backoff_factor=0.5,
- growth_interval=2000,
- hysteresis=2,
+ initial_scale: int = 2**16, # grad scaler config
+ min_scale: int = 1,
+ growth_factor: float = 2.,
+ backoff_factor: float = .5,
+ growth_interval: int = 2000,
+ hysteresis: int = 2,
max_scale: int = 2**24,
-
- # grad clipping
- clip_grad_norm=0.0,
- verbose=False,
-
- # communication
- reduce_bucket_size=1024 * 1024,
- communication_dtype=None,
- overlap_communication=False,
-
- # stage 2
- partition_grad=False,
- dp_parallel_mode=ParallelMode.DATA,
- mp_parallel_mode=ParallelMode.MODEL,
-
- # cpu offload
- cpu_offload=False,
-
- # forced dtype
- forced_dtype=None):
+ clip_grad_norm: float = 0.0, # grad clipping
+ verbose: bool = False,
+ reduce_bucket_size: int = 1024 * 1024, # communication
+ communication_dtype: Optional[torch.dtype] = None,
+ overlap_communication: bool = False,
+ partition_grad: bool = False, # stage 2 flag
+ cpu_offload: bool = False, # cpu offload
+ forced_dtype: Optional[torch.dtype] = None):
# TODO: add support for
# 1. fp16 master weights
@@ -76,21 +63,32 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
# stage 2
self._partition_grads = partition_grad
- # cpu_offload
self._cpu_offload = cpu_offload
- # get process groups
- self._dp_parallel_mode = dp_parallel_mode
- self._mp_parallel_mode = mp_parallel_mode
- self._local_rank = gpc.get_local_rank(dp_parallel_mode)
- self._world_size = gpc.get_world_size(dp_parallel_mode)
+ colo_pg = self._search_colo_process_group()
+ if isinstance(colo_pg, ProcessGroup):
+ self._local_rank = colo_pg.dp_local_rank()
+ self._world_size = colo_pg.dp_world_size()
+ self._dp_global_ranks = colo_pg.get_ranks_in_dp()
+ self._dp_torch_group = colo_pg.dp_process_group()
+ self._mp_torch_group = None
+ if colo_pg.tp_world_size() > 1:
+ self._mp_torch_group = colo_pg.tp_process_group()
+ elif colo_pg is None:
+ dp_parallel_mode = ParallelMode.DATA
+ mp_parallel_mode = ParallelMode.MODEL
- self._dp_group = gpc.get_group(dp_parallel_mode)
- if gpc.is_initialized(mp_parallel_mode) and gpc.get_world_size(mp_parallel_mode) > 1:
- self._mp_group = gpc.get_group(mp_parallel_mode)
+ self._dp_parallel_mode = dp_parallel_mode
+ self._mp_parallel_mode = mp_parallel_mode
+ self._local_rank = gpc.get_local_rank(dp_parallel_mode)
+ self._world_size = gpc.get_world_size(dp_parallel_mode)
+ self._dp_global_ranks = gpc.get_ranks_in_group(dp_parallel_mode)
+ self._dp_torch_group = gpc.get_group(dp_parallel_mode)
+ self._mp_torch_group = None
+ if gpc.is_initialized(mp_parallel_mode) and gpc.get_world_size(mp_parallel_mode) > 1:
+ self._mp_torch_group = gpc.get_group(mp_parallel_mode)
else:
- self._mp_group = None
-
+ raise NotImplementedError
# fp16 and fp32 params for mixed precision training
self._fp16_param_groups = dict()
self._fp32_flat_param_groups_of_current_rank = dict()
@@ -126,9 +124,9 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
# ParameterStore will manage the tensor buffers used for zero
# it will not manage the tensors used by mixed precision training
- self._param_store = ParameterStore(self._dp_parallel_mode)
- self._grad_store = GradientStore(self._dp_parallel_mode)
- self._bucket_store = BucketStore(self._dp_parallel_mode)
+ self._param_store = ParameterStore(self._dp_torch_group)
+ self._grad_store = GradientStore(self._dp_torch_group)
+ self._bucket_store = BucketStore(self._dp_torch_group)
# iterate over the param group in the optimizer
# partition these param groups for data parallel training
@@ -209,6 +207,30 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
def num_param_groups(self):
return len(self._fp16_param_groups)
+ def _sanity_checks(self):
+ assert torch.cuda.is_available(), 'CUDA is required'
+ for param_group in self.optim.param_groups:
+ group_params = param_group['params']
+ for param in group_params:
+ assert param.dtype == self._dtype, \
+ f"Parameters are expected to have the same dtype `{self._dtype}`, but got `{param.dtype}`"
+
+ def _search_colo_process_group(self):
+ colo_flag = False
+ colo_pg = None
+ for param_group in self.optim.param_groups:
+ group_params = param_group['params']
+ for param in group_params:
+ if isinstance(param, ColoParameter):
+ colo_flag = True
+ if colo_pg is None:
+ colo_pg = param.get_process_group()
+ else:
+ assert colo_pg == param.get_process_group(), "All parameters should be in a same process group"
+ elif colo_flag:
+ raise RuntimeError("All parameters should be ColoParameter if you use ColoParameter.")
+ return colo_pg
+
def _partition_param_list(self, param_list):
params_per_rank = [[] for _ in range(self._world_size)]
numel_per_rank = [0 for _ in range(self._world_size)]
@@ -223,22 +245,16 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
numel_per_rank[rank_to_go] += param.numel()
if self._verbose:
- self._logger.info(f'Number of elements on ranks: {numel_per_rank}',
- ranks=[0],
- parallel_mode=self._dp_parallel_mode)
+ self._logger.info(f'Number of elements on ranks: {numel_per_rank}', ranks=[0])
return params_per_rank
- def _sanity_checks(self):
- assert torch.cuda.is_available(), 'CUDA is required'
- for param_group in self.optim.param_groups:
- group_params = param_group['params']
- for param in group_params:
- assert param.dtype == self._dtype, \
- f"Parameters are expected to have the same dtype `{self._dtype}`, but got `{param.dtype}`"
+ ###########################
+ # Backward Reduction Hook #
+ ###########################
- ###########################################################
- # Backward Reduction Hook
- ###########################################################
+ def _grad_handler(self, param, grad, reduce_rank):
+ self._add_to_reduction_bucket(param, reduce_rank)
+ return grad
def _attach_reduction_hook(self):
# we iterate over the fp16 params
@@ -256,53 +272,61 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
else:
reduce_rank = None
- def _define_and_attach(param, reduce_rank):
- # get the AccumulateGrad object of the param itself
- accum_grad_obj = get_grad_accumulate_object(param)
- self._grad_store.add_accumulate_grad_object(accum_grad_obj)
+ param.register_hook(partial(self._grad_handler, param, reduce_rank=reduce_rank))
- reduction_func = partial(self._reduce_and_remove_grads_by_bucket,
- param=param,
- reduce_rank=reduce_rank)
+ def _reduce_tensor_bucket(self, bucket: TensorBucket, reduce_rank):
+ if self._overlap_communication:
+ torch.cuda.synchronize()
+ self._param_store.clear_grads_of_previous_reduced_params()
+ stream = self._comm_stream
+ else:
+ stream = torch.cuda.current_stream()
- # define hook
- # NOT IMPORTANT BUT GOOD TO KNOW:
- # args here is not grad, but allow_unreacable and accumulate_grad
- def reduce_grad_hook(*args):
- reduction_func()
+ with torch.cuda.stream(stream):
+ flat = bucket.flatten()
+ reduce_global_rank = None
+ if reduce_rank is not None:
+ reduce_global_rank = self._dp_global_ranks[reduce_rank]
+ reduced_flat = reduce_tensor_dp_group(tensor=flat,
+ dtype=self._communication_dtype,
+ dst_local_rank=reduce_rank,
+ dst_global_rank=reduce_global_rank,
+ group=self._dp_torch_group)
- accum_grad_obj.register_hook(reduce_grad_hook)
+ # update the reduced tensor
+ if reduce_rank is None or reduce_rank == self._local_rank:
+ bucket.unflatten_and_copy(reduced_flat)
- _define_and_attach(param, reduce_rank)
+ def _reduce_tensor_list_with_one_dtype(self, tensor_list, bucket_size, reduce_rank):
+ param_bucket = TensorBucket(size=bucket_size)
- def _reduce_and_remove_grads_by_bucket(self, param, reduce_rank=None):
- param_size = param.numel()
+ for tensor in tensor_list:
+ param_bucket.add_to_bucket(tensor, allow_oversize=True)
- # check if the bucket is full
- # if full, will reduce the grads already in the bucket
- # after reduction, the bucket will be empty
- if self._bucket_store.num_elements_in_bucket(reduce_rank) + param_size > self._reduce_bucket_size:
- self._reduce_grads_in_bucket(reduce_rank)
+ if param_bucket.is_full_or_oversized():
+ self._reduce_tensor_bucket(bucket=param_bucket, reduce_rank=reduce_rank)
+ param_bucket.empty()
- # the param must not be reduced to ensure correctness
- is_param_reduced = self._param_store.is_param_reduced(param)
- if is_param_reduced:
- msg = f'Parameter of size ({param.size()}) has already been reduced, ' \
- + 'duplicate reduction will lead to arithmetic incorrectness'
- raise RuntimeError(msg)
+ if not param_bucket.is_empty():
+ self._reduce_tensor_bucket(bucket=param_bucket, reduce_rank=reduce_rank)
- # the param must have grad for reduction
- assert param.grad is not None, f'Parameter of size ({param.size()}) has None grad, cannot be reduced'
+ def _reduce_grads(self, reduce_rank, grads, bucket_size):
+ grad_buckets_by_dtype = split_half_float_double(grads)
- self._bucket_store.add_num_elements_in_bucket(param_size, reduce_rank)
- self._bucket_store.add_grad(param.grad, reduce_rank)
- self._bucket_store.add_param(param, reduce_rank)
+ for tensor_list in grad_buckets_by_dtype:
+ self._reduce_tensor_list_with_one_dtype(tensor_list=tensor_list,
+ bucket_size=bucket_size,
+ reduce_rank=reduce_rank)
- def _reduce_grads_in_bucket(self, reduce_rank=None):
+ #######################
+ # Reduction Functions #
+ #######################
+
+ def _run_reduction(self, reduce_rank=None):
# reduce grads
- self._reduce_grads_by_rank(reduce_rank=reduce_rank,
- grads=self._bucket_store.get_grad(reduce_rank=reduce_rank),
- bucket_size=self._bucket_store.num_elements_in_bucket(reduce_rank))
+ self._reduce_grads(reduce_rank=reduce_rank,
+ grads=self._bucket_store.get_grad(reduce_rank=reduce_rank),
+ bucket_size=self._bucket_store.num_elements_in_bucket(reduce_rank))
# use communication stream if overlapping
# communication with computation
@@ -339,46 +363,24 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
self._bucket_store.reset_by_rank(reduce_rank)
- def _reduce_grads_by_rank(self, reduce_rank, grads, bucket_size):
- grad_buckets_by_dtype = split_half_float_double(grads)
+ def _add_to_reduction_bucket(self, param, reduce_rank=None):
+ param_size = param.numel()
- for tensor_list in grad_buckets_by_dtype:
- self._reduce_no_retain(tensor_list=tensor_list, bucket_size=bucket_size, reduce_rank=reduce_rank)
+ # check if the bucket is full
+ # if full, will reduce the grads already in the bucket
+ # after reduction, the bucket will be empty
+ if self._bucket_store.num_elements_in_bucket(reduce_rank) + param_size > self._reduce_bucket_size:
+ self._run_reduction(reduce_rank)
- ##############################
- # Reduction Utility Function #
- ##############################
- def _reduce_no_retain(self, tensor_list, bucket_size, reduce_rank):
- param_bucket = TensorBucket(size=bucket_size)
+ # the param must not be reduced to ensure correctness
+ is_param_reduced = self._param_store.is_param_reduced(param)
+ if is_param_reduced:
+ msg = f'Parameter of size ({param.size()}) has already been reduced, ' \
+ + 'duplicate reduction will lead to arithmetic incorrectness'
+ raise RuntimeError(msg)
- for tensor in tensor_list:
- param_bucket.add_to_bucket(tensor, allow_oversize=True)
-
- if param_bucket.is_full_or_oversized():
- self._reduce_and_copy(bucket=param_bucket, reduce_rank=reduce_rank)
- param_bucket.empty()
-
- if not param_bucket.is_empty():
- self._reduce_and_copy(bucket=param_bucket, reduce_rank=reduce_rank)
-
- def _reduce_and_copy(self, bucket: TensorBucket, reduce_rank):
- if self._overlap_communication:
- torch.cuda.synchronize()
- self._param_store.clear_grads_of_previous_reduced_params()
- stream = self._comm_stream
- else:
- stream = torch.cuda.current_stream()
-
- with torch.cuda.stream(stream):
- flat = bucket.flatten()
- reduced_flat = reduce_tensor(tensor=flat,
- dtype=self._communication_dtype,
- dst_rank=reduce_rank,
- parallel_mode=self._dp_parallel_mode)
-
- # update the reduced tensor
- if reduce_rank is None or reduce_rank == self._local_rank:
- bucket.unflatten_and_copy(reduced_flat)
+ self._bucket_store.add_num_elements_in_bucket(param_size, reduce_rank)
+ self._bucket_store.add_param(param, reduce_rank)
################################
# torch.optim.Optimizer methods
@@ -443,8 +445,8 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
norm_group = compute_norm(gradients=self._grad_store._averaged_gradients[group_id],
params=self._param_store.get_fp16_params_by_rank_group(group_id=group_id,
rank=self._local_rank),
- dp_group=self._dp_group,
- mp_group=self._mp_group)
+ dp_group=self._dp_torch_group,
+ mp_group=self._mp_torch_group)
norm_groups.append(norm_group)
# create flat gradient for the flat fp32 params
@@ -482,9 +484,10 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
# broadcast the updated model weights
handles = []
for group_id in range(self.num_param_groups):
- for rank in range(self._world_size):
- fp16_param = self._param_store.get_flat_fp16_param_by_rank_group(rank=rank, group_id=group_id)
- handle = dist.broadcast(fp16_param, src=rank, group=self._dp_group, async_op=True)
+ for index in range(self._world_size):
+ rank = self._dp_global_ranks[index]
+ fp16_param = self._param_store.get_flat_fp16_param_by_rank_group(rank=index, group_id=group_id)
+ handle = dist.broadcast(fp16_param, src=rank, group=self._dp_torch_group, async_op=True)
handles.append(handle)
for handle in handles:
@@ -506,11 +509,11 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
break
# all-reduce across dp group
- dist.all_reduce(self._found_overflow, op=dist.ReduceOp.MAX, group=self._dp_group)
+ dist.all_reduce(self._found_overflow, op=dist.ReduceOp.MAX, group=self._dp_torch_group)
# all-reduce over model parallel group
- if self._mp_group:
- dist.all_reduce(self._found_overflow, op=dist.ReduceOp.MAX, group=self._mp_group)
+ if self._mp_torch_group:
+ dist.all_reduce(self._found_overflow, op=dist.ReduceOp.MAX, group=self._mp_torch_group)
if self._found_overflow.item() > 0:
return True
@@ -569,11 +572,11 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
param_group = self._fp16_param_groups[group_id]
for param in param_group:
if param.grad is not None:
- self._reduce_and_remove_grads_by_bucket(param)
+ self._add_to_reduction_bucket(param)
# we need to reduce the gradients
# left in the communication bucket
- self._reduce_grads_in_bucket()
+ self._run_reduction()
def _reduce_grad_stage2(self):
# when partition_grads is True, reduction hooks
@@ -581,4 +584,4 @@ class LowLevelZeroOptimizer(ColossalaiOptimizer):
# only need to reduce the gradients
# left in the communication bucket
for reduce_rank in range(self._world_size):
- self._reduce_grads_in_bucket(reduce_rank)
+ self._run_reduction(reduce_rank)
diff --git a/colossalai/zero/utils/gemini_hook.py b/colossalai/zero/utils/gemini_hook.py
index 35569c717..bddc307a0 100644
--- a/colossalai/zero/utils/gemini_hook.py
+++ b/colossalai/zero/utils/gemini_hook.py
@@ -8,6 +8,7 @@ import torch
from colossalai.gemini import TensorState
from colossalai.gemini.gemini_mgr import GeminiManager
from colossalai.tensor.param_op_hook import ColoParamOpHook
+from colossalai.utils import is_ddp_ignored
class TrainingPhase(Enum):
@@ -24,7 +25,7 @@ class GeminiZeROHook(ColoParamOpHook):
self._training_phase = TrainingPhase.FORWARD
def pre_op(self, params):
- params = [p for p in params if not getattr(p, '_ddp_to_ignore', False)]
+ params = [p for p in params if not is_ddp_ignored(p)]
chunks = self._chunk_manager.get_chunks(params)
for p in params:
self._chunk_manager.trans_tensor_state(p, TensorState.COMPUTE)
@@ -37,7 +38,7 @@ class GeminiZeROHook(ColoParamOpHook):
self._gemini_manager.record_model_data_volume()
def post_op(self, params):
- params = [p for p in params if not getattr(p, '_ddp_to_ignore', False)]
+ params = [p for p in params if not is_ddp_ignored(p)]
for p in params:
tensor_state = TensorState.HOLD if self._training_phase == TrainingPhase.FORWARD or not p.requires_grad else TensorState.HOLD_AFTER_BWD
self._chunk_manager.trans_tensor_state(p, tensor_state)
diff --git a/docker/Dockerfile b/docker/Dockerfile
index bcb7c0fff..0faba17b9 100644
--- a/docker/Dockerfile
+++ b/docker/Dockerfile
@@ -1,17 +1,18 @@
FROM hpcaitech/cuda-conda:11.3
# install torch
-RUN conda install pytorch torchvision torchaudio cudatoolkit=11.3 -c pytorch
+RUN conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.3 -c pytorch
# install apex
RUN git clone https://github.com/NVIDIA/apex && \
cd apex && \
+ pip install packaging && \
pip install -v --disable-pip-version-check --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" --global-option="--fast_layer_norm" ./
# install colossalai
RUN git clone https://github.com/hpcaitech/ColossalAI.git \
&& cd ./ColossalAI \
- && pip install -v --no-cache-dir .
+ && CUDA_EXT=1 pip install -v --no-cache-dir .
# install titans
RUN pip install --no-cache-dir titans
diff --git a/examples/README.md b/examples/README.md
index 53ab0896d..78facea54 100644
--- a/examples/README.md
+++ b/examples/README.md
@@ -1,28 +1,40 @@
-## Examples folder document
+# Colossal-AI Examples
## Table of Contents
-
-## Example folder description
+- [Colossal-AI Examples](#colossal-ai-examples)
+ - [Table of Contents](#table-of-contents)
+ - [Overview](#overview)
+ - [Folder Structure](#folder-structure)
+ - [Integrate Your Example With Testing](#integrate-your-example-with-testing)
-This folder provides several examples using colossalai. The images folder includes model like diffusion, dreambooth and vit. The language folder includes gpt, opt, palm and roberta. The tutorial folder is for concept illustration, such as auto-parallel, hybrid-parallel and so on.
+## Overview
+This folder provides several examples accelerated by Colossal-AI. The `tutorial` folder is for everyone to quickly try out the different features in Colossal-AI. Other folders such as `images` and `language` include a wide range of deep learning tasks and applications.
-## Integrate Your Example With System Testing
+## Folder Structure
-For example code contributor, to meet the expectation and test your code automatically using github workflow function, here are several steps:
+```text
+└─ examples
+ └─ images
+ └─ vit
+ └─ test_ci.sh
+ └─ train.py
+ └─ README.md
+ └─ ...
+ └─ ...
+```
+## Integrate Your Example With Testing
-- (must) Have a test_ci.sh file in the folder like shown below in 'File Structure Chart'
-- The dataset should be located in the company's machine and can be announced using environment variable and thus no need for a separate terminal command.
-- The model parameters should be small to allow fast testing.
-- File Structure Chart
+Regular checks are important to ensure that all examples run without apparent bugs and stay compatible with the latest API.
+Colossal-AI runs workflows to check for examples on a on-pull-request and weekly basis.
+When a new example is added or changed, the workflow will run the example to test whether it can run.
+Moreover, Colossal-AI will run testing for examples every week.
- └─examples
- └─images
- └─vit
- └─requirements.txt
- └─test_ci.sh
+Therefore, it is essential for the example contributors to know how to integrate your example with the testing workflow. Simply, you can follow the steps below.
+
+1. Create a script called `test_ci.sh` in your example folder
+2. Configure your testing parameters such as number steps, batch size in `test_ci.sh`, e.t.c. Keep these parameters small such that each example only takes several minutes.
+3. Export your dataset path with the prefix `/data` and make sure you have a copy of the dataset in the `/data/scratch/examples-data` directory on the CI machine. Community contributors can contact us via slack to request for downloading the dataset on the CI machine.
+4. Implement the logic such as dependency setup and example execution
diff --git a/examples/images/diffusion/README.md b/examples/images/diffusion/README.md
index abb1d24c0..ddc7e2d97 100644
--- a/examples/images/diffusion/README.md
+++ b/examples/images/diffusion/README.md
@@ -26,6 +26,16 @@ Acceleration of AIGC (AI-Generated Content) models such as [Stable Diffusion v1]
More details can be found in our [blog of Stable Diffusion v1](https://www.hpc-ai.tech/blog/diffusion-pretraining-and-hardware-fine-tuning-can-be-almost-7x-cheaper) and [blog of Stable Diffusion v2](https://www.hpc-ai.tech/blog/colossal-ai-0-2-0).
+
+## Roadmap
+This project is in rapid development.
+
+- [X] Train a stable diffusion model v1/v2 from scatch
+- [X] Finetune a pretrained Stable diffusion v1 model
+- [X] Inference a pretrained model using PyTorch
+- [ ] Finetune a pretrained Stable diffusion v2 model
+- [ ] Inference a pretrained model using TensoRT
+
## Installation
### Option #1: install from source
@@ -123,7 +133,7 @@ git clone https://huggingface.co/CompVis/stable-diffusion-v1-4
### stable-diffusion-v1-5 from runway
-If you want to useed the Last [stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) wiegh from runwayml
+If you want to useed the Last [stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) weight from runwayml
```
git lfs install
@@ -156,7 +166,7 @@ You can change the trainging config in the yaml file
- precision: the precision type used in training, default 16 (fp16), you must use fp16 if you want to apply colossalai
- more information about the configuration of ColossalAIStrategy can be found [here](https://pytorch-lightning.readthedocs.io/en/latest/advanced/model_parallel.html#colossal-ai)
-## Finetune Example
+## Finetune Example (Work In Progress)
### Training on Teyvat Datasets
We provide the finetuning example on [Teyvat](https://huggingface.co/datasets/Fazzie/Teyvat) dataset, which is create by BLIP generated captions.
diff --git a/examples/tutorial/stable_diffusion/ldm/data/__init__.py b/examples/images/diffusion/test_ci.sh
similarity index 100%
rename from examples/tutorial/stable_diffusion/ldm/data/__init__.py
rename to examples/images/diffusion/test_ci.sh
diff --git a/examples/tutorial/stable_diffusion/ldm/models/diffusion/__init__.py b/examples/images/dreambooth/test_ci.sh
similarity index 100%
rename from examples/tutorial/stable_diffusion/ldm/models/diffusion/__init__.py
rename to examples/images/dreambooth/test_ci.sh
diff --git a/examples/images/dreambooth/train_dreambooth_colossalai.py b/examples/images/dreambooth/train_dreambooth_colossalai.py
index b7e24bfe4..9c72c06e7 100644
--- a/examples/images/dreambooth/train_dreambooth_colossalai.py
+++ b/examples/images/dreambooth/train_dreambooth_colossalai.py
@@ -153,7 +153,8 @@ def parse_args(input_args=None):
"--gradient_accumulation_steps",
type=int,
default=1,
- help="Number of updates steps to accumulate before performing a backward/update pass.",
+ help=
+ "Number of updates steps to accumulate before performing a backward/update pass. If using Gemini, it must be 1",
)
parser.add_argument(
"--gradient_checkpointing",
@@ -355,10 +356,14 @@ def gemini_zero_dpp(model: torch.nn.Module, placememt_policy: str = "auto"):
def main(args):
- colossalai.launch_from_torch(config={})
- if args.seed is not None:
- gpc.set_seed(args.seed)
+ if args.seed is None:
+ colossalai.launch_from_torch(config={})
+ else:
+ colossalai.launch_from_torch(config={}, seed=args.seed)
+
+ local_rank = gpc.get_local_rank(ParallelMode.DATA)
+ world_size = gpc.get_world_size(ParallelMode.DATA)
if args.with_prior_preservation:
class_images_dir = Path(args.class_data_dir)
@@ -387,7 +392,7 @@ def main(args):
for example in tqdm(
sample_dataloader,
desc="Generating class images",
- disable=not gpc.get_local_rank(ParallelMode.DATA) == 0,
+ disable=not local_rank == 0,
):
images = pipeline(example["prompt"]).images
@@ -399,7 +404,7 @@ def main(args):
del pipeline
# Handle the repository creation
- if gpc.get_local_rank(ParallelMode.DATA) == 0:
+ if local_rank == 0:
if args.push_to_hub:
if args.hub_model_id is None:
repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
@@ -464,8 +469,9 @@ def main(args):
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
+ assert args.gradient_accumulation_steps == 1, "if using ColossalAI gradient_accumulation_steps must be set to 1."
if args.scale_lr:
- args.learning_rate = args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * gpc.get_world_size(ParallelMode.DATA)
+ args.learning_rate = args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * world_size
unet = gemini_zero_dpp(unet, args.placement)
@@ -554,7 +560,7 @@ def main(args):
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Train!
- total_batch_size = args.train_batch_size * gpc.get_world_size(ParallelMode.DATA) * args.gradient_accumulation_steps
+ total_batch_size = args.train_batch_size * world_size * args.gradient_accumulation_steps
logger.info("***** Running training *****", ranks=[0])
logger.info(f" Num examples = {len(train_dataset)}", ranks=[0])
@@ -566,7 +572,7 @@ def main(args):
logger.info(f" Total optimization steps = {args.max_train_steps}", ranks=[0])
# Only show the progress bar once on each machine.
- progress_bar = tqdm(range(args.max_train_steps), disable=not gpc.get_local_rank(ParallelMode.DATA) == 0)
+ progress_bar = tqdm(range(args.max_train_steps), disable=not local_rank == 0)
progress_bar.set_description("Steps")
global_step = 0
@@ -643,7 +649,7 @@ def main(args):
if global_step % args.save_steps == 0:
torch.cuda.synchronize()
torch_unet = get_static_torch_model(unet)
- if gpc.get_local_rank(ParallelMode.DATA) == 0:
+ if local_rank == 0:
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
unet=torch_unet,
@@ -658,7 +664,7 @@ def main(args):
torch.cuda.synchronize()
unet = get_static_torch_model(unet)
- if gpc.get_local_rank(ParallelMode.DATA) == 0:
+ if local_rank == 0:
pipeline = DiffusionPipeline.from_pretrained(
args.pretrained_model_name_or_path,
unet=unet,
diff --git a/examples/images/vit/configs/vit_1d_tp2_ci.py b/examples/images/vit/configs/vit_1d_tp2_ci.py
new file mode 100644
index 000000000..e491e4ada
--- /dev/null
+++ b/examples/images/vit/configs/vit_1d_tp2_ci.py
@@ -0,0 +1,32 @@
+from colossalai.amp import AMP_TYPE
+
+# hyperparameters
+# BATCH_SIZE is as per GPU
+# global batch size = BATCH_SIZE x data parallel size
+BATCH_SIZE = 8
+LEARNING_RATE = 3e-3
+WEIGHT_DECAY = 0.3
+NUM_EPOCHS = 3
+WARMUP_EPOCHS = 1
+
+# model config
+IMG_SIZE = 224
+PATCH_SIZE = 16
+HIDDEN_SIZE = 32
+DEPTH = 2
+NUM_HEADS = 4
+MLP_RATIO = 4
+NUM_CLASSES = 10
+CHECKPOINT = False
+SEQ_LENGTH = (IMG_SIZE // PATCH_SIZE)**2 + 1 # add 1 for cls token
+
+USE_DDP = True
+TP_WORLD_SIZE = 2
+TP_TYPE = 'row'
+parallel = dict(tensor=dict(mode="1d", size=TP_WORLD_SIZE),)
+
+fp16 = dict(mode=AMP_TYPE.NAIVE)
+clip_grad_norm = 1.0
+gradient_accumulation = 2
+
+LOG_PATH = "./log_ci"
diff --git a/examples/images/vit/requirements.txt b/examples/images/vit/requirements.txt
index 137a69e80..1f69794eb 100644
--- a/examples/images/vit/requirements.txt
+++ b/examples/images/vit/requirements.txt
@@ -1,2 +1,8 @@
colossalai >= 0.1.12
torch >= 1.8.1
+numpy>=1.24.1
+timm>=0.6.12
+titans>=0.0.7
+tqdm>=4.61.2
+transformers>=4.25.1
+nvidia-dali-cuda110>=1.8.0 --extra-index-url https://developer.download.nvidia.com/compute/redist
diff --git a/examples/images/vit/test_ci.sh b/examples/images/vit/test_ci.sh
new file mode 100644
index 000000000..41d25ee23
--- /dev/null
+++ b/examples/images/vit/test_ci.sh
@@ -0,0 +1,9 @@
+export OMP_NUM_THREADS=4
+
+pip install -r requirements.txt
+
+# train
+colossalai run \
+--nproc_per_node 4 train.py \
+--config configs/vit_1d_tp2_ci.py \
+--dummy_data
diff --git a/examples/images/vit/train.py b/examples/images/vit/train.py
index de39801c7..0b4489244 100644
--- a/examples/images/vit/train.py
+++ b/examples/images/vit/train.py
@@ -7,6 +7,7 @@ import torch.nn.functional as F
from timm.models.vision_transformer import _create_vision_transformer
from titans.dataloader.imagenet import build_dali_imagenet
from tqdm import tqdm
+from vit import DummyDataLoader
import colossalai
from colossalai.core import global_context as gpc
@@ -56,8 +57,8 @@ def init_spec_func(model, tp_type):
def train_imagenet():
parser = colossalai.get_default_parser()
- parser.add_argument('--from_torch', default=True, action='store_true')
- parser.add_argument('--resume_from', default=False)
+ parser.add_argument('--resume_from', default=False, action='store_true')
+ parser.add_argument('--dummy_data', default=False, action='store_true')
args = parser.parse_args()
colossalai.launch_from_torch(config=args.config)
@@ -74,10 +75,22 @@ def train_imagenet():
logger.log_to_file(log_path)
logger.info('Build data loader', ranks=[0])
- root = os.environ['DATA']
- train_dataloader, test_dataloader = build_dali_imagenet(root,
- train_batch_size=gpc.config.BATCH_SIZE,
- test_batch_size=gpc.config.BATCH_SIZE)
+ if not args.dummy_data:
+ root = os.environ['DATA']
+ train_dataloader, test_dataloader = build_dali_imagenet(root,
+ train_batch_size=gpc.config.BATCH_SIZE,
+ test_batch_size=gpc.config.BATCH_SIZE)
+ else:
+ train_dataloader = DummyDataLoader(length=10,
+ batch_size=gpc.config.BATCH_SIZE,
+ category=gpc.config.NUM_CLASSES,
+ image_size=gpc.config.IMG_SIZE,
+ return_dict=False)
+ test_dataloader = DummyDataLoader(length=5,
+ batch_size=gpc.config.BATCH_SIZE,
+ category=gpc.config.NUM_CLASSES,
+ image_size=gpc.config.IMG_SIZE,
+ return_dict=False)
logger.info('Build model', ranks=[0])
diff --git a/examples/images/vit/vit.py b/examples/images/vit/vit.py
index 14c870b39..f22e8ea90 100644
--- a/examples/images/vit/vit.py
+++ b/examples/images/vit/vit.py
@@ -32,21 +32,24 @@ class DummyDataGenerator(ABC):
class DummyDataLoader(DummyDataGenerator):
- batch_size = 4
- channel = 3
- category = 8
- image_size = 224
+
+ def __init__(self, length=10, batch_size=4, channel=3, category=8, image_size=224, return_dict=True):
+ super().__init__(length)
+ self.batch_size = batch_size
+ self.channel = channel
+ self.category = category
+ self.image_size = image_size
+ self.return_dict = return_dict
def generate(self):
image_dict = {}
- image_dict['pixel_values'] = torch.rand(DummyDataLoader.batch_size,
- DummyDataLoader.channel,
- DummyDataLoader.image_size,
- DummyDataLoader.image_size,
- device=get_current_device()) * 2 - 1
- image_dict['label'] = torch.randint(DummyDataLoader.category, (DummyDataLoader.batch_size,),
+ image_dict['pixel_values'] = torch.rand(
+ self.batch_size, self.channel, self.image_size, self.image_size, device=get_current_device()) * 2 - 1
+ image_dict['label'] = torch.randint(self.category, (self.batch_size,),
dtype=torch.int64,
device=get_current_device())
+ if not self.return_dict:
+ return image_dict['pixel_values'], image_dict['label']
return image_dict
diff --git a/examples/language/gpt/README.md b/examples/language/gpt/README.md
index 8fdf6be3b..7e6acb3d3 100644
--- a/examples/language/gpt/README.md
+++ b/examples/language/gpt/README.md
@@ -39,9 +39,15 @@ If you want to test ZeRO1 and ZeRO2 in Colossal-AI, you need to ensure Colossal-
For simplicity, the input data is randonly generated here.
## Training
-We provide two solutions. One utilizes the hybrid parallel strategies of Gemini, DDP/ZeRO, and Tensor Parallelism.
-The other one uses Pipeline Parallelism Only.
-In the future, we are going merge them together and they can be used orthogonally to each other.
+We provide two stable solutions.
+One utilizes the Gemini to implement hybrid parallel strategies of Gemini, DDP/ZeRO, and Tensor Parallelism for a huggingface GPT model.
+The other one use [Titans](https://github.com/hpcaitech/Titans), a distributed executed model zoo maintained by ColossalAI,to implement the hybrid parallel strategies of TP + ZeRO + PP.
+
+We recommend using Gemini to qucikly run your model in a distributed manner.
+It doesn't require significant changes to the model structures, therefore you can apply it on a new model easily.
+And use Titans as an advanced weapon to pursue a more extreme performance.
+Titans has included the some typical models, such as Vit and GPT.
+However, it requires some efforts to start if facing a new model structure.
### GeminiDPP/ZeRO + Tensor Parallelism
```bash
@@ -56,6 +62,11 @@ The `train_gpt_demo.py` provides three distributed plans, you can choose the pla
- Pytorch DDP
- Pytorch ZeRO
+### Titans (Tensor Parallelism) + ZeRO + Pipeline Parallelism
+
+Titans provides a customized GPT model, which uses distributed operators as building blocks.
+In [./titans/README.md], we provide a hybrid parallelism of ZeRO, TP and PP.
+You can switch parallel strategies using a config file.
## Performance
diff --git a/examples/language/gpt/experiments/auto_parallel/auto_parallel_with_gpt.py b/examples/language/gpt/experiments/auto_parallel/auto_parallel_with_gpt.py
index 85c8d64d7..6ceb7fd87 100644
--- a/examples/language/gpt/experiments/auto_parallel/auto_parallel_with_gpt.py
+++ b/examples/language/gpt/experiments/auto_parallel/auto_parallel_with_gpt.py
@@ -16,14 +16,14 @@ from colossalai.device.device_mesh import DeviceMesh
from colossalai.initialize import launch_from_torch
from colossalai.logging import disable_existing_loggers, get_dist_logger
-BATCH_SIZE = 8
-SEQ_LENGTH = 128
-HIDDEN_DIM = 3072
+BATCH_SIZE = 16
+SEQ_LENGTH = 1024
+HIDDEN_DIM = 4096
NUM_HEADS = 16
-NUM_LAYERS = 1
+NUM_LAYERS = 4
VOCAB_SIZE = 50257
NUM_STEPS = 10
-FP16 = False
+FP16 = True
def get_cpu_mem():
@@ -40,7 +40,7 @@ def get_mem_info(prefix=''):
def get_tflops(model_numel, batch_size, seq_len, step_time):
# Tflops_per_GPU = global_batch * global_numel * seq_len * 8 / #gpu
- return model_numel * batch_size * seq_len * 8 / 1e12 / (step_time + 1e-12) / 4
+ return model_numel * batch_size * seq_len * 8 / 1e12 / (step_time + 1e-12) / 8
# Randomly Generated Data
@@ -66,13 +66,7 @@ def main():
'attention_mask': torch.zeros((BATCH_SIZE, SEQ_LENGTH), dtype=torch.int64).to('meta'),
}
- # Both device mesh initialization and model initialization will be integrated into autoparallelize
- physical_mesh_id = torch.arange(0, 4)
- mesh_shape = (2, 2)
- device_mesh = DeviceMesh(physical_mesh_id, mesh_shape, init_process_group=True)
-
- # Enable auto-parallel
- gm, solution = initialize_model(model, meta_input_sample, device_mesh, return_solution=True)
+ gm, solution = autoparallelize(model, meta_input_sample, return_solution=True)
# print solution on rank 0
if gpc.get_global_rank() == 0:
diff --git a/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_12_layers.pt b/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_12_layers.pt
new file mode 100644
index 000000000..7b8cd7edd
Binary files /dev/null and b/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_12_layers.pt differ
diff --git a/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_1_layers.pt b/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_1_layers.pt
new file mode 100644
index 000000000..9b431a45b
Binary files /dev/null and b/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_1_layers.pt differ
diff --git a/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_4_layers.pt b/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_4_layers.pt
new file mode 100644
index 000000000..79a448c1b
Binary files /dev/null and b/examples/language/gpt/experiments/auto_parallel/saved_solution/solution_4_layers.pt differ
diff --git a/examples/language/gpt/experiments/pipeline_parallel/requirements.txt b/examples/language/gpt/experiments/pipeline_parallel/requirements.txt
new file mode 100644
index 000000000..137a69e80
--- /dev/null
+++ b/examples/language/gpt/experiments/pipeline_parallel/requirements.txt
@@ -0,0 +1,2 @@
+colossalai >= 0.1.12
+torch >= 1.8.1
diff --git a/examples/language/gpt/experiments/pipeline_parallel/train_gpt_pp.py b/examples/language/gpt/experiments/pipeline_parallel/train_gpt_pp.py
index 79efa61b0..c3451c18d 100644
--- a/examples/language/gpt/experiments/pipeline_parallel/train_gpt_pp.py
+++ b/examples/language/gpt/experiments/pipeline_parallel/train_gpt_pp.py
@@ -120,7 +120,7 @@ def run_master(args):
logger.info(f'{rank=} numel in the partition:{numel}')
# build optim
- pp_engine.initialize_optimizer(HybridAdam, lr=1e-3)
+ pp_engine.initialize_optimizer(torch.optim.Adam, lr=1e-3)
ranks_tflops = {}
for n in range(NUM_STEPS):
diff --git a/examples/language/gpt/gemini/benchmark_gemini.sh b/examples/language/gpt/gemini/benchmark_gemini.sh
index 13086666e..9a630b2ff 100644
--- a/examples/language/gpt/gemini/benchmark_gemini.sh
+++ b/examples/language/gpt/gemini/benchmark_gemini.sh
@@ -1,18 +1,20 @@
for MODEL_TYPE in "gpt2_medium"; do
- for BATCH_SIZE in 16; do
- for GPUNUM in 1 2 4 8; do
- for TPDEGREE in 1 2 4 8; do
- if [ ${TPDEGREE} -gt ${GPUNUM} ]; then
- continue
- fi
- for PLACEMENT in "cpu" "auto"; do
- echo "****************** Begin ***************************"
- echo "* benchmrking MODEL_TYPE ${MODEL_TYPE} BS ${BATCH_SIZE} BS ${BS} GPUNUM ${GPUNUM} TPDEGREE ${TPDEGREE} PLACEMENT ${PLACEMENT}"
- MODEL_TYPE=${MODEL_TYPE} BATCH_SIZE=${BATCH_SIZE} GPUNUM=${GPUNUM} TPDEGREE=${TPDEGREE} PLACEMENT=${PLACEMENT} \
- bash ./gemini/run_gemini.sh
- echo "****************** Finished ***************************"
- echo ""
- echo ""
+ for DISTPLAN in "colossalai"; do
+ for BATCH_SIZE in 16; do
+ for GPUNUM in 1 2 4 8; do
+ for TPDEGREE in 1 2 4 8; do
+ if [ ${TPDEGREE} -gt ${GPUNUM} ]; then
+ continue
+ fi
+ for PLACEMENT in "cpu" "auto"; do
+ echo "****************** Begin ***************************"
+ echo "+ benchmrking MODEL ${MODEL_TYPE} DISTPLAN ${DISTPLAN} GPU ${GPUNUM} BS ${BATCH_SIZE} TP ${TPDEGREE} POLICY ${PLACEMENT}"
+ MODEL_TYPE=${MODEL_TYPE} DISTPLAN=${DISTPLAN} BATCH_SIZE=${BATCH_SIZE} GPUNUM=${GPUNUM} TPDEGREE=${TPDEGREE} PLACEMENT=${PLACEMENT} \
+ bash ./run_gemini.sh
+ echo "****************** Finished ***************************"
+ echo ""
+ echo ""
+ done
done
done
done
diff --git a/examples/language/gpt/gemini/commons/model_zoo.py b/examples/language/gpt/gemini/commons/model_zoo.py
index c31b3fa6d..65124d9e4 100644
--- a/examples/language/gpt/gemini/commons/model_zoo.py
+++ b/examples/language/gpt/gemini/commons/model_zoo.py
@@ -53,6 +53,14 @@ def gpt2_24b(checkpoint=True):
return GPTLMModel(hidden_size=8192, num_layers=30, num_attention_heads=16, checkpoint=checkpoint)
+def gpt2_30b(checkpoint=True):
+ return GPTLMModel(hidden_size=8192, num_layers=37, num_attention_heads=16, checkpoint=checkpoint)
+
+
+def gpt2_40b(checkpoint=True):
+ return GPTLMModel(hidden_size=8192, num_layers=50, num_attention_heads=16, checkpoint=checkpoint)
+
+
def model_builder(model_size: str) -> callable:
if model_size == "gpt2_medium":
return gpt2_medium
@@ -66,6 +74,10 @@ def model_builder(model_size: str) -> callable:
return gpt2_20b
elif model_size == "gpt2_24b":
return gpt2_24b
+ elif model_size == "gpt2_30b":
+ return gpt2_30b
+ elif model_size == "gpt2_40b":
+ return gpt2_40b
else:
raise TypeError(f"model_builder {model_size}")
diff --git a/examples/language/gpt/gemini/requirements.txt b/examples/language/gpt/gemini/requirements.txt
new file mode 100644
index 000000000..137a69e80
--- /dev/null
+++ b/examples/language/gpt/gemini/requirements.txt
@@ -0,0 +1,2 @@
+colossalai >= 0.1.12
+torch >= 1.8.1
diff --git a/examples/language/gpt/gemini/run_gemini.sh b/examples/language/gpt/gemini/run_gemini.sh
index ad577c350..6f0710d54 100644
--- a/examples/language/gpt/gemini/run_gemini.sh
+++ b/examples/language/gpt/gemini/run_gemini.sh
@@ -1,15 +1,15 @@
set -x
# distplan in ["colossalai", "zero1", "zero2", "torch_ddp", "torch_zero"]
-export DISTPAN=${DISTPAN:-"colossalai"}
+export DISTPLAN=${DISTPLAN:-"colossalai"}
-# The following options only valid when DISTPAN="colossalai"
+# The following options only valid when DISTPLAN="colossalai"
export GPUNUM=${GPUNUM:-1}
export TPDEGREE=${TPDEGREE:-1}
export PLACEMENT=${PLACEMENT:-"cpu"}
export USE_SHARD_INIT=${USE_SHARD_INIT:-False}
export BATCH_SIZE=${BATCH_SIZE:-16}
export MODEL_TYPE=${MODEL_TYPE:-"gpt2_medium"}
-
+export TRAIN_STEP=${TRAIN_STEP:-10}
# export PYTHONPATH=$PWD:$PYTHONPATH
mkdir -p gemini_logs
@@ -20,5 +20,6 @@ torchrun --standalone --nproc_per_node=${GPUNUM} ./train_gpt_demo.py \
--batch_size=${BATCH_SIZE} \
--placement=${PLACEMENT} \
--shardinit=${USE_SHARD_INIT} \
---distplan=${DISTPAN} \
-2>&1 | tee ./gemini_logs/${MODEL_TYPE}_${DISTPAN}_gpu_${GPUNUM}_bs_${BATCH_SIZE}_tp_${TPDEGREE}_${PLACEMENT}.log
+--distplan=${DISTPLAN} \
+--train_step=${TRAIN_STEP} \
+2>&1 | tee ./gemini_logs/${MODEL_TYPE}_${DISTPLAN}_gpu_${GPUNUM}_bs_${BATCH_SIZE}_tp_${TPDEGREE}_${PLACEMENT}.log
diff --git a/examples/language/gpt/gemini/test_ci.sh b/examples/language/gpt/gemini/test_ci.sh
new file mode 100644
index 000000000..6079d5ed6
--- /dev/null
+++ b/examples/language/gpt/gemini/test_ci.sh
@@ -0,0 +1,35 @@
+set -x
+$(cd `dirname $0`;pwd)
+export TRAIN_STEP=4
+
+for MODEL_TYPE in "gpt2_medium"; do
+ for DISTPLAN in "colossalai"; do
+ for BATCH_SIZE in 2; do
+ for GPUNUM in 1 4; do
+ for TPDEGREE in 1 2; do
+ if [ ${TPDEGREE} -gt ${GPUNUM} ]; then
+ continue
+ fi
+ for PLACEMENT in "cpu" "auto"; do
+ MODEL_TYPE=${MODEL_TYPE} DISTPLAN=${DISTPLAN} BATCH_SIZE=${BATCH_SIZE} GPUNUM=${GPUNUM} TPDEGREE=${TPDEGREE} PLACEMENT=${PLACEMENT} \
+ bash ./run_gemini.sh
+ done
+ done
+ done
+ done
+ done
+
+ for DISTPLAN in "zero1" "zero2"; do
+ for BATCH_SIZE in 2; do
+ for GPUNUM in 1 4; do
+ for TPDEGREE in 1; do
+ if [ ${TPDEGREE} -gt ${GPUNUM} ]; then
+ continue
+ fi
+ MODEL_TYPE=${MODEL_TYPE} DISTPLAN=${DISTPLAN} BATCH_SIZE=${BATCH_SIZE} GPUNUM=${GPUNUM} TPDEGREE=${TPDEGREE}\
+ bash ./run_gemini.sh
+ done
+ done
+ done
+ done
+done
diff --git a/examples/language/gpt/gemini/train_gpt_demo.py b/examples/language/gpt/gemini/train_gpt_demo.py
index 29f8c8ef1..285706596 100644
--- a/examples/language/gpt/gemini/train_gpt_demo.py
+++ b/examples/language/gpt/gemini/train_gpt_demo.py
@@ -65,6 +65,13 @@ def parse_args():
default="gpt2_medium",
help="model model scale",
)
+ parser.add_argument(
+ "--train_step",
+ type=int,
+ default=10,
+ help="training iterations for test",
+ )
+
args = parser.parse_args()
return args
@@ -180,17 +187,18 @@ def tensor_parallelize(model: torch.nn.Module, pg: ProcessGroup):
# Gemini + ZeRO DDP
-def build_gemini(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto"):
+def build_gemini(model: torch.nn.Module, pg: ProcessGroup, placement_policy: str = "auto", ddp_flag: bool = True):
fp16_init_scale = 2**5
gpu_margin_mem_ratio_for_auto = 0
if version.parse(CAI_VERSION) > version.parse("0.1.10"):
model = GeminiDDP(model,
+ strict_ddp_mode=ddp_flag,
device=get_current_device(),
placement_policy=placement_policy,
pin_memory=True,
hidden_dim=model.config.n_embd,
- search_range_mb=64)
+ search_range_mb=128)
# configure the const policy
if placement_policy == 'const':
model.gemini_manager._placement_policy.set_const_memory_boundary(2 * 1024)
@@ -236,7 +244,8 @@ def main():
SEQ_LEN = 1024
VOCAB_SIZE = 50257
- NUM_STEPS = 10
+ NUM_STEPS = args.train_step
+
WARMUP_STEPS = 1
assert WARMUP_STEPS < NUM_STEPS, "warmup steps should smaller than the total steps"
assert (NUM_STEPS - WARMUP_STEPS) % 2 == 1, "the number of valid steps should be odd to take the median "
@@ -270,14 +279,17 @@ def main():
tp_pg = ProcessGroup(tp_degree=args.tp_degree)
# Tensor Parallelism (TP)
- tensor_parallelize(model, tp_pg)
+ # You should notice that v0.1.10 is not compatible with TP degree > 1
+ if args.tp_degree > 1:
+ tensor_parallelize(model, tp_pg)
# build a Gemini model and a highly optimized cpu optimizer
# Gemini + ZeRO DP, Note it must be used after TP
- model, optimizer = build_gemini(model, tp_pg, args.placement)
+ model, optimizer = build_gemini(model, tp_pg, args.placement, args.tp_degree == 1)
logger.info(get_mem_info(prefix='After init optim, '), ranks=[0])
else:
+ assert args.tp_degree == 1, "The degree of TP should be 1 for DDP examples."
model = model_builder(args.model_type)(checkpoint=True).cuda()
if args.distplan.startswith("torch"):
@@ -288,12 +300,17 @@ def main():
from torch.distributed.optim import ZeroRedundancyOptimizer
optimizer = ZeroRedundancyOptimizer(model.parameters(), optimizer_class=torch.optim.Adam, lr=0.01)
elif args.distplan.startswith("zero"):
- partition_flag = args.distplan == "zero2"
+ model = model.half()
+ partition_flag = (args.distplan == "zero2")
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
- optimizer = LowLevelZeroOptimizer(optimizer,
- overlap_communication=True,
- partition_grad=partition_flag,
- verbose=True)
+
+ optimizer = LowLevelZeroOptimizer(
+ optimizer,
+ reduce_bucket_size=12 * 1024 * 1024,
+ overlap_communication=True,
+ partition_grad=partition_flag,
+ verbose=True,
+ )
# model is shared after TP
numel = get_model_size(model)
diff --git a/examples/language/gpt/requirements.txt b/examples/language/gpt/requirements.txt
index e1f131468..ef58bb76b 100644
--- a/examples/language/gpt/requirements.txt
+++ b/examples/language/gpt/requirements.txt
@@ -1 +1,2 @@
transformers >= 4.23
+colossalai
diff --git a/examples/language/gpt/test_ci.sh b/examples/language/gpt/test_ci.sh
index ad0cfa325..d67c17229 100644
--- a/examples/language/gpt/test_ci.sh
+++ b/examples/language/gpt/test_ci.sh
@@ -1,16 +1,2 @@
-pip install -r requirements.txt
-
-# distplan in ["colossalai", "zero1", "zero2", "torch_ddp", "torch_zero"]
-export DISTPAN="colossalai"
-
-# The following options only valid when DISTPAN="colossalai"
-export TPDEGREE=2
-export GPUNUM=4
-export PLACEMENT='cpu'
-export USE_SHARD_INIT=False
-export BATCH_SIZE=8
-export MODEL_TYPE="gpt2_medium"
-
-
-mkdir -p logs
-torchrun --standalone --nproc_per_node=${GPUNUM} train_gpt_demo.py --tp_degree=${TPDEGREE} --model_type=${MODEL_TYPE} --batch_size=${BATCH_SIZE} --placement ${PLACEMENT} --shardinit ${USE_SHARD_INIT} --distplan ${DISTPAN} 2>&1 | tee ./logs/${MODEL_TYPE}_${DISTPAN}_gpu_${GPUNUM}_bs_${BATCH_SIZE}_tp_${TPDEGREE}.log
+set -x
+cd gemini && bash test_ci.sh
diff --git a/examples/language/gpt/titans/LICENSE b/examples/language/gpt/titans/LICENSE
new file mode 100644
index 000000000..261eeb9e9
--- /dev/null
+++ b/examples/language/gpt/titans/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/examples/language/gpt/titans/README.md b/examples/language/gpt/titans/README.md
new file mode 100644
index 000000000..fe1854c9f
--- /dev/null
+++ b/examples/language/gpt/titans/README.md
@@ -0,0 +1,48 @@
+# Run GPT With Colossal-AI
+
+## How to Prepare Webtext Dataset
+
+You can download the preprocessed sample dataset for this demo via our [Google Drive sharing link](https://drive.google.com/file/d/1QKI6k-e2gJ7XgS8yIpgPPiMmwiBP_BPE/view?usp=sharing).
+
+
+You can also avoid dataset preparation by using `--use_dummy_dataset` during running.
+
+## Run this Demo
+
+Use the following commands to install prerequisites.
+
+```bash
+# assuming using cuda 11.3
+pip install -r requirements.txt
+```
+
+Use the following commands to execute training.
+
+```Bash
+#!/usr/bin/env sh
+# if you want to use real dataset, then remove --use_dummy_dataset
+# export DATA=/path/to/small-gpt-dataset.json'
+
+# run on a single node
+colossalai run --nproc_per_node= train_gpt.py --config configs/ --from_torch --use_dummy_dataset
+
+# run on multiple nodes with slurm
+colossalai run --nproc_per_node= \
+ --master_addr \
+ --master_port \
+ --hosts \
+ train_gpt.py \
+ --config configs/ \
+ --from_torch \
+ --use_dummy_dataset
+
+# run on multiple nodes with slurm
+srun python \
+ train_gpt.py \
+ --config configs/ \
+ --host \
+ --use_dummy_dataset
+
+```
+
+You can set the `` to any file in the `configs` folder. To simply get it running, you can start with `gpt_small_zero3_pp1d.py` on a single node first. You can view the explanations in the config file regarding how to change the parallel setting.
diff --git a/examples/language/gpt/titans/configs/gpt2_small_zero3_pp1d.py b/examples/language/gpt/titans/configs/gpt2_small_zero3_pp1d.py
new file mode 100644
index 000000000..7bf533039
--- /dev/null
+++ b/examples/language/gpt/titans/configs/gpt2_small_zero3_pp1d.py
@@ -0,0 +1,31 @@
+from model import GPT2_small_pipeline_hybrid
+
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.zero.shard_utils import TensorShardStrategy
+
+BATCH_SIZE = 8
+NUM_EPOCHS = 10
+SEQ_LEN = 1024
+NUM_MICRO_BATCHES = 4
+HIDDEN_SIZE = 768
+TENSOR_SHAPE = (BATCH_SIZE // NUM_MICRO_BATCHES, SEQ_LEN, HIDDEN_SIZE)
+
+# if you do no want zero, just comment out this dictionary
+zero = dict(model_config=dict(tensor_placement_policy='cuda', shard_strategy=TensorShardStrategy()),
+ optimizer_config=dict(initial_scale=2**5))
+
+optimizer = dict(
+ type=HybridAdam,
+ lr=0.000015,
+ weight_decay=1e-2,
+)
+
+model = dict(type=GPT2_small_pipeline_hybrid, checkpoint=True, num_chunks=1)
+
+# pipeline parallel: modify integer value for the number of pipeline stages
+# tensor parallel: modify size to set the tensor parallel size, usually the number of GPUs per node
+# for the current model implementation, mode can only be 1D or None
+parallel = dict(
+ pipeline=1,
+ tensor=dict(size=2, mode='1d'),
+)
diff --git a/examples/language/gpt/titans/configs/gpt3_zero3_pp1d.py b/examples/language/gpt/titans/configs/gpt3_zero3_pp1d.py
new file mode 100644
index 000000000..9f9816b30
--- /dev/null
+++ b/examples/language/gpt/titans/configs/gpt3_zero3_pp1d.py
@@ -0,0 +1,31 @@
+from model import GPT3_pipeline_hybrid
+
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.zero.shard_utils import TensorShardStrategy
+
+BATCH_SIZE = 192
+NUM_EPOCHS = 60
+SEQ_LEN = 2048
+NUM_MICRO_BATCHES = 192
+HIDDEN_SIZE = 12288
+TENSOR_SHAPE = (BATCH_SIZE // NUM_MICRO_BATCHES, SEQ_LEN, HIDDEN_SIZE)
+
+# if you do no want zero, just comment out this dictionary
+zero = dict(model_config=dict(tensor_placement_policy='cuda', shard_strategy=TensorShardStrategy()),
+ optimizer_config=dict(initial_scale=2**16))
+
+optimizer = dict(
+ type=HybridAdam,
+ lr=0.00015,
+ weight_decay=1e-2,
+)
+
+model = dict(type=GPT3_pipeline_hybrid, checkpoint=True, num_chunks=1)
+
+# pipeline parallel: modify integer value for the number of pipeline stages
+# tensor parallel: modify size to set the tensor parallel size, usually the number of GPUs per node
+# for the current model implementation, mode can only be 1D or None
+parallel = dict(
+ pipeline=1,
+ tensor=dict(size=2, mode='1d'), # for the current model implementation, mode can only be 1D or None
+)
diff --git a/examples/language/gpt/titans/dataset/webtext.py b/examples/language/gpt/titans/dataset/webtext.py
new file mode 100644
index 000000000..64f5944a9
--- /dev/null
+++ b/examples/language/gpt/titans/dataset/webtext.py
@@ -0,0 +1,43 @@
+import json
+import os
+from typing import Optional
+
+import torch
+from torch.utils.data import Dataset
+from transformers import GPT2Tokenizer
+
+from colossalai.registry import DATASETS
+
+
+@DATASETS.register_module
+class WebtextDataset(Dataset):
+
+ def __init__(self, path: Optional[str] = None, seq_len=1024) -> None:
+ super().__init__()
+ if path is not None:
+ root = os.path.dirname(path)
+ encoded_data_cache_path = os.path.join(root, f'gpt_webtext_{seq_len}.pt')
+ if os.path.isfile(encoded_data_cache_path):
+ seq_len_, data, attention_mask = torch.load(encoded_data_cache_path)
+ if seq_len_ == seq_len:
+ self.data = data
+ self.attention_mask = attention_mask
+ return
+ raw_data = []
+ with open(path) as f:
+ for line in f.readlines():
+ raw_data.append(json.loads(line)['text'])
+ tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
+ tokenizer.pad_token = tokenizer.unk_token
+ encoded_data = tokenizer(raw_data, padding=True, truncation=True, max_length=seq_len, return_tensors='pt')
+ self.data = encoded_data['input_ids']
+ self.attention_mask = encoded_data['attention_mask']
+ else:
+ self.data = torch.randint(0, 50257, (10240, seq_len))
+ self.attention_mask = torch.ones_like(self.data)
+
+ def __len__(self):
+ return len(self.data)
+
+ def __getitem__(self, index):
+ return {'input_ids': self.data[index], 'attention_mask': self.attention_mask[index]}, self.data[index]
diff --git a/examples/language/gpt/titans/model/__init__.py b/examples/language/gpt/titans/model/__init__.py
new file mode 100644
index 000000000..eec48ef89
--- /dev/null
+++ b/examples/language/gpt/titans/model/__init__.py
@@ -0,0 +1,3 @@
+from .embed import vocab_parallel_cross_entropy
+from .gpt1d import *
+from .pipeline_gpt1d import *
diff --git a/examples/language/gpt/titans/model/embed.py b/examples/language/gpt/titans/model/embed.py
new file mode 100644
index 000000000..6369b9f8c
--- /dev/null
+++ b/examples/language/gpt/titans/model/embed.py
@@ -0,0 +1,599 @@
+import torch
+import torch.nn.init as init
+from torch import Tensor
+from torch import distributed as dist
+from torch import nn as nn
+from torch.nn import functional as F
+from torch.nn.parameter import Parameter
+
+from colossalai.context import ParallelMode, seed
+from colossalai.core import global_context as gpc
+from colossalai.nn.layer.base_layer import ParallelLayer
+from colossalai.nn.layer.parallel_1d._utils import gather_forward_split_backward, reduce_grad, reduce_input
+from colossalai.nn.layer.parallel_1d.layers import Linear1D_Row
+from colossalai.nn.layer.utils import divide
+from colossalai.registry import LAYERS, LOSSES, MODELS
+from colossalai.utils import get_current_device
+
+
+class VocabParallelEmbedding(torch.nn.Module):
+ """Language model embeddings.
+
+ Arguments:
+ hidden_size: hidden size
+ vocab_size: vocabulary size
+ max_sequence_length: maximum size of sequence. This
+ is used for positional embedding
+ embedding_dropout_prob: dropout probability for embeddings
+ init_method: weight initialization method
+ num_tokentypes: size of the token-type embeddings. 0 value
+ will ignore this embedding
+ """
+
+ def __init__(self,
+ hidden_size,
+ vocab_size,
+ max_sequence_length,
+ embedding_dropout_prob,
+ num_tokentypes=0,
+ dtype=torch.float):
+ super(VocabParallelEmbedding, self).__init__()
+
+ self.hidden_size = hidden_size
+ self.num_tokentypes = num_tokentypes
+
+ # Word embeddings (parallel).
+ self.word_embeddings = VocabParallelEmbedding1D(vocab_size, self.hidden_size, dtype=dtype)
+ self._word_embeddings_key = 'word_embeddings'
+
+ # Position embedding (serial).
+ self.position_embeddings = torch.nn.Embedding(max_sequence_length, self.hidden_size, dtype=dtype)
+ self._position_embeddings_key = 'position_embeddings'
+ # Initialize the position embeddings.
+ # self.init_method(self.position_embeddings.weight)
+
+ # Token type embedding.
+ # Add this as an optional field that can be added through
+ # method call so we can load a pretrain model without
+ # token types and add them as needed.
+ self._tokentype_embeddings_key = 'tokentype_embeddings'
+ if self.num_tokentypes > 0:
+ self.tokentype_embeddings = torch.nn.Embedding(self.num_tokentypes, self.hidden_size, dtype=dtype)
+ # Initialize the token-type embeddings.
+ # self.init_method(self.tokentype_embeddings.weight)
+ else:
+ self.tokentype_embeddings = None
+
+ # Embeddings dropout
+ self.embedding_dropout = torch.nn.Dropout(embedding_dropout_prob)
+
+ def zero_parameters(self):
+ """Zero out all parameters in embedding."""
+ self.word_embeddings.weight.data.fill_(0)
+ self.word_embeddings.weight.shared = True
+ self.position_embeddings.weight.data.fill_(0)
+ self.position_embeddings.weight.shared = True
+ if self.num_tokentypes > 0:
+ self.tokentype_embeddings.weight.data.fill_(0)
+ self.tokentype_embeddings.weight.shared = True
+
+ def add_tokentype_embeddings(self, num_tokentypes):
+ """Add token-type embedding. This function is provided so we can add
+ token-type embeddings in case the pretrained model does not have it.
+ This allows us to load the model normally and then add this embedding.
+ """
+ if self.tokentype_embeddings is not None:
+ raise Exception('tokentype embeddings is already initialized')
+ if torch.distributed.get_rank() == 0:
+ print('adding embedding for {} tokentypes'.format(num_tokentypes), flush=True)
+ self.num_tokentypes = num_tokentypes
+ self.tokentype_embeddings = torch.nn.Embedding(num_tokentypes, self.hidden_size)
+ # Initialize the token-type embeddings.
+ # self.init_method(self.tokentype_embeddings.weight)
+
+ def forward(self, input_ids, position_ids=None, tokentype_ids=None):
+ # Embeddings.
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+ words_embeddings = self.word_embeddings(input_ids)
+
+ if position_ids is not None:
+ position_ids = position_ids.view(-1, input_shape[-1])
+ if position_ids is None:
+ position_ids = torch.arange(0, input_shape[-1] + 0, dtype=torch.long, device=get_current_device())
+ position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
+ position_embeddings = self.position_embeddings(position_ids)
+
+ embeddings = words_embeddings + position_embeddings
+
+ # Dropout.
+ with seed(ParallelMode.TENSOR):
+ embeddings = self.embedding_dropout(embeddings)
+ return embeddings
+
+ def state_dict_for_save_checkpoint(self, destination=None, prefix='', keep_vars=False):
+ """For easy load."""
+
+ state_dict_ = {}
+ state_dict_[self._word_embeddings_key] \
+ = self.word_embeddings.state_dict(destination, prefix, keep_vars)
+ state_dict_[self._position_embeddings_key] \
+ = self.position_embeddings.state_dict(
+ destination, prefix, keep_vars)
+ if self.num_tokentypes > 0:
+ state_dict_[self._tokentype_embeddings_key] \
+ = self.tokentype_embeddings.state_dict(
+ destination, prefix, keep_vars)
+
+ return state_dict_
+
+ def load_state_dict(self, state_dict, strict=True):
+ """Customized load."""
+
+ # Word embedding.
+ if self._word_embeddings_key in state_dict:
+ state_dict_ = state_dict[self._word_embeddings_key]
+ else:
+ # for backward compatibility.
+ state_dict_ = {}
+ for key in state_dict.keys():
+ if 'word_embeddings' in key:
+ state_dict_[key.split('word_embeddings.')[1]] \
+ = state_dict[key]
+ self.word_embeddings.load_state_dict(state_dict_, strict=strict)
+
+ # Position embedding.
+ if self._position_embeddings_key in state_dict:
+ state_dict_ = state_dict[self._position_embeddings_key]
+ else:
+ # for backward compatibility.
+ state_dict_ = {}
+ for key in state_dict.keys():
+ if 'position_embeddings' in key:
+ state_dict_[key.split('position_embeddings.')[1]] \
+ = state_dict[key]
+ self.position_embeddings.load_state_dict(state_dict_, strict=strict)
+
+ # Tokentype embedding.
+ if self.num_tokentypes > 0:
+ state_dict_ = {}
+ if self._tokentype_embeddings_key in state_dict:
+ state_dict_ = state_dict[self._tokentype_embeddings_key]
+ else:
+ # for backward compatibility.
+ for key in state_dict.keys():
+ if 'tokentype_embeddings' in key:
+ state_dict_[key.split('tokentype_embeddings.')[1]] \
+ = state_dict[key]
+ if len(state_dict_.keys()) > 0:
+ self.tokentype_embeddings.load_state_dict(state_dict_, strict=strict)
+ else:
+ print('***WARNING*** expected tokentype embeddings in the '
+ 'checkpoint but could not find it',
+ flush=True)
+
+
+class VocabParallelEmbedding1D(torch.nn.Module):
+ """Embedding parallelized in the vocabulary dimension.
+
+ This is mainly adapted from torch.nn.Embedding and all the default
+ values are kept.
+ Arguments:
+ num_embeddings: vocabulary size.
+ embedding_dim: size of hidden state.
+ init_method: method to initialize weights.
+ """
+
+ def __init__(self, num_embeddings, embedding_dim, dtype=None, init_method=None):
+ super(VocabParallelEmbedding1D, self).__init__()
+ # Keep the input dimensions.
+ self.num_embeddings = num_embeddings
+ self.embedding_dim = embedding_dim
+ # Set the details for compatibility.
+ self.padding_idx = None
+ self.max_norm = None
+ self.norm_type = 2.
+ self.scale_grad_by_freq = False
+ self.sparse = False
+ self._weight = None
+ self.tensor_model_parallel_size = gpc.tensor_parallel_size
+ # Divide the weight matrix along the vocabulary dimension.
+ self.vocab_start_index, self.vocab_end_index = \
+ VocabUtility.vocab_range_from_global_vocab_size(
+ self.num_embeddings, gpc.get_local_rank(ParallelMode.PARALLEL_1D),
+ self.tensor_model_parallel_size)
+ self.num_embeddings_per_partition = self.vocab_end_index - \
+ self.vocab_start_index
+
+ # Allocate weights and initialize.
+ factory_kwargs = {'device': get_current_device(), 'dtype': dtype}
+ self.weight = Parameter(torch.empty(self.num_embeddings_per_partition, self.embedding_dim, **factory_kwargs))
+ init.uniform_(self.weight, -1, 1)
+
+ def forward(self, input_):
+ if self.tensor_model_parallel_size > 1:
+ # Build the mask.
+ input_mask = (input_ < self.vocab_start_index) | \
+ (input_ >= self.vocab_end_index)
+ # Mask the input.
+ masked_input = input_.clone() - self.vocab_start_index
+ masked_input[input_mask] = 0
+ else:
+ masked_input = input_
+ # Get the embeddings.
+ output_parallel = F.embedding(masked_input, self.weight, self.padding_idx, self.max_norm, self.norm_type,
+ self.scale_grad_by_freq, self.sparse)
+ # Mask the output embedding.
+ if self.tensor_model_parallel_size > 1:
+ output_parallel[input_mask, :] = 0.0
+ # Reduce across all the model parallel GPUs.
+ output = output = reduce_input(output_parallel, ParallelMode.PARALLEL_1D)
+ return output
+
+
+@LOSSES.register_module
+class vocab_parallel_cross_entropy(nn.Module):
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, vocab_parallel_logits, target):
+ """Helper function for the cross entropy."""
+ vocab_parallel_logits = vocab_parallel_logits[..., :-1, :].contiguous()
+ target = target[..., 1:].contiguous()
+ return _VocabParallelCrossEntropy.apply(vocab_parallel_logits.view(-1, vocab_parallel_logits.size(-1)),
+ target.view(-1))
+
+
+class _VocabParallelCrossEntropy(torch.autograd.Function):
+
+ @staticmethod
+ def forward(ctx, vocab_parallel_logits, target):
+
+ # Maximum value along vocab dimension across all GPUs.
+ logits_max = torch.max(vocab_parallel_logits, dim=-1)[0]
+ torch.distributed.all_reduce(logits_max,
+ op=torch.distributed.ReduceOp.MAX,
+ group=gpc.get_group(ParallelMode.PARALLEL_1D))
+ # Subtract the maximum value.
+ vocab_parallel_logits.sub_(logits_max.unsqueeze(dim=-1))
+
+ # Get the partition's vocab indices
+ get_vocab_range = VocabUtility.vocab_range_from_per_partition_vocab_size
+ partition_vocab_size = vocab_parallel_logits.size()[-1]
+ rank = gpc.get_local_rank(ParallelMode.PARALLEL_1D)
+ world_size = gpc.tensor_parallel_size
+ vocab_start_index, vocab_end_index = get_vocab_range(partition_vocab_size, rank, world_size)
+
+ # Create a mask of valid vocab ids (1 means it needs to be masked).
+ target_mask = (target < vocab_start_index) | (target >= vocab_end_index)
+ masked_target = target.clone() - vocab_start_index
+ masked_target[target_mask] = 0
+
+ # Get predicted-logits = logits[target].
+ # For Simplicity, we convert logits to a 2-D tensor with size
+ # [*, partition-vocab-size] and target to a 1-D tensor of size [*].
+ logits_2d = vocab_parallel_logits.view(-1, partition_vocab_size)
+ masked_target_1d = masked_target.view(-1)
+ arange_1d = torch.arange(start=0, end=logits_2d.size()[0], device=logits_2d.device)
+ predicted_logits_1d = logits_2d[arange_1d, masked_target_1d]
+ predicted_logits_1d = predicted_logits_1d.clone().contiguous()
+ predicted_logits = predicted_logits_1d.view_as(target)
+ predicted_logits[target_mask] = 0.0
+ # All reduce is needed to get the chunks from other GPUs.
+ torch.distributed.all_reduce(predicted_logits,
+ op=torch.distributed.ReduceOp.SUM,
+ group=gpc.get_group(ParallelMode.PARALLEL_1D))
+
+ # Sum of exponential of logits along vocab dimension across all GPUs.
+ exp_logits = vocab_parallel_logits
+ torch.exp(vocab_parallel_logits, out=exp_logits)
+ sum_exp_logits = exp_logits.sum(dim=-1)
+ torch.distributed.all_reduce(sum_exp_logits,
+ op=torch.distributed.ReduceOp.SUM,
+ group=gpc.get_group(ParallelMode.PARALLEL_1D))
+
+ # Loss = log(sum(exp(logits))) - predicted-logit.
+ loss = torch.log(sum_exp_logits) - predicted_logits
+ loss = loss.mean()
+ # Store softmax, target-mask and masked-target for backward pass.
+ exp_logits.div_(sum_exp_logits.unsqueeze(dim=-1))
+ ctx.save_for_backward(exp_logits, target_mask, masked_target_1d)
+ return loss
+
+ @staticmethod
+ def backward(ctx, grad_output):
+
+ # Retreive tensors from the forward path.
+ softmax, target_mask, masked_target_1d = ctx.saved_tensors
+
+ # All the inputs have softmax as their gradient.
+ grad_input = softmax
+ # For simplicity, work with the 2D gradient.
+ partition_vocab_size = softmax.size()[-1]
+ grad_2d = grad_input.view(-1, partition_vocab_size)
+
+ # Add the gradient from matching classes.
+ arange_1d = torch.arange(start=0, end=grad_2d.size()[0], device=grad_2d.device)
+ grad_2d[arange_1d, masked_target_1d] -= (1.0 - target_mask.view(-1).float())
+
+ # Finally elementwise multiplication with the output gradients.
+ grad_input.mul_(grad_output.unsqueeze(dim=-1))
+
+ return grad_input, None
+
+
+class VocabUtility:
+ """Split the vocabulary into `world_size` chunks amd return the
+ first and last index of the vocabulary belonging to the `rank`
+ partition: Note that indices in [fist, last)"""
+
+ @staticmethod
+ def vocab_range_from_per_partition_vocab_size(per_partition_vocab_size, rank, world_size):
+ index_f = rank * per_partition_vocab_size
+ index_l = index_f + per_partition_vocab_size
+ return index_f, index_l
+
+ @staticmethod
+ def vocab_range_from_global_vocab_size(global_vocab_size, rank, world_size):
+ per_partition_vocab_size = divide(global_vocab_size, world_size)
+ return VocabUtility.vocab_range_from_per_partition_vocab_size(per_partition_vocab_size, rank, world_size)
+
+
+class VocabParallelGPTLMHead1D(ParallelLayer):
+ """
+ Language model head that shares the same parameters with the embedding matrix.
+ """
+
+ def __init__(self, embed=None, vocab_size=None, dtype=None, embed_dim=None):
+ super().__init__()
+ if embed is not None:
+ self.head = embed
+ else:
+ self.head = VocabParallelEmbedding1D(vocab_size, embed_dim, dtype=dtype)
+
+ def forward(self, x: Tensor) -> Tensor:
+ x = reduce_grad(x, ParallelMode.PARALLEL_1D)
+ x = F.linear(x, self.head.weight)
+ return x
+
+
+###################################
+
+
+class HiddenParallelEmbedding(torch.nn.Module):
+ """Language model embeddings.
+
+ Arguments:
+ hidden_size: hidden size
+ vocab_size: vocabulary size
+ max_sequence_length: maximum size of sequence. This
+ is used for positional embedding
+ embedding_dropout_prob: dropout probability for embeddings
+ init_method: weight initialization method
+ num_tokentypes: size of the token-type embeddings. 0 value
+ will ignore this embedding
+ """
+
+ def __init__(
+ self,
+ hidden_size,
+ vocab_size,
+ max_sequence_length,
+ embedding_dropout_prob,
+ dtype=torch.float,
+ padding_idx: int = 0,
+ num_tokentypes=0,
+ ):
+ super(HiddenParallelEmbedding, self).__init__()
+
+ self.hidden_size = hidden_size
+ self.num_tokentypes = num_tokentypes
+
+ # Word embeddings (parallel).
+ self.word_embeddings = HiddenParallelEmbedding1D(vocab_size, hidden_size, dtype, padding_idx)
+ self._word_embeddings_key = 'word_embeddings'
+
+ # Position embedding (serial).
+ self.position_embeddings = torch.nn.Embedding(max_sequence_length, self.hidden_size)
+ self._position_embeddings_key = 'position_embeddings'
+ # Initialize the position embeddings.
+ # self.init_method(self.position_embeddings.weight)
+
+ # Token type embedding.
+ # Add this as an optional field that can be added through
+ # method call so we can load a pretrain model without
+ # token types and add them as needed.
+ self._tokentype_embeddings_key = 'tokentype_embeddings'
+ if self.num_tokentypes > 0:
+ self.tokentype_embeddings = torch.nn.Embedding(self.num_tokentypes, self.hidden_size)
+ # Initialize the token-type embeddings.
+ # self.init_method(self.tokentype_embeddings.weight)
+ else:
+ self.tokentype_embeddings = None
+
+ # Embeddings dropout
+ self.embedding_dropout = torch.nn.Dropout(embedding_dropout_prob)
+
+ def zero_parameters(self):
+ """Zero out all parameters in embedding."""
+ self.word_embeddings.weight.data.fill_(0)
+ self.word_embeddings.weight.shared = True
+ self.position_embeddings.weight.data.fill_(0)
+ self.position_embeddings.weight.shared = True
+ if self.num_tokentypes > 0:
+ self.tokentype_embeddings.weight.data.fill_(0)
+ self.tokentype_embeddings.weight.shared = True
+
+ def add_tokentype_embeddings(self, num_tokentypes):
+ """Add token-type embedding. This function is provided so we can add
+ token-type embeddings in case the pretrained model does not have it.
+ This allows us to load the model normally and then add this embedding.
+ """
+ if self.tokentype_embeddings is not None:
+ raise Exception('tokentype embeddings is already initialized')
+ if torch.distributed.get_rank() == 0:
+ print('adding embedding for {} tokentypes'.format(num_tokentypes), flush=True)
+ self.num_tokentypes = num_tokentypes
+ self.tokentype_embeddings = torch.nn.Embedding(num_tokentypes, self.hidden_size)
+ # Initialize the token-type embeddings.
+ # self.init_method(self.tokentype_embeddings.weight)
+
+ def forward(self, input_ids, position_ids=None, tokentype_ids=None):
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ input_ids = input_ids.view(-1, input_shape[-1])
+ words_embeddings = self.word_embeddings(input_ids)
+
+ if position_ids is not None:
+ position_ids = position_ids.view(-1, input_shape[-1])
+ if position_ids is None:
+ position_ids = torch.arange(0, input_shape[-1] + 0, dtype=torch.long, device=get_current_device())
+ position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
+ position_embeddings = self.position_embeddings(position_ids)
+
+ embeddings = words_embeddings + position_embeddings
+
+ # Dropout.
+ with seed(ParallelMode.TENSOR):
+ embeddings = self.embedding_dropout(embeddings)
+ return embeddings
+
+ def state_dict_for_save_checkpoint(self, destination=None, prefix='', keep_vars=False):
+ """For easy load."""
+
+ state_dict_ = {}
+ state_dict_[self._word_embeddings_key] \
+ = self.word_embeddings.state_dict(destination, prefix, keep_vars)
+ state_dict_[self._position_embeddings_key] \
+ = self.position_embeddings.state_dict(
+ destination, prefix, keep_vars)
+ if self.num_tokentypes > 0:
+ state_dict_[self._tokentype_embeddings_key] \
+ = self.tokentype_embeddings.state_dict(
+ destination, prefix, keep_vars)
+
+ return state_dict_
+
+ def load_state_dict(self, state_dict, strict=True):
+ """Customized load."""
+
+ # Word embedding.
+ if self._word_embeddings_key in state_dict:
+ state_dict_ = state_dict[self._word_embeddings_key]
+ else:
+ # for backward compatibility.
+ state_dict_ = {}
+ for key in state_dict.keys():
+ if 'word_embeddings' in key:
+ state_dict_[key.split('word_embeddings.')[1]] \
+ = state_dict[key]
+ self.word_embeddings.load_state_dict(state_dict_, strict=strict)
+
+ # Position embedding.
+ if self._position_embeddings_key in state_dict:
+ state_dict_ = state_dict[self._position_embeddings_key]
+ else:
+ # for backward compatibility.
+ state_dict_ = {}
+ for key in state_dict.keys():
+ if 'position_embeddings' in key:
+ state_dict_[key.split('position_embeddings.')[1]] \
+ = state_dict[key]
+ self.position_embeddings.load_state_dict(state_dict_, strict=strict)
+
+ # Tokentype embedding.
+ if self.num_tokentypes > 0:
+ state_dict_ = {}
+ if self._tokentype_embeddings_key in state_dict:
+ state_dict_ = state_dict[self._tokentype_embeddings_key]
+ else:
+ # for backward compatibility.
+ for key in state_dict.keys():
+ if 'tokentype_embeddings' in key:
+ state_dict_[key.split('tokentype_embeddings.')[1]] \
+ = state_dict[key]
+ if len(state_dict_.keys()) > 0:
+ self.tokentype_embeddings.load_state_dict(state_dict_, strict=strict)
+ else:
+ print('***WARNING*** expected tokentype embeddings in the '
+ 'checkpoint but could not find it',
+ flush=True)
+
+
+class HiddenParallelEmbedding1D(torch.nn.Module):
+ """Embedding parallelized in the vocabulary dimension.
+
+ This is mainly adapted from torch.nn.Embedding and all the default
+ values are kept.
+ Arguments:
+ num_embeddings: vocabulary size.
+ embedding_dim: size of hidden state.
+ init_method: method to initialize weights.
+ """
+
+ def __init__(self, num_embeddings, embedding_dim, dtype=torch.float, padding_idx: int = None, init_method=None):
+ super(HiddenParallelEmbedding1D, self).__init__()
+ # Keep the input dimensions.
+ self.num_embeddings = num_embeddings
+ self.embedding_dim = embedding_dim
+ embed_dim_per_partition = divide(embedding_dim, gpc.tensor_parallel_size)
+ # Set the details for compatibility.
+ self.padding_idx = padding_idx
+ self.max_norm = None
+ self.norm_type = 2.
+ self.scale_grad_by_freq = False
+ self.sparse = False
+ self._weight = None
+
+ # Allocate weights and initialize.
+ factory_kwargs = {'device': get_current_device(), 'dtype': dtype}
+ self.weight = Parameter(torch.empty(num_embeddings, embed_dim_per_partition, **factory_kwargs))
+ init.uniform_(self.weight, -1, 1)
+
+ def forward(self, input_):
+
+ # Get the embeddings.
+ output_parallel = F.embedding(input_, self.weight, self.padding_idx, self.max_norm, self.norm_type,
+ self.scale_grad_by_freq, self.sparse)
+
+ # Reduce across all the model parallel GPUs.
+ output = gather_forward_split_backward(output_parallel, ParallelMode.PARALLEL_1D, dim=-1)
+ return output
+
+
+@LAYERS.register_module
+class HiddenParallelGPTLMHead1D(ParallelLayer):
+ """
+ Language model head that shares the same parameters with the embedding matrix.
+ """
+
+ def __init__(
+ self,
+ embed=None,
+ embed_dim=None,
+ vocab_size=None,
+ dtype=None,
+ ):
+ super().__init__()
+ if embed is not None:
+ self.head = embed
+ self.synced_embed = True
+ else:
+ # self.embedding = HiddenParallelEmbedding1D(vocab_size, hidden_size, dtype, padding_idx)
+ # (hidden_size/q, vocab_size)
+ self.synced_embed = False
+ self.head = Linear1D_Row(in_features=embed_dim,
+ out_features=vocab_size,
+ bias=False,
+ dtype=dtype,
+ parallel_input=False)
+
+ def forward(self, x: Tensor) -> Tensor:
+ if self.synced_embed:
+ x = F.linear(x, self.head.weight)
+ else:
+ x = self.head(x)
+
+ return x
diff --git a/examples/language/gpt/titans/model/gpt1d.py b/examples/language/gpt/titans/model/gpt1d.py
new file mode 100644
index 000000000..2edd03606
--- /dev/null
+++ b/examples/language/gpt/titans/model/gpt1d.py
@@ -0,0 +1,349 @@
+#!/usr/bin/env python
+# -*- encoding: utf-8 -*-
+
+import math
+
+import torch
+from torch import Tensor
+from torch import nn as nn
+
+from colossalai import kernel
+from colossalai import nn as col_nn
+from colossalai.core import global_context as gpc
+from colossalai.kernel.cuda_native.scaled_softmax import AttnMaskType
+from colossalai.nn.layer import Linear1D_Col, Linear1D_Row
+from colossalai.nn.layer.base_layer import ParallelLayer
+from colossalai.nn.layer.utils import ACT2FN, divide
+from colossalai.utils import checkpoint
+from colossalai.utils.activation_checkpoint import checkpoint
+
+__all__ = [
+ 'GPTMLP1D', 'GPTSelfAttention1D', 'GPTTransformerLayer1D', 'FusedGPTSelfAttention1D', 'FusedGPTTransformerLayer1D'
+]
+
+
+class GPTMLP1D(ParallelLayer):
+
+ def __init__(
+ self,
+ in_features: int,
+ mlp_ratio: int,
+ act_func: str = 'gelu',
+ dropout_prob: float = 0.,
+ dtype=None,
+ checkpoint: bool = False,
+ skip_bias_add: bool = False,
+ ):
+ super().__init__()
+
+ self.in_features = in_features
+ self.mlp_ratio = mlp_ratio
+ self.checkpoint = checkpoint
+ self.skip_bias_add = skip_bias_add
+
+ self.act = ACT2FN[act_func]
+ skip_dense_1_add_bias = False
+
+ # Project to mlp_ratio * h.
+ self.dense_1 = Linear1D_Col(
+ self.in_features,
+ int(self.mlp_ratio * self.in_features),
+ dtype=dtype,
+ gather_output=False,
+ skip_bias_add=skip_dense_1_add_bias,
+ )
+
+ # Project back to h.
+ self.dense_2 = Linear1D_Row(
+ int(self.mlp_ratio * self.in_features),
+ self.in_features,
+ dtype=dtype,
+ parallel_input=True,
+ )
+
+ self.dropout = col_nn.Dropout(dropout_prob)
+
+ def _forward(self, hidden_states: Tensor) -> Tensor:
+ intermediate_output = self.dense_1(hidden_states)
+ intermediate_output = self.act(intermediate_output)
+
+ output = self.dense_2(intermediate_output)
+ output = self.dropout(output)
+ return output
+
+ def _checkpoint_forward(self, hidden_states: Tensor) -> Tensor:
+ return checkpoint(self._forward, False, hidden_states)
+
+ def forward(self, hidden_states: Tensor) -> Tensor:
+ if self.checkpoint:
+ return self._checkpoint_forward(hidden_states)
+ else:
+ return self._forward(hidden_states)
+
+
+class GenericGPTSelfAttention1D(ParallelLayer):
+
+ def __init__(
+ self,
+ hidden_size: int,
+ num_attention_heads: int,
+ attention_dropout_prob: float,
+ hidden_dropout_prob: float,
+ dtype=None,
+ checkpoint: bool = False,
+ max_position_embeddings=1024,
+ ):
+ super().__init__()
+ self.hidden_size = hidden_size
+ self.attention_head_size = divide(hidden_size, num_attention_heads)
+ self.num_attention_heads_per_partition = divide(num_attention_heads, gpc.tensor_parallel_size)
+ self.hidden_size_per_partition = divide(hidden_size, gpc.tensor_parallel_size)
+ self.checkpoint = checkpoint
+ self.query_key_value = Linear1D_Col(
+ hidden_size,
+ 3 * hidden_size,
+ dtype=dtype,
+ )
+ self.attention_dropout = col_nn.Dropout(attention_dropout_prob)
+ self.dense = Linear1D_Row(
+ hidden_size,
+ hidden_size,
+ dtype=dtype,
+ parallel_input=True,
+ )
+ self.dropout = col_nn.Dropout(hidden_dropout_prob)
+
+ def softmax_forward(self, attention_scores, attention_mask, query_layer, key_layer):
+ raise NotImplementedError
+
+ def _forward(self, hidden_states: Tensor, attention_mask=None) -> Tensor:
+ query_key_value = self.query_key_value(hidden_states)
+ new_qkv_shape = query_key_value.shape[:-1] + \
+ (self.num_attention_heads_per_partition, 3 * self.attention_head_size)
+ query_key_value = query_key_value.view(new_qkv_shape)
+ query_key_value = query_key_value.permute((0, 2, 1, 3))
+ query_layer, key_layer, value_layer = torch.chunk(query_key_value, 3, dim=-1)
+
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ attention_scores = self.softmax_forward(attention_scores, attention_mask, query_layer, key_layer)
+
+ attention_scores = attention_scores.type(value_layer.dtype)
+
+ attention_probs = self.attention_dropout(attention_scores)
+
+ context_layer = torch.matmul(attention_probs, value_layer)
+ context_layer = context_layer.transpose(1, 2)
+ new_context_layer_shape = context_layer.size()[:-2] + (self.hidden_size_per_partition,)
+ context_layer = context_layer.reshape(new_context_layer_shape)
+ output = self.dense(context_layer)
+ output = self.dropout(output)
+
+ return output
+
+ def _checkpoint_forward(self, hidden_states: Tensor, attention_mask=None) -> Tensor:
+ return checkpoint(self._forward, False, hidden_states, attention_mask)
+
+ def forward(self, hidden_states: Tensor, attention_mask=None) -> Tensor:
+ if self.checkpoint:
+ return self._checkpoint_forward(hidden_states, attention_mask)
+ else:
+ return self._forward(hidden_states, attention_mask)
+
+
+class GPTSelfAttention1D(GenericGPTSelfAttention1D):
+
+ def __init__(self,
+ hidden_size: int,
+ num_attention_heads: int,
+ attention_dropout_prob: float,
+ hidden_dropout_prob: float,
+ dtype=None,
+ checkpoint: bool = False,
+ max_position_embeddings=1024):
+ super().__init__(hidden_size,
+ num_attention_heads,
+ attention_dropout_prob,
+ hidden_dropout_prob,
+ dtype=dtype,
+ checkpoint=checkpoint,
+ max_position_embeddings=max_position_embeddings)
+ self.softmax = nn.Softmax(dim=-1)
+ max_positions = max_position_embeddings
+ self.register_buffer(
+ "bias",
+ torch.tril(torch.ones((max_positions, max_positions),
+ dtype=torch.uint8)).view(1, 1, max_positions, max_positions),
+ )
+ self.register_buffer("masked_bias", torch.tensor(-1e4))
+
+ def softmax_forward(self, attention_scores, attention_mask, query_layer, key_layer):
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ # causal mask
+ query_length, key_length = query_layer.size(-2), key_layer.size(-2)
+ causal_mask = self.bias[:, :, key_length - query_length:key_length, :key_length].bool()
+ attention_scores = torch.where(causal_mask, attention_scores, self.masked_bias.to(attention_scores))
+ if attention_mask is not None:
+ # Apply the attention mask
+ attention_scores = attention_scores + attention_mask
+ attention_scores = self.softmax(attention_scores)
+ return attention_scores
+
+
+class FusedGPTSelfAttention1D(GenericGPTSelfAttention1D):
+
+ def __init__(self,
+ hidden_size: int,
+ num_attention_heads: int,
+ attention_dropout_prob: float,
+ hidden_dropout_prob: float,
+ dtype=None,
+ checkpoint: bool = False,
+ max_position_embeddings=1024):
+ super().__init__(hidden_size,
+ num_attention_heads,
+ attention_dropout_prob,
+ hidden_dropout_prob,
+ dtype=dtype,
+ checkpoint=checkpoint,
+ max_position_embeddings=max_position_embeddings)
+ self.softmax = kernel.FusedScaleMaskSoftmax(input_in_fp16=True,
+ input_in_bf16=False,
+ attn_mask_type=AttnMaskType.causal,
+ scaled_masked_softmax_fusion=True,
+ mask_func=None,
+ softmax_in_fp32=True,
+ scale=math.sqrt(self.attention_head_size))
+
+ def softmax_forward(self, attention_scores, attention_mask, query_layer, key_layer):
+ return self.softmax(attention_scores, attention_mask)
+
+
+class GenericGPTTransformerLayer1D(ParallelLayer):
+
+ def __init__(self,
+ hidden_size: int,
+ num_attention_heads: int,
+ act_func: str = 'gelu',
+ mlp_ratio: float = 4.0,
+ attention_dropout_prob: float = 0.,
+ hidden_dropout_prob: float = 0.,
+ dtype=None,
+ checkpoint: bool = False,
+ max_position_embeddings: int = 1024,
+ layer_norm_epsilon: float = 1e-5,
+ apply_post_layer_norm: bool = False,
+ attention=None,
+ layer_norm=None):
+ super().__init__()
+ self.checkpoint = checkpoint
+ self.dtype = dtype
+ self.norm1 = layer_norm(hidden_size, eps=layer_norm_epsilon)
+ self.apply_post_layer_norm = apply_post_layer_norm
+ self.attention = attention(
+ hidden_size=hidden_size,
+ num_attention_heads=num_attention_heads,
+ attention_dropout_prob=attention_dropout_prob,
+ hidden_dropout_prob=hidden_dropout_prob,
+ dtype=dtype,
+ max_position_embeddings=max_position_embeddings,
+ checkpoint=False,
+ )
+
+ self.norm2 = layer_norm(hidden_size, eps=layer_norm_epsilon)
+ self.mlp = GPTMLP1D(
+ in_features=hidden_size,
+ dropout_prob=hidden_dropout_prob,
+ act_func=act_func,
+ mlp_ratio=mlp_ratio,
+ dtype=dtype,
+ checkpoint=False,
+ )
+
+ def _forward(self, hidden_states, attention_mask) -> Tensor:
+ if not self.apply_post_layer_norm:
+ residual = hidden_states
+ hidden_states = self.norm1(hidden_states)
+ if self.apply_post_layer_norm:
+ residual = hidden_states
+ attention_output = self.attention(hidden_states, attention_mask)
+ hidden_states = residual + attention_output
+
+ if not self.apply_post_layer_norm:
+ residual = hidden_states
+ hidden_states = self.norm2(hidden_states)
+ if self.apply_post_layer_norm:
+ residual = hidden_states
+ feed_forward_hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + feed_forward_hidden_states
+
+ output = (hidden_states, attention_mask)
+ return output
+
+ def forward(self, hidden_states, attention_mask):
+ if self.checkpoint:
+ return checkpoint(self._forward, False, hidden_states, attention_mask)
+ else:
+ return self._forward(hidden_states, attention_mask)
+
+
+class GPTTransformerLayer1D(GenericGPTTransformerLayer1D):
+
+ def __init__(self,
+ hidden_size: int,
+ num_attention_heads: int,
+ act_func: str = 'gelu',
+ mlp_ratio: float = 4,
+ attention_dropout_prob: float = 0,
+ hidden_dropout_prob: float = 0,
+ dtype=None,
+ checkpoint: bool = False,
+ max_position_embeddings: int = 1024,
+ layer_norm_epsilon: float = 0.00001,
+ apply_post_layer_norm: bool = False):
+ attention = GPTSelfAttention1D
+ layer_norm = nn.LayerNorm
+ super().__init__(hidden_size,
+ num_attention_heads,
+ act_func=act_func,
+ mlp_ratio=mlp_ratio,
+ attention_dropout_prob=attention_dropout_prob,
+ hidden_dropout_prob=hidden_dropout_prob,
+ dtype=dtype,
+ checkpoint=checkpoint,
+ max_position_embeddings=max_position_embeddings,
+ layer_norm_epsilon=layer_norm_epsilon,
+ apply_post_layer_norm=apply_post_layer_norm,
+ attention=attention,
+ layer_norm=layer_norm)
+
+
+class FusedGPTTransformerLayer1D(GenericGPTTransformerLayer1D):
+
+ def __init__(self,
+ hidden_size: int,
+ num_attention_heads: int,
+ act_func: str = 'gelu',
+ mlp_ratio: float = 4,
+ attention_dropout_prob: float = 0,
+ hidden_dropout_prob: float = 0,
+ dtype=None,
+ checkpoint: bool = False,
+ max_position_embeddings: int = 1024,
+ layer_norm_epsilon: float = 0.00001,
+ apply_post_layer_norm: bool = False):
+ attention = FusedGPTSelfAttention1D
+ layer_norm = kernel.LayerNorm
+ super().__init__(hidden_size,
+ num_attention_heads,
+ act_func=act_func,
+ mlp_ratio=mlp_ratio,
+ attention_dropout_prob=attention_dropout_prob,
+ hidden_dropout_prob=hidden_dropout_prob,
+ dtype=dtype,
+ checkpoint=checkpoint,
+ max_position_embeddings=max_position_embeddings,
+ layer_norm_epsilon=layer_norm_epsilon,
+ apply_post_layer_norm=apply_post_layer_norm,
+ attention=attention,
+ layer_norm=layer_norm)
diff --git a/examples/language/gpt/titans/model/pipeline_gpt1d.py b/examples/language/gpt/titans/model/pipeline_gpt1d.py
new file mode 100644
index 000000000..30180285b
--- /dev/null
+++ b/examples/language/gpt/titans/model/pipeline_gpt1d.py
@@ -0,0 +1,322 @@
+import inspect
+
+# import model_zoo.gpt.gpt as col_gpt
+import titans.model.gpt.gpt as col_gpt
+import torch
+import torch.nn as nn
+
+from colossalai import kernel
+from colossalai import nn as col_nn
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.logging import get_dist_logger
+from colossalai.nn.layer.wrapper import PipelineSharedModuleWrapper
+from colossalai.pipeline.utils import partition_uniform
+
+from .embed import HiddenParallelEmbedding, HiddenParallelGPTLMHead1D, VocabParallelEmbedding, VocabParallelGPTLMHead1D
+from .gpt1d import FusedGPTTransformerLayer1D, GPTTransformerLayer1D
+
+__all__ = [
+ 'GPT2_small_pipeline_1D',
+ 'GPT2_exlarge_pipeline_1D',
+ 'GPT3_pipeline_1D',
+ 'GPT2_exlarge_pipeline_hybrid',
+ 'GPT2_small_pipeline_hybrid',
+ 'GPT3_pipeline_hybrid',
+]
+
+
+class GenericPipelineGPT(nn.Module):
+
+ def __init__(self, embedding=None, blocks=None, norm=None, head=None) -> None:
+ super().__init__()
+ self.embedding = embedding
+ self.blocks = blocks
+ self.norm = norm
+ self.head = head
+ assert blocks is not None
+ if norm is not None or head is not None:
+ assert norm is not None and head is not None
+
+ def forward(self, hidden_states=None, input_ids=None, attention_mask=None):
+ if self.embedding is not None:
+ hidden_states = self.embedding(input_ids=input_ids)
+ batch_size = hidden_states.shape[0]
+ attention_mask = attention_mask.view(batch_size, -1)
+ attention_mask = attention_mask[:, None, None, :]
+ attention_mask = attention_mask.to(dtype=hidden_states.dtype) # fp16 compatibility
+ attention_mask = (1.0 - attention_mask) * -10000.0
+ for block in self.blocks:
+ hidden_states, attention_mask = block(hidden_states, attention_mask)
+ if self.norm is not None:
+ hidden_states = self.head(self.norm(hidden_states))
+ return hidden_states
+
+
+class PipelineGPT1D(GenericPipelineGPT):
+
+ def __init__(self,
+ num_layers: int = 12,
+ hidden_size: int = 768,
+ num_attention_heads: int = 12,
+ vocab_size: int = 50304,
+ embed_drop_rate: float = 0.,
+ act_func: str = 'gelu',
+ mlp_ratio: int = 4.0,
+ attn_drop_rate: float = 0.,
+ drop_rate: float = 0.,
+ dtype: torch.dtype = torch.float,
+ checkpoint: bool = False,
+ max_position_embeddings: int = 1024,
+ layer_norm_epsilon: float = 1e-5,
+ apply_post_layer_norm: bool = False,
+ first: bool = False,
+ last: bool = False,
+ embed_split_hidden=False):
+ embedding = None
+ norm = None
+ head = None
+ embed_cls = VocabParallelEmbedding
+ head_cls = VocabParallelGPTLMHead1D
+ if embed_split_hidden:
+ embed_cls = HiddenParallelEmbedding
+ head_cls = HiddenParallelGPTLMHead1D
+ if first:
+ embedding = embed_cls(hidden_size, vocab_size, max_position_embeddings, embed_drop_rate, dtype=dtype)
+ blocks = nn.ModuleList([
+ GPTTransformerLayer1D(hidden_size,
+ num_attention_heads,
+ act_func=act_func,
+ mlp_ratio=mlp_ratio,
+ attention_dropout_prob=attn_drop_rate,
+ hidden_dropout_prob=drop_rate,
+ dtype=dtype,
+ checkpoint=checkpoint,
+ max_position_embeddings=max_position_embeddings,
+ layer_norm_epsilon=layer_norm_epsilon,
+ apply_post_layer_norm=apply_post_layer_norm) for _ in range(num_layers)
+ ])
+ if last:
+ norm = nn.LayerNorm(hidden_size, eps=layer_norm_epsilon)
+ head = head_cls(vocab_size=vocab_size, embed_dim=hidden_size, dtype=dtype)
+ super().__init__(embedding=embedding, blocks=blocks, norm=norm, head=head)
+
+
+class FusedPipelineGPT1D(GenericPipelineGPT):
+
+ def __init__(self,
+ num_layers: int = 12,
+ hidden_size: int = 768,
+ num_attention_heads: int = 12,
+ vocab_size: int = 50304,
+ embed_drop_rate: float = 0.,
+ act_func: str = 'gelu',
+ mlp_ratio: int = 4.0,
+ attn_drop_rate: float = 0.,
+ drop_rate: float = 0.,
+ dtype: torch.dtype = torch.float,
+ checkpoint: bool = False,
+ max_position_embeddings: int = 1024,
+ layer_norm_epsilon: float = 1e-5,
+ apply_post_layer_norm: bool = False,
+ first: bool = False,
+ last: bool = False,
+ embed_split_hidden=False):
+ embedding = None
+ norm = None
+ head = None
+ embed_cls = VocabParallelEmbedding
+ head_cls = VocabParallelGPTLMHead1D
+ if embed_split_hidden:
+ embed_cls = HiddenParallelEmbedding
+ head_cls = HiddenParallelGPTLMHead1D
+ if first:
+ embedding = embed_cls(hidden_size, vocab_size, max_position_embeddings, embed_drop_rate, dtype=dtype)
+ blocks = nn.ModuleList([
+ FusedGPTTransformerLayer1D(hidden_size,
+ num_attention_heads,
+ act_func=act_func,
+ mlp_ratio=mlp_ratio,
+ attention_dropout_prob=attn_drop_rate,
+ hidden_dropout_prob=drop_rate,
+ dtype=dtype,
+ checkpoint=checkpoint,
+ max_position_embeddings=max_position_embeddings,
+ layer_norm_epsilon=layer_norm_epsilon,
+ apply_post_layer_norm=apply_post_layer_norm) for _ in range(num_layers)
+ ])
+ if last:
+ norm = kernel.LayerNorm(hidden_size, eps=layer_norm_epsilon)
+ head = head_cls(vocab_size=vocab_size, embed_dim=hidden_size, dtype=dtype)
+ super().__init__(embedding=embedding, blocks=blocks, norm=norm, head=head)
+
+ def forward(self, hidden_states=None, input_ids=None, attention_mask=None):
+ if self.embedding is not None:
+ hidden_states = self.embedding(input_ids=input_ids)
+ attention_mask = attention_mask.to(dtype=hidden_states.dtype) # fp16 compatibility
+ for block in self.blocks:
+ hidden_states, attention_mask = block(hidden_states, attention_mask)
+ if self.norm is not None:
+ hidden_states = self.head(self.norm(hidden_states))
+ return hidden_states
+
+
+class PipelineGPTHybrid(GenericPipelineGPT):
+
+ def __init__(self,
+ num_layers: int = 12,
+ hidden_size: int = 768,
+ num_attention_heads: int = 12,
+ vocab_size: int = 50304,
+ embed_drop_rate: float = 0.,
+ act_func: str = 'gelu',
+ mlp_ratio: int = 4,
+ attn_drop_rate: float = 0.,
+ drop_rate: float = 0.,
+ dtype: torch.dtype = torch.float,
+ checkpoint: bool = False,
+ max_position_embeddings: int = 1024,
+ layer_norm_epsilon: float = 1e-5,
+ apply_post_layer_norm: bool = False,
+ first: bool = False,
+ last: bool = False,
+ embed_split_hidden=False):
+ embedding = None
+ norm = None
+ head = None
+ if first:
+ embedding = col_gpt.GPTEmbedding(hidden_size,
+ vocab_size,
+ max_position_embeddings,
+ dropout=embed_drop_rate,
+ dtype=dtype)
+ blocks = nn.ModuleList([
+ col_gpt.GPTBlock(hidden_size,
+ num_attention_heads,
+ mlp_ratio=mlp_ratio,
+ attention_dropout=attn_drop_rate,
+ dropout=drop_rate,
+ dtype=dtype,
+ checkpoint=checkpoint,
+ activation=nn.functional.gelu) for _ in range(num_layers)
+ ])
+ if last:
+ norm = col_nn.LayerNorm(hidden_size, eps=layer_norm_epsilon)
+ # head = col_gpt.GPTLMHead(vocab_size=vocab_size,
+ # hidden_size=hidden_size,
+ # dtype=dtype,
+ # bias=False)
+ head = col_nn.Classifier(hidden_size, vocab_size, dtype=dtype, bias=False)
+ super().__init__(embedding=embedding, blocks=blocks, norm=norm, head=head)
+
+
+def _filter_kwargs(func, kwargs):
+ sig = inspect.signature(func)
+ return {k: v for k, v in kwargs.items() if k in sig.parameters}
+
+
+def _build_generic_gpt_pipeline_1d(module_cls, num_layers, num_chunks, device=torch.device('cuda'), **kwargs):
+ logger = get_dist_logger()
+
+ if gpc.is_initialized(ParallelMode.PIPELINE):
+ pipeline_size = gpc.get_world_size(ParallelMode.PIPELINE)
+ pipeline_rank = gpc.get_local_rank(ParallelMode.PIPELINE)
+ else:
+ pipeline_size = 1
+ pipeline_rank = 0
+ rank = gpc.get_global_rank()
+
+ if pipeline_size > 1:
+ wrapper = PipelineSharedModuleWrapper([0, pipeline_size - 1])
+ else:
+ wrapper = None
+ parts = partition_uniform(num_layers, pipeline_size, num_chunks)[pipeline_rank]
+ models = []
+ for start, end in parts:
+ kwargs['num_layers'] = end - start
+ kwargs['first'] = start == 0
+ kwargs['last'] = end == num_layers
+ logger.info(f'Rank{rank} build layer {start}-{end}, {end-start}/{num_layers} layers')
+ chunk = module_cls(**_filter_kwargs(module_cls.__init__, kwargs)).to(device)
+
+ if wrapper is not None:
+ if start == 0:
+ wrapper.register_module(chunk.embedding.word_embeddings)
+ elif end == num_layers:
+ wrapper.register_module(chunk.head)
+ models.append(chunk)
+ if len(models) == 1:
+ model = models[0]
+ else:
+ model = nn.ModuleList(models)
+
+ numel = 0
+ for _, param in model.named_parameters(recurse=True):
+ numel += param.numel()
+ logger.info(f'Rank{rank}/{pipeline_rank} model size = {numel * 2 / 1e9} GB')
+ return model
+
+
+def _build_gpt_pipeline_1d(num_layers, num_chunks, device=torch.device('cuda'), fused=False, **kwargs):
+ model = FusedPipelineGPT1D if fused else PipelineGPT1D
+ return _build_generic_gpt_pipeline_1d(model, num_layers, num_chunks, device, **kwargs)
+
+
+def _build_gpt_pipeline_hybrid(num_layers, num_chunks, device=torch.device('cuda'), **kwargs):
+ return _build_generic_gpt_pipeline_1d(PipelineGPTHybrid, num_layers, num_chunks, device, **kwargs)
+
+
+def GPT2_small_pipeline_1D(num_chunks=1, checkpoint=False, dtype=torch.float, embed_split_hidden=False, fused=False):
+ cfg = dict(hidden_size=768,
+ num_attention_heads=12,
+ checkpoint=checkpoint,
+ dtype=dtype,
+ embed_split_hidden=embed_split_hidden)
+ return _build_gpt_pipeline_1d(12, num_chunks, fused=fused, **cfg)
+
+
+def GPT2_exlarge_pipeline_1D(num_chunks=1, checkpoint=False, dtype=torch.float, embed_split_hidden=False, fused=False):
+ cfg = dict(hidden_size=1600,
+ num_attention_heads=32,
+ checkpoint=checkpoint,
+ dtype=dtype,
+ embed_split_hidden=embed_split_hidden)
+ return _build_gpt_pipeline_1d(48, num_chunks, fused=fused, **cfg)
+
+
+def GPT3_pipeline_1D(num_chunks=1, checkpoint=False, dtype=torch.float, embed_split_hidden=False, fused=False):
+ cfg = dict(hidden_size=12288,
+ num_attention_heads=96,
+ checkpoint=checkpoint,
+ max_position_embeddings=2048,
+ dtype=dtype,
+ embed_split_hidden=embed_split_hidden)
+ return _build_gpt_pipeline_1d(96, num_chunks, fused=fused, **cfg)
+
+
+def GPT2_exlarge_pipeline_hybrid(num_chunks=1, checkpoint=False, dtype=torch.float, embed_split_hidden=False):
+ cfg = dict(hidden_size=1600,
+ num_attention_heads=32,
+ checkpoint=checkpoint,
+ dtype=dtype,
+ embed_split_hidden=embed_split_hidden)
+ return _build_gpt_pipeline_hybrid(48, num_chunks, **cfg)
+
+
+def GPT2_small_pipeline_hybrid(num_chunks=1, checkpoint=False, dtype=torch.float, embed_split_hidden=False):
+ cfg = dict(hidden_size=768,
+ num_attention_heads=12,
+ checkpoint=checkpoint,
+ dtype=dtype,
+ embed_split_hidden=embed_split_hidden)
+ return _build_gpt_pipeline_hybrid(12, num_chunks, **cfg)
+
+
+def GPT3_pipeline_hybrid(num_chunks=1, checkpoint=False, dtype=torch.float, embed_split_hidden=False):
+ cfg = dict(hidden_size=12288,
+ num_attention_heads=96,
+ checkpoint=checkpoint,
+ max_position_embeddings=2048,
+ dtype=dtype,
+ embed_split_hidden=embed_split_hidden)
+ return _build_gpt_pipeline_hybrid(96, num_chunks, **cfg)
diff --git a/examples/language/gpt/titans/requirements.txt b/examples/language/gpt/titans/requirements.txt
new file mode 100644
index 000000000..64ff7a4ab
--- /dev/null
+++ b/examples/language/gpt/titans/requirements.txt
@@ -0,0 +1,4 @@
+torch==1.12.1
+titans==0.0.7
+colossalai==0.2.0+torch1.12cu11.3
+-f https://release.colossalai.org
diff --git a/examples/language/gpt/titans/run.sh b/examples/language/gpt/titans/run.sh
new file mode 100644
index 000000000..a1a7fc737
--- /dev/null
+++ b/examples/language/gpt/titans/run.sh
@@ -0,0 +1,3 @@
+export DATA=/data/scratch/gpt_data/small-gpt-dataset.json
+DUMMY_DATA=--use_dummy_dataset
+colossalai run --nproc_per_node=2 train_gpt.py --config ./configs/gpt2_small_zero3_pp1d.py --from_torch $DUMMY_DATA
diff --git a/examples/language/gpt/titans/test_ci.sh b/examples/language/gpt/titans/test_ci.sh
new file mode 100644
index 000000000..7cb24c1a4
--- /dev/null
+++ b/examples/language/gpt/titans/test_ci.sh
@@ -0,0 +1 @@
+colossalai run --nproc_per_node=4 train_gpt.py --config ./configs/gpt2_small_zero3_pp1d.py --from_torch --use_dummy_dataset
diff --git a/examples/language/gpt/titans/train_gpt.py b/examples/language/gpt/titans/train_gpt.py
new file mode 100644
index 000000000..66225d6c8
--- /dev/null
+++ b/examples/language/gpt/titans/train_gpt.py
@@ -0,0 +1,113 @@
+import contextlib
+import os
+
+import torch
+import torch.nn as nn
+from dataset.webtext import WebtextDataset
+from titans.model.gpt import GPTLMLoss
+
+import colossalai
+import colossalai.utils as utils
+from colossalai.context.parallel_mode import ParallelMode
+from colossalai.core import global_context as gpc
+from colossalai.logging import disable_existing_loggers, get_dist_logger
+from colossalai.nn import LinearWarmupLR
+from colossalai.trainer import Trainer, hooks
+from colossalai.utils import colo_set_process_memory_fraction, is_using_pp
+from colossalai.utils.timer import MultiTimer
+from colossalai.zero.init_ctx import ZeroInitContext
+
+
+def calc_local_model_size(model: torch.nn.Module):
+ numel_per_device = 0
+ for p in model.parameters():
+ numel_per_device += p.numel()
+ return numel_per_device
+
+
+VOCAB_SIZE = 50257
+
+
+def main():
+ parser = colossalai.get_default_parser()
+ parser.add_argument('--from_torch', default=False, action='store_true')
+ parser.add_argument('--use_dummy_dataset', default=False, action='store_true')
+ args = parser.parse_args()
+ disable_existing_loggers()
+ if args.from_torch:
+ colossalai.launch_from_torch(config=args.config)
+ else:
+ colossalai.launch_from_slurm(config=args.config, host=args.host, port=29500, seed=42)
+ logger = get_dist_logger()
+
+ data_path = None if args.use_dummy_dataset else os.environ['DATA']
+ logger.info(f'Build data loader from path {data_path}', ranks=[0])
+
+ train_ds = WebtextDataset(path=data_path, seq_len=gpc.config.SEQ_LEN)
+ train_dataloader = utils.get_dataloader(train_ds,
+ seed=42,
+ batch_size=gpc.config.BATCH_SIZE,
+ pin_memory=True,
+ shuffle=True,
+ drop_last=True)
+
+ logger.info('Build model', ranks=[0])
+ use_pipeline = is_using_pp()
+ use_interleaved = hasattr(gpc.config.model, 'num_chunks')
+ use_zero3 = hasattr(gpc.config, 'zero')
+ ctx = contextlib.nullcontext()
+ if use_zero3:
+ ctx = ZeroInitContext(target_device=torch.cuda.current_device(),
+ shard_strategy=gpc.config.zero.model_config.shard_strategy,
+ shard_param=True)
+ with ctx:
+ model = gpc.config.model.pop('type')(**gpc.config.model)
+ if use_pipeline and use_interleaved and not isinstance(model, nn.ModuleList):
+ model = nn.ModuleList([model])
+
+ if use_zero3:
+ numel = ctx.model_numel_tensor.item()
+ else:
+ numel = calc_local_model_size(model)
+
+ tflop = numel * gpc.config.BATCH_SIZE * gpc.config.SEQ_LEN \
+ * gpc.get_world_size(ParallelMode.MODEL) * gpc.get_world_size(ParallelMode.DATA) * 8 / (1024 ** 4)
+
+ criterion = getattr(gpc.config, 'loss_fn', None)
+ if criterion is not None:
+ criterion = criterion.type()
+ else:
+ criterion = GPTLMLoss()
+ logger.info('Build optimizer', ranks=[0])
+ optimizer = gpc.config.optimizer.pop('type')(model.parameters(), **gpc.config.optimizer)
+ lr_scheduler = LinearWarmupLR(optimizer, total_steps=gpc.config.NUM_EPOCHS, warmup_steps=5)
+ engine, train_dataloader, _, lr_scheduler = colossalai.initialize(model,
+ optimizer,
+ criterion,
+ train_dataloader=train_dataloader,
+ lr_scheduler=lr_scheduler)
+ global_batch_size = gpc.config.BATCH_SIZE * \
+ gpc.get_world_size(ParallelMode.DATA) * getattr(gpc.config, "gradient_accumulation", 1)
+ logger.info(f'Init done, global batch size = {global_batch_size}', ranks=[0])
+ timier = MultiTimer()
+ trainer = Trainer(engine=engine, logger=logger, timer=timier)
+ hook_list = [
+ hooks.LossHook(),
+ hooks.LRSchedulerHook(lr_scheduler=lr_scheduler, by_epoch=True),
+ hooks.LogMetricByEpochHook(logger),
+ hooks.ThroughputHook(ignored_steps=10, tflop_per_step=tflop),
+ hooks.LogMetricByStepHook(),
+ hooks.LogMemoryByEpochHook(logger),
+ # hooks.LogMemoryByEpochHook(logger),
+ # hooks.LogTimingByEpochHook(timer, logger),
+ ]
+ trainer.fit(train_dataloader=train_dataloader,
+ epochs=gpc.config.NUM_EPOCHS,
+ test_interval=1,
+ hooks=hook_list,
+ display_progress=True,
+ return_output_label=False)
+
+
+if __name__ == '__main__':
+ main()
diff --git a/examples/language/opt/requirements.txt b/examples/language/opt/requirements.txt
new file mode 100644
index 000000000..137a69e80
--- /dev/null
+++ b/examples/language/opt/requirements.txt
@@ -0,0 +1,2 @@
+colossalai >= 0.1.12
+torch >= 1.8.1
diff --git a/examples/language/opt/test_ci.sh b/examples/language/opt/test_ci.sh
new file mode 100644
index 000000000..317f602cd
--- /dev/null
+++ b/examples/language/opt/test_ci.sh
@@ -0,0 +1,4 @@
+for GPUNUM in 2 1
+do
+env BS=2 MODEL="125m" GPUNUM=$GPUNUM bash ./run_gemini.sh
+done
diff --git a/examples/language/palm/run.sh b/examples/language/palm/run.sh
index 4aa868953..7a533509e 100644
--- a/examples/language/palm/run.sh
+++ b/examples/language/palm/run.sh
@@ -8,4 +8,4 @@ export PLACEMENT='cpu'
export USE_SHARD_INIT=False
export BATCH_SIZE=4
-env OMP_NUM_THREADS=12 torchrun --standalone --nproc_per_node=${GPUNUM} --master_port 29501 train_new.py --tp_degree=${TPDEGREE} --batch_size=${BATCH_SIZE} --placement ${PLACEMENT} --shardinit ${USE_SHARD_INIT} --distplan ${DISTPAN} 2>&1 | tee run.log
\ No newline at end of file
+env OMP_NUM_THREADS=12 torchrun --standalone --nproc_per_node=${GPUNUM} --master_port 29501 train.py --tp_degree=${TPDEGREE} --batch_size=${BATCH_SIZE} --placement ${PLACEMENT} --shardinit ${USE_SHARD_INIT} --distplan ${DISTPAN} 2>&1 | tee run.log
diff --git a/examples/language/palm/test_ci.sh b/examples/language/palm/test_ci.sh
new file mode 100644
index 000000000..f21095578
--- /dev/null
+++ b/examples/language/palm/test_ci.sh
@@ -0,0 +1,9 @@
+$(cd `dirname $0`;pwd)
+
+for BATCH_SIZE in 2
+do
+for GPUNUM in 1 4
+do
+env OMP_NUM_THREADS=12 torchrun --standalone --nproc_per_node=${GPUNUM} --master_port 29501 train.py --dummy_data=True --batch_size=${BATCH_SIZE} 2>&1 | tee run.log
+done
+done
diff --git a/examples/language/palm/train.py b/examples/language/palm/train.py
index 7c080b7f3..2f012780d 100644
--- a/examples/language/palm/train.py
+++ b/examples/language/palm/train.py
@@ -1,27 +1,30 @@
import gzip
import random
+from functools import partial
+from time import time
import numpy as np
import torch
+import torch.nn as nn
import torch.optim as optim
import tqdm
from packaging import version
from palm_pytorch import PaLM
from palm_pytorch.autoregressive_wrapper import AutoregressiveWrapper
-from torch.nn import functional as F
from torch.utils.data import DataLoader, Dataset
import colossalai
from colossalai.logging import disable_existing_loggers, get_dist_logger
from colossalai.nn.optimizer.gemini_optimizer import GeminiAdamOptimizer
-from colossalai.nn.parallel import GeminiDDP, ZeroDDP
+from colossalai.nn.parallel import ZeroDDP
from colossalai.tensor import ColoParameter, ComputePattern, ComputeSpec, ProcessGroup, ReplicaSpec, ShardSpec
from colossalai.utils import MultiTimer, get_current_device
from colossalai.utils.model.colo_init_context import ColoInitContext
# constants
-NUM_BATCHES = int(1000)
+NUM_BATCHES = int(10)
+WARMUP_BATCHES = 1
GRADIENT_ACCUMULATE_EVERY = 1
LEARNING_RATE = 2e-4
VALIDATE_EVERY = 100
@@ -63,9 +66,16 @@ def parse_args():
default=8,
help="batch size per DP group of training.",
)
+ parser.add_argument(
+ "--dummy_data",
+ type=bool,
+ default=False,
+ help="use dummy dataset.",
+ )
args = parser.parse_args()
return args
+
# helpers
def cycle(loader):
while True:
@@ -77,10 +87,22 @@ def decode_token(token):
return str(chr(max(32, token)))
+def get_tflops(model_numel, batch_size, seq_len, step_time):
+ return model_numel * batch_size * seq_len * 8 / 1e12 / (step_time + 1e-12)
+
+
def decode_tokens(tokens):
return "".join(list(map(decode_token, tokens)))
+def get_model_size(model: nn.Module):
+ total_numel = 0
+ for module in model.modules():
+ for p in module.parameters(recurse=False):
+ total_numel += p.numel()
+ return total_numel
+
+
# Gemini + ZeRO DDP
def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy: str = "auto"):
cai_version = colossalai.__version__
@@ -104,6 +126,7 @@ def gemini_zero_dpp(model: torch.nn.Module, pg: ProcessGroup, placememt_policy:
raise NotImplemented(f"CAI version {cai_version} is not supported")
return model
+
## Parameter Sharding Strategies for Tensor Parallelism
def split_param_single_dim_tp1d(dim: int, param: ColoParameter, pg: ProcessGroup):
spec = (ShardSpec([dim], [pg.tp_world_size()]), ComputeSpec(ComputePattern.TP1D))
@@ -117,6 +140,7 @@ def split_param_row_tp1d(param: ColoParameter, pg: ProcessGroup):
def split_param_col_tp1d(param: ColoParameter, pg: ProcessGroup):
split_param_single_dim_tp1d(-1, param, pg)
+
# Tensor Parallel
def tensor_parallelize(model: torch.nn.Module, pg: ProcessGroup):
"""tensor_parallelize
@@ -143,20 +167,33 @@ def tensor_parallelize(model: torch.nn.Module, pg: ProcessGroup):
split_param_row_tp1d(param, pg) # row slice
else:
param.set_dist_spec(ReplicaSpec())
-
param.visited = True
args = parse_args()
if args.distplan not in ["colossalai", "pytorch"]:
- raise TypeError(f"{args.distplan} is error")
+ raise TypeError(f"{args.distplan} is error")
disable_existing_loggers()
colossalai.launch_from_torch(config={})
+logger = get_dist_logger()
-with gzip.open("./data/enwik8.gz") as file:
- X = np.fromstring(file.read(int(95e6)), dtype=np.uint8)
- trX, vaX = np.split(X, [int(90e6)])
- data_train, data_val = torch.from_numpy(trX), torch.from_numpy(vaX)
+
+def generate_dataset(dummy_data: bool = False):
+ if not dummy_data:
+ with gzip.open("./data/enwik8.gz") as file:
+ X = np.fromstring(file.read(int(95e6)), dtype=np.uint8)
+ trX, vaX = np.split(X, [int(90e6)])
+ data_train, data_val = torch.from_numpy(trX), torch.from_numpy(vaX)
+ # print(f"data_train {data_train.shape} {data_train.dtype} {max(data_train)} {min(data_train)}")
+ # print(f"data_val {data_val.shape} {data_val.dtype} {max(data_val)} {min(data_val)}")
+ return data_train, data_val
+ else:
+ return torch.randint(0, 100, (90000000,)), torch.randint(0, 100, (5000000,))
+
+
+data_train, data_val = generate_dataset(args.dummy_data)
+
+print("generate dataset ready!")
class TextSamplerDataset(Dataset):
@@ -188,7 +225,7 @@ if args.distplan == "colossalai":
ctx = ColoInitContext(device='cpu', default_dist_spec=default_dist_spec, default_pg=default_pg)
with ctx:
- model = PaLM(num_tokens=256, dim=512, depth=8)
+ model = PaLM(num_tokens=50304, dim=4096, depth=64)
model = AutoregressiveWrapper(model, max_seq_len=SEQ_LEN)
pg = default_pg
@@ -205,25 +242,42 @@ else:
model.cuda()
optim = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
-
+# model is shared after TP
+numel = get_model_size(model)
+get_tflops_func = partial(get_tflops, numel, args.batch_size, SEQ_LEN)
# training
model.train()
-
+tflops_list = []
for i in tqdm.tqdm(range(NUM_BATCHES), mininterval=10.0, desc="training"):
if args.distplan == "colossalai":
optimizer.zero_grad()
-
+ start = time()
loss = model(next(train_loader))
+ fwd_end = time()
+ fwd_time = fwd_end - start
# loss.backward()
optimizer.backward(loss)
+ bwd_end = time()
+ bwd_time = bwd_end - fwd_end
- print(f"training loss: {loss.item()}")
+ # print(f"training loss: {loss.item()}")
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.5)
# optim.step()
# optim.zero_grad()
optimizer.step()
+ optim_time = time() - bwd_end
+ step_time = time() - start
+
+ step_tflops = get_tflops_func(step_time)
+ logger.info(
+ f"[{i + 1}/{NUM_BATCHES}] Loss:{loss.item():.3f}, Step time: {step_time:.3f}s, TFLOPS: {get_tflops_func(step_time):.3f}, FWD time: {fwd_time:.3f}s, BWD time: {bwd_time:.3f}s, OPTIM time: {optim_time:.3f}s",
+ ranks=[0],
+ )
+ if i >= WARMUP_BATCHES:
+ tflops_list.append(step_tflops)
+
else:
for __ in range(GRADIENT_ACCUMULATE_EVERY):
loss = model(next(train_loader))
@@ -234,12 +288,16 @@ for i in tqdm.tqdm(range(NUM_BATCHES), mininterval=10.0, desc="training"):
optim.step()
optim.zero_grad()
- # TODO
- # if i % VALIDATE_EVERY == 0:
- # model.eval()
- # with torch.no_grad():
- # loss = model(next(val_loader))
- # print(f"validation loss: {loss.item()}")
+tflops_list.sort()
+median_index = ((NUM_BATCHES - WARMUP_BATCHES) >> 1) + WARMUP_BATCHES
+logger.info(f"Median TFLOPS is {tflops_list[median_index]:.3f}")
+
+# TODO
+# if i % VALIDATE_EVERY == 0:
+# model.eval()
+# with torch.no_grad():
+# loss = model(next(val_loader))
+# print(f"validation loss: {loss.item()}")
# if i % GENERATE_EVERY == 0:
# model.eval()
@@ -249,4 +307,4 @@ for i in tqdm.tqdm(range(NUM_BATCHES), mininterval=10.0, desc="training"):
# sample = model.generate(inp[None, ...], GENERATE_LENGTH)
# output_str = decode_tokens(sample[0])
- # print(output_str)
\ No newline at end of file
+ # print(output_str)
diff --git a/examples/tutorial/README.md b/examples/tutorial/README.md
index bef7c8905..9c61e41cd 100644
--- a/examples/tutorial/README.md
+++ b/examples/tutorial/README.md
@@ -39,9 +39,6 @@ quickly deploy large AI model training and inference, reducing large AI model tr
- Try pre-trained OPT model weights with Colossal-AI
- Fine-tuning OPT with limited hardware using ZeRO, Gemini and parallelism
- Deploy the fine-tuned model to inference service
- - Acceleration of Stable Diffusion
- - Stable Diffusion with Lightning
- - Try Lightning Colossal-AI strategy to optimize memory and accelerate speed
## Discussion
@@ -168,26 +165,3 @@ docker run -it --rm --gpus all --ipc host -p 7070:7070 hpcaitech/tutorial:opt-in
```bash
python opt_fastapi.py opt-125m --tp 2 --checkpoint /data/opt-125m
```
-
-## 🖼️ Accelerate Stable Diffusion with Colossal-AI
-1. Create a new environment for diffusion
-```bash
-conda env create -f environment.yaml
-conda activate ldm
-```
-2. Install Colossal-AI from our official page
-```bash
-pip install colossalai==0.1.10+torch1.11cu11.3 -f https://release.colossalai.org
-```
-3. Install PyTorch Lightning compatible commit
-```bash
-git clone https://github.com/Lightning-AI/lightning && cd lightning && git reset --hard b04a7aa
-pip install -r requirements.txt && pip install .
-cd ..
-```
-
-4. Comment out the `from_pretrained` field in the `train_colossalai_cifar10.yaml`.
-5. Run training with CIFAR10.
-```bash
-python main.py -logdir /tmp -t true -postfix test -b configs/train_colossalai_cifar10.yaml
-```
diff --git a/examples/tutorial/auto_parallel/README.md b/examples/tutorial/auto_parallel/README.md
index e99a018c2..bb014b906 100644
--- a/examples/tutorial/auto_parallel/README.md
+++ b/examples/tutorial/auto_parallel/README.md
@@ -1,15 +1,45 @@
-# Auto-Parallelism with ResNet
+# Auto-Parallelism
+
+## Table of contents
+
+- [Auto-Parallelism](#auto-parallelism)
+ - [Table of contents](#table-of-contents)
+ - [📚 Overview](#-overview)
+ - [🚀 Quick Start](#-quick-start)
+ - [Setup](#setup)
+ - [Auto-Parallel Tutorial](#auto-parallel-tutorial)
+ - [Auto-Checkpoint Tutorial](#auto-checkpoint-tutorial)
+
+
+## 📚 Overview
+
+This tutorial folder contains a simple demo to run auto-parallelism with ResNet. Meanwhile, this diretory also contains demo scripts to run automatic activation checkpointing, but both features are still experimental for now and no guarantee that they will work for your version of Colossal-AI.
+
+## 🚀 Quick Start
+
+### Setup
+
+1. Create a conda environment
-## 🚀Quick Start
-### Auto-Parallel Tutorial
-1. Install `pulp` and `coin-or-cbc` for the solver.
```bash
-pip install pulp
+conda create -n auto python=3.8
+conda activate auto
+```
+
+2. Install `requirements` and `coin-or-cbc` for the solver.
+
+```bash
+pip install -r requirements.txt
conda install -c conda-forge coin-or-cbc
```
-2. Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
+
+
+### Auto-Parallel Tutorial
+
+Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
+
```bash
-colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py -s
+colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
```
You should expect to the log like this. This log shows the edge cost on the computation graph as well as the sharding strategy for an operation. For example, `layer1_0_conv1 S01R = S01R X RR` means that the first dimension (batch) of the input and output is sharded while the weight is not sharded (S means sharded, R means replicated), simply equivalent to data parallel training.
@@ -17,57 +47,6 @@ You should expect to the log like this. This log shows the edge cost on the comp
### Auto-Checkpoint Tutorial
-1. Stay in the `auto_parallel` folder.
-2. Install the dependencies.
-```bash
-pip install matplotlib transformers
-```
-3. Run a simple resnet50 benchmark to automatically checkpoint the model.
-```bash
-python auto_ckpt_solver_test.py --model resnet50
-```
-
-You should expect the log to be like this
-
-
-This shows that given different memory budgets, the model is automatically injected with activation checkpoint and its time taken per iteration. You can run this benchmark for GPT as well but it can much longer since the model is larger.
-```bash
-python auto_ckpt_solver_test.py --model gpt2
-```
-
-4. Run a simple benchmark to find the optimal batch size for checkpointed model.
-```bash
-python auto_ckpt_batchsize_test.py
-```
-
-You can expect the log to be like
-
-
-
-## Prepare Dataset
-
-We use CIFAR10 dataset in this example. You should invoke the `donwload_cifar10.py` in the tutorial root directory or directly run the `auto_parallel_with_resnet.py`.
-The dataset will be downloaded to `colossalai/examples/tutorials/data` by default.
-If you wish to use customized directory for the dataset. You can set the environment variable `DATA` via the following command.
-
-```bash
-export DATA=/path/to/data
-```
-
-## extra requirements to use autoparallel
-
-```bash
-pip install pulp
-conda install coin-or-cbc
-```
-
-## Run on 2*2 device mesh
-
-```bash
-colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
-```
-
-## Auto Checkpoint Benchmarking
We prepare two bechmarks for you to test the performance of auto checkpoint
@@ -86,21 +65,3 @@ python auto_ckpt_solver_test.py --model resnet50
# tun auto_ckpt_batchsize_test.py
python auto_ckpt_batchsize_test.py
```
-
-There are some results for your reference
-
-## Auto Checkpoint Solver Test
-
-### ResNet 50
-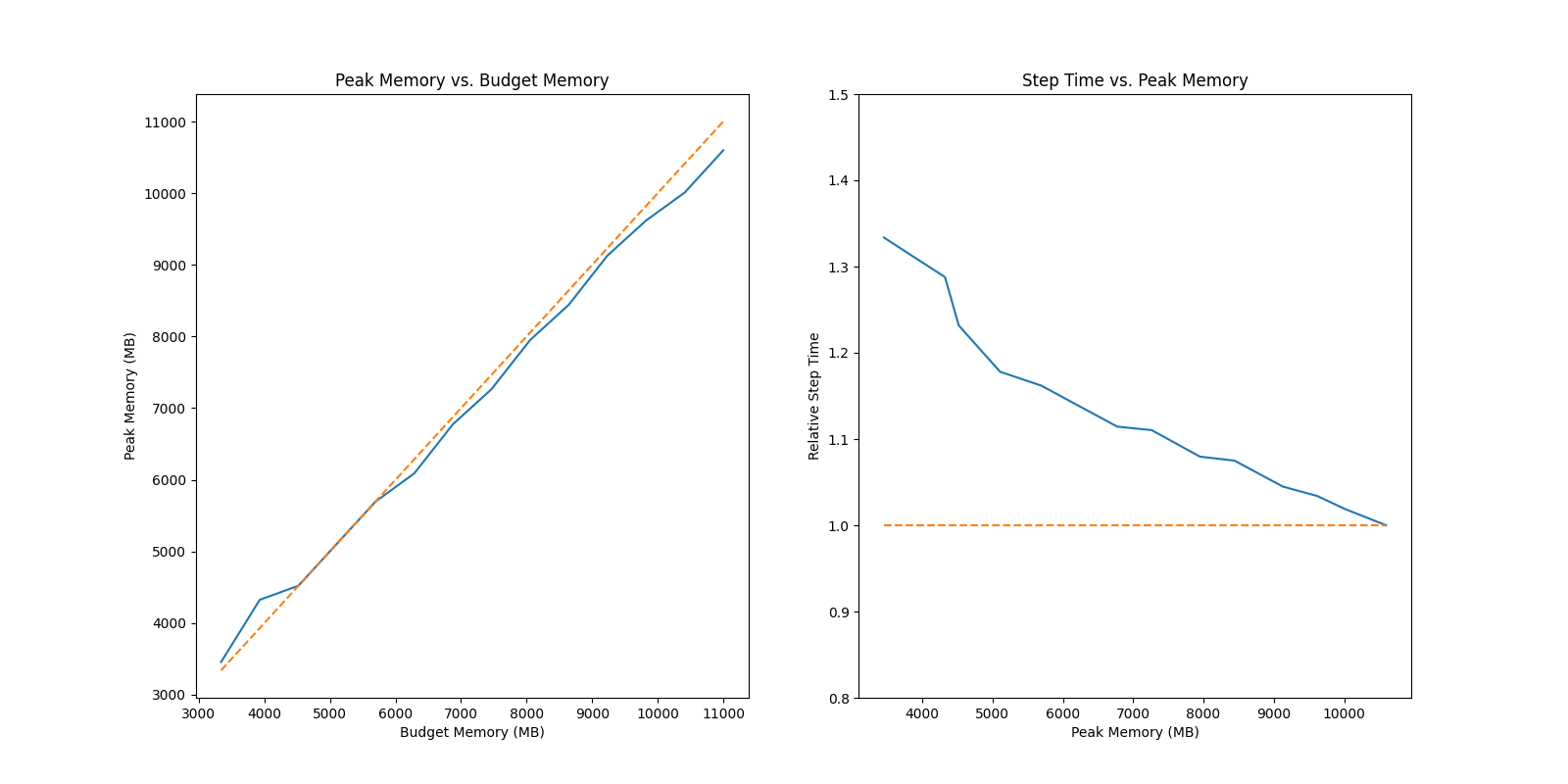
-
-### GPT2 Medium
-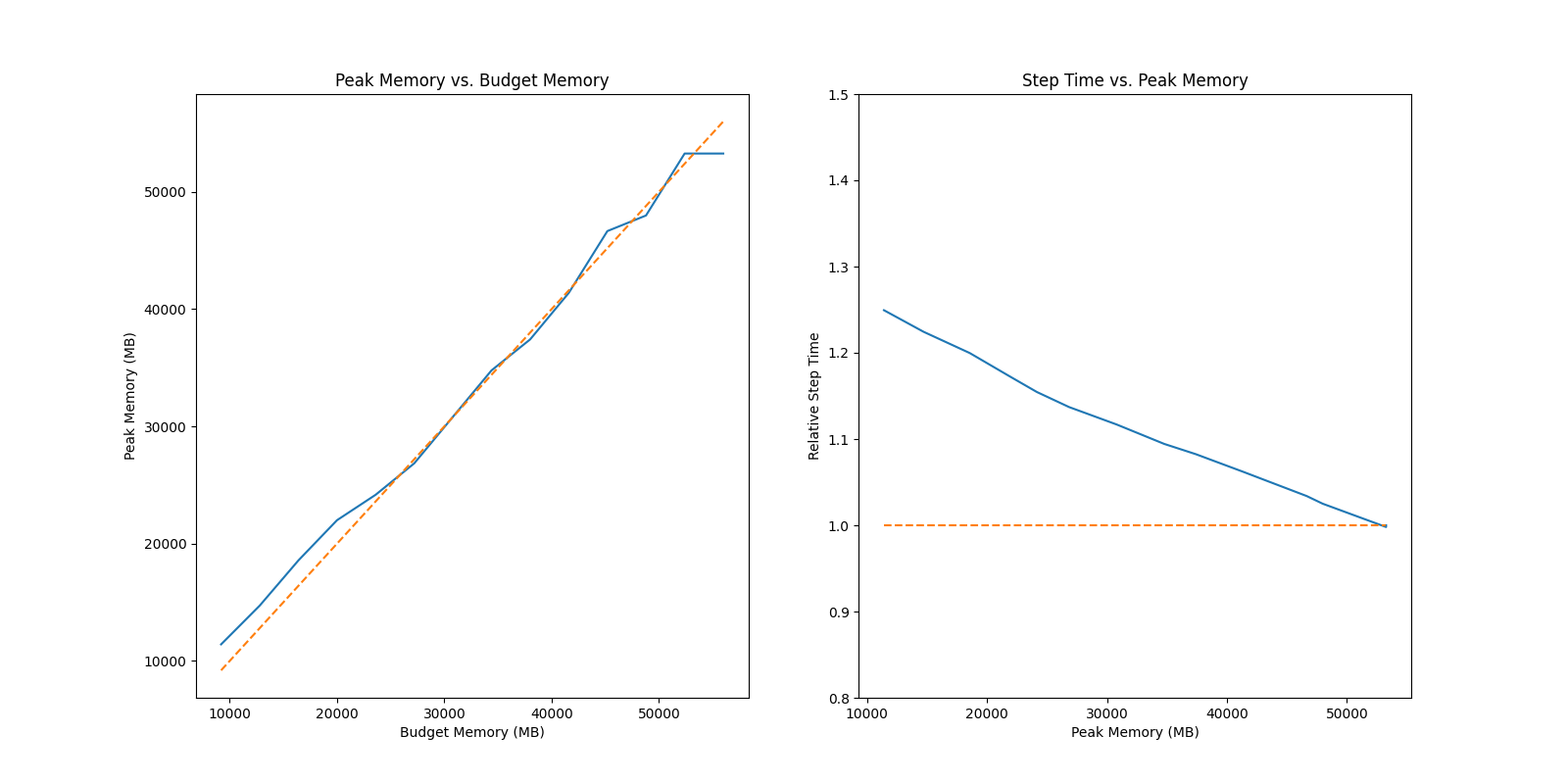
-
-## Auto Checkpoint Batch Size Test
-```bash
-===============test summary================
-batch_size: 512, peak memory: 73314.392 MB, through put: 254.286 images/s
-batch_size: 1024, peak memory: 73316.216 MB, through put: 397.608 images/s
-batch_size: 2048, peak memory: 72927.837 MB, through put: 277.429 images/s
-```
diff --git a/examples/tutorial/auto_parallel/auto_parallel_with_resnet.py b/examples/tutorial/auto_parallel/auto_parallel_with_resnet.py
index e4aff13e4..15429f19c 100644
--- a/examples/tutorial/auto_parallel/auto_parallel_with_resnet.py
+++ b/examples/tutorial/auto_parallel/auto_parallel_with_resnet.py
@@ -1,37 +1,12 @@
-import argparse
-import os
-from pathlib import Path
-
import torch
-from titans.utils import barrier_context
-from torch.fx import GraphModule
-from torchvision import transforms
-from torchvision.datasets import CIFAR10
from torchvision.models import resnet50
from tqdm import tqdm
import colossalai
-from colossalai.auto_parallel.passes.runtime_apply_pass import runtime_apply_pass
-from colossalai.auto_parallel.passes.runtime_preparation_pass import runtime_preparation_pass
-from colossalai.auto_parallel.tensor_shard.solver.cost_graph import CostGraph
-from colossalai.auto_parallel.tensor_shard.solver.graph_analysis import GraphAnalyser
-from colossalai.auto_parallel.tensor_shard.solver.options import DataloaderOption, SolverOptions
-from colossalai.auto_parallel.tensor_shard.solver.solver import Solver
-from colossalai.auto_parallel.tensor_shard.solver.strategies_constructor import StrategiesConstructor
+from colossalai.auto_parallel.tensor_shard.initialize import autoparallelize
from colossalai.core import global_context as gpc
-from colossalai.device.device_mesh import DeviceMesh
-from colossalai.fx.tracer.tracer import ColoTracer
from colossalai.logging import get_dist_logger
from colossalai.nn.lr_scheduler import CosineAnnealingLR
-from colossalai.utils import get_dataloader
-
-DATA_ROOT = Path(os.environ.get('DATA', '../data')).absolute()
-
-
-def parse_args():
- parser = argparse.ArgumentParser()
- parser.add_argument('-s', '--synthetic', action="store_true", help="use synthetic dataset instead of CIFAR10")
- return parser.parse_args()
def synthesize_data():
@@ -41,82 +16,15 @@ def synthesize_data():
def main():
- args = parse_args()
colossalai.launch_from_torch(config='./config.py')
logger = get_dist_logger()
- if not args.synthetic:
- with barrier_context():
- # build dataloaders
- train_dataset = CIFAR10(root=DATA_ROOT,
- download=True,
- transform=transforms.Compose([
- transforms.RandomCrop(size=32, padding=4),
- transforms.RandomHorizontalFlip(),
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.4914, 0.4822, 0.4465],
- std=[0.2023, 0.1994, 0.2010]),
- ]))
-
- test_dataset = CIFAR10(root=DATA_ROOT,
- train=False,
- transform=transforms.Compose([
- transforms.ToTensor(),
- transforms.Normalize(mean=[0.4914, 0.4822, 0.4465], std=[0.2023, 0.1994, 0.2010]),
- ]))
-
- train_dataloader = get_dataloader(
- dataset=train_dataset,
- add_sampler=True,
- shuffle=True,
- batch_size=gpc.config.BATCH_SIZE,
- pin_memory=True,
- )
-
- test_dataloader = get_dataloader(
- dataset=test_dataset,
- add_sampler=True,
- batch_size=gpc.config.BATCH_SIZE,
- pin_memory=True,
- )
- else:
- train_dataloader, test_dataloader = None, None
-
- # initialize device mesh
- physical_mesh_id = torch.arange(0, 4)
- mesh_shape = (2, 2)
- device_mesh = DeviceMesh(physical_mesh_id, mesh_shape, init_process_group=True)
-
# trace the model with meta data
- tracer = ColoTracer()
model = resnet50(num_classes=10).cuda()
input_sample = {'x': torch.rand([gpc.config.BATCH_SIZE * torch.distributed.get_world_size(), 3, 32, 32]).to('meta')}
- graph = tracer.trace(root=model, meta_args=input_sample)
- gm = GraphModule(model, graph, model.__class__.__name__)
- gm.recompile()
-
- # prepare info for solver
- solver_options = SolverOptions(dataloader_option=DataloaderOption.DISTRIBUTED)
- strategies_constructor = StrategiesConstructor(graph, device_mesh, solver_options)
- strategies_constructor.build_strategies_and_cost()
- cost_graph = CostGraph(strategies_constructor.leaf_strategies)
- cost_graph.simplify_graph()
- graph_analyser = GraphAnalyser(gm)
-
- # solve the solution
- solver = Solver(gm.graph, strategies_constructor, cost_graph, graph_analyser)
- ret = solver.call_solver_serialized_args()
- solution = list(ret[0])
- if gpc.get_global_rank() == 0:
- for index, node in enumerate(graph.nodes):
- print(node.name, node.strategies_vector[solution[index]].name)
-
- # process the graph for distributed training ability
- gm, sharding_spec_dict, origin_spec_dict, comm_actions_dict = runtime_preparation_pass(gm, solution, device_mesh)
- gm = runtime_apply_pass(gm)
- gm.recompile()
+ model = autoparallelize(model, input_sample)
# build criterion
criterion = torch.nn.CrossEntropyLoss()
@@ -127,65 +35,45 @@ def main():
lr_scheduler = CosineAnnealingLR(optimizer, total_steps=gpc.config.NUM_EPOCHS)
for epoch in range(gpc.config.NUM_EPOCHS):
- gm.train()
+ model.train()
- if args.synthetic:
- # if we use synthetic data
- # we assume it only has 30 steps per epoch
- num_steps = range(30)
-
- else:
- # we use the actual number of steps for training
- num_steps = range(len(train_dataloader))
- data_iter = iter(train_dataloader)
+ # if we use synthetic data
+ # we assume it only has 10 steps per epoch
+ num_steps = range(10)
progress = tqdm(num_steps)
for _ in progress:
- if args.synthetic:
- # generate fake data
- img, label = synthesize_data()
- else:
- # get the real data
- img, label = next(data_iter)
+ # generate fake data
+ img, label = synthesize_data()
img = img.cuda()
label = label.cuda()
optimizer.zero_grad()
- output = gm(img, sharding_spec_dict, origin_spec_dict, comm_actions_dict)
+ output = model(img)
train_loss = criterion(output, label)
train_loss.backward(train_loss)
optimizer.step()
lr_scheduler.step()
# run evaluation
- gm.eval()
+ model.eval()
correct = 0
total = 0
- if args.synthetic:
- # if we use synthetic data
- # we assume it only has 10 steps for evaluation
- num_steps = range(30)
-
- else:
- # we use the actual number of steps for training
- num_steps = range(len(test_dataloader))
- data_iter = iter(test_dataloader)
+ # if we use synthetic data
+ # we assume it only has 10 steps for evaluation
+ num_steps = range(10)
progress = tqdm(num_steps)
for _ in progress:
- if args.synthetic:
- # generate fake data
- img, label = synthesize_data()
- else:
- # get the real data
- img, label = next(data_iter)
+ # generate fake data
+ img, label = synthesize_data()
img = img.cuda()
label = label.cuda()
with torch.no_grad():
- output = gm(img, sharding_spec_dict, origin_spec_dict, comm_actions_dict)
+ output = model(img)
test_loss = criterion(output, label)
pred = torch.argmax(output, dim=-1)
correct += torch.sum(pred == label)
diff --git a/examples/tutorial/auto_parallel/config.py b/examples/tutorial/auto_parallel/config.py
index fa14eda74..52e0abcef 100644
--- a/examples/tutorial/auto_parallel/config.py
+++ b/examples/tutorial/auto_parallel/config.py
@@ -1,2 +1,2 @@
-BATCH_SIZE = 128
-NUM_EPOCHS = 10
+BATCH_SIZE = 32
+NUM_EPOCHS = 2
diff --git a/examples/tutorial/auto_parallel/requirements.txt b/examples/tutorial/auto_parallel/requirements.txt
index 137a69e80..ce89e7c80 100644
--- a/examples/tutorial/auto_parallel/requirements.txt
+++ b/examples/tutorial/auto_parallel/requirements.txt
@@ -1,2 +1,7 @@
-colossalai >= 0.1.12
-torch >= 1.8.1
+torch
+colossalai
+titans
+pulp
+datasets
+matplotlib
+transformers
diff --git a/examples/tutorial/stable_diffusion/setup.py b/examples/tutorial/auto_parallel/setup.py
similarity index 68%
rename from examples/tutorial/stable_diffusion/setup.py
rename to examples/tutorial/auto_parallel/setup.py
index a24d54167..6e6cff32e 100644
--- a/examples/tutorial/stable_diffusion/setup.py
+++ b/examples/tutorial/auto_parallel/setup.py
@@ -1,7 +1,7 @@
-from setuptools import setup, find_packages
+from setuptools import find_packages, setup
setup(
- name='latent-diffusion',
+ name='auto_parallel',
version='0.0.1',
description='',
packages=find_packages(),
@@ -10,4 +10,4 @@ setup(
'numpy',
'tqdm',
],
-)
\ No newline at end of file
+)
diff --git a/examples/tutorial/auto_parallel/test_ci.sh b/examples/tutorial/auto_parallel/test_ci.sh
new file mode 100644
index 000000000..bf6275b67
--- /dev/null
+++ b/examples/tutorial/auto_parallel/test_ci.sh
@@ -0,0 +1,6 @@
+#!/bin/bash
+set -euxo pipefail
+
+pip install -r requirements.txt
+conda install -c conda-forge coin-or-cbc
+colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
diff --git a/examples/tutorial/hybrid_parallel/README.md b/examples/tutorial/hybrid_parallel/README.md
index 6f975e863..1b5e54f92 100644
--- a/examples/tutorial/hybrid_parallel/README.md
+++ b/examples/tutorial/hybrid_parallel/README.md
@@ -1,45 +1,40 @@
# Multi-dimensional Parallelism with Colossal-AI
+## Table of contents
-## 🚀Quick Start
-1. Install our model zoo.
-```bash
-pip install titans
-```
-2. Run with synthetic data which is of similar shape to CIFAR10 with the `-s` flag.
-```bash
-colossalai run --nproc_per_node 4 train.py --config config.py -s
+- [Overview](#-overview)
+- [Quick Start](#-quick-start)
+
+## 📚 Overview
+
+This example lets you to quickly try out the hybrid parallelism provided by Colossal-AI.
+You can change the parameters below to try out different settings in the `config.py`.
+
+```python
+# parallel setting
+TENSOR_PARALLEL_SIZE = 2
+TENSOR_PARALLEL_MODE = '1d'
+
+parallel = dict(
+ pipeline=2,
+ tensor=dict(mode=TENSOR_PARALLEL_MODE, size=TENSOR_PARALLEL_SIZE),
+)
```
-3. Modify the config file to play with different types of tensor parallelism, for example, change tensor parallel size to be 4 and mode to be 2d and run on 8 GPUs.
+## 🚀 Quick Start
+1. Install PyTorch
-## Install Titans Model Zoo
+2. Install the dependencies.
```bash
-pip install titans
+pip install -r requirements.txt
```
-
-## Prepare Dataset
-
-We use CIFAR10 dataset in this example. You should invoke the `donwload_cifar10.py` in the tutorial root directory or directly run the `auto_parallel_with_resnet.py`.
-The dataset will be downloaded to `colossalai/examples/tutorials/data` by default.
-If you wish to use customized directory for the dataset. You can set the environment variable `DATA` via the following command.
+3. Run the training scripts with synthetic data.
```bash
-export DATA=/path/to/data
-```
-
-
-## Run on 2*2 device mesh
-
-Current configuration setting on `config.py` is TP=2, PP=2.
-
-```bash
-# train with cifar10
colossalai run --nproc_per_node 4 train.py --config config.py
-
-# train with synthetic data
-colossalai run --nproc_per_node 4 train.py --config config.py -s
```
+
+4. Modify the config file to play with different types of tensor parallelism, for example, change tensor parallel size to be 4 and mode to be 2d and run on 8 GPUs.
diff --git a/examples/tutorial/hybrid_parallel/config.py b/examples/tutorial/hybrid_parallel/config.py
index 2450ab1c7..fe9abf2f1 100644
--- a/examples/tutorial/hybrid_parallel/config.py
+++ b/examples/tutorial/hybrid_parallel/config.py
@@ -3,20 +3,20 @@ from colossalai.amp import AMP_TYPE
# hyperparameters
# BATCH_SIZE is as per GPU
# global batch size = BATCH_SIZE x data parallel size
-BATCH_SIZE = 256
+BATCH_SIZE = 4
LEARNING_RATE = 3e-3
WEIGHT_DECAY = 0.3
-NUM_EPOCHS = 10
-WARMUP_EPOCHS = 3
+NUM_EPOCHS = 2
+WARMUP_EPOCHS = 1
# model config
IMG_SIZE = 224
PATCH_SIZE = 16
-HIDDEN_SIZE = 512
+HIDDEN_SIZE = 128
DEPTH = 4
NUM_HEADS = 4
MLP_RATIO = 2
-NUM_CLASSES = 1000
+NUM_CLASSES = 10
CHECKPOINT = False
SEQ_LENGTH = (IMG_SIZE // PATCH_SIZE)**2 + 1 # add 1 for cls token
diff --git a/examples/tutorial/hybrid_parallel/requirements.txt b/examples/tutorial/hybrid_parallel/requirements.txt
index 137a69e80..99b7ecfe1 100644
--- a/examples/tutorial/hybrid_parallel/requirements.txt
+++ b/examples/tutorial/hybrid_parallel/requirements.txt
@@ -1,2 +1,3 @@
-colossalai >= 0.1.12
-torch >= 1.8.1
+torch
+colossalai
+titans
diff --git a/examples/tutorial/hybrid_parallel/test_ci.sh b/examples/tutorial/hybrid_parallel/test_ci.sh
new file mode 100644
index 000000000..e0dbef354
--- /dev/null
+++ b/examples/tutorial/hybrid_parallel/test_ci.sh
@@ -0,0 +1,5 @@
+#!/bin/bash
+set -euxo pipefail
+
+pip install -r requirements.txt
+colossalai run --nproc_per_node 4 train.py --config config.py
diff --git a/examples/tutorial/hybrid_parallel/train.py b/examples/tutorial/hybrid_parallel/train.py
index 0f2a207cb..4953d5350 100644
--- a/examples/tutorial/hybrid_parallel/train.py
+++ b/examples/tutorial/hybrid_parallel/train.py
@@ -1,7 +1,6 @@
import os
import torch
-from titans.dataloader.cifar10 import build_cifar
from titans.model.vit.vit import _create_vit_model
from tqdm import tqdm
@@ -12,7 +11,7 @@ from colossalai.logging import get_dist_logger
from colossalai.nn import CrossEntropyLoss
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
from colossalai.pipeline.pipelinable import PipelinableContext
-from colossalai.utils import get_dataloader, is_using_pp
+from colossalai.utils import is_using_pp
class DummyDataloader():
@@ -42,12 +41,9 @@ class DummyDataloader():
def main():
- # initialize distributed setting
- parser = colossalai.get_default_parser()
- parser.add_argument('-s', '--synthetic', action="store_true", help="whether use synthetic data")
- args = parser.parse_args()
-
# launch from torch
+ parser = colossalai.get_default_parser()
+ args = parser.parse_args()
colossalai.launch_from_torch(config=args.config)
# get logger
@@ -94,15 +90,10 @@ def main():
pipeline_stage = gpc.get_local_rank(ParallelMode.PIPELINE)
logger.info(f"number of parameters: {total_numel} on pipeline stage {pipeline_stage}")
- # create dataloaders
- root = os.environ.get('DATA', '../data')
- if args.synthetic:
- # if we use synthetic dataset
- # we train for 30 steps and eval for 10 steps per epoch
- train_dataloader = DummyDataloader(length=30, batch_size=gpc.config.BATCH_SIZE)
- test_dataloader = DummyDataloader(length=10, batch_size=gpc.config.BATCH_SIZE)
- else:
- train_dataloader, test_dataloader = build_cifar(gpc.config.BATCH_SIZE, root, pad_if_needed=True)
+ # use synthetic dataset
+ # we train for 10 steps and eval for 5 steps per epoch
+ train_dataloader = DummyDataloader(length=10, batch_size=gpc.config.BATCH_SIZE)
+ test_dataloader = DummyDataloader(length=5, batch_size=gpc.config.BATCH_SIZE)
# create loss function
criterion = CrossEntropyLoss(label_smoothing=0.1)
@@ -139,6 +130,7 @@ def main():
engine.execute_schedule(data_iter, return_output_label=False)
engine.step()
lr_scheduler.step()
+ gpc.destroy()
if __name__ == '__main__':
diff --git a/examples/tutorial/large_batch_optimizer/README.md b/examples/tutorial/large_batch_optimizer/README.md
index 20bddb383..1a17c2d87 100644
--- a/examples/tutorial/large_batch_optimizer/README.md
+++ b/examples/tutorial/large_batch_optimizer/README.md
@@ -1,31 +1,37 @@
-# Comparison of Large Batch Training Optimization
+# Large Batch Training Optimization
-## 🚀Quick Start
-Run with synthetic data
-```bash
-colossalai run --nproc_per_node 4 train.py --config config.py -s
+## Table of contents
+
+- [Large Batch Training Optimization](#large-batch-training-optimization)
+ - [Table of contents](#table-of-contents)
+ - [📚 Overview](#-overview)
+ - [🚀 Quick Start](#-quick-start)
+
+## 📚 Overview
+
+This example lets you to quickly try out the large batch training optimization provided by Colossal-AI. We use synthetic dataset to go through the process, thus, you don't need to prepare any dataset. You can try out the `Lamb` and `Lars` optimizers from Colossal-AI with the following code.
+
+```python
+from colossalai.nn.optimizer import Lamb, Lars
```
+## 🚀 Quick Start
-## Prepare Dataset
+1. Install PyTorch
-We use CIFAR10 dataset in this example. You should invoke the `donwload_cifar10.py` in the tutorial root directory or directly run the `auto_parallel_with_resnet.py`.
-The dataset will be downloaded to `colossalai/examples/tutorials/data` by default.
-If you wish to use customized directory for the dataset. You can set the environment variable `DATA` via the following command.
+2. Install the dependencies.
```bash
-export DATA=/path/to/data
+pip install -r requirements.txt
```
-You can also use synthetic data for this tutorial if you don't wish to download the `CIFAR10` dataset by adding the `-s` or `--synthetic` flag to the command.
-
-
-## Run on 2*2 device mesh
+3. Run the training scripts with synthetic data.
```bash
-# run with cifar10
-colossalai run --nproc_per_node 4 train.py --config config.py
+# run on 4 GPUs
+# run with lars
+colossalai run --nproc_per_node 4 train.py --config config.py --optimizer lars
-# run with synthetic dataset
-colossalai run --nproc_per_node 4 train.py --config config.py -s
+# run with lamb
+colossalai run --nproc_per_node 4 train.py --config config.py --optimizer lamb
```
diff --git a/examples/tutorial/large_batch_optimizer/config.py b/examples/tutorial/large_batch_optimizer/config.py
index e019154e4..2efa0ffd0 100644
--- a/examples/tutorial/large_batch_optimizer/config.py
+++ b/examples/tutorial/large_batch_optimizer/config.py
@@ -6,31 +6,11 @@ from colossalai.amp import AMP_TYPE
BATCH_SIZE = 512
LEARNING_RATE = 3e-3
WEIGHT_DECAY = 0.3
-NUM_EPOCHS = 10
-WARMUP_EPOCHS = 3
+NUM_EPOCHS = 2
+WARMUP_EPOCHS = 1
# model config
-IMG_SIZE = 224
-PATCH_SIZE = 16
-HIDDEN_SIZE = 512
-DEPTH = 4
-NUM_HEADS = 4
-MLP_RATIO = 2
-NUM_CLASSES = 1000
-CHECKPOINT = False
-SEQ_LENGTH = (IMG_SIZE // PATCH_SIZE)**2 + 1 # add 1 for cls token
-
-# parallel setting
-TENSOR_PARALLEL_SIZE = 2
-TENSOR_PARALLEL_MODE = '1d'
-
-parallel = dict(
- pipeline=2,
- tensor=dict(mode=TENSOR_PARALLEL_MODE, size=TENSOR_PARALLEL_SIZE),
-)
+NUM_CLASSES = 10
fp16 = dict(mode=AMP_TYPE.NAIVE)
clip_grad_norm = 1.0
-
-# pipeline config
-NUM_MICRO_BATCHES = parallel['pipeline']
diff --git a/examples/tutorial/large_batch_optimizer/requirements.txt b/examples/tutorial/large_batch_optimizer/requirements.txt
index 137a69e80..c01328775 100644
--- a/examples/tutorial/large_batch_optimizer/requirements.txt
+++ b/examples/tutorial/large_batch_optimizer/requirements.txt
@@ -1,2 +1,3 @@
-colossalai >= 0.1.12
-torch >= 1.8.1
+colossalai
+torch
+titans
diff --git a/examples/tutorial/large_batch_optimizer/test_ci.sh b/examples/tutorial/large_batch_optimizer/test_ci.sh
new file mode 100644
index 000000000..89f426c54
--- /dev/null
+++ b/examples/tutorial/large_batch_optimizer/test_ci.sh
@@ -0,0 +1,8 @@
+#!/bin/bash
+set -euxo pipefail
+
+pip install -r requirements.txt
+
+# run test
+colossalai run --nproc_per_node 4 --master_port 29500 train.py --config config.py --optimizer lars
+colossalai run --nproc_per_node 4 --master_port 29501 train.py --config config.py --optimizer lamb
diff --git a/examples/tutorial/large_batch_optimizer/train.py b/examples/tutorial/large_batch_optimizer/train.py
index d403c275d..35e54582f 100644
--- a/examples/tutorial/large_batch_optimizer/train.py
+++ b/examples/tutorial/large_batch_optimizer/train.py
@@ -1,19 +1,13 @@
-import os
-
import torch
-from titans.dataloader.cifar10 import build_cifar
-from titans.model.vit.vit import _create_vit_model
+import torch.nn as nn
+from torchvision.models import resnet18
from tqdm import tqdm
import colossalai
-from colossalai.context import ParallelMode
from colossalai.core import global_context as gpc
from colossalai.logging import get_dist_logger
-from colossalai.nn import CrossEntropyLoss
from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
from colossalai.nn.optimizer import Lamb, Lars
-from colossalai.pipeline.pipelinable import PipelinableContext
-from colossalai.utils import get_dataloader, is_using_pp
class DummyDataloader():
@@ -45,7 +39,10 @@ class DummyDataloader():
def main():
# initialize distributed setting
parser = colossalai.get_default_parser()
- parser.add_argument('-s', '--synthetic', action="store_true", help="whether use synthetic data")
+ parser.add_argument('--optimizer',
+ choices=['lars', 'lamb'],
+ help="Choose your large-batch optimizer",
+ required=True)
args = parser.parse_args()
# launch from torch
@@ -55,59 +52,22 @@ def main():
logger = get_dist_logger()
logger.info("initialized distributed environment", ranks=[0])
- if hasattr(gpc.config, 'LOG_PATH'):
- if gpc.get_global_rank() == 0:
- log_path = gpc.config.LOG_PATH
- if not os.path.exists(log_path):
- os.mkdir(log_path)
- logger.log_to_file(log_path)
+ # create synthetic dataloaders
+ train_dataloader = DummyDataloader(length=10, batch_size=gpc.config.BATCH_SIZE)
+ test_dataloader = DummyDataloader(length=5, batch_size=gpc.config.BATCH_SIZE)
- use_pipeline = is_using_pp()
-
- # create model
- model_kwargs = dict(img_size=gpc.config.IMG_SIZE,
- patch_size=gpc.config.PATCH_SIZE,
- hidden_size=gpc.config.HIDDEN_SIZE,
- depth=gpc.config.DEPTH,
- num_heads=gpc.config.NUM_HEADS,
- mlp_ratio=gpc.config.MLP_RATIO,
- num_classes=10,
- init_method='jax',
- checkpoint=gpc.config.CHECKPOINT)
-
- if use_pipeline:
- pipelinable = PipelinableContext()
- with pipelinable:
- model = _create_vit_model(**model_kwargs)
- pipelinable.to_layer_list()
- pipelinable.policy = "uniform"
- model = pipelinable.partition(1, gpc.pipeline_parallel_size, gpc.get_local_rank(ParallelMode.PIPELINE))
- else:
- model = _create_vit_model(**model_kwargs)
-
- # count number of parameters
- total_numel = 0
- for p in model.parameters():
- total_numel += p.numel()
- if not gpc.is_initialized(ParallelMode.PIPELINE):
- pipeline_stage = 0
- else:
- pipeline_stage = gpc.get_local_rank(ParallelMode.PIPELINE)
- logger.info(f"number of parameters: {total_numel} on pipeline stage {pipeline_stage}")
-
- # create dataloaders
- root = os.environ.get('DATA', '../data/')
- if args.synthetic:
- train_dataloader = DummyDataloader(length=30, batch_size=gpc.config.BATCH_SIZE)
- test_dataloader = DummyDataloader(length=10, batch_size=gpc.config.BATCH_SIZE)
- else:
- train_dataloader, test_dataloader = build_cifar(gpc.config.BATCH_SIZE, root, pad_if_needed=True)
+ # build model
+ model = resnet18(num_classes=gpc.config.NUM_CLASSES)
# create loss function
- criterion = CrossEntropyLoss(label_smoothing=0.1)
+ criterion = nn.CrossEntropyLoss()
# create optimizer
- optimizer = Lars(model.parameters(), lr=gpc.config.LEARNING_RATE, weight_decay=gpc.config.WEIGHT_DECAY)
+ if args.optimizer == "lars":
+ optim_cls = Lars
+ elif args.optimizer == "lamb":
+ optim_cls = Lamb
+ optimizer = optim_cls(model.parameters(), lr=gpc.config.LEARNING_RATE, weight_decay=gpc.config.WEIGHT_DECAY)
# create lr scheduler
lr_scheduler = CosineAnnealingWarmupLR(optimizer=optimizer,
diff --git a/examples/tutorial/sequence_parallel/README.md b/examples/tutorial/sequence_parallel/README.md
index 7058f53db..1b7c60e22 100644
--- a/examples/tutorial/sequence_parallel/README.md
+++ b/examples/tutorial/sequence_parallel/README.md
@@ -1,139 +1,56 @@
-# Sequence Parallelism with BERT
+# Sequence Parallelism
-In this example, we implemented BERT with sequence parallelism. Sequence parallelism splits the input tensor and intermediate
+## Table of contents
+
+- [Sequence Parallelism](#sequence-parallelism)
+ - [Table of contents](#table-of-contents)
+ - [📚 Overview](#-overview)
+ - [🚀 Quick Start](#-quick-start)
+ - [🏎 How to Train with Sequence Parallelism](#-how-to-train-with-sequence-parallelism)
+ - [Step 1. Configure your parameters](#step-1-configure-your-parameters)
+ - [Step 2. Invoke parallel training](#step-2-invoke-parallel-training)
+
+## 📚 Overview
+
+In this tutorial, we implemented BERT with sequence parallelism. Sequence parallelism splits the input tensor and intermediate
activation along the sequence dimension. This method can achieve better memory efficiency and allows us to train with larger batch size and longer sequence length.
Paper: [Sequence Parallelism: Long Sequence Training from System Perspective](https://arxiv.org/abs/2105.13120)
-## 🚀Quick Start
-1. Run with the following command
+## 🚀 Quick Start
+
+1. Install PyTorch
+
+2. Install the dependencies.
+
+```bash
+pip install -r requirements.txt
+```
+
+3. Run with the following command
+
```bash
export PYTHONPATH=$PWD
-colossalai run --nproc_per_node 4 train.py -s
-```
-2. The default config is sequence parallel size = 2, pipeline size = 1, let’s change pipeline size to be 2 and try it again.
-
-## How to Prepare WikiPedia Dataset
-
-First, let's prepare the WikiPedia dataset from scratch. To generate a preprocessed dataset, we need four items:
-1. raw WikiPedia dataset
-2. wikipedia extractor (extract data from the raw dataset)
-3. vocabulary file
-4. preprocessing scripts (generate final data from extracted data)
-
-For the preprocessing script, we thank Megatron-LM for providing a preprocessing script to generate the corpus file.
-
-```python
-# download raw data
-mkdir data && cd ./data
-wget https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-pages-articles.xml.bz2
-
-# install wiki extractor
-git clone https://github.com/FrankLeeeee/wikiextractor.git
-pip install ./wikiextractor
-
-# extractmodule
-wikiextractor --json enwiki-latest-pages-articles.xml.bz2
-cat text/*/* > ./corpus.json
-cd ..
-
-# download vocab file
-mkdir vocab && cd ./vocab
-wget https://s3.amazonaws.com/models.huggingface.co/bert/bert-large-uncased-vocab.txt
-cd ..
-
-# preprocess some data
-git clone https://github.com/NVIDIA/Megatron-LM.git
-cd ./Megatron-LM
-python tools/preprocess_data.py \
- --input ../data/corpus.json \
- --output-prefix my-bert \
- --vocab ../vocab/bert-large-uncased-vocab.txt \
- --dataset-impl mmap \
- --tokenizer-type BertWordPieceLowerCase \
- --split-sentences \
- --workers 24
+# run with synthetic dataset
+colossalai run --nproc_per_node 4 train.py
```
-After running the preprocessing scripts, you will obtain two files:
-1. my-bert_text_sentence.bin
-2. my-bert_text_sentence.idx
+> The default config is sequence parallel size = 2, pipeline size = 1, let’s change pipeline size to be 2 and try it again.
-If you happen to encouter `index out of range` problem when running Megatron's script,
-this is probably because that a sentence starts with a punctuation and cannot be tokenized. A work-around is to update `Encoder.encode` method with the code below:
-```python
-class Encoder(object):
- def __init__(self, args):
- ...
-
- def initializer(self):
- ...
-
- def encode(self, json_line):
- data = json.loads(json_line)
- ids = {}
- for key in self.args.json_keys:
- text = data[key]
- doc_ids = []
-
- # lsg: avoid sentences which start with a punctuation
- # as it cannot be tokenized by splitter
- if len(text) > 0 and text[0] in string.punctuation:
- text = text[1:]
-
- for sentence in Encoder.splitter.tokenize(text):
- sentence_ids = Encoder.tokenizer.tokenize(sentence)
- if len(sentence_ids) > 0:
- doc_ids.append(sentence_ids)
- if len(doc_ids) > 0 and self.args.append_eod:
- doc_ids[-1].append(Encoder.tokenizer.eod)
- ids[key] = doc_ids
- return ids, len(json_line)
-```
-
-## How to Train with Sequence Parallelism
+## 🏎 How to Train with Sequence Parallelism
We provided `train.py` for you to execute training. Before invoking the script, there are several
steps to perform.
-### Step 1. Set data path and vocab path
-
-At the top of `config.py`, you can see two global variables `DATA_PATH` and `VOCAB_FILE_PATH`.
-
-```python
-DATA_PATH =
-VOCAB_FILE_PATH =
-```
-
-`DATA_PATH` refers to the path to the data file generated by Megatron's script. For example, in the section above, you should get two data files (my-bert_text_sentence.bin and my-bert_text_sentence.idx). You just need to `DATA_PATH` to the path to the bin file without the file extension.
-
-For example, if your my-bert_text_sentence.bin is /home/Megatron-LM/my-bert_text_sentence.bin, then you should set
-
-```python
-DATA_PATH = '/home/Megatron-LM/my-bert_text_sentence'
-```
-
-The `VOCAB_FILE_PATH` refers to the path to the vocabulary downloaded when you prepare the dataset
-(e.g. bert-large-uncased-vocab.txt).
-
-### Step 3. Make Dataset Helper
-
-Build BERT dataset helper. Requirements are `CUDA`, `g++`, `pybind11` and `make`.
-
-```python
-cd ./data/datasets
-make
-```
-
-### Step 3. Configure your parameters
+### Step 1. Configure your parameters
In the `config.py` provided, a set of parameters are defined including training scheme, model, etc.
You can also modify the ColossalAI setting. For example, if you wish to parallelize over the
sequence dimension on 8 GPUs. You can change `size=4` to `size=8`. If you wish to use pipeline parallelism, you can set `pipeline=`.
-### Step 4. Invoke parallel training
+### Step 2. Invoke parallel training
Lastly, you can start training with sequence parallelism. How you invoke `train.py` depends on your
machine setting.
diff --git a/examples/tutorial/sequence_parallel/config.py b/examples/tutorial/sequence_parallel/config.py
index df0c5282f..6edf9cc2c 100644
--- a/examples/tutorial/sequence_parallel/config.py
+++ b/examples/tutorial/sequence_parallel/config.py
@@ -1,11 +1,8 @@
from colossalai.amp import AMP_TYPE
-DATA_PATH = ''
-VOCAB_FILE_PATH = ''
-
# hyper-parameters
-TRAIN_ITERS = 1000000
-DECAY_ITERS = 990000
+TRAIN_ITERS = 10
+DECAY_ITERS = 4
WARMUP_FRACTION = 0.01
GLOBAL_BATCH_SIZE = 32 # dp world size * sentences per GPU
EVAL_ITERS = 10
@@ -13,12 +10,12 @@ EVAL_INTERVAL = 10
LR = 0.0001
MIN_LR = 1e-05
WEIGHT_DECAY = 0.01
-SEQ_LENGTH = 512
+SEQ_LENGTH = 128
# BERT config
-DEPTH = 12
-NUM_ATTENTION_HEADS = 12
-HIDDEN_SIZE = 768
+DEPTH = 4
+NUM_ATTENTION_HEADS = 4
+HIDDEN_SIZE = 128
# model config
ADD_BINARY_HEAD = False
diff --git a/examples/tutorial/sequence_parallel/requirements.txt b/examples/tutorial/sequence_parallel/requirements.txt
index 137a69e80..b49a94554 100644
--- a/examples/tutorial/sequence_parallel/requirements.txt
+++ b/examples/tutorial/sequence_parallel/requirements.txt
@@ -1,2 +1,2 @@
-colossalai >= 0.1.12
-torch >= 1.8.1
+colossalai
+torch
diff --git a/examples/tutorial/sequence_parallel/test_ci.sh b/examples/tutorial/sequence_parallel/test_ci.sh
new file mode 100644
index 000000000..7bc20de3b
--- /dev/null
+++ b/examples/tutorial/sequence_parallel/test_ci.sh
@@ -0,0 +1,7 @@
+#!/bin/bash
+set -euxo pipefail
+
+pip install -r requirements.txt
+
+# run test
+colossalai run --nproc_per_node 4 train.py
diff --git a/examples/tutorial/sequence_parallel/train.py b/examples/tutorial/sequence_parallel/train.py
index b92061000..a89747b58 100644
--- a/examples/tutorial/sequence_parallel/train.py
+++ b/examples/tutorial/sequence_parallel/train.py
@@ -1,9 +1,8 @@
import argparse
import torch
-from data import build_train_valid_test_data_iterators
from data.bert_helper import SequenceParallelDataIterator, get_batch_for_sequence_parallel
-from data.tokenizer import get_padded_vocab_size, initialize_tokenizer
+from data.dummy_dataloader import DummyDataloader
from loss_func.bert_loss import BertLoss
from lr_scheduler import AnnealingLR
from model.bert import BertForPretrain, build_pipeline_bert
@@ -36,7 +35,7 @@ def parse_args():
def pipeline_data_process_func(stage_output, micro_batch_data):
- tokens, types, sentence_order, loss_mask, lm_labels, padding_mask = micro_batch_data
+ tokens, types, sentence_order, loss_mask, lm_labels, padding_mask = micro_batch_data
if gpc.is_first_rank(ParallelMode.PIPELINE):
data = (tokens, padding_mask, types, lm_labels)
label = (loss_mask, sentence_order)
@@ -53,36 +52,15 @@ def main():
logger = get_dist_logger()
- # build dataloader
- if not args.synthetic:
- initialize_tokenizer(gpc.config.VOCAB_FILE_PATH, tokenizer_type='BertWordPieceLowerCase')
- VOCAB_SIZE = get_padded_vocab_size()
- trainloader, validloader, testloader = build_train_valid_test_data_iterators(
- train_iters=gpc.config.TRAIN_ITERS,
- global_batch_size=gpc.config.GLOBAL_BATCH_SIZE,
- eval_interval=gpc.config.EVAL_INTERVAL,
- eval_iters=gpc.config.EVAL_ITERS,
- data_prefix=[gpc.config.DATA_PATH],
- data_impl='mmap',
- splits_string='949,50,1',
- max_seq_length=gpc.config.SEQ_LENGTH,
- masked_lm_prob=0.15,
- short_seq_prob=0.1,
- seed=1234,
- skip_warmup=True,
- binary_head=False,
- )
- else:
- from data.dummy_dataloader import DummyDataloader
-
- BATCH_SIZE_PER_GPUS = gpc.config.GLOBAL_BATCH_SIZE // gpc.get_world_size(ParallelMode.DATA)
- VOCAB_SIZE = 30528
- trainloader = DummyDataloader(batch_size=BATCH_SIZE_PER_GPUS,
- vocab_size=VOCAB_SIZE,
- seq_length=gpc.config.SEQ_LENGTH)
- validloader = DummyDataloader(batch_size=BATCH_SIZE_PER_GPUS,
- vocab_size=VOCAB_SIZE,
- seq_length=gpc.config.SEQ_LENGTH)
+ # build synthetic dataloader
+ BATCH_SIZE_PER_GPUS = gpc.config.GLOBAL_BATCH_SIZE // gpc.get_world_size(ParallelMode.DATA)
+ VOCAB_SIZE = 30528
+ trainloader = DummyDataloader(batch_size=BATCH_SIZE_PER_GPUS,
+ vocab_size=VOCAB_SIZE,
+ seq_length=gpc.config.SEQ_LENGTH)
+ validloader = DummyDataloader(batch_size=BATCH_SIZE_PER_GPUS,
+ vocab_size=VOCAB_SIZE,
+ seq_length=gpc.config.SEQ_LENGTH)
logger.info("Dataloaders are built", ranks=[0])
diff --git a/examples/tutorial/stable_diffusion/LICENSE b/examples/tutorial/stable_diffusion/LICENSE
deleted file mode 100644
index 0e609df0d..000000000
--- a/examples/tutorial/stable_diffusion/LICENSE
+++ /dev/null
@@ -1,82 +0,0 @@
-Copyright (c) 2022 Robin Rombach and Patrick Esser and contributors
-
-CreativeML Open RAIL-M
-dated August 22, 2022
-
-Section I: PREAMBLE
-
-Multimodal generative models are being widely adopted and used, and have the potential to transform the way artists, among other individuals, conceive and benefit from AI or ML technologies as a tool for content creation.
-
-Notwithstanding the current and potential benefits that these artifacts can bring to society at large, there are also concerns about potential misuses of them, either due to their technical limitations or ethical considerations.
-
-In short, this license strives for both the open and responsible downstream use of the accompanying model. When it comes to the open character, we took inspiration from open source permissive licenses regarding the grant of IP rights. Referring to the downstream responsible use, we added use-based restrictions not permitting the use of the Model in very specific scenarios, in order for the licensor to be able to enforce the license in case potential misuses of the Model may occur. At the same time, we strive to promote open and responsible research on generative models for art and content generation.
-
-Even though downstream derivative versions of the model could be released under different licensing terms, the latter will always have to include - at minimum - the same use-based restrictions as the ones in the original license (this license). We believe in the intersection between open and responsible AI development; thus, this License aims to strike a balance between both in order to enable responsible open-science in the field of AI.
-
-This License governs the use of the model (and its derivatives) and is informed by the model card associated with the model.
-
-NOW THEREFORE, You and Licensor agree as follows:
-
-1. Definitions
-
-- "License" means the terms and conditions for use, reproduction, and Distribution as defined in this document.
-- "Data" means a collection of information and/or content extracted from the dataset used with the Model, including to train, pretrain, or otherwise evaluate the Model. The Data is not licensed under this License.
-- "Output" means the results of operating a Model as embodied in informational content resulting therefrom.
-- "Model" means any accompanying machine-learning based assemblies (including checkpoints), consisting of learnt weights, parameters (including optimizer states), corresponding to the model architecture as embodied in the Complementary Material, that have been trained or tuned, in whole or in part on the Data, using the Complementary Material.
-- "Derivatives of the Model" means all modifications to the Model, works based on the Model, or any other model which is created or initialized by transfer of patterns of the weights, parameters, activations or output of the Model, to the other model, in order to cause the other model to perform similarly to the Model, including - but not limited to - distillation methods entailing the use of intermediate data representations or methods based on the generation of synthetic data by the Model for training the other model.
-- "Complementary Material" means the accompanying source code and scripts used to define, run, load, benchmark or evaluate the Model, and used to prepare data for training or evaluation, if any. This includes any accompanying documentation, tutorials, examples, etc, if any.
-- "Distribution" means any transmission, reproduction, publication or other sharing of the Model or Derivatives of the Model to a third party, including providing the Model as a hosted service made available by electronic or other remote means - e.g. API-based or web access.
-- "Licensor" means the copyright owner or entity authorized by the copyright owner that is granting the License, including the persons or entities that may have rights in the Model and/or distributing the Model.
-- "You" (or "Your") means an individual or Legal Entity exercising permissions granted by this License and/or making use of the Model for whichever purpose and in any field of use, including usage of the Model in an end-use application - e.g. chatbot, translator, image generator.
-- "Third Parties" means individuals or legal entities that are not under common control with Licensor or You.
-- "Contribution" means any work of authorship, including the original version of the Model and any modifications or additions to that Model or Derivatives of the Model thereof, that is intentionally submitted to Licensor for inclusion in the Model by the copyright owner or by an individual or Legal Entity authorized to submit on behalf of the copyright owner. For the purposes of this definition, "submitted" means any form of electronic, verbal, or written communication sent to the Licensor or its representatives, including but not limited to communication on electronic mailing lists, source code control systems, and issue tracking systems that are managed by, or on behalf of, the Licensor for the purpose of discussing and improving the Model, but excluding communication that is conspicuously marked or otherwise designated in writing by the copyright owner as "Not a Contribution."
-- "Contributor" means Licensor and any individual or Legal Entity on behalf of whom a Contribution has been received by Licensor and subsequently incorporated within the Model.
-
-Section II: INTELLECTUAL PROPERTY RIGHTS
-
-Both copyright and patent grants apply to the Model, Derivatives of the Model and Complementary Material. The Model and Derivatives of the Model are subject to additional terms as described in Section III.
-
-2. Grant of Copyright License. Subject to the terms and conditions of this License, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable copyright license to reproduce, prepare, publicly display, publicly perform, sublicense, and distribute the Complementary Material, the Model, and Derivatives of the Model.
-3. Grant of Patent License. Subject to the terms and conditions of this License and where and as applicable, each Contributor hereby grants to You a perpetual, worldwide, non-exclusive, no-charge, royalty-free, irrevocable (except as stated in this paragraph) patent license to make, have made, use, offer to sell, sell, import, and otherwise transfer the Model and the Complementary Material, where such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Model to which such Contribution(s) was submitted. If You institute patent litigation against any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Model and/or Complementary Material or a Contribution incorporated within the Model and/or Complementary Material constitutes direct or contributory patent infringement, then any patent licenses granted to You under this License for the Model and/or Work shall terminate as of the date such litigation is asserted or filed.
-
-Section III: CONDITIONS OF USAGE, DISTRIBUTION AND REDISTRIBUTION
-
-4. Distribution and Redistribution. You may host for Third Party remote access purposes (e.g. software-as-a-service), reproduce and distribute copies of the Model or Derivatives of the Model thereof in any medium, with or without modifications, provided that You meet the following conditions:
-Use-based restrictions as referenced in paragraph 5 MUST be included as an enforceable provision by You in any type of legal agreement (e.g. a license) governing the use and/or distribution of the Model or Derivatives of the Model, and You shall give notice to subsequent users You Distribute to, that the Model or Derivatives of the Model are subject to paragraph 5. This provision does not apply to the use of Complementary Material.
-You must give any Third Party recipients of the Model or Derivatives of the Model a copy of this License;
-You must cause any modified files to carry prominent notices stating that You changed the files;
-You must retain all copyright, patent, trademark, and attribution notices excluding those notices that do not pertain to any part of the Model, Derivatives of the Model.
-You may add Your own copyright statement to Your modifications and may provide additional or different license terms and conditions - respecting paragraph 4.a. - for use, reproduction, or Distribution of Your modifications, or for any such Derivatives of the Model as a whole, provided Your use, reproduction, and Distribution of the Model otherwise complies with the conditions stated in this License.
-5. Use-based restrictions. The restrictions set forth in Attachment A are considered Use-based restrictions. Therefore You cannot use the Model and the Derivatives of the Model for the specified restricted uses. You may use the Model subject to this License, including only for lawful purposes and in accordance with the License. Use may include creating any content with, finetuning, updating, running, training, evaluating and/or reparametrizing the Model. You shall require all of Your users who use the Model or a Derivative of the Model to comply with the terms of this paragraph (paragraph 5).
-6. The Output You Generate. Except as set forth herein, Licensor claims no rights in the Output You generate using the Model. You are accountable for the Output you generate and its subsequent uses. No use of the output can contravene any provision as stated in the License.
-
-Section IV: OTHER PROVISIONS
-
-7. Updates and Runtime Restrictions. To the maximum extent permitted by law, Licensor reserves the right to restrict (remotely or otherwise) usage of the Model in violation of this License, update the Model through electronic means, or modify the Output of the Model based on updates. You shall undertake reasonable efforts to use the latest version of the Model.
-8. Trademarks and related. Nothing in this License permits You to make use of Licensors’ trademarks, trade names, logos or to otherwise suggest endorsement or misrepresent the relationship between the parties; and any rights not expressly granted herein are reserved by the Licensors.
-9. Disclaimer of Warranty. Unless required by applicable law or agreed to in writing, Licensor provides the Model and the Complementary Material (and each Contributor provides its Contributions) on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied, including, without limitation, any warranties or conditions of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A PARTICULAR PURPOSE. You are solely responsible for determining the appropriateness of using or redistributing the Model, Derivatives of the Model, and the Complementary Material and assume any risks associated with Your exercise of permissions under this License.
-10. Limitation of Liability. In no event and under no legal theory, whether in tort (including negligence), contract, or otherwise, unless required by applicable law (such as deliberate and grossly negligent acts) or agreed to in writing, shall any Contributor be liable to You for damages, including any direct, indirect, special, incidental, or consequential damages of any character arising as a result of this License or out of the use or inability to use the Model and the Complementary Material (including but not limited to damages for loss of goodwill, work stoppage, computer failure or malfunction, or any and all other commercial damages or losses), even if such Contributor has been advised of the possibility of such damages.
-11. Accepting Warranty or Additional Liability. While redistributing the Model, Derivatives of the Model and the Complementary Material thereof, You may choose to offer, and charge a fee for, acceptance of support, warranty, indemnity, or other liability obligations and/or rights consistent with this License. However, in accepting such obligations, You may act only on Your own behalf and on Your sole responsibility, not on behalf of any other Contributor, and only if You agree to indemnify, defend, and hold each Contributor harmless for any liability incurred by, or claims asserted against, such Contributor by reason of your accepting any such warranty or additional liability.
-12. If any provision of this License is held to be invalid, illegal or unenforceable, the remaining provisions shall be unaffected thereby and remain valid as if such provision had not been set forth herein.
-
-END OF TERMS AND CONDITIONS
-
-
-
-
-Attachment A
-
-Use Restrictions
-
-You agree not to use the Model or Derivatives of the Model:
-- In any way that violates any applicable national, federal, state, local or international law or regulation;
-- For the purpose of exploiting, harming or attempting to exploit or harm minors in any way;
-- To generate or disseminate verifiably false information and/or content with the purpose of harming others;
-- To generate or disseminate personal identifiable information that can be used to harm an individual;
-- To defame, disparage or otherwise harass others;
-- For fully automated decision making that adversely impacts an individual’s legal rights or otherwise creates or modifies a binding, enforceable obligation;
-- For any use intended to or which has the effect of discriminating against or harming individuals or groups based on online or offline social behavior or known or predicted personal or personality characteristics;
-- To exploit any of the vulnerabilities of a specific group of persons based on their age, social, physical or mental characteristics, in order to materially distort the behavior of a person pertaining to that group in a manner that causes or is likely to cause that person or another person physical or psychological harm;
-- For any use intended to or which has the effect of discriminating against individuals or groups based on legally protected characteristics or categories;
-- To provide medical advice and medical results interpretation;
-- To generate or disseminate information for the purpose to be used for administration of justice, law enforcement, immigration or asylum processes, such as predicting an individual will commit fraud/crime commitment (e.g. by text profiling, drawing causal relationships between assertions made in documents, indiscriminate and arbitrarily-targeted use).
diff --git a/examples/tutorial/stable_diffusion/README.md b/examples/tutorial/stable_diffusion/README.md
deleted file mode 100644
index a0ece4485..000000000
--- a/examples/tutorial/stable_diffusion/README.md
+++ /dev/null
@@ -1,149 +0,0 @@
-# Stable Diffusion with Colossal-AI
-*[Colosssal-AI](https://github.com/hpcaitech/ColossalAI) provides a faster and lower cost solution for pretraining and
-fine-tuning for AIGC (AI-Generated Content) applications such as the model [stable-diffusion](https://github.com/CompVis/stable-diffusion) from [Stability AI](https://stability.ai/).*
-
-We take advantage of [Colosssal-AI](https://github.com/hpcaitech/ColossalAI) to exploit multiple optimization strategies
-, e.g. data parallelism, tensor parallelism, mixed precision & ZeRO, to scale the training to multiple GPUs.
-
-## 🚀Quick Start
-1. Create a new environment for diffusion
-```bash
-conda env create -f environment.yaml
-conda activate ldm
-```
-2. Install Colossal-AI from our official page
-```bash
-pip install colossalai==0.1.10+torch1.11cu11.3 -f https://release.colossalai.org
-```
-3. Install PyTorch Lightning compatible commit
-```bash
-git clone https://github.com/Lightning-AI/lightning && cd lightning && git reset --hard b04a7aa
-pip install -r requirements.txt && pip install .
-cd ..
-```
-
-4. Comment out the `from_pretrained` field in the `train_colossalai_cifar10.yaml`.
-5. Run training with CIFAR10.
-```bash
-python main.py -logdir /tmp -t true -postfix test -b configs/train_colossalai_cifar10.yaml
-```
-
-## Stable Diffusion
-[Stable Diffusion](https://huggingface.co/CompVis/stable-diffusion) is a latent text-to-image diffusion
-model.
-Thanks to a generous compute donation from [Stability AI](https://stability.ai/) and support from [LAION](https://laion.ai/), we were able to train a Latent Diffusion Model on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database.
-Similar to Google's [Imagen](https://arxiv.org/abs/2205.11487),
-this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts.
-
-
-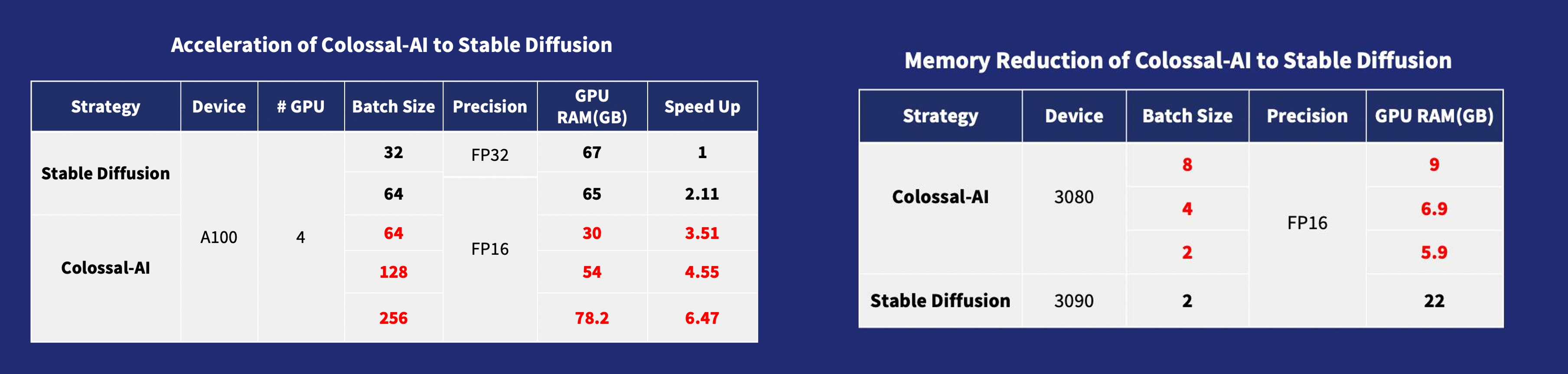 -
-
-
-[Stable Diffusion with Colossal-AI](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion) provides **6.5x faster training and pretraining cost saving, the hardware cost of fine-tuning can be almost 7X cheaper** (from RTX3090/4090 24GB to RTX3050/2070 8GB).
-
-
- -
-
-
-## Requirements
-A suitable [conda](https://conda.io/) environment named `ldm` can be created
-and activated with:
-
-```
-conda env create -f environment.yaml
-conda activate ldm
-```
-
-You can also update an existing [latent diffusion](https://github.com/CompVis/latent-diffusion) environment by running
-
-```
-conda install pytorch torchvision -c pytorch
-pip install transformers==4.19.2 diffusers invisible-watermark
-pip install -e .
-```
-
-### Install [Colossal-AI v0.1.10](https://colossalai.org/download/) From Our Official Website
-```
-pip install colossalai==0.1.10+torch1.11cu11.3 -f https://release.colossalai.org
-```
-
-### Install [Lightning](https://github.com/Lightning-AI/lightning)
-We use the Sep. 2022 version with commit id as `b04a7aa`.
-```
-git clone https://github.com/Lightning-AI/lightning && cd lightning && git reset --hard b04a7aa
-pip install -r requirements.txt && pip install .
-```
-
-> The specified version is due to the interface incompatibility caused by the latest update of [Lightning](https://github.com/Lightning-AI/lightning), which will be fixed in the near future.
-
-## Dataset
-The dataSet is from [LAION-5B](https://laion.ai/blog/laion-5b/), the subset of [LAION](https://laion.ai/),
-you should the change the `data.file_path` in the `config/train_colossalai.yaml`
-
-## Training
-
-We provide the script `train.sh` to run the training task , and two Stategy in `configs`:`train_colossalai.yaml`
-
-For example, you can run the training from colossalai by
-```
-python main.py --logdir /tmp -t --postfix test -b configs/train_colossalai.yaml
-```
-
-- you can change the `--logdir` the save the log information and the last checkpoint
-
-### Training config
-You can change the trainging config in the yaml file
-
-- accelerator: acceleratortype, default 'gpu'
-- devices: device number used for training, default 4
-- max_epochs: max training epochs
-- precision: usefp16 for training or not, default 16, you must use fp16 if you want to apply colossalai
-
-## Example
-
-### Training on cifar10
-
-We provide the finetuning example on CIFAR10 dataset
-
-You can run by config `train_colossalai_cifar10.yaml`
-```
-python main.py --logdir /tmp -t --postfix test -b configs/train_colossalai_cifar10.yaml
-```
-
-
-
-## Comments
-
-- Our codebase for the diffusion models builds heavily on [OpenAI's ADM codebase](https://github.com/openai/guided-diffusion)
-, [lucidrains](https://github.com/lucidrains/denoising-diffusion-pytorch),
-[Stable Diffusion](https://github.com/CompVis/stable-diffusion), [Lightning](https://github.com/Lightning-AI/lightning) and [Hugging Face](https://huggingface.co/CompVis/stable-diffusion).
-Thanks for open-sourcing!
-
-- The implementation of the transformer encoder is from [x-transformers](https://github.com/lucidrains/x-transformers) by [lucidrains](https://github.com/lucidrains?tab=repositories).
-
-- The implementation of [flash attention](https://github.com/HazyResearch/flash-attention) is from [HazyResearch](https://github.com/HazyResearch).
-
-## BibTeX
-
-```
-@article{bian2021colossal,
- title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
- author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
- journal={arXiv preprint arXiv:2110.14883},
- year={2021}
-}
-@misc{rombach2021highresolution,
- title={High-Resolution Image Synthesis with Latent Diffusion Models},
- author={Robin Rombach and Andreas Blattmann and Dominik Lorenz and Patrick Esser and Björn Ommer},
- year={2021},
- eprint={2112.10752},
- archivePrefix={arXiv},
- primaryClass={cs.CV}
-}
-@article{dao2022flashattention,
- title={FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness},
- author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{\'e}, Christopher},
- journal={arXiv preprint arXiv:2205.14135},
- year={2022}
-}
-```
diff --git a/examples/tutorial/stable_diffusion/configs/train_colossalai.yaml b/examples/tutorial/stable_diffusion/configs/train_colossalai.yaml
deleted file mode 100644
index c457787dd..000000000
--- a/examples/tutorial/stable_diffusion/configs/train_colossalai.yaml
+++ /dev/null
@@ -1,116 +0,0 @@
-model:
- base_learning_rate: 1.0e-04
- target: ldm.models.diffusion.ddpm.LatentDiffusion
- params:
- linear_start: 0.00085
- linear_end: 0.0120
- num_timesteps_cond: 1
- log_every_t: 200
- timesteps: 1000
- first_stage_key: image
- cond_stage_key: caption
- image_size: 64
- channels: 4
- cond_stage_trainable: false # Note: different from the one we trained before
- conditioning_key: crossattn
- monitor: val/loss_simple_ema
- scale_factor: 0.18215
- use_ema: False
-
- scheduler_config: # 10000 warmup steps
- target: ldm.lr_scheduler.LambdaLinearScheduler
- params:
- warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
- cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
- f_start: [ 1.e-6 ]
- f_max: [ 1.e-4 ]
- f_min: [ 1.e-10 ]
-
- unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- image_size: 32 # unused
- from_pretrained: '/data/scratch/diffuser/stable-diffusion-v1-4/unet/diffusion_pytorch_model.bin'
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_heads: 8
- use_spatial_transformer: True
- transformer_depth: 1
- context_dim: 768
- use_checkpoint: False
- legacy: False
-
- first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- from_pretrained: '/data/scratch/diffuser/stable-diffusion-v1-4/vae/diffusion_pytorch_model.bin'
- monitor: val/rec_loss
- ddconfig:
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
-
- cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
- params:
- use_fp16: True
-
-data:
- target: main.DataModuleFromConfig
- params:
- batch_size: 64
- wrap: False
- train:
- target: ldm.data.base.Txt2ImgIterableBaseDataset
- params:
- file_path: "/data/scratch/diffuser/laion_part0/"
- world_size: 1
- rank: 0
-
-lightning:
- trainer:
- accelerator: 'gpu'
- devices: 4
- log_gpu_memory: all
- max_epochs: 2
- precision: 16
- auto_select_gpus: False
- strategy:
- target: pytorch_lightning.strategies.ColossalAIStrategy
- params:
- use_chunk: False
- enable_distributed_storage: True,
- placement_policy: cuda
- force_outputs_fp32: False
-
- log_every_n_steps: 2
- logger: True
- default_root_dir: "/tmp/diff_log/"
- profiler: pytorch
-
- logger_config:
- wandb:
- target: pytorch_lightning.loggers.WandbLogger
- params:
- name: nowname
- save_dir: "/tmp/diff_log/"
- offline: opt.debug
- id: nowname
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/configs/train_colossalai_cifar10.yaml b/examples/tutorial/stable_diffusion/configs/train_colossalai_cifar10.yaml
deleted file mode 100644
index 63b9d1c01..000000000
--- a/examples/tutorial/stable_diffusion/configs/train_colossalai_cifar10.yaml
+++ /dev/null
@@ -1,123 +0,0 @@
-model:
- base_learning_rate: 1.0e-04
- target: ldm.models.diffusion.ddpm.LatentDiffusion
- params:
- linear_start: 0.00085
- linear_end: 0.0120
- num_timesteps_cond: 1
- log_every_t: 200
- timesteps: 1000
- first_stage_key: image
- cond_stage_key: txt
- image_size: 64
- channels: 4
- cond_stage_trainable: false # Note: different from the one we trained before
- conditioning_key: crossattn
- monitor: val/loss_simple_ema
- scale_factor: 0.18215
- use_ema: False
-
- scheduler_config: # 10000 warmup steps
- target: ldm.lr_scheduler.LambdaLinearScheduler
- params:
- warm_up_steps: [ 1 ] # NOTE for resuming. use 10000 if starting from scratch
- cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
- f_start: [ 1.e-6 ]
- f_max: [ 1.e-4 ]
- f_min: [ 1.e-10 ]
-
- unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- image_size: 32 # unused
- from_pretrained: '/data/scratch/diffuser/stable-diffusion-v1-4/unet/diffusion_pytorch_model.bin'
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_heads: 8
- use_spatial_transformer: True
- transformer_depth: 1
- context_dim: 768
- use_checkpoint: False
- legacy: False
-
- first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- from_pretrained: '/data/scratch/diffuser/stable-diffusion-v1-4/vae/diffusion_pytorch_model.bin'
- monitor: val/rec_loss
- ddconfig:
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
-
- cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
- params:
- use_fp16: True
-
-data:
- target: main.DataModuleFromConfig
- params:
- batch_size: 4
- num_workers: 4
- train:
- target: ldm.data.cifar10.hf_dataset
- params:
- name: cifar10
- image_transforms:
- - target: torchvision.transforms.Resize
- params:
- size: 512
- interpolation: 3
- - target: torchvision.transforms.RandomCrop
- params:
- size: 512
- - target: torchvision.transforms.RandomHorizontalFlip
-
-lightning:
- trainer:
- accelerator: 'gpu'
- devices: 2
- log_gpu_memory: all
- max_epochs: 2
- precision: 16
- auto_select_gpus: False
- strategy:
- target: pytorch_lightning.strategies.ColossalAIStrategy
- params:
- use_chunk: False
- enable_distributed_storage: True,
- placement_policy: cuda
- force_outputs_fp32: False
-
- log_every_n_steps: 2
- logger: True
- default_root_dir: "/tmp/diff_log/"
- profiler: pytorch
-
- logger_config:
- wandb:
- target: pytorch_lightning.loggers.WandbLogger
- params:
- name: nowname
- save_dir: "/tmp/diff_log/"
- offline: opt.debug
- id: nowname
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/configs/train_ddp.yaml b/examples/tutorial/stable_diffusion/configs/train_ddp.yaml
deleted file mode 100644
index 90d41258f..000000000
--- a/examples/tutorial/stable_diffusion/configs/train_ddp.yaml
+++ /dev/null
@@ -1,113 +0,0 @@
-model:
- base_learning_rate: 1.0e-04
- target: ldm.models.diffusion.ddpm.LatentDiffusion
- params:
- linear_start: 0.00085
- linear_end: 0.0120
- num_timesteps_cond: 1
- log_every_t: 200
- timesteps: 1000
- first_stage_key: image
- cond_stage_key: caption
- image_size: 32
- channels: 4
- cond_stage_trainable: false # Note: different from the one we trained before
- conditioning_key: crossattn
- monitor: val/loss_simple_ema
- scale_factor: 0.18215
- use_ema: False
-
- scheduler_config: # 10000 warmup steps
- target: ldm.lr_scheduler.LambdaLinearScheduler
- params:
- warm_up_steps: [ 100 ]
- cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
- f_start: [ 1.e-6 ]
- f_max: [ 1.e-4 ]
- f_min: [ 1.e-10 ]
-
- unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- image_size: 32 # unused
- from_pretrained: '/data/scratch/diffuser/stable-diffusion-v1-4/unet/diffusion_pytorch_model.bin'
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_heads: 8
- use_spatial_transformer: True
- transformer_depth: 1
- context_dim: 768
- use_checkpoint: False
- legacy: False
-
- first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- from_pretrained: '/data/scratch/diffuser/stable-diffusion-v1-4/vae/diffusion_pytorch_model.bin'
- monitor: val/rec_loss
- ddconfig:
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
-
- cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
- params:
- use_fp16: True
-
-data:
- target: main.DataModuleFromConfig
- params:
- batch_size: 64
- wrap: False
- train:
- target: ldm.data.base.Txt2ImgIterableBaseDataset
- params:
- file_path: "/data/scratch/diffuser/laion_part0/"
- world_size: 1
- rank: 0
-
-lightning:
- trainer:
- accelerator: 'gpu'
- devices: 4
- log_gpu_memory: all
- max_epochs: 2
- precision: 16
- auto_select_gpus: False
- strategy:
- target: pytorch_lightning.strategies.DDPStrategy
- params:
- find_unused_parameters: False
- log_every_n_steps: 2
-# max_steps: 6o
- logger: True
- default_root_dir: "/tmp/diff_log/"
- # profiler: pytorch
-
- logger_config:
- wandb:
- target: pytorch_lightning.loggers.WandbLogger
- params:
- name: nowname
- save_dir: "/tmp/diff_log/"
- offline: opt.debug
- id: nowname
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/configs/train_pokemon.yaml b/examples/tutorial/stable_diffusion/configs/train_pokemon.yaml
deleted file mode 100644
index 8b5d2adfa..000000000
--- a/examples/tutorial/stable_diffusion/configs/train_pokemon.yaml
+++ /dev/null
@@ -1,121 +0,0 @@
-model:
- base_learning_rate: 1.0e-04
- target: ldm.models.diffusion.ddpm.LatentDiffusion
- params:
- linear_start: 0.00085
- linear_end: 0.0120
- num_timesteps_cond: 1
- log_every_t: 200
- timesteps: 1000
- first_stage_key: image
- cond_stage_key: caption
- image_size: 32
- channels: 4
- cond_stage_trainable: false # Note: different from the one we trained before
- conditioning_key: crossattn
- monitor: val/loss_simple_ema
- scale_factor: 0.18215
- use_ema: False
- check_nan_inf: False
-
- scheduler_config: # 10000 warmup steps
- target: ldm.lr_scheduler.LambdaLinearScheduler
- params:
- warm_up_steps: [ 10000 ]
- cycle_lengths: [ 10000000000000 ] # incredibly large number to prevent corner cases
- f_start: [ 1.e-6 ]
- f_max: [ 1.e-4 ]
- f_min: [ 1.e-10 ]
-
- unet_config:
- target: ldm.modules.diffusionmodules.openaimodel.UNetModel
- params:
- image_size: 32 # unused
- from_pretrained: '/data/scratch/diffuser/stable-diffusion-v1-4/unet/diffusion_pytorch_model.bin'
- in_channels: 4
- out_channels: 4
- model_channels: 320
- attention_resolutions: [ 4, 2, 1 ]
- num_res_blocks: 2
- channel_mult: [ 1, 2, 4, 4 ]
- num_heads: 8
- use_spatial_transformer: True
- transformer_depth: 1
- context_dim: 768
- use_checkpoint: False
- legacy: False
-
- first_stage_config:
- target: ldm.models.autoencoder.AutoencoderKL
- params:
- embed_dim: 4
- from_pretrained: '/data/scratch/diffuser/stable-diffusion-v1-4/vae/diffusion_pytorch_model.bin'
- monitor: val/rec_loss
- ddconfig:
- double_z: true
- z_channels: 4
- resolution: 256
- in_channels: 3
- out_ch: 3
- ch: 128
- ch_mult:
- - 1
- - 2
- - 4
- - 4
- num_res_blocks: 2
- attn_resolutions: []
- dropout: 0.0
- lossconfig:
- target: torch.nn.Identity
-
- cond_stage_config:
- target: ldm.modules.encoders.modules.FrozenCLIPEmbedder
- params:
- use_fp16: True
-
-data:
- target: main.DataModuleFromConfig
- params:
- batch_size: 32
- wrap: False
- train:
- target: ldm.data.pokemon.PokemonDataset
- # params:
- # file_path: "/data/scratch/diffuser/laion_part0/"
- # world_size: 1
- # rank: 0
-
-lightning:
- trainer:
- accelerator: 'gpu'
- devices: 4
- log_gpu_memory: all
- max_epochs: 2
- precision: 16
- auto_select_gpus: False
- strategy:
- target: pytorch_lightning.strategies.ColossalAIStrategy
- params:
- use_chunk: False
- enable_distributed_storage: True,
- placement_policy: cuda
- force_outputs_fp32: False
- initial_scale: 65536
- min_scale: 1
- max_scale: 65536
- # max_scale: 4294967296
-
- log_every_n_steps: 2
- logger: True
- default_root_dir: "/tmp/diff_log/"
- profiler: pytorch
-
- logger_config:
- wandb:
- target: pytorch_lightning.loggers.WandbLogger
- params:
- name: nowname
- save_dir: "/tmp/diff_log/"
- offline: opt.debug
- id: nowname
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/environment.yaml b/examples/tutorial/stable_diffusion/environment.yaml
deleted file mode 100644
index 7d8aec86f..000000000
--- a/examples/tutorial/stable_diffusion/environment.yaml
+++ /dev/null
@@ -1,34 +0,0 @@
-name: ldm
-channels:
- - pytorch
- - defaults
-dependencies:
- - python=3.9.12
- - pip=20.3
- - cudatoolkit=11.3
- - pytorch=1.11.0
- - torchvision=0.12.0
- - numpy=1.19.2
- - pip:
- - albumentations==0.4.3
- - datasets
- - diffusers
- - opencv-python==4.6.0.66
- - pudb==2019.2
- - invisible-watermark
- - imageio==2.9.0
- - imageio-ffmpeg==0.4.2
- - pytorch-lightning==1.8.0
- - omegaconf==2.1.1
- - test-tube>=0.7.5
- - streamlit>=0.73.1
- - einops==0.3.0
- - torch-fidelity==0.3.0
- - transformers==4.19.2
- - torchmetrics==0.7.0
- - kornia==0.6
- - prefetch_generator
- - colossalai
- - -e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
- - -e git+https://github.com/openai/CLIP.git@main#egg=clip
- - -e .
diff --git a/examples/tutorial/stable_diffusion/ldm/data/base.py b/examples/tutorial/stable_diffusion/ldm/data/base.py
deleted file mode 100644
index 4f3cd3571..000000000
--- a/examples/tutorial/stable_diffusion/ldm/data/base.py
+++ /dev/null
@@ -1,75 +0,0 @@
-import math
-from abc import abstractmethod
-
-import torch
-from torch.utils.data import Dataset, ConcatDataset, ChainDataset, IterableDataset
-import os
-import numpy as np
-import cv2
-
-class Txt2ImgIterableBaseDataset(IterableDataset):
- '''
- Define an interface to make the IterableDatasets for text2img data chainable
- '''
- def __init__(self, file_path: str, rank, world_size):
- super().__init__()
- self.file_path = file_path
- self.folder_list = []
- self.file_list = []
- self.txt_list = []
- self.info = self._get_file_info(file_path)
- self.start = self.info['start']
- self.end = self.info['end']
- self.rank = rank
-
- self.world_size = world_size
- # self.per_worker = int(math.floor((self.end - self.start) / float(self.world_size)))
- # self.iter_start = self.start + self.rank * self.per_worker
- # self.iter_end = min(self.iter_start + self.per_worker, self.end)
- # self.num_records = self.iter_end - self.iter_start
- # self.valid_ids = [i for i in range(self.iter_end)]
- self.num_records = self.end - self.start
- self.valid_ids = [i for i in range(self.end)]
-
- print(f'{self.__class__.__name__} dataset contains {self.__len__()} examples.')
-
- def __len__(self):
- # return self.iter_end - self.iter_start
- return self.end - self.start
-
- def __iter__(self):
- sample_iterator = self._sample_generator(self.start, self.end)
- # sample_iterator = self._sample_generator(self.iter_start, self.iter_end)
- return sample_iterator
-
- def _sample_generator(self, start, end):
- for idx in range(start, end):
- file_name = self.file_list[idx]
- txt_name = self.txt_list[idx]
- f_ = open(txt_name, 'r')
- txt_ = f_.read()
- f_.close()
- image = cv2.imdecode(np.fromfile(file_name, dtype=np.uint8), 1)
- image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
- image = torch.from_numpy(image) / 255
- yield {"caption": txt_, "image":image}
-
-
- def _get_file_info(self, file_path):
- info = \
- {
- "start": 1,
- "end": 0,
- }
- self.folder_list = [file_path + i for i in os.listdir(file_path) if '.' not in i]
- for folder in self.folder_list:
- files = [folder + '/' + i for i in os.listdir(folder) if 'jpg' in i]
- txts = [k.replace('jpg', 'txt') for k in files]
- self.file_list.extend(files)
- self.txt_list.extend(txts)
- info['end'] = len(self.file_list)
- # with open(file_path, 'r') as fin:
- # for _ in enumerate(fin):
- # info['end'] += 1
- # self.txt_list = [k.replace('jpg', 'txt') for k in self.file_list]
- return info
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/ldm/data/cifar10.py b/examples/tutorial/stable_diffusion/ldm/data/cifar10.py
deleted file mode 100644
index 53cd61263..000000000
--- a/examples/tutorial/stable_diffusion/ldm/data/cifar10.py
+++ /dev/null
@@ -1,184 +0,0 @@
-from typing import Dict
-import numpy as np
-from omegaconf import DictConfig, ListConfig
-import torch
-from torch.utils.data import Dataset
-from pathlib import Path
-import json
-from PIL import Image
-from torchvision import transforms
-from einops import rearrange
-from ldm.util import instantiate_from_config
-from datasets import load_dataset
-
-def make_multi_folder_data(paths, caption_files=None, **kwargs):
- """Make a concat dataset from multiple folders
- Don't suport captions yet
- If paths is a list, that's ok, if it's a Dict interpret it as:
- k=folder v=n_times to repeat that
- """
- list_of_paths = []
- if isinstance(paths, (Dict, DictConfig)):
- assert caption_files is None, \
- "Caption files not yet supported for repeats"
- for folder_path, repeats in paths.items():
- list_of_paths.extend([folder_path]*repeats)
- paths = list_of_paths
-
- if caption_files is not None:
- datasets = [FolderData(p, caption_file=c, **kwargs) for (p, c) in zip(paths, caption_files)]
- else:
- datasets = [FolderData(p, **kwargs) for p in paths]
- return torch.utils.data.ConcatDataset(datasets)
-
-class FolderData(Dataset):
- def __init__(self,
- root_dir,
- caption_file=None,
- image_transforms=[],
- ext="jpg",
- default_caption="",
- postprocess=None,
- return_paths=False,
- ) -> None:
- """Create a dataset from a folder of images.
- If you pass in a root directory it will be searched for images
- ending in ext (ext can be a list)
- """
- self.root_dir = Path(root_dir)
- self.default_caption = default_caption
- self.return_paths = return_paths
- if isinstance(postprocess, DictConfig):
- postprocess = instantiate_from_config(postprocess)
- self.postprocess = postprocess
- if caption_file is not None:
- with open(caption_file, "rt") as f:
- ext = Path(caption_file).suffix.lower()
- if ext == ".json":
- captions = json.load(f)
- elif ext == ".jsonl":
- lines = f.readlines()
- lines = [json.loads(x) for x in lines]
- captions = {x["file_name"]: x["text"].strip("\n") for x in lines}
- else:
- raise ValueError(f"Unrecognised format: {ext}")
- self.captions = captions
- else:
- self.captions = None
-
- if not isinstance(ext, (tuple, list, ListConfig)):
- ext = [ext]
-
- # Only used if there is no caption file
- self.paths = []
- for e in ext:
- self.paths.extend(list(self.root_dir.rglob(f"*.{e}")))
- if isinstance(image_transforms, ListConfig):
- image_transforms = [instantiate_from_config(tt) for tt in image_transforms]
- image_transforms.extend([transforms.ToTensor(),
- transforms.Lambda(lambda x: rearrange(x * 2. - 1., 'c h w -> h w c'))])
- image_transforms = transforms.Compose(image_transforms)
- self.tform = image_transforms
-
-
- def __len__(self):
- if self.captions is not None:
- return len(self.captions.keys())
- else:
- return len(self.paths)
-
- def __getitem__(self, index):
- data = {}
- if self.captions is not None:
- chosen = list(self.captions.keys())[index]
- caption = self.captions.get(chosen, None)
- if caption is None:
- caption = self.default_caption
- filename = self.root_dir/chosen
- else:
- filename = self.paths[index]
-
- if self.return_paths:
- data["path"] = str(filename)
-
- im = Image.open(filename)
- im = self.process_im(im)
- data["image"] = im
-
- if self.captions is not None:
- data["txt"] = caption
- else:
- data["txt"] = self.default_caption
-
- if self.postprocess is not None:
- data = self.postprocess(data)
-
- return data
-
- def process_im(self, im):
- im = im.convert("RGB")
- return self.tform(im)
-
-def hf_dataset(
- name,
- image_transforms=[],
- image_column="img",
- label_column="label",
- text_column="txt",
- split='train',
- image_key='image',
- caption_key='txt',
- ):
- """Make huggingface dataset with appropriate list of transforms applied
- """
- ds = load_dataset(name, split=split)
- image_transforms = [instantiate_from_config(tt) for tt in image_transforms]
- image_transforms.extend([transforms.ToTensor(),
- transforms.Lambda(lambda x: rearrange(x * 2. - 1., 'c h w -> h w c'))])
- tform = transforms.Compose(image_transforms)
-
- assert image_column in ds.column_names, f"Didn't find column {image_column} in {ds.column_names}"
- assert label_column in ds.column_names, f"Didn't find column {label_column} in {ds.column_names}"
-
- def pre_process(examples):
- processed = {}
- processed[image_key] = [tform(im) for im in examples[image_column]]
-
- label_to_text_dict = {0: "airplane", 1: "automobile", 2: "bird", 3: "cat", 4: "deer", 5: "dog", 6: "frog", 7: "horse", 8: "ship", 9: "truck"}
-
- processed[caption_key] = [label_to_text_dict[label] for label in examples[label_column]]
-
- return processed
-
- ds.set_transform(pre_process)
- return ds
-
-class TextOnly(Dataset):
- def __init__(self, captions, output_size, image_key="image", caption_key="txt", n_gpus=1):
- """Returns only captions with dummy images"""
- self.output_size = output_size
- self.image_key = image_key
- self.caption_key = caption_key
- if isinstance(captions, Path):
- self.captions = self._load_caption_file(captions)
- else:
- self.captions = captions
-
- if n_gpus > 1:
- # hack to make sure that all the captions appear on each gpu
- repeated = [n_gpus*[x] for x in self.captions]
- self.captions = []
- [self.captions.extend(x) for x in repeated]
-
- def __len__(self):
- return len(self.captions)
-
- def __getitem__(self, index):
- dummy_im = torch.zeros(3, self.output_size, self.output_size)
- dummy_im = rearrange(dummy_im * 2. - 1., 'c h w -> h w c')
- return {self.image_key: dummy_im, self.caption_key: self.captions[index]}
-
- def _load_caption_file(self, filename):
- with open(filename, 'rt') as f:
- captions = f.readlines()
- return [x.strip('\n') for x in captions]
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/ldm/data/imagenet.py b/examples/tutorial/stable_diffusion/ldm/data/imagenet.py
deleted file mode 100644
index 1c473f9c6..000000000
--- a/examples/tutorial/stable_diffusion/ldm/data/imagenet.py
+++ /dev/null
@@ -1,394 +0,0 @@
-import os, yaml, pickle, shutil, tarfile, glob
-import cv2
-import albumentations
-import PIL
-import numpy as np
-import torchvision.transforms.functional as TF
-from omegaconf import OmegaConf
-from functools import partial
-from PIL import Image
-from tqdm import tqdm
-from torch.utils.data import Dataset, Subset
-
-import taming.data.utils as tdu
-from taming.data.imagenet import str_to_indices, give_synsets_from_indices, download, retrieve
-from taming.data.imagenet import ImagePaths
-
-from ldm.modules.image_degradation import degradation_fn_bsr, degradation_fn_bsr_light
-
-
-def synset2idx(path_to_yaml="data/index_synset.yaml"):
- with open(path_to_yaml) as f:
- di2s = yaml.load(f)
- return dict((v,k) for k,v in di2s.items())
-
-
-class ImageNetBase(Dataset):
- def __init__(self, config=None):
- self.config = config or OmegaConf.create()
- if not type(self.config)==dict:
- self.config = OmegaConf.to_container(self.config)
- self.keep_orig_class_label = self.config.get("keep_orig_class_label", False)
- self.process_images = True # if False we skip loading & processing images and self.data contains filepaths
- self._prepare()
- self._prepare_synset_to_human()
- self._prepare_idx_to_synset()
- self._prepare_human_to_integer_label()
- self._load()
-
- def __len__(self):
- return len(self.data)
-
- def __getitem__(self, i):
- return self.data[i]
-
- def _prepare(self):
- raise NotImplementedError()
-
- def _filter_relpaths(self, relpaths):
- ignore = set([
- "n06596364_9591.JPEG",
- ])
- relpaths = [rpath for rpath in relpaths if not rpath.split("/")[-1] in ignore]
- if "sub_indices" in self.config:
- indices = str_to_indices(self.config["sub_indices"])
- synsets = give_synsets_from_indices(indices, path_to_yaml=self.idx2syn) # returns a list of strings
- self.synset2idx = synset2idx(path_to_yaml=self.idx2syn)
- files = []
- for rpath in relpaths:
- syn = rpath.split("/")[0]
- if syn in synsets:
- files.append(rpath)
- return files
- else:
- return relpaths
-
- def _prepare_synset_to_human(self):
- SIZE = 2655750
- URL = "https://heibox.uni-heidelberg.de/f/9f28e956cd304264bb82/?dl=1"
- self.human_dict = os.path.join(self.root, "synset_human.txt")
- if (not os.path.exists(self.human_dict) or
- not os.path.getsize(self.human_dict)==SIZE):
- download(URL, self.human_dict)
-
- def _prepare_idx_to_synset(self):
- URL = "https://heibox.uni-heidelberg.de/f/d835d5b6ceda4d3aa910/?dl=1"
- self.idx2syn = os.path.join(self.root, "index_synset.yaml")
- if (not os.path.exists(self.idx2syn)):
- download(URL, self.idx2syn)
-
- def _prepare_human_to_integer_label(self):
- URL = "https://heibox.uni-heidelberg.de/f/2362b797d5be43b883f6/?dl=1"
- self.human2integer = os.path.join(self.root, "imagenet1000_clsidx_to_labels.txt")
- if (not os.path.exists(self.human2integer)):
- download(URL, self.human2integer)
- with open(self.human2integer, "r") as f:
- lines = f.read().splitlines()
- assert len(lines) == 1000
- self.human2integer_dict = dict()
- for line in lines:
- value, key = line.split(":")
- self.human2integer_dict[key] = int(value)
-
- def _load(self):
- with open(self.txt_filelist, "r") as f:
- self.relpaths = f.read().splitlines()
- l1 = len(self.relpaths)
- self.relpaths = self._filter_relpaths(self.relpaths)
- print("Removed {} files from filelist during filtering.".format(l1 - len(self.relpaths)))
-
- self.synsets = [p.split("/")[0] for p in self.relpaths]
- self.abspaths = [os.path.join(self.datadir, p) for p in self.relpaths]
-
- unique_synsets = np.unique(self.synsets)
- class_dict = dict((synset, i) for i, synset in enumerate(unique_synsets))
- if not self.keep_orig_class_label:
- self.class_labels = [class_dict[s] for s in self.synsets]
- else:
- self.class_labels = [self.synset2idx[s] for s in self.synsets]
-
- with open(self.human_dict, "r") as f:
- human_dict = f.read().splitlines()
- human_dict = dict(line.split(maxsplit=1) for line in human_dict)
-
- self.human_labels = [human_dict[s] for s in self.synsets]
-
- labels = {
- "relpath": np.array(self.relpaths),
- "synsets": np.array(self.synsets),
- "class_label": np.array(self.class_labels),
- "human_label": np.array(self.human_labels),
- }
-
- if self.process_images:
- self.size = retrieve(self.config, "size", default=256)
- self.data = ImagePaths(self.abspaths,
- labels=labels,
- size=self.size,
- random_crop=self.random_crop,
- )
- else:
- self.data = self.abspaths
-
-
-class ImageNetTrain(ImageNetBase):
- NAME = "ILSVRC2012_train"
- URL = "http://www.image-net.org/challenges/LSVRC/2012/"
- AT_HASH = "a306397ccf9c2ead27155983c254227c0fd938e2"
- FILES = [
- "ILSVRC2012_img_train.tar",
- ]
- SIZES = [
- 147897477120,
- ]
-
- def __init__(self, process_images=True, data_root=None, **kwargs):
- self.process_images = process_images
- self.data_root = data_root
- super().__init__(**kwargs)
-
- def _prepare(self):
- if self.data_root:
- self.root = os.path.join(self.data_root, self.NAME)
- else:
- cachedir = os.environ.get("XDG_CACHE_HOME", os.path.expanduser("~/.cache"))
- self.root = os.path.join(cachedir, "autoencoders/data", self.NAME)
-
- self.datadir = os.path.join(self.root, "data")
- self.txt_filelist = os.path.join(self.root, "filelist.txt")
- self.expected_length = 1281167
- self.random_crop = retrieve(self.config, "ImageNetTrain/random_crop",
- default=True)
- if not tdu.is_prepared(self.root):
- # prep
- print("Preparing dataset {} in {}".format(self.NAME, self.root))
-
- datadir = self.datadir
- if not os.path.exists(datadir):
- path = os.path.join(self.root, self.FILES[0])
- if not os.path.exists(path) or not os.path.getsize(path)==self.SIZES[0]:
- import academictorrents as at
- atpath = at.get(self.AT_HASH, datastore=self.root)
- assert atpath == path
-
- print("Extracting {} to {}".format(path, datadir))
- os.makedirs(datadir, exist_ok=True)
- with tarfile.open(path, "r:") as tar:
- tar.extractall(path=datadir)
-
- print("Extracting sub-tars.")
- subpaths = sorted(glob.glob(os.path.join(datadir, "*.tar")))
- for subpath in tqdm(subpaths):
- subdir = subpath[:-len(".tar")]
- os.makedirs(subdir, exist_ok=True)
- with tarfile.open(subpath, "r:") as tar:
- tar.extractall(path=subdir)
-
- filelist = glob.glob(os.path.join(datadir, "**", "*.JPEG"))
- filelist = [os.path.relpath(p, start=datadir) for p in filelist]
- filelist = sorted(filelist)
- filelist = "\n".join(filelist)+"\n"
- with open(self.txt_filelist, "w") as f:
- f.write(filelist)
-
- tdu.mark_prepared(self.root)
-
-
-class ImageNetValidation(ImageNetBase):
- NAME = "ILSVRC2012_validation"
- URL = "http://www.image-net.org/challenges/LSVRC/2012/"
- AT_HASH = "5d6d0df7ed81efd49ca99ea4737e0ae5e3a5f2e5"
- VS_URL = "https://heibox.uni-heidelberg.de/f/3e0f6e9c624e45f2bd73/?dl=1"
- FILES = [
- "ILSVRC2012_img_val.tar",
- "validation_synset.txt",
- ]
- SIZES = [
- 6744924160,
- 1950000,
- ]
-
- def __init__(self, process_images=True, data_root=None, **kwargs):
- self.data_root = data_root
- self.process_images = process_images
- super().__init__(**kwargs)
-
- def _prepare(self):
- if self.data_root:
- self.root = os.path.join(self.data_root, self.NAME)
- else:
- cachedir = os.environ.get("XDG_CACHE_HOME", os.path.expanduser("~/.cache"))
- self.root = os.path.join(cachedir, "autoencoders/data", self.NAME)
- self.datadir = os.path.join(self.root, "data")
- self.txt_filelist = os.path.join(self.root, "filelist.txt")
- self.expected_length = 50000
- self.random_crop = retrieve(self.config, "ImageNetValidation/random_crop",
- default=False)
- if not tdu.is_prepared(self.root):
- # prep
- print("Preparing dataset {} in {}".format(self.NAME, self.root))
-
- datadir = self.datadir
- if not os.path.exists(datadir):
- path = os.path.join(self.root, self.FILES[0])
- if not os.path.exists(path) or not os.path.getsize(path)==self.SIZES[0]:
- import academictorrents as at
- atpath = at.get(self.AT_HASH, datastore=self.root)
- assert atpath == path
-
- print("Extracting {} to {}".format(path, datadir))
- os.makedirs(datadir, exist_ok=True)
- with tarfile.open(path, "r:") as tar:
- tar.extractall(path=datadir)
-
- vspath = os.path.join(self.root, self.FILES[1])
- if not os.path.exists(vspath) or not os.path.getsize(vspath)==self.SIZES[1]:
- download(self.VS_URL, vspath)
-
- with open(vspath, "r") as f:
- synset_dict = f.read().splitlines()
- synset_dict = dict(line.split() for line in synset_dict)
-
- print("Reorganizing into synset folders")
- synsets = np.unique(list(synset_dict.values()))
- for s in synsets:
- os.makedirs(os.path.join(datadir, s), exist_ok=True)
- for k, v in synset_dict.items():
- src = os.path.join(datadir, k)
- dst = os.path.join(datadir, v)
- shutil.move(src, dst)
-
- filelist = glob.glob(os.path.join(datadir, "**", "*.JPEG"))
- filelist = [os.path.relpath(p, start=datadir) for p in filelist]
- filelist = sorted(filelist)
- filelist = "\n".join(filelist)+"\n"
- with open(self.txt_filelist, "w") as f:
- f.write(filelist)
-
- tdu.mark_prepared(self.root)
-
-
-
-class ImageNetSR(Dataset):
- def __init__(self, size=None,
- degradation=None, downscale_f=4, min_crop_f=0.5, max_crop_f=1.,
- random_crop=True):
- """
- Imagenet Superresolution Dataloader
- Performs following ops in order:
- 1. crops a crop of size s from image either as random or center crop
- 2. resizes crop to size with cv2.area_interpolation
- 3. degrades resized crop with degradation_fn
-
- :param size: resizing to size after cropping
- :param degradation: degradation_fn, e.g. cv_bicubic or bsrgan_light
- :param downscale_f: Low Resolution Downsample factor
- :param min_crop_f: determines crop size s,
- where s = c * min_img_side_len with c sampled from interval (min_crop_f, max_crop_f)
- :param max_crop_f: ""
- :param data_root:
- :param random_crop:
- """
- self.base = self.get_base()
- assert size
- assert (size / downscale_f).is_integer()
- self.size = size
- self.LR_size = int(size / downscale_f)
- self.min_crop_f = min_crop_f
- self.max_crop_f = max_crop_f
- assert(max_crop_f <= 1.)
- self.center_crop = not random_crop
-
- self.image_rescaler = albumentations.SmallestMaxSize(max_size=size, interpolation=cv2.INTER_AREA)
-
- self.pil_interpolation = False # gets reset later if incase interp_op is from pillow
-
- if degradation == "bsrgan":
- self.degradation_process = partial(degradation_fn_bsr, sf=downscale_f)
-
- elif degradation == "bsrgan_light":
- self.degradation_process = partial(degradation_fn_bsr_light, sf=downscale_f)
-
- else:
- interpolation_fn = {
- "cv_nearest": cv2.INTER_NEAREST,
- "cv_bilinear": cv2.INTER_LINEAR,
- "cv_bicubic": cv2.INTER_CUBIC,
- "cv_area": cv2.INTER_AREA,
- "cv_lanczos": cv2.INTER_LANCZOS4,
- "pil_nearest": PIL.Image.NEAREST,
- "pil_bilinear": PIL.Image.BILINEAR,
- "pil_bicubic": PIL.Image.BICUBIC,
- "pil_box": PIL.Image.BOX,
- "pil_hamming": PIL.Image.HAMMING,
- "pil_lanczos": PIL.Image.LANCZOS,
- }[degradation]
-
- self.pil_interpolation = degradation.startswith("pil_")
-
- if self.pil_interpolation:
- self.degradation_process = partial(TF.resize, size=self.LR_size, interpolation=interpolation_fn)
-
- else:
- self.degradation_process = albumentations.SmallestMaxSize(max_size=self.LR_size,
- interpolation=interpolation_fn)
-
- def __len__(self):
- return len(self.base)
-
- def __getitem__(self, i):
- example = self.base[i]
- image = Image.open(example["file_path_"])
-
- if not image.mode == "RGB":
- image = image.convert("RGB")
-
- image = np.array(image).astype(np.uint8)
-
- min_side_len = min(image.shape[:2])
- crop_side_len = min_side_len * np.random.uniform(self.min_crop_f, self.max_crop_f, size=None)
- crop_side_len = int(crop_side_len)
-
- if self.center_crop:
- self.cropper = albumentations.CenterCrop(height=crop_side_len, width=crop_side_len)
-
- else:
- self.cropper = albumentations.RandomCrop(height=crop_side_len, width=crop_side_len)
-
- image = self.cropper(image=image)["image"]
- image = self.image_rescaler(image=image)["image"]
-
- if self.pil_interpolation:
- image_pil = PIL.Image.fromarray(image)
- LR_image = self.degradation_process(image_pil)
- LR_image = np.array(LR_image).astype(np.uint8)
-
- else:
- LR_image = self.degradation_process(image=image)["image"]
-
- example["image"] = (image/127.5 - 1.0).astype(np.float32)
- example["LR_image"] = (LR_image/127.5 - 1.0).astype(np.float32)
-
- return example
-
-
-class ImageNetSRTrain(ImageNetSR):
- def __init__(self, **kwargs):
- super().__init__(**kwargs)
-
- def get_base(self):
- with open("data/imagenet_train_hr_indices.p", "rb") as f:
- indices = pickle.load(f)
- dset = ImageNetTrain(process_images=False,)
- return Subset(dset, indices)
-
-
-class ImageNetSRValidation(ImageNetSR):
- def __init__(self, **kwargs):
- super().__init__(**kwargs)
-
- def get_base(self):
- with open("data/imagenet_val_hr_indices.p", "rb") as f:
- indices = pickle.load(f)
- dset = ImageNetValidation(process_images=False,)
- return Subset(dset, indices)
diff --git a/examples/tutorial/stable_diffusion/ldm/data/lsun.py b/examples/tutorial/stable_diffusion/ldm/data/lsun.py
deleted file mode 100644
index 6256e4571..000000000
--- a/examples/tutorial/stable_diffusion/ldm/data/lsun.py
+++ /dev/null
@@ -1,92 +0,0 @@
-import os
-import numpy as np
-import PIL
-from PIL import Image
-from torch.utils.data import Dataset
-from torchvision import transforms
-
-
-class LSUNBase(Dataset):
- def __init__(self,
- txt_file,
- data_root,
- size=None,
- interpolation="bicubic",
- flip_p=0.5
- ):
- self.data_paths = txt_file
- self.data_root = data_root
- with open(self.data_paths, "r") as f:
- self.image_paths = f.read().splitlines()
- self._length = len(self.image_paths)
- self.labels = {
- "relative_file_path_": [l for l in self.image_paths],
- "file_path_": [os.path.join(self.data_root, l)
- for l in self.image_paths],
- }
-
- self.size = size
- self.interpolation = {"linear": PIL.Image.LINEAR,
- "bilinear": PIL.Image.BILINEAR,
- "bicubic": PIL.Image.BICUBIC,
- "lanczos": PIL.Image.LANCZOS,
- }[interpolation]
- self.flip = transforms.RandomHorizontalFlip(p=flip_p)
-
- def __len__(self):
- return self._length
-
- def __getitem__(self, i):
- example = dict((k, self.labels[k][i]) for k in self.labels)
- image = Image.open(example["file_path_"])
- if not image.mode == "RGB":
- image = image.convert("RGB")
-
- # default to score-sde preprocessing
- img = np.array(image).astype(np.uint8)
- crop = min(img.shape[0], img.shape[1])
- h, w, = img.shape[0], img.shape[1]
- img = img[(h - crop) // 2:(h + crop) // 2,
- (w - crop) // 2:(w + crop) // 2]
-
- image = Image.fromarray(img)
- if self.size is not None:
- image = image.resize((self.size, self.size), resample=self.interpolation)
-
- image = self.flip(image)
- image = np.array(image).astype(np.uint8)
- example["image"] = (image / 127.5 - 1.0).astype(np.float32)
- return example
-
-
-class LSUNChurchesTrain(LSUNBase):
- def __init__(self, **kwargs):
- super().__init__(txt_file="data/lsun/church_outdoor_train.txt", data_root="data/lsun/churches", **kwargs)
-
-
-class LSUNChurchesValidation(LSUNBase):
- def __init__(self, flip_p=0., **kwargs):
- super().__init__(txt_file="data/lsun/church_outdoor_val.txt", data_root="data/lsun/churches",
- flip_p=flip_p, **kwargs)
-
-
-class LSUNBedroomsTrain(LSUNBase):
- def __init__(self, **kwargs):
- super().__init__(txt_file="data/lsun/bedrooms_train.txt", data_root="data/lsun/bedrooms", **kwargs)
-
-
-class LSUNBedroomsValidation(LSUNBase):
- def __init__(self, flip_p=0.0, **kwargs):
- super().__init__(txt_file="data/lsun/bedrooms_val.txt", data_root="data/lsun/bedrooms",
- flip_p=flip_p, **kwargs)
-
-
-class LSUNCatsTrain(LSUNBase):
- def __init__(self, **kwargs):
- super().__init__(txt_file="data/lsun/cat_train.txt", data_root="data/lsun/cats", **kwargs)
-
-
-class LSUNCatsValidation(LSUNBase):
- def __init__(self, flip_p=0., **kwargs):
- super().__init__(txt_file="data/lsun/cat_val.txt", data_root="data/lsun/cats",
- flip_p=flip_p, **kwargs)
diff --git a/examples/tutorial/stable_diffusion/ldm/lr_scheduler.py b/examples/tutorial/stable_diffusion/ldm/lr_scheduler.py
deleted file mode 100644
index be39da9ca..000000000
--- a/examples/tutorial/stable_diffusion/ldm/lr_scheduler.py
+++ /dev/null
@@ -1,98 +0,0 @@
-import numpy as np
-
-
-class LambdaWarmUpCosineScheduler:
- """
- note: use with a base_lr of 1.0
- """
- def __init__(self, warm_up_steps, lr_min, lr_max, lr_start, max_decay_steps, verbosity_interval=0):
- self.lr_warm_up_steps = warm_up_steps
- self.lr_start = lr_start
- self.lr_min = lr_min
- self.lr_max = lr_max
- self.lr_max_decay_steps = max_decay_steps
- self.last_lr = 0.
- self.verbosity_interval = verbosity_interval
-
- def schedule(self, n, **kwargs):
- if self.verbosity_interval > 0:
- if n % self.verbosity_interval == 0: print(f"current step: {n}, recent lr-multiplier: {self.last_lr}")
- if n < self.lr_warm_up_steps:
- lr = (self.lr_max - self.lr_start) / self.lr_warm_up_steps * n + self.lr_start
- self.last_lr = lr
- return lr
- else:
- t = (n - self.lr_warm_up_steps) / (self.lr_max_decay_steps - self.lr_warm_up_steps)
- t = min(t, 1.0)
- lr = self.lr_min + 0.5 * (self.lr_max - self.lr_min) * (
- 1 + np.cos(t * np.pi))
- self.last_lr = lr
- return lr
-
- def __call__(self, n, **kwargs):
- return self.schedule(n,**kwargs)
-
-
-class LambdaWarmUpCosineScheduler2:
- """
- supports repeated iterations, configurable via lists
- note: use with a base_lr of 1.0.
- """
- def __init__(self, warm_up_steps, f_min, f_max, f_start, cycle_lengths, verbosity_interval=0):
- assert len(warm_up_steps) == len(f_min) == len(f_max) == len(f_start) == len(cycle_lengths)
- self.lr_warm_up_steps = warm_up_steps
- self.f_start = f_start
- self.f_min = f_min
- self.f_max = f_max
- self.cycle_lengths = cycle_lengths
- self.cum_cycles = np.cumsum([0] + list(self.cycle_lengths))
- self.last_f = 0.
- self.verbosity_interval = verbosity_interval
-
- def find_in_interval(self, n):
- interval = 0
- for cl in self.cum_cycles[1:]:
- if n <= cl:
- return interval
- interval += 1
-
- def schedule(self, n, **kwargs):
- cycle = self.find_in_interval(n)
- n = n - self.cum_cycles[cycle]
- if self.verbosity_interval > 0:
- if n % self.verbosity_interval == 0: print(f"current step: {n}, recent lr-multiplier: {self.last_f}, "
- f"current cycle {cycle}")
- if n < self.lr_warm_up_steps[cycle]:
- f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[cycle] * n + self.f_start[cycle]
- self.last_f = f
- return f
- else:
- t = (n - self.lr_warm_up_steps[cycle]) / (self.cycle_lengths[cycle] - self.lr_warm_up_steps[cycle])
- t = min(t, 1.0)
- f = self.f_min[cycle] + 0.5 * (self.f_max[cycle] - self.f_min[cycle]) * (
- 1 + np.cos(t * np.pi))
- self.last_f = f
- return f
-
- def __call__(self, n, **kwargs):
- return self.schedule(n, **kwargs)
-
-
-class LambdaLinearScheduler(LambdaWarmUpCosineScheduler2):
-
- def schedule(self, n, **kwargs):
- cycle = self.find_in_interval(n)
- n = n - self.cum_cycles[cycle]
- if self.verbosity_interval > 0:
- if n % self.verbosity_interval == 0: print(f"current step: {n}, recent lr-multiplier: {self.last_f}, "
- f"current cycle {cycle}")
-
- if n < self.lr_warm_up_steps[cycle]:
- f = (self.f_max[cycle] - self.f_start[cycle]) / self.lr_warm_up_steps[cycle] * n + self.f_start[cycle]
- self.last_f = f
- return f
- else:
- f = self.f_min[cycle] + (self.f_max[cycle] - self.f_min[cycle]) * (self.cycle_lengths[cycle] - n) / (self.cycle_lengths[cycle])
- self.last_f = f
- return f
-
diff --git a/examples/tutorial/stable_diffusion/ldm/models/autoencoder.py b/examples/tutorial/stable_diffusion/ldm/models/autoencoder.py
deleted file mode 100644
index 873d8b69b..000000000
--- a/examples/tutorial/stable_diffusion/ldm/models/autoencoder.py
+++ /dev/null
@@ -1,544 +0,0 @@
-import torch
-import pytorch_lightning as pl
-import torch.nn.functional as F
-from contextlib import contextmanager
-
-from taming.modules.vqvae.quantize import VectorQuantizer2 as VectorQuantizer
-
-from ldm.modules.diffusionmodules.model import Encoder, Decoder
-from ldm.modules.distributions.distributions import DiagonalGaussianDistribution
-
-from ldm.util import instantiate_from_config
-
-
-class VQModel(pl.LightningModule):
- def __init__(self,
- ddconfig,
- lossconfig,
- n_embed,
- embed_dim,
- ckpt_path=None,
- ignore_keys=[],
- image_key="image",
- colorize_nlabels=None,
- monitor=None,
- batch_resize_range=None,
- scheduler_config=None,
- lr_g_factor=1.0,
- remap=None,
- sane_index_shape=False, # tell vector quantizer to return indices as bhw
- use_ema=False
- ):
- super().__init__()
- self.embed_dim = embed_dim
- self.n_embed = n_embed
- self.image_key = image_key
- self.encoder = Encoder(**ddconfig)
- self.decoder = Decoder(**ddconfig)
- self.loss = instantiate_from_config(lossconfig)
- self.quantize = VectorQuantizer(n_embed, embed_dim, beta=0.25,
- remap=remap,
- sane_index_shape=sane_index_shape)
- self.quant_conv = torch.nn.Conv2d(ddconfig["z_channels"], embed_dim, 1)
- self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
- if colorize_nlabels is not None:
- assert type(colorize_nlabels)==int
- self.register_buffer("colorize", torch.randn(3, colorize_nlabels, 1, 1))
- if monitor is not None:
- self.monitor = monitor
- self.batch_resize_range = batch_resize_range
- if self.batch_resize_range is not None:
- print(f"{self.__class__.__name__}: Using per-batch resizing in range {batch_resize_range}.")
-
- self.use_ema = use_ema
- if self.use_ema:
- self.model_ema = LitEma(self)
- print(f"Keeping EMAs of {len(list(self.model_ema.buffers()))}.")
-
- if ckpt_path is not None:
- self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys)
- self.scheduler_config = scheduler_config
- self.lr_g_factor = lr_g_factor
-
- @contextmanager
- def ema_scope(self, context=None):
- if self.use_ema:
- self.model_ema.store(self.parameters())
- self.model_ema.copy_to(self)
- if context is not None:
- print(f"{context}: Switched to EMA weights")
- try:
- yield None
- finally:
- if self.use_ema:
- self.model_ema.restore(self.parameters())
- if context is not None:
- print(f"{context}: Restored training weights")
-
- def init_from_ckpt(self, path, ignore_keys=list()):
- sd = torch.load(path, map_location="cpu")["state_dict"]
- keys = list(sd.keys())
- for k in keys:
- for ik in ignore_keys:
- if k.startswith(ik):
- print("Deleting key {} from state_dict.".format(k))
- del sd[k]
- missing, unexpected = self.load_state_dict(sd, strict=False)
- print(f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys")
- if len(missing) > 0:
- print(f"Missing Keys: {missing}")
- print(f"Unexpected Keys: {unexpected}")
-
- def on_train_batch_end(self, *args, **kwargs):
- if self.use_ema:
- self.model_ema(self)
-
- def encode(self, x):
- h = self.encoder(x)
- h = self.quant_conv(h)
- quant, emb_loss, info = self.quantize(h)
- return quant, emb_loss, info
-
- def encode_to_prequant(self, x):
- h = self.encoder(x)
- h = self.quant_conv(h)
- return h
-
- def decode(self, quant):
- quant = self.post_quant_conv(quant)
- dec = self.decoder(quant)
- return dec
-
- def decode_code(self, code_b):
- quant_b = self.quantize.embed_code(code_b)
- dec = self.decode(quant_b)
- return dec
-
- def forward(self, input, return_pred_indices=False):
- quant, diff, (_,_,ind) = self.encode(input)
- dec = self.decode(quant)
- if return_pred_indices:
- return dec, diff, ind
- return dec, diff
-
- def get_input(self, batch, k):
- x = batch[k]
- if len(x.shape) == 3:
- x = x[..., None]
- x = x.permute(0, 3, 1, 2).to(memory_format=torch.contiguous_format).float()
- if self.batch_resize_range is not None:
- lower_size = self.batch_resize_range[0]
- upper_size = self.batch_resize_range[1]
- if self.global_step <= 4:
- # do the first few batches with max size to avoid later oom
- new_resize = upper_size
- else:
- new_resize = np.random.choice(np.arange(lower_size, upper_size+16, 16))
- if new_resize != x.shape[2]:
- x = F.interpolate(x, size=new_resize, mode="bicubic")
- x = x.detach()
- return x
-
- def training_step(self, batch, batch_idx, optimizer_idx):
- # https://github.com/pytorch/pytorch/issues/37142
- # try not to fool the heuristics
- x = self.get_input(batch, self.image_key)
- xrec, qloss, ind = self(x, return_pred_indices=True)
-
- if optimizer_idx == 0:
- # autoencode
- aeloss, log_dict_ae = self.loss(qloss, x, xrec, optimizer_idx, self.global_step,
- last_layer=self.get_last_layer(), split="train",
- predicted_indices=ind)
-
- self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=True)
- return aeloss
-
- if optimizer_idx == 1:
- # discriminator
- discloss, log_dict_disc = self.loss(qloss, x, xrec, optimizer_idx, self.global_step,
- last_layer=self.get_last_layer(), split="train")
- self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=True)
- return discloss
-
- def validation_step(self, batch, batch_idx):
- log_dict = self._validation_step(batch, batch_idx)
- with self.ema_scope():
- log_dict_ema = self._validation_step(batch, batch_idx, suffix="_ema")
- return log_dict
-
- def _validation_step(self, batch, batch_idx, suffix=""):
- x = self.get_input(batch, self.image_key)
- xrec, qloss, ind = self(x, return_pred_indices=True)
- aeloss, log_dict_ae = self.loss(qloss, x, xrec, 0,
- self.global_step,
- last_layer=self.get_last_layer(),
- split="val"+suffix,
- predicted_indices=ind
- )
-
- discloss, log_dict_disc = self.loss(qloss, x, xrec, 1,
- self.global_step,
- last_layer=self.get_last_layer(),
- split="val"+suffix,
- predicted_indices=ind
- )
- rec_loss = log_dict_ae[f"val{suffix}/rec_loss"]
- self.log(f"val{suffix}/rec_loss", rec_loss,
- prog_bar=True, logger=True, on_step=False, on_epoch=True, sync_dist=True)
- self.log(f"val{suffix}/aeloss", aeloss,
- prog_bar=True, logger=True, on_step=False, on_epoch=True, sync_dist=True)
- if version.parse(pl.__version__) >= version.parse('1.4.0'):
- del log_dict_ae[f"val{suffix}/rec_loss"]
- self.log_dict(log_dict_ae)
- self.log_dict(log_dict_disc)
- return self.log_dict
-
- def configure_optimizers(self):
- lr_d = self.learning_rate
- lr_g = self.lr_g_factor*self.learning_rate
- print("lr_d", lr_d)
- print("lr_g", lr_g)
- opt_ae = torch.optim.Adam(list(self.encoder.parameters())+
- list(self.decoder.parameters())+
- list(self.quantize.parameters())+
- list(self.quant_conv.parameters())+
- list(self.post_quant_conv.parameters()),
- lr=lr_g, betas=(0.5, 0.9))
- opt_disc = torch.optim.Adam(self.loss.discriminator.parameters(),
- lr=lr_d, betas=(0.5, 0.9))
-
- if self.scheduler_config is not None:
- scheduler = instantiate_from_config(self.scheduler_config)
-
- print("Setting up LambdaLR scheduler...")
- scheduler = [
- {
- 'scheduler': LambdaLR(opt_ae, lr_lambda=scheduler.schedule),
- 'interval': 'step',
- 'frequency': 1
- },
- {
- 'scheduler': LambdaLR(opt_disc, lr_lambda=scheduler.schedule),
- 'interval': 'step',
- 'frequency': 1
- },
- ]
- return [opt_ae, opt_disc], scheduler
- return [opt_ae, opt_disc], []
-
- def get_last_layer(self):
- return self.decoder.conv_out.weight
-
- def log_images(self, batch, only_inputs=False, plot_ema=False, **kwargs):
- log = dict()
- x = self.get_input(batch, self.image_key)
- x = x.to(self.device)
- if only_inputs:
- log["inputs"] = x
- return log
- xrec, _ = self(x)
- if x.shape[1] > 3:
- # colorize with random projection
- assert xrec.shape[1] > 3
- x = self.to_rgb(x)
- xrec = self.to_rgb(xrec)
- log["inputs"] = x
- log["reconstructions"] = xrec
- if plot_ema:
- with self.ema_scope():
- xrec_ema, _ = self(x)
- if x.shape[1] > 3: xrec_ema = self.to_rgb(xrec_ema)
- log["reconstructions_ema"] = xrec_ema
- return log
-
- def to_rgb(self, x):
- assert self.image_key == "segmentation"
- if not hasattr(self, "colorize"):
- self.register_buffer("colorize", torch.randn(3, x.shape[1], 1, 1).to(x))
- x = F.conv2d(x, weight=self.colorize)
- x = 2.*(x-x.min())/(x.max()-x.min()) - 1.
- return x
-
-
-class VQModelInterface(VQModel):
- def __init__(self, embed_dim, *args, **kwargs):
- super().__init__(embed_dim=embed_dim, *args, **kwargs)
- self.embed_dim = embed_dim
-
- def encode(self, x):
- h = self.encoder(x)
- h = self.quant_conv(h)
- return h
-
- def decode(self, h, force_not_quantize=False):
- # also go through quantization layer
- if not force_not_quantize:
- quant, emb_loss, info = self.quantize(h)
- else:
- quant = h
- quant = self.post_quant_conv(quant)
- dec = self.decoder(quant)
- return dec
-
-
-class AutoencoderKL(pl.LightningModule):
- def __init__(self,
- ddconfig,
- lossconfig,
- embed_dim,
- ckpt_path=None,
- ignore_keys=[],
- image_key="image",
- colorize_nlabels=None,
- monitor=None,
- from_pretrained: str=None
- ):
- super().__init__()
- self.image_key = image_key
- self.encoder = Encoder(**ddconfig)
- self.decoder = Decoder(**ddconfig)
- self.loss = instantiate_from_config(lossconfig)
- assert ddconfig["double_z"]
- self.quant_conv = torch.nn.Conv2d(2*ddconfig["z_channels"], 2*embed_dim, 1)
- self.post_quant_conv = torch.nn.Conv2d(embed_dim, ddconfig["z_channels"], 1)
- self.embed_dim = embed_dim
- if colorize_nlabels is not None:
- assert type(colorize_nlabels)==int
- self.register_buffer("colorize", torch.randn(3, colorize_nlabels, 1, 1))
- if monitor is not None:
- self.monitor = monitor
- if ckpt_path is not None:
- self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys)
- from diffusers.modeling_utils import load_state_dict
- if from_pretrained is not None:
- state_dict = load_state_dict(from_pretrained)
- self._load_pretrained_model(state_dict)
-
- def _state_key_mapping(self, state_dict: dict):
- import re
- res_dict = {}
- key_list = state_dict.keys()
- key_str = " ".join(key_list)
- up_block_pattern = re.compile('upsamplers')
- p1 = re.compile('mid.block_[0-9]')
- p2 = re.compile('decoder.up.[0-9]')
- up_blocks_count = int(len(re.findall(up_block_pattern, key_str)) / 2 + 1)
- for key_, val_ in state_dict.items():
- key_ = key_.replace("up_blocks", "up").replace("down_blocks", "down").replace('resnets', 'block')\
- .replace('mid_block', 'mid').replace("mid.block.", "mid.block_")\
- .replace('mid.attentions.0.key', 'mid.attn_1.k')\
- .replace('mid.attentions.0.query', 'mid.attn_1.q') \
- .replace('mid.attentions.0.value', 'mid.attn_1.v') \
- .replace('mid.attentions.0.group_norm', 'mid.attn_1.norm') \
- .replace('mid.attentions.0.proj_attn', 'mid.attn_1.proj_out')\
- .replace('upsamplers.0', 'upsample')\
- .replace('downsamplers.0', 'downsample')\
- .replace('conv_shortcut', 'nin_shortcut')\
- .replace('conv_norm_out', 'norm_out')
-
- mid_list = re.findall(p1, key_)
- if len(mid_list) != 0:
- mid_str = mid_list[0]
- mid_id = int(mid_str[-1]) + 1
- key_ = key_.replace(mid_str, mid_str[:-1] + str(mid_id))
-
- up_list = re.findall(p2, key_)
- if len(up_list) != 0:
- up_str = up_list[0]
- up_id = up_blocks_count - 1 -int(up_str[-1])
- key_ = key_.replace(up_str, up_str[:-1] + str(up_id))
- res_dict[key_] = val_
- return res_dict
-
- def _load_pretrained_model(self, state_dict, ignore_mismatched_sizes=False):
- state_dict = self._state_key_mapping(state_dict)
- model_state_dict = self.state_dict()
- loaded_keys = [k for k in state_dict.keys()]
- expected_keys = list(model_state_dict.keys())
- original_loaded_keys = loaded_keys
- missing_keys = list(set(expected_keys) - set(loaded_keys))
- unexpected_keys = list(set(loaded_keys) - set(expected_keys))
-
- def _find_mismatched_keys(
- state_dict,
- model_state_dict,
- loaded_keys,
- ignore_mismatched_sizes,
- ):
- mismatched_keys = []
- if ignore_mismatched_sizes:
- for checkpoint_key in loaded_keys:
- model_key = checkpoint_key
-
- if (
- model_key in model_state_dict
- and state_dict[checkpoint_key].shape != model_state_dict[model_key].shape
- ):
- mismatched_keys.append(
- (checkpoint_key, state_dict[checkpoint_key].shape, model_state_dict[model_key].shape)
- )
- del state_dict[checkpoint_key]
- return mismatched_keys
- if state_dict is not None:
- # Whole checkpoint
- mismatched_keys = _find_mismatched_keys(
- state_dict,
- model_state_dict,
- original_loaded_keys,
- ignore_mismatched_sizes,
- )
- error_msgs = self._load_state_dict_into_model(state_dict)
- return missing_keys, unexpected_keys, mismatched_keys, error_msgs
-
- def _load_state_dict_into_model(self, state_dict):
- # Convert old format to new format if needed from a PyTorch state_dict
- # copy state_dict so _load_from_state_dict can modify it
- state_dict = state_dict.copy()
- error_msgs = []
-
- # PyTorch's `_load_from_state_dict` does not copy parameters in a module's descendants
- # so we need to apply the function recursively.
- def load(module: torch.nn.Module, prefix=""):
- args = (state_dict, prefix, {}, True, [], [], error_msgs)
- module._load_from_state_dict(*args)
-
- for name, child in module._modules.items():
- if child is not None:
- load(child, prefix + name + ".")
-
- load(self)
-
- return error_msgs
-
- def init_from_ckpt(self, path, ignore_keys=list()):
- sd = torch.load(path, map_location="cpu")["state_dict"]
- keys = list(sd.keys())
- for k in keys:
- for ik in ignore_keys:
- if k.startswith(ik):
- print("Deleting key {} from state_dict.".format(k))
- del sd[k]
- self.load_state_dict(sd, strict=False)
- print(f"Restored from {path}")
-
- def encode(self, x):
- h = self.encoder(x)
- moments = self.quant_conv(h)
- posterior = DiagonalGaussianDistribution(moments)
- return posterior
-
- def decode(self, z):
- z = self.post_quant_conv(z)
- dec = self.decoder(z)
- return dec
-
- def forward(self, input, sample_posterior=True):
- posterior = self.encode(input)
- if sample_posterior:
- z = posterior.sample()
- else:
- z = posterior.mode()
- dec = self.decode(z)
- return dec, posterior
-
- def get_input(self, batch, k):
- x = batch[k]
- if len(x.shape) == 3:
- x = x[..., None]
- x = x.permute(0, 3, 1, 2).to(memory_format=torch.contiguous_format).float()
- return x
-
- def training_step(self, batch, batch_idx, optimizer_idx):
- inputs = self.get_input(batch, self.image_key)
- reconstructions, posterior = self(inputs)
-
- if optimizer_idx == 0:
- # train encoder+decoder+logvar
- aeloss, log_dict_ae = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step,
- last_layer=self.get_last_layer(), split="train")
- self.log("aeloss", aeloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
- self.log_dict(log_dict_ae, prog_bar=False, logger=True, on_step=True, on_epoch=False)
- return aeloss
-
- if optimizer_idx == 1:
- # train the discriminator
- discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step,
- last_layer=self.get_last_layer(), split="train")
-
- self.log("discloss", discloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
- self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=False)
- return discloss
-
- def validation_step(self, batch, batch_idx):
- inputs = self.get_input(batch, self.image_key)
- reconstructions, posterior = self(inputs)
- aeloss, log_dict_ae = self.loss(inputs, reconstructions, posterior, 0, self.global_step,
- last_layer=self.get_last_layer(), split="val")
-
- discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, 1, self.global_step,
- last_layer=self.get_last_layer(), split="val")
-
- self.log("val/rec_loss", log_dict_ae["val/rec_loss"])
- self.log_dict(log_dict_ae)
- self.log_dict(log_dict_disc)
- return self.log_dict
-
- def configure_optimizers(self):
- lr = self.learning_rate
- opt_ae = torch.optim.Adam(list(self.encoder.parameters())+
- list(self.decoder.parameters())+
- list(self.quant_conv.parameters())+
- list(self.post_quant_conv.parameters()),
- lr=lr, betas=(0.5, 0.9))
- opt_disc = torch.optim.Adam(self.loss.discriminator.parameters(),
- lr=lr, betas=(0.5, 0.9))
- return [opt_ae, opt_disc], []
-
- def get_last_layer(self):
- return self.decoder.conv_out.weight
-
- @torch.no_grad()
- def log_images(self, batch, only_inputs=False, **kwargs):
- log = dict()
- x = self.get_input(batch, self.image_key)
- x = x.to(self.device)
- if not only_inputs:
- xrec, posterior = self(x)
- if x.shape[1] > 3:
- # colorize with random projection
- assert xrec.shape[1] > 3
- x = self.to_rgb(x)
- xrec = self.to_rgb(xrec)
- log["samples"] = self.decode(torch.randn_like(posterior.sample()))
- log["reconstructions"] = xrec
- log["inputs"] = x
- return log
-
- def to_rgb(self, x):
- assert self.image_key == "segmentation"
- if not hasattr(self, "colorize"):
- self.register_buffer("colorize", torch.randn(3, x.shape[1], 1, 1).to(x))
- x = F.conv2d(x, weight=self.colorize)
- x = 2.*(x-x.min())/(x.max()-x.min()) - 1.
- return x
-
-
-class IdentityFirstStage(torch.nn.Module):
- def __init__(self, *args, vq_interface=False, **kwargs):
- self.vq_interface = vq_interface # TODO: Should be true by default but check to not break older stuff
- super().__init__()
-
- def encode(self, x, *args, **kwargs):
- return x
-
- def decode(self, x, *args, **kwargs):
- return x
-
- def quantize(self, x, *args, **kwargs):
- if self.vq_interface:
- return x, None, [None, None, None]
- return x
-
- def forward(self, x, *args, **kwargs):
- return x
diff --git a/examples/tutorial/stable_diffusion/ldm/models/diffusion/classifier.py b/examples/tutorial/stable_diffusion/ldm/models/diffusion/classifier.py
deleted file mode 100644
index 67e98b9d8..000000000
--- a/examples/tutorial/stable_diffusion/ldm/models/diffusion/classifier.py
+++ /dev/null
@@ -1,267 +0,0 @@
-import os
-import torch
-import pytorch_lightning as pl
-from omegaconf import OmegaConf
-from torch.nn import functional as F
-from torch.optim import AdamW
-from torch.optim.lr_scheduler import LambdaLR
-from copy import deepcopy
-from einops import rearrange
-from glob import glob
-from natsort import natsorted
-
-from ldm.modules.diffusionmodules.openaimodel import EncoderUNetModel, UNetModel
-from ldm.util import log_txt_as_img, default, ismap, instantiate_from_config
-
-__models__ = {
- 'class_label': EncoderUNetModel,
- 'segmentation': UNetModel
-}
-
-
-def disabled_train(self, mode=True):
- """Overwrite model.train with this function to make sure train/eval mode
- does not change anymore."""
- return self
-
-
-class NoisyLatentImageClassifier(pl.LightningModule):
-
- def __init__(self,
- diffusion_path,
- num_classes,
- ckpt_path=None,
- pool='attention',
- label_key=None,
- diffusion_ckpt_path=None,
- scheduler_config=None,
- weight_decay=1.e-2,
- log_steps=10,
- monitor='val/loss',
- *args,
- **kwargs):
- super().__init__(*args, **kwargs)
- self.num_classes = num_classes
- # get latest config of diffusion model
- diffusion_config = natsorted(glob(os.path.join(diffusion_path, 'configs', '*-project.yaml')))[-1]
- self.diffusion_config = OmegaConf.load(diffusion_config).model
- self.diffusion_config.params.ckpt_path = diffusion_ckpt_path
- self.load_diffusion()
-
- self.monitor = monitor
- self.numd = self.diffusion_model.first_stage_model.encoder.num_resolutions - 1
- self.log_time_interval = self.diffusion_model.num_timesteps // log_steps
- self.log_steps = log_steps
-
- self.label_key = label_key if not hasattr(self.diffusion_model, 'cond_stage_key') \
- else self.diffusion_model.cond_stage_key
-
- assert self.label_key is not None, 'label_key neither in diffusion model nor in model.params'
-
- if self.label_key not in __models__:
- raise NotImplementedError()
-
- self.load_classifier(ckpt_path, pool)
-
- self.scheduler_config = scheduler_config
- self.use_scheduler = self.scheduler_config is not None
- self.weight_decay = weight_decay
-
- def init_from_ckpt(self, path, ignore_keys=list(), only_model=False):
- sd = torch.load(path, map_location="cpu")
- if "state_dict" in list(sd.keys()):
- sd = sd["state_dict"]
- keys = list(sd.keys())
- for k in keys:
- for ik in ignore_keys:
- if k.startswith(ik):
- print("Deleting key {} from state_dict.".format(k))
- del sd[k]
- missing, unexpected = self.load_state_dict(sd, strict=False) if not only_model else self.model.load_state_dict(
- sd, strict=False)
- print(f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys")
- if len(missing) > 0:
- print(f"Missing Keys: {missing}")
- if len(unexpected) > 0:
- print(f"Unexpected Keys: {unexpected}")
-
- def load_diffusion(self):
- model = instantiate_from_config(self.diffusion_config)
- self.diffusion_model = model.eval()
- self.diffusion_model.train = disabled_train
- for param in self.diffusion_model.parameters():
- param.requires_grad = False
-
- def load_classifier(self, ckpt_path, pool):
- model_config = deepcopy(self.diffusion_config.params.unet_config.params)
- model_config.in_channels = self.diffusion_config.params.unet_config.params.out_channels
- model_config.out_channels = self.num_classes
- if self.label_key == 'class_label':
- model_config.pool = pool
-
- self.model = __models__[self.label_key](**model_config)
- if ckpt_path is not None:
- print('#####################################################################')
- print(f'load from ckpt "{ckpt_path}"')
- print('#####################################################################')
- self.init_from_ckpt(ckpt_path)
-
- @torch.no_grad()
- def get_x_noisy(self, x, t, noise=None):
- noise = default(noise, lambda: torch.randn_like(x))
- continuous_sqrt_alpha_cumprod = None
- if self.diffusion_model.use_continuous_noise:
- continuous_sqrt_alpha_cumprod = self.diffusion_model.sample_continuous_noise_level(x.shape[0], t + 1)
- # todo: make sure t+1 is correct here
-
- return self.diffusion_model.q_sample(x_start=x, t=t, noise=noise,
- continuous_sqrt_alpha_cumprod=continuous_sqrt_alpha_cumprod)
-
- def forward(self, x_noisy, t, *args, **kwargs):
- return self.model(x_noisy, t)
-
- @torch.no_grad()
- def get_input(self, batch, k):
- x = batch[k]
- if len(x.shape) == 3:
- x = x[..., None]
- x = rearrange(x, 'b h w c -> b c h w')
- x = x.to(memory_format=torch.contiguous_format).float()
- return x
-
- @torch.no_grad()
- def get_conditioning(self, batch, k=None):
- if k is None:
- k = self.label_key
- assert k is not None, 'Needs to provide label key'
-
- targets = batch[k].to(self.device)
-
- if self.label_key == 'segmentation':
- targets = rearrange(targets, 'b h w c -> b c h w')
- for down in range(self.numd):
- h, w = targets.shape[-2:]
- targets = F.interpolate(targets, size=(h // 2, w // 2), mode='nearest')
-
- # targets = rearrange(targets,'b c h w -> b h w c')
-
- return targets
-
- def compute_top_k(self, logits, labels, k, reduction="mean"):
- _, top_ks = torch.topk(logits, k, dim=1)
- if reduction == "mean":
- return (top_ks == labels[:, None]).float().sum(dim=-1).mean().item()
- elif reduction == "none":
- return (top_ks == labels[:, None]).float().sum(dim=-1)
-
- def on_train_epoch_start(self):
- # save some memory
- self.diffusion_model.model.to('cpu')
-
- @torch.no_grad()
- def write_logs(self, loss, logits, targets):
- log_prefix = 'train' if self.training else 'val'
- log = {}
- log[f"{log_prefix}/loss"] = loss.mean()
- log[f"{log_prefix}/acc@1"] = self.compute_top_k(
- logits, targets, k=1, reduction="mean"
- )
- log[f"{log_prefix}/acc@5"] = self.compute_top_k(
- logits, targets, k=5, reduction="mean"
- )
-
- self.log_dict(log, prog_bar=False, logger=True, on_step=self.training, on_epoch=True)
- self.log('loss', log[f"{log_prefix}/loss"], prog_bar=True, logger=False)
- self.log('global_step', self.global_step, logger=False, on_epoch=False, prog_bar=True)
- lr = self.optimizers().param_groups[0]['lr']
- self.log('lr_abs', lr, on_step=True, logger=True, on_epoch=False, prog_bar=True)
-
- def shared_step(self, batch, t=None):
- x, *_ = self.diffusion_model.get_input(batch, k=self.diffusion_model.first_stage_key)
- targets = self.get_conditioning(batch)
- if targets.dim() == 4:
- targets = targets.argmax(dim=1)
- if t is None:
- t = torch.randint(0, self.diffusion_model.num_timesteps, (x.shape[0],), device=self.device).long()
- else:
- t = torch.full(size=(x.shape[0],), fill_value=t, device=self.device).long()
- x_noisy = self.get_x_noisy(x, t)
- logits = self(x_noisy, t)
-
- loss = F.cross_entropy(logits, targets, reduction='none')
-
- self.write_logs(loss.detach(), logits.detach(), targets.detach())
-
- loss = loss.mean()
- return loss, logits, x_noisy, targets
-
- def training_step(self, batch, batch_idx):
- loss, *_ = self.shared_step(batch)
- return loss
-
- def reset_noise_accs(self):
- self.noisy_acc = {t: {'acc@1': [], 'acc@5': []} for t in
- range(0, self.diffusion_model.num_timesteps, self.diffusion_model.log_every_t)}
-
- def on_validation_start(self):
- self.reset_noise_accs()
-
- @torch.no_grad()
- def validation_step(self, batch, batch_idx):
- loss, *_ = self.shared_step(batch)
-
- for t in self.noisy_acc:
- _, logits, _, targets = self.shared_step(batch, t)
- self.noisy_acc[t]['acc@1'].append(self.compute_top_k(logits, targets, k=1, reduction='mean'))
- self.noisy_acc[t]['acc@5'].append(self.compute_top_k(logits, targets, k=5, reduction='mean'))
-
- return loss
-
- def configure_optimizers(self):
- optimizer = AdamW(self.model.parameters(), lr=self.learning_rate, weight_decay=self.weight_decay)
-
- if self.use_scheduler:
- scheduler = instantiate_from_config(self.scheduler_config)
-
- print("Setting up LambdaLR scheduler...")
- scheduler = [
- {
- 'scheduler': LambdaLR(optimizer, lr_lambda=scheduler.schedule),
- 'interval': 'step',
- 'frequency': 1
- }]
- return [optimizer], scheduler
-
- return optimizer
-
- @torch.no_grad()
- def log_images(self, batch, N=8, *args, **kwargs):
- log = dict()
- x = self.get_input(batch, self.diffusion_model.first_stage_key)
- log['inputs'] = x
-
- y = self.get_conditioning(batch)
-
- if self.label_key == 'class_label':
- y = log_txt_as_img((x.shape[2], x.shape[3]), batch["human_label"])
- log['labels'] = y
-
- if ismap(y):
- log['labels'] = self.diffusion_model.to_rgb(y)
-
- for step in range(self.log_steps):
- current_time = step * self.log_time_interval
-
- _, logits, x_noisy, _ = self.shared_step(batch, t=current_time)
-
- log[f'inputs@t{current_time}'] = x_noisy
-
- pred = F.one_hot(logits.argmax(dim=1), num_classes=self.num_classes)
- pred = rearrange(pred, 'b h w c -> b c h w')
-
- log[f'pred@t{current_time}'] = self.diffusion_model.to_rgb(pred)
-
- for key in log:
- log[key] = log[key][:N]
-
- return log
diff --git a/examples/tutorial/stable_diffusion/ldm/models/diffusion/ddim.py b/examples/tutorial/stable_diffusion/ldm/models/diffusion/ddim.py
deleted file mode 100644
index 91335d637..000000000
--- a/examples/tutorial/stable_diffusion/ldm/models/diffusion/ddim.py
+++ /dev/null
@@ -1,240 +0,0 @@
-"""SAMPLING ONLY."""
-
-import torch
-import numpy as np
-from tqdm import tqdm
-from functools import partial
-
-from ldm.modules.diffusionmodules.util import make_ddim_sampling_parameters, make_ddim_timesteps, noise_like, \
- extract_into_tensor
-
-
-class DDIMSampler(object):
- def __init__(self, model, schedule="linear", **kwargs):
- super().__init__()
- self.model = model
- self.ddpm_num_timesteps = model.num_timesteps
- self.schedule = schedule
-
- def register_buffer(self, name, attr):
- if type(attr) == torch.Tensor:
- if attr.device != torch.device("cuda"):
- attr = attr.to(torch.device("cuda"))
- setattr(self, name, attr)
-
- def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True):
- self.ddim_timesteps = make_ddim_timesteps(ddim_discr_method=ddim_discretize, num_ddim_timesteps=ddim_num_steps,
- num_ddpm_timesteps=self.ddpm_num_timesteps,verbose=verbose)
- alphas_cumprod = self.model.alphas_cumprod
- assert alphas_cumprod.shape[0] == self.ddpm_num_timesteps, 'alphas have to be defined for each timestep'
- to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device)
-
- self.register_buffer('betas', to_torch(self.model.betas))
- self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
- self.register_buffer('alphas_cumprod_prev', to_torch(self.model.alphas_cumprod_prev))
-
- # calculations for diffusion q(x_t | x_{t-1}) and others
- self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod.cpu())))
- self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod.cpu())))
- self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod.cpu())))
- self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu())))
- self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu() - 1)))
-
- # ddim sampling parameters
- ddim_sigmas, ddim_alphas, ddim_alphas_prev = make_ddim_sampling_parameters(alphacums=alphas_cumprod.cpu(),
- ddim_timesteps=self.ddim_timesteps,
- eta=ddim_eta,verbose=verbose)
- self.register_buffer('ddim_sigmas', ddim_sigmas)
- self.register_buffer('ddim_alphas', ddim_alphas)
- self.register_buffer('ddim_alphas_prev', ddim_alphas_prev)
- self.register_buffer('ddim_sqrt_one_minus_alphas', np.sqrt(1. - ddim_alphas))
- sigmas_for_original_sampling_steps = ddim_eta * torch.sqrt(
- (1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod) * (
- 1 - self.alphas_cumprod / self.alphas_cumprod_prev))
- self.register_buffer('ddim_sigmas_for_original_num_steps', sigmas_for_original_sampling_steps)
-
- @torch.no_grad()
- def sample(self,
- S,
- batch_size,
- shape,
- conditioning=None,
- callback=None,
- normals_sequence=None,
- img_callback=None,
- quantize_x0=False,
- eta=0.,
- mask=None,
- x0=None,
- temperature=1.,
- noise_dropout=0.,
- score_corrector=None,
- corrector_kwargs=None,
- verbose=True,
- x_T=None,
- log_every_t=100,
- unconditional_guidance_scale=1.,
- unconditional_conditioning=None,
- # this has to come in the same format as the conditioning, # e.g. as encoded tokens, ...
- **kwargs
- ):
- if conditioning is not None:
- if isinstance(conditioning, dict):
- cbs = conditioning[list(conditioning.keys())[0]].shape[0]
- if cbs != batch_size:
- print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}")
- else:
- if conditioning.shape[0] != batch_size:
- print(f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}")
-
- self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose)
- # sampling
- C, H, W = shape
- size = (batch_size, C, H, W)
- print(f'Data shape for DDIM sampling is {size}, eta {eta}')
-
- samples, intermediates = self.ddim_sampling(conditioning, size,
- callback=callback,
- img_callback=img_callback,
- quantize_denoised=quantize_x0,
- mask=mask, x0=x0,
- ddim_use_original_steps=False,
- noise_dropout=noise_dropout,
- temperature=temperature,
- score_corrector=score_corrector,
- corrector_kwargs=corrector_kwargs,
- x_T=x_T,
- log_every_t=log_every_t,
- unconditional_guidance_scale=unconditional_guidance_scale,
- unconditional_conditioning=unconditional_conditioning,
- )
- return samples, intermediates
-
- @torch.no_grad()
- def ddim_sampling(self, cond, shape,
- x_T=None, ddim_use_original_steps=False,
- callback=None, timesteps=None, quantize_denoised=False,
- mask=None, x0=None, img_callback=None, log_every_t=100,
- temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
- unconditional_guidance_scale=1., unconditional_conditioning=None,):
- device = self.model.betas.device
- b = shape[0]
- if x_T is None:
- img = torch.randn(shape, device=device)
- else:
- img = x_T
-
- if timesteps is None:
- timesteps = self.ddpm_num_timesteps if ddim_use_original_steps else self.ddim_timesteps
- elif timesteps is not None and not ddim_use_original_steps:
- subset_end = int(min(timesteps / self.ddim_timesteps.shape[0], 1) * self.ddim_timesteps.shape[0]) - 1
- timesteps = self.ddim_timesteps[:subset_end]
-
- intermediates = {'x_inter': [img], 'pred_x0': [img]}
- time_range = reversed(range(0,timesteps)) if ddim_use_original_steps else np.flip(timesteps)
- total_steps = timesteps if ddim_use_original_steps else timesteps.shape[0]
- print(f"Running DDIM Sampling with {total_steps} timesteps")
-
- iterator = tqdm(time_range, desc='DDIM Sampler', total=total_steps)
-
- for i, step in enumerate(iterator):
- index = total_steps - i - 1
- ts = torch.full((b,), step, device=device, dtype=torch.long)
-
- if mask is not None:
- assert x0 is not None
- img_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass?
- img = img_orig * mask + (1. - mask) * img
- outs = self.p_sample_ddim(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
- quantize_denoised=quantize_denoised, temperature=temperature,
- noise_dropout=noise_dropout, score_corrector=score_corrector,
- corrector_kwargs=corrector_kwargs,
- unconditional_guidance_scale=unconditional_guidance_scale,
- unconditional_conditioning=unconditional_conditioning)
- img, pred_x0 = outs
- if callback: callback(i)
- if img_callback: img_callback(pred_x0, i)
-
- if index % log_every_t == 0 or index == total_steps - 1:
- intermediates['x_inter'].append(img)
- intermediates['pred_x0'].append(pred_x0)
-
- return img, intermediates
-
- @torch.no_grad()
- def p_sample_ddim(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
- temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
- unconditional_guidance_scale=1., unconditional_conditioning=None):
- b, *_, device = *x.shape, x.device
-
- if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
- e_t = self.model.apply_model(x, t, c)
- else:
- x_in = torch.cat([x] * 2)
- t_in = torch.cat([t] * 2)
- c_in = torch.cat([unconditional_conditioning, c])
- e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
- e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
-
- if score_corrector is not None:
- assert self.model.parameterization == "eps"
- e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
-
- alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
- alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
- sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
- sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
- # select parameters corresponding to the currently considered timestep
- a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
- a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
- sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
- sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)
-
- # current prediction for x_0
- pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
- if quantize_denoised:
- pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
- # direction pointing to x_t
- dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
- noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
- if noise_dropout > 0.:
- noise = torch.nn.functional.dropout(noise, p=noise_dropout)
- x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
- return x_prev, pred_x0
-
- @torch.no_grad()
- def stochastic_encode(self, x0, t, use_original_steps=False, noise=None):
- # fast, but does not allow for exact reconstruction
- # t serves as an index to gather the correct alphas
- if use_original_steps:
- sqrt_alphas_cumprod = self.sqrt_alphas_cumprod
- sqrt_one_minus_alphas_cumprod = self.sqrt_one_minus_alphas_cumprod
- else:
- sqrt_alphas_cumprod = torch.sqrt(self.ddim_alphas)
- sqrt_one_minus_alphas_cumprod = self.ddim_sqrt_one_minus_alphas
-
- if noise is None:
- noise = torch.randn_like(x0)
- return (extract_into_tensor(sqrt_alphas_cumprod, t, x0.shape) * x0 +
- extract_into_tensor(sqrt_one_minus_alphas_cumprod, t, x0.shape) * noise)
-
- @torch.no_grad()
- def decode(self, x_latent, cond, t_start, unconditional_guidance_scale=1.0, unconditional_conditioning=None,
- use_original_steps=False):
-
- timesteps = np.arange(self.ddpm_num_timesteps) if use_original_steps else self.ddim_timesteps
- timesteps = timesteps[:t_start]
-
- time_range = np.flip(timesteps)
- total_steps = timesteps.shape[0]
- print(f"Running DDIM Sampling with {total_steps} timesteps")
-
- iterator = tqdm(time_range, desc='Decoding image', total=total_steps)
- x_dec = x_latent
- for i, step in enumerate(iterator):
- index = total_steps - i - 1
- ts = torch.full((x_latent.shape[0],), step, device=x_latent.device, dtype=torch.long)
- x_dec, _ = self.p_sample_ddim(x_dec, cond, ts, index=index, use_original_steps=use_original_steps,
- unconditional_guidance_scale=unconditional_guidance_scale,
- unconditional_conditioning=unconditional_conditioning)
- return x_dec
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/ldm/models/diffusion/ddpm.py b/examples/tutorial/stable_diffusion/ldm/models/diffusion/ddpm.py
deleted file mode 100644
index 9633ec3d8..000000000
--- a/examples/tutorial/stable_diffusion/ldm/models/diffusion/ddpm.py
+++ /dev/null
@@ -1,1554 +0,0 @@
-import torch
-import torch.nn as nn
-import numpy as np
-import pytorch_lightning as pl
-from torch.optim.lr_scheduler import LambdaLR
-from einops import rearrange, repeat
-from contextlib import contextmanager
-from functools import partial
-from tqdm import tqdm
-from torchvision.utils import make_grid
-
-from pytorch_lightning.utilities.rank_zero import rank_zero_only
-from pytorch_lightning.utilities import rank_zero_info
-
-from ldm.util import log_txt_as_img, exists, default, ismap, isimage, mean_flat, count_params, instantiate_from_config
-from ldm.modules.ema import LitEma
-from ldm.modules.distributions.distributions import normal_kl, DiagonalGaussianDistribution
-from ldm.models.autoencoder import VQModelInterface, IdentityFirstStage, AutoencoderKL
-from ldm.modules.diffusionmodules.util import make_beta_schedule, extract_into_tensor, noise_like
-from ldm.models.diffusion.ddim import DDIMSampler
-from ldm.modules.diffusionmodules.openaimodel import AttentionPool2d
-from ldm.modules.x_transformer import *
-from ldm.modules.encoders.modules import *
-
-from ldm.modules.ema import LitEma
-from ldm.modules.distributions.distributions import normal_kl, DiagonalGaussianDistribution
-from ldm.models.autoencoder import *
-from ldm.models.diffusion.ddim import *
-from ldm.modules.diffusionmodules.openaimodel import *
-from ldm.modules.diffusionmodules.model import *
-
-
-from ldm.modules.diffusionmodules.model import Model, Encoder, Decoder
-
-from ldm.util import instantiate_from_config
-
-from einops import rearrange, repeat
-
-
-
-
-__conditioning_keys__ = {'concat': 'c_concat',
- 'crossattn': 'c_crossattn',
- 'adm': 'y'}
-
-
-def disabled_train(self, mode=True):
- """Overwrite model.train with this function to make sure train/eval mode
- does not change anymore."""
- return self
-
-
-def uniform_on_device(r1, r2, shape, device):
- return (r1 - r2) * torch.rand(*shape, device=device) + r2
-
-
-class DDPM(pl.LightningModule):
- # classic DDPM with Gaussian diffusion, in image space
- def __init__(self,
- unet_config,
- timesteps=1000,
- beta_schedule="linear",
- loss_type="l2",
- ckpt_path=None,
- ignore_keys=[],
- load_only_unet=False,
- monitor="val/loss",
- use_ema=True,
- first_stage_key="image",
- image_size=256,
- channels=3,
- log_every_t=100,
- clip_denoised=True,
- linear_start=1e-4,
- linear_end=2e-2,
- cosine_s=8e-3,
- given_betas=None,
- original_elbo_weight=0.,
- v_posterior=0., # weight for choosing posterior variance as sigma = (1-v) * beta_tilde + v * beta
- l_simple_weight=1.,
- conditioning_key=None,
- parameterization="eps", # all assuming fixed variance schedules
- scheduler_config=None,
- use_positional_encodings=False,
- learn_logvar=False,
- logvar_init=0.,
- use_fp16 = True,
- ):
- super().__init__()
- assert parameterization in ["eps", "x0"], 'currently only supporting "eps" and "x0"'
- self.parameterization = parameterization
- rank_zero_info(f"{self.__class__.__name__}: Running in {self.parameterization}-prediction mode")
- self.cond_stage_model = None
- self.clip_denoised = clip_denoised
- self.log_every_t = log_every_t
- self.first_stage_key = first_stage_key
- self.image_size = image_size # try conv?
- self.channels = channels
- self.use_positional_encodings = use_positional_encodings
- self.unet_config = unet_config
- self.conditioning_key = conditioning_key
- # self.model = DiffusionWrapper(unet_config, conditioning_key)
- # count_params(self.model, verbose=True)
- self.use_ema = use_ema
- # if self.use_ema:
- # self.model_ema = LitEma(self.model)
- # print(f"Keeping EMAs of {len(list(self.model_ema.buffers()))}.")
-
- self.use_scheduler = scheduler_config is not None
- if self.use_scheduler:
- self.scheduler_config = scheduler_config
-
- self.v_posterior = v_posterior
- self.original_elbo_weight = original_elbo_weight
- self.l_simple_weight = l_simple_weight
-
- if monitor is not None:
- self.monitor = monitor
- self.ckpt_path = ckpt_path
- self.ignore_keys = ignore_keys
- self.load_only_unet = load_only_unet
- self.given_betas = given_betas
- self.beta_schedule = beta_schedule
- self.timesteps = timesteps
- self.linear_start = linear_start
- self.linear_end = linear_end
- self.cosine_s = cosine_s
- # if ckpt_path is not None:
- # self.init_from_ckpt(ckpt_path, ignore_keys=ignore_keys, only_model=load_only_unet)
- #
- # self.register_schedule(given_betas=given_betas, beta_schedule=beta_schedule, timesteps=timesteps,
- # linear_start=linear_start, linear_end=linear_end, cosine_s=cosine_s)
-
- self.loss_type = loss_type
-
- self.learn_logvar = learn_logvar
- self.logvar_init = logvar_init
- # self.logvar = torch.full(fill_value=logvar_init, size=(self.num_timesteps,))
- # if self.learn_logvar:
- # self.logvar = nn.Parameter(self.logvar, requires_grad=True)
- # self.logvar = nn.Parameter(self.logvar, requires_grad=True)
-
- self.use_fp16 = use_fp16
- if use_fp16:
- self.unet_config["params"].update({"use_fp16": True})
- rank_zero_info("Using FP16 for UNet = {}".format(self.unet_config["params"]["use_fp16"]))
- else:
- self.unet_config["params"].update({"use_fp16": False})
- rank_zero_info("Using FP16 for UNet = {}".format(self.unet_config["params"]["use_fp16"]))
-
- def register_schedule(self, given_betas=None, beta_schedule="linear", timesteps=1000,
- linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
- if exists(given_betas):
- betas = given_betas
- else:
- betas = make_beta_schedule(beta_schedule, timesteps, linear_start=linear_start, linear_end=linear_end,
- cosine_s=cosine_s)
- alphas = 1. - betas
- alphas_cumprod = np.cumprod(alphas, axis=0)
- alphas_cumprod_prev = np.append(1., alphas_cumprod[:-1])
-
- timesteps, = betas.shape
- self.num_timesteps = int(timesteps)
- self.linear_start = linear_start
- self.linear_end = linear_end
- assert alphas_cumprod.shape[0] == self.num_timesteps, 'alphas have to be defined for each timestep'
-
- to_torch = partial(torch.tensor, dtype=torch.float32)
-
- self.register_buffer('betas', to_torch(betas))
- self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
- self.register_buffer('alphas_cumprod_prev', to_torch(alphas_cumprod_prev))
-
- # calculations for diffusion q(x_t | x_{t-1}) and others
- self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod)))
- self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod)))
- self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod)))
- self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod)))
- self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod - 1)))
-
- # calculations for posterior q(x_{t-1} | x_t, x_0)
- posterior_variance = (1 - self.v_posterior) * betas * (1. - alphas_cumprod_prev) / (
- 1. - alphas_cumprod) + self.v_posterior * betas
- # above: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t)
- self.register_buffer('posterior_variance', to_torch(posterior_variance))
- # below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
- self.register_buffer('posterior_log_variance_clipped', to_torch(np.log(np.maximum(posterior_variance, 1e-20))))
- self.register_buffer('posterior_mean_coef1', to_torch(
- betas * np.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod)))
- self.register_buffer('posterior_mean_coef2', to_torch(
- (1. - alphas_cumprod_prev) * np.sqrt(alphas) / (1. - alphas_cumprod)))
-
- if self.parameterization == "eps":
- lvlb_weights = self.betas ** 2 / (
- 2 * self.posterior_variance * to_torch(alphas) * (1 - self.alphas_cumprod))
- elif self.parameterization == "x0":
- lvlb_weights = 0.5 * np.sqrt(torch.Tensor(alphas_cumprod)) / (2. * 1 - torch.Tensor(alphas_cumprod))
- else:
- raise NotImplementedError("mu not supported")
- # TODO how to choose this term
- lvlb_weights[0] = lvlb_weights[1]
- self.register_buffer('lvlb_weights', lvlb_weights, persistent=False)
- assert not torch.isnan(self.lvlb_weights).all()
-
- @contextmanager
- def ema_scope(self, context=None):
- if self.use_ema:
- self.model_ema.store(self.model.parameters())
- self.model_ema.copy_to(self.model)
- if context is not None:
- print(f"{context}: Switched to EMA weights")
- try:
- yield None
- finally:
- if self.use_ema:
- self.model_ema.restore(self.model.parameters())
- if context is not None:
- print(f"{context}: Restored training weights")
-
- def init_from_ckpt(self, path, ignore_keys=list(), only_model=False):
- sd = torch.load(path, map_location="cpu")
- if "state_dict" in list(sd.keys()):
- sd = sd["state_dict"]
- keys = list(sd.keys())
- for k in keys:
- for ik in ignore_keys:
- if k.startswith(ik):
- print("Deleting key {} from state_dict.".format(k))
- del sd[k]
- missing, unexpected = self.load_state_dict(sd, strict=False) if not only_model else self.model.load_state_dict(
- sd, strict=False)
- print(f"Restored from {path} with {len(missing)} missing and {len(unexpected)} unexpected keys")
- if len(missing) > 0:
- print(f"Missing Keys: {missing}")
- if len(unexpected) > 0:
- print(f"Unexpected Keys: {unexpected}")
-
- def q_mean_variance(self, x_start, t):
- """
- Get the distribution q(x_t | x_0).
- :param x_start: the [N x C x ...] tensor of noiseless inputs.
- :param t: the number of diffusion steps (minus 1). Here, 0 means one step.
- :return: A tuple (mean, variance, log_variance), all of x_start's shape.
- """
- mean = (extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start)
- variance = extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
- log_variance = extract_into_tensor(self.log_one_minus_alphas_cumprod, t, x_start.shape)
- return mean, variance, log_variance
-
- def predict_start_from_noise(self, x_t, t, noise):
- return (
- extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
- extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
- )
-
- def q_posterior(self, x_start, x_t, t):
- posterior_mean = (
- extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start +
- extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t
- )
- posterior_variance = extract_into_tensor(self.posterior_variance, t, x_t.shape)
- posterior_log_variance_clipped = extract_into_tensor(self.posterior_log_variance_clipped, t, x_t.shape)
- return posterior_mean, posterior_variance, posterior_log_variance_clipped
-
- def p_mean_variance(self, x, t, clip_denoised: bool):
- model_out = self.model(x, t)
- if self.parameterization == "eps":
- x_recon = self.predict_start_from_noise(x, t=t, noise=model_out)
- elif self.parameterization == "x0":
- x_recon = model_out
- if clip_denoised:
- x_recon.clamp_(-1., 1.)
-
- model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start=x_recon, x_t=x, t=t)
- return model_mean, posterior_variance, posterior_log_variance
-
- @torch.no_grad()
- def p_sample(self, x, t, clip_denoised=True, repeat_noise=False):
- b, *_, device = *x.shape, x.device
- model_mean, _, model_log_variance = self.p_mean_variance(x=x, t=t, clip_denoised=clip_denoised)
- noise = noise_like(x.shape, device, repeat_noise)
- # no noise when t == 0
- nonzero_mask = (1 - (t == 0).float()).reshape(b, *((1,) * (len(x.shape) - 1)))
- return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
-
- @torch.no_grad()
- def p_sample_loop(self, shape, return_intermediates=False):
- device = self.betas.device
- b = shape[0]
- img = torch.randn(shape, device=device)
- intermediates = [img]
- for i in tqdm(reversed(range(0, self.num_timesteps)), desc='Sampling t', total=self.num_timesteps):
- img = self.p_sample(img, torch.full((b,), i, device=device, dtype=torch.long),
- clip_denoised=self.clip_denoised)
- if i % self.log_every_t == 0 or i == self.num_timesteps - 1:
- intermediates.append(img)
- if return_intermediates:
- return img, intermediates
- return img
-
- @torch.no_grad()
- def sample(self, batch_size=16, return_intermediates=False):
- image_size = self.image_size
- channels = self.channels
- return self.p_sample_loop((batch_size, channels, image_size, image_size),
- return_intermediates=return_intermediates)
-
- def q_sample(self, x_start, t, noise=None):
- noise = default(noise, lambda: torch.randn_like(x_start))
- return (extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
- extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise)
-
- def get_loss(self, pred, target, mean=True):
-
- if pred.isnan().any():
- print("Warning: Prediction has nan values")
- lr = self.optimizers().param_groups[0]['lr']
- # self.log('lr_abs', lr, prog_bar=True, logger=True, on_step=True, on_epoch=False)
- print(f"lr: {lr}")
- if pred.isinf().any():
- print("Warning: Prediction has inf values")
-
- if self.use_fp16:
- target = target.half()
-
- if self.loss_type == 'l1':
- loss = (target - pred).abs()
- if mean:
- loss = loss.mean()
- elif self.loss_type == 'l2':
- if mean:
- loss = torch.nn.functional.mse_loss(target, pred)
- else:
- loss = torch.nn.functional.mse_loss(target, pred, reduction='none')
- else:
- raise NotImplementedError("unknown loss type '{loss_type}'")
-
- if loss.isnan().any():
- print("Warning: loss has nan values")
- print("loss: ", loss[0][0][0])
- raise ValueError("loss has nan values")
- if loss.isinf().any():
- print("Warning: loss has inf values")
- print("loss: ", loss)
- raise ValueError("loss has inf values")
-
- return loss
-
- def p_losses(self, x_start, t, noise=None):
- noise = default(noise, lambda: torch.randn_like(x_start))
- x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
- model_out = self.model(x_noisy, t)
-
- loss_dict = {}
- if self.parameterization == "eps":
- target = noise
- elif self.parameterization == "x0":
- target = x_start
- else:
- raise NotImplementedError(f"Paramterization {self.parameterization} not yet supported")
-
- loss = self.get_loss(model_out, target, mean=False).mean(dim=[1, 2, 3])
-
- log_prefix = 'train' if self.training else 'val'
-
- loss_dict.update({f'{log_prefix}/loss_simple': loss.mean()})
- loss_simple = loss.mean() * self.l_simple_weight
-
- loss_vlb = (self.lvlb_weights[t] * loss).mean()
- loss_dict.update({f'{log_prefix}/loss_vlb': loss_vlb})
-
- loss = loss_simple + self.original_elbo_weight * loss_vlb
-
- loss_dict.update({f'{log_prefix}/loss': loss})
-
- return loss, loss_dict
-
- def forward(self, x, *args, **kwargs):
- # b, c, h, w, device, img_size, = *x.shape, x.device, self.image_size
- # assert h == img_size and w == img_size, f'height and width of image must be {img_size}'
- t = torch.randint(0, self.num_timesteps, (x.shape[0],), device=self.device).long()
- return self.p_losses(x, t, *args, **kwargs)
-
- def get_input(self, batch, k):
- # print("+" * 30)
- # print(batch['jpg'].shape)
- # print(len(batch['txt']))
- # print(k)
- # print("=" * 30)
- if not isinstance(batch, torch.Tensor):
- x = batch[k]
- else:
- x = batch
- if len(x.shape) == 3:
- x = x[..., None]
- x = rearrange(x, 'b h w c -> b c h w')
-
- if self.use_fp16:
- x = x.to(memory_format=torch.contiguous_format).float().half()
- else:
- x = x.to(memory_format=torch.contiguous_format).float()
-
- return x
-
- def shared_step(self, batch):
- x = self.get_input(batch, self.first_stage_key)
- loss, loss_dict = self(x)
- return loss, loss_dict
-
- def training_step(self, batch, batch_idx):
- loss, loss_dict = self.shared_step(batch)
-
- self.log_dict(loss_dict, prog_bar=True,
- logger=True, on_step=True, on_epoch=True)
-
- self.log("global_step", self.global_step,
- prog_bar=True, logger=True, on_step=True, on_epoch=False)
-
- if self.use_scheduler:
- lr = self.optimizers().param_groups[0]['lr']
- self.log('lr_abs', lr, prog_bar=True, logger=True, on_step=True, on_epoch=False)
-
- return loss
-
- @torch.no_grad()
- def validation_step(self, batch, batch_idx):
- _, loss_dict_no_ema = self.shared_step(batch)
- with self.ema_scope():
- _, loss_dict_ema = self.shared_step(batch)
- loss_dict_ema = {key + '_ema': loss_dict_ema[key] for key in loss_dict_ema}
- self.log_dict(loss_dict_no_ema, prog_bar=False, logger=True, on_step=False, on_epoch=True)
- self.log_dict(loss_dict_ema, prog_bar=False, logger=True, on_step=False, on_epoch=True)
-
- def on_train_batch_end(self, *args, **kwargs):
- if self.use_ema:
- self.model_ema(self.model)
-
- def _get_rows_from_list(self, samples):
- n_imgs_per_row = len(samples)
- denoise_grid = rearrange(samples, 'n b c h w -> b n c h w')
- denoise_grid = rearrange(denoise_grid, 'b n c h w -> (b n) c h w')
- denoise_grid = make_grid(denoise_grid, nrow=n_imgs_per_row)
- return denoise_grid
-
- @torch.no_grad()
- def log_images(self, batch, N=8, n_row=2, sample=True, return_keys=None, **kwargs):
- log = dict()
- x = self.get_input(batch, self.first_stage_key)
- N = min(x.shape[0], N)
- n_row = min(x.shape[0], n_row)
- x = x.to(self.device)[:N]
- log["inputs"] = x
-
- # get diffusion row
- diffusion_row = list()
- x_start = x[:n_row]
-
- for t in range(self.num_timesteps):
- if t % self.log_every_t == 0 or t == self.num_timesteps - 1:
- t = repeat(torch.tensor([t]), '1 -> b', b=n_row)
- t = t.to(self.device).long()
- noise = torch.randn_like(x_start)
- x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
- diffusion_row.append(x_noisy)
-
- log["diffusion_row"] = self._get_rows_from_list(diffusion_row)
-
- if sample:
- # get denoise row
- with self.ema_scope("Plotting"):
- samples, denoise_row = self.sample(batch_size=N, return_intermediates=True)
-
- log["samples"] = samples
- log["denoise_row"] = self._get_rows_from_list(denoise_row)
-
- if return_keys:
- if np.intersect1d(list(log.keys()), return_keys).shape[0] == 0:
- return log
- else:
- return {key: log[key] for key in return_keys}
- return log
-
- def configure_optimizers(self):
- lr = self.learning_rate
- params = list(self.model.parameters())
- if self.learn_logvar:
- params = params + [self.logvar]
- opt = torch.optim.AdamW(params, lr=lr)
- return opt
-
-
-class LatentDiffusion(DDPM):
- """main class"""
- def __init__(self,
- first_stage_config,
- cond_stage_config,
- num_timesteps_cond=None,
- cond_stage_key="image",
- cond_stage_trainable=False,
- concat_mode=True,
- cond_stage_forward=None,
- conditioning_key=None,
- scale_factor=1.0,
- scale_by_std=False,
- use_fp16=True,
- *args, **kwargs):
- self.num_timesteps_cond = default(num_timesteps_cond, 1)
- self.scale_by_std = scale_by_std
- assert self.num_timesteps_cond <= kwargs['timesteps']
- # for backwards compatibility after implementation of DiffusionWrapper
- if conditioning_key is None:
- conditioning_key = 'concat' if concat_mode else 'crossattn'
- if cond_stage_config == '__is_unconditional__':
- conditioning_key = None
- ckpt_path = kwargs.pop("ckpt_path", None)
- ignore_keys = kwargs.pop("ignore_keys", [])
- super().__init__(conditioning_key=conditioning_key, use_fp16=use_fp16, *args, **kwargs)
- self.concat_mode = concat_mode
- self.cond_stage_trainable = cond_stage_trainable
- self.cond_stage_key = cond_stage_key
- try:
- self.num_downs = len(first_stage_config.params.ddconfig.ch_mult) - 1
- except:
- self.num_downs = 0
- if not scale_by_std:
- self.scale_factor = scale_factor
- else:
- self.register_buffer('scale_factor', torch.tensor(scale_factor))
- self.first_stage_config = first_stage_config
- self.cond_stage_config = cond_stage_config
- if self.use_fp16:
- self.cond_stage_config["params"].update({"use_fp16": True})
- rank_zero_info("Using fp16 for conditioning stage = {}".format(self.cond_stage_config["params"]["use_fp16"]))
- else:
- self.cond_stage_config["params"].update({"use_fp16": False})
- rank_zero_info("Using fp16 for conditioning stage = {}".format(self.cond_stage_config["params"]["use_fp16"]))
- # self.instantiate_first_stage(first_stage_config)
- # self.instantiate_cond_stage(cond_stage_config)
- self.cond_stage_forward = cond_stage_forward
- self.clip_denoised = False
- self.bbox_tokenizer = None
-
- self.restarted_from_ckpt = False
- if ckpt_path is not None:
- self.init_from_ckpt(ckpt_path, ignore_keys)
- self.restarted_from_ckpt = True
-
-
-
- def configure_sharded_model(self) -> None:
- self.model = DiffusionWrapper(self.unet_config, self.conditioning_key)
- count_params(self.model, verbose=True)
- if self.use_ema:
- self.model_ema = LitEma(self.model)
- print(f"Keeping EMAs of {len(list(self.model_ema.buffers()))}.")
-
-
- self.register_schedule(given_betas=self.given_betas, beta_schedule=self.beta_schedule, timesteps=self.timesteps,
- linear_start=self.linear_start, linear_end=self.linear_end, cosine_s=self.cosine_s)
-
- self.logvar = torch.full(fill_value=self.logvar_init, size=(self.num_timesteps,))
- if self.learn_logvar:
- self.logvar = nn.Parameter(self.logvar, requires_grad=True)
- # self.logvar = nn.Parameter(self.logvar, requires_grad=True)
- if self.ckpt_path is not None:
- self.init_from_ckpt(self.ckpt_path, self.ignore_keys)
- self.restarted_from_ckpt = True
-
- # TODO()
- # for p in self.model.modules():
- # if not p.parameters().data.is_contiguous:
- # p.data = p.data.contiguous()
-
- self.instantiate_first_stage(self.first_stage_config)
- self.instantiate_cond_stage(self.cond_stage_config)
-
- def make_cond_schedule(self, ):
- self.cond_ids = torch.full(size=(self.num_timesteps,), fill_value=self.num_timesteps - 1, dtype=torch.long)
- ids = torch.round(torch.linspace(0, self.num_timesteps - 1, self.num_timesteps_cond)).long()
- self.cond_ids[:self.num_timesteps_cond] = ids
-
-
-
- @rank_zero_only
- @torch.no_grad()
- # def on_train_batch_start(self, batch, batch_idx, dataloader_idx):
- def on_train_batch_start(self, batch, batch_idx):
- # only for very first batch
- if self.scale_by_std and self.current_epoch == 0 and self.global_step == 0 and batch_idx == 0 and not self.restarted_from_ckpt:
- assert self.scale_factor == 1., 'rather not use custom rescaling and std-rescaling simultaneously'
- # set rescale weight to 1./std of encodings
- print("### USING STD-RESCALING ###")
- x = super().get_input(batch, self.first_stage_key)
- x = x.to(self.device)
- encoder_posterior = self.encode_first_stage(x)
- z = self.get_first_stage_encoding(encoder_posterior).detach()
- del self.scale_factor
- self.register_buffer('scale_factor', 1. / z.flatten().std())
- print(f"setting self.scale_factor to {self.scale_factor}")
- print("### USING STD-RESCALING ###")
-
- def register_schedule(self,
- given_betas=None, beta_schedule="linear", timesteps=1000,
- linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
- super().register_schedule(given_betas, beta_schedule, timesteps, linear_start, linear_end, cosine_s)
-
- self.shorten_cond_schedule = self.num_timesteps_cond > 1
- if self.shorten_cond_schedule:
- self.make_cond_schedule()
-
- def instantiate_first_stage(self, config):
- model = instantiate_from_config(config)
- self.first_stage_model = model.eval()
- self.first_stage_model.train = disabled_train
- for param in self.first_stage_model.parameters():
- param.requires_grad = False
-
- def instantiate_cond_stage(self, config):
- if not self.cond_stage_trainable:
- if config == "__is_first_stage__":
- print("Using first stage also as cond stage.")
- self.cond_stage_model = self.first_stage_model
- elif config == "__is_unconditional__":
- print(f"Training {self.__class__.__name__} as an unconditional model.")
- self.cond_stage_model = None
- # self.be_unconditional = True
- else:
- model = instantiate_from_config(config)
- self.cond_stage_model = model.eval()
- self.cond_stage_model.train = disabled_train
- for param in self.cond_stage_model.parameters():
- param.requires_grad = False
- else:
- assert config != '__is_first_stage__'
- assert config != '__is_unconditional__'
- model = instantiate_from_config(config)
- self.cond_stage_model = model
-
- def _get_denoise_row_from_list(self, samples, desc='', force_no_decoder_quantization=False):
- denoise_row = []
- for zd in tqdm(samples, desc=desc):
- denoise_row.append(self.decode_first_stage(zd.to(self.device),
- force_not_quantize=force_no_decoder_quantization))
- n_imgs_per_row = len(denoise_row)
- denoise_row = torch.stack(denoise_row) # n_log_step, n_row, C, H, W
- denoise_grid = rearrange(denoise_row, 'n b c h w -> b n c h w')
- denoise_grid = rearrange(denoise_grid, 'b n c h w -> (b n) c h w')
- denoise_grid = make_grid(denoise_grid, nrow=n_imgs_per_row)
- return denoise_grid
-
- def get_first_stage_encoding(self, encoder_posterior):
- if isinstance(encoder_posterior, DiagonalGaussianDistribution):
- z = encoder_posterior.sample()
- elif isinstance(encoder_posterior, torch.Tensor):
- z = encoder_posterior
- else:
- raise NotImplementedError(f"encoder_posterior of type '{type(encoder_posterior)}' not yet implemented")
- return self.scale_factor * z
-
- def get_learned_conditioning(self, c):
- if self.cond_stage_forward is None:
- if hasattr(self.cond_stage_model, 'encode') and callable(self.cond_stage_model.encode):
- c = self.cond_stage_model.encode(c)
- if isinstance(c, DiagonalGaussianDistribution):
- c = c.mode()
- else:
- c = self.cond_stage_model(c)
- else:
- assert hasattr(self.cond_stage_model, self.cond_stage_forward)
- c = getattr(self.cond_stage_model, self.cond_stage_forward)(c)
- return c
-
- def meshgrid(self, h, w):
- y = torch.arange(0, h).view(h, 1, 1).repeat(1, w, 1)
- x = torch.arange(0, w).view(1, w, 1).repeat(h, 1, 1)
-
- arr = torch.cat([y, x], dim=-1)
- return arr
-
- def delta_border(self, h, w):
- """
- :param h: height
- :param w: width
- :return: normalized distance to image border,
- wtith min distance = 0 at border and max dist = 0.5 at image center
- """
- lower_right_corner = torch.tensor([h - 1, w - 1]).view(1, 1, 2)
- arr = self.meshgrid(h, w) / lower_right_corner
- dist_left_up = torch.min(arr, dim=-1, keepdims=True)[0]
- dist_right_down = torch.min(1 - arr, dim=-1, keepdims=True)[0]
- edge_dist = torch.min(torch.cat([dist_left_up, dist_right_down], dim=-1), dim=-1)[0]
- return edge_dist
-
- def get_weighting(self, h, w, Ly, Lx, device):
- weighting = self.delta_border(h, w)
- weighting = torch.clip(weighting, self.split_input_params["clip_min_weight"],
- self.split_input_params["clip_max_weight"], )
- weighting = weighting.view(1, h * w, 1).repeat(1, 1, Ly * Lx).to(device)
-
- if self.split_input_params["tie_braker"]:
- L_weighting = self.delta_border(Ly, Lx)
- L_weighting = torch.clip(L_weighting,
- self.split_input_params["clip_min_tie_weight"],
- self.split_input_params["clip_max_tie_weight"])
-
- L_weighting = L_weighting.view(1, 1, Ly * Lx).to(device)
- weighting = weighting * L_weighting
- return weighting
-
- def get_fold_unfold(self, x, kernel_size, stride, uf=1, df=1): # todo load once not every time, shorten code
- """
- :param x: img of size (bs, c, h, w)
- :return: n img crops of size (n, bs, c, kernel_size[0], kernel_size[1])
- """
- bs, nc, h, w = x.shape
-
- # number of crops in image
- Ly = (h - kernel_size[0]) // stride[0] + 1
- Lx = (w - kernel_size[1]) // stride[1] + 1
-
- if uf == 1 and df == 1:
- fold_params = dict(kernel_size=kernel_size, dilation=1, padding=0, stride=stride)
- unfold = torch.nn.Unfold(**fold_params)
-
- fold = torch.nn.Fold(output_size=x.shape[2:], **fold_params)
-
- weighting = self.get_weighting(kernel_size[0], kernel_size[1], Ly, Lx, x.device).to(x.dtype)
- normalization = fold(weighting).view(1, 1, h, w) # normalizes the overlap
- weighting = weighting.view((1, 1, kernel_size[0], kernel_size[1], Ly * Lx))
-
- elif uf > 1 and df == 1:
- fold_params = dict(kernel_size=kernel_size, dilation=1, padding=0, stride=stride)
- unfold = torch.nn.Unfold(**fold_params)
-
- fold_params2 = dict(kernel_size=(kernel_size[0] * uf, kernel_size[0] * uf),
- dilation=1, padding=0,
- stride=(stride[0] * uf, stride[1] * uf))
- fold = torch.nn.Fold(output_size=(x.shape[2] * uf, x.shape[3] * uf), **fold_params2)
-
- weighting = self.get_weighting(kernel_size[0] * uf, kernel_size[1] * uf, Ly, Lx, x.device).to(x.dtype)
- normalization = fold(weighting).view(1, 1, h * uf, w * uf) # normalizes the overlap
- weighting = weighting.view((1, 1, kernel_size[0] * uf, kernel_size[1] * uf, Ly * Lx))
-
- elif df > 1 and uf == 1:
- fold_params = dict(kernel_size=kernel_size, dilation=1, padding=0, stride=stride)
- unfold = torch.nn.Unfold(**fold_params)
-
- fold_params2 = dict(kernel_size=(kernel_size[0] // df, kernel_size[0] // df),
- dilation=1, padding=0,
- stride=(stride[0] // df, stride[1] // df))
- fold = torch.nn.Fold(output_size=(x.shape[2] // df, x.shape[3] // df), **fold_params2)
-
- weighting = self.get_weighting(kernel_size[0] // df, kernel_size[1] // df, Ly, Lx, x.device).to(x.dtype)
- normalization = fold(weighting).view(1, 1, h // df, w // df) # normalizes the overlap
- weighting = weighting.view((1, 1, kernel_size[0] // df, kernel_size[1] // df, Ly * Lx))
-
- else:
- raise NotImplementedError
-
- return fold, unfold, normalization, weighting
-
- @torch.no_grad()
- def get_input(self, batch, k, return_first_stage_outputs=False, force_c_encode=False,
- cond_key=None, return_original_cond=False, bs=None):
- x = super().get_input(batch, k)
- if bs is not None:
- x = x[:bs]
- x = x.to(self.device)
- encoder_posterior = self.encode_first_stage(x)
- z = self.get_first_stage_encoding(encoder_posterior).detach()
-
- if self.model.conditioning_key is not None:
- if cond_key is None:
- cond_key = self.cond_stage_key
- if cond_key != self.first_stage_key:
- if cond_key in ['caption', 'coordinates_bbox', 'txt']:
- xc = batch[cond_key]
- elif cond_key == 'class_label':
- xc = batch
- else:
- xc = super().get_input(batch, cond_key).to(self.device)
- else:
- xc = x
- if not self.cond_stage_trainable or force_c_encode:
- if isinstance(xc, dict) or isinstance(xc, list):
- # import pudb; pudb.set_trace()
- c = self.get_learned_conditioning(xc)
- else:
- c = self.get_learned_conditioning(xc.to(self.device))
- else:
- c = xc
- if bs is not None:
- c = c[:bs]
-
- if self.use_positional_encodings:
- pos_x, pos_y = self.compute_latent_shifts(batch)
- ckey = __conditioning_keys__[self.model.conditioning_key]
- c = {ckey: c, 'pos_x': pos_x, 'pos_y': pos_y}
-
- else:
- c = None
- xc = None
- if self.use_positional_encodings:
- pos_x, pos_y = self.compute_latent_shifts(batch)
- c = {'pos_x': pos_x, 'pos_y': pos_y}
- out = [z, c]
- if return_first_stage_outputs:
- xrec = self.decode_first_stage(z)
- out.extend([x, xrec])
- if return_original_cond:
- out.append(xc)
- return out
-
- @torch.no_grad()
- def decode_first_stage(self, z, predict_cids=False, force_not_quantize=False):
- if predict_cids:
- if z.dim() == 4:
- z = torch.argmax(z.exp(), dim=1).long()
- z = self.first_stage_model.quantize.get_codebook_entry(z, shape=None)
- z = rearrange(z, 'b h w c -> b c h w').contiguous()
-
- z = 1. / self.scale_factor * z
-
- if hasattr(self, "split_input_params"):
- if self.split_input_params["patch_distributed_vq"]:
- ks = self.split_input_params["ks"] # eg. (128, 128)
- stride = self.split_input_params["stride"] # eg. (64, 64)
- uf = self.split_input_params["vqf"]
- bs, nc, h, w = z.shape
- if ks[0] > h or ks[1] > w:
- ks = (min(ks[0], h), min(ks[1], w))
- print("reducing Kernel")
-
- if stride[0] > h or stride[1] > w:
- stride = (min(stride[0], h), min(stride[1], w))
- print("reducing stride")
-
- fold, unfold, normalization, weighting = self.get_fold_unfold(z, ks, stride, uf=uf)
-
- z = unfold(z) # (bn, nc * prod(**ks), L)
- # 1. Reshape to img shape
- z = z.view((z.shape[0], -1, ks[0], ks[1], z.shape[-1])) # (bn, nc, ks[0], ks[1], L )
-
- # 2. apply model loop over last dim
- if isinstance(self.first_stage_model, VQModelInterface):
- output_list = [self.first_stage_model.decode(z[:, :, :, :, i],
- force_not_quantize=predict_cids or force_not_quantize)
- for i in range(z.shape[-1])]
- else:
-
- output_list = [self.first_stage_model.decode(z[:, :, :, :, i])
- for i in range(z.shape[-1])]
-
- o = torch.stack(output_list, axis=-1) # # (bn, nc, ks[0], ks[1], L)
- o = o * weighting
- # Reverse 1. reshape to img shape
- o = o.view((o.shape[0], -1, o.shape[-1])) # (bn, nc * ks[0] * ks[1], L)
- # stitch crops together
- decoded = fold(o)
- decoded = decoded / normalization # norm is shape (1, 1, h, w)
- return decoded
- else:
- if isinstance(self.first_stage_model, VQModelInterface):
- return self.first_stage_model.decode(z, force_not_quantize=predict_cids or force_not_quantize)
- else:
- return self.first_stage_model.decode(z)
-
- else:
- if isinstance(self.first_stage_model, VQModelInterface):
- return self.first_stage_model.decode(z, force_not_quantize=predict_cids or force_not_quantize)
- else:
- return self.first_stage_model.decode(z)
-
- # same as above but without decorator
- def differentiable_decode_first_stage(self, z, predict_cids=False, force_not_quantize=False):
- if predict_cids:
- if z.dim() == 4:
- z = torch.argmax(z.exp(), dim=1).long()
- z = self.first_stage_model.quantize.get_codebook_entry(z, shape=None)
- z = rearrange(z, 'b h w c -> b c h w').contiguous()
-
- z = 1. / self.scale_factor * z
-
- if hasattr(self, "split_input_params"):
- if self.split_input_params["patch_distributed_vq"]:
- ks = self.split_input_params["ks"] # eg. (128, 128)
- stride = self.split_input_params["stride"] # eg. (64, 64)
- uf = self.split_input_params["vqf"]
- bs, nc, h, w = z.shape
- if ks[0] > h or ks[1] > w:
- ks = (min(ks[0], h), min(ks[1], w))
- print("reducing Kernel")
-
- if stride[0] > h or stride[1] > w:
- stride = (min(stride[0], h), min(stride[1], w))
- print("reducing stride")
-
- fold, unfold, normalization, weighting = self.get_fold_unfold(z, ks, stride, uf=uf)
-
- z = unfold(z) # (bn, nc * prod(**ks), L)
- # 1. Reshape to img shape
- z = z.view((z.shape[0], -1, ks[0], ks[1], z.shape[-1])) # (bn, nc, ks[0], ks[1], L )
-
- # 2. apply model loop over last dim
- if isinstance(self.first_stage_model, VQModelInterface):
- output_list = [self.first_stage_model.decode(z[:, :, :, :, i],
- force_not_quantize=predict_cids or force_not_quantize)
- for i in range(z.shape[-1])]
- else:
-
- output_list = [self.first_stage_model.decode(z[:, :, :, :, i])
- for i in range(z.shape[-1])]
-
- o = torch.stack(output_list, axis=-1) # # (bn, nc, ks[0], ks[1], L)
- o = o * weighting
- # Reverse 1. reshape to img shape
- o = o.view((o.shape[0], -1, o.shape[-1])) # (bn, nc * ks[0] * ks[1], L)
- # stitch crops together
- decoded = fold(o)
- decoded = decoded / normalization # norm is shape (1, 1, h, w)
- return decoded
- else:
- if isinstance(self.first_stage_model, VQModelInterface):
- return self.first_stage_model.decode(z, force_not_quantize=predict_cids or force_not_quantize)
- else:
- return self.first_stage_model.decode(z)
-
- else:
- if isinstance(self.first_stage_model, VQModelInterface):
- return self.first_stage_model.decode(z, force_not_quantize=predict_cids or force_not_quantize)
- else:
- return self.first_stage_model.decode(z)
-
- @torch.no_grad()
- def encode_first_stage(self, x):
- if hasattr(self, "split_input_params"):
- if self.split_input_params["patch_distributed_vq"]:
- ks = self.split_input_params["ks"] # eg. (128, 128)
- stride = self.split_input_params["stride"] # eg. (64, 64)
- df = self.split_input_params["vqf"]
- self.split_input_params['original_image_size'] = x.shape[-2:]
- bs, nc, h, w = x.shape
- if ks[0] > h or ks[1] > w:
- ks = (min(ks[0], h), min(ks[1], w))
- print("reducing Kernel")
-
- if stride[0] > h or stride[1] > w:
- stride = (min(stride[0], h), min(stride[1], w))
- print("reducing stride")
-
- fold, unfold, normalization, weighting = self.get_fold_unfold(x, ks, stride, df=df)
- z = unfold(x) # (bn, nc * prod(**ks), L)
- # Reshape to img shape
- z = z.view((z.shape[0], -1, ks[0], ks[1], z.shape[-1])) # (bn, nc, ks[0], ks[1], L )
-
- output_list = [self.first_stage_model.encode(z[:, :, :, :, i])
- for i in range(z.shape[-1])]
-
- o = torch.stack(output_list, axis=-1)
- o = o * weighting
-
- # Reverse reshape to img shape
- o = o.view((o.shape[0], -1, o.shape[-1])) # (bn, nc * ks[0] * ks[1], L)
- # stitch crops together
- decoded = fold(o)
- decoded = decoded / normalization
- return decoded
-
- else:
- return self.first_stage_model.encode(x)
- else:
- return self.first_stage_model.encode(x)
-
- def shared_step(self, batch, **kwargs):
- x, c = self.get_input(batch, self.first_stage_key)
- loss = self(x, c)
- return loss
-
- def forward(self, x, c, *args, **kwargs):
- t = torch.randint(0, self.num_timesteps, (x.shape[0],), device=self.device).long()
- if self.model.conditioning_key is not None:
- assert c is not None
- if self.cond_stage_trainable:
- c = self.get_learned_conditioning(c)
- if self.shorten_cond_schedule: # TODO: drop this option
- tc = self.cond_ids[t].to(self.device)
- c = self.q_sample(x_start=c, t=tc, noise=torch.randn_like(c.float()))
- return self.p_losses(x, c, t, *args, **kwargs)
-
- def _rescale_annotations(self, bboxes, crop_coordinates): # TODO: move to dataset
- def rescale_bbox(bbox):
- x0 = clamp((bbox[0] - crop_coordinates[0]) / crop_coordinates[2])
- y0 = clamp((bbox[1] - crop_coordinates[1]) / crop_coordinates[3])
- w = min(bbox[2] / crop_coordinates[2], 1 - x0)
- h = min(bbox[3] / crop_coordinates[3], 1 - y0)
- return x0, y0, w, h
-
- return [rescale_bbox(b) for b in bboxes]
-
- def apply_model(self, x_noisy, t, cond, return_ids=False):
- if isinstance(cond, dict):
- # hybrid case, cond is exptected to be a dict
- pass
- else:
- if not isinstance(cond, list):
- cond = [cond]
- key = 'c_concat' if self.model.conditioning_key == 'concat' else 'c_crossattn'
- cond = {key: cond}
-
- if hasattr(self, "split_input_params"):
- assert len(cond) == 1 # todo can only deal with one conditioning atm
- assert not return_ids
- ks = self.split_input_params["ks"] # eg. (128, 128)
- stride = self.split_input_params["stride"] # eg. (64, 64)
-
- h, w = x_noisy.shape[-2:]
-
- fold, unfold, normalization, weighting = self.get_fold_unfold(x_noisy, ks, stride)
-
- z = unfold(x_noisy) # (bn, nc * prod(**ks), L)
- # Reshape to img shape
- z = z.view((z.shape[0], -1, ks[0], ks[1], z.shape[-1])) # (bn, nc, ks[0], ks[1], L )
- z_list = [z[:, :, :, :, i] for i in range(z.shape[-1])]
- if self.cond_stage_key in ["image", "LR_image", "segmentation",
- 'bbox_img'] and self.model.conditioning_key: # todo check for completeness
- c_key = next(iter(cond.keys())) # get key
- c = next(iter(cond.values())) # get value
- assert (len(c) == 1) # todo extend to list with more than one elem
- c = c[0] # get element
-
- c = unfold(c)
- c = c.view((c.shape[0], -1, ks[0], ks[1], c.shape[-1])) # (bn, nc, ks[0], ks[1], L )
-
- cond_list = [{c_key: [c[:, :, :, :, i]]} for i in range(c.shape[-1])]
-
- elif self.cond_stage_key == 'coordinates_bbox':
- assert 'original_image_size' in self.split_input_params, 'BoudingBoxRescaling is missing original_image_size'
-
- # assuming padding of unfold is always 0 and its dilation is always 1
- n_patches_per_row = int((w - ks[0]) / stride[0] + 1)
- full_img_h, full_img_w = self.split_input_params['original_image_size']
- # as we are operating on latents, we need the factor from the original image size to the
- # spatial latent size to properly rescale the crops for regenerating the bbox annotations
- num_downs = self.first_stage_model.encoder.num_resolutions - 1
- rescale_latent = 2 ** (num_downs)
-
- # get top left postions of patches as conforming for the bbbox tokenizer, therefore we
- # need to rescale the tl patch coordinates to be in between (0,1)
- tl_patch_coordinates = [(rescale_latent * stride[0] * (patch_nr % n_patches_per_row) / full_img_w,
- rescale_latent * stride[1] * (patch_nr // n_patches_per_row) / full_img_h)
- for patch_nr in range(z.shape[-1])]
-
- # patch_limits are tl_coord, width and height coordinates as (x_tl, y_tl, h, w)
- patch_limits = [(x_tl, y_tl,
- rescale_latent * ks[0] / full_img_w,
- rescale_latent * ks[1] / full_img_h) for x_tl, y_tl in tl_patch_coordinates]
- # patch_values = [(np.arange(x_tl,min(x_tl+ks, 1.)),np.arange(y_tl,min(y_tl+ks, 1.))) for x_tl, y_tl in tl_patch_coordinates]
-
- # tokenize crop coordinates for the bounding boxes of the respective patches
- patch_limits_tknzd = [torch.LongTensor(self.bbox_tokenizer._crop_encoder(bbox))[None].to(self.device)
- for bbox in patch_limits] # list of length l with tensors of shape (1, 2)
- print(patch_limits_tknzd[0].shape)
- # cut tknzd crop position from conditioning
- assert isinstance(cond, dict), 'cond must be dict to be fed into model'
- cut_cond = cond['c_crossattn'][0][..., :-2].to(self.device)
- print(cut_cond.shape)
-
- adapted_cond = torch.stack([torch.cat([cut_cond, p], dim=1) for p in patch_limits_tknzd])
- adapted_cond = rearrange(adapted_cond, 'l b n -> (l b) n')
- print(adapted_cond.shape)
- adapted_cond = self.get_learned_conditioning(adapted_cond)
- print(adapted_cond.shape)
- adapted_cond = rearrange(adapted_cond, '(l b) n d -> l b n d', l=z.shape[-1])
- print(adapted_cond.shape)
-
- cond_list = [{'c_crossattn': [e]} for e in adapted_cond]
-
- else:
- cond_list = [cond for i in range(z.shape[-1])] # Todo make this more efficient
-
- # apply model by loop over crops
- output_list = [self.model(z_list[i], t, **cond_list[i]) for i in range(z.shape[-1])]
- assert not isinstance(output_list[0],
- tuple) # todo cant deal with multiple model outputs check this never happens
-
- o = torch.stack(output_list, axis=-1)
- o = o * weighting
- # Reverse reshape to img shape
- o = o.view((o.shape[0], -1, o.shape[-1])) # (bn, nc * ks[0] * ks[1], L)
- # stitch crops together
- x_recon = fold(o) / normalization
-
- else:
- x_recon = self.model(x_noisy, t, **cond)
-
- if isinstance(x_recon, tuple) and not return_ids:
- return x_recon[0]
- else:
- return x_recon
-
- def _predict_eps_from_xstart(self, x_t, t, pred_xstart):
- return (extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t - pred_xstart) / \
- extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
-
- def _prior_bpd(self, x_start):
- """
- Get the prior KL term for the variational lower-bound, measured in
- bits-per-dim.
- This term can't be optimized, as it only depends on the encoder.
- :param x_start: the [N x C x ...] tensor of inputs.
- :return: a batch of [N] KL values (in bits), one per batch element.
- """
- batch_size = x_start.shape[0]
- t = torch.tensor([self.num_timesteps - 1] * batch_size, device=x_start.device)
- qt_mean, _, qt_log_variance = self.q_mean_variance(x_start, t)
- kl_prior = normal_kl(mean1=qt_mean, logvar1=qt_log_variance, mean2=0.0, logvar2=0.0)
- return mean_flat(kl_prior) / np.log(2.0)
-
- def p_losses(self, x_start, cond, t, noise=None):
- noise = default(noise, lambda: torch.randn_like(x_start))
- x_noisy = self.q_sample(x_start=x_start, t=t, noise=noise)
- model_output = self.apply_model(x_noisy, t, cond)
-
- loss_dict = {}
- prefix = 'train' if self.training else 'val'
-
- if self.parameterization == "x0":
- target = x_start
- elif self.parameterization == "eps":
- target = noise
- else:
- raise NotImplementedError()
-
- loss_simple = self.get_loss(model_output, target, mean=False).mean([1, 2, 3])
- loss_dict.update({f'{prefix}/loss_simple': loss_simple.mean()})
-
- logvar_t = self.logvar[t].to(self.device)
- loss = loss_simple / torch.exp(logvar_t) + logvar_t
- # loss = loss_simple / torch.exp(self.logvar) + self.logvar
- if self.learn_logvar:
- loss_dict.update({f'{prefix}/loss_gamma': loss.mean()})
- loss_dict.update({'logvar': self.logvar.data.mean()})
-
- loss = self.l_simple_weight * loss.mean()
-
- loss_vlb = self.get_loss(model_output, target, mean=False).mean(dim=(1, 2, 3))
- loss_vlb = (self.lvlb_weights[t] * loss_vlb).mean()
- loss_dict.update({f'{prefix}/loss_vlb': loss_vlb})
- loss += (self.original_elbo_weight * loss_vlb)
- loss_dict.update({f'{prefix}/loss': loss})
-
- return loss, loss_dict
-
- def p_mean_variance(self, x, c, t, clip_denoised: bool, return_codebook_ids=False, quantize_denoised=False,
- return_x0=False, score_corrector=None, corrector_kwargs=None):
- t_in = t
- model_out = self.apply_model(x, t_in, c, return_ids=return_codebook_ids)
-
- if score_corrector is not None:
- assert self.parameterization == "eps"
- model_out = score_corrector.modify_score(self, model_out, x, t, c, **corrector_kwargs)
-
- if return_codebook_ids:
- model_out, logits = model_out
-
- if self.parameterization == "eps":
- x_recon = self.predict_start_from_noise(x, t=t, noise=model_out)
- elif self.parameterization == "x0":
- x_recon = model_out
- else:
- raise NotImplementedError()
-
- if clip_denoised:
- x_recon.clamp_(-1., 1.)
- if quantize_denoised:
- x_recon, _, [_, _, indices] = self.first_stage_model.quantize(x_recon)
- model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start=x_recon, x_t=x, t=t)
- if return_codebook_ids:
- return model_mean, posterior_variance, posterior_log_variance, logits
- elif return_x0:
- return model_mean, posterior_variance, posterior_log_variance, x_recon
- else:
- return model_mean, posterior_variance, posterior_log_variance
-
- @torch.no_grad()
- def p_sample(self, x, c, t, clip_denoised=False, repeat_noise=False,
- return_codebook_ids=False, quantize_denoised=False, return_x0=False,
- temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None):
- b, *_, device = *x.shape, x.device
- outputs = self.p_mean_variance(x=x, c=c, t=t, clip_denoised=clip_denoised,
- return_codebook_ids=return_codebook_ids,
- quantize_denoised=quantize_denoised,
- return_x0=return_x0,
- score_corrector=score_corrector, corrector_kwargs=corrector_kwargs)
- if return_codebook_ids:
- raise DeprecationWarning("Support dropped.")
- model_mean, _, model_log_variance, logits = outputs
- elif return_x0:
- model_mean, _, model_log_variance, x0 = outputs
- else:
- model_mean, _, model_log_variance = outputs
-
- noise = noise_like(x.shape, device, repeat_noise) * temperature
- if noise_dropout > 0.:
- noise = torch.nn.functional.dropout(noise, p=noise_dropout)
- # no noise when t == 0
- nonzero_mask = (1 - (t == 0).float()).reshape(b, *((1,) * (len(x.shape) - 1)))
-
- if return_codebook_ids:
- return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise, logits.argmax(dim=1)
- if return_x0:
- return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise, x0
- else:
- return model_mean + nonzero_mask * (0.5 * model_log_variance).exp() * noise
-
- @torch.no_grad()
- def progressive_denoising(self, cond, shape, verbose=True, callback=None, quantize_denoised=False,
- img_callback=None, mask=None, x0=None, temperature=1., noise_dropout=0.,
- score_corrector=None, corrector_kwargs=None, batch_size=None, x_T=None, start_T=None,
- log_every_t=None):
- if not log_every_t:
- log_every_t = self.log_every_t
- timesteps = self.num_timesteps
- if batch_size is not None:
- b = batch_size if batch_size is not None else shape[0]
- shape = [batch_size] + list(shape)
- else:
- b = batch_size = shape[0]
- if x_T is None:
- img = torch.randn(shape, device=self.device)
- else:
- img = x_T
- intermediates = []
- if cond is not None:
- if isinstance(cond, dict):
- cond = {key: cond[key][:batch_size] if not isinstance(cond[key], list) else
- list(map(lambda x: x[:batch_size], cond[key])) for key in cond}
- else:
- cond = [c[:batch_size] for c in cond] if isinstance(cond, list) else cond[:batch_size]
-
- if start_T is not None:
- timesteps = min(timesteps, start_T)
- iterator = tqdm(reversed(range(0, timesteps)), desc='Progressive Generation',
- total=timesteps) if verbose else reversed(
- range(0, timesteps))
- if type(temperature) == float:
- temperature = [temperature] * timesteps
-
- for i in iterator:
- ts = torch.full((b,), i, device=self.device, dtype=torch.long)
- if self.shorten_cond_schedule:
- assert self.model.conditioning_key != 'hybrid'
- tc = self.cond_ids[ts].to(cond.device)
- cond = self.q_sample(x_start=cond, t=tc, noise=torch.randn_like(cond))
-
- img, x0_partial = self.p_sample(img, cond, ts,
- clip_denoised=self.clip_denoised,
- quantize_denoised=quantize_denoised, return_x0=True,
- temperature=temperature[i], noise_dropout=noise_dropout,
- score_corrector=score_corrector, corrector_kwargs=corrector_kwargs)
- if mask is not None:
- assert x0 is not None
- img_orig = self.q_sample(x0, ts)
- img = img_orig * mask + (1. - mask) * img
-
- if i % log_every_t == 0 or i == timesteps - 1:
- intermediates.append(x0_partial)
- if callback: callback(i)
- if img_callback: img_callback(img, i)
- return img, intermediates
-
- @torch.no_grad()
- def p_sample_loop(self, cond, shape, return_intermediates=False,
- x_T=None, verbose=True, callback=None, timesteps=None, quantize_denoised=False,
- mask=None, x0=None, img_callback=None, start_T=None,
- log_every_t=None):
-
- if not log_every_t:
- log_every_t = self.log_every_t
- device = self.betas.device
- b = shape[0]
- if x_T is None:
- img = torch.randn(shape, device=device)
- else:
- img = x_T
-
- intermediates = [img]
- if timesteps is None:
- timesteps = self.num_timesteps
-
- if start_T is not None:
- timesteps = min(timesteps, start_T)
- iterator = tqdm(reversed(range(0, timesteps)), desc='Sampling t', total=timesteps) if verbose else reversed(
- range(0, timesteps))
-
- if mask is not None:
- assert x0 is not None
- assert x0.shape[2:3] == mask.shape[2:3] # spatial size has to match
-
- for i in iterator:
- ts = torch.full((b,), i, device=device, dtype=torch.long)
- if self.shorten_cond_schedule:
- assert self.model.conditioning_key != 'hybrid'
- tc = self.cond_ids[ts].to(cond.device)
- cond = self.q_sample(x_start=cond, t=tc, noise=torch.randn_like(cond))
-
- img = self.p_sample(img, cond, ts,
- clip_denoised=self.clip_denoised,
- quantize_denoised=quantize_denoised)
- if mask is not None:
- img_orig = self.q_sample(x0, ts)
- img = img_orig * mask + (1. - mask) * img
-
- if i % log_every_t == 0 or i == timesteps - 1:
- intermediates.append(img)
- if callback: callback(i)
- if img_callback: img_callback(img, i)
-
- if return_intermediates:
- return img, intermediates
- return img
-
- @torch.no_grad()
- def sample(self, cond, batch_size=16, return_intermediates=False, x_T=None,
- verbose=True, timesteps=None, quantize_denoised=False,
- mask=None, x0=None, shape=None,**kwargs):
- if shape is None:
- shape = (batch_size, self.channels, self.image_size, self.image_size)
- if cond is not None:
- if isinstance(cond, dict):
- cond = {key: cond[key][:batch_size] if not isinstance(cond[key], list) else
- list(map(lambda x: x[:batch_size], cond[key])) for key in cond}
- else:
- cond = [c[:batch_size] for c in cond] if isinstance(cond, list) else cond[:batch_size]
- return self.p_sample_loop(cond,
- shape,
- return_intermediates=return_intermediates, x_T=x_T,
- verbose=verbose, timesteps=timesteps, quantize_denoised=quantize_denoised,
- mask=mask, x0=x0)
-
- @torch.no_grad()
- def sample_log(self,cond,batch_size,ddim, ddim_steps,**kwargs):
-
- if ddim:
- ddim_sampler = DDIMSampler(self)
- shape = (self.channels, self.image_size, self.image_size)
- samples, intermediates =ddim_sampler.sample(ddim_steps,batch_size,
- shape,cond,verbose=False,**kwargs)
-
- else:
- samples, intermediates = self.sample(cond=cond, batch_size=batch_size,
- return_intermediates=True,**kwargs)
-
- return samples, intermediates
-
-
- @torch.no_grad()
- def log_images(self, batch, N=8, n_row=4, sample=True, ddim_steps=200, ddim_eta=1., return_keys=None,
- quantize_denoised=True, inpaint=True, plot_denoise_rows=False, plot_progressive_rows=True,
- plot_diffusion_rows=True, **kwargs):
-
- use_ddim = ddim_steps is not None
-
- log = dict()
- z, c, x, xrec, xc = self.get_input(batch, self.first_stage_key,
- return_first_stage_outputs=True,
- force_c_encode=True,
- return_original_cond=True,
- bs=N)
- N = min(x.shape[0], N)
- n_row = min(x.shape[0], n_row)
- log["inputs"] = x
- log["reconstruction"] = xrec
- if self.model.conditioning_key is not None:
- if hasattr(self.cond_stage_model, "decode"):
- xc = self.cond_stage_model.decode(c)
- log["conditioning"] = xc
- elif self.cond_stage_key in ["caption"]:
- xc = log_txt_as_img((x.shape[2], x.shape[3]), batch["caption"])
- log["conditioning"] = xc
- elif self.cond_stage_key == 'class_label':
- xc = log_txt_as_img((x.shape[2], x.shape[3]), batch["human_label"])
- log['conditioning'] = xc
- elif isimage(xc):
- log["conditioning"] = xc
- if ismap(xc):
- log["original_conditioning"] = self.to_rgb(xc)
-
- if plot_diffusion_rows:
- # get diffusion row
- diffusion_row = list()
- z_start = z[:n_row]
- for t in range(self.num_timesteps):
- if t % self.log_every_t == 0 or t == self.num_timesteps - 1:
- t = repeat(torch.tensor([t]), '1 -> b', b=n_row)
- t = t.to(self.device).long()
- noise = torch.randn_like(z_start)
- z_noisy = self.q_sample(x_start=z_start, t=t, noise=noise)
- diffusion_row.append(self.decode_first_stage(z_noisy))
-
- diffusion_row = torch.stack(diffusion_row) # n_log_step, n_row, C, H, W
- diffusion_grid = rearrange(diffusion_row, 'n b c h w -> b n c h w')
- diffusion_grid = rearrange(diffusion_grid, 'b n c h w -> (b n) c h w')
- diffusion_grid = make_grid(diffusion_grid, nrow=diffusion_row.shape[0])
- log["diffusion_row"] = diffusion_grid
-
- if sample:
- # get denoise row
- with self.ema_scope("Plotting"):
- samples, z_denoise_row = self.sample_log(cond=c,batch_size=N,ddim=use_ddim,
- ddim_steps=ddim_steps,eta=ddim_eta)
- # samples, z_denoise_row = self.sample(cond=c, batch_size=N, return_intermediates=True)
- x_samples = self.decode_first_stage(samples)
- log["samples"] = x_samples
- if plot_denoise_rows:
- denoise_grid = self._get_denoise_row_from_list(z_denoise_row)
- log["denoise_row"] = denoise_grid
-
- if quantize_denoised and not isinstance(self.first_stage_model, AutoencoderKL) and not isinstance(
- self.first_stage_model, IdentityFirstStage):
- # also display when quantizing x0 while sampling
- with self.ema_scope("Plotting Quantized Denoised"):
- samples, z_denoise_row = self.sample_log(cond=c,batch_size=N,ddim=use_ddim,
- ddim_steps=ddim_steps,eta=ddim_eta,
- quantize_denoised=True)
- # samples, z_denoise_row = self.sample(cond=c, batch_size=N, return_intermediates=True,
- # quantize_denoised=True)
- x_samples = self.decode_first_stage(samples.to(self.device))
- log["samples_x0_quantized"] = x_samples
-
- if inpaint:
- # make a simple center square
- b, h, w = z.shape[0], z.shape[2], z.shape[3]
- mask = torch.ones(N, h, w).to(self.device)
- # zeros will be filled in
- mask[:, h // 4:3 * h // 4, w // 4:3 * w // 4] = 0.
- mask = mask[:, None, ...]
- with self.ema_scope("Plotting Inpaint"):
-
- samples, _ = self.sample_log(cond=c,batch_size=N,ddim=use_ddim, eta=ddim_eta,
- ddim_steps=ddim_steps, x0=z[:N], mask=mask)
- x_samples = self.decode_first_stage(samples.to(self.device))
- log["samples_inpainting"] = x_samples
- log["mask"] = mask
-
- # outpaint
- with self.ema_scope("Plotting Outpaint"):
- samples, _ = self.sample_log(cond=c, batch_size=N, ddim=use_ddim,eta=ddim_eta,
- ddim_steps=ddim_steps, x0=z[:N], mask=mask)
- x_samples = self.decode_first_stage(samples.to(self.device))
- log["samples_outpainting"] = x_samples
-
- if plot_progressive_rows:
- with self.ema_scope("Plotting Progressives"):
- img, progressives = self.progressive_denoising(c,
- shape=(self.channels, self.image_size, self.image_size),
- batch_size=N)
- prog_row = self._get_denoise_row_from_list(progressives, desc="Progressive Generation")
- log["progressive_row"] = prog_row
-
- if return_keys:
- if np.intersect1d(list(log.keys()), return_keys).shape[0] == 0:
- return log
- else:
- return {key: log[key] for key in return_keys}
- return log
-
- def configure_optimizers(self):
- lr = self.learning_rate
- params = list(self.model.parameters())
- if self.cond_stage_trainable:
- print(f"{self.__class__.__name__}: Also optimizing conditioner params!")
- params = params + list(self.cond_stage_model.parameters())
- if self.learn_logvar:
- print('Diffusion model optimizing logvar')
- params.append(self.logvar)
- from colossalai.nn.optimizer import HybridAdam
- opt = HybridAdam(params, lr=lr)
- # opt = torch.optim.AdamW(params, lr=lr)
- if self.use_scheduler:
- assert 'target' in self.scheduler_config
- scheduler = instantiate_from_config(self.scheduler_config)
-
- rank_zero_info("Setting up LambdaLR scheduler...")
- scheduler = [
- {
- 'scheduler': LambdaLR(opt, lr_lambda=scheduler.schedule),
- 'interval': 'step',
- 'frequency': 1
- }]
- return [opt], scheduler
- return opt
-
- @torch.no_grad()
- def to_rgb(self, x):
- x = x.float()
- if not hasattr(self, "colorize"):
- self.colorize = torch.randn(3, x.shape[1], 1, 1).to(x)
- x = nn.functional.conv2d(x, weight=self.colorize)
- x = 2. * (x - x.min()) / (x.max() - x.min()) - 1.
- return x
-
-
-class DiffusionWrapper(pl.LightningModule):
- def __init__(self, diff_model_config, conditioning_key):
- super().__init__()
- self.diffusion_model = instantiate_from_config(diff_model_config)
- self.conditioning_key = conditioning_key
- assert self.conditioning_key in [None, 'concat', 'crossattn', 'hybrid', 'adm']
-
- def forward(self, x, t, c_concat: list = None, c_crossattn: list = None):
- if self.conditioning_key is None:
- out = self.diffusion_model(x, t)
- elif self.conditioning_key == 'concat':
- xc = torch.cat([x] + c_concat, dim=1)
- out = self.diffusion_model(xc, t)
- elif self.conditioning_key == 'crossattn':
- cc = torch.cat(c_crossattn, 1)
- out = self.diffusion_model(x, t, context=cc)
- elif self.conditioning_key == 'hybrid':
- xc = torch.cat([x] + c_concat, dim=1)
- cc = torch.cat(c_crossattn, 1)
- out = self.diffusion_model(xc, t, context=cc)
- elif self.conditioning_key == 'adm':
- cc = c_crossattn[0]
- out = self.diffusion_model(x, t, y=cc)
- else:
- raise NotImplementedError()
-
- return out
-
-
-class Layout2ImgDiffusion(LatentDiffusion):
- # TODO: move all layout-specific hacks to this class
- def __init__(self, cond_stage_key, *args, **kwargs):
- assert cond_stage_key == 'coordinates_bbox', 'Layout2ImgDiffusion only for cond_stage_key="coordinates_bbox"'
- super().__init__(cond_stage_key=cond_stage_key, *args, **kwargs)
-
- def log_images(self, batch, N=8, *args, **kwargs):
- logs = super().log_images(batch=batch, N=N, *args, **kwargs)
-
- key = 'train' if self.training else 'validation'
- dset = self.trainer.datamodule.datasets[key]
- mapper = dset.conditional_builders[self.cond_stage_key]
-
- bbox_imgs = []
- map_fn = lambda catno: dset.get_textual_label(dset.get_category_id(catno))
- for tknzd_bbox in batch[self.cond_stage_key][:N]:
- bboximg = mapper.plot(tknzd_bbox.detach().cpu(), map_fn, (256, 256))
- bbox_imgs.append(bboximg)
-
- cond_img = torch.stack(bbox_imgs, dim=0)
- logs['bbox_image'] = cond_img
- return logs
diff --git a/examples/tutorial/stable_diffusion/ldm/models/diffusion/plms.py b/examples/tutorial/stable_diffusion/ldm/models/diffusion/plms.py
deleted file mode 100644
index 78eeb1003..000000000
--- a/examples/tutorial/stable_diffusion/ldm/models/diffusion/plms.py
+++ /dev/null
@@ -1,236 +0,0 @@
-"""SAMPLING ONLY."""
-
-import torch
-import numpy as np
-from tqdm import tqdm
-from functools import partial
-
-from ldm.modules.diffusionmodules.util import make_ddim_sampling_parameters, make_ddim_timesteps, noise_like
-
-
-class PLMSSampler(object):
- def __init__(self, model, schedule="linear", **kwargs):
- super().__init__()
- self.model = model
- self.ddpm_num_timesteps = model.num_timesteps
- self.schedule = schedule
-
- def register_buffer(self, name, attr):
- if type(attr) == torch.Tensor:
- if attr.device != torch.device("cuda"):
- attr = attr.to(torch.device("cuda"))
- setattr(self, name, attr)
-
- def make_schedule(self, ddim_num_steps, ddim_discretize="uniform", ddim_eta=0., verbose=True):
- if ddim_eta != 0:
- raise ValueError('ddim_eta must be 0 for PLMS')
- self.ddim_timesteps = make_ddim_timesteps(ddim_discr_method=ddim_discretize, num_ddim_timesteps=ddim_num_steps,
- num_ddpm_timesteps=self.ddpm_num_timesteps,verbose=verbose)
- alphas_cumprod = self.model.alphas_cumprod
- assert alphas_cumprod.shape[0] == self.ddpm_num_timesteps, 'alphas have to be defined for each timestep'
- to_torch = lambda x: x.clone().detach().to(torch.float32).to(self.model.device)
-
- self.register_buffer('betas', to_torch(self.model.betas))
- self.register_buffer('alphas_cumprod', to_torch(alphas_cumprod))
- self.register_buffer('alphas_cumprod_prev', to_torch(self.model.alphas_cumprod_prev))
-
- # calculations for diffusion q(x_t | x_{t-1}) and others
- self.register_buffer('sqrt_alphas_cumprod', to_torch(np.sqrt(alphas_cumprod.cpu())))
- self.register_buffer('sqrt_one_minus_alphas_cumprod', to_torch(np.sqrt(1. - alphas_cumprod.cpu())))
- self.register_buffer('log_one_minus_alphas_cumprod', to_torch(np.log(1. - alphas_cumprod.cpu())))
- self.register_buffer('sqrt_recip_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu())))
- self.register_buffer('sqrt_recipm1_alphas_cumprod', to_torch(np.sqrt(1. / alphas_cumprod.cpu() - 1)))
-
- # ddim sampling parameters
- ddim_sigmas, ddim_alphas, ddim_alphas_prev = make_ddim_sampling_parameters(alphacums=alphas_cumprod.cpu(),
- ddim_timesteps=self.ddim_timesteps,
- eta=ddim_eta,verbose=verbose)
- self.register_buffer('ddim_sigmas', ddim_sigmas)
- self.register_buffer('ddim_alphas', ddim_alphas)
- self.register_buffer('ddim_alphas_prev', ddim_alphas_prev)
- self.register_buffer('ddim_sqrt_one_minus_alphas', np.sqrt(1. - ddim_alphas))
- sigmas_for_original_sampling_steps = ddim_eta * torch.sqrt(
- (1 - self.alphas_cumprod_prev) / (1 - self.alphas_cumprod) * (
- 1 - self.alphas_cumprod / self.alphas_cumprod_prev))
- self.register_buffer('ddim_sigmas_for_original_num_steps', sigmas_for_original_sampling_steps)
-
- @torch.no_grad()
- def sample(self,
- S,
- batch_size,
- shape,
- conditioning=None,
- callback=None,
- normals_sequence=None,
- img_callback=None,
- quantize_x0=False,
- eta=0.,
- mask=None,
- x0=None,
- temperature=1.,
- noise_dropout=0.,
- score_corrector=None,
- corrector_kwargs=None,
- verbose=True,
- x_T=None,
- log_every_t=100,
- unconditional_guidance_scale=1.,
- unconditional_conditioning=None,
- # this has to come in the same format as the conditioning, # e.g. as encoded tokens, ...
- **kwargs
- ):
- if conditioning is not None:
- if isinstance(conditioning, dict):
- cbs = conditioning[list(conditioning.keys())[0]].shape[0]
- if cbs != batch_size:
- print(f"Warning: Got {cbs} conditionings but batch-size is {batch_size}")
- else:
- if conditioning.shape[0] != batch_size:
- print(f"Warning: Got {conditioning.shape[0]} conditionings but batch-size is {batch_size}")
-
- self.make_schedule(ddim_num_steps=S, ddim_eta=eta, verbose=verbose)
- # sampling
- C, H, W = shape
- size = (batch_size, C, H, W)
- print(f'Data shape for PLMS sampling is {size}')
-
- samples, intermediates = self.plms_sampling(conditioning, size,
- callback=callback,
- img_callback=img_callback,
- quantize_denoised=quantize_x0,
- mask=mask, x0=x0,
- ddim_use_original_steps=False,
- noise_dropout=noise_dropout,
- temperature=temperature,
- score_corrector=score_corrector,
- corrector_kwargs=corrector_kwargs,
- x_T=x_T,
- log_every_t=log_every_t,
- unconditional_guidance_scale=unconditional_guidance_scale,
- unconditional_conditioning=unconditional_conditioning,
- )
- return samples, intermediates
-
- @torch.no_grad()
- def plms_sampling(self, cond, shape,
- x_T=None, ddim_use_original_steps=False,
- callback=None, timesteps=None, quantize_denoised=False,
- mask=None, x0=None, img_callback=None, log_every_t=100,
- temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
- unconditional_guidance_scale=1., unconditional_conditioning=None,):
- device = self.model.betas.device
- b = shape[0]
- if x_T is None:
- img = torch.randn(shape, device=device)
- else:
- img = x_T
-
- if timesteps is None:
- timesteps = self.ddpm_num_timesteps if ddim_use_original_steps else self.ddim_timesteps
- elif timesteps is not None and not ddim_use_original_steps:
- subset_end = int(min(timesteps / self.ddim_timesteps.shape[0], 1) * self.ddim_timesteps.shape[0]) - 1
- timesteps = self.ddim_timesteps[:subset_end]
-
- intermediates = {'x_inter': [img], 'pred_x0': [img]}
- time_range = list(reversed(range(0,timesteps))) if ddim_use_original_steps else np.flip(timesteps)
- total_steps = timesteps if ddim_use_original_steps else timesteps.shape[0]
- print(f"Running PLMS Sampling with {total_steps} timesteps")
-
- iterator = tqdm(time_range, desc='PLMS Sampler', total=total_steps)
- old_eps = []
-
- for i, step in enumerate(iterator):
- index = total_steps - i - 1
- ts = torch.full((b,), step, device=device, dtype=torch.long)
- ts_next = torch.full((b,), time_range[min(i + 1, len(time_range) - 1)], device=device, dtype=torch.long)
-
- if mask is not None:
- assert x0 is not None
- img_orig = self.model.q_sample(x0, ts) # TODO: deterministic forward pass?
- img = img_orig * mask + (1. - mask) * img
-
- outs = self.p_sample_plms(img, cond, ts, index=index, use_original_steps=ddim_use_original_steps,
- quantize_denoised=quantize_denoised, temperature=temperature,
- noise_dropout=noise_dropout, score_corrector=score_corrector,
- corrector_kwargs=corrector_kwargs,
- unconditional_guidance_scale=unconditional_guidance_scale,
- unconditional_conditioning=unconditional_conditioning,
- old_eps=old_eps, t_next=ts_next)
- img, pred_x0, e_t = outs
- old_eps.append(e_t)
- if len(old_eps) >= 4:
- old_eps.pop(0)
- if callback: callback(i)
- if img_callback: img_callback(pred_x0, i)
-
- if index % log_every_t == 0 or index == total_steps - 1:
- intermediates['x_inter'].append(img)
- intermediates['pred_x0'].append(pred_x0)
-
- return img, intermediates
-
- @torch.no_grad()
- def p_sample_plms(self, x, c, t, index, repeat_noise=False, use_original_steps=False, quantize_denoised=False,
- temperature=1., noise_dropout=0., score_corrector=None, corrector_kwargs=None,
- unconditional_guidance_scale=1., unconditional_conditioning=None, old_eps=None, t_next=None):
- b, *_, device = *x.shape, x.device
-
- def get_model_output(x, t):
- if unconditional_conditioning is None or unconditional_guidance_scale == 1.:
- e_t = self.model.apply_model(x, t, c)
- else:
- x_in = torch.cat([x] * 2)
- t_in = torch.cat([t] * 2)
- c_in = torch.cat([unconditional_conditioning, c])
- e_t_uncond, e_t = self.model.apply_model(x_in, t_in, c_in).chunk(2)
- e_t = e_t_uncond + unconditional_guidance_scale * (e_t - e_t_uncond)
-
- if score_corrector is not None:
- assert self.model.parameterization == "eps"
- e_t = score_corrector.modify_score(self.model, e_t, x, t, c, **corrector_kwargs)
-
- return e_t
-
- alphas = self.model.alphas_cumprod if use_original_steps else self.ddim_alphas
- alphas_prev = self.model.alphas_cumprod_prev if use_original_steps else self.ddim_alphas_prev
- sqrt_one_minus_alphas = self.model.sqrt_one_minus_alphas_cumprod if use_original_steps else self.ddim_sqrt_one_minus_alphas
- sigmas = self.model.ddim_sigmas_for_original_num_steps if use_original_steps else self.ddim_sigmas
-
- def get_x_prev_and_pred_x0(e_t, index):
- # select parameters corresponding to the currently considered timestep
- a_t = torch.full((b, 1, 1, 1), alphas[index], device=device)
- a_prev = torch.full((b, 1, 1, 1), alphas_prev[index], device=device)
- sigma_t = torch.full((b, 1, 1, 1), sigmas[index], device=device)
- sqrt_one_minus_at = torch.full((b, 1, 1, 1), sqrt_one_minus_alphas[index],device=device)
-
- # current prediction for x_0
- pred_x0 = (x - sqrt_one_minus_at * e_t) / a_t.sqrt()
- if quantize_denoised:
- pred_x0, _, *_ = self.model.first_stage_model.quantize(pred_x0)
- # direction pointing to x_t
- dir_xt = (1. - a_prev - sigma_t**2).sqrt() * e_t
- noise = sigma_t * noise_like(x.shape, device, repeat_noise) * temperature
- if noise_dropout > 0.:
- noise = torch.nn.functional.dropout(noise, p=noise_dropout)
- x_prev = a_prev.sqrt() * pred_x0 + dir_xt + noise
- return x_prev, pred_x0
-
- e_t = get_model_output(x, t)
- if len(old_eps) == 0:
- # Pseudo Improved Euler (2nd order)
- x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t, index)
- e_t_next = get_model_output(x_prev, t_next)
- e_t_prime = (e_t + e_t_next) / 2
- elif len(old_eps) == 1:
- # 2nd order Pseudo Linear Multistep (Adams-Bashforth)
- e_t_prime = (3 * e_t - old_eps[-1]) / 2
- elif len(old_eps) == 2:
- # 3nd order Pseudo Linear Multistep (Adams-Bashforth)
- e_t_prime = (23 * e_t - 16 * old_eps[-1] + 5 * old_eps[-2]) / 12
- elif len(old_eps) >= 3:
- # 4nd order Pseudo Linear Multistep (Adams-Bashforth)
- e_t_prime = (55 * e_t - 59 * old_eps[-1] + 37 * old_eps[-2] - 9 * old_eps[-3]) / 24
-
- x_prev, pred_x0 = get_x_prev_and_pred_x0(e_t_prime, index)
-
- return x_prev, pred_x0, e_t
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/attention.py b/examples/tutorial/stable_diffusion/ldm/modules/attention.py
deleted file mode 100644
index 3401ceafd..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/attention.py
+++ /dev/null
@@ -1,314 +0,0 @@
-from inspect import isfunction
-import math
-import torch
-import torch.nn.functional as F
-from torch import nn, einsum
-from einops import rearrange, repeat
-
-from torch.utils import checkpoint
-
-try:
- from ldm.modules.flash_attention import flash_attention_qkv, flash_attention_q_kv
- FlASH_AVAILABLE = True
-except:
- FlASH_AVAILABLE = False
-
-USE_FLASH = False
-
-
-def enable_flash_attention():
- global USE_FLASH
- USE_FLASH = True
- if FlASH_AVAILABLE is False:
- print("Please install flash attention to activate new attention kernel.\n" +
- "Use \'pip install git+https://github.com/HazyResearch/flash-attention.git@c422fee3776eb3ea24e011ef641fd5fbeb212623#egg=flash_attn\'")
-
-
-def exists(val):
- return val is not None
-
-
-def uniq(arr):
- return{el: True for el in arr}.keys()
-
-
-def default(val, d):
- if exists(val):
- return val
- return d() if isfunction(d) else d
-
-
-def max_neg_value(t):
- return -torch.finfo(t.dtype).max
-
-
-def init_(tensor):
- dim = tensor.shape[-1]
- std = 1 / math.sqrt(dim)
- tensor.uniform_(-std, std)
- return tensor
-
-
-# feedforward
-class GEGLU(nn.Module):
- def __init__(self, dim_in, dim_out):
- super().__init__()
- self.proj = nn.Linear(dim_in, dim_out * 2)
-
- def forward(self, x):
- x, gate = self.proj(x).chunk(2, dim=-1)
- return x * F.gelu(gate)
-
-
-class FeedForward(nn.Module):
- def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
- super().__init__()
- inner_dim = int(dim * mult)
- dim_out = default(dim_out, dim)
- project_in = nn.Sequential(
- nn.Linear(dim, inner_dim),
- nn.GELU()
- ) if not glu else GEGLU(dim, inner_dim)
-
- self.net = nn.Sequential(
- project_in,
- nn.Dropout(dropout),
- nn.Linear(inner_dim, dim_out)
- )
-
- def forward(self, x):
- return self.net(x)
-
-
-def zero_module(module):
- """
- Zero out the parameters of a module and return it.
- """
- for p in module.parameters():
- p.detach().zero_()
- return module
-
-
-def Normalize(in_channels):
- return torch.nn.GroupNorm(num_groups=32, num_channels=in_channels, eps=1e-6, affine=True)
-
-
-class LinearAttention(nn.Module):
- def __init__(self, dim, heads=4, dim_head=32):
- super().__init__()
- self.heads = heads
- hidden_dim = dim_head * heads
- self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False)
- self.to_out = nn.Conv2d(hidden_dim, dim, 1)
-
- def forward(self, x):
- b, c, h, w = x.shape
- qkv = self.to_qkv(x)
- q, k, v = rearrange(qkv, 'b (qkv heads c) h w -> qkv b heads c (h w)', heads = self.heads, qkv=3)
- k = k.softmax(dim=-1)
- context = torch.einsum('bhdn,bhen->bhde', k, v)
- out = torch.einsum('bhde,bhdn->bhen', context, q)
- out = rearrange(out, 'b heads c (h w) -> b (heads c) h w', heads=self.heads, h=h, w=w)
- return self.to_out(out)
-
-
-class SpatialSelfAttention(nn.Module):
- def __init__(self, in_channels):
- super().__init__()
- self.in_channels = in_channels
-
- self.norm = Normalize(in_channels)
- self.q = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
- self.k = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
- self.v = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
- self.proj_out = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
-
- def forward(self, x):
- h_ = x
- h_ = self.norm(h_)
- q = self.q(h_)
- k = self.k(h_)
- v = self.v(h_)
-
- # compute attention
- b,c,h,w = q.shape
- q = rearrange(q, 'b c h w -> b (h w) c')
- k = rearrange(k, 'b c h w -> b c (h w)')
- w_ = torch.einsum('bij,bjk->bik', q, k)
-
- w_ = w_ * (int(c)**(-0.5))
- w_ = torch.nn.functional.softmax(w_, dim=2)
-
- # attend to values
- v = rearrange(v, 'b c h w -> b c (h w)')
- w_ = rearrange(w_, 'b i j -> b j i')
- h_ = torch.einsum('bij,bjk->bik', v, w_)
- h_ = rearrange(h_, 'b c (h w) -> b c h w', h=h)
- h_ = self.proj_out(h_)
-
- return x+h_
-
-
-class CrossAttention(nn.Module):
- def __init__(self, query_dim, context_dim=None, heads=8, dim_head=64, dropout=0.):
- super().__init__()
- inner_dim = dim_head * heads
- context_dim = default(context_dim, query_dim)
-
- self.scale = dim_head ** -0.5
- self.heads = heads
-
- self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
- self.to_k = nn.Linear(context_dim, inner_dim, bias=False)
- self.to_v = nn.Linear(context_dim, inner_dim, bias=False)
-
- self.to_out = nn.Sequential(
- nn.Linear(inner_dim, query_dim),
- nn.Dropout(dropout)
- )
-
- def forward(self, x, context=None, mask=None):
- q = self.to_q(x)
- context = default(context, x)
- k = self.to_k(context)
- v = self.to_v(context)
- dim_head = q.shape[-1] / self.heads
-
- if USE_FLASH and FlASH_AVAILABLE and q.dtype in (torch.float16, torch.bfloat16) and \
- dim_head <= 128 and (dim_head % 8) == 0:
- # print("in flash")
- if q.shape[1] == k.shape[1]:
- out = self._flash_attention_qkv(q, k, v)
- else:
- out = self._flash_attention_q_kv(q, k, v)
- else:
- out = self._native_attention(q, k, v, self.heads, mask)
-
- return self.to_out(out)
-
- def _native_attention(self, q, k, v, h, mask):
- q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h=h), (q, k, v))
- sim = einsum('b i d, b j d -> b i j', q, k) * self.scale
- if exists(mask):
- mask = rearrange(mask, 'b ... -> b (...)')
- max_neg_value = -torch.finfo(sim.dtype).max
- mask = repeat(mask, 'b j -> (b h) () j', h=h)
- sim.masked_fill_(~mask, max_neg_value)
- # attention, what we cannot get enough of
- out = sim.softmax(dim=-1)
- out = einsum('b i j, b j d -> b i d', out, v)
- out = rearrange(out, '(b h) n d -> b n (h d)', h=h)
- return out
-
- def _flash_attention_qkv(self, q, k, v):
- qkv = torch.stack([q, k, v], dim=2)
- b = qkv.shape[0]
- n = qkv.shape[1]
- qkv = rearrange(qkv, 'b n t (h d) -> (b n) t h d', h=self.heads)
- out = flash_attention_qkv(qkv, self.scale, b, n)
- out = rearrange(out, '(b n) h d -> b n (h d)', b=b, h=self.heads)
- return out
-
- def _flash_attention_q_kv(self, q, k, v):
- kv = torch.stack([k, v], dim=2)
- b = q.shape[0]
- q_seqlen = q.shape[1]
- kv_seqlen = kv.shape[1]
- q = rearrange(q, 'b n (h d) -> (b n) h d', h=self.heads)
- kv = rearrange(kv, 'b n t (h d) -> (b n) t h d', h=self.heads)
- out = flash_attention_q_kv(q, kv, self.scale, b, q_seqlen, kv_seqlen)
- out = rearrange(out, '(b n) h d -> b n (h d)', b=b, h=self.heads)
- return out
-
-
-class BasicTransformerBlock(nn.Module):
- def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, use_checkpoint=False):
- super().__init__()
- self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout) # is a self-attention
- self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
- self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim,
- heads=n_heads, dim_head=d_head, dropout=dropout) # is self-attn if context is none
- self.norm1 = nn.LayerNorm(dim)
- self.norm2 = nn.LayerNorm(dim)
- self.norm3 = nn.LayerNorm(dim)
- self.use_checkpoint = use_checkpoint
-
- def forward(self, x, context=None):
-
-
- if self.use_checkpoint:
- return checkpoint(self._forward, x, context)
- else:
- return self._forward(x, context)
-
- def _forward(self, x, context=None):
- x = self.attn1(self.norm1(x)) + x
- x = self.attn2(self.norm2(x), context=context) + x
- x = self.ff(self.norm3(x)) + x
- return x
-
-
-
-class SpatialTransformer(nn.Module):
- """
- Transformer block for image-like data.
- First, project the input (aka embedding)
- and reshape to b, t, d.
- Then apply standard transformer action.
- Finally, reshape to image
- """
- def __init__(self, in_channels, n_heads, d_head,
- depth=1, dropout=0., context_dim=None, use_checkpoint=False):
- super().__init__()
- self.in_channels = in_channels
- inner_dim = n_heads * d_head
- self.norm = Normalize(in_channels)
-
- self.proj_in = nn.Conv2d(in_channels,
- inner_dim,
- kernel_size=1,
- stride=1,
- padding=0)
-
- self.transformer_blocks = nn.ModuleList(
- [BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim, use_checkpoint=use_checkpoint)
- for d in range(depth)]
- )
-
- self.proj_out = zero_module(nn.Conv2d(inner_dim,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0))
-
-
- def forward(self, x, context=None):
- # note: if no context is given, cross-attention defaults to self-attention
- b, c, h, w = x.shape
- x_in = x
- x = self.norm(x)
- x = self.proj_in(x)
- x = rearrange(x, 'b c h w -> b (h w) c')
- x = x.contiguous()
- for block in self.transformer_blocks:
- x = block(x, context=context)
- x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
- x = x.contiguous()
- x = self.proj_out(x)
- return x + x_in
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/__init__.py b/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/__init__.py
deleted file mode 100644
index e69de29bb..000000000
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/model.py b/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/model.py
deleted file mode 100644
index 3c28492c5..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/model.py
+++ /dev/null
@@ -1,862 +0,0 @@
-# pytorch_diffusion + derived encoder decoder
-import math
-import torch
-import torch.nn as nn
-import numpy as np
-from einops import rearrange
-
-from ldm.util import instantiate_from_config
-from ldm.modules.attention import LinearAttention
-
-
-def get_timestep_embedding(timesteps, embedding_dim):
- """
- This matches the implementation in Denoising Diffusion Probabilistic Models:
- From Fairseq.
- Build sinusoidal embeddings.
- This matches the implementation in tensor2tensor, but differs slightly
- from the description in Section 3.5 of "Attention Is All You Need".
- """
- assert len(timesteps.shape) == 1
-
- half_dim = embedding_dim // 2
- emb = math.log(10000) / (half_dim - 1)
- emb = torch.exp(torch.arange(half_dim, dtype=torch.float32) * -emb)
- emb = emb.to(device=timesteps.device)
- emb = timesteps.float()[:, None] * emb[None, :]
- emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
- if embedding_dim % 2 == 1: # zero pad
- emb = torch.nn.functional.pad(emb, (0,1,0,0))
- return emb
-
-
-def nonlinearity(x):
- # swish
- return x*torch.sigmoid(x)
-
-
-def Normalize(in_channels, num_groups=32):
- return torch.nn.GroupNorm(num_groups=num_groups, num_channels=in_channels, eps=1e-6, affine=True)
-
-
-class Upsample(nn.Module):
- def __init__(self, in_channels, with_conv):
- super().__init__()
- self.with_conv = with_conv
- if self.with_conv:
- self.conv = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=3,
- stride=1,
- padding=1)
-
- def forward(self, x):
- x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
- if self.with_conv:
- x = self.conv(x)
- return x
-
-
-class Downsample(nn.Module):
- def __init__(self, in_channels, with_conv):
- super().__init__()
- self.with_conv = with_conv
- if self.with_conv:
- # no asymmetric padding in torch conv, must do it ourselves
- self.conv = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=3,
- stride=2,
- padding=0)
-
- def forward(self, x):
- if self.with_conv:
- pad = (0,1,0,1)
- x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
- x = self.conv(x)
- else:
- x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
- return x
-
-
-class ResnetBlock(nn.Module):
- def __init__(self, *, in_channels, out_channels=None, conv_shortcut=False,
- dropout, temb_channels=512):
- super().__init__()
- self.in_channels = in_channels
- out_channels = in_channels if out_channels is None else out_channels
- self.out_channels = out_channels
- self.use_conv_shortcut = conv_shortcut
-
- self.norm1 = Normalize(in_channels)
- self.conv1 = torch.nn.Conv2d(in_channels,
- out_channels,
- kernel_size=3,
- stride=1,
- padding=1)
- if temb_channels > 0:
- self.temb_proj = torch.nn.Linear(temb_channels,
- out_channels)
- self.norm2 = Normalize(out_channels)
- self.dropout = torch.nn.Dropout(dropout)
- self.conv2 = torch.nn.Conv2d(out_channels,
- out_channels,
- kernel_size=3,
- stride=1,
- padding=1)
- if self.in_channels != self.out_channels:
- if self.use_conv_shortcut:
- self.conv_shortcut = torch.nn.Conv2d(in_channels,
- out_channels,
- kernel_size=3,
- stride=1,
- padding=1)
- else:
- self.nin_shortcut = torch.nn.Conv2d(in_channels,
- out_channels,
- kernel_size=1,
- stride=1,
- padding=0)
-
- def forward(self, x, temb):
- h = x
- h = self.norm1(h)
- h = nonlinearity(h)
- h = self.conv1(h)
-
- if temb is not None:
- h = h + self.temb_proj(nonlinearity(temb))[:,:,None,None]
-
- h = self.norm2(h)
- h = nonlinearity(h)
- h = self.dropout(h)
- h = self.conv2(h)
-
- if self.in_channels != self.out_channels:
- if self.use_conv_shortcut:
- x = self.conv_shortcut(x)
- else:
- x = self.nin_shortcut(x)
-
- return x+h
-
-
-class LinAttnBlock(LinearAttention):
- """to match AttnBlock usage"""
- def __init__(self, in_channels):
- super().__init__(dim=in_channels, heads=1, dim_head=in_channels)
-
-
-class AttnBlock(nn.Module):
- def __init__(self, in_channels):
- super().__init__()
- self.in_channels = in_channels
-
- self.norm = Normalize(in_channels)
- self.q = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
- self.k = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
- self.v = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
- self.proj_out = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=1,
- stride=1,
- padding=0)
-
-
- def forward(self, x):
- h_ = x
- h_ = self.norm(h_)
- q = self.q(h_)
- k = self.k(h_)
- v = self.v(h_)
-
- # compute attention
- b,c,h,w = q.shape
- q = q.reshape(b,c,h*w)
- q = q.permute(0,2,1) # b,hw,c
- k = k.reshape(b,c,h*w) # b,c,hw
- w_ = torch.bmm(q,k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
- w_ = w_ * (int(c)**(-0.5))
- w_ = torch.nn.functional.softmax(w_, dim=2)
-
- # attend to values
- v = v.reshape(b,c,h*w)
- w_ = w_.permute(0,2,1) # b,hw,hw (first hw of k, second of q)
- h_ = torch.bmm(v,w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
- h_ = h_.reshape(b,c,h,w)
-
- h_ = self.proj_out(h_)
-
- return x+h_
-
-
-def make_attn(in_channels, attn_type="vanilla"):
- assert attn_type in ["vanilla", "linear", "none"], f'attn_type {attn_type} unknown'
- print(f"making attention of type '{attn_type}' with {in_channels} in_channels")
- if attn_type == "vanilla":
- return AttnBlock(in_channels)
- elif attn_type == "none":
- return nn.Identity(in_channels)
- else:
- return LinAttnBlock(in_channels)
-
-class temb_module(nn.Module):
- def __init__(self):
- super().__init__()
- pass
-
-class Model(nn.Module):
- def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
- attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels,
- resolution, use_timestep=True, use_linear_attn=False, attn_type="vanilla"):
- super().__init__()
- if use_linear_attn: attn_type = "linear"
- self.ch = ch
- self.temb_ch = self.ch*4
- self.num_resolutions = len(ch_mult)
- self.num_res_blocks = num_res_blocks
- self.resolution = resolution
- self.in_channels = in_channels
-
- self.use_timestep = use_timestep
- if self.use_timestep:
- # timestep embedding
- # self.temb = nn.Module()
- self.temb = temb_module()
- self.temb.dense = nn.ModuleList([
- torch.nn.Linear(self.ch,
- self.temb_ch),
- torch.nn.Linear(self.temb_ch,
- self.temb_ch),
- ])
-
- # downsampling
- self.conv_in = torch.nn.Conv2d(in_channels,
- self.ch,
- kernel_size=3,
- stride=1,
- padding=1)
-
- curr_res = resolution
- in_ch_mult = (1,)+tuple(ch_mult)
- self.down = nn.ModuleList()
- for i_level in range(self.num_resolutions):
- block = nn.ModuleList()
- attn = nn.ModuleList()
- block_in = ch*in_ch_mult[i_level]
- block_out = ch*ch_mult[i_level]
- for i_block in range(self.num_res_blocks):
- block.append(ResnetBlock(in_channels=block_in,
- out_channels=block_out,
- temb_channels=self.temb_ch,
- dropout=dropout))
- block_in = block_out
- if curr_res in attn_resolutions:
- attn.append(make_attn(block_in, attn_type=attn_type))
- # down = nn.Module()
- down = Down_module()
- down.block = block
- down.attn = attn
- if i_level != self.num_resolutions-1:
- down.downsample = Downsample(block_in, resamp_with_conv)
- curr_res = curr_res // 2
- self.down.append(down)
-
- # middle
- # self.mid = nn.Module()
- self.mid = Mid_module()
- self.mid.block_1 = ResnetBlock(in_channels=block_in,
- out_channels=block_in,
- temb_channels=self.temb_ch,
- dropout=dropout)
- self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
- self.mid.block_2 = ResnetBlock(in_channels=block_in,
- out_channels=block_in,
- temb_channels=self.temb_ch,
- dropout=dropout)
-
- # upsampling
- self.up = nn.ModuleList()
- for i_level in reversed(range(self.num_resolutions)):
- block = nn.ModuleList()
- attn = nn.ModuleList()
- block_out = ch*ch_mult[i_level]
- skip_in = ch*ch_mult[i_level]
- for i_block in range(self.num_res_blocks+1):
- if i_block == self.num_res_blocks:
- skip_in = ch*in_ch_mult[i_level]
- block.append(ResnetBlock(in_channels=block_in+skip_in,
- out_channels=block_out,
- temb_channels=self.temb_ch,
- dropout=dropout))
- block_in = block_out
- if curr_res in attn_resolutions:
- attn.append(make_attn(block_in, attn_type=attn_type))
- # up = nn.Module()
- up = Up_module()
- up.block = block
- up.attn = attn
- if i_level != 0:
- up.upsample = Upsample(block_in, resamp_with_conv)
- curr_res = curr_res * 2
- self.up.insert(0, up) # prepend to get consistent order
-
- # end
- self.norm_out = Normalize(block_in)
- self.conv_out = torch.nn.Conv2d(block_in,
- out_ch,
- kernel_size=3,
- stride=1,
- padding=1)
-
- def forward(self, x, t=None, context=None):
- #assert x.shape[2] == x.shape[3] == self.resolution
- if context is not None:
- # assume aligned context, cat along channel axis
- x = torch.cat((x, context), dim=1)
- if self.use_timestep:
- # timestep embedding
- assert t is not None
- temb = get_timestep_embedding(t, self.ch)
- temb = self.temb.dense[0](temb)
- temb = nonlinearity(temb)
- temb = self.temb.dense[1](temb)
- else:
- temb = None
-
- # downsampling
- hs = [self.conv_in(x)]
- for i_level in range(self.num_resolutions):
- for i_block in range(self.num_res_blocks):
- h = self.down[i_level].block[i_block](hs[-1], temb)
- if len(self.down[i_level].attn) > 0:
- h = self.down[i_level].attn[i_block](h)
- hs.append(h)
- if i_level != self.num_resolutions-1:
- hs.append(self.down[i_level].downsample(hs[-1]))
-
- # middle
- h = hs[-1]
- h = self.mid.block_1(h, temb)
- h = self.mid.attn_1(h)
- h = self.mid.block_2(h, temb)
-
- # upsampling
- for i_level in reversed(range(self.num_resolutions)):
- for i_block in range(self.num_res_blocks+1):
- h = self.up[i_level].block[i_block](
- torch.cat([h, hs.pop()], dim=1), temb)
- if len(self.up[i_level].attn) > 0:
- h = self.up[i_level].attn[i_block](h)
- if i_level != 0:
- h = self.up[i_level].upsample(h)
-
- # end
- h = self.norm_out(h)
- h = nonlinearity(h)
- h = self.conv_out(h)
- return h
-
- def get_last_layer(self):
- return self.conv_out.weight
-
-class Down_module(nn.Module):
- def __init__(self):
- super().__init__()
- pass
-
-class Up_module(nn.Module):
- def __init__(self):
- super().__init__()
- pass
-
-class Mid_module(nn.Module):
- def __init__(self):
- super().__init__()
- pass
-
-
-class Encoder(nn.Module):
- def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
- attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels,
- resolution, z_channels, double_z=True, use_linear_attn=False, attn_type="vanilla",
- **ignore_kwargs):
- super().__init__()
- if use_linear_attn: attn_type = "linear"
- self.ch = ch
- self.temb_ch = 0
- self.num_resolutions = len(ch_mult)
- self.num_res_blocks = num_res_blocks
- self.resolution = resolution
- self.in_channels = in_channels
-
- # downsampling
- self.conv_in = torch.nn.Conv2d(in_channels,
- self.ch,
- kernel_size=3,
- stride=1,
- padding=1)
-
- curr_res = resolution
- in_ch_mult = (1,)+tuple(ch_mult)
- self.in_ch_mult = in_ch_mult
- self.down = nn.ModuleList()
- for i_level in range(self.num_resolutions):
- block = nn.ModuleList()
- attn = nn.ModuleList()
- block_in = ch*in_ch_mult[i_level]
- block_out = ch*ch_mult[i_level]
- for i_block in range(self.num_res_blocks):
- block.append(ResnetBlock(in_channels=block_in,
- out_channels=block_out,
- temb_channels=self.temb_ch,
- dropout=dropout))
- block_in = block_out
- if curr_res in attn_resolutions:
- attn.append(make_attn(block_in, attn_type=attn_type))
- # down = nn.Module()
- down = Down_module()
- down.block = block
- down.attn = attn
- if i_level != self.num_resolutions-1:
- down.downsample = Downsample(block_in, resamp_with_conv)
- curr_res = curr_res // 2
- self.down.append(down)
-
- # middle
- # self.mid = nn.Module()
- self.mid = Mid_module()
- self.mid.block_1 = ResnetBlock(in_channels=block_in,
- out_channels=block_in,
- temb_channels=self.temb_ch,
- dropout=dropout)
- self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
- self.mid.block_2 = ResnetBlock(in_channels=block_in,
- out_channels=block_in,
- temb_channels=self.temb_ch,
- dropout=dropout)
-
- # end
- self.norm_out = Normalize(block_in)
- self.conv_out = torch.nn.Conv2d(block_in,
- 2*z_channels if double_z else z_channels,
- kernel_size=3,
- stride=1,
- padding=1)
-
- def forward(self, x):
- # timestep embedding
- temb = None
-
- # downsampling
- hs = [self.conv_in(x)]
- for i_level in range(self.num_resolutions):
- for i_block in range(self.num_res_blocks):
- h = self.down[i_level].block[i_block](hs[-1], temb)
- if len(self.down[i_level].attn) > 0:
- h = self.down[i_level].attn[i_block](h)
- hs.append(h)
- if i_level != self.num_resolutions-1:
- hs.append(self.down[i_level].downsample(hs[-1]))
-
- # middle
- h = hs[-1]
- h = self.mid.block_1(h, temb)
- h = self.mid.attn_1(h)
- h = self.mid.block_2(h, temb)
-
- # end
- h = self.norm_out(h)
- h = nonlinearity(h)
- h = self.conv_out(h)
- return h
-
-
-class Decoder(nn.Module):
- def __init__(self, *, ch, out_ch, ch_mult=(1,2,4,8), num_res_blocks,
- attn_resolutions, dropout=0.0, resamp_with_conv=True, in_channels,
- resolution, z_channels, give_pre_end=False, tanh_out=False, use_linear_attn=False,
- attn_type="vanilla", **ignorekwargs):
- super().__init__()
- if use_linear_attn: attn_type = "linear"
- self.ch = ch
- self.temb_ch = 0
- self.num_resolutions = len(ch_mult)
- self.num_res_blocks = num_res_blocks
- self.resolution = resolution
- self.in_channels = in_channels
- self.give_pre_end = give_pre_end
- self.tanh_out = tanh_out
-
- # compute in_ch_mult, block_in and curr_res at lowest res
- in_ch_mult = (1,)+tuple(ch_mult)
- block_in = ch*ch_mult[self.num_resolutions-1]
- curr_res = resolution // 2**(self.num_resolutions-1)
- self.z_shape = (1,z_channels,curr_res,curr_res)
- print("Working with z of shape {} = {} dimensions.".format(
- self.z_shape, np.prod(self.z_shape)))
-
- # z to block_in
- self.conv_in = torch.nn.Conv2d(z_channels,
- block_in,
- kernel_size=3,
- stride=1,
- padding=1)
-
- # middle
- # self.mid = nn.Module()
- self.mid = Mid_module()
- self.mid.block_1 = ResnetBlock(in_channels=block_in,
- out_channels=block_in,
- temb_channels=self.temb_ch,
- dropout=dropout)
- self.mid.attn_1 = make_attn(block_in, attn_type=attn_type)
- self.mid.block_2 = ResnetBlock(in_channels=block_in,
- out_channels=block_in,
- temb_channels=self.temb_ch,
- dropout=dropout)
-
- # upsampling
- self.up = nn.ModuleList()
- for i_level in reversed(range(self.num_resolutions)):
- block = nn.ModuleList()
- attn = nn.ModuleList()
- block_out = ch*ch_mult[i_level]
- for i_block in range(self.num_res_blocks+1):
- block.append(ResnetBlock(in_channels=block_in,
- out_channels=block_out,
- temb_channels=self.temb_ch,
- dropout=dropout))
- block_in = block_out
- if curr_res in attn_resolutions:
- attn.append(make_attn(block_in, attn_type=attn_type))
- # up = nn.Module()
- up = Up_module()
- up.block = block
- up.attn = attn
- if i_level != 0:
- up.upsample = Upsample(block_in, resamp_with_conv)
- curr_res = curr_res * 2
- self.up.insert(0, up) # prepend to get consistent order
-
- # end
- self.norm_out = Normalize(block_in)
- self.conv_out = torch.nn.Conv2d(block_in,
- out_ch,
- kernel_size=3,
- stride=1,
- padding=1)
-
- def forward(self, z):
- #assert z.shape[1:] == self.z_shape[1:]
- self.last_z_shape = z.shape
-
- # timestep embedding
- temb = None
-
- # z to block_in
- h = self.conv_in(z)
-
- # middle
- h = self.mid.block_1(h, temb)
- h = self.mid.attn_1(h)
- h = self.mid.block_2(h, temb)
-
- # upsampling
- for i_level in reversed(range(self.num_resolutions)):
- for i_block in range(self.num_res_blocks+1):
- h = self.up[i_level].block[i_block](h, temb)
- if len(self.up[i_level].attn) > 0:
- h = self.up[i_level].attn[i_block](h)
- if i_level != 0:
- h = self.up[i_level].upsample(h)
-
- # end
- if self.give_pre_end:
- return h
-
- h = self.norm_out(h)
- h = nonlinearity(h)
- h = self.conv_out(h)
- if self.tanh_out:
- h = torch.tanh(h)
- return h
-
-
-class SimpleDecoder(nn.Module):
- def __init__(self, in_channels, out_channels, *args, **kwargs):
- super().__init__()
- self.model = nn.ModuleList([nn.Conv2d(in_channels, in_channels, 1),
- ResnetBlock(in_channels=in_channels,
- out_channels=2 * in_channels,
- temb_channels=0, dropout=0.0),
- ResnetBlock(in_channels=2 * in_channels,
- out_channels=4 * in_channels,
- temb_channels=0, dropout=0.0),
- ResnetBlock(in_channels=4 * in_channels,
- out_channels=2 * in_channels,
- temb_channels=0, dropout=0.0),
- nn.Conv2d(2*in_channels, in_channels, 1),
- Upsample(in_channels, with_conv=True)])
- # end
- self.norm_out = Normalize(in_channels)
- self.conv_out = torch.nn.Conv2d(in_channels,
- out_channels,
- kernel_size=3,
- stride=1,
- padding=1)
-
- def forward(self, x):
- for i, layer in enumerate(self.model):
- if i in [1,2,3]:
- x = layer(x, None)
- else:
- x = layer(x)
-
- h = self.norm_out(x)
- h = nonlinearity(h)
- x = self.conv_out(h)
- return x
-
-
-class UpsampleDecoder(nn.Module):
- def __init__(self, in_channels, out_channels, ch, num_res_blocks, resolution,
- ch_mult=(2,2), dropout=0.0):
- super().__init__()
- # upsampling
- self.temb_ch = 0
- self.num_resolutions = len(ch_mult)
- self.num_res_blocks = num_res_blocks
- block_in = in_channels
- curr_res = resolution // 2 ** (self.num_resolutions - 1)
- self.res_blocks = nn.ModuleList()
- self.upsample_blocks = nn.ModuleList()
- for i_level in range(self.num_resolutions):
- res_block = []
- block_out = ch * ch_mult[i_level]
- for i_block in range(self.num_res_blocks + 1):
- res_block.append(ResnetBlock(in_channels=block_in,
- out_channels=block_out,
- temb_channels=self.temb_ch,
- dropout=dropout))
- block_in = block_out
- self.res_blocks.append(nn.ModuleList(res_block))
- if i_level != self.num_resolutions - 1:
- self.upsample_blocks.append(Upsample(block_in, True))
- curr_res = curr_res * 2
-
- # end
- self.norm_out = Normalize(block_in)
- self.conv_out = torch.nn.Conv2d(block_in,
- out_channels,
- kernel_size=3,
- stride=1,
- padding=1)
-
- def forward(self, x):
- # upsampling
- h = x
- for k, i_level in enumerate(range(self.num_resolutions)):
- for i_block in range(self.num_res_blocks + 1):
- h = self.res_blocks[i_level][i_block](h, None)
- if i_level != self.num_resolutions - 1:
- h = self.upsample_blocks[k](h)
- h = self.norm_out(h)
- h = nonlinearity(h)
- h = self.conv_out(h)
- return h
-
-
-class LatentRescaler(nn.Module):
- def __init__(self, factor, in_channels, mid_channels, out_channels, depth=2):
- super().__init__()
- # residual block, interpolate, residual block
- self.factor = factor
- self.conv_in = nn.Conv2d(in_channels,
- mid_channels,
- kernel_size=3,
- stride=1,
- padding=1)
- self.res_block1 = nn.ModuleList([ResnetBlock(in_channels=mid_channels,
- out_channels=mid_channels,
- temb_channels=0,
- dropout=0.0) for _ in range(depth)])
- self.attn = AttnBlock(mid_channels)
- self.res_block2 = nn.ModuleList([ResnetBlock(in_channels=mid_channels,
- out_channels=mid_channels,
- temb_channels=0,
- dropout=0.0) for _ in range(depth)])
-
- self.conv_out = nn.Conv2d(mid_channels,
- out_channels,
- kernel_size=1,
- )
-
- def forward(self, x):
- x = self.conv_in(x)
- for block in self.res_block1:
- x = block(x, None)
- x = torch.nn.functional.interpolate(x, size=(int(round(x.shape[2]*self.factor)), int(round(x.shape[3]*self.factor))))
- x = self.attn(x)
- for block in self.res_block2:
- x = block(x, None)
- x = self.conv_out(x)
- return x
-
-
-class MergedRescaleEncoder(nn.Module):
- def __init__(self, in_channels, ch, resolution, out_ch, num_res_blocks,
- attn_resolutions, dropout=0.0, resamp_with_conv=True,
- ch_mult=(1,2,4,8), rescale_factor=1.0, rescale_module_depth=1):
- super().__init__()
- intermediate_chn = ch * ch_mult[-1]
- self.encoder = Encoder(in_channels=in_channels, num_res_blocks=num_res_blocks, ch=ch, ch_mult=ch_mult,
- z_channels=intermediate_chn, double_z=False, resolution=resolution,
- attn_resolutions=attn_resolutions, dropout=dropout, resamp_with_conv=resamp_with_conv,
- out_ch=None)
- self.rescaler = LatentRescaler(factor=rescale_factor, in_channels=intermediate_chn,
- mid_channels=intermediate_chn, out_channels=out_ch, depth=rescale_module_depth)
-
- def forward(self, x):
- x = self.encoder(x)
- x = self.rescaler(x)
- return x
-
-
-class MergedRescaleDecoder(nn.Module):
- def __init__(self, z_channels, out_ch, resolution, num_res_blocks, attn_resolutions, ch, ch_mult=(1,2,4,8),
- dropout=0.0, resamp_with_conv=True, rescale_factor=1.0, rescale_module_depth=1):
- super().__init__()
- tmp_chn = z_channels*ch_mult[-1]
- self.decoder = Decoder(out_ch=out_ch, z_channels=tmp_chn, attn_resolutions=attn_resolutions, dropout=dropout,
- resamp_with_conv=resamp_with_conv, in_channels=None, num_res_blocks=num_res_blocks,
- ch_mult=ch_mult, resolution=resolution, ch=ch)
- self.rescaler = LatentRescaler(factor=rescale_factor, in_channels=z_channels, mid_channels=tmp_chn,
- out_channels=tmp_chn, depth=rescale_module_depth)
-
- def forward(self, x):
- x = self.rescaler(x)
- x = self.decoder(x)
- return x
-
-
-class Upsampler(nn.Module):
- def __init__(self, in_size, out_size, in_channels, out_channels, ch_mult=2):
- super().__init__()
- assert out_size >= in_size
- num_blocks = int(np.log2(out_size//in_size))+1
- factor_up = 1.+ (out_size % in_size)
- print(f"Building {self.__class__.__name__} with in_size: {in_size} --> out_size {out_size} and factor {factor_up}")
- self.rescaler = LatentRescaler(factor=factor_up, in_channels=in_channels, mid_channels=2*in_channels,
- out_channels=in_channels)
- self.decoder = Decoder(out_ch=out_channels, resolution=out_size, z_channels=in_channels, num_res_blocks=2,
- attn_resolutions=[], in_channels=None, ch=in_channels,
- ch_mult=[ch_mult for _ in range(num_blocks)])
-
- def forward(self, x):
- x = self.rescaler(x)
- x = self.decoder(x)
- return x
-
-
-class Resize(nn.Module):
- def __init__(self, in_channels=None, learned=False, mode="bilinear"):
- super().__init__()
- self.with_conv = learned
- self.mode = mode
- if self.with_conv:
- print(f"Note: {self.__class__.__name} uses learned downsampling and will ignore the fixed {mode} mode")
- raise NotImplementedError()
- assert in_channels is not None
- # no asymmetric padding in torch conv, must do it ourselves
- self.conv = torch.nn.Conv2d(in_channels,
- in_channels,
- kernel_size=4,
- stride=2,
- padding=1)
-
- def forward(self, x, scale_factor=1.0):
- if scale_factor==1.0:
- return x
- else:
- x = torch.nn.functional.interpolate(x, mode=self.mode, align_corners=False, scale_factor=scale_factor)
- return x
-
-class FirstStagePostProcessor(nn.Module):
-
- def __init__(self, ch_mult:list, in_channels,
- pretrained_model:nn.Module=None,
- reshape=False,
- n_channels=None,
- dropout=0.,
- pretrained_config=None):
- super().__init__()
- if pretrained_config is None:
- assert pretrained_model is not None, 'Either "pretrained_model" or "pretrained_config" must not be None'
- self.pretrained_model = pretrained_model
- else:
- assert pretrained_config is not None, 'Either "pretrained_model" or "pretrained_config" must not be None'
- self.instantiate_pretrained(pretrained_config)
-
- self.do_reshape = reshape
-
- if n_channels is None:
- n_channels = self.pretrained_model.encoder.ch
-
- self.proj_norm = Normalize(in_channels,num_groups=in_channels//2)
- self.proj = nn.Conv2d(in_channels,n_channels,kernel_size=3,
- stride=1,padding=1)
-
- blocks = []
- downs = []
- ch_in = n_channels
- for m in ch_mult:
- blocks.append(ResnetBlock(in_channels=ch_in,out_channels=m*n_channels,dropout=dropout))
- ch_in = m * n_channels
- downs.append(Downsample(ch_in, with_conv=False))
-
- self.model = nn.ModuleList(blocks)
- self.downsampler = nn.ModuleList(downs)
-
-
- def instantiate_pretrained(self, config):
- model = instantiate_from_config(config)
- self.pretrained_model = model.eval()
- # self.pretrained_model.train = False
- for param in self.pretrained_model.parameters():
- param.requires_grad = False
-
-
- @torch.no_grad()
- def encode_with_pretrained(self,x):
- c = self.pretrained_model.encode(x)
- if isinstance(c, DiagonalGaussianDistribution):
- c = c.mode()
- return c
-
- def forward(self,x):
- z_fs = self.encode_with_pretrained(x)
- z = self.proj_norm(z_fs)
- z = self.proj(z)
- z = nonlinearity(z)
-
- for submodel, downmodel in zip(self.model,self.downsampler):
- z = submodel(z,temb=None)
- z = downmodel(z)
-
- if self.do_reshape:
- z = rearrange(z,'b c h w -> b (h w) c')
- return z
-
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/openaimodel.py b/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/openaimodel.py
deleted file mode 100644
index 3aedc2205..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/openaimodel.py
+++ /dev/null
@@ -1,1152 +0,0 @@
-from abc import abstractmethod
-from functools import partial
-import math
-from typing import Iterable
-
-import numpy as np
-import torch
-import torch as th
-import torch.nn as nn
-import torch.nn.functional as F
-from torch.utils import checkpoint
-
-from ldm.modules.diffusionmodules.util import (
- conv_nd,
- linear,
- avg_pool_nd,
- zero_module,
- normalization,
- timestep_embedding,
-)
-from ldm.modules.attention import SpatialTransformer
-
-
-# dummy replace
-def convert_module_to_f16(x):
- # for n,p in x.named_parameter():
- # print(f"convert module {n} to_f16")
- # p.data = p.data.half()
- pass
-
-def convert_module_to_f32(x):
- pass
-
-
-## go
-class AttentionPool2d(nn.Module):
- """
- Adapted from CLIP: https://github.com/openai/CLIP/blob/main/clip/model.py
- """
-
- def __init__(
- self,
- spacial_dim: int,
- embed_dim: int,
- num_heads_channels: int,
- output_dim: int = None,
- ):
- super().__init__()
- self.positional_embedding = nn.Parameter(th.randn(embed_dim, spacial_dim ** 2 + 1) / embed_dim ** 0.5)
- self.qkv_proj = conv_nd(1, embed_dim, 3 * embed_dim, 1)
- self.c_proj = conv_nd(1, embed_dim, output_dim or embed_dim, 1)
- self.num_heads = embed_dim // num_heads_channels
- self.attention = QKVAttention(self.num_heads)
-
- def forward(self, x):
- b, c, *_spatial = x.shape
- x = x.reshape(b, c, -1) # NC(HW)
- x = th.cat([x.mean(dim=-1, keepdim=True), x], dim=-1) # NC(HW+1)
- x = x + self.positional_embedding[None, :, :].to(x.dtype) # NC(HW+1)
- x = self.qkv_proj(x)
- x = self.attention(x)
- x = self.c_proj(x)
- return x[:, :, 0]
-
-
-class TimestepBlock(nn.Module):
- """
- Any module where forward() takes timestep embeddings as a second argument.
- """
-
- @abstractmethod
- def forward(self, x, emb):
- """
- Apply the module to `x` given `emb` timestep embeddings.
- """
-
-
-class TimestepEmbedSequential(nn.Sequential, TimestepBlock):
- """
- A sequential module that passes timestep embeddings to the children that
- support it as an extra input.
- """
-
- def forward(self, x, emb, context=None):
- for layer in self:
- if isinstance(layer, TimestepBlock):
- x = layer(x, emb)
- elif isinstance(layer, SpatialTransformer):
- x = layer(x, context)
- else:
- x = layer(x)
- return x
-
-
-class Upsample(nn.Module):
- """
- An upsampling layer with an optional convolution.
- :param channels: channels in the inputs and outputs.
- :param use_conv: a bool determining if a convolution is applied.
- :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
- upsampling occurs in the inner-two dimensions.
- """
-
- def __init__(self, channels, use_conv, dims=2, out_channels=None, padding=1):
- super().__init__()
- self.channels = channels
- self.out_channels = out_channels or channels
- self.use_conv = use_conv
- self.dims = dims
- if use_conv:
- self.conv = conv_nd(dims, self.channels, self.out_channels, 3, padding=padding)
-
- def forward(self, x):
- assert x.shape[1] == self.channels
- if self.dims == 3:
- x = F.interpolate(
- x, (x.shape[2], x.shape[3] * 2, x.shape[4] * 2), mode="nearest"
- )
- else:
- x = F.interpolate(x, scale_factor=2, mode="nearest")
- if self.use_conv:
- x = self.conv(x)
- return x
-
-class TransposedUpsample(nn.Module):
- 'Learned 2x upsampling without padding'
- def __init__(self, channels, out_channels=None, ks=5):
- super().__init__()
- self.channels = channels
- self.out_channels = out_channels or channels
-
- self.up = nn.ConvTranspose2d(self.channels,self.out_channels,kernel_size=ks,stride=2)
-
- def forward(self,x):
- return self.up(x)
-
-
-class Downsample(nn.Module):
- """
- A downsampling layer with an optional convolution.
- :param channels: channels in the inputs and outputs.
- :param use_conv: a bool determining if a convolution is applied.
- :param dims: determines if the signal is 1D, 2D, or 3D. If 3D, then
- downsampling occurs in the inner-two dimensions.
- """
-
- def __init__(self, channels, use_conv, dims=2, out_channels=None,padding=1):
- super().__init__()
- self.channels = channels
- self.out_channels = out_channels or channels
- self.use_conv = use_conv
- self.dims = dims
- stride = 2 if dims != 3 else (1, 2, 2)
- if use_conv:
- self.op = conv_nd(
- dims, self.channels, self.out_channels, 3, stride=stride, padding=padding
- )
- else:
- assert self.channels == self.out_channels
- self.op = avg_pool_nd(dims, kernel_size=stride, stride=stride)
-
- def forward(self, x):
- assert x.shape[1] == self.channels
- return self.op(x)
-
-
-class ResBlock(TimestepBlock):
- """
- A residual block that can optionally change the number of channels.
- :param channels: the number of input channels.
- :param emb_channels: the number of timestep embedding channels.
- :param dropout: the rate of dropout.
- :param out_channels: if specified, the number of out channels.
- :param use_conv: if True and out_channels is specified, use a spatial
- convolution instead of a smaller 1x1 convolution to change the
- channels in the skip connection.
- :param dims: determines if the signal is 1D, 2D, or 3D.
- :param use_checkpoint: if True, use gradient checkpointing on this module.
- :param up: if True, use this block for upsampling.
- :param down: if True, use this block for downsampling.
- """
-
- def __init__(
- self,
- channels,
- emb_channels,
- dropout,
- out_channels=None,
- use_conv=False,
- use_scale_shift_norm=False,
- dims=2,
- use_checkpoint=False,
- up=False,
- down=False,
- ):
- super().__init__()
- self.channels = channels
- self.emb_channels = emb_channels
- self.dropout = dropout
- self.out_channels = out_channels or channels
- self.use_conv = use_conv
- self.use_checkpoint = use_checkpoint
- self.use_scale_shift_norm = use_scale_shift_norm
-
- self.in_layers = nn.Sequential(
- normalization(channels),
- nn.SiLU(),
- conv_nd(dims, channels, self.out_channels, 3, padding=1),
- )
-
- self.updown = up or down
-
- if up:
- self.h_upd = Upsample(channels, False, dims)
- self.x_upd = Upsample(channels, False, dims)
- elif down:
- self.h_upd = Downsample(channels, False, dims)
- self.x_upd = Downsample(channels, False, dims)
- else:
- self.h_upd = self.x_upd = nn.Identity()
-
- self.emb_layers = nn.Sequential(
- nn.SiLU(),
- linear(
- emb_channels,
- 2 * self.out_channels if use_scale_shift_norm else self.out_channels,
- ),
- )
- self.out_layers = nn.Sequential(
- normalization(self.out_channels),
- nn.SiLU(),
- nn.Dropout(p=dropout),
- zero_module(
- conv_nd(dims, self.out_channels, self.out_channels, 3, padding=1)
- ),
- )
-
- if self.out_channels == channels:
- self.skip_connection = nn.Identity()
- elif use_conv:
- self.skip_connection = conv_nd(
- dims, channels, self.out_channels, 3, padding=1
- )
- else:
- self.skip_connection = conv_nd(dims, channels, self.out_channels, 1)
-
- def forward(self, x, emb):
- """
- Apply the block to a Tensor, conditioned on a timestep embedding.
- :param x: an [N x C x ...] Tensor of features.
- :param emb: an [N x emb_channels] Tensor of timestep embeddings.
- :return: an [N x C x ...] Tensor of outputs.
- """
- if self.use_checkpoint:
- return checkpoint(self._forward, x, emb)
- else:
- return self._forward(x, emb)
-
-
- def _forward(self, x, emb):
- if self.updown:
- in_rest, in_conv = self.in_layers[:-1], self.in_layers[-1]
- h = in_rest(x)
- h = self.h_upd(h)
- x = self.x_upd(x)
- h = in_conv(h)
- else:
- h = self.in_layers(x)
- emb_out = self.emb_layers(emb).type(h.dtype)
- while len(emb_out.shape) < len(h.shape):
- emb_out = emb_out[..., None]
- if self.use_scale_shift_norm:
- out_norm, out_rest = self.out_layers[0], self.out_layers[1:]
- scale, shift = th.chunk(emb_out, 2, dim=1)
- h = out_norm(h) * (1 + scale) + shift
- h = out_rest(h)
- else:
- h = h + emb_out
- h = self.out_layers(h)
- return self.skip_connection(x) + h
-
-
-class AttentionBlock(nn.Module):
- """
- An attention block that allows spatial positions to attend to each other.
- Originally ported from here, but adapted to the N-d case.
- https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/models/unet.py#L66.
- """
-
- def __init__(
- self,
- channels,
- num_heads=1,
- num_head_channels=-1,
- use_checkpoint=False,
- use_new_attention_order=False,
- ):
- super().__init__()
- self.channels = channels
- if num_head_channels == -1:
- self.num_heads = num_heads
- else:
- assert (
- channels % num_head_channels == 0
- ), f"q,k,v channels {channels} is not divisible by num_head_channels {num_head_channels}"
- self.num_heads = channels // num_head_channels
- self.use_checkpoint = use_checkpoint
- self.norm = normalization(channels)
- self.qkv = conv_nd(1, channels, channels * 3, 1)
- if use_new_attention_order:
- # split qkv before split heads
- self.attention = QKVAttention(self.num_heads)
- else:
- # split heads before split qkv
- self.attention = QKVAttentionLegacy(self.num_heads)
-
- self.proj_out = zero_module(conv_nd(1, channels, channels, 1))
-
- def forward(self, x):
- if self.use_checkpoint:
- return checkpoint(self._forward, x) # TODO: check checkpoint usage, is True # TODO: fix the .half call!!!
- #return pt_checkpoint(self._forward, x) # pytorch
- else:
- return self._forward(x)
-
- def _forward(self, x):
- b, c, *spatial = x.shape
- x = x.reshape(b, c, -1)
- qkv = self.qkv(self.norm(x))
- h = self.attention(qkv)
- h = self.proj_out(h)
- return (x + h).reshape(b, c, *spatial)
-
-
-def count_flops_attn(model, _x, y):
- """
- A counter for the `thop` package to count the operations in an
- attention operation.
- Meant to be used like:
- macs, params = thop.profile(
- model,
- inputs=(inputs, timestamps),
- custom_ops={QKVAttention: QKVAttention.count_flops},
- )
- """
- b, c, *spatial = y[0].shape
- num_spatial = int(np.prod(spatial))
- # We perform two matmuls with the same number of ops.
- # The first computes the weight matrix, the second computes
- # the combination of the value vectors.
- matmul_ops = 2 * b * (num_spatial ** 2) * c
- model.total_ops += th.DoubleTensor([matmul_ops])
-
-
-class QKVAttentionLegacy(nn.Module):
- """
- A module which performs QKV attention. Matches legacy QKVAttention + input/ouput heads shaping
- """
-
- def __init__(self, n_heads):
- super().__init__()
- self.n_heads = n_heads
-
- def forward(self, qkv):
- """
- Apply QKV attention.
- :param qkv: an [N x (H * 3 * C) x T] tensor of Qs, Ks, and Vs.
- :return: an [N x (H * C) x T] tensor after attention.
- """
- bs, width, length = qkv.shape
- assert width % (3 * self.n_heads) == 0
- ch = width // (3 * self.n_heads)
- q, k, v = qkv.reshape(bs * self.n_heads, ch * 3, length).split(ch, dim=1)
- scale = 1 / math.sqrt(math.sqrt(ch))
- weight = th.einsum(
- "bct,bcs->bts", q * scale, k * scale
- ) # More stable with f16 than dividing afterwards
- weight = th.softmax(weight.float(), dim=-1).type(weight.dtype)
- a = th.einsum("bts,bcs->bct", weight, v)
- return a.reshape(bs, -1, length)
-
- @staticmethod
- def count_flops(model, _x, y):
- return count_flops_attn(model, _x, y)
-
-
-class QKVAttention(nn.Module):
- """
- A module which performs QKV attention and splits in a different order.
- """
-
- def __init__(self, n_heads):
- super().__init__()
- self.n_heads = n_heads
-
- def forward(self, qkv):
- """
- Apply QKV attention.
- :param qkv: an [N x (3 * H * C) x T] tensor of Qs, Ks, and Vs.
- :return: an [N x (H * C) x T] tensor after attention.
- """
- bs, width, length = qkv.shape
- assert width % (3 * self.n_heads) == 0
- ch = width // (3 * self.n_heads)
- q, k, v = qkv.chunk(3, dim=1)
- scale = 1 / math.sqrt(math.sqrt(ch))
- weight = th.einsum(
- "bct,bcs->bts",
- (q * scale).view(bs * self.n_heads, ch, length),
- (k * scale).view(bs * self.n_heads, ch, length),
- ) # More stable with f16 than dividing afterwards
- weight = th.softmax(weight.float(), dim=-1).type(weight.dtype)
- a = th.einsum("bts,bcs->bct", weight, v.reshape(bs * self.n_heads, ch, length))
- return a.reshape(bs, -1, length)
-
- @staticmethod
- def count_flops(model, _x, y):
- return count_flops_attn(model, _x, y)
-
-
-class UNetModel(nn.Module):
- """
- The full UNet model with attention and timestep embedding.
- :param in_channels: channels in the input Tensor.
- :param model_channels: base channel count for the model.
- :param out_channels: channels in the output Tensor.
- :param num_res_blocks: number of residual blocks per downsample.
- :param attention_resolutions: a collection of downsample rates at which
- attention will take place. May be a set, list, or tuple.
- For example, if this contains 4, then at 4x downsampling, attention
- will be used.
- :param dropout: the dropout probability.
- :param channel_mult: channel multiplier for each level of the UNet.
- :param conv_resample: if True, use learned convolutions for upsampling and
- downsampling.
- :param dims: determines if the signal is 1D, 2D, or 3D.
- :param num_classes: if specified (as an int), then this model will be
- class-conditional with `num_classes` classes.
- :param use_checkpoint: use gradient checkpointing to reduce memory usage.
- :param num_heads: the number of attention heads in each attention layer.
- :param num_heads_channels: if specified, ignore num_heads and instead use
- a fixed channel width per attention head.
- :param num_heads_upsample: works with num_heads to set a different number
- of heads for upsampling. Deprecated.
- :param use_scale_shift_norm: use a FiLM-like conditioning mechanism.
- :param resblock_updown: use residual blocks for up/downsampling.
- :param use_new_attention_order: use a different attention pattern for potentially
- increased efficiency.
- """
-
- def __init__(
- self,
- image_size,
- in_channels,
- model_channels,
- out_channels,
- num_res_blocks,
- attention_resolutions,
- dropout=0,
- channel_mult=(1, 2, 4, 8),
- conv_resample=True,
- dims=2,
- num_classes=None,
- use_checkpoint=False,
- use_fp16=False,
- num_heads=-1,
- num_head_channels=-1,
- num_heads_upsample=-1,
- use_scale_shift_norm=False,
- resblock_updown=False,
- use_new_attention_order=False,
- use_spatial_transformer=False, # custom transformer support
- transformer_depth=1, # custom transformer support
- context_dim=None, # custom transformer support
- n_embed=None, # custom support for prediction of discrete ids into codebook of first stage vq model
- legacy=True,
- from_pretrained: str=None
- ):
- super().__init__()
- if use_spatial_transformer:
- assert context_dim is not None, 'Fool!! You forgot to include the dimension of your cross-attention conditioning...'
-
- if context_dim is not None:
- assert use_spatial_transformer, 'Fool!! You forgot to use the spatial transformer for your cross-attention conditioning...'
- from omegaconf.listconfig import ListConfig
- if type(context_dim) == ListConfig:
- context_dim = list(context_dim)
-
- if num_heads_upsample == -1:
- num_heads_upsample = num_heads
-
- if num_heads == -1:
- assert num_head_channels != -1, 'Either num_heads or num_head_channels has to be set'
-
- if num_head_channels == -1:
- assert num_heads != -1, 'Either num_heads or num_head_channels has to be set'
-
- self.image_size = image_size
- self.in_channels = in_channels
- self.model_channels = model_channels
- self.out_channels = out_channels
- self.num_res_blocks = num_res_blocks
- self.attention_resolutions = attention_resolutions
- self.dropout = dropout
- self.channel_mult = channel_mult
- self.conv_resample = conv_resample
- self.num_classes = num_classes
- self.use_checkpoint = use_checkpoint
- self.dtype = th.float16 if use_fp16 else th.float32
- self.num_heads = num_heads
- self.num_head_channels = num_head_channels
- self.num_heads_upsample = num_heads_upsample
- self.predict_codebook_ids = n_embed is not None
-
- time_embed_dim = model_channels * 4
- self.time_embed = nn.Sequential(
- linear(model_channels, time_embed_dim),
- nn.SiLU(),
- linear(time_embed_dim, time_embed_dim),
- )
-
- if self.num_classes is not None:
- self.label_emb = nn.Embedding(num_classes, time_embed_dim)
-
- self.input_blocks = nn.ModuleList(
- [
- TimestepEmbedSequential(
- conv_nd(dims, in_channels, model_channels, 3, padding=1)
- )
- ]
- )
- self._feature_size = model_channels
- input_block_chans = [model_channels]
- ch = model_channels
- ds = 1
- for level, mult in enumerate(channel_mult):
- for _ in range(num_res_blocks):
- layers = [
- ResBlock(
- ch,
- time_embed_dim,
- dropout,
- out_channels=mult * model_channels,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- )
- ]
- ch = mult * model_channels
- if ds in attention_resolutions:
- if num_head_channels == -1:
- dim_head = ch // num_heads
- else:
- num_heads = ch // num_head_channels
- dim_head = num_head_channels
- if legacy:
- #num_heads = 1
- dim_head = ch // num_heads if use_spatial_transformer else num_head_channels
- layers.append(
- AttentionBlock(
- ch,
- use_checkpoint=use_checkpoint,
- num_heads=num_heads,
- num_head_channels=dim_head,
- use_new_attention_order=use_new_attention_order,
- ) if not use_spatial_transformer else SpatialTransformer(
- ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim, use_checkpoint=use_checkpoint,
- )
- )
- self.input_blocks.append(TimestepEmbedSequential(*layers))
- self._feature_size += ch
- input_block_chans.append(ch)
- if level != len(channel_mult) - 1:
- out_ch = ch
- self.input_blocks.append(
- TimestepEmbedSequential(
- ResBlock(
- ch,
- time_embed_dim,
- dropout,
- out_channels=out_ch,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- down=True,
- )
- if resblock_updown
- else Downsample(
- ch, conv_resample, dims=dims, out_channels=out_ch
- )
- )
- )
- ch = out_ch
- input_block_chans.append(ch)
- ds *= 2
- self._feature_size += ch
-
- if num_head_channels == -1:
- dim_head = ch // num_heads
- else:
- num_heads = ch // num_head_channels
- dim_head = num_head_channels
- if legacy:
- #num_heads = 1
- dim_head = ch // num_heads if use_spatial_transformer else num_head_channels
- self.middle_block = TimestepEmbedSequential(
- ResBlock(
- ch,
- time_embed_dim,
- dropout,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- ),
- AttentionBlock(
- ch,
- use_checkpoint=use_checkpoint,
- num_heads=num_heads,
- num_head_channels=dim_head,
- use_new_attention_order=use_new_attention_order,
- ) if not use_spatial_transformer else SpatialTransformer(
- ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim
- ),
- ResBlock(
- ch,
- time_embed_dim,
- dropout,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- ),
- )
- self._feature_size += ch
-
- self.output_blocks = nn.ModuleList([])
- for level, mult in list(enumerate(channel_mult))[::-1]:
- for i in range(num_res_blocks + 1):
- ich = input_block_chans.pop()
- layers = [
- ResBlock(
- ch + ich,
- time_embed_dim,
- dropout,
- out_channels=model_channels * mult,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- )
- ]
- ch = model_channels * mult
- if ds in attention_resolutions:
- if num_head_channels == -1:
- dim_head = ch // num_heads
- else:
- num_heads = ch // num_head_channels
- dim_head = num_head_channels
- if legacy:
- #num_heads = 1
- dim_head = ch // num_heads if use_spatial_transformer else num_head_channels
- layers.append(
- AttentionBlock(
- ch,
- use_checkpoint=use_checkpoint,
- num_heads=num_heads_upsample,
- num_head_channels=dim_head,
- use_new_attention_order=use_new_attention_order,
- ) if not use_spatial_transformer else SpatialTransformer(
- ch, num_heads, dim_head, depth=transformer_depth, context_dim=context_dim
- )
- )
- if level and i == num_res_blocks:
- out_ch = ch
- layers.append(
- ResBlock(
- ch,
- time_embed_dim,
- dropout,
- out_channels=out_ch,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- up=True,
- )
- if resblock_updown
- else Upsample(ch, conv_resample, dims=dims, out_channels=out_ch)
- )
- ds //= 2
- self.output_blocks.append(TimestepEmbedSequential(*layers))
- self._feature_size += ch
-
- self.out = nn.Sequential(
- normalization(ch),
- nn.SiLU(),
- zero_module(conv_nd(dims, model_channels, out_channels, 3, padding=1)),
- )
- if self.predict_codebook_ids:
- self.id_predictor = nn.Sequential(
- normalization(ch),
- conv_nd(dims, model_channels, n_embed, 1),
- #nn.LogSoftmax(dim=1) # change to cross_entropy and produce non-normalized logits
- )
- # if use_fp16:
- # self.convert_to_fp16()
- from diffusers.modeling_utils import load_state_dict
- if from_pretrained is not None:
- state_dict = load_state_dict(from_pretrained)
- self._load_pretrained_model(state_dict)
-
- def _input_blocks_mapping(self, input_dict):
- res_dict = {}
- for key_, value_ in input_dict.items():
- id_0 = int(key_[13])
- if "resnets" in key_:
- id_1 = int(key_[23])
- target_id = 3 * id_0 + 1 + id_1
- post_fix = key_[25:].replace('time_emb_proj', 'emb_layers.1')\
- .replace('norm1', 'in_layers.0')\
- .replace('norm2', 'out_layers.0')\
- .replace('conv1', 'in_layers.2')\
- .replace('conv2', 'out_layers.3')\
- .replace('conv_shortcut', 'skip_connection')
- res_dict["input_blocks." + str(target_id) + '.0.' + post_fix] = value_
- elif "attentions" in key_:
- id_1 = int(key_[26])
- target_id = 3 * id_0 + 1 + id_1
- post_fix = key_[28:]
- res_dict["input_blocks." + str(target_id) + '.1.' + post_fix] = value_
- elif "downsamplers" in key_:
- post_fix = key_[35:]
- target_id = 3 * (id_0 + 1)
- res_dict["input_blocks." + str(target_id) + '.0.op.' + post_fix] = value_
- return res_dict
-
-
- def _mid_blocks_mapping(self, mid_dict):
- res_dict = {}
- for key_, value_ in mid_dict.items():
- if "resnets" in key_:
- temp_key_ =key_.replace('time_emb_proj', 'emb_layers.1') \
- .replace('norm1', 'in_layers.0') \
- .replace('norm2', 'out_layers.0') \
- .replace('conv1', 'in_layers.2') \
- .replace('conv2', 'out_layers.3') \
- .replace('conv_shortcut', 'skip_connection')\
- .replace('middle_block.resnets.0', 'middle_block.0')\
- .replace('middle_block.resnets.1', 'middle_block.2')
- res_dict[temp_key_] = value_
- elif "attentions" in key_:
- res_dict[key_.replace('attentions.0', '1')] = value_
- return res_dict
-
- def _other_blocks_mapping(self, other_dict):
- res_dict = {}
- for key_, value_ in other_dict.items():
- tmp_key = key_.replace('conv_in', 'input_blocks.0.0')\
- .replace('time_embedding.linear_1', 'time_embed.0')\
- .replace('time_embedding.linear_2', 'time_embed.2')\
- .replace('conv_norm_out', 'out.0')\
- .replace('conv_out', 'out.2')
- res_dict[tmp_key] = value_
- return res_dict
-
-
- def _output_blocks_mapping(self, output_dict):
- res_dict = {}
- for key_, value_ in output_dict.items():
- id_0 = int(key_[14])
- if "resnets" in key_:
- id_1 = int(key_[24])
- target_id = 3 * id_0 + id_1
- post_fix = key_[26:].replace('time_emb_proj', 'emb_layers.1') \
- .replace('norm1', 'in_layers.0') \
- .replace('norm2', 'out_layers.0') \
- .replace('conv1', 'in_layers.2') \
- .replace('conv2', 'out_layers.3') \
- .replace('conv_shortcut', 'skip_connection')
- res_dict["output_blocks." + str(target_id) + '.0.' + post_fix] = value_
- elif "attentions" in key_:
- id_1 = int(key_[27])
- target_id = 3 * id_0 + id_1
- post_fix = key_[29:]
- res_dict["output_blocks." + str(target_id) + '.1.' + post_fix] = value_
- elif "upsamplers" in key_:
- post_fix = key_[34:]
- target_id = 3 * (id_0 + 1) - 1
- mid_str = '.2.conv.' if target_id != 2 else '.1.conv.'
- res_dict["output_blocks." + str(target_id) + mid_str + post_fix] = value_
- return res_dict
-
- def _state_key_mapping(self, state_dict: dict):
- import re
- res_dict = {}
- input_dict = {}
- mid_dict = {}
- output_dict = {}
- other_dict = {}
- for key_, value_ in state_dict.items():
- if "down_blocks" in key_:
- input_dict[key_.replace('down_blocks', 'input_blocks')] = value_
- elif "up_blocks" in key_:
- output_dict[key_.replace('up_blocks', 'output_blocks')] = value_
- elif "mid_block" in key_:
- mid_dict[key_.replace('mid_block', 'middle_block')] = value_
- else:
- other_dict[key_] = value_
-
- input_dict = self._input_blocks_mapping(input_dict)
- output_dict = self._output_blocks_mapping(output_dict)
- mid_dict = self._mid_blocks_mapping(mid_dict)
- other_dict = self._other_blocks_mapping(other_dict)
- # key_list = state_dict.keys()
- # key_str = " ".join(key_list)
-
- # for key_, val_ in state_dict.items():
- # key_ = key_.replace("down_blocks", "input_blocks")\
- # .replace("up_blocks", 'output_blocks')
- # res_dict[key_] = val_
- res_dict.update(input_dict)
- res_dict.update(output_dict)
- res_dict.update(mid_dict)
- res_dict.update(other_dict)
-
- return res_dict
-
- def _load_pretrained_model(self, state_dict, ignore_mismatched_sizes=False):
- state_dict = self._state_key_mapping(state_dict)
- model_state_dict = self.state_dict()
- loaded_keys = [k for k in state_dict.keys()]
- expected_keys = list(model_state_dict.keys())
- original_loaded_keys = loaded_keys
- missing_keys = list(set(expected_keys) - set(loaded_keys))
- unexpected_keys = list(set(loaded_keys) - set(expected_keys))
-
- def _find_mismatched_keys(
- state_dict,
- model_state_dict,
- loaded_keys,
- ignore_mismatched_sizes,
- ):
- mismatched_keys = []
- if ignore_mismatched_sizes:
- for checkpoint_key in loaded_keys:
- model_key = checkpoint_key
-
- if (
- model_key in model_state_dict
- and state_dict[checkpoint_key].shape != model_state_dict[model_key].shape
- ):
- mismatched_keys.append(
- (checkpoint_key, state_dict[checkpoint_key].shape, model_state_dict[model_key].shape)
- )
- del state_dict[checkpoint_key]
- return mismatched_keys
- if state_dict is not None:
- # Whole checkpoint
- mismatched_keys = _find_mismatched_keys(
- state_dict,
- model_state_dict,
- original_loaded_keys,
- ignore_mismatched_sizes,
- )
- error_msgs = self._load_state_dict_into_model(state_dict)
- return missing_keys, unexpected_keys, mismatched_keys, error_msgs
-
- def _load_state_dict_into_model(self, state_dict):
- # Convert old format to new format if needed from a PyTorch state_dict
- # copy state_dict so _load_from_state_dict can modify it
- state_dict = state_dict.copy()
- error_msgs = []
-
- # PyTorch's `_load_from_state_dict` does not copy parameters in a module's descendants
- # so we need to apply the function recursively.
- def load(module: torch.nn.Module, prefix=""):
- args = (state_dict, prefix, {}, True, [], [], error_msgs)
- module._load_from_state_dict(*args)
-
- for name, child in module._modules.items():
- if child is not None:
- load(child, prefix + name + ".")
-
- load(self)
-
- return error_msgs
-
- def convert_to_fp16(self):
- """
- Convert the torso of the model to float16.
- """
- self.input_blocks.apply(convert_module_to_f16)
- self.middle_block.apply(convert_module_to_f16)
- self.output_blocks.apply(convert_module_to_f16)
-
- def convert_to_fp32(self):
- """
- Convert the torso of the model to float32.
- """
- self.input_blocks.apply(convert_module_to_f32)
- self.middle_block.apply(convert_module_to_f32)
- self.output_blocks.apply(convert_module_to_f32)
-
- def forward(self, x, timesteps=None, context=None, y=None,**kwargs):
- """
- Apply the model to an input batch.
- :param x: an [N x C x ...] Tensor of inputs.
- :param timesteps: a 1-D batch of timesteps.
- :param context: conditioning plugged in via crossattn
- :param y: an [N] Tensor of labels, if class-conditional.
- :return: an [N x C x ...] Tensor of outputs.
- """
- assert (y is not None) == (
- self.num_classes is not None
- ), "must specify y if and only if the model is class-conditional"
- hs = []
- t_emb = timestep_embedding(timesteps, self.model_channels, repeat_only=False)
- emb = self.time_embed(t_emb)
-
- if self.num_classes is not None:
- assert y.shape == (x.shape[0],)
- emb = emb + self.label_emb(y)
-
- h = x.type(self.dtype)
- for module in self.input_blocks:
- h = module(h, emb, context)
- hs.append(h)
- h = self.middle_block(h, emb, context)
- for module in self.output_blocks:
- h = th.cat([h, hs.pop()], dim=1)
- h = module(h, emb, context)
- h = h.type(self.dtype)
- if self.predict_codebook_ids:
- return self.id_predictor(h)
- else:
- return self.out(h)
-
-
-class EncoderUNetModel(nn.Module):
- """
- The half UNet model with attention and timestep embedding.
- For usage, see UNet.
- """
-
- def __init__(
- self,
- image_size,
- in_channels,
- model_channels,
- out_channels,
- num_res_blocks,
- attention_resolutions,
- dropout=0,
- channel_mult=(1, 2, 4, 8),
- conv_resample=True,
- dims=2,
- use_checkpoint=False,
- use_fp16=False,
- num_heads=1,
- num_head_channels=-1,
- num_heads_upsample=-1,
- use_scale_shift_norm=False,
- resblock_updown=False,
- use_new_attention_order=False,
- pool="adaptive",
- *args,
- **kwargs
- ):
- super().__init__()
-
- if num_heads_upsample == -1:
- num_heads_upsample = num_heads
-
- self.in_channels = in_channels
- self.model_channels = model_channels
- self.out_channels = out_channels
- self.num_res_blocks = num_res_blocks
- self.attention_resolutions = attention_resolutions
- self.dropout = dropout
- self.channel_mult = channel_mult
- self.conv_resample = conv_resample
- self.use_checkpoint = use_checkpoint
- self.dtype = th.float16 if use_fp16 else th.float32
- self.num_heads = num_heads
- self.num_head_channels = num_head_channels
- self.num_heads_upsample = num_heads_upsample
-
- time_embed_dim = model_channels * 4
- self.time_embed = nn.Sequential(
- linear(model_channels, time_embed_dim),
- nn.SiLU(),
- linear(time_embed_dim, time_embed_dim),
- )
-
- self.input_blocks = nn.ModuleList(
- [
- TimestepEmbedSequential(
- conv_nd(dims, in_channels, model_channels, 3, padding=1)
- )
- ]
- )
- self._feature_size = model_channels
- input_block_chans = [model_channels]
- ch = model_channels
- ds = 1
- for level, mult in enumerate(channel_mult):
- for _ in range(num_res_blocks):
- layers = [
- ResBlock(
- ch,
- time_embed_dim,
- dropout,
- out_channels=mult * model_channels,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- )
- ]
- ch = mult * model_channels
- if ds in attention_resolutions:
- layers.append(
- AttentionBlock(
- ch,
- use_checkpoint=use_checkpoint,
- num_heads=num_heads,
- num_head_channels=num_head_channels,
- use_new_attention_order=use_new_attention_order,
- )
- )
- self.input_blocks.append(TimestepEmbedSequential(*layers))
- self._feature_size += ch
- input_block_chans.append(ch)
- if level != len(channel_mult) - 1:
- out_ch = ch
- self.input_blocks.append(
- TimestepEmbedSequential(
- ResBlock(
- ch,
- time_embed_dim,
- dropout,
- out_channels=out_ch,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- down=True,
- )
- if resblock_updown
- else Downsample(
- ch, conv_resample, dims=dims, out_channels=out_ch
- )
- )
- )
- ch = out_ch
- input_block_chans.append(ch)
- ds *= 2
- self._feature_size += ch
-
- self.middle_block = TimestepEmbedSequential(
- ResBlock(
- ch,
- time_embed_dim,
- dropout,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- ),
- AttentionBlock(
- ch,
- use_checkpoint=use_checkpoint,
- num_heads=num_heads,
- num_head_channels=num_head_channels,
- use_new_attention_order=use_new_attention_order,
- ),
- ResBlock(
- ch,
- time_embed_dim,
- dropout,
- dims=dims,
- use_checkpoint=use_checkpoint,
- use_scale_shift_norm=use_scale_shift_norm,
- ),
- )
- self._feature_size += ch
- self.pool = pool
- if pool == "adaptive":
- self.out = nn.Sequential(
- normalization(ch),
- nn.SiLU(),
- nn.AdaptiveAvgPool2d((1, 1)),
- zero_module(conv_nd(dims, ch, out_channels, 1)),
- nn.Flatten(),
- )
- elif pool == "attention":
- assert num_head_channels != -1
- self.out = nn.Sequential(
- normalization(ch),
- nn.SiLU(),
- AttentionPool2d(
- (image_size // ds), ch, num_head_channels, out_channels
- ),
- )
- elif pool == "spatial":
- self.out = nn.Sequential(
- nn.Linear(self._feature_size, 2048),
- nn.ReLU(),
- nn.Linear(2048, self.out_channels),
- )
- elif pool == "spatial_v2":
- self.out = nn.Sequential(
- nn.Linear(self._feature_size, 2048),
- normalization(2048),
- nn.SiLU(),
- nn.Linear(2048, self.out_channels),
- )
- else:
- raise NotImplementedError(f"Unexpected {pool} pooling")
-
- def convert_to_fp16(self):
- """
- Convert the torso of the model to float16.
- """
- self.input_blocks.apply(convert_module_to_f16)
- self.middle_block.apply(convert_module_to_f16)
-
- def convert_to_fp32(self):
- """
- Convert the torso of the model to float32.
- """
- self.input_blocks.apply(convert_module_to_f32)
- self.middle_block.apply(convert_module_to_f32)
-
- def forward(self, x, timesteps):
- """
- Apply the model to an input batch.
- :param x: an [N x C x ...] Tensor of inputs.
- :param timesteps: a 1-D batch of timesteps.
- :return: an [N x K] Tensor of outputs.
- """
- emb = self.time_embed(timestep_embedding(timesteps, self.model_channels))
-
- results = []
- h = x.type(self.dtype)
- for module in self.input_blocks:
- h = module(h, emb)
- if self.pool.startswith("spatial"):
- results.append(h.type(x.dtype).mean(dim=(2, 3)))
- h = self.middle_block(h, emb)
- if self.pool.startswith("spatial"):
- results.append(h.type(x.dtype).mean(dim=(2, 3)))
- h = th.cat(results, axis=-1)
- return self.out(h)
- else:
- h = h.type(self.dtype)
- return self.out(h)
-
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/util.py b/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/util.py
deleted file mode 100644
index a7db9369c..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/diffusionmodules/util.py
+++ /dev/null
@@ -1,276 +0,0 @@
-# adopted from
-# https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
-# and
-# https://github.com/lucidrains/denoising-diffusion-pytorch/blob/7706bdfc6f527f58d33f84b7b522e61e6e3164b3/denoising_diffusion_pytorch/denoising_diffusion_pytorch.py
-# and
-# https://github.com/openai/guided-diffusion/blob/0ba878e517b276c45d1195eb29f6f5f72659a05b/guided_diffusion/nn.py
-#
-# thanks!
-
-
-import os
-import math
-import torch
-import torch.nn as nn
-import numpy as np
-from einops import repeat
-
-from ldm.util import instantiate_from_config
-
-
-def make_beta_schedule(schedule, n_timestep, linear_start=1e-4, linear_end=2e-2, cosine_s=8e-3):
- if schedule == "linear":
- betas = (
- torch.linspace(linear_start ** 0.5, linear_end ** 0.5, n_timestep, dtype=torch.float64) ** 2
- )
-
- elif schedule == "cosine":
- timesteps = (
- torch.arange(n_timestep + 1, dtype=torch.float64) / n_timestep + cosine_s
- )
- alphas = timesteps / (1 + cosine_s) * np.pi / 2
- alphas = torch.cos(alphas).pow(2)
- alphas = alphas / alphas[0]
- betas = 1 - alphas[1:] / alphas[:-1]
- betas = np.clip(betas, a_min=0, a_max=0.999)
-
- elif schedule == "sqrt_linear":
- betas = torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64)
- elif schedule == "sqrt":
- betas = torch.linspace(linear_start, linear_end, n_timestep, dtype=torch.float64) ** 0.5
- else:
- raise ValueError(f"schedule '{schedule}' unknown.")
- return betas.numpy()
-
-
-def make_ddim_timesteps(ddim_discr_method, num_ddim_timesteps, num_ddpm_timesteps, verbose=True):
- if ddim_discr_method == 'uniform':
- c = num_ddpm_timesteps // num_ddim_timesteps
- ddim_timesteps = np.asarray(list(range(0, num_ddpm_timesteps, c)))
- elif ddim_discr_method == 'quad':
- ddim_timesteps = ((np.linspace(0, np.sqrt(num_ddpm_timesteps * .8), num_ddim_timesteps)) ** 2).astype(int)
- else:
- raise NotImplementedError(f'There is no ddim discretization method called "{ddim_discr_method}"')
-
- # assert ddim_timesteps.shape[0] == num_ddim_timesteps
- # add one to get the final alpha values right (the ones from first scale to data during sampling)
- steps_out = ddim_timesteps + 1
- if verbose:
- print(f'Selected timesteps for ddim sampler: {steps_out}')
- return steps_out
-
-
-def make_ddim_sampling_parameters(alphacums, ddim_timesteps, eta, verbose=True):
- # select alphas for computing the variance schedule
- alphas = alphacums[ddim_timesteps]
- alphas_prev = np.asarray([alphacums[0]] + alphacums[ddim_timesteps[:-1]].tolist())
-
- # according the the formula provided in https://arxiv.org/abs/2010.02502
- sigmas = eta * np.sqrt((1 - alphas_prev) / (1 - alphas) * (1 - alphas / alphas_prev))
- if verbose:
- print(f'Selected alphas for ddim sampler: a_t: {alphas}; a_(t-1): {alphas_prev}')
- print(f'For the chosen value of eta, which is {eta}, '
- f'this results in the following sigma_t schedule for ddim sampler {sigmas}')
- return sigmas, alphas, alphas_prev
-
-
-def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
- """
- Create a beta schedule that discretizes the given alpha_t_bar function,
- which defines the cumulative product of (1-beta) over time from t = [0,1].
- :param num_diffusion_timesteps: the number of betas to produce.
- :param alpha_bar: a lambda that takes an argument t from 0 to 1 and
- produces the cumulative product of (1-beta) up to that
- part of the diffusion process.
- :param max_beta: the maximum beta to use; use values lower than 1 to
- prevent singularities.
- """
- betas = []
- for i in range(num_diffusion_timesteps):
- t1 = i / num_diffusion_timesteps
- t2 = (i + 1) / num_diffusion_timesteps
- betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
- return np.array(betas)
-
-
-def extract_into_tensor(a, t, x_shape):
- b, *_ = t.shape
- out = a.gather(-1, t)
- return out.reshape(b, *((1,) * (len(x_shape) - 1)))
-
-
-def checkpoint(func, inputs, params, flag):
- """
- Evaluate a function without caching intermediate activations, allowing for
- reduced memory at the expense of extra compute in the backward pass.
- :param func: the function to evaluate.
- :param inputs: the argument sequence to pass to `func`.
- :param params: a sequence of parameters `func` depends on but does not
- explicitly take as arguments.
- :param flag: if False, disable gradient checkpointing.
- """
- if flag:
- args = tuple(inputs) + tuple(params)
- return CheckpointFunction.apply(func, len(inputs), *args)
- else:
- return func(*inputs)
-
-
-class CheckpointFunction(torch.autograd.Function):
- @staticmethod
- def forward(ctx, run_function, length, *args):
- ctx.run_function = run_function
- ctx.input_tensors = list(args[:length])
- ctx.input_params = list(args[length:])
-
- with torch.no_grad():
- output_tensors = ctx.run_function(*ctx.input_tensors)
- return output_tensors
-
- @staticmethod
- def backward(ctx, *output_grads):
- ctx.input_tensors = [x.detach().requires_grad_(True) for x in ctx.input_tensors]
- with torch.enable_grad():
- # Fixes a bug where the first op in run_function modifies the
- # Tensor storage in place, which is not allowed for detach()'d
- # Tensors.
- shallow_copies = [x.view_as(x) for x in ctx.input_tensors]
- output_tensors = ctx.run_function(*shallow_copies)
- input_grads = torch.autograd.grad(
- output_tensors,
- ctx.input_tensors + ctx.input_params,
- output_grads,
- allow_unused=True,
- )
- del ctx.input_tensors
- del ctx.input_params
- del output_tensors
- return (None, None) + input_grads
-
-
-def timestep_embedding(timesteps, dim, max_period=10000, repeat_only=False, use_fp16=True):
- """
- Create sinusoidal timestep embeddings.
- :param timesteps: a 1-D Tensor of N indices, one per batch element.
- These may be fractional.
- :param dim: the dimension of the output.
- :param max_period: controls the minimum frequency of the embeddings.
- :return: an [N x dim] Tensor of positional embeddings.
- """
- if not repeat_only:
- half = dim // 2
- freqs = torch.exp(
- -math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
- ).to(device=timesteps.device)
- args = timesteps[:, None].float() * freqs[None]
- embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
- if dim % 2:
- embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
- else:
- embedding = repeat(timesteps, 'b -> b d', d=dim)
- if use_fp16:
- return embedding.half()
- else:
- return embedding
-
-
-def zero_module(module):
- """
- Zero out the parameters of a module and return it.
- """
- for p in module.parameters():
- p.detach().zero_()
- return module
-
-
-def scale_module(module, scale):
- """
- Scale the parameters of a module and return it.
- """
- for p in module.parameters():
- p.detach().mul_(scale)
- return module
-
-
-def mean_flat(tensor):
- """
- Take the mean over all non-batch dimensions.
- """
- return tensor.mean(dim=list(range(1, len(tensor.shape))))
-
-
-def normalization(channels, precision=16):
- """
- Make a standard normalization layer.
- :param channels: number of input channels.
- :return: an nn.Module for normalization.
- """
- if precision == 16:
- return GroupNorm16(16, channels)
- else:
- return GroupNorm32(32, channels)
-
-
-# PyTorch 1.7 has SiLU, but we support PyTorch 1.5.
-class SiLU(nn.Module):
- def forward(self, x):
- return x * torch.sigmoid(x)
-
-class GroupNorm16(nn.GroupNorm):
- def forward(self, x):
- return super().forward(x.half()).type(x.dtype)
-
-class GroupNorm32(nn.GroupNorm):
- def forward(self, x):
- return super().forward(x.float()).type(x.dtype)
-
-def conv_nd(dims, *args, **kwargs):
- """
- Create a 1D, 2D, or 3D convolution module.
- """
- if dims == 1:
- return nn.Conv1d(*args, **kwargs)
- elif dims == 2:
- return nn.Conv2d(*args, **kwargs)
- elif dims == 3:
- return nn.Conv3d(*args, **kwargs)
- raise ValueError(f"unsupported dimensions: {dims}")
-
-
-def linear(*args, **kwargs):
- """
- Create a linear module.
- """
- return nn.Linear(*args, **kwargs)
-
-
-def avg_pool_nd(dims, *args, **kwargs):
- """
- Create a 1D, 2D, or 3D average pooling module.
- """
- if dims == 1:
- return nn.AvgPool1d(*args, **kwargs)
- elif dims == 2:
- return nn.AvgPool2d(*args, **kwargs)
- elif dims == 3:
- return nn.AvgPool3d(*args, **kwargs)
- raise ValueError(f"unsupported dimensions: {dims}")
-
-
-class HybridConditioner(nn.Module):
-
- def __init__(self, c_concat_config, c_crossattn_config):
- super().__init__()
- self.concat_conditioner = instantiate_from_config(c_concat_config)
- self.crossattn_conditioner = instantiate_from_config(c_crossattn_config)
-
- def forward(self, c_concat, c_crossattn):
- c_concat = self.concat_conditioner(c_concat)
- c_crossattn = self.crossattn_conditioner(c_crossattn)
- return {'c_concat': [c_concat], 'c_crossattn': [c_crossattn]}
-
-
-def noise_like(shape, device, repeat=False):
- repeat_noise = lambda: torch.randn((1, *shape[1:]), device=device).repeat(shape[0], *((1,) * (len(shape) - 1)))
- noise = lambda: torch.randn(shape, device=device)
- return repeat_noise() if repeat else noise()
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/distributions/__init__.py b/examples/tutorial/stable_diffusion/ldm/modules/distributions/__init__.py
deleted file mode 100644
index e69de29bb..000000000
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/distributions/distributions.py b/examples/tutorial/stable_diffusion/ldm/modules/distributions/distributions.py
deleted file mode 100644
index f2b8ef901..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/distributions/distributions.py
+++ /dev/null
@@ -1,92 +0,0 @@
-import torch
-import numpy as np
-
-
-class AbstractDistribution:
- def sample(self):
- raise NotImplementedError()
-
- def mode(self):
- raise NotImplementedError()
-
-
-class DiracDistribution(AbstractDistribution):
- def __init__(self, value):
- self.value = value
-
- def sample(self):
- return self.value
-
- def mode(self):
- return self.value
-
-
-class DiagonalGaussianDistribution(object):
- def __init__(self, parameters, deterministic=False):
- self.parameters = parameters
- self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
- self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
- self.deterministic = deterministic
- self.std = torch.exp(0.5 * self.logvar)
- self.var = torch.exp(self.logvar)
- if self.deterministic:
- self.var = self.std = torch.zeros_like(self.mean).to(device=self.parameters.device)
-
- def sample(self):
- x = self.mean + self.std * torch.randn(self.mean.shape).to(device=self.parameters.device)
- return x
-
- def kl(self, other=None):
- if self.deterministic:
- return torch.Tensor([0.])
- else:
- if other is None:
- return 0.5 * torch.sum(torch.pow(self.mean, 2)
- + self.var - 1.0 - self.logvar,
- dim=[1, 2, 3])
- else:
- return 0.5 * torch.sum(
- torch.pow(self.mean - other.mean, 2) / other.var
- + self.var / other.var - 1.0 - self.logvar + other.logvar,
- dim=[1, 2, 3])
-
- def nll(self, sample, dims=[1,2,3]):
- if self.deterministic:
- return torch.Tensor([0.])
- logtwopi = np.log(2.0 * np.pi)
- return 0.5 * torch.sum(
- logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var,
- dim=dims)
-
- def mode(self):
- return self.mean
-
-
-def normal_kl(mean1, logvar1, mean2, logvar2):
- """
- source: https://github.com/openai/guided-diffusion/blob/27c20a8fab9cb472df5d6bdd6c8d11c8f430b924/guided_diffusion/losses.py#L12
- Compute the KL divergence between two gaussians.
- Shapes are automatically broadcasted, so batches can be compared to
- scalars, among other use cases.
- """
- tensor = None
- for obj in (mean1, logvar1, mean2, logvar2):
- if isinstance(obj, torch.Tensor):
- tensor = obj
- break
- assert tensor is not None, "at least one argument must be a Tensor"
-
- # Force variances to be Tensors. Broadcasting helps convert scalars to
- # Tensors, but it does not work for torch.exp().
- logvar1, logvar2 = [
- x if isinstance(x, torch.Tensor) else torch.tensor(x).to(tensor)
- for x in (logvar1, logvar2)
- ]
-
- return 0.5 * (
- -1.0
- + logvar2
- - logvar1
- + torch.exp(logvar1 - logvar2)
- + ((mean1 - mean2) ** 2) * torch.exp(-logvar2)
- )
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/ema.py b/examples/tutorial/stable_diffusion/ldm/modules/ema.py
deleted file mode 100644
index c8c75af43..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/ema.py
+++ /dev/null
@@ -1,76 +0,0 @@
-import torch
-from torch import nn
-
-
-class LitEma(nn.Module):
- def __init__(self, model, decay=0.9999, use_num_upates=True):
- super().__init__()
- if decay < 0.0 or decay > 1.0:
- raise ValueError('Decay must be between 0 and 1')
-
- self.m_name2s_name = {}
- self.register_buffer('decay', torch.tensor(decay, dtype=torch.float32))
- self.register_buffer('num_updates', torch.tensor(0,dtype=torch.int) if use_num_upates
- else torch.tensor(-1,dtype=torch.int))
-
- for name, p in model.named_parameters():
- if p.requires_grad:
- #remove as '.'-character is not allowed in buffers
- s_name = name.replace('.','')
- self.m_name2s_name.update({name:s_name})
- self.register_buffer(s_name,p.clone().detach().data)
-
- self.collected_params = []
-
- def forward(self,model):
- decay = self.decay
-
- if self.num_updates >= 0:
- self.num_updates += 1
- decay = min(self.decay,(1 + self.num_updates) / (10 + self.num_updates))
-
- one_minus_decay = 1.0 - decay
-
- with torch.no_grad():
- m_param = dict(model.named_parameters())
- shadow_params = dict(self.named_buffers())
-
- for key in m_param:
- if m_param[key].requires_grad:
- sname = self.m_name2s_name[key]
- shadow_params[sname] = shadow_params[sname].type_as(m_param[key])
- shadow_params[sname].sub_(one_minus_decay * (shadow_params[sname] - m_param[key]))
- else:
- assert not key in self.m_name2s_name
-
- def copy_to(self, model):
- m_param = dict(model.named_parameters())
- shadow_params = dict(self.named_buffers())
- for key in m_param:
- if m_param[key].requires_grad:
- m_param[key].data.copy_(shadow_params[self.m_name2s_name[key]].data)
- else:
- assert not key in self.m_name2s_name
-
- def store(self, parameters):
- """
- Save the current parameters for restoring later.
- Args:
- parameters: Iterable of `torch.nn.Parameter`; the parameters to be
- temporarily stored.
- """
- self.collected_params = [param.clone() for param in parameters]
-
- def restore(self, parameters):
- """
- Restore the parameters stored with the `store` method.
- Useful to validate the model with EMA parameters without affecting the
- original optimization process. Store the parameters before the
- `copy_to` method. After validation (or model saving), use this to
- restore the former parameters.
- Args:
- parameters: Iterable of `torch.nn.Parameter`; the parameters to be
- updated with the stored parameters.
- """
- for c_param, param in zip(self.collected_params, parameters):
- param.data.copy_(c_param.data)
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/encoders/__init__.py b/examples/tutorial/stable_diffusion/ldm/modules/encoders/__init__.py
deleted file mode 100644
index e69de29bb..000000000
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/encoders/modules.py b/examples/tutorial/stable_diffusion/ldm/modules/encoders/modules.py
deleted file mode 100644
index 8cfc01e5d..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/encoders/modules.py
+++ /dev/null
@@ -1,264 +0,0 @@
-import types
-
-import torch
-import torch.nn as nn
-from functools import partial
-import clip
-from einops import rearrange, repeat
-from transformers import CLIPTokenizer, CLIPTextModel, CLIPTextConfig
-import kornia
-from transformers.models.clip.modeling_clip import CLIPTextTransformer
-
-from ldm.modules.x_transformer import Encoder, TransformerWrapper # TODO: can we directly rely on lucidrains code and simply add this as a reuirement? --> test
-
-
-class AbstractEncoder(nn.Module):
- def __init__(self):
- super().__init__()
-
- def encode(self, *args, **kwargs):
- raise NotImplementedError
-
-
-
-class ClassEmbedder(nn.Module):
- def __init__(self, embed_dim, n_classes=1000, key='class'):
- super().__init__()
- self.key = key
- self.embedding = nn.Embedding(n_classes, embed_dim)
-
- def forward(self, batch, key=None):
- if key is None:
- key = self.key
- # this is for use in crossattn
- c = batch[key][:, None]
- c = self.embedding(c)
- return c
-
-
-class TransformerEmbedder(AbstractEncoder):
- """Some transformer encoder layers"""
- def __init__(self, n_embed, n_layer, vocab_size, max_seq_len=77, device="cuda"):
- super().__init__()
- self.device = device
- self.transformer = TransformerWrapper(num_tokens=vocab_size, max_seq_len=max_seq_len,
- attn_layers=Encoder(dim=n_embed, depth=n_layer))
-
- def forward(self, tokens):
- tokens = tokens.to(self.device) # meh
- z = self.transformer(tokens, return_embeddings=True)
- return z
-
- def encode(self, x):
- return self(x)
-
-
-class BERTTokenizer(AbstractEncoder):
- """ Uses a pretrained BERT tokenizer by huggingface. Vocab size: 30522 (?)"""
- def __init__(self, device="cuda", vq_interface=True, max_length=77):
- super().__init__()
- from transformers import BertTokenizerFast # TODO: add to reuquirements
- self.tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
- self.device = device
- self.vq_interface = vq_interface
- self.max_length = max_length
-
- def forward(self, text):
- batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
- return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
- tokens = batch_encoding["input_ids"].to(self.device)
- return tokens
-
- @torch.no_grad()
- def encode(self, text):
- tokens = self(text)
- if not self.vq_interface:
- return tokens
- return None, None, [None, None, tokens]
-
- def decode(self, text):
- return text
-
-
-class BERTEmbedder(AbstractEncoder):
- """Uses the BERT tokenizr model and add some transformer encoder layers"""
- def __init__(self, n_embed, n_layer, vocab_size=30522, max_seq_len=77,
- device="cuda",use_tokenizer=True, embedding_dropout=0.0):
- super().__init__()
- self.use_tknz_fn = use_tokenizer
- if self.use_tknz_fn:
- self.tknz_fn = BERTTokenizer(vq_interface=False, max_length=max_seq_len)
- self.device = device
- self.transformer = TransformerWrapper(num_tokens=vocab_size, max_seq_len=max_seq_len,
- attn_layers=Encoder(dim=n_embed, depth=n_layer),
- emb_dropout=embedding_dropout)
-
- def forward(self, text):
- if self.use_tknz_fn:
- tokens = self.tknz_fn(text)#.to(self.device)
- else:
- tokens = text
- z = self.transformer(tokens, return_embeddings=True)
- return z
-
- def encode(self, text):
- # output of length 77
- return self(text)
-
-
-class SpatialRescaler(nn.Module):
- def __init__(self,
- n_stages=1,
- method='bilinear',
- multiplier=0.5,
- in_channels=3,
- out_channels=None,
- bias=False):
- super().__init__()
- self.n_stages = n_stages
- assert self.n_stages >= 0
- assert method in ['nearest','linear','bilinear','trilinear','bicubic','area']
- self.multiplier = multiplier
- self.interpolator = partial(torch.nn.functional.interpolate, mode=method)
- self.remap_output = out_channels is not None
- if self.remap_output:
- print(f'Spatial Rescaler mapping from {in_channels} to {out_channels} channels after resizing.')
- self.channel_mapper = nn.Conv2d(in_channels,out_channels,1,bias=bias)
-
- def forward(self,x):
- for stage in range(self.n_stages):
- x = self.interpolator(x, scale_factor=self.multiplier)
-
-
- if self.remap_output:
- x = self.channel_mapper(x)
- return x
-
- def encode(self, x):
- return self(x)
-
-
-class CLIPTextModelZero(CLIPTextModel):
- config_class = CLIPTextConfig
-
- def __init__(self, config: CLIPTextConfig):
- super().__init__(config)
- self.text_model = CLIPTextTransformerZero(config)
-
-class CLIPTextTransformerZero(CLIPTextTransformer):
- def _build_causal_attention_mask(self, bsz, seq_len):
- # lazily create causal attention mask, with full attention between the vision tokens
- # pytorch uses additive attention mask; fill with -inf
- mask = torch.empty(bsz, seq_len, seq_len)
- mask.fill_(float("-inf"))
- mask.triu_(1) # zero out the lower diagonal
- mask = mask.unsqueeze(1) # expand mask
- return mask.half()
-
-class FrozenCLIPEmbedder(AbstractEncoder):
- """Uses the CLIP transformer encoder for text (from Hugging Face)"""
- def __init__(self, version="openai/clip-vit-large-patch14", device="cuda", max_length=77, use_fp16=True):
- super().__init__()
- self.tokenizer = CLIPTokenizer.from_pretrained(version)
-
- if use_fp16:
- self.transformer = CLIPTextModelZero.from_pretrained(version)
- else:
- self.transformer = CLIPTextModel.from_pretrained(version)
-
- # print(self.transformer.modules())
- # print("check model dtyoe: {}, {}".format(self.tokenizer.dtype, self.transformer.dtype))
- self.device = device
- self.max_length = max_length
- self.freeze()
-
- def freeze(self):
- self.transformer = self.transformer.eval()
- for param in self.parameters():
- param.requires_grad = False
-
- def forward(self, text):
- batch_encoding = self.tokenizer(text, truncation=True, max_length=self.max_length, return_length=True,
- return_overflowing_tokens=False, padding="max_length", return_tensors="pt")
- # tokens = batch_encoding["input_ids"].to(self.device)
- tokens = batch_encoding["input_ids"].to(self.device)
- # print("token type: {}".format(tokens.dtype))
- outputs = self.transformer(input_ids=tokens)
-
- z = outputs.last_hidden_state
- return z
-
- def encode(self, text):
- return self(text)
-
-
-class FrozenCLIPTextEmbedder(nn.Module):
- """
- Uses the CLIP transformer encoder for text.
- """
- def __init__(self, version='ViT-L/14', device="cuda", max_length=77, n_repeat=1, normalize=True):
- super().__init__()
- self.model, _ = clip.load(version, jit=False, device="cpu")
- self.device = device
- self.max_length = max_length
- self.n_repeat = n_repeat
- self.normalize = normalize
-
- def freeze(self):
- self.model = self.model.eval()
- for param in self.parameters():
- param.requires_grad = False
-
- def forward(self, text):
- tokens = clip.tokenize(text).to(self.device)
- z = self.model.encode_text(tokens)
- if self.normalize:
- z = z / torch.linalg.norm(z, dim=1, keepdim=True)
- return z
-
- def encode(self, text):
- z = self(text)
- if z.ndim==2:
- z = z[:, None, :]
- z = repeat(z, 'b 1 d -> b k d', k=self.n_repeat)
- return z
-
-
-class FrozenClipImageEmbedder(nn.Module):
- """
- Uses the CLIP image encoder.
- """
- def __init__(
- self,
- model,
- jit=False,
- device='cuda' if torch.cuda.is_available() else 'cpu',
- antialias=False,
- ):
- super().__init__()
- self.model, _ = clip.load(name=model, device=device, jit=jit)
-
- self.antialias = antialias
-
- self.register_buffer('mean', torch.Tensor([0.48145466, 0.4578275, 0.40821073]), persistent=False)
- self.register_buffer('std', torch.Tensor([0.26862954, 0.26130258, 0.27577711]), persistent=False)
-
- def preprocess(self, x):
- # normalize to [0,1]
- x = kornia.geometry.resize(x, (224, 224),
- interpolation='bicubic',align_corners=True,
- antialias=self.antialias)
- x = (x + 1.) / 2.
- # renormalize according to clip
- x = kornia.enhance.normalize(x, self.mean, self.std)
- return x
-
- def forward(self, x):
- # x is assumed to be in range [-1,1]
- return self.model.encode_image(self.preprocess(x))
-
-
-if __name__ == "__main__":
- from ldm.util import count_params
- model = FrozenCLIPEmbedder()
- count_params(model, verbose=True)
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/flash_attention.py b/examples/tutorial/stable_diffusion/ldm/modules/flash_attention.py
deleted file mode 100644
index 2a7a73879..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/flash_attention.py
+++ /dev/null
@@ -1,50 +0,0 @@
-"""
-Fused Attention
-===============
-This is a Triton implementation of the Flash Attention algorithm
-(see: Dao et al., https://arxiv.org/pdf/2205.14135v2.pdf; Rabe and Staats https://arxiv.org/pdf/2112.05682v2.pdf; Triton https://github.com/openai/triton)
-"""
-
-import torch
-try:
- from flash_attn.flash_attn_interface import flash_attn_unpadded_qkvpacked_func, flash_attn_unpadded_kvpacked_func
-except ImportError:
- raise ImportError('please install flash_attn from https://github.com/HazyResearch/flash-attention')
-
-
-
-def flash_attention_qkv(qkv, sm_scale, batch_size, seq_len):
- """
- Arguments:
- qkv: (batch*seq, 3, nheads, headdim)
- batch_size: int.
- seq_len: int.
- sm_scale: float. The scaling of QK^T before applying softmax.
- Return:
- out: (total, nheads, headdim).
- """
- max_s = seq_len
- cu_seqlens = torch.arange(0, (batch_size + 1) * seq_len, step=seq_len, dtype=torch.int32,
- device=qkv.device)
- out = flash_attn_unpadded_qkvpacked_func(
- qkv, cu_seqlens, max_s, 0.0,
- softmax_scale=sm_scale, causal=False
- )
- return out
-
-
-def flash_attention_q_kv(q, kv, sm_scale, batch_size, q_seqlen, kv_seqlen):
- """
- Arguments:
- q: (batch*seq, nheads, headdim)
- kv: (batch*seq, 2, nheads, headdim)
- batch_size: int.
- seq_len: int.
- sm_scale: float. The scaling of QK^T before applying softmax.
- Return:
- out: (total, nheads, headdim).
- """
- cu_seqlens_q = torch.arange(0, (batch_size + 1) * q_seqlen, step=q_seqlen, dtype=torch.int32, device=q.device)
- cu_seqlens_k = torch.arange(0, (batch_size + 1) * kv_seqlen, step=kv_seqlen, dtype=torch.int32, device=kv.device)
- out = flash_attn_unpadded_kvpacked_func(q, kv, cu_seqlens_q, cu_seqlens_k, q_seqlen, kv_seqlen, 0.0, sm_scale)
- return out
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/__init__.py b/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/__init__.py
deleted file mode 100644
index 7836cada8..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/__init__.py
+++ /dev/null
@@ -1,2 +0,0 @@
-from ldm.modules.image_degradation.bsrgan import degradation_bsrgan_variant as degradation_fn_bsr
-from ldm.modules.image_degradation.bsrgan_light import degradation_bsrgan_variant as degradation_fn_bsr_light
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/bsrgan.py b/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/bsrgan.py
deleted file mode 100644
index 32ef56169..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/bsrgan.py
+++ /dev/null
@@ -1,730 +0,0 @@
-# -*- coding: utf-8 -*-
-"""
-# --------------------------------------------
-# Super-Resolution
-# --------------------------------------------
-#
-# Kai Zhang (cskaizhang@gmail.com)
-# https://github.com/cszn
-# From 2019/03--2021/08
-# --------------------------------------------
-"""
-
-import numpy as np
-import cv2
-import torch
-
-from functools import partial
-import random
-from scipy import ndimage
-import scipy
-import scipy.stats as ss
-from scipy.interpolate import interp2d
-from scipy.linalg import orth
-import albumentations
-
-import ldm.modules.image_degradation.utils_image as util
-
-
-def modcrop_np(img, sf):
- '''
- Args:
- img: numpy image, WxH or WxHxC
- sf: scale factor
- Return:
- cropped image
- '''
- w, h = img.shape[:2]
- im = np.copy(img)
- return im[:w - w % sf, :h - h % sf, ...]
-
-
-"""
-# --------------------------------------------
-# anisotropic Gaussian kernels
-# --------------------------------------------
-"""
-
-
-def analytic_kernel(k):
- """Calculate the X4 kernel from the X2 kernel (for proof see appendix in paper)"""
- k_size = k.shape[0]
- # Calculate the big kernels size
- big_k = np.zeros((3 * k_size - 2, 3 * k_size - 2))
- # Loop over the small kernel to fill the big one
- for r in range(k_size):
- for c in range(k_size):
- big_k[2 * r:2 * r + k_size, 2 * c:2 * c + k_size] += k[r, c] * k
- # Crop the edges of the big kernel to ignore very small values and increase run time of SR
- crop = k_size // 2
- cropped_big_k = big_k[crop:-crop, crop:-crop]
- # Normalize to 1
- return cropped_big_k / cropped_big_k.sum()
-
-
-def anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6):
- """ generate an anisotropic Gaussian kernel
- Args:
- ksize : e.g., 15, kernel size
- theta : [0, pi], rotation angle range
- l1 : [0.1,50], scaling of eigenvalues
- l2 : [0.1,l1], scaling of eigenvalues
- If l1 = l2, will get an isotropic Gaussian kernel.
- Returns:
- k : kernel
- """
-
- v = np.dot(np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]]), np.array([1., 0.]))
- V = np.array([[v[0], v[1]], [v[1], -v[0]]])
- D = np.array([[l1, 0], [0, l2]])
- Sigma = np.dot(np.dot(V, D), np.linalg.inv(V))
- k = gm_blur_kernel(mean=[0, 0], cov=Sigma, size=ksize)
-
- return k
-
-
-def gm_blur_kernel(mean, cov, size=15):
- center = size / 2.0 + 0.5
- k = np.zeros([size, size])
- for y in range(size):
- for x in range(size):
- cy = y - center + 1
- cx = x - center + 1
- k[y, x] = ss.multivariate_normal.pdf([cx, cy], mean=mean, cov=cov)
-
- k = k / np.sum(k)
- return k
-
-
-def shift_pixel(x, sf, upper_left=True):
- """shift pixel for super-resolution with different scale factors
- Args:
- x: WxHxC or WxH
- sf: scale factor
- upper_left: shift direction
- """
- h, w = x.shape[:2]
- shift = (sf - 1) * 0.5
- xv, yv = np.arange(0, w, 1.0), np.arange(0, h, 1.0)
- if upper_left:
- x1 = xv + shift
- y1 = yv + shift
- else:
- x1 = xv - shift
- y1 = yv - shift
-
- x1 = np.clip(x1, 0, w - 1)
- y1 = np.clip(y1, 0, h - 1)
-
- if x.ndim == 2:
- x = interp2d(xv, yv, x)(x1, y1)
- if x.ndim == 3:
- for i in range(x.shape[-1]):
- x[:, :, i] = interp2d(xv, yv, x[:, :, i])(x1, y1)
-
- return x
-
-
-def blur(x, k):
- '''
- x: image, NxcxHxW
- k: kernel, Nx1xhxw
- '''
- n, c = x.shape[:2]
- p1, p2 = (k.shape[-2] - 1) // 2, (k.shape[-1] - 1) // 2
- x = torch.nn.functional.pad(x, pad=(p1, p2, p1, p2), mode='replicate')
- k = k.repeat(1, c, 1, 1)
- k = k.view(-1, 1, k.shape[2], k.shape[3])
- x = x.view(1, -1, x.shape[2], x.shape[3])
- x = torch.nn.functional.conv2d(x, k, bias=None, stride=1, padding=0, groups=n * c)
- x = x.view(n, c, x.shape[2], x.shape[3])
-
- return x
-
-
-def gen_kernel(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]), min_var=0.6, max_var=10., noise_level=0):
- """"
- # modified version of https://github.com/assafshocher/BlindSR_dataset_generator
- # Kai Zhang
- # min_var = 0.175 * sf # variance of the gaussian kernel will be sampled between min_var and max_var
- # max_var = 2.5 * sf
- """
- # Set random eigen-vals (lambdas) and angle (theta) for COV matrix
- lambda_1 = min_var + np.random.rand() * (max_var - min_var)
- lambda_2 = min_var + np.random.rand() * (max_var - min_var)
- theta = np.random.rand() * np.pi # random theta
- noise = -noise_level + np.random.rand(*k_size) * noise_level * 2
-
- # Set COV matrix using Lambdas and Theta
- LAMBDA = np.diag([lambda_1, lambda_2])
- Q = np.array([[np.cos(theta), -np.sin(theta)],
- [np.sin(theta), np.cos(theta)]])
- SIGMA = Q @ LAMBDA @ Q.T
- INV_SIGMA = np.linalg.inv(SIGMA)[None, None, :, :]
-
- # Set expectation position (shifting kernel for aligned image)
- MU = k_size // 2 - 0.5 * (scale_factor - 1) # - 0.5 * (scale_factor - k_size % 2)
- MU = MU[None, None, :, None]
-
- # Create meshgrid for Gaussian
- [X, Y] = np.meshgrid(range(k_size[0]), range(k_size[1]))
- Z = np.stack([X, Y], 2)[:, :, :, None]
-
- # Calcualte Gaussian for every pixel of the kernel
- ZZ = Z - MU
- ZZ_t = ZZ.transpose(0, 1, 3, 2)
- raw_kernel = np.exp(-0.5 * np.squeeze(ZZ_t @ INV_SIGMA @ ZZ)) * (1 + noise)
-
- # shift the kernel so it will be centered
- # raw_kernel_centered = kernel_shift(raw_kernel, scale_factor)
-
- # Normalize the kernel and return
- # kernel = raw_kernel_centered / np.sum(raw_kernel_centered)
- kernel = raw_kernel / np.sum(raw_kernel)
- return kernel
-
-
-def fspecial_gaussian(hsize, sigma):
- hsize = [hsize, hsize]
- siz = [(hsize[0] - 1.0) / 2.0, (hsize[1] - 1.0) / 2.0]
- std = sigma
- [x, y] = np.meshgrid(np.arange(-siz[1], siz[1] + 1), np.arange(-siz[0], siz[0] + 1))
- arg = -(x * x + y * y) / (2 * std * std)
- h = np.exp(arg)
- h[h < scipy.finfo(float).eps * h.max()] = 0
- sumh = h.sum()
- if sumh != 0:
- h = h / sumh
- return h
-
-
-def fspecial_laplacian(alpha):
- alpha = max([0, min([alpha, 1])])
- h1 = alpha / (alpha + 1)
- h2 = (1 - alpha) / (alpha + 1)
- h = [[h1, h2, h1], [h2, -4 / (alpha + 1), h2], [h1, h2, h1]]
- h = np.array(h)
- return h
-
-
-def fspecial(filter_type, *args, **kwargs):
- '''
- python code from:
- https://github.com/ronaldosena/imagens-medicas-2/blob/40171a6c259edec7827a6693a93955de2bd39e76/Aulas/aula_2_-_uniform_filter/matlab_fspecial.py
- '''
- if filter_type == 'gaussian':
- return fspecial_gaussian(*args, **kwargs)
- if filter_type == 'laplacian':
- return fspecial_laplacian(*args, **kwargs)
-
-
-"""
-# --------------------------------------------
-# degradation models
-# --------------------------------------------
-"""
-
-
-def bicubic_degradation(x, sf=3):
- '''
- Args:
- x: HxWxC image, [0, 1]
- sf: down-scale factor
- Return:
- bicubicly downsampled LR image
- '''
- x = util.imresize_np(x, scale=1 / sf)
- return x
-
-
-def srmd_degradation(x, k, sf=3):
- ''' blur + bicubic downsampling
- Args:
- x: HxWxC image, [0, 1]
- k: hxw, double
- sf: down-scale factor
- Return:
- downsampled LR image
- Reference:
- @inproceedings{zhang2018learning,
- title={Learning a single convolutional super-resolution network for multiple degradations},
- author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- pages={3262--3271},
- year={2018}
- }
- '''
- x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap') # 'nearest' | 'mirror'
- x = bicubic_degradation(x, sf=sf)
- return x
-
-
-def dpsr_degradation(x, k, sf=3):
- ''' bicubic downsampling + blur
- Args:
- x: HxWxC image, [0, 1]
- k: hxw, double
- sf: down-scale factor
- Return:
- downsampled LR image
- Reference:
- @inproceedings{zhang2019deep,
- title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
- author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- pages={1671--1681},
- year={2019}
- }
- '''
- x = bicubic_degradation(x, sf=sf)
- x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
- return x
-
-
-def classical_degradation(x, k, sf=3):
- ''' blur + downsampling
- Args:
- x: HxWxC image, [0, 1]/[0, 255]
- k: hxw, double
- sf: down-scale factor
- Return:
- downsampled LR image
- '''
- x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
- # x = filters.correlate(x, np.expand_dims(np.flip(k), axis=2))
- st = 0
- return x[st::sf, st::sf, ...]
-
-
-def add_sharpening(img, weight=0.5, radius=50, threshold=10):
- """USM sharpening. borrowed from real-ESRGAN
- Input image: I; Blurry image: B.
- 1. K = I + weight * (I - B)
- 2. Mask = 1 if abs(I - B) > threshold, else: 0
- 3. Blur mask:
- 4. Out = Mask * K + (1 - Mask) * I
- Args:
- img (Numpy array): Input image, HWC, BGR; float32, [0, 1].
- weight (float): Sharp weight. Default: 1.
- radius (float): Kernel size of Gaussian blur. Default: 50.
- threshold (int):
- """
- if radius % 2 == 0:
- radius += 1
- blur = cv2.GaussianBlur(img, (radius, radius), 0)
- residual = img - blur
- mask = np.abs(residual) * 255 > threshold
- mask = mask.astype('float32')
- soft_mask = cv2.GaussianBlur(mask, (radius, radius), 0)
-
- K = img + weight * residual
- K = np.clip(K, 0, 1)
- return soft_mask * K + (1 - soft_mask) * img
-
-
-def add_blur(img, sf=4):
- wd2 = 4.0 + sf
- wd = 2.0 + 0.2 * sf
- if random.random() < 0.5:
- l1 = wd2 * random.random()
- l2 = wd2 * random.random()
- k = anisotropic_Gaussian(ksize=2 * random.randint(2, 11) + 3, theta=random.random() * np.pi, l1=l1, l2=l2)
- else:
- k = fspecial('gaussian', 2 * random.randint(2, 11) + 3, wd * random.random())
- img = ndimage.filters.convolve(img, np.expand_dims(k, axis=2), mode='mirror')
-
- return img
-
-
-def add_resize(img, sf=4):
- rnum = np.random.rand()
- if rnum > 0.8: # up
- sf1 = random.uniform(1, 2)
- elif rnum < 0.7: # down
- sf1 = random.uniform(0.5 / sf, 1)
- else:
- sf1 = 1.0
- img = cv2.resize(img, (int(sf1 * img.shape[1]), int(sf1 * img.shape[0])), interpolation=random.choice([1, 2, 3]))
- img = np.clip(img, 0.0, 1.0)
-
- return img
-
-
-# def add_Gaussian_noise(img, noise_level1=2, noise_level2=25):
-# noise_level = random.randint(noise_level1, noise_level2)
-# rnum = np.random.rand()
-# if rnum > 0.6: # add color Gaussian noise
-# img += np.random.normal(0, noise_level / 255.0, img.shape).astype(np.float32)
-# elif rnum < 0.4: # add grayscale Gaussian noise
-# img += np.random.normal(0, noise_level / 255.0, (*img.shape[:2], 1)).astype(np.float32)
-# else: # add noise
-# L = noise_level2 / 255.
-# D = np.diag(np.random.rand(3))
-# U = orth(np.random.rand(3, 3))
-# conv = np.dot(np.dot(np.transpose(U), D), U)
-# img += np.random.multivariate_normal([0, 0, 0], np.abs(L ** 2 * conv), img.shape[:2]).astype(np.float32)
-# img = np.clip(img, 0.0, 1.0)
-# return img
-
-def add_Gaussian_noise(img, noise_level1=2, noise_level2=25):
- noise_level = random.randint(noise_level1, noise_level2)
- rnum = np.random.rand()
- if rnum > 0.6: # add color Gaussian noise
- img = img + np.random.normal(0, noise_level / 255.0, img.shape).astype(np.float32)
- elif rnum < 0.4: # add grayscale Gaussian noise
- img = img + np.random.normal(0, noise_level / 255.0, (*img.shape[:2], 1)).astype(np.float32)
- else: # add noise
- L = noise_level2 / 255.
- D = np.diag(np.random.rand(3))
- U = orth(np.random.rand(3, 3))
- conv = np.dot(np.dot(np.transpose(U), D), U)
- img = img + np.random.multivariate_normal([0, 0, 0], np.abs(L ** 2 * conv), img.shape[:2]).astype(np.float32)
- img = np.clip(img, 0.0, 1.0)
- return img
-
-
-def add_speckle_noise(img, noise_level1=2, noise_level2=25):
- noise_level = random.randint(noise_level1, noise_level2)
- img = np.clip(img, 0.0, 1.0)
- rnum = random.random()
- if rnum > 0.6:
- img += img * np.random.normal(0, noise_level / 255.0, img.shape).astype(np.float32)
- elif rnum < 0.4:
- img += img * np.random.normal(0, noise_level / 255.0, (*img.shape[:2], 1)).astype(np.float32)
- else:
- L = noise_level2 / 255.
- D = np.diag(np.random.rand(3))
- U = orth(np.random.rand(3, 3))
- conv = np.dot(np.dot(np.transpose(U), D), U)
- img += img * np.random.multivariate_normal([0, 0, 0], np.abs(L ** 2 * conv), img.shape[:2]).astype(np.float32)
- img = np.clip(img, 0.0, 1.0)
- return img
-
-
-def add_Poisson_noise(img):
- img = np.clip((img * 255.0).round(), 0, 255) / 255.
- vals = 10 ** (2 * random.random() + 2.0) # [2, 4]
- if random.random() < 0.5:
- img = np.random.poisson(img * vals).astype(np.float32) / vals
- else:
- img_gray = np.dot(img[..., :3], [0.299, 0.587, 0.114])
- img_gray = np.clip((img_gray * 255.0).round(), 0, 255) / 255.
- noise_gray = np.random.poisson(img_gray * vals).astype(np.float32) / vals - img_gray
- img += noise_gray[:, :, np.newaxis]
- img = np.clip(img, 0.0, 1.0)
- return img
-
-
-def add_JPEG_noise(img):
- quality_factor = random.randint(30, 95)
- img = cv2.cvtColor(util.single2uint(img), cv2.COLOR_RGB2BGR)
- result, encimg = cv2.imencode('.jpg', img, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
- img = cv2.imdecode(encimg, 1)
- img = cv2.cvtColor(util.uint2single(img), cv2.COLOR_BGR2RGB)
- return img
-
-
-def random_crop(lq, hq, sf=4, lq_patchsize=64):
- h, w = lq.shape[:2]
- rnd_h = random.randint(0, h - lq_patchsize)
- rnd_w = random.randint(0, w - lq_patchsize)
- lq = lq[rnd_h:rnd_h + lq_patchsize, rnd_w:rnd_w + lq_patchsize, :]
-
- rnd_h_H, rnd_w_H = int(rnd_h * sf), int(rnd_w * sf)
- hq = hq[rnd_h_H:rnd_h_H + lq_patchsize * sf, rnd_w_H:rnd_w_H + lq_patchsize * sf, :]
- return lq, hq
-
-
-def degradation_bsrgan(img, sf=4, lq_patchsize=72, isp_model=None):
- """
- This is the degradation model of BSRGAN from the paper
- "Designing a Practical Degradation Model for Deep Blind Image Super-Resolution"
- ----------
- img: HXWXC, [0, 1], its size should be large than (lq_patchsizexsf)x(lq_patchsizexsf)
- sf: scale factor
- isp_model: camera ISP model
- Returns
- -------
- img: low-quality patch, size: lq_patchsizeXlq_patchsizeXC, range: [0, 1]
- hq: corresponding high-quality patch, size: (lq_patchsizexsf)X(lq_patchsizexsf)XC, range: [0, 1]
- """
- isp_prob, jpeg_prob, scale2_prob = 0.25, 0.9, 0.25
- sf_ori = sf
-
- h1, w1 = img.shape[:2]
- img = img.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
- h, w = img.shape[:2]
-
- if h < lq_patchsize * sf or w < lq_patchsize * sf:
- raise ValueError(f'img size ({h1}X{w1}) is too small!')
-
- hq = img.copy()
-
- if sf == 4 and random.random() < scale2_prob: # downsample1
- if np.random.rand() < 0.5:
- img = cv2.resize(img, (int(1 / 2 * img.shape[1]), int(1 / 2 * img.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- img = util.imresize_np(img, 1 / 2, True)
- img = np.clip(img, 0.0, 1.0)
- sf = 2
-
- shuffle_order = random.sample(range(7), 7)
- idx1, idx2 = shuffle_order.index(2), shuffle_order.index(3)
- if idx1 > idx2: # keep downsample3 last
- shuffle_order[idx1], shuffle_order[idx2] = shuffle_order[idx2], shuffle_order[idx1]
-
- for i in shuffle_order:
-
- if i == 0:
- img = add_blur(img, sf=sf)
-
- elif i == 1:
- img = add_blur(img, sf=sf)
-
- elif i == 2:
- a, b = img.shape[1], img.shape[0]
- # downsample2
- if random.random() < 0.75:
- sf1 = random.uniform(1, 2 * sf)
- img = cv2.resize(img, (int(1 / sf1 * img.shape[1]), int(1 / sf1 * img.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- k = fspecial('gaussian', 25, random.uniform(0.1, 0.6 * sf))
- k_shifted = shift_pixel(k, sf)
- k_shifted = k_shifted / k_shifted.sum() # blur with shifted kernel
- img = ndimage.filters.convolve(img, np.expand_dims(k_shifted, axis=2), mode='mirror')
- img = img[0::sf, 0::sf, ...] # nearest downsampling
- img = np.clip(img, 0.0, 1.0)
-
- elif i == 3:
- # downsample3
- img = cv2.resize(img, (int(1 / sf * a), int(1 / sf * b)), interpolation=random.choice([1, 2, 3]))
- img = np.clip(img, 0.0, 1.0)
-
- elif i == 4:
- # add Gaussian noise
- img = add_Gaussian_noise(img, noise_level1=2, noise_level2=25)
-
- elif i == 5:
- # add JPEG noise
- if random.random() < jpeg_prob:
- img = add_JPEG_noise(img)
-
- elif i == 6:
- # add processed camera sensor noise
- if random.random() < isp_prob and isp_model is not None:
- with torch.no_grad():
- img, hq = isp_model.forward(img.copy(), hq)
-
- # add final JPEG compression noise
- img = add_JPEG_noise(img)
-
- # random crop
- img, hq = random_crop(img, hq, sf_ori, lq_patchsize)
-
- return img, hq
-
-
-# todo no isp_model?
-def degradation_bsrgan_variant(image, sf=4, isp_model=None):
- """
- This is the degradation model of BSRGAN from the paper
- "Designing a Practical Degradation Model for Deep Blind Image Super-Resolution"
- ----------
- sf: scale factor
- isp_model: camera ISP model
- Returns
- -------
- img: low-quality patch, size: lq_patchsizeXlq_patchsizeXC, range: [0, 1]
- hq: corresponding high-quality patch, size: (lq_patchsizexsf)X(lq_patchsizexsf)XC, range: [0, 1]
- """
- image = util.uint2single(image)
- isp_prob, jpeg_prob, scale2_prob = 0.25, 0.9, 0.25
- sf_ori = sf
-
- h1, w1 = image.shape[:2]
- image = image.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
- h, w = image.shape[:2]
-
- hq = image.copy()
-
- if sf == 4 and random.random() < scale2_prob: # downsample1
- if np.random.rand() < 0.5:
- image = cv2.resize(image, (int(1 / 2 * image.shape[1]), int(1 / 2 * image.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- image = util.imresize_np(image, 1 / 2, True)
- image = np.clip(image, 0.0, 1.0)
- sf = 2
-
- shuffle_order = random.sample(range(7), 7)
- idx1, idx2 = shuffle_order.index(2), shuffle_order.index(3)
- if idx1 > idx2: # keep downsample3 last
- shuffle_order[idx1], shuffle_order[idx2] = shuffle_order[idx2], shuffle_order[idx1]
-
- for i in shuffle_order:
-
- if i == 0:
- image = add_blur(image, sf=sf)
-
- elif i == 1:
- image = add_blur(image, sf=sf)
-
- elif i == 2:
- a, b = image.shape[1], image.shape[0]
- # downsample2
- if random.random() < 0.75:
- sf1 = random.uniform(1, 2 * sf)
- image = cv2.resize(image, (int(1 / sf1 * image.shape[1]), int(1 / sf1 * image.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- k = fspecial('gaussian', 25, random.uniform(0.1, 0.6 * sf))
- k_shifted = shift_pixel(k, sf)
- k_shifted = k_shifted / k_shifted.sum() # blur with shifted kernel
- image = ndimage.filters.convolve(image, np.expand_dims(k_shifted, axis=2), mode='mirror')
- image = image[0::sf, 0::sf, ...] # nearest downsampling
- image = np.clip(image, 0.0, 1.0)
-
- elif i == 3:
- # downsample3
- image = cv2.resize(image, (int(1 / sf * a), int(1 / sf * b)), interpolation=random.choice([1, 2, 3]))
- image = np.clip(image, 0.0, 1.0)
-
- elif i == 4:
- # add Gaussian noise
- image = add_Gaussian_noise(image, noise_level1=2, noise_level2=25)
-
- elif i == 5:
- # add JPEG noise
- if random.random() < jpeg_prob:
- image = add_JPEG_noise(image)
-
- # elif i == 6:
- # # add processed camera sensor noise
- # if random.random() < isp_prob and isp_model is not None:
- # with torch.no_grad():
- # img, hq = isp_model.forward(img.copy(), hq)
-
- # add final JPEG compression noise
- image = add_JPEG_noise(image)
- image = util.single2uint(image)
- example = {"image":image}
- return example
-
-
-# TODO incase there is a pickle error one needs to replace a += x with a = a + x in add_speckle_noise etc...
-def degradation_bsrgan_plus(img, sf=4, shuffle_prob=0.5, use_sharp=True, lq_patchsize=64, isp_model=None):
- """
- This is an extended degradation model by combining
- the degradation models of BSRGAN and Real-ESRGAN
- ----------
- img: HXWXC, [0, 1], its size should be large than (lq_patchsizexsf)x(lq_patchsizexsf)
- sf: scale factor
- use_shuffle: the degradation shuffle
- use_sharp: sharpening the img
- Returns
- -------
- img: low-quality patch, size: lq_patchsizeXlq_patchsizeXC, range: [0, 1]
- hq: corresponding high-quality patch, size: (lq_patchsizexsf)X(lq_patchsizexsf)XC, range: [0, 1]
- """
-
- h1, w1 = img.shape[:2]
- img = img.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
- h, w = img.shape[:2]
-
- if h < lq_patchsize * sf or w < lq_patchsize * sf:
- raise ValueError(f'img size ({h1}X{w1}) is too small!')
-
- if use_sharp:
- img = add_sharpening(img)
- hq = img.copy()
-
- if random.random() < shuffle_prob:
- shuffle_order = random.sample(range(13), 13)
- else:
- shuffle_order = list(range(13))
- # local shuffle for noise, JPEG is always the last one
- shuffle_order[2:6] = random.sample(shuffle_order[2:6], len(range(2, 6)))
- shuffle_order[9:13] = random.sample(shuffle_order[9:13], len(range(9, 13)))
-
- poisson_prob, speckle_prob, isp_prob = 0.1, 0.1, 0.1
-
- for i in shuffle_order:
- if i == 0:
- img = add_blur(img, sf=sf)
- elif i == 1:
- img = add_resize(img, sf=sf)
- elif i == 2:
- img = add_Gaussian_noise(img, noise_level1=2, noise_level2=25)
- elif i == 3:
- if random.random() < poisson_prob:
- img = add_Poisson_noise(img)
- elif i == 4:
- if random.random() < speckle_prob:
- img = add_speckle_noise(img)
- elif i == 5:
- if random.random() < isp_prob and isp_model is not None:
- with torch.no_grad():
- img, hq = isp_model.forward(img.copy(), hq)
- elif i == 6:
- img = add_JPEG_noise(img)
- elif i == 7:
- img = add_blur(img, sf=sf)
- elif i == 8:
- img = add_resize(img, sf=sf)
- elif i == 9:
- img = add_Gaussian_noise(img, noise_level1=2, noise_level2=25)
- elif i == 10:
- if random.random() < poisson_prob:
- img = add_Poisson_noise(img)
- elif i == 11:
- if random.random() < speckle_prob:
- img = add_speckle_noise(img)
- elif i == 12:
- if random.random() < isp_prob and isp_model is not None:
- with torch.no_grad():
- img, hq = isp_model.forward(img.copy(), hq)
- else:
- print('check the shuffle!')
-
- # resize to desired size
- img = cv2.resize(img, (int(1 / sf * hq.shape[1]), int(1 / sf * hq.shape[0])),
- interpolation=random.choice([1, 2, 3]))
-
- # add final JPEG compression noise
- img = add_JPEG_noise(img)
-
- # random crop
- img, hq = random_crop(img, hq, sf, lq_patchsize)
-
- return img, hq
-
-
-if __name__ == '__main__':
- print("hey")
- img = util.imread_uint('utils/test.png', 3)
- print(img)
- img = util.uint2single(img)
- print(img)
- img = img[:448, :448]
- h = img.shape[0] // 4
- print("resizing to", h)
- sf = 4
- deg_fn = partial(degradation_bsrgan_variant, sf=sf)
- for i in range(20):
- print(i)
- img_lq = deg_fn(img)
- print(img_lq)
- img_lq_bicubic = albumentations.SmallestMaxSize(max_size=h, interpolation=cv2.INTER_CUBIC)(image=img)["image"]
- print(img_lq.shape)
- print("bicubic", img_lq_bicubic.shape)
- print(img_hq.shape)
- lq_nearest = cv2.resize(util.single2uint(img_lq), (int(sf * img_lq.shape[1]), int(sf * img_lq.shape[0])),
- interpolation=0)
- lq_bicubic_nearest = cv2.resize(util.single2uint(img_lq_bicubic), (int(sf * img_lq.shape[1]), int(sf * img_lq.shape[0])),
- interpolation=0)
- img_concat = np.concatenate([lq_bicubic_nearest, lq_nearest, util.single2uint(img_hq)], axis=1)
- util.imsave(img_concat, str(i) + '.png')
-
-
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/bsrgan_light.py b/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/bsrgan_light.py
deleted file mode 100644
index 9e1f82399..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/bsrgan_light.py
+++ /dev/null
@@ -1,650 +0,0 @@
-# -*- coding: utf-8 -*-
-import numpy as np
-import cv2
-import torch
-
-from functools import partial
-import random
-from scipy import ndimage
-import scipy
-import scipy.stats as ss
-from scipy.interpolate import interp2d
-from scipy.linalg import orth
-import albumentations
-
-import ldm.modules.image_degradation.utils_image as util
-
-"""
-# --------------------------------------------
-# Super-Resolution
-# --------------------------------------------
-#
-# Kai Zhang (cskaizhang@gmail.com)
-# https://github.com/cszn
-# From 2019/03--2021/08
-# --------------------------------------------
-"""
-
-
-def modcrop_np(img, sf):
- '''
- Args:
- img: numpy image, WxH or WxHxC
- sf: scale factor
- Return:
- cropped image
- '''
- w, h = img.shape[:2]
- im = np.copy(img)
- return im[:w - w % sf, :h - h % sf, ...]
-
-
-"""
-# --------------------------------------------
-# anisotropic Gaussian kernels
-# --------------------------------------------
-"""
-
-
-def analytic_kernel(k):
- """Calculate the X4 kernel from the X2 kernel (for proof see appendix in paper)"""
- k_size = k.shape[0]
- # Calculate the big kernels size
- big_k = np.zeros((3 * k_size - 2, 3 * k_size - 2))
- # Loop over the small kernel to fill the big one
- for r in range(k_size):
- for c in range(k_size):
- big_k[2 * r:2 * r + k_size, 2 * c:2 * c + k_size] += k[r, c] * k
- # Crop the edges of the big kernel to ignore very small values and increase run time of SR
- crop = k_size // 2
- cropped_big_k = big_k[crop:-crop, crop:-crop]
- # Normalize to 1
- return cropped_big_k / cropped_big_k.sum()
-
-
-def anisotropic_Gaussian(ksize=15, theta=np.pi, l1=6, l2=6):
- """ generate an anisotropic Gaussian kernel
- Args:
- ksize : e.g., 15, kernel size
- theta : [0, pi], rotation angle range
- l1 : [0.1,50], scaling of eigenvalues
- l2 : [0.1,l1], scaling of eigenvalues
- If l1 = l2, will get an isotropic Gaussian kernel.
- Returns:
- k : kernel
- """
-
- v = np.dot(np.array([[np.cos(theta), -np.sin(theta)], [np.sin(theta), np.cos(theta)]]), np.array([1., 0.]))
- V = np.array([[v[0], v[1]], [v[1], -v[0]]])
- D = np.array([[l1, 0], [0, l2]])
- Sigma = np.dot(np.dot(V, D), np.linalg.inv(V))
- k = gm_blur_kernel(mean=[0, 0], cov=Sigma, size=ksize)
-
- return k
-
-
-def gm_blur_kernel(mean, cov, size=15):
- center = size / 2.0 + 0.5
- k = np.zeros([size, size])
- for y in range(size):
- for x in range(size):
- cy = y - center + 1
- cx = x - center + 1
- k[y, x] = ss.multivariate_normal.pdf([cx, cy], mean=mean, cov=cov)
-
- k = k / np.sum(k)
- return k
-
-
-def shift_pixel(x, sf, upper_left=True):
- """shift pixel for super-resolution with different scale factors
- Args:
- x: WxHxC or WxH
- sf: scale factor
- upper_left: shift direction
- """
- h, w = x.shape[:2]
- shift = (sf - 1) * 0.5
- xv, yv = np.arange(0, w, 1.0), np.arange(0, h, 1.0)
- if upper_left:
- x1 = xv + shift
- y1 = yv + shift
- else:
- x1 = xv - shift
- y1 = yv - shift
-
- x1 = np.clip(x1, 0, w - 1)
- y1 = np.clip(y1, 0, h - 1)
-
- if x.ndim == 2:
- x = interp2d(xv, yv, x)(x1, y1)
- if x.ndim == 3:
- for i in range(x.shape[-1]):
- x[:, :, i] = interp2d(xv, yv, x[:, :, i])(x1, y1)
-
- return x
-
-
-def blur(x, k):
- '''
- x: image, NxcxHxW
- k: kernel, Nx1xhxw
- '''
- n, c = x.shape[:2]
- p1, p2 = (k.shape[-2] - 1) // 2, (k.shape[-1] - 1) // 2
- x = torch.nn.functional.pad(x, pad=(p1, p2, p1, p2), mode='replicate')
- k = k.repeat(1, c, 1, 1)
- k = k.view(-1, 1, k.shape[2], k.shape[3])
- x = x.view(1, -1, x.shape[2], x.shape[3])
- x = torch.nn.functional.conv2d(x, k, bias=None, stride=1, padding=0, groups=n * c)
- x = x.view(n, c, x.shape[2], x.shape[3])
-
- return x
-
-
-def gen_kernel(k_size=np.array([15, 15]), scale_factor=np.array([4, 4]), min_var=0.6, max_var=10., noise_level=0):
- """"
- # modified version of https://github.com/assafshocher/BlindSR_dataset_generator
- # Kai Zhang
- # min_var = 0.175 * sf # variance of the gaussian kernel will be sampled between min_var and max_var
- # max_var = 2.5 * sf
- """
- # Set random eigen-vals (lambdas) and angle (theta) for COV matrix
- lambda_1 = min_var + np.random.rand() * (max_var - min_var)
- lambda_2 = min_var + np.random.rand() * (max_var - min_var)
- theta = np.random.rand() * np.pi # random theta
- noise = -noise_level + np.random.rand(*k_size) * noise_level * 2
-
- # Set COV matrix using Lambdas and Theta
- LAMBDA = np.diag([lambda_1, lambda_2])
- Q = np.array([[np.cos(theta), -np.sin(theta)],
- [np.sin(theta), np.cos(theta)]])
- SIGMA = Q @ LAMBDA @ Q.T
- INV_SIGMA = np.linalg.inv(SIGMA)[None, None, :, :]
-
- # Set expectation position (shifting kernel for aligned image)
- MU = k_size // 2 - 0.5 * (scale_factor - 1) # - 0.5 * (scale_factor - k_size % 2)
- MU = MU[None, None, :, None]
-
- # Create meshgrid for Gaussian
- [X, Y] = np.meshgrid(range(k_size[0]), range(k_size[1]))
- Z = np.stack([X, Y], 2)[:, :, :, None]
-
- # Calcualte Gaussian for every pixel of the kernel
- ZZ = Z - MU
- ZZ_t = ZZ.transpose(0, 1, 3, 2)
- raw_kernel = np.exp(-0.5 * np.squeeze(ZZ_t @ INV_SIGMA @ ZZ)) * (1 + noise)
-
- # shift the kernel so it will be centered
- # raw_kernel_centered = kernel_shift(raw_kernel, scale_factor)
-
- # Normalize the kernel and return
- # kernel = raw_kernel_centered / np.sum(raw_kernel_centered)
- kernel = raw_kernel / np.sum(raw_kernel)
- return kernel
-
-
-def fspecial_gaussian(hsize, sigma):
- hsize = [hsize, hsize]
- siz = [(hsize[0] - 1.0) / 2.0, (hsize[1] - 1.0) / 2.0]
- std = sigma
- [x, y] = np.meshgrid(np.arange(-siz[1], siz[1] + 1), np.arange(-siz[0], siz[0] + 1))
- arg = -(x * x + y * y) / (2 * std * std)
- h = np.exp(arg)
- h[h < scipy.finfo(float).eps * h.max()] = 0
- sumh = h.sum()
- if sumh != 0:
- h = h / sumh
- return h
-
-
-def fspecial_laplacian(alpha):
- alpha = max([0, min([alpha, 1])])
- h1 = alpha / (alpha + 1)
- h2 = (1 - alpha) / (alpha + 1)
- h = [[h1, h2, h1], [h2, -4 / (alpha + 1), h2], [h1, h2, h1]]
- h = np.array(h)
- return h
-
-
-def fspecial(filter_type, *args, **kwargs):
- '''
- python code from:
- https://github.com/ronaldosena/imagens-medicas-2/blob/40171a6c259edec7827a6693a93955de2bd39e76/Aulas/aula_2_-_uniform_filter/matlab_fspecial.py
- '''
- if filter_type == 'gaussian':
- return fspecial_gaussian(*args, **kwargs)
- if filter_type == 'laplacian':
- return fspecial_laplacian(*args, **kwargs)
-
-
-"""
-# --------------------------------------------
-# degradation models
-# --------------------------------------------
-"""
-
-
-def bicubic_degradation(x, sf=3):
- '''
- Args:
- x: HxWxC image, [0, 1]
- sf: down-scale factor
- Return:
- bicubicly downsampled LR image
- '''
- x = util.imresize_np(x, scale=1 / sf)
- return x
-
-
-def srmd_degradation(x, k, sf=3):
- ''' blur + bicubic downsampling
- Args:
- x: HxWxC image, [0, 1]
- k: hxw, double
- sf: down-scale factor
- Return:
- downsampled LR image
- Reference:
- @inproceedings{zhang2018learning,
- title={Learning a single convolutional super-resolution network for multiple degradations},
- author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- pages={3262--3271},
- year={2018}
- }
- '''
- x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap') # 'nearest' | 'mirror'
- x = bicubic_degradation(x, sf=sf)
- return x
-
-
-def dpsr_degradation(x, k, sf=3):
- ''' bicubic downsampling + blur
- Args:
- x: HxWxC image, [0, 1]
- k: hxw, double
- sf: down-scale factor
- Return:
- downsampled LR image
- Reference:
- @inproceedings{zhang2019deep,
- title={Deep Plug-and-Play Super-Resolution for Arbitrary Blur Kernels},
- author={Zhang, Kai and Zuo, Wangmeng and Zhang, Lei},
- booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
- pages={1671--1681},
- year={2019}
- }
- '''
- x = bicubic_degradation(x, sf=sf)
- x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
- return x
-
-
-def classical_degradation(x, k, sf=3):
- ''' blur + downsampling
- Args:
- x: HxWxC image, [0, 1]/[0, 255]
- k: hxw, double
- sf: down-scale factor
- Return:
- downsampled LR image
- '''
- x = ndimage.filters.convolve(x, np.expand_dims(k, axis=2), mode='wrap')
- # x = filters.correlate(x, np.expand_dims(np.flip(k), axis=2))
- st = 0
- return x[st::sf, st::sf, ...]
-
-
-def add_sharpening(img, weight=0.5, radius=50, threshold=10):
- """USM sharpening. borrowed from real-ESRGAN
- Input image: I; Blurry image: B.
- 1. K = I + weight * (I - B)
- 2. Mask = 1 if abs(I - B) > threshold, else: 0
- 3. Blur mask:
- 4. Out = Mask * K + (1 - Mask) * I
- Args:
- img (Numpy array): Input image, HWC, BGR; float32, [0, 1].
- weight (float): Sharp weight. Default: 1.
- radius (float): Kernel size of Gaussian blur. Default: 50.
- threshold (int):
- """
- if radius % 2 == 0:
- radius += 1
- blur = cv2.GaussianBlur(img, (radius, radius), 0)
- residual = img - blur
- mask = np.abs(residual) * 255 > threshold
- mask = mask.astype('float32')
- soft_mask = cv2.GaussianBlur(mask, (radius, radius), 0)
-
- K = img + weight * residual
- K = np.clip(K, 0, 1)
- return soft_mask * K + (1 - soft_mask) * img
-
-
-def add_blur(img, sf=4):
- wd2 = 4.0 + sf
- wd = 2.0 + 0.2 * sf
-
- wd2 = wd2/4
- wd = wd/4
-
- if random.random() < 0.5:
- l1 = wd2 * random.random()
- l2 = wd2 * random.random()
- k = anisotropic_Gaussian(ksize=random.randint(2, 11) + 3, theta=random.random() * np.pi, l1=l1, l2=l2)
- else:
- k = fspecial('gaussian', random.randint(2, 4) + 3, wd * random.random())
- img = ndimage.filters.convolve(img, np.expand_dims(k, axis=2), mode='mirror')
-
- return img
-
-
-def add_resize(img, sf=4):
- rnum = np.random.rand()
- if rnum > 0.8: # up
- sf1 = random.uniform(1, 2)
- elif rnum < 0.7: # down
- sf1 = random.uniform(0.5 / sf, 1)
- else:
- sf1 = 1.0
- img = cv2.resize(img, (int(sf1 * img.shape[1]), int(sf1 * img.shape[0])), interpolation=random.choice([1, 2, 3]))
- img = np.clip(img, 0.0, 1.0)
-
- return img
-
-
-# def add_Gaussian_noise(img, noise_level1=2, noise_level2=25):
-# noise_level = random.randint(noise_level1, noise_level2)
-# rnum = np.random.rand()
-# if rnum > 0.6: # add color Gaussian noise
-# img += np.random.normal(0, noise_level / 255.0, img.shape).astype(np.float32)
-# elif rnum < 0.4: # add grayscale Gaussian noise
-# img += np.random.normal(0, noise_level / 255.0, (*img.shape[:2], 1)).astype(np.float32)
-# else: # add noise
-# L = noise_level2 / 255.
-# D = np.diag(np.random.rand(3))
-# U = orth(np.random.rand(3, 3))
-# conv = np.dot(np.dot(np.transpose(U), D), U)
-# img += np.random.multivariate_normal([0, 0, 0], np.abs(L ** 2 * conv), img.shape[:2]).astype(np.float32)
-# img = np.clip(img, 0.0, 1.0)
-# return img
-
-def add_Gaussian_noise(img, noise_level1=2, noise_level2=25):
- noise_level = random.randint(noise_level1, noise_level2)
- rnum = np.random.rand()
- if rnum > 0.6: # add color Gaussian noise
- img = img + np.random.normal(0, noise_level / 255.0, img.shape).astype(np.float32)
- elif rnum < 0.4: # add grayscale Gaussian noise
- img = img + np.random.normal(0, noise_level / 255.0, (*img.shape[:2], 1)).astype(np.float32)
- else: # add noise
- L = noise_level2 / 255.
- D = np.diag(np.random.rand(3))
- U = orth(np.random.rand(3, 3))
- conv = np.dot(np.dot(np.transpose(U), D), U)
- img = img + np.random.multivariate_normal([0, 0, 0], np.abs(L ** 2 * conv), img.shape[:2]).astype(np.float32)
- img = np.clip(img, 0.0, 1.0)
- return img
-
-
-def add_speckle_noise(img, noise_level1=2, noise_level2=25):
- noise_level = random.randint(noise_level1, noise_level2)
- img = np.clip(img, 0.0, 1.0)
- rnum = random.random()
- if rnum > 0.6:
- img += img * np.random.normal(0, noise_level / 255.0, img.shape).astype(np.float32)
- elif rnum < 0.4:
- img += img * np.random.normal(0, noise_level / 255.0, (*img.shape[:2], 1)).astype(np.float32)
- else:
- L = noise_level2 / 255.
- D = np.diag(np.random.rand(3))
- U = orth(np.random.rand(3, 3))
- conv = np.dot(np.dot(np.transpose(U), D), U)
- img += img * np.random.multivariate_normal([0, 0, 0], np.abs(L ** 2 * conv), img.shape[:2]).astype(np.float32)
- img = np.clip(img, 0.0, 1.0)
- return img
-
-
-def add_Poisson_noise(img):
- img = np.clip((img * 255.0).round(), 0, 255) / 255.
- vals = 10 ** (2 * random.random() + 2.0) # [2, 4]
- if random.random() < 0.5:
- img = np.random.poisson(img * vals).astype(np.float32) / vals
- else:
- img_gray = np.dot(img[..., :3], [0.299, 0.587, 0.114])
- img_gray = np.clip((img_gray * 255.0).round(), 0, 255) / 255.
- noise_gray = np.random.poisson(img_gray * vals).astype(np.float32) / vals - img_gray
- img += noise_gray[:, :, np.newaxis]
- img = np.clip(img, 0.0, 1.0)
- return img
-
-
-def add_JPEG_noise(img):
- quality_factor = random.randint(80, 95)
- img = cv2.cvtColor(util.single2uint(img), cv2.COLOR_RGB2BGR)
- result, encimg = cv2.imencode('.jpg', img, [int(cv2.IMWRITE_JPEG_QUALITY), quality_factor])
- img = cv2.imdecode(encimg, 1)
- img = cv2.cvtColor(util.uint2single(img), cv2.COLOR_BGR2RGB)
- return img
-
-
-def random_crop(lq, hq, sf=4, lq_patchsize=64):
- h, w = lq.shape[:2]
- rnd_h = random.randint(0, h - lq_patchsize)
- rnd_w = random.randint(0, w - lq_patchsize)
- lq = lq[rnd_h:rnd_h + lq_patchsize, rnd_w:rnd_w + lq_patchsize, :]
-
- rnd_h_H, rnd_w_H = int(rnd_h * sf), int(rnd_w * sf)
- hq = hq[rnd_h_H:rnd_h_H + lq_patchsize * sf, rnd_w_H:rnd_w_H + lq_patchsize * sf, :]
- return lq, hq
-
-
-def degradation_bsrgan(img, sf=4, lq_patchsize=72, isp_model=None):
- """
- This is the degradation model of BSRGAN from the paper
- "Designing a Practical Degradation Model for Deep Blind Image Super-Resolution"
- ----------
- img: HXWXC, [0, 1], its size should be large than (lq_patchsizexsf)x(lq_patchsizexsf)
- sf: scale factor
- isp_model: camera ISP model
- Returns
- -------
- img: low-quality patch, size: lq_patchsizeXlq_patchsizeXC, range: [0, 1]
- hq: corresponding high-quality patch, size: (lq_patchsizexsf)X(lq_patchsizexsf)XC, range: [0, 1]
- """
- isp_prob, jpeg_prob, scale2_prob = 0.25, 0.9, 0.25
- sf_ori = sf
-
- h1, w1 = img.shape[:2]
- img = img.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
- h, w = img.shape[:2]
-
- if h < lq_patchsize * sf or w < lq_patchsize * sf:
- raise ValueError(f'img size ({h1}X{w1}) is too small!')
-
- hq = img.copy()
-
- if sf == 4 and random.random() < scale2_prob: # downsample1
- if np.random.rand() < 0.5:
- img = cv2.resize(img, (int(1 / 2 * img.shape[1]), int(1 / 2 * img.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- img = util.imresize_np(img, 1 / 2, True)
- img = np.clip(img, 0.0, 1.0)
- sf = 2
-
- shuffle_order = random.sample(range(7), 7)
- idx1, idx2 = shuffle_order.index(2), shuffle_order.index(3)
- if idx1 > idx2: # keep downsample3 last
- shuffle_order[idx1], shuffle_order[idx2] = shuffle_order[idx2], shuffle_order[idx1]
-
- for i in shuffle_order:
-
- if i == 0:
- img = add_blur(img, sf=sf)
-
- elif i == 1:
- img = add_blur(img, sf=sf)
-
- elif i == 2:
- a, b = img.shape[1], img.shape[0]
- # downsample2
- if random.random() < 0.75:
- sf1 = random.uniform(1, 2 * sf)
- img = cv2.resize(img, (int(1 / sf1 * img.shape[1]), int(1 / sf1 * img.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- k = fspecial('gaussian', 25, random.uniform(0.1, 0.6 * sf))
- k_shifted = shift_pixel(k, sf)
- k_shifted = k_shifted / k_shifted.sum() # blur with shifted kernel
- img = ndimage.filters.convolve(img, np.expand_dims(k_shifted, axis=2), mode='mirror')
- img = img[0::sf, 0::sf, ...] # nearest downsampling
- img = np.clip(img, 0.0, 1.0)
-
- elif i == 3:
- # downsample3
- img = cv2.resize(img, (int(1 / sf * a), int(1 / sf * b)), interpolation=random.choice([1, 2, 3]))
- img = np.clip(img, 0.0, 1.0)
-
- elif i == 4:
- # add Gaussian noise
- img = add_Gaussian_noise(img, noise_level1=2, noise_level2=8)
-
- elif i == 5:
- # add JPEG noise
- if random.random() < jpeg_prob:
- img = add_JPEG_noise(img)
-
- elif i == 6:
- # add processed camera sensor noise
- if random.random() < isp_prob and isp_model is not None:
- with torch.no_grad():
- img, hq = isp_model.forward(img.copy(), hq)
-
- # add final JPEG compression noise
- img = add_JPEG_noise(img)
-
- # random crop
- img, hq = random_crop(img, hq, sf_ori, lq_patchsize)
-
- return img, hq
-
-
-# todo no isp_model?
-def degradation_bsrgan_variant(image, sf=4, isp_model=None):
- """
- This is the degradation model of BSRGAN from the paper
- "Designing a Practical Degradation Model for Deep Blind Image Super-Resolution"
- ----------
- sf: scale factor
- isp_model: camera ISP model
- Returns
- -------
- img: low-quality patch, size: lq_patchsizeXlq_patchsizeXC, range: [0, 1]
- hq: corresponding high-quality patch, size: (lq_patchsizexsf)X(lq_patchsizexsf)XC, range: [0, 1]
- """
- image = util.uint2single(image)
- isp_prob, jpeg_prob, scale2_prob = 0.25, 0.9, 0.25
- sf_ori = sf
-
- h1, w1 = image.shape[:2]
- image = image.copy()[:w1 - w1 % sf, :h1 - h1 % sf, ...] # mod crop
- h, w = image.shape[:2]
-
- hq = image.copy()
-
- if sf == 4 and random.random() < scale2_prob: # downsample1
- if np.random.rand() < 0.5:
- image = cv2.resize(image, (int(1 / 2 * image.shape[1]), int(1 / 2 * image.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- image = util.imresize_np(image, 1 / 2, True)
- image = np.clip(image, 0.0, 1.0)
- sf = 2
-
- shuffle_order = random.sample(range(7), 7)
- idx1, idx2 = shuffle_order.index(2), shuffle_order.index(3)
- if idx1 > idx2: # keep downsample3 last
- shuffle_order[idx1], shuffle_order[idx2] = shuffle_order[idx2], shuffle_order[idx1]
-
- for i in shuffle_order:
-
- if i == 0:
- image = add_blur(image, sf=sf)
-
- # elif i == 1:
- # image = add_blur(image, sf=sf)
-
- if i == 0:
- pass
-
- elif i == 2:
- a, b = image.shape[1], image.shape[0]
- # downsample2
- if random.random() < 0.8:
- sf1 = random.uniform(1, 2 * sf)
- image = cv2.resize(image, (int(1 / sf1 * image.shape[1]), int(1 / sf1 * image.shape[0])),
- interpolation=random.choice([1, 2, 3]))
- else:
- k = fspecial('gaussian', 25, random.uniform(0.1, 0.6 * sf))
- k_shifted = shift_pixel(k, sf)
- k_shifted = k_shifted / k_shifted.sum() # blur with shifted kernel
- image = ndimage.filters.convolve(image, np.expand_dims(k_shifted, axis=2), mode='mirror')
- image = image[0::sf, 0::sf, ...] # nearest downsampling
-
- image = np.clip(image, 0.0, 1.0)
-
- elif i == 3:
- # downsample3
- image = cv2.resize(image, (int(1 / sf * a), int(1 / sf * b)), interpolation=random.choice([1, 2, 3]))
- image = np.clip(image, 0.0, 1.0)
-
- elif i == 4:
- # add Gaussian noise
- image = add_Gaussian_noise(image, noise_level1=1, noise_level2=2)
-
- elif i == 5:
- # add JPEG noise
- if random.random() < jpeg_prob:
- image = add_JPEG_noise(image)
- #
- # elif i == 6:
- # # add processed camera sensor noise
- # if random.random() < isp_prob and isp_model is not None:
- # with torch.no_grad():
- # img, hq = isp_model.forward(img.copy(), hq)
-
- # add final JPEG compression noise
- image = add_JPEG_noise(image)
- image = util.single2uint(image)
- example = {"image": image}
- return example
-
-
-
-
-if __name__ == '__main__':
- print("hey")
- img = util.imread_uint('utils/test.png', 3)
- img = img[:448, :448]
- h = img.shape[0] // 4
- print("resizing to", h)
- sf = 4
- deg_fn = partial(degradation_bsrgan_variant, sf=sf)
- for i in range(20):
- print(i)
- img_hq = img
- img_lq = deg_fn(img)["image"]
- img_hq, img_lq = util.uint2single(img_hq), util.uint2single(img_lq)
- print(img_lq)
- img_lq_bicubic = albumentations.SmallestMaxSize(max_size=h, interpolation=cv2.INTER_CUBIC)(image=img_hq)["image"]
- print(img_lq.shape)
- print("bicubic", img_lq_bicubic.shape)
- print(img_hq.shape)
- lq_nearest = cv2.resize(util.single2uint(img_lq), (int(sf * img_lq.shape[1]), int(sf * img_lq.shape[0])),
- interpolation=0)
- lq_bicubic_nearest = cv2.resize(util.single2uint(img_lq_bicubic),
- (int(sf * img_lq.shape[1]), int(sf * img_lq.shape[0])),
- interpolation=0)
- img_concat = np.concatenate([lq_bicubic_nearest, lq_nearest, util.single2uint(img_hq)], axis=1)
- util.imsave(img_concat, str(i) + '.png')
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/utils/test.png b/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/utils/test.png
deleted file mode 100644
index 4249b43de..000000000
Binary files a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/utils/test.png and /dev/null differ
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/utils_image.py b/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/utils_image.py
deleted file mode 100644
index 0175f155a..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/image_degradation/utils_image.py
+++ /dev/null
@@ -1,916 +0,0 @@
-import os
-import math
-import random
-import numpy as np
-import torch
-import cv2
-from torchvision.utils import make_grid
-from datetime import datetime
-#import matplotlib.pyplot as plt # TODO: check with Dominik, also bsrgan.py vs bsrgan_light.py
-
-
-os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
-
-
-'''
-# --------------------------------------------
-# Kai Zhang (github: https://github.com/cszn)
-# 03/Mar/2019
-# --------------------------------------------
-# https://github.com/twhui/SRGAN-pyTorch
-# https://github.com/xinntao/BasicSR
-# --------------------------------------------
-'''
-
-
-IMG_EXTENSIONS = ['.jpg', '.JPG', '.jpeg', '.JPEG', '.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP', '.tif']
-
-
-def is_image_file(filename):
- return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)
-
-
-def get_timestamp():
- return datetime.now().strftime('%y%m%d-%H%M%S')
-
-
-def imshow(x, title=None, cbar=False, figsize=None):
- plt.figure(figsize=figsize)
- plt.imshow(np.squeeze(x), interpolation='nearest', cmap='gray')
- if title:
- plt.title(title)
- if cbar:
- plt.colorbar()
- plt.show()
-
-
-def surf(Z, cmap='rainbow', figsize=None):
- plt.figure(figsize=figsize)
- ax3 = plt.axes(projection='3d')
-
- w, h = Z.shape[:2]
- xx = np.arange(0,w,1)
- yy = np.arange(0,h,1)
- X, Y = np.meshgrid(xx, yy)
- ax3.plot_surface(X,Y,Z,cmap=cmap)
- #ax3.contour(X,Y,Z, zdim='z',offset=-2,cmap=cmap)
- plt.show()
-
-
-'''
-# --------------------------------------------
-# get image pathes
-# --------------------------------------------
-'''
-
-
-def get_image_paths(dataroot):
- paths = None # return None if dataroot is None
- if dataroot is not None:
- paths = sorted(_get_paths_from_images(dataroot))
- return paths
-
-
-def _get_paths_from_images(path):
- assert os.path.isdir(path), '{:s} is not a valid directory'.format(path)
- images = []
- for dirpath, _, fnames in sorted(os.walk(path)):
- for fname in sorted(fnames):
- if is_image_file(fname):
- img_path = os.path.join(dirpath, fname)
- images.append(img_path)
- assert images, '{:s} has no valid image file'.format(path)
- return images
-
-
-'''
-# --------------------------------------------
-# split large images into small images
-# --------------------------------------------
-'''
-
-
-def patches_from_image(img, p_size=512, p_overlap=64, p_max=800):
- w, h = img.shape[:2]
- patches = []
- if w > p_max and h > p_max:
- w1 = list(np.arange(0, w-p_size, p_size-p_overlap, dtype=np.int))
- h1 = list(np.arange(0, h-p_size, p_size-p_overlap, dtype=np.int))
- w1.append(w-p_size)
- h1.append(h-p_size)
-# print(w1)
-# print(h1)
- for i in w1:
- for j in h1:
- patches.append(img[i:i+p_size, j:j+p_size,:])
- else:
- patches.append(img)
-
- return patches
-
-
-def imssave(imgs, img_path):
- """
- imgs: list, N images of size WxHxC
- """
- img_name, ext = os.path.splitext(os.path.basename(img_path))
-
- for i, img in enumerate(imgs):
- if img.ndim == 3:
- img = img[:, :, [2, 1, 0]]
- new_path = os.path.join(os.path.dirname(img_path), img_name+str('_s{:04d}'.format(i))+'.png')
- cv2.imwrite(new_path, img)
-
-
-def split_imageset(original_dataroot, taget_dataroot, n_channels=3, p_size=800, p_overlap=96, p_max=1000):
- """
- split the large images from original_dataroot into small overlapped images with size (p_size)x(p_size),
- and save them into taget_dataroot; only the images with larger size than (p_max)x(p_max)
- will be splitted.
- Args:
- original_dataroot:
- taget_dataroot:
- p_size: size of small images
- p_overlap: patch size in training is a good choice
- p_max: images with smaller size than (p_max)x(p_max) keep unchanged.
- """
- paths = get_image_paths(original_dataroot)
- for img_path in paths:
- # img_name, ext = os.path.splitext(os.path.basename(img_path))
- img = imread_uint(img_path, n_channels=n_channels)
- patches = patches_from_image(img, p_size, p_overlap, p_max)
- imssave(patches, os.path.join(taget_dataroot,os.path.basename(img_path)))
- #if original_dataroot == taget_dataroot:
- #del img_path
-
-'''
-# --------------------------------------------
-# makedir
-# --------------------------------------------
-'''
-
-
-def mkdir(path):
- if not os.path.exists(path):
- os.makedirs(path)
-
-
-def mkdirs(paths):
- if isinstance(paths, str):
- mkdir(paths)
- else:
- for path in paths:
- mkdir(path)
-
-
-def mkdir_and_rename(path):
- if os.path.exists(path):
- new_name = path + '_archived_' + get_timestamp()
- print('Path already exists. Rename it to [{:s}]'.format(new_name))
- os.rename(path, new_name)
- os.makedirs(path)
-
-
-'''
-# --------------------------------------------
-# read image from path
-# opencv is fast, but read BGR numpy image
-# --------------------------------------------
-'''
-
-
-# --------------------------------------------
-# get uint8 image of size HxWxn_channles (RGB)
-# --------------------------------------------
-def imread_uint(path, n_channels=3):
- # input: path
- # output: HxWx3(RGB or GGG), or HxWx1 (G)
- if n_channels == 1:
- img = cv2.imread(path, 0) # cv2.IMREAD_GRAYSCALE
- img = np.expand_dims(img, axis=2) # HxWx1
- elif n_channels == 3:
- img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # BGR or G
- if img.ndim == 2:
- img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB) # GGG
- else:
- img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # RGB
- return img
-
-
-# --------------------------------------------
-# matlab's imwrite
-# --------------------------------------------
-def imsave(img, img_path):
- img = np.squeeze(img)
- if img.ndim == 3:
- img = img[:, :, [2, 1, 0]]
- cv2.imwrite(img_path, img)
-
-def imwrite(img, img_path):
- img = np.squeeze(img)
- if img.ndim == 3:
- img = img[:, :, [2, 1, 0]]
- cv2.imwrite(img_path, img)
-
-
-
-# --------------------------------------------
-# get single image of size HxWxn_channles (BGR)
-# --------------------------------------------
-def read_img(path):
- # read image by cv2
- # return: Numpy float32, HWC, BGR, [0,1]
- img = cv2.imread(path, cv2.IMREAD_UNCHANGED) # cv2.IMREAD_GRAYSCALE
- img = img.astype(np.float32) / 255.
- if img.ndim == 2:
- img = np.expand_dims(img, axis=2)
- # some images have 4 channels
- if img.shape[2] > 3:
- img = img[:, :, :3]
- return img
-
-
-'''
-# --------------------------------------------
-# image format conversion
-# --------------------------------------------
-# numpy(single) <---> numpy(unit)
-# numpy(single) <---> tensor
-# numpy(unit) <---> tensor
-# --------------------------------------------
-'''
-
-
-# --------------------------------------------
-# numpy(single) [0, 1] <---> numpy(unit)
-# --------------------------------------------
-
-
-def uint2single(img):
-
- return np.float32(img/255.)
-
-
-def single2uint(img):
-
- return np.uint8((img.clip(0, 1)*255.).round())
-
-
-def uint162single(img):
-
- return np.float32(img/65535.)
-
-
-def single2uint16(img):
-
- return np.uint16((img.clip(0, 1)*65535.).round())
-
-
-# --------------------------------------------
-# numpy(unit) (HxWxC or HxW) <---> tensor
-# --------------------------------------------
-
-
-# convert uint to 4-dimensional torch tensor
-def uint2tensor4(img):
- if img.ndim == 2:
- img = np.expand_dims(img, axis=2)
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.).unsqueeze(0)
-
-
-# convert uint to 3-dimensional torch tensor
-def uint2tensor3(img):
- if img.ndim == 2:
- img = np.expand_dims(img, axis=2)
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().div(255.)
-
-
-# convert 2/3/4-dimensional torch tensor to uint
-def tensor2uint(img):
- img = img.data.squeeze().float().clamp_(0, 1).cpu().numpy()
- if img.ndim == 3:
- img = np.transpose(img, (1, 2, 0))
- return np.uint8((img*255.0).round())
-
-
-# --------------------------------------------
-# numpy(single) (HxWxC) <---> tensor
-# --------------------------------------------
-
-
-# convert single (HxWxC) to 3-dimensional torch tensor
-def single2tensor3(img):
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float()
-
-
-# convert single (HxWxC) to 4-dimensional torch tensor
-def single2tensor4(img):
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1).float().unsqueeze(0)
-
-
-# convert torch tensor to single
-def tensor2single(img):
- img = img.data.squeeze().float().cpu().numpy()
- if img.ndim == 3:
- img = np.transpose(img, (1, 2, 0))
-
- return img
-
-# convert torch tensor to single
-def tensor2single3(img):
- img = img.data.squeeze().float().cpu().numpy()
- if img.ndim == 3:
- img = np.transpose(img, (1, 2, 0))
- elif img.ndim == 2:
- img = np.expand_dims(img, axis=2)
- return img
-
-
-def single2tensor5(img):
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float().unsqueeze(0)
-
-
-def single32tensor5(img):
- return torch.from_numpy(np.ascontiguousarray(img)).float().unsqueeze(0).unsqueeze(0)
-
-
-def single42tensor4(img):
- return torch.from_numpy(np.ascontiguousarray(img)).permute(2, 0, 1, 3).float()
-
-
-# from skimage.io import imread, imsave
-def tensor2img(tensor, out_type=np.uint8, min_max=(0, 1)):
- '''
- Converts a torch Tensor into an image Numpy array of BGR channel order
- Input: 4D(B,(3/1),H,W), 3D(C,H,W), or 2D(H,W), any range, RGB channel order
- Output: 3D(H,W,C) or 2D(H,W), [0,255], np.uint8 (default)
- '''
- tensor = tensor.squeeze().float().cpu().clamp_(*min_max) # squeeze first, then clamp
- tensor = (tensor - min_max[0]) / (min_max[1] - min_max[0]) # to range [0,1]
- n_dim = tensor.dim()
- if n_dim == 4:
- n_img = len(tensor)
- img_np = make_grid(tensor, nrow=int(math.sqrt(n_img)), normalize=False).numpy()
- img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR
- elif n_dim == 3:
- img_np = tensor.numpy()
- img_np = np.transpose(img_np[[2, 1, 0], :, :], (1, 2, 0)) # HWC, BGR
- elif n_dim == 2:
- img_np = tensor.numpy()
- else:
- raise TypeError(
- 'Only support 4D, 3D and 2D tensor. But received with dimension: {:d}'.format(n_dim))
- if out_type == np.uint8:
- img_np = (img_np * 255.0).round()
- # Important. Unlike matlab, numpy.unit8() WILL NOT round by default.
- return img_np.astype(out_type)
-
-
-'''
-# --------------------------------------------
-# Augmentation, flipe and/or rotate
-# --------------------------------------------
-# The following two are enough.
-# (1) augmet_img: numpy image of WxHxC or WxH
-# (2) augment_img_tensor4: tensor image 1xCxWxH
-# --------------------------------------------
-'''
-
-
-def augment_img(img, mode=0):
- '''Kai Zhang (github: https://github.com/cszn)
- '''
- if mode == 0:
- return img
- elif mode == 1:
- return np.flipud(np.rot90(img))
- elif mode == 2:
- return np.flipud(img)
- elif mode == 3:
- return np.rot90(img, k=3)
- elif mode == 4:
- return np.flipud(np.rot90(img, k=2))
- elif mode == 5:
- return np.rot90(img)
- elif mode == 6:
- return np.rot90(img, k=2)
- elif mode == 7:
- return np.flipud(np.rot90(img, k=3))
-
-
-def augment_img_tensor4(img, mode=0):
- '''Kai Zhang (github: https://github.com/cszn)
- '''
- if mode == 0:
- return img
- elif mode == 1:
- return img.rot90(1, [2, 3]).flip([2])
- elif mode == 2:
- return img.flip([2])
- elif mode == 3:
- return img.rot90(3, [2, 3])
- elif mode == 4:
- return img.rot90(2, [2, 3]).flip([2])
- elif mode == 5:
- return img.rot90(1, [2, 3])
- elif mode == 6:
- return img.rot90(2, [2, 3])
- elif mode == 7:
- return img.rot90(3, [2, 3]).flip([2])
-
-
-def augment_img_tensor(img, mode=0):
- '''Kai Zhang (github: https://github.com/cszn)
- '''
- img_size = img.size()
- img_np = img.data.cpu().numpy()
- if len(img_size) == 3:
- img_np = np.transpose(img_np, (1, 2, 0))
- elif len(img_size) == 4:
- img_np = np.transpose(img_np, (2, 3, 1, 0))
- img_np = augment_img(img_np, mode=mode)
- img_tensor = torch.from_numpy(np.ascontiguousarray(img_np))
- if len(img_size) == 3:
- img_tensor = img_tensor.permute(2, 0, 1)
- elif len(img_size) == 4:
- img_tensor = img_tensor.permute(3, 2, 0, 1)
-
- return img_tensor.type_as(img)
-
-
-def augment_img_np3(img, mode=0):
- if mode == 0:
- return img
- elif mode == 1:
- return img.transpose(1, 0, 2)
- elif mode == 2:
- return img[::-1, :, :]
- elif mode == 3:
- img = img[::-1, :, :]
- img = img.transpose(1, 0, 2)
- return img
- elif mode == 4:
- return img[:, ::-1, :]
- elif mode == 5:
- img = img[:, ::-1, :]
- img = img.transpose(1, 0, 2)
- return img
- elif mode == 6:
- img = img[:, ::-1, :]
- img = img[::-1, :, :]
- return img
- elif mode == 7:
- img = img[:, ::-1, :]
- img = img[::-1, :, :]
- img = img.transpose(1, 0, 2)
- return img
-
-
-def augment_imgs(img_list, hflip=True, rot=True):
- # horizontal flip OR rotate
- hflip = hflip and random.random() < 0.5
- vflip = rot and random.random() < 0.5
- rot90 = rot and random.random() < 0.5
-
- def _augment(img):
- if hflip:
- img = img[:, ::-1, :]
- if vflip:
- img = img[::-1, :, :]
- if rot90:
- img = img.transpose(1, 0, 2)
- return img
-
- return [_augment(img) for img in img_list]
-
-
-'''
-# --------------------------------------------
-# modcrop and shave
-# --------------------------------------------
-'''
-
-
-def modcrop(img_in, scale):
- # img_in: Numpy, HWC or HW
- img = np.copy(img_in)
- if img.ndim == 2:
- H, W = img.shape
- H_r, W_r = H % scale, W % scale
- img = img[:H - H_r, :W - W_r]
- elif img.ndim == 3:
- H, W, C = img.shape
- H_r, W_r = H % scale, W % scale
- img = img[:H - H_r, :W - W_r, :]
- else:
- raise ValueError('Wrong img ndim: [{:d}].'.format(img.ndim))
- return img
-
-
-def shave(img_in, border=0):
- # img_in: Numpy, HWC or HW
- img = np.copy(img_in)
- h, w = img.shape[:2]
- img = img[border:h-border, border:w-border]
- return img
-
-
-'''
-# --------------------------------------------
-# image processing process on numpy image
-# channel_convert(in_c, tar_type, img_list):
-# rgb2ycbcr(img, only_y=True):
-# bgr2ycbcr(img, only_y=True):
-# ycbcr2rgb(img):
-# --------------------------------------------
-'''
-
-
-def rgb2ycbcr(img, only_y=True):
- '''same as matlab rgb2ycbcr
- only_y: only return Y channel
- Input:
- uint8, [0, 255]
- float, [0, 1]
- '''
- in_img_type = img.dtype
- img.astype(np.float32)
- if in_img_type != np.uint8:
- img *= 255.
- # convert
- if only_y:
- rlt = np.dot(img, [65.481, 128.553, 24.966]) / 255.0 + 16.0
- else:
- rlt = np.matmul(img, [[65.481, -37.797, 112.0], [128.553, -74.203, -93.786],
- [24.966, 112.0, -18.214]]) / 255.0 + [16, 128, 128]
- if in_img_type == np.uint8:
- rlt = rlt.round()
- else:
- rlt /= 255.
- return rlt.astype(in_img_type)
-
-
-def ycbcr2rgb(img):
- '''same as matlab ycbcr2rgb
- Input:
- uint8, [0, 255]
- float, [0, 1]
- '''
- in_img_type = img.dtype
- img.astype(np.float32)
- if in_img_type != np.uint8:
- img *= 255.
- # convert
- rlt = np.matmul(img, [[0.00456621, 0.00456621, 0.00456621], [0, -0.00153632, 0.00791071],
- [0.00625893, -0.00318811, 0]]) * 255.0 + [-222.921, 135.576, -276.836]
- if in_img_type == np.uint8:
- rlt = rlt.round()
- else:
- rlt /= 255.
- return rlt.astype(in_img_type)
-
-
-def bgr2ycbcr(img, only_y=True):
- '''bgr version of rgb2ycbcr
- only_y: only return Y channel
- Input:
- uint8, [0, 255]
- float, [0, 1]
- '''
- in_img_type = img.dtype
- img.astype(np.float32)
- if in_img_type != np.uint8:
- img *= 255.
- # convert
- if only_y:
- rlt = np.dot(img, [24.966, 128.553, 65.481]) / 255.0 + 16.0
- else:
- rlt = np.matmul(img, [[24.966, 112.0, -18.214], [128.553, -74.203, -93.786],
- [65.481, -37.797, 112.0]]) / 255.0 + [16, 128, 128]
- if in_img_type == np.uint8:
- rlt = rlt.round()
- else:
- rlt /= 255.
- return rlt.astype(in_img_type)
-
-
-def channel_convert(in_c, tar_type, img_list):
- # conversion among BGR, gray and y
- if in_c == 3 and tar_type == 'gray': # BGR to gray
- gray_list = [cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) for img in img_list]
- return [np.expand_dims(img, axis=2) for img in gray_list]
- elif in_c == 3 and tar_type == 'y': # BGR to y
- y_list = [bgr2ycbcr(img, only_y=True) for img in img_list]
- return [np.expand_dims(img, axis=2) for img in y_list]
- elif in_c == 1 and tar_type == 'RGB': # gray/y to BGR
- return [cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) for img in img_list]
- else:
- return img_list
-
-
-'''
-# --------------------------------------------
-# metric, PSNR and SSIM
-# --------------------------------------------
-'''
-
-
-# --------------------------------------------
-# PSNR
-# --------------------------------------------
-def calculate_psnr(img1, img2, border=0):
- # img1 and img2 have range [0, 255]
- #img1 = img1.squeeze()
- #img2 = img2.squeeze()
- if not img1.shape == img2.shape:
- raise ValueError('Input images must have the same dimensions.')
- h, w = img1.shape[:2]
- img1 = img1[border:h-border, border:w-border]
- img2 = img2[border:h-border, border:w-border]
-
- img1 = img1.astype(np.float64)
- img2 = img2.astype(np.float64)
- mse = np.mean((img1 - img2)**2)
- if mse == 0:
- return float('inf')
- return 20 * math.log10(255.0 / math.sqrt(mse))
-
-
-# --------------------------------------------
-# SSIM
-# --------------------------------------------
-def calculate_ssim(img1, img2, border=0):
- '''calculate SSIM
- the same outputs as MATLAB's
- img1, img2: [0, 255]
- '''
- #img1 = img1.squeeze()
- #img2 = img2.squeeze()
- if not img1.shape == img2.shape:
- raise ValueError('Input images must have the same dimensions.')
- h, w = img1.shape[:2]
- img1 = img1[border:h-border, border:w-border]
- img2 = img2[border:h-border, border:w-border]
-
- if img1.ndim == 2:
- return ssim(img1, img2)
- elif img1.ndim == 3:
- if img1.shape[2] == 3:
- ssims = []
- for i in range(3):
- ssims.append(ssim(img1[:,:,i], img2[:,:,i]))
- return np.array(ssims).mean()
- elif img1.shape[2] == 1:
- return ssim(np.squeeze(img1), np.squeeze(img2))
- else:
- raise ValueError('Wrong input image dimensions.')
-
-
-def ssim(img1, img2):
- C1 = (0.01 * 255)**2
- C2 = (0.03 * 255)**2
-
- img1 = img1.astype(np.float64)
- img2 = img2.astype(np.float64)
- kernel = cv2.getGaussianKernel(11, 1.5)
- window = np.outer(kernel, kernel.transpose())
-
- mu1 = cv2.filter2D(img1, -1, window)[5:-5, 5:-5] # valid
- mu2 = cv2.filter2D(img2, -1, window)[5:-5, 5:-5]
- mu1_sq = mu1**2
- mu2_sq = mu2**2
- mu1_mu2 = mu1 * mu2
- sigma1_sq = cv2.filter2D(img1**2, -1, window)[5:-5, 5:-5] - mu1_sq
- sigma2_sq = cv2.filter2D(img2**2, -1, window)[5:-5, 5:-5] - mu2_sq
- sigma12 = cv2.filter2D(img1 * img2, -1, window)[5:-5, 5:-5] - mu1_mu2
-
- ssim_map = ((2 * mu1_mu2 + C1) * (2 * sigma12 + C2)) / ((mu1_sq + mu2_sq + C1) *
- (sigma1_sq + sigma2_sq + C2))
- return ssim_map.mean()
-
-
-'''
-# --------------------------------------------
-# matlab's bicubic imresize (numpy and torch) [0, 1]
-# --------------------------------------------
-'''
-
-
-# matlab 'imresize' function, now only support 'bicubic'
-def cubic(x):
- absx = torch.abs(x)
- absx2 = absx**2
- absx3 = absx**3
- return (1.5*absx3 - 2.5*absx2 + 1) * ((absx <= 1).type_as(absx)) + \
- (-0.5*absx3 + 2.5*absx2 - 4*absx + 2) * (((absx > 1)*(absx <= 2)).type_as(absx))
-
-
-def calculate_weights_indices(in_length, out_length, scale, kernel, kernel_width, antialiasing):
- if (scale < 1) and (antialiasing):
- # Use a modified kernel to simultaneously interpolate and antialias- larger kernel width
- kernel_width = kernel_width / scale
-
- # Output-space coordinates
- x = torch.linspace(1, out_length, out_length)
-
- # Input-space coordinates. Calculate the inverse mapping such that 0.5
- # in output space maps to 0.5 in input space, and 0.5+scale in output
- # space maps to 1.5 in input space.
- u = x / scale + 0.5 * (1 - 1 / scale)
-
- # What is the left-most pixel that can be involved in the computation?
- left = torch.floor(u - kernel_width / 2)
-
- # What is the maximum number of pixels that can be involved in the
- # computation? Note: it's OK to use an extra pixel here; if the
- # corresponding weights are all zero, it will be eliminated at the end
- # of this function.
- P = math.ceil(kernel_width) + 2
-
- # The indices of the input pixels involved in computing the k-th output
- # pixel are in row k of the indices matrix.
- indices = left.view(out_length, 1).expand(out_length, P) + torch.linspace(0, P - 1, P).view(
- 1, P).expand(out_length, P)
-
- # The weights used to compute the k-th output pixel are in row k of the
- # weights matrix.
- distance_to_center = u.view(out_length, 1).expand(out_length, P) - indices
- # apply cubic kernel
- if (scale < 1) and (antialiasing):
- weights = scale * cubic(distance_to_center * scale)
- else:
- weights = cubic(distance_to_center)
- # Normalize the weights matrix so that each row sums to 1.
- weights_sum = torch.sum(weights, 1).view(out_length, 1)
- weights = weights / weights_sum.expand(out_length, P)
-
- # If a column in weights is all zero, get rid of it. only consider the first and last column.
- weights_zero_tmp = torch.sum((weights == 0), 0)
- if not math.isclose(weights_zero_tmp[0], 0, rel_tol=1e-6):
- indices = indices.narrow(1, 1, P - 2)
- weights = weights.narrow(1, 1, P - 2)
- if not math.isclose(weights_zero_tmp[-1], 0, rel_tol=1e-6):
- indices = indices.narrow(1, 0, P - 2)
- weights = weights.narrow(1, 0, P - 2)
- weights = weights.contiguous()
- indices = indices.contiguous()
- sym_len_s = -indices.min() + 1
- sym_len_e = indices.max() - in_length
- indices = indices + sym_len_s - 1
- return weights, indices, int(sym_len_s), int(sym_len_e)
-
-
-# --------------------------------------------
-# imresize for tensor image [0, 1]
-# --------------------------------------------
-def imresize(img, scale, antialiasing=True):
- # Now the scale should be the same for H and W
- # input: img: pytorch tensor, CHW or HW [0,1]
- # output: CHW or HW [0,1] w/o round
- need_squeeze = True if img.dim() == 2 else False
- if need_squeeze:
- img.unsqueeze_(0)
- in_C, in_H, in_W = img.size()
- out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
- kernel_width = 4
- kernel = 'cubic'
-
- # Return the desired dimension order for performing the resize. The
- # strategy is to perform the resize first along the dimension with the
- # smallest scale factor.
- # Now we do not support this.
-
- # get weights and indices
- weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
- in_H, out_H, scale, kernel, kernel_width, antialiasing)
- weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
- in_W, out_W, scale, kernel, kernel_width, antialiasing)
- # process H dimension
- # symmetric copying
- img_aug = torch.FloatTensor(in_C, in_H + sym_len_Hs + sym_len_He, in_W)
- img_aug.narrow(1, sym_len_Hs, in_H).copy_(img)
-
- sym_patch = img[:, :sym_len_Hs, :]
- inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(1, inv_idx)
- img_aug.narrow(1, 0, sym_len_Hs).copy_(sym_patch_inv)
-
- sym_patch = img[:, -sym_len_He:, :]
- inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(1, inv_idx)
- img_aug.narrow(1, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
-
- out_1 = torch.FloatTensor(in_C, out_H, in_W)
- kernel_width = weights_H.size(1)
- for i in range(out_H):
- idx = int(indices_H[i][0])
- for j in range(out_C):
- out_1[j, i, :] = img_aug[j, idx:idx + kernel_width, :].transpose(0, 1).mv(weights_H[i])
-
- # process W dimension
- # symmetric copying
- out_1_aug = torch.FloatTensor(in_C, out_H, in_W + sym_len_Ws + sym_len_We)
- out_1_aug.narrow(2, sym_len_Ws, in_W).copy_(out_1)
-
- sym_patch = out_1[:, :, :sym_len_Ws]
- inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(2, inv_idx)
- out_1_aug.narrow(2, 0, sym_len_Ws).copy_(sym_patch_inv)
-
- sym_patch = out_1[:, :, -sym_len_We:]
- inv_idx = torch.arange(sym_patch.size(2) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(2, inv_idx)
- out_1_aug.narrow(2, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
-
- out_2 = torch.FloatTensor(in_C, out_H, out_W)
- kernel_width = weights_W.size(1)
- for i in range(out_W):
- idx = int(indices_W[i][0])
- for j in range(out_C):
- out_2[j, :, i] = out_1_aug[j, :, idx:idx + kernel_width].mv(weights_W[i])
- if need_squeeze:
- out_2.squeeze_()
- return out_2
-
-
-# --------------------------------------------
-# imresize for numpy image [0, 1]
-# --------------------------------------------
-def imresize_np(img, scale, antialiasing=True):
- # Now the scale should be the same for H and W
- # input: img: Numpy, HWC or HW [0,1]
- # output: HWC or HW [0,1] w/o round
- img = torch.from_numpy(img)
- need_squeeze = True if img.dim() == 2 else False
- if need_squeeze:
- img.unsqueeze_(2)
-
- in_H, in_W, in_C = img.size()
- out_C, out_H, out_W = in_C, math.ceil(in_H * scale), math.ceil(in_W * scale)
- kernel_width = 4
- kernel = 'cubic'
-
- # Return the desired dimension order for performing the resize. The
- # strategy is to perform the resize first along the dimension with the
- # smallest scale factor.
- # Now we do not support this.
-
- # get weights and indices
- weights_H, indices_H, sym_len_Hs, sym_len_He = calculate_weights_indices(
- in_H, out_H, scale, kernel, kernel_width, antialiasing)
- weights_W, indices_W, sym_len_Ws, sym_len_We = calculate_weights_indices(
- in_W, out_W, scale, kernel, kernel_width, antialiasing)
- # process H dimension
- # symmetric copying
- img_aug = torch.FloatTensor(in_H + sym_len_Hs + sym_len_He, in_W, in_C)
- img_aug.narrow(0, sym_len_Hs, in_H).copy_(img)
-
- sym_patch = img[:sym_len_Hs, :, :]
- inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(0, inv_idx)
- img_aug.narrow(0, 0, sym_len_Hs).copy_(sym_patch_inv)
-
- sym_patch = img[-sym_len_He:, :, :]
- inv_idx = torch.arange(sym_patch.size(0) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(0, inv_idx)
- img_aug.narrow(0, sym_len_Hs + in_H, sym_len_He).copy_(sym_patch_inv)
-
- out_1 = torch.FloatTensor(out_H, in_W, in_C)
- kernel_width = weights_H.size(1)
- for i in range(out_H):
- idx = int(indices_H[i][0])
- for j in range(out_C):
- out_1[i, :, j] = img_aug[idx:idx + kernel_width, :, j].transpose(0, 1).mv(weights_H[i])
-
- # process W dimension
- # symmetric copying
- out_1_aug = torch.FloatTensor(out_H, in_W + sym_len_Ws + sym_len_We, in_C)
- out_1_aug.narrow(1, sym_len_Ws, in_W).copy_(out_1)
-
- sym_patch = out_1[:, :sym_len_Ws, :]
- inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(1, inv_idx)
- out_1_aug.narrow(1, 0, sym_len_Ws).copy_(sym_patch_inv)
-
- sym_patch = out_1[:, -sym_len_We:, :]
- inv_idx = torch.arange(sym_patch.size(1) - 1, -1, -1).long()
- sym_patch_inv = sym_patch.index_select(1, inv_idx)
- out_1_aug.narrow(1, sym_len_Ws + in_W, sym_len_We).copy_(sym_patch_inv)
-
- out_2 = torch.FloatTensor(out_H, out_W, in_C)
- kernel_width = weights_W.size(1)
- for i in range(out_W):
- idx = int(indices_W[i][0])
- for j in range(out_C):
- out_2[:, i, j] = out_1_aug[:, idx:idx + kernel_width, j].mv(weights_W[i])
- if need_squeeze:
- out_2.squeeze_()
-
- return out_2.numpy()
-
-
-if __name__ == '__main__':
- print('---')
-# img = imread_uint('test.bmp', 3)
-# img = uint2single(img)
-# img_bicubic = imresize_np(img, 1/4)
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/losses/__init__.py b/examples/tutorial/stable_diffusion/ldm/modules/losses/__init__.py
deleted file mode 100644
index 876d7c5bd..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/losses/__init__.py
+++ /dev/null
@@ -1 +0,0 @@
-from ldm.modules.losses.contperceptual import LPIPSWithDiscriminator
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/losses/contperceptual.py b/examples/tutorial/stable_diffusion/ldm/modules/losses/contperceptual.py
deleted file mode 100644
index 672c1e32a..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/losses/contperceptual.py
+++ /dev/null
@@ -1,111 +0,0 @@
-import torch
-import torch.nn as nn
-
-from taming.modules.losses.vqperceptual import * # TODO: taming dependency yes/no?
-
-
-class LPIPSWithDiscriminator(nn.Module):
- def __init__(self, disc_start, logvar_init=0.0, kl_weight=1.0, pixelloss_weight=1.0,
- disc_num_layers=3, disc_in_channels=3, disc_factor=1.0, disc_weight=1.0,
- perceptual_weight=1.0, use_actnorm=False, disc_conditional=False,
- disc_loss="hinge"):
-
- super().__init__()
- assert disc_loss in ["hinge", "vanilla"]
- self.kl_weight = kl_weight
- self.pixel_weight = pixelloss_weight
- self.perceptual_loss = LPIPS().eval()
- self.perceptual_weight = perceptual_weight
- # output log variance
- self.logvar = nn.Parameter(torch.ones(size=()) * logvar_init)
-
- self.discriminator = NLayerDiscriminator(input_nc=disc_in_channels,
- n_layers=disc_num_layers,
- use_actnorm=use_actnorm
- ).apply(weights_init)
- self.discriminator_iter_start = disc_start
- self.disc_loss = hinge_d_loss if disc_loss == "hinge" else vanilla_d_loss
- self.disc_factor = disc_factor
- self.discriminator_weight = disc_weight
- self.disc_conditional = disc_conditional
-
- def calculate_adaptive_weight(self, nll_loss, g_loss, last_layer=None):
- if last_layer is not None:
- nll_grads = torch.autograd.grad(nll_loss, last_layer, retain_graph=True)[0]
- g_grads = torch.autograd.grad(g_loss, last_layer, retain_graph=True)[0]
- else:
- nll_grads = torch.autograd.grad(nll_loss, self.last_layer[0], retain_graph=True)[0]
- g_grads = torch.autograd.grad(g_loss, self.last_layer[0], retain_graph=True)[0]
-
- d_weight = torch.norm(nll_grads) / (torch.norm(g_grads) + 1e-4)
- d_weight = torch.clamp(d_weight, 0.0, 1e4).detach()
- d_weight = d_weight * self.discriminator_weight
- return d_weight
-
- def forward(self, inputs, reconstructions, posteriors, optimizer_idx,
- global_step, last_layer=None, cond=None, split="train",
- weights=None):
- rec_loss = torch.abs(inputs.contiguous() - reconstructions.contiguous())
- if self.perceptual_weight > 0:
- p_loss = self.perceptual_loss(inputs.contiguous(), reconstructions.contiguous())
- rec_loss = rec_loss + self.perceptual_weight * p_loss
-
- nll_loss = rec_loss / torch.exp(self.logvar) + self.logvar
- weighted_nll_loss = nll_loss
- if weights is not None:
- weighted_nll_loss = weights*nll_loss
- weighted_nll_loss = torch.sum(weighted_nll_loss) / weighted_nll_loss.shape[0]
- nll_loss = torch.sum(nll_loss) / nll_loss.shape[0]
- kl_loss = posteriors.kl()
- kl_loss = torch.sum(kl_loss) / kl_loss.shape[0]
-
- # now the GAN part
- if optimizer_idx == 0:
- # generator update
- if cond is None:
- assert not self.disc_conditional
- logits_fake = self.discriminator(reconstructions.contiguous())
- else:
- assert self.disc_conditional
- logits_fake = self.discriminator(torch.cat((reconstructions.contiguous(), cond), dim=1))
- g_loss = -torch.mean(logits_fake)
-
- if self.disc_factor > 0.0:
- try:
- d_weight = self.calculate_adaptive_weight(nll_loss, g_loss, last_layer=last_layer)
- except RuntimeError:
- assert not self.training
- d_weight = torch.tensor(0.0)
- else:
- d_weight = torch.tensor(0.0)
-
- disc_factor = adopt_weight(self.disc_factor, global_step, threshold=self.discriminator_iter_start)
- loss = weighted_nll_loss + self.kl_weight * kl_loss + d_weight * disc_factor * g_loss
-
- log = {"{}/total_loss".format(split): loss.clone().detach().mean(), "{}/logvar".format(split): self.logvar.detach(),
- "{}/kl_loss".format(split): kl_loss.detach().mean(), "{}/nll_loss".format(split): nll_loss.detach().mean(),
- "{}/rec_loss".format(split): rec_loss.detach().mean(),
- "{}/d_weight".format(split): d_weight.detach(),
- "{}/disc_factor".format(split): torch.tensor(disc_factor),
- "{}/g_loss".format(split): g_loss.detach().mean(),
- }
- return loss, log
-
- if optimizer_idx == 1:
- # second pass for discriminator update
- if cond is None:
- logits_real = self.discriminator(inputs.contiguous().detach())
- logits_fake = self.discriminator(reconstructions.contiguous().detach())
- else:
- logits_real = self.discriminator(torch.cat((inputs.contiguous().detach(), cond), dim=1))
- logits_fake = self.discriminator(torch.cat((reconstructions.contiguous().detach(), cond), dim=1))
-
- disc_factor = adopt_weight(self.disc_factor, global_step, threshold=self.discriminator_iter_start)
- d_loss = disc_factor * self.disc_loss(logits_real, logits_fake)
-
- log = {"{}/disc_loss".format(split): d_loss.clone().detach().mean(),
- "{}/logits_real".format(split): logits_real.detach().mean(),
- "{}/logits_fake".format(split): logits_fake.detach().mean()
- }
- return d_loss, log
-
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/losses/vqperceptual.py b/examples/tutorial/stable_diffusion/ldm/modules/losses/vqperceptual.py
deleted file mode 100644
index f69981769..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/losses/vqperceptual.py
+++ /dev/null
@@ -1,167 +0,0 @@
-import torch
-from torch import nn
-import torch.nn.functional as F
-from einops import repeat
-
-from taming.modules.discriminator.model import NLayerDiscriminator, weights_init
-from taming.modules.losses.lpips import LPIPS
-from taming.modules.losses.vqperceptual import hinge_d_loss, vanilla_d_loss
-
-
-def hinge_d_loss_with_exemplar_weights(logits_real, logits_fake, weights):
- assert weights.shape[0] == logits_real.shape[0] == logits_fake.shape[0]
- loss_real = torch.mean(F.relu(1. - logits_real), dim=[1,2,3])
- loss_fake = torch.mean(F.relu(1. + logits_fake), dim=[1,2,3])
- loss_real = (weights * loss_real).sum() / weights.sum()
- loss_fake = (weights * loss_fake).sum() / weights.sum()
- d_loss = 0.5 * (loss_real + loss_fake)
- return d_loss
-
-def adopt_weight(weight, global_step, threshold=0, value=0.):
- if global_step < threshold:
- weight = value
- return weight
-
-
-def measure_perplexity(predicted_indices, n_embed):
- # src: https://github.com/karpathy/deep-vector-quantization/blob/main/model.py
- # eval cluster perplexity. when perplexity == num_embeddings then all clusters are used exactly equally
- encodings = F.one_hot(predicted_indices, n_embed).float().reshape(-1, n_embed)
- avg_probs = encodings.mean(0)
- perplexity = (-(avg_probs * torch.log(avg_probs + 1e-10)).sum()).exp()
- cluster_use = torch.sum(avg_probs > 0)
- return perplexity, cluster_use
-
-def l1(x, y):
- return torch.abs(x-y)
-
-
-def l2(x, y):
- return torch.pow((x-y), 2)
-
-
-class VQLPIPSWithDiscriminator(nn.Module):
- def __init__(self, disc_start, codebook_weight=1.0, pixelloss_weight=1.0,
- disc_num_layers=3, disc_in_channels=3, disc_factor=1.0, disc_weight=1.0,
- perceptual_weight=1.0, use_actnorm=False, disc_conditional=False,
- disc_ndf=64, disc_loss="hinge", n_classes=None, perceptual_loss="lpips",
- pixel_loss="l1"):
- super().__init__()
- assert disc_loss in ["hinge", "vanilla"]
- assert perceptual_loss in ["lpips", "clips", "dists"]
- assert pixel_loss in ["l1", "l2"]
- self.codebook_weight = codebook_weight
- self.pixel_weight = pixelloss_weight
- if perceptual_loss == "lpips":
- print(f"{self.__class__.__name__}: Running with LPIPS.")
- self.perceptual_loss = LPIPS().eval()
- else:
- raise ValueError(f"Unknown perceptual loss: >> {perceptual_loss} <<")
- self.perceptual_weight = perceptual_weight
-
- if pixel_loss == "l1":
- self.pixel_loss = l1
- else:
- self.pixel_loss = l2
-
- self.discriminator = NLayerDiscriminator(input_nc=disc_in_channels,
- n_layers=disc_num_layers,
- use_actnorm=use_actnorm,
- ndf=disc_ndf
- ).apply(weights_init)
- self.discriminator_iter_start = disc_start
- if disc_loss == "hinge":
- self.disc_loss = hinge_d_loss
- elif disc_loss == "vanilla":
- self.disc_loss = vanilla_d_loss
- else:
- raise ValueError(f"Unknown GAN loss '{disc_loss}'.")
- print(f"VQLPIPSWithDiscriminator running with {disc_loss} loss.")
- self.disc_factor = disc_factor
- self.discriminator_weight = disc_weight
- self.disc_conditional = disc_conditional
- self.n_classes = n_classes
-
- def calculate_adaptive_weight(self, nll_loss, g_loss, last_layer=None):
- if last_layer is not None:
- nll_grads = torch.autograd.grad(nll_loss, last_layer, retain_graph=True)[0]
- g_grads = torch.autograd.grad(g_loss, last_layer, retain_graph=True)[0]
- else:
- nll_grads = torch.autograd.grad(nll_loss, self.last_layer[0], retain_graph=True)[0]
- g_grads = torch.autograd.grad(g_loss, self.last_layer[0], retain_graph=True)[0]
-
- d_weight = torch.norm(nll_grads) / (torch.norm(g_grads) + 1e-4)
- d_weight = torch.clamp(d_weight, 0.0, 1e4).detach()
- d_weight = d_weight * self.discriminator_weight
- return d_weight
-
- def forward(self, codebook_loss, inputs, reconstructions, optimizer_idx,
- global_step, last_layer=None, cond=None, split="train", predicted_indices=None):
- if not exists(codebook_loss):
- codebook_loss = torch.tensor([0.]).to(inputs.device)
- #rec_loss = torch.abs(inputs.contiguous() - reconstructions.contiguous())
- rec_loss = self.pixel_loss(inputs.contiguous(), reconstructions.contiguous())
- if self.perceptual_weight > 0:
- p_loss = self.perceptual_loss(inputs.contiguous(), reconstructions.contiguous())
- rec_loss = rec_loss + self.perceptual_weight * p_loss
- else:
- p_loss = torch.tensor([0.0])
-
- nll_loss = rec_loss
- #nll_loss = torch.sum(nll_loss) / nll_loss.shape[0]
- nll_loss = torch.mean(nll_loss)
-
- # now the GAN part
- if optimizer_idx == 0:
- # generator update
- if cond is None:
- assert not self.disc_conditional
- logits_fake = self.discriminator(reconstructions.contiguous())
- else:
- assert self.disc_conditional
- logits_fake = self.discriminator(torch.cat((reconstructions.contiguous(), cond), dim=1))
- g_loss = -torch.mean(logits_fake)
-
- try:
- d_weight = self.calculate_adaptive_weight(nll_loss, g_loss, last_layer=last_layer)
- except RuntimeError:
- assert not self.training
- d_weight = torch.tensor(0.0)
-
- disc_factor = adopt_weight(self.disc_factor, global_step, threshold=self.discriminator_iter_start)
- loss = nll_loss + d_weight * disc_factor * g_loss + self.codebook_weight * codebook_loss.mean()
-
- log = {"{}/total_loss".format(split): loss.clone().detach().mean(),
- "{}/quant_loss".format(split): codebook_loss.detach().mean(),
- "{}/nll_loss".format(split): nll_loss.detach().mean(),
- "{}/rec_loss".format(split): rec_loss.detach().mean(),
- "{}/p_loss".format(split): p_loss.detach().mean(),
- "{}/d_weight".format(split): d_weight.detach(),
- "{}/disc_factor".format(split): torch.tensor(disc_factor),
- "{}/g_loss".format(split): g_loss.detach().mean(),
- }
- if predicted_indices is not None:
- assert self.n_classes is not None
- with torch.no_grad():
- perplexity, cluster_usage = measure_perplexity(predicted_indices, self.n_classes)
- log[f"{split}/perplexity"] = perplexity
- log[f"{split}/cluster_usage"] = cluster_usage
- return loss, log
-
- if optimizer_idx == 1:
- # second pass for discriminator update
- if cond is None:
- logits_real = self.discriminator(inputs.contiguous().detach())
- logits_fake = self.discriminator(reconstructions.contiguous().detach())
- else:
- logits_real = self.discriminator(torch.cat((inputs.contiguous().detach(), cond), dim=1))
- logits_fake = self.discriminator(torch.cat((reconstructions.contiguous().detach(), cond), dim=1))
-
- disc_factor = adopt_weight(self.disc_factor, global_step, threshold=self.discriminator_iter_start)
- d_loss = disc_factor * self.disc_loss(logits_real, logits_fake)
-
- log = {"{}/disc_loss".format(split): d_loss.clone().detach().mean(),
- "{}/logits_real".format(split): logits_real.detach().mean(),
- "{}/logits_fake".format(split): logits_fake.detach().mean()
- }
- return d_loss, log
diff --git a/examples/tutorial/stable_diffusion/ldm/modules/x_transformer.py b/examples/tutorial/stable_diffusion/ldm/modules/x_transformer.py
deleted file mode 100644
index 5fc15bf9c..000000000
--- a/examples/tutorial/stable_diffusion/ldm/modules/x_transformer.py
+++ /dev/null
@@ -1,641 +0,0 @@
-"""shout-out to https://github.com/lucidrains/x-transformers/tree/main/x_transformers"""
-import torch
-from torch import nn, einsum
-import torch.nn.functional as F
-from functools import partial
-from inspect import isfunction
-from collections import namedtuple
-from einops import rearrange, repeat, reduce
-
-# constants
-
-DEFAULT_DIM_HEAD = 64
-
-Intermediates = namedtuple('Intermediates', [
- 'pre_softmax_attn',
- 'post_softmax_attn'
-])
-
-LayerIntermediates = namedtuple('Intermediates', [
- 'hiddens',
- 'attn_intermediates'
-])
-
-
-class AbsolutePositionalEmbedding(nn.Module):
- def __init__(self, dim, max_seq_len):
- super().__init__()
- self.emb = nn.Embedding(max_seq_len, dim)
- self.init_()
-
- def init_(self):
- nn.init.normal_(self.emb.weight, std=0.02)
-
- def forward(self, x):
- n = torch.arange(x.shape[1], device=x.device)
- return self.emb(n)[None, :, :]
-
-
-class FixedPositionalEmbedding(nn.Module):
- def __init__(self, dim):
- super().__init__()
- inv_freq = 1. / (10000 ** (torch.arange(0, dim, 2).float() / dim))
- self.register_buffer('inv_freq', inv_freq)
-
- def forward(self, x, seq_dim=1, offset=0):
- t = torch.arange(x.shape[seq_dim], device=x.device).type_as(self.inv_freq) + offset
- sinusoid_inp = torch.einsum('i , j -> i j', t, self.inv_freq)
- emb = torch.cat((sinusoid_inp.sin(), sinusoid_inp.cos()), dim=-1)
- return emb[None, :, :]
-
-
-# helpers
-
-def exists(val):
- return val is not None
-
-
-def default(val, d):
- if exists(val):
- return val
- return d() if isfunction(d) else d
-
-
-def always(val):
- def inner(*args, **kwargs):
- return val
- return inner
-
-
-def not_equals(val):
- def inner(x):
- return x != val
- return inner
-
-
-def equals(val):
- def inner(x):
- return x == val
- return inner
-
-
-def max_neg_value(tensor):
- return -torch.finfo(tensor.dtype).max
-
-
-# keyword argument helpers
-
-def pick_and_pop(keys, d):
- values = list(map(lambda key: d.pop(key), keys))
- return dict(zip(keys, values))
-
-
-def group_dict_by_key(cond, d):
- return_val = [dict(), dict()]
- for key in d.keys():
- match = bool(cond(key))
- ind = int(not match)
- return_val[ind][key] = d[key]
- return (*return_val,)
-
-
-def string_begins_with(prefix, str):
- return str.startswith(prefix)
-
-
-def group_by_key_prefix(prefix, d):
- return group_dict_by_key(partial(string_begins_with, prefix), d)
-
-
-def groupby_prefix_and_trim(prefix, d):
- kwargs_with_prefix, kwargs = group_dict_by_key(partial(string_begins_with, prefix), d)
- kwargs_without_prefix = dict(map(lambda x: (x[0][len(prefix):], x[1]), tuple(kwargs_with_prefix.items())))
- return kwargs_without_prefix, kwargs
-
-
-# classes
-class Scale(nn.Module):
- def __init__(self, value, fn):
- super().__init__()
- self.value = value
- self.fn = fn
-
- def forward(self, x, **kwargs):
- x, *rest = self.fn(x, **kwargs)
- return (x * self.value, *rest)
-
-
-class Rezero(nn.Module):
- def __init__(self, fn):
- super().__init__()
- self.fn = fn
- self.g = nn.Parameter(torch.zeros(1))
-
- def forward(self, x, **kwargs):
- x, *rest = self.fn(x, **kwargs)
- return (x * self.g, *rest)
-
-
-class ScaleNorm(nn.Module):
- def __init__(self, dim, eps=1e-5):
- super().__init__()
- self.scale = dim ** -0.5
- self.eps = eps
- self.g = nn.Parameter(torch.ones(1))
-
- def forward(self, x):
- norm = torch.norm(x, dim=-1, keepdim=True) * self.scale
- return x / norm.clamp(min=self.eps) * self.g
-
-
-class RMSNorm(nn.Module):
- def __init__(self, dim, eps=1e-8):
- super().__init__()
- self.scale = dim ** -0.5
- self.eps = eps
- self.g = nn.Parameter(torch.ones(dim))
-
- def forward(self, x):
- norm = torch.norm(x, dim=-1, keepdim=True) * self.scale
- return x / norm.clamp(min=self.eps) * self.g
-
-
-class Residual(nn.Module):
- def forward(self, x, residual):
- return x + residual
-
-
-class GRUGating(nn.Module):
- def __init__(self, dim):
- super().__init__()
- self.gru = nn.GRUCell(dim, dim)
-
- def forward(self, x, residual):
- gated_output = self.gru(
- rearrange(x, 'b n d -> (b n) d'),
- rearrange(residual, 'b n d -> (b n) d')
- )
-
- return gated_output.reshape_as(x)
-
-
-# feedforward
-
-class GEGLU(nn.Module):
- def __init__(self, dim_in, dim_out):
- super().__init__()
- self.proj = nn.Linear(dim_in, dim_out * 2)
-
- def forward(self, x):
- x, gate = self.proj(x).chunk(2, dim=-1)
- return x * F.gelu(gate)
-
-
-class FeedForward(nn.Module):
- def __init__(self, dim, dim_out=None, mult=4, glu=False, dropout=0.):
- super().__init__()
- inner_dim = int(dim * mult)
- dim_out = default(dim_out, dim)
- project_in = nn.Sequential(
- nn.Linear(dim, inner_dim),
- nn.GELU()
- ) if not glu else GEGLU(dim, inner_dim)
-
- self.net = nn.Sequential(
- project_in,
- nn.Dropout(dropout),
- nn.Linear(inner_dim, dim_out)
- )
-
- def forward(self, x):
- return self.net(x)
-
-
-# attention.
-class Attention(nn.Module):
- def __init__(
- self,
- dim,
- dim_head=DEFAULT_DIM_HEAD,
- heads=8,
- causal=False,
- mask=None,
- talking_heads=False,
- sparse_topk=None,
- use_entmax15=False,
- num_mem_kv=0,
- dropout=0.,
- on_attn=False
- ):
- super().__init__()
- if use_entmax15:
- raise NotImplementedError("Check out entmax activation instead of softmax activation!")
- self.scale = dim_head ** -0.5
- self.heads = heads
- self.causal = causal
- self.mask = mask
-
- inner_dim = dim_head * heads
-
- self.to_q = nn.Linear(dim, inner_dim, bias=False)
- self.to_k = nn.Linear(dim, inner_dim, bias=False)
- self.to_v = nn.Linear(dim, inner_dim, bias=False)
- self.dropout = nn.Dropout(dropout)
-
- # talking heads
- self.talking_heads = talking_heads
- if talking_heads:
- self.pre_softmax_proj = nn.Parameter(torch.randn(heads, heads))
- self.post_softmax_proj = nn.Parameter(torch.randn(heads, heads))
-
- # explicit topk sparse attention
- self.sparse_topk = sparse_topk
-
- # entmax
- #self.attn_fn = entmax15 if use_entmax15 else F.softmax
- self.attn_fn = F.softmax
-
- # add memory key / values
- self.num_mem_kv = num_mem_kv
- if num_mem_kv > 0:
- self.mem_k = nn.Parameter(torch.randn(heads, num_mem_kv, dim_head))
- self.mem_v = nn.Parameter(torch.randn(heads, num_mem_kv, dim_head))
-
- # attention on attention
- self.attn_on_attn = on_attn
- self.to_out = nn.Sequential(nn.Linear(inner_dim, dim * 2), nn.GLU()) if on_attn else nn.Linear(inner_dim, dim)
-
- def forward(
- self,
- x,
- context=None,
- mask=None,
- context_mask=None,
- rel_pos=None,
- sinusoidal_emb=None,
- prev_attn=None,
- mem=None
- ):
- b, n, _, h, talking_heads, device = *x.shape, self.heads, self.talking_heads, x.device
- kv_input = default(context, x)
-
- q_input = x
- k_input = kv_input
- v_input = kv_input
-
- if exists(mem):
- k_input = torch.cat((mem, k_input), dim=-2)
- v_input = torch.cat((mem, v_input), dim=-2)
-
- if exists(sinusoidal_emb):
- # in shortformer, the query would start at a position offset depending on the past cached memory
- offset = k_input.shape[-2] - q_input.shape[-2]
- q_input = q_input + sinusoidal_emb(q_input, offset=offset)
- k_input = k_input + sinusoidal_emb(k_input)
-
- q = self.to_q(q_input)
- k = self.to_k(k_input)
- v = self.to_v(v_input)
-
- q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h=h), (q, k, v))
-
- input_mask = None
- if any(map(exists, (mask, context_mask))):
- q_mask = default(mask, lambda: torch.ones((b, n), device=device).bool())
- k_mask = q_mask if not exists(context) else context_mask
- k_mask = default(k_mask, lambda: torch.ones((b, k.shape[-2]), device=device).bool())
- q_mask = rearrange(q_mask, 'b i -> b () i ()')
- k_mask = rearrange(k_mask, 'b j -> b () () j')
- input_mask = q_mask * k_mask
-
- if self.num_mem_kv > 0:
- mem_k, mem_v = map(lambda t: repeat(t, 'h n d -> b h n d', b=b), (self.mem_k, self.mem_v))
- k = torch.cat((mem_k, k), dim=-2)
- v = torch.cat((mem_v, v), dim=-2)
- if exists(input_mask):
- input_mask = F.pad(input_mask, (self.num_mem_kv, 0), value=True)
-
- dots = einsum('b h i d, b h j d -> b h i j', q, k) * self.scale
- mask_value = max_neg_value(dots)
-
- if exists(prev_attn):
- dots = dots + prev_attn
-
- pre_softmax_attn = dots
-
- if talking_heads:
- dots = einsum('b h i j, h k -> b k i j', dots, self.pre_softmax_proj).contiguous()
-
- if exists(rel_pos):
- dots = rel_pos(dots)
-
- if exists(input_mask):
- dots.masked_fill_(~input_mask, mask_value)
- del input_mask
-
- if self.causal:
- i, j = dots.shape[-2:]
- r = torch.arange(i, device=device)
- mask = rearrange(r, 'i -> () () i ()') < rearrange(r, 'j -> () () () j')
- mask = F.pad(mask, (j - i, 0), value=False)
- dots.masked_fill_(mask, mask_value)
- del mask
-
- if exists(self.sparse_topk) and self.sparse_topk < dots.shape[-1]:
- top, _ = dots.topk(self.sparse_topk, dim=-1)
- vk = top[..., -1].unsqueeze(-1).expand_as(dots)
- mask = dots < vk
- dots.masked_fill_(mask, mask_value)
- del mask
-
- attn = self.attn_fn(dots, dim=-1)
- post_softmax_attn = attn
-
- attn = self.dropout(attn)
-
- if talking_heads:
- attn = einsum('b h i j, h k -> b k i j', attn, self.post_softmax_proj).contiguous()
-
- out = einsum('b h i j, b h j d -> b h i d', attn, v)
- out = rearrange(out, 'b h n d -> b n (h d)')
-
- intermediates = Intermediates(
- pre_softmax_attn=pre_softmax_attn,
- post_softmax_attn=post_softmax_attn
- )
-
- return self.to_out(out), intermediates
-
-
-class AttentionLayers(nn.Module):
- def __init__(
- self,
- dim,
- depth,
- heads=8,
- causal=False,
- cross_attend=False,
- only_cross=False,
- use_scalenorm=False,
- use_rmsnorm=False,
- use_rezero=False,
- rel_pos_num_buckets=32,
- rel_pos_max_distance=128,
- position_infused_attn=False,
- custom_layers=None,
- sandwich_coef=None,
- par_ratio=None,
- residual_attn=False,
- cross_residual_attn=False,
- macaron=False,
- pre_norm=True,
- gate_residual=False,
- **kwargs
- ):
- super().__init__()
- ff_kwargs, kwargs = groupby_prefix_and_trim('ff_', kwargs)
- attn_kwargs, _ = groupby_prefix_and_trim('attn_', kwargs)
-
- dim_head = attn_kwargs.get('dim_head', DEFAULT_DIM_HEAD)
-
- self.dim = dim
- self.depth = depth
- self.layers = nn.ModuleList([])
-
- self.has_pos_emb = position_infused_attn
- self.pia_pos_emb = FixedPositionalEmbedding(dim) if position_infused_attn else None
- self.rotary_pos_emb = always(None)
-
- assert rel_pos_num_buckets <= rel_pos_max_distance, 'number of relative position buckets must be less than the relative position max distance'
- self.rel_pos = None
-
- self.pre_norm = pre_norm
-
- self.residual_attn = residual_attn
- self.cross_residual_attn = cross_residual_attn
-
- norm_class = ScaleNorm if use_scalenorm else nn.LayerNorm
- norm_class = RMSNorm if use_rmsnorm else norm_class
- norm_fn = partial(norm_class, dim)
-
- norm_fn = nn.Identity if use_rezero else norm_fn
- branch_fn = Rezero if use_rezero else None
-
- if cross_attend and not only_cross:
- default_block = ('a', 'c', 'f')
- elif cross_attend and only_cross:
- default_block = ('c', 'f')
- else:
- default_block = ('a', 'f')
-
- if macaron:
- default_block = ('f',) + default_block
-
- if exists(custom_layers):
- layer_types = custom_layers
- elif exists(par_ratio):
- par_depth = depth * len(default_block)
- assert 1 < par_ratio <= par_depth, 'par ratio out of range'
- default_block = tuple(filter(not_equals('f'), default_block))
- par_attn = par_depth // par_ratio
- depth_cut = par_depth * 2 // 3 # 2 / 3 attention layer cutoff suggested by PAR paper
- par_width = (depth_cut + depth_cut // par_attn) // par_attn
- assert len(default_block) <= par_width, 'default block is too large for par_ratio'
- par_block = default_block + ('f',) * (par_width - len(default_block))
- par_head = par_block * par_attn
- layer_types = par_head + ('f',) * (par_depth - len(par_head))
- elif exists(sandwich_coef):
- assert sandwich_coef > 0 and sandwich_coef <= depth, 'sandwich coefficient should be less than the depth'
- layer_types = ('a',) * sandwich_coef + default_block * (depth - sandwich_coef) + ('f',) * sandwich_coef
- else:
- layer_types = default_block * depth
-
- self.layer_types = layer_types
- self.num_attn_layers = len(list(filter(equals('a'), layer_types)))
-
- for layer_type in self.layer_types:
- if layer_type == 'a':
- layer = Attention(dim, heads=heads, causal=causal, **attn_kwargs)
- elif layer_type == 'c':
- layer = Attention(dim, heads=heads, **attn_kwargs)
- elif layer_type == 'f':
- layer = FeedForward(dim, **ff_kwargs)
- layer = layer if not macaron else Scale(0.5, layer)
- else:
- raise Exception(f'invalid layer type {layer_type}')
-
- if isinstance(layer, Attention) and exists(branch_fn):
- layer = branch_fn(layer)
-
- if gate_residual:
- residual_fn = GRUGating(dim)
- else:
- residual_fn = Residual()
-
- self.layers.append(nn.ModuleList([
- norm_fn(),
- layer,
- residual_fn
- ]))
-
- def forward(
- self,
- x,
- context=None,
- mask=None,
- context_mask=None,
- mems=None,
- return_hiddens=False
- ):
- hiddens = []
- intermediates = []
- prev_attn = None
- prev_cross_attn = None
-
- mems = mems.copy() if exists(mems) else [None] * self.num_attn_layers
-
- for ind, (layer_type, (norm, block, residual_fn)) in enumerate(zip(self.layer_types, self.layers)):
- is_last = ind == (len(self.layers) - 1)
-
- if layer_type == 'a':
- hiddens.append(x)
- layer_mem = mems.pop(0)
-
- residual = x
-
- if self.pre_norm:
- x = norm(x)
-
- if layer_type == 'a':
- out, inter = block(x, mask=mask, sinusoidal_emb=self.pia_pos_emb, rel_pos=self.rel_pos,
- prev_attn=prev_attn, mem=layer_mem)
- elif layer_type == 'c':
- out, inter = block(x, context=context, mask=mask, context_mask=context_mask, prev_attn=prev_cross_attn)
- elif layer_type == 'f':
- out = block(x)
-
- x = residual_fn(out, residual)
-
- if layer_type in ('a', 'c'):
- intermediates.append(inter)
-
- if layer_type == 'a' and self.residual_attn:
- prev_attn = inter.pre_softmax_attn
- elif layer_type == 'c' and self.cross_residual_attn:
- prev_cross_attn = inter.pre_softmax_attn
-
- if not self.pre_norm and not is_last:
- x = norm(x)
-
- if return_hiddens:
- intermediates = LayerIntermediates(
- hiddens=hiddens,
- attn_intermediates=intermediates
- )
-
- return x, intermediates
-
- return x
-
-
-class Encoder(AttentionLayers):
- def __init__(self, **kwargs):
- assert 'causal' not in kwargs, 'cannot set causality on encoder'
- super().__init__(causal=False, **kwargs)
-
-
-
-class TransformerWrapper(nn.Module):
- def __init__(
- self,
- *,
- num_tokens,
- max_seq_len,
- attn_layers,
- emb_dim=None,
- max_mem_len=0.,
- emb_dropout=0.,
- num_memory_tokens=None,
- tie_embedding=False,
- use_pos_emb=True
- ):
- super().__init__()
- assert isinstance(attn_layers, AttentionLayers), 'attention layers must be one of Encoder or Decoder'
-
- dim = attn_layers.dim
- emb_dim = default(emb_dim, dim)
-
- self.max_seq_len = max_seq_len
- self.max_mem_len = max_mem_len
- self.num_tokens = num_tokens
-
- self.token_emb = nn.Embedding(num_tokens, emb_dim)
- self.pos_emb = AbsolutePositionalEmbedding(emb_dim, max_seq_len) if (
- use_pos_emb and not attn_layers.has_pos_emb) else always(0)
- self.emb_dropout = nn.Dropout(emb_dropout)
-
- self.project_emb = nn.Linear(emb_dim, dim) if emb_dim != dim else nn.Identity()
- self.attn_layers = attn_layers
- self.norm = nn.LayerNorm(dim)
-
- self.init_()
-
- self.to_logits = nn.Linear(dim, num_tokens) if not tie_embedding else lambda t: t @ self.token_emb.weight.t()
-
- # memory tokens (like [cls]) from Memory Transformers paper
- num_memory_tokens = default(num_memory_tokens, 0)
- self.num_memory_tokens = num_memory_tokens
- if num_memory_tokens > 0:
- self.memory_tokens = nn.Parameter(torch.randn(num_memory_tokens, dim))
-
- # let funnel encoder know number of memory tokens, if specified
- if hasattr(attn_layers, 'num_memory_tokens'):
- attn_layers.num_memory_tokens = num_memory_tokens
-
- def init_(self):
- nn.init.normal_(self.token_emb.weight, std=0.02)
-
- def forward(
- self,
- x,
- return_embeddings=False,
- mask=None,
- return_mems=False,
- return_attn=False,
- mems=None,
- **kwargs
- ):
- b, n, device, num_mem = *x.shape, x.device, self.num_memory_tokens
- x = self.token_emb(x)
- x += self.pos_emb(x)
- x = self.emb_dropout(x)
-
- x = self.project_emb(x)
-
- if num_mem > 0:
- mem = repeat(self.memory_tokens, 'n d -> b n d', b=b)
- x = torch.cat((mem, x), dim=1)
-
- # auto-handle masking after appending memory tokens
- if exists(mask):
- mask = F.pad(mask, (num_mem, 0), value=True)
-
- x, intermediates = self.attn_layers(x, mask=mask, mems=mems, return_hiddens=True, **kwargs)
- x = self.norm(x)
-
- mem, x = x[:, :num_mem], x[:, num_mem:]
-
- out = self.to_logits(x) if not return_embeddings else x
-
- if return_mems:
- hiddens = intermediates.hiddens
- new_mems = list(map(lambda pair: torch.cat(pair, dim=-2), zip(mems, hiddens))) if exists(mems) else hiddens
- new_mems = list(map(lambda t: t[..., -self.max_mem_len:, :].detach(), new_mems))
- return out, new_mems
-
- if return_attn:
- attn_maps = list(map(lambda t: t.post_softmax_attn, intermediates.attn_intermediates))
- return out, attn_maps
-
- return out
-
diff --git a/examples/tutorial/stable_diffusion/ldm/util.py b/examples/tutorial/stable_diffusion/ldm/util.py
deleted file mode 100644
index 8ba38853e..000000000
--- a/examples/tutorial/stable_diffusion/ldm/util.py
+++ /dev/null
@@ -1,203 +0,0 @@
-import importlib
-
-import torch
-import numpy as np
-from collections import abc
-from einops import rearrange
-from functools import partial
-
-import multiprocessing as mp
-from threading import Thread
-from queue import Queue
-
-from inspect import isfunction
-from PIL import Image, ImageDraw, ImageFont
-
-
-def log_txt_as_img(wh, xc, size=10):
- # wh a tuple of (width, height)
- # xc a list of captions to plot
- b = len(xc)
- txts = list()
- for bi in range(b):
- txt = Image.new("RGB", wh, color="white")
- draw = ImageDraw.Draw(txt)
- font = ImageFont.truetype('data/DejaVuSans.ttf', size=size)
- nc = int(40 * (wh[0] / 256))
- lines = "\n".join(xc[bi][start:start + nc] for start in range(0, len(xc[bi]), nc))
-
- try:
- draw.text((0, 0), lines, fill="black", font=font)
- except UnicodeEncodeError:
- print("Cant encode string for logging. Skipping.")
-
- txt = np.array(txt).transpose(2, 0, 1) / 127.5 - 1.0
- txts.append(txt)
- txts = np.stack(txts)
- txts = torch.tensor(txts)
- return txts
-
-
-def ismap(x):
- if not isinstance(x, torch.Tensor):
- return False
- return (len(x.shape) == 4) and (x.shape[1] > 3)
-
-
-def isimage(x):
- if not isinstance(x, torch.Tensor):
- return False
- return (len(x.shape) == 4) and (x.shape[1] == 3 or x.shape[1] == 1)
-
-
-def exists(x):
- return x is not None
-
-
-def default(val, d):
- if exists(val):
- return val
- return d() if isfunction(d) else d
-
-
-def mean_flat(tensor):
- """
- https://github.com/openai/guided-diffusion/blob/27c20a8fab9cb472df5d6bdd6c8d11c8f430b924/guided_diffusion/nn.py#L86
- Take the mean over all non-batch dimensions.
- """
- return tensor.mean(dim=list(range(1, len(tensor.shape))))
-
-
-def count_params(model, verbose=False):
- total_params = sum(p.numel() for p in model.parameters())
- if verbose:
- print(f"{model.__class__.__name__} has {total_params * 1.e-6:.2f} M params.")
- return total_params
-
-
-def instantiate_from_config(config):
- if not "target" in config:
- if config == '__is_first_stage__':
- return None
- elif config == "__is_unconditional__":
- return None
- raise KeyError("Expected key `target` to instantiate.")
- return get_obj_from_str(config["target"])(**config.get("params", dict()))
-
-
-def get_obj_from_str(string, reload=False):
- module, cls = string.rsplit(".", 1)
- if reload:
- module_imp = importlib.import_module(module)
- importlib.reload(module_imp)
- return getattr(importlib.import_module(module, package=None), cls)
-
-
-def _do_parallel_data_prefetch(func, Q, data, idx, idx_to_fn=False):
- # create dummy dataset instance
-
- # run prefetching
- if idx_to_fn:
- res = func(data, worker_id=idx)
- else:
- res = func(data)
- Q.put([idx, res])
- Q.put("Done")
-
-
-def parallel_data_prefetch(
- func: callable, data, n_proc, target_data_type="ndarray", cpu_intensive=True, use_worker_id=False
-):
- # if target_data_type not in ["ndarray", "list"]:
- # raise ValueError(
- # "Data, which is passed to parallel_data_prefetch has to be either of type list or ndarray."
- # )
- if isinstance(data, np.ndarray) and target_data_type == "list":
- raise ValueError("list expected but function got ndarray.")
- elif isinstance(data, abc.Iterable):
- if isinstance(data, dict):
- print(
- f'WARNING:"data" argument passed to parallel_data_prefetch is a dict: Using only its values and disregarding keys.'
- )
- data = list(data.values())
- if target_data_type == "ndarray":
- data = np.asarray(data)
- else:
- data = list(data)
- else:
- raise TypeError(
- f"The data, that shall be processed parallel has to be either an np.ndarray or an Iterable, but is actually {type(data)}."
- )
-
- if cpu_intensive:
- Q = mp.Queue(1000)
- proc = mp.Process
- else:
- Q = Queue(1000)
- proc = Thread
- # spawn processes
- if target_data_type == "ndarray":
- arguments = [
- [func, Q, part, i, use_worker_id]
- for i, part in enumerate(np.array_split(data, n_proc))
- ]
- else:
- step = (
- int(len(data) / n_proc + 1)
- if len(data) % n_proc != 0
- else int(len(data) / n_proc)
- )
- arguments = [
- [func, Q, part, i, use_worker_id]
- for i, part in enumerate(
- [data[i: i + step] for i in range(0, len(data), step)]
- )
- ]
- processes = []
- for i in range(n_proc):
- p = proc(target=_do_parallel_data_prefetch, args=arguments[i])
- processes += [p]
-
- # start processes
- print(f"Start prefetching...")
- import time
-
- start = time.time()
- gather_res = [[] for _ in range(n_proc)]
- try:
- for p in processes:
- p.start()
-
- k = 0
- while k < n_proc:
- # get result
- res = Q.get()
- if res == "Done":
- k += 1
- else:
- gather_res[res[0]] = res[1]
-
- except Exception as e:
- print("Exception: ", e)
- for p in processes:
- p.terminate()
-
- raise e
- finally:
- for p in processes:
- p.join()
- print(f"Prefetching complete. [{time.time() - start} sec.]")
-
- if target_data_type == 'ndarray':
- if not isinstance(gather_res[0], np.ndarray):
- return np.concatenate([np.asarray(r) for r in gather_res], axis=0)
-
- # order outputs
- return np.concatenate(gather_res, axis=0)
- elif target_data_type == 'list':
- out = []
- for r in gather_res:
- out.extend(r)
- return out
- else:
- return gather_res
diff --git a/examples/tutorial/stable_diffusion/main.py b/examples/tutorial/stable_diffusion/main.py
deleted file mode 100644
index 7cd00e4c0..000000000
--- a/examples/tutorial/stable_diffusion/main.py
+++ /dev/null
@@ -1,830 +0,0 @@
-import argparse, os, sys, datetime, glob, importlib, csv
-import numpy as np
-import time
-import torch
-import torchvision
-import pytorch_lightning as pl
-
-from packaging import version
-from omegaconf import OmegaConf
-from torch.utils.data import random_split, DataLoader, Dataset, Subset
-from functools import partial
-from PIL import Image
-# from pytorch_lightning.strategies.colossalai import ColossalAIStrategy
-# from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
-from colossalai.nn.optimizer import HybridAdam
-from prefetch_generator import BackgroundGenerator
-
-from pytorch_lightning import seed_everything
-from pytorch_lightning.trainer import Trainer
-from pytorch_lightning.callbacks import ModelCheckpoint, Callback, LearningRateMonitor
-from pytorch_lightning.utilities.rank_zero import rank_zero_only
-from pytorch_lightning.utilities import rank_zero_info
-from diffusers.models.unet_2d import UNet2DModel
-
-from clip.model import Bottleneck
-from transformers.models.clip.modeling_clip import CLIPTextTransformer
-
-from ldm.data.base import Txt2ImgIterableBaseDataset
-from ldm.util import instantiate_from_config
-import clip
-from einops import rearrange, repeat
-from transformers import CLIPTokenizer, CLIPTextModel
-import kornia
-
-from ldm.modules.x_transformer import *
-from ldm.modules.encoders.modules import *
-from taming.modules.diffusionmodules.model import ResnetBlock
-from taming.modules.transformer.mingpt import *
-from taming.modules.transformer.permuter import *
-
-
-from ldm.modules.ema import LitEma
-from ldm.modules.distributions.distributions import normal_kl, DiagonalGaussianDistribution
-from ldm.models.autoencoder import AutoencoderKL
-from ldm.models.autoencoder import *
-from ldm.models.diffusion.ddim import *
-from ldm.modules.diffusionmodules.openaimodel import *
-from ldm.modules.diffusionmodules.model import *
-from ldm.modules.diffusionmodules.model import Decoder, Encoder, Up_module, Down_module, Mid_module, temb_module
-from ldm.modules.attention import enable_flash_attention
-
-class DataLoaderX(DataLoader):
-
- def __iter__(self):
- return BackgroundGenerator(super().__iter__())
-
-
-def get_parser(**parser_kwargs):
- def str2bool(v):
- if isinstance(v, bool):
- return v
- if v.lower() in ("yes", "true", "t", "y", "1"):
- return True
- elif v.lower() in ("no", "false", "f", "n", "0"):
- return False
- else:
- raise argparse.ArgumentTypeError("Boolean value expected.")
-
- parser = argparse.ArgumentParser(**parser_kwargs)
- parser.add_argument(
- "-n",
- "--name",
- type=str,
- const=True,
- default="",
- nargs="?",
- help="postfix for logdir",
- )
- parser.add_argument(
- "-r",
- "--resume",
- type=str,
- const=True,
- default="",
- nargs="?",
- help="resume from logdir or checkpoint in logdir",
- )
- parser.add_argument(
- "-b",
- "--base",
- nargs="*",
- metavar="base_config.yaml",
- help="paths to base configs. Loaded from left-to-right. "
- "Parameters can be overwritten or added with command-line options of the form `--key value`.",
- default=list(),
- )
- parser.add_argument(
- "-t",
- "--train",
- type=str2bool,
- const=True,
- default=False,
- nargs="?",
- help="train",
- )
- parser.add_argument(
- "--no-test",
- type=str2bool,
- const=True,
- default=False,
- nargs="?",
- help="disable test",
- )
- parser.add_argument(
- "-p",
- "--project",
- help="name of new or path to existing project"
- )
- parser.add_argument(
- "-d",
- "--debug",
- type=str2bool,
- nargs="?",
- const=True,
- default=False,
- help="enable post-mortem debugging",
- )
- parser.add_argument(
- "-s",
- "--seed",
- type=int,
- default=23,
- help="seed for seed_everything",
- )
- parser.add_argument(
- "-f",
- "--postfix",
- type=str,
- default="",
- help="post-postfix for default name",
- )
- parser.add_argument(
- "-l",
- "--logdir",
- type=str,
- default="logs",
- help="directory for logging dat shit",
- )
- parser.add_argument(
- "--scale_lr",
- type=str2bool,
- nargs="?",
- const=True,
- default=True,
- help="scale base-lr by ngpu * batch_size * n_accumulate",
- )
- parser.add_argument(
- "--use_fp16",
- type=str2bool,
- nargs="?",
- const=True,
- default=True,
- help="whether to use fp16",
- )
- parser.add_argument(
- "--flash",
- type=str2bool,
- const=True,
- default=False,
- nargs="?",
- help="whether to use flash attention",
- )
- return parser
-
-
-def nondefault_trainer_args(opt):
- parser = argparse.ArgumentParser()
- parser = Trainer.add_argparse_args(parser)
- args = parser.parse_args([])
- return sorted(k for k in vars(args) if getattr(opt, k) != getattr(args, k))
-
-
-class WrappedDataset(Dataset):
- """Wraps an arbitrary object with __len__ and __getitem__ into a pytorch dataset"""
-
- def __init__(self, dataset):
- self.data = dataset
-
- def __len__(self):
- return len(self.data)
-
- def __getitem__(self, idx):
- return self.data[idx]
-
-
-def worker_init_fn(_):
- worker_info = torch.utils.data.get_worker_info()
-
- dataset = worker_info.dataset
- worker_id = worker_info.id
-
- if isinstance(dataset, Txt2ImgIterableBaseDataset):
- split_size = dataset.num_records // worker_info.num_workers
- # reset num_records to the true number to retain reliable length information
- dataset.sample_ids = dataset.valid_ids[worker_id * split_size:(worker_id + 1) * split_size]
- current_id = np.random.choice(len(np.random.get_state()[1]), 1)
- return np.random.seed(np.random.get_state()[1][current_id] + worker_id)
- else:
- return np.random.seed(np.random.get_state()[1][0] + worker_id)
-
-
-class DataModuleFromConfig(pl.LightningDataModule):
- def __init__(self, batch_size, train=None, validation=None, test=None, predict=None,
- wrap=False, num_workers=None, shuffle_test_loader=False, use_worker_init_fn=False,
- shuffle_val_dataloader=False):
- super().__init__()
- self.batch_size = batch_size
- self.dataset_configs = dict()
- self.num_workers = num_workers if num_workers is not None else batch_size * 2
- self.use_worker_init_fn = use_worker_init_fn
- if train is not None:
- self.dataset_configs["train"] = train
- self.train_dataloader = self._train_dataloader
- if validation is not None:
- self.dataset_configs["validation"] = validation
- self.val_dataloader = partial(self._val_dataloader, shuffle=shuffle_val_dataloader)
- if test is not None:
- self.dataset_configs["test"] = test
- self.test_dataloader = partial(self._test_dataloader, shuffle=shuffle_test_loader)
- if predict is not None:
- self.dataset_configs["predict"] = predict
- self.predict_dataloader = self._predict_dataloader
- self.wrap = wrap
-
- def prepare_data(self):
- for data_cfg in self.dataset_configs.values():
- instantiate_from_config(data_cfg)
-
- def setup(self, stage=None):
- self.datasets = dict(
- (k, instantiate_from_config(self.dataset_configs[k]))
- for k in self.dataset_configs)
- if self.wrap:
- for k in self.datasets:
- self.datasets[k] = WrappedDataset(self.datasets[k])
-
- def _train_dataloader(self):
- is_iterable_dataset = isinstance(self.datasets['train'], Txt2ImgIterableBaseDataset)
- if is_iterable_dataset or self.use_worker_init_fn:
- init_fn = worker_init_fn
- else:
- init_fn = None
- return DataLoaderX(self.datasets["train"], batch_size=self.batch_size,
- num_workers=self.num_workers, shuffle=False if is_iterable_dataset else True,
- worker_init_fn=init_fn)
-
- def _val_dataloader(self, shuffle=False):
- if isinstance(self.datasets['validation'], Txt2ImgIterableBaseDataset) or self.use_worker_init_fn:
- init_fn = worker_init_fn
- else:
- init_fn = None
- return DataLoaderX(self.datasets["validation"],
- batch_size=self.batch_size,
- num_workers=self.num_workers,
- worker_init_fn=init_fn,
- shuffle=shuffle)
-
- def _test_dataloader(self, shuffle=False):
- is_iterable_dataset = isinstance(self.datasets['train'], Txt2ImgIterableBaseDataset)
- if is_iterable_dataset or self.use_worker_init_fn:
- init_fn = worker_init_fn
- else:
- init_fn = None
-
- # do not shuffle dataloader for iterable dataset
- shuffle = shuffle and (not is_iterable_dataset)
-
- return DataLoaderX(self.datasets["test"], batch_size=self.batch_size,
- num_workers=self.num_workers, worker_init_fn=init_fn, shuffle=shuffle)
-
- def _predict_dataloader(self, shuffle=False):
- if isinstance(self.datasets['predict'], Txt2ImgIterableBaseDataset) or self.use_worker_init_fn:
- init_fn = worker_init_fn
- else:
- init_fn = None
- return DataLoaderX(self.datasets["predict"], batch_size=self.batch_size,
- num_workers=self.num_workers, worker_init_fn=init_fn)
-
-
-class SetupCallback(Callback):
- def __init__(self, resume, now, logdir, ckptdir, cfgdir, config, lightning_config):
- super().__init__()
- self.resume = resume
- self.now = now
- self.logdir = logdir
- self.ckptdir = ckptdir
- self.cfgdir = cfgdir
- self.config = config
- self.lightning_config = lightning_config
-
- def on_keyboard_interrupt(self, trainer, pl_module):
- if trainer.global_rank == 0:
- print("Summoning checkpoint.")
- ckpt_path = os.path.join(self.ckptdir, "last.ckpt")
- trainer.save_checkpoint(ckpt_path)
-
- # def on_pretrain_routine_start(self, trainer, pl_module):
- def on_fit_start(self, trainer, pl_module):
- if trainer.global_rank == 0:
- # Create logdirs and save configs
- os.makedirs(self.logdir, exist_ok=True)
- os.makedirs(self.ckptdir, exist_ok=True)
- os.makedirs(self.cfgdir, exist_ok=True)
-
- if "callbacks" in self.lightning_config:
- if 'metrics_over_trainsteps_checkpoint' in self.lightning_config['callbacks']:
- os.makedirs(os.path.join(self.ckptdir, 'trainstep_checkpoints'), exist_ok=True)
- print("Project config")
- print(OmegaConf.to_yaml(self.config))
- OmegaConf.save(self.config,
- os.path.join(self.cfgdir, "{}-project.yaml".format(self.now)))
-
- print("Lightning config")
- print(OmegaConf.to_yaml(self.lightning_config))
- OmegaConf.save(OmegaConf.create({"lightning": self.lightning_config}),
- os.path.join(self.cfgdir, "{}-lightning.yaml".format(self.now)))
-
- else:
- # ModelCheckpoint callback created log directory --- remove it
- if not self.resume and os.path.exists(self.logdir):
- dst, name = os.path.split(self.logdir)
- dst = os.path.join(dst, "child_runs", name)
- os.makedirs(os.path.split(dst)[0], exist_ok=True)
- try:
- os.rename(self.logdir, dst)
- except FileNotFoundError:
- pass
-
-
-class ImageLogger(Callback):
- def __init__(self, batch_frequency, max_images, clamp=True, increase_log_steps=True,
- rescale=True, disabled=False, log_on_batch_idx=False, log_first_step=False,
- log_images_kwargs=None):
- super().__init__()
- self.rescale = rescale
- self.batch_freq = batch_frequency
- self.max_images = max_images
- self.logger_log_images = {
- pl.loggers.CSVLogger: self._testtube,
- }
- self.log_steps = [2 ** n for n in range(int(np.log2(self.batch_freq)) + 1)]
- if not increase_log_steps:
- self.log_steps = [self.batch_freq]
- self.clamp = clamp
- self.disabled = disabled
- self.log_on_batch_idx = log_on_batch_idx
- self.log_images_kwargs = log_images_kwargs if log_images_kwargs else {}
- self.log_first_step = log_first_step
-
- @rank_zero_only
- def _testtube(self, pl_module, images, batch_idx, split):
- for k in images:
- grid = torchvision.utils.make_grid(images[k])
- grid = (grid + 1.0) / 2.0 # -1,1 -> 0,1; c,h,w
-
- tag = f"{split}/{k}"
- pl_module.logger.experiment.add_image(
- tag, grid,
- global_step=pl_module.global_step)
-
- @rank_zero_only
- def log_local(self, save_dir, split, images,
- global_step, current_epoch, batch_idx):
- root = os.path.join(save_dir, "images", split)
- for k in images:
- grid = torchvision.utils.make_grid(images[k], nrow=4)
- if self.rescale:
- grid = (grid + 1.0) / 2.0 # -1,1 -> 0,1; c,h,w
- grid = grid.transpose(0, 1).transpose(1, 2).squeeze(-1)
- grid = grid.numpy()
- grid = (grid * 255).astype(np.uint8)
- filename = "{}_gs-{:06}_e-{:06}_b-{:06}.png".format(
- k,
- global_step,
- current_epoch,
- batch_idx)
- path = os.path.join(root, filename)
- os.makedirs(os.path.split(path)[0], exist_ok=True)
- Image.fromarray(grid).save(path)
-
- def log_img(self, pl_module, batch, batch_idx, split="train"):
- check_idx = batch_idx if self.log_on_batch_idx else pl_module.global_step
- if (self.check_frequency(check_idx) and # batch_idx % self.batch_freq == 0
- hasattr(pl_module, "log_images") and
- callable(pl_module.log_images) and
- self.max_images > 0):
- logger = type(pl_module.logger)
-
- is_train = pl_module.training
- if is_train:
- pl_module.eval()
-
- with torch.no_grad():
- images = pl_module.log_images(batch, split=split, **self.log_images_kwargs)
-
- for k in images:
- N = min(images[k].shape[0], self.max_images)
- images[k] = images[k][:N]
- if isinstance(images[k], torch.Tensor):
- images[k] = images[k].detach().cpu()
- if self.clamp:
- images[k] = torch.clamp(images[k], -1., 1.)
-
- self.log_local(pl_module.logger.save_dir, split, images,
- pl_module.global_step, pl_module.current_epoch, batch_idx)
-
- logger_log_images = self.logger_log_images.get(logger, lambda *args, **kwargs: None)
- logger_log_images(pl_module, images, pl_module.global_step, split)
-
- if is_train:
- pl_module.train()
-
- def check_frequency(self, check_idx):
- if ((check_idx % self.batch_freq) == 0 or (check_idx in self.log_steps)) and (
- check_idx > 0 or self.log_first_step):
- try:
- self.log_steps.pop(0)
- except IndexError as e:
- print(e)
- pass
- return True
- return False
-
- def on_train_batch_end(self, trainer, pl_module, outputs, batch, batch_idx):
- # if not self.disabled and (pl_module.global_step > 0 or self.log_first_step):
- # self.log_img(pl_module, batch, batch_idx, split="train")
- pass
-
- def on_validation_batch_end(self, trainer, pl_module, outputs, batch, batch_idx):
- if not self.disabled and pl_module.global_step > 0:
- self.log_img(pl_module, batch, batch_idx, split="val")
- if hasattr(pl_module, 'calibrate_grad_norm'):
- if (pl_module.calibrate_grad_norm and batch_idx % 25 == 0) and batch_idx > 0:
- self.log_gradients(trainer, pl_module, batch_idx=batch_idx)
-
-
-class CUDACallback(Callback):
- # see https://github.com/SeanNaren/minGPT/blob/master/mingpt/callback.py
-
- def on_train_start(self, trainer, pl_module):
- rank_zero_info("Training is starting")
-
- def on_train_end(self, trainer, pl_module):
- rank_zero_info("Training is ending")
-
- def on_train_epoch_start(self, trainer, pl_module):
- # Reset the memory use counter
- torch.cuda.reset_peak_memory_stats(trainer.strategy.root_device.index)
- torch.cuda.synchronize(trainer.strategy.root_device.index)
- self.start_time = time.time()
-
- def on_train_epoch_end(self, trainer, pl_module):
- torch.cuda.synchronize(trainer.strategy.root_device.index)
- max_memory = torch.cuda.max_memory_allocated(trainer.strategy.root_device.index) / 2 ** 20
- epoch_time = time.time() - self.start_time
-
- try:
- max_memory = trainer.strategy.reduce(max_memory)
- epoch_time = trainer.strategy.reduce(epoch_time)
-
- rank_zero_info(f"Average Epoch time: {epoch_time:.2f} seconds")
- rank_zero_info(f"Average Peak memory {max_memory:.2f}MiB")
- except AttributeError:
- pass
-
-
-if __name__ == "__main__":
- # custom parser to specify config files, train, test and debug mode,
- # postfix, resume.
- # `--key value` arguments are interpreted as arguments to the trainer.
- # `nested.key=value` arguments are interpreted as config parameters.
- # configs are merged from left-to-right followed by command line parameters.
-
- # model:
- # base_learning_rate: float
- # target: path to lightning module
- # params:
- # key: value
- # data:
- # target: main.DataModuleFromConfig
- # params:
- # batch_size: int
- # wrap: bool
- # train:
- # target: path to train dataset
- # params:
- # key: value
- # validation:
- # target: path to validation dataset
- # params:
- # key: value
- # test:
- # target: path to test dataset
- # params:
- # key: value
- # lightning: (optional, has sane defaults and can be specified on cmdline)
- # trainer:
- # additional arguments to trainer
- # logger:
- # logger to instantiate
- # modelcheckpoint:
- # modelcheckpoint to instantiate
- # callbacks:
- # callback1:
- # target: importpath
- # params:
- # key: value
-
- now = datetime.datetime.now().strftime("%Y-%m-%dT%H-%M-%S")
-
- # add cwd for convenience and to make classes in this file available when
- # running as `python main.py`
- # (in particular `main.DataModuleFromConfig`)
- sys.path.append(os.getcwd())
-
- parser = get_parser()
- parser = Trainer.add_argparse_args(parser)
-
- opt, unknown = parser.parse_known_args()
- if opt.name and opt.resume:
- raise ValueError(
- "-n/--name and -r/--resume cannot be specified both."
- "If you want to resume training in a new log folder, "
- "use -n/--name in combination with --resume_from_checkpoint"
- )
- if opt.flash:
- enable_flash_attention()
- if opt.resume:
- if not os.path.exists(opt.resume):
- raise ValueError("Cannot find {}".format(opt.resume))
- if os.path.isfile(opt.resume):
- paths = opt.resume.split("/")
- # idx = len(paths)-paths[::-1].index("logs")+1
- # logdir = "/".join(paths[:idx])
- logdir = "/".join(paths[:-2])
- ckpt = opt.resume
- else:
- assert os.path.isdir(opt.resume), opt.resume
- logdir = opt.resume.rstrip("/")
- ckpt = os.path.join(logdir, "checkpoints", "last.ckpt")
-
- opt.resume_from_checkpoint = ckpt
- base_configs = sorted(glob.glob(os.path.join(logdir, "configs/*.yaml")))
- opt.base = base_configs + opt.base
- _tmp = logdir.split("/")
- nowname = _tmp[-1]
- else:
- if opt.name:
- name = "_" + opt.name
- elif opt.base:
- cfg_fname = os.path.split(opt.base[0])[-1]
- cfg_name = os.path.splitext(cfg_fname)[0]
- name = "_" + cfg_name
- else:
- name = ""
- nowname = now + name + opt.postfix
- logdir = os.path.join(opt.logdir, nowname)
-
- ckptdir = os.path.join(logdir, "checkpoints")
- cfgdir = os.path.join(logdir, "configs")
- seed_everything(opt.seed)
-
- try:
- # init and save configs
- configs = [OmegaConf.load(cfg) for cfg in opt.base]
- cli = OmegaConf.from_dotlist(unknown)
- config = OmegaConf.merge(*configs, cli)
- lightning_config = config.pop("lightning", OmegaConf.create())
- # merge trainer cli with config
- trainer_config = lightning_config.get("trainer", OmegaConf.create())
-
- for k in nondefault_trainer_args(opt):
- trainer_config[k] = getattr(opt, k)
-
- print(trainer_config)
- if not trainer_config["accelerator"] == "gpu":
- del trainer_config["accelerator"]
- cpu = True
- print("Running on CPU")
- else:
- cpu = False
- print("Running on GPU")
- trainer_opt = argparse.Namespace(**trainer_config)
- lightning_config.trainer = trainer_config
-
- # model
- use_fp16 = trainer_config.get("precision", 32) == 16
- if use_fp16:
- config.model["params"].update({"use_fp16": True})
- print("Using FP16 = {}".format(config.model["params"]["use_fp16"]))
- else:
- config.model["params"].update({"use_fp16": False})
- print("Using FP16 = {}".format(config.model["params"]["use_fp16"]))
-
- model = instantiate_from_config(config.model)
- # trainer and callbacks
- trainer_kwargs = dict()
-
- # config the logger
- # default logger configs
- default_logger_cfgs = {
- "wandb": {
- "target": "pytorch_lightning.loggers.WandbLogger",
- "params": {
- "name": nowname,
- "save_dir": logdir,
- "offline": opt.debug,
- "id": nowname,
- }
- },
- "tensorboard":{
- "target": "pytorch_lightning.loggers.TensorBoardLogger",
- "params":{
- "save_dir": logdir,
- "name": "diff_tb",
- "log_graph": True
- }
- }
- }
-
- default_logger_cfg = default_logger_cfgs["tensorboard"]
- if "logger" in lightning_config:
- logger_cfg = lightning_config.logger
- else:
- logger_cfg = default_logger_cfg
- logger_cfg = OmegaConf.merge(default_logger_cfg, logger_cfg)
- trainer_kwargs["logger"] = instantiate_from_config(logger_cfg)
-
- # config the strategy, defualt is ddp
- if "strategy" in trainer_config:
- strategy_cfg = trainer_config["strategy"]
- print("Using strategy: {}".format(strategy_cfg["target"]))
- else:
- strategy_cfg = {
- "target": "pytorch_lightning.strategies.DDPStrategy",
- "params": {
- "find_unused_parameters": False
- }
- }
- print("Using strategy: DDPStrategy")
-
- trainer_kwargs["strategy"] = instantiate_from_config(strategy_cfg)
-
- # modelcheckpoint - use TrainResult/EvalResult(checkpoint_on=metric) to
- # specify which metric is used to determine best models
- default_modelckpt_cfg = {
- "target": "pytorch_lightning.callbacks.ModelCheckpoint",
- "params": {
- "dirpath": ckptdir,
- "filename": "{epoch:06}",
- "verbose": True,
- "save_last": True,
- }
- }
- if hasattr(model, "monitor"):
- print(f"Monitoring {model.monitor} as checkpoint metric.")
- default_modelckpt_cfg["params"]["monitor"] = model.monitor
- default_modelckpt_cfg["params"]["save_top_k"] = 3
-
- if "modelcheckpoint" in lightning_config:
- modelckpt_cfg = lightning_config.modelcheckpoint
- else:
- modelckpt_cfg = OmegaConf.create()
- modelckpt_cfg = OmegaConf.merge(default_modelckpt_cfg, modelckpt_cfg)
- print(f"Merged modelckpt-cfg: \n{modelckpt_cfg}")
- if version.parse(pl.__version__) < version.parse('1.4.0'):
- trainer_kwargs["checkpoint_callback"] = instantiate_from_config(modelckpt_cfg)
-
- # add callback which sets up log directory
- default_callbacks_cfg = {
- "setup_callback": {
- "target": "main.SetupCallback",
- "params": {
- "resume": opt.resume,
- "now": now,
- "logdir": logdir,
- "ckptdir": ckptdir,
- "cfgdir": cfgdir,
- "config": config,
- "lightning_config": lightning_config,
- }
- },
- "image_logger": {
- "target": "main.ImageLogger",
- "params": {
- "batch_frequency": 750,
- "max_images": 4,
- "clamp": True
- }
- },
- "learning_rate_logger": {
- "target": "main.LearningRateMonitor",
- "params": {
- "logging_interval": "step",
- # "log_momentum": True
- }
- },
- "cuda_callback": {
- "target": "main.CUDACallback"
- },
- }
- if version.parse(pl.__version__) >= version.parse('1.4.0'):
- default_callbacks_cfg.update({'checkpoint_callback': modelckpt_cfg})
-
- if "callbacks" in lightning_config:
- callbacks_cfg = lightning_config.callbacks
- else:
- callbacks_cfg = OmegaConf.create()
-
- if 'metrics_over_trainsteps_checkpoint' in callbacks_cfg:
- print(
- 'Caution: Saving checkpoints every n train steps without deleting. This might require some free space.')
- default_metrics_over_trainsteps_ckpt_dict = {
- 'metrics_over_trainsteps_checkpoint':
- {"target": 'pytorch_lightning.callbacks.ModelCheckpoint',
- 'params': {
- "dirpath": os.path.join(ckptdir, 'trainstep_checkpoints'),
- "filename": "{epoch:06}-{step:09}",
- "verbose": True,
- 'save_top_k': -1,
- 'every_n_train_steps': 10000,
- 'save_weights_only': True
- }
- }
- }
- default_callbacks_cfg.update(default_metrics_over_trainsteps_ckpt_dict)
-
- callbacks_cfg = OmegaConf.merge(default_callbacks_cfg, callbacks_cfg)
- if 'ignore_keys_callback' in callbacks_cfg and hasattr(trainer_opt, 'resume_from_checkpoint'):
- callbacks_cfg.ignore_keys_callback.params['ckpt_path'] = trainer_opt.resume_from_checkpoint
- elif 'ignore_keys_callback' in callbacks_cfg:
- del callbacks_cfg['ignore_keys_callback']
-
- trainer_kwargs["callbacks"] = [instantiate_from_config(callbacks_cfg[k]) for k in callbacks_cfg]
-
- trainer = Trainer.from_argparse_args(trainer_opt, **trainer_kwargs)
- trainer.logdir = logdir ###
-
- # data
- data = instantiate_from_config(config.data)
- # NOTE according to https://pytorch-lightning.readthedocs.io/en/latest/datamodules.html
- # calling these ourselves should not be necessary but it is.
- # lightning still takes care of proper multiprocessing though
- data.prepare_data()
- data.setup()
- print("#### Data #####")
- for k in data.datasets:
- print(f"{k}, {data.datasets[k].__class__.__name__}, {len(data.datasets[k])}")
-
- # configure learning rate
- bs, base_lr = config.data.params.batch_size, config.model.base_learning_rate
- if not cpu:
- ngpu = trainer_config["devices"]
- else:
- ngpu = 1
- if 'accumulate_grad_batches' in lightning_config.trainer:
- accumulate_grad_batches = lightning_config.trainer.accumulate_grad_batches
- else:
- accumulate_grad_batches = 1
- print(f"accumulate_grad_batches = {accumulate_grad_batches}")
- lightning_config.trainer.accumulate_grad_batches = accumulate_grad_batches
- if opt.scale_lr:
- model.learning_rate = accumulate_grad_batches * ngpu * bs * base_lr
- print(
- "Setting learning rate to {:.2e} = {} (accumulate_grad_batches) * {} (num_gpus) * {} (batchsize) * {:.2e} (base_lr)".format(
- model.learning_rate, accumulate_grad_batches, ngpu, bs, base_lr))
- else:
- model.learning_rate = base_lr
- print("++++ NOT USING LR SCALING ++++")
- print(f"Setting learning rate to {model.learning_rate:.2e}")
-
-
- # allow checkpointing via USR1
- def melk(*args, **kwargs):
- # run all checkpoint hooks
- if trainer.global_rank == 0:
- print("Summoning checkpoint.")
- ckpt_path = os.path.join(ckptdir, "last.ckpt")
- trainer.save_checkpoint(ckpt_path)
-
-
- def divein(*args, **kwargs):
- if trainer.global_rank == 0:
- import pudb;
- pudb.set_trace()
-
-
- import signal
-
- signal.signal(signal.SIGUSR1, melk)
- signal.signal(signal.SIGUSR2, divein)
-
- # run
- if opt.train:
- try:
- for name, m in model.named_parameters():
- print(name)
- trainer.fit(model, data)
- except Exception:
- melk()
- raise
- # if not opt.no_test and not trainer.interrupted:
- # trainer.test(model, data)
- except Exception:
- if opt.debug and trainer.global_rank == 0:
- try:
- import pudb as debugger
- except ImportError:
- import pdb as debugger
- debugger.post_mortem()
- raise
- finally:
- # move newly created debug project to debug_runs
- if opt.debug and not opt.resume and trainer.global_rank == 0:
- dst, name = os.path.split(logdir)
- dst = os.path.join(dst, "debug_runs", name)
- os.makedirs(os.path.split(dst)[0], exist_ok=True)
- os.rename(logdir, dst)
- if trainer.global_rank == 0:
- print(trainer.profiler.summary())
diff --git a/examples/tutorial/stable_diffusion/requirements.txt b/examples/tutorial/stable_diffusion/requirements.txt
deleted file mode 100644
index a57003562..000000000
--- a/examples/tutorial/stable_diffusion/requirements.txt
+++ /dev/null
@@ -1,22 +0,0 @@
-albumentations==0.4.3
-diffusers
-pudb==2019.2
-datasets
-invisible-watermark
-imageio==2.9.0
-imageio-ffmpeg==0.4.2
-omegaconf==2.1.1
-multiprocess
-test-tube>=0.7.5
-streamlit>=0.73.1
-einops==0.3.0
-torch-fidelity==0.3.0
-transformers==4.19.2
-torchmetrics==0.6.0
-kornia==0.6
-opencv-python==4.6.0.66
-prefetch_generator
-colossalai
--e git+https://github.com/CompVis/taming-transformers.git@master#egg=taming-transformers
--e git+https://github.com/openai/CLIP.git@main#egg=clip
--e .
diff --git a/examples/tutorial/stable_diffusion/scripts/download_first_stages.sh b/examples/tutorial/stable_diffusion/scripts/download_first_stages.sh
deleted file mode 100644
index a8d79e99c..000000000
--- a/examples/tutorial/stable_diffusion/scripts/download_first_stages.sh
+++ /dev/null
@@ -1,41 +0,0 @@
-#!/bin/bash
-wget -O models/first_stage_models/kl-f4/model.zip https://ommer-lab.com/files/latent-diffusion/kl-f4.zip
-wget -O models/first_stage_models/kl-f8/model.zip https://ommer-lab.com/files/latent-diffusion/kl-f8.zip
-wget -O models/first_stage_models/kl-f16/model.zip https://ommer-lab.com/files/latent-diffusion/kl-f16.zip
-wget -O models/first_stage_models/kl-f32/model.zip https://ommer-lab.com/files/latent-diffusion/kl-f32.zip
-wget -O models/first_stage_models/vq-f4/model.zip https://ommer-lab.com/files/latent-diffusion/vq-f4.zip
-wget -O models/first_stage_models/vq-f4-noattn/model.zip https://ommer-lab.com/files/latent-diffusion/vq-f4-noattn.zip
-wget -O models/first_stage_models/vq-f8/model.zip https://ommer-lab.com/files/latent-diffusion/vq-f8.zip
-wget -O models/first_stage_models/vq-f8-n256/model.zip https://ommer-lab.com/files/latent-diffusion/vq-f8-n256.zip
-wget -O models/first_stage_models/vq-f16/model.zip https://ommer-lab.com/files/latent-diffusion/vq-f16.zip
-
-
-
-cd models/first_stage_models/kl-f4
-unzip -o model.zip
-
-cd ../kl-f8
-unzip -o model.zip
-
-cd ../kl-f16
-unzip -o model.zip
-
-cd ../kl-f32
-unzip -o model.zip
-
-cd ../vq-f4
-unzip -o model.zip
-
-cd ../vq-f4-noattn
-unzip -o model.zip
-
-cd ../vq-f8
-unzip -o model.zip
-
-cd ../vq-f8-n256
-unzip -o model.zip
-
-cd ../vq-f16
-unzip -o model.zip
-
-cd ../..
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/scripts/download_models.sh b/examples/tutorial/stable_diffusion/scripts/download_models.sh
deleted file mode 100644
index 84297d7b8..000000000
--- a/examples/tutorial/stable_diffusion/scripts/download_models.sh
+++ /dev/null
@@ -1,49 +0,0 @@
-#!/bin/bash
-wget -O models/ldm/celeba256/celeba-256.zip https://ommer-lab.com/files/latent-diffusion/celeba.zip
-wget -O models/ldm/ffhq256/ffhq-256.zip https://ommer-lab.com/files/latent-diffusion/ffhq.zip
-wget -O models/ldm/lsun_churches256/lsun_churches-256.zip https://ommer-lab.com/files/latent-diffusion/lsun_churches.zip
-wget -O models/ldm/lsun_beds256/lsun_beds-256.zip https://ommer-lab.com/files/latent-diffusion/lsun_bedrooms.zip
-wget -O models/ldm/text2img256/model.zip https://ommer-lab.com/files/latent-diffusion/text2img.zip
-wget -O models/ldm/cin256/model.zip https://ommer-lab.com/files/latent-diffusion/cin.zip
-wget -O models/ldm/semantic_synthesis512/model.zip https://ommer-lab.com/files/latent-diffusion/semantic_synthesis.zip
-wget -O models/ldm/semantic_synthesis256/model.zip https://ommer-lab.com/files/latent-diffusion/semantic_synthesis256.zip
-wget -O models/ldm/bsr_sr/model.zip https://ommer-lab.com/files/latent-diffusion/sr_bsr.zip
-wget -O models/ldm/layout2img-openimages256/model.zip https://ommer-lab.com/files/latent-diffusion/layout2img_model.zip
-wget -O models/ldm/inpainting_big/model.zip https://ommer-lab.com/files/latent-diffusion/inpainting_big.zip
-
-
-
-cd models/ldm/celeba256
-unzip -o celeba-256.zip
-
-cd ../ffhq256
-unzip -o ffhq-256.zip
-
-cd ../lsun_churches256
-unzip -o lsun_churches-256.zip
-
-cd ../lsun_beds256
-unzip -o lsun_beds-256.zip
-
-cd ../text2img256
-unzip -o model.zip
-
-cd ../cin256
-unzip -o model.zip
-
-cd ../semantic_synthesis512
-unzip -o model.zip
-
-cd ../semantic_synthesis256
-unzip -o model.zip
-
-cd ../bsr_sr
-unzip -o model.zip
-
-cd ../layout2img-openimages256
-unzip -o model.zip
-
-cd ../inpainting_big
-unzip -o model.zip
-
-cd ../..
diff --git a/examples/tutorial/stable_diffusion/scripts/img2img.py b/examples/tutorial/stable_diffusion/scripts/img2img.py
deleted file mode 100644
index 421e2151d..000000000
--- a/examples/tutorial/stable_diffusion/scripts/img2img.py
+++ /dev/null
@@ -1,293 +0,0 @@
-"""make variations of input image"""
-
-import argparse, os, sys, glob
-import PIL
-import torch
-import numpy as np
-from omegaconf import OmegaConf
-from PIL import Image
-from tqdm import tqdm, trange
-from itertools import islice
-from einops import rearrange, repeat
-from torchvision.utils import make_grid
-from torch import autocast
-from contextlib import nullcontext
-import time
-from pytorch_lightning import seed_everything
-
-from ldm.util import instantiate_from_config
-from ldm.models.diffusion.ddim import DDIMSampler
-from ldm.models.diffusion.plms import PLMSSampler
-
-
-def chunk(it, size):
- it = iter(it)
- return iter(lambda: tuple(islice(it, size)), ())
-
-
-def load_model_from_config(config, ckpt, verbose=False):
- print(f"Loading model from {ckpt}")
- pl_sd = torch.load(ckpt, map_location="cpu")
- if "global_step" in pl_sd:
- print(f"Global Step: {pl_sd['global_step']}")
- sd = pl_sd["state_dict"]
- model = instantiate_from_config(config.model)
- m, u = model.load_state_dict(sd, strict=False)
- if len(m) > 0 and verbose:
- print("missing keys:")
- print(m)
- if len(u) > 0 and verbose:
- print("unexpected keys:")
- print(u)
-
- model.cuda()
- model.eval()
- return model
-
-
-def load_img(path):
- image = Image.open(path).convert("RGB")
- w, h = image.size
- print(f"loaded input image of size ({w}, {h}) from {path}")
- w, h = map(lambda x: x - x % 32, (w, h)) # resize to integer multiple of 32
- image = image.resize((w, h), resample=PIL.Image.LANCZOS)
- image = np.array(image).astype(np.float32) / 255.0
- image = image[None].transpose(0, 3, 1, 2)
- image = torch.from_numpy(image)
- return 2.*image - 1.
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--prompt",
- type=str,
- nargs="?",
- default="a painting of a virus monster playing guitar",
- help="the prompt to render"
- )
-
- parser.add_argument(
- "--init-img",
- type=str,
- nargs="?",
- help="path to the input image"
- )
-
- parser.add_argument(
- "--outdir",
- type=str,
- nargs="?",
- help="dir to write results to",
- default="outputs/img2img-samples"
- )
-
- parser.add_argument(
- "--skip_grid",
- action='store_true',
- help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
- )
-
- parser.add_argument(
- "--skip_save",
- action='store_true',
- help="do not save indiviual samples. For speed measurements.",
- )
-
- parser.add_argument(
- "--ddim_steps",
- type=int,
- default=50,
- help="number of ddim sampling steps",
- )
-
- parser.add_argument(
- "--plms",
- action='store_true',
- help="use plms sampling",
- )
- parser.add_argument(
- "--fixed_code",
- action='store_true',
- help="if enabled, uses the same starting code across all samples ",
- )
-
- parser.add_argument(
- "--ddim_eta",
- type=float,
- default=0.0,
- help="ddim eta (eta=0.0 corresponds to deterministic sampling",
- )
- parser.add_argument(
- "--n_iter",
- type=int,
- default=1,
- help="sample this often",
- )
- parser.add_argument(
- "--C",
- type=int,
- default=4,
- help="latent channels",
- )
- parser.add_argument(
- "--f",
- type=int,
- default=8,
- help="downsampling factor, most often 8 or 16",
- )
- parser.add_argument(
- "--n_samples",
- type=int,
- default=2,
- help="how many samples to produce for each given prompt. A.k.a batch size",
- )
- parser.add_argument(
- "--n_rows",
- type=int,
- default=0,
- help="rows in the grid (default: n_samples)",
- )
- parser.add_argument(
- "--scale",
- type=float,
- default=5.0,
- help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
- )
-
- parser.add_argument(
- "--strength",
- type=float,
- default=0.75,
- help="strength for noising/unnoising. 1.0 corresponds to full destruction of information in init image",
- )
- parser.add_argument(
- "--from-file",
- type=str,
- help="if specified, load prompts from this file",
- )
- parser.add_argument(
- "--config",
- type=str,
- default="configs/stable-diffusion/v1-inference.yaml",
- help="path to config which constructs model",
- )
- parser.add_argument(
- "--ckpt",
- type=str,
- default="models/ldm/stable-diffusion-v1/model.ckpt",
- help="path to checkpoint of model",
- )
- parser.add_argument(
- "--seed",
- type=int,
- default=42,
- help="the seed (for reproducible sampling)",
- )
- parser.add_argument(
- "--precision",
- type=str,
- help="evaluate at this precision",
- choices=["full", "autocast"],
- default="autocast"
- )
-
- opt = parser.parse_args()
- seed_everything(opt.seed)
-
- config = OmegaConf.load(f"{opt.config}")
- model = load_model_from_config(config, f"{opt.ckpt}")
-
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model = model.to(device)
-
- if opt.plms:
- raise NotImplementedError("PLMS sampler not (yet) supported")
- sampler = PLMSSampler(model)
- else:
- sampler = DDIMSampler(model)
-
- os.makedirs(opt.outdir, exist_ok=True)
- outpath = opt.outdir
-
- batch_size = opt.n_samples
- n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
- if not opt.from_file:
- prompt = opt.prompt
- assert prompt is not None
- data = [batch_size * [prompt]]
-
- else:
- print(f"reading prompts from {opt.from_file}")
- with open(opt.from_file, "r") as f:
- data = f.read().splitlines()
- data = list(chunk(data, batch_size))
-
- sample_path = os.path.join(outpath, "samples")
- os.makedirs(sample_path, exist_ok=True)
- base_count = len(os.listdir(sample_path))
- grid_count = len(os.listdir(outpath)) - 1
-
- assert os.path.isfile(opt.init_img)
- init_image = load_img(opt.init_img).to(device)
- init_image = repeat(init_image, '1 ... -> b ...', b=batch_size)
- init_latent = model.get_first_stage_encoding(model.encode_first_stage(init_image)) # move to latent space
-
- sampler.make_schedule(ddim_num_steps=opt.ddim_steps, ddim_eta=opt.ddim_eta, verbose=False)
-
- assert 0. <= opt.strength <= 1., 'can only work with strength in [0.0, 1.0]'
- t_enc = int(opt.strength * opt.ddim_steps)
- print(f"target t_enc is {t_enc} steps")
-
- precision_scope = autocast if opt.precision == "autocast" else nullcontext
- with torch.no_grad():
- with precision_scope("cuda"):
- with model.ema_scope():
- tic = time.time()
- all_samples = list()
- for n in trange(opt.n_iter, desc="Sampling"):
- for prompts in tqdm(data, desc="data"):
- uc = None
- if opt.scale != 1.0:
- uc = model.get_learned_conditioning(batch_size * [""])
- if isinstance(prompts, tuple):
- prompts = list(prompts)
- c = model.get_learned_conditioning(prompts)
-
- # encode (scaled latent)
- z_enc = sampler.stochastic_encode(init_latent, torch.tensor([t_enc]*batch_size).to(device))
- # decode it
- samples = sampler.decode(z_enc, c, t_enc, unconditional_guidance_scale=opt.scale,
- unconditional_conditioning=uc,)
-
- x_samples = model.decode_first_stage(samples)
- x_samples = torch.clamp((x_samples + 1.0) / 2.0, min=0.0, max=1.0)
-
- if not opt.skip_save:
- for x_sample in x_samples:
- x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
- Image.fromarray(x_sample.astype(np.uint8)).save(
- os.path.join(sample_path, f"{base_count:05}.png"))
- base_count += 1
- all_samples.append(x_samples)
-
- if not opt.skip_grid:
- # additionally, save as grid
- grid = torch.stack(all_samples, 0)
- grid = rearrange(grid, 'n b c h w -> (n b) c h w')
- grid = make_grid(grid, nrow=n_rows)
-
- # to image
- grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
- Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
- grid_count += 1
-
- toc = time.time()
-
- print(f"Your samples are ready and waiting for you here: \n{outpath} \n"
- f" \nEnjoy.")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/tutorial/stable_diffusion/scripts/inpaint.py b/examples/tutorial/stable_diffusion/scripts/inpaint.py
deleted file mode 100644
index d6e6387a9..000000000
--- a/examples/tutorial/stable_diffusion/scripts/inpaint.py
+++ /dev/null
@@ -1,98 +0,0 @@
-import argparse, os, sys, glob
-from omegaconf import OmegaConf
-from PIL import Image
-from tqdm import tqdm
-import numpy as np
-import torch
-from main import instantiate_from_config
-from ldm.models.diffusion.ddim import DDIMSampler
-
-
-def make_batch(image, mask, device):
- image = np.array(Image.open(image).convert("RGB"))
- image = image.astype(np.float32)/255.0
- image = image[None].transpose(0,3,1,2)
- image = torch.from_numpy(image)
-
- mask = np.array(Image.open(mask).convert("L"))
- mask = mask.astype(np.float32)/255.0
- mask = mask[None,None]
- mask[mask < 0.5] = 0
- mask[mask >= 0.5] = 1
- mask = torch.from_numpy(mask)
-
- masked_image = (1-mask)*image
-
- batch = {"image": image, "mask": mask, "masked_image": masked_image}
- for k in batch:
- batch[k] = batch[k].to(device=device)
- batch[k] = batch[k]*2.0-1.0
- return batch
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "--indir",
- type=str,
- nargs="?",
- help="dir containing image-mask pairs (`example.png` and `example_mask.png`)",
- )
- parser.add_argument(
- "--outdir",
- type=str,
- nargs="?",
- help="dir to write results to",
- )
- parser.add_argument(
- "--steps",
- type=int,
- default=50,
- help="number of ddim sampling steps",
- )
- opt = parser.parse_args()
-
- masks = sorted(glob.glob(os.path.join(opt.indir, "*_mask.png")))
- images = [x.replace("_mask.png", ".png") for x in masks]
- print(f"Found {len(masks)} inputs.")
-
- config = OmegaConf.load("models/ldm/inpainting_big/config.yaml")
- model = instantiate_from_config(config.model)
- model.load_state_dict(torch.load("models/ldm/inpainting_big/last.ckpt")["state_dict"],
- strict=False)
-
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model = model.to(device)
- sampler = DDIMSampler(model)
-
- os.makedirs(opt.outdir, exist_ok=True)
- with torch.no_grad():
- with model.ema_scope():
- for image, mask in tqdm(zip(images, masks)):
- outpath = os.path.join(opt.outdir, os.path.split(image)[1])
- batch = make_batch(image, mask, device=device)
-
- # encode masked image and concat downsampled mask
- c = model.cond_stage_model.encode(batch["masked_image"])
- cc = torch.nn.functional.interpolate(batch["mask"],
- size=c.shape[-2:])
- c = torch.cat((c, cc), dim=1)
-
- shape = (c.shape[1]-1,)+c.shape[2:]
- samples_ddim, _ = sampler.sample(S=opt.steps,
- conditioning=c,
- batch_size=c.shape[0],
- shape=shape,
- verbose=False)
- x_samples_ddim = model.decode_first_stage(samples_ddim)
-
- image = torch.clamp((batch["image"]+1.0)/2.0,
- min=0.0, max=1.0)
- mask = torch.clamp((batch["mask"]+1.0)/2.0,
- min=0.0, max=1.0)
- predicted_image = torch.clamp((x_samples_ddim+1.0)/2.0,
- min=0.0, max=1.0)
-
- inpainted = (1-mask)*image+mask*predicted_image
- inpainted = inpainted.cpu().numpy().transpose(0,2,3,1)[0]*255
- Image.fromarray(inpainted.astype(np.uint8)).save(outpath)
diff --git a/examples/tutorial/stable_diffusion/scripts/knn2img.py b/examples/tutorial/stable_diffusion/scripts/knn2img.py
deleted file mode 100644
index e6eaaecab..000000000
--- a/examples/tutorial/stable_diffusion/scripts/knn2img.py
+++ /dev/null
@@ -1,398 +0,0 @@
-import argparse, os, sys, glob
-import clip
-import torch
-import torch.nn as nn
-import numpy as np
-from omegaconf import OmegaConf
-from PIL import Image
-from tqdm import tqdm, trange
-from itertools import islice
-from einops import rearrange, repeat
-from torchvision.utils import make_grid
-import scann
-import time
-from multiprocessing import cpu_count
-
-from ldm.util import instantiate_from_config, parallel_data_prefetch
-from ldm.models.diffusion.ddim import DDIMSampler
-from ldm.models.diffusion.plms import PLMSSampler
-from ldm.modules.encoders.modules import FrozenClipImageEmbedder, FrozenCLIPTextEmbedder
-
-DATABASES = [
- "openimages",
- "artbench-art_nouveau",
- "artbench-baroque",
- "artbench-expressionism",
- "artbench-impressionism",
- "artbench-post_impressionism",
- "artbench-realism",
- "artbench-romanticism",
- "artbench-renaissance",
- "artbench-surrealism",
- "artbench-ukiyo_e",
-]
-
-
-def chunk(it, size):
- it = iter(it)
- return iter(lambda: tuple(islice(it, size)), ())
-
-
-def load_model_from_config(config, ckpt, verbose=False):
- print(f"Loading model from {ckpt}")
- pl_sd = torch.load(ckpt, map_location="cpu")
- if "global_step" in pl_sd:
- print(f"Global Step: {pl_sd['global_step']}")
- sd = pl_sd["state_dict"]
- model = instantiate_from_config(config.model)
- m, u = model.load_state_dict(sd, strict=False)
- if len(m) > 0 and verbose:
- print("missing keys:")
- print(m)
- if len(u) > 0 and verbose:
- print("unexpected keys:")
- print(u)
-
- model.cuda()
- model.eval()
- return model
-
-
-class Searcher(object):
- def __init__(self, database, retriever_version='ViT-L/14'):
- assert database in DATABASES
- # self.database = self.load_database(database)
- self.database_name = database
- self.searcher_savedir = f'data/rdm/searchers/{self.database_name}'
- self.database_path = f'data/rdm/retrieval_databases/{self.database_name}'
- self.retriever = self.load_retriever(version=retriever_version)
- self.database = {'embedding': [],
- 'img_id': [],
- 'patch_coords': []}
- self.load_database()
- self.load_searcher()
-
- def train_searcher(self, k,
- metric='dot_product',
- searcher_savedir=None):
-
- print('Start training searcher')
- searcher = scann.scann_ops_pybind.builder(self.database['embedding'] /
- np.linalg.norm(self.database['embedding'], axis=1)[:, np.newaxis],
- k, metric)
- self.searcher = searcher.score_brute_force().build()
- print('Finish training searcher')
-
- if searcher_savedir is not None:
- print(f'Save trained searcher under "{searcher_savedir}"')
- os.makedirs(searcher_savedir, exist_ok=True)
- self.searcher.serialize(searcher_savedir)
-
- def load_single_file(self, saved_embeddings):
- compressed = np.load(saved_embeddings)
- self.database = {key: compressed[key] for key in compressed.files}
- print('Finished loading of clip embeddings.')
-
- def load_multi_files(self, data_archive):
- out_data = {key: [] for key in self.database}
- for d in tqdm(data_archive, desc=f'Loading datapool from {len(data_archive)} individual files.'):
- for key in d.files:
- out_data[key].append(d[key])
-
- return out_data
-
- def load_database(self):
-
- print(f'Load saved patch embedding from "{self.database_path}"')
- file_content = glob.glob(os.path.join(self.database_path, '*.npz'))
-
- if len(file_content) == 1:
- self.load_single_file(file_content[0])
- elif len(file_content) > 1:
- data = [np.load(f) for f in file_content]
- prefetched_data = parallel_data_prefetch(self.load_multi_files, data,
- n_proc=min(len(data), cpu_count()), target_data_type='dict')
-
- self.database = {key: np.concatenate([od[key] for od in prefetched_data], axis=1)[0] for key in
- self.database}
- else:
- raise ValueError(f'No npz-files in specified path "{self.database_path}" is this directory existing?')
-
- print(f'Finished loading of retrieval database of length {self.database["embedding"].shape[0]}.')
-
- def load_retriever(self, version='ViT-L/14', ):
- model = FrozenClipImageEmbedder(model=version)
- if torch.cuda.is_available():
- model.cuda()
- model.eval()
- return model
-
- def load_searcher(self):
- print(f'load searcher for database {self.database_name} from {self.searcher_savedir}')
- self.searcher = scann.scann_ops_pybind.load_searcher(self.searcher_savedir)
- print('Finished loading searcher.')
-
- def search(self, x, k):
- if self.searcher is None and self.database['embedding'].shape[0] < 2e4:
- self.train_searcher(k) # quickly fit searcher on the fly for small databases
- assert self.searcher is not None, 'Cannot search with uninitialized searcher'
- if isinstance(x, torch.Tensor):
- x = x.detach().cpu().numpy()
- if len(x.shape) == 3:
- x = x[:, 0]
- query_embeddings = x / np.linalg.norm(x, axis=1)[:, np.newaxis]
-
- start = time.time()
- nns, distances = self.searcher.search_batched(query_embeddings, final_num_neighbors=k)
- end = time.time()
-
- out_embeddings = self.database['embedding'][nns]
- out_img_ids = self.database['img_id'][nns]
- out_pc = self.database['patch_coords'][nns]
-
- out = {'nn_embeddings': out_embeddings / np.linalg.norm(out_embeddings, axis=-1)[..., np.newaxis],
- 'img_ids': out_img_ids,
- 'patch_coords': out_pc,
- 'queries': x,
- 'exec_time': end - start,
- 'nns': nns,
- 'q_embeddings': query_embeddings}
-
- return out
-
- def __call__(self, x, n):
- return self.search(x, n)
-
-
-if __name__ == "__main__":
- parser = argparse.ArgumentParser()
- # TODO: add n_neighbors and modes (text-only, text-image-retrieval, image-image retrieval etc)
- # TODO: add 'image variation' mode when knn=0 but a single image is given instead of a text prompt?
- parser.add_argument(
- "--prompt",
- type=str,
- nargs="?",
- default="a painting of a virus monster playing guitar",
- help="the prompt to render"
- )
-
- parser.add_argument(
- "--outdir",
- type=str,
- nargs="?",
- help="dir to write results to",
- default="outputs/txt2img-samples"
- )
-
- parser.add_argument(
- "--skip_grid",
- action='store_true',
- help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
- )
-
- parser.add_argument(
- "--ddim_steps",
- type=int,
- default=50,
- help="number of ddim sampling steps",
- )
-
- parser.add_argument(
- "--n_repeat",
- type=int,
- default=1,
- help="number of repeats in CLIP latent space",
- )
-
- parser.add_argument(
- "--plms",
- action='store_true',
- help="use plms sampling",
- )
-
- parser.add_argument(
- "--ddim_eta",
- type=float,
- default=0.0,
- help="ddim eta (eta=0.0 corresponds to deterministic sampling",
- )
- parser.add_argument(
- "--n_iter",
- type=int,
- default=1,
- help="sample this often",
- )
-
- parser.add_argument(
- "--H",
- type=int,
- default=768,
- help="image height, in pixel space",
- )
-
- parser.add_argument(
- "--W",
- type=int,
- default=768,
- help="image width, in pixel space",
- )
-
- parser.add_argument(
- "--n_samples",
- type=int,
- default=3,
- help="how many samples to produce for each given prompt. A.k.a batch size",
- )
-
- parser.add_argument(
- "--n_rows",
- type=int,
- default=0,
- help="rows in the grid (default: n_samples)",
- )
-
- parser.add_argument(
- "--scale",
- type=float,
- default=5.0,
- help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
- )
-
- parser.add_argument(
- "--from-file",
- type=str,
- help="if specified, load prompts from this file",
- )
-
- parser.add_argument(
- "--config",
- type=str,
- default="configs/retrieval-augmented-diffusion/768x768.yaml",
- help="path to config which constructs model",
- )
-
- parser.add_argument(
- "--ckpt",
- type=str,
- default="models/rdm/rdm768x768/model.ckpt",
- help="path to checkpoint of model",
- )
-
- parser.add_argument(
- "--clip_type",
- type=str,
- default="ViT-L/14",
- help="which CLIP model to use for retrieval and NN encoding",
- )
- parser.add_argument(
- "--database",
- type=str,
- default='artbench-surrealism',
- choices=DATABASES,
- help="The database used for the search, only applied when --use_neighbors=True",
- )
- parser.add_argument(
- "--use_neighbors",
- default=False,
- action='store_true',
- help="Include neighbors in addition to text prompt for conditioning",
- )
- parser.add_argument(
- "--knn",
- default=10,
- type=int,
- help="The number of included neighbors, only applied when --use_neighbors=True",
- )
-
- opt = parser.parse_args()
-
- config = OmegaConf.load(f"{opt.config}")
- model = load_model_from_config(config, f"{opt.ckpt}")
-
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model = model.to(device)
-
- clip_text_encoder = FrozenCLIPTextEmbedder(opt.clip_type).to(device)
-
- if opt.plms:
- sampler = PLMSSampler(model)
- else:
- sampler = DDIMSampler(model)
-
- os.makedirs(opt.outdir, exist_ok=True)
- outpath = opt.outdir
-
- batch_size = opt.n_samples
- n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
- if not opt.from_file:
- prompt = opt.prompt
- assert prompt is not None
- data = [batch_size * [prompt]]
-
- else:
- print(f"reading prompts from {opt.from_file}")
- with open(opt.from_file, "r") as f:
- data = f.read().splitlines()
- data = list(chunk(data, batch_size))
-
- sample_path = os.path.join(outpath, "samples")
- os.makedirs(sample_path, exist_ok=True)
- base_count = len(os.listdir(sample_path))
- grid_count = len(os.listdir(outpath)) - 1
-
- print(f"sampling scale for cfg is {opt.scale:.2f}")
-
- searcher = None
- if opt.use_neighbors:
- searcher = Searcher(opt.database)
-
- with torch.no_grad():
- with model.ema_scope():
- for n in trange(opt.n_iter, desc="Sampling"):
- all_samples = list()
- for prompts in tqdm(data, desc="data"):
- print("sampling prompts:", prompts)
- if isinstance(prompts, tuple):
- prompts = list(prompts)
- c = clip_text_encoder.encode(prompts)
- uc = None
- if searcher is not None:
- nn_dict = searcher(c, opt.knn)
- c = torch.cat([c, torch.from_numpy(nn_dict['nn_embeddings']).cuda()], dim=1)
- if opt.scale != 1.0:
- uc = torch.zeros_like(c)
- if isinstance(prompts, tuple):
- prompts = list(prompts)
- shape = [16, opt.H // 16, opt.W // 16] # note: currently hardcoded for f16 model
- samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
- conditioning=c,
- batch_size=c.shape[0],
- shape=shape,
- verbose=False,
- unconditional_guidance_scale=opt.scale,
- unconditional_conditioning=uc,
- eta=opt.ddim_eta,
- )
-
- x_samples_ddim = model.decode_first_stage(samples_ddim)
- x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
-
- for x_sample in x_samples_ddim:
- x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
- Image.fromarray(x_sample.astype(np.uint8)).save(
- os.path.join(sample_path, f"{base_count:05}.png"))
- base_count += 1
- all_samples.append(x_samples_ddim)
-
- if not opt.skip_grid:
- # additionally, save as grid
- grid = torch.stack(all_samples, 0)
- grid = rearrange(grid, 'n b c h w -> (n b) c h w')
- grid = make_grid(grid, nrow=n_rows)
-
- # to image
- grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
- Image.fromarray(grid.astype(np.uint8)).save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
- grid_count += 1
-
- print(f"Your samples are ready and waiting for you here: \n{outpath} \nEnjoy.")
diff --git a/examples/tutorial/stable_diffusion/scripts/sample_diffusion.py b/examples/tutorial/stable_diffusion/scripts/sample_diffusion.py
deleted file mode 100644
index 876fe3c36..000000000
--- a/examples/tutorial/stable_diffusion/scripts/sample_diffusion.py
+++ /dev/null
@@ -1,313 +0,0 @@
-import argparse, os, sys, glob, datetime, yaml
-import torch
-import time
-import numpy as np
-from tqdm import trange
-
-from omegaconf import OmegaConf
-from PIL import Image
-
-from ldm.models.diffusion.ddim import DDIMSampler
-from ldm.util import instantiate_from_config
-
-rescale = lambda x: (x + 1.) / 2.
-
-def custom_to_pil(x):
- x = x.detach().cpu()
- x = torch.clamp(x, -1., 1.)
- x = (x + 1.) / 2.
- x = x.permute(1, 2, 0).numpy()
- x = (255 * x).astype(np.uint8)
- x = Image.fromarray(x)
- if not x.mode == "RGB":
- x = x.convert("RGB")
- return x
-
-
-def custom_to_np(x):
- # saves the batch in adm style as in https://github.com/openai/guided-diffusion/blob/main/scripts/image_sample.py
- sample = x.detach().cpu()
- sample = ((sample + 1) * 127.5).clamp(0, 255).to(torch.uint8)
- sample = sample.permute(0, 2, 3, 1)
- sample = sample.contiguous()
- return sample
-
-
-def logs2pil(logs, keys=["sample"]):
- imgs = dict()
- for k in logs:
- try:
- if len(logs[k].shape) == 4:
- img = custom_to_pil(logs[k][0, ...])
- elif len(logs[k].shape) == 3:
- img = custom_to_pil(logs[k])
- else:
- print(f"Unknown format for key {k}. ")
- img = None
- except:
- img = None
- imgs[k] = img
- return imgs
-
-
-@torch.no_grad()
-def convsample(model, shape, return_intermediates=True,
- verbose=True,
- make_prog_row=False):
-
-
- if not make_prog_row:
- return model.p_sample_loop(None, shape,
- return_intermediates=return_intermediates, verbose=verbose)
- else:
- return model.progressive_denoising(
- None, shape, verbose=True
- )
-
-
-@torch.no_grad()
-def convsample_ddim(model, steps, shape, eta=1.0
- ):
- ddim = DDIMSampler(model)
- bs = shape[0]
- shape = shape[1:]
- samples, intermediates = ddim.sample(steps, batch_size=bs, shape=shape, eta=eta, verbose=False,)
- return samples, intermediates
-
-
-@torch.no_grad()
-def make_convolutional_sample(model, batch_size, vanilla=False, custom_steps=None, eta=1.0,):
-
-
- log = dict()
-
- shape = [batch_size,
- model.model.diffusion_model.in_channels,
- model.model.diffusion_model.image_size,
- model.model.diffusion_model.image_size]
-
- with model.ema_scope("Plotting"):
- t0 = time.time()
- if vanilla:
- sample, progrow = convsample(model, shape,
- make_prog_row=True)
- else:
- sample, intermediates = convsample_ddim(model, steps=custom_steps, shape=shape,
- eta=eta)
-
- t1 = time.time()
-
- x_sample = model.decode_first_stage(sample)
-
- log["sample"] = x_sample
- log["time"] = t1 - t0
- log['throughput'] = sample.shape[0] / (t1 - t0)
- print(f'Throughput for this batch: {log["throughput"]}')
- return log
-
-def run(model, logdir, batch_size=50, vanilla=False, custom_steps=None, eta=None, n_samples=50000, nplog=None):
- if vanilla:
- print(f'Using Vanilla DDPM sampling with {model.num_timesteps} sampling steps.')
- else:
- print(f'Using DDIM sampling with {custom_steps} sampling steps and eta={eta}')
-
-
- tstart = time.time()
- n_saved = len(glob.glob(os.path.join(logdir,'*.png')))-1
- # path = logdir
- if model.cond_stage_model is None:
- all_images = []
-
- print(f"Running unconditional sampling for {n_samples} samples")
- for _ in trange(n_samples // batch_size, desc="Sampling Batches (unconditional)"):
- logs = make_convolutional_sample(model, batch_size=batch_size,
- vanilla=vanilla, custom_steps=custom_steps,
- eta=eta)
- n_saved = save_logs(logs, logdir, n_saved=n_saved, key="sample")
- all_images.extend([custom_to_np(logs["sample"])])
- if n_saved >= n_samples:
- print(f'Finish after generating {n_saved} samples')
- break
- all_img = np.concatenate(all_images, axis=0)
- all_img = all_img[:n_samples]
- shape_str = "x".join([str(x) for x in all_img.shape])
- nppath = os.path.join(nplog, f"{shape_str}-samples.npz")
- np.savez(nppath, all_img)
-
- else:
- raise NotImplementedError('Currently only sampling for unconditional models supported.')
-
- print(f"sampling of {n_saved} images finished in {(time.time() - tstart) / 60.:.2f} minutes.")
-
-
-def save_logs(logs, path, n_saved=0, key="sample", np_path=None):
- for k in logs:
- if k == key:
- batch = logs[key]
- if np_path is None:
- for x in batch:
- img = custom_to_pil(x)
- imgpath = os.path.join(path, f"{key}_{n_saved:06}.png")
- img.save(imgpath)
- n_saved += 1
- else:
- npbatch = custom_to_np(batch)
- shape_str = "x".join([str(x) for x in npbatch.shape])
- nppath = os.path.join(np_path, f"{n_saved}-{shape_str}-samples.npz")
- np.savez(nppath, npbatch)
- n_saved += npbatch.shape[0]
- return n_saved
-
-
-def get_parser():
- parser = argparse.ArgumentParser()
- parser.add_argument(
- "-r",
- "--resume",
- type=str,
- nargs="?",
- help="load from logdir or checkpoint in logdir",
- )
- parser.add_argument(
- "-n",
- "--n_samples",
- type=int,
- nargs="?",
- help="number of samples to draw",
- default=50000
- )
- parser.add_argument(
- "-e",
- "--eta",
- type=float,
- nargs="?",
- help="eta for ddim sampling (0.0 yields deterministic sampling)",
- default=1.0
- )
- parser.add_argument(
- "-v",
- "--vanilla_sample",
- default=False,
- action='store_true',
- help="vanilla sampling (default option is DDIM sampling)?",
- )
- parser.add_argument(
- "-l",
- "--logdir",
- type=str,
- nargs="?",
- help="extra logdir",
- default="none"
- )
- parser.add_argument(
- "-c",
- "--custom_steps",
- type=int,
- nargs="?",
- help="number of steps for ddim and fastdpm sampling",
- default=50
- )
- parser.add_argument(
- "--batch_size",
- type=int,
- nargs="?",
- help="the bs",
- default=10
- )
- return parser
-
-
-def load_model_from_config(config, sd):
- model = instantiate_from_config(config)
- model.load_state_dict(sd,strict=False)
- model.cuda()
- model.eval()
- return model
-
-
-def load_model(config, ckpt, gpu, eval_mode):
- if ckpt:
- print(f"Loading model from {ckpt}")
- pl_sd = torch.load(ckpt, map_location="cpu")
- global_step = pl_sd["global_step"]
- else:
- pl_sd = {"state_dict": None}
- global_step = None
- model = load_model_from_config(config.model,
- pl_sd["state_dict"])
-
- return model, global_step
-
-
-if __name__ == "__main__":
- now = datetime.datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
- sys.path.append(os.getcwd())
- command = " ".join(sys.argv)
-
- parser = get_parser()
- opt, unknown = parser.parse_known_args()
- ckpt = None
-
- if not os.path.exists(opt.resume):
- raise ValueError("Cannot find {}".format(opt.resume))
- if os.path.isfile(opt.resume):
- # paths = opt.resume.split("/")
- try:
- logdir = '/'.join(opt.resume.split('/')[:-1])
- # idx = len(paths)-paths[::-1].index("logs")+1
- print(f'Logdir is {logdir}')
- except ValueError:
- paths = opt.resume.split("/")
- idx = -2 # take a guess: path/to/logdir/checkpoints/model.ckpt
- logdir = "/".join(paths[:idx])
- ckpt = opt.resume
- else:
- assert os.path.isdir(opt.resume), f"{opt.resume} is not a directory"
- logdir = opt.resume.rstrip("/")
- ckpt = os.path.join(logdir, "model.ckpt")
-
- base_configs = sorted(glob.glob(os.path.join(logdir, "config.yaml")))
- opt.base = base_configs
-
- configs = [OmegaConf.load(cfg) for cfg in opt.base]
- cli = OmegaConf.from_dotlist(unknown)
- config = OmegaConf.merge(*configs, cli)
-
- gpu = True
- eval_mode = True
-
- if opt.logdir != "none":
- locallog = logdir.split(os.sep)[-1]
- if locallog == "": locallog = logdir.split(os.sep)[-2]
- print(f"Switching logdir from '{logdir}' to '{os.path.join(opt.logdir, locallog)}'")
- logdir = os.path.join(opt.logdir, locallog)
-
- print(config)
-
- model, global_step = load_model(config, ckpt, gpu, eval_mode)
- print(f"global step: {global_step}")
- print(75 * "=")
- print("logging to:")
- logdir = os.path.join(logdir, "samples", f"{global_step:08}", now)
- imglogdir = os.path.join(logdir, "img")
- numpylogdir = os.path.join(logdir, "numpy")
-
- os.makedirs(imglogdir)
- os.makedirs(numpylogdir)
- print(logdir)
- print(75 * "=")
-
- # write config out
- sampling_file = os.path.join(logdir, "sampling_config.yaml")
- sampling_conf = vars(opt)
-
- with open(sampling_file, 'w') as f:
- yaml.dump(sampling_conf, f, default_flow_style=False)
- print(sampling_conf)
-
-
- run(model, imglogdir, eta=opt.eta,
- vanilla=opt.vanilla_sample, n_samples=opt.n_samples, custom_steps=opt.custom_steps,
- batch_size=opt.batch_size, nplog=numpylogdir)
-
- print("done.")
diff --git a/examples/tutorial/stable_diffusion/scripts/tests/test_checkpoint.py b/examples/tutorial/stable_diffusion/scripts/tests/test_checkpoint.py
deleted file mode 100644
index a32e66d44..000000000
--- a/examples/tutorial/stable_diffusion/scripts/tests/test_checkpoint.py
+++ /dev/null
@@ -1,37 +0,0 @@
-import os
-import sys
-from copy import deepcopy
-
-import yaml
-from datetime import datetime
-
-from diffusers import StableDiffusionPipeline
-import torch
-from ldm.util import instantiate_from_config
-from main import get_parser
-
-if __name__ == "__main__":
- with torch.no_grad():
- yaml_path = "../../train_colossalai.yaml"
- with open(yaml_path, 'r', encoding='utf-8') as f:
- config = f.read()
- base_config = yaml.load(config, Loader=yaml.FullLoader)
- unet_config = base_config['model']['params']['unet_config']
- diffusion_model = instantiate_from_config(unet_config).to("cuda:0")
-
- pipe = StableDiffusionPipeline.from_pretrained(
- "/data/scratch/diffuser/stable-diffusion-v1-4"
- ).to("cuda:0")
- dif_model_2 = pipe.unet
-
- random_input_ = torch.rand((4, 4, 32, 32)).to("cuda:0")
- random_input_2 = torch.clone(random_input_).to("cuda:0")
- time_stamp = torch.randint(20, (4,)).to("cuda:0")
- time_stamp2 = torch.clone(time_stamp).to("cuda:0")
- context_ = torch.rand((4, 77, 768)).to("cuda:0")
- context_2 = torch.clone(context_).to("cuda:0")
-
- out_1 = diffusion_model(random_input_, time_stamp, context_)
- out_2 = dif_model_2(random_input_2, time_stamp2, context_2)
- print(out_1.shape)
- print(out_2['sample'].shape)
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/scripts/tests/test_watermark.py b/examples/tutorial/stable_diffusion/scripts/tests/test_watermark.py
deleted file mode 100644
index f93f8a6e7..000000000
--- a/examples/tutorial/stable_diffusion/scripts/tests/test_watermark.py
+++ /dev/null
@@ -1,18 +0,0 @@
-import cv2
-import fire
-from imwatermark import WatermarkDecoder
-
-
-def testit(img_path):
- bgr = cv2.imread(img_path)
- decoder = WatermarkDecoder('bytes', 136)
- watermark = decoder.decode(bgr, 'dwtDct')
- try:
- dec = watermark.decode('utf-8')
- except:
- dec = "null"
- print(dec)
-
-
-if __name__ == "__main__":
- fire.Fire(testit)
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/scripts/train_searcher.py b/examples/tutorial/stable_diffusion/scripts/train_searcher.py
deleted file mode 100644
index 1e7904889..000000000
--- a/examples/tutorial/stable_diffusion/scripts/train_searcher.py
+++ /dev/null
@@ -1,147 +0,0 @@
-import os, sys
-import numpy as np
-import scann
-import argparse
-import glob
-from multiprocessing import cpu_count
-from tqdm import tqdm
-
-from ldm.util import parallel_data_prefetch
-
-
-def search_bruteforce(searcher):
- return searcher.score_brute_force().build()
-
-
-def search_partioned_ah(searcher, dims_per_block, aiq_threshold, reorder_k,
- partioning_trainsize, num_leaves, num_leaves_to_search):
- return searcher.tree(num_leaves=num_leaves,
- num_leaves_to_search=num_leaves_to_search,
- training_sample_size=partioning_trainsize). \
- score_ah(dims_per_block, anisotropic_quantization_threshold=aiq_threshold).reorder(reorder_k).build()
-
-
-def search_ah(searcher, dims_per_block, aiq_threshold, reorder_k):
- return searcher.score_ah(dims_per_block, anisotropic_quantization_threshold=aiq_threshold).reorder(
- reorder_k).build()
-
-def load_datapool(dpath):
-
-
- def load_single_file(saved_embeddings):
- compressed = np.load(saved_embeddings)
- database = {key: compressed[key] for key in compressed.files}
- return database
-
- def load_multi_files(data_archive):
- database = {key: [] for key in data_archive[0].files}
- for d in tqdm(data_archive, desc=f'Loading datapool from {len(data_archive)} individual files.'):
- for key in d.files:
- database[key].append(d[key])
-
- return database
-
- print(f'Load saved patch embedding from "{dpath}"')
- file_content = glob.glob(os.path.join(dpath, '*.npz'))
-
- if len(file_content) == 1:
- data_pool = load_single_file(file_content[0])
- elif len(file_content) > 1:
- data = [np.load(f) for f in file_content]
- prefetched_data = parallel_data_prefetch(load_multi_files, data,
- n_proc=min(len(data), cpu_count()), target_data_type='dict')
-
- data_pool = {key: np.concatenate([od[key] for od in prefetched_data], axis=1)[0] for key in prefetched_data[0].keys()}
- else:
- raise ValueError(f'No npz-files in specified path "{dpath}" is this directory existing?')
-
- print(f'Finished loading of retrieval database of length {data_pool["embedding"].shape[0]}.')
- return data_pool
-
-
-def train_searcher(opt,
- metric='dot_product',
- partioning_trainsize=None,
- reorder_k=None,
- # todo tune
- aiq_thld=0.2,
- dims_per_block=2,
- num_leaves=None,
- num_leaves_to_search=None,):
-
- data_pool = load_datapool(opt.database)
- k = opt.knn
-
- if not reorder_k:
- reorder_k = 2 * k
-
- # normalize
- # embeddings =
- searcher = scann.scann_ops_pybind.builder(data_pool['embedding'] / np.linalg.norm(data_pool['embedding'], axis=1)[:, np.newaxis], k, metric)
- pool_size = data_pool['embedding'].shape[0]
-
- print(*(['#'] * 100))
- print('Initializing scaNN searcher with the following values:')
- print(f'k: {k}')
- print(f'metric: {metric}')
- print(f'reorder_k: {reorder_k}')
- print(f'anisotropic_quantization_threshold: {aiq_thld}')
- print(f'dims_per_block: {dims_per_block}')
- print(*(['#'] * 100))
- print('Start training searcher....')
- print(f'N samples in pool is {pool_size}')
-
- # this reflects the recommended design choices proposed at
- # https://github.com/google-research/google-research/blob/aca5f2e44e301af172590bb8e65711f0c9ee0cfd/scann/docs/algorithms.md
- if pool_size < 2e4:
- print('Using brute force search.')
- searcher = search_bruteforce(searcher)
- elif 2e4 <= pool_size and pool_size < 1e5:
- print('Using asymmetric hashing search and reordering.')
- searcher = search_ah(searcher, dims_per_block, aiq_thld, reorder_k)
- else:
- print('Using using partioning, asymmetric hashing search and reordering.')
-
- if not partioning_trainsize:
- partioning_trainsize = data_pool['embedding'].shape[0] // 10
- if not num_leaves:
- num_leaves = int(np.sqrt(pool_size))
-
- if not num_leaves_to_search:
- num_leaves_to_search = max(num_leaves // 20, 1)
-
- print('Partitioning params:')
- print(f'num_leaves: {num_leaves}')
- print(f'num_leaves_to_search: {num_leaves_to_search}')
- # self.searcher = self.search_ah(searcher, dims_per_block, aiq_thld, reorder_k)
- searcher = search_partioned_ah(searcher, dims_per_block, aiq_thld, reorder_k,
- partioning_trainsize, num_leaves, num_leaves_to_search)
-
- print('Finish training searcher')
- searcher_savedir = opt.target_path
- os.makedirs(searcher_savedir, exist_ok=True)
- searcher.serialize(searcher_savedir)
- print(f'Saved trained searcher under "{searcher_savedir}"')
-
-if __name__ == '__main__':
- sys.path.append(os.getcwd())
- parser = argparse.ArgumentParser()
- parser.add_argument('--database',
- '-d',
- default='data/rdm/retrieval_databases/openimages',
- type=str,
- help='path to folder containing the clip feature of the database')
- parser.add_argument('--target_path',
- '-t',
- default='data/rdm/searchers/openimages',
- type=str,
- help='path to the target folder where the searcher shall be stored.')
- parser.add_argument('--knn',
- '-k',
- default=20,
- type=int,
- help='number of nearest neighbors, for which the searcher shall be optimized')
-
- opt, _ = parser.parse_known_args()
-
- train_searcher(opt,)
\ No newline at end of file
diff --git a/examples/tutorial/stable_diffusion/scripts/txt2img.py b/examples/tutorial/stable_diffusion/scripts/txt2img.py
deleted file mode 100644
index 59c16a1db..000000000
--- a/examples/tutorial/stable_diffusion/scripts/txt2img.py
+++ /dev/null
@@ -1,344 +0,0 @@
-import argparse, os, sys, glob
-import cv2
-import torch
-import numpy as np
-from omegaconf import OmegaConf
-from PIL import Image
-from tqdm import tqdm, trange
-from imwatermark import WatermarkEncoder
-from itertools import islice
-from einops import rearrange
-from torchvision.utils import make_grid
-import time
-from pytorch_lightning import seed_everything
-from torch import autocast
-from contextlib import contextmanager, nullcontext
-
-from ldm.util import instantiate_from_config
-from ldm.models.diffusion.ddim import DDIMSampler
-from ldm.models.diffusion.plms import PLMSSampler
-
-from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
-from transformers import AutoFeatureExtractor
-
-
-# load safety model
-safety_model_id = "CompVis/stable-diffusion-safety-checker"
-safety_feature_extractor = AutoFeatureExtractor.from_pretrained(safety_model_id)
-safety_checker = StableDiffusionSafetyChecker.from_pretrained(safety_model_id)
-
-
-def chunk(it, size):
- it = iter(it)
- return iter(lambda: tuple(islice(it, size)), ())
-
-
-def numpy_to_pil(images):
- """
- Convert a numpy image or a batch of images to a PIL image.
- """
- if images.ndim == 3:
- images = images[None, ...]
- images = (images * 255).round().astype("uint8")
- pil_images = [Image.fromarray(image) for image in images]
-
- return pil_images
-
-
-def load_model_from_config(config, ckpt, verbose=False):
- print(f"Loading model from {ckpt}")
- pl_sd = torch.load(ckpt, map_location="cpu")
- if "global_step" in pl_sd:
- print(f"Global Step: {pl_sd['global_step']}")
- sd = pl_sd["state_dict"]
- model = instantiate_from_config(config.model)
- m, u = model.load_state_dict(sd, strict=False)
- if len(m) > 0 and verbose:
- print("missing keys:")
- print(m)
- if len(u) > 0 and verbose:
- print("unexpected keys:")
- print(u)
-
- model.cuda()
- model.eval()
- return model
-
-
-def put_watermark(img, wm_encoder=None):
- if wm_encoder is not None:
- img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
- img = wm_encoder.encode(img, 'dwtDct')
- img = Image.fromarray(img[:, :, ::-1])
- return img
-
-
-def load_replacement(x):
- try:
- hwc = x.shape
- y = Image.open("assets/rick.jpeg").convert("RGB").resize((hwc[1], hwc[0]))
- y = (np.array(y)/255.0).astype(x.dtype)
- assert y.shape == x.shape
- return y
- except Exception:
- return x
-
-
-def check_safety(x_image):
- safety_checker_input = safety_feature_extractor(numpy_to_pil(x_image), return_tensors="pt")
- x_checked_image, has_nsfw_concept = safety_checker(images=x_image, clip_input=safety_checker_input.pixel_values)
- assert x_checked_image.shape[0] == len(has_nsfw_concept)
- for i in range(len(has_nsfw_concept)):
- if has_nsfw_concept[i]:
- x_checked_image[i] = load_replacement(x_checked_image[i])
- return x_checked_image, has_nsfw_concept
-
-
-def main():
- parser = argparse.ArgumentParser()
-
- parser.add_argument(
- "--prompt",
- type=str,
- nargs="?",
- default="a painting of a virus monster playing guitar",
- help="the prompt to render"
- )
- parser.add_argument(
- "--outdir",
- type=str,
- nargs="?",
- help="dir to write results to",
- default="outputs/txt2img-samples"
- )
- parser.add_argument(
- "--skip_grid",
- action='store_true',
- help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
- )
- parser.add_argument(
- "--skip_save",
- action='store_true',
- help="do not save individual samples. For speed measurements.",
- )
- parser.add_argument(
- "--ddim_steps",
- type=int,
- default=50,
- help="number of ddim sampling steps",
- )
- parser.add_argument(
- "--plms",
- action='store_true',
- help="use plms sampling",
- )
- parser.add_argument(
- "--laion400m",
- action='store_true',
- help="uses the LAION400M model",
- )
- parser.add_argument(
- "--fixed_code",
- action='store_true',
- help="if enabled, uses the same starting code across samples ",
- )
- parser.add_argument(
- "--ddim_eta",
- type=float,
- default=0.0,
- help="ddim eta (eta=0.0 corresponds to deterministic sampling",
- )
- parser.add_argument(
- "--n_iter",
- type=int,
- default=2,
- help="sample this often",
- )
- parser.add_argument(
- "--H",
- type=int,
- default=512,
- help="image height, in pixel space",
- )
- parser.add_argument(
- "--W",
- type=int,
- default=512,
- help="image width, in pixel space",
- )
- parser.add_argument(
- "--C",
- type=int,
- default=4,
- help="latent channels",
- )
- parser.add_argument(
- "--f",
- type=int,
- default=8,
- help="downsampling factor",
- )
- parser.add_argument(
- "--n_samples",
- type=int,
- default=3,
- help="how many samples to produce for each given prompt. A.k.a. batch size",
- )
- parser.add_argument(
- "--n_rows",
- type=int,
- default=0,
- help="rows in the grid (default: n_samples)",
- )
- parser.add_argument(
- "--scale",
- type=float,
- default=7.5,
- help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
- )
- parser.add_argument(
- "--from-file",
- type=str,
- help="if specified, load prompts from this file",
- )
- parser.add_argument(
- "--config",
- type=str,
- default="configs/stable-diffusion/v1-inference.yaml",
- help="path to config which constructs model",
- )
- parser.add_argument(
- "--ckpt",
- type=str,
- default="models/ldm/stable-diffusion-v1/model.ckpt",
- help="path to checkpoint of model",
- )
- parser.add_argument(
- "--seed",
- type=int,
- default=42,
- help="the seed (for reproducible sampling)",
- )
- parser.add_argument(
- "--precision",
- type=str,
- help="evaluate at this precision",
- choices=["full", "autocast"],
- default="autocast"
- )
- opt = parser.parse_args()
-
- if opt.laion400m:
- print("Falling back to LAION 400M model...")
- opt.config = "configs/latent-diffusion/txt2img-1p4B-eval.yaml"
- opt.ckpt = "models/ldm/text2img-large/model.ckpt"
- opt.outdir = "outputs/txt2img-samples-laion400m"
-
- seed_everything(opt.seed)
-
- config = OmegaConf.load(f"{opt.config}")
- model = load_model_from_config(config, f"{opt.ckpt}")
-
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model = model.to(device)
-
- if opt.plms:
- sampler = PLMSSampler(model)
- else:
- sampler = DDIMSampler(model)
-
- os.makedirs(opt.outdir, exist_ok=True)
- outpath = opt.outdir
-
- print("Creating invisible watermark encoder (see https://github.com/ShieldMnt/invisible-watermark)...")
- wm = "StableDiffusionV1"
- wm_encoder = WatermarkEncoder()
- wm_encoder.set_watermark('bytes', wm.encode('utf-8'))
-
- batch_size = opt.n_samples
- n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
- if not opt.from_file:
- prompt = opt.prompt
- assert prompt is not None
- data = [batch_size * [prompt]]
-
- else:
- print(f"reading prompts from {opt.from_file}")
- with open(opt.from_file, "r") as f:
- data = f.read().splitlines()
- data = list(chunk(data, batch_size))
-
- sample_path = os.path.join(outpath, "samples")
- os.makedirs(sample_path, exist_ok=True)
- base_count = len(os.listdir(sample_path))
- grid_count = len(os.listdir(outpath)) - 1
-
- start_code = None
- if opt.fixed_code:
- start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
-
- precision_scope = autocast if opt.precision=="autocast" else nullcontext
- with torch.no_grad():
- with precision_scope("cuda"):
- with model.ema_scope():
- tic = time.time()
- all_samples = list()
- for n in trange(opt.n_iter, desc="Sampling"):
- for prompts in tqdm(data, desc="data"):
- uc = None
- if opt.scale != 1.0:
- uc = model.get_learned_conditioning(batch_size * [""])
- if isinstance(prompts, tuple):
- prompts = list(prompts)
- c = model.get_learned_conditioning(prompts)
- shape = [opt.C, opt.H // opt.f, opt.W // opt.f]
- samples_ddim, _ = sampler.sample(S=opt.ddim_steps,
- conditioning=c,
- batch_size=opt.n_samples,
- shape=shape,
- verbose=False,
- unconditional_guidance_scale=opt.scale,
- unconditional_conditioning=uc,
- eta=opt.ddim_eta,
- x_T=start_code)
-
- x_samples_ddim = model.decode_first_stage(samples_ddim)
- x_samples_ddim = torch.clamp((x_samples_ddim + 1.0) / 2.0, min=0.0, max=1.0)
- x_samples_ddim = x_samples_ddim.cpu().permute(0, 2, 3, 1).numpy()
-
- x_checked_image, has_nsfw_concept = check_safety(x_samples_ddim)
-
- x_checked_image_torch = torch.from_numpy(x_checked_image).permute(0, 3, 1, 2)
-
- if not opt.skip_save:
- for x_sample in x_checked_image_torch:
- x_sample = 255. * rearrange(x_sample.cpu().numpy(), 'c h w -> h w c')
- img = Image.fromarray(x_sample.astype(np.uint8))
- img = put_watermark(img, wm_encoder)
- img.save(os.path.join(sample_path, f"{base_count:05}.png"))
- base_count += 1
-
- if not opt.skip_grid:
- all_samples.append(x_checked_image_torch)
-
- if not opt.skip_grid:
- # additionally, save as grid
- grid = torch.stack(all_samples, 0)
- grid = rearrange(grid, 'n b c h w -> (n b) c h w')
- grid = make_grid(grid, nrow=n_rows)
-
- # to image
- grid = 255. * rearrange(grid, 'c h w -> h w c').cpu().numpy()
- img = Image.fromarray(grid.astype(np.uint8))
- img = put_watermark(img, wm_encoder)
- img.save(os.path.join(outpath, f'grid-{grid_count:04}.png'))
- grid_count += 1
-
- toc = time.time()
-
- print(f"Your samples are ready and waiting for you here: \n{outpath} \n"
- f" \nEnjoy.")
-
-
-if __name__ == "__main__":
- main()
diff --git a/examples/tutorial/stable_diffusion/train.sh b/examples/tutorial/stable_diffusion/train.sh
deleted file mode 100644
index 63abcadbf..000000000
--- a/examples/tutorial/stable_diffusion/train.sh
+++ /dev/null
@@ -1,4 +0,0 @@
-HF_DATASETS_OFFLINE=1
-TRANSFORMERS_OFFLINE=1
-
-python main.py --logdir /tmp -t --postfix test -b configs/train_colossalai.yaml
diff --git a/requirements/requirements-test.txt b/requirements/requirements-test.txt
index f9e8960d2..9ef0a682b 100644
--- a/requirements/requirements-test.txt
+++ b/requirements/requirements-test.txt
@@ -1,5 +1,6 @@
fbgemm-gpu==0.2.0
pytest
+pytest-cov
torchvision
transformers
timm
diff --git a/setup.py b/setup.py
index 38d5fa91c..b9cd9e5e4 100644
--- a/setup.py
+++ b/setup.py
@@ -1,5 +1,6 @@
import os
import re
+from datetime import datetime
from setuptools import find_packages, setup
@@ -20,18 +21,22 @@ except ImportError:
TORCH_AVAILABLE = False
CUDA_HOME = None
-
# ninja build does not work unless include_dirs are abs path
this_dir = os.path.dirname(os.path.abspath(__file__))
build_cuda_ext = False
ext_modules = []
+is_nightly = int(os.environ.get('NIGHTLY', '0')) == 1
if int(os.environ.get('CUDA_EXT', '0')) == 1:
if not TORCH_AVAILABLE:
- raise ModuleNotFoundError("PyTorch is not found while CUDA_EXT=1. You need to install PyTorch first in order to build CUDA extensions")
+ raise ModuleNotFoundError(
+ "PyTorch is not found while CUDA_EXT=1. You need to install PyTorch first in order to build CUDA extensions"
+ )
if not CUDA_HOME:
- raise RuntimeError("CUDA_HOME is not found while CUDA_EXT=1. You need to export CUDA_HOME environment vairable or install CUDA Toolkit first in order to build CUDA extensions")
+ raise RuntimeError(
+ "CUDA_HOME is not found while CUDA_EXT=1. You need to export CUDA_HOME environment vairable or install CUDA Toolkit first in order to build CUDA extensions"
+ )
build_cuda_ext = True
@@ -139,8 +144,19 @@ if build_cuda_ext:
print(f'===== Building Extension {name} =====')
ext_modules.append(builder_cls().builder())
-setup(name='colossalai',
- version=get_version(),
+# always put not nightly branch as the if branch
+# otherwise github will treat colossalai-nightly as the project name
+# and it will mess up with the dependency graph insights
+if not is_nightly:
+ version = get_version()
+ package_name = 'colossalai'
+else:
+ # use date as the nightly version
+ version = datetime.today().strftime('%Y.%m.%d')
+ package_name = 'colossalai-nightly'
+
+setup(name=package_name,
+ version=version,
packages=find_packages(exclude=(
'benchmark',
'docker',
@@ -179,4 +195,9 @@ setup(name='colossalai',
'Topic :: Scientific/Engineering :: Artificial Intelligence',
'Topic :: System :: Distributed Computing',
],
- package_data={'colossalai': ['_C/*.pyi', 'kernel/cuda_native/csrc/*', 'kernel/cuda_native/csrc/kernel/*', 'kernel/cuda_native/csrc/kernels/include/*']})
+ package_data={
+ 'colossalai': [
+ '_C/*.pyi', 'kernel/cuda_native/csrc/*', 'kernel/cuda_native/csrc/kernel/*',
+ 'kernel/cuda_native/csrc/kernels/include/*'
+ ]
+ })
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_checkpoint.py b/tests/test_auto_parallel/test_tensor_shard/test_checkpoint.py
new file mode 100644
index 000000000..0b42722fe
--- /dev/null
+++ b/tests/test_auto_parallel/test_tensor_shard/test_checkpoint.py
@@ -0,0 +1,70 @@
+from functools import partial
+from typing import Optional, Tuple, Union
+
+import pytest
+import torch
+import torch.multiprocessing as mp
+import torch.nn as nn
+from torch.utils.checkpoint import checkpoint
+from transformers.pytorch_utils import Conv1D
+
+from colossalai.auto_parallel.tensor_shard.initialize import initialize_model
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.fx.graph_module import ColoGraphModule
+from colossalai.fx.tracer import ColoTracer
+from colossalai.initialize import launch
+from colossalai.logging import disable_existing_loggers
+from colossalai.tensor.shape_consistency import ShapeConsistencyManager
+from colossalai.testing import rerun_if_address_is_in_use
+from colossalai.testing.pytest_wrapper import run_on_environment_flag
+from colossalai.utils import free_port
+
+HIDDEN_SIZE = 16
+
+
+class GPT2MLPWithCkpt(nn.Module):
+
+ def __init__(self, intermediate_size, hidden_size):
+ super().__init__()
+ embed_dim = hidden_size
+ self.c_fc = Conv1D(intermediate_size, embed_dim)
+ self.c_proj = Conv1D(embed_dim, intermediate_size)
+ self.act = torch.nn.ReLU()
+
+ def forward(self, hidden_states: Optional[Tuple[torch.FloatTensor]]) -> torch.FloatTensor:
+ hidden_states = self.c_fc(hidden_states)
+ hidden_states = checkpoint(self.c_proj, hidden_states)
+ hidden_states = self.act(hidden_states)
+
+ return hidden_states
+
+
+def check_act_ckpt(rank, world_size, port):
+ disable_existing_loggers()
+ launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ model = GPT2MLPWithCkpt(intermediate_size=4 * HIDDEN_SIZE, hidden_size=HIDDEN_SIZE)
+ input_sample = {
+ 'hidden_states': torch.rand(1, 64, HIDDEN_SIZE).to('meta'),
+ }
+ physical_mesh_id = torch.arange(0, 4)
+ mesh_shape = (2, 2)
+ # [[0, 1]
+ # [2, 3]]
+ device_mesh = DeviceMesh(physical_mesh_id, mesh_shape, init_process_group=True)
+ gm = initialize_model(model, input_sample, device_mesh)
+ code = gm.module.graph.python_code('self').src
+ assert "runtime_comm_spec_apply_1 = colossalai_auto_parallel_passes_runtime_apply_pass_runtime_comm_spec_apply(linear_1, comm_actions_dict, 12, 'linear_1')" in code
+ assert "view_3 = colossalai.utils.activation_checkpoint.checkpoint(self.checkpoint_0, False, view_1, comm_actions_dict, use_reentrant=True)" in code
+
+
+@run_on_environment_flag(name='AUTO_PARALLEL')
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+def test_mlp_layer():
+ world_size = 4
+ run_func = partial(check_act_ckpt, world_size=world_size, port=free_port())
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_mlp_layer()
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
index 42430d5a2..50385c045 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_binary_elementwise_handler.py
@@ -122,25 +122,41 @@ def check_binary_elementwise_handler_with_tensor(rank, op, other_dim, world_size
assert input_sharding_spec.sharding_sequence[-1] == other_sharding_spec.sharding_sequence[-1]
-def check_binary_elementwise_handler_with_int(rank, op, other_dim, world_size, port):
+class BEOpModelWithNodeConst(nn.Module):
+
+ def __init__(self, op):
+ super().__init__()
+ self.op = op
+
+ def forward(self, x1):
+ const = x1.dim()
+ out = self.op(x1, const)
+ return out
+
+
+class BEOpModelWithIntConst(nn.Module):
+
+ def __init__(self, op, const):
+ super().__init__()
+ self.op = op
+ self.const = const
+
+ def forward(self, x1):
+ out = self.op(x1, self.const)
+ return out
+
+
+def check_binary_elementwise_handler_with_int(rank, op, other_dim, model_cls, world_size, port):
disable_existing_loggers()
launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
- class BinaryElementwiseOpModel(nn.Module):
-
- def __init__(self, op, const):
- super().__init__()
- self.op = op
- self.const = const
-
- def forward(self, x1):
- out = self.op(x1, self.const)
- return out
-
physical_mesh_id = torch.arange(0, 4)
mesh_shape = (2, 2)
device_mesh = DeviceMesh(physical_mesh_id, mesh_shape, init_process_group=True)
- model = BinaryElementwiseOpModel(op, other_dim).cuda()
+ if model_cls == BEOpModelWithNodeConst:
+ model = model_cls(op).cuda()
+ else:
+ model = model_cls(op, other_dim).cuda()
x1 = torch.rand(4, 4).cuda()
# the index of binary-elementwise node in computation graph
node_index = 1
@@ -159,9 +175,14 @@ def check_binary_elementwise_handler_with_int(rank, op, other_dim, world_size, p
tracer = ColoTracer()
meta_args = {'x1': torch.rand(4, 4).to('meta')}
graph = tracer.trace(model, meta_args=meta_args)
+ print(graph)
+ # assert False
gm = ColoGraphModule(model, graph)
- op_node = list(graph.nodes)[1]
+ if model_cls == BEOpModelWithNodeConst:
+ op_node = list(graph.nodes)[2]
+ else:
+ op_node = list(graph.nodes)[1]
strategies_vector = StrategiesVector(op_node)
# build handler
@@ -212,7 +233,7 @@ def check_binary_elementwise_handler_with_int(rank, op, other_dim, world_size, p
@parameterize('other_dim', [1, 2])
@pytest.mark.dist
@rerun_if_address_is_in_use()
-def test_binary_elementwise_handler(op, other_dim):
+def test_binary_elementwise_handler_with_tensor(op, other_dim):
world_size = 4
run_func_tensor = partial(check_binary_elementwise_handler_with_tensor,
op=op,
@@ -220,8 +241,19 @@ def test_binary_elementwise_handler(op, other_dim):
world_size=world_size,
port=free_port())
mp.spawn(run_func_tensor, nprocs=world_size)
+
+
+@run_on_environment_flag(name='AUTO_PARALLEL')
+@parameterize('op', [torch.add])
+@parameterize('other_dim', [1, 2])
+@parameterize('model_cls', [BEOpModelWithNodeConst, BEOpModelWithIntConst])
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+def test_binary_elementwise_handler_with_int(op, model_cls, other_dim):
+ world_size = 4
run_func_int = partial(check_binary_elementwise_handler_with_int,
op=op,
+ model_cls=model_cls,
other_dim=other_dim,
world_size=world_size,
port=free_port())
@@ -229,4 +261,5 @@ def test_binary_elementwise_handler(op, other_dim):
if __name__ == '__main__':
- test_binary_elementwise_handler()
+ test_binary_elementwise_handler_with_tensor()
+ test_binary_elementwise_handler_with_int()
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py
new file mode 100644
index 000000000..fda041110
--- /dev/null
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/test_shard_option.py
@@ -0,0 +1,112 @@
+from functools import partial
+
+import torch
+import torch.multiprocessing as mp
+import torch.nn as nn
+
+from colossalai.auto_parallel.tensor_shard.node_handler import LinearFunctionHandler
+from colossalai.auto_parallel.tensor_shard.node_handler.option import ShardOption
+from colossalai.auto_parallel.tensor_shard.sharding_strategy import StrategiesVector
+from colossalai.device.device_mesh import DeviceMesh
+from colossalai.fx import ColoGraphModule, ColoTracer
+from colossalai.testing import parameterize
+from colossalai.testing.pytest_wrapper import run_on_environment_flag
+from colossalai.testing.utils import parameterize
+
+
+class LinearModel(nn.Module):
+
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, input, others, bias=None):
+ x = nn.functional.linear(input, others, bias=bias)
+ return x
+
+
+def check_shard_option(shard_option):
+ model = LinearModel().cuda()
+ physical_mesh_id = torch.arange(0, 4)
+ mesh_shape = (2, 2)
+ device_mesh = DeviceMesh(physical_mesh_id, mesh_shape)
+
+ tracer = ColoTracer()
+ graph = tracer.trace(model,
+ meta_args={
+ "input": torch.rand(4, 4, 4, 16).to('meta'),
+ 'others': torch.rand(32, 16).to('meta')
+ })
+ gm = ColoGraphModule(model, graph)
+ linear_func_node = list(graph.nodes)[2]
+ strategies_vector = StrategiesVector(linear_func_node)
+
+ # build handler
+ handler = LinearFunctionHandler(node=linear_func_node,
+ device_mesh=device_mesh,
+ strategies_vector=strategies_vector,
+ shard_option=shard_option)
+
+ strategies_vector = handler.register_strategy(compute_resharding_cost=False)
+ strategy_name_list = [val.name for val in strategies_vector]
+
+ # SS = SR x RS
+ assert 'S1S0 = S1R x RS0_0' in strategy_name_list
+ assert 'S0S1 = S0R x RS1_1' in strategy_name_list
+ assert 'S0S1 = S0R x RS1_2' in strategy_name_list
+ assert 'S0S1 = S0R x RS1_0' in strategy_name_list
+ assert 'S1S0 = S1R x RS0_1' in strategy_name_list
+ assert 'S1S0 = S1R x RS0_2' in strategy_name_list
+
+ # SR = SS x SR
+ assert 'S0R = S0S1 x S1R_1' in strategy_name_list
+ assert 'S0R = S0S1 x S1R_2' in strategy_name_list
+ assert 'S1R = S1S0 x S0R_0' in strategy_name_list
+ assert 'S0R = S0S1 x S1R_0' in strategy_name_list
+ assert 'S1R = S1S0 x S0R_1' in strategy_name_list
+ assert 'S1R = S1S0 x S0R_2' in strategy_name_list
+
+ # RS = RS x SS
+ assert 'RS0 = RS1 x S1S0' in strategy_name_list
+ assert 'RS1 = RS0 x S0S1' in strategy_name_list
+
+ # S01R = S01R x RR
+ assert 'S01R = S01R x RR_0' in strategy_name_list
+ assert 'S01R = S01R x RR_1' in strategy_name_list
+ assert 'S01R = S01R x RR_2' in strategy_name_list
+
+ # RR = RS01 x S01R
+ assert 'RR = RS01 x S01R' in strategy_name_list
+
+ # RS01 = RR x RS01
+ assert 'RS01 = RR x RS01' in strategy_name_list
+
+ if shard_option == ShardOption.SHARD:
+ # RR = RS x SR
+ assert 'RR = RS0 x S0R' in strategy_name_list
+ assert 'RR = RS1 x S1R' in strategy_name_list
+
+ # RS= RR x RS
+ assert 'RS0 = RR x RS0' in strategy_name_list
+ assert 'RS1 = RR x RS1' in strategy_name_list
+
+ if shard_option == ShardOption.STANDARD:
+ # RR = RS x SR
+ assert 'RR = RS0 x S0R' in strategy_name_list
+ assert 'RR = RS1 x S1R' in strategy_name_list
+
+ # RS= RR x RS
+ assert 'RS0 = RR x RS0' in strategy_name_list
+ assert 'RS1 = RR x RS1' in strategy_name_list
+
+ # RR = RR x RR
+ assert 'RR = RR x RR' in strategy_name_list
+
+
+@run_on_environment_flag(name='AUTO_PARALLEL')
+def test_shard_option():
+ for shard_option in [ShardOption.STANDARD, ShardOption.SHARD, ShardOption.FULL_SHARD]:
+ check_shard_option(shard_option)
+
+
+if __name__ == '__main__':
+ test_shard_option()
diff --git a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py
index d02e1e31e..db76ed9b8 100644
--- a/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py
+++ b/tests/test_auto_parallel/test_tensor_shard/test_node_handler/utils.py
@@ -90,7 +90,8 @@ def numerical_test_for_node_strategy(model: torch.nn.Module,
solver_options = SolverOptions()
strategies_constructor = StrategiesConstructor(graph, device_mesh, solver_options)
strategies_constructor.build_strategies_and_cost()
- target_node = list(graph.nodes)[node_index]
+ target_node = [strategies_vector.node for strategies_vector in strategies_constructor.leaf_strategies
+ ][node_index]
if node_type == 'normal':
solution_len = len(strategies_constructor.leaf_strategies)
solution = [0] * solution_len
@@ -112,7 +113,7 @@ def numerical_test_for_node_strategy(model: torch.nn.Module,
ret = solver.call_solver_serialized_args()
solution = list(ret[0])
gm, sharding_spec_dict, origin_spec_dict, comm_actions_dict = runtime_preparation_pass(
- gm, solution, device_mesh)
+ gm, solution, device_mesh, strategies_constructor)
gm = runtime_apply_pass(gm)
gm.recompile()
diff --git a/tests/test_autochunk/benchmark_simple_evoformer.py b/tests/test_autochunk/benchmark_simple_evoformer.py
new file mode 100644
index 000000000..8b5d8a8be
--- /dev/null
+++ b/tests/test_autochunk/benchmark_simple_evoformer.py
@@ -0,0 +1,94 @@
+import time
+
+import torch
+import torch.fx
+from simple_evoformer import base_evoformer, openfold_evoformer
+
+from colossalai.autochunk.autochunk_codegen import AutoChunkCodeGen
+from colossalai.fx import ColoTracer
+from colossalai.fx.graph_module import ColoGraphModule
+from colossalai.fx.passes.meta_info_prop import MetaInfoProp
+from colossalai.fx.profiler import MetaTensor
+
+
+def _benchmark_evoformer(model: torch.nn.Module, node, pair, title, chunk_size=None):
+ torch.cuda.reset_peak_memory_stats()
+ now_mem = torch.cuda.memory_allocated() / 1024**2
+
+ loop = 3
+ with torch.no_grad():
+ for _ in range(loop // 2 + 1):
+ if chunk_size:
+ model(node, pair, chunk_size)
+ else:
+ model(node, pair)
+ torch.cuda.synchronize()
+ time1 = time.time()
+ for _ in range(loop):
+ if chunk_size:
+ model(node, pair, chunk_size)
+ else:
+ model(node, pair)
+ torch.cuda.synchronize()
+ time2 = time.time()
+
+ new_max_mem = torch.cuda.max_memory_allocated() / 1024**2
+ print("%s: time %.4fs, mem %dMB" % (title, (time2 - time1) / loop, new_max_mem - now_mem))
+
+
+def _build_autochunk(model, max_memory, node, pair):
+ # trace the module and replace codegen
+ graph = ColoTracer().trace(
+ model,
+ meta_args={
+ "node": node.to(torch.device("meta")),
+ "pair": pair.to(torch.device("meta")),
+ },
+ )
+
+ gm_prop = torch.fx.symbolic_trace(model) # must use symbolic_trace
+ interp = MetaInfoProp(gm_prop)
+ interp.propagate(MetaTensor(node, fake_device="cuda:0"), MetaTensor(pair, fake_device="cuda:0"))
+
+ # now run it twice to get meta info in graph module, not necessary
+ gm = torch.fx.GraphModule(model, graph)
+ interp = MetaInfoProp(gm)
+ interp.propagate(MetaTensor(node, fake_device="cuda:0"), MetaTensor(pair, fake_device="cuda:0"))
+
+ # set code_gen
+ codegen = AutoChunkCodeGen(gm_prop, max_memory, print_mem=False)
+ graph.set_codegen(codegen)
+ gm = ColoGraphModule(model, graph)
+ gm.recompile()
+
+ # print
+ # code = graph.python_code("self").src
+ # print(code)
+ return gm
+
+
+def benchmark_evoformer():
+ # init data and model
+ msa_len = 128
+ pair_len = 256
+ node = torch.randn(1, msa_len, pair_len, 256).cuda()
+ pair = torch.randn(1, pair_len, pair_len, 128).cuda()
+ model = base_evoformer().cuda()
+
+ # build autochunk model
+ # max_memory = 1000 # MB, fit memory mode
+ max_memory = None # min memory mode
+ autochunk = _build_autochunk(base_evoformer().cuda(), max_memory, node, pair)
+
+ # build openfold
+ chunk_size = 64
+ openfold = openfold_evoformer().cuda()
+
+ # benchmark
+ _benchmark_evoformer(model, node, pair, "base")
+ _benchmark_evoformer(openfold, node, pair, "openfold", chunk_size=chunk_size)
+ _benchmark_evoformer(autochunk, node, pair, "autochunk")
+
+
+if __name__ == "__main__":
+ benchmark_evoformer()
diff --git a/tests/test_autochunk/test_evoformer_codegen.py b/tests/test_autochunk/test_evoformer_codegen.py
new file mode 100644
index 000000000..ba6a57a51
--- /dev/null
+++ b/tests/test_autochunk/test_evoformer_codegen.py
@@ -0,0 +1,163 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.fx
+import torch.multiprocessing as mp
+
+try:
+ from fastfold.model.nn.evoformer import EvoformerBlock
+ HAS_REPO = True
+except:
+ HAS_REPO = False
+
+import colossalai
+from colossalai.core import global_context as gpc
+from colossalai.fx._compatibility import is_compatible_with_meta
+from colossalai.fx.codegen.activation_checkpoint_codegen import CODEGEN_AVAILABLE
+from colossalai.fx.graph_module import ColoGraphModule
+from colossalai.fx.passes.meta_info_prop import MetaInfoProp
+from colossalai.utils import free_port
+
+if CODEGEN_AVAILABLE and is_compatible_with_meta():
+ from colossalai.autochunk.autochunk_codegen import AutoChunkCodeGen
+ from colossalai.fx.profiler import MetaTensor
+ from colossalai.fx.tracer.experimental import ColoTracer, symbolic_trace
+
+
+def _test_fwd(model: torch.nn.Module, gm: ColoGraphModule, node, pair, node_mask, pair_mask):
+ # for memory test
+ # model = model.cuda()
+ # torch.cuda.reset_peak_memory_stats()
+ # now_mem = torch.cuda.memory_allocated() / 1024**2
+ # with torch.no_grad():
+ # node1 = node.clone()
+ # pair1 = pair.clone()
+ # node_mask1 = node_mask.clone()
+ # pair_mask1 = pair_mask.clone()
+ # gm(node1, pair1, node_mask1, pair_mask1)
+ # new_max_mem = torch.cuda.max_memory_allocated() / 1024**2
+ # print("autochunk max mem:%.2f"% (new_max_mem - now_mem))
+
+ # test forward
+ model = model.cuda()
+ with torch.no_grad():
+ non_fx_out = model(node, pair, node_mask, pair_mask)
+ fx_out = gm(node, pair, node_mask, pair_mask)
+
+ assert torch.allclose(non_fx_out[0], fx_out[0],
+ atol=1e-4), "fx_out doesn't comply with original output, diff is %.2e" % torch.mean(
+ torch.abs(non_fx_out[0] - fx_out[0]))
+ assert torch.allclose(non_fx_out[1], fx_out[1],
+ atol=1e-4), "fx_out doesn't comply with original output, diff is %.2e" % torch.mean(
+ torch.abs(non_fx_out[1] - fx_out[1]))
+
+
+def _build_openfold():
+ model = EvoformerBlock(
+ c_m=256,
+ c_z=128,
+ c_hidden_msa_att=32,
+ c_hidden_opm=32,
+ c_hidden_mul=128,
+ c_hidden_pair_att=32,
+ no_heads_msa=8,
+ no_heads_pair=4,
+ transition_n=4,
+ msa_dropout=0.15,
+ pair_dropout=0.15,
+ inf=1e4,
+ eps=1e-4,
+ is_multimer=False,
+ ).eval().cuda()
+ return model
+
+
+def _test_evoformer_codegen(rank, msa_len, pair_len, max_memory):
+ # launch colossalai
+ colossalai.launch(
+ config={},
+ rank=rank,
+ world_size=1,
+ host="localhost",
+ port=free_port(),
+ backend="nccl",
+ )
+
+ # build model and input
+ model = _build_openfold()
+ node = torch.randn(1, msa_len, pair_len, 256).cuda()
+ node_mask = torch.randn(1, msa_len, pair_len).cuda()
+ pair = torch.randn(1, pair_len, pair_len, 128).cuda()
+ pair_mask = torch.randn(1, pair_len, pair_len).cuda()
+
+ # trace the meta graph and setup codegen
+ meta_graph = symbolic_trace(
+ model,
+ meta_args={
+ "m": node.to(torch.device("meta")),
+ "z": pair.to(torch.device("meta")),
+ "msa_mask": node_mask.to(torch.device("meta")),
+ "pair_mask": pair_mask.to(torch.device("meta")),
+ },
+ concrete_args={
+ "chunk_size": None,
+ "_mask_trans": True,
+ },
+ )
+ interp = MetaInfoProp(meta_graph)
+ interp.propagate(
+ MetaTensor(node, fake_device="cuda:0"),
+ MetaTensor(pair, fake_device="cuda:0"),
+ MetaTensor(node_mask, fake_device="cuda:0"),
+ MetaTensor(pair_mask, fake_device="cuda:0"),
+ )
+ codegen = AutoChunkCodeGen(meta_graph, max_memory=max_memory, print_mem=False)
+
+ # trace and recompile
+ # MetaInfoProp requires symbolic_trace but CodeGen requires ColoTracer
+ graph = ColoTracer().trace(
+ model,
+ meta_args={
+ "m": node.to(torch.device("meta")),
+ "z": pair.to(torch.device("meta")),
+ "msa_mask": node_mask.to(torch.device("meta")),
+ "pair_mask": pair_mask.to(torch.device("meta")),
+ },
+ concrete_args={
+ "chunk_size": None,
+ "_mask_trans": True,
+ },
+ )
+ graph.set_codegen(codegen)
+ gm = ColoGraphModule(model, graph, ckpt_codegen=False)
+ gm.recompile()
+
+ # assert we have inserted chunk
+ code = graph.python_code("self").src
+ # print(code)
+ assert "chunk_result = None; chunk_size = None;" in code
+
+ _test_fwd(model, gm, node, pair, node_mask, pair_mask)
+ gpc.destroy()
+
+
+@pytest.mark.skipif(
+ not (CODEGEN_AVAILABLE and is_compatible_with_meta() and HAS_REPO),
+ reason="torch version is lower than 1.12.0",
+)
+@pytest.mark.parametrize("max_memory", [None, 24, 28, 32])
+@pytest.mark.parametrize("msa_len", [32])
+@pytest.mark.parametrize("pair_len", [64])
+def test_evoformer_codegen(msa_len, pair_len, max_memory):
+ run_func = partial(
+ _test_evoformer_codegen,
+ msa_len=msa_len,
+ pair_len=pair_len,
+ max_memory=max_memory,
+ )
+ mp.spawn(run_func, nprocs=1)
+
+
+if __name__ == "__main__":
+ _test_evoformer_codegen(0, 32, 64, 24)
diff --git a/tests/test_autochunk/test_evoformer_stack_codegen.py b/tests/test_autochunk/test_evoformer_stack_codegen.py
new file mode 100644
index 000000000..5fabb2702
--- /dev/null
+++ b/tests/test_autochunk/test_evoformer_stack_codegen.py
@@ -0,0 +1,163 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.fx
+import torch.multiprocessing as mp
+
+try:
+ from fastfold.model.nn.evoformer import EvoformerStack
+ HAS_REPO = True
+except:
+ HAS_REPO = False
+
+import colossalai
+from colossalai.core import global_context as gpc
+from colossalai.fx._compatibility import is_compatible_with_meta
+from colossalai.fx.codegen.activation_checkpoint_codegen import CODEGEN_AVAILABLE
+from colossalai.fx.graph_module import ColoGraphModule
+from colossalai.fx.passes.meta_info_prop import MetaInfoProp
+from colossalai.utils import free_port
+
+if CODEGEN_AVAILABLE and is_compatible_with_meta():
+ from colossalai.autochunk.autochunk_codegen import AutoChunkCodeGen
+ from colossalai.fx.profiler import MetaTensor
+ from colossalai.fx.tracer.experimental import ColoTracer, symbolic_trace
+
+
+def _test_fwd(model: torch.nn.Module, gm: ColoGraphModule, node, pair, node_mask, pair_mask):
+ # for memory test
+ # model = model.cuda()
+ # torch.cuda.reset_peak_memory_stats()
+ # now_mem = torch.cuda.memory_allocated() / 1024**2
+ # with torch.no_grad():
+ # node1 = node.clone()
+ # pair1 = pair.clone()
+ # node_mask1 = node_mask.clone()
+ # pair_mask1 = pair_mask.clone()
+ # gm(node1, pair1, node_mask1, pair_mask1, None)
+ # new_max_mem = torch.cuda.max_memory_allocated() / 1024**2
+ # print("autochunk max mem:%.2f"% (new_max_mem - now_mem))
+
+ # test forward
+ model = model.cuda()
+ with torch.no_grad():
+ non_fx_out = model(node, pair, node_mask, pair_mask, None)
+ fx_out = gm(node, pair, node_mask, pair_mask, None)
+
+ assert torch.allclose(non_fx_out[0], fx_out[0],
+ atol=1e-4), "fx_out doesn't comply with original output, diff is %.2e" % torch.mean(
+ torch.abs(non_fx_out[0] - fx_out[0]))
+ assert torch.allclose(non_fx_out[1], fx_out[1],
+ atol=1e-4), "fx_out doesn't comply with original output, diff is %.2e" % torch.mean(
+ torch.abs(non_fx_out[1] - fx_out[1]))
+
+
+def _build_openfold():
+ model = EvoformerStack(
+ c_m=256,
+ c_z=128,
+ c_hidden_msa_att=32,
+ c_hidden_opm=32,
+ c_hidden_mul=128,
+ c_hidden_pair_att=32,
+ c_s=384,
+ no_heads_msa=8,
+ no_heads_pair=4,
+ no_blocks=2, # 48
+ transition_n=4,
+ msa_dropout=0.15,
+ pair_dropout=0.25,
+ blocks_per_ckpt=None,
+ inf=1000000000.0,
+ eps=1e-08,
+ clear_cache_between_blocks=False,
+ is_multimer=False,
+ ).eval().cuda()
+ return model
+
+
+def _test_evoformer_stack_codegen(rank, msa_len, pair_len, max_memory):
+ # launch colossalai
+ colossalai.launch(
+ config={},
+ rank=rank,
+ world_size=1,
+ host="localhost",
+ port=free_port(),
+ backend="nccl",
+ )
+
+ # build model and input
+ model = _build_openfold()
+ node = torch.randn(1, msa_len, pair_len, 256).cuda()
+ node_mask = torch.randn(1, msa_len, pair_len).cuda()
+ pair = torch.randn(1, pair_len, pair_len, 128).cuda()
+ pair_mask = torch.randn(1, pair_len, pair_len).cuda()
+
+ # trace the meta graph and setup codegen
+ meta_graph = symbolic_trace(
+ model,
+ meta_args={
+ "m": node.to(torch.device("meta")),
+ "z": pair.to(torch.device("meta")),
+ "msa_mask": node_mask.to(torch.device("meta")),
+ "pair_mask": pair_mask.to(torch.device("meta")),
+ },
+ concrete_args={
+ "chunk_size": None,
+ "_mask_trans": True,
+ },
+ )
+ interp = MetaInfoProp(meta_graph)
+ interp.propagate(MetaTensor(node, fake_device="cuda:0"), MetaTensor(pair, fake_device="cuda:0"),
+ MetaTensor(node_mask, fake_device="cuda:0"), MetaTensor(pair_mask, fake_device="cuda:0"), None)
+ codegen = AutoChunkCodeGen(meta_graph, max_memory=max_memory, print_mem=False, print_progress=False)
+
+ # trace and recompile
+ # MetaInfoProp requires symbolic_trace but CodeGen requires ColoTracer
+ graph = ColoTracer().trace(
+ model,
+ meta_args={
+ "m": node.to(torch.device("meta")),
+ "z": pair.to(torch.device("meta")),
+ "msa_mask": node_mask.to(torch.device("meta")),
+ "pair_mask": pair_mask.to(torch.device("meta")),
+ },
+ concrete_args={
+ "chunk_size": None,
+ "_mask_trans": True,
+ },
+ )
+ graph.set_codegen(codegen)
+ gm = ColoGraphModule(model, graph, ckpt_codegen=False)
+ gm.recompile()
+
+ # assert we have inserted chunk
+ code = graph.python_code("self").src
+ # print(code)
+ assert "chunk_result = None; chunk_size = None;" in code
+
+ _test_fwd(model, gm, node, pair, node_mask, pair_mask)
+ gpc.destroy()
+
+
+@pytest.mark.skipif(
+ not (CODEGEN_AVAILABLE and is_compatible_with_meta() and HAS_REPO),
+ reason="torch version is lower than 1.12.0",
+)
+@pytest.mark.parametrize("max_memory", [None, 24, 28, 32])
+@pytest.mark.parametrize("msa_len", [32])
+@pytest.mark.parametrize("pair_len", [64])
+def test_evoformer_stack_codegen(msa_len, pair_len, max_memory):
+ run_func = partial(
+ _test_evoformer_stack_codegen,
+ msa_len=msa_len,
+ pair_len=pair_len,
+ max_memory=max_memory,
+ )
+ mp.spawn(run_func, nprocs=1)
+
+
+if __name__ == "__main__":
+ _test_evoformer_stack_codegen(0, 32, 64, None)
diff --git a/tests/test_autochunk/test_extramsa_codegen.py b/tests/test_autochunk/test_extramsa_codegen.py
new file mode 100644
index 000000000..2a41452a2
--- /dev/null
+++ b/tests/test_autochunk/test_extramsa_codegen.py
@@ -0,0 +1,164 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.fx
+import torch.multiprocessing as mp
+
+try:
+ from fastfold.model.nn.evoformer import ExtraMSABlock
+ HAS_REPO = True
+except:
+ HAS_REPO = False
+
+import colossalai
+from colossalai.core import global_context as gpc
+from colossalai.fx._compatibility import is_compatible_with_meta
+from colossalai.fx.codegen.activation_checkpoint_codegen import CODEGEN_AVAILABLE
+from colossalai.fx.graph_module import ColoGraphModule
+from colossalai.fx.passes.meta_info_prop import MetaInfoProp
+from colossalai.utils import free_port
+
+if CODEGEN_AVAILABLE and is_compatible_with_meta():
+ from colossalai.autochunk.autochunk_codegen import AutoChunkCodeGen
+ from colossalai.fx.profiler import MetaTensor
+ from colossalai.fx.tracer.experimental import ColoTracer, symbolic_trace
+
+
+def _test_fwd(model: torch.nn.Module, gm: ColoGraphModule, node, pair, node_mask, pair_mask):
+ # for memory test
+ # model = model.cuda()
+ # torch.cuda.reset_peak_memory_stats()
+ # now_mem = torch.cuda.memory_allocated() / 1024**2
+ # with torch.no_grad():
+ # node1 = node.clone()
+ # pair1 = pair.clone()
+ # node_mask1 = node_mask.clone()
+ # pair_mask1 = pair_mask.clone()
+ # gm(node1, pair1, node_mask1, pair_mask1)
+ # new_max_mem = torch.cuda.max_memory_allocated() / 1024**2
+ # print("autochunk max mem:%.2f"% (new_max_mem - now_mem))
+
+ # test forward
+ model = model.cuda()
+ with torch.no_grad():
+ non_fx_out = model(node, pair, node_mask, pair_mask)
+ fx_out = gm(node, pair, node_mask, pair_mask)
+
+ assert torch.allclose(non_fx_out[0], fx_out[0],
+ atol=1e-4), "fx_out doesn't comply with original output, diff is %.2e" % torch.mean(
+ torch.abs(non_fx_out[0] - fx_out[0]))
+ assert torch.allclose(non_fx_out[1], fx_out[1],
+ atol=1e-4), "fx_out doesn't comply with original output, diff is %.2e" % torch.mean(
+ torch.abs(non_fx_out[1] - fx_out[1]))
+
+
+def _build_openfold():
+ model = ExtraMSABlock(
+ c_m=256,
+ c_z=128,
+ c_hidden_msa_att=32,
+ c_hidden_opm=32,
+ c_hidden_mul=128,
+ c_hidden_pair_att=32,
+ no_heads_msa=8,
+ no_heads_pair=4,
+ transition_n=4,
+ msa_dropout=0.15,
+ pair_dropout=0.15,
+ inf=1e4,
+ eps=1e-4,
+ ckpt=False,
+ is_multimer=False,
+ ).eval().cuda()
+ return model
+
+
+def _test_extramsa_codegen(rank, msa_len, pair_len, max_memory):
+ # launch colossalai
+ colossalai.launch(
+ config={},
+ rank=rank,
+ world_size=1,
+ host="localhost",
+ port=free_port(),
+ backend="nccl",
+ )
+
+ # build model and input
+ model = _build_openfold()
+ node = torch.randn(1, msa_len, pair_len, 256).cuda()
+ node_mask = torch.randn(1, msa_len, pair_len).cuda()
+ pair = torch.randn(1, pair_len, pair_len, 128).cuda()
+ pair_mask = torch.randn(1, pair_len, pair_len).cuda()
+
+ # trace the meta graph and setup codegen
+ meta_graph = symbolic_trace(
+ model,
+ meta_args={
+ "m": node.to(torch.device("meta")),
+ "z": pair.to(torch.device("meta")),
+ "msa_mask": node_mask.to(torch.device("meta")),
+ "pair_mask": pair_mask.to(torch.device("meta")),
+ },
+ concrete_args={
+ "chunk_size": None,
+ "_chunk_logits": 1024,
+ },
+ )
+ interp = MetaInfoProp(meta_graph)
+ interp.propagate(
+ MetaTensor(node, fake_device="cuda:0"),
+ MetaTensor(pair, fake_device="cuda:0"),
+ MetaTensor(node_mask, fake_device="cuda:0"),
+ MetaTensor(pair_mask, fake_device="cuda:0"),
+ )
+ codegen = AutoChunkCodeGen(meta_graph, max_memory=max_memory, print_mem=False)
+
+ # trace and recompile
+ # MetaInfoProp requires symbolic_trace but CodeGen requires ColoTracer
+ graph = ColoTracer().trace(
+ model,
+ meta_args={
+ "m": node.to(torch.device("meta")),
+ "z": pair.to(torch.device("meta")),
+ "msa_mask": node_mask.to(torch.device("meta")),
+ "pair_mask": pair_mask.to(torch.device("meta")),
+ },
+ concrete_args={
+ "chunk_size": None,
+ "_chunk_logits": 1024,
+ },
+ )
+ graph.set_codegen(codegen)
+ gm = ColoGraphModule(model, graph, ckpt_codegen=False)
+ gm.recompile()
+
+ # assert we have inserted chunk
+ code = graph.python_code("self").src
+ # print(code)
+ assert "chunk_result = None; chunk_size = None;" in code
+
+ _test_fwd(model, gm, node, pair, node_mask, pair_mask)
+ gpc.destroy()
+
+
+@pytest.mark.skipif(
+ not (CODEGEN_AVAILABLE and is_compatible_with_meta() and HAS_REPO),
+ reason="torch version is lower than 1.12.0",
+)
+@pytest.mark.parametrize("max_memory", [None, 24, 28, 32])
+@pytest.mark.parametrize("msa_len", [32])
+@pytest.mark.parametrize("pair_len", [64])
+def test_extramsa_codegen(msa_len, pair_len, max_memory):
+ run_func = partial(
+ _test_extramsa_codegen,
+ msa_len=msa_len,
+ pair_len=pair_len,
+ max_memory=max_memory,
+ )
+ mp.spawn(run_func, nprocs=1)
+
+
+if __name__ == "__main__":
+ _test_extramsa_codegen(0, 32, 64, None)
diff --git a/tests/test_autochunk/test_simple_evoformer_codegen.py b/tests/test_autochunk/test_simple_evoformer_codegen.py
new file mode 100644
index 000000000..7fe149c57
--- /dev/null
+++ b/tests/test_autochunk/test_simple_evoformer_codegen.py
@@ -0,0 +1,104 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.fx
+import torch.multiprocessing as mp
+
+try:
+ from simple_evoformer import base_evoformer
+ HAS_REPO = True
+except:
+ HAS_REPO = False
+
+import colossalai
+from colossalai.core import global_context as gpc
+from colossalai.fx import ColoTracer, symbolic_trace
+from colossalai.fx._compatibility import is_compatible_with_meta
+from colossalai.fx.codegen.activation_checkpoint_codegen import CODEGEN_AVAILABLE
+from colossalai.fx.graph_module import ColoGraphModule
+from colossalai.fx.passes.meta_info_prop import MetaInfoProp
+from colossalai.utils import free_port
+
+if CODEGEN_AVAILABLE and is_compatible_with_meta():
+ from colossalai.autochunk.autochunk_codegen import AutoChunkCodeGen
+ from colossalai.fx.profiler import MetaTensor
+
+
+def _test_fwd(model: torch.nn.Module, gm: ColoGraphModule, node, pair):
+ with torch.no_grad():
+ non_fx_out = model(node, pair)
+ fx_out = gm(node, pair)
+
+ assert torch.allclose(non_fx_out[0], fx_out[0],
+ atol=1e-4), "fx_out doesn't comply with original output, diff is %.2e" % torch.mean(
+ torch.abs(non_fx_out[0] - fx_out[0]))
+ assert torch.allclose(non_fx_out[1], fx_out[1],
+ atol=1e-4), "fx_out doesn't comply with original output, diff is %.2e" % torch.mean(
+ torch.abs(non_fx_out[1] - fx_out[1]))
+
+
+def _test_simple_evoformer_codegen(rank, msa_len, pair_len, max_memory):
+ # launch colossalai
+ colossalai.launch(
+ config={},
+ rank=rank,
+ world_size=1,
+ host="localhost",
+ port=free_port(),
+ backend="nccl",
+ )
+
+ # build model and input
+ model = base_evoformer().cuda()
+ node = torch.randn(1, msa_len, pair_len, 256).cuda()
+ pair = torch.randn(1, pair_len, pair_len, 128).cuda()
+
+ # meta info prop
+ meta_graph = symbolic_trace(model,
+ meta_args={
+ "node": node.to(torch.device("meta")),
+ "pair": pair.to(torch.device("meta")),
+ }) # must use symbolic_trace
+ interp = MetaInfoProp(meta_graph)
+ interp.propagate(MetaTensor(node, fake_device="cuda:0"), MetaTensor(pair, fake_device="cuda:0"))
+ codegen = AutoChunkCodeGen(meta_graph, max_memory=max_memory)
+
+ # trace the module and replace codegen
+ graph = ColoTracer().trace(
+ model,
+ meta_args={
+ "node": node.to(torch.device("meta")),
+ "pair": pair.to(torch.device("meta")),
+ },
+ )
+ graph.set_codegen(codegen)
+ gm = ColoGraphModule(model, graph, ckpt_codegen=False)
+ gm.recompile()
+
+ # assert we have inserted chunk
+ code = graph.python_code("self").src
+ # print(code)
+ assert "chunk_result = None; chunk_size = None;" in code
+
+ _test_fwd(model, gm, node, pair)
+ gpc.destroy()
+
+
+@pytest.mark.skipif(not (CODEGEN_AVAILABLE and is_compatible_with_meta() and HAS_REPO),
+ reason='torch version is lower than 1.12.0')
+@pytest.mark.parametrize("max_memory", [None, 20, 25, 30])
+@pytest.mark.parametrize("msa_len", [32])
+@pytest.mark.parametrize("pair_len", [64])
+def test_simple_evoformer_codegen(msa_len, pair_len, max_memory):
+ run_func = partial(
+ _test_simple_evoformer_codegen,
+ msa_len=msa_len,
+ pair_len=pair_len,
+ max_memory=max_memory,
+ )
+ mp.spawn(run_func, nprocs=1)
+
+
+if __name__ == "__main__":
+ _test_simple_evoformer_codegen(0, 32, 64, 25)
diff --git a/tests/test_autochunk/test_simple_evoformer_search.py b/tests/test_autochunk/test_simple_evoformer_search.py
new file mode 100644
index 000000000..89f28d625
--- /dev/null
+++ b/tests/test_autochunk/test_simple_evoformer_search.py
@@ -0,0 +1,97 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.fx
+import torch.multiprocessing as mp
+
+try:
+ from simple_evoformer import base_evoformer
+ HAS_REPO = True
+except:
+ HAS_REPO = False
+
+import colossalai
+from colossalai.core import global_context as gpc
+from colossalai.fx import symbolic_trace
+from colossalai.fx._compatibility import is_compatible_with_meta
+from colossalai.fx.codegen.activation_checkpoint_codegen import CODEGEN_AVAILABLE
+from colossalai.fx.passes.meta_info_prop import MetaInfoProp
+from colossalai.utils import free_port
+
+if CODEGEN_AVAILABLE and is_compatible_with_meta():
+ from colossalai.autochunk.autochunk_codegen import AutoChunkCodeGen
+ from colossalai.fx.profiler import MetaTensor
+
+
+def assert_chunk_infos(chunk_infos, max_memory, msa_len, pair_len):
+ found_regions = [i["region"] for i in chunk_infos]
+
+ if msa_len == 32 and pair_len == 64:
+ if max_memory is None:
+ target_regions = [(142, 154), (366, 373), (234, 283), (302, 351), (127, 134), (211, 228), (174, 191),
+ (161, 166), (198, 203), (7, 57)]
+ elif max_memory == 20:
+ target_regions = [(142, 154), (369, 373), (235, 269), (303, 351), (130, 131)]
+ elif max_memory == 25:
+ target_regions = [(144, 154), (369, 370)]
+ elif max_memory == 30:
+ target_regions = [(144, 154)]
+ else:
+ raise NotImplementedError()
+ else:
+ raise NotImplementedError()
+
+ assert found_regions == target_regions, "found regions %s doesn't equal target regions %s" % (
+ str(found_regions),
+ str(target_regions),
+ )
+
+
+def _test_simple_evoformer_search(rank, msa_len, pair_len, max_memory):
+ # launch colossalai
+ colossalai.launch(
+ config={},
+ rank=rank,
+ world_size=1,
+ host="localhost",
+ port=free_port(),
+ backend="nccl",
+ )
+
+ # build model and input
+ model = base_evoformer().cuda()
+ node = torch.randn(1, msa_len, pair_len, 256).cuda()
+ pair = torch.randn(1, pair_len, pair_len, 128).cuda()
+
+ meta_graph = symbolic_trace(model,
+ meta_args={
+ "node": node.to(torch.device("meta")),
+ "pair": pair.to(torch.device("meta")),
+ }) # must use symbolic_trace
+ interp = MetaInfoProp(meta_graph)
+ interp.propagate(MetaTensor(node, fake_device="cuda:0"), MetaTensor(pair, fake_device="cuda:0"))
+ codegen = AutoChunkCodeGen(meta_graph, max_memory=max_memory)
+ chunk_infos = codegen.chunk_infos
+ assert_chunk_infos(chunk_infos, max_memory, msa_len, pair_len)
+
+ gpc.destroy()
+
+
+@pytest.mark.skipif(not (CODEGEN_AVAILABLE and is_compatible_with_meta() and HAS_REPO),
+ reason="torch version is lower than 1.12.0")
+@pytest.mark.parametrize("max_memory", [None, 20, 25, 30])
+@pytest.mark.parametrize("msa_len", [32])
+@pytest.mark.parametrize("pair_len", [64])
+def test_simple_evoformer_search(msa_len, pair_len, max_memory):
+ run_func = partial(
+ _test_simple_evoformer_search,
+ msa_len=msa_len,
+ pair_len=pair_len,
+ max_memory=max_memory,
+ )
+ mp.spawn(run_func, nprocs=1)
+
+
+if __name__ == "__main__":
+ _test_simple_evoformer_search(0, 32, 64, 20)
diff --git a/tests/test_gemini/update/test_grad_clip.py b/tests/test_gemini/update/test_grad_clip.py
index 185521edb..fda1cf8cf 100644
--- a/tests/test_gemini/update/test_grad_clip.py
+++ b/tests/test_gemini/update/test_grad_clip.py
@@ -31,8 +31,6 @@ def check_param(model: ZeroDDP, torch_model: torch.nn.Module):
for key, value in torch_dict.items():
# key is 'module.model.PARAMETER', so we truncate it
key = key[7:]
- if key == 'model.lm_head.weight':
- continue
assert key in zero_dict, "{} not in ZeRO dictionary.".format(key)
temp_zero_value = zero_dict[key].to(device=value.device, dtype=value.dtype)
# debug_print([0], "max range: ", key, torch.max(torch.abs(value - temp_zero_value)))
diff --git a/tests/test_gemini/update/test_inference.py b/tests/test_gemini/update/test_inference.py
new file mode 100644
index 000000000..aec945fc9
--- /dev/null
+++ b/tests/test_gemini/update/test_inference.py
@@ -0,0 +1,122 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.testing import assert_close
+
+import colossalai
+from colossalai.amp import convert_to_apex_amp
+from colossalai.gemini.chunk import ChunkManager, init_chunk_manager, search_chunk_configuration
+from colossalai.gemini.gemini_mgr import GeminiManager
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.nn.optimizer.zero_optimizer import ZeroOptimizer
+from colossalai.nn.parallel import ZeroDDP
+from colossalai.testing import parameterize, rerun_if_address_is_in_use
+from colossalai.utils import free_port
+from colossalai.utils.cuda import get_current_device
+from colossalai.utils.model.colo_init_context import ColoInitContext, post_process_colo_init_ctx
+from tests.components_to_test import run_fwd_bwd
+from tests.components_to_test.registry import non_distributed_component_funcs
+from tests.test_tensor.common_utils import debug_print, set_seed
+
+
+def check_param(model: ZeroDDP, torch_model: torch.nn.Module):
+ zero_dict = model.state_dict(only_rank_0=False)
+ torch_dict = torch_model.state_dict()
+
+ for key, value in torch_dict.items():
+ # key is 'module.model.PARAMETER', so we truncate it
+ key = key[7:]
+ assert key in zero_dict, "{} not in ZeRO dictionary.".format(key)
+ temp_zero_value = zero_dict[key].to(device=value.device, dtype=value.dtype)
+ # debug_print([0], "max range: ", key, torch.max(torch.abs(value - temp_zero_value)))
+ assert_close(value, temp_zero_value, rtol=1e-3, atol=4e-3)
+
+
+@parameterize('placement_policy', ['cuda', 'cpu', 'auto', 'const'])
+@parameterize('model_name', ['gpt2'])
+def exam_inference(placement_policy, model_name: str):
+ set_seed(19360226)
+ get_components_func = non_distributed_component_funcs.get_callable(model_name)
+ model_builder, train_dataloader, test_dataloader, optimizer_class, criterion = get_components_func()
+
+ torch_model = model_builder().cuda()
+ amp_config = dict(opt_level='O2', keep_batchnorm_fp32=False, loss_scale=128)
+ torch_optim = torch.optim.Adam(torch_model.parameters(), lr=1e-3)
+ torch_model, torch_optim = convert_to_apex_amp(torch_model, torch_optim, amp_config)
+ torch_model = DDP(torch_model, device_ids=[dist.get_rank()])
+
+ init_dev = get_current_device()
+ with ColoInitContext(device=init_dev):
+ model = model_builder()
+
+ for torch_p, p in zip(torch_model.parameters(), model.parameters()):
+ p.data.copy_(torch_p.data)
+
+ world_size = torch.distributed.get_world_size()
+ config_dict, _ = search_chunk_configuration(model, search_range_mb=1, search_interval_byte=100)
+ config_dict[world_size]['chunk_size'] = 5000
+ config_dict[world_size]['keep_gathered'] = False
+ if placement_policy != 'cuda':
+ init_device = torch.device('cpu')
+ else:
+ init_device = None
+ chunk_manager = ChunkManager(config_dict, init_device=init_device)
+ gemini_manager = GeminiManager(placement_policy, chunk_manager)
+ model = ZeroDDP(model, gemini_manager, pin_memory=True)
+
+ optimizer = HybridAdam(model.parameters(), lr=1e-3)
+ zero_optim = ZeroOptimizer(optimizer, model, initial_scale=128)
+
+ model.eval()
+ torch_model.eval()
+
+ set_seed(dist.get_rank() * 3 + 128)
+ train_dataloader = iter(train_dataloader)
+
+ def train_iter():
+ input_ids, label = next(train_dataloader)
+ input_ids, label = input_ids.cuda(), label.cuda()
+ zero_optim.zero_grad()
+ torch_optim.zero_grad()
+ torch_loss = run_fwd_bwd(torch_model, input_ids, label, criterion, torch_optim)
+ loss = run_fwd_bwd(model, input_ids, label, criterion, zero_optim)
+ assert_close(torch_loss, loss)
+ zero_optim.step()
+ torch_optim.step()
+ check_param(model, torch_model)
+
+ def inference_iter():
+ input_ids, label = next(train_dataloader)
+ input_ids, label = input_ids.cuda(), label.cuda()
+ with torch.no_grad():
+ torch_output = torch_model(input_ids)
+ torch_loss = criterion(torch_output.float(), label)
+ zero_output = model(input_ids)
+ zero_loss = criterion(zero_output.float(), label)
+ assert_close(torch_loss, zero_loss)
+
+ train_iter()
+ inference_iter()
+ train_iter()
+
+
+def run_dist(rank, world_size, port):
+ config = {}
+ colossalai.launch(config=config, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
+ exam_inference()
+
+
+@pytest.mark.dist
+@pytest.mark.parametrize('world_size', [1, 4])
+@rerun_if_address_is_in_use()
+def test_inference(world_size):
+ run_func = partial(run_dist, world_size=world_size, port=free_port())
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_inference(1)
diff --git a/tests/test_gemini/update/test_optim.py b/tests/test_gemini/update/test_optim.py
index 34509cc0c..07e6e65f2 100644
--- a/tests/test_gemini/update/test_optim.py
+++ b/tests/test_gemini/update/test_optim.py
@@ -36,8 +36,6 @@ def check_param(model: ZeroDDP, torch_model: torch.nn.Module):
for key, value in torch_dict.items():
# key is 'module.model.PARAMETER', so we truncate it
key = key[7:]
- if key == 'model.lm_head.weight':
- continue
assert key in zero_dict, "{} not in ZeRO dictionary.".format(key)
temp_zero_value = zero_dict[key].to(device=value.device, dtype=value.dtype)
# debug_print([0], "max range: ", key, torch.max(torch.abs(value - temp_zero_value)))
diff --git a/tests/test_gemini/update/test_zeroddp_state_dict.py b/tests/test_gemini/update/test_zeroddp_state_dict.py
index 7b0c6e37a..266b8eab1 100644
--- a/tests/test_gemini/update/test_zeroddp_state_dict.py
+++ b/tests/test_gemini/update/test_zeroddp_state_dict.py
@@ -4,6 +4,7 @@ import pytest
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
+from torch.testing import assert_close
import colossalai
from colossalai.gemini.chunk import ChunkManager, search_chunk_configuration
@@ -17,6 +18,13 @@ from tests.components_to_test.registry import non_distributed_component_funcs
from tests.test_tensor.common_utils import debug_print, set_seed
+def ignore_the_first_parameter(model: torch.nn.Module):
+ for name, param in model.named_parameters():
+ print(f"parameter `{name}` is set ignored")
+ ZeroDDP.set_params_to_ignore([param])
+ return
+
+
@parameterize('placement_policy', ['cuda', 'cpu', 'auto'])
@parameterize('keep_gathered', [True, False])
@parameterize('model_name', ['gpt2', 'bert'])
@@ -45,11 +53,9 @@ def exam_state_dict(placement_policy, keep_gathered, model_name: str):
torch_dict = torch_model.state_dict()
for key, value in torch_dict.items():
- if key == 'model.lm_head.weight':
- continue
assert key in zero_dict, "{} not in ZeRO dictionary.".format(key)
temp_zero_value = zero_dict[key].to(device=value.device, dtype=value.dtype)
- assert torch.equal(value, temp_zero_value), "parameter '{}' has problem.".format(key)
+ assert_close(value, temp_zero_value, rtol=1e-3, atol=1e-5)
@parameterize('placement_policy', ['cuda', 'cpu', 'auto'])
@@ -84,11 +90,9 @@ def exam_load_state_dict(placement_policy, keep_gathered, model_name: str):
zero_dict = model.state_dict(only_rank_0=False)
for key, value in torch_dict.items():
- if key == 'model.lm_head.weight':
- continue
assert key in zero_dict, "{} not in ZeRO dictionary.".format(key)
temp_zero_value = zero_dict[key].to(device=value.device, dtype=value.dtype)
- assert torch.equal(value, temp_zero_value), "parameter '{}' has problem.".format(key)
+ assert_close(value, temp_zero_value, rtol=1e-3, atol=1e-5)
def run_dist(rank, world_size, port):
diff --git a/tests/test_tensor/common_utils/_utils.py b/tests/test_tensor/common_utils/_utils.py
index 6b58aa801..b405f8cd2 100644
--- a/tests/test_tensor/common_utils/_utils.py
+++ b/tests/test_tensor/common_utils/_utils.py
@@ -4,6 +4,7 @@ import random
import numpy as np
import torch
import torch.distributed as dist
+from torch.testing import assert_close
from colossalai.context import ParallelMode
from colossalai.core import global_context as gpc
@@ -41,14 +42,20 @@ def broadcast_tensor_chunk(tensor, chunk_size=1, local_rank=0):
return tensor_chunk.clone()
-def tensor_equal(A, B):
- return torch.allclose(A, B, rtol=1e-3, atol=1e-1)
+def tensor_equal(t_a: torch.Tensor, t_b: torch.Tensor, rtol: float = 1e-3, atol: float = 1e-1):
+ assert_close(t_a, t_b, rtol=rtol, atol=atol)
+ return True
-def tensor_shard_equal(tensor: torch.Tensor, shard: torch.Tensor, rank, world_size):
+def tensor_shard_equal(tensor: torch.Tensor,
+ shard: torch.Tensor,
+ rank: int,
+ world_size: int,
+ rtol: float = 1e-3,
+ atol: float = 1e-1):
assert tensor.ndim == shard.ndim
if tensor.shape == shard.shape:
- return tensor_equal(tensor, shard)
+ return tensor_equal(tensor, shard, rtol, atol)
else:
dims_not_eq = torch.nonzero(torch.tensor(tensor.shape) != torch.tensor(shard.shape))
if dims_not_eq.numel() == 1:
@@ -58,7 +65,7 @@ def tensor_shard_equal(tensor: torch.Tensor, shard: torch.Tensor, rank, world_si
world_size = gpc.get_world_size(ParallelMode.PARALLEL_1D)
if rank is None:
rank = gpc.get_local_rank(ParallelMode.PARALLEL_1D)
- return tensor_equal(tensor.chunk(world_size, dim)[rank], shard)
+ return tensor_equal(tensor.chunk(world_size, dim)[rank], shard, rtol, atol)
else:
raise NotImplementedError
diff --git a/tests/test_tensor/test_tp_with_zero.py b/tests/test_tensor/test_tp_with_zero.py
index 33db676cb..83645bc6e 100644
--- a/tests/test_tensor/test_tp_with_zero.py
+++ b/tests/test_tensor/test_tp_with_zero.py
@@ -27,8 +27,6 @@ def check_param(model: ZeroDDP, torch_model: torch.nn.Module, pg: ProcessGroup):
for key, value in torch_dict.items():
# key is 'module.model.PARAMETER', so we truncate it
key = key[7:]
- if key == 'model.lm_head.weight':
- continue
assert key in zero_dict, "{} not in ZeRO dictionary.".format(key)
temp_zero_value = zero_dict[key].to(device=value.device, dtype=value.dtype)
# debug_print([0], "max range: ", key, torch.max(torch.abs(value - temp_zero_value)))
@@ -95,7 +93,7 @@ def run_gpt(placement_policy, tp_init_spec_func=None):
else:
init_device = None
- model = GeminiDDP(model, init_device, placement_policy, True, False, 32)
+ model = GeminiDDP(model, init_device, placement_policy, True, False)
# The same as the following 3 lines
# chunk_manager = ChunkManager(config_dict, init_device=init_device)
# gemini_manager = GeminiManager(placement_policy, chunk_manager)
diff --git a/tests/test_zero/low_level_zero/test_grad_acc.py b/tests/test_zero/low_level_zero/test_grad_acc.py
index c23b3a3e8..69795ed6a 100644
--- a/tests/test_zero/low_level_zero/test_grad_acc.py
+++ b/tests/test_zero/low_level_zero/test_grad_acc.py
@@ -9,6 +9,7 @@ from torch.nn.parallel import DistributedDataParallel as DDP
from torch.testing import assert_close
import colossalai
+from colossalai.tensor import ProcessGroup
from colossalai.testing.random import seed_all
from colossalai.utils import free_port
from colossalai.zero import LowLevelZeroOptimizer
@@ -34,7 +35,6 @@ def exam_zero_1_2_grad_acc():
# create model
zero1_model = TestModel().cuda()
zero2_model = copy.deepcopy(zero1_model)
-
# create optimizer
zero1_optimizer = torch.optim.Adam(zero1_model.parameters(), lr=1)
zero2_optimizer = torch.optim.Adam(zero2_model.parameters(), lr=1)
@@ -92,6 +92,7 @@ def exam_zero_1_grad_acc():
zero_model = TestModel()
torch_model = copy.deepcopy(zero_model)
+ seed_all(2008)
zero_model = zero_model.cuda()
torch_model = DDP(torch_model.cuda(), bucket_cap_mb=0)
@@ -153,7 +154,7 @@ def run_dist(rank, world_size, port):
colossalai.launch(config=dict(), rank=rank, world_size=world_size, port=port, host='localhost')
exam_zero_1_grad_acc()
- # exam_zero_1_2_grad_acc()
+ exam_zero_1_2_grad_acc()
@pytest.mark.dist
diff --git a/tests/test_zero/low_level_zero/test_zero1_2.py b/tests/test_zero/low_level_zero/test_zero1_2.py
index b02d3a6a4..8771bfbe6 100644
--- a/tests/test_zero/low_level_zero/test_zero1_2.py
+++ b/tests/test_zero/low_level_zero/test_zero1_2.py
@@ -115,7 +115,7 @@ def exam_zero_1_torch_ddp():
torch_model = copy.deepcopy(zero_model)
zero_model = zero_model.cuda().half()
- # torch_model = DDP(torch_model.cuda(), bucket_cap_mb=0)
+ torch_model = DDP(torch_model.cuda(), bucket_cap_mb=0)
torch_model = torch_model.cuda()
# for (n, p), z1p in zip(torch_model.named_parameters(), zero_model.parameters()):
diff --git a/tests/test_zero/low_level_zero/test_zero_init.py b/tests/test_zero/low_level_zero/test_zero_init.py
new file mode 100644
index 000000000..84d7b8c51
--- /dev/null
+++ b/tests/test_zero/low_level_zero/test_zero_init.py
@@ -0,0 +1,61 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.distributed as dist
+import torch.multiprocessing as mp
+import torch.nn as nn
+
+import colossalai
+from colossalai.tensor import ProcessGroup
+from colossalai.utils import free_port, get_current_device
+from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.zero import LowLevelZeroOptimizer
+
+
+class TestModel(nn.Module):
+
+ def __init__(self):
+ super(TestModel, self).__init__()
+ self.linear1 = nn.Linear(128, 256)
+ self.linear2 = nn.Linear(256, 512)
+
+ def forward(self, x):
+ x = self.linear1(x)
+ x = self.linear2(x)
+ return x
+
+
+def exam_zero_init():
+ dp_2_tp_2_pg = ProcessGroup(dp_degree=2, tp_degree=2)
+ model1 = TestModel().cuda()
+ with ColoInitContext(device=get_current_device(), default_pg=dp_2_tp_2_pg):
+ model2 = TestModel()
+ optimizer1 = LowLevelZeroOptimizer(torch.optim.Adam(model1.parameters(), lr=1))
+ optimizer2 = LowLevelZeroOptimizer(torch.optim.Adam(model2.parameters(), lr=1))
+
+ assert optimizer1._local_rank == optimizer2._local_rank
+ assert optimizer1._world_size == optimizer2._world_size
+ assert optimizer1._dp_global_ranks == optimizer2._dp_global_ranks
+
+ mp_group1 = optimizer1._mp_torch_group
+ mp_group2 = optimizer2._mp_torch_group
+ assert dist.get_world_size(mp_group1) == dist.get_world_size(mp_group2)
+ assert dist.get_rank(mp_group1) == dist.get_rank(mp_group2)
+
+
+def run_dist(rank, world_size, port):
+ config_dict = dict(parallel=dict(data=2, tensor=dict(size=2, mode='1d')))
+ colossalai.launch(config=config_dict, rank=rank, world_size=world_size, port=port, host='localhost')
+ exam_zero_init()
+
+
+@pytest.mark.dist
+def test_zero_init():
+ world_size = 4
+ run_func = partial(run_dist, world_size=world_size, port=free_port())
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_zero_init()
diff --git a/tests/test_zero/low_level_zero/test_zero_tp.py b/tests/test_zero/low_level_zero/test_zero_tp.py
new file mode 100644
index 000000000..8ba6e3cb6
--- /dev/null
+++ b/tests/test_zero/low_level_zero/test_zero_tp.py
@@ -0,0 +1,98 @@
+from functools import partial
+
+import pytest
+import torch
+import torch.multiprocessing as mp
+import torch.nn as nn
+from torch.nn.parallel import DistributedDataParallel as DDP
+from torch.testing import assert_close
+
+import colossalai
+from colossalai.tensor import ProcessGroup
+from colossalai.testing import parameterize, rerun_if_address_is_in_use
+from colossalai.utils import free_port, get_current_device
+from colossalai.utils.model.colo_init_context import ColoInitContext
+from colossalai.zero import LowLevelZeroOptimizer
+from tests.test_tensor.common_utils import set_seed, split_param_col_tp1d, split_param_row_tp1d, tensor_shard_equal
+
+
+def strict_shard_equal(tensor, shard, tp_pg, rtol=1e-3, atol=1e-4):
+ return tensor_shard_equal(tensor, shard, tp_pg.tp_local_rank(), tp_pg.tp_world_size(), rtol, atol)
+
+
+class TestModel(nn.Module):
+
+ def __init__(self):
+ super(TestModel, self).__init__()
+ self.linear1 = nn.Linear(32, 128)
+ self.act = nn.GELU()
+ self.linear2 = nn.Linear(128, 32)
+
+ def forward(self, x):
+ y = self.linear1(x)
+ y = self.act(y)
+ y = self.linear2(y)
+ return x + y
+
+
+@parameterize("overlap_flag", [False, True])
+@parameterize("partition_flag", [False, True])
+def exam_zero_with_tp(overlap_flag, partition_flag):
+ set_seed(233010)
+ tp_pg = ProcessGroup(tp_degree=2)
+
+ with ColoInitContext(device=get_current_device(), default_pg=tp_pg):
+ hybrid_model = TestModel()
+ torch_model = TestModel().cuda()
+ for pt, ph in zip(torch_model.parameters(), hybrid_model.parameters()):
+ pt.data.copy_(ph.data)
+
+ for name, param in hybrid_model.named_parameters():
+ if 'linear1' in name:
+ split_param_row_tp1d(param, tp_pg)
+ param.compute_spec.set_output_replicate(False)
+ if 'linear2.weight' in name:
+ split_param_col_tp1d(param, tp_pg)
+
+ torch_model = DDP(torch_model, device_ids=[tp_pg.rank()], process_group=tp_pg.dp_process_group())
+ torch_optim = torch.optim.Adam(torch_model.parameters(), lr=1)
+ hybrid_optim = torch.optim.Adam(hybrid_model.parameters(), lr=1)
+ hybrid_optim = LowLevelZeroOptimizer(hybrid_optim,
+ initial_scale=1,
+ overlap_communication=overlap_flag,
+ partition_grad=partition_flag)
+
+ dp_local_rank = tp_pg.dp_local_rank()
+ set_seed(255 + dp_local_rank)
+
+ data = torch.randn(8, 32, device=get_current_device())
+ torch_loss = torch_model(data).sum()
+ hybrid_loss = hybrid_model(data).sum()
+ assert_close(torch_loss, hybrid_loss)
+
+ torch_loss.backward()
+ hybrid_optim.backward(hybrid_loss)
+ hybrid_optim.sync_grad()
+
+ torch_optim.step()
+ hybrid_optim.step()
+
+ for (name, pt), ph in zip(torch_model.named_parameters(), hybrid_model.parameters()):
+ assert strict_shard_equal(pt.data, ph.data, tp_pg)
+
+
+def run_dist(rank, world_size, port):
+ colossalai.launch(config={}, rank=rank, world_size=world_size, port=port, host='localhost')
+ exam_zero_with_tp()
+
+
+@pytest.mark.dist
+@rerun_if_address_is_in_use()
+def test_zero_with_tp():
+ world_size = 4
+ run_func = partial(run_dist, world_size=world_size, port=free_port())
+ mp.spawn(run_func, nprocs=world_size)
+
+
+if __name__ == '__main__':
+ test_zero_with_tp()