mirror of https://github.com/hpcaitech/ColossalAI
[doc] Update the user guide and the development document in Colossal-Inference (#5086)
* doc/ Update the user guide and the development document * update quick start example and readmepull/5092/head
parent
42b2d6f3a5
commit
79c4bff452
|
|
@ -1,154 +1,58 @@
|
|||
# 🚀 Colossal-Inference
|
||||
# Colossal-Inference
|
||||
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [💡 Introduction](#introduction)
|
||||
- [🔗 Design](#design)
|
||||
- [🔨 Usage](#usage)
|
||||
- [Quick start](#quick-start)
|
||||
- [Example](#example)
|
||||
- [📊 Performance](#performance)
|
||||
- 💡 Introduction
|
||||
- 🔗 Design
|
||||
- 🗺 Roadmap
|
||||
- 📊 Performance
|
||||
|
||||
## Introduction
|
||||
## 💡 Introduction
|
||||
|
||||
`Colossal Inference` is a module that contains colossal-ai designed inference framework, featuring high performance, steady and easy usability. `Colossal Inference` incorporated the advantages of the latest open-source inference systems, including LightLLM, TGI, vLLM, FasterTransformer and flash attention. while combining the design of Colossal AI, especially Shardformer, to reduce the learning curve for users.
|
||||
**Colossal-Inference** is the inference module of Colossal-AI, featuring high performance, steady and easy usability. **Colossal-Inference** incorporates the advantages of the latest open-source inference systems, including LightLLM, TGI, FasterTransformer and flash-attention. Additionally, it incorporates design principles from Colossal AI, especially Shardformer, aiming to provide an efficient and scalable solution for large model inference.
|
||||
|
||||
## Design
|
||||
|
||||
Colossal Inference is composed of three main components:
|
||||
|
||||
1. High performance kernels and ops: which are inspired from existing libraries and modified correspondingly.
|
||||
2. Efficient memory management mechanism:which includes the key-value cache manager, allowing for zero memory waste during inference.
|
||||
1. `cache manager`: serves as a memory manager to help manage the key-value cache, it integrates functions such as memory allocation, indexing and release.
|
||||
2. `batch_infer_info`: holds all essential elements of a batch inference, which is updated every batch.
|
||||
3. High-level inference engine combined with `Shardformer`: it allows our inference framework to easily invoke and utilize various parallel methods.
|
||||
1. `HybridEngine`: it is a high level interface that integrates with shardformer, especially for multi-card (tensor parallel, pipline parallel) inference:
|
||||
2. `modeling.llama.LlamaInferenceForwards`: contains the `forward` methods for llama inference. (in this case : llama)
|
||||
3. `policies.llama.LlamaModelInferPolicy` : contains the policies for `llama` models, which is used to call `shardformer` and segmentate the model forward in tensor parallelism way.
|
||||
## 🔗 Design
|
||||
|
||||
|
||||
## Architecture of inference:
|
||||
### Architecture of inference:
|
||||
|
||||
In this section we discuss how the colossal inference works and integrates with the `Shardformer` . The details can be found in our codes.
|
||||
An overview of the Colossal-Inference is below:
|
||||
|
||||
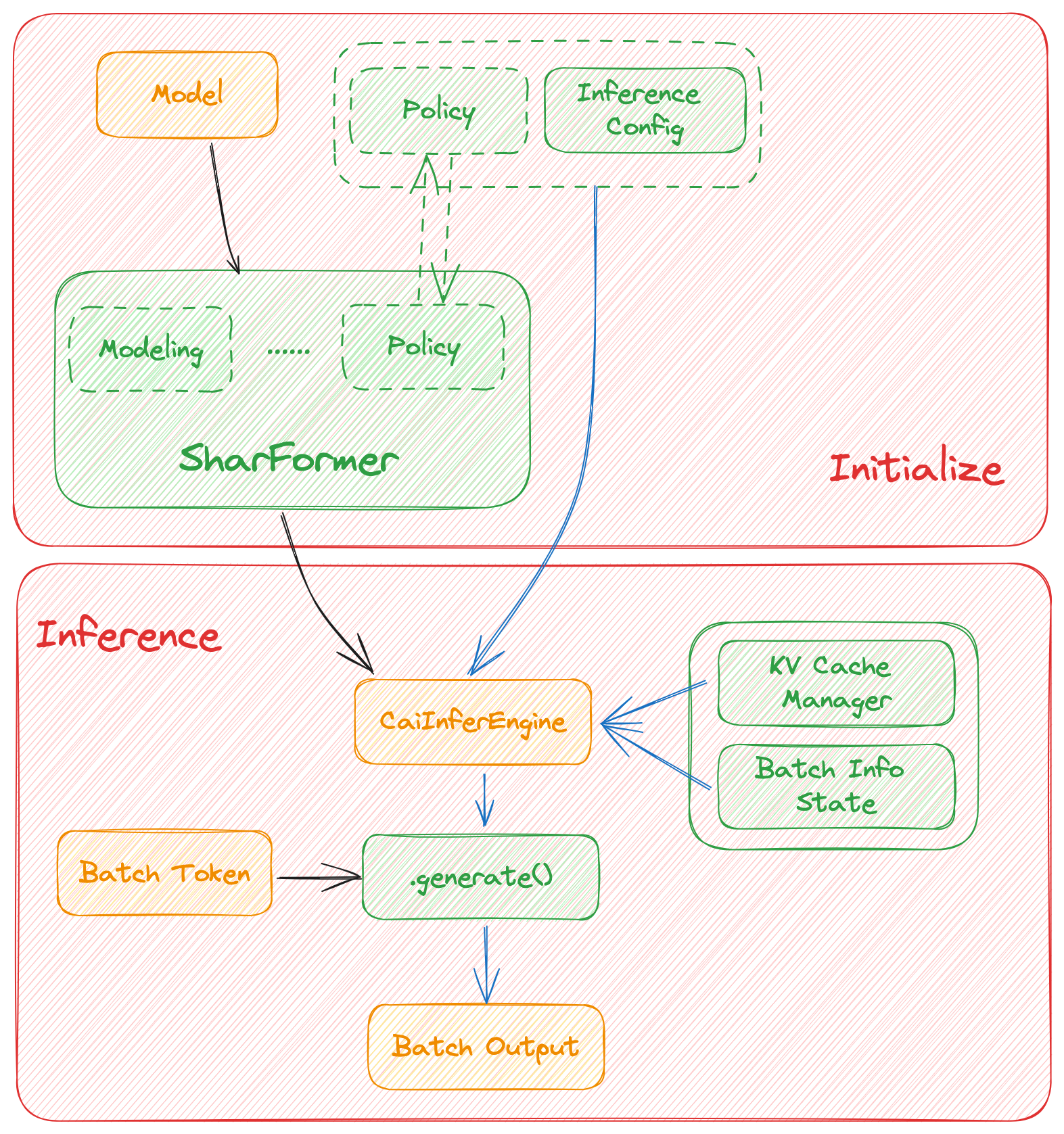
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/inference/inference-arch.png" alt="Colossal-Inference" style="zoom:33%;" />
|
||||
|
||||
## Roadmap of our implementation
|
||||
### Components
|
||||
|
||||
Colossal-Inference is composed of three main components:
|
||||
|
||||
1. High-level inference engine: it allows our inference framework to easily invoke and utilize various parallel methods.
|
||||
1. `HybridEngine`: it is a high level interface that integrates with shardformer, especially for multi-card (tensor parallel, pipline parallel) inference
|
||||
2. Efficient memory management mechanism: Include the key-value cache manager, allowing for zero memory waste during inference.
|
||||
1. `cache manager`: serves as a memory manager to help manage the key-value cache, it integrates functions such as memory allocation, indexing and release.
|
||||
2. `batch_infer_info`: holds all essential elements of a batch inference, which is updated every batch.
|
||||
3. High performance kernels and ops: which are inspired from existing libraries and modified correspondingly.
|
||||
|
||||
## 🗺 Roadmap
|
||||
|
||||
- [x] Design cache manager and batch infer state
|
||||
- [x] Design TpInference engine to integrates with `Shardformer`
|
||||
- [x] Register corresponding high-performance `kernel` and `ops`
|
||||
- [x] Design policies and forwards (e.g. `Llama` and `Bloom`)
|
||||
- [x] policy
|
||||
- [x] context forward
|
||||
- [x] token forward
|
||||
- [x] support flash-decoding
|
||||
- [x] policy
|
||||
- [x] context forward
|
||||
- [x] token forward
|
||||
- [x] support flash-decoding
|
||||
- [x] Support all models
|
||||
- [x] Llama
|
||||
- [x] Llama-2
|
||||
- [x] Bloom
|
||||
- [x] Chatglm2
|
||||
- [x] Llama
|
||||
- [x] Llama-2
|
||||
- [x] Bloom
|
||||
- [x] Chatglm2
|
||||
- [x] Quantization
|
||||
- [x] GPTQ
|
||||
- [x] SmoothQuant
|
||||
- [x] GPTQ
|
||||
- [x] SmoothQuant
|
||||
- [ ] Benchmarking for all models
|
||||
|
||||
## Get started
|
||||
|
||||
### Installation
|
||||
|
||||
```bash
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
### Requirements
|
||||
|
||||
Install dependencies.
|
||||
|
||||
```bash
|
||||
pip install -r requirements/requirements-infer.txt
|
||||
|
||||
# if you want use smoothquant quantization, please install torch-int
|
||||
git clone --recurse-submodules https://github.com/Guangxuan-Xiao/torch-int.git
|
||||
cd torch-int
|
||||
git checkout 65266db1eadba5ca78941b789803929e6e6c6856
|
||||
pip install -r requirements.txt
|
||||
source environment.sh
|
||||
bash build_cutlass.sh
|
||||
python setup.py install
|
||||
```
|
||||
|
||||
### Docker
|
||||
|
||||
You can use docker run to use docker container to set-up environment
|
||||
|
||||
```
|
||||
# env: python==3.8, cuda 11.6, pytorch == 1.13.1 triton==2.0.0.dev20221202, vllm kernels support, flash-attention-2 kernels support
|
||||
docker pull hpcaitech/colossalai-inference:v2
|
||||
docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcaitech/colossalai-inference:v2 /bin/bash
|
||||
|
||||
# enter into docker container
|
||||
cd /path/to/CollossalAI
|
||||
pip install -e .
|
||||
|
||||
```
|
||||
|
||||
## Usage
|
||||
### Quick start
|
||||
|
||||
example files are in
|
||||
|
||||
```bash
|
||||
cd ColossalAI/examples
|
||||
python hybrid_llama.py --path /path/to/model --tp_size 2 --pp_size 2 --batch_size 4 --max_input_size 32 --max_out_len 16 --micro_batch_size 2
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Example
|
||||
```python
|
||||
# import module
|
||||
from colossalai.inference import CaiInferEngine
|
||||
import colossalai
|
||||
from transformers import LlamaForCausalLM, LlamaTokenizer
|
||||
|
||||
#launch distributed environment
|
||||
colossalai.launch_from_torch(config={})
|
||||
|
||||
# load original model and tokenizer
|
||||
model = LlamaForCausalLM.from_pretrained("/path/to/model")
|
||||
tokenizer = LlamaTokenizer.from_pretrained("/path/to/model")
|
||||
|
||||
# generate token ids
|
||||
input = ["Introduce a landmark in London","Introduce a landmark in Singapore"]
|
||||
data = tokenizer(input, return_tensors='pt')
|
||||
|
||||
# set parallel parameters
|
||||
tp_size=2
|
||||
pp_size=2
|
||||
max_output_len=32
|
||||
micro_batch_size=1
|
||||
|
||||
# initial inference engine
|
||||
engine = CaiInferEngine(
|
||||
tp_size=tp_size,
|
||||
pp_size=pp_size,
|
||||
model=model,
|
||||
max_output_len=max_output_len,
|
||||
micro_batch_size=micro_batch_size,
|
||||
)
|
||||
|
||||
# inference
|
||||
output = engine.generate(data)
|
||||
|
||||
# get results
|
||||
if dist.get_rank() == 0:
|
||||
assert len(output[0]) == max_output_len, f"{len(output)}, {max_output_len}"
|
||||
|
||||
```
|
||||
|
||||
## Performance
|
||||
## 📊 Performance
|
||||
|
||||
### environment:
|
||||
|
||||
|
|
@ -182,45 +86,46 @@ Currently the stats below are calculated based on A100 (single GPU), and we calc
|
|||
|
||||
|
||||
### Pipline Parallelism Inference
|
||||
|
||||
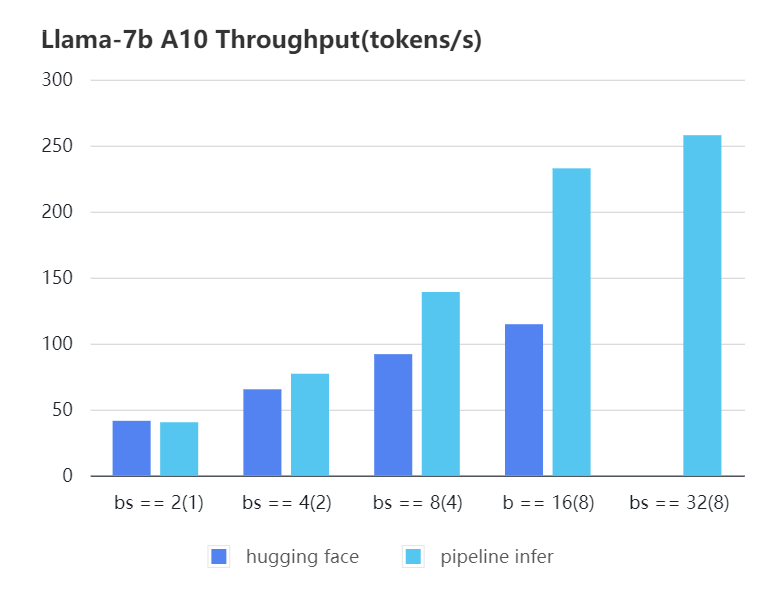
We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `Pipeline Inference` and `hugging face` pipeline. The test environment is 2 * A10, 20G / 2 * A800, 80G. We set input length=1024, output length=128.
|
||||
|
||||
|
||||
#### A10 7b, fp16
|
||||
|
||||
| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
|
||||
| :-------------------------: | :---: | :---:| :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference | 40.35 | 77.10| 139.03| 232.70| 257.81| OOM |
|
||||
| Hugging Face | 41.43 | 65.30| 91.93 | 114.62| OOM | OOM |
|
||||
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16) |
|
||||
| :--------------------------: | :---: | :---: | :----: | :----: | :----: | :----: |
|
||||
| Pipeline Inference | 40.35 | 77.10 | 139.03 | 232.70 | 257.81 | OOM |
|
||||
| Hugging Face | 41.43 | 65.30 | 91.93 | 114.62 | OOM | OOM |
|
||||
|
||||
|
||||
|
||||
|
||||
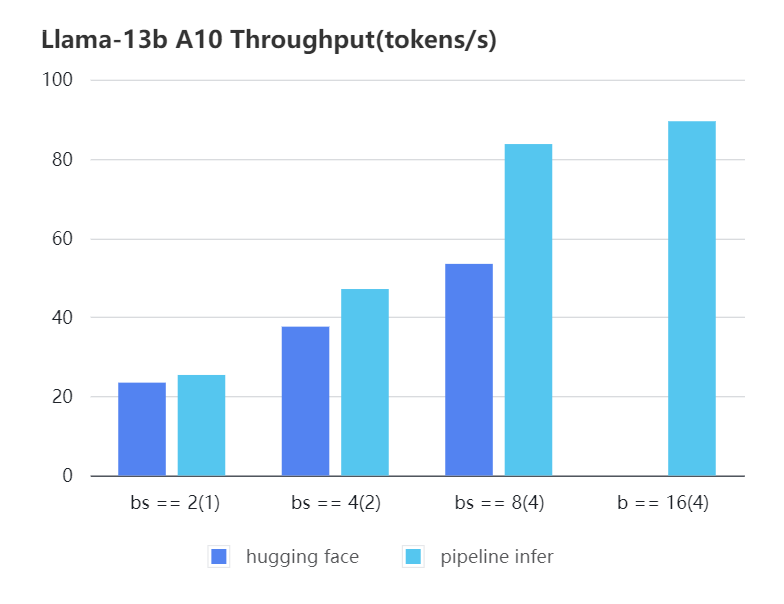
#### A10 13b, fp16
|
||||
|
||||
| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
|
||||
| :---: | :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
|
||||
| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
|
||||
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(4) |
|
||||
| :--------------------------: | :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
|
||||
| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
|
||||
|
||||
|
||||
|
||||
|
||||
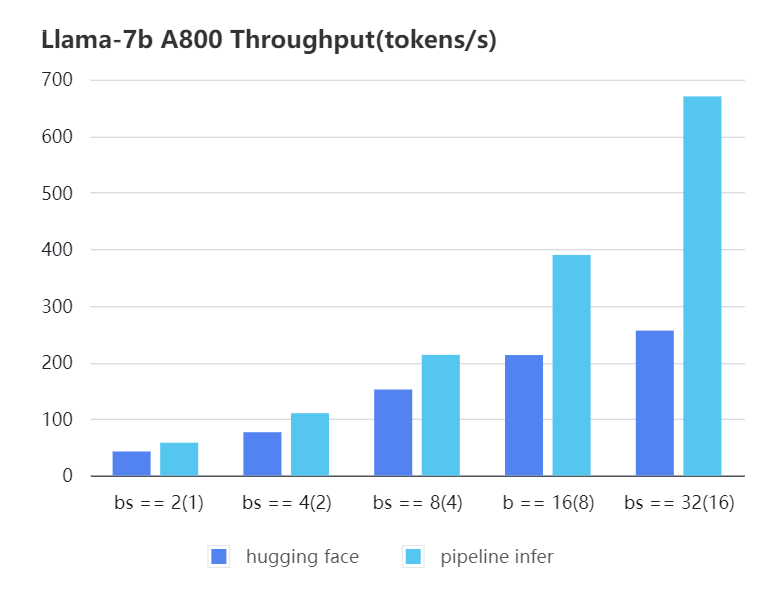
#### A800 7b, fp16
|
||||
|
||||
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
|
||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
|
||||
| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
|
||||
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
|
||||
| :--------------------------: | :---: | :----: | :----: | :----: | :----: |
|
||||
| Pipeline Inference | 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
|
||||
| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
|
||||
|
||||
|
||||
|
||||
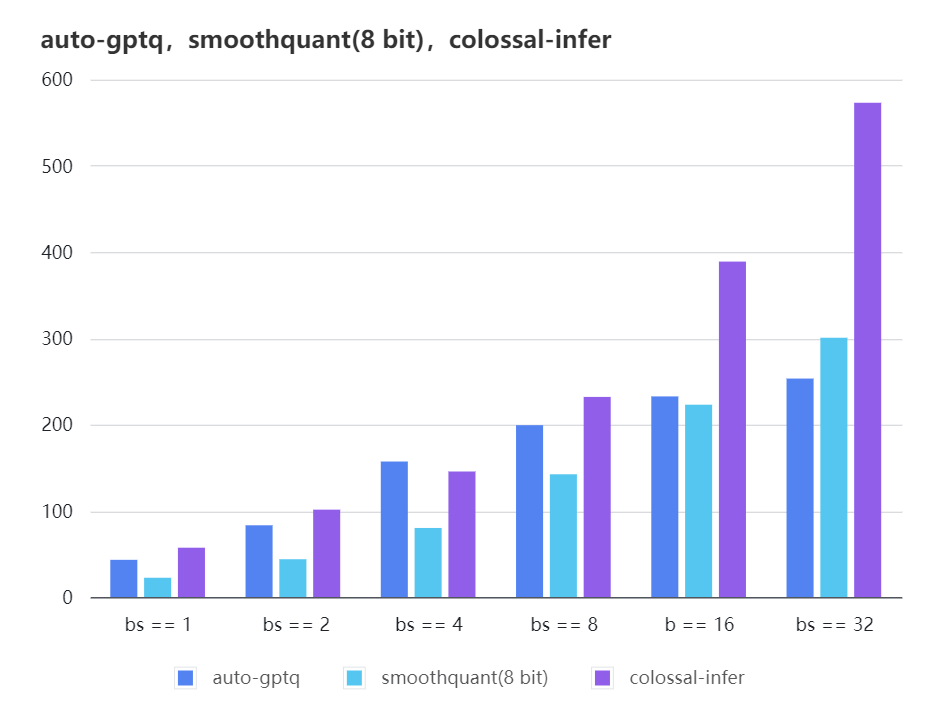
### Quantization LLama
|
||||
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :---------------------: | :----: | :----: | :----: |
|
||||
| auto-gptq | 199.20 | 232.56 | 253.26 |
|
||||
| smooth-quant | 142.28 | 222.96 | 300.59 |
|
||||
| colossal-gptq | 231.98 | 388.87 | 573.03 |
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :-----------: | :----: | :----: | :----: |
|
||||
| auto-gptq | 199.20 | 232.56 | 253.26 |
|
||||
| smooth-quant | 142.28 | 222.96 | 300.59 |
|
||||
| colossal-gptq | 231.98 | 388.87 | 573.03 |
|
||||
|
||||
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,122 @@
|
|||
# Colossal-Inference
|
||||
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- 📚 [Introduction](#📚-introduction)
|
||||
- 🔨 [Installation](#🔨-installation)
|
||||
- 🚀 [Quick Start](#🚀-quick-start)
|
||||
- 💡 [Usage](#💡-usage)
|
||||
|
||||
## 📚 Introduction
|
||||
|
||||
This example lets you to set up and quickly try out our Colossal-Inference.
|
||||
|
||||
## 🔨 Installation
|
||||
|
||||
### Install From Source
|
||||
|
||||
Prerequistes:
|
||||
|
||||
- Python == 3.9
|
||||
- PyTorch >= 2.1.0
|
||||
- CUDA == 11.8
|
||||
- Linux OS
|
||||
|
||||
We strongly recommend you use [Anaconda](https://www.anaconda.com/) to create a new environment (Python >= 3.9) to run our examples:
|
||||
|
||||
```shell
|
||||
# Create a new conda environment
|
||||
conda create -n inference python=3.9 -y
|
||||
conda activate inference
|
||||
```
|
||||
|
||||
Install the latest PyTorch (with CUDA == 11.8) using conda:
|
||||
|
||||
```shell
|
||||
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
|
||||
```
|
||||
|
||||
Install Colossal-AI from source:
|
||||
|
||||
```shell
|
||||
# Clone Colossal-AI repository to your workspace
|
||||
git clone https://github.com/hpcaitech/ColossalAI.git
|
||||
cd ColossalAI
|
||||
|
||||
# Install Colossal-AI from source
|
||||
pip install .
|
||||
```
|
||||
|
||||
Install inference dependencies:
|
||||
|
||||
```shell
|
||||
# Install inference dependencies
|
||||
pip install -r requirements/requirements-infer.txt
|
||||
```
|
||||
|
||||
**(Optional)** If you want to use [SmoothQuant](https://github.com/mit-han-lab/smoothquant) quantization, you need to install `torch-int` following this [instruction](https://github.com/Guangxuan-Xiao/torch-int#:~:text=cmake%20%3E%3D%203.12-,Installation,-git%20clone%20%2D%2Drecurse).
|
||||
|
||||
### Use Colossal-Inference in Docker
|
||||
|
||||
#### Pull from DockerHub
|
||||
|
||||
You can directly pull the docker image from our [DockerHub page](https://hub.docker.com/r/hpcaitech/colossalai). The image is automatically uploaded upon release.
|
||||
|
||||
```shell
|
||||
docker pull hpcaitech/colossal-inference:latest
|
||||
```
|
||||
|
||||
#### Build On Your Own
|
||||
|
||||
Run the following command to build a docker image from Dockerfile provided.
|
||||
|
||||
```shell
|
||||
cd ColossalAI/inference/dokcer
|
||||
docker build
|
||||
```
|
||||
|
||||
Run the following command to start the docker container in interactive mode.
|
||||
|
||||
```shell
|
||||
docker run -it --gpus all --name Colossal-Inference -v $PWD:/workspace -w /workspace hpcaitech/colossal-inference:latest /bin/bash
|
||||
```
|
||||
|
||||
\[Todo\]: Waiting for new Docker file (Li Cuiqing)
|
||||
|
||||
## 🚀 Quick Start
|
||||
|
||||
You can try the inference example using [`Colossal-LLaMA-2-7B`](https://huggingface.co/hpcai-tech/Colossal-LLaMA-2-7b-base) following the instructions below:
|
||||
|
||||
```shell
|
||||
cd ColossalAI/examples/inference
|
||||
python example.py -m hpcai-tech/Colossal-LLaMA-2-7b-base -b 4 --max_input_len 128 --max_output_len 64 --dtype fp16
|
||||
```
|
||||
|
||||
Examples for quantized inference will coming soon!
|
||||
|
||||
## 💡 Usage
|
||||
|
||||
A general way to use Colossal-Inference will be:
|
||||
|
||||
```python
|
||||
# Import required modules
|
||||
import ...
|
||||
|
||||
# Prepare your model
|
||||
model = ...
|
||||
|
||||
# Declare configurations
|
||||
tp_size = ...
|
||||
pp_size = ...
|
||||
...
|
||||
|
||||
# Create an inference engine
|
||||
engine = InferenceEngine(model, [tp_size, pp_size, ...])
|
||||
|
||||
# Tokenize the input
|
||||
inputs = ...
|
||||
|
||||
# Perform inferencing based on the inputs
|
||||
outputs = engine.generate(inputs)
|
||||
```
|
||||
|
|
@ -1,6 +1,5 @@
|
|||
import argparse
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from transformers import LlamaForCausalLM, LlamaTokenizer
|
||||
|
||||
|
|
@ -16,9 +15,7 @@ INPUT_TEXTS = [
|
|||
|
||||
|
||||
def run_inference(args):
|
||||
llama_model_path = args.model_path
|
||||
llama_tokenize_path = args.tokenizer_path or args.model_path
|
||||
|
||||
model_name_or_path = args.model_name_or_path
|
||||
max_input_len = args.max_input_len
|
||||
max_output_len = args.max_output_len
|
||||
max_batch_size = args.batch_size
|
||||
|
|
@ -27,22 +24,10 @@ def run_inference(args):
|
|||
pp_size = args.pp_size
|
||||
rank = dist.get_rank()
|
||||
|
||||
tokenizer = LlamaTokenizer.from_pretrained(llama_tokenize_path, padding_side="left")
|
||||
tokenizer = LlamaTokenizer.from_pretrained(model_name_or_path, padding_side="left")
|
||||
tokenizer.pad_token_id = tokenizer.eos_token_id
|
||||
|
||||
if args.quant is None:
|
||||
model = LlamaForCausalLM.from_pretrained(llama_model_path, pad_token_id=tokenizer.pad_token_id)
|
||||
elif args.quant == "gptq":
|
||||
from auto_gptq import AutoGPTQForCausalLM
|
||||
|
||||
model = AutoGPTQForCausalLM.from_quantized(
|
||||
llama_model_path, inject_fused_attention=False, device=torch.cuda.current_device()
|
||||
)
|
||||
elif args.quant == "smoothquant":
|
||||
from colossalai.inference.quant.smoothquant.models.llama import SmoothLlamaForCausalLM
|
||||
|
||||
model = SmoothLlamaForCausalLM.from_quantized(llama_model_path, model_basename=args.smoothquant_base_name)
|
||||
model = model.cuda()
|
||||
model = LlamaForCausalLM.from_pretrained(model_name_or_path, pad_token_id=tokenizer.pad_token_id)
|
||||
|
||||
engine = InferenceEngine(
|
||||
tp_size=tp_size,
|
||||
|
|
@ -52,7 +37,6 @@ def run_inference(args):
|
|||
max_output_len=max_output_len,
|
||||
max_batch_size=max_batch_size,
|
||||
micro_batch_size=micro_batch_size,
|
||||
quant=args.quant,
|
||||
dtype=args.dtype,
|
||||
)
|
||||
|
||||
|
|
@ -63,8 +47,8 @@ def run_inference(args):
|
|||
if rank == 0:
|
||||
output_texts = tokenizer.batch_decode(outputs, skip_special_tokens=True)
|
||||
for input_text, output_text in zip(INPUT_TEXTS, output_texts):
|
||||
print(f"Input: {input_text}")
|
||||
print(f"Output: {output_text}")
|
||||
print(f"\n[Input]:\n {input_text}")
|
||||
print(f"[Output]:\n {output_text}")
|
||||
|
||||
|
||||
def run_tp_pipeline_inference(rank, world_size, port, args):
|
||||
|
|
@ -74,18 +58,11 @@ def run_tp_pipeline_inference(rank, world_size, port, args):
|
|||
|
||||
if __name__ == "__main__":
|
||||
parser = argparse.ArgumentParser()
|
||||
parser.add_argument("-p", "--model_path", type=str, help="Model path", required=True)
|
||||
parser.add_argument(
|
||||
"-m", "--model_name_or_path", type=str, help="Model name from huggingface or local path", default=None
|
||||
)
|
||||
parser.add_argument("-i", "--input", default="What is the longest river in the world?")
|
||||
parser.add_argument("-t", "--tokenizer_path", type=str, help="Tokenizer path", default=None)
|
||||
parser.add_argument(
|
||||
"-q",
|
||||
"--quant",
|
||||
type=str,
|
||||
choices=["gptq", "smoothquant"],
|
||||
default=None,
|
||||
help="quantization type: 'gptq' or 'smoothquant'",
|
||||
)
|
||||
parser.add_argument("--smoothquant_base_name", type=str, default=None, help="soothquant base name")
|
||||
parser.add_argument("--tp_size", type=int, default=1, help="Tensor parallel size")
|
||||
parser.add_argument("--pp_size", type=int, default=1, help="Pipeline parallel size")
|
||||
parser.add_argument("-b", "--batch_size", type=int, default=4, help="Maximum batch size")
|
||||
Loading…
Reference in New Issue