
@@ -162,20 +184,20 @@ Model performance in [Anthropics paper](https://arxiv.org/abs/2204.05862):
We also train the reward model based on LLaMA-7B, which reaches the ACC of 72.06% after 1 epoch, performing almost the same as Anthropic's best RM.
### Arg List
-- --strategy: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
-- --model: model type, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
-- --pretrain: pretrain model, type=str, default=None
-- --model_path: the path of rm model(if continue to train), type=str, default=None
-- --save_path: path to save the model, type=str, default='output'
-- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
-- --max_epochs: max epochs for training, type=int, default=3
-- --dataset: dataset name, type=str, choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static']
-- --subset: subset of the dataset, type=str, default=None
-- --batch_size: batch size while training, type=int, default=4
-- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
-- --loss_func: which kind of loss function, choices=['log_sig', 'log_exp']
-- --max_len: max sentence length for generation, type=int, default=512
-- --test: whether is only testing, if it's true, the dataset will be small
+
+- `--strategy`: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
+- `--model`: model type, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
+- `--pretrain`: pretrain model, type=str, default=None
+- `--model_path`: the path of rm model(if continue to train), type=str, default=None
+- `--save_path`: path to save the model, type=str, default='output'
+- `--need_optim_ckpt`: whether to save optim ckpt, type=bool, default=False
+- `--max_epochs`: max epochs for training, type=int, default=3
+- `--dataset`: dataset name, type=str, choices=['Anthropic/hh-rlhf', 'Dahoas/rm-static']
+- `--subset`: subset of the dataset, type=str, default=None
+- `--batch_size`: batch size while training, type=int, default=4
+- `--lora_rank`: low-rank adaptation matrices rank, type=int, default=0
+- `--loss_func`: which kind of loss function, choices=['log_sig', 'log_exp']
+- `--max_len`: max sentence length for generation, type=int, default=512
## Stage3 - Training model using prompts with RL
@@ -186,53 +208,89 @@ Stage3 uses reinforcement learning algorithm, which is the most complex part of
You can run the `examples/train_prompts.sh` to start PPO training.
+
You can also use the cmd following to start PPO training.
[[Stage3 tutorial video]](https://www.youtube.com/watch?v=Z8wwSHxPL9g)
-```
+```bash
torchrun --standalone --nproc_per_node=4 train_prompts.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --prompt_dataset /path/to/your/prompt_dataset \
- --pretrain_dataset /path/to/your/pretrain_dataset \
- --rm_pretrain /your/pretrain/rm/definition \
- --rm_path /your/rm/model/path
+ --pretrain "/path/to/LLaMa-7B/" \
+ --model 'llama' \
+ --strategy colossalai_zero2 \
+ --prompt_dataset /path/to/your/prompt_dataset \
+ --pretrain_dataset /path/to/your/pretrain_dataset \
+ --rm_pretrain /your/pretrain/rm/definition \
+ --rm_path /your/rm/model/path
```
Prompt dataset: the instruction dataset mentioned in the above figure which includes the instructions, e.g. you can use the [script](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/generate_prompt_dataset.py) which samples `instinwild_en.json` or `instinwild_ch.json` in [InstructionWild](https://github.com/XueFuzhao/InstructionWild/tree/main/data#instructwild-data) to generate the prompt dataset.
Pretrain dataset: the pretrain dataset including the instruction and corresponding response, e.g. you can use the [InstructWild Data](https://github.com/XueFuzhao/InstructionWild/tree/main/data) in stage 1 supervised instructs tuning.
+**Note**: the required datasets follow the following format,
+
+- `pretrain dataset`
+
+ ```json
+ [
+ {
+ "instruction": "Provide a list of the top 10 most popular mobile games in Asia",
+ "input": "",
+ "output": "The top 10 most popular mobile games in Asia are:\n1) PUBG Mobile\n2) Pokemon Go\n3) Candy Crush Saga\n4) Free Fire\n5) Clash of Clans\n6) Mario Kart Tour\n7) Arena of Valor\n8) Fantasy Westward Journey\n9) Subway Surfers\n10) ARK Survival Evolved",
+ "id": 0
+ },
+ ...
+ ]
+ ```
+
+- `prompt dataset`
+
+ ```json
+ [
+ {
+ "instruction": "Edit this paragraph to make it more concise: \"Yesterday, I went to the store and bought some things. Then, I came home and put them away. After that, I went for a walk and met some friends.\"",
+ "id": 0
+ },
+ {
+ "instruction": "Write a descriptive paragraph about a memorable vacation you went on",
+ "id": 1
+ },
+ ...
+ ]
+ ```
+
### Arg List
-- --strategy: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
-- --model: model type of actor, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
-- --pretrain: pretrain model, type=str, default=None
-- --rm_model: reward model type, type=str, choices=['gpt2', 'bloom', 'opt', 'llama'], default=None
-- --rm_pretrain: pretrain model for reward model, type=str, default=None
-- --rm_path: the path of rm model, type=str, default=None
-- --save_path: path to save the model, type=str, default='output'
-- --prompt_dataset: path of the prompt dataset, type=str, default=None
-- --pretrain_dataset: path of the ptx dataset, type=str, default=None
-- --need_optim_ckpt: whether to save optim ckpt, type=bool, default=False
-- --num_episodes: num of episodes for training, type=int, default=10
-- --num_update_steps: number of steps to update policy per episode, type=int
-- --num_collect_steps: number of steps to collect experience per episode, type=int
-- --train_batch_size: batch size while training, type=int, default=8
-- --ptx_batch_size: batch size to compute ptx loss, type=int, default=1
-- --experience_batch_size: batch size to make experience, type=int, default=8
-- --lora_rank: low-rank adaptation matrices rank, type=int, default=0
-- --kl_coef: kl_coef using for computing reward, type=float, default=0.1
-- --ptx_coef: ptx_coef using for computing policy loss, type=float, default=0.9
+
+- `--strategy`: the strategy using for training, choices=['ddp', 'colossalai_gemini', 'colossalai_zero2'], default='colossalai_zero2'
+- `--model`: model type of actor, choices=['gpt2', 'bloom', 'opt', 'llama'], default='bloom'
+- `--pretrain`: pretrain model, type=str, default=None
+- `--rm_model`: reward model type, type=str, choices=['gpt2', 'bloom', 'opt', 'llama'], default=None
+- `--rm_pretrain`: pretrain model for reward model, type=str, default=None
+- `--rm_path`: the path of rm model, type=str, default=None
+- `--save_path`: path to save the model, type=str, default='output'
+- `--prompt_dataset`: path of the prompt dataset, type=str, default=None
+- `--pretrain_dataset`: path of the ptx dataset, type=str, default=None
+- `--need_optim_ckpt`: whether to save optim ckpt, type=bool, default=False
+- `--num_episodes`: num of episodes for training, type=int, default=10
+- `--num_update_steps`: number of steps to update policy per episode, type=int
+- `--num_collect_steps`: number of steps to collect experience per episode, type=int
+- `--train_batch_size`: batch size while training, type=int, default=8
+- `--ptx_batch_size`: batch size to compute ptx loss, type=int, default=1
+- `--experience_batch_size`: batch size to make experience, type=int, default=8
+- `--lora_rank`: low-rank adaptation matrices rank, type=int, default=0
+- `--kl_coef`: kl_coef using for computing reward, type=float, default=0.1
+- `--ptx_coef`: ptx_coef using for computing policy loss, type=float, default=0.9
## Inference example - After Stage3
+
We support different inference options, including int8 and int4 quantization.
For details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
-
## Attention
+
The examples are demos for the whole training process.You need to change the hyper-parameters to reach great performance.
#### data
+
- [x] [rm-static](https://huggingface.co/datasets/Dahoas/rm-static)
- [x] [hh-rlhf](https://huggingface.co/datasets/Anthropic/hh-rlhf)
- [ ] [openai/summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)
@@ -242,14 +300,16 @@ The examples are demos for the whole training process.You need to change the hyp
## Support Model
### GPT
-- [x] GPT2-S (s)
-- [x] GPT2-M (m)
-- [x] GPT2-L (l)
-- [x] GPT2-XL (xl)
-- [x] GPT2-4B (4b)
-- [ ] GPT2-6B (6b)
+
+- [x] GPT2-S (s)
+- [x] GPT2-M (m)
+- [x] GPT2-L (l)
+- [x] GPT2-XL (xl)
+- [x] GPT2-4B (4b)
+- [ ] GPT2-6B (6b)
### BLOOM
+
- [x] [BLOOM-560m](https://huggingface.co/bigscience/bloom-560m)
- [x] [BLOOM-1b1](https://huggingface.co/bigscience/bloom-1b1)
- [x] [BLOOM-3b](https://huggingface.co/bigscience/bloom-3b)
@@ -257,6 +317,7 @@ The examples are demos for the whole training process.You need to change the hyp
- [ ] [BLOOM-175b](https://huggingface.co/bigscience/bloom)
### OPT
+
- [x] [OPT-125M](https://huggingface.co/facebook/opt-125m)
- [x] [OPT-350M](https://huggingface.co/facebook/opt-350m)
- [x] [OPT-1.3B](https://huggingface.co/facebook/opt-1.3b)
@@ -266,10 +327,11 @@ The examples are demos for the whole training process.You need to change the hyp
- [ ] [OPT-30B](https://huggingface.co/facebook/opt-30b)
### [LLaMA](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md)
-- [x] LLaMA-7B
-- [x] LLaMA-13B
-- [ ] LLaMA-33B
-- [ ] LLaMA-65B
+
+- [x] LLaMA-7B
+- [x] LLaMA-13B
+- [ ] LLaMA-33B
+- [ ] LLaMA-65B
## Add your own models
@@ -282,12 +344,12 @@ if it is supported in huggingface [transformers](https://github.com/huggingface/
r you can build your own model by yourself.
### Actor model
-```
+
+```python
from ..base import Actor
from transformers.models.coati import CoatiModel
class CoatiActor(Actor):
-
def __init__(self,
pretrained: Optional[str] = None,
checkpoint: bool = False,
@@ -302,7 +364,8 @@ class CoatiActor(Actor):
```
### Reward model
-```
+
+```python
from ..base import RewardModel
from transformers.models.coati import CoatiModel
@@ -325,12 +388,11 @@ class CoatiRM(RewardModel):
### Critic model
-```
+```python
from ..base import Critic
from transformers.models.coati import CoatiModel
class CoatiCritic(Critic):
-
def __init__(self,
pretrained: Optional[str] = None,
checkpoint: bool = False,
diff --git a/applications/Chat/examples/community/README.md b/applications/Chat/examples/community/README.md
index cd7b9d99b..e14ac1767 100644
--- a/applications/Chat/examples/community/README.md
+++ b/applications/Chat/examples/community/README.md
@@ -1,5 +1,9 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# Community Examples
+
---
+
We are thrilled to announce the latest updates to ColossalChat, an open-source solution for cloning ChatGPT with a complete RLHF (Reinforcement Learning with Human Feedback) pipeline.
As Colossal-AI undergoes major updates, we are actively maintaining ColossalChat to stay aligned with the project's progress. With the introduction of Community-driven example, we aim to create a collaborative platform for developers to contribute exotic features built on top of ColossalChat.
@@ -14,11 +18,12 @@ For more information about community pipelines, please have a look at this [issu
Community examples consist of both inference and training examples that have been added by the community. Please have a look at the following table to get an overview of all community examples. Click on the Code Example to get a copy-and-paste ready code example that you can try out. If a community doesn't work as expected, please open an issue and ping the author on it.
-| Example | Description | Code Example | Colab | Author |
-|:---------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------:|
-| Peft | Adding Peft support for SFT and Prompts model training | [Huggingface Peft](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/peft) | - | [YY Lin](https://github.com/yynil) |
-| Train prompts on Ray | A Ray based implementation of Train prompts example | [Training On Ray](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/ray) | - | [MisterLin1995](https://github.com/MisterLin1995) |
-|...|...|...|...|...|
+| Example | Description | Code Example | Colab | Author |
+| :------------------- | :----------------------------------------------------- | :-------------------------------------------------------------------------------------------------------------- | :---- | ------------------------------------------------: |
+| Peft | Adding Peft support for SFT and Prompts model training | [Huggingface Peft](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/peft) | - | [YY Lin](https://github.com/yynil) |
+| Train prompts on Ray | A Ray based implementation of Train prompts example | [Training On Ray](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples/community/ray) | - | [MisterLin1995](https://github.com/MisterLin1995) |
+| ... | ... | ... | ... | ... |
### How to get involved
+
To join our community-driven initiative, please visit the [ColossalChat GitHub repository](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples), review the provided information, and explore the codebase. To contribute, create a new issue outlining your proposed feature or enhancement, and our team will review and provide feedback. We look forward to collaborating with you on this exciting project!
diff --git a/applications/Chat/examples/community/peft/README.md b/applications/Chat/examples/community/peft/README.md
index 844bfd3d2..8b2edc48c 100644
--- a/applications/Chat/examples/community/peft/README.md
+++ b/applications/Chat/examples/community/peft/README.md
@@ -1,3 +1,5 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# Add Peft support for SFT and Prompts model training
The original implementation just adopts the loralib and merges the layers into the final model. The huggingface peft is a better lora model implementation and can be easily training and distributed.
@@ -5,7 +7,9 @@ The original implementation just adopts the loralib and merges the layers into t
Since reward model is relative small, I just keep it as original one. I suggest train full model to get the proper reward/critic model.
# Preliminary installation
+
Since the current pypi peft package(0.2) has some bugs, please install the peft package using source.
+
```
git clone https://github.com/huggingface/peft
cd peft
@@ -13,6 +17,7 @@ pip install .
```
# Usage
+
For SFT training, just call train_peft_sft.py
Its arguments are almost identical to train_sft.py instead adding a new eval_dataset if you have a eval_dataset file. The data file is just a plain datafile, please check the format in the easy_dataset.py.
@@ -21,4 +26,5 @@ For stage-3 rlhf training, call train_peft_prompts.py.
Its arguments are almost identical to train_prompts.py. The only difference is that I use text files to indicate the prompt and pretrained data file. The models are included in easy_models.py. Currently only bloom models are tested, but technically gpt2/opt/llama should be supported.
# Dataformat
+
Please refer the formats in test_sft.txt, test_prompts.txt, test_pretrained.txt.
diff --git a/applications/Chat/examples/community/ray/README.md b/applications/Chat/examples/community/ray/README.md
index 64360bd73..a679a5833 100644
--- a/applications/Chat/examples/community/ray/README.md
+++ b/applications/Chat/examples/community/ray/README.md
@@ -1,17 +1,31 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# ColossalAI on Ray
+
## Abstract
+
This is an experimental effort to run ColossalAI Chat training on Ray
+
## How to use?
+
### 1. Setup Ray clusters
+
Please follow the official [Ray cluster setup instructions](https://docs.ray.io/en/latest/cluster/getting-started.html) to setup an cluster with GPU support. Record the cluster's api server endpoint, it should be something similar to http://your.head.node.addrees:8265
+
### 2. Clone repo
+
Clone this project:
+
```shell
git clone https://github.com/hpcaitech/ColossalAI.git
```
+
### 3. Submit the ray job
+
```shell
python applications/Chat/examples/community/ray/ray_job_script.py http://your.head.node.addrees:8265
```
+
### 4. View your job on the Ray Dashboard
+
Open your ray cluster dashboard http://your.head.node.addrees:8265 to view your submitted training job.
diff --git a/applications/Chat/inference/README.md b/applications/Chat/inference/README.md
index 4848817e0..eea4ef5b8 100644
--- a/applications/Chat/inference/README.md
+++ b/applications/Chat/inference/README.md
@@ -20,21 +20,21 @@ Tha data is from [LLaMA Int8 4bit ChatBot Guide v2](https://rentry.org/llama-tar
### 8-bit
-| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
-| :---: | :---: | :---: | :---: | :---: |
-| LLaMA-7B | 9.2GB | 10GB | 24GB | 3060 12GB, RTX 3080 10GB, RTX 3090 |
-| LLaMA-13B | 16.3GB | 20GB | 32GB | RTX 3090 Ti, RTX 4090 |
-| LLaMA-30B | 36GB | 40GB | 64GB | A6000 48GB, A100 40GB |
-| LLaMA-65B | 74GB | 80GB | 128GB | A100 80GB |
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :-------: | :---------: | :-----------------: | :----------: | :--------------------------------: |
+| LLaMA-7B | 9.2GB | 10GB | 24GB | 3060 12GB, RTX 3080 10GB, RTX 3090 |
+| LLaMA-13B | 16.3GB | 20GB | 32GB | RTX 3090 Ti, RTX 4090 |
+| LLaMA-30B | 36GB | 40GB | 64GB | A6000 48GB, A100 40GB |
+| LLaMA-65B | 74GB | 80GB | 128GB | A100 80GB |
### 4-bit
-| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
-| :---: | :---: | :---: | :---: | :---: |
-| LLaMA-7B | 3.5GB | 6GB | 16GB | RTX 1660, 2060, AMD 5700xt, RTX 3050, 3060 |
-| LLaMA-13B | 6.5GB | 10GB | 32GB | AMD 6900xt, RTX 2060 12GB, 3060 12GB, 3080, A2000 |
-| LLaMA-30B | 15.8GB | 20GB | 64GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 |
-| LLaMA-65B | 31.2GB | 40GB | 128GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000, Titan Ada |
+| Model | Min GPU RAM | Recommended GPU RAM | Min RAM/Swap | Card examples |
+| :-------: | :---------: | :-----------------: | :----------: | :--------------------------------------------------------: |
+| LLaMA-7B | 3.5GB | 6GB | 16GB | RTX 1660, 2060, AMD 5700xt, RTX 3050, 3060 |
+| LLaMA-13B | 6.5GB | 10GB | 32GB | AMD 6900xt, RTX 2060 12GB, 3060 12GB, 3080, A2000 |
+| LLaMA-30B | 15.8GB | 20GB | 64GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 |
+| LLaMA-65B | 31.2GB | 40GB | 128GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000, Titan Ada |
## General setup
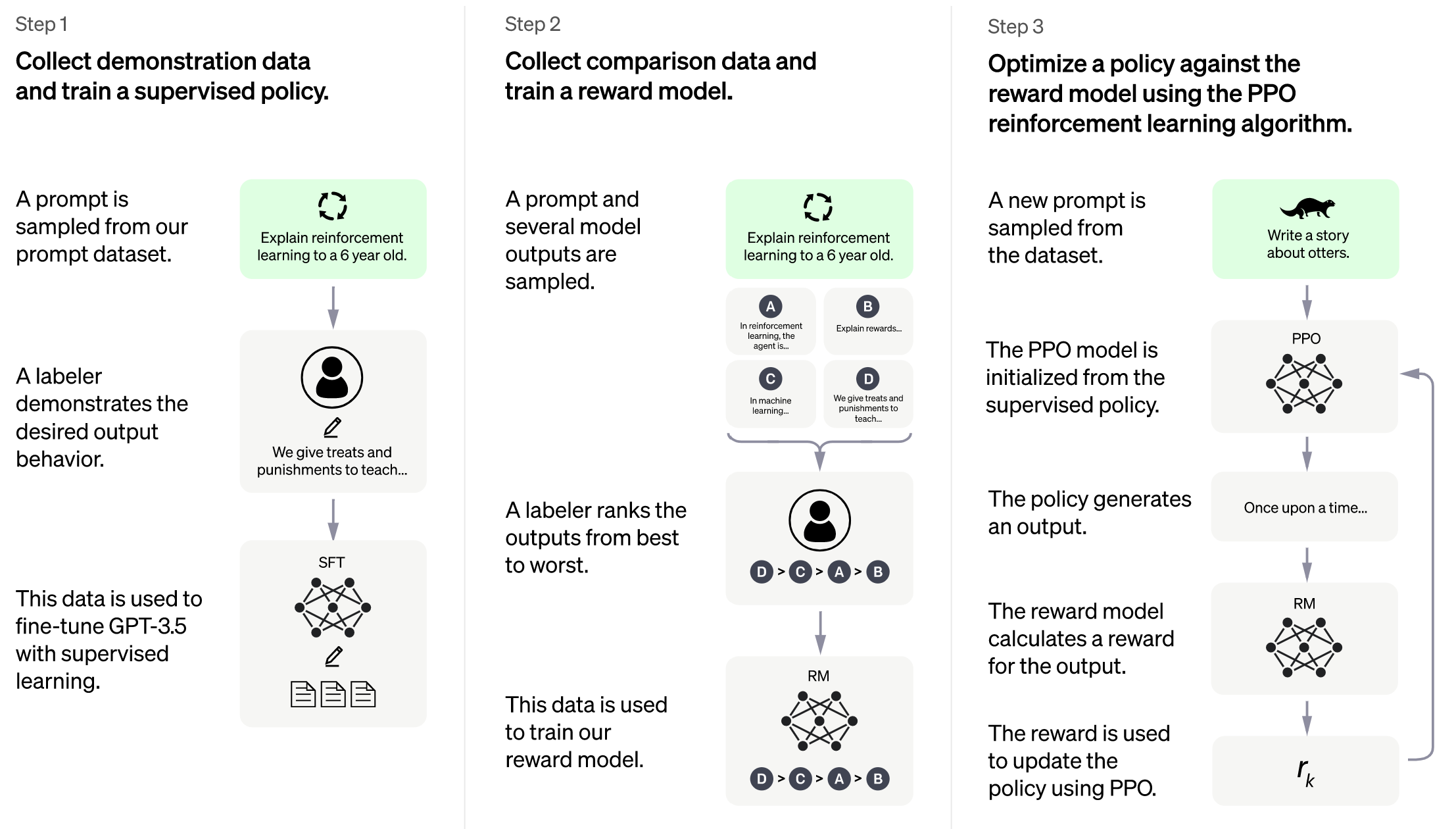 - Image source: https://openai.com/blog/chatgpt
+Image source: https://openai.com/blog/chatgpt
+
**As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
-
More details can be found in the latest news.
-* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
-* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
+
+- [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+- [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
## Online demo
+
- Image source: https://openai.com/blog/chatgpt
+Image source: https://openai.com/blog/chatgpt
+
**As Colossal-AI is undergoing some major updates, this project will be actively maintained to stay in line with the Colossal-AI project.**
-
More details can be found in the latest news.
-* [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
-* [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
+
+- [2023/03] [ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline](https://medium.com/@yangyou_berkeley/colossalchat-an-open-source-solution-for-cloning-chatgpt-with-a-complete-rlhf-pipeline-5edf08fb538b)
+- [2023/02] [Open Source Solution Replicates ChatGPT Training Process! Ready to go with only 1.6GB GPU Memory](https://www.hpc-ai.tech/blog/colossal-ai-chatgpt)
## Online demo
+
 @@ -83,13 +87,13 @@ More details can be found in the latest news.
@@ -83,13 +87,13 @@ More details can be found in the latest news.
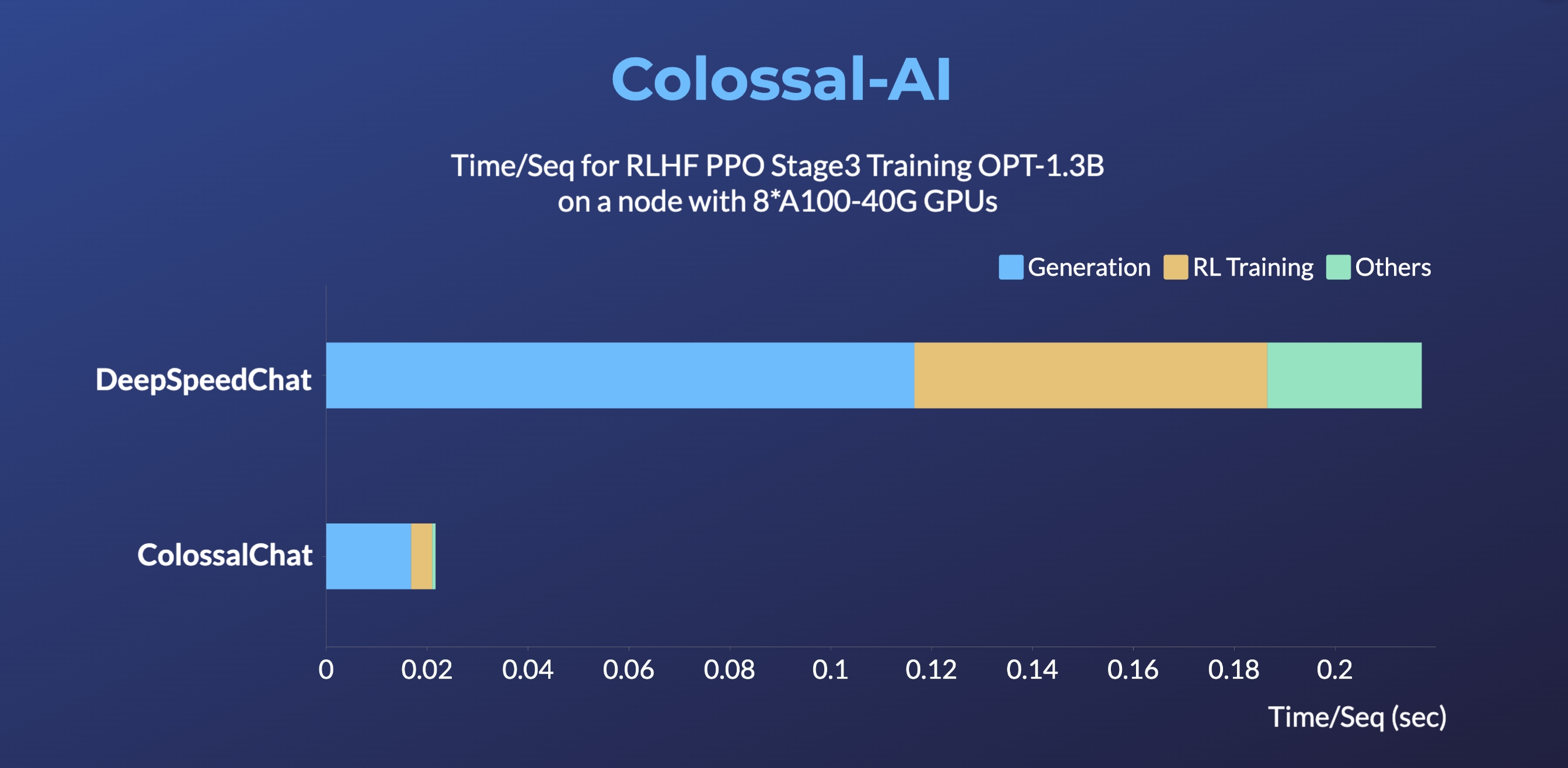 -> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32
+> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: `torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32`
## Install
### Install the environment
-```shell
+```bash
conda create -n coati
conda activate coati
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -99,7 +103,7 @@ pip install .
### Install the Transformers
-```shell
+```bash
pip install transformers==4.30.2
```
@@ -107,10 +111,11 @@ pip install transformers==4.30.2
### Supervised datasets collection
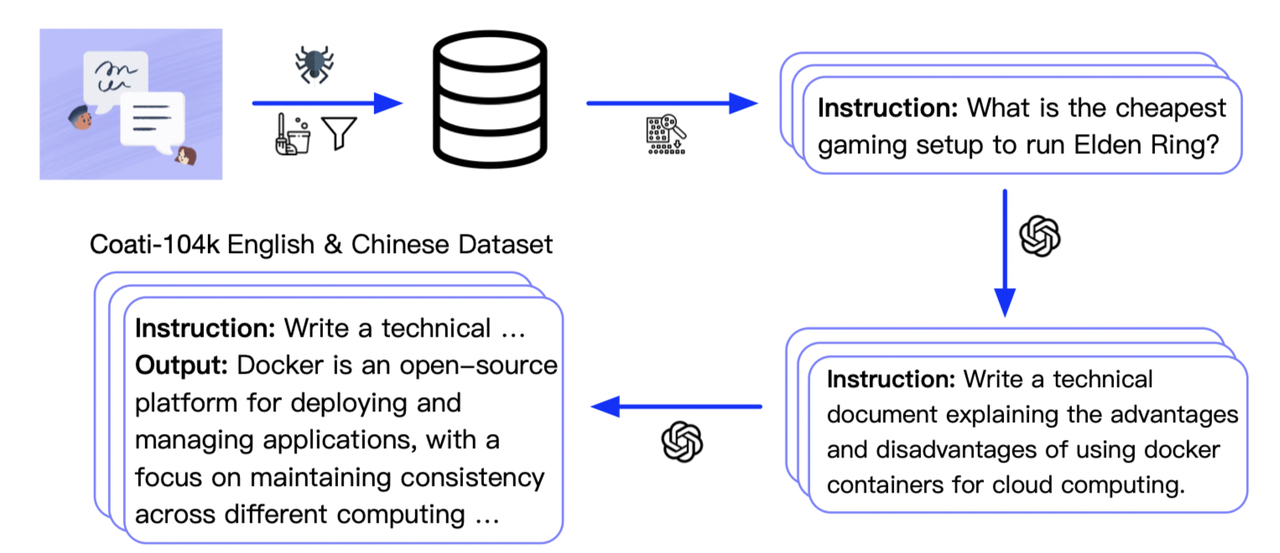
-we collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
-[InstructionWild](https://github.com/XueFuzhao/InstructionWild)
+We collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
+[InstructionWild](https://github.com/XueFuzhao/InstructionWild) and in this [file](https://github.com/XueFuzhao/InstructionWild/blob/main/data/README.md).
Here is how we collected the data
+
-> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32
+> DeepSpeedChat performance comes from its blog on 2023 April 12, ColossalChat performance can be reproduced on an AWS p4d.24xlarge node with 8 A100-40G GPUs with the following command: `torchrun --standalone --nproc_per_node 8 benchmark_opt_lora_dummy.py --num_collect_steps 1 --use_kernels --strategy colossalai_zero2 --experience_batch_size 64 --train_batch_size 32`
## Install
### Install the environment
-```shell
+```bash
conda create -n coati
conda activate coati
git clone https://github.com/hpcaitech/ColossalAI.git
@@ -99,7 +103,7 @@ pip install .
### Install the Transformers
-```shell
+```bash
pip install transformers==4.30.2
```
@@ -107,10 +111,11 @@ pip install transformers==4.30.2
### Supervised datasets collection
-we collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
-[InstructionWild](https://github.com/XueFuzhao/InstructionWild)
+We collected 104K bilingual datasets of Chinese and English, and you can find the datasets in this repo
+[InstructionWild](https://github.com/XueFuzhao/InstructionWild) and in this [file](https://github.com/XueFuzhao/InstructionWild/blob/main/data/README.md).
Here is how we collected the data
+
 @@ -397,18 +455,22 @@ Thanks so much to all of our amazing contributors!
| Better Cases | 38 ⚔ **41** | **45** ⚔ 33 |
| Win Rate | 48% ⚔ **52%** | **58%** ⚔ 42% |
| Average Score | 7.06 ⚔ **7.13** | **7.31** ⚔ 6.82 |
+
- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
## Authors
Coati is developed by ColossalAI Team:
+
- [Fazzie](https://fazzie-key.cool/about/index.html)
- [FrankLeeeee](https://github.com/FrankLeeeee)
- [BlueRum](https://github.com/ht-zhou)
- [ver217](https://github.com/ver217)
- [ofey404](https://github.com/ofey404)
+- [Wenhao Chen](https://github.com/CWHer)
The Phd student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
+
- [Zangwei Zheng](https://github.com/zhengzangw)
- [Xue Fuzhao](https://github.com/XueFuzhao)
diff --git a/applications/Chat/benchmarks/README.md b/applications/Chat/benchmarks/README.md
index bc8ad8ba9..c13f34858 100644
--- a/applications/Chat/benchmarks/README.md
+++ b/applications/Chat/benchmarks/README.md
@@ -27,9 +27,12 @@ We also provide various training strategies:
We only support `torchrun` to launch now. E.g.
-```shell
+```bash
# run OPT-125M with no lora (lora_rank=0) on single-node single-GPU with min batch size
-torchrun --standalone --nproc_per_node 1 benchmark_opt_lora_dummy.py --model 125m --critic_model 125m --strategy ddp --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
+torchrun --standalone --nproc_per_node 1 benchmark_opt_lora_dummy.py \
+ --model 125m --critic_model 125m --strategy ddp \
+ --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
# run Actor (OPT-1.3B) and Critic (OPT-350M) with lora_rank=4 on single-node 4-GPU
-torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py --model 1.3b --critic_model 350m --strategy colossalai_zero2 --lora_rank 4
+torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py \
+ --model 1.3b --critic_model 350m --strategy colossalai_zero2 --lora_rank 4
```
diff --git a/applications/Chat/coati/ray/README.md b/applications/Chat/coati/ray/README.md
index 228155a68..79b1db347 100644
--- a/applications/Chat/coati/ray/README.md
+++ b/applications/Chat/coati/ray/README.md
@@ -1,3 +1,5 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# Distributed PPO Training on Stage 3
## Detach Experience Makers and Trainers
@@ -26,124 +28,137 @@ See examples at `ColossalAI/application/Chat/examples/ray`
- define makers' environment variables :
- ```python
- env_info_makers = [{
- 'local_rank': '0',
- 'rank': str(rank),
- 'world_size': str(num_makers),
- 'master_port': maker_port,
- 'master_addr': master_addr
- } for rank in range(num_makers)]
+ ```python
+ env_info_makers = [{
+ 'local_rank': '0',
+ 'rank': str(rank),
+ 'world_size': str(num_makers),
+ 'master_port': maker_port,
+ 'master_addr': master_addr
+ } for rank in range(num_makers)]
+
+ ```
- ```
- define maker models :
- ```python
- def model_fn():
- actor = get_actor_from_args(...)
- critic = get_critic_from_args(...)
- reward_model = get_reward_model_from_args(...)
- initial_model = get_actor_from_args(...)
- return actor, critic, reward_model, initial_model
- ```
+ ```python
+ def model_fn():
+ actor = get_actor_from_args(...)
+ critic = get_critic_from_args(...)
+ reward_model = get_reward_model_from_args(...)
+ initial_model = get_actor_from_args(...)
+ return actor, critic, reward_model, initial_model
+
+ ```
+
- set experience_holder_refs :
- ```python
- experience_holder_refs = [
- ExperienceMakerHolder.options(
- name=f"maker_{i}",
- num_gpus=1,
- max_concurrency=2
- ).remote(
- detached_trainer_name_list=[f"trainer_{x}" for x in target_trainers(...)],
- model_fn=model_fn,
- ...)
- for i, env_info_maker in enumerate(env_info_makers)
- ]
- ```
- The names in the `detached_trainer_name_list` refer to the target trainers that the maker should send experience to.
- We set a trainer's name the same as a maker, by `.options(name="str")`. See below.
+ ```python
+ experience_holder_refs = [
+ ExperienceMakerHolder.options(
+ name=f"maker_{i}",
+ num_gpus=1,
+ max_concurrency=2
+ ).remote(
+ detached_trainer_name_list=[f"trainer_{x}" for x in target_trainers(...)],
+ model_fn=model_fn,
+ ...)
+ for i, env_info_maker in enumerate(env_info_makers)
+ ]
+ ```
+
+ The names in the `detached_trainer_name_list` refer to the target trainers that the maker should send experience to.
+ We set a trainer's name the same as a maker, by `.options(name="str")`. See below.
### Setup Trainers
- define trainers' environment variables :
- ```python
- env_info_trainers = [{
- 'local_rank': '0',
- 'rank': str(rank),
- 'world_size': str(num_trainers),
- 'master_port': trainer_port,
- 'master_addr': master_addr
- } for rank in range(num_trainers)]
- ```
+ ```python
+ env_info_trainers = [{
+ 'local_rank': '0',
+ 'rank': str(rank),
+ 'world_size': str(num_trainers),
+ 'master_port': trainer_port,
+ 'master_addr': master_addr
+ } for rank in range(num_trainers)]
+ ```
- define trainer models :
- ```python
- def trainer_model_fn():
- actor = get_actor_from_args(...)
- critic = get_critic_from_args(...)
- return actor, critic
- ```
+ ```python
+ def trainer_model_fn():
+ actor = get_actor_from_args(...)
+ critic = get_critic_from_args(...)
+ return actor, critic
+ ```
+
- set trainer_refs :
- ```python
- trainer_refs = [
- DetachedPPOTrainer.options(
- name=f"trainer{i}",
- num_gpus=1,
- max_concurrency=2
- ).remote(
- experience_maker_holder_name_list=[f"maker{x}" for x in target_makers(...)],
- model_fn = trainer_model_fn(),
- ...)
- for i, env_info_trainer in enumerate(env_info_trainers)
- ]
- ```
- The names in `experience_maker_holder_name_list` refer to the target makers that the trainer should send updated models to.
- By setting `detached_trainer_name_list` and `experience_maker_holder_name_list`, we can customize the transmission graph.
+ ```python
+ trainer_refs = [
+ DetachedPPOTrainer.options(
+ name=f"trainer{i}",
+ num_gpus=1,
+ max_concurrency=2
+ ).remote(
+ experience_maker_holder_name_list=[f"maker{x}" for x in target_makers(...)],
+ model_fn = trainer_model_fn(),
+ ...)
+ for i, env_info_trainer in enumerate(env_info_trainers)
+ ]
+ ```
+ The names in `experience_maker_holder_name_list` refer to the target makers that the trainer should send updated models to.
+ By setting `detached_trainer_name_list` and `experience_maker_holder_name_list`, we can customize the transmission graph.
### Launch Jobs
+
- define data_loader :
- ```python
- def data_loader_fn():
- return = torch.utils.data.DataLoader(dataset=dataset)
- ```
+ ```python
+ def data_loader_fn():
+ return = torch.utils.data.DataLoader(dataset=dataset)
+
+ ```
+
- launch makers :
- ```python
- wait_tasks = []
- for experience_holder_ref in experience_holder_refs:
- wait_tasks.append(
- experience_holder_ref.workingloop.remote(data_loader_fn(),
- num_steps=experience_steps))
- ```
+ ```python
+ wait_tasks = []
+ for experience_holder_ref in experience_holder_refs:
+ wait_tasks.append(
+ experience_holder_ref.workingloop.remote(data_loader_fn(),
+ num_steps=experience_steps))
+
+ ```
- launch trainers :
- ```python
- for trainer_ref in trainer_refs:
- wait_tasks.append(trainer_ref.fit.remote(total_steps, update_steps, train_epochs))
- ```
+
+ ```python
+ for trainer_ref in trainer_refs:
+ wait_tasks.append(trainer_ref.fit.remote(total_steps, update_steps, train_epochs))
+ ```
- wait for done :
- ```python
- ray.get(wait_tasks)
- ```
+ ```python
+ ray.get(wait_tasks)
+ ```
## Flexible Structure
We can deploy different strategies to makers and trainers. Here are some notions.
### 2 Makers 1 Trainer
+
@@ -397,18 +455,22 @@ Thanks so much to all of our amazing contributors!
| Better Cases | 38 ⚔ **41** | **45** ⚔ 33 |
| Win Rate | 48% ⚔ **52%** | **58%** ⚔ 42% |
| Average Score | 7.06 ⚔ **7.13** | **7.31** ⚔ 6.82 |
+
- Our Coati-7B model performs better than Alpaca-7B when using GPT-4 to evaluate model performance. The Coati-7B model we evaluate is an old version we trained a few weeks ago and the new version is around the corner.
## Authors
Coati is developed by ColossalAI Team:
+
- [Fazzie](https://fazzie-key.cool/about/index.html)
- [FrankLeeeee](https://github.com/FrankLeeeee)
- [BlueRum](https://github.com/ht-zhou)
- [ver217](https://github.com/ver217)
- [ofey404](https://github.com/ofey404)
+- [Wenhao Chen](https://github.com/CWHer)
The Phd student from [(HPC-AI) Lab](https://ai.comp.nus.edu.sg/) also contributed a lot to this project.
+
- [Zangwei Zheng](https://github.com/zhengzangw)
- [Xue Fuzhao](https://github.com/XueFuzhao)
diff --git a/applications/Chat/benchmarks/README.md b/applications/Chat/benchmarks/README.md
index bc8ad8ba9..c13f34858 100644
--- a/applications/Chat/benchmarks/README.md
+++ b/applications/Chat/benchmarks/README.md
@@ -27,9 +27,12 @@ We also provide various training strategies:
We only support `torchrun` to launch now. E.g.
-```shell
+```bash
# run OPT-125M with no lora (lora_rank=0) on single-node single-GPU with min batch size
-torchrun --standalone --nproc_per_node 1 benchmark_opt_lora_dummy.py --model 125m --critic_model 125m --strategy ddp --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
+torchrun --standalone --nproc_per_node 1 benchmark_opt_lora_dummy.py \
+ --model 125m --critic_model 125m --strategy ddp \
+ --experience_batch_size 1 --train_batch_size 1 --lora_rank 0
# run Actor (OPT-1.3B) and Critic (OPT-350M) with lora_rank=4 on single-node 4-GPU
-torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py --model 1.3b --critic_model 350m --strategy colossalai_zero2 --lora_rank 4
+torchrun --standalone --nproc_per_node 4 benchmark_opt_lora_dummy.py \
+ --model 1.3b --critic_model 350m --strategy colossalai_zero2 --lora_rank 4
```
diff --git a/applications/Chat/coati/ray/README.md b/applications/Chat/coati/ray/README.md
index 228155a68..79b1db347 100644
--- a/applications/Chat/coati/ray/README.md
+++ b/applications/Chat/coati/ray/README.md
@@ -1,3 +1,5 @@
+:warning: **This content may be outdated since the major update of Colossal Chat. We will update this content soon.**
+
# Distributed PPO Training on Stage 3
## Detach Experience Makers and Trainers
@@ -26,124 +28,137 @@ See examples at `ColossalAI/application/Chat/examples/ray`
- define makers' environment variables :
- ```python
- env_info_makers = [{
- 'local_rank': '0',
- 'rank': str(rank),
- 'world_size': str(num_makers),
- 'master_port': maker_port,
- 'master_addr': master_addr
- } for rank in range(num_makers)]
+ ```python
+ env_info_makers = [{
+ 'local_rank': '0',
+ 'rank': str(rank),
+ 'world_size': str(num_makers),
+ 'master_port': maker_port,
+ 'master_addr': master_addr
+ } for rank in range(num_makers)]
+
+ ```
- ```
- define maker models :
- ```python
- def model_fn():
- actor = get_actor_from_args(...)
- critic = get_critic_from_args(...)
- reward_model = get_reward_model_from_args(...)
- initial_model = get_actor_from_args(...)
- return actor, critic, reward_model, initial_model
- ```
+ ```python
+ def model_fn():
+ actor = get_actor_from_args(...)
+ critic = get_critic_from_args(...)
+ reward_model = get_reward_model_from_args(...)
+ initial_model = get_actor_from_args(...)
+ return actor, critic, reward_model, initial_model
+
+ ```
+
- set experience_holder_refs :
- ```python
- experience_holder_refs = [
- ExperienceMakerHolder.options(
- name=f"maker_{i}",
- num_gpus=1,
- max_concurrency=2
- ).remote(
- detached_trainer_name_list=[f"trainer_{x}" for x in target_trainers(...)],
- model_fn=model_fn,
- ...)
- for i, env_info_maker in enumerate(env_info_makers)
- ]
- ```
- The names in the `detached_trainer_name_list` refer to the target trainers that the maker should send experience to.
- We set a trainer's name the same as a maker, by `.options(name="str")`. See below.
+ ```python
+ experience_holder_refs = [
+ ExperienceMakerHolder.options(
+ name=f"maker_{i}",
+ num_gpus=1,
+ max_concurrency=2
+ ).remote(
+ detached_trainer_name_list=[f"trainer_{x}" for x in target_trainers(...)],
+ model_fn=model_fn,
+ ...)
+ for i, env_info_maker in enumerate(env_info_makers)
+ ]
+ ```
+
+ The names in the `detached_trainer_name_list` refer to the target trainers that the maker should send experience to.
+ We set a trainer's name the same as a maker, by `.options(name="str")`. See below.
### Setup Trainers
- define trainers' environment variables :
- ```python
- env_info_trainers = [{
- 'local_rank': '0',
- 'rank': str(rank),
- 'world_size': str(num_trainers),
- 'master_port': trainer_port,
- 'master_addr': master_addr
- } for rank in range(num_trainers)]
- ```
+ ```python
+ env_info_trainers = [{
+ 'local_rank': '0',
+ 'rank': str(rank),
+ 'world_size': str(num_trainers),
+ 'master_port': trainer_port,
+ 'master_addr': master_addr
+ } for rank in range(num_trainers)]
+ ```
- define trainer models :
- ```python
- def trainer_model_fn():
- actor = get_actor_from_args(...)
- critic = get_critic_from_args(...)
- return actor, critic
- ```
+ ```python
+ def trainer_model_fn():
+ actor = get_actor_from_args(...)
+ critic = get_critic_from_args(...)
+ return actor, critic
+ ```
+
- set trainer_refs :
- ```python
- trainer_refs = [
- DetachedPPOTrainer.options(
- name=f"trainer{i}",
- num_gpus=1,
- max_concurrency=2
- ).remote(
- experience_maker_holder_name_list=[f"maker{x}" for x in target_makers(...)],
- model_fn = trainer_model_fn(),
- ...)
- for i, env_info_trainer in enumerate(env_info_trainers)
- ]
- ```
- The names in `experience_maker_holder_name_list` refer to the target makers that the trainer should send updated models to.
- By setting `detached_trainer_name_list` and `experience_maker_holder_name_list`, we can customize the transmission graph.
+ ```python
+ trainer_refs = [
+ DetachedPPOTrainer.options(
+ name=f"trainer{i}",
+ num_gpus=1,
+ max_concurrency=2
+ ).remote(
+ experience_maker_holder_name_list=[f"maker{x}" for x in target_makers(...)],
+ model_fn = trainer_model_fn(),
+ ...)
+ for i, env_info_trainer in enumerate(env_info_trainers)
+ ]
+ ```
+ The names in `experience_maker_holder_name_list` refer to the target makers that the trainer should send updated models to.
+ By setting `detached_trainer_name_list` and `experience_maker_holder_name_list`, we can customize the transmission graph.
### Launch Jobs
+
- define data_loader :
- ```python
- def data_loader_fn():
- return = torch.utils.data.DataLoader(dataset=dataset)
- ```
+ ```python
+ def data_loader_fn():
+ return = torch.utils.data.DataLoader(dataset=dataset)
+
+ ```
+
- launch makers :
- ```python
- wait_tasks = []
- for experience_holder_ref in experience_holder_refs:
- wait_tasks.append(
- experience_holder_ref.workingloop.remote(data_loader_fn(),
- num_steps=experience_steps))
- ```
+ ```python
+ wait_tasks = []
+ for experience_holder_ref in experience_holder_refs:
+ wait_tasks.append(
+ experience_holder_ref.workingloop.remote(data_loader_fn(),
+ num_steps=experience_steps))
+
+ ```
- launch trainers :
- ```python
- for trainer_ref in trainer_refs:
- wait_tasks.append(trainer_ref.fit.remote(total_steps, update_steps, train_epochs))
- ```
+
+ ```python
+ for trainer_ref in trainer_refs:
+ wait_tasks.append(trainer_ref.fit.remote(total_steps, update_steps, train_epochs))
+ ```
- wait for done :
- ```python
- ray.get(wait_tasks)
- ```
+ ```python
+ ray.get(wait_tasks)
+ ```
## Flexible Structure
We can deploy different strategies to makers and trainers. Here are some notions.
### 2 Makers 1 Trainer
+


