 +
+
+
+ -### Stage1 - Supervised instructs tuning
+### RLHF Training Stage1 - Supervised instructs tuning
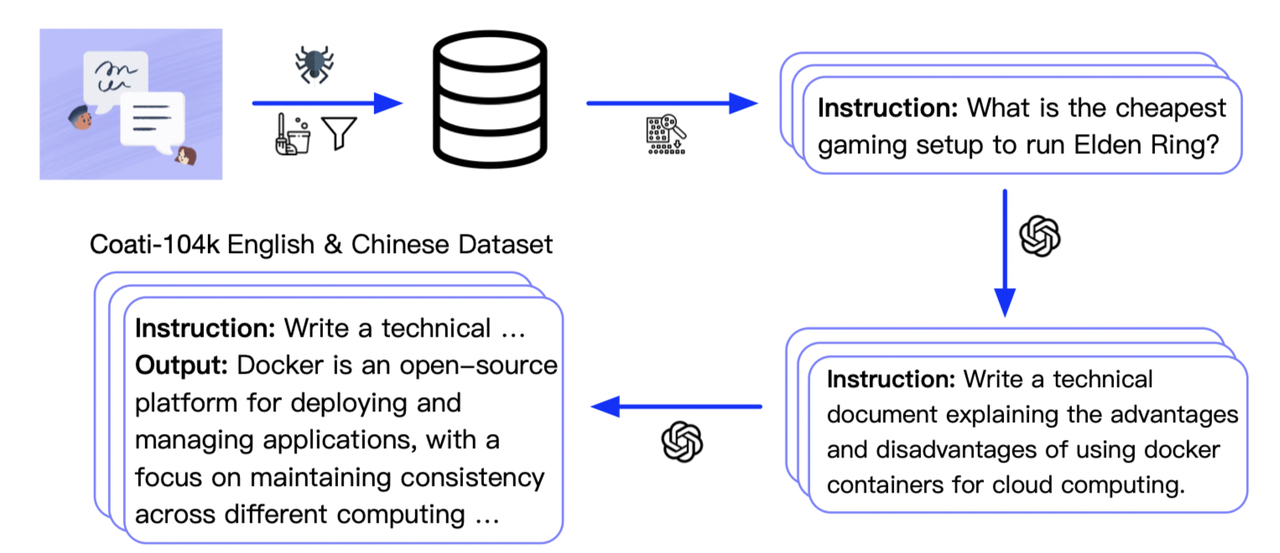
-Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model
+Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model.
-you can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning
+You can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning.
-```
-torchrun --standalone --nproc_per_node=4 train_sft.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --log_interval 10 \
- --save_path /path/to/Coati-7B \
- --dataset /path/to/data.json \
- --batch_size 4 \
- --accimulation_steps 8 \
- --lr 2e-5 \
- --max_datasets_size 512 \
- --max_epochs 1 \
-```
-
-### Stage2 - Training reward model
+### RLHF Training Stage2 - Training reward model
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model
-you can run the `examples/train_rm.sh` to start a reward model training
-
-```
-torchrun --standalone --nproc_per_node=4 train_reward_model.py
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --loss_fn 'log_exp'\
- --save_path 'rmstatic.pt' \
-```
+You can run the `examples/train_rm.sh` to start a reward model training.
-### Stage3 - Training model with reinforcement learning by human feedback
+### RLHF Training Stage3 - Training model with reinforcement learning by human feedback
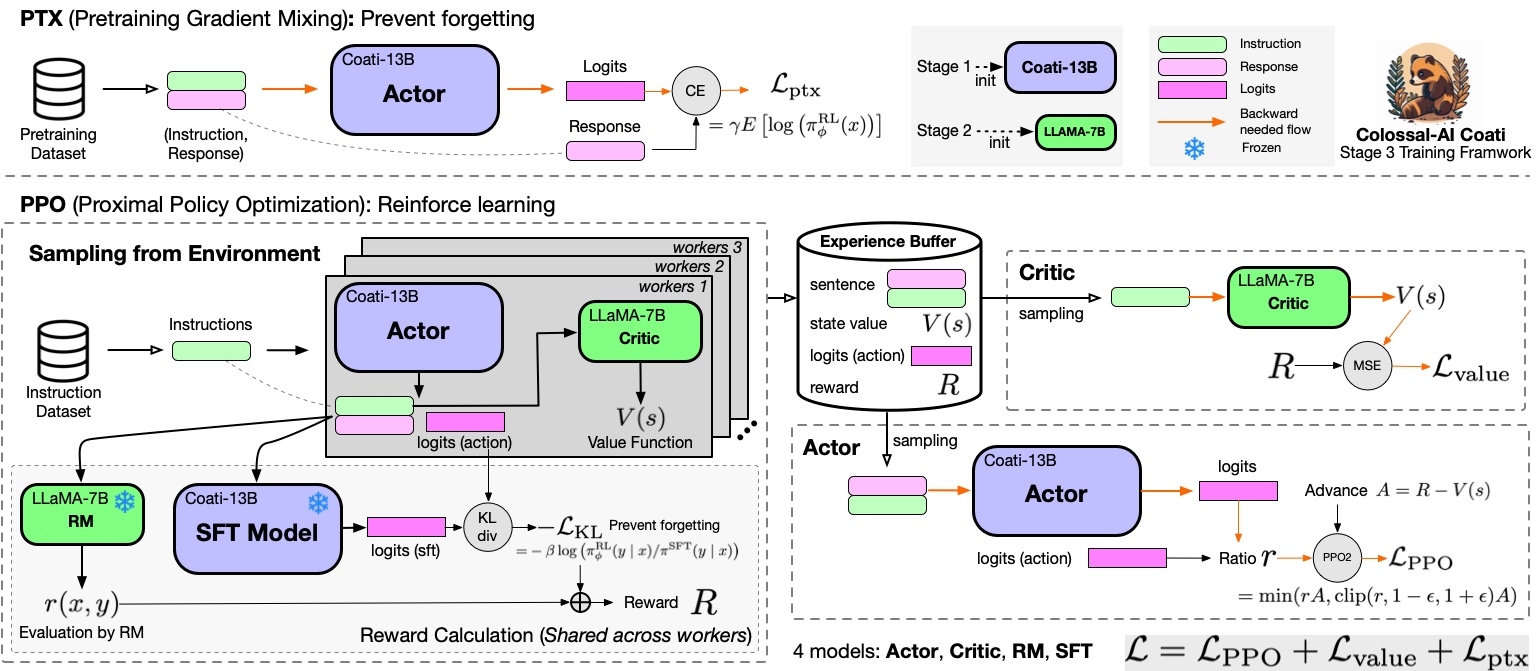
Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process:
@@ -151,63 +125,16 @@ Stage3 uses reinforcement learning algorithm, which is the most complex part of
-### Stage1 - Supervised instructs tuning
+### RLHF Training Stage1 - Supervised instructs tuning
-Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model
+Stage1 is supervised instructs fine-tuning, which uses the datasets mentioned earlier to fine-tune the model.
-you can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning
+You can run the `examples/train_sft.sh` to start a supervised instructs fine-tuning.
-```
-torchrun --standalone --nproc_per_node=4 train_sft.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --log_interval 10 \
- --save_path /path/to/Coati-7B \
- --dataset /path/to/data.json \
- --batch_size 4 \
- --accimulation_steps 8 \
- --lr 2e-5 \
- --max_datasets_size 512 \
- --max_epochs 1 \
-```
-
-### Stage2 - Training reward model
+### RLHF Training Stage2 - Training reward model
Stage2 trains a reward model, which obtains corresponding scores by manually ranking different outputs for the same prompt and supervises the training of the reward model
-you can run the `examples/train_rm.sh` to start a reward model training
-
-```
-torchrun --standalone --nproc_per_node=4 train_reward_model.py
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --loss_fn 'log_exp'\
- --save_path 'rmstatic.pt' \
-```
+You can run the `examples/train_rm.sh` to start a reward model training.
-### Stage3 - Training model with reinforcement learning by human feedback
+### RLHF Training Stage3 - Training model with reinforcement learning by human feedback
Stage3 uses reinforcement learning algorithm, which is the most complex part of the training process:
@@ -151,63 +125,16 @@ Stage3 uses reinforcement learning algorithm, which is the most complex part of
 -you can run the `examples/train_prompts.sh` to start training PPO with human feedback
-
-```
-torchrun --standalone --nproc_per_node=4 train_prompts.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --prompt_path /path/to/your/prompt_dataset \
- --pretrain_dataset /path/to/your/pretrain_dataset \
- --rm_pretrain /your/pretrain/rm/defination \
- --rm_path /your/rm/model/path
-```
+You can run the `examples/train_prompts.sh` to start training PPO with human feedback.
For more details, see [`examples/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples).
-### Inference - After Training
-#### 8-bit setup
-
-8-bit quantization is originally supported by the latest [transformers](https://github.com/huggingface/transformers). Please install it from source.
-
-Please ensure you have downloaded HF-format model weights of LLaMA models.
+### Inference Quantization and Serving - After Training
-Usage:
+We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
-```python
-from transformers import LlamaForCausalLM
-USE_8BIT = True # use 8-bit quantization; otherwise, use fp16
-model = LlamaForCausalLM.from_pretrained(
- "pretrained/path",
- load_in_8bit=USE_8BIT,
- torch_dtype=torch.float16,
- device_map="auto",
- )
-if not USE_8BIT:
- model.half() # use fp16
-model.eval()
-```
-
-**Troubleshooting**: if you get errors indicating your CUDA-related libraries are not found when loading the 8-bit model, you can check whether your `LD_LIBRARY_PATH` is correct.
-
-E.g. you can set `export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH`.
-
-#### 4-bit setup
-
-Please ensure you have downloaded the HF-format model weights of LLaMA models first.
-
-Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight conversion scripts.
-
-After installing this lib, we may convert the original HF-format LLaMA model weights to a 4-bit version.
-
-```shell
-CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4 --groupsize 128 --save llama7b-4bit.pt
-```
-
-Run this command in your cloned `GPTQ-for-LLaMa` directory, then you will get a 4-bit weight file `llama7b-4bit-128g.pt`.
-
-**Troubleshooting**: if you get errors about `position_ids`, you can checkout to commit `50287c3b9ae4a3b66f6b5127c643ec39b769b155`(`GPTQ-for-LLaMa` repo).
+We support 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inference. You can
+Online inference server scripts can help you deploy your own services.
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
@@ -283,24 +210,27 @@ For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tre
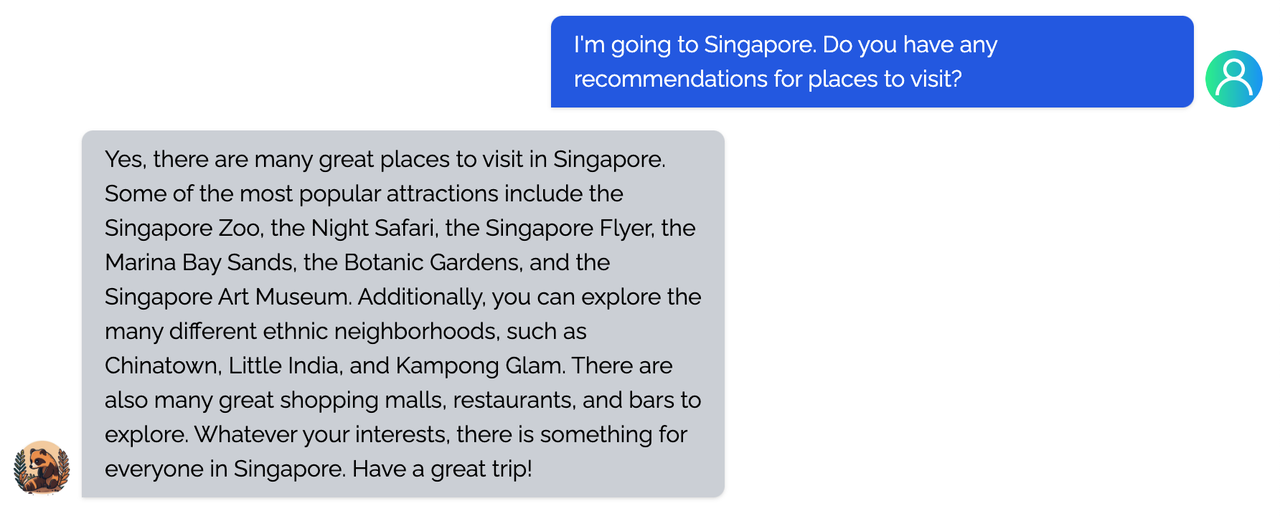
You can find more examples in this [repo](https://github.com/XueFuzhao/InstructionWild/blob/main/comparison.md).
-### Limitation for LLaMA-finetuned models
+### Limitation
+
+
+
-you can run the `examples/train_prompts.sh` to start training PPO with human feedback
-
-```
-torchrun --standalone --nproc_per_node=4 train_prompts.py \
- --pretrain "/path/to/LLaMa-7B/" \
- --model 'llama' \
- --strategy colossalai_zero2 \
- --prompt_path /path/to/your/prompt_dataset \
- --pretrain_dataset /path/to/your/pretrain_dataset \
- --rm_pretrain /your/pretrain/rm/defination \
- --rm_path /your/rm/model/path
-```
+You can run the `examples/train_prompts.sh` to start training PPO with human feedback.
For more details, see [`examples/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/examples).
-### Inference - After Training
-#### 8-bit setup
-
-8-bit quantization is originally supported by the latest [transformers](https://github.com/huggingface/transformers). Please install it from source.
-
-Please ensure you have downloaded HF-format model weights of LLaMA models.
+### Inference Quantization and Serving - After Training
-Usage:
+We provide an online inference server and a benchmark. We aim to run inference on single GPU, so quantization is essential when using large models.
-```python
-from transformers import LlamaForCausalLM
-USE_8BIT = True # use 8-bit quantization; otherwise, use fp16
-model = LlamaForCausalLM.from_pretrained(
- "pretrained/path",
- load_in_8bit=USE_8BIT,
- torch_dtype=torch.float16,
- device_map="auto",
- )
-if not USE_8BIT:
- model.half() # use fp16
-model.eval()
-```
-
-**Troubleshooting**: if you get errors indicating your CUDA-related libraries are not found when loading the 8-bit model, you can check whether your `LD_LIBRARY_PATH` is correct.
-
-E.g. you can set `export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH`.
-
-#### 4-bit setup
-
-Please ensure you have downloaded the HF-format model weights of LLaMA models first.
-
-Then you can follow [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa). This lib provides efficient CUDA kernels and weight conversion scripts.
-
-After installing this lib, we may convert the original HF-format LLaMA model weights to a 4-bit version.
-
-```shell
-CUDA_VISIBLE_DEVICES=0 python llama.py /path/to/pretrained/llama-7b c4 --wbits 4 --groupsize 128 --save llama7b-4bit.pt
-```
-
-Run this command in your cloned `GPTQ-for-LLaMa` directory, then you will get a 4-bit weight file `llama7b-4bit-128g.pt`.
-
-**Troubleshooting**: if you get errors about `position_ids`, you can checkout to commit `50287c3b9ae4a3b66f6b5127c643ec39b769b155`(`GPTQ-for-LLaMa` repo).
+We support 8-bit quantization (RTN), 4-bit quantization (GPTQ), and FP16 inference. You can
+Online inference server scripts can help you deploy your own services.
For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat/inference).
@@ -283,24 +210,27 @@ For more details, see [`inference/`](https://github.com/hpcaitech/ColossalAI/tre
You can find more examples in this [repo](https://github.com/XueFuzhao/InstructionWild/blob/main/comparison.md).
-### Limitation for LLaMA-finetuned models
+### Limitation
+
+
+
