mirror of https://github.com/hpcaitech/ColossalAI
[Inference] First PR for rebuild colossal-infer (#5143)
* add engine and scheduler * add dirs --------- Co-authored-by: CjhHa1 <cjh18671720497outlook.com>pull/5258/head
parent
c174c4fc5f
commit
4cf4682e70
|
|
@ -1,229 +0,0 @@
|
|||
# 🚀 Colossal-Inference
|
||||
|
||||
|
||||
## Table of Contents
|
||||
|
||||
- [💡 Introduction](#introduction)
|
||||
- [🔗 Design](#design)
|
||||
- [🔨 Usage](#usage)
|
||||
- [Quick start](#quick-start)
|
||||
- [Example](#example)
|
||||
- [📊 Performance](#performance)
|
||||
|
||||
## Introduction
|
||||
|
||||
`Colossal Inference` is a module that contains colossal-ai designed inference framework, featuring high performance, steady and easy usability. `Colossal Inference` incorporated the advantages of the latest open-source inference systems, including LightLLM, TGI, vLLM, FasterTransformer and flash attention. while combining the design of Colossal AI, especially Shardformer, to reduce the learning curve for users.
|
||||
|
||||
## Design
|
||||
|
||||
Colossal Inference is composed of three main components:
|
||||
|
||||
1. High performance kernels and ops: which are inspired from existing libraries and modified correspondingly.
|
||||
2. Efficient memory management mechanism:which includes the key-value cache manager, allowing for zero memory waste during inference.
|
||||
1. `cache manager`: serves as a memory manager to help manage the key-value cache, it integrates functions such as memory allocation, indexing and release.
|
||||
2. `batch_infer_info`: holds all essential elements of a batch inference, which is updated every batch.
|
||||
3. High-level inference engine combined with `Shardformer`: it allows our inference framework to easily invoke and utilize various parallel methods.
|
||||
1. `HybridEngine`: it is a high level interface that integrates with shardformer, especially for multi-card (tensor parallel, pipline parallel) inference:
|
||||
2. `modeling.llama.LlamaInferenceForwards`: contains the `forward` methods for llama inference. (in this case : llama)
|
||||
3. `policies.llama.LlamaModelInferPolicy` : contains the policies for `llama` models, which is used to call `shardformer` and segmentate the model forward in tensor parallelism way.
|
||||
|
||||
|
||||
## Architecture of inference:
|
||||
|
||||
In this section we discuss how the colossal inference works and integrates with the `Shardformer` . The details can be found in our codes.
|
||||
|
||||
<img src="https://raw.githubusercontent.com/hpcaitech/public_assets/main/colossalai/img/inference/inference-arch.png" alt="Colossal-Inference" style="zoom: 33%;"/>
|
||||
|
||||
## Roadmap of our implementation
|
||||
|
||||
- [x] Design cache manager and batch infer state
|
||||
- [x] Design TpInference engine to integrates with `Shardformer`
|
||||
- [x] Register corresponding high-performance `kernel` and `ops`
|
||||
- [x] Design policies and forwards (e.g. `Llama` and `Bloom`)
|
||||
- [x] policy
|
||||
- [x] context forward
|
||||
- [x] token forward
|
||||
- [x] support flash-decoding
|
||||
- [x] Support all models
|
||||
- [x] Llama
|
||||
- [x] Llama-2
|
||||
- [x] Bloom
|
||||
- [x] Chatglm2
|
||||
- [x] Quantization
|
||||
- [x] GPTQ
|
||||
- [x] SmoothQuant
|
||||
- [ ] Benchmarking for all models
|
||||
|
||||
## Get started
|
||||
|
||||
### Installation
|
||||
|
||||
```bash
|
||||
pip install -e .
|
||||
```
|
||||
|
||||
### Requirements
|
||||
|
||||
Install dependencies.
|
||||
|
||||
```bash
|
||||
pip install -r requirements/requirements-infer.txt
|
||||
|
||||
# if you want use smoothquant quantization, please install torch-int
|
||||
git clone --recurse-submodules https://github.com/Guangxuan-Xiao/torch-int.git
|
||||
cd torch-int
|
||||
git checkout 65266db1eadba5ca78941b789803929e6e6c6856
|
||||
pip install -r requirements.txt
|
||||
source environment.sh
|
||||
bash build_cutlass.sh
|
||||
python setup.py install
|
||||
```
|
||||
|
||||
### Docker
|
||||
|
||||
You can use docker run to use docker container to set-up environment
|
||||
|
||||
```
|
||||
# env: python==3.8, cuda 11.6, pytorch == 1.13.1 triton==2.0.0.dev20221202, vllm kernels support, flash-attention-2 kernels support
|
||||
docker pull hpcaitech/colossalai-inference:v2
|
||||
docker run -it --gpus all --name ANY_NAME -v $PWD:/workspace -w /workspace hpcaitech/colossalai-inference:v2 /bin/bash
|
||||
|
||||
# enter into docker container
|
||||
cd /path/to/CollossalAI
|
||||
pip install -e .
|
||||
|
||||
```
|
||||
|
||||
## Usage
|
||||
### Quick start
|
||||
|
||||
example files are in
|
||||
|
||||
```bash
|
||||
cd ColossalAI/examples
|
||||
python hybrid_llama.py --path /path/to/model --tp_size 2 --pp_size 2 --batch_size 4 --max_input_size 32 --max_out_len 16 --micro_batch_size 2
|
||||
```
|
||||
|
||||
|
||||
|
||||
### Example
|
||||
```python
|
||||
# import module
|
||||
from colossalai.inference import CaiInferEngine
|
||||
import colossalai
|
||||
from transformers import LlamaForCausalLM, LlamaTokenizer
|
||||
|
||||
#launch distributed environment
|
||||
colossalai.launch_from_torch(config={})
|
||||
|
||||
# load original model and tokenizer
|
||||
model = LlamaForCausalLM.from_pretrained("/path/to/model")
|
||||
tokenizer = LlamaTokenizer.from_pretrained("/path/to/model")
|
||||
|
||||
# generate token ids
|
||||
input = ["Introduce a landmark in London","Introduce a landmark in Singapore"]
|
||||
data = tokenizer(input, return_tensors='pt')
|
||||
|
||||
# set parallel parameters
|
||||
tp_size=2
|
||||
pp_size=2
|
||||
max_output_len=32
|
||||
micro_batch_size=1
|
||||
|
||||
# initial inference engine
|
||||
engine = CaiInferEngine(
|
||||
tp_size=tp_size,
|
||||
pp_size=pp_size,
|
||||
model=model,
|
||||
max_output_len=max_output_len,
|
||||
micro_batch_size=micro_batch_size,
|
||||
)
|
||||
|
||||
# inference
|
||||
output = engine.generate(data)
|
||||
|
||||
# get results
|
||||
if dist.get_rank() == 0:
|
||||
assert len(output[0]) == max_output_len, f"{len(output)}, {max_output_len}"
|
||||
|
||||
```
|
||||
|
||||
## Performance
|
||||
|
||||
### environment:
|
||||
|
||||
We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `colossal-inference` and original `hugging-face torch fp16`.
|
||||
|
||||
For various models, experiments were conducted using multiple batch sizes under the consistent model configuration of `7 billion(7b)` parameters, `1024` input length, and 128 output length. The obtained results are as follows (due to time constraints, the evaluation has currently been performed solely on the `A100` single GPU performance; multi-GPU performance will be addressed in the future):
|
||||
|
||||
### Single GPU Performance:
|
||||
|
||||
Currently the stats below are calculated based on A100 (single GPU), and we calculate token latency based on average values of context-forward and decoding forward process, which means we combine both of processes to calculate token generation times. We are actively developing new features and methods to further optimize the performance of LLM models. Please stay tuned.
|
||||
|
||||
### Tensor Parallelism Inference
|
||||
|
||||
##### Llama
|
||||
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :---------------------: | :----: | :----: | :----: |
|
||||
| hugging-face torch fp16 | 199.12 | 246.56 | 278.4 |
|
||||
| colossal-inference | 326.4 | 582.72 | 816.64 |
|
||||
|
||||
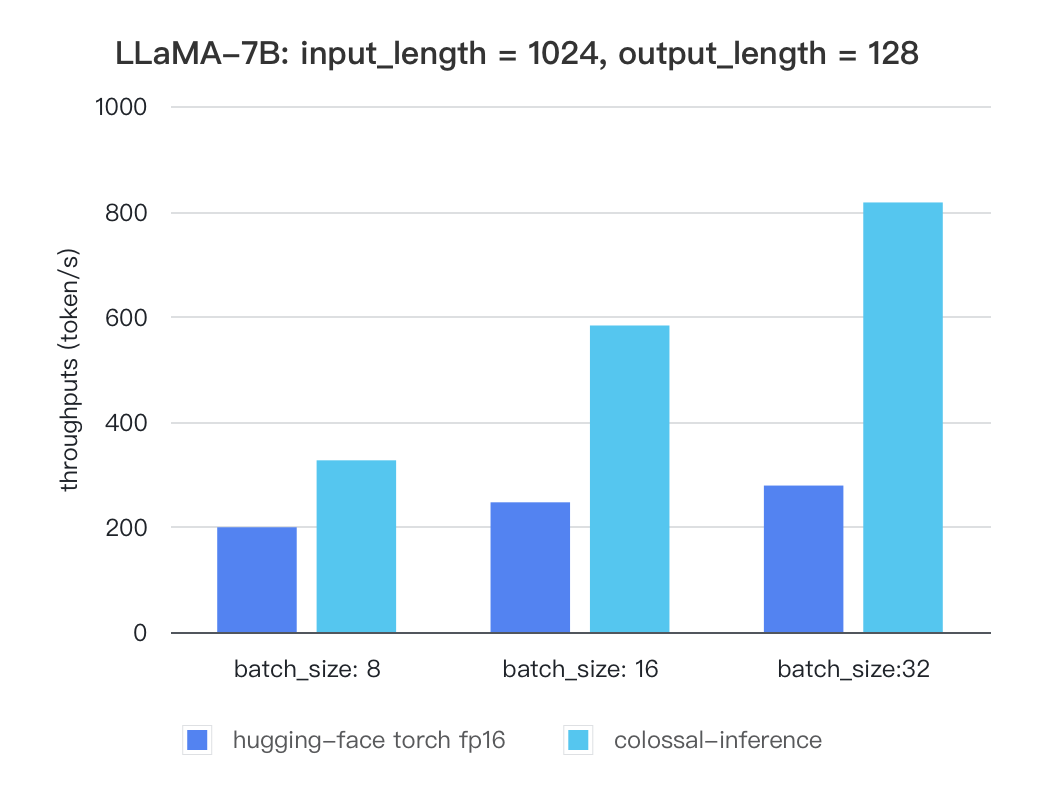
|
||||
|
||||
#### Bloom
|
||||
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :---------------------: | :----: | :----: | :----: |
|
||||
| hugging-face torch fp16 | 189.68 | 226.66 | 249.61 |
|
||||
| colossal-inference | 323.28 | 538.52 | 611.64 |
|
||||
|
||||
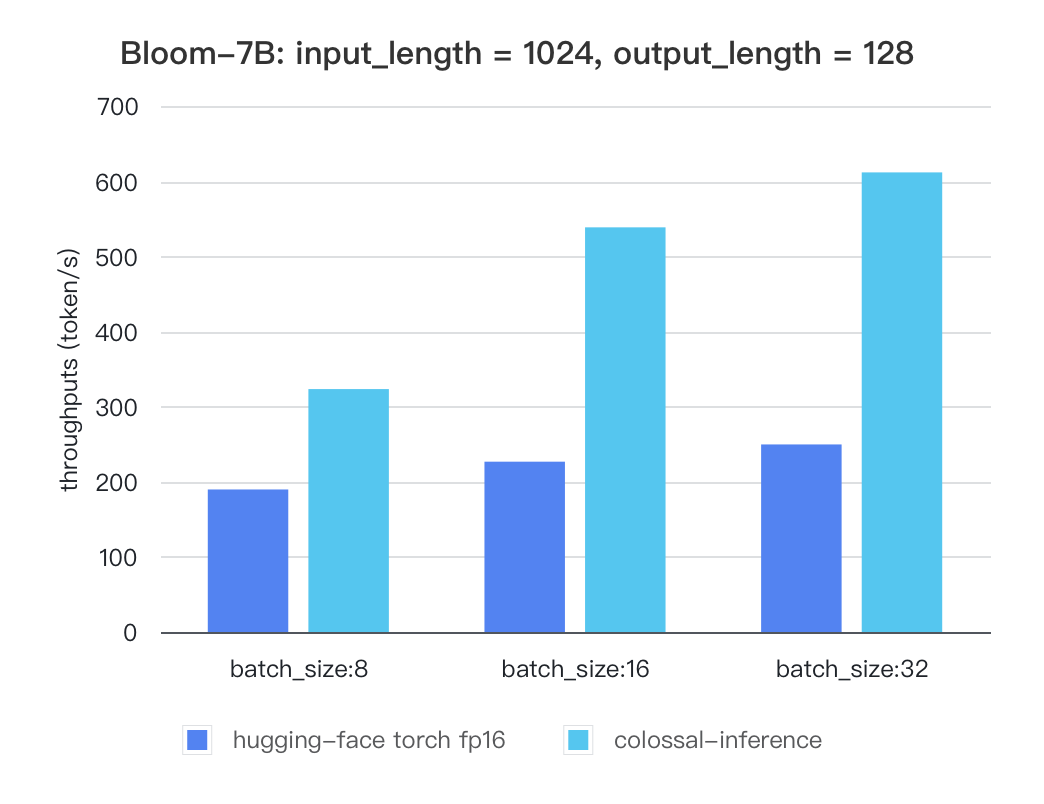
|
||||
|
||||
|
||||
### Pipline Parallelism Inference
|
||||
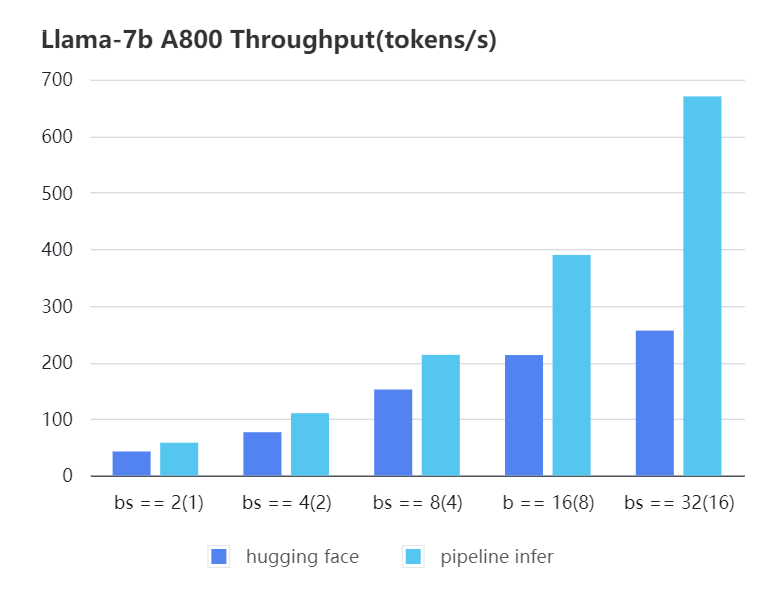
We conducted multiple benchmark tests to evaluate the performance. We compared the inference `latency` and `throughputs` between `Pipeline Inference` and `hugging face` pipeline. The test environment is 2 * A10, 20G / 2 * A800, 80G. We set input length=1024, output length=128.
|
||||
|
||||
|
||||
#### A10 7b, fp16
|
||||
|
||||
| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(8) | 32(8) | 32(16)|
|
||||
| :-------------------------: | :---: | :---:| :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference | 40.35 | 77.10| 139.03| 232.70| 257.81| OOM |
|
||||
| Hugging Face | 41.43 | 65.30| 91.93 | 114.62| OOM | OOM |
|
||||
|
||||
|
||||
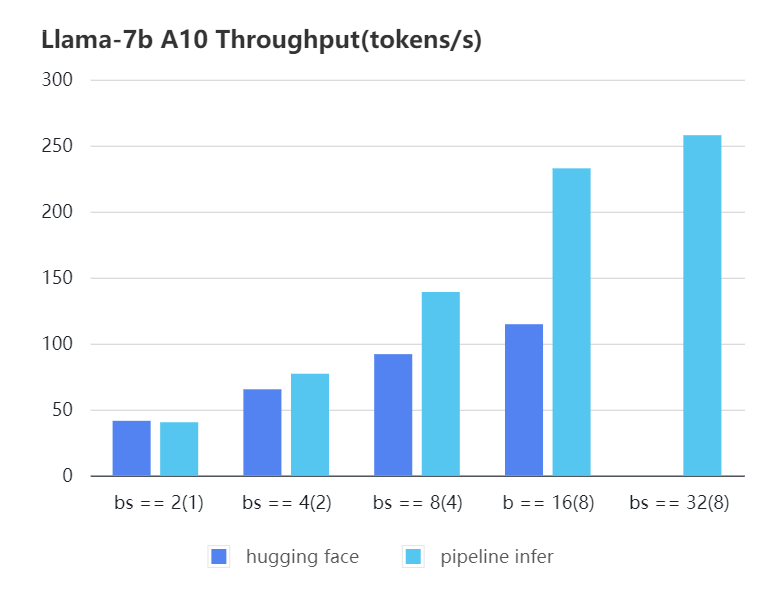
|
||||
|
||||
#### A10 13b, fp16
|
||||
|
||||
| batch_size(micro_batch size)| 2(1) | 4(2) | 8(4) | 16(4) |
|
||||
| :---: | :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference | 25.39 | 47.09 | 83.7 | 89.46 |
|
||||
| Hugging Face | 23.48 | 37.59 | 53.44 | OOM |
|
||||
|
||||
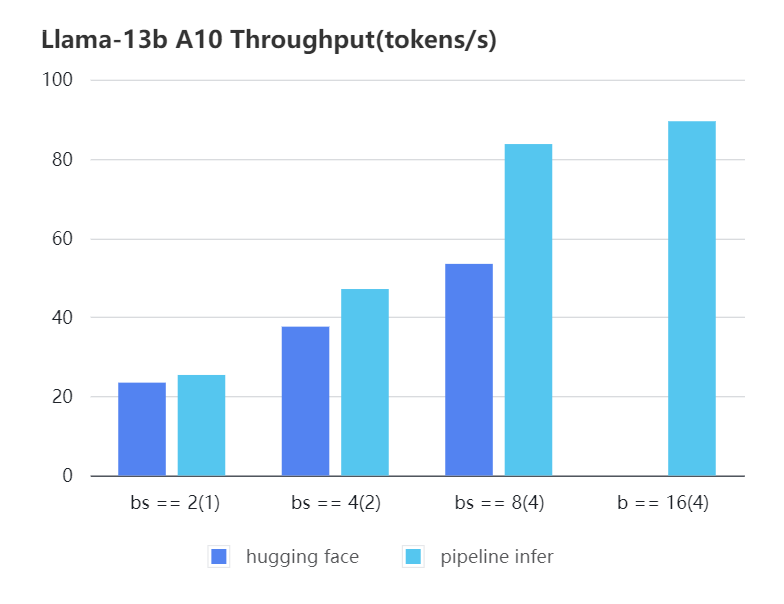
|
||||
|
||||
|
||||
#### A800 7b, fp16
|
||||
|
||||
| batch_size(micro_batch size) | 2(1) | 4(2) | 8(4) | 16(8) | 32(16) |
|
||||
| :---: | :---: | :---: | :---: | :---: | :---: |
|
||||
| Pipeline Inference| 57.97 | 110.13 | 213.33 | 389.86 | 670.12 |
|
||||
| Hugging Face | 42.44 | 76.5 | 151.97 | 212.88 | 256.13 |
|
||||
|
||||
|
||||
|
||||
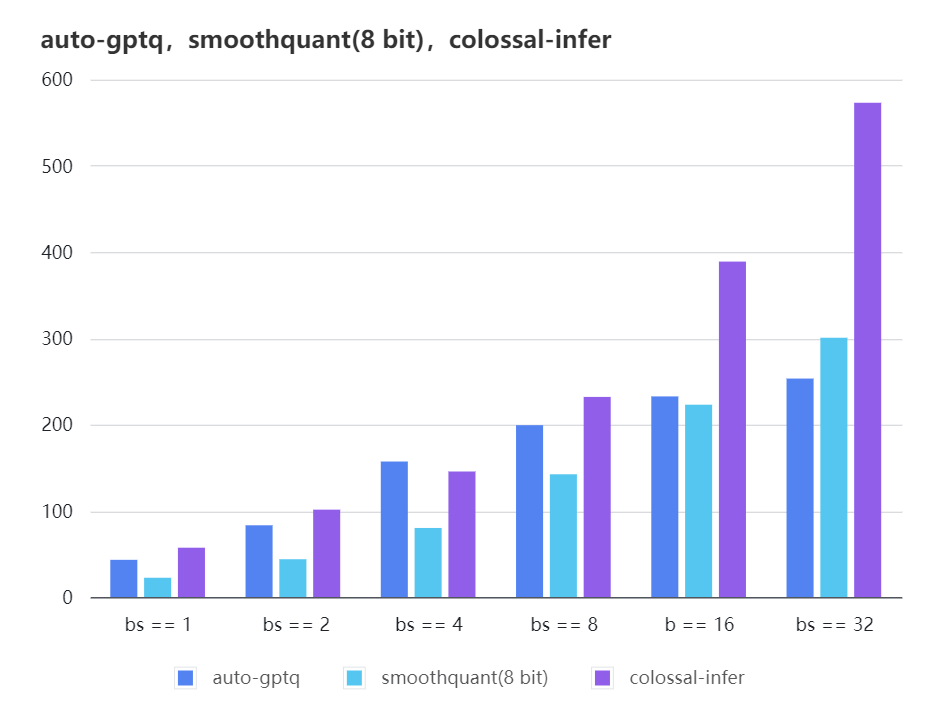
### Quantization LLama
|
||||
|
||||
| batch_size | 8 | 16 | 32 |
|
||||
| :---------------------: | :----: | :----: | :----: |
|
||||
| auto-gptq | 199.20 | 232.56 | 253.26 |
|
||||
| smooth-quant | 142.28 | 222.96 | 300.59 |
|
||||
| colossal-gptq | 231.98 | 388.87 | 573.03 |
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
The results of more models are coming soon!
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
from .engine import InferenceEngine
|
||||
from .engine.policies import BloomModelInferPolicy, ChatGLM2InferPolicy, LlamaModelInferPolicy
|
||||
|
||||
__all__ = ["InferenceEngine", "LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy"]
|
||||
|
|
@ -0,0 +1,73 @@
|
|||
from logging import Logger
|
||||
from typing import Optional
|
||||
|
||||
from .request_handler import RequestHandler
|
||||
|
||||
|
||||
class InferEngine:
|
||||
"""
|
||||
InferEngine is the core component for Inference.
|
||||
|
||||
It is responsible for launch the inference process, including:
|
||||
- Initialize model and distributed training environment(if needed)
|
||||
- Launch request_handler and corresponding kv cache manager
|
||||
- Receive requests and generate texts.
|
||||
- Log the generation process
|
||||
|
||||
Args:
|
||||
colossal_config: We provide a unified config api for that wrapped all the configs. You can use it to replace the below configs.
|
||||
model_config : The configuration for the model.
|
||||
parallel_config: The configuration for parallelize model.
|
||||
cache_config : Configuration for initialize and manage kv cache.
|
||||
tokenizer (Tokenizer): The tokenizer to be used for inference.
|
||||
use_logger (bool): Determine whether or not to log the generation process.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
model_config,
|
||||
cache_config,
|
||||
parallel_config,
|
||||
tokenizer,
|
||||
use_logger: bool = False,
|
||||
colossal_config: Optional["ColossalInferConfig"] = None,
|
||||
) -> None:
|
||||
assert colossal_config or (
|
||||
model_config and cache_config and parallel_config
|
||||
), "Please provide colossal_config or model_config, cache_config, parallel_config"
|
||||
if colossal_config:
|
||||
model_config, cache_config, parallel_config = colossal_config
|
||||
|
||||
self.model_config = model_config
|
||||
self.cache_config = cache_config
|
||||
self.parallel_config = parallel_config
|
||||
self._verify_config()
|
||||
|
||||
self._init_model()
|
||||
self.request_handler = RequestHandler(cache_config)
|
||||
if use_logger:
|
||||
self.logger = Logger()
|
||||
|
||||
def _init_model(self):
|
||||
"""
|
||||
Initialize model and distributed training environment(if needed).
|
||||
May need to provide two different initialization methods:
|
||||
1. 用户自定义(from local path)
|
||||
2. 从checkpoint加载(hugging face)
|
||||
"""
|
||||
|
||||
def _verify_config(self):
|
||||
"""
|
||||
Verify the configuration to avoid potential bugs.
|
||||
"""
|
||||
|
||||
def generate(self):
|
||||
pass
|
||||
|
||||
def step(self):
|
||||
"""
|
||||
In each step, do the follows:
|
||||
1. Run request_handler to update the kv cache and running input_ids
|
||||
2. Run model to generate the next token
|
||||
3. Check whether there is finied request and decode
|
||||
"""
|
||||
|
|
@ -0,0 +1,10 @@
|
|||
class RequestHandler:
|
||||
def __init__(self, cache_config) -> None:
|
||||
self.cache_config = cache_config
|
||||
self._init_cache()
|
||||
|
||||
def _init_cache(self):
|
||||
pass
|
||||
|
||||
def schedule(self, request):
|
||||
pass
|
||||
|
|
@ -1,3 +0,0 @@
|
|||
from .engine import InferenceEngine
|
||||
|
||||
__all__ = ["InferenceEngine"]
|
||||
|
|
@ -1,195 +0,0 @@
|
|||
from typing import Union
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.nn as nn
|
||||
from transformers.utils import logging
|
||||
|
||||
from colossalai.cluster import ProcessGroupMesh
|
||||
from colossalai.pipeline.schedule.generate import GenerateSchedule
|
||||
from colossalai.pipeline.stage_manager import PipelineStageManager
|
||||
from colossalai.shardformer import ShardConfig, ShardFormer
|
||||
from colossalai.shardformer.policies.base_policy import Policy
|
||||
|
||||
from ..kv_cache import MemoryManager
|
||||
from .microbatch_manager import MicroBatchManager
|
||||
from .policies import model_policy_map
|
||||
|
||||
PP_AXIS, TP_AXIS = 0, 1
|
||||
|
||||
_supported_models = [
|
||||
"LlamaForCausalLM",
|
||||
"BloomForCausalLM",
|
||||
"LlamaGPTQForCausalLM",
|
||||
"SmoothLlamaForCausalLM",
|
||||
"ChatGLMForConditionalGeneration",
|
||||
]
|
||||
|
||||
|
||||
class InferenceEngine:
|
||||
"""
|
||||
InferenceEngine is a class that handles the pipeline parallel inference.
|
||||
|
||||
Args:
|
||||
tp_size (int): the size of tensor parallelism.
|
||||
pp_size (int): the size of pipeline parallelism.
|
||||
dtype (str): the data type of the model, should be one of 'fp16', 'fp32', 'bf16'.
|
||||
model (`nn.Module`): the model not in pipeline style, and will be modified with `ShardFormer`.
|
||||
model_policy (`colossalai.shardformer.policies.base_policy.Policy`): the policy to shardformer model. It will be determined by the model type if not provided.
|
||||
micro_batch_size (int): the micro batch size. Only useful when `pp_size` > 1.
|
||||
micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
|
||||
max_batch_size (int): the maximum batch size.
|
||||
max_input_len (int): the maximum input length.
|
||||
max_output_len (int): the maximum output length.
|
||||
quant (str): the quantization method, should be one of 'smoothquant', 'gptq', None.
|
||||
verbose (bool): whether to return the time cost of each step.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
tp_size: int = 1,
|
||||
pp_size: int = 1,
|
||||
dtype: str = "fp16",
|
||||
model: nn.Module = None,
|
||||
model_policy: Policy = None,
|
||||
micro_batch_size: int = 1,
|
||||
micro_batch_buffer_size: int = None,
|
||||
max_batch_size: int = 4,
|
||||
max_input_len: int = 32,
|
||||
max_output_len: int = 32,
|
||||
quant: str = None,
|
||||
verbose: bool = False,
|
||||
# TODO: implement early_stopping, and various gerneration options
|
||||
early_stopping: bool = False,
|
||||
do_sample: bool = False,
|
||||
num_beams: int = 1,
|
||||
) -> None:
|
||||
if quant == "gptq":
|
||||
from ..quant.gptq import GPTQManager
|
||||
|
||||
self.gptq_manager = GPTQManager(model.quantize_config, max_input_len=max_input_len)
|
||||
model = model.model
|
||||
elif quant == "smoothquant":
|
||||
model = model.model
|
||||
|
||||
assert model.__class__.__name__ in _supported_models, f"Model {model.__class__.__name__} is not supported."
|
||||
assert (
|
||||
tp_size * pp_size == dist.get_world_size()
|
||||
), f"TP size({tp_size}) * PP size({pp_size}) should be equal to the global world size ({dist.get_world_size()})"
|
||||
assert model, "Model should be provided."
|
||||
assert dtype in ["fp16", "fp32", "bf16"], "dtype should be one of 'fp16', 'fp32', 'bf16'"
|
||||
|
||||
assert max_batch_size <= 64, "Max batch size exceeds the constraint"
|
||||
assert max_input_len + max_output_len <= 4096, "Max length exceeds the constraint"
|
||||
assert quant in ["smoothquant", "gptq", None], "quant should be one of 'smoothquant', 'gptq'"
|
||||
self.pp_size = pp_size
|
||||
self.tp_size = tp_size
|
||||
self.quant = quant
|
||||
|
||||
logger = logging.get_logger(__name__)
|
||||
if quant == "smoothquant" and dtype != "fp32":
|
||||
dtype = "fp32"
|
||||
logger.warning_once("Warning: smoothquant only support fp32 and int8 mix precision. set dtype to fp32")
|
||||
|
||||
if dtype == "fp16":
|
||||
self.dtype = torch.float16
|
||||
model.half()
|
||||
elif dtype == "bf16":
|
||||
self.dtype = torch.bfloat16
|
||||
model.to(torch.bfloat16)
|
||||
else:
|
||||
self.dtype = torch.float32
|
||||
|
||||
if model_policy is None:
|
||||
model_policy = model_policy_map[model.config.model_type]()
|
||||
|
||||
# Init pg mesh
|
||||
pg_mesh = ProcessGroupMesh(pp_size, tp_size)
|
||||
|
||||
stage_manager = PipelineStageManager(pg_mesh, PP_AXIS, True if pp_size * tp_size > 1 else False)
|
||||
self.cache_manager_list = [
|
||||
self._init_manager(model, max_batch_size, max_input_len, max_output_len)
|
||||
for _ in range(micro_batch_buffer_size or pp_size)
|
||||
]
|
||||
self.mb_manager = MicroBatchManager(
|
||||
stage_manager.stage,
|
||||
micro_batch_size,
|
||||
micro_batch_buffer_size or pp_size,
|
||||
max_input_len,
|
||||
max_output_len,
|
||||
self.cache_manager_list,
|
||||
)
|
||||
self.verbose = verbose
|
||||
self.schedule = GenerateSchedule(stage_manager, self.mb_manager, verbose)
|
||||
|
||||
self.model = self._shardformer(
|
||||
model, model_policy, stage_manager, pg_mesh.get_group_along_axis(TP_AXIS) if pp_size * tp_size > 1 else None
|
||||
)
|
||||
if quant == "gptq":
|
||||
self.gptq_manager.post_init_gptq_buffer(self.model)
|
||||
|
||||
def generate(self, input_list: Union[list, dict]):
|
||||
"""
|
||||
Args:
|
||||
input_list (list): a list of input data, each element is a `BatchEncoding` or `dict`.
|
||||
|
||||
Returns:
|
||||
out (list): a list of output data, each element is a list of token.
|
||||
timestamp (float): the time cost of the inference, only return when verbose is `True`.
|
||||
"""
|
||||
|
||||
out, timestamp = self.schedule.generate_step(self.model, iter([input_list]))
|
||||
if self.verbose:
|
||||
return out, timestamp
|
||||
else:
|
||||
return out
|
||||
|
||||
def _shardformer(self, model, model_policy, stage_manager, tp_group):
|
||||
shardconfig = ShardConfig(
|
||||
tensor_parallel_process_group=tp_group,
|
||||
pipeline_stage_manager=stage_manager,
|
||||
enable_tensor_parallelism=(self.tp_size > 1),
|
||||
enable_fused_normalization=False,
|
||||
enable_all_optimization=False,
|
||||
enable_flash_attention=False,
|
||||
enable_jit_fused=False,
|
||||
enable_sequence_parallelism=False,
|
||||
extra_kwargs={"quant": self.quant},
|
||||
)
|
||||
shardformer = ShardFormer(shard_config=shardconfig)
|
||||
shard_model, _ = shardformer.optimize(model, model_policy)
|
||||
return shard_model.cuda()
|
||||
|
||||
def _init_manager(self, model, max_batch_size: int, max_input_len: int, max_output_len: int) -> None:
|
||||
max_total_token_num = max_batch_size * (max_input_len + max_output_len)
|
||||
if model.config.model_type == "llama":
|
||||
head_dim = model.config.hidden_size // model.config.num_attention_heads
|
||||
head_num = model.config.num_key_value_heads // self.tp_size
|
||||
num_hidden_layers = (
|
||||
model.config.num_hidden_layers
|
||||
if hasattr(model.config, "num_hidden_layers")
|
||||
else model.config.num_layers
|
||||
)
|
||||
layer_num = num_hidden_layers // self.pp_size
|
||||
elif model.config.model_type == "bloom":
|
||||
head_dim = model.config.hidden_size // model.config.n_head
|
||||
head_num = model.config.n_head // self.tp_size
|
||||
num_hidden_layers = model.config.n_layer
|
||||
layer_num = num_hidden_layers // self.pp_size
|
||||
elif model.config.model_type == "chatglm":
|
||||
head_dim = model.config.hidden_size // model.config.num_attention_heads
|
||||
if model.config.multi_query_attention:
|
||||
head_num = model.config.multi_query_group_num // self.tp_size
|
||||
else:
|
||||
head_num = model.config.num_attention_heads // self.tp_size
|
||||
num_hidden_layers = model.config.num_layers
|
||||
layer_num = num_hidden_layers // self.pp_size
|
||||
else:
|
||||
raise NotImplementedError("Only support llama, bloom and chatglm model.")
|
||||
|
||||
if self.quant == "smoothquant":
|
||||
cache_manager = MemoryManager(max_total_token_num, torch.int8, head_num, head_dim, layer_num)
|
||||
else:
|
||||
cache_manager = MemoryManager(max_total_token_num, self.dtype, head_num, head_dim, layer_num)
|
||||
return cache_manager
|
||||
|
|
@ -1,248 +0,0 @@
|
|||
from enum import Enum
|
||||
from typing import Dict
|
||||
|
||||
import torch
|
||||
|
||||
from ..kv_cache import BatchInferState, MemoryManager
|
||||
|
||||
__all__ = "MicroBatchManager"
|
||||
|
||||
|
||||
class Status(Enum):
|
||||
PREFILL = 1
|
||||
GENERATE = 2
|
||||
DONE = 3
|
||||
COOLDOWN = 4
|
||||
|
||||
|
||||
class MicroBatchDescription:
|
||||
"""
|
||||
This is the class to record the infomation of each microbatch, and also do some update operation.
|
||||
This clase is the base class of `HeadMicroBatchDescription` and `BodyMicroBatchDescription`, for more
|
||||
details, please refer to the doc of these two classes blow.
|
||||
|
||||
Args:
|
||||
inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
|
||||
output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
inputs_dict: Dict[str, torch.Tensor],
|
||||
max_input_len: int,
|
||||
max_output_len: int,
|
||||
cache_manager: MemoryManager,
|
||||
) -> None:
|
||||
self.mb_length = inputs_dict["input_ids"].shape[-1]
|
||||
self.target_length = self.mb_length + max_output_len
|
||||
self.infer_state = BatchInferState.init_from_batch(
|
||||
batch=inputs_dict, max_input_len=max_input_len, max_output_len=max_output_len, cache_manager=cache_manager
|
||||
)
|
||||
# print(f"[init] {inputs_dict}, {max_input_len}, {max_output_len}, {cache_manager}, {self.infer_state}")
|
||||
|
||||
def update(self, *args, **kwargs):
|
||||
pass
|
||||
|
||||
@property
|
||||
def state(self):
|
||||
"""
|
||||
Return the state of current micro batch, when current length is equal to target length,
|
||||
the state is DONE, otherwise GENERATE
|
||||
|
||||
"""
|
||||
# TODO: add the condition for early stopping
|
||||
if self.cur_length == self.target_length:
|
||||
return Status.DONE
|
||||
elif self.cur_length == self.target_length - 1:
|
||||
return Status.COOLDOWN
|
||||
else:
|
||||
return Status.GENERATE
|
||||
|
||||
@property
|
||||
def cur_length(self):
|
||||
"""
|
||||
Return the current sequnence length of micro batch
|
||||
|
||||
"""
|
||||
|
||||
|
||||
class HeadMicroBatchDescription(MicroBatchDescription):
|
||||
"""
|
||||
This class is used to record the infomation of the first stage of pipeline, the first stage should have attributes `input_ids` and `attention_mask`
|
||||
and `new_tokens`, and the `new_tokens` is the tokens generated by the first stage. Also due to the schdule of pipeline, the operation to update the
|
||||
information and the condition to determine the state is different from other stages.
|
||||
|
||||
Args:
|
||||
inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
|
||||
output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
inputs_dict: Dict[str, torch.Tensor],
|
||||
max_input_len: int,
|
||||
max_output_len: int,
|
||||
cache_manager: MemoryManager,
|
||||
) -> None:
|
||||
super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
|
||||
assert inputs_dict is not None
|
||||
assert inputs_dict.get("input_ids") is not None and inputs_dict.get("attention_mask") is not None
|
||||
self.input_ids = inputs_dict["input_ids"]
|
||||
self.attn_mask = inputs_dict["attention_mask"]
|
||||
self.new_tokens = None
|
||||
|
||||
def update(self, new_token: torch.Tensor = None):
|
||||
if new_token is not None:
|
||||
self._update_newtokens(new_token)
|
||||
if self.state is not Status.DONE and new_token is not None:
|
||||
self._update_attnmask()
|
||||
|
||||
def _update_newtokens(self, new_token: torch.Tensor):
|
||||
if self.new_tokens is None:
|
||||
self.new_tokens = new_token
|
||||
else:
|
||||
self.new_tokens = torch.cat([self.new_tokens, new_token], dim=-1)
|
||||
|
||||
def _update_attnmask(self):
|
||||
self.attn_mask = torch.cat(
|
||||
(self.attn_mask, torch.ones((self.attn_mask.shape[0], 1), dtype=torch.int64, device="cuda")), dim=-1
|
||||
)
|
||||
|
||||
@property
|
||||
def cur_length(self):
|
||||
"""
|
||||
When there is no new_token, the length is mb_length, otherwise the sequence length is `mb_length` plus the length of new_token
|
||||
|
||||
"""
|
||||
if self.new_tokens is None:
|
||||
return self.mb_length
|
||||
else:
|
||||
return self.mb_length + len(self.new_tokens[0])
|
||||
|
||||
|
||||
class BodyMicroBatchDescription(MicroBatchDescription):
|
||||
"""
|
||||
This class is used to record the infomation of the stages except the first stage of pipeline, the stages should have attributes `hidden_states` and `past_key_values`,
|
||||
|
||||
Args:
|
||||
inputs_dict (Dict[str, torch.Tensor]): will always be `None`. Other stages only receive hiddenstates from previous stage.
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
inputs_dict: Dict[str, torch.Tensor],
|
||||
max_input_len: int,
|
||||
max_output_len: int,
|
||||
cache_manager: MemoryManager,
|
||||
) -> None:
|
||||
super().__init__(inputs_dict, max_input_len, max_output_len, cache_manager)
|
||||
|
||||
@property
|
||||
def cur_length(self):
|
||||
"""
|
||||
When there is no kv_cache, the length is mb_length, otherwise the sequence length is `kv_cache[0][0].shape[-2]` plus 1
|
||||
|
||||
"""
|
||||
return self.infer_state.seq_len.max().item()
|
||||
|
||||
|
||||
class MicroBatchManager:
|
||||
"""
|
||||
MicroBatchManager is a class that manages the micro batch.
|
||||
|
||||
Args:
|
||||
stage (int): stage id of current stage.
|
||||
micro_batch_size (int): the micro batch size.
|
||||
micro_batch_buffer_size (int): the buffer size for micro batch. Normally, it should be the same as the number of pipeline stages.
|
||||
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
stage: int,
|
||||
micro_batch_size: int,
|
||||
micro_batch_buffer_size: int,
|
||||
max_input_len: int,
|
||||
max_output_len: int,
|
||||
cache_manager_list: MemoryManager,
|
||||
):
|
||||
self.stage = stage
|
||||
self.micro_batch_size = micro_batch_size
|
||||
self.buffer_size = micro_batch_buffer_size
|
||||
self.max_input_len = max_input_len
|
||||
self.max_output_len = max_output_len
|
||||
self.cache_manager_list = cache_manager_list
|
||||
self.mb_descrption_buffer = {}
|
||||
self.new_tokens_buffer = {}
|
||||
self.idx = 0
|
||||
|
||||
def add_descrption(self, inputs_dict: Dict[str, torch.Tensor]):
|
||||
if self.stage == 0:
|
||||
self.mb_descrption_buffer[self.idx] = HeadMicroBatchDescription(
|
||||
inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
|
||||
)
|
||||
else:
|
||||
self.mb_descrption_buffer[self.idx] = BodyMicroBatchDescription(
|
||||
inputs_dict, self.max_input_len, self.max_output_len, self.cache_manager_list[self.idx]
|
||||
)
|
||||
|
||||
def step(self, new_token: torch.Tensor = None):
|
||||
"""
|
||||
Update the state if microbatch manager, 2 conditions.
|
||||
1. For first stage in PREFILL, receive inputs and outputs, `_add_descrption` will save its inputs.
|
||||
2. For other conditon, only receive the output of previous stage, and update the descrption.
|
||||
|
||||
Args:
|
||||
inputs_dict (Dict[str, torch.Tensor]): the inputs of current stage. The key should have `input_ids` and `attention_mask`.
|
||||
output_dict (Dict[str, torch.Tensor]): the outputs of previous stage. The key should have `hidden_states` and `past_key_values`.
|
||||
new_token (torch.Tensor): the new token generated by current stage.
|
||||
"""
|
||||
# Add descrption first if the descrption is None
|
||||
self.cur_descrption.update(new_token)
|
||||
return self.cur_state
|
||||
|
||||
def export_new_tokens(self):
|
||||
new_tokens_list = []
|
||||
for i in self.mb_descrption_buffer.values():
|
||||
new_tokens_list.extend(i.new_tokens.tolist())
|
||||
return new_tokens_list
|
||||
|
||||
def is_micro_batch_done(self):
|
||||
if len(self.mb_descrption_buffer) == 0:
|
||||
return False
|
||||
for mb in self.mb_descrption_buffer.values():
|
||||
if mb.state != Status.DONE:
|
||||
return False
|
||||
return True
|
||||
|
||||
def clear(self):
|
||||
self.mb_descrption_buffer.clear()
|
||||
for cache in self.cache_manager_list:
|
||||
cache.free_all()
|
||||
|
||||
def next(self):
|
||||
self.idx = (self.idx + 1) % self.buffer_size
|
||||
|
||||
def _remove_descrption(self):
|
||||
self.mb_descrption_buffer.pop(self.idx)
|
||||
|
||||
@property
|
||||
def cur_descrption(self) -> MicroBatchDescription:
|
||||
return self.mb_descrption_buffer.get(self.idx)
|
||||
|
||||
@property
|
||||
def cur_infer_state(self):
|
||||
if self.cur_descrption is None:
|
||||
return None
|
||||
return self.cur_descrption.infer_state
|
||||
|
||||
@property
|
||||
def cur_state(self):
|
||||
"""
|
||||
Return the state of current micro batch, when current descrption is None, the state is PREFILL
|
||||
|
||||
"""
|
||||
if self.cur_descrption is None:
|
||||
return Status.PREFILL
|
||||
return self.cur_descrption.state
|
||||
|
|
@ -1,5 +0,0 @@
|
|||
from .bloom import BloomInferenceForwards
|
||||
from .chatglm2 import ChatGLM2InferenceForwards
|
||||
from .llama import LlamaInferenceForwards
|
||||
|
||||
__all__ = ["LlamaInferenceForwards", "BloomInferenceForwards", "ChatGLM2InferenceForwards"]
|
||||
|
|
@ -1,67 +0,0 @@
|
|||
"""
|
||||
Utils for model inference
|
||||
"""
|
||||
import os
|
||||
|
||||
import torch
|
||||
|
||||
from colossalai.kernel.triton.copy_kv_cache_dest import copy_kv_cache_to_dest
|
||||
|
||||
|
||||
def copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
|
||||
"""
|
||||
This function copies the key and value cache to the memory cache
|
||||
Args:
|
||||
layer_id : id of current layer
|
||||
key_buffer : key cache
|
||||
value_buffer : value cache
|
||||
context_mem_index : index of memory cache in kv cache manager
|
||||
mem_manager : cache manager
|
||||
"""
|
||||
copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
|
||||
copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
|
||||
|
||||
|
||||
def init_to_get_rotary(self, base=10000, use_elem=False):
|
||||
"""
|
||||
This function initializes the rotary positional embedding, it is compatible for all models and is called in ShardFormer
|
||||
Args:
|
||||
self : Model that holds the rotary positional embedding
|
||||
base : calculation arg
|
||||
use_elem : activated when using chatglm-based models
|
||||
"""
|
||||
self.config.head_dim_ = self.config.hidden_size // self.config.num_attention_heads
|
||||
if not hasattr(self.config, "rope_scaling"):
|
||||
rope_scaling_factor = 1.0
|
||||
else:
|
||||
rope_scaling_factor = self.config.rope_scaling.factor if self.config.rope_scaling is not None else 1.0
|
||||
|
||||
if hasattr(self.config, "max_sequence_length"):
|
||||
max_seq_len = self.config.max_sequence_length
|
||||
elif hasattr(self.config, "max_position_embeddings"):
|
||||
max_seq_len = self.config.max_position_embeddings * rope_scaling_factor
|
||||
else:
|
||||
max_seq_len = 2048 * rope_scaling_factor
|
||||
base = float(base)
|
||||
|
||||
# NTK ref: https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
|
||||
ntk_alpha = os.environ.get("INFER_NTK_ALPHA", None)
|
||||
|
||||
if ntk_alpha is not None:
|
||||
ntk_alpha = float(ntk_alpha)
|
||||
assert ntk_alpha >= 1, "NTK alpha must be greater than or equal to 1"
|
||||
if ntk_alpha > 1:
|
||||
print(f"Note: NTK enabled, alpha set to {ntk_alpha}")
|
||||
max_seq_len *= ntk_alpha
|
||||
base = base * (ntk_alpha ** (self.head_dim_ / (self.head_dim_ - 2))) # Base change formula
|
||||
|
||||
n_elem = self.config.head_dim_
|
||||
if use_elem:
|
||||
n_elem //= 2
|
||||
|
||||
inv_freq = 1.0 / (base ** (torch.arange(0, n_elem, 2, device="cpu", dtype=torch.float32) / n_elem))
|
||||
t = torch.arange(max_seq_len + 1024 * 64, device="cpu", dtype=torch.float32) / rope_scaling_factor
|
||||
freqs = torch.outer(t, inv_freq)
|
||||
|
||||
self._cos_cached = torch.cos(freqs).to(torch.float16).cuda()
|
||||
self._sin_cached = torch.sin(freqs).to(torch.float16).cuda()
|
||||
|
|
@ -1,452 +0,0 @@
|
|||
import math
|
||||
import warnings
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
from torch.nn import functional as F
|
||||
from transformers.models.bloom.modeling_bloom import (
|
||||
BaseModelOutputWithPastAndCrossAttentions,
|
||||
BloomAttention,
|
||||
BloomBlock,
|
||||
BloomForCausalLM,
|
||||
BloomModel,
|
||||
)
|
||||
from transformers.utils import logging
|
||||
|
||||
from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
|
||||
from colossalai.kernel.triton import bloom_context_attn_fwd, copy_kv_cache_to_dest, token_attention_fwd
|
||||
from colossalai.pipeline.stage_manager import PipelineStageManager
|
||||
|
||||
try:
|
||||
from lightllm.models.bloom.triton_kernel.context_flashattention_nopad import (
|
||||
context_attention_fwd as lightllm_bloom_context_attention_fwd,
|
||||
)
|
||||
|
||||
HAS_LIGHTLLM_KERNEL = True
|
||||
except:
|
||||
HAS_LIGHTLLM_KERNEL = False
|
||||
|
||||
|
||||
def generate_alibi(n_head, dtype=torch.float16):
|
||||
"""
|
||||
This method is adapted from `_generate_alibi` function
|
||||
in `lightllm/models/bloom/layer_weights/transformer_layer_weight.py`
|
||||
of the ModelTC/lightllm GitHub repository.
|
||||
This method is originally the `build_alibi_tensor` function
|
||||
in `transformers/models/bloom/modeling_bloom.py`
|
||||
of the huggingface/transformers GitHub repository.
|
||||
"""
|
||||
|
||||
def get_slopes_power_of_2(n):
|
||||
start = 2 ** (-(2 ** -(math.log2(n) - 3)))
|
||||
return [start * start**i for i in range(n)]
|
||||
|
||||
def get_slopes(n):
|
||||
if math.log2(n).is_integer():
|
||||
return get_slopes_power_of_2(n)
|
||||
else:
|
||||
closest_power_of_2 = 2 ** math.floor(math.log2(n))
|
||||
slopes_power_of_2 = get_slopes_power_of_2(closest_power_of_2)
|
||||
slopes_double = get_slopes(2 * closest_power_of_2)
|
||||
slopes_combined = slopes_power_of_2 + slopes_double[0::2][: n - closest_power_of_2]
|
||||
return slopes_combined
|
||||
|
||||
slopes = get_slopes(n_head)
|
||||
return torch.tensor(slopes, dtype=dtype)
|
||||
|
||||
|
||||
class BloomInferenceForwards:
|
||||
"""
|
||||
This class serves a micro library for bloom inference forwards.
|
||||
We intend to replace the forward methods for BloomForCausalLM, BloomModel, BloomBlock, and BloomAttention,
|
||||
as well as prepare_inputs_for_generation method for BloomForCausalLM.
|
||||
For future improvement, we might want to skip replacing methods for BloomForCausalLM,
|
||||
and call BloomModel.forward iteratively in TpInferEngine
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def bloom_for_causal_lm_forward(
|
||||
self: BloomForCausalLM,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
head_mask: Optional[torch.Tensor] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
labels: Optional[torch.Tensor] = None,
|
||||
use_cache: Optional[bool] = False,
|
||||
output_attentions: Optional[bool] = False,
|
||||
output_hidden_states: Optional[bool] = False,
|
||||
return_dict: Optional[bool] = False,
|
||||
infer_state: BatchInferState = None,
|
||||
stage_manager: Optional[PipelineStageManager] = None,
|
||||
hidden_states: Optional[torch.FloatTensor] = None,
|
||||
stage_index: Optional[List[int]] = None,
|
||||
tp_group: Optional[dist.ProcessGroup] = None,
|
||||
**deprecated_arguments,
|
||||
):
|
||||
r"""
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
|
||||
`labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
|
||||
are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
|
||||
"""
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
if deprecated_arguments.pop("position_ids", False) is not False:
|
||||
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
|
||||
warnings.warn(
|
||||
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
|
||||
" passing `position_ids`.",
|
||||
FutureWarning,
|
||||
)
|
||||
|
||||
# TODO(jianghai): left the recording kv-value tensors as () or None type, this feature may be added in the future.
|
||||
if output_attentions:
|
||||
logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
|
||||
output_attentions = False
|
||||
if output_hidden_states:
|
||||
logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
|
||||
output_hidden_states = False
|
||||
|
||||
# If is first stage and hidden_states is not None, go throught lm_head first
|
||||
if stage_manager.is_first_stage() and hidden_states is not None:
|
||||
lm_logits = self.lm_head(hidden_states)
|
||||
return {"logits": lm_logits}
|
||||
|
||||
outputs = BloomInferenceForwards.bloom_model_forward(
|
||||
self.transformer,
|
||||
input_ids,
|
||||
past_key_values=past_key_values,
|
||||
attention_mask=attention_mask,
|
||||
head_mask=head_mask,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
infer_state=infer_state,
|
||||
stage_manager=stage_manager,
|
||||
hidden_states=hidden_states,
|
||||
stage_index=stage_index,
|
||||
tp_group=tp_group,
|
||||
)
|
||||
|
||||
return outputs
|
||||
|
||||
@staticmethod
|
||||
def bloom_model_forward(
|
||||
self: BloomModel,
|
||||
input_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
head_mask: Optional[torch.LongTensor] = None,
|
||||
inputs_embeds: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = False,
|
||||
return_dict: Optional[bool] = None,
|
||||
infer_state: BatchInferState = None,
|
||||
stage_manager: Optional[PipelineStageManager] = None,
|
||||
hidden_states: Optional[torch.FloatTensor] = None,
|
||||
stage_index: Optional[List[int]] = None,
|
||||
tp_group: Optional[dist.ProcessGroup] = None,
|
||||
**deprecated_arguments,
|
||||
) -> Union[Tuple[torch.Tensor, ...], BaseModelOutputWithPastAndCrossAttentions]:
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
# add warnings here
|
||||
if output_attentions:
|
||||
logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
|
||||
output_attentions = False
|
||||
if output_hidden_states:
|
||||
logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
|
||||
output_hidden_states = False
|
||||
if use_cache:
|
||||
logger.warning_once("use_cache=True is not supported for pipeline models at the moment.")
|
||||
use_cache = False
|
||||
|
||||
if deprecated_arguments.pop("position_ids", False) is not False:
|
||||
# `position_ids` could have been `torch.Tensor` or `None` so defaulting pop to `False` allows to detect if users were passing explicitly `None`
|
||||
warnings.warn(
|
||||
"`position_ids` have no functionality in BLOOM and will be removed in v5.0.0. You can safely ignore"
|
||||
" passing `position_ids`.",
|
||||
FutureWarning,
|
||||
)
|
||||
if len(deprecated_arguments) > 0:
|
||||
raise ValueError(f"Got unexpected arguments: {deprecated_arguments}")
|
||||
|
||||
# Prepare head mask if needed
|
||||
# 1.0 in head_mask indicate we keep the head
|
||||
# attention_probs has shape batch_size x num_heads x N x N
|
||||
# head_mask has shape n_layer x batch x num_heads x N x N
|
||||
head_mask = self.get_head_mask(head_mask, self.config.n_layer)
|
||||
|
||||
# first stage
|
||||
if stage_manager.is_first_stage():
|
||||
# check inputs and inputs embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size, seq_length = input_ids.shape
|
||||
elif inputs_embeds is not None:
|
||||
batch_size, seq_length, _ = inputs_embeds.shape
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.word_embeddings(input_ids)
|
||||
|
||||
hidden_states = self.word_embeddings_layernorm(inputs_embeds)
|
||||
# other stage
|
||||
else:
|
||||
input_shape = hidden_states.shape[:-1]
|
||||
batch_size, seq_length = input_shape
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
past_key_values_length = 0
|
||||
else:
|
||||
past_key_values_length = infer_state.max_len_in_batch - 1
|
||||
|
||||
if seq_length != 1:
|
||||
# prefill stage
|
||||
infer_state.is_context_stage = True # set prefill stage, notify attention layer
|
||||
infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
|
||||
BatchInferState.init_block_loc(
|
||||
infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
|
||||
)
|
||||
else:
|
||||
infer_state.is_context_stage = False
|
||||
alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
|
||||
if alloc_mem is not None:
|
||||
infer_state.decode_is_contiguous = True
|
||||
infer_state.decode_mem_index = alloc_mem[0]
|
||||
infer_state.decode_mem_start = alloc_mem[1]
|
||||
infer_state.decode_mem_end = alloc_mem[2]
|
||||
infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
|
||||
else:
|
||||
print(f" *** Encountered allocation non-contiguous")
|
||||
print(f" infer_state.max_len_in_batch : {infer_state.max_len_in_batch}")
|
||||
infer_state.decode_is_contiguous = False
|
||||
alloc_mem = infer_state.cache_manager.alloc(batch_size)
|
||||
infer_state.decode_mem_index = alloc_mem
|
||||
infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
|
||||
|
||||
if attention_mask is None:
|
||||
attention_mask = torch.ones((batch_size, infer_state.max_len_in_batch), device=hidden_states.device)
|
||||
else:
|
||||
attention_mask = attention_mask.to(hidden_states.device)
|
||||
|
||||
# NOTE revise: we might want to store a single 1D alibi(length is #heads) in model,
|
||||
# or store to BatchInferState to prevent re-calculating
|
||||
# When we have multiple process group (e.g. dp together with tp), we need to pass the pg to here
|
||||
tp_size = dist.get_world_size(tp_group) if tp_group is not None else 1
|
||||
curr_tp_rank = dist.get_rank(tp_group) if tp_group is not None else 0
|
||||
alibi = (
|
||||
generate_alibi(self.num_heads * tp_size)
|
||||
.contiguous()[curr_tp_rank * self.num_heads : (curr_tp_rank + 1) * self.num_heads]
|
||||
.cuda()
|
||||
)
|
||||
causal_mask = self._prepare_attn_mask(
|
||||
attention_mask,
|
||||
input_shape=(batch_size, seq_length),
|
||||
past_key_values_length=past_key_values_length,
|
||||
)
|
||||
|
||||
infer_state.decode_layer_id = 0
|
||||
|
||||
start_idx, end_idx = stage_index[0], stage_index[1]
|
||||
if past_key_values is None:
|
||||
past_key_values = tuple([None] * (end_idx - start_idx + 1))
|
||||
|
||||
for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
|
||||
block = self.h[idx]
|
||||
outputs = block(
|
||||
hidden_states,
|
||||
layer_past=past_key_value,
|
||||
attention_mask=causal_mask,
|
||||
head_mask=head_mask[idx],
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
alibi=alibi,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
|
||||
infer_state.decode_layer_id += 1
|
||||
hidden_states = outputs[0]
|
||||
|
||||
if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
|
||||
hidden_states = self.ln_f(hidden_states)
|
||||
|
||||
# update indices
|
||||
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
|
||||
infer_state.seq_len += 1
|
||||
infer_state.max_len_in_batch += 1
|
||||
|
||||
# always return dict for imediate stage
|
||||
return {"hidden_states": hidden_states}
|
||||
|
||||
@staticmethod
|
||||
def bloom_block_forward(
|
||||
self: BloomBlock,
|
||||
hidden_states: torch.Tensor,
|
||||
alibi: torch.Tensor,
|
||||
attention_mask: torch.Tensor,
|
||||
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
|
||||
head_mask: Optional[torch.Tensor] = None,
|
||||
use_cache: bool = False,
|
||||
output_attentions: bool = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
):
|
||||
# hidden_states: [batch_size, seq_length, hidden_size]
|
||||
|
||||
# Layer norm at the beginning of the transformer layer.
|
||||
layernorm_output = self.input_layernorm(hidden_states)
|
||||
|
||||
# Layer norm post the self attention.
|
||||
if self.apply_residual_connection_post_layernorm:
|
||||
residual = layernorm_output
|
||||
else:
|
||||
residual = hidden_states
|
||||
|
||||
# Self attention.
|
||||
attn_outputs = self.self_attention(
|
||||
layernorm_output,
|
||||
residual,
|
||||
layer_past=layer_past,
|
||||
attention_mask=attention_mask,
|
||||
alibi=alibi,
|
||||
head_mask=head_mask,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
|
||||
attention_output = attn_outputs[0]
|
||||
|
||||
outputs = attn_outputs[1:]
|
||||
|
||||
layernorm_output = self.post_attention_layernorm(attention_output)
|
||||
|
||||
# Get residual
|
||||
if self.apply_residual_connection_post_layernorm:
|
||||
residual = layernorm_output
|
||||
else:
|
||||
residual = attention_output
|
||||
|
||||
# MLP.
|
||||
output = self.mlp(layernorm_output, residual)
|
||||
|
||||
if use_cache:
|
||||
outputs = (output,) + outputs
|
||||
else:
|
||||
outputs = (output,) + outputs[1:]
|
||||
|
||||
return outputs # hidden_states, present, attentions
|
||||
|
||||
@staticmethod
|
||||
def bloom_attention_forward(
|
||||
self: BloomAttention,
|
||||
hidden_states: torch.Tensor,
|
||||
residual: torch.Tensor,
|
||||
alibi: torch.Tensor,
|
||||
attention_mask: torch.Tensor,
|
||||
layer_past: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
|
||||
head_mask: Optional[torch.Tensor] = None,
|
||||
use_cache: bool = False,
|
||||
output_attentions: bool = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
):
|
||||
fused_qkv = self.query_key_value(hidden_states) # [batch_size, seq_length, 3 x hidden_size]
|
||||
|
||||
# 3 x [batch_size, seq_length, num_heads, head_dim]
|
||||
(query_layer, key_layer, value_layer) = self._split_heads(fused_qkv)
|
||||
batch_size, q_length, H, D_HEAD = query_layer.shape
|
||||
k = key_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
|
||||
v = value_layer.reshape(-1, H, D_HEAD) # batch_size * q_length, H, D_HEAD, q_lenth == 1
|
||||
|
||||
mem_manager = infer_state.cache_manager
|
||||
layer_id = infer_state.decode_layer_id
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
# context process
|
||||
max_input_len = q_length
|
||||
b_start_loc = infer_state.start_loc
|
||||
b_seq_len = infer_state.seq_len[:batch_size]
|
||||
q = query_layer.reshape(-1, H, D_HEAD)
|
||||
|
||||
copy_kv_cache_to_dest(k, infer_state.context_mem_index, mem_manager.key_buffer[layer_id])
|
||||
copy_kv_cache_to_dest(v, infer_state.context_mem_index, mem_manager.value_buffer[layer_id])
|
||||
|
||||
# output = self.output[:batch_size*q_length, :, :]
|
||||
output = torch.empty_like(q)
|
||||
|
||||
if HAS_LIGHTLLM_KERNEL:
|
||||
lightllm_bloom_context_attention_fwd(q, k, v, output, alibi, b_start_loc, b_seq_len, max_input_len)
|
||||
else:
|
||||
bloom_context_attn_fwd(q, k, v, output, b_start_loc, b_seq_len, max_input_len, alibi)
|
||||
|
||||
context_layer = output.view(batch_size, q_length, H * D_HEAD)
|
||||
else:
|
||||
# query_layer = query_layer.transpose(1, 2).reshape(batch_size * self.num_heads, q_length, self.head_dim)
|
||||
# need shape: batch_size, H, D_HEAD (q_length == 1), input q shape : (batch_size, q_length(1), H, D_HEAD)
|
||||
assert q_length == 1, "for non-context process, we only support q_length == 1"
|
||||
q = query_layer.reshape(-1, H, D_HEAD)
|
||||
|
||||
if infer_state.decode_is_contiguous:
|
||||
# if decode is contiguous, then we copy to key cache and value cache in cache manager directly
|
||||
cache_k = infer_state.cache_manager.key_buffer[layer_id][
|
||||
infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
|
||||
]
|
||||
cache_v = infer_state.cache_manager.value_buffer[layer_id][
|
||||
infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
|
||||
]
|
||||
cache_k.copy_(k)
|
||||
cache_v.copy_(v)
|
||||
else:
|
||||
# if decode is not contiguous, use triton kernel to copy key and value cache
|
||||
# k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head]
|
||||
copy_kv_cache_to_dest(k, infer_state.decode_mem_index, mem_manager.key_buffer[layer_id])
|
||||
copy_kv_cache_to_dest(v, infer_state.decode_mem_index, mem_manager.value_buffer[layer_id])
|
||||
|
||||
b_start_loc = infer_state.start_loc
|
||||
b_loc = infer_state.block_loc
|
||||
b_seq_len = infer_state.seq_len
|
||||
output = torch.empty_like(q)
|
||||
token_attention_fwd(
|
||||
q,
|
||||
mem_manager.key_buffer[layer_id],
|
||||
mem_manager.value_buffer[layer_id],
|
||||
output,
|
||||
b_loc,
|
||||
b_start_loc,
|
||||
b_seq_len,
|
||||
infer_state.max_len_in_batch,
|
||||
alibi,
|
||||
)
|
||||
|
||||
context_layer = output.view(batch_size, q_length, H * D_HEAD)
|
||||
|
||||
# NOTE: always set present as none for now, instead of returning past key value to the next decoding,
|
||||
# we create the past key value pair from the cache manager
|
||||
present = None
|
||||
|
||||
# aggregate results across tp ranks. See here: https://github.com/pytorch/pytorch/issues/76232
|
||||
if self.pretraining_tp > 1 and self.slow_but_exact:
|
||||
slices = self.hidden_size / self.pretraining_tp
|
||||
output_tensor = torch.zeros_like(context_layer)
|
||||
for i in range(self.pretraining_tp):
|
||||
output_tensor = output_tensor + F.linear(
|
||||
context_layer[:, :, int(i * slices) : int((i + 1) * slices)],
|
||||
self.dense.weight[:, int(i * slices) : int((i + 1) * slices)],
|
||||
)
|
||||
else:
|
||||
output_tensor = self.dense(context_layer)
|
||||
|
||||
# dropout is not required here during inference
|
||||
output_tensor = residual + output_tensor
|
||||
|
||||
outputs = (output_tensor, present)
|
||||
assert output_attentions is False, "we do not support output_attentions at this time"
|
||||
|
||||
return outputs
|
||||
|
|
@ -1,492 +0,0 @@
|
|||
from typing import List, Optional, Tuple
|
||||
|
||||
import torch
|
||||
from transformers.utils import logging
|
||||
|
||||
from colossalai.inference.kv_cache import BatchInferState
|
||||
from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
|
||||
from colossalai.pipeline.stage_manager import PipelineStageManager
|
||||
from colossalai.shardformer import ShardConfig
|
||||
from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
|
||||
ChatGLMForConditionalGeneration,
|
||||
ChatGLMModel,
|
||||
GLMBlock,
|
||||
GLMTransformer,
|
||||
SelfAttention,
|
||||
split_tensor_along_last_dim,
|
||||
)
|
||||
|
||||
from ._utils import copy_kv_to_mem_cache
|
||||
|
||||
try:
|
||||
from lightllm.models.chatglm2.triton_kernel.rotary_emb import rotary_emb_fwd as chatglm2_rotary_emb_fwd
|
||||
from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
|
||||
context_attention_fwd as lightllm_llama2_context_attention_fwd,
|
||||
)
|
||||
|
||||
HAS_LIGHTLLM_KERNEL = True
|
||||
except:
|
||||
print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
|
||||
HAS_LIGHTLLM_KERNEL = False
|
||||
|
||||
|
||||
def get_masks(self, input_ids, past_length, padding_mask=None):
|
||||
batch_size, seq_length = input_ids.shape
|
||||
full_attention_mask = torch.ones(batch_size, seq_length, seq_length, device=input_ids.device)
|
||||
full_attention_mask.tril_()
|
||||
if past_length:
|
||||
full_attention_mask = torch.cat(
|
||||
(
|
||||
torch.ones(batch_size, seq_length, past_length, device=input_ids.device),
|
||||
full_attention_mask,
|
||||
),
|
||||
dim=-1,
|
||||
)
|
||||
|
||||
if padding_mask is not None:
|
||||
full_attention_mask = full_attention_mask * padding_mask.unsqueeze(1)
|
||||
if not past_length and padding_mask is not None:
|
||||
full_attention_mask -= padding_mask.unsqueeze(-1) - 1
|
||||
full_attention_mask = (full_attention_mask < 0.5).bool()
|
||||
full_attention_mask.unsqueeze_(1)
|
||||
return full_attention_mask
|
||||
|
||||
|
||||
def get_position_ids(batch_size, seq_length, device):
|
||||
position_ids = torch.arange(seq_length, dtype=torch.long, device=device).unsqueeze(0).repeat(batch_size, 1)
|
||||
return position_ids
|
||||
|
||||
|
||||
class ChatGLM2InferenceForwards:
|
||||
"""
|
||||
This class holds forwards for Chatglm2 inference.
|
||||
We intend to replace the forward methods for ChatGLMModel, ChatGLMEecoderLayer, and ChatGLMAttention.
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def chatglm_for_conditional_generation_forward(
|
||||
self: ChatGLMForConditionalGeneration,
|
||||
input_ids: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
past_key_values: Optional[Tuple[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
labels: Optional[torch.Tensor] = None,
|
||||
use_cache: Optional[bool] = True,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
return_last_logit: Optional[bool] = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
stage_manager: Optional[PipelineStageManager] = None,
|
||||
hidden_states: Optional[torch.FloatTensor] = None,
|
||||
stage_index: Optional[List[int]] = None,
|
||||
shard_config: ShardConfig = None,
|
||||
):
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
if output_attentions:
|
||||
logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
|
||||
output_attentions = False
|
||||
if output_hidden_states:
|
||||
logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
|
||||
output_hidden_states = False
|
||||
|
||||
# If is first stage and hidden_states is not None, go throught lm_head first
|
||||
if stage_manager.is_first_stage() and hidden_states is not None:
|
||||
if return_last_logit:
|
||||
hidden_states = hidden_states[-1:]
|
||||
lm_logits = self.transformer.output_layer(hidden_states)
|
||||
lm_logits = lm_logits.transpose(0, 1).contiguous()
|
||||
return {"logits": lm_logits}
|
||||
|
||||
outputs = self.transformer(
|
||||
input_ids=input_ids,
|
||||
position_ids=position_ids,
|
||||
attention_mask=attention_mask,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
infer_state=infer_state,
|
||||
stage_manager=stage_manager,
|
||||
hidden_states=hidden_states,
|
||||
stage_index=stage_index,
|
||||
shard_config=shard_config,
|
||||
)
|
||||
|
||||
return outputs
|
||||
|
||||
@staticmethod
|
||||
def chatglm_model_forward(
|
||||
self: ChatGLMModel,
|
||||
input_ids: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.Tensor] = None,
|
||||
attention_mask: Optional[torch.BoolTensor] = None,
|
||||
full_attention_mask: Optional[torch.BoolTensor] = None,
|
||||
past_key_values: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor], ...]] = None,
|
||||
inputs_embeds: Optional[torch.Tensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
infer_state: BatchInferState = None,
|
||||
stage_manager: Optional[PipelineStageManager] = None,
|
||||
hidden_states: Optional[torch.FloatTensor] = None,
|
||||
stage_index: Optional[List[int]] = None,
|
||||
shard_config: ShardConfig = None,
|
||||
):
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
|
||||
if stage_manager.is_first_stage():
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size, seq_length = input_ids.shape
|
||||
elif inputs_embeds is not None:
|
||||
batch_size, seq_length, _ = inputs_embeds.shape
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embedding(input_ids)
|
||||
if position_ids is None:
|
||||
position_ids = get_position_ids(batch_size, seq_length, input_ids.device)
|
||||
hidden_states = inputs_embeds
|
||||
else:
|
||||
assert hidden_states is not None, "hidden_states should not be None in non-first stage"
|
||||
seq_length, batch_size, _ = hidden_states.shape
|
||||
if position_ids is None:
|
||||
position_ids = get_position_ids(batch_size, seq_length, hidden_states.device)
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
past_key_values_length = 0
|
||||
else:
|
||||
past_key_values_length = infer_state.max_len_in_batch - 1
|
||||
|
||||
seq_length_with_past = seq_length + past_key_values_length
|
||||
|
||||
# prefill stage at first
|
||||
if seq_length != 1:
|
||||
infer_state.is_context_stage = True
|
||||
infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
|
||||
infer_state.init_block_loc(
|
||||
infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
|
||||
)
|
||||
else:
|
||||
infer_state.is_context_stage = False
|
||||
alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
|
||||
if alloc_mem is not None:
|
||||
infer_state.decode_is_contiguous = True
|
||||
infer_state.decode_mem_index = alloc_mem[0]
|
||||
infer_state.decode_mem_start = alloc_mem[1]
|
||||
infer_state.decode_mem_end = alloc_mem[2]
|
||||
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
|
||||
else:
|
||||
print(f" *** Encountered allocation non-contiguous")
|
||||
print(
|
||||
f" infer_state.cache_manager.past_key_values_length: {infer_state.cache_manager.past_key_values_length}"
|
||||
)
|
||||
infer_state.decode_is_contiguous = False
|
||||
alloc_mem = infer_state.cache_manager.alloc(batch_size)
|
||||
infer_state.decode_mem_index = alloc_mem
|
||||
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
|
||||
|
||||
# related to rotary embedding
|
||||
if infer_state.is_context_stage:
|
||||
infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
|
||||
position_ids.view(-1).shape[0], -1
|
||||
)
|
||||
infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
|
||||
position_ids.view(-1).shape[0], -1
|
||||
)
|
||||
else:
|
||||
seq_len = infer_state.seq_len
|
||||
infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
|
||||
infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
|
||||
infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
|
||||
|
||||
if self.pre_seq_len is not None:
|
||||
if past_key_values is None:
|
||||
past_key_values = self.get_prompt(
|
||||
batch_size=batch_size,
|
||||
device=input_ids.device,
|
||||
dtype=inputs_embeds.dtype,
|
||||
)
|
||||
if attention_mask is not None:
|
||||
attention_mask = torch.cat(
|
||||
[
|
||||
attention_mask.new_ones((batch_size, self.pre_seq_len)),
|
||||
attention_mask,
|
||||
],
|
||||
dim=-1,
|
||||
)
|
||||
if full_attention_mask is None:
|
||||
if (attention_mask is not None and not attention_mask.all()) or (past_key_values and seq_length != 1):
|
||||
full_attention_mask = get_masks(
|
||||
self, input_ids, infer_state.cache_manager.past_key_values_length, padding_mask=attention_mask
|
||||
)
|
||||
|
||||
# Run encoder.
|
||||
hidden_states = self.encoder(
|
||||
hidden_states,
|
||||
full_attention_mask,
|
||||
kv_caches=past_key_values,
|
||||
use_cache=use_cache,
|
||||
output_hidden_states=output_hidden_states,
|
||||
infer_state=infer_state,
|
||||
stage_manager=stage_manager,
|
||||
stage_index=stage_index,
|
||||
shard_config=shard_config,
|
||||
)
|
||||
|
||||
# update indices
|
||||
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
|
||||
infer_state.seq_len += 1
|
||||
infer_state.max_len_in_batch += 1
|
||||
|
||||
return {"hidden_states": hidden_states}
|
||||
|
||||
@staticmethod
|
||||
def chatglm_encoder_forward(
|
||||
self: GLMTransformer,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
kv_caches=None,
|
||||
use_cache: Optional[bool] = True,
|
||||
output_hidden_states: Optional[bool] = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
stage_manager: Optional[PipelineStageManager] = None,
|
||||
stage_index: Optional[List[int]] = None,
|
||||
shard_config: ShardConfig = None,
|
||||
):
|
||||
hidden_states = hidden_states.transpose(0, 1).contiguous()
|
||||
|
||||
infer_state.decode_layer_id = 0
|
||||
start_idx, end_idx = stage_index[0], stage_index[1]
|
||||
if kv_caches is None:
|
||||
kv_caches = tuple([None] * (end_idx - start_idx + 1))
|
||||
|
||||
for idx, kv_cache in zip(range(start_idx, end_idx), kv_caches):
|
||||
layer = self.layers[idx]
|
||||
layer_ret = layer(
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
kv_cache=kv_cache,
|
||||
use_cache=use_cache,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
infer_state.decode_layer_id += 1
|
||||
|
||||
hidden_states, _ = layer_ret
|
||||
|
||||
hidden_states = hidden_states.transpose(0, 1).contiguous()
|
||||
|
||||
if self.post_layer_norm and (stage_manager.is_last_stage() or stage_manager.num_stages == 1):
|
||||
# Final layer norm.
|
||||
hidden_states = self.final_layernorm(hidden_states)
|
||||
|
||||
return hidden_states
|
||||
|
||||
@staticmethod
|
||||
def chatglm_glmblock_forward(
|
||||
self: GLMBlock,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
kv_cache=None,
|
||||
use_cache=True,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
):
|
||||
# hidden_states: [s, b, h]
|
||||
|
||||
# Layer norm at the beginning of the transformer layer.
|
||||
layernorm_output = self.input_layernorm(hidden_states)
|
||||
# Self attention.
|
||||
attention_output, kv_cache = self.self_attention(
|
||||
layernorm_output,
|
||||
attention_mask,
|
||||
kv_cache=kv_cache,
|
||||
use_cache=use_cache,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
# Residual connection.
|
||||
if self.apply_residual_connection_post_layernorm:
|
||||
residual = layernorm_output
|
||||
else:
|
||||
residual = hidden_states
|
||||
layernorm_input = torch.nn.functional.dropout(attention_output, p=self.hidden_dropout, training=self.training)
|
||||
layernorm_input = residual + layernorm_input
|
||||
# Layer norm post the self attention.
|
||||
layernorm_output = self.post_attention_layernorm(layernorm_input)
|
||||
# MLP.
|
||||
mlp_output = self.mlp(layernorm_output)
|
||||
|
||||
# Second residual connection.
|
||||
if self.apply_residual_connection_post_layernorm:
|
||||
residual = layernorm_output
|
||||
else:
|
||||
residual = layernorm_input
|
||||
|
||||
output = torch.nn.functional.dropout(mlp_output, p=self.hidden_dropout, training=self.training)
|
||||
output = residual + output
|
||||
return output, kv_cache
|
||||
|
||||
@staticmethod
|
||||
def chatglm_flash_attn_kvcache_forward(
|
||||
self: SelfAttention,
|
||||
hidden_states,
|
||||
attention_mask,
|
||||
kv_cache=None,
|
||||
use_cache=True,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
):
|
||||
assert use_cache is True, "use_cache should be set to True using this chatglm attention"
|
||||
# hidden_states: original :[sq, b, h] --> this [b, sq, h]
|
||||
batch_size = hidden_states.shape[0]
|
||||
hidden_size = hidden_states.shape[-1]
|
||||
# Attention heads [sq, b, h] --> [sq, b, (np * 3 * hn)]
|
||||
mixed_x_layer = self.query_key_value(hidden_states)
|
||||
if self.multi_query_attention:
|
||||
(query_layer, key_layer, value_layer) = mixed_x_layer.split(
|
||||
[
|
||||
self.num_attention_heads_per_partition * self.hidden_size_per_attention_head,
|
||||
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
|
||||
self.num_multi_query_groups_per_partition * self.hidden_size_per_attention_head,
|
||||
],
|
||||
dim=-1,
|
||||
)
|
||||
query_layer = query_layer.view(
|
||||
query_layer.size()[:-1]
|
||||
+ (
|
||||
self.num_attention_heads_per_partition,
|
||||
self.hidden_size_per_attention_head,
|
||||
)
|
||||
)
|
||||
key_layer = key_layer.view(
|
||||
key_layer.size()[:-1]
|
||||
+ (
|
||||
self.num_multi_query_groups_per_partition,
|
||||
self.hidden_size_per_attention_head,
|
||||
)
|
||||
)
|
||||
value_layer = value_layer.view(
|
||||
value_layer.size()[:-1]
|
||||
+ (
|
||||
self.num_multi_query_groups_per_partition,
|
||||
self.hidden_size_per_attention_head,
|
||||
)
|
||||
)
|
||||
|
||||
else:
|
||||
new_tensor_shape = mixed_x_layer.size()[:-1] + (
|
||||
self.num_attention_heads_per_partition,
|
||||
3 * self.hidden_size_per_attention_head,
|
||||
)
|
||||
mixed_x_layer = mixed_x_layer.view(*new_tensor_shape)
|
||||
# [sq, b, np, 3 * hn] --> 3 [sq, b, np, hn]
|
||||
(query_layer, key_layer, value_layer) = split_tensor_along_last_dim(mixed_x_layer, 3)
|
||||
cos, sin = infer_state.position_cos, infer_state.position_sin
|
||||
|
||||
chatglm2_rotary_emb_fwd(
|
||||
query_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head), cos, sin
|
||||
)
|
||||
if self.multi_query_attention:
|
||||
chatglm2_rotary_emb_fwd(
|
||||
key_layer.view(-1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head),
|
||||
cos,
|
||||
sin,
|
||||
)
|
||||
else:
|
||||
chatglm2_rotary_emb_fwd(
|
||||
key_layer.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
|
||||
cos,
|
||||
sin,
|
||||
)
|
||||
|
||||
# reshape q k v to [bsz*sql, num_heads, head_dim] 2*1 ,32/2 ,128
|
||||
query_layer = query_layer.reshape(
|
||||
-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head
|
||||
)
|
||||
key_layer = key_layer.reshape(
|
||||
-1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
|
||||
)
|
||||
value_layer = value_layer.reshape(
|
||||
-1, self.num_multi_query_groups_per_partition, self.hidden_size_per_attention_head
|
||||
)
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
# first token generation:
|
||||
# copy key and value calculated in current step to memory manager
|
||||
copy_kv_to_mem_cache(
|
||||
infer_state.decode_layer_id,
|
||||
key_layer,
|
||||
value_layer,
|
||||
infer_state.context_mem_index,
|
||||
infer_state.cache_manager,
|
||||
)
|
||||
attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
|
||||
|
||||
# NOTE: no bug in context attn fwd (del it )
|
||||
lightllm_llama2_context_attention_fwd(
|
||||
query_layer,
|
||||
key_layer,
|
||||
value_layer,
|
||||
attn_output.view(-1, self.num_attention_heads_per_partition, self.hidden_size_per_attention_head),
|
||||
infer_state.start_loc,
|
||||
infer_state.seq_len,
|
||||
infer_state.max_len_in_batch,
|
||||
)
|
||||
|
||||
else:
|
||||
if infer_state.decode_is_contiguous:
|
||||
# if decode is contiguous, then we copy to key cache and value cache in cache manager directly
|
||||
cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
|
||||
infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
|
||||
]
|
||||
cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
|
||||
infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
|
||||
]
|
||||
cache_k.copy_(key_layer)
|
||||
cache_v.copy_(value_layer)
|
||||
else:
|
||||
# if decode is not contiguous, use triton kernel to copy key and value cache
|
||||
# k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
|
||||
copy_kv_to_mem_cache(
|
||||
infer_state.decode_layer_id,
|
||||
key_layer,
|
||||
value_layer,
|
||||
infer_state.decode_mem_index,
|
||||
infer_state.cache_manager,
|
||||
)
|
||||
|
||||
# second token and follows
|
||||
attn_output = torch.empty_like(query_layer.contiguous().view(-1, self.projection_size))
|
||||
cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
|
||||
: infer_state.decode_mem_end, :, :
|
||||
]
|
||||
cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
|
||||
: infer_state.decode_mem_end, :, :
|
||||
]
|
||||
|
||||
# ==================================
|
||||
# core attention computation is replaced by triton kernel
|
||||
# ==================================
|
||||
Llama2TokenAttentionForwards.token_attn(
|
||||
query_layer,
|
||||
cache_k,
|
||||
cache_v,
|
||||
attn_output,
|
||||
infer_state.block_loc,
|
||||
infer_state.start_loc,
|
||||
infer_state.seq_len,
|
||||
infer_state.max_len_in_batch,
|
||||
infer_state.other_kv_index,
|
||||
)
|
||||
|
||||
# =================
|
||||
# Output:[b,sq, h]
|
||||
# =================
|
||||
output = self.dense(attn_output).reshape(batch_size, -1, hidden_size)
|
||||
|
||||
return output, kv_cache
|
||||
|
|
@ -1,492 +0,0 @@
|
|||
# This code is adapted from huggingface transformers: https://github.com/huggingface/transformers/blob/v4.34.1/src/transformers/models/llama/modeling_llama.py
|
||||
import math
|
||||
from typing import List, Optional, Tuple
|
||||
|
||||
import torch
|
||||
from transformers.models.llama.modeling_llama import LlamaAttention, LlamaDecoderLayer, LlamaForCausalLM, LlamaModel
|
||||
from transformers.utils import logging
|
||||
|
||||
from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
|
||||
from colossalai.kernel.triton import llama_context_attn_fwd, token_attention_fwd
|
||||
from colossalai.kernel.triton.token_attention_kernel import Llama2TokenAttentionForwards
|
||||
from colossalai.pipeline.stage_manager import PipelineStageManager
|
||||
|
||||
from ._utils import copy_kv_to_mem_cache
|
||||
|
||||
try:
|
||||
from lightllm.models.llama2.triton_kernel.context_flashattention_nopad import (
|
||||
context_attention_fwd as lightllm_llama2_context_attention_fwd,
|
||||
)
|
||||
from lightllm.models.llama.triton_kernel.context_flashattention_nopad import (
|
||||
context_attention_fwd as lightllm_context_attention_fwd,
|
||||
)
|
||||
from lightllm.models.llama.triton_kernel.rotary_emb import rotary_emb_fwd as llama_rotary_embedding_fwd
|
||||
|
||||
HAS_LIGHTLLM_KERNEL = True
|
||||
except:
|
||||
print("please install lightllm from source to run inference: https://github.com/ModelTC/lightllm")
|
||||
HAS_LIGHTLLM_KERNEL = False
|
||||
|
||||
try:
|
||||
from colossalai.kernel.triton.flash_decoding import token_flash_decoding
|
||||
HAS_TRITON_FLASH_DECODING_KERNEL = True
|
||||
except:
|
||||
print("no triton flash decoding support, please install lightllm from https://github.com/ModelTC/lightllm/blob/ece7b43f8a6dfa74027adc77c2c176cff28c76c8")
|
||||
HAS_TRITON_FLASH_DECODING_KERNEL = False
|
||||
|
||||
try:
|
||||
from flash_attn import flash_attn_with_kvcache
|
||||
HAS_FLASH_KERNEL = True
|
||||
except:
|
||||
HAS_FLASH_KERNEL = False
|
||||
print("please install flash attentiom from https://github.com/Dao-AILab/flash-attention")
|
||||
|
||||
|
||||
def rotate_half(x):
|
||||
"""Rotates half the hidden dims of the input."""
|
||||
x1 = x[..., : x.shape[-1] // 2]
|
||||
x2 = x[..., x.shape[-1] // 2 :]
|
||||
return torch.cat((-x2, x1), dim=-1)
|
||||
|
||||
def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
|
||||
# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
|
||||
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
|
||||
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
|
||||
cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
|
||||
sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
|
||||
|
||||
q_embed = (q * cos) + (rotate_half(q) * sin)
|
||||
k_embed = (k * cos) + (rotate_half(k) * sin)
|
||||
return q_embed, k_embed
|
||||
|
||||
|
||||
def llama_triton_context_attention(
|
||||
query_states, key_states, value_states, attn_output, infer_state, num_key_value_groups=1
|
||||
):
|
||||
if num_key_value_groups == 1:
|
||||
if HAS_LIGHTLLM_KERNEL is False:
|
||||
llama_context_attn_fwd(
|
||||
query_states,
|
||||
key_states,
|
||||
value_states,
|
||||
attn_output,
|
||||
infer_state.start_loc,
|
||||
infer_state.seq_len,
|
||||
infer_state.max_len_in_batch,
|
||||
)
|
||||
else:
|
||||
lightllm_context_attention_fwd(
|
||||
query_states,
|
||||
key_states,
|
||||
value_states,
|
||||
attn_output,
|
||||
infer_state.start_loc,
|
||||
infer_state.seq_len,
|
||||
infer_state.max_len_in_batch,
|
||||
)
|
||||
else:
|
||||
assert HAS_LIGHTLLM_KERNEL is True, "You have to install lightllm kernels to run llama2 model"
|
||||
lightllm_llama2_context_attention_fwd(
|
||||
query_states,
|
||||
key_states,
|
||||
value_states,
|
||||
attn_output,
|
||||
infer_state.start_loc,
|
||||
infer_state.seq_len,
|
||||
infer_state.max_len_in_batch,
|
||||
)
|
||||
|
||||
def llama_triton_token_attention(query_states, attn_output, infer_state, num_key_value_groups=1, q_head_num = -1, head_dim = -1):
|
||||
if HAS_TRITON_FLASH_DECODING_KERNEL and q_head_num != -1 and head_dim != -1:
|
||||
token_flash_decoding(q = query_states,
|
||||
o_tensor = attn_output,
|
||||
infer_state = infer_state,
|
||||
q_head_num = q_head_num,
|
||||
head_dim = head_dim,
|
||||
cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
|
||||
cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id])
|
||||
return
|
||||
|
||||
if num_key_value_groups == 1:
|
||||
token_attention_fwd(
|
||||
query_states,
|
||||
infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
|
||||
infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
|
||||
attn_output,
|
||||
infer_state.block_loc,
|
||||
infer_state.start_loc,
|
||||
infer_state.seq_len,
|
||||
infer_state.max_len_in_batch,
|
||||
)
|
||||
else:
|
||||
Llama2TokenAttentionForwards.token_attn(
|
||||
query_states,
|
||||
infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
|
||||
infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
|
||||
attn_output,
|
||||
infer_state.block_loc,
|
||||
infer_state.start_loc,
|
||||
infer_state.seq_len,
|
||||
infer_state.max_len_in_batch,
|
||||
infer_state.other_kv_index,
|
||||
)
|
||||
|
||||
|
||||
class LlamaInferenceForwards:
|
||||
"""
|
||||
This class holds forwards for llama inference.
|
||||
We intend to replace the forward methods for LlamaModel, LlamaDecoderLayer, and LlamaAttention for LlamaForCausalLM.
|
||||
"""
|
||||
|
||||
@staticmethod
|
||||
def llama_causal_lm_forward(
|
||||
self: LlamaForCausalLM,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
labels: Optional[torch.LongTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
infer_state: BatchInferState = None,
|
||||
stage_manager: Optional[PipelineStageManager] = None,
|
||||
hidden_states: Optional[torch.FloatTensor] = None,
|
||||
stage_index: Optional[List[int]] = None,
|
||||
):
|
||||
r"""
|
||||
Args:
|
||||
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
|
||||
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
|
||||
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
|
||||
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
|
||||
|
||||
"""
|
||||
logger = logging.get_logger(__name__)
|
||||
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
if output_attentions:
|
||||
logger.warning_once("output_attentions=True is not supported for pipeline models at the moment.")
|
||||
output_attentions = False
|
||||
if output_hidden_states:
|
||||
logger.warning_once("output_hidden_states=True is not supported for pipeline models at the moment.")
|
||||
output_hidden_states = False
|
||||
|
||||
# If is first stage and hidden_states is None, go throught lm_head first
|
||||
if stage_manager.is_first_stage() and hidden_states is not None:
|
||||
lm_logits = self.lm_head(hidden_states)
|
||||
return {"logits": lm_logits}
|
||||
|
||||
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
|
||||
outputs = LlamaInferenceForwards.llama_model_forward(
|
||||
self.model,
|
||||
input_ids=input_ids,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_values=past_key_values,
|
||||
inputs_embeds=inputs_embeds,
|
||||
use_cache=use_cache,
|
||||
output_attentions=output_attentions,
|
||||
output_hidden_states=output_hidden_states,
|
||||
return_dict=return_dict,
|
||||
infer_state=infer_state,
|
||||
stage_manager=stage_manager,
|
||||
hidden_states=hidden_states,
|
||||
stage_index=stage_index,
|
||||
)
|
||||
|
||||
return outputs
|
||||
|
||||
@staticmethod
|
||||
def llama_model_forward(
|
||||
self: LlamaModel,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
infer_state: BatchInferState = None,
|
||||
stage_manager: Optional[PipelineStageManager] = None,
|
||||
hidden_states: Optional[torch.FloatTensor] = None,
|
||||
stage_index: Optional[List[int]] = None,
|
||||
):
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if stage_manager is None or stage_manager.is_first_stage():
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size, seq_length = input_ids.shape
|
||||
elif inputs_embeds is not None:
|
||||
batch_size, seq_length, _ = inputs_embeds.shape
|
||||
else:
|
||||
raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
|
||||
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embed_tokens(input_ids)
|
||||
hidden_states = inputs_embeds
|
||||
else:
|
||||
assert stage_manager is not None
|
||||
assert hidden_states is not None, f"hidden_state should not be none in stage {stage_manager.stage}"
|
||||
input_shape = hidden_states.shape[:-1]
|
||||
batch_size, seq_length = input_shape
|
||||
device = hidden_states.device
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
past_key_values_length = 0
|
||||
else:
|
||||
past_key_values_length = infer_state.max_len_in_batch - 1
|
||||
|
||||
# NOTE: differentiate with prefill stage
|
||||
# block_loc require different value-assigning method for two different stage
|
||||
if use_cache and seq_length != 1:
|
||||
# NOTE assume prefill stage
|
||||
# allocate memory block
|
||||
infer_state.is_context_stage = True # set prefill stage, notify attention layer
|
||||
infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
|
||||
infer_state.init_block_loc(
|
||||
infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
|
||||
)
|
||||
else:
|
||||
infer_state.is_context_stage = False
|
||||
alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
|
||||
if alloc_mem is not None:
|
||||
infer_state.decode_is_contiguous = True
|
||||
infer_state.decode_mem_index = alloc_mem[0]
|
||||
infer_state.decode_mem_start = alloc_mem[1]
|
||||
infer_state.decode_mem_end = alloc_mem[2]
|
||||
infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
|
||||
else:
|
||||
infer_state.decode_is_contiguous = False
|
||||
alloc_mem = infer_state.cache_manager.alloc(batch_size)
|
||||
infer_state.decode_mem_index = alloc_mem
|
||||
infer_state.block_loc[:, infer_state.max_len_in_batch - 1] = infer_state.decode_mem_index
|
||||
|
||||
if position_ids is None:
|
||||
position_ids = torch.arange(
|
||||
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
|
||||
)
|
||||
position_ids = position_ids.repeat(batch_size, 1)
|
||||
position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
|
||||
else:
|
||||
position_ids = position_ids.view(-1, seq_length).long()
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
|
||||
position_ids.view(-1).shape[0], -1
|
||||
)
|
||||
infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
|
||||
position_ids.view(-1).shape[0], -1
|
||||
)
|
||||
|
||||
else:
|
||||
seq_len = infer_state.seq_len
|
||||
infer_state.position_cos = torch.index_select(self._cos_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
|
||||
infer_state.position_sin = torch.index_select(self._sin_cached, 0, seq_len - 1).view(seq_len.shape[0], -1)
|
||||
infer_state.other_kv_index = infer_state.block_loc[0, infer_state.max_len_in_batch - 1].item()
|
||||
|
||||
# embed positions
|
||||
if attention_mask is None:
|
||||
attention_mask = torch.ones(
|
||||
(batch_size, infer_state.max_len_in_batch), dtype=torch.bool, device=hidden_states.device
|
||||
)
|
||||
|
||||
attention_mask = self._prepare_decoder_attention_mask(
|
||||
attention_mask, (batch_size, seq_length), hidden_states, past_key_values_length
|
||||
)
|
||||
|
||||
# decoder layers
|
||||
infer_state.decode_layer_id = 0
|
||||
|
||||
start_idx, end_idx = stage_index[0], stage_index[1]
|
||||
if past_key_values is None:
|
||||
past_key_values = tuple([None] * (end_idx - start_idx + 1))
|
||||
|
||||
for idx, past_key_value in zip(range(start_idx, end_idx), past_key_values):
|
||||
decoder_layer = self.layers[idx]
|
||||
# NOTE: modify here for passing args to decoder layer
|
||||
layer_outputs = decoder_layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_value,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
infer_state.decode_layer_id += 1
|
||||
hidden_states = layer_outputs[0]
|
||||
|
||||
if stage_manager.is_last_stage() or stage_manager.num_stages == 1:
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# update indices
|
||||
# infer_state.block_loc[:, infer_state.max_len_in_batch-1] = infer_state.total_token_num + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
|
||||
infer_state.start_loc += torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
|
||||
infer_state.seq_len += 1
|
||||
infer_state.max_len_in_batch += 1
|
||||
|
||||
return {"hidden_states": hidden_states}
|
||||
|
||||
@staticmethod
|
||||
def llama_decoder_layer_forward(
|
||||
self: LlamaDecoderLayer,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: Optional[bool] = False,
|
||||
use_cache: Optional[bool] = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
residual = hidden_states
|
||||
|
||||
hidden_states = self.input_layernorm(hidden_states)
|
||||
# Self Attention
|
||||
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_value,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
# Fully Connected
|
||||
residual = hidden_states
|
||||
hidden_states = self.post_attention_layernorm(hidden_states)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
outputs = (hidden_states,)
|
||||
|
||||
if output_attentions:
|
||||
outputs += (self_attn_weights,)
|
||||
|
||||
if use_cache:
|
||||
outputs += (present_key_value,)
|
||||
|
||||
return outputs
|
||||
|
||||
@staticmethod
|
||||
def llama_flash_attn_kvcache_forward(
|
||||
self: LlamaAttention,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: bool = False,
|
||||
use_cache: bool = False,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
assert use_cache is True, "use_cache should be set to True using this llama attention"
|
||||
|
||||
bsz, q_len, _ = hidden_states.size()
|
||||
|
||||
# NOTE might think about better way to handle transposed k and v
|
||||
# key_states [bs, seq_len, num_heads, head_dim/embed_size_per_head]
|
||||
# key_states_transposed [bs, num_heads, seq_len, head_dim/embed_size_per_head]
|
||||
|
||||
query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim)
|
||||
key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
|
||||
value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim)
|
||||
|
||||
# NOTE might want to revise
|
||||
# need some way to record the length of past key values cache
|
||||
# since we won't return past_key_value_cache right now
|
||||
|
||||
cos, sin = infer_state.position_cos, infer_state.position_sin
|
||||
|
||||
llama_rotary_embedding_fwd(query_states.view(-1, self.num_heads, self.head_dim), cos, sin)
|
||||
llama_rotary_embedding_fwd(key_states.view(-1, self.num_key_value_heads, self.head_dim), cos, sin)
|
||||
|
||||
query_states = query_states.reshape(-1, self.num_heads, self.head_dim)
|
||||
key_states = key_states.reshape(-1, self.num_key_value_heads, self.head_dim)
|
||||
value_states = value_states.reshape(-1, self.num_key_value_heads, self.head_dim)
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
# first token generation
|
||||
# copy key and value calculated in current step to memory manager
|
||||
copy_kv_to_mem_cache(
|
||||
infer_state.decode_layer_id,
|
||||
key_states,
|
||||
value_states,
|
||||
infer_state.context_mem_index,
|
||||
infer_state.cache_manager,
|
||||
)
|
||||
attn_output = torch.empty_like(query_states)
|
||||
|
||||
llama_triton_context_attention(
|
||||
query_states,
|
||||
key_states,
|
||||
value_states,
|
||||
attn_output,
|
||||
infer_state,
|
||||
num_key_value_groups=self.num_key_value_groups,
|
||||
)
|
||||
else:
|
||||
if infer_state.decode_is_contiguous:
|
||||
# if decode is contiguous, then we copy to key cache and value cache in cache manager directly
|
||||
cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
|
||||
infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
|
||||
]
|
||||
cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
|
||||
infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
|
||||
]
|
||||
cache_k.copy_(key_states)
|
||||
cache_v.copy_(value_states)
|
||||
else:
|
||||
# if decode is not contiguous, use triton kernel to copy key and value cache
|
||||
# k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
|
||||
copy_kv_to_mem_cache(
|
||||
infer_state.decode_layer_id,
|
||||
key_states,
|
||||
value_states,
|
||||
infer_state.decode_mem_index,
|
||||
infer_state.cache_manager,
|
||||
)
|
||||
|
||||
if HAS_LIGHTLLM_KERNEL:
|
||||
|
||||
attn_output = torch.empty_like(query_states)
|
||||
llama_triton_token_attention(query_states = query_states,
|
||||
attn_output = attn_output,
|
||||
infer_state = infer_state,
|
||||
num_key_value_groups = self.num_key_value_groups,
|
||||
q_head_num = q_len * self.num_heads,
|
||||
head_dim = self.head_dim)
|
||||
else:
|
||||
self.num_heads // self.num_key_value_heads
|
||||
cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id]
|
||||
cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id]
|
||||
|
||||
query_states = query_states.view(bsz, -1, self.num_heads, self.head_dim)
|
||||
copy_cache_k = cache_k.view(bsz, -1, self.num_key_value_heads, self.head_dim)
|
||||
copy_cache_v = cache_v.view(bsz, -1, self.num_key_value_heads, self.head_dim)
|
||||
|
||||
attn_output = flash_attn_with_kvcache(
|
||||
q=query_states,
|
||||
k_cache=copy_cache_k,
|
||||
v_cache=copy_cache_v,
|
||||
softmax_scale=1 / math.sqrt(self.head_dim),
|
||||
causal=True,
|
||||
)
|
||||
|
||||
attn_output = attn_output.view(bsz, q_len, self.hidden_size)
|
||||
|
||||
attn_output = self.o_proj(attn_output)
|
||||
|
||||
# return past_key_value as None
|
||||
return attn_output, None, None
|
||||
|
|
@ -1,11 +0,0 @@
|
|||
from .bloom import BloomModelInferPolicy
|
||||
from .chatglm2 import ChatGLM2InferPolicy
|
||||
from .llama import LlamaModelInferPolicy
|
||||
|
||||
model_policy_map = {
|
||||
"llama": LlamaModelInferPolicy,
|
||||
"bloom": BloomModelInferPolicy,
|
||||
"chatglm": ChatGLM2InferPolicy,
|
||||
}
|
||||
|
||||
__all__ = ["LlamaModelInferPolicy", "BloomModelInferPolicy", "ChatGLM2InferPolicy", "model_polic_map"]
|
||||
|
|
@ -1,127 +0,0 @@
|
|||
from functools import partial
|
||||
from typing import List
|
||||
|
||||
import torch
|
||||
from torch.nn import LayerNorm, Module
|
||||
|
||||
import colossalai.shardformer.layer as col_nn
|
||||
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
|
||||
from colossalai.shardformer.policies.bloom import BloomForCausalLMPolicy
|
||||
|
||||
from ..modeling.bloom import BloomInferenceForwards
|
||||
|
||||
try:
|
||||
from colossalai.kernel.triton import layer_norm
|
||||
|
||||
HAS_TRITON_NORM = True
|
||||
except:
|
||||
print("Some of our kernels require triton. You might want to install triton from https://github.com/openai/triton")
|
||||
HAS_TRITON_NORM = False
|
||||
|
||||
|
||||
def get_triton_layernorm_forward():
|
||||
if HAS_TRITON_NORM:
|
||||
|
||||
def _triton_layernorm_forward(self: LayerNorm, hidden_states: torch.Tensor):
|
||||
return layer_norm(hidden_states, self.weight.data, self.bias, self.eps)
|
||||
|
||||
return _triton_layernorm_forward
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class BloomModelInferPolicy(BloomForCausalLMPolicy):
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
def module_policy(self):
|
||||
from transformers.models.bloom.modeling_bloom import BloomAttention, BloomBlock, BloomForCausalLM, BloomModel
|
||||
|
||||
policy = super().module_policy()
|
||||
if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
|
||||
from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
|
||||
|
||||
policy[BloomBlock] = ModulePolicyDescription(
|
||||
attribute_replacement={
|
||||
"self_attention.hidden_size": self.model.config.hidden_size
|
||||
// self.shard_config.tensor_parallel_size,
|
||||
"self_attention.split_size": self.model.config.hidden_size
|
||||
// self.shard_config.tensor_parallel_size,
|
||||
"self_attention.num_heads": self.model.config.n_head // self.shard_config.tensor_parallel_size,
|
||||
},
|
||||
sub_module_replacement=[
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attention.query_key_value",
|
||||
target_module=ColCaiQuantLinear,
|
||||
kwargs={"split_num": 3},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attention.dense", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attention.attention_dropout",
|
||||
target_module=col_nn.DropoutForParallelInput,
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="mlp.dense_h_to_4h", target_module=ColCaiQuantLinear, kwargs={"split_num": 1}
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="mlp.dense_4h_to_h", target_module=RowCaiQuantLinear, kwargs={"split_num": 1}
|
||||
),
|
||||
],
|
||||
)
|
||||
# NOTE set inference mode to shard config
|
||||
self.shard_config._infer()
|
||||
|
||||
# set as default, in inference we also use pipeline style forward, just setting stage as 1
|
||||
self.set_pipeline_forward(
|
||||
model_cls=BloomForCausalLM,
|
||||
new_forward=partial(
|
||||
BloomInferenceForwards.bloom_for_causal_lm_forward,
|
||||
tp_group=self.shard_config.tensor_parallel_process_group,
|
||||
),
|
||||
policy=policy,
|
||||
)
|
||||
|
||||
method_replacement = {"forward": BloomInferenceForwards.bloom_model_forward}
|
||||
self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomModel)
|
||||
|
||||
method_replacement = {"forward": BloomInferenceForwards.bloom_block_forward}
|
||||
self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=BloomBlock)
|
||||
|
||||
method_replacement = {"forward": BloomInferenceForwards.bloom_attention_forward}
|
||||
self.append_or_create_method_replacement(
|
||||
description=method_replacement, policy=policy, target_key=BloomAttention
|
||||
)
|
||||
|
||||
if HAS_TRITON_NORM:
|
||||
infer_method = get_triton_layernorm_forward()
|
||||
method_replacement = {"forward": partial(infer_method)}
|
||||
self.append_or_create_method_replacement(
|
||||
description=method_replacement, policy=policy, target_key=LayerNorm
|
||||
)
|
||||
|
||||
return policy
|
||||
|
||||
def get_held_layers(self) -> List[Module]:
|
||||
"""Get pipeline layers for current stage."""
|
||||
assert self.pipeline_stage_manager is not None
|
||||
|
||||
if self.model.__class__.__name__ == "BloomModel":
|
||||
module = self.model
|
||||
else:
|
||||
module = self.model.transformer
|
||||
stage_manager = self.pipeline_stage_manager
|
||||
|
||||
held_layers = []
|
||||
layers_per_stage = self.distribute_layers(len(module.h), stage_manager.num_stages)
|
||||
if stage_manager.is_first_stage():
|
||||
held_layers.append(module.word_embeddings)
|
||||
held_layers.append(module.word_embeddings_layernorm)
|
||||
held_layers.append(self.model.lm_head)
|
||||
start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
|
||||
held_layers.extend(module.h[start_idx:end_idx])
|
||||
if stage_manager.is_last_stage():
|
||||
held_layers.append(module.ln_f)
|
||||
|
||||
return held_layers
|
||||
|
|
@ -1,89 +0,0 @@
|
|||
from typing import List
|
||||
|
||||
import torch.nn as nn
|
||||
|
||||
from colossalai.shardformer.modeling.chatglm2_6b.modeling_chatglm import (
|
||||
ChatGLMForConditionalGeneration,
|
||||
ChatGLMModel,
|
||||
GLMBlock,
|
||||
GLMTransformer,
|
||||
SelfAttention,
|
||||
)
|
||||
|
||||
# import colossalai
|
||||
from colossalai.shardformer.policies.chatglm2 import ChatGLMModelPolicy
|
||||
|
||||
from ..modeling._utils import init_to_get_rotary
|
||||
from ..modeling.chatglm2 import ChatGLM2InferenceForwards
|
||||
|
||||
try:
|
||||
HAS_TRITON_RMSNORM = True
|
||||
except:
|
||||
print("you should install triton from https://github.com/openai/triton")
|
||||
HAS_TRITON_RMSNORM = False
|
||||
|
||||
|
||||
class ChatGLM2InferPolicy(ChatGLMModelPolicy):
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
def module_policy(self):
|
||||
policy = super().module_policy()
|
||||
self.shard_config._infer()
|
||||
|
||||
model_infer_forward = ChatGLM2InferenceForwards.chatglm_model_forward
|
||||
method_replacement = {"forward": model_infer_forward}
|
||||
self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=ChatGLMModel)
|
||||
|
||||
encoder_infer_forward = ChatGLM2InferenceForwards.chatglm_encoder_forward
|
||||
method_replacement = {"forward": encoder_infer_forward}
|
||||
self.append_or_create_method_replacement(
|
||||
description=method_replacement, policy=policy, target_key=GLMTransformer
|
||||
)
|
||||
|
||||
encoder_layer_infer_forward = ChatGLM2InferenceForwards.chatglm_glmblock_forward
|
||||
method_replacement = {"forward": encoder_layer_infer_forward}
|
||||
self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=GLMBlock)
|
||||
|
||||
attn_infer_forward = ChatGLM2InferenceForwards.chatglm_flash_attn_kvcache_forward
|
||||
method_replacement = {"forward": attn_infer_forward}
|
||||
self.append_or_create_method_replacement(
|
||||
description=method_replacement, policy=policy, target_key=SelfAttention
|
||||
)
|
||||
if self.shard_config.enable_tensor_parallelism:
|
||||
policy[GLMBlock].attribute_replacement["self_attention.num_multi_query_groups_per_partition"] = (
|
||||
self.model.config.multi_query_group_num // self.shard_config.tensor_parallel_size
|
||||
)
|
||||
# for rmsnorm and others, we need to check the shape
|
||||
|
||||
self.set_pipeline_forward(
|
||||
model_cls=ChatGLMForConditionalGeneration,
|
||||
new_forward=ChatGLM2InferenceForwards.chatglm_for_conditional_generation_forward,
|
||||
policy=policy,
|
||||
)
|
||||
|
||||
return policy
|
||||
|
||||
def get_held_layers(self) -> List[nn.Module]:
|
||||
module = self.model.transformer
|
||||
stage_manager = self.pipeline_stage_manager
|
||||
|
||||
held_layers = []
|
||||
layers_per_stage = self.distribute_layers(module.num_layers, stage_manager.num_stages)
|
||||
if stage_manager.is_first_stage():
|
||||
held_layers.append(module.embedding)
|
||||
held_layers.append(module.output_layer)
|
||||
start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
|
||||
held_layers.extend(module.encoder.layers[start_idx:end_idx])
|
||||
if stage_manager.is_last_stage():
|
||||
if module.encoder.post_layer_norm:
|
||||
held_layers.append(module.encoder.final_layernorm)
|
||||
|
||||
# rotary_pos_emb is needed for all stages
|
||||
held_layers.append(module.rotary_pos_emb)
|
||||
|
||||
return held_layers
|
||||
|
||||
def postprocess(self):
|
||||
init_to_get_rotary(self.model.transformer)
|
||||
return self.model
|
||||
|
|
@ -1,206 +0,0 @@
|
|||
from functools import partial
|
||||
from typing import List
|
||||
|
||||
import torch
|
||||
from torch.nn import Module
|
||||
from transformers.models.llama.modeling_llama import (
|
||||
LlamaAttention,
|
||||
LlamaDecoderLayer,
|
||||
LlamaForCausalLM,
|
||||
LlamaModel,
|
||||
LlamaRMSNorm,
|
||||
)
|
||||
|
||||
from colossalai.shardformer.policies.base_policy import ModulePolicyDescription, SubModuleReplacementDescription
|
||||
|
||||
# import colossalai
|
||||
from colossalai.shardformer.policies.llama import LlamaForCausalLMPolicy
|
||||
|
||||
from ..modeling._utils import init_to_get_rotary
|
||||
from ..modeling.llama import LlamaInferenceForwards
|
||||
|
||||
try:
|
||||
from colossalai.kernel.triton import rmsnorm_forward
|
||||
|
||||
HAS_TRITON_RMSNORM = True
|
||||
except:
|
||||
print("you should install triton from https://github.com/openai/triton")
|
||||
HAS_TRITON_RMSNORM = False
|
||||
|
||||
|
||||
def get_triton_rmsnorm_forward():
|
||||
if HAS_TRITON_RMSNORM:
|
||||
|
||||
def _triton_rmsnorm_forward(self: LlamaRMSNorm, hidden_states: torch.Tensor):
|
||||
return rmsnorm_forward(hidden_states, self.weight.data, self.variance_epsilon)
|
||||
|
||||
return _triton_rmsnorm_forward
|
||||
else:
|
||||
return None
|
||||
|
||||
|
||||
class LlamaModelInferPolicy(LlamaForCausalLMPolicy):
|
||||
def __init__(self) -> None:
|
||||
super().__init__()
|
||||
|
||||
def module_policy(self):
|
||||
policy = super().module_policy()
|
||||
decoder_attribute_replacement = {
|
||||
"self_attn.hidden_size": self.model.config.hidden_size // self.shard_config.tensor_parallel_size,
|
||||
"self_attn.num_heads": self.model.config.num_attention_heads // self.shard_config.tensor_parallel_size,
|
||||
"self_attn.num_key_value_heads": self.model.config.num_key_value_heads
|
||||
// self.shard_config.tensor_parallel_size,
|
||||
}
|
||||
if self.shard_config.extra_kwargs.get("quant", None) == "gptq":
|
||||
from colossalai.inference.quant.gptq.cai_gptq import ColCaiQuantLinear, RowCaiQuantLinear
|
||||
|
||||
policy[LlamaDecoderLayer] = ModulePolicyDescription(
|
||||
attribute_replacement=decoder_attribute_replacement,
|
||||
sub_module_replacement=[
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attn.q_proj",
|
||||
target_module=ColCaiQuantLinear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attn.k_proj",
|
||||
target_module=ColCaiQuantLinear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attn.v_proj",
|
||||
target_module=ColCaiQuantLinear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attn.o_proj",
|
||||
target_module=RowCaiQuantLinear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="mlp.gate_proj",
|
||||
target_module=ColCaiQuantLinear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="mlp.up_proj",
|
||||
target_module=ColCaiQuantLinear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="mlp.down_proj",
|
||||
target_module=RowCaiQuantLinear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
],
|
||||
)
|
||||
|
||||
elif self.shard_config.extra_kwargs.get("quant", None) == "smoothquant":
|
||||
from colossalai.inference.quant.smoothquant.models.llama import LlamaSmoothquantDecoderLayer
|
||||
from colossalai.inference.quant.smoothquant.models.parallel_linear import (
|
||||
ColW8A8BFP32OFP32Linear,
|
||||
RowW8A8B8O8Linear,
|
||||
RowW8A8BFP32O32LinearSiLU,
|
||||
RowW8A8BFP32OFP32Linear,
|
||||
)
|
||||
|
||||
policy[LlamaSmoothquantDecoderLayer] = ModulePolicyDescription(
|
||||
attribute_replacement=decoder_attribute_replacement,
|
||||
sub_module_replacement=[
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attn.q_proj",
|
||||
target_module=RowW8A8B8O8Linear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attn.k_proj",
|
||||
target_module=RowW8A8B8O8Linear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attn.v_proj",
|
||||
target_module=RowW8A8B8O8Linear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="self_attn.o_proj",
|
||||
target_module=ColW8A8BFP32OFP32Linear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="mlp.gate_proj",
|
||||
target_module=RowW8A8BFP32O32LinearSiLU,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="mlp.up_proj",
|
||||
target_module=RowW8A8BFP32OFP32Linear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
SubModuleReplacementDescription(
|
||||
suffix="mlp.down_proj",
|
||||
target_module=ColW8A8BFP32OFP32Linear,
|
||||
kwargs={"split_num": 1},
|
||||
),
|
||||
],
|
||||
)
|
||||
self.shard_config._infer()
|
||||
|
||||
infer_forward = LlamaInferenceForwards.llama_model_forward
|
||||
method_replacement = {"forward": partial(infer_forward)}
|
||||
self.append_or_create_method_replacement(description=method_replacement, policy=policy, target_key=LlamaModel)
|
||||
|
||||
infer_forward = LlamaInferenceForwards.llama_decoder_layer_forward
|
||||
method_replacement = {"forward": partial(infer_forward)}
|
||||
self.append_or_create_method_replacement(
|
||||
description=method_replacement, policy=policy, target_key=LlamaDecoderLayer
|
||||
)
|
||||
|
||||
infer_forward = LlamaInferenceForwards.llama_flash_attn_kvcache_forward
|
||||
method_replacement = {"forward": partial(infer_forward)}
|
||||
self.append_or_create_method_replacement(
|
||||
description=method_replacement, policy=policy, target_key=LlamaAttention
|
||||
)
|
||||
|
||||
# set as default, in inference we also use pipeline style forward, just setting stage as 1
|
||||
self.set_pipeline_forward(
|
||||
model_cls=LlamaForCausalLM, new_forward=LlamaInferenceForwards.llama_causal_lm_forward, policy=policy
|
||||
)
|
||||
|
||||
infer_forward = None
|
||||
if HAS_TRITON_RMSNORM:
|
||||
infer_forward = get_triton_rmsnorm_forward()
|
||||
|
||||
if infer_forward is not None:
|
||||
method_replacement = {"forward": partial(infer_forward)}
|
||||
self.append_or_create_method_replacement(
|
||||
description=method_replacement, policy=policy, target_key=LlamaRMSNorm
|
||||
)
|
||||
|
||||
return policy
|
||||
|
||||
def postprocess(self):
|
||||
init_to_get_rotary(self.model.model)
|
||||
return self.model
|
||||
|
||||
def get_held_layers(self) -> List[Module]:
|
||||
"""Get pipeline layers for current stage."""
|
||||
assert self.pipeline_stage_manager is not None
|
||||
|
||||
if self.model.__class__.__name__ == "LlamaModel":
|
||||
module = self.model
|
||||
else:
|
||||
module = self.model.model
|
||||
stage_manager = self.pipeline_stage_manager
|
||||
|
||||
held_layers = []
|
||||
layers_per_stage = self.distribute_layers(len(module.layers), stage_manager.num_stages)
|
||||
if stage_manager.is_first_stage():
|
||||
held_layers.append(module.embed_tokens)
|
||||
held_layers.append(self.model.lm_head)
|
||||
start_idx, end_idx = self.get_stage_index(layers_per_stage, stage_manager.stage)
|
||||
held_layers.extend(module.layers[start_idx:end_idx])
|
||||
if stage_manager.is_last_stage():
|
||||
held_layers.append(module.norm)
|
||||
|
||||
return held_layers
|
||||
|
|
@ -1,2 +0,0 @@
|
|||
from .batch_infer_state import BatchInferState
|
||||
from .kvcache_manager import MemoryManager
|
||||
|
|
@ -1,118 +0,0 @@
|
|||
# might want to consider combine with InferenceConfig in colossalai/ppinference/inference_config.py later
|
||||
from dataclasses import dataclass
|
||||
|
||||
import torch
|
||||
from transformers.tokenization_utils_base import BatchEncoding
|
||||
|
||||
from .kvcache_manager import MemoryManager
|
||||
|
||||
|
||||
# adapted from: lightllm/server/router/model_infer/infer_batch.py
|
||||
@dataclass
|
||||
class BatchInferState:
|
||||
r"""
|
||||
Information to be passed and used for a batch of inputs during
|
||||
a single model forward
|
||||
"""
|
||||
batch_size: int
|
||||
max_len_in_batch: int
|
||||
|
||||
cache_manager: MemoryManager = None
|
||||
|
||||
block_loc: torch.Tensor = None
|
||||
start_loc: torch.Tensor = None
|
||||
seq_len: torch.Tensor = None
|
||||
past_key_values_len: int = None
|
||||
|
||||
is_context_stage: bool = False
|
||||
context_mem_index: torch.Tensor = None
|
||||
decode_is_contiguous: bool = None
|
||||
decode_mem_start: int = None
|
||||
decode_mem_end: int = None
|
||||
decode_mem_index: torch.Tensor = None
|
||||
decode_layer_id: int = None
|
||||
|
||||
device: torch.device = torch.device("cuda")
|
||||
|
||||
@property
|
||||
def total_token_num(self):
|
||||
# return self.batch_size * self.max_len_in_batch
|
||||
assert self.seq_len is not None and self.seq_len.size(0) > 0
|
||||
return int(torch.sum(self.seq_len))
|
||||
|
||||
def set_cache_manager(self, manager: MemoryManager):
|
||||
self.cache_manager = manager
|
||||
|
||||
# adapted from: https://github.com/ModelTC/lightllm/blob/28c1267cfca536b7b4f28e921e03de735b003039/lightllm/common/infer_utils.py#L1
|
||||
@staticmethod
|
||||
def init_block_loc(
|
||||
b_loc: torch.Tensor, seq_len: torch.Tensor, max_len_in_batch: int, alloc_mem_index: torch.Tensor
|
||||
):
|
||||
"""in-place update block loc mapping based on the sequence length of the inputs in current bath"""
|
||||
start_index = 0
|
||||
seq_len_numpy = seq_len.cpu().numpy()
|
||||
for i, cur_seq_len in enumerate(seq_len_numpy):
|
||||
b_loc[i, max_len_in_batch - cur_seq_len : max_len_in_batch] = alloc_mem_index[
|
||||
start_index : start_index + cur_seq_len
|
||||
]
|
||||
start_index += cur_seq_len
|
||||
return
|
||||
|
||||
@classmethod
|
||||
def init_from_batch(
|
||||
cls,
|
||||
batch: torch.Tensor,
|
||||
max_input_len: int,
|
||||
max_output_len: int,
|
||||
cache_manager: MemoryManager,
|
||||
):
|
||||
if not isinstance(batch, (BatchEncoding, dict, list, torch.Tensor)):
|
||||
raise TypeError(f"batch type {type(batch)} is not supported in prepare_batch_state")
|
||||
|
||||
input_ids_list = None
|
||||
attention_mask = None
|
||||
|
||||
if isinstance(batch, (BatchEncoding, dict)):
|
||||
input_ids_list = batch["input_ids"]
|
||||
attention_mask = batch["attention_mask"]
|
||||
else:
|
||||
input_ids_list = batch
|
||||
if isinstance(input_ids_list[0], int): # for a single input
|
||||
input_ids_list = [input_ids_list]
|
||||
attention_mask = [attention_mask] if attention_mask is not None else attention_mask
|
||||
|
||||
batch_size = len(input_ids_list)
|
||||
|
||||
seq_start_indexes = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
|
||||
seq_lengths = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
|
||||
start_index = 0
|
||||
|
||||
max_len_in_batch = -1
|
||||
if isinstance(batch, (BatchEncoding, dict)):
|
||||
for i, attn_mask in enumerate(attention_mask):
|
||||
curr_seq_len = len(attn_mask)
|
||||
seq_lengths[i] = curr_seq_len
|
||||
seq_start_indexes[i] = start_index
|
||||
start_index += curr_seq_len
|
||||
max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
|
||||
else:
|
||||
length = max(len(input_id) for input_id in input_ids_list)
|
||||
for i, input_ids in enumerate(input_ids_list):
|
||||
curr_seq_len = length
|
||||
seq_lengths[i] = curr_seq_len
|
||||
seq_start_indexes[i] = start_index
|
||||
start_index += curr_seq_len
|
||||
max_len_in_batch = curr_seq_len if curr_seq_len > max_len_in_batch else max_len_in_batch
|
||||
block_loc = torch.zeros((batch_size, max_input_len + max_output_len), dtype=torch.long, device="cuda")
|
||||
|
||||
return cls(
|
||||
batch_size=batch_size,
|
||||
max_len_in_batch=max_len_in_batch,
|
||||
seq_len=seq_lengths.to("cuda"),
|
||||
start_loc=seq_start_indexes.to("cuda"),
|
||||
block_loc=block_loc,
|
||||
decode_layer_id=0,
|
||||
past_key_values_len=0,
|
||||
is_context_stage=True,
|
||||
cache_manager=cache_manager,
|
||||
)
|
||||
|
|
@ -1,106 +0,0 @@
|
|||
"""
|
||||
Refered/Modified from lightllm/common/mem_manager.py
|
||||
of the ModelTC/lightllm GitHub repository
|
||||
https://github.com/ModelTC/lightllm/blob/050af3ce65edca617e2f30ec2479397d5bb248c9/lightllm/common/mem_manager.py
|
||||
we slightly changed it to make it suitable for our colossal-ai shardformer TP-engine design.
|
||||
"""
|
||||
import torch
|
||||
from transformers.utils import logging
|
||||
|
||||
|
||||
class MemoryManager:
|
||||
r"""
|
||||
Manage token block indexes and allocate physical memory for key and value cache
|
||||
|
||||
Args:
|
||||
size: maximum token number used as the size of key and value buffer
|
||||
dtype: data type of cached key and value
|
||||
head_num: number of heads the memory manager is responsible for
|
||||
head_dim: embedded size per head
|
||||
layer_num: the number of layers in the model
|
||||
device: device used to store the key and value cache
|
||||
"""
|
||||
|
||||
def __init__(
|
||||
self,
|
||||
size: int,
|
||||
dtype: torch.dtype,
|
||||
head_num: int,
|
||||
head_dim: int,
|
||||
layer_num: int,
|
||||
device: torch.device = torch.device("cuda"),
|
||||
):
|
||||
self.logger = logging.get_logger(__name__)
|
||||
self.available_size = size
|
||||
self.max_len_in_batch = 0
|
||||
self._init_mem_states(size, device)
|
||||
self._init_kv_buffers(size, device, dtype, head_num, head_dim, layer_num)
|
||||
|
||||
def _init_mem_states(self, size, device):
|
||||
"""Initialize tensors used to manage memory states"""
|
||||
self.mem_state = torch.ones((size,), dtype=torch.bool, device=device)
|
||||
self.mem_cum_sum = torch.empty((size,), dtype=torch.int32, device=device)
|
||||
self.indexes = torch.arange(0, size, dtype=torch.long, device=device)
|
||||
|
||||
def _init_kv_buffers(self, size, device, dtype, head_num, head_dim, layer_num):
|
||||
"""Initialize key buffer and value buffer on specified device"""
|
||||
self.key_buffer = [
|
||||
torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
|
||||
]
|
||||
self.value_buffer = [
|
||||
torch.empty((size, head_num, head_dim), dtype=dtype, device=device) for _ in range(layer_num)
|
||||
]
|
||||
|
||||
@torch.no_grad()
|
||||
def alloc(self, required_size):
|
||||
"""allocate space of required_size by providing indexes representing available physical spaces"""
|
||||
if required_size > self.available_size:
|
||||
self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
|
||||
return None
|
||||
torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
|
||||
select_index = torch.logical_and(self.mem_cum_sum <= required_size, self.mem_state == 1)
|
||||
select_index = self.indexes[select_index]
|
||||
self.mem_state[select_index] = 0
|
||||
self.available_size -= len(select_index)
|
||||
return select_index
|
||||
|
||||
@torch.no_grad()
|
||||
def alloc_contiguous(self, required_size):
|
||||
"""allocate contiguous space of required_size"""
|
||||
if required_size > self.available_size:
|
||||
self.logger.warning(f"No enough cache: required_size {required_size} " f"left_size {self.available_size}")
|
||||
return None
|
||||
torch.cumsum(self.mem_state, dim=0, dtype=torch.int32, out=self.mem_cum_sum)
|
||||
sum_size = len(self.mem_cum_sum)
|
||||
loc_sums = (
|
||||
self.mem_cum_sum[required_size - 1 :]
|
||||
- self.mem_cum_sum[0 : sum_size - required_size + 1]
|
||||
+ self.mem_state[0 : sum_size - required_size + 1]
|
||||
)
|
||||
can_used_loc = self.indexes[0 : sum_size - required_size + 1][loc_sums == required_size]
|
||||
if can_used_loc.shape[0] == 0:
|
||||
self.logger.info(
|
||||
f"No enough contiguous cache: required_size {required_size} " f"left_size {self.available_size}"
|
||||
)
|
||||
return None
|
||||
start_loc = can_used_loc[0]
|
||||
select_index = self.indexes[start_loc : start_loc + required_size]
|
||||
self.mem_state[select_index] = 0
|
||||
self.available_size -= len(select_index)
|
||||
start = start_loc.item()
|
||||
end = start + required_size
|
||||
return select_index, start, end
|
||||
|
||||
@torch.no_grad()
|
||||
def free(self, free_index):
|
||||
"""free memory by updating memory states based on given indexes"""
|
||||
self.available_size += free_index.shape[0]
|
||||
self.mem_state[free_index] = 1
|
||||
|
||||
@torch.no_grad()
|
||||
def free_all(self):
|
||||
"""free all memory by updating memory states"""
|
||||
self.available_size = len(self.mem_state)
|
||||
self.mem_state[:] = 1
|
||||
self.max_len_in_batch = 0
|
||||
# self.logger.info("freed all space of memory manager")
|
||||
|
|
@ -1 +0,0 @@
|
|||
from .smoothquant.models.llama import SmoothLlamaForCausalLM
|
||||
|
|
@ -1,5 +0,0 @@
|
|||
from .cai_gptq import HAS_AUTO_GPTQ
|
||||
|
||||
if HAS_AUTO_GPTQ:
|
||||
from .cai_gptq import CaiGPTQLinearOp, CaiQuantLinear
|
||||
from .gptq_manager import GPTQManager
|
||||
|
|
@ -1,14 +0,0 @@
|
|||
import warnings
|
||||
|
||||
HAS_AUTO_GPTQ = False
|
||||
try:
|
||||
import auto_gptq
|
||||
|
||||
HAS_AUTO_GPTQ = True
|
||||
except ImportError:
|
||||
warnings.warn("please install auto-gptq from https://github.com/PanQiWei/AutoGPTQ")
|
||||
HAS_AUTO_GPTQ = False
|
||||
|
||||
if HAS_AUTO_GPTQ:
|
||||
from .cai_quant_linear import CaiQuantLinear, ColCaiQuantLinear, RowCaiQuantLinear
|
||||
from .gptq_op import CaiGPTQLinearOp
|
||||
|
|
@ -1,354 +0,0 @@
|
|||
# Adapted from AutoGPTQ auto_gptq: https://github.com/PanQiWei/AutoGPTQ
|
||||
|
||||
import math
|
||||
import warnings
|
||||
from typing import List, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.nn as nn
|
||||
from torch.distributed import ProcessGroup
|
||||
|
||||
from colossalai.lazy import LazyInitContext
|
||||
from colossalai.shardformer.layer import ParallelModule
|
||||
|
||||
from .gptq_op import CaiGPTQLinearOp
|
||||
|
||||
HAS_GPTQ_CUDA = False
|
||||
try:
|
||||
from colossalai.kernel.op_builder.gptq import GPTQBuilder
|
||||
gptq_cuda = GPTQBuilder().load()
|
||||
HAS_GPTQ_CUDA = True
|
||||
except ImportError:
|
||||
warnings.warn('CUDA gptq is not installed')
|
||||
HAS_GPTQ_CUDA = False
|
||||
|
||||
|
||||
class CaiQuantLinear(nn.Module):
|
||||
|
||||
def __init__(self, bits, groupsize, infeatures, outfeatures, bias, tp_size=1, tp_rank=0, row_split=False):
|
||||
super().__init__()
|
||||
if bits not in [2, 4, 8]:
|
||||
raise NotImplementedError("Only 2,4,8 bits are supported.")
|
||||
self.infeatures = infeatures
|
||||
self.outfeatures = outfeatures
|
||||
self.bits = bits
|
||||
self.maxq = 2**self.bits - 1
|
||||
self.groupsize = groupsize if groupsize != -1 else infeatures
|
||||
|
||||
self.register_buffer('qweight', torch.zeros((infeatures // 32 * self.bits, outfeatures), dtype=torch.int32))
|
||||
self.register_buffer(
|
||||
'qzeros',
|
||||
torch.zeros((math.ceil(infeatures / self.groupsize), outfeatures // 32 * self.bits), dtype=torch.int32))
|
||||
self.register_buffer('scales',
|
||||
torch.zeros((math.ceil(infeatures / self.groupsize), outfeatures), dtype=torch.float16))
|
||||
if row_split:
|
||||
self.register_buffer(
|
||||
'g_idx',
|
||||
torch.tensor([(i + (tp_rank * self.infeatures)) // self.groupsize for i in range(infeatures)],
|
||||
dtype=torch.int32))
|
||||
else:
|
||||
self.register_buffer('g_idx',
|
||||
torch.tensor([i // self.groupsize for i in range(infeatures)], dtype=torch.int32))
|
||||
|
||||
if bias:
|
||||
self.register_buffer('bias', torch.zeros((outfeatures), dtype=torch.float16))
|
||||
else:
|
||||
self.bias = None
|
||||
|
||||
self.gptq_linear = CaiGPTQLinearOp(groupsize, bits)
|
||||
|
||||
self.q4 = None
|
||||
self.empty_tensor = torch.empty((1, 1), device="meta")
|
||||
self.tp_size = tp_size
|
||||
self.tp_rank = tp_rank
|
||||
self.row_split = row_split
|
||||
|
||||
def pack(self, linear, scales, zeros, g_idx=None):
|
||||
|
||||
g_idx = g_idx.clone() if g_idx is not None else torch.tensor(
|
||||
[i // self.groupsize for i in range(self.infeatures)], dtype=torch.int32)
|
||||
|
||||
scales = scales.t().contiguous()
|
||||
zeros = zeros.t().contiguous()
|
||||
scale_zeros = zeros * scales
|
||||
half_scales = scales.clone().half()
|
||||
# print("scale shape ", scales.shape, scale_zeros.shape, linear.weight.shape)
|
||||
self.scales = scales.clone().half()
|
||||
if linear.bias is not None:
|
||||
self.bias = linear.bias.clone().half()
|
||||
|
||||
wn = 8
|
||||
pbits = 32
|
||||
ptype = torch.int32
|
||||
unsign_type = np.uint32
|
||||
sign_type = np.int32
|
||||
|
||||
intweight = []
|
||||
for idx in range(self.infeatures):
|
||||
intweight.append(
|
||||
torch.round(
|
||||
(linear.weight.data[:, idx] + scale_zeros[g_idx[idx]]) / half_scales[g_idx[idx]]).to(ptype)[:,
|
||||
None])
|
||||
intweight = torch.cat(intweight, dim=1)
|
||||
intweight = intweight.t().contiguous()
|
||||
intweight = intweight.numpy().astype(unsign_type)
|
||||
qweight = np.zeros((intweight.shape[0] // pbits * self.bits, intweight.shape[1]), dtype=unsign_type)
|
||||
|
||||
i = 0
|
||||
row = 0
|
||||
|
||||
while row < qweight.shape[0]:
|
||||
if self.bits in [2, 4, 8]:
|
||||
for j in range(i, i + (pbits // self.bits)):
|
||||
qweight[row] |= intweight[j] << (self.bits * (j - i))
|
||||
i += pbits // self.bits
|
||||
row += 1
|
||||
else:
|
||||
raise NotImplementedError("Only 2,4,8 bits are supported.")
|
||||
qweight = qweight.astype(sign_type)
|
||||
qweight1 = torch.from_numpy(qweight)
|
||||
qweight1 = qweight1.contiguous() #.to("cuda")
|
||||
self.qweight.data.copy_(qweight1)
|
||||
|
||||
qzeros = np.zeros((zeros.shape[0], zeros.shape[1] // pbits * self.bits), dtype=unsign_type)
|
||||
zeros -= 1
|
||||
zeros = zeros.numpy().astype(unsign_type)
|
||||
i = 0
|
||||
col = 0
|
||||
while col < qzeros.shape[1]:
|
||||
if self.bits in [2, 4, 8]:
|
||||
for j in range(i, i + (pbits // self.bits)):
|
||||
qzeros[:, col] |= zeros[:, j] << (self.bits * (j - i))
|
||||
i += pbits // self.bits
|
||||
col += 1
|
||||
else:
|
||||
raise NotImplementedError("Only 2,4,8 bits are supported.")
|
||||
qzeros = qzeros.astype(sign_type)
|
||||
qzeros = torch.from_numpy(qzeros)
|
||||
qzeros = qzeros
|
||||
self.qzeros.data.copy_(qzeros)
|
||||
|
||||
if torch.equal(self.g_idx.to(g_idx.device), g_idx):
|
||||
self.g_idx = None
|
||||
else:
|
||||
self.g_idx = g_idx
|
||||
|
||||
def init_q4(self):
|
||||
assert self.qweight.device.type == "cuda"
|
||||
self.q4_width = self.qweight.shape[1]
|
||||
if self.g_idx is not None:
|
||||
if self.row_split and torch.equal(
|
||||
self.g_idx,
|
||||
torch.tensor(
|
||||
[(i + (self.tp_rank * self.infeatures)) // self.groupsize for i in range(self.infeatures)],
|
||||
dtype=torch.int32,
|
||||
device=self.g_idx.device)):
|
||||
self.g_idx = None
|
||||
elif torch.equal(
|
||||
self.g_idx,
|
||||
torch.tensor([i // self.groupsize for i in range(self.infeatures)],
|
||||
dtype=torch.int32,
|
||||
device=self.g_idx.device)):
|
||||
self.g_idx = None
|
||||
|
||||
if self.g_idx is not None:
|
||||
g_idx = self.g_idx.to("cpu")
|
||||
else:
|
||||
g_idx = self.empty_tensor
|
||||
|
||||
self.q4 = gptq_cuda.make_q4(self.qweight, self.qzeros, self.scales, g_idx, torch.cuda.current_device())
|
||||
torch.cuda.synchronize()
|
||||
|
||||
def forward(self, x):
|
||||
outshape = x.shape[:-1] + (self.outfeatures,)
|
||||
|
||||
if HAS_GPTQ_CUDA and self.bits == 4:
|
||||
|
||||
if self.q4 is None:
|
||||
self.init_q4()
|
||||
|
||||
x = x.view(-1, x.shape[-1])
|
||||
output = torch.empty((x.shape[0], self.outfeatures), dtype=torch.float16, device=x.device)
|
||||
gptq_cuda.q4_matmul(x.half(), self.q4, output)
|
||||
if self.bias is not None and (not self.row_split or self.tp_size == 1):
|
||||
output.add_(self.bias)
|
||||
else:
|
||||
if self.bias is not None and (not self.row_split or self.tp_size == 1):
|
||||
bias = self.bias
|
||||
else:
|
||||
bias = None
|
||||
output = self.gptq_linear(
|
||||
x,
|
||||
self.qweight,
|
||||
self.scales,
|
||||
self.qzeros,
|
||||
g_idx=self.g_idx,
|
||||
bias=bias,
|
||||
)
|
||||
return output.view(outshape)
|
||||
|
||||
|
||||
def split_column_copy(gptq_linear, cai_linear, tp_size=1, tp_rank=0, split_num=1):
|
||||
|
||||
qweights = gptq_linear.qweight.split(gptq_linear.out_features // split_num, dim=-1)
|
||||
qzeros = gptq_linear.qzeros.split(gptq_linear.out_features // (32 // cai_linear.bits) // split_num, dim=-1)
|
||||
scales = gptq_linear.scales.split(gptq_linear.out_features // split_num, dim=-1)
|
||||
g_idx = gptq_linear.g_idx
|
||||
if gptq_linear.bias is not None:
|
||||
bias = gptq_linear.bias.split(gptq_linear.out_features // split_num, dim=-1)
|
||||
|
||||
cai_split_out_features = cai_linear.outfeatures // split_num
|
||||
zero_split_block = cai_linear.outfeatures // (32 // cai_linear.bits) // split_num
|
||||
|
||||
for i in range(split_num):
|
||||
cai_linear.qweight[:, i * cai_split_out_features:(i + 1) *
|
||||
cai_split_out_features] = qweights[i][:, tp_rank * cai_split_out_features:(tp_rank + 1) *
|
||||
cai_split_out_features]
|
||||
cai_linear.qzeros[:, i * zero_split_block:(i + 1) *
|
||||
zero_split_block] = qzeros[i][:, tp_rank * zero_split_block:(tp_rank + 1) * zero_split_block]
|
||||
cai_linear.scales[:, i * cai_split_out_features:(i + 1) *
|
||||
cai_split_out_features] = scales[i][:, tp_rank * cai_split_out_features:(tp_rank + 1) *
|
||||
cai_split_out_features]
|
||||
if cai_linear.bias is not None:
|
||||
cai_linear.bias[i * cai_split_out_features:(i + 1) *
|
||||
cai_split_out_features] = bias[i][tp_rank * cai_split_out_features:(tp_rank + 1) *
|
||||
cai_split_out_features]
|
||||
|
||||
cai_linear.g_idx.copy_(g_idx)
|
||||
|
||||
|
||||
def split_row_copy(gptq_linear, cai_linear, tp_rank=0, split_num=1):
|
||||
|
||||
qweights = gptq_linear.qweight.split(gptq_linear.in_features // split_num, dim=0)
|
||||
qzeros = gptq_linear.qzeros.split(gptq_linear.in_features // split_num, dim=0)
|
||||
scales = gptq_linear.scales.split(gptq_linear.in_features // split_num, dim=0)
|
||||
g_idxs = gptq_linear.g_idx.split(gptq_linear.in_features // split_num, dim=0)
|
||||
|
||||
cai_split_in_features = cai_linear.infeatures // (32 // cai_linear.bits) // split_num
|
||||
zero_split_block = cai_linear.infeatures // cai_linear.groupsize // split_num
|
||||
idx_split_features = cai_linear.infeatures // split_num
|
||||
|
||||
for i in range(split_num):
|
||||
cai_linear.qweight[i * cai_split_in_features:(i + 1) *
|
||||
cai_split_in_features, :] = qweights[i][tp_rank * cai_split_in_features:(tp_rank + 1) *
|
||||
cai_split_in_features, :]
|
||||
cai_linear.qzeros[i * zero_split_block:(i + 1) *
|
||||
zero_split_block, :] = qzeros[i][tp_rank * zero_split_block:(tp_rank + 1) *
|
||||
zero_split_block, :]
|
||||
cai_linear.scales[i * zero_split_block:(i + 1) *
|
||||
zero_split_block, :] = scales[i][tp_rank * zero_split_block:(tp_rank + 1) *
|
||||
zero_split_block, :]
|
||||
cai_linear.g_idx[i * idx_split_features:(i + 1) *
|
||||
idx_split_features] = g_idxs[i][tp_rank * idx_split_features:(tp_rank + 1) *
|
||||
idx_split_features]
|
||||
if cai_linear.bias is not None:
|
||||
cai_linear.bias.copy_(gptq_linear.bias)
|
||||
|
||||
|
||||
class RowCaiQuantLinear(CaiQuantLinear, ParallelModule):
|
||||
|
||||
def __init__(self, bits, groupsize, infeatures, outfeatures, bias, tp_size=1, tp_rank=0, row_split=False):
|
||||
|
||||
super().__init__(bits,
|
||||
groupsize,
|
||||
infeatures,
|
||||
outfeatures,
|
||||
bias,
|
||||
tp_size=tp_size,
|
||||
tp_rank=tp_rank,
|
||||
row_split=row_split)
|
||||
self.process_group = None
|
||||
|
||||
@staticmethod
|
||||
def from_native_module(module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args,
|
||||
**kwargs) -> ParallelModule:
|
||||
LazyInitContext.materialize(module)
|
||||
# get the attributes
|
||||
in_features = module.in_features
|
||||
|
||||
# ensure only one process group is passed
|
||||
if isinstance(process_group, (list, tuple)):
|
||||
assert len(process_group) == 1, \
|
||||
f'Expected only one process group, got {len(process_group)}.'
|
||||
process_group = process_group[0]
|
||||
|
||||
tp_size = dist.get_world_size(process_group)
|
||||
tp_rank = dist.get_rank(process_group)
|
||||
|
||||
if in_features < tp_size:
|
||||
return module
|
||||
|
||||
if in_features % tp_size != 0:
|
||||
raise ValueError(
|
||||
f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!")
|
||||
linear_1d = RowCaiQuantLinear(module.bits,
|
||||
module.group_size,
|
||||
module.in_features // tp_size,
|
||||
module.out_features,
|
||||
module.bias is not None,
|
||||
tp_size=tp_size,
|
||||
tp_rank=tp_rank,
|
||||
row_split=True)
|
||||
linear_1d.process_group = process_group
|
||||
|
||||
split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
|
||||
return linear_1d
|
||||
|
||||
def forward(self, x):
|
||||
output = super().forward(x)
|
||||
if self.tp_size > 1:
|
||||
dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
|
||||
if self.bias is not None:
|
||||
output.add_(self.bias)
|
||||
return output
|
||||
|
||||
|
||||
class ColCaiQuantLinear(CaiQuantLinear, ParallelModule):
|
||||
|
||||
def __init__(self, bits, groupsize, infeatures, outfeatures, bias, tp_size=1, tp_rank=0, row_split=False):
|
||||
|
||||
super().__init__(bits,
|
||||
groupsize,
|
||||
infeatures,
|
||||
outfeatures,
|
||||
bias,
|
||||
tp_size=tp_size,
|
||||
tp_rank=tp_rank,
|
||||
row_split=row_split)
|
||||
self.process_group = None
|
||||
|
||||
@staticmethod
|
||||
def from_native_module(module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args,
|
||||
**kwargs) -> ParallelModule:
|
||||
LazyInitContext.materialize(module)
|
||||
# get the attributes
|
||||
in_features = module.in_features
|
||||
|
||||
# ensure only one process group is passed
|
||||
if isinstance(process_group, (list, tuple)):
|
||||
assert len(process_group) == 1, \
|
||||
f'Expected only one process group, got {len(process_group)}.'
|
||||
process_group = process_group[0]
|
||||
|
||||
tp_size = dist.get_world_size(process_group)
|
||||
tp_rank = dist.get_rank(process_group)
|
||||
|
||||
if in_features < tp_size:
|
||||
return module
|
||||
|
||||
if in_features % tp_size != 0:
|
||||
raise ValueError(
|
||||
f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!")
|
||||
linear_1d = ColCaiQuantLinear(module.bits,
|
||||
module.group_size,
|
||||
module.in_features,
|
||||
module.out_features // tp_size,
|
||||
module.bias is not None,
|
||||
tp_size=tp_size,
|
||||
tp_rank=tp_rank)
|
||||
linear_1d.process_group = process_group
|
||||
|
||||
split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
|
||||
return linear_1d
|
||||
|
|
@ -1,58 +0,0 @@
|
|||
import torch
|
||||
|
||||
from colossalai.kernel.triton import gptq_fused_linear_triton
|
||||
|
||||
|
||||
class CaiGPTQLinearOp(torch.nn.Module):
|
||||
def __init__(self, gptq_group_size, gptq_quant_bits):
|
||||
super(CaiGPTQLinearOp, self).__init__()
|
||||
self.group_size = gptq_group_size
|
||||
self.bits = gptq_quant_bits
|
||||
self.maxq = 2**self.bits - 1
|
||||
self.empty_tensor = torch.zeros(4, device=torch.cuda.current_device())
|
||||
|
||||
def forward(
|
||||
self,
|
||||
input: torch.Tensor,
|
||||
weight: torch.Tensor,
|
||||
weight_scales: torch.Tensor,
|
||||
weight_zeros: torch.Tensor,
|
||||
g_idx: torch.Tensor = None,
|
||||
act_type=0,
|
||||
bias: torch.Tensor = None,
|
||||
residual: torch.Tensor = None,
|
||||
qkv_fused=False,
|
||||
):
|
||||
add_bias = True
|
||||
if bias is None:
|
||||
bias = self.empty_tensor
|
||||
add_bias = False
|
||||
|
||||
add_residual = True
|
||||
if residual is None:
|
||||
residual = self.empty_tensor
|
||||
add_residual = False
|
||||
x = input.view(-1, input.shape[-1])
|
||||
|
||||
out = gptq_fused_linear_triton(
|
||||
x,
|
||||
weight,
|
||||
weight_scales,
|
||||
weight_zeros,
|
||||
bias,
|
||||
residual,
|
||||
self.bits,
|
||||
self.maxq,
|
||||
self.group_size,
|
||||
qkv_fused,
|
||||
add_bias,
|
||||
add_residual,
|
||||
act_type=act_type,
|
||||
g_idx=g_idx,
|
||||
)
|
||||
if qkv_fused:
|
||||
out = out.view(3, input.shape[0], input.shape[1], weight.shape[-1])
|
||||
else:
|
||||
out = out.view(input.shape[0], input.shape[1], weight.shape[-1])
|
||||
|
||||
return out
|
||||
|
|
@ -1,61 +0,0 @@
|
|||
import torch
|
||||
|
||||
|
||||
class GPTQManager:
|
||||
def __init__(self, quant_config, max_input_len: int = 1):
|
||||
self.max_dq_buffer_size = 1
|
||||
self.max_inner_outer_dim = 1
|
||||
self.bits = quant_config.bits
|
||||
self.use_act_order = quant_config.desc_act
|
||||
self.max_input_len = 1
|
||||
self.gptq_temp_state_buffer = None
|
||||
self.gptq_temp_dq_buffer = None
|
||||
self.quant_config = quant_config
|
||||
|
||||
def post_init_gptq_buffer(self, model: torch.nn.Module) -> None:
|
||||
from .cai_gptq import CaiQuantLinear
|
||||
|
||||
HAS_GPTQ_CUDA = False
|
||||
try:
|
||||
from colossalai.kernel.op_builder.gptq import GPTQBuilder
|
||||
|
||||
gptq_cuda = GPTQBuilder().load()
|
||||
HAS_GPTQ_CUDA = True
|
||||
except ImportError:
|
||||
warnings.warn("CUDA gptq is not installed")
|
||||
HAS_GPTQ_CUDA = False
|
||||
|
||||
for name, submodule in model.named_modules():
|
||||
if isinstance(submodule, CaiQuantLinear):
|
||||
self.max_dq_buffer_size = max(self.max_dq_buffer_size, submodule.qweight.numel() * 8)
|
||||
|
||||
if self.use_act_order:
|
||||
self.max_inner_outer_dim = max(
|
||||
self.max_inner_outer_dim, submodule.infeatures, submodule.outfeatures
|
||||
)
|
||||
self.bits = submodule.bits
|
||||
if not (HAS_GPTQ_CUDA and self.bits == 4):
|
||||
return
|
||||
|
||||
max_input_len = 1
|
||||
if self.use_act_order:
|
||||
max_input_len = self.max_input_len
|
||||
# The temp_state buffer is required to reorder X in the act-order case.
|
||||
# The temp_dq buffer is required to dequantize weights when using cuBLAS, typically for the prefill.
|
||||
self.gptq_temp_state_buffer = torch.zeros(
|
||||
(max_input_len, self.max_inner_outer_dim), dtype=torch.float16, device=torch.cuda.current_device()
|
||||
)
|
||||
self.gptq_temp_dq_buffer = torch.zeros(
|
||||
(1, self.max_dq_buffer_size), dtype=torch.float16, device=torch.cuda.current_device()
|
||||
)
|
||||
|
||||
gptq_cuda.prepare_buffers(
|
||||
torch.device(torch.cuda.current_device()), self.gptq_temp_state_buffer, self.gptq_temp_dq_buffer
|
||||
)
|
||||
# Using the default from exllama repo here.
|
||||
matmul_recons_thd = 8
|
||||
matmul_fused_remap = False
|
||||
matmul_no_half2 = False
|
||||
gptq_cuda.set_tuning_params(matmul_recons_thd, matmul_fused_remap, matmul_no_half2)
|
||||
|
||||
torch.cuda.empty_cache()
|
||||
|
|
@ -1,10 +0,0 @@
|
|||
try:
|
||||
import torch_int
|
||||
|
||||
HAS_TORCH_INT = True
|
||||
except ImportError:
|
||||
HAS_TORCH_INT = False
|
||||
print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
|
||||
|
||||
if HAS_TORCH_INT:
|
||||
from .llama import LLamaSmoothquantAttention, LlamaSmoothquantMLP
|
||||
|
|
@ -1,494 +0,0 @@
|
|||
# Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ
|
||||
# Adapted from smoothquant: https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/calibration.py
|
||||
# Adapted from smoothquant: https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/smooth.py
|
||||
|
||||
import os
|
||||
import warnings
|
||||
from abc import abstractmethod
|
||||
from functools import partial
|
||||
from os.path import isdir, isfile, join
|
||||
from typing import Dict, List, Optional, Union
|
||||
|
||||
import numpy as np
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import transformers
|
||||
from safetensors.torch import save_file as safe_save
|
||||
from tqdm import tqdm
|
||||
from transformers import AutoConfig, AutoModelForCausalLM, PreTrainedModel
|
||||
from transformers.modeling_utils import no_init_weights
|
||||
from transformers.utils.generic import ContextManagers
|
||||
from transformers.utils.hub import PushToHubMixin, cached_file
|
||||
|
||||
from colossalai.inference.kv_cache.batch_infer_state import BatchInferState, MemoryManager
|
||||
|
||||
try:
|
||||
import accelerate
|
||||
|
||||
HAS_ACCELERATE = True
|
||||
except ImportError:
|
||||
HAS_ACCELERATE = False
|
||||
print("accelerate is not installed.")
|
||||
|
||||
|
||||
SUPPORTED_MODELS = ["llama"]
|
||||
|
||||
|
||||
class BaseSmoothForCausalLM(nn.Module, PushToHubMixin):
|
||||
layer_type: str = None
|
||||
|
||||
def __init__(self, model: PreTrainedModel, quantized: bool = False):
|
||||
super().__init__()
|
||||
|
||||
self.model = model
|
||||
self.model_type = self.model.config.model_type
|
||||
self._quantized = quantized
|
||||
self.config = self.model.config
|
||||
self.cache_manager = None
|
||||
self.max_total_token_num = 0
|
||||
|
||||
@property
|
||||
def quantized(self):
|
||||
return self._quantized
|
||||
|
||||
def init_cache_manager(self, max_total_token_num=2048):
|
||||
if self.config.model_type == "llama":
|
||||
head_num = self.config.num_key_value_heads
|
||||
layer_num = self.config.num_hidden_layers
|
||||
head_dim = self.config.hidden_size // head_num
|
||||
|
||||
self.cache_manager = MemoryManager(max_total_token_num, torch.int8, head_num, head_dim, layer_num)
|
||||
self.max_total_token_num = max_total_token_num
|
||||
|
||||
def init_batch_state(self, max_output_len=256, **kwargs):
|
||||
input_ids = kwargs["input_ids"]
|
||||
batch_size = len(input_ids)
|
||||
|
||||
seq_start_indexes = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
|
||||
seq_lengths = torch.zeros(batch_size, dtype=torch.int32, device="cuda")
|
||||
start_index = 0
|
||||
max_len_in_batch = -1
|
||||
|
||||
for i in range(batch_size):
|
||||
seq_len = len(input_ids[i])
|
||||
seq_lengths[i] = seq_len
|
||||
seq_start_indexes[i] = start_index
|
||||
start_index += seq_len
|
||||
max_len_in_batch = seq_len if seq_len > max_len_in_batch else max_len_in_batch
|
||||
|
||||
if "max_total_token_num" in kwargs.keys():
|
||||
max_total_token_num = kwargs["max_total_token_num"]
|
||||
self.init_cache_manager(max_total_token_num)
|
||||
|
||||
if "max_new_tokens" in kwargs.keys():
|
||||
max_output_len = kwargs["max_new_tokens"]
|
||||
|
||||
if batch_size * (max_len_in_batch + max_output_len) > self.max_total_token_num:
|
||||
max_total_token_num = batch_size * (max_len_in_batch + max_output_len)
|
||||
warnings.warn(f"reset max tokens to {max_total_token_num}")
|
||||
self.init_cache_manager(max_total_token_num)
|
||||
|
||||
block_loc = torch.empty((batch_size, max_len_in_batch + max_output_len), dtype=torch.long, device="cuda")
|
||||
batch_infer_state = BatchInferState(batch_size, max_len_in_batch)
|
||||
batch_infer_state.seq_len = seq_lengths.to("cuda")
|
||||
batch_infer_state.start_loc = seq_start_indexes.to("cuda")
|
||||
batch_infer_state.block_loc = block_loc
|
||||
batch_infer_state.decode_layer_id = 0
|
||||
batch_infer_state.is_context_stage = True
|
||||
batch_infer_state.set_cache_manager(self.cache_manager)
|
||||
batch_infer_state.cache_manager.free_all()
|
||||
return batch_infer_state
|
||||
|
||||
@abstractmethod
|
||||
@torch.inference_mode()
|
||||
def quantize(
|
||||
self,
|
||||
examples: List[Dict[str, Union[List[int], torch.LongTensor]]],
|
||||
):
|
||||
if self.quantized:
|
||||
raise EnvironmentError("can't execute quantize because the model is quantized.")
|
||||
|
||||
def forward(self, *args, **kwargs):
|
||||
return self.model(*args, **kwargs)
|
||||
|
||||
def generate(self, **kwargs):
|
||||
"""shortcut for model.generate"""
|
||||
|
||||
batch_infer_state = self.init_batch_state(**kwargs)
|
||||
if self.config.model_type == "llama":
|
||||
setattr(self.model.model, "infer_state", batch_infer_state)
|
||||
|
||||
with torch.inference_mode():
|
||||
return self.model.generate(**kwargs)
|
||||
|
||||
def prepare_inputs_for_generation(self, *args, **kwargs):
|
||||
"""shortcut for model.prepare_inputs_for_generation"""
|
||||
return self.model.prepare_inputs_for_generation(*args, **kwargs)
|
||||
|
||||
def collect_act_scales(self, model, tokenizer, dataset, device, num_samples=512, seq_len=512):
|
||||
for text in tqdm(dataset):
|
||||
input_ids = tokenizer(text, return_tensors="pt", max_length=seq_len, truncation=True).input_ids.to(device)
|
||||
model(input_ids)
|
||||
|
||||
def collect_act_dict(self, model, tokenizer, dataset, act_dict, device, num_samples=512, seq_len=512):
|
||||
pbar = tqdm(dataset)
|
||||
for text in pbar:
|
||||
input_ids = tokenizer(text, return_tensors="pt", max_length=seq_len, truncation=True).input_ids.to(device)
|
||||
model(input_ids)
|
||||
mean_scale = np.mean([v["input"] for v in act_dict.values()])
|
||||
pbar.set_description(f"Mean input scale: {mean_scale:.2f}")
|
||||
|
||||
# Adatped from https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/calibration.py
|
||||
def get_act_scales(self, model, tokenizer, dataset, num_samples=512, seq_len=512):
|
||||
model.eval()
|
||||
device = next(model.parameters()).device
|
||||
act_scales = {}
|
||||
|
||||
def stat_tensor(name, tensor):
|
||||
hidden_dim = tensor.shape[-1]
|
||||
tensor = tensor.view(-1, hidden_dim).abs().detach()
|
||||
comming_max = torch.max(tensor, dim=0)[0].float().cpu()
|
||||
if name in act_scales:
|
||||
act_scales[name] = torch.max(act_scales[name], comming_max)
|
||||
else:
|
||||
act_scales[name] = comming_max
|
||||
|
||||
def stat_input_hook(m, x, y, name):
|
||||
if isinstance(x, tuple):
|
||||
x = x[0]
|
||||
stat_tensor(name, x)
|
||||
|
||||
hooks = []
|
||||
for name, m in model.named_modules():
|
||||
if isinstance(m, nn.Linear):
|
||||
hooks.append(m.register_forward_hook(partial(stat_input_hook, name=name)))
|
||||
|
||||
self.collect_act_scales(model, tokenizer, dataset, device, num_samples, seq_len)
|
||||
|
||||
for h in hooks:
|
||||
h.remove()
|
||||
|
||||
return act_scales
|
||||
|
||||
# Adapted from https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/smooth.py
|
||||
@torch.no_grad()
|
||||
def smooth_ln_fcs(self, ln, fcs, act_scales, alpha=0.5):
|
||||
if not isinstance(fcs, list):
|
||||
fcs = [fcs]
|
||||
for fc in fcs:
|
||||
assert isinstance(fc, nn.Linear)
|
||||
assert ln.weight.numel() == fc.in_features == act_scales.numel()
|
||||
|
||||
device, dtype = fcs[0].weight.device, fcs[0].weight.dtype
|
||||
act_scales = act_scales.to(device=device, dtype=dtype)
|
||||
weight_scales = torch.cat([fc.weight.abs().max(dim=0, keepdim=True)[0] for fc in fcs], dim=0)
|
||||
weight_scales = weight_scales.max(dim=0)[0].clamp(min=1e-5)
|
||||
|
||||
scales = (act_scales.pow(alpha) / weight_scales.pow(1 - alpha)).clamp(min=1e-5).to(device).to(dtype)
|
||||
|
||||
ln.weight.div_(scales)
|
||||
if hasattr(ln, "bias"):
|
||||
ln.bias.div_(scales)
|
||||
|
||||
for fc in fcs:
|
||||
fc.weight.mul_(scales.view(1, -1))
|
||||
|
||||
@classmethod
|
||||
def create_quantized_model(model):
|
||||
raise NotImplementedError("Not implement create_quantized_model method")
|
||||
|
||||
# Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/modeling/_base.py
|
||||
def save_quantized(
|
||||
self,
|
||||
save_dir: str,
|
||||
model_basename: str,
|
||||
use_safetensors: bool = False,
|
||||
safetensors_metadata: Optional[Dict[str, str]] = None,
|
||||
):
|
||||
"""save quantized model and configs to local disk"""
|
||||
os.makedirs(save_dir, exist_ok=True)
|
||||
|
||||
if not self.quantized:
|
||||
raise EnvironmentError("can only save quantized model, please execute .quantize first.")
|
||||
|
||||
self.model.to("cpu")
|
||||
|
||||
model_base_name = model_basename # or f"smooth-"
|
||||
if use_safetensors:
|
||||
model_save_name = model_base_name + ".safetensors"
|
||||
state_dict = self.model.state_dict()
|
||||
state_dict = {k: v.clone().contiguous() for k, v in state_dict.items()}
|
||||
if safetensors_metadata is None:
|
||||
safetensors_metadata = {}
|
||||
elif not isinstance(safetensors_metadata, dict):
|
||||
raise TypeError("safetensors_metadata must be a dictionary.")
|
||||
else:
|
||||
print(f"Received safetensors_metadata: {safetensors_metadata}")
|
||||
new_safetensors_metadata = {}
|
||||
converted_keys = False
|
||||
for key, value in safetensors_metadata.items():
|
||||
if not isinstance(key, str) or not isinstance(value, str):
|
||||
converted_keys = True
|
||||
try:
|
||||
new_key = str(key)
|
||||
new_value = str(value)
|
||||
except Exception as e:
|
||||
raise TypeError(
|
||||
f"safetensors_metadata: both keys and values must be strings and an error occured when trying to convert them: {e}"
|
||||
)
|
||||
if new_key in new_safetensors_metadata:
|
||||
print(
|
||||
f"After converting safetensors_metadata keys to strings, the key '{new_key}' is duplicated. Ensure that all your metadata keys are strings to avoid overwriting."
|
||||
)
|
||||
new_safetensors_metadata[new_key] = new_value
|
||||
safetensors_metadata = new_safetensors_metadata
|
||||
if converted_keys:
|
||||
print(
|
||||
f"One or more safetensors_metadata keys or values had to be converted to str(). Final safetensors_metadata: {safetensors_metadata}"
|
||||
)
|
||||
|
||||
# Format is required to enable Accelerate to load the metadata
|
||||
# otherwise it raises an OSError
|
||||
safetensors_metadata["format"] = "pt"
|
||||
|
||||
safe_save(state_dict, join(save_dir, model_save_name), safetensors_metadata)
|
||||
else:
|
||||
model_save_name = model_base_name + ".bin"
|
||||
torch.save(self.model.state_dict(), join(save_dir, model_save_name))
|
||||
|
||||
self.model.config.save_pretrained(save_dir)
|
||||
|
||||
# Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/modeling/_base.py
|
||||
def save_pretrained(
|
||||
self,
|
||||
save_dir: str,
|
||||
use_safetensors: bool = False,
|
||||
safetensors_metadata: Optional[Dict[str, str]] = None,
|
||||
**kwargs,
|
||||
):
|
||||
"""alias of save_quantized"""
|
||||
warnings.warn("you are using save_pretrained, which will re-direct to save_quantized.")
|
||||
self.save_quantized(save_dir, use_safetensors, safetensors_metadata)
|
||||
|
||||
# Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/modeling/_base.py
|
||||
@classmethod
|
||||
def from_pretrained(
|
||||
cls,
|
||||
pretrained_model_name_or_path: str,
|
||||
max_memory: Optional[dict] = None,
|
||||
trust_remote_code: bool = False,
|
||||
torch_dtype: torch.dtype = torch.float16,
|
||||
**model_init_kwargs,
|
||||
):
|
||||
if not torch.cuda.is_available():
|
||||
raise EnvironmentError("Load pretrained model to do quantization requires CUDA available.")
|
||||
|
||||
def skip(*args, **kwargs):
|
||||
pass
|
||||
|
||||
torch.nn.init.kaiming_uniform_ = skip
|
||||
torch.nn.init.uniform_ = skip
|
||||
torch.nn.init.normal_ = skip
|
||||
|
||||
# Parameters related to loading from Hugging Face Hub
|
||||
cache_dir = model_init_kwargs.pop("cache_dir", None)
|
||||
force_download = model_init_kwargs.pop("force_download", False)
|
||||
resume_download = model_init_kwargs.pop("resume_download", False)
|
||||
proxies = model_init_kwargs.pop("proxies", None)
|
||||
local_files_only = model_init_kwargs.pop("local_files_only", False)
|
||||
use_auth_token = model_init_kwargs.pop("use_auth_token", None)
|
||||
revision = model_init_kwargs.pop("revision", None)
|
||||
subfolder = model_init_kwargs.pop("subfolder", "")
|
||||
model_init_kwargs.pop("_commit_hash", None)
|
||||
|
||||
cached_file_kwargs = {
|
||||
"cache_dir": cache_dir,
|
||||
"force_download": force_download,
|
||||
"proxies": proxies,
|
||||
"resume_download": resume_download,
|
||||
"local_files_only": local_files_only,
|
||||
"use_auth_token": use_auth_token,
|
||||
"revision": revision,
|
||||
"subfolder": subfolder,
|
||||
}
|
||||
|
||||
config = AutoConfig.from_pretrained(pretrained_model_name_or_path, trust_remote_code=True, **cached_file_kwargs)
|
||||
if config.model_type not in SUPPORTED_MODELS:
|
||||
raise TypeError(f"{config.model_type} isn't supported yet.")
|
||||
|
||||
# enforce some values despite user specified
|
||||
model_init_kwargs["torch_dtype"] = torch_dtype
|
||||
model_init_kwargs["trust_remote_code"] = trust_remote_code
|
||||
if max_memory:
|
||||
if "disk" in max_memory:
|
||||
raise NotImplementedError("disk offload not support yet.")
|
||||
with accelerate.init_empty_weights():
|
||||
model = AutoModelForCausalLM.from_config(config, trust_remote_code=True)
|
||||
model.tie_weights()
|
||||
|
||||
max_memory = accelerate.utils.get_balanced_memory(
|
||||
model,
|
||||
max_memory=max_memory,
|
||||
no_split_module_classes=[cls.layer_type],
|
||||
dtype=model_init_kwargs["torch_dtype"],
|
||||
low_zero=False,
|
||||
)
|
||||
model_init_kwargs["device_map"] = accelerate.infer_auto_device_map(
|
||||
model,
|
||||
max_memory=max_memory,
|
||||
no_split_module_classes=[cls.layer_type],
|
||||
dtype=model_init_kwargs["torch_dtype"],
|
||||
)
|
||||
model_init_kwargs["low_cpu_mem_usage"] = True
|
||||
|
||||
del model
|
||||
else:
|
||||
model_init_kwargs["device_map"] = None
|
||||
model_init_kwargs["low_cpu_mem_usage"] = False
|
||||
|
||||
torch.cuda.empty_cache()
|
||||
|
||||
merged_kwargs = {**model_init_kwargs, **cached_file_kwargs}
|
||||
model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, **merged_kwargs)
|
||||
|
||||
model_config = model.config.to_dict()
|
||||
seq_len_keys = ["max_position_embeddings", "seq_length", "n_positions"]
|
||||
if any([k in model_config for k in seq_len_keys]):
|
||||
for key in seq_len_keys:
|
||||
if key in model_config:
|
||||
model.seqlen = model_config[key]
|
||||
break
|
||||
else:
|
||||
warnings.warn("can't get model's sequence length from model config, will set to 4096.")
|
||||
model.seqlen = 4096
|
||||
model.eval()
|
||||
|
||||
return cls(model, False)
|
||||
|
||||
# Adapted from AutoGPTQ: https://github.com/PanQiWei/AutoGPTQ/blob/main/auto_gptq/modeling/_base.py
|
||||
@classmethod
|
||||
def from_quantized(
|
||||
cls,
|
||||
model_name_or_path: Optional[str],
|
||||
model_basename: Optional[str] = None,
|
||||
device_map: Optional[Union[str, Dict[str, Union[int, str]]]] = None,
|
||||
max_memory: Optional[dict] = None,
|
||||
device: Optional[Union[str, int]] = None,
|
||||
low_cpu_mem_usage: bool = False,
|
||||
torch_dtype: Optional[torch.dtype] = None,
|
||||
use_safetensors: bool = False,
|
||||
trust_remote_code: bool = False,
|
||||
**kwargs,
|
||||
):
|
||||
"""load quantized model from local disk"""
|
||||
|
||||
# Parameters related to loading from Hugging Face Hub
|
||||
cache_dir = kwargs.pop("cache_dir", None)
|
||||
force_download = kwargs.pop("force_download", False)
|
||||
resume_download = kwargs.pop("resume_download", False)
|
||||
proxies = kwargs.pop("proxies", None)
|
||||
local_files_only = kwargs.pop("local_files_only", False)
|
||||
use_auth_token = kwargs.pop("use_auth_token", None)
|
||||
revision = kwargs.pop("revision", None)
|
||||
subfolder = kwargs.pop("subfolder", "")
|
||||
commit_hash = kwargs.pop("_commit_hash", None)
|
||||
|
||||
cached_file_kwargs = {
|
||||
"cache_dir": cache_dir,
|
||||
"force_download": force_download,
|
||||
"proxies": proxies,
|
||||
"resume_download": resume_download,
|
||||
"local_files_only": local_files_only,
|
||||
"use_auth_token": use_auth_token,
|
||||
"revision": revision,
|
||||
"subfolder": subfolder,
|
||||
"_raise_exceptions_for_missing_entries": False,
|
||||
"_commit_hash": commit_hash,
|
||||
}
|
||||
|
||||
# == step1: prepare configs and file names == #
|
||||
config = AutoConfig.from_pretrained(
|
||||
model_name_or_path, trust_remote_code=trust_remote_code, **cached_file_kwargs
|
||||
)
|
||||
|
||||
if config.model_type not in SUPPORTED_MODELS:
|
||||
raise TypeError(f"{config.model_type} isn't supported yet.")
|
||||
|
||||
extensions = []
|
||||
if use_safetensors:
|
||||
extensions.append(".safetensors")
|
||||
else:
|
||||
extensions += [".bin", ".pt"]
|
||||
|
||||
model_name_or_path = str(model_name_or_path)
|
||||
is_local = isdir(model_name_or_path)
|
||||
|
||||
resolved_archive_file = None
|
||||
if is_local:
|
||||
model_save_name = join(model_name_or_path, model_basename)
|
||||
for ext in extensions:
|
||||
if isfile(model_save_name + ext):
|
||||
resolved_archive_file = model_save_name + ext
|
||||
break
|
||||
else: # remote
|
||||
for ext in extensions:
|
||||
resolved_archive_file = cached_file(model_name_or_path, model_basename + ext, **cached_file_kwargs)
|
||||
if resolved_archive_file is not None:
|
||||
break
|
||||
|
||||
if resolved_archive_file is None: # Could not find a model file to use
|
||||
raise FileNotFoundError(f"Could not find model in {model_name_or_path}")
|
||||
|
||||
model_save_name = resolved_archive_file
|
||||
|
||||
# == step2: convert model to quantized-model (replace Linear) == #
|
||||
def skip(*args, **kwargs):
|
||||
pass
|
||||
|
||||
torch.nn.init.kaiming_uniform_ = skip
|
||||
torch.nn.init.uniform_ = skip
|
||||
torch.nn.init.normal_ = skip
|
||||
|
||||
transformers.modeling_utils._init_weights = False
|
||||
|
||||
init_contexts = [no_init_weights()]
|
||||
if low_cpu_mem_usage:
|
||||
init_contexts.append(accelerate.init_empty_weights(include_buffers=True))
|
||||
|
||||
with ContextManagers(init_contexts):
|
||||
model = AutoModelForCausalLM.from_config(
|
||||
config, trust_remote_code=trust_remote_code, torch_dtype=torch_dtype
|
||||
)
|
||||
cls.create_quantized_model(model)
|
||||
model.tie_weights()
|
||||
|
||||
# == step3: load checkpoint to quantized-model == #
|
||||
accelerate.utils.modeling.load_checkpoint_in_model(
|
||||
model, checkpoint=model_save_name, offload_state_dict=True, offload_buffers=True
|
||||
)
|
||||
|
||||
# == step4: set seqlen == #
|
||||
model_config = model.config.to_dict()
|
||||
seq_len_keys = ["max_position_embeddings", "seq_length", "n_positions"]
|
||||
if any([k in model_config for k in seq_len_keys]):
|
||||
for key in seq_len_keys:
|
||||
if key in model_config:
|
||||
model.seqlen = model_config[key]
|
||||
break
|
||||
else:
|
||||
warnings.warn("can't get model's sequence length from model config, will set to 4096.")
|
||||
model.seqlen = 4096
|
||||
|
||||
return cls(
|
||||
model,
|
||||
True,
|
||||
)
|
||||
|
||||
def __getattr__(self, item):
|
||||
try:
|
||||
return super().__getattr__(item)
|
||||
except:
|
||||
return getattr(self.model, item)
|
||||
|
||||
|
||||
__all__ = ["BaseSmoothForCausalLM"]
|
||||
|
|
@ -1,189 +0,0 @@
|
|||
# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
|
||||
|
||||
import torch
|
||||
|
||||
try:
|
||||
from torch_int._CUDA import linear_a8_w8_b8_o8, linear_a8_w8_bfp32_ofp32
|
||||
from torch_int.functional.quantization import quantize_per_tensor_absmax
|
||||
|
||||
HAS_TORCH_INT = True
|
||||
except ImportError:
|
||||
HAS_TORCH_INT = False
|
||||
print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
|
||||
|
||||
|
||||
try:
|
||||
from colossalai.kernel.op_builder.smoothquant import SmoothquantBuilder
|
||||
|
||||
smoothquant_cuda = SmoothquantBuilder().load()
|
||||
HAS_SMOOTHQUANT_CUDA = True
|
||||
except:
|
||||
HAS_SMOOTHQUANT_CUDA = False
|
||||
print("CUDA smoothquant linear is not installed")
|
||||
|
||||
|
||||
class W8A8BFP32O32LinearSiLU(torch.nn.Module):
|
||||
def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
|
||||
super().__init__()
|
||||
self.in_features = in_features
|
||||
self.out_features = out_features
|
||||
|
||||
self.register_buffer(
|
||||
"weight",
|
||||
torch.randint(
|
||||
-127,
|
||||
127,
|
||||
(self.out_features, self.in_features),
|
||||
dtype=torch.int8,
|
||||
requires_grad=False,
|
||||
),
|
||||
)
|
||||
self.register_buffer(
|
||||
"bias",
|
||||
torch.zeros((1, self.out_features), dtype=torch.float, requires_grad=False),
|
||||
)
|
||||
self.register_buffer("a", torch.tensor(alpha))
|
||||
|
||||
def to(self, *args, **kwargs):
|
||||
super().to(*args, **kwargs)
|
||||
self.weight = self.weight.to(*args, **kwargs)
|
||||
self.bias = self.bias.to(*args, **kwargs)
|
||||
return self
|
||||
|
||||
@torch.no_grad()
|
||||
def forward(self, x):
|
||||
x_shape = x.shape
|
||||
x = x.view(-1, x_shape[-1])
|
||||
y = smoothquant_cuda.linear_silu_a8_w8_bfp32_ofp32(x, self.weight, self.bias, self.a.item(), 1.0)
|
||||
y = y.view(*x_shape[:-1], -1)
|
||||
return y
|
||||
|
||||
@staticmethod
|
||||
def from_float(module: torch.nn.Linear, input_scale):
|
||||
int8_module = W8A8BFP32O32LinearSiLU(module.in_features, module.out_features)
|
||||
int8_weight, weight_scale = quantize_per_tensor_absmax(module.weight)
|
||||
alpha = input_scale * weight_scale
|
||||
int8_module.weight = int8_weight
|
||||
if module.bias is not None:
|
||||
int8_module.bias.data.copy_(module.bias.to(torch.float))
|
||||
int8_module.a = alpha
|
||||
return int8_module
|
||||
|
||||
|
||||
# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
|
||||
class W8A8B8O8Linear(torch.nn.Module):
|
||||
# For qkv_proj
|
||||
def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
|
||||
super().__init__()
|
||||
self.in_features = in_features
|
||||
self.out_features = out_features
|
||||
|
||||
self.register_buffer(
|
||||
"weight",
|
||||
torch.randint(
|
||||
-127,
|
||||
127,
|
||||
(self.out_features, self.in_features),
|
||||
dtype=torch.int8,
|
||||
requires_grad=False,
|
||||
),
|
||||
)
|
||||
self.register_buffer(
|
||||
"bias",
|
||||
torch.zeros((1, self.out_features), dtype=torch.int8, requires_grad=False),
|
||||
)
|
||||
self.register_buffer("a", torch.tensor(alpha))
|
||||
self.register_buffer("b", torch.tensor(beta))
|
||||
|
||||
def to(self, *args, **kwargs):
|
||||
super().to(*args, **kwargs)
|
||||
self.weight = self.weight.to(*args, **kwargs)
|
||||
self.bias = self.bias.to(*args, **kwargs)
|
||||
return self
|
||||
|
||||
@torch.no_grad()
|
||||
def forward(self, x):
|
||||
x_shape = x.shape
|
||||
x = x.view(-1, x_shape[-1])
|
||||
y = linear_a8_w8_b8_o8(x, self.weight, self.bias, self.a.item(), self.b.item())
|
||||
y = y.view(*x_shape[:-1], -1)
|
||||
return y
|
||||
|
||||
@staticmethod
|
||||
def from_float(module: torch.nn.Linear, input_scale, output_scale):
|
||||
int8_module = W8A8B8O8Linear(module.in_features, module.out_features)
|
||||
int8_weight, weight_scale = quantize_per_tensor_absmax(module.weight)
|
||||
alpha = input_scale * weight_scale / output_scale
|
||||
int8_module.weight = int8_weight
|
||||
int8_module.a = alpha
|
||||
|
||||
if module.bias is not None:
|
||||
int8_bias, bias_scale = quantize_per_tensor_absmax(module.bias)
|
||||
int8_module.bias = int8_bias
|
||||
beta = bias_scale / output_scale
|
||||
int8_module.b = beta
|
||||
|
||||
return int8_module
|
||||
|
||||
|
||||
# modified from torch-int: https://github.com/Guangxuan-Xiao/torch-int/blob/main/torch_int/nn/linear.py
|
||||
class W8A8BFP32OFP32Linear(torch.nn.Module):
|
||||
# For fc2 and out_proj
|
||||
def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
|
||||
super().__init__()
|
||||
self.in_features = in_features
|
||||
self.out_features = out_features
|
||||
|
||||
self.register_buffer(
|
||||
"weight",
|
||||
torch.randint(
|
||||
-127,
|
||||
127,
|
||||
(self.out_features, self.in_features),
|
||||
dtype=torch.int8,
|
||||
requires_grad=False,
|
||||
),
|
||||
)
|
||||
self.register_buffer(
|
||||
"bias",
|
||||
torch.zeros((1, self.out_features), dtype=torch.float32, requires_grad=False),
|
||||
)
|
||||
self.register_buffer("a", torch.tensor(alpha))
|
||||
|
||||
def _apply(self, fn):
|
||||
# prevent the bias from being converted to half
|
||||
super()._apply(fn)
|
||||
if self.bias is not None:
|
||||
self.bias = self.bias.to(torch.float32)
|
||||
return self
|
||||
|
||||
def to(self, *args, **kwargs):
|
||||
super().to(*args, **kwargs)
|
||||
self.weight = self.weight.to(*args, **kwargs)
|
||||
if self.bias is not None:
|
||||
self.bias = self.bias.to(*args, **kwargs)
|
||||
self.bias = self.bias.to(torch.float32)
|
||||
return self
|
||||
|
||||
@torch.no_grad()
|
||||
def forward(self, x):
|
||||
x_shape = x.shape
|
||||
x = x.view(-1, x_shape[-1])
|
||||
y = linear_a8_w8_bfp32_ofp32(x, self.weight, self.bias, self.a.item(), 1)
|
||||
y = y.view(*x_shape[:-1], -1)
|
||||
return y
|
||||
|
||||
@staticmethod
|
||||
def from_float(module: torch.nn.Linear, input_scale):
|
||||
int8_module = W8A8BFP32OFP32Linear(module.in_features, module.out_features)
|
||||
int8_weight, weight_scale = quantize_per_tensor_absmax(module.weight)
|
||||
alpha = input_scale * weight_scale
|
||||
int8_module.weight = int8_weight
|
||||
int8_module.a = alpha
|
||||
int8_module.input_scale = input_scale
|
||||
int8_module.weight_scale = weight_scale
|
||||
|
||||
if module.bias is not None:
|
||||
int8_module.bias = module.bias.to(torch.float32)
|
||||
|
||||
return int8_module
|
||||
|
|
@ -1,852 +0,0 @@
|
|||
import math
|
||||
import os
|
||||
import types
|
||||
from collections import defaultdict
|
||||
from functools import partial
|
||||
from typing import List, Optional, Tuple, Union
|
||||
|
||||
import torch
|
||||
import torch.nn as nn
|
||||
import torch.nn.functional as F
|
||||
from transformers import PreTrainedModel
|
||||
from transformers.modeling_outputs import BaseModelOutputWithPast
|
||||
from transformers.models.llama.configuration_llama import LlamaConfig
|
||||
from transformers.models.llama.modeling_llama import (
|
||||
LLAMA_INPUTS_DOCSTRING,
|
||||
LlamaAttention,
|
||||
LlamaDecoderLayer,
|
||||
LlamaMLP,
|
||||
LlamaRotaryEmbedding,
|
||||
rotate_half,
|
||||
)
|
||||
from transformers.utils import add_start_docstrings_to_model_forward
|
||||
|
||||
from colossalai.inference.kv_cache.batch_infer_state import BatchInferState
|
||||
from colossalai.kernel.triton import (
|
||||
copy_kv_cache_to_dest,
|
||||
int8_rotary_embedding_fwd,
|
||||
smooth_llama_context_attn_fwd,
|
||||
smooth_token_attention_fwd,
|
||||
)
|
||||
|
||||
try:
|
||||
from torch_int.nn.bmm import BMM_S8T_S8N_F32T, BMM_S8T_S8N_S8T
|
||||
|
||||
HAS_TORCH_INT = True
|
||||
except ImportError:
|
||||
HAS_TORCH_INT = False
|
||||
print("Not install torch_int. Please install torch_int from https://github.com/Guangxuan-Xiao/torch-int")
|
||||
|
||||
|
||||
from .base_model import BaseSmoothForCausalLM
|
||||
from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
|
||||
|
||||
|
||||
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
|
||||
"""
|
||||
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
|
||||
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
|
||||
"""
|
||||
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
|
||||
if n_rep == 1:
|
||||
return hidden_states
|
||||
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
|
||||
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
|
||||
|
||||
|
||||
class LLamaSmoothquantAttention(nn.Module):
|
||||
def __init__(
|
||||
self,
|
||||
hidden_size: int,
|
||||
num_heads: int,
|
||||
):
|
||||
super().__init__()
|
||||
self.hidden_size = hidden_size
|
||||
self.num_heads = num_heads
|
||||
self.head_dim = hidden_size // num_heads
|
||||
|
||||
if (self.head_dim * num_heads) != self.hidden_size:
|
||||
raise ValueError(
|
||||
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
|
||||
f" and `num_heads`: {num_heads})."
|
||||
)
|
||||
|
||||
self.qk_bmm = BMM_S8T_S8N_F32T(1.0)
|
||||
self.pv_bmm = BMM_S8T_S8N_S8T(1.0)
|
||||
|
||||
self.k_proj = W8A8B8O8Linear(hidden_size, hidden_size)
|
||||
self.v_proj = W8A8B8O8Linear(hidden_size, hidden_size)
|
||||
self.q_proj = W8A8B8O8Linear(hidden_size, hidden_size)
|
||||
self.o_proj = W8A8BFP32OFP32Linear(hidden_size, hidden_size)
|
||||
|
||||
self.register_buffer("q_output_scale", torch.tensor([1.0]))
|
||||
self.register_buffer("k_output_scale", torch.tensor([1.0]))
|
||||
self.register_buffer("v_output_scale", torch.tensor([1.0]))
|
||||
self.register_buffer("q_rotary_output_scale", torch.tensor([1.0]))
|
||||
self.register_buffer("k_rotary_output_scale", torch.tensor([1.0]))
|
||||
self.register_buffer("out_input_scale", torch.tensor([1.0]))
|
||||
self.register_buffer("attn_input_scale", torch.tensor([1.0]))
|
||||
|
||||
self._init_rope()
|
||||
self.num_key_value_heads = num_heads
|
||||
|
||||
def _init_rope(self):
|
||||
self.rotary_emb = LlamaRotaryEmbedding(
|
||||
self.head_dim,
|
||||
max_position_embeddings=2048,
|
||||
base=10000.0,
|
||||
)
|
||||
|
||||
@staticmethod
|
||||
def pack(
|
||||
module: LlamaAttention,
|
||||
attn_input_scale: float,
|
||||
q_output_scale: float,
|
||||
k_output_scale: float,
|
||||
v_output_scale: float,
|
||||
q_rotary_output_scale: float,
|
||||
k_rotary_output_scale: float,
|
||||
out_input_scale: float,
|
||||
):
|
||||
int8_module = LLamaSmoothquantAttention(module.hidden_size, module.num_heads)
|
||||
|
||||
int8_module.attn_input_scale = torch.tensor([attn_input_scale])
|
||||
|
||||
int8_module.q_output_scale = torch.tensor([q_output_scale])
|
||||
int8_module.k_output_scale = torch.tensor([k_output_scale])
|
||||
int8_module.v_output_scale = torch.tensor([v_output_scale])
|
||||
|
||||
int8_module.q_rotary_output_scale = torch.tensor([q_rotary_output_scale])
|
||||
int8_module.k_rotary_output_scale = torch.tensor([k_rotary_output_scale])
|
||||
|
||||
int8_module.q_proj = W8A8B8O8Linear.from_float(module.q_proj, attn_input_scale, q_output_scale)
|
||||
int8_module.k_proj = W8A8B8O8Linear.from_float(module.k_proj, attn_input_scale, k_output_scale)
|
||||
int8_module.v_proj = W8A8B8O8Linear.from_float(module.v_proj, attn_input_scale, v_output_scale)
|
||||
int8_module.o_proj = W8A8BFP32OFP32Linear.from_float(module.o_proj, out_input_scale)
|
||||
|
||||
int8_module.out_input_scale = torch.tensor([out_input_scale])
|
||||
|
||||
return int8_module
|
||||
|
||||
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
|
||||
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
|
||||
|
||||
@torch.no_grad()
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: bool = False,
|
||||
use_cache: bool = False,
|
||||
padding_mask: Optional[torch.LongTensor] = None,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
bsz, q_len, _ = hidden_states.size()
|
||||
|
||||
query_states = self.q_proj(hidden_states)
|
||||
key_states = self.k_proj(hidden_states)
|
||||
value_states = self.v_proj(hidden_states)
|
||||
|
||||
cos, sin = infer_state.position_cos, infer_state.position_sin
|
||||
|
||||
int8_rotary_embedding_fwd(
|
||||
query_states.view(-1, self.num_heads, self.head_dim),
|
||||
cos,
|
||||
sin,
|
||||
self.q_output_scale.item(),
|
||||
self.q_rotary_output_scale.item(),
|
||||
)
|
||||
int8_rotary_embedding_fwd(
|
||||
key_states.view(-1, self.num_heads, self.head_dim),
|
||||
cos,
|
||||
sin,
|
||||
self.k_output_scale.item(),
|
||||
self.k_rotary_output_scale.item(),
|
||||
)
|
||||
|
||||
def _copy_kv_to_mem_cache(layer_id, key_buffer, value_buffer, context_mem_index, mem_manager):
|
||||
copy_kv_cache_to_dest(key_buffer, context_mem_index, mem_manager.key_buffer[layer_id])
|
||||
copy_kv_cache_to_dest(value_buffer, context_mem_index, mem_manager.value_buffer[layer_id])
|
||||
return
|
||||
|
||||
query_states = query_states.view(-1, self.num_heads, self.head_dim)
|
||||
key_states = key_states.view(-1, self.num_heads, self.head_dim)
|
||||
value_states = value_states.view(-1, self.num_heads, self.head_dim)
|
||||
|
||||
if infer_state.is_context_stage:
|
||||
# first token generation
|
||||
|
||||
# copy key and value calculated in current step to memory manager
|
||||
_copy_kv_to_mem_cache(
|
||||
infer_state.decode_layer_id,
|
||||
key_states,
|
||||
value_states,
|
||||
infer_state.context_mem_index,
|
||||
infer_state.cache_manager,
|
||||
)
|
||||
|
||||
attn_output = torch.empty_like(query_states)
|
||||
|
||||
smooth_llama_context_attn_fwd(
|
||||
query_states,
|
||||
key_states,
|
||||
value_states,
|
||||
attn_output,
|
||||
self.q_rotary_output_scale.item(),
|
||||
self.k_rotary_output_scale.item(),
|
||||
self.v_output_scale.item(),
|
||||
self.out_input_scale.item(),
|
||||
infer_state.start_loc,
|
||||
infer_state.seq_len,
|
||||
q_len,
|
||||
)
|
||||
|
||||
else:
|
||||
if infer_state.decode_is_contiguous:
|
||||
# if decode is contiguous, then we copy to key cache and value cache in cache manager directly
|
||||
cache_k = infer_state.cache_manager.key_buffer[infer_state.decode_layer_id][
|
||||
infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
|
||||
]
|
||||
cache_v = infer_state.cache_manager.value_buffer[infer_state.decode_layer_id][
|
||||
infer_state.decode_mem_start : infer_state.decode_mem_end, :, :
|
||||
]
|
||||
cache_k.copy_(key_states)
|
||||
cache_v.copy_(value_states)
|
||||
else:
|
||||
# if decode is not contiguous, use triton kernel to copy key and value cache
|
||||
# k, v shape: [batch_size, num_heads, head_dim/embed_size_per_head
|
||||
_copy_kv_to_mem_cache(
|
||||
infer_state.decode_layer_id,
|
||||
key_states,
|
||||
value_states,
|
||||
infer_state.decode_mem_index,
|
||||
infer_state.cache_manager,
|
||||
)
|
||||
|
||||
# (batch_size, seqlen, nheads, headdim)
|
||||
attn_output = torch.empty_like(query_states)
|
||||
|
||||
smooth_token_attention_fwd(
|
||||
query_states,
|
||||
infer_state.cache_manager.key_buffer[infer_state.decode_layer_id],
|
||||
infer_state.cache_manager.value_buffer[infer_state.decode_layer_id],
|
||||
attn_output,
|
||||
self.q_rotary_output_scale.item(),
|
||||
self.k_rotary_output_scale.item(),
|
||||
self.v_output_scale.item(),
|
||||
self.out_input_scale.item(),
|
||||
infer_state.block_loc,
|
||||
infer_state.start_loc,
|
||||
infer_state.seq_len,
|
||||
infer_state.max_len_in_batch,
|
||||
)
|
||||
|
||||
attn_output = attn_output.view(bsz, q_len, self.num_heads * self.head_dim)
|
||||
attn_output = self.o_proj(attn_output)
|
||||
|
||||
return attn_output, None, None
|
||||
|
||||
|
||||
class LlamaLayerNormQ(torch.nn.Module):
|
||||
def __init__(self, dim, eps=1e-5):
|
||||
super().__init__()
|
||||
self.input_scale = 1.0
|
||||
self.variance_epsilon = eps
|
||||
self.register_buffer("weight", torch.ones(dim, dtype=torch.float32))
|
||||
|
||||
def forward(self, x):
|
||||
ln_output_fp = torch.nn.functional.layer_norm(x, x.shape[-1:], self.weight, None, self.variance_epsilon)
|
||||
ln_output_int8 = ln_output_fp.round().clamp(-128, 127).to(torch.int8)
|
||||
return ln_output_int8
|
||||
|
||||
@staticmethod
|
||||
def from_float(module: torch.nn.LayerNorm, output_scale: float):
|
||||
assert module.weight.shape[0] == module.weight.numel()
|
||||
q_module = LlamaLayerNormQ(module.weight.shape[0], module.variance_epsilon)
|
||||
q_module.weight = module.weight / output_scale
|
||||
return q_module
|
||||
|
||||
|
||||
class LlamaSmoothquantMLP(nn.Module):
|
||||
def __init__(self, intermediate_size, hidden_size):
|
||||
super().__init__()
|
||||
self.gate_proj = W8A8BFP32O32LinearSiLU(hidden_size, intermediate_size)
|
||||
self.up_proj = W8A8BFP32OFP32Linear(hidden_size, intermediate_size)
|
||||
self.down_proj = W8A8BFP32OFP32Linear(intermediate_size, hidden_size)
|
||||
self.register_buffer("down_proj_input_scale", torch.tensor([1.0]))
|
||||
|
||||
@staticmethod
|
||||
def pack(
|
||||
mlp_module: LlamaMLP,
|
||||
gate_proj_input_scale: float,
|
||||
up_proj_input_scale: float,
|
||||
down_proj_input_scale: float,
|
||||
):
|
||||
int8_module = LlamaSmoothquantMLP(
|
||||
mlp_module.intermediate_size,
|
||||
mlp_module.hidden_size,
|
||||
)
|
||||
|
||||
int8_module.gate_proj = W8A8BFP32O32LinearSiLU.from_float(mlp_module.gate_proj, gate_proj_input_scale)
|
||||
int8_module.up_proj = W8A8BFP32OFP32Linear.from_float(mlp_module.up_proj, up_proj_input_scale)
|
||||
int8_module.down_proj = W8A8BFP32OFP32Linear.from_float(mlp_module.down_proj, down_proj_input_scale)
|
||||
int8_module.down_proj_input_scale = torch.tensor([down_proj_input_scale])
|
||||
return int8_module
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
):
|
||||
x_shape = hidden_states.shape
|
||||
gate_out = self.gate_proj(hidden_states)
|
||||
up_out = self.up_proj(hidden_states)
|
||||
inter_out = gate_out * up_out
|
||||
inter_out = inter_out.div_(self.down_proj_input_scale.item()).round().clamp(-128, 127).to(torch.int8)
|
||||
down_out = self.down_proj(inter_out)
|
||||
down_out = down_out.view(*x_shape[:-1], -1)
|
||||
return down_out
|
||||
|
||||
|
||||
class LlamaSmoothquantDecoderLayer(nn.Module):
|
||||
def __init__(self, config: LlamaConfig):
|
||||
super().__init__()
|
||||
self.hidden_size = config.hidden_size
|
||||
self.self_attn = LLamaSmoothquantAttention(config.hidden_size, config.num_attention_heads)
|
||||
|
||||
self.mlp = LlamaSmoothquantMLP(config.intermediate_size, config.hidden_size)
|
||||
self.input_layernorm = LlamaLayerNormQ(config.hidden_size, eps=config.rms_norm_eps)
|
||||
|
||||
self.post_attention_layernorm = LlamaLayerNormQ(config.hidden_size, eps=config.rms_norm_eps)
|
||||
|
||||
@staticmethod
|
||||
def pack(
|
||||
module: LlamaDecoderLayer,
|
||||
attn_input_scale: float,
|
||||
q_output_scale: float,
|
||||
k_output_scale: float,
|
||||
v_output_scale: float,
|
||||
q_rotary_output_scale: float,
|
||||
k_rotary_output_scale: float,
|
||||
out_input_scale: float,
|
||||
gate_input_scale: float,
|
||||
up_input_scale: float,
|
||||
down_input_scale: float,
|
||||
):
|
||||
config = module.self_attn.config
|
||||
int8_decoder_layer = LlamaSmoothquantDecoderLayer(config)
|
||||
|
||||
int8_decoder_layer.input_layernorm = LlamaLayerNormQ.from_float(module.input_layernorm, attn_input_scale)
|
||||
int8_decoder_layer.self_attn = LLamaSmoothquantAttention.pack(
|
||||
module.self_attn,
|
||||
attn_input_scale,
|
||||
q_output_scale,
|
||||
k_output_scale,
|
||||
v_output_scale,
|
||||
q_rotary_output_scale,
|
||||
k_rotary_output_scale,
|
||||
out_input_scale,
|
||||
)
|
||||
|
||||
int8_decoder_layer.post_attention_layernorm = LlamaLayerNormQ.from_float(
|
||||
module.post_attention_layernorm, gate_input_scale
|
||||
)
|
||||
|
||||
int8_decoder_layer.mlp = LlamaSmoothquantMLP.pack(
|
||||
module.mlp,
|
||||
gate_input_scale,
|
||||
up_input_scale,
|
||||
down_input_scale,
|
||||
)
|
||||
|
||||
return int8_decoder_layer
|
||||
|
||||
def forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: Optional[bool] = False,
|
||||
use_cache: Optional[bool] = False,
|
||||
padding_mask: Optional[torch.LongTensor] = None,
|
||||
infer_state: Optional[BatchInferState] = None,
|
||||
) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
|
||||
"""
|
||||
Args:
|
||||
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
|
||||
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
|
||||
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
|
||||
output_attentions (`bool`, *optional*):
|
||||
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
|
||||
returned tensors for more detail.
|
||||
use_cache (`bool`, *optional*):
|
||||
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
|
||||
(see `past_key_values`).
|
||||
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
|
||||
"""
|
||||
|
||||
residual = hidden_states
|
||||
|
||||
hidden_states = self.input_layernorm(hidden_states)
|
||||
|
||||
# Self Attention
|
||||
hidden_states, self_attn_weights, present_key_value = self.self_attn(
|
||||
hidden_states=hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_value,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
padding_mask=padding_mask,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
# Fully Connected
|
||||
residual = hidden_states
|
||||
hidden_states = self.post_attention_layernorm(hidden_states)
|
||||
hidden_states = self.mlp(hidden_states)
|
||||
hidden_states = residual + hidden_states
|
||||
|
||||
return hidden_states, None, None
|
||||
|
||||
|
||||
class LlamaApplyRotary(nn.Module):
|
||||
def __init__(self):
|
||||
super().__init__()
|
||||
|
||||
def forward(self, x, cos, sin, position_ids):
|
||||
# The first two dimensions of cos and sin are always 1, so we can `squeeze` them.
|
||||
cos = cos.squeeze(1).squeeze(0) # [seq_len, dim]
|
||||
sin = sin.squeeze(1).squeeze(0) # [seq_len, dim]
|
||||
cos = cos[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
|
||||
sin = sin[position_ids].unsqueeze(1) # [bs, 1, seq_len, dim]
|
||||
x_embed = (x * cos) + (rotate_half(x) * sin)
|
||||
|
||||
return x_embed
|
||||
|
||||
|
||||
# Adapted from https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py
|
||||
def llama_decoder_layer_forward(
|
||||
self,
|
||||
hidden_states: torch.Tensor,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_value: Optional[Tuple[torch.Tensor]] = None,
|
||||
output_attentions: bool = False,
|
||||
use_cache: bool = False,
|
||||
padding_mask: Optional[torch.LongTensor] = None,
|
||||
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
|
||||
bsz, q_len, _ = hidden_states.size()
|
||||
|
||||
if self.config.pretraining_tp > 1:
|
||||
key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.config.pretraining_tp
|
||||
query_slices = self.q_proj.weight.split((self.num_heads * self.head_dim) // self.config.pretraining_tp, dim=0)
|
||||
key_slices = self.k_proj.weight.split(key_value_slicing, dim=0)
|
||||
value_slices = self.v_proj.weight.split(key_value_slicing, dim=0)
|
||||
|
||||
query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.config.pretraining_tp)]
|
||||
query_states = torch.cat(query_states, dim=-1)
|
||||
|
||||
key_states = [F.linear(hidden_states, key_slices[i]) for i in range(self.config.pretraining_tp)]
|
||||
key_states = torch.cat(key_states, dim=-1)
|
||||
|
||||
value_states = [F.linear(hidden_states, value_slices[i]) for i in range(self.config.pretraining_tp)]
|
||||
value_states = torch.cat(value_states, dim=-1)
|
||||
|
||||
else:
|
||||
query_states = self.q_proj(hidden_states)
|
||||
key_states = self.k_proj(hidden_states)
|
||||
value_states = self.v_proj(hidden_states)
|
||||
|
||||
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
|
||||
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
||||
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
|
||||
|
||||
kv_seq_len = key_states.shape[-2]
|
||||
if past_key_value is not None:
|
||||
kv_seq_len += past_key_value[0].shape[-2]
|
||||
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
|
||||
query_states = self.q_apply_rotary(query_states, cos, sin, position_ids)
|
||||
key_states = self.k_apply_rotary(key_states, cos, sin, position_ids)
|
||||
|
||||
if past_key_value is not None:
|
||||
# reuse k, v, self_attention
|
||||
key_states = torch.cat([past_key_value[0], key_states], dim=2)
|
||||
value_states = torch.cat([past_key_value[1], value_states], dim=2)
|
||||
|
||||
past_key_value = (key_states, value_states) if use_cache else None
|
||||
|
||||
key_states = repeat_kv(key_states, self.num_key_value_groups)
|
||||
value_states = repeat_kv(value_states, self.num_key_value_groups)
|
||||
|
||||
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
|
||||
|
||||
if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
|
||||
raise ValueError(
|
||||
f"Attention weights should be of size {(bsz, self.num_heads, q_len, kv_seq_len)}, but is"
|
||||
f" {attn_weights.size()}"
|
||||
)
|
||||
|
||||
if attention_mask is not None:
|
||||
if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
|
||||
raise ValueError(
|
||||
f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
|
||||
)
|
||||
attn_weights = attn_weights + attention_mask
|
||||
|
||||
# upcast attention to fp32
|
||||
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
|
||||
attn_output = torch.matmul(attn_weights, value_states)
|
||||
|
||||
if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
|
||||
raise ValueError(
|
||||
f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
|
||||
f" {attn_output.size()}"
|
||||
)
|
||||
|
||||
attn_output = attn_output.transpose(1, 2).contiguous()
|
||||
|
||||
attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
|
||||
|
||||
if self.config.pretraining_tp > 1:
|
||||
attn_output = attn_output.split(self.hidden_size // self.config.pretraining_tp, dim=2)
|
||||
o_proj_slices = self.o_proj.weight.split(self.hidden_size // self.config.pretraining_tp, dim=1)
|
||||
attn_output = sum([F.linear(attn_output[i], o_proj_slices[i]) for i in range(self.config.pretraining_tp)])
|
||||
else:
|
||||
attn_output = self.o_proj(attn_output)
|
||||
|
||||
if not output_attentions:
|
||||
attn_weights = None
|
||||
|
||||
return attn_output, attn_weights, past_key_value
|
||||
|
||||
|
||||
def init_to_get_rotary(config, base=10000, use_elem=False):
|
||||
"""
|
||||
This function initializes the rotary positional embedding, it is compatible for all models and is called in ShardFormer
|
||||
Args:
|
||||
base : calculation arg
|
||||
use_elem : activated when using chatglm-based models
|
||||
"""
|
||||
config.head_dim_ = config.hidden_size // config.num_attention_heads
|
||||
if not hasattr(config, "rope_scaling"):
|
||||
rope_scaling_factor = 1.0
|
||||
else:
|
||||
rope_scaling_factor = config.rope_scaling.factor if config.rope_scaling is not None else 1.0
|
||||
|
||||
if hasattr(config, "max_sequence_length"):
|
||||
max_seq_len = config.max_sequence_length
|
||||
elif hasattr(config, "max_position_embeddings"):
|
||||
max_seq_len = config.max_position_embeddings * rope_scaling_factor
|
||||
else:
|
||||
max_seq_len = 2048 * rope_scaling_factor
|
||||
base = float(base)
|
||||
|
||||
# NTK ref: https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
|
||||
try:
|
||||
ntk_alpha = float(os.environ.get("INFER_NTK_ALPHA", 1))
|
||||
assert ntk_alpha >= 1
|
||||
if ntk_alpha > 1:
|
||||
print(f"Note: NTK enabled, alpha set to {ntk_alpha}")
|
||||
max_seq_len *= ntk_alpha
|
||||
base = base * (ntk_alpha ** (config.head_dim_ / (config.head_dim_ - 2))) # Base change formula
|
||||
except:
|
||||
pass
|
||||
|
||||
n_elem = config.head_dim_
|
||||
if use_elem:
|
||||
n_elem //= 2
|
||||
|
||||
inv_freq = 1.0 / (base ** (torch.arange(0, n_elem, 2, device="cpu", dtype=torch.float32) / n_elem))
|
||||
t = torch.arange(max_seq_len + 1024 * 64, device="cpu", dtype=torch.float32) / rope_scaling_factor
|
||||
freqs = torch.outer(t, inv_freq)
|
||||
|
||||
_cos_cached = torch.cos(freqs).to(torch.float)
|
||||
_sin_cached = torch.sin(freqs).to(torch.float)
|
||||
return _cos_cached, _sin_cached
|
||||
|
||||
|
||||
# Adapted from https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py
|
||||
@add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING)
|
||||
def llama_model_forward(
|
||||
self,
|
||||
input_ids: torch.LongTensor = None,
|
||||
attention_mask: Optional[torch.Tensor] = None,
|
||||
position_ids: Optional[torch.LongTensor] = None,
|
||||
past_key_values: Optional[List[torch.FloatTensor]] = None,
|
||||
inputs_embeds: Optional[torch.FloatTensor] = None,
|
||||
use_cache: Optional[bool] = None,
|
||||
output_attentions: Optional[bool] = None,
|
||||
output_hidden_states: Optional[bool] = None,
|
||||
return_dict: Optional[bool] = None,
|
||||
) -> Union[Tuple, BaseModelOutputWithPast]:
|
||||
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
|
||||
output_hidden_states = (
|
||||
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
|
||||
)
|
||||
use_cache = use_cache if use_cache is not None else self.config.use_cache
|
||||
|
||||
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
|
||||
|
||||
# retrieve input_ids and inputs_embeds
|
||||
if input_ids is not None and inputs_embeds is not None:
|
||||
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
|
||||
elif input_ids is not None:
|
||||
batch_size, seq_length = input_ids.shape
|
||||
elif inputs_embeds is not None:
|
||||
batch_size, seq_length, _ = inputs_embeds.shape
|
||||
else:
|
||||
raise ValueError("You have to specify either input_ids or inputs_embeds")
|
||||
|
||||
infer_state = self.infer_state
|
||||
if infer_state.is_context_stage:
|
||||
past_key_values_length = 0
|
||||
else:
|
||||
past_key_values_length = infer_state.max_len_in_batch - 1
|
||||
|
||||
seq_length_with_past = seq_length + past_key_values_length
|
||||
|
||||
# NOTE: differentiate with prefill stage
|
||||
# block_loc require different value-assigning method for two different stage
|
||||
# NOTE: differentiate with prefill stage
|
||||
# block_loc require different value-assigning method for two different stage
|
||||
if infer_state.is_context_stage:
|
||||
infer_state.context_mem_index = infer_state.cache_manager.alloc(infer_state.total_token_num)
|
||||
infer_state.init_block_loc(
|
||||
infer_state.block_loc, infer_state.seq_len, seq_length, infer_state.context_mem_index
|
||||
)
|
||||
else:
|
||||
alloc_mem = infer_state.cache_manager.alloc_contiguous(batch_size)
|
||||
if alloc_mem is not None:
|
||||
infer_state.decode_is_contiguous = True
|
||||
infer_state.decode_mem_index = alloc_mem[0]
|
||||
infer_state.decode_mem_start = alloc_mem[1]
|
||||
infer_state.decode_mem_end = alloc_mem[2]
|
||||
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
|
||||
else:
|
||||
print(f" *** Encountered allocation non-contiguous")
|
||||
print(f" infer_state.cache_manager.max_len_in_batch: {infer_state.max_len_in_batch}")
|
||||
infer_state.decode_is_contiguous = False
|
||||
alloc_mem = infer_state.cache_manager.alloc(batch_size)
|
||||
infer_state.decode_mem_index = alloc_mem
|
||||
infer_state.block_loc[:, seq_length_with_past - 1] = infer_state.decode_mem_index
|
||||
|
||||
if position_ids is None:
|
||||
device = input_ids.device if input_ids is not None else inputs_embeds.device
|
||||
position_ids = torch.arange(
|
||||
past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
|
||||
)
|
||||
position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
|
||||
else:
|
||||
position_ids = position_ids.view(-1, seq_length).long()
|
||||
|
||||
if inputs_embeds is None:
|
||||
inputs_embeds = self.embed_tokens(input_ids)
|
||||
# embed positions
|
||||
if attention_mask is None:
|
||||
attention_mask = torch.ones((batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device)
|
||||
padding_mask = None
|
||||
else:
|
||||
if 0 in attention_mask:
|
||||
padding_mask = attention_mask
|
||||
else:
|
||||
padding_mask = None
|
||||
|
||||
attention_mask = self._prepare_decoder_attention_mask(
|
||||
attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
|
||||
)
|
||||
|
||||
hidden_states = inputs_embeds
|
||||
|
||||
if self.gradient_checkpointing and self.training:
|
||||
raise NotImplementedError("not implement gradient_checkpointing and training options ")
|
||||
|
||||
if past_key_values_length == 0:
|
||||
infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(
|
||||
position_ids.view(-1).shape[0], -1
|
||||
)
|
||||
infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(
|
||||
position_ids.view(-1).shape[0], -1
|
||||
)
|
||||
else:
|
||||
infer_state.position_cos = torch.index_select(self._cos_cached, 0, position_ids.view(-1)).view(batch_size, -1)
|
||||
infer_state.position_sin = torch.index_select(self._sin_cached, 0, position_ids.view(-1)).view(batch_size, -1)
|
||||
|
||||
# decoder layers
|
||||
all_hidden_states = () if output_hidden_states else None
|
||||
all_self_attns = () if output_attentions else None
|
||||
next_decoder_cache = () if use_cache else None
|
||||
infer_state.decode_layer_id = 0
|
||||
for idx, decoder_layer in enumerate(self.layers):
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
past_key_value = past_key_values[idx] if past_key_values is not None else None
|
||||
|
||||
layer_outputs = decoder_layer(
|
||||
hidden_states,
|
||||
attention_mask=attention_mask,
|
||||
position_ids=position_ids,
|
||||
past_key_value=past_key_value,
|
||||
output_attentions=output_attentions,
|
||||
use_cache=use_cache,
|
||||
padding_mask=padding_mask,
|
||||
infer_state=infer_state,
|
||||
)
|
||||
|
||||
hidden_states = layer_outputs[0]
|
||||
infer_state.decode_layer_id += 1
|
||||
|
||||
if use_cache:
|
||||
next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
|
||||
|
||||
if output_attentions:
|
||||
all_self_attns += (layer_outputs[1],)
|
||||
|
||||
hidden_states = self.norm(hidden_states)
|
||||
|
||||
# add hidden states from the last decoder layer
|
||||
if output_hidden_states:
|
||||
all_hidden_states += (hidden_states,)
|
||||
|
||||
infer_state.is_context_stage = False
|
||||
infer_state.start_loc = infer_state.start_loc + torch.arange(0, batch_size, dtype=torch.int32, device="cuda")
|
||||
infer_state.seq_len += 1
|
||||
infer_state.max_len_in_batch += 1
|
||||
|
||||
next_cache = next_decoder_cache if use_cache else None
|
||||
if not return_dict:
|
||||
return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
|
||||
return BaseModelOutputWithPast(
|
||||
last_hidden_state=hidden_states,
|
||||
past_key_values=next_cache,
|
||||
hidden_states=all_hidden_states,
|
||||
attentions=all_self_attns,
|
||||
)
|
||||
|
||||
|
||||
class SmoothLlamaForCausalLM(BaseSmoothForCausalLM):
|
||||
layer_type = "LlamaDecoderLayer"
|
||||
|
||||
def __init__(self, model: PreTrainedModel, quantized: bool = False):
|
||||
super().__init__(model, quantized)
|
||||
|
||||
# Adatped from https://github.com/mit-han-lab/smoothquant/blob/main/smoothquant/calibration.py
|
||||
def get_act_dict(
|
||||
self,
|
||||
tokenizer,
|
||||
dataset,
|
||||
num_samples=512,
|
||||
seq_len=512,
|
||||
):
|
||||
llama_model = self.model
|
||||
|
||||
llama_model.eval()
|
||||
device = next(llama_model.parameters()).device
|
||||
# print("model:", llama_model)
|
||||
act_dict = defaultdict(dict)
|
||||
|
||||
def stat_io_hook(m, x, y, name):
|
||||
if isinstance(x, tuple):
|
||||
x = x[0]
|
||||
if name not in act_dict or "input" not in act_dict[name]:
|
||||
act_dict[name]["input"] = x.detach().abs().max().item()
|
||||
else:
|
||||
act_dict[name]["input"] = max(act_dict[name]["input"], x.detach().abs().max().item())
|
||||
if isinstance(y, tuple):
|
||||
y = y[0]
|
||||
if name not in act_dict or "output" not in act_dict[name]:
|
||||
act_dict[name]["output"] = y.detach().abs().max().item()
|
||||
else:
|
||||
act_dict[name]["output"] = max(act_dict[name]["output"], y.detach().abs().max().item())
|
||||
|
||||
for name, m in llama_model.named_modules():
|
||||
if isinstance(m, LlamaAttention):
|
||||
setattr(m, "q_apply_rotary", LlamaApplyRotary())
|
||||
setattr(m, "k_apply_rotary", LlamaApplyRotary())
|
||||
m.forward = types.MethodType(llama_decoder_layer_forward, m)
|
||||
|
||||
hooks = []
|
||||
for name, m in llama_model.named_modules():
|
||||
if isinstance(m, LlamaApplyRotary):
|
||||
hooks.append(m.register_forward_hook(partial(stat_io_hook, name=name)))
|
||||
if isinstance(m, torch.nn.Linear):
|
||||
hooks.append(m.register_forward_hook(partial(stat_io_hook, name=name)))
|
||||
|
||||
self.collect_act_dict(llama_model, tokenizer, dataset, act_dict, device, num_samples, seq_len)
|
||||
|
||||
for hook in hooks:
|
||||
hook.remove()
|
||||
return act_dict
|
||||
|
||||
def smooth_fn(self, scales, alpha=0.5):
|
||||
model = self.model
|
||||
for name, module in model.named_modules():
|
||||
if isinstance(module, LlamaDecoderLayer):
|
||||
attn_ln = module.input_layernorm
|
||||
qkv = [module.self_attn.q_proj, module.self_attn.k_proj, module.self_attn.v_proj]
|
||||
qkv_input_scales = scales[name + ".self_attn.q_proj"]
|
||||
self.smooth_ln_fcs(attn_ln, qkv, qkv_input_scales, alpha)
|
||||
|
||||
def create_quantized_model(model):
|
||||
llama_config = model.config
|
||||
for i, layer in enumerate(model.model.layers):
|
||||
model.model.layers[i] = LlamaSmoothquantDecoderLayer(llama_config)
|
||||
|
||||
model.model.forward = types.MethodType(llama_model_forward, model.model)
|
||||
cos, sin = init_to_get_rotary(llama_config)
|
||||
model.model.register_buffer("_cos_cached", cos)
|
||||
model.model.register_buffer("_sin_cached", sin)
|
||||
|
||||
def quantized(
|
||||
self,
|
||||
tokenizer,
|
||||
dataset,
|
||||
num_samples=512,
|
||||
seq_len=512,
|
||||
alpha=0.5,
|
||||
):
|
||||
llama_model = self.model
|
||||
llama_config = llama_model.config
|
||||
|
||||
act_scales = self.get_act_scales(llama_model, tokenizer, dataset, num_samples, seq_len)
|
||||
|
||||
self.smooth_fn(act_scales, alpha)
|
||||
|
||||
act_dict = self.get_act_dict(tokenizer, dataset, num_samples, seq_len)
|
||||
decoder_layer_scales = []
|
||||
|
||||
for idx in range(llama_config.num_hidden_layers):
|
||||
scale_dict = {}
|
||||
scale_dict["attn_input_scale"] = act_dict[f"model.layers.{idx}.self_attn.q_proj"]["input"] / 127
|
||||
scale_dict["q_output_scale"] = act_dict[f"model.layers.{idx}.self_attn.q_proj"]["output"] / 127
|
||||
scale_dict["k_output_scale"] = act_dict[f"model.layers.{idx}.self_attn.k_proj"]["output"] / 127
|
||||
scale_dict["v_output_scale"] = act_dict[f"model.layers.{idx}.self_attn.v_proj"]["output"] / 127
|
||||
|
||||
scale_dict["q_rotary_output_scale"] = (
|
||||
act_dict[f"model.layers.{idx}.self_attn.q_apply_rotary"]["output"] / 127
|
||||
)
|
||||
scale_dict["k_rotary_output_scale"] = (
|
||||
act_dict[f"model.layers.{idx}.self_attn.k_apply_rotary"]["output"] / 127
|
||||
)
|
||||
|
||||
scale_dict["out_input_scale"] = act_dict[f"model.layers.{idx}.self_attn.o_proj"]["input"] / 127
|
||||
|
||||
scale_dict["gate_input_scale"] = act_dict[f"model.layers.{idx}.mlp.gate_proj"]["input"] / 127
|
||||
scale_dict["up_input_scale"] = act_dict[f"model.layers.{idx}.mlp.up_proj"]["input"] / 127
|
||||
scale_dict["down_input_scale"] = act_dict[f"model.layers.{idx}.mlp.down_proj"]["input"] / 127
|
||||
|
||||
decoder_layer_scales.append(scale_dict)
|
||||
|
||||
for i, layer in enumerate(llama_model.model.layers):
|
||||
orig_layer = layer
|
||||
llama_model.model.layers[i] = LlamaSmoothquantDecoderLayer.pack(orig_layer, **decoder_layer_scales[i])
|
||||
|
||||
llama_model.model.forward = types.MethodType(llama_model_forward, llama_model.model)
|
||||
|
||||
cos, sin = init_to_get_rotary(llama_config)
|
||||
llama_model.model.register_buffer("_cos_cached", cos.to(self.model.device))
|
||||
llama_model.model.register_buffer("_sin_cached", sin.to(self.model.device))
|
||||
|
|
@ -1,264 +0,0 @@
|
|||
from typing import List, Union
|
||||
|
||||
import torch
|
||||
import torch.distributed as dist
|
||||
import torch.nn as nn
|
||||
from torch.distributed import ProcessGroup
|
||||
|
||||
from colossalai.lazy import LazyInitContext
|
||||
from colossalai.shardformer.layer import ParallelModule
|
||||
|
||||
from .linear import W8A8B8O8Linear, W8A8BFP32O32LinearSiLU, W8A8BFP32OFP32Linear
|
||||
|
||||
|
||||
def split_row_copy(smooth_linear, para_linear, tp_size=1, tp_rank=0, split_num=1):
|
||||
qweights = smooth_linear.weight.split(smooth_linear.out_features // split_num, dim=0)
|
||||
if smooth_linear.bias is not None:
|
||||
bias = smooth_linear.bias.split(smooth_linear.out_features // split_num, dim=0)
|
||||
|
||||
smooth_split_out_features = para_linear.out_features // split_num
|
||||
|
||||
for i in range(split_num):
|
||||
para_linear.weight[i * smooth_split_out_features : (i + 1) * smooth_split_out_features, :] = qweights[i][
|
||||
tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features, :
|
||||
]
|
||||
|
||||
if para_linear.bias is not None:
|
||||
para_linear.bias[:, i * smooth_split_out_features : (i + 1) * smooth_split_out_features] = bias[i][
|
||||
:, tp_rank * smooth_split_out_features : (tp_rank + 1) * smooth_split_out_features
|
||||
]
|
||||
|
||||
|
||||
def split_column_copy(smooth_linear, para_linear, tp_rank=0, split_num=1):
|
||||
qweights = smooth_linear.weight.split(smooth_linear.in_features // split_num, dim=-1)
|
||||
|
||||
smooth_split_in_features = para_linear.in_features // split_num
|
||||
|
||||
for i in range(split_num):
|
||||
para_linear.weight[:, i * smooth_split_in_features : (i + 1) * smooth_split_in_features] = qweights[i][
|
||||
:, tp_rank * smooth_split_in_features : (tp_rank + 1) * smooth_split_in_features
|
||||
]
|
||||
|
||||
if smooth_linear.bias is not None:
|
||||
para_linear.bias.copy_(smooth_linear.bias)
|
||||
|
||||
|
||||
class RowW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
|
||||
def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
|
||||
super().__init__(in_features, out_features, alpha, beta)
|
||||
self.process_group = None
|
||||
self.tp_size = 1
|
||||
self.tp_rank = 0
|
||||
|
||||
@staticmethod
|
||||
def from_native_module(
|
||||
module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
|
||||
) -> ParallelModule:
|
||||
LazyInitContext.materialize(module)
|
||||
# get the attributes
|
||||
out_features = module.out_features
|
||||
|
||||
# ensure only one process group is passed
|
||||
if isinstance(process_group, (list, tuple)):
|
||||
assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
|
||||
process_group = process_group[0]
|
||||
|
||||
tp_size = dist.get_world_size(process_group)
|
||||
tp_rank = dist.get_rank(process_group)
|
||||
|
||||
if out_features < tp_size:
|
||||
return module
|
||||
|
||||
if out_features % tp_size != 0:
|
||||
raise ValueError(
|
||||
f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
|
||||
)
|
||||
linear_1d = RowW8A8B8O8Linear(module.in_features, module.out_features // tp_size)
|
||||
linear_1d.tp_size = tp_size
|
||||
linear_1d.tp_rank = tp_rank
|
||||
linear_1d.process_group = process_group
|
||||
linear_1d.a = module.a.clone().detach()
|
||||
linear_1d.b = module.b.clone().detach()
|
||||
split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
|
||||
return linear_1d
|
||||
|
||||
|
||||
class ColW8A8B8O8Linear(W8A8B8O8Linear, ParallelModule):
|
||||
def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
|
||||
super().__init__(in_features, out_features, alpha, beta)
|
||||
self.process_group = None
|
||||
self.tp_size = 1
|
||||
self.tp_rank = 0
|
||||
|
||||
@staticmethod
|
||||
def from_native_module(
|
||||
module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
|
||||
) -> ParallelModule:
|
||||
LazyInitContext.materialize(module)
|
||||
# get the attributes
|
||||
in_features = module.in_features
|
||||
|
||||
# ensure only one process group is passed
|
||||
if isinstance(process_group, (list, tuple)):
|
||||
assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
|
||||
process_group = process_group[0]
|
||||
|
||||
tp_size = dist.get_world_size(process_group)
|
||||
tp_rank = dist.get_rank(process_group)
|
||||
|
||||
if in_features < tp_size:
|
||||
return module
|
||||
|
||||
if in_features % tp_size != 0:
|
||||
raise ValueError(
|
||||
f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
|
||||
)
|
||||
linear_1d = ColW8A8B8O8Linear(module.in_features // tp_size, module.out_features)
|
||||
linear_1d.tp_size = tp_size
|
||||
linear_1d.tp_rank = tp_rank
|
||||
linear_1d.process_group = process_group
|
||||
linear_1d.a = torch.tensor(module.a)
|
||||
linear_1d.b = torch.tensor(module.b)
|
||||
|
||||
split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
|
||||
if linear_1d.bias is not None:
|
||||
linear_1d.bias = linear_1d.bias // tp_size
|
||||
|
||||
return linear_1d
|
||||
|
||||
@torch.no_grad()
|
||||
def forward(self, x):
|
||||
output = super().forward(x)
|
||||
if self.tp_size > 1:
|
||||
dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
|
||||
return output
|
||||
|
||||
|
||||
class RowW8A8BFP32O32LinearSiLU(W8A8BFP32O32LinearSiLU, ParallelModule):
|
||||
def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
|
||||
super().__init__(in_features, out_features, alpha, beta)
|
||||
self.process_group = None
|
||||
self.tp_size = 1
|
||||
self.tp_rank = 0
|
||||
|
||||
@staticmethod
|
||||
def from_native_module(
|
||||
module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
|
||||
) -> ParallelModule:
|
||||
LazyInitContext.materialize(module)
|
||||
# get the attributes
|
||||
out_features = module.out_features
|
||||
|
||||
# ensure only one process group is passed
|
||||
if isinstance(process_group, (list, tuple)):
|
||||
assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
|
||||
process_group = process_group[0]
|
||||
|
||||
tp_size = dist.get_world_size(process_group)
|
||||
tp_rank = dist.get_rank(process_group)
|
||||
|
||||
if out_features < tp_size:
|
||||
return module
|
||||
|
||||
if out_features % tp_size != 0:
|
||||
raise ValueError(
|
||||
f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
|
||||
)
|
||||
linear_1d = RowW8A8BFP32O32LinearSiLU(module.in_features, module.out_features // tp_size)
|
||||
linear_1d.tp_size = tp_size
|
||||
linear_1d.tp_rank = tp_rank
|
||||
linear_1d.process_group = process_group
|
||||
linear_1d.a = module.a.clone().detach()
|
||||
|
||||
split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
|
||||
return linear_1d
|
||||
|
||||
|
||||
class RowW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
|
||||
def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
|
||||
super().__init__(in_features, out_features, alpha, beta)
|
||||
self.process_group = None
|
||||
self.tp_size = 1
|
||||
self.tp_rank = 0
|
||||
|
||||
@staticmethod
|
||||
def from_native_module(
|
||||
module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
|
||||
) -> ParallelModule:
|
||||
LazyInitContext.materialize(module)
|
||||
# get the attributes
|
||||
out_features = module.out_features
|
||||
|
||||
# ensure only one process group is passed
|
||||
if isinstance(process_group, (list, tuple)):
|
||||
assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
|
||||
process_group = process_group[0]
|
||||
|
||||
tp_size = dist.get_world_size(process_group)
|
||||
tp_rank = dist.get_rank(process_group)
|
||||
|
||||
if out_features < tp_size:
|
||||
return module
|
||||
|
||||
if out_features % tp_size != 0:
|
||||
raise ValueError(
|
||||
f"The size of out_features:{out_features} is not integer multiples of tensor parallel size: {tp_size}!"
|
||||
)
|
||||
linear_1d = RowW8A8BFP32OFP32Linear(module.in_features, module.out_features // tp_size)
|
||||
linear_1d.tp_size = tp_size
|
||||
linear_1d.tp_rank = tp_rank
|
||||
linear_1d.process_group = process_group
|
||||
linear_1d.a = module.a.clone().detach()
|
||||
|
||||
split_row_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
|
||||
return linear_1d
|
||||
|
||||
|
||||
class ColW8A8BFP32OFP32Linear(W8A8BFP32OFP32Linear, ParallelModule):
|
||||
def __init__(self, in_features, out_features, alpha=1.0, beta=1.0):
|
||||
super().__init__(in_features, out_features, alpha, beta)
|
||||
self.process_group = None
|
||||
self.tp_size = 1
|
||||
self.tp_rank = 0
|
||||
|
||||
@staticmethod
|
||||
def from_native_module(
|
||||
module: nn.Module, process_group: Union[ProcessGroup, List[ProcessGroup]], *args, **kwargs
|
||||
) -> ParallelModule:
|
||||
LazyInitContext.materialize(module)
|
||||
# get the attributes
|
||||
in_features = module.in_features
|
||||
|
||||
# ensure only one process group is passed
|
||||
if isinstance(process_group, (list, tuple)):
|
||||
assert len(process_group) == 1, f"Expected only one process group, got {len(process_group)}."
|
||||
process_group = process_group[0]
|
||||
|
||||
tp_size = dist.get_world_size(process_group)
|
||||
tp_rank = dist.get_rank(process_group)
|
||||
|
||||
if in_features < tp_size:
|
||||
return module
|
||||
|
||||
if in_features % tp_size != 0:
|
||||
raise ValueError(
|
||||
f"The size of in_features:{in_features} is not integer multiples of tensor parallel size: {tp_size}!"
|
||||
)
|
||||
linear_1d = ColW8A8BFP32OFP32Linear(module.in_features // tp_size, module.out_features)
|
||||
linear_1d.tp_size = tp_size
|
||||
linear_1d.tp_rank = tp_rank
|
||||
linear_1d.process_group = process_group
|
||||
linear_1d.a = module.a.clone().detach()
|
||||
|
||||
split_column_copy(module, linear_1d, tp_rank=tp_rank, **kwargs)
|
||||
if linear_1d.bias is not None:
|
||||
linear_1d.bias = linear_1d.bias / tp_size
|
||||
|
||||
return linear_1d
|
||||
|
||||
@torch.no_grad()
|
||||
def forward(self, x):
|
||||
output = super().forward(x)
|
||||
if self.tp_size > 1:
|
||||
dist.all_reduce(output, op=dist.ReduceOp.SUM, group=self.process_group)
|
||||
return output
|
||||
|
|
@ -0,0 +1,3 @@
|
|||
"""
|
||||
The abstraction of request and sequence are defined here.
|
||||
"""
|
||||
Loading…
Reference in New Issue