mirror of https://github.com/hpcaitech/ColossalAI
[tutorial] modify hands-on of auto activation checkpoint (#1920)
* [sc] SC tutorial for auto checkpoint * [sc] polish examples * [sc] polish readme * [sc] polish readme and help information * [sc] polish readme and help information * [sc] modify auto checkpoint benchmark * [sc] remove imgspull/1922/head
parent
ff16773ded
commit
24cbee0ebe
|
|
@ -19,79 +19,38 @@ colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py
|
|||
|
||||
## Auto Checkpoint Benchmarking
|
||||
|
||||
We prepare three demos for you to test the performance of auto checkpoint, the test `demo_resnet50.py` and `demo_gpt2_medium.py` will show you the ability of solver to search checkpoint strategy that could fit in the given budget.
|
||||
We prepare two bechmarks for you to test the performance of auto checkpoint
|
||||
|
||||
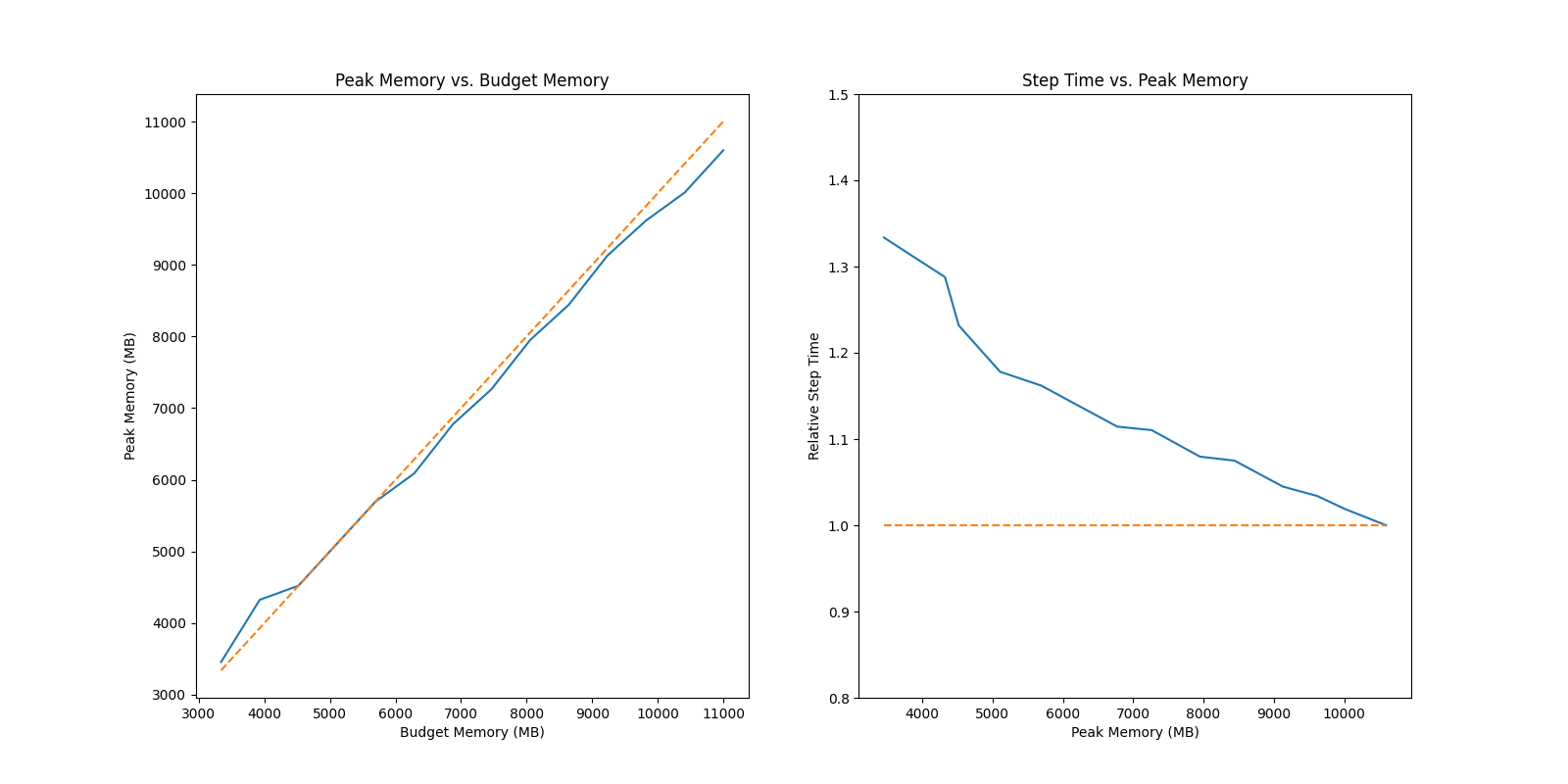
The first test `auto_ckpt_solver_test.py` will show you the ability of solver to search checkpoint strategy that could fit in the given budget (test on GPT2 Medium and ResNet 50). It will output the benchmark summary and data visualization of peak memory vs. budget memory and relative step time vs. peak memory.
|
||||
|
||||
The second test `auto_ckpt_batchsize_test.py` will show you the advantage of fitting larger batchsize training into limited GPU memory with the help of our activation checkpoint solver (test on ResNet152). It will output the benchmark summary.
|
||||
|
||||
The usage of the above two test
|
||||
```bash
|
||||
python demo_resnet50.py --help
|
||||
usage: ResNet50 Auto Activation Benchmark [-h] [--batch_size BATCH_SIZE] [--num_steps NUM_STEPS] [--sample_points SAMPLE_POINTS] [--free_memory FREE_MEMORY]
|
||||
[--start_factor START_FACTOR]
|
||||
# run auto_ckpt_solver_test.py on gpt2 medium
|
||||
python auto_ckpt_solver_test.py --model gpt2
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
--batch_size BATCH_SIZE
|
||||
batch size for benchmark, default 128
|
||||
--num_steps NUM_STEPS
|
||||
number of test steps for benchmark, default 5
|
||||
--sample_points SAMPLE_POINTS
|
||||
number of sample points for benchmark from start memory budget to maximum memory budget (free_memory), default 15
|
||||
--free_memory FREE_MEMORY
|
||||
maximum memory budget in MB for benchmark, default 11000 MB
|
||||
--start_factor START_FACTOR
|
||||
start memory budget factor for benchmark, the start memory budget will be free_memory / start_factor, default 4
|
||||
# run auto_ckpt_solver_test.py on resnet50
|
||||
python auto_ckpt_solver_test.py --model resnet50
|
||||
|
||||
# run with default settings
|
||||
python demo_resnet50.py
|
||||
|
||||
python demo_gpt2_medium.py --help
|
||||
usage: GPT2 medium Auto Activation Benchmark [-h] [--batch_size BATCH_SIZE] [--num_steps NUM_STEPS] [--sample_points SAMPLE_POINTS] [--free_memory FREE_MEMORY]
|
||||
[--start_factor START_FACTOR]
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
--batch_size BATCH_SIZE
|
||||
batch size for benchmark, default 8
|
||||
--num_steps NUM_STEPS
|
||||
number of test steps for benchmark, default 5
|
||||
--sample_points SAMPLE_POINTS
|
||||
number of sample points for benchmark from start memory budget to maximum memory budget (free_memory), default 15
|
||||
--free_memory FREE_MEMORY
|
||||
maximum memory budget in MB for benchmark, default 56000 MB
|
||||
--start_factor START_FACTOR
|
||||
start memory budget factor for benchmark, the start memory budget will be free_memory / start_factor, default 10
|
||||
|
||||
# run with default settings
|
||||
python demo_gpt2_medium.py
|
||||
# tun auto_ckpt_batchsize_test.py
|
||||
python auto_ckpt_batchsize_test.py
|
||||
```
|
||||
|
||||
There are some results for your reference
|
||||
|
||||
## Auto Checkpoint Solver Test
|
||||
|
||||
### ResNet 50
|
||||
|
||||
|
||||
### GPT2 Medium
|
||||
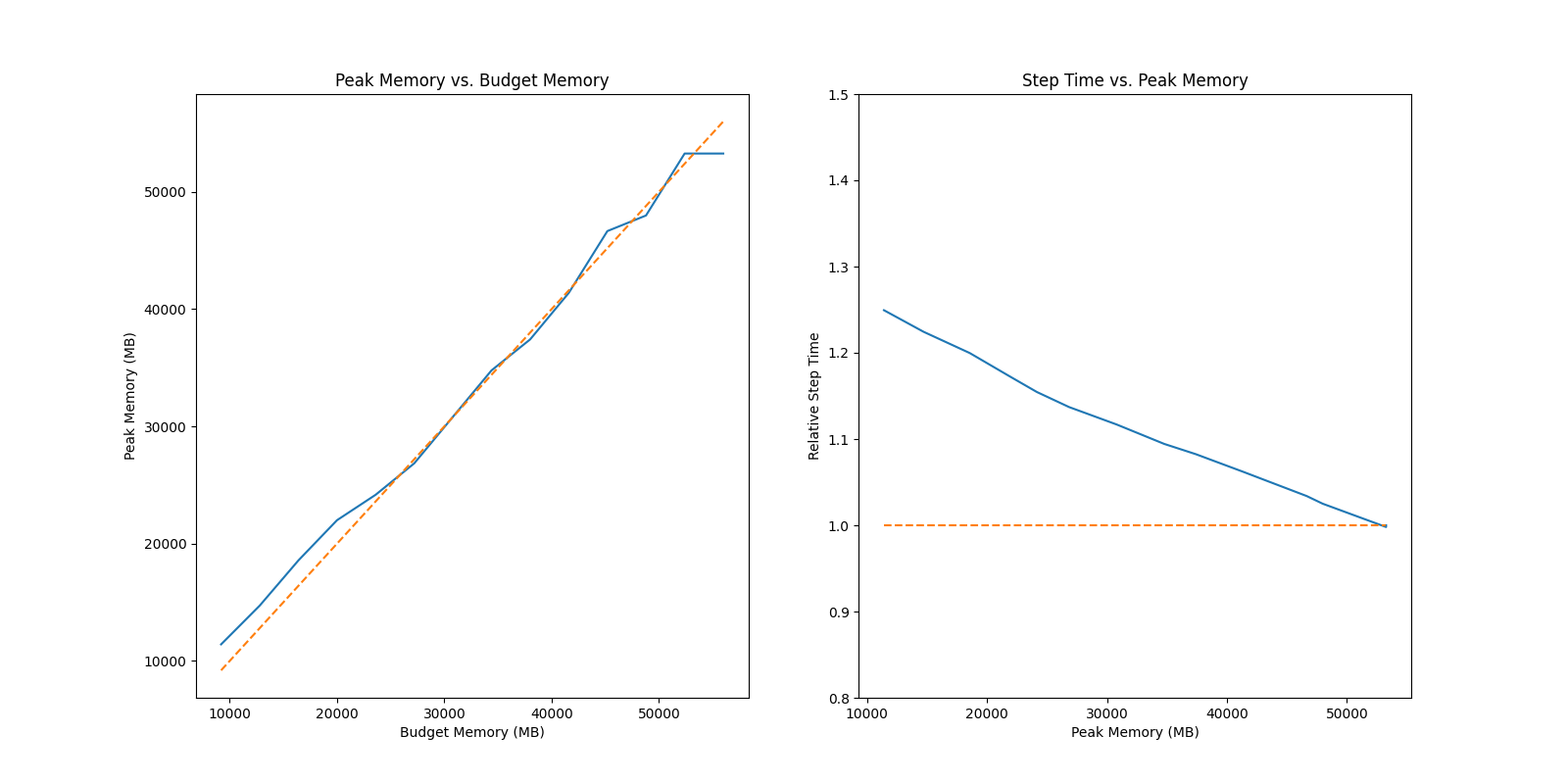
|
||||
|
||||
We also prepare the demo `demo_resnet152.py` to manifest the benefit of auto activation with large batch, the usage is listed as follows
|
||||
```bash
|
||||
python demo_resnet152.py --help
|
||||
usage: ResNet152 Auto Activation Through Put Benchmark [-h] [--num_steps NUM_STEPS]
|
||||
|
||||
optional arguments:
|
||||
-h, --help show this help message and exit
|
||||
--num_steps NUM_STEPS
|
||||
number of test steps for benchmark, default 5
|
||||
|
||||
# run with default settings
|
||||
python demo_resnet152.py
|
||||
```
|
||||
|
||||
here are some results on our end for your reference
|
||||
## Auto Checkpoint Batch Size Test
|
||||
```bash
|
||||
===============test summary================
|
||||
batch_size: 512, peak memory: 73314.392 MB, through put: 254.286 images/s
|
||||
batch_size: 1024, peak memory: 73316.216 MB, through put: 397.608 images/s
|
||||
batch_size: 2048, peak memory: 72927.837 MB, through put: 277.429 images/s
|
||||
```
|
||||
|
||||
The above tests will output the test summary and a plot of the benchmarking results.
|
||||
|
|
|
|||
|
|
@ -8,7 +8,7 @@ import numpy as np
|
|||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
import torchvision.models as tm
|
||||
from bench_utils import bench
|
||||
from bench_utils import bench, data_gen_resnet
|
||||
|
||||
import colossalai
|
||||
from colossalai.auto_parallel.checkpoint import CheckpointSolverRotor
|
||||
|
|
@ -16,19 +16,14 @@ from colossalai.fx import metainfo_trace, symbolic_trace
|
|||
from colossalai.utils import free_port
|
||||
|
||||
|
||||
def data_gen(batch_size, shape, device='cuda'):
|
||||
"""
|
||||
Generate random data for benchmarking
|
||||
"""
|
||||
data = torch.empty(batch_size, *shape, device=device)
|
||||
label = torch.empty(batch_size, dtype=torch.long, device=device).random_(1000)
|
||||
return (data,), label
|
||||
|
||||
|
||||
def _resnet152_benchmark(rank, world_size, port, num_steps):
|
||||
"""Resnet152 benchmark
|
||||
def _benchmark(rank, world_size, port):
|
||||
"""Auto activation checkpoint batchsize benchmark
|
||||
This benchmark test the through put of Resnet152 with our activation solver given the memory budget of 95% of
|
||||
maximum GPU memory, and with the batch size of [512, 1024, 2048]
|
||||
maximum GPU memory, and with the batch size of [512, 1024, 2048], you could see that using auto activation
|
||||
checkpoint with optimality guarantee, we might be able to find better batch size for the model, as larger batch
|
||||
size means that we are able to use larger portion of GPU FLOPS, while recomputation scheduling with our solver
|
||||
only result in minor performance drop. So at last we might be able to find better training batch size for our
|
||||
model (combine with large batch training optimizer such as LAMB).
|
||||
"""
|
||||
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
|
||||
model = tm.resnet152()
|
||||
|
|
@ -42,33 +37,23 @@ def _resnet152_benchmark(rank, world_size, port, num_steps):
|
|||
gm.graph = solver.solve()
|
||||
peak_mem, step_time = bench(gm,
|
||||
torch.nn.CrossEntropyLoss(),
|
||||
partial(data_gen, batch_size=batch_size, shape=(3, 224, 224)),
|
||||
num_steps=num_steps)
|
||||
partial(data_gen_resnet, batch_size=batch_size, shape=(3, 224, 224)),
|
||||
num_steps=5)
|
||||
peak_mems.append(peak_mem)
|
||||
through_puts.append(batch_size / step_time * 1.0e3)
|
||||
gm.graph = deepcopy(raw_graph)
|
||||
|
||||
# print results
|
||||
print("===============test summary================")
|
||||
print("===============benchmark summary================")
|
||||
for batch_size, peak_mem, through_put in zip(batch_sizes, peak_mems, through_puts):
|
||||
print(f'batch_size: {int(batch_size)}, peak memory: {peak_mem:.3f} MB, through put: {through_put:.3f} images/s')
|
||||
|
||||
plt.plot(batch_sizes, through_puts)
|
||||
plt.xlabel("batch size")
|
||||
plt.ylabel("through put (images/s)")
|
||||
plt.title("Resnet152 benchmark")
|
||||
plt.savefig("resnet152_benchmark.png")
|
||||
|
||||
|
||||
def resnet152_benchmark(num_steps):
|
||||
def auto_activation_checkpoint_batchsize_benchmark():
|
||||
world_size = 1
|
||||
run_func_module = partial(_resnet152_benchmark, world_size=world_size, port=free_port(), num_steps=num_steps)
|
||||
run_func_module = partial(_benchmark, world_size=world_size, port=free_port())
|
||||
mp.spawn(run_func_module, nprocs=world_size)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = ArgumentParser("ResNet152 Auto Activation Through Put Benchmark")
|
||||
parser.add_argument("--num_steps", type=int, default=5, help="number of test steps for benchmark, default 5")
|
||||
args = parser.parse_args()
|
||||
|
||||
resnet152_benchmark(args.num_steps)
|
||||
auto_activation_checkpoint_batchsize_benchmark()
|
||||
|
|
@ -0,0 +1,89 @@
|
|||
import time
|
||||
from argparse import ArgumentParser
|
||||
from functools import partial
|
||||
|
||||
import matplotlib.pyplot as plt
|
||||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
import torchvision.models as tm
|
||||
from bench_utils import GPTLMLoss, bench_rotor, data_gen_gpt2, data_gen_resnet, gpt2_medium
|
||||
|
||||
import colossalai
|
||||
from colossalai.auto_parallel.checkpoint import CheckpointSolverRotor
|
||||
from colossalai.fx import metainfo_trace, symbolic_trace
|
||||
from colossalai.utils import free_port
|
||||
|
||||
|
||||
def _benchmark(rank, world_size, port, args):
|
||||
"""
|
||||
Auto activation checkpoint solver benchmark, we provide benchmark on two models: gpt2_medium and resnet50.
|
||||
The benchmark will sample in a range of memory budget for each model and output the benchmark summary and
|
||||
data visualization of peak memory vs. budget memory and relative step time vs. peak memory.
|
||||
"""
|
||||
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
|
||||
if args.model == 'resnet50':
|
||||
model = tm.resnet50()
|
||||
data_gen = partial(data_gen_resnet, batch_size=128, shape=(3, 224, 224))
|
||||
gm = symbolic_trace(model)
|
||||
gm = metainfo_trace(gm, torch.empty(128, 3, 224, 224, device='meta'))
|
||||
loss = torch.nn.CrossEntropyLoss()
|
||||
else:
|
||||
model = gpt2_medium()
|
||||
data_gen = partial(data_gen_gpt2, batch_size=8, seq_len=1024, vocab_size=50257)
|
||||
data, mask = data_gen(device='meta')[0]
|
||||
gm = symbolic_trace(model, meta_args={'input_ids': data, 'attention_mask': mask})
|
||||
gm = metainfo_trace(gm, data, mask)
|
||||
loss = GPTLMLoss()
|
||||
|
||||
free_memory = 11000 * 1024**2 if args.model == 'resnet50' else 56000 * 1024**2
|
||||
start_factor = 4 if args.model == 'resnet50' else 10
|
||||
|
||||
# trace and benchmark
|
||||
budgets, peak_hist, step_hist = bench_rotor(gm,
|
||||
loss,
|
||||
data_gen,
|
||||
num_steps=5,
|
||||
sample_points=15,
|
||||
free_memory=free_memory,
|
||||
start_factor=start_factor)
|
||||
|
||||
# print summary
|
||||
print("==============benchmark summary==============")
|
||||
for budget, peak, step in zip(budgets, peak_hist, step_hist):
|
||||
print(f'memory budget: {budget:.3f} MB, peak memory: {peak:.3f} MB, step time: {step:.3f} MS')
|
||||
|
||||
# plot valid results
|
||||
fig, axs = plt.subplots(1, 2, figsize=(16, 8))
|
||||
valid_idx = step_hist.index(next(step for step in step_hist if step != float("inf")))
|
||||
|
||||
# plot peak memory vs. budget memory
|
||||
axs[0].plot(budgets[valid_idx:], peak_hist[valid_idx:])
|
||||
axs[0].plot([budgets[valid_idx], budgets[-1]], [budgets[valid_idx], budgets[-1]], linestyle='--')
|
||||
axs[0].set_xlabel("Budget Memory (MB)")
|
||||
axs[0].set_ylabel("Peak Memory (MB)")
|
||||
axs[0].set_title("Peak Memory vs. Budget Memory")
|
||||
|
||||
# plot relative step time vs. budget memory
|
||||
axs[1].plot(peak_hist[valid_idx:], [step_time / step_hist[-1] for step_time in step_hist[valid_idx:]])
|
||||
axs[1].plot([peak_hist[valid_idx], peak_hist[-1]], [1.0, 1.0], linestyle='--')
|
||||
axs[1].set_xlabel("Peak Memory (MB)")
|
||||
axs[1].set_ylabel("Relative Step Time")
|
||||
axs[1].set_title("Step Time vs. Peak Memory")
|
||||
axs[1].set_ylim(0.8, 1.5)
|
||||
|
||||
# save plot
|
||||
fig.savefig(f"{args.model}_benchmark.png")
|
||||
|
||||
|
||||
def auto_activation_checkpoint_benchmark(args):
|
||||
world_size = 1
|
||||
run_func_module = partial(_benchmark, world_size=world_size, port=free_port(), args=args)
|
||||
mp.spawn(run_func_module, nprocs=world_size)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = ArgumentParser("Auto Activation Checkpoint Solver Benchmark")
|
||||
parser.add_argument("--model", type=str, default='gpt2', choices=['gpt2', 'resnet50'])
|
||||
args = parser.parse_args()
|
||||
|
||||
auto_activation_checkpoint_benchmark(args)
|
||||
|
|
@ -1,108 +0,0 @@
|
|||
import time
|
||||
from argparse import ArgumentParser
|
||||
from functools import partial
|
||||
|
||||
import matplotlib.pyplot as plt
|
||||
import torch
|
||||
import torch.multiprocessing as mp
|
||||
import torchvision.models as tm
|
||||
from bench_utils import GPTLMLoss, bench_rotor, gpt2_medium
|
||||
|
||||
import colossalai
|
||||
from colossalai.auto_parallel.checkpoint import CheckpointSolverRotor
|
||||
from colossalai.fx import metainfo_trace, symbolic_trace
|
||||
from colossalai.utils import free_port
|
||||
|
||||
|
||||
def data_gen(batch_size, seq_len, vocab_size, device='cuda:0'):
|
||||
"""
|
||||
Generate random data for benchmarking
|
||||
"""
|
||||
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len), device=device)
|
||||
attention_mask = torch.ones_like(input_ids, device=device)
|
||||
return (input_ids, attention_mask), attention_mask
|
||||
|
||||
|
||||
def _gpt2_benchmark(rank, world_size, port, batch_size, num_steps, sample_points, free_memory, start_factor):
|
||||
colossalai.launch(config={}, rank=rank, world_size=world_size, host='localhost', port=port, backend='nccl')
|
||||
model = gpt2_medium()
|
||||
|
||||
# trace and benchmark
|
||||
data, mask = data_gen(batch_size, 1024, 50257, device='meta')[0]
|
||||
gm = symbolic_trace(model, meta_args={'input_ids': data, 'attention_mask': mask})
|
||||
gm = metainfo_trace(gm, data, mask)
|
||||
budgets, peak_hist, step_hist = bench_rotor(gm,
|
||||
GPTLMLoss(),
|
||||
partial(data_gen, batch_size=batch_size, seq_len=1024,
|
||||
vocab_size=50257),
|
||||
num_steps=num_steps,
|
||||
sample_points=sample_points,
|
||||
free_memory=free_memory,
|
||||
start_factor=start_factor)
|
||||
|
||||
# print summary
|
||||
print("==============test summary==============")
|
||||
for budget, peak, step in zip(budgets, peak_hist, step_hist):
|
||||
print(f'memory budget: {budget:.3f} MB, peak memory: {peak:.3f} MB, step time: {step:.3f} MS')
|
||||
|
||||
# plot valid results
|
||||
fig, axs = plt.subplots(1, 2, figsize=(16, 8))
|
||||
valid_idx = step_hist.index(next(step for step in step_hist if step != float("inf")))
|
||||
|
||||
# plot peak memory vs. budget memory
|
||||
axs[0].plot(budgets[valid_idx:], peak_hist[valid_idx:])
|
||||
axs[0].plot([budgets[valid_idx], budgets[-1]], [budgets[valid_idx], budgets[-1]], linestyle='--')
|
||||
axs[0].set_xlabel("Budget Memory (MB)")
|
||||
axs[0].set_ylabel("Peak Memory (MB)")
|
||||
axs[0].set_title("Peak Memory vs. Budget Memory")
|
||||
|
||||
# plot relative step time vs. budget memory
|
||||
axs[1].plot(peak_hist[valid_idx:], [step_time / step_hist[-1] for step_time in step_hist[valid_idx:]])
|
||||
axs[1].plot([peak_hist[valid_idx], peak_hist[-1]], [1.0, 1.0], linestyle='--')
|
||||
axs[1].set_xlabel("Peak Memory (MB)")
|
||||
axs[1].set_ylabel("Relative Step Time")
|
||||
axs[1].set_title("Step Time vs. Peak Memory")
|
||||
axs[1].set_ylim(0.8, 1.5)
|
||||
|
||||
# save plot
|
||||
fig.savefig("gpt2_benchmark.png")
|
||||
|
||||
|
||||
def gpt2_benchmark(batch_size, num_steps, sample_points, free_memory, start_factor):
|
||||
world_size = 1
|
||||
run_func_module = partial(_gpt2_benchmark,
|
||||
world_size=world_size,
|
||||
port=free_port(),
|
||||
batch_size=batch_size,
|
||||
num_steps=num_steps,
|
||||
sample_points=sample_points,
|
||||
free_memory=free_memory,
|
||||
start_factor=start_factor)
|
||||
mp.spawn(run_func_module, nprocs=world_size)
|
||||
|
||||
|
||||
if __name__ == "__main__":
|
||||
parser = ArgumentParser("GPT2 medium Auto Activation Benchmark")
|
||||
parser.add_argument("--batch_size", type=int, default=8, help="batch size for benchmark, default 8")
|
||||
parser.add_argument("--num_steps", type=int, default=5, help="number of test steps for benchmark, default 5")
|
||||
parser.add_argument(
|
||||
"--sample_points",
|
||||
type=int,
|
||||
default=15,
|
||||
help=
|
||||
"number of sample points for benchmark from start memory budget to maximum memory budget (free_memory), default 15"
|
||||
)
|
||||
parser.add_argument("--free_memory",
|
||||
type=int,
|
||||
default=56000,
|
||||
help="maximum memory budget in MB for benchmark, default 56000 MB")
|
||||
parser.add_argument(
|
||||
"--start_factor",
|
||||
type=int,
|
||||
default=10,
|
||||
help=
|
||||
"start memory budget factor for benchmark, the start memory budget will be free_memory / start_factor, default 10"
|
||||
)
|
||||
args = parser.parse_args()
|
||||
|
||||
gpt2_benchmark(args.batch_size, args.num_steps, args.sample_points, args.free_memory * 1024**2, args.start_factor)
|
||||
|
|
@ -154,3 +154,21 @@ def gpt2_xl(checkpoint=False):
|
|||
|
||||
def gpt2_6b(checkpoint=False):
|
||||
return GPTLMModel(hidden_size=4096, num_layers=30, num_attention_heads=16, checkpoint=checkpoint)
|
||||
|
||||
|
||||
def data_gen_gpt2(batch_size, seq_len, vocab_size, device='cuda:0'):
|
||||
"""
|
||||
Generate random data for gpt2 benchmarking
|
||||
"""
|
||||
input_ids = torch.randint(0, vocab_size, (batch_size, seq_len), device=device)
|
||||
attention_mask = torch.ones_like(input_ids, device=device)
|
||||
return (input_ids, attention_mask), attention_mask
|
||||
|
||||
|
||||
def data_gen_resnet(batch_size, shape, device='cuda:0'):
|
||||
"""
|
||||
Generate random data for resnet benchmarking
|
||||
"""
|
||||
data = torch.empty(batch_size, *shape, device=device)
|
||||
label = torch.empty(batch_size, dtype=torch.long, device=device).random_(1000)
|
||||
return (data,), label
|
||||
|
|
|
|||
Loading…
Reference in New Issue