diff --git a/colossalai/cli/launcher/run.py b/colossalai/cli/launcher/run.py
index 5e74c2c4f..d2d02811a 100644
--- a/colossalai/cli/launcher/run.py
+++ b/colossalai/cli/launcher/run.py
@@ -265,6 +265,10 @@ def launch_multi_processes(args: Config) -> None:
# establish remote connection
runner.connect(host_info_list=active_device_pool, workdir=curr_path, env=env)
+ # overwrite master addr when num_nodes > 1 and not specified
+ if len(active_device_pool) > 1 and args.master_addr == "127.0.0.1":
+ args.master_addr = active_device_pool.hostinfo_list[0].hostname
+
# execute distributed launching command
for node_id, hostinfo in enumerate(active_device_pool):
cmd = get_launch_command(master_addr=args.master_addr,
diff --git a/colossalai/kernel/cuda_native/mha/mem_eff_attn.py b/colossalai/kernel/cuda_native/mha/mem_eff_attn.py
index e83beb8b2..8a8980808 100644
--- a/colossalai/kernel/cuda_native/mha/mem_eff_attn.py
+++ b/colossalai/kernel/cuda_native/mha/mem_eff_attn.py
@@ -2,7 +2,13 @@ import warnings
HAS_MEM_EFF_ATTN = False
try:
- from xformers.ops.fmha import memory_efficient_attention
+ from xformers.ops.fmha import MemoryEfficientAttentionCutlassOp, memory_efficient_attention
+ from xformers.ops.fmha.attn_bias import (
+ BlockDiagonalCausalMask,
+ BlockDiagonalMask,
+ LowerTriangularMask,
+ LowerTriangularMaskWithTensorBias,
+ )
HAS_MEM_EFF_ATTN = True
except ImportError:
warnings.warn('please install xformers from https://github.com/facebookresearch/xformers')
@@ -16,13 +22,6 @@ if HAS_MEM_EFF_ATTN:
from typing import Optional
import torch
- from xformers.ops.fmha import MemoryEfficientAttentionCutlassOp
- from xformers.ops.fmha.attn_bias import (
- BlockDiagonalCausalMask,
- BlockDiagonalMask,
- LowerTriangularMask,
- LowerTriangularMaskWithTensorBias,
- )
from .utils import SeqLenInfo
diff --git a/examples/language/llama/README.md b/examples/language/llama/README.md
deleted file mode 100644
index 871804f2c..000000000
--- a/examples/language/llama/README.md
+++ /dev/null
@@ -1,11 +0,0 @@
-# Pretraining LLaMA: best practices for building LLaMA-like base models
-
-
-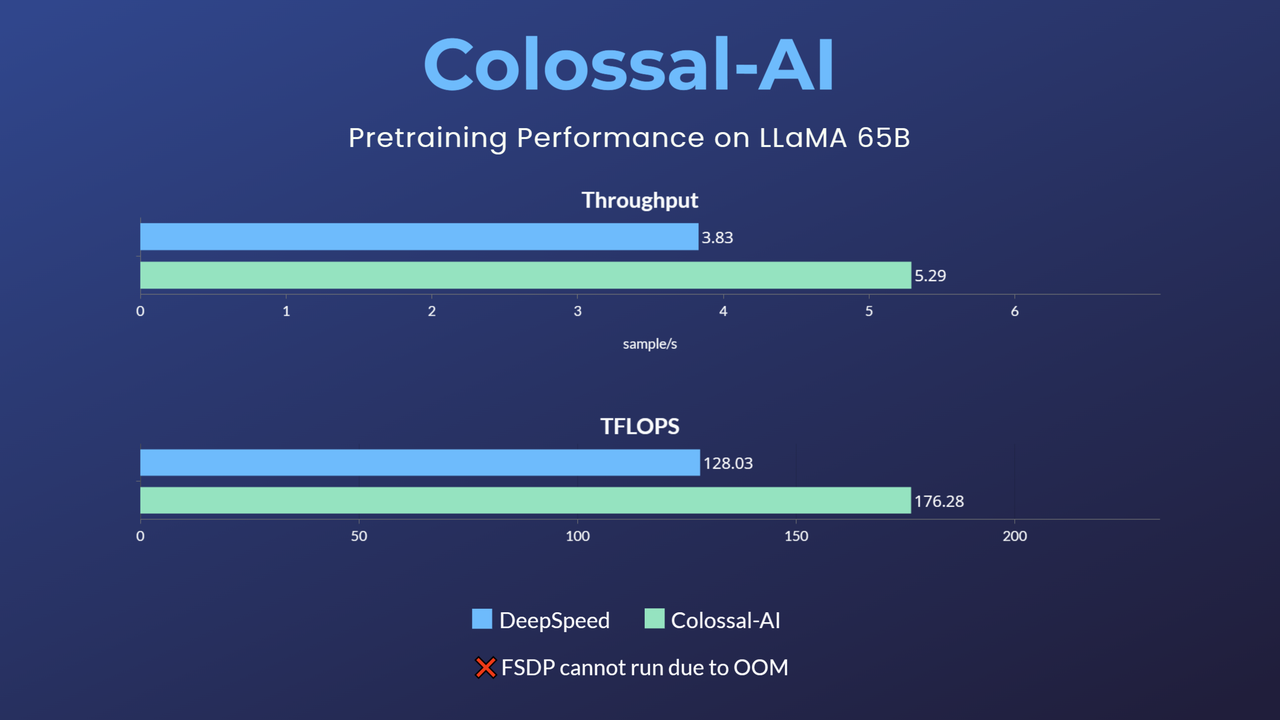 -
-
-
-- 65-billion-parameter large model pretraining accelerated by 38%
-[[code]](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama)
-[[blog]](https://www.hpc-ai.tech/blog/large-model-pretraining)
-
-> Since the main branch is being updated, in order to maintain the stability of the code, this example is temporarily kept as an [independent branch](https://github.com/hpcaitech/ColossalAI/tree/example/llama/examples/language/llama).
diff --git a/examples/language/llama2/README.md b/examples/language/llama2/README.md
new file mode 100644
index 000000000..b64b5d29e
--- /dev/null
+++ b/examples/language/llama2/README.md
@@ -0,0 +1,176 @@
+# Pretraining LLaMA-2: best practices for building LLaMA-2-like base models
+
+## Dataset
+
+Different from the original LLaMA, we use [RedPajama](https://www.together.xyz/blog/redpajama) dataset, which is a reproduction of the LLaMA training dataset containing over 1.2 trillion tokens. The full dataset is ~5TB unzipped on disk and ~3TB to download compressed.
+
+A smaller, more consumable random sample can be downloaded through [Hugging Face](https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T). If you just want to try out the pretraining script, you can use a 1B-token sample subset of RedPajama, which is available at [Hugging Face](https://huggingface.co/datasets/togethercomputer/RedPajama-Data-1T-Sample).
+
+RedPajama-Data-1T consists of seven data slices:
+
+| | RedPajama | LLaMA |
+|---------------|--------------|---------------|
+| CommonCrawl | 878 billion | 852 billion |
+| C4 | 175 billion | 190 billion |
+| Github | 59 billion | 100 billion |
+| Books | 26 billion | 25 billion |
+| ArXiv | 28 billion | 33 billion |
+| Wikipedia | 24 billion | 25 billion |
+| StackExchange | 20 billion | 27 billion |
+| Total | 1.2 trillion | 1.25 trillion |
+
+## Training
+
+We follow the hyperparameter settings from the original LLaMA paper. We use AdamW with $beta1=0.9$ and $beta2=0.95$. We use a cosine learning rate schedule, such that the final learning rate is equal to 10% of the maximal learning rate. We use a weight decay of 0.1 and gradient clipping of 1.0. We use 2,000 warmup steps.
+
+| params | learning rate | batch size |
+|--------|---------------|------------|
+| 6.7B | 3.0e-4 | 4M |
+| 13.0B | 3.0e-4 | 4M |
+| 32.5B | 1.5e-4 | 4M |
+| 65.2B | 1.5e-4 | 4M |
+
+## Usage
+
+### 1. Installation
+
+Please install the latest ColossalAI from source.
+
+```bash
+CUDA_EXT=1 pip install -U git+https://github.com/hpcaitech/ColossalAI
+```
+
+Then install other dependencies.
+
+```bash
+pip install -r requirements.txt
+```
+
+Additionally, we recommend you to use torch 1.13.1. We've tested our code on torch 1.13.1 and found it's compatible with our code and flash attention.
+
+### 2. Download the dataset
+
+The dataset can be automatically downloaded by using `huggingface/datasets`. You can specify the dataset path by `-d` or `--dataset`. The default dataset is `togethercomputer/RedPajama-Data-1T-Sample`.
+
+### 3. Command line arguments
+
+Yon can use colossalai run to launch multi-nodes training:
+```bash
+colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
+pretrain.py --OTHER_CONFIGURATIONS
+```
+
+Here is a sample hostfile:
+
+```text
+hostname1
+hostname2
+hostname3
+hostname4
+```
+
+Make sure master node can access all nodes (including itself) by ssh without password.
+
+Here is details about CLI arguments:
+
+- Model configuration: `-c`, `--config`. `7b`, `13b`, `30b` and `65b` are supported.
+- Booster plugin: `-p`, `--plugin`. `gemini`, `gemini_auto`, `zero2` and `zero2_cpu` are supported. For more details, please refer to [Booster plugins](https://colossalai.org/docs/basics/booster_plugins).
+- Dataset path: `-d`, `--dataset`. The default dataset is `togethercomputer/RedPajama-Data-1T-Sample`. It support any dataset from `datasets` with the same data format as RedPajama.
+- Number of epochs: `-e`, `--num_epochs`. The default value is 1.
+- Local batch size: `-b`, `--batch_size`. Batch size per GPU. The default value is 2.
+- Learning rate: `--lr`. The default value is 3e-4.
+- Weight decay: `-w`, `--weight_decay`. The default value is 0.1.
+- Warmup steps: `-s`, `--warmup_steps`. The default value is 2000.
+- Gradient checkpointing: `-g`, `--gradient_checkpoint`. The default value is `False`. This saves memory at the cost of speed. You'd better enable this option when training with a large batch size.
+- Max length: `-l`, `--max_length`. The default value is 4096.
+- Mixed precision: `-x`, `--mixed_precision`. The default value is "fp16". "fp16" and "bf16" are supported.
+- Save interval: `-i`, `--save_interval`. The interval (steps) of saving checkpoints. The default value is 1000.
+- Checkpoint directory: `-o`, `--save_dir`. The directoty path to save checkpoints. The default value is `checkpoint`.
+- Checkpoint to load: `-f`, `--load`. The checkpoint path to load. The default value is `None`.
+- Gradient clipping: `--gradient_clipping`. The default value is 1.0.
+- Tensorboard log directory: `-t`, `--tensorboard_dir`. The directory path to save tensorboard logs. The default value is `tb_logs`.
+- Flash attention: `-a`, `--flash_attention`. If you want to use flash attention, you must install `flash-attn`. The default value is `False`. This is helpful to accelerate training while saving memory. We recommend you always use flash attention.
+
+
+### 4. Shell Script Examples
+
+For your convenience, we provide some shell scripts to run benchmark with various configurations.
+
+You can find them in `scripts/benchmark_7B` and `scripts/benchmark_70B` directory. The main command should be in the format of:
+```bash
+colossalai run --nproc_per_node YOUR_GPU_PER_NODE --hostfile YOUR_HOST_FILE \
+benchmark.py --OTHER_CONFIGURATIONS
+```
+Here we will show an example of how to run training
+llama pretraining with `gemini, batch_size=16, sequence_length=4096, gradient_checkpoint=True, flash_attn=True`.
+
+#### a. Running environment
+This experiment was performed on 4 computing nodes with 32 A800 GPUs in total. The nodes are
+connected with RDMA and GPUs within one node are fully connected with NVLink.
+
+#### b. Running command
+
+```bash
+cd scripts/benchmark_7B
+```
+
+First, put your host file (`hosts.txt`) in this directory with your real host ip or host name.
+
+Here is a sample `hosts.txt`:
+```text
+hostname1
+hostname2
+hostname3
+hostname4
+```
+
+Then add environment variables to script if needed.
+
+Finally, run the following command to start training:
+
+```bash
+bash gemini.sh
+```
+#### c. Results
+If you run the above command successfully, you will get the following results:
+`max memory usage: 55491.10 MB, throughput: 24.26 samples/s, TFLOPS/GPU: 167.43`.
+
+
+## Reference
+```
+@article{bian2021colossal,
+ title={Colossal-AI: A Unified Deep Learning System For Large-Scale Parallel Training},
+ author={Bian, Zhengda and Liu, Hongxin and Wang, Boxiang and Huang, Haichen and Li, Yongbin and Wang, Chuanrui and Cui, Fan and You, Yang},
+ journal={arXiv preprint arXiv:2110.14883},
+ year={2021}
+}
+```
+
+```bibtex
+@software{openlm2023openllama,
+ author = {Geng, Xinyang and Liu, Hao},
+ title = {OpenLLaMA: An Open Reproduction of LLaMA},
+ month = May,
+ year = 2023,
+ url = {https://github.com/openlm-research/open_llama}
+}
+```
+
+```bibtex
+@software{together2023redpajama,
+ author = {Together Computer},
+ title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
+ month = April,
+ year = 2023,
+ url = {https://github.com/togethercomputer/RedPajama-Data}
+}
+```
+
+```bibtex
+@article{touvron2023llama,
+ title={Llama: Open and efficient foundation language models},
+ author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
+ journal={arXiv preprint arXiv:2302.13971},
+ year={2023}
+}
+```
diff --git a/examples/language/llama2/attn.py b/examples/language/llama2/attn.py
new file mode 100644
index 000000000..15f76647c
--- /dev/null
+++ b/examples/language/llama2/attn.py
@@ -0,0 +1,83 @@
+from types import MethodType
+from typing import Optional, Tuple
+
+import torch
+import torch.nn as nn
+from transformers.models.llama.modeling_llama import LlamaAttention, apply_rotary_pos_emb, repeat_kv
+
+SUPPORT_XFORMERS = False
+SUPPORT_FLASH2 = False
+try:
+ import xformers.ops as xops
+ SUPPORT_XFORMERS = True
+except ImportError:
+ pass
+
+try:
+ from flash_attn import flash_attn_func
+ SUPPORT_FLASH2 = True
+except ImportError:
+ pass
+
+SUPPORT_FLASH = SUPPORT_XFORMERS or SUPPORT_FLASH2
+
+
+def llama_flash_attention(
+ self: LlamaAttention,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+ # [bsz, nh, t, hd]
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ # repeat k/v heads if n_kv_heads < n_heads
+ key_states = repeat_kv(key_states, self.num_key_value_groups)
+ value_states = repeat_kv(value_states, self.num_key_value_groups)
+
+ # q, k, v is [B, H, S, K] and xformers need [B, S, H, K]. returns [B, S, H, K]
+ query_states = query_states.transpose(1, 2)
+ key_states = key_states.transpose(1, 2)
+ value_states = value_states.transpose(1, 2)
+ if SUPPORT_FLASH2:
+ attn_output = flash_attn_func(query_states, key_states, value_states, causal=True)
+ else:
+ attn_output = xops.memory_efficient_attention(query_states,
+ key_states,
+ value_states,
+ attn_bias=xops.LowerTriangularMask())
+
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+def replace_xformers(model: nn.Module):
+ for module in model.modules():
+ if isinstance(module, LlamaAttention):
+ module.forward = MethodType(llama_flash_attention, module)
diff --git a/examples/language/llama2/benchmark.py b/examples/language/llama2/benchmark.py
new file mode 100644
index 000000000..1b947cef9
--- /dev/null
+++ b/examples/language/llama2/benchmark.py
@@ -0,0 +1,211 @@
+import argparse
+import resource
+from contextlib import nullcontext
+
+import torch
+from attn import SUPPORT_FLASH, replace_xformers
+from data_utils import RandomDataset
+from model_utils import format_numel_str, get_model_numel
+from performance_evaluator import PerformanceEvaluator
+from torch.distributed.fsdp.fully_sharded_data_parallel import CPUOffload, MixedPrecision
+from tqdm import tqdm
+from transformers.models.llama.configuration_llama import LlamaConfig
+from transformers.models.llama.modeling_llama import LlamaForCausalLM
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin, HybridParallelPlugin, TorchFSDPPlugin
+from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.utils import get_current_device
+
+# ==============================
+# Constants
+# ==============================
+
+MODEL_CONFIGS = {
+ '7b':
+ LlamaConfig(max_position_embeddings=4096),
+ '13b':
+ LlamaConfig(hidden_size=5120,
+ intermediate_size=13824,
+ num_hidden_layers=40,
+ num_attention_heads=40,
+ max_position_embeddings=4096),
+ '70b':
+ LlamaConfig(hidden_size=8192,
+ intermediate_size=28672,
+ num_hidden_layers=80,
+ num_attention_heads=64,
+ max_position_embeddings=4096,
+ num_key_value_heads=8),
+}
+
+
+def main():
+ # ==============================
+ # Parse Arguments
+ # ==============================
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-c', '--config', type=str, default='7b', help='Model configuration')
+ parser.add_argument('-p',
+ '--plugin',
+ choices=['gemini', 'gemini_auto', 'fsdp', 'fsdp_cpu', '3d', '3d_cpu'],
+ default='gemini',
+ help='Choose which plugin to use')
+ parser.add_argument('-b', '--batch_size', type=int, default=2, help='Batch size')
+ parser.add_argument('-s', '--num_steps', type=int, default=5, help='Number of steps to run')
+ parser.add_argument('-i', '--ignore_steps', type=int, default=2, help='Number of steps to ignore')
+ parser.add_argument('-g', '--grad_checkpoint', action='store_true', help='Use gradient checkpointing')
+ parser.add_argument('-l', '--max_length', type=int, default=4096, help='Max sequence length')
+ parser.add_argument('-w',
+ '--warmup_ratio',
+ type=float,
+ default=0.8,
+ help='warm up ratio of non-model data. Only for gemini-auto')
+ parser.add_argument('-m', '--memory_limit', type=int, help='Gemini memory limit in mb')
+ parser.add_argument('-x', '--xformers', action='store_true', help='Use xformers')
+ parser.add_argument('--shard_param_frac', type=float, default=1.0, help='Shard param fraction. Only for gemini')
+ parser.add_argument('--offload_optim_frac', type=float, default=0.0, help='Offload optim fraction. Only for gemini')
+ parser.add_argument('--offload_param_frac', type=float, default=0.0, help='Offload param fraction. Only for gemini')
+ parser.add_argument('--tp', type=int, default=1, help='Tensor parallel size')
+ parser.add_argument('--pp', type=int, default=1, help='Pipeline parallel size')
+ parser.add_argument('--mbs', type=int, default=1)
+ parser.add_argument('--zero', type=int, default=0)
+ args = parser.parse_args()
+
+ colossalai.launch_from_torch({})
+ coordinator = DistCoordinator()
+
+ def empty_init():
+ pass
+
+ # ==============================
+ # Initialize Booster
+ # ==============================
+ use_empty_init = True
+ if args.plugin == 'gemini':
+ plugin = GeminiPlugin(precision='bf16',
+ shard_param_frac=args.shard_param_frac,
+ offload_optim_frac=args.offload_optim_frac,
+ offload_param_frac=args.offload_param_frac)
+ elif args.plugin == 'gemini_auto':
+ plugin = GeminiPlugin(placement_policy='auto', precision='bf16', warmup_non_model_data_ratio=args.warmup_ratio)
+ elif args.plugin == 'fsdp':
+ if use_empty_init:
+ plugin = TorchFSDPPlugin(
+ mixed_precision=MixedPrecision(param_dtype=torch.float16,
+ reduce_dtype=torch.float16,
+ buffer_dtype=torch.float16),
+ param_init_fn=empty_init(),
+ )
+ else:
+ plugin = TorchFSDPPlugin(mixed_precision=MixedPrecision(
+ param_dtype=torch.float16, reduce_dtype=torch.float16, buffer_dtype=torch.float16))
+ elif args.plugin == 'fsdp_cpu':
+ if use_empty_init:
+ plugin = TorchFSDPPlugin(
+ mixed_precision=MixedPrecision(param_dtype=torch.float16,
+ reduce_dtype=torch.float16,
+ buffer_dtype=torch.float16),
+ cpu_offload=CPUOffload(offload_params=True),
+ param_init_fn=empty_init(),
+ )
+ else:
+ plugin = TorchFSDPPlugin(mixed_precision=MixedPrecision(param_dtype=torch.float16,
+ reduce_dtype=torch.float16,
+ buffer_dtype=torch.float16),
+ cpu_offload=CPUOffload(offload_params=True))
+ elif args.plugin == '3d':
+ plugin = HybridParallelPlugin(tp_size=args.tp,
+ pp_size=args.pp,
+ zero_stage=args.zero,
+ enable_fused_normalization=True,
+ num_microbatches=args.mbs,
+ precision='bf16')
+ elif args.plugin == '3d_cpu':
+ plugin = HybridParallelPlugin(tp_size=args.tp,
+ pp_size=args.pp,
+ zero_stage=args.zero,
+ cpu_offload=True,
+ enable_fused_normalization=True,
+ num_microbatches=args.mbs,
+ initial_scale=2**8,
+ precision='bf16')
+ else:
+ raise ValueError(f'Unknown plugin {args.plugin}')
+
+ booster = Booster(plugin=plugin)
+
+ # ==============================
+ # Initialize Dataset and Dataloader
+ # ==============================
+ dp_size = plugin.dp_size if isinstance(plugin, HybridParallelPlugin) else coordinator.world_size
+
+ config = MODEL_CONFIGS[args.config]
+ dataset = RandomDataset(num_samples=args.batch_size * args.num_steps * dp_size,
+ max_length=args.max_length,
+ vocab_size=config.vocab_size)
+ dataloader = plugin.prepare_dataloader(dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)
+
+ # ==============================
+ # Initialize Model and Optimizer
+ # ==============================
+ init_ctx = LazyInitContext(
+ default_device=get_current_device()) if isinstance(plugin,
+ (GeminiPlugin, HybridParallelPlugin)) else nullcontext()
+
+ with init_ctx:
+ model = LlamaForCausalLM(config)
+
+ if args.grad_checkpoint:
+ model.gradient_checkpointing_enable()
+
+ if args.xformers:
+ assert SUPPORT_FLASH, 'Use flash attention while xfomers is not installed'
+ replace_xformers(model)
+
+ model_numel = get_model_numel(model)
+ coordinator.print_on_master(f'Model params: {format_numel_str(model_numel)}')
+ performance_evaluator = PerformanceEvaluator(model_numel,
+ args.grad_checkpoint,
+ args.ignore_steps,
+ dp_world_size=dp_size)
+
+ optimizer = HybridAdam(model.parameters())
+ torch.set_default_dtype(torch.bfloat16)
+ model, optimizer, _, dataloader, _ = booster.boost(model, optimizer, dataloader=dataloader)
+ torch.set_default_dtype(torch.float)
+ coordinator.print_on_master(f'Booster init max CUDA memory: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB')
+ coordinator.print_on_master(
+ f'Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss/1024:.2f} MB')
+
+ if isinstance(plugin, HybridParallelPlugin) and args.pp > 1:
+ data_iter = iter(dataloader)
+ for step in tqdm(range(len(dataloader)), desc='Step', disable=not coordinator.is_master()):
+ performance_evaluator.on_step_start(step)
+ booster.execute_pipeline(data_iter,
+ model,
+ criterion=lambda outputs, inputs: outputs[0],
+ optimizer=optimizer,
+ return_loss=False)
+ optimizer.step()
+ optimizer.zero_grad()
+ performance_evaluator.on_step_end(input_ids=torch.empty(args.batch_size, args.max_length))
+ else:
+ for step, batch in enumerate(tqdm(dataloader, desc='Step', disable=not coordinator.is_master())):
+ performance_evaluator.on_step_start(step)
+ outputs = model(**batch)
+ loss = outputs[0]
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ optimizer.zero_grad()
+ performance_evaluator.on_step_end(**batch)
+
+ performance_evaluator.on_fit_end()
+ coordinator.print_on_master(f'Max CUDA memory usage: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/examples/language/llama2/data_utils.py b/examples/language/llama2/data_utils.py
new file mode 100644
index 000000000..25d0e1bd9
--- /dev/null
+++ b/examples/language/llama2/data_utils.py
@@ -0,0 +1,119 @@
+import json
+import random
+from typing import Iterator, Optional
+
+import numpy as np
+import torch
+from torch.distributed import ProcessGroup
+from torch.distributed.distributed_c10d import _get_default_group
+from torch.utils.data import DataLoader, Dataset, DistributedSampler
+
+from colossalai.utils import get_current_device
+
+
+class StatefulDistributedSampler(DistributedSampler):
+
+ def __init__(self,
+ dataset: Dataset,
+ num_replicas: Optional[int] = None,
+ rank: Optional[int] = None,
+ shuffle: bool = True,
+ seed: int = 0,
+ drop_last: bool = False) -> None:
+ super().__init__(dataset, num_replicas, rank, shuffle, seed, drop_last)
+ self.start_index: int = 0
+
+ def __iter__(self) -> Iterator:
+ iterator = super().__iter__()
+ indices = list(iterator)
+ indices = indices[self.start_index:]
+ return iter(indices)
+
+ def __len__(self) -> int:
+ return self.num_samples - self.start_index
+
+ def set_start_index(self, start_index: int) -> None:
+ self.start_index = start_index
+
+
+def prepare_dataloader(dataset,
+ batch_size,
+ shuffle=False,
+ seed=1024,
+ drop_last=False,
+ pin_memory=False,
+ num_workers=0,
+ process_group: Optional[ProcessGroup] = None,
+ **kwargs):
+ r"""
+ Prepare a dataloader for distributed training. The dataloader will be wrapped by
+ `torch.utils.data.DataLoader` and `StatefulDistributedSampler`.
+
+
+ Args:
+ dataset (`torch.utils.data.Dataset`): The dataset to be loaded.
+ shuffle (bool, optional): Whether to shuffle the dataset. Defaults to False.
+ seed (int, optional): Random worker seed for sampling, defaults to 1024.
+ add_sampler: Whether to add ``DistributedDataParallelSampler`` to the dataset. Defaults to True.
+ drop_last (bool, optional): Set to True to drop the last incomplete batch, if the dataset size
+ is not divisible by the batch size. If False and the size of dataset is not divisible by
+ the batch size, then the last batch will be smaller, defaults to False.
+ pin_memory (bool, optional): Whether to pin memory address in CPU memory. Defaults to False.
+ num_workers (int, optional): Number of worker threads for this dataloader. Defaults to 0.
+ kwargs (dict): optional parameters for ``torch.utils.data.DataLoader``, more details could be found in
+ `DataLoader `_.
+
+ Returns:
+ :class:`torch.utils.data.DataLoader`: A DataLoader used for training or testing.
+ """
+ _kwargs = kwargs.copy()
+ process_group = process_group or _get_default_group()
+ sampler = StatefulDistributedSampler(dataset,
+ num_replicas=process_group.size(),
+ rank=process_group.rank(),
+ shuffle=shuffle)
+
+ # Deterministic dataloader
+ def seed_worker(worker_id):
+ worker_seed = seed
+ np.random.seed(worker_seed)
+ torch.manual_seed(worker_seed)
+ random.seed(worker_seed)
+
+ return DataLoader(dataset,
+ batch_size=batch_size,
+ sampler=sampler,
+ worker_init_fn=seed_worker,
+ drop_last=drop_last,
+ pin_memory=pin_memory,
+ num_workers=num_workers,
+ **_kwargs)
+
+
+def load_json(file_path: str):
+ with open(file_path, 'r') as f:
+ return json.load(f)
+
+
+def save_json(data, file_path: str):
+ with open(file_path, 'w') as f:
+ json.dump(data, f, indent=4)
+
+
+class RandomDataset(Dataset):
+
+ def __init__(self, num_samples: int = 1000, max_length: int = 2048, vocab_size: int = 32000):
+ self.num_samples = num_samples
+ self.max_length = max_length
+ self.input_ids = torch.randint(0, vocab_size, (num_samples, max_length), device=get_current_device())
+ self.attention_mask = torch.ones_like(self.input_ids)
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, idx):
+ return {
+ 'input_ids': self.input_ids[idx],
+ 'attention_mask': self.attention_mask[idx],
+ 'labels': self.input_ids[idx]
+ }
diff --git a/examples/language/llama2/model_utils.py b/examples/language/llama2/model_utils.py
new file mode 100644
index 000000000..431ff5cfb
--- /dev/null
+++ b/examples/language/llama2/model_utils.py
@@ -0,0 +1,32 @@
+from contextlib import contextmanager
+
+import torch
+import torch.nn as nn
+
+
+@contextmanager
+def low_precision_init(target_dtype: torch.dtype = torch.float16):
+ dtype = torch.get_default_dtype()
+ try:
+ torch.set_default_dtype(target_dtype)
+ yield
+ finally:
+ torch.set_default_dtype(dtype)
+
+
+def get_model_numel(model: nn.Module) -> int:
+ return sum(p.numel() for p in model.parameters())
+
+
+def format_numel_str(numel: int) -> str:
+ B = 1024**3
+ M = 1024**2
+ K = 1024
+ if numel >= B:
+ return f'{numel / B:.2f} B'
+ elif numel >= M:
+ return f'{numel / M:.2f} M'
+ elif numel >= K:
+ return f'{numel / K:.2f} K'
+ else:
+ return f'{numel}'
diff --git a/examples/language/llama2/performance_evaluator.py b/examples/language/llama2/performance_evaluator.py
new file mode 100644
index 000000000..711b99c54
--- /dev/null
+++ b/examples/language/llama2/performance_evaluator.py
@@ -0,0 +1,102 @@
+from time import time
+from typing import Optional
+
+import torch
+import torch.distributed as dist
+from torch import Tensor
+
+from colossalai.cluster import DistCoordinator
+
+
+def divide(x: float, y: float) -> float:
+ if y == 0:
+ return float('inf')
+ elif y == float('inf'):
+ return float('nan')
+ return x / y
+
+
+@torch.no_grad()
+def all_reduce_mean(x: float, world_size: int) -> float:
+ if world_size == 1:
+ return x
+ tensor = torch.tensor([x], device=torch.cuda.current_device())
+ dist.all_reduce(tensor)
+ tensor = tensor / world_size
+ return tensor.item()
+
+
+class Timer:
+
+ def __init__(self) -> None:
+ self.start_time: Optional[float] = None
+ self.duration: float = 0.
+
+ def start(self) -> None:
+ self.start_time = time()
+
+ def end(self) -> None:
+ assert self.start_time is not None
+ self.duration += time() - self.start_time
+ self.start_time = None
+
+ def reset(self) -> None:
+ self.duration = 0.
+
+
+class PerformanceEvaluator:
+ """
+ Callback for valuate the performance of the model.
+ Args:
+ actor_num_params: The number of parameters of the actor model.
+ critic_num_params: The number of parameters of the critic model.
+ initial_model_num_params: The number of parameters of the initial model.
+ reward_model_num_params: The number of parameters of the reward model.
+ enable_grad_checkpoint: Whether to enable gradient checkpointing.
+ ignore_episodes: The number of episodes to ignore when calculating the performance.
+ """
+
+ def __init__(self,
+ model_numel: int,
+ enable_grad_checkpoint: bool = False,
+ ignore_steps: int = 0,
+ dp_world_size: Optional[int] = None) -> None:
+ self.model_numel = model_numel
+ self.enable_grad_checkpoint = enable_grad_checkpoint
+ self.ignore_steps = ignore_steps
+
+ self.coordinator = DistCoordinator()
+ self.dp_world_size = dp_world_size or self.coordinator.world_size
+ self.disable: bool = False
+ self.timer = Timer()
+ self.num_samples: int = 0
+ self.flop: int = 0
+
+ def on_step_start(self, step: int) -> None:
+ self.disable = self.ignore_steps > 0 and step < self.ignore_steps
+ if self.disable:
+ return
+ torch.cuda.synchronize()
+ self.timer.start()
+
+ def on_step_end(self, input_ids: Tensor, **kwargs) -> None:
+ if self.disable:
+ return
+ torch.cuda.synchronize()
+ self.timer.end()
+
+ batch_size, seq_len = input_ids.shape
+
+ self.num_samples += batch_size
+ self.flop += batch_size * seq_len * self.model_numel * 2 * (3 + int(self.enable_grad_checkpoint))
+
+ def on_fit_end(self) -> None:
+ avg_duration = all_reduce_mean(self.timer.duration, self.coordinator.world_size)
+ avg_throughput = self.num_samples * self.dp_world_size / (avg_duration + 1e-12)
+ mp_world_size = self.coordinator.world_size // self.dp_world_size
+ avg_tflops_per_gpu = self.flop / 1e12 / (avg_duration + 1e-12) / mp_world_size
+ self.coordinator.print_on_master(
+ f'num_samples: {self.num_samples}, dp_world_size: {self.dp_world_size}, flop: {self.flop}, avg_duration: {avg_duration}, '
+ f'avg_throughput: {avg_throughput}')
+ self.coordinator.print_on_master(
+ f'Throughput: {avg_throughput:.2f} samples/sec, TFLOPS per GPU: {avg_tflops_per_gpu:.2f}')
diff --git a/examples/language/llama2/pretrain.py b/examples/language/llama2/pretrain.py
new file mode 100644
index 000000000..b72a30196
--- /dev/null
+++ b/examples/language/llama2/pretrain.py
@@ -0,0 +1,275 @@
+import argparse
+import os
+import resource
+from contextlib import nullcontext
+from functools import partial
+from typing import Optional, Tuple
+
+import torch
+import torch.distributed as dist
+import torch.nn as nn
+from attn import SUPPORT_XFORMERS, replace_xformers
+from data_utils import load_json, prepare_dataloader, save_json
+from datasets import load_dataset
+from torch.optim import Optimizer
+from torch.optim.lr_scheduler import _LRScheduler
+from torch.utils.tensorboard import SummaryWriter
+from tqdm import tqdm
+from transformers.models.llama.configuration_llama import LlamaConfig
+from transformers.models.llama.modeling_llama import LlamaForCausalLM
+from transformers.models.llama.tokenization_llama import LlamaTokenizer
+
+import colossalai
+from colossalai.booster import Booster
+from colossalai.booster.plugin import GeminiPlugin, LowLevelZeroPlugin
+from colossalai.cluster import DistCoordinator
+from colossalai.lazy import LazyInitContext
+from colossalai.nn.lr_scheduler import CosineAnnealingWarmupLR
+from colossalai.nn.optimizer import HybridAdam
+from colossalai.utils import get_current_device
+
+MODEL_CONFIGS = {
+ '7b':
+ LlamaConfig(max_position_embeddings=4096),
+ '13b':
+ LlamaConfig(hidden_size=5120,
+ intermediate_size=13824,
+ num_hidden_layers=40,
+ num_attention_heads=40,
+ max_position_embeddings=4096),
+ '70b':
+ LlamaConfig(hidden_size=8192,
+ intermediate_size=28672,
+ num_hidden_layers=80,
+ num_attention_heads=64,
+ max_position_embeddings=4096,
+ num_key_value_heads=8),
+}
+
+
+def get_model_numel(model: nn.Module) -> int:
+ return sum(p.numel() for p in model.parameters())
+
+
+def format_numel_str(numel: int) -> str:
+ B = 1024**3
+ M = 1024**2
+ K = 1024
+ if numel >= B:
+ return f'{numel / B:.2f} B'
+ elif numel >= M:
+ return f'{numel / M:.2f} M'
+ elif numel >= K:
+ return f'{numel / K:.2f} K'
+ else:
+ return f'{numel}'
+
+
+def tokenize_batch(batch, tokenizer: Optional[LlamaTokenizer] = None, max_length: int = 2048):
+ texts = [sample['text'] for sample in batch]
+ data = tokenizer(texts, return_tensors="pt", padding='max_length', truncation=True, max_length=max_length)
+ data['labels'] = data['input_ids'].clone()
+ return data
+
+
+def all_reduce_mean(tensor: torch.Tensor) -> torch.Tensor:
+ dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
+ tensor.div_(dist.get_world_size())
+ return tensor
+
+
+def save(booster: Booster, model: nn.Module, optimizer: Optimizer, lr_scheduler: _LRScheduler, epoch: int, step: int,
+ batch_size: int, coordinator: DistCoordinator, save_dir: str):
+ save_dir = os.path.join(save_dir, f'epoch{epoch}-step{step}')
+ os.makedirs(os.path.join(save_dir, 'model'), exist_ok=True)
+
+ booster.save_model(model, os.path.join(save_dir, 'model'), shard=True)
+ booster.save_optimizer(optimizer, os.path.join(save_dir, 'optimizer'), shard=True)
+ booster.save_lr_scheduler(lr_scheduler, os.path.join(save_dir, 'lr_scheduler'))
+ running_states = {
+ 'epoch': epoch,
+ 'step': step,
+ 'sample_start_index': step * batch_size,
+ }
+ if coordinator.is_master():
+ save_json(running_states, os.path.join(save_dir, 'running_states.json'))
+
+
+def load(booster: Booster, model: nn.Module, optimizer: Optimizer, lr_scheduler: _LRScheduler,
+ load_dir: str) -> Tuple[int, int, int]:
+ booster.load_model(model, os.path.join(load_dir, 'model'))
+ booster.load_optimizer(optimizer, os.path.join(load_dir, 'optimizer'))
+ booster.load_lr_scheduler(lr_scheduler, os.path.join(load_dir, 'lr_scheduler'))
+ running_states = load_json(os.path.join(load_dir, 'running_states.json'))
+ return running_states['epoch'], running_states['step'], running_states['sample_start_index']
+
+
+def main():
+ # ==============================
+ # Parse Arguments
+ # ==============================
+ parser = argparse.ArgumentParser()
+ parser.add_argument('-c', '--config', type=str, default='7b', help='Model configuration')
+ parser.add_argument('-p',
+ '--plugin',
+ choices=['gemini', 'gemini_auto', 'zero2', 'zero2_cpu'],
+ default='gemini',
+ help='Choose which plugin to use')
+ parser.add_argument('-d',
+ '--dataset',
+ type=str,
+ default='togethercomputer/RedPajama-Data-1T-Sample',
+ help='Data set path')
+ parser.add_argument('-e', '--num_epochs', type=int, default=1, help='Number of epochs')
+ parser.add_argument('-b', '--batch_size', type=int, default=2, help='Local batch size')
+ parser.add_argument('--lr', type=float, default=3e-4, help='Learning rate')
+ parser.add_argument('-w', '--weigth_decay', type=float, default=0.1, help='Weight decay')
+ parser.add_argument('-s', '--warmup_steps', type=int, default=2000, help='Warmup steps')
+ parser.add_argument('-g', '--grad_checkpoint', action='store_true', help='Use gradient checkpointing')
+ parser.add_argument('-l', '--max_length', type=int, default=4096, help='Max sequence length')
+ parser.add_argument('-x', '--mixed_precision', default='fp16', choices=['fp16', 'bf16'], help='Mixed precision')
+ parser.add_argument('-i', '--save_interval', type=int, default=1000, help='Save interval')
+ parser.add_argument('-o', '--save_dir', type=str, default='checkpoint', help='Checkpoint directory')
+ parser.add_argument('-f', '--load', type=str, default=None, help='Load checkpoint')
+ parser.add_argument('--grad_clip', type=float, default=1.0, help='Gradient clipping')
+ parser.add_argument('-t', '--tensorboard_dir', type=str, default='tb_logs', help='Tensorboard directory')
+ parser.add_argument('-a', '--flash_attention', action='store_true', help='Use Flash Attention')
+ args = parser.parse_args()
+
+ # ==============================
+ # Initialize Distributed Training
+ # ==============================
+ colossalai.launch_from_torch({})
+ coordinator = DistCoordinator()
+
+ # ==============================
+ # Initialize Tensorboard
+ # ==============================
+ if coordinator.is_master():
+ os.makedirs(args.tensorboard_dir, exist_ok=True)
+ writer = SummaryWriter(args.tensorboard_dir)
+
+ # ==============================
+ # Initialize Booster
+ # ==============================
+ if args.plugin == 'gemini':
+ plugin = GeminiPlugin(precision=args.mixed_precision, initial_scale=2**16, max_norm=args.grad_clip)
+ elif args.plugin == 'gemini_auto':
+ plugin = GeminiPlugin(precision=args.mixed_precision,
+ placement_policy='auto',
+ initial_scale=2**16,
+ max_norm=args.grad_clip)
+ elif args.plugin == 'zero2':
+ plugin = LowLevelZeroPlugin(stage=2,
+ precision=args.mixed_precision,
+ initial_scale=2**16,
+ max_norm=args.grad_clip)
+ elif args.plugin == 'zero2_cpu':
+ plugin = LowLevelZeroPlugin(stage=2,
+ precision=args.mixed_precision,
+ initial_scale=2**16,
+ cpu_offload=True,
+ max_norm=args.grad_clip)
+ else:
+ raise ValueError(f'Unknown plugin {args.plugin}')
+
+ booster = Booster(plugin=plugin)
+
+ # ==============================
+ # Initialize Tokenizer, Dataset and Dataloader
+ # ==============================
+ tokenizer = LlamaTokenizer.from_pretrained('hf-internal-testing/llama-tokenizer')
+ # follows fast chat: https://github.com/lm-sys/FastChat/blob/main/fastchat/train/train.py#L257
+ tokenizer.pad_token = tokenizer.unk_token
+
+ dataset = load_dataset(args.dataset)
+ train_ds = dataset['train']
+ dataloader = prepare_dataloader(train_ds,
+ batch_size=args.batch_size,
+ shuffle=True,
+ drop_last=True,
+ collate_fn=partial(tokenize_batch, tokenizer=tokenizer, max_length=args.max_length))
+
+ # ==============================
+ # Initialize Model, Optimizer and LR Scheduler
+ # ==============================
+ config = MODEL_CONFIGS[args.config]
+ init_ctx = LazyInitContext(
+ default_device=get_current_device()) if isinstance(plugin, GeminiPlugin) else nullcontext()
+
+ with init_ctx:
+ model = LlamaForCausalLM(config)
+
+ if args.grad_checkpoint:
+ model.gradient_checkpointing_enable()
+ if args.flash_attention:
+ assert SUPPORT_XFORMERS, 'Use flash attention while xfomers is not installed'
+ replace_xformers(model)
+
+ model_numel = get_model_numel(model)
+ coordinator.print_on_master(f'Model params: {format_numel_str(model_numel)}')
+
+ optimizer = HybridAdam(model.parameters(), lr=args.lr, betas=(0.9, 0.95), weight_decay=args.weigth_decay)
+ lr_scheduler = CosineAnnealingWarmupLR(optimizer,
+ total_steps=args.num_epochs * len(dataloader),
+ warmup_steps=args.warmup_steps,
+ eta_min=0.1 * args.lr)
+ default_dtype = torch.float16 if args.mixed_precision == 'fp16' else torch.bfloat16
+ torch.set_default_dtype(default_dtype)
+ model, optimizer, _, dataloader, lr_scheduler = booster.boost(model,
+ optimizer,
+ dataloader=dataloader,
+ lr_scheduler=lr_scheduler)
+ torch.set_default_dtype(torch.float)
+
+ coordinator.print_on_master(f'Booster init max CUDA memory: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB')
+ coordinator.print_on_master(
+ f'Booster init max CPU memory: {resource.getrusage(resource.RUSAGE_SELF).ru_maxrss/1024:.2f} MB')
+
+ # load checkpoint if specified
+ start_epoch = 0
+ start_step = 0
+ sampler_start_idx = 0
+ if args.load is not None:
+ coordinator.print_on_master('Loading checkpoint')
+ start_epoch, start_step, sampler_start_idx = load(booster, model, optimizer, lr_scheduler, args.load)
+ coordinator.print_on_master(f'Loaded checkpoint {args.load} at epoch {start_epoch} step {start_step}')
+
+ num_steps_per_epoch = len(dataloader)
+ # if resume training, set the sampler start index to the correct value
+ dataloader.sampler.set_start_index(sampler_start_idx)
+ for epoch in range(start_epoch, args.num_epochs):
+ dataloader.sampler.set_epoch(epoch)
+ with tqdm(enumerate(dataloader),
+ desc=f'Epoch {epoch}',
+ disable=not coordinator.is_master(),
+ total=num_steps_per_epoch,
+ initial=start_step) as pbar:
+ for step, batch in pbar:
+ batch = {k: v.cuda() for k, v in batch.items()}
+ outputs = model(**batch)
+ loss = outputs[0]
+ booster.backward(loss, optimizer)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ all_reduce_mean(loss)
+ pbar.set_postfix({'loss': loss.item()})
+ if coordinator.is_master():
+ writer.add_scalar('loss', loss.item(), epoch * num_steps_per_epoch + step)
+
+ if args.save_interval > 0 and (step + 1) % args.save_interval == 0:
+ coordinator.print_on_master(f'Saving checkpoint')
+ save(booster, model, optimizer, lr_scheduler, epoch, step + 1, args.batch_size, coordinator,
+ args.save_dir)
+ coordinator.print_on_master(f'Saved checkpoint at epoch {epoch} step {step + 1}')
+ # the continue epochs are not resumed, so we need to reset the sampler start index and start step
+ dataloader.sampler.set_start_index(0)
+ start_step = 0
+
+ coordinator.print_on_master(f'Max CUDA memory usage: {torch.cuda.max_memory_allocated()/1024**2:.2f} MB')
+
+
+if __name__ == '__main__':
+ main()
diff --git a/examples/language/llama2/requirements.txt b/examples/language/llama2/requirements.txt
new file mode 100644
index 000000000..3ddf21ffe
--- /dev/null
+++ b/examples/language/llama2/requirements.txt
@@ -0,0 +1,9 @@
+colossalai>=0.3.0
+datasets
+numpy
+torch>=1.12.0,<=2.0.0
+tqdm
+transformers
+flash-attn>=2.0.0,<=2.0.5
+SentencePiece==0.1.99
+tensorboard==2.14.0
diff --git a/examples/language/llama2/scripts/benchmark_70B/3d.sh b/examples/language/llama2/scripts/benchmark_70B/3d.sh
new file mode 100644
index 000000000..d50c57042
--- /dev/null
+++ b/examples/language/llama2/scripts/benchmark_70B/3d.sh
@@ -0,0 +1,17 @@
+#!/bin/bash
+
+# TODO: fix this
+echo "3D parallel for LLaMA-2 is not ready yet"
+exit 1
+
+################
+#Load your environments and modules here
+################
+
+HOSTFILE=$(realpath hosts.txt)
+
+cd ../..
+
+export OMP_NUM_THREADS=8
+
+colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -c 70b -p 3d -g -x -b 8 --tp 4 --pp 2 --mbs 4
diff --git a/examples/language/llama2/scripts/benchmark_70B/gemini.sh b/examples/language/llama2/scripts/benchmark_70B/gemini.sh
new file mode 100644
index 000000000..c80d4d9f2
--- /dev/null
+++ b/examples/language/llama2/scripts/benchmark_70B/gemini.sh
@@ -0,0 +1,13 @@
+#!/bin/bash
+
+################
+#Load your environments and modules here
+################
+
+HOSTFILE=$(realpath hosts.txt)
+
+cd ../..
+
+export OMP_NUM_THREADS=8
+
+colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -c 70b -g -x -b 2
diff --git a/examples/language/llama2/scripts/benchmark_70B/gemini_auto.sh b/examples/language/llama2/scripts/benchmark_70B/gemini_auto.sh
new file mode 100644
index 000000000..ce3b2f217
--- /dev/null
+++ b/examples/language/llama2/scripts/benchmark_70B/gemini_auto.sh
@@ -0,0 +1,13 @@
+#!/bin/bash
+
+################
+#Load your environments and modules here
+################
+
+HOSTFILE=$(realpath hosts.txt)
+
+cd ../..
+
+export OMP_NUM_THREADS=8
+
+colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -c 70b -p gemini_auto -g -x -b 2
diff --git a/examples/language/llama2/scripts/benchmark_7B/gemini.sh b/examples/language/llama2/scripts/benchmark_7B/gemini.sh
new file mode 100644
index 000000000..db4968a8d
--- /dev/null
+++ b/examples/language/llama2/scripts/benchmark_7B/gemini.sh
@@ -0,0 +1,13 @@
+#!/bin/bash
+
+################
+#Load your environments and modules here
+################
+
+HOSTFILE=$(realpath hosts.txt)
+
+cd ../..
+
+export OMP_NUM_THREADS=8
+
+colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -g -x -b 16
diff --git a/examples/language/llama2/scripts/benchmark_7B/gemini_auto.sh b/examples/language/llama2/scripts/benchmark_7B/gemini_auto.sh
new file mode 100644
index 000000000..59ec1c1a7
--- /dev/null
+++ b/examples/language/llama2/scripts/benchmark_7B/gemini_auto.sh
@@ -0,0 +1,13 @@
+#!/bin/bash
+
+################
+#Load your environments and modules here
+################
+
+HOSTFILE=$(realpath hosts.txt)
+
+cd ../..
+
+export OMP_NUM_THREADS=8
+
+colossalai run --nproc_per_node 8 --hostfile $HOSTFILE benchmark.py -p gemini_auto -g -x -b 16
diff --git a/examples/language/llama/test_ci.sh b/examples/language/llama2/test_ci.sh
similarity index 100%
rename from examples/language/llama/test_ci.sh
rename to examples/language/llama2/test_ci.sh