mirror of https://github.com/hpcaitech/ColossalAI
[tutorial] polish README (#2568)
parent
2eb4268b47
commit
039b0c487b
|
|
@ -109,8 +109,7 @@ Colossal-AI 为您提供了一系列并行组件。我们的目标是让您的
|
|||
- 基于参数文件的并行化
|
||||
- 推理
|
||||
- [Energon-AI](https://github.com/hpcaitech/EnergonAI)
|
||||
- Colossal-AI 成功案例
|
||||
- 生物医药: [FastFold](https://github.com/hpcaitech/FastFold) 加速蛋白质结构预测 AlphaFold 训练与推理
|
||||
|
||||
<p align="right">(<a href="#top">返回顶端</a>)</p>
|
||||
|
||||
## 并行训练样例展示
|
||||
|
|
|
|||
|
|
@ -114,9 +114,7 @@ distributed training and inference in a few lines.
|
|||
|
||||
- Inference
|
||||
- [Energon-AI](https://github.com/hpcaitech/EnergonAI)
|
||||
|
||||
- Colossal-AI in the Real World
|
||||
- Biomedicine: [FastFold](https://github.com/hpcaitech/FastFold) accelerates training and inference of AlphaFold protein structure
|
||||
|
||||
<p align="right">(<a href="#top">back to top</a>)</p>
|
||||
|
||||
## Parallel Training Demo
|
||||
|
|
|
|||
|
|
@ -15,30 +15,18 @@ quickly deploy large AI model training and inference, reducing large AI model tr
|
|||
[**Colossal-AI**](https://github.com/hpcaitech/ColossalAI) |
|
||||
[**Paper**](https://arxiv.org/abs/2110.14883) |
|
||||
[**Documentation**](https://www.colossalai.org/) |
|
||||
[**Forum**](https://github.com/hpcaitech/ColossalAI/discussions) |
|
||||
[**Issue**](https://github.com/hpcaitech/ColossalAI/issues/new/choose) |
|
||||
[**Slack**](https://join.slack.com/t/colossalaiworkspace/shared_invite/zt-z7b26eeb-CBp7jouvu~r0~lcFzX832w)
|
||||
|
||||
## Table of Content
|
||||
|
||||
- Multi-dimensional Parallelism
|
||||
- Know the components and sketch of Colossal-AI
|
||||
- Step-by-step from PyTorch to Colossal-AI
|
||||
- Try data/pipeline parallelism and 1D/2D/2.5D/3D tensor parallelism using a unified model
|
||||
- Sequence Parallelism
|
||||
- Try sequence parallelism with BERT
|
||||
- Combination of data/pipeline/sequence parallelism
|
||||
- Faster training and longer sequence length
|
||||
- Large Batch Training Optimization
|
||||
- Comparison of small/large batch size with SGD/LARS optimizer
|
||||
- Acceleration from a larger batch size
|
||||
- Auto-Parallelism
|
||||
- Parallelism with normal non-distributed training code
|
||||
- Model tracing + solution solving + runtime communication inserting all in one auto-parallelism system
|
||||
- Try single program, multiple data (SPMD) parallel with auto-parallelism SPMD solver on ResNet50
|
||||
- Fine-tuning and Serving for OPT
|
||||
- Try pre-trained OPT model weights with Colossal-AI
|
||||
- Fine-tuning OPT with limited hardware using ZeRO, Gemini and parallelism
|
||||
- Deploy the fine-tuned model to inference service
|
||||
- Multi-dimensional Parallelism [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/hybrid_parallel)
|
||||
- Sequence Parallelism [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/sequence_parallel)
|
||||
- Large Batch Training Optimization [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/large_batch_optimizer)
|
||||
- Automatic Parallelism [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/auto_parallel)
|
||||
- Fine-tuning and Inference for OPT [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/opt)
|
||||
- Optimized AlphaFold [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/tutorial/fastfold)
|
||||
- Optimized Stable Diffusion [[code]](https://github.com/hpcaitech/ColossalAI/tree/main/examples/images/diffusion)
|
||||
|
||||
|
||||
## Discussion
|
||||
|
|
@ -71,97 +59,3 @@ Then clone the Colossal-AI repository from GitHub.
|
|||
git clone https://github.com/hpcaitech/ColossalAI.git
|
||||
cd ColossalAI/examples/tutorial
|
||||
```
|
||||
|
||||
## 🔥 Multi-dimensional Hybrid Parallel with Vision Transformer
|
||||
1. Go to **hybrid_parallel** folder in the **tutorial** directory.
|
||||
2. Install our model zoo.
|
||||
```bash
|
||||
pip install titans
|
||||
```
|
||||
3. Run with synthetic data which is of similar shape to CIFAR10 with the `-s` flag.
|
||||
```bash
|
||||
colossalai run --nproc_per_node 4 train.py --config config.py -s
|
||||
```
|
||||
|
||||
4. Modify the config file to play with different types of tensor parallelism, for example, change tensor parallel size to be 4 and mode to be 2d and run on 8 GPUs.
|
||||
|
||||
## ☀️ Sequence Parallel with BERT
|
||||
1. Go to the **sequence_parallel** folder in the **tutorial** directory.
|
||||
2. Run with the following command
|
||||
```bash
|
||||
export PYTHONPATH=$PWD
|
||||
colossalai run --nproc_per_node 4 train.py -s
|
||||
```
|
||||
3. The default config is sequence parallel size = 2, pipeline size = 1, let’s change pipeline size to be 2 and try it again.
|
||||
|
||||
## 📕 Large batch optimization with LARS and LAMB
|
||||
1. Go to the **large_batch_optimizer** folder in the **tutorial** directory.
|
||||
2. Run with synthetic data
|
||||
```bash
|
||||
colossalai run --nproc_per_node 4 train.py --config config.py -s
|
||||
```
|
||||
|
||||
## 😀 Auto-Parallel Tutorial
|
||||
1. Go to the **auto_parallel** folder in the **tutorial** directory.
|
||||
2. Install `pulp` and `coin-or-cbc` for the solver.
|
||||
```bash
|
||||
pip install pulp
|
||||
conda install -c conda-forge coin-or-cbc
|
||||
```
|
||||
2. Run the auto parallel resnet example with 4 GPUs with synthetic dataset.
|
||||
```bash
|
||||
colossalai run --nproc_per_node 4 auto_parallel_with_resnet.py -s
|
||||
```
|
||||
|
||||
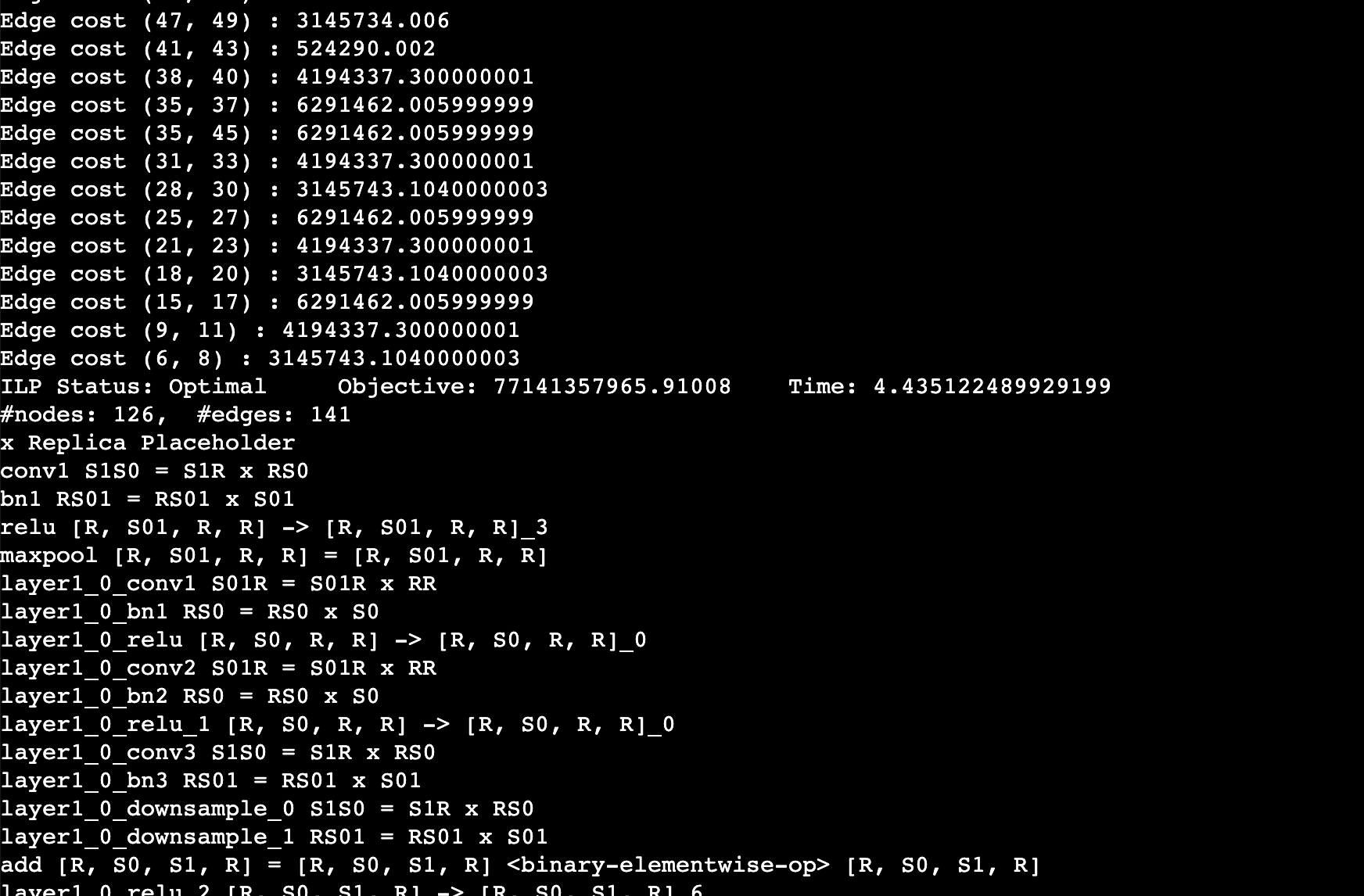
You should expect to the log like this. This log shows the edge cost on the computation graph as well as the sharding strategy for an operation. For example, `layer1_0_conv1 S01R = S01R X RR` means that the first dimension (batch) of the input and output is sharded while the weight is not sharded (S means sharded, R means replicated), simply equivalent to data parallel training.
|
||||
|
||||
|
||||
## 🎆 Auto-Checkpoint Tutorial
|
||||
1. Stay in the `auto_parallel` folder.
|
||||
2. Install the dependencies.
|
||||
```bash
|
||||
pip install matplotlib transformers
|
||||
```
|
||||
3. Run a simple resnet50 benchmark to automatically checkpoint the model.
|
||||
```bash
|
||||
python auto_ckpt_solver_test.py --model resnet50
|
||||
```
|
||||
|
||||
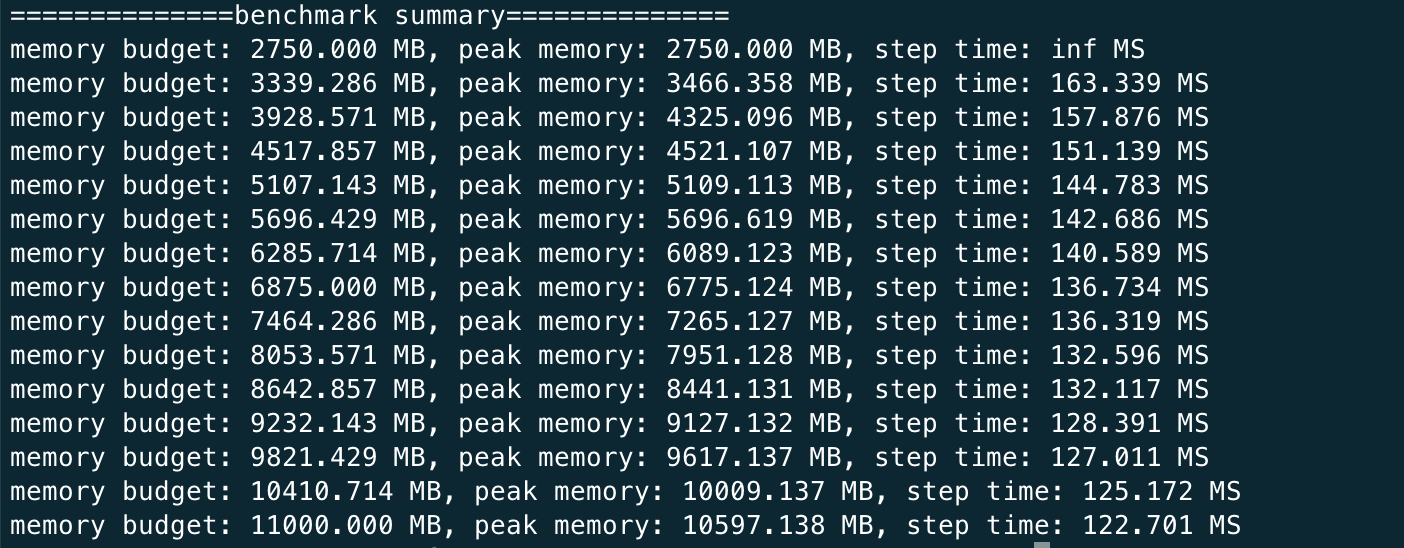
You should expect the log to be like this
|
||||
|
||||
|
||||
This shows that given different memory budgets, the model is automatically injected with activation checkpoint and its time taken per iteration. You can run this benchmark for GPT as well but it can much longer since the model is larger.
|
||||
```bash
|
||||
python auto_ckpt_solver_test.py --model gpt2
|
||||
```
|
||||
|
||||
4. Run a simple benchmark to find the optimal batch size for checkpointed model.
|
||||
```bash
|
||||
python auto_ckpt_batchsize_test.py
|
||||
```
|
||||
|
||||
You can expect the log to be like
|
||||

|
||||
|
||||
## 🚀 Run OPT finetuning and inference
|
||||
1. Install the dependency
|
||||
```bash
|
||||
pip install datasets accelerate
|
||||
```
|
||||
2. Run finetuning with synthetic datasets with one GPU
|
||||
```bash
|
||||
bash ./run_clm_synthetic.sh
|
||||
```
|
||||
3. Run finetuning with 4 GPUs
|
||||
```bash
|
||||
bash ./run_clm_synthetic.sh 16 0 125m 4
|
||||
```
|
||||
4. Run inference with OPT 125M
|
||||
```bash
|
||||
docker hpcaitech/tutorial:opt-inference
|
||||
docker run -it --rm --gpus all --ipc host -p 7070:7070 hpcaitech/tutorial:opt-inference
|
||||
```
|
||||
5. Start the http server inside the docker container with tensor parallel size 2
|
||||
```bash
|
||||
python opt_fastapi.py opt-125m --tp 2 --checkpoint /data/opt-125m
|
||||
```
|
||||
|
|
|
|||
|
|
@ -10,7 +10,7 @@
|
|||
|
||||
## 📚 Overview
|
||||
|
||||
This example lets you to try out the inference of FastFold.
|
||||
This example lets you to try out the inference of [FastFold](https://github.com/hpcaitech/FastFold).
|
||||
|
||||
## 🚀 Quick Start
|
||||
|
||||
|
|
@ -41,7 +41,7 @@ You can find predictions under the `outputs` dir.
|
|||
|
||||
## 🔍 Dive into FastFold
|
||||
|
||||
There are another features of FastFold, such as:
|
||||
There are another features of [FastFold](https://github.com/hpcaitech/FastFold), such as:
|
||||
+ more excellent kernel based on triton
|
||||
+ much faster data processing based on ray
|
||||
+ training supported
|
||||
|
|
|
|||
Loading…
Reference in New Issue