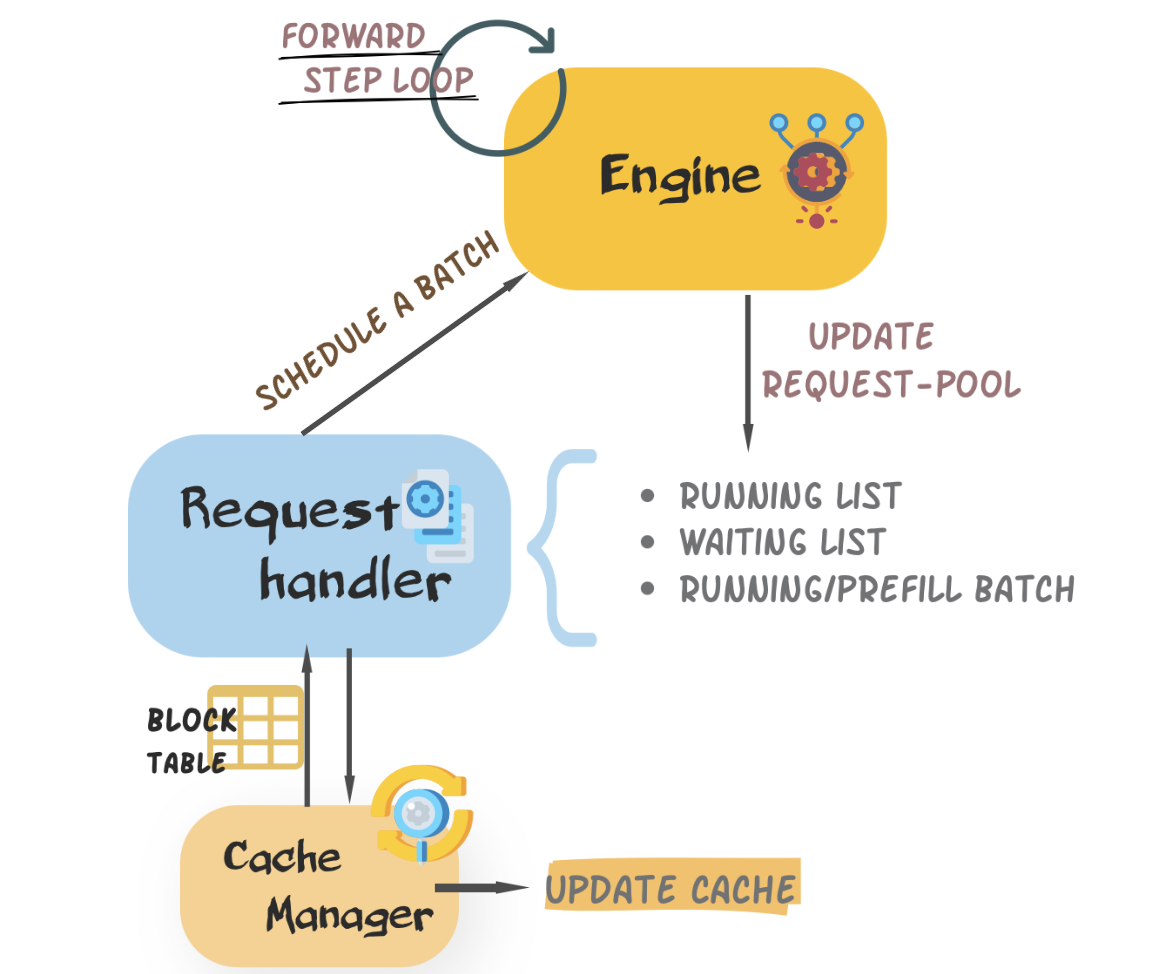

@@ -57,48 +67,71 @@ We design a unified blocked type cache and cache manager to distribute memory. T ### :railway_car: Modeling + Modeling contains models and layers, which are hand-crafted for better performance easier usage. Deeply integrated with `shardformer`, we also construct policy for our models. In order to minimize users' learning costs, our models are aligned with [Transformers](https://github.com/huggingface/transformers) ## 🕹 Usage ### :arrow_right: Quick Start -You can enjoy your fast generation journey within three step + ```python -# First, create a model in "transformers" way, you can provide a model config or use the default one. -model = transformers.LlamaForCausalLM(config).cuda() -# Second, create an inference_config +import torch +import transformers +import colossalai +from colossalai.inference import InferenceEngine, InferenceConfig +from pprint import pprint + +colossalai.launch_from_torch(config={}) + +# Step 1: create a model in "transformers" way +model_path = "lmsys/vicuna-7b-v1.3" +model = transformers.LlamaForCausalLM.from_pretrained(model_path).cuda() +tokenizer = transformers.LlamaTokenizer.from_pretrained(model_path) + +# Step 2: create an inference_config inference_config = InferenceConfig( - dtype=args.dtype, - max_batch_size=args.max_batch_size, - max_input_len=args.seq_len, - max_output_len=args.output_len, + dtype=torch.float16, + max_batch_size=4, + max_input_len=1024, + max_output_len=512, ) -# Third, create an engine with model and config + +# Step 3: create an engine with model and config engine = InferenceEngine(model, tokenizer, inference_config, verbose=True) -# Try fast infrence now! -prompts = {'Nice to meet you, Colossal-Inference!'} -engine.generate(prompts) - +# Step 4: try inference +generation_config = transformers.GenerationConfig( + pad_token_id=tokenizer.pad_token_id, + max_new_tokens=512, + ) +prompts = ['Who is the best player in the history of NBA?'] +engine.add_request(prompts=prompts) +response = engine.generate(generation_config) +pprint(response) ``` ### :bookmark: Customize your inference engine -Besides the basic fast-start inference, you can also customize your inference engine via modifying config or upload your own model or decoding components (logit processors or sampling strategies). +Besides the basic quick-start inference, you can also customize your inference engine via modifying config or upload your own model or decoding components (logit processors or sampling strategies). + #### Inference Config Inference Config is a unified api for generation process. You can define the value of args to control the generation, like `max_batch_size`,`max_output_len`,`dtype` to decide the how many sequences can be handled at a time, and how many tokens to output. Refer to the source code for more detail. + #### Generation Config In colossal-inference, Generation config api is inherited from [Transformers](https://github.com/huggingface/transformers). Usage is aligned. By default, it is automatically generated by our system and you don't bother to construct one. If you have such demand, you can also create your own and send it to your engine. #### Logit Processors -Logit Processosr receives logits and return processed ones, take the following step to make your own. +The `Logit Processosr` receives logits and return processed results. You can take the following step to make your own. + ```python @register_logit_processor("name") def xx_logit_processor(logits, args): logits = do_some_process(logits) return logits ``` + #### Sampling Strategies We offer 3 main sampling strategies now (i.e. `greedy sample`, `multinomial sample`, `beam_search sample`), you can refer to [sampler](/ColossalAI/colossalai/inference/sampler.py) for more details. We would strongly appreciate if you can contribute your varities. + ## 🪅 Support Matrix | Model | KV Cache | Paged Attention | Kernels | Tensor Parallelism | Speculative Decoding | @@ -158,5 +191,4 @@ If you wish to cite relevant research papars, you can find the reference below. } # we do not find any research work related to lightllm - ``` diff --git a/colossalai/inference/__init__.py b/colossalai/inference/__init__.py index e69de29bb..5f2effca6 100644 --- a/colossalai/inference/__init__.py +++ b/colossalai/inference/__init__.py @@ -0,0 +1,4 @@ +from .config import InferenceConfig +from .core import InferenceEngine + +__all__ = ["InferenceConfig", "InferenceEngine"] diff --git a/colossalai/inference/core/__init__.py b/colossalai/inference/core/__init__.py new file mode 100644 index 000000000..c18c2e59b --- /dev/null +++ b/colossalai/inference/core/__init__.py @@ -0,0 +1,4 @@ +from .engine import InferenceEngine +from .request_handler import RequestHandler + +__all__ = ["InferenceEngine", "RequestHandler"] diff --git a/colossalai/inference/core/engine.py b/colossalai/inference/core/engine.py index 7b21d1750..e88962f85 100644 --- a/colossalai/inference/core/engine.py +++ b/colossalai/inference/core/engine.py @@ -17,6 +17,8 @@ from colossalai.shardformer.policies.base_policy import Policy from .request_handler import RequestHandler +__all__ = ["InferenceEngine"] + PP_AXIS, TP_AXIS = 0, 1 _supported_models = [ diff --git a/colossalai/inference/core/request_handler.py b/colossalai/inference/core/request_handler.py index 80d77d097..85e41ea73 100644 --- a/colossalai/inference/core/request_handler.py +++ b/colossalai/inference/core/request_handler.py @@ -11,6 +11,8 @@ from colossalai.inference.sampler import * from colossalai.inference.struct import BatchInfo, RequestStatus, Sequence from colossalai.logging import get_dist_logger +__all__ = ["RunningList", "RequestHandler"] + logger = get_dist_logger(__name__) diff --git a/colossalai/inference/kv_cache/block_cache.py b/colossalai/inference/kv_cache/block_cache.py index c9a38e2d5..755c9581e 100644 --- a/colossalai/inference/kv_cache/block_cache.py +++ b/colossalai/inference/kv_cache/block_cache.py @@ -1,5 +1,7 @@ from typing import Any +__all__ = ["CacheBlock"] + class CacheBlock: """A simplified version of logical cache block used for Paged Attention.""" diff --git a/colossalai/inference/kv_cache/kvcache_manager.py b/colossalai/inference/kv_cache/kvcache_manager.py index bd15ce2bd..d16ced8e9 100644 --- a/colossalai/inference/kv_cache/kvcache_manager.py +++ b/colossalai/inference/kv_cache/kvcache_manager.py @@ -10,6 +10,8 @@ from colossalai.utils import get_current_device from .block_cache import CacheBlock +__all__ = ["KVCacheManager"] + GIGABYTE = 1024**3 diff --git a/colossalai/inference/modeling/__init__.py b/colossalai/inference/modeling/__init__.py new file mode 100644 index 000000000..e69de29bb diff --git a/colossalai/inference/modeling/layers/__init__.py b/colossalai/inference/modeling/layers/__init__.py new file mode 100644 index 000000000..e69de29bb diff --git a/requirements/requirements.txt b/requirements/requirements.txt index 095617d76..7fac7f204 100644 --- a/requirements/requirements.txt +++ b/requirements/requirements.txt @@ -16,3 +16,4 @@ ray sentencepiece google protobuf +ordered-set