mirror of https://github.com/THUDM/ChatGLM-6B
|
|
||
|---|---|---|
| resources | ||
| LICENSE | ||
| MODEL_LICENSE | ||
| README.md | ||
| cli_demo.py | ||
| web_demo.py | ||
README.md
ChatGLM-6B
介绍
ChatGLM-6B 是一个开源的、支持中英双语问答和对话的预训练语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。ChatGLM-6B 使用了和 ChatGLM(内测中,地址 https://chatglm.cn)相同的技术面向中文问答和对话进行优化。
使用方式
使用前请先安装transformers>=4.23.1和icetk。
pip install "transformers>=4.23.1,icetk"
代码调用
可以通过如下代码调用 ChatGLM-6B 模型来生成对话。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
history = []
query = "你好"
response, history = model.chat(tokenizer, query, history=history)
print(response)
query = "晚上睡不着应该怎么办"
response, history = model.chat(tokenizer, query, history=history)
print(history)
完整的模型实现可以在 HuggingFace Hub 上查看。
Demo
我们提供了一个基于 Gradio 的网页版 Demo 和一个命令行 Demo。使用时首先需要下载本仓库:
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
网页版 Demo
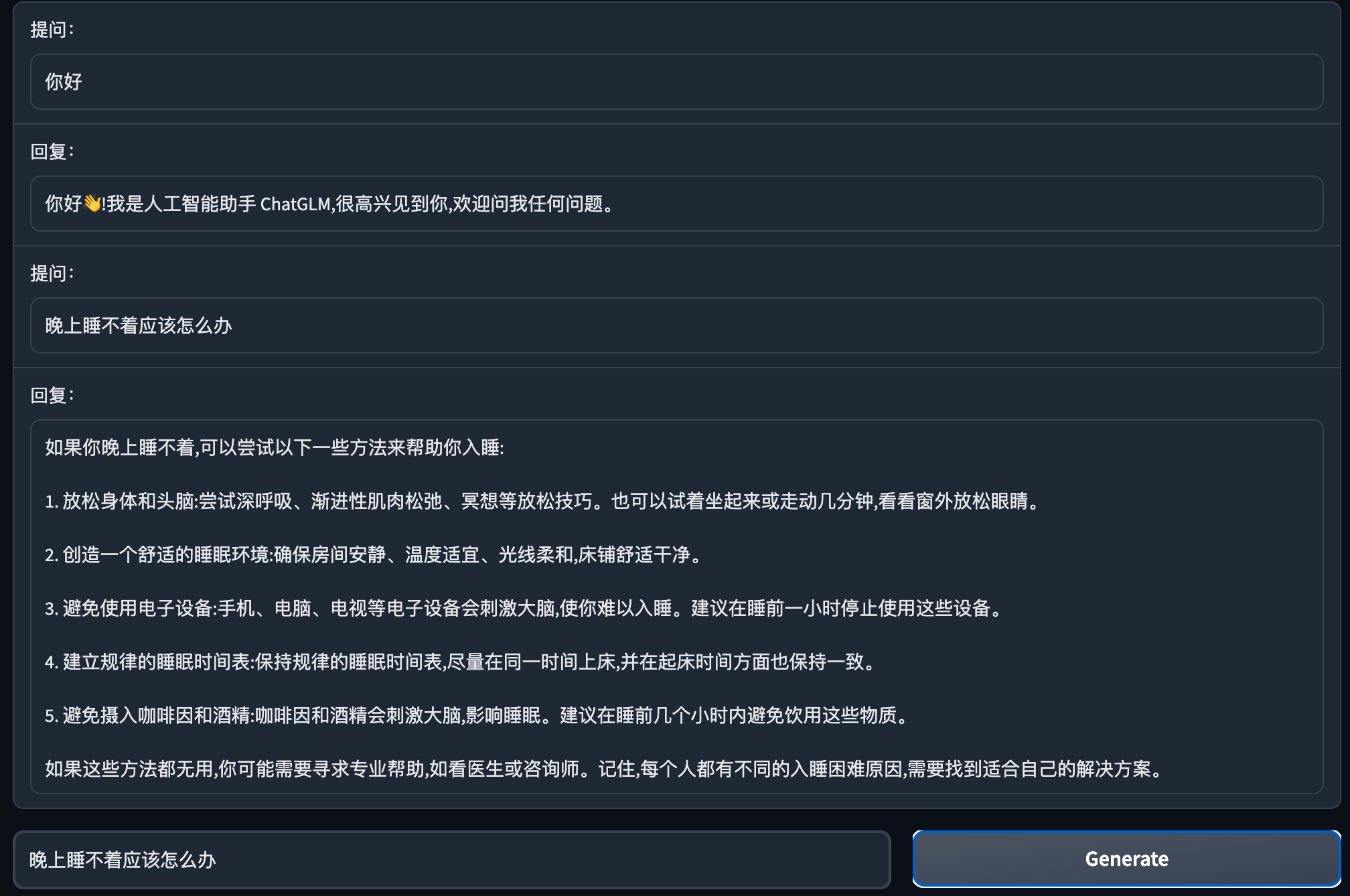
首先安装 Gradio
pip install gradio
然后运行仓库中的 web_demo.py:
python web_demo.py
程序会运行一个 Web Server,并输出地址。在浏览器中打开输出的地址即可使用。
命令行 Demo

运行仓库中 cli_demo.py:
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入clear可以清空对话历史,输入stop终止程序。
模型量化
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果你的 GPU 显存有限,可以尝试使用 transformers 提供的 8bit 量化功能,即将代码中的
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
替换为(8bit 量化)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(8).cuda()
或者(4bit 量化)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().quantize(4).cuda()
使用 8-bit 量化之后大约需要 8GB 的 GPU 显存,使用 4-bit 量化之后大约需要 4GB 的 GPU 显存。
引用
如果你觉得我们的工作有帮助的话,请考虑引用下列论文
@inproceedings{
zeng2023glm-130b,
title={{GLM}-130B: An Open Bilingual Pre-trained Model},
author={Aohan Zeng and Xiao Liu and Zhengxiao Du and Zihan Wang and Hanyu Lai and Ming Ding and Zhuoyi Yang and Yifan Xu and Wendi Zheng and Xiao Xia and Weng Lam Tam and Zixuan Ma and Yufei Xue and Jidong Zhai and Wenguang Chen and Zhiyuan Liu and Peng Zhang and Yuxiao Dong and Jie Tang},
booktitle={The Eleventh International Conference on Learning Representations (ICLR)},
year={2023},
url={https://openreview.net/forum?id=-Aw0rrrPUF}
}
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}